Abstract
Background: Since 2023, ChatGPT-4 has been impactful across several sectors including healthcare, where it aids in medical information analysis and education. Electronic patient-reported outcomes (ePROs) play a crucial role in monitoring cancer patients’ post-treatment symptoms, enabling early interventions. However, managing the voluminous ePRO data presents significant challenges. This study assesses the feasibility of utilizing ChatGPT-4 for analyzing side effect data from ePROs. Methods: Thirty cancer patients were consecutively collected via a web-based ePRO platform, reporting side effects over 4 weeks. ChatGPT-4, simulating oncologists, dietitians, and nurses, analyzed this data and offered improvement suggestions, which were then reviewed by professionals in those fields. Results: Two oncologists, two dieticians, and two nurses evaluated the AI’s performance across roles with 540 reviews. ChatGPT-4 excelled in data accuracy and completeness and was noted for its empathy and support, enhancing communication and reducing caregiver stress. It was potentially effective as a dietician. Discussion: This study offers preliminary insights into the feasibility of integrating AI tools like ChatGPT-4 into ePRO cancer care, highlighting its potential to reduce healthcare provider workload. Key directions for future research include enhancing AI’s capabilities in cancer care knowledge validation, emotional support, improving doctor-patient communication, increasing patient health literacy, and minimizing errors in AI-driven clinical processes. As technology advances, AI holds promise for playing a more significant role in ePRO cancer care and supporting shared decision-making between clinicians and patients.
1. Introduction
ChatGPT, an advanced AI Large Language Model (LLM) technology, was launched by the American artificial intelligence research lab OpenAI at the end of November 2022 [1]. Through extensive data training, ChatGPT assists in analyzing medical records [2], providing psychological health support [3], and aiding medical research in the field of medicine [4]. This technology is reshaping our medical practices, sparking a new revolution in healthcare [5]. In March 2023, OpenAI released ChatGPT-4, a more human-like general AI than its predecessor, ChatGPT-3.5 [1]. It demonstrates superior performance in understanding, reasoning, and responding to complex questions. By September 2023, OpenAI updated ChatGPT to perform internet searches through Microsoft’s Bing search engine, breaking free from the data limitations of September 2021 [6].
In the medical field, ChatGPT-4, through its deep learning and natural language processing capabilities, has passed the three-stage United States Medical Licensing Examination (USMLE) [7]. This marks a significant milestone in the maturity of AI in healthcare. It can assist medical professionals in handling a vast amount of medical literature [8], clinical records, insurance documents, and patient inquiries [9]. ChatGPT-4 can provide information on clinical trials relevant to patient needs [2], assist doctors in quickly accessing information on related cases, and offer suggestions based on the latest medical education and research [10], thereby enhancing work efficiency and the accuracy of information processing.
In the field of cancer, ChatGPT-4 can assist in patient education for cancer patients, analysis of next-generation genetic data in cancer (NGS) [2], care recommendations for patients with hepatitis and cirrhosis [11], clarifying common cancer myths [12,13], and answering health-related questions on social media [3]. While ChatGPT-4 provides professional and accurate responses and its conversational manner is warm, empathetic [3], and patient, it is not yet able to provide complete and correct guidance for cancer treatment [13,14].
In modern cancer care, the increasing application of electronic patient-reported outcomes (ePROs) underscores their importance in enhancing patient care quality and treatment effectiveness [15,16]. EPROs allow patients to report their health status, symptoms, and quality of life through digital platforms, providing valuable firsthand data for medical teams [17]. This approach not only helps physicians understand and manage symptoms more precisely but also gives patients a greater sense of participation and control during treatment [18].
Increasing research shows that the care model of electronic patient-reported outcomes (ePROs) provides patient data that can be increasingly integrated into clinical decision support tools [18,19,20,21,22]. This aids healthcare professionals in timely identifying and addressing potential health issues, thereby preventing disease progression or mitigating side effects. Recent ePROs research can help patients improve treatment tolerance, improve survival rates, enhance communication and interaction between doctors and patients, reduce unnecessary emergency department visits and hospitalizations [16], and decrease medical expenses, leading to better cost-effectiveness [23]. Additionally, the accumulation of ePROs data offers a rich resource for clinical research, contributing to improved future cancer treatment strategies and patient care models [24]. It also helps reduce carbon emissions, aiding hospital ESG (environmental, social, and governance) transformation [23,25], and provides better cancer care during the COVID-19 pandemic [15].
However, ePROs generate vast amounts of electronic symptom data from patients, necessitating additional nurses and time for interpretation, analysis, and further generation of clinical decision-making processes for symptom management [19,21]. For instance, when a patient reports persistent diarrhea accompanied by significant weight loss, healthcare providers may analyze the data to determine whether immediate intervention, such as a telephone reminder to return to the hospital for examination, is necessary. Additionally, this process may require collaboration with a dietitian to provide tailored health education on nutrition and hydration strategies, aiming to mitigate further deterioration and improve the patient’s quality of life.
In a medical environment marked by a shortage of oncology staff and overburdened healthcare personnel [26,27], ePROs may contribute to an increased workload. However, integrating ChatGPT-4 to analyze medical data, drive innovation, assist with patient discharge notes, and provide educational support could help alleviate the burden on healthcare teams and enhance patient care [2,4,9,10,28].
We conducted a pilot study utilizing ChatGPT-4 to analyze ePRO data on patient-reported side effects. ChatGPT-4 was employed to simulate various roles within the medical team, aiming to analyze side effect data across different cancer types, patient age groups, and treatment modalities, while providing recommendations for improvement. The medical team subsequently evaluated the feasibility of incorporating ChatGPT-4’s analytical responses into clinical decision-making processes.
2. Materials and Methods
2.1. Data Collection and Preparation
We utilize a web-based electronic patient-reported outcome system (developed by Cancell Tech Co., Ltd., Taipei , Taiwan, available at [29]), which was launched in January 2023 for use by cancer patients. Each patient can create their own account with a password, agree to the terms of use for clinical study by signing a consent form, and then log in to use the system. Patients are required to fill in basic information such as name, gender, age, type of cancer, stage, and current treatment. During their treatment, patients subjectively report symptoms of side effects twice a week using the electronic patient-reported outcome system, which incorporates common cancer side effects as defined by NCI/ASCO [16,30]. The data recorded by the patients include quantifiable metrics such as weight and body temperature; scores for quality of life and mood on a scale from 1 to 5, where higher scores indicate better states; and pain scores also ranging from 1 to 5, with higher scores indicating more severe pain. Symptoms such as reduced appetite, stomach discomfort, diarrhea, constipation, nausea and vomiting, coughing, shortness of breath, fatigue, depression, and insomnia are rated on a four-point scale: none for no symptoms; mild, moderate, and severe symptoms; and radiation dermatitis using grading, covering a total of 16 symptom items. The data are stored in AWS cloud storage, with firewalls and other cybersecurity measures in place for data protection.
To gain an initial understanding of the ePRO data analysis for different cancer types, we consecutively collected 30 patients who had completed the ePRO side effect data for at least 4 weeks from September 2023 to December 2023. We de-linked and de-identified the basic information of these patients, retaining only their age, type of cancer, gender, stage, and treatment method, along with the ePRO side effect symptom data, for further analysis by ChatGPT-4.
Among the 30 de-identified patients, an example of ePRO side effect data collected during treatment for nasopharyngeal cancer is presented. The data was formatted in Excel and then copied and pasted into a new conversation in ChatGPT-4 on the OpenAI website [31], as shown in Figure 1.
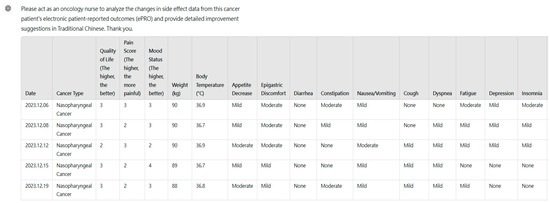
Figure 1.
Example of ePRO data from a nasopharyngeal cancer patient used to prompt GPT-4 to act as a nurse for evaluating the data.
2.2. ChatGPT-4 Prompt
We referred to the prompt engineering recommendations from the OpenAI website (https://platform.openai.com/docs/guides/prompt-engineering (accessed on 5 January 2024) [32] and adopted the “adopt persona” approach to have ChatGPT-4 simulate three types of professionals. For each new conversation, we made a prompt to request ChatGPT-4 to simulate the roles of an oncologist, a dietitian, and a nurse, respectively, to analyze the changes in 4 weeks of ePRO side effect data for these 30 patients undergoing cancer treatment, providing analysis and improvement suggestions, as shown in Figure 1. The prompt used was as follows: “Please act as an oncologist (or a dietitian, or a nurse) to analyze the changes in the side effect data from this cancer patient’s electronic patient-reported outcomes (ePRO) and provide detailed improvement suggestions in Traditional Chinese. Thank you.” It was the same for all patients. We made 90 prompts and then collected 90 corresponding responses across the three expert roles of 30 patients generated by ChatGPT-4. (Each patient received 3 sets of expert simulations by ChatGPT-4.) An example of a response from GPT-4 acting as a nurse for a nasopharyngeal cancer patient’s ePRO data is shown in Table 1.

Table 1.
Example of a response of GPT-4 acting as a nurse to evaluate a nasopharyngeal cancer patient’s ePRO data, with subsequent review by the oncologist, dietitian, and nurse.
2.3. Evaluation Workflow
Thirty patients received a total of 90 sets of recommendations generated by ChatGPT-4 across the three expert roles.
These recommendations were then evaluated by a senior medical team comprising 2 oncologists, 2 oncology dietitians, and 2 oncology nurses, resulting in 180 evaluations per role, totaling 540 evaluations. The medical teams evaluated all responses, including the patient’s ePRO data and ChatGPT-4’s replies, using eight criteria grounded in their professional expertise. The eight criteria were: response completeness, content accuracy, minimized risk to the patient, empathy demonstrated in the reply, emotional support provided, improvement in patient communication efficiency, the potential of ChatGPT-4 to alleviate the medical care workload when used cautiously, and its effectiveness in enhancing patient health literacy regarding their disease. The evaluations were scored on a scale from 0 to 10, with 0 representing very poor and 10 representing very good evaluation, with examples in Table 1. ANOVA statistical analysis was used to determine if there were any significant differences among the eight evaluation criteria for the three simulated professions by ChatGPT-4. This study workflow is shown in Figure 2.

Figure 2.
The evaluation workflow of this study.
The study was approved by the institutional review board of China Medical University and Hospital, Taichung, Taiwan (No.:ePRO_HN_001/CMUH112-REC2-128).
3. Results
Among the 30 consecutively selected cancer patients, there were eight cases of breast cancer, seven cases of head and neck cancer, three cases of lung cancer, and two cases each of prostate cancer, pancreatic cancer, lymphoma, renal cell carcinoma, uterine sarcoma, and endometrial cancer. In terms of cancer stages, there were five cases of stage I, seven cases of stage II, eight cases of stage III, and ten cases of stage IV. The median age was 55 years. Regarding treatment methods, 12 patients received chemotherapy, 8 underwent concurrent chemoradiotherapy, 5 had radiotherapy, and 5 were given targeted therapy. There were 11 male patients and 19 female patients. The patients’ characteristics are in Table 2.
Table 2.
Patient characteristics.
The two oncologists evaluating GPT-4 included a radiation oncologist and a hematologist-oncologist. Furthermore, two oncologists, two oncology nutritionists, and two oncology nurses assessed GPT-4’s simulated performance across three roles in the treatment of 30 patients, resulting in 180 evaluations per role, totaling 540 evaluations.
When ChatGPT-4 performed as an oncologist, dietitian, and nurse in analyzing the ePRO data of 30 patients, the average evaluation scores for each role are presented in Table 3.
Table 3.
Scores of GPT-4 acting as an oncologist, dietitian, and nurse evaluating ePRO data and ANOVA statistical analysis.
ChatGPT-4 was assigned three roles: oncologist, dietitian, and nurse. Analysis of ePRO data from 30 patients across eight criteria, using ANOVA, revealed no significant differences (p > 0.05) among the three roles, as shown in Table 3. The average scores across the eight criteria were 6.85/10 for the oncologist, 7.31/10 for the dietitian, and 7.16/10 for the nurse. ChatGPT-4 achieved its highest performance in the role of dietitian. There are some examples of good responses from ChatGPT-4 in Table 4.
Table 4.
The examples of good responses from ChatGPT-4.
4. Discussion
In this study, electronic patient-reported outcomes (ePROs) were employed to gather data on patients’ self-reported health status, symptoms, and quality of life via digital devices. While the extensive data from ePROs facilitates early intervention and mitigates side effects, it also significantly increases the workload for medical teams [19,20]. ChatGPT-4 demonstrated its potential in effectively processing and analyzing these vast volumes of data, enabling medical professionals to better comprehend patient needs and respond in an empathetic and emotionally supportive manner [33].
The analysis of ePRO data in traditional Chinese from 30 consecutive cancer patients by ChatGPT-4 yielded ratings from “acceptable” to “good”; the average score achieved was 6.85 to 7.31, showing no significant differences when simulating the roles of oncologists, dietitians, and nurses. ChatGPT-4 particularly excelled in completeness and accuracy, indicating its effectiveness in processing ePRO data and identifying critical side effects. This underscores the potential of AI to enhance clinical decision-making and patient care, particularly by aiding healthcare professionals in managing extensive patient-reported outcomes amidst a demanding medical workflow.
The minimal patient harm observed can likely be attributed to the careful limitation of ChatGPT-4’s evaluation to ePRO content only [34]. This suggests a need for continued caution when employing AI technologies based on large language models. Future improvements in AI response accuracy and correctness may be achieved through retrieval-augmented generation (RAG), which could help prevent incorrect answers that might negatively impact patients [35]. Nonetheless, the moderate scores for empathy and emotional support highlight AI’s limitations in fully addressing the emotional needs of patients, suggesting that AI tools should be used in conjunction with personal interactions from healthcare professionals to meet comprehensive patient needs comprehensively [33].
Moreover, this study initially demonstrates AI’s potential to assist medical teams in utilizing ePROs for enhanced patient care, improving communication efficiency with patients, reducing medical care stress, and increasing health literacy. These results support further research to explore and integrate ChatGPT-4 and other AI technologies into clinical ePRO applications for cancer care, aiming to foster patient-centered care and improve treatment outcomes.
While the recommendations provided by ChatGPT-4 in the roles of oncologist, dietitian, and nurse were statistically similar, the model received higher evaluations when simulating the role of an oncology dietitian. This may reflect the significant role of nutritional education in managing cancer side effects via ePROs and highlights the importance of nutritional support in enhancing patient quality of life. It could also suggest that ChatGPT-4 has specific advantages in delivering nutritional literacy and education, emphasizing the unique and crucial role of a virtual dietitian in patient care [28].
This pilot study encountered several limitations, such as a small sample size and issues with the misidentification of worsened ePRO side effects. The diversity of the data input into ChatGPT, including a range of cancer types, stages, treatments, and patient demographics, added complexity but also presented unique opportunities. This heterogeneity allowed us to test the model’s ability to generalize across varied clinical scenarios, which is crucial for its applicability in real-world settings. However, it also posed challenges in ensuring the consistency and accuracy of the AI’s outputs, as well as in verifying the authenticity of patient-reported ePRO data. Potential bias may exist since ChatGPT’s performance was evaluated by only six professionals. Additionally, as a large language model, ChatGPT-4 was not specifically designed to adhere to the Health Insurance Portability and Accountability Act (HIPAA) [2], posing potential risks associated with race, age, and gender disparities. Furthermore, the model’s lack of accuracy and verified sources in providing cancer treatment recommendations warrants a cautious approach [13,14].
A further limitation is the degree to which ChatGPT-4 truly understands the distinctions among the roles of oncologist, dietitian, and nurse. The prompt to “act like an [expert]” remains somewhat open-ended, and it is unclear how ChatGPT-4 interprets each professional domain. This ambiguity may influence the validity of role-based responses and warrants more detailed instructions or context to ensure accurate role simulation.
In practical applications, the use of large language models like ChatGPT-4 in healthcare must consider data privacy, model bias, and the safe use of AI in medical decision-making processes. Future developments should balance technological innovation with legal and medical ethics to ensure that AI not only enhances healthcare efficiency but also safeguards patient rights and interests [10].
Overall, this study provides preliminary insights into the feasibility of integrating AI tools like ChatGPT-4 into ePRO cancer care. It highlights the potential to reduce healthcare provider workload and suggests directions for future research and applications. These include enhancing AI’s capability to revalidate cancer care knowledge through techniques like RAG and multimodal LLMs. Additionally, AI can provide emotional support and empathy, enhance doctor-patient communication, increase patient health literacy, reduce the burden on healthcare providers, minimize potential errors in AI-driven clinical processes, and further explore the optimal application of AI in various medical roles. With continued technological advancements and empirical research, AI has the potential to play a more significant role in ePRO cancer care and facilitate shared decision-making between clinicians and patients.
Author Contributions
For research articles with five authors, a short paragraph specifying their individual contributions were provided. Conceptualization, C.L. and T.W.; methodology, C.L.; software, C.L.; validation, C.C., M.L. and Y.W.; formal analysis, C.L.; investigation, C.L.; resources, T.W.; data curation, T.W.; writing—original draft preparation, C.L.; writing—review and editing, C.L.; visualization, C.L.; supervision, T.W.; project administration, C.L.; funding acquisition, T.W., C.C., M.L. and Y.W.; the three authors contributed equally to this work and share second authorship. Corresponding author: T.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially supported by China Medical University Hospital (CMUH) Grant DMR-111-076.
Institutional Review Board Statement
The study was approved by the institutional review board of China Medical University and Hospital, Taichung, Taiwan (No.: ePRO_HN_001/CMUH112-REC2-128, first approved on 8 August 2023).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The study detail data are unavailable due to privacy or ethical restrictions.
Acknowledgments
This brief text acknowledges the contributions of the Radiation Oncology department at China Medical University Hospital, Cancell Tech Co., Ltd., and OpenAI’s ChatGPT-4 for their respective roles in this research and for assistance in polishing the English translation.
Conflicts of Interest
The first author, Chih Ying Liao, is a consulting scholar oncologist for the ePRO platform of Cancell Tech Co., Ltd. (https://cancell.tw) for this study providing a clinical opinion about the ePRO system development. The other four authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Open AI. ChatGPT: Optimizing Language Models for Dialogue. Available online: https://openai.com/blog/chatgpt/ (accessed on 15 February 2023).
- Uprety, D.; Zhu, D.; West, H. ChatGPT—A Promising Generative AI Tool and Its Implications for Cancer Care. Cancer 2023, 129, 2284–2289. [Google Scholar] [CrossRef]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589. [Google Scholar] [CrossRef]
- Waisberg, E.; Ong, J.; Masalkhi, M.; Kamran, S.A.; Zaman, N.; Sarker, P.; Lee, A.G.; Tavakkoli, A. GPT-4: A New Era of Artificial Intelligence in Medicine. Ir. J. Med. Sci. 1971 2023, 192, 3197–3200. [Google Scholar] [CrossRef]
- Hopkins, A.M.; Logan, J.M.; Kichenadasse, G.; Sorich, M.J. Artificial Intelligence Chatbots Will Revolutionize How Cancer Patients Access Information: ChatGPT Represents a Paradigm-Shift. JNCI Cancer Spectr. 2023, 7, pkad010. [Google Scholar] [CrossRef] [PubMed]
- Browsing Is Rolling Back out to Plus Users. Available online: https://help.openai.com/en/articles/6825453-chatgpt-release-notes#h_4799933861 (accessed on 27 September 2023).
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Tan, M. The Role of ChatGPT in Scientific Communication: Writing Better Scientific Review Articles. Am. J. Cancer Res. 2023, 13, 1148. [Google Scholar] [PubMed]
- Liu, J.; Wang, C.; Liu, S. Utility of ChatGPT in Clinical Practice. J. Med. Internet Res. 2023, 25, e48568. [Google Scholar] [CrossRef]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in Medicine: An Overview of Its Applications, Advantages, Limitations, Future Prospects, and Ethical Considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Yeo, Y.H.; Samaan, J.S.; Ng, W.H.; Ting, P.-S.; Trivedi, H.; Vipani, A.; Ayoub, W.; Yang, J.D.; Liran, O.; Spiegel, B.; et al. Assessing the Performance of ChatGPT in Answering Questions Regarding Cirrhosis and Hepatocellular Carcinoma. Clin. Mol. Hepatol. 2023, 29, 721–732. [Google Scholar] [CrossRef] [PubMed]
- Johnson, S.B.; King, A.J.; Warner, E.L.; Aneja, S.; Kann, B.H.; Bylund, C.L. Using ChatGPT to Evaluate Cancer Myths and Misconceptions: Artificial Intelligence and Cancer Information. JNCI Cancer Spectr. 2023, 7, pkad015. [Google Scholar] [CrossRef]
- Dennstädt, F.; Hastings, J.; Putora, P.M.; Vu, E.; Fischer, G.F.; Süveg, K.; Glatzer, M.; Riggenbach, E.; Hà, H.-L.; Cihoric, N. Exploring Capabilities of Large Language Models Such as ChatGPT in Radiation Oncology. Adv. Radiat. Oncol. 2024, 9, 101400. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Kann, B.H.; Foote, M.B.; Aerts, H.J.W.L.; Savova, G.K.; Mak, R.H.; Bitterman, D.S. Use of Artificial Intelligence Chatbots for Cancer Treatment Information. JAMA Oncol. 2023, 9, 1459–1462. [Google Scholar] [CrossRef]
- Frailley, S.A.; Blakely, L.J.; Owens, L.; Roush, A.; Perry, T.S.; Hellen, V.; Dickson, N.R. Electronic Patient-Reported Outcomes (ePRO) Platform Engagement in Cancer Patients during COVID-19. J. Clin. Oncol. 2020, 38 (Suppl. S29), 172. [Google Scholar] [CrossRef]
- Basch, E.; Deal, A.M.; Dueck, A.C.; Scher, H.I.; Kris, M.G.; Hudis, C.; Schrag, D. Overall Survival Results of a Trial Assessing Patient-Reported Outcomes for Symptom Monitoring During Routine Cancer Treatment. JAMA 2017, 318, 197. [Google Scholar] [CrossRef]
- Meirte, J.; Hellemans, N.; Anthonissen, M.; Denteneer, L.; Maertens, K.; Moortgat, P.; Van Daele, U. Benefits and Disadvantages of Electronic Patient-Reported Outcome Measures: Systematic Review. JMIR Perioper. Med. 2020, 3, e15588. [Google Scholar] [CrossRef]
- Basch, E.; Barbera, L.; Kerrigan, C.L.; Velikova, G. Implementation of Patient-Reported Outcomes in Routine Medical Care. Am. Soc. Clin. Oncol. Educ. Book 2018, 38, 122–134. [Google Scholar] [CrossRef]
- Daly, B.; Nicholas, K.; Flynn, J.; Silva, N.; Panageas, K.; Mao, J.J.; Gazit, L.; Gorenshteyn, D.; Sokolowski, S.; Newman, T.; et al. Analysis of a Remote Monitoring Program for Symptoms Among Adults With Cancer Receiving Antineoplastic Therapy. JAMA Netw. Open 2022, 5, e221078. [Google Scholar] [CrossRef] [PubMed]
- Basch, E.; Stover, A.M.; Schrag, D.; Chung, A.; Jansen, J.; Henson, S.; Carr, P.; Ginos, B.; Deal, A.; Spears, P.A.; et al. Clinical Utility and User Perceptions of a Digital System for Electronic Patient-Reported Symptom Monitoring During Routine Cancer Care: Findings From the PRO-TECT Trial. JCO Clin. Cancer Inform. 2020, 4, 947–957. [Google Scholar] [CrossRef] [PubMed]
- Rocque, G.B. Learning From Real-World Implementation of Daily Home-Based Symptom Monitoring in Patients With Cancer. JAMA Netw. Open 2022, 5, e221090. [Google Scholar] [CrossRef] [PubMed]
- Denis, F.; Basch, E.; Septans, A.-L.; Bennouna, J.; Urban, T.; Dueck, A.C.; Letellier, C. Two-Year Survival Comparing Web-Based Symptom Monitoring vs Routine Surveillance Following Treatment for Lung Cancer. JAMA 2019, 321, 306. [Google Scholar] [CrossRef] [PubMed]
- Lizée, T.; Basch, E.; Trémolières, P.; Voog, E.; Domont, J.; Peyraga, G.; Urban, T.; Bennouna, J.; Septans, A.-L.; Balavoine, M.; et al. Cost-Effectiveness of Web-Based Patient-Reported Outcome Surveillance in Patients With Lung Cancer. J. Thorac. Oncol. 2019, 14, 1012–1020. [Google Scholar] [CrossRef] [PubMed]
- Schwartzberg, L. Electronic Patient-Reported Outcomes: The Time Is Ripe for Integration Into Patient Care and Clinical Research. Am. Soc. Clin. Oncol. Educ. Book 2016, 36, e89–e96. [Google Scholar] [CrossRef]
- Lokmic-Tomkins, Z.; Davies, S.; Block, L.J.; Cochrane, L.; Dorin, A.; Von Gerich, H.; Lozada-Perezmitre, E.; Reid, L.; Peltonen, L.-M. Assessing the Carbon Footprint of Digital Health Interventions: A Scoping Review. J. Am. Med. Inform. Assoc. 2022, 29, 2128–2139. [Google Scholar] [CrossRef] [PubMed]
- Gesner, E.; Dykes, P.C.; Zhang, L.; Gazarian, P. Documentation Burden in Nursing and Its Role in Clinician Burnout Syndrome. Appl. Clin. Inform. 2022, 13, 983–990. [Google Scholar] [CrossRef] [PubMed]
- Guveli, H.; Anuk, D.; Oflaz, S.; Guveli, M.E.; Yildirim, N.K.; Ozkan, M.; Ozkan, S. Oncology Staff: Burnout, Job Satisfaction and Coping with Stress. Psychooncology 2015, 24, 926–931. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.B. ChatGPT as a Virtual Dietitian: Exploring Its Potential as a Tool for Improving Nutrition Knowledge. Appl. Syst. Innov. 2023, 6, 96. [Google Scholar] [CrossRef]
- Cancell Tech Co., Ltd. Taiwan Web ePRO System. Available online: https://cancell.tw (accessed on 1 August 2023).
- National Cancer Institute Side Effect of Cancer Treatment. Available online: https://www.cancer.gov/about-cancer/treatment/side-effects (accessed on 1 August 2023).
- Open Ai ChatGPT. Available online: https://chat.openai.com (accessed on 5 January 2024).
- ChatGPT Prompt Engineering Guide. Available online: https://platform.openai.com/docs/guides/prompt-engineering (accessed on 5 January 2024).
- Sorin, V.; Brin, D.; Barash, Y.; Konen, E.; Charney, A.; Nadkarni, G.; Klang, E. Large Language Models (LLMs) and Empathy—A Systematic Review. medRxiv 2023. [Google Scholar] [CrossRef]
- Athaluri, S.A.; Manthena, S.V.; Kesapragada, V.S.R.K.M.; Yarlagadda, V.; Dave, T.; Duddumpudi, R.T.S. Exploring the Boundaries of Reality: Investigating the Phenomenon of Artificial Intelligence Hallucination in Scientific Writing Through ChatGPT References. Cureus 2023, 15, e37432. [Google Scholar] [CrossRef] [PubMed]
- Kresevic, S.; Giuffrè, M.; Ajcevic, M.; Accardo, A.; Crocè, L.S.; Shung, D.L. Optimization of hepatological clinical guidelines interpretation by large language models: A retrieval augmented generation-based framework. NPJ Digit. Med. 2024, 7, 102. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).