Highlights
- A general lightweight SLAM system is proposed that achieves high real-time performance by replacing traditional feature matching with efficient sparse optical flow tracking.
- A coarse-to-fine pose estimation strategy ensures robust and accurate camera localization through RANSAC PnP and subsequent nonlinear optimization.
What are the main findings?
- A lightweight visual SLAM approach for RGB-D and stereo cameras is proposed, incorporating loop detection and re-localization.
- A three-strategy adaptive ORB feature extraction method is combined with a coarse-to-fine, two-stage pose estimation process to improve localization accuracy.
What are the implications of the main findings?
- The findings demonstrate that high-precision visual localization and mapping can be achieved without compromising computational efficiency.
- The integration of multi-level optical flow with coarse-to-fine pose refinement enables GL-VSLAM to balance accuracy and speed for deployment on resource-limited platforms.
Abstract
Feature-based indirect SLAM is more robust than direct SLAM; however, feature extraction and descriptor computation are time-consuming. In this paper, we propose GL-VSLAM, a general lightweight visual SLAM approach designed for RGB-D and stereo cameras. GL-VSLAM utilizes sparse optical flow matching based on uniform motion model prediction to establish keypoint correspondences between consecutive frames, rather than relying on descriptor-based feature matching, thereby achieving high real-time performance. To enhance positioning accuracy, we adopt a coarse-to-fine strategy for pose estimation in two stages. In the first stage, the initial camera pose is estimated using RANSAC PnP based on robust keypoint correspondences from sparse optical flow. In the second stage, the camera pose is further refined by minimizing the reprojection error. Keypoints and descriptors are extracted from keyframes for backend optimization and loop closure detection. We evaluate our system on the TUM and KITTI datasets, as well as in a real-world environment, and compare it with several state-of-the-art methods. Experimental results demonstrate that our method achieves comparable positioning accuracy, while its efficiency is up to twice that of ORB-SLAM2.
1. Introduction
Simultaneous localization and mapping (SLAM) encompasses techniques aimed at concurrently constructing a map of an unfamiliar environment and determining the sensor’s position within it. Emphasizing real-time performance, SLAM plays a vital role in enabling autonomous vehicles, drones, and mobile robots to navigate and localize effectively in uncharted areas [1,2,3]. Among various sensors, cameras are particularly advantageous due to their compact size, low energy consumption, and ability to capture rich information, making them one of the key external sensors for SLAM systems. When cameras are used as the main sensor, the system is referred to as visual SLAM (VSLAM). VSLAM can be divided into two main categories: direct methods, which are based on photometric measurements, and indirect methods, which rely on feature extraction and matching, depending on the visual measurement techniques and error models used. Direct methods [4,5,6] bypass the need for keypoint and descriptor extraction, instead utilizing pixel-level intensity values for matching and optimization. These methods estimate camera poses by minimizing photometric errors, which significantly enhances real-time performance. Direct methods, however, face challenges in map reuse, loop detection, and re-localization after tracking loss. In contrast, indirect methods [7,8] offer stable performance, are less affected by lighting conditions, and are more suitable for loop detection and map reuse. As a result, indirect methods are more widely applicable. These methods typically involve extracting sparse, stable keypoints from each frame, performing feature matching based on their descriptors, and optimizing camera poses by minimizing reprojection errors.
VSLAM requires both high accuracy and low computational cost [9,10,11]. The efficiency of feature extraction and the precision of pose estimation are key factors influencing system performance. Among various feature extraction methods [12,13,14,15], oriented FAST and rotated BRIEF (ORB) [15] features are commonly used due to their stability and efficiency. The ORB algorithm addresses the non-directional limitation of the features from the accelerated segment test (FAST) [14] corner detector and utilizes the fast-binary descriptor binary robust independent elementary features (BRIEF) [16], significantly accelerating the feature extraction process. This improves real-time performance and enhances algorithm robustness. However, the extracted feature points tend to cluster together. In situations where the sensor is obstructed or external factors cause abrupt lighting changes, images may become blurred, making it challenging to extract stable feature points using a fixed threshold. Mur-Artal [8] et al. introduced a quadtree-based ORB feature extraction method in ORB-SLAM2 to improve uniformity. However, this approach uses a fixed threshold for the entire image, which struggles to adapt to varying regional feature complexity. Additionally, the quadtree method increases computational complexity. Wu [17] et al. developed an adaptive ORB feature detection method with a variable extraction radius to enhance efficiency. However, this approach does not ensure uniform distribution or distinctiveness of feature points across different image regions. Ma [18] et al. proposed a threshold extraction algorithm based on gray clustering, offering some adaptability to ambient light changes. However, its performance is weaker at cluster boundaries, and the method incurs high computational costs.
Minimizing photometric errors in direct methods or reprojection errors in indirect methods can be framed as a nonlinear least squares problem, typically solved using bundle adjustment (BA) algorithms [19] for pose estimation and optimization. Forster et al. [5] introduced semi-direct visual odometry (SVO), which minimizes the photometric error between feature points in the previous frame and corresponding projected points in the current frame. The camera pose relative to the previous frame was then obtained, followed by optimization of the 2D coordinates of the projected points to achieve accurate pose estimation through reprojection error minimization. Direct sparse odometry (DSO) [6], proposed by Engel, is a direct visual odometry method that lacks loop detection and map reuse capabilities. It samples pixels with significant intensity gradients and incorporates photometric error and model parameters into the optimization function, enabling semi-dense mapping on a standard CPU. ORB-SLAM [7] is a real-time monocular SLAM system that utilizes feature points, capable of functioning effectively in both indoor and outdoor settings. It demonstrates strong robustness against abrupt motion. The backend utilizes bundle adjustment (BA) for global pose optimization and a loop detection algorithm based on the bag-of-words model. ORB-SLAM2 [8] extends ORB-SLAM by incorporating stereo and RGB-D cameras for sparse 3D reconstruction. ORB-SLAM3 [20] builds upon ORB-SLAM2 by integrating an inertial measurement unit (IMU). Visual–inertial navigation system—Mono (VINS-Mono) [21], a visual–inertial odometry system, employs tightly coupled sliding window nonlinear optimization, using optical flow and Harris corner points in the frontend for visual processing. The backend performs system state updates and optimizations by minimizing reprojection errors and IMU measurement residuals and supports online extrinsic calibration, loop detection, and pose graph optimization. Qin et al. later expanded VINS-Mono to develop a visual–inertial navigation system—fusion (VINS-Fusion) [22], which integrates multiple visual–inertial sensors for autonomous precise positioning.
In recent years, learning-based SLAM methods have emerged, leveraging task-specific datasets to enhance their predictive capabilities. iMAP [23] pioneered the use of a multilayer perceptron (MLP) to represent scene maps within SLAM, integrating implicit neural networks to achieve commendable tracking and mapping performance on benchmark datasets. NICE-SLAM [24] combines neural implicit decoders with hierarchical grid-based representations, facilitating scalable and efficient mapping of large-scale indoor environments. However, these methods typically require substantial computational resources and suffer from limited generalization across diverse environments.
A complete VSLAM system consists of three main components: tracking, local mapping, and loop closure. The tracking thread, responsible for estimating the current camera pose in real-time, feeds this information to the backend for optimization and loop closure. Consequently, the performance and accuracy of the tracking thread are crucial for the overall efficiency of the VSLAM system. In this paper, we present a lightweight visual SLAM approach built upon ORB-SLAM2 [8]. As illustrated in Figure 1, our method leverages sparse optical flow for tracking adjacent frames within the tracking thread, eliminating the need for redundant feature extraction, which significantly enhances the system’s real-time performance.
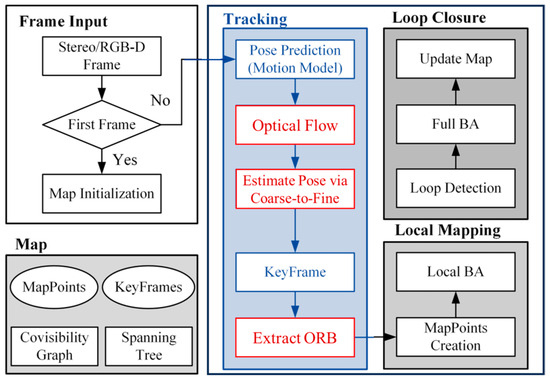
Figure 1.
The system consists of three threads: tracking, local mapping, and loop closure. The tracking thread outputs camera pose estimates and selects keyframes in real-time. The local mapping thread performs local BA on keyframes to optimize the local map. The loop closure thread performs loop detection to correct accumulated drift and executes BA to optimize the global trajectory and map. The system maintains a map structure, including map points, keyframes, a co-visibility graph, and a spanning tree. The structure is compact and can timely remove unused information while retaining useful observations, avoiding redundant computation.
The main contributions are as follows:
- (1)
- We propose a lightweight visual SLAM approach for RGB-D and stereo cameras, which includes loop detection and re-localization. This directly addresses the computational bottleneck of descriptor-based feature matching in systems like ORB-SLAM2. Instead of relying on redundant feature extraction, correspondences between adjacent frames are established by minimizing grayscale error. Keypoints are only extracted, and descriptors are computed to build a bag-of-words model [25] for backend optimization and loop closure detection when a keyframe decision is made.
- (2)
- We propose a three-strategy ORB feature adaptive extraction algorithm to overcome the poor adaptability of fixed-threshold feature extraction to varying environments. During feature extraction, an adaptive threshold is used to retain real features while considering the difference between global and local images, improving adaptability to complex environments. When using quadtrees to filter feature points, the maximum depth of the quadtree is set to avoid over-subdivision while ensuring the number of extracted feature points, thus improving algorithm efficiency.
- (3)
- We introduce a coarse-to-fine strategy to enhance pose estimation accuracy in two stages, effectively resolving the vulnerability of single-stage pose estimation in rapid motion scenarios. Initially, the pose predicted by the uniform motion model serves as the starting point for optical flow tracking, minimizing the algorithm’s iterations. Then, the camera pose estimated using PnP based on the feature points tracked by optical flow is refined by further optimizing the pose through reprojection error minimization.
2. Three-Strategy ORB Feature Adaptive Extraction Algorithm
ORB-SLAM2 [8] uses a quadtree-based ORB feature extraction method to enhance uniformity. However, it applies a fixed threshold across the entire image, which does not effectively accommodate the varying complexity of features in different regions. Additionally, the introduction of the quadtree algorithm increases computational overhead. This paper proposes a three-strategy ORB feature adaptive extraction algorithm to address the above issues. Figure 2 shows the workflow diagram, where represents the total number of quadtree nodes and “depth” represents the current quadtree depth. The main implementations are as follows:
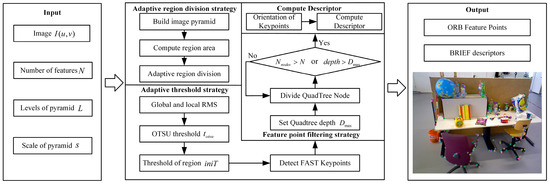
Figure 2.
The extraction algorithm includes three strategies: adaptive region division strategy, adaptive extraction threshold strategy, and feature point filtering strategy based on an improved quadtree.
- (1)
- Adaptive region division strategy adaptively divides regions based on the area and number of extracted features in each pyramid level, improving the rationality of region division and adaptability to complex environments.
- (2)
- Adaptive extraction threshold strategy adaptively adjusts the threshold through gray information, global threshold extraction coefficient, and the OTSU [26] threshold or minimum extraction threshold of each region in each level image. This can maximally retain real features while considering differences between global and local images, better adapting to changes in brightness and textures of different regions. This strategy enhances the accuracy and robustness of feature extraction, improving the precision of feature matching.
- (3)
- The feature point filtering strategy based on an improved quadtree adjusts the maximum division depth of quadtree nodes at different pyramid levels. This approach not only ensures the desired number of feature points but also eliminates redundant points, retaining those with higher responses. As a result, the spatial distribution of feature points is optimized, enhancing the overall efficiency of the algorithm.
2.1. Adaptive Region Division Strategy
The image pyramid is built as shown in Figure 3. The number of feature points is distributed to each level of the pyramid, with as the number of points extracted in the th level:
where is the expected number of feature points, is the pyramid scale factor, and is the number of pyramid levels. Experimental tests found that by replacing with in the above formula, it can increase the number of feature points in higher levels and make the distribution of feature quantities more uniform across levels, improving the precision of feature matching. According to the size of each level image and the allocated number of feature points , the side length of the regions to be divided in the th level image can be calculated. Let the width and height of the th level image be and , respectively. Then,
where represents the length of the side of the divided region. The function takes the integer of the function result, and is a proportional coefficient. The number of columns and rows of the regions for each pyramid level are then calculated based on the size of the corresponding level image as follows:
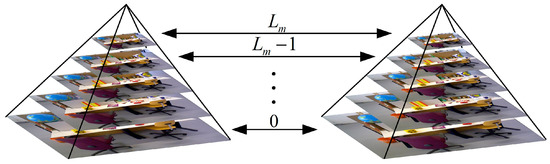
Figure 3.
Pyramids built based on the level and scale factor.
The actual width and height of the regions are then determined based on the calculated number of columns and rows as follows:
In our implementation, the expected number of features is set to 1000, the pyramid scale factor to 1.2, and the number of pyramid levels to 8, following the parameter configuration recommended in the original ORB algorithm publication [8]. The proportional coefficient in Equation (2) is empirically set to 0.8 to balance the granularity of region division and computational efficiency.
2.2. Adaptive Extraction Threshold Strategy
ORB features are derived from FAST corners, with additional scale and rotation invariance. FAST corners identify keypoints by comparing the grayscale differences between a pixel and its neighbors. The feature extraction threshold defines the minimum grayscale difference necessary to detect a corner, which also represents the maximum noise tolerance the method can handle. This paper adaptively adjusts the extraction threshold based on the root mean square contrast divided into global and local regions. This can better adapt to changes in brightness and textures of different regions, thereby enhancing the accuracy and robustness of feature extraction. The image is divided into pixel levels. represents the number of pixels, and represents the probability at the pixel level. The threshold t divides the image into foreground and background . Then,
where and represent the probability that a pixel is assigned to the foreground and the background, respectively. Then, the foreground gray mean and background gray mean are as follows:
The between-class variance is then obtained:
The pixel levels are traversed in the region to obtain the gray threshold , which maximizes the between-class variance . According to the contrast and gray distribution characteristics of the image, a self-adaptive threshold is dynamically calculated for FAST corner detection:
where is a proportional coefficient. and represent the maximum and minimum gray values in the image, respectively. In our implementation, the coefficient is set to 5 (or 10 in high-contrast scenes), following the standard configuration of the FAST corner detector. To suppress noise-induced responses, the minimum extraction threshold is fixed at 5. These parameter settings were selected based on empirical evaluation on the TUM [27] and KITTI [28] datasets and are consistent with commonly used FAST/ORB configurations.
The root mean square (RMS) contrast of an image can reflect the degree of dispersion between the pixel values and the mean value. A larger value indicates clearer edge information and better image quality, requiring a larger threshold extraction coefficient. Conversely, when the RMS is small, a smaller threshold extraction coefficient should be set. Firstly, the RMS contrast of each local divided region is calculated. If the value is greater than the preset threshold, the feature extraction threshold of the region is calculated directly according to Equation (10). Otherwise, the RMS of the whole image is calculated first to determine the threshold extraction coefficient, and then the region-adaptive threshold is calculated by combining the brightness of the region so as to fully consider the quality differences between different regions of the image, realize automatic adjustment of the threshold, and improve the corner detection effect, as shown in Equation (12).
where and represents the global and the local RMS contrast, represents the global threshold extraction coefficient, represents the adaptive parameter of image quality, and represents the adaptive parameter of foreground and background segmentation threshold.
2.3. Feature Point Filtering Strategy Based on Improved Quadtree
In the feature point filtering process of the quadtree division method in ORB-SLAM2 [8], the splitting depth of the quadtree is not restricted, resulting in too many splits and reducing the efficiency of the algorithm. In addition, the extracted feature points are overly uniformly distributed. To solve the above problems, this paper dynamically sets the maximum depth of quadtree nodes based on the number of feature points to be extracted on the th layer of the pyramid. The minimum when is taken as the depth of the th layer image, and the maximum depth of this layer image is calculated as follows:
where represents the number of child nodes without feature points among the 4 child nodes after splitting the root node of the quadtree, . First, each layer image is taken as the root node of the quadtree and split into 4 child nodes. Then, it is judged whether each child node contains feature points. If yes, the feature point within the child node is retained when each child node contains only one feature point. When each child node contains multiple feature points, the child node is split into 4 child nodes, and the depth and the total number of nodes after splitting are recorded; otherwise, the child node is deleted. When the total number of nodes in each layer image satisfies or satisfies or all nodes inside only have one feature point left, the feature point with the maximum Harris response in all nodes is taken as the screened feature point.
This can avoid excessive redundant subdivision while ensuring the number of extracted feature points, thus improving the efficiency of the algorithm. At the same time, by limiting the depth to control the number of feature points in each node, it can make the distribution of feature points in different regions of the image more uniform. The pseudocode of the three-strategy ORB feature adaptive extraction algorithm is shown in Algorithm 1, where represents the number of feature points in the node, represents the number of nodes, and represents the number of sub-nodes of the current node.
| Algorithm 1: Three-strategy ORB feature adaptive extraction algorithm |
| Input: Image , Number of features , Levels of pyramid , Scale factor of pyramid |
| Output: Uniformly distribute feature points and descriptors |
| 1: Compute Pyramid(, , ); |
| 2: for to do |
| 3: Divide image into cells; |
| 4: for to do |
| 5: for to do |
| 6: ; |
| 7: Compute Adaptive threshold ; |
| 8: Feature Extraction(, ); |
| 9: end for |
| 10: end for |
| 11: Set maximum depth of quadtree by; |
| 12: while do |
| 13: if then |
| 14: if then |
| 15: Split Node; |
| 16: else |
| 17: Save Node; |
| 18: end if |
| 19: end if |
| 20: if or then |
| 21: Finish Split and Non-Maximum Suppression; |
| 22: end if |
| 23: end while |
| 24: Restore the feature points to original image; |
| 25: end for |
| 26: return feature points and descriptors; |
To ensure the reproducibility of our method, all hyperparameters used in the three-strategy ORB feature extraction algorithm and the coarse-to-fine pose estimation pipeline are summarized in Table 1, together with the rationale behind their selection. These parameters follow the standard ORB-SLAM2 [8] configuration or are empirically tuned to balance feature density, robustness, and computational efficiency.

Table 1.
Hyperparameter settings used in our method.
3. Coarse-to-Fine Pose Estimation
Our Tracking thread adopts a uniform motion model to predict the current camera pose, then projects the 3D points in the world coordinate system to 2D points in the pixel coordinate system of the current frame based on the predicted pose, providing initial values for optical flow tracking. We use a multilayer optical flow method based on image pyramids to track feature points and remove tracking outlier pairs through backward optical flow tracking and the RANSAC algorithm. Finally, the camera pose estimated by PnP is used as the initial value, and the accurate camera pose is obtained by minimizing the reprojection error, as shown in the pseudocode in Algorithm 2.
| Algorithm 2: Coarse-to-fine pose estimation algorithm |
| Input: Keypoints and world points on the reference frame; last two frame poses , ; |
| Output: Optimized camera pose ; |
| 1: Predict keypoints according to the Uniform Motion Model by Equation (16): ; |
| 2: Solve the movement vector with Algorithm 3; |
| 3: Establish keypoint correspondences between adjacent frames by refining inliers using the outlier removal strategy described in Section 3.2; |
| 4: Calculate the initial camera pose using RANSAC PnP on the inliers; |
| 5: Further refine the pose by optimizing Equation (22); |
| 6: return ; |
| Algorithm 3: Multi-level optical flow method based on the uniform motion model |
| Input: Current frame and keypoint , next frame , and initial value ; |
| Output: Movement vector and keypoint correspondence; |
| 1: Build image pyramid: ; |
| 2: Keypoints on pyramid level : ; |
| 3: for do |
| 4: Objective function by Equation (21): ; |
| 5: Iteratively compute the optical flow of level : ; |
| 6: Use the optical flow result of level as the initial value for optical flow computation of level : ; |
| 7: end for |
| 8: return and ; |
3.1. Multi-Level Optical Flow Method Based on the Uniform Motion Model
Uniform Motion Model: It is assumed that the camera’s linear and angular velocities remain unchanged from the previous frame to the current frame. By calculating the relative motion increment between the two frames based on velocity and time interval, the current frame pose is estimated based on the previous frame pose using the estimated motion increment. The uniform motion model is shown in Figure 4, from which we can obtain the following:
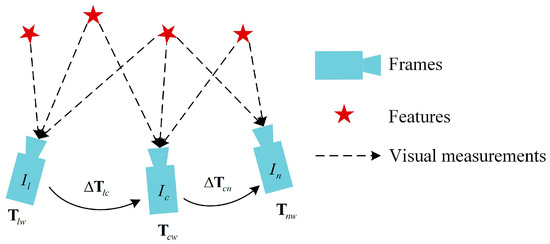
Figure 4.
Uniform motion model. are three consecutive frames, represent the poses of the three image frames in the world coordinate system, and represent the relative motion increments between adjacent frames.
Given the poses of two frames , in the world coordinate system and the homogeneous coordinate of a 3D point in the world coordinate system, the predicted homogeneous coordinate of the 2D point in the pixel coordinate system of the frame is as follows:
where represents the camera intrinsic matrix.
Optical flow tracks the movement of pixels over time in image sequences using the correlation between consecutive frames to establish correspondences. The principles of optical flow are based on two assumptions [29]:
Grayscale invariance: The pixel grayscale value of the same spatial point is the same in different images. Assuming a spatial point at time is located at position in the previous frame image with grayscale value , at time , the spatial point is located at position in the current frame, based on the grayscale invariance assumption.
Taylor expanding the left side of the equation and keeping the first-order term:
where and represent the image gradient in the and directions, respectively, at the pixel point, and represents the grayscale derivative over time at that point. Let and represent the pixel motion velocities in the and axes, respectively, then
Equation (19) cannot obtain a unique solution for ; therefore, the neighborhood motion consistency assumption is needed.
Neighborhood motion consistency: All pixels within a neighborhood have the same motion. For a neighborhood centered at pixel , all pixels within it have consistent motion:
Equation (20) is an overdetermined system of equations with respect to and , so the optical flow matching problem can be converted into solving a nonlinear optimization problem.
To find the matching point of a point in image frame in image frame based on the initial value estimated by the motion model, where is the optical flow of pixel , the optimal pixel offset is obtained by minimizing the grayscale error with the following objective function:
Due to the grayscale invariance assumption and the neighborhood motion consistency assumption of optical flow, optical flow methods are quite sensitive to changes in image brightness. Additionally, the motion of objects between adjacent frames must be sufficiently small. Therefore, an image pyramid is introduced to address situations where the image displacement is large, as shown in Figure 3.
When the pixel motion in the original image is fast, the pixel motion speed at higher layers is progressively decreased according to the pyramid scale factor , ensuring the optical flow assumptions by reducing pixel motion. Optical flow tracking is performed from the top layer to the bottom layer of the image pyramid sequentially, with the result of each layer used as the initial value for optical flow at the next layer, and the optical flow result at the bottom layer taken as the final result for this optical flow tracking, as shown in the pseudocode in Algorithm 3.
3.2. Outlier Removal
The multi-level optical flow method based on the uniform motion model can better track feature points of keyframes, but there may still be some incorrectly tracked feature points. To this end, we adopt two efficient strategies to refine inliers:
- (1)
- Reverse optical flow tracking: Taking the optical flow obtained from tracking as the prediction value and tracking it reversely to the current frame, the distance between the feature points corresponding to the reverse tracking and forward tracking is compared; if the distance is greater than a threshold, it is considered as an outlier and removed.
- (2)
- Fundamental matrix based on RANSAC [30]: For the feature points remaining after outlier removal by reverse optical flow tracking, the fundamental matrix between the previous frame and current frame is calculated, and RANSAC is used to remove outliers.
3.3. Pose Optimization
We employ a coarse-to-fine strategy to enhance pose estimation accuracy. Initially, an approximate camera pose is obtained using the RANSAC-based PnP algorithm on feature points tracked via optical flow. The pose is then refined by minimizing reprojection error. For RGB-D cameras, the 3D coordinates of feature points are directly derived from the depth image. In the case of stereo cameras, optical flow is used to match feature points between the left and right images, and their 3D positions in the world coordinate system are computed through triangulation. This approach begins with a rough pose estimation and iteratively refines it to improve accuracy.
According to feature point coordinates and their 3D positions in the world coordinate system, a least squares problem is built to optimize the camera pose so that the reprojection error between the 2D coordinates of feature points and the 2D coordinates obtained by projecting the 3D points according to the current pose is minimized, with the set of all matches:
where denotes the homogeneous pixel coordinate of the -th inlier feature point in the current frame, is the corresponding 3D point in the world coordinate system, represents the depth value (or the stereo-derived scale) of the -th feature point, and is the intrinsic matrix of the camera. The initial pose estimate is obtained using the RANSAC-based PnP algorithm and is subsequently refined by minimizing Equation (22) through a nonlinear least squares optimization.
3.4. New Keyframe Decision
By using keyframes to represent neighboring frames, the number of frames to be optimized can be effectively reduced, improving the computational efficiency of the algorithm. This paper integrates temporal description, spatial description, and scene description to determine whether to add a keyframe:
- (1)
- The time interval between the current frame and the previous keyframe exceeds a threshold ;
- (2)
- The number of inlier points tracked by optical flow in the current frame is less than a threshold ;
- (3)
- The ratio of inlier matches between the current and previous frames falls below a predefined threshold ;
- (4)
- The pose change between the current frame and the previous keyframe is greater than a threshold .
4. Experimental Results
To ensure a fair comparison, we reproduced the results of ORB-SLAM2 [8], ORB-SLAM3 [20], and VINS-Fusion [22] using their official implementations on our evaluation platform. All methods were tested under the same hardware and dataset conditions. For learning-based methods such as NICE-SLAM [24] and iMAP [23], whose source codes involve complex training pipelines, we referred to the results reported in their original publications. The parameters for all reproduced methods were kept consistent with the original papers. Each sequence was executed five times, and the median results are reported to reduce the effects of runtime variability.
For both RGB-D and stereo experiments, we assumed that the cameras were fully calibrated prior to running our system. For the RGB-D configuration, depth images were registered to the RGB frame and undistorted using the intrinsic parameters provided by the camera. For the stereo configuration, the intrinsic and extrinsic parameters, including the baseline, were taken directly from the official KITTI calibration files and kept fixed during all experiments. These calibration assumptions ensure consistent reprojection accuracy and directly influence the precision of pose estimation.
We evaluated the localization accuracy and processing time of each frame in the tracking thread using two well-known public datasets: the Technical University of Munich (TUM) RGB-D dataset [27] and the Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) dataset [28]. We tested both RGB-D and stereo cameras with these datasets. The localization accuracy was compared with that of other open-source SLAM systems. To minimize the nondeterminism inherent in the multithreading system, each sequence was run five times, and the median results were used to determine the accuracy of the estimated trajectory. As shown in Section 4.1, we tested our proposed three-strategy ORB feature adaptive extraction algorithm, which demonstrates that our method achieves higher computational efficiency and accuracy. Additionally, we also conducted tests in a real-world environment to further validate our system’s performance.
4.1. Feature Matching
We evaluated the performance of the three-strategy ORB feature adaptive extraction algorithm proposed by us based on the inlier rate and computation time. Since our method is implemented based on the feature extraction algorithm of ORB-SLAM2, we compared it with ORB-SLAM2. Using the TUM dataset for testing, we first set the expected number of feature points as , the number of pyramid layers as , and the pyramid scale factor as . We obtained matched pairs using brute force matching and then used the RANSAC algorithm to remove outliers and obtain inliers [30].
The comparison of feature matching results between ORB-SLAM2 and our method is shown in Table 2. The quantitative results are shown in Table 3, where “Matches” refers to the matched pairs obtained by brute force matching, “Inliers” refers to the matched pairs after screening, “Ratio” refers to the ratio of “Inliers” to “Matches”, and “Time” refers to the time consumed by feature extraction. The results show that our method achieves higher accuracy than ORB-SLAM2 while reducing computational time. As can be seen from Table 2, even after removing most mismatches through the RANSAC algorithm, there are still some mismatches in the feature extraction method of ORB-SLAM2, while our method has almost no mismatches.
Table 2.
Comparison of feature matching results.
Table 3.
Feature matching comparison of ratio (%) and time (ms).
4.2. Localization Accuracy and Efficiency Experiments
We evaluated the proposed method based on localization accuracy and frontend odometry tracking time. The absolute pose error (APE) was used to measure the error between the estimated trajectory from the system and the ground truth, calculated as follows:
where is the estimated pose from the system at time , and is the ground truth pose. A lower APE indicates higher localization accuracy.
4.2.1. TUM RGB-D Dataset
The TUM dataset consists of indoor sequences captured by RGB-D cameras, including various lighting, structural, and textural conditions. Since our proposed method is implemented based on ORB-SLAM2, we compared it with ORB-SLAM2 and other representative visual SLAM systems in terms of average per-frame frontend odometry tracking time and trajectory error comparison, as shown in Table 4 and Table 5, respectively.
Table 4.
Average time (ms) comparison on the TUM dataset.
Table 5.
RMSE (m) comparison on the TUM dataset; “–” means that we could not obtain the value from the literature.
In Table 4, our method exhibits marginally higher RMSE in sequences like fr1/desk1 and fr1/desk2. This stems from repetitive textures and weak features in these scenes, causing brief optical flow mismatches. To preserve real-time performance, we restricted feature matching and local BA to keyframes, yielding sparser constraints than full feature-based or dense optimization methods, thus reducing drift suppression in texture-limited scenarios.
The experimental results indicate that both our method and ORB-SLAM2 exhibit high robustness. Notably, our approach extracts features and descriptors exclusively for keyframes, leading to nearly a twofold improvement in computational efficiency. Furthermore, in the fr3/ntf sequences characterized by vigorous camera motion, our method achieves higher localization accuracy compared to other state-of-the-art visual SLAM systems. Figure 5 shows the comparison of per-frame processing time in the frontend tracking thread for the fr1/desk1 sequence.
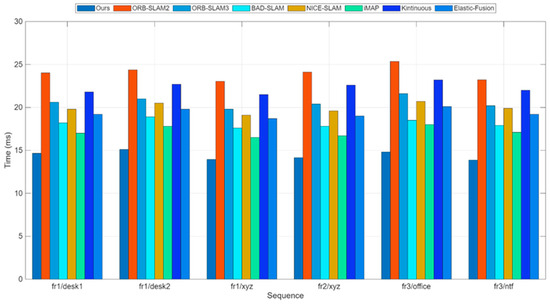
Figure 5.
Time consumption comparison for RGB-D on the TUM dataset. Average runtime comparison of all six sequences for different methods; more details are in Table 4.
Due to the improvements we made to the feature extraction algorithm in ORB-SLAM2, the stability and efficiency of feature extraction are enhanced. Therefore, the keyframe processing time of our method is slightly lower than ORB-SLAM2. Moreover, using the pose predicted by the uniform motion model as the initial value for optical flow tracking effectively reduces the iteration time of the multilayer optical flow method. Figure 5 shows the comparison of average per-frame processing time between our method and ORB-SLAM2 on six sequences from the TUM dataset. Figure 6 shows the trajectory and error comparison on the fr1/desk1 and fr3/office sequences.
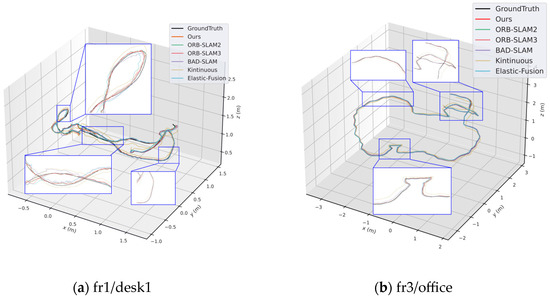
Figure 6.
Localization accuracy comparison on the TUM dataset. (a) results on the fr1/desk1 sequence, (b) results on the fr3/office sequence.
All experiments were conducted on a workstation equipped with an Intel Core i7 CPU (Intel Corporation, Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3080 GPU (NVIDIA Corporation, Santa Clara, CA, USA). The system was compiled using g++ with -O3 optimization, and all methods were executed under identical hardware and compilation settings to ensure a fair comparison.
Figure 7 shows the outlier removal results in two adjacent frames of the TUM dataset. Table 6 shows the time required for optical flow tracking and outlier removal. Reverse optical flow tracking takes the multilayer optical flow tracking result as the initial value, which can reduce the number of algorithm iterations and thus improve the running speed. Our method averages 2.04 ms to track an image of size 640 × 480 per frame.

Figure 7.
Keypoint tracking examples of the system on the TUM dataset, with 1000 features extracted per frame. The first to sixth rows show keypoint tracking examples on the TUM dataset. The left and right images in (a) represent the reference and current frame, respectively (image pairs). (b) The multilayer optical flow tracking result based on the uniform motion model (MOF). (c) The outlier removal result of reverse optical flow tracking (ROF). (d) The outlier removal result based on the fundamental matrix using RANSAC (RANSAC). (Blue represents the final retained feature points after the two-stage outlier removal process, red indicates the outliers eliminated by backward optical flow tracking, green denotes the outliers removed through the RANSAC-based fundamental matrix estimation).
Table 6.
Time (ms) of the multi-level optical flow method and outlier removal on the TUM dataset.
4.2.2. KITTI Stereo Dataset
The KITTI dataset consists of outdoor sequences captured by a stereo camera in urban and highway environments. We compared our method with ORB-SLAM2 and VINS-Fusion [22], a stereo-only and loop closure-enabled system, respectively. Table 7 and Table 8 show the comparison results of frontend odometry tracking time and trajectory errors, respectively.
Table 7.
Average time (ms) comparison on the KITTI dataset.
Table 8.
RMSE (m) comparison on the KITTI dataset.
Our method is capable of loop detection and re-localization in loop closure scenarios. In the KITTI-01 sequence, there are more dynamic obstacles and larger disparity changes when the vehicle turns, so our localization accuracy is relatively lower on this sequence. However, the tracking thread speed of our method is significantly better than ORB-SLAM2. Figure 8 shows the comparison of per-frame tracking time in the frontend thread on the KITTI-01 sequence. Figure 8 shows the average per-frame processing time comparison between our method and ORB-SLAM2 on six KITTI sequences. Figure 9 illustrates the trajectories of different methods on 02 and 05.
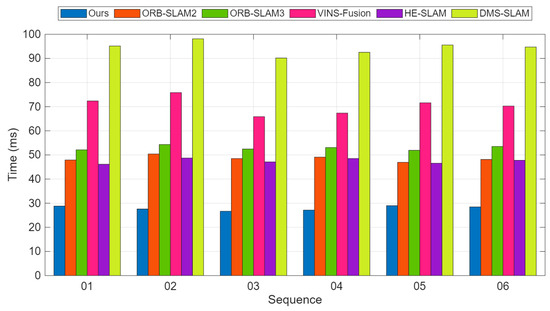
Figure 8.
Time consumption comparison for stereo on the KITTI dataset. Average runtime comparison of all six sequences for different methods. More details are in Table 7.
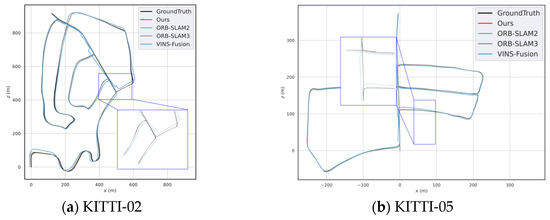
Figure 9.
Trajectory comparison on sequence (a) results on the KITTI-02 sequence and (b) results on the KITTI-05 sequence.
Our method achieved trajectory accuracy comparable to ORB-SLAM2 while demonstrating significantly higher localization precision than VINS-Fusion in both sequences.
Figure 10 shows the outlier removal results in two adjacent frames of the KITTI dataset. Table 9 shows the time required for optical flow tracking and outlier removal. Our method averages 3.97 ms to track an image of size 1226 × 370 per frame on the KITTI dataset.

Figure 10.
Keypoint tracking examples on the KITTI dataset. (a) Scene 1; (b) Scene 2. Each group of images from top to bottom shows the reference and current frame (image pairs), the multilayer optical flow–tracking result based on a uniform motion model (MOF), the outlier-removal result of reverse optical flow tracking (ROF), and the outlier-removal result based on the fundamental matrix using RANSAC. Blue represents the final retained feature points after the two-stage outlier-removal process; red indicates the outliers eliminated by backward optical-flow tracking; green denotes the outliers removed through the RANSAC-based fundamental matrix estimation.
Table 9.
Time (ms) of the multi-level optical flow method and outlier removal on the KITTI dataset.
As shown in Table 8, the proposed method exhibits a noticeable performance degradation on KITTI sequences 01 and 02 compared to other sequences. This is primarily due to the nature of these sequences, which involve high-speed driving scenarios with frequent sharp turns and the presence of dynamic objects such as cars and pedestrians. Under such conditions, the assumptions of the optical flow method—namely, small inter-frame motion and photometric consistency—tend to break down. Rapid rotational motion can cause large pixel displacements between consecutive frames, which challenges the accuracy of sparse optical flow tracking. In addition, dynamic objects introduce inconsistent motion patterns, making it difficult to establish stable correspondences, especially when no semantic filtering is applied.
These results highlight the limitations of our method in highly dynamic or rapidly changing environments. In future work, we aim to address this by integrating IMU data for improved pose prediction and incorporating semantic segmentation modules to suppress the influence of dynamic elements in the scene.
4.2.3. Real-World Experiments
To further validate the effectiveness of the proposed method, we conducted tests in a real-world environment. The mobile robot used in the experiment is shown in Figure 11 and is equipped with an Intel RealSense D435 depth camera (Intel Corporation, Santa Clara, CA, USA), a RoboSense LiDAR (RoboSense, Shenzhen, China). In this experiment, we only utilized the camera and GPS, where the camera was used to capture image frames, and the GPS data served as the reference ground truth.

Figure 11.
The mobile robot is equipped with a RealSense depth camera (1280 × 720 resolution) and a GPS. The depth camera captures image frame data, while the GPS data serves as the ground truth for the robot’s pose.
To ensure accurate synchronization between the camera and GPS data, we adopted a timestamp-based synchronization approach. Each image frame and corresponding GPS reading was assigned a precise timestamp, and the data were temporally aligned using interpolation to match each camera frame with its corresponding GPS position. In cases where the time deviation exceeded a defined threshold, a temporal windowing strategy was employed to discard misaligned data, thereby guaranteeing high-quality input. We selected absolute pose error (APE) as the primary evaluation metric, as it quantitatively measures the accuracy of the estimated trajectory with respect to ground truth. By computing the deviation between the estimated and reference poses, APE offers an intuitive and reliable indicator of localization accuracy, particularly in real-world scenarios. This metric is widely adopted in SLAM systems, especially in dynamic environments, due to its effectiveness in assessing trajectory consistency across different motion patterns. In addition, we also computed the root mean square error (RMSE) to evaluate the system’s positional stability and consistency over time. Experiments were conducted across various real-world environments, encompassing both loop and non-loop scenarios, to comprehensively assess the robustness and accuracy of our system under dynamic and complex conditions.
We conducted six experiments in different environments, including both loop and non-loop scenarios, and compared the localization results of our method with ORB-SLAM2, as summarized in Table 10 and Table 11. The results for each sequence are presented as the median values across five executions, where RMSE denotes the translational error in meters, and time represents the average per-frame tracking time in milliseconds. The experimental results indicate that the computation time of our method is significantly lower than that of ORB-SLAM2. In the st2 and st5 sequences, our method achieves higher localization accuracy than ORB-SLAM2, and it also demonstrates strong competitiveness in other sequences. The comparison of localization trajectories for all sequences is shown in Figure 12.
Table 10.
Average runtime (ms) comparison on real-world dataset.
Table 11.
RMSE (m) comparison on real-world dataset.
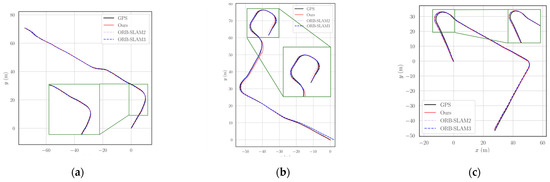
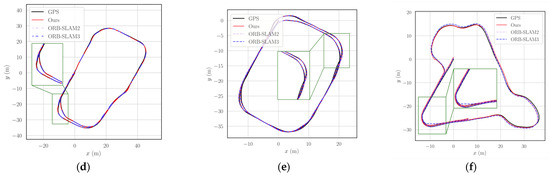
Figure 12.
Comparison of the trajectories between our method and ORB-SLAM2 in real-world scenarios. (a) st1; (b) st2; (c) st3; (d) st4; (e) st5; (f) st6. Each subplot illustrates the GPS ground truth, the trajectories estimated by ORB-SLAM2 and ORB-SLAM3, and the trajectories obtained by our method.
Figure 13 illustrates the outlier removal results for two consecutive frames in a real-world environment. Table 12 provides the computational details, showing that our method achieves an average processing time of 3.85 ms per frame for 1280 × 720 images, highlighting its efficiency in optical flow tracking and outlier removal.

Figure 13.
Examples of keypoint tracking in a real-world environment are presented, with 2000 features extracted per frame. (Blue represents the final retained feature points after the two-stage outlier removal process, red indicates the outliers eliminated by backward optical flow tracking, green denotes the outliers removed through the RANSAC-based fundamental matrix estimation).
Table 12.
Processing time (ms) of the multi-level optical flow method and outlier removal in a real-world environment.
5. Conclusions
We propose a general lightweight visual SLAM approach for RGB-D and stereo cameras: GL-VSLAM. GL-VSLAM uses a multi-level optical flow method based on the uniform motion model prediction to replace feature matching based on descriptors, significantly improving running efficiency. To ensure the positioning accuracy of the system, a coarse-to-fine strategy is introduced to improve the accuracy of pose estimation. The initial value of the camera pose is calculated by PnP based on the robust keypoint correspondences obtained by sparse optical flow, and a further refined pose is obtained by minimizing reprojection error. Our method balances the competing needs between localization accuracy and computational complexity. Qualitative and quantitative results show that our method achieves state-of-the-art accuracy and faster speed performance, which is almost two times that of ORB-SLAM2. However, the optical-flow-based tracking still relies on the assumptions of photometric consistency and small inter-frame motion, and its robustness may degrade in the presence of rapid rotations, significant motion blur, or abrupt illumination changes. Furthermore, without semantic or motion segmentation, the system remains sensitive to dynamic objects that introduce inconsistent motion patterns and reduce the stability of optical flow correspondences. These factors limit performance in highly dynamic or rapidly changing environments and motivate further enhancements to improve robustness.
In future work, we plan to further integrate an IMU and LiDAR to mitigate the limitations of a single sensor and enhance robustness in scenarios involving rapid motion.
Author Contributions
Conceptualization, X.L. and T.L.; methodology, Y.Z.; software, Z.L. and L.B.; validation, Z.L. and L.B.; formal analysis, Y.N.; investigation, Y.Z.; resources, Y.N.; data curation, Z.L.; writing—original draft preparation, Y.Z.; writing—review and editing, X.L. and T.L.; visualization, Y.N.; supervision, T.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Shaanxi Province Natural Science Basic Research Program under Grant 2025SYSSYSZD-105.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available in public repositories. The TUM RGB-D dataset is available at https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 10 August 2025). The KITTI Odometry dataset is available at https://www.cvlibs.net/datasets/kitti (accessed on 10 August 2025). The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| Abbreviations | English full form |
| APE | Absolute Pose Error |
| BA | Bundle Adjustment |
| BRIEF | Binary Robust Independent Elementary Features |
| DSO | Direct Sparse Odometry |
| FAST | Features from Accelerated Segment Test |
| GPS | Global Positioning System |
| IMU | Inertial Measurement Unit |
| LiDAR | Light Detection And Ranging |
| MLP | Multilayer Perceptron |
| MOF | Multi-level Optical Flow |
| ORB | Oriented FAST and Rotated BRIEF |
| OTSU | Otsu Thresholding Method |
| PnP | Perspective-n-Point |
| RANSAC | Random Sample Consensus |
| RMS | Root Mean Square |
| RMSE | Root Mean Square Error |
| ROF | Reverse Optical Flow Tracking |
| SLAM | Simultaneous Localization And Mapping |
| SVO | Semi-Direct Visual Odometry |
| VINS-Mono | Visual–Inertial Navigation System—Mono |
| VINS-Fusion | Visual–Inertial Navigation System—Fusion |
| VSLAM | Visual Simultaneous Localization and Mapping |
References
- Li, G.; Chi, X.; Qu, X. Depth Estimation Based on Monocular Camera Sensors in Autonomous Vehicles: A Self-supervised Learning Approach. Automot. Innov. 2023, 6, 268–280. [Google Scholar] [CrossRef]
- Ning, Y.; Li, T.; Du, W. Inverse kinematics and planning/control co-design method of redundant manipulator for precision operation: Design and experiments. Robot. Comput.-Integr. Manuf. 2023, 80, 102457. [Google Scholar] [CrossRef]
- Wijaya, B.; Jiang, K.; Yang, M. Crowdsourced Road Semantics Mapping Based on Pixel-Wise Confidence Level. Automot. Innov. 2022, 5, 43–56. [Google Scholar] [CrossRef]
- Engel, J.; Stückler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1935–1942. [Google Scholar]
- Forster, C.; Zhang, Z.; Gassner, M. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2016, 33, 249–265. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Whelan, T.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.; McDonald, J. Kintinuous: Spatially extended kinectfusion. In Proceedings of the 2012 Robotics: Science and Systems Conference, Sydney, Australia, 9–13 July 2012. [Google Scholar]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-time dense SLAM and light source estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Schops, T.; Sattler, T.; Pollefeys, M. BAD SLAM: Bundle adjusted direct RGB-D SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 134–144. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary robust independent elementary features. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Wu, X.; Sun, C.; Chen, L.; Zou, T.; Yang, W.; Xiao, H. Adaptive ORB feature detection with a variable extraction radius in RoI for complex illumination scenes. Robot. Auton. Syst. 2022, 157, 104248. [Google Scholar] [CrossRef]
- Ma, Y.; Shi, L. A modified multiple self-adaptive thresholds fast feature points extraction algorithm based on image gray clustering. In Proceedings of the 2017 International Applied Computational Electromagnetics Society Symposium (ACES), Suzhou, China, 1–4 August 2017; pp. 1–5. [Google Scholar]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An accurate open-source library for visual, visual–inertial, and multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Qin, T.; Cao, S.; Pan, J.; Shen, S. A general optimization-based framework for global pose estimation with multiple sensors. arXiv 2019, arXiv:1901.03642. [Google Scholar] [CrossRef]
- Sucar, E.; Liu, S.; Ortiz, J.; Davison, A.J. iMAP: Implicit mapping and positioning in real-time. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6229–6238. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. NICE-SLAM: Neural implicit scalable encoding for SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 12786–12796. [Google Scholar]
- Gálvez-López, D.; Tardos, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. Automatica 1975, 11, 23–27. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, T.; Liu, Y.; Yan, Q. 14 Lectures on Visual SLAM: From Theory to Practice; Publishing House of Electronics Industry: Beijing, China, 2017; pp. 206–234. [Google Scholar]
- Cantzler, H. Random Sample Consensus (RANSAC); Institute for Perception, Action and Behaviour, Division of Informatics, University of Edinburgh: Edinburgh, UK, 1981; p. 3. [Google Scholar]
- Fang, Y.; Shan, G.; Wang, T.; Li, X.; Liu, W.; Snoussi, H. He-slam: A stereo slam system based on histogram equalization and orb features. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018. [Google Scholar]
- Liu, G.; Zeng, W.; Feng, B.; Xu, F. DMS-SLAM: A general visual SLAM system for dynamic scenes with multiple sensors. Sensors 2019, 19, 3714. [Google Scholar] [CrossRef] [PubMed]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).