Abstract
It is known that the harmonic mean estimator is a consistent estimator of the marginal likelihood and is easy to implement, but it has severe biases and does not change as much as the prior distribution changes. In this study, we investigate the use of the harmonic mean estimator to select the hypothetical income distribution from grouped data through Monte Carlo simulations and apply it to real data in Japan. From the results, we confirm that there are significant biases, but it can be reliably used to select an appropriate model only when the sample size is large enough under appropriate prior settings.
1. Introduction
Non-negative statistical distributions and their applications are studied and used in areas such as finance (Higbee & McDonald, 2024), among others. One such example is the work of Professor Chris Heyde; see, for example, Heyde (1964, 1986). Among them, income distribution is widely considered to be one of the most important research areas involving non-negative-valued random variables, and such distributions are relevant to societal outcomes in general. In estimating an income distribution, the choice of the initial hypothetical income distribution is a crucial consideration. However, we face a trade-off between fitting a precise hypothetical income distribution and the interpretability of the parameters. Therefore, in empirical studies, we often start with distributions such as the lognormal (LN) distribution, the Dagum (DA) distribution introduced by Dagum (1977), the Singh–Maddala (SM) distribution proposed by Singh and Maddala (1976), and others. These distributions are preferred for better interpretability of the parameters. In addition, the estimation of the more flexible generalized beta distribution of the second kind (hereinafter referred to as GB2 distribution), introduced by McDonald (1984), is also examined within a Bayesian framework by Kakamu and Nishino (2019).
Several Bayesian model selection criteria exist for choosing the most appropriate hypothetical income distribution from a set of candidate distributions (see, for example, Ando (2010) for Bayesian model selection). Among these criteria, the marginal likelihood is a common choice for selecting the hypothetical income distribution, and various estimators have been proposed for its accurate estimation. Accurate estimation of the marginal likelihood is critical when dealing with Bayesian model averaging (BMA) or Bayes factor estimation. Inaccurate estimates can lead to inappropriate inference. Therefore, the precision of marginal likelihood estimators is extensively studied in the literature, with works such as Friel and Wyse (2012); Kass and Raftery (1995) providing valuable insights. On the other hand, the harmonic mean estimator introduced by Newton and Raftery (1994) is a consistent estimator of the marginal likelihood and is easy to implement. However, it has been criticized for its significant biases and limited responsiveness to changes in prior information. Consequently, its use in BMA or Bayes factor estimation is controversial. However, if the sole objective is to select an appropriate hypothetical income distribution, it remains unclear whether the harmonic mean estimator can effectively serve this purpose.
This study explores the application of the harmonic mean estimator in selecting a hypothetical income distribution from grouped data using Monte Carlo simulations. We also apply this estimator to real data from a Japanese case study. Our results confirm the presence of significant biases in the harmonic mean estimator. Nevertheless, it can prove valuable in selecting an appropriate model, but its effectiveness is significantly more pronounced when the sample size is sufficiently large under appropriate prior settings.
The remainder of this paper is organized as follows. In Section 2, we explain the method for selecting the hypothetical income distribution using marginal likelihoods from grouped data. In Section 3 we implement the Monte Carlo simulations. Section 4 examines the real data in Japan. Finally, brief conclusions are given in Section 5.
2. Selecting the Hypothetical Income Distribution
Income data are published as grouped data in many countries. In grouped data, suppose that the income units are grouped into K income classes, viz., , , …, , with and : Let n be the total number of units and be the number of units in the interval and for and therefore . There are two types of grouped data (see Eckernkemper & Gribisch, 2021) and we assume the type of quantile form in this study (see Nishino & Kakamu, 2011). From the grouped data, we assume the hypothetical distribution and estimate its parameters.
Let be a vector of parameters for the assumed hypothetical income distribution. Let and be the probability density function (PDF) and cumulative distribution function (CDF) of the hypothetical income distribution, respectively. Given the grouped data, and , the likelihood function based on the selected order statistics by Nishino and Kakamu (2011) is given as follows:
To proceed with the Bayesian analysis, we need to assume the prior distribution as . Given the likelihood function (1) and prior distribution , the posterior distribution is expressed as
where is called the marginal likelihood and used as a criterion to select the hypothetical income distribution. Using the posterior distribution, posterior inference via the Markov chain Monte Carlo (MCMC) method is implemented. This procedure is explained in Appendix A. In this study, the LN, DA, and SM distributions, which are denoted by , , and , respectively, are assumed as hypothetical income distributions.1
In this study, we focus on the estimation of the marginal likelihood, which is estimated from the MCMC draws . As is shown by Gelfand and Dey (1994), for any proper PDF ,
for any hypothetical income distribution. Therefore, using the MCMC draws, we can obtain the estimator of the marginal likelihood as follows:
In Equation (2), the choice of is important and we need to specify it. Two major approaches are the harmonic mean estimator by Newton and Raftery (1994) and modified harmonic mean estimator by Geweke (1999). If we set , then it becomes the harmonic mean estimator by Newton and Raftery (1994) as follows:
It is a consistent estimator of the marginal likelihood and easy to implement. However, it is also known that its variance can go to infinity, since it contains the inverse of the likelihood function, and that the harmonic mean estimator will not change much as the prior changes, even though the marginal likelihood is very sensitive to changes in the prior distribution.
To overcome the severe downside to this estimator, Geweke (1999) proposed the modified harmonic mean estimator. It is calculated as follows:
where is a truncated normal distribution as follows:
where and are the sample mean and covariance matrix from and P is the normalizing constant, which satisfies and is the quantile of the distribution with degrees of freedom d. This approach is popular and is used in the analyses of income distribution, for example, by Griffiths et al. (2005) for the purpose of the BMA.
Another approach is proposed by Chib (1995) and Chib and Jeliazkov (2001) for the Gibbs sampler and Metropolis–Hastings (MH) algorithm, respectively. Their idea is based on the basic marginal likelihood identity as follows:
At any point , which is, for example, the posterior mean, in the case of the MH algorithm, Chib and Jeliazkov (2001) showed that can be estimated as follows:
where is the PDF of the proposal distribution.
Using the quantity, the marginal likelihood can be calculated as follows:
From the number of citations which these articles have gained, it is clear that their approach is popular among practitioners.
As a final note to this section, we briefly discuss the properties of marginal likelihood estimators. All estimators are consistent but biased. The difference lies in the size of the biases and the computational procedures. From the point of view of biases, the harmonic mean estimator is highly sensitive to the values of the likelihood in low-probability regions, a few extreme samples can dominate the estimate, and outliers in the parameter space can significantly affect the estimation result, making the method less robust. The modified harmonic mean estimator is proposed to overcome the problem of the harmonic mean estimator, but it is known that the estimators have biases when estimating high-dimensional parameter models such as latent variable models (see Chan & Grant, 2015). Finally, for the estimator of Chib and Jeliazkov (2001), difficulties can arise when this method is applied to mixture models, hidden Markov models, and other models that give rise to label switching and parameter non-identifiability, and the bias in these estimates is reported in Chan and Eisenstat (2015). From a computational point of view, the harmonic mean estimator is the easiest method to implement. On the other hand, the method by Chib and Jeliazkov (2001) increases in computational complexity as the dimension of parameters increases. Moreover, implementation is more involved, especially for computing numerical standard errors of marginal likelihood estimates. For a more comprehensive review of marginal likelihood estimation, see Chan and Eisenstat (2015); Friel and Wyse (2012); Han and Carlin (2001).
Using these three estimators of the marginal likelihood, we examine the selection of the hypothetical income distribution through Monte Carlo simulations and apply it to real data in Japan. All the results reported here were generated using Ox 9.10 (macOS_64/Parallel) (see Doornik, 2013).
3. Simulation Studies
We now explain the setup for the Monte Carlo simulations. First, we set the number of observations as n = 1000, 10,000, and 100,000 to evaluate the effect of the number of observations. In addition, we assume the number of groups as decile ().2 Given n and , we consider two scenarios in which the true data generating processes (DGPs) follow the LN distribution and GB2 distribution3, denoted by , and L samples of for are generated. That is, we perform L simulation runs for these two distributions; in this section, L = 1000.
The simulation procedure is as follows:
- (i)
- Given the true DGP, we generate random numbers s, from the distribution.
- (ii)
- We sort the random numbers in ascending order and pick up , where for .
- (iii)
- Given and the hyper-parameters (), we obtain the estimates and marginal likelihoods assuming the LN, DA, and SM distributions. In the MCMC procedure, we run a random walk MH (RWMH) algorithm, with 4000 iterations excluding the first 2000 iterations. For the modified harmonic mean estimator, , and are considered.
- (iv)
- We repeat (i)–(iii) L times, where L = 1000, as mentioned above.
- (v)
- From L marginal likelihoods, we count the distribution with the largest marginal likelihood.
In the first scenario, we assume the true DGP as the LN distribution with and and examine the prior sensitivity. Therefore, we assume , , , , for the LN distribution and the same hyper-parameters (, ) with the LN distribution for the SM and DA distributions.4
In the second scenario, the purpose of the analysis is to analyze whether the true distribution can be properly selected and what selection is made when the true distribution is not included in the candidate distributions. Therefore, we assume the GB2 distribution with , , , , , , where the first two cases assume that the true distributions are the DA distributions, the second two cases assume the true distributions are the SM distributions, and last two cases assume that the true distributions are not included in the candidate distributions. It should be mentioned that, as shown by Kakamu (2016), the SM distributions are selected if and , while the DA distributions are selected if and , in terms of AIC.5 As the hyper-parameters, we set for all cases.
Table 1 displays the results of our Monte Carlo simulations, assuming the LN distribution. The results reveal that when the sample size n is sufficiently large, for example, n = 100,000, the LN distribution is consistently selected correctly across all estimators, regardless of the hyper-parameter choices. However, as the sample size n decreases, the choice of hyper-parameters begins to influence the selection of the hypothetical income distribution, particularly when using Equations (4) and (5). In cases where the prior for becomes diffuse, i.e., when is large, the DA or SM distributions are preferred over the LN distribution, even if the true DGP is the LN distribution. Moreover, when and are large, the DA distribution is favored. It seems to be affected by the prior information when the sample size is not large enough, because it is well-known that biases of Equations (4) and (5) are relatively smaller than Equation (3). It is also consistent with the previous literature because the harmonic mean estimator will not change much as the prior changes. Therefore, it is worth noting that the use of the harmonic mean estimator should be criticized when the sample size is not large enough and/or when we assume some tight prior distribution.

Table 1.
Monte Carlo results of the log of marginal likelihoods for the LN distribution.
To investigate why the true distribution is not selected in small samples and under certain prior settings, we examined the empirical distributions of the log of marginal likelihoods and the posterior means from the LN, DA, and SM distributions. Table 2 presents the means and standard deviations of the log of marginal likelihoods obtained from Monte Carlo simulations. The results reveal the following: First, the distribution with the highest mean marginal likelihood was consistently selected. Second, the means reported by Geweke (1999) and Chib and Jeliazkov (2001) are similar, whereas those of Newton and Raftery (1994) differ from Geweke (1999) and Chib and Jeliazkov (2001) across all cases. Third, when n = 1000, the marginal likelihood estimates appear relatively stable for Newton and Raftery (1994). However, these estimates change when is altered or when and are adjusted. In particular, the changes in the marginal likelihood estimates for LN, when and are varied, indicate greater sensitivity to the choice of hyper-parameters compared to changes in . Needless to say, the marginal likelihood estimates are even more sensitive to the choice of hyper-parameters in Geweke (1999) and Chib and Jeliazkov (2001). Based on these observations, we proceed to examine the posterior estimates derived from the three distributions.
Table 2.
Summary statistics of the log of marginal likelihoods for the LN distribution.
Table 3, Table 4 and Table 5 present summaries of the empirical distributions of the posterior means derived from the LN, DA, and SM distributions. The means and standard deviations of the posterior means from the LN distribution (see Table 3) exhibit minimal variation, whereas those from the DA and SM distributions (see Table 4 and Table 5) show noticeable changes, particularly when the sample size is small (n = 1000). Additionally, it is noteworthy that the influence of the prior settings persists even when the sample size increases to n = 100,000 (e.g., for and ). This indicates that the choice of hyper-parameters affects the posterior estimates of the hypothetical income distribution, leading to variations in the marginal likelihood estimates, particularly for Chib and Jeliazkov (2001); Geweke (1999).
Table 3.
Summary statistics of the LN distribution.
Table 4.
Summary statistics of the DA distribution.
Table 5.
Summary statistics of the SM distribution.
To sum up, when the sample size is sufficiently large, the posterior estimates of the LN, DA, and SA do not change and the weight of the prior distribution seems to be sufficiently small (see Table 3, Table 4 and Table 5). Therefore, the marginal likelihood estimates of Newton and Raftery (1994), Geweke (1999), and Chib (1995) do not change, even when the hyper-parameters have changed (see Table 2). On the other hand, the posterior estimates of the DA and SM distributions are different when the hyper-parameters have changed (see Table 4 and Table 5), but the posterior estimates of the LN distribution, especially the ones of , have small biases; however, the biases do not change so much, even when the hyper-parameters have changed (see Table 3). Moreover, the marginal likelihood estimates of Geweke (1999) and Chib (1995) require prior distribution to estimate them. We think these facts lead to small changes in the marginal likelihoods of Geweke (1999) and Chib (1995) and the wrong choice of hypothetical income distribution depending on the hyper-parameter settings (see Table 2). These results suggest that selecting appropriate hyper-parameters is crucial, especially when the sample size is small. However, with a sufficiently large sample size and appropriate prior settings, valid model selection can still be achieved.
Table 6 presents the results of our Monte Carlo simulations under the assumption of the GB2 distribution. Similar to the findings under the LN distribution, when the sample size n is sufficiently large, for instance, n = 100,000, the true distribution is consistently favored, aligning with Kakamu (2016), even when the true distributions are not included among the candidate distributions. However, as the sample size n decreases, the performance of Equation (3) declines compared to Equations (4) and (5).6 Consequently, when the sample size n is not sufficiently large, caution is warranted when using Equation (3).
Table 6.
Monte Carlo results of the log of marginal likelihoods for the GB2 distribution.
In summary, when employing the marginal likelihood for selecting the hypothetical income distribution, Equations (4) and (5) are typically preferred. However, it is essential to exercise caution in choosing the hyper-parameters when using these equations. On the other hand, if the sample size n is sufficiently large, Equation (3) can also be used effectively without the need to be overly concerned about hyper-parameter selection.
4. Empirical Example
Using the Japanese household survey, Family Income and Expenditure Survey in 2020, which was compiled by the Statistics Bureau of the Ministry of Internal Affairs and Communications, we will consider the choice of the hypothetical income distributions. There are data on two types of households: two-or-more-person households and workers’ households (unit: million yen). The sample size for each dataset is n = 10,000 and the dataset in decile form is utilized; therefore, = 1000 for .7 Finally, we set the hyper-parameters to , , and and run the RWMH algorithm using 22,000 iterations while discarding the first 2000 iterations.
Table 7 shows the results for the log of the marginal likelihoods for both two-or-more person households and workers’ households. From the table, although we can confirm that there are severe biases in the values of the log of the marginal likelihood using (3), we can see that the LN distribution was chosen as the most suitable hypothetical income distribution in both datasets, as was using (4) and (5). In this sense, if the model selection is only performed using the marginal likelihoods, then using (3) is not considered to be a major problem.
Table 7.
Empirical results of the log of marginal likelihoods.
Since the LN distributions are selected from three hypothetical income distributions for both datasets, the posterior estimates from the LN distribution are shown in Table 8 with the trace plots shown in Figure 1. The trace plots confirm that the convergence of the MCMC chains is fast with respect to mixing. Therefore, we can conclude that the algorithm described in Appendix A works well for the LN distribution with the datasets. Focusing on the posterior estimates, we see that the standard deviations are very small, with narrow 95% credible intervals. This suggests that the fits of the LN distribution are very good and is the reason why the LN distributions are chosen as the hypothetical income distribution for the datasets.
Table 8.
Posterior estimates of the LN distribution.
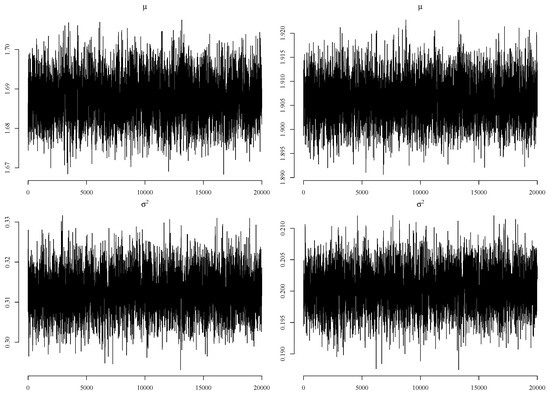
Figure 1.
The trace plots for two-or-more person (left) and workers’ (right) households.
5. Conclusions
This study investigated the performance of the marginal likelihood in selecting the hypothetical income distribution from grouped data, with a specific focus on the harmonic mean estimator, using Monte Carlo simulations. The results confirmed that the harmonic mean estimator can effectively choose the appropriate hypothetical income distribution when the sample size is sufficiently large under appropriate prior settings, despite the presence of severe biases observed in the empirical example. Consequently, the harmonic mean estimator, due to its pronounced bias, may cause problems when used to compute BMA or Bayes factors, but it remains a valuable tool for selecting the appropriate model, provided the sample size is sufficient under the appropriate prior settings.
As the remaining issue, it is reasonable to examine other marginal likelihood estimators, such as those by Chan and Eisenstat (2015) and Chan (2023). It is our future remark, but our findings represent an interesting first step.
Funding
This research was partially supported by JSPS KAKENHI (grant numbers: JP20H00080 and JP20K01590).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data is available from the author upon request.
Acknowledgments
We would like to thank the editor and reviewers for their useful comments, which substantially improve the study. We would also like to thank Conan Liu for English language editing.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A
In this appendix, we introduce a MCMC method using a RWMH algorithm to estimate the parameters of the distributions, which is used by Chotikapanich and Griffiths (2000) and Kakamu (2016). To obtain the posterior estimates for the LN, DA, and SM distributions, we implement the following RWMH algorithm in the general setting.
- Set and initial value .
- Generate a candidate value from , where c is a tuning parameter and is the maximum likelihood covariance estimate.8
- Computeand if any of the elements of fall outside the feasible parameter region, then .
- Generate a value u from , where is a uniform distribution on the interval .
- If , set , otherwise .
- Return to step 2, with r set to .
Appendix B
In this appendix, we report the Monte Carlo experiments for the information criteria. To examine the performance of the information criteria, we examined the Akaike information criterion (AIC), Bayesian information criterion (BIC), and deviance information criterion (DIC), as in Doğan (2023), through Monte Carlo simulation. The simulation settings are the same as those in Section 3. Table A1 and Table A2 show the results of our Monte Carlo simulation, which counts the distribution with the smallest information criteria, for the cases where the true DGPs are the LN and GB2 distributions, respectively. From the tables, we can confirm that the performance of the information criteria is almost the same as that of Newton and Raftery (1994) in general. The differences appear when n = 1000. Especially, in the case of the LN distribution, as is different from the marginal likelihoods, the LN distributions are preferred to other distributions without being affected by the prior distributions. Moreover, the performance of AIC and BIC seems to be poorer than that of DIC in both cases. It suggests that the penalty term of DIC works well, while the number of parameters does not work well to select an appropriate hypothetical income distribution. Therefore, we can conclude that DIC becomes a candidate for selecting a hypothetical income distribution when the sample size is small.
Table A1.
Monte Carlo results of the information criteria for the LN distribution.
Table A1.
Monte Carlo results of the information criteria for the LN distribution.
| , , , | |||||||||||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 699 | 66 | 235 | 987 | 8 | 5 | 1000 | 0 | 0 | ||
| BIC | 699 | 66 | 235 | 987 | 8 | 5 | 1000 | 0 | 0 | ||
| DIC | 776 | 156 | 71 | 991 | 3 | 5 | 1000 | 0 | 0 | ||
| , , , | |||||||||||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 696 | 67 | 237 | 987 | 8 | 5 | 1000 | 0 | 0 | ||
| BIC | 696 | 67 | 237 | 987 | 8 | 5 | 1000 | 0 | 0 | ||
| DIC | 781 | 149 | 70 | 990 | 4 | 6 | 1000 | 0 | 0 | ||
| , , , | |||||||||||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 697 | 67 | 236 | 987 | 8 | 5 | 1000 | 0 | 0 | ||
| BIC | 697 | 67 | 236 | 987 | 8 | 5 | 1000 | 0 | 0 | ||
| DIC | 783 | 150 | 67 | 991 | 3 | 6 | 1000 | 0 | 0 | ||
| , , , | |||||||||||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 698 | 73 | 229 | 986 | 9 | 5 | 1000 | 0 | 0 | ||
| BIC | 698 | 73 | 229 | 986 | 9 | 5 | 1000 | 0 | 0 | ||
| DIC | 787 | 150 | 63 | 991 | 3 | 6 | 1000 | 0 | 0 | ||
| , , , | |||||||||||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 725 | 75 | 200 | 989 | 4 | 7 | 1000 | 0 | 0 | ||
| BIC | 725 | 75 | 200 | 989 | 4 | 7 | 1000 | 0 | 0 | ||
| DIC | 781 | 80 | 139 | 992 | 3 | 5 | 1000 | 0 | 0 | ||
Table A2.
Monte Carlo results of the information criteria for the GB2 distribution.
Table A2.
Monte Carlo results of the information criteria for the GB2 distribution.
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 113 | 305 | 582 | 0 | 801 | 199 | 0 | 997 | 3 | ||
| BIC | 113 | 305 | 582 | 0 | 801 | 199 | 0 | 997 | 3 | ||
| DIC | 108 | 787 | 105 | 0 | 806 | 194 | 0 | 997 | 3 | ||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 2 | 479 | 519 | 0 | 953 | 47 | 0 | 1000 | 0 | ||
| BIC | 2 | 481 | 517 | 0 | 953 | 47 | 0 | 1000 | 0 | ||
| DIC | 1 | 929 | 70 | 0 | 977 | 23 | 0 | 1000 | 0 | ||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 80 | 438 | 482 | 0 | 192 | 808 | 0 | 1 | 999 | ||
| BIC | 80 | 438 | 482 | 0 | 192 | 808 | 0 | 1 | 999 | ||
| DIC | 128 | 390 | 482 | 0 | 196 | 804 | 0 | 1 | 999 | ||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 5 | 302 | 693 | 0 | 32 | 968 | 0 | 0 | 1000 | ||
| BIC | 5 | 302 | 693 | 0 | 32 | 968 | 0 | 0 | 1000 | ||
| DIC | 8 | 192 | 800 | 0 | 32 | 968 | 0 | 0 | 1000 | ||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 180 | 432 | 388 | 1 | 992 | 7 | 0 | 1000 | 0 | ||
| BIC | 180 | 432 | 388 | 1 | 992 | 7 | 0 | 1000 | 0 | ||
| DIC | 186 | 747 | 67 | 1 | 992 | 7 | 0 | 1000 | 0 | ||
| n = 1000 | n = 10,000 | n = 100,000 | |||||||||
| LN | DA | SM | LN | DA | SM | LN | DA | SM | |||
| AIC | 153 | 249 | 598 | 0 | 10 | 990 | 0 | 0 | 1000 | ||
| BIC | 153 | 249 | 598 | 0 | 10 | 990 | 0 | 0 | 1000 | ||
| DIC | 213 | 217 | 570 | 1 | 9 | 990 | 0 | 0 | 1000 | ||
Notes
| 1 | For prior distributions, we assume , for the LN distribution, , , for the DA distribution, and , , for the SM distribution, respectively, where is a normal distribution and is a gamma distribution. |
| 2 | It should be mentioned that the number of income classes K also plays an important role in the performance of the estimator. As it has already been discussed in Kakamu and Nishino (2019) that the estimates become worse when K is small, we focus on the effects of n and prior hyper-parameters in this study. |
| 3 | The probability density function of the GB2 distribution is expressed by |
| 4 | From the nature of the gamma distribution, as increases, the expectation and variance increase, while as increases, the expectation is larger and variance is smaller. As is well known, as increases, the variance becomes large in the case of a normal distribution, i.e., the prior distribution becomes diffuse. |
| 5 | It is not our concern, but it is interesting to examine the performance of the information criteria for selecting the hypothetical income distribution (see Doğan (2023) for the case of spatial models). These results are reported in Appendix B. |
| 6 | It is worthwhile to mention that if for the DA distribution or for the SM distribution, the performance of the model selection becomes worse. It is also consistent with the results from Kakamu (2016). |
| 7 | For more details, see http://www.stat.go.jp/english/ (accessed on 31 January 2025). |
| 8 | It is sometimes difficult to find the mode of the parameters by the maximum likelihood method. Therefore, we implement the simulated annealing of Goffe et al. (1994). In addition, if the Cholesky decomposition of fails, the modified Cholesky of Nocedal and Wright (2000) is used. The appropriate choice of step sizes used in the random walk chain is determined by the procedure in Holloway et al. (2002) during the burn-in period. |
References
- Ando, T. (2010). Bayesian model selection and statistical modeling. Statistics: A Series of Textbooks and Monographs. Taylor & Francis. [Google Scholar]
- Chan, J. C. C. (2023). Comparing stochastic volatility specifications for large Bayesian VARs. Journal of Econometrics, 235(2), 1419–1446. [Google Scholar] [CrossRef]
- Chan, J. C. C., & Eisenstat, E. (2015). Marginal likelihood estimation with the cross-entropy method. Econometric Reviews, 34(3), 256–285. [Google Scholar] [CrossRef]
- Chan, J. C. C., & Grant, A. L. (2015). Pitfalls of estimating the marginal likelihood using modified harmonic mean. Economics Letters, 131, 29–33. [Google Scholar] [CrossRef]
- Chib, S. (1995). Marginal likelihood from the Gibbs output. Journal of the American Statistical Association, 90(432), 1313–1321. [Google Scholar] [CrossRef]
- Chib, S., & Jeliazkov, I. (2001). Marginal likelihood from the Metropolis–Hastings output. Journal of the American Statistical Association, 96(453), 270–281. [Google Scholar] [CrossRef]
- Chotikapanich, D., & Griffiths, W. E. (2000). Posterior distributions for the Gini coefficient using grouped data. Australian & New Zealand Journal of Statistics, 42(4), 383–392. [Google Scholar]
- Dagum, C. (1977). A new model of personal income distribution: Specification and estimation. Economie Appliquée, 30, 413–437. [Google Scholar] [CrossRef]
- Doğan, O. (2023). Modified harmonic mean method for spatial autoregressive models. Economics Letters, 223, 110978. [Google Scholar] [CrossRef]
- Doornik, J. A. (2013). OxTM 7: An object-oriented matrix programming language. Timberlake Consultants Press. [Google Scholar]
- Eckernkemper, T., & Gribisch, B. (2021). Classical and Bayesian inference for income distributions using grouped data. Oxford Bulletin of Economics and Statistics, 83(1), 32–65. [Google Scholar] [CrossRef]
- Friel, N., & Wyse, J. (2012). Estimating the evidence—A review. Statistica Neerlandica, 66(3), 288–308. [Google Scholar] [CrossRef]
- Gelfand, A. E., & Dey, D. K. (1994). Bayesian model choice: Asymptotics and exact calculations. Journal of the Royal Statistical Society. Series B (Methodological), 56(3), 501–514. [Google Scholar] [CrossRef]
- Geweke, J. (1999). Using simulation methods for Bayesian econometric models: Inference, development, and communication. Econometric Reviews, 18(1), 1–73. [Google Scholar] [CrossRef]
- Goffe, W. L., Ferrier, G. D., & Rogers, J. (1994). Global optimization of statistical functions with simulated annealing. Journal of Econometrics, 60(1–2), 65–99. [Google Scholar] [CrossRef]
- Griffiths, W. E., Chotikapanich, D., & Rao, D. S. P. (2005). Averaging income distributions. Bulletin of Economic Research, 57(4), 347–367. [Google Scholar] [CrossRef]
- Han, C., & Carlin, B. P. (2001). Markov chain Monte Carlo methods for computing Bayes factor: A comparative review. Journal of the Statistical Association, 96(455), 1122–1132. [Google Scholar] [CrossRef]
- Heyde, C. C. (1964). On a property of the lognormal distribution. Journal of the Royal Statistical Society. Series B (Methodological), 25(2), 392–393. [Google Scholar] [CrossRef]
- Heyde, C. C. (1986). Random sum distributions. In N. L. Johnson, & S. Kotz (Eds.), Encyclopedia of statistical sciences (Vol. 7, pp. 565–567). Wiley. [Google Scholar]
- Higbee, J. D., & McDonald, J. B. (2024). A comparison of the GB2 and skewed generalized log-t distributions with an application in finance. Journal of Econometrics, 240(2), 105064. [Google Scholar] [CrossRef]
- Holloway, G., Shankar, B., & Rahmanb, S. (2002). Bayesian spatial probit estimation: A primer and an application to HYV rice adoption. Agricultural Economics, 27(3), 383–402. [Google Scholar] [CrossRef]
- Kakamu, K. (2016). Simulation studies comparing Dagum and Singh-Maddala income distributions. Computational Economics, 48, 593–605. [Google Scholar] [CrossRef]
- Kakamu, K., & Nishino, H. (2019). Bayesian estimation of beta-type distribution parameters based on grouped data. Computational Economics, 54, 625–645. [Google Scholar] [CrossRef]
- Kass, R. E., & Raftery, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90(430), 773–795. [Google Scholar] [CrossRef]
- McDonald, J. B. (1984). Some generalized functions for the size distribution of income. Econometrica, 52(3), 647–665. [Google Scholar] [CrossRef]
- Newton, M. A., & Raftery, A. E. (1994). Approximate bayesian inference with the weighted likelihood bootstrap. Journal of the Royal Statistical Society. Series B (Methodological), 56(1), 3–48. [Google Scholar] [CrossRef]
- Nishino, H., & Kakamu, K. (2011). Grouped data estimation and testing of Gini coefficients using lognormal distributions. Sankhyā: The Indian Journal of Statistics, Series B, 73(2), 193–210. [Google Scholar] [CrossRef]
- Nocedal, J., & Wright, S. (2000). Numerical optimization (2nd ed.). Springer. [Google Scholar]
- Singh, S. K., & Maddala, G. S. (1976). A function for size distribution of incomes. Econometrica, 44(5), 963–970. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).