Abstract
Deep neural networks (DNNs) have achieved remarkable progress across various domains, yet they remain highly vulnerable to adversarial attacks, which significantly hinder their deployment in safety-critical applications. While stochastic defenses have shown promise, most existing approaches rely on fixed noise injection and fail to account for the geometric stability of the decision space. To address these limitations, we introduce a novel framework, which named as Dual Stochasticity and Geometric Normalization (DSGN). Specifically, DSGN incorporates learnable, input-dependent Gaussian noise into both the feature representation and classifier weights, creating a dual-path stochastic modeling mechanism that captures multi-level predictive uncertainty. To enhance decision consistency, both noisy components are projected onto a unit hypersphere via normalization, constraining the logit space and promoting angular margin separation. This design stabilizes both the representation and decision geometry, leading to more stable decision boundaries and improved robustness. We evaluate the effectiveness of DSGN on several benchmark datasets and CNNs. Our results indicate that DSGN achieves a robust accuracy improvement of approximately 1% to 6% over the state-of-the-arts baseline model under PGD and 1% to 17% improvement under AutoAttack, demonstrating its effectiveness in enhancing adversarial robustness while maintaining high clean accuracy.
1. Introduction
In recent years, deep neural networks (DNNs) have achieved significant success in tasks such as image classification [1], object detection [2,3], and natural language processing [4]. However, despite its excellent performance, DNN is still highly susceptible to adversarial samples—these carefully designed, almost imperceptible small perturbations to humans can cause the model to make erroneous or even dangerous predictions [5,6], posing significant challenges to its reliable deployment in safe and critical task scenarios. Even more concerning is that such vulnerabilities are not isolated phenomena. The comprehensive survey “Threatened Artificial Intelligence Agents: Key Security Challenges and Future Directions” [7] further highlights that adversarial attacks have become one of the main security risks faced by artificial intelligence systems, exacerbating concerns about their credibility and robustness.
Adversarial attacks are typically categorized into white-box and black-box paradigms. In white-box settings, attackers have full access to the model’s architecture, parameters, and gradients, allowing them to craft highly effective adversarial examples via backpropagation [5,8]. In contrast, black-box attacks estimate gradients via surrogate models or query feedback, yet still manage to generate transferable perturbations that can evade defenses [9]. These threats underscore the urgent need for robust and generalizable defense mechanisms.
A promising line of research introduces stochasticity into deep networks to improve adversarial robustness [10,11,12,13]. Instead of relying on fixed parameters, these approaches introduce randomness into the model, allowing it to better capture uncertainty and explore a local neighborhood in the parameter space. This idea is partly inspired by probabilistic modeling principles in variational autoencoders and Bayesian neural networks, where stochastic latent representations have been shown to improve uncertainty estimation and robustness under distributional variations. Theoretical studies also suggest that randomized models can provide stronger robustness guarantees than deterministic ones under certain conditions [14,15].
However, most existing randomization-based defenses adopt fixed noise distributions and operate at a single model level, which restricts their adaptability to input-dependent uncertainty and fails to capture multi-level stochastic interactions within the network [10,12]. Moreover, these methods often ignore the geometric structure of features and classifier weights, leading to poorly calibrated decision boundaries and reduced consistency between clean and adversarial predictions [16].
To solve these issues, this work introduces Dual Stochasticity and Geometric Normalization (DSGN), a novel defense framework that compellingly integrates a dual-path stochastic mechanism with geometric normalization to significantly enhance the adversarial robustness of deep networks. Specifically, DSGN injects learnable, input-dependent Gaussian noise into both feature embeddings and classifier weights, enabling data-driven uncertainty modeling across representational and decision levels. To explicitly stabilize the model geometry, we normalize the noisy features and weights onto the unit hypersphere, thereby enforcing consistent vector magnitudes across both spaces. This constrains the decision function to rely mainly on angular differences, which are inherently more robust to norm-bounded adversarial perturbations that typically attempt to exploit radial (magnitude) changes. By restricting radial variations, the normalization enforces smoother and more stable decision boundaries, enhancing overall adversarial robustness and training stability.
Unlike prior randomization defenses that rely on fixed noise or single-level injection, DSGN jointly models uncertainty in both representation and decision spaces with adaptive noise, and explicitly regularizes the geometry of features and classifier weights. Extensive experiments on multiple benchmarks and diverse attack settings demonstrate that DSGN consistently enhances adversarial robustness while maintaining high clean accuracy.
Our contributions are summarized as follows:
- We develop a dual-path stochastic mechanism that injects learnable, input-conditioned Gaussian noise into both feature embeddings and classifier weights, enabling joint uncertainty modeling across representational and decision levels.
- We introduce a geometric normalization strategy that projects noisy features and classifier weights onto a unit hypersphere, enhancing angular discriminability and improving decision consistency.
- We provide both theoretical and empirical analyses demonstrating how stochastic and geometric components jointly stabilize the logit geometry, yielding stronger adversarial robustness while maintaining high clean accuracy.
The rest of the article is organized as follows. Section 2 reviews essential concepts and techniques related to adversarial attacks, defense strategies. Section 3 introduces our proposed framework designed to enhance model robustness under adversarial conditions. In Section 4, we present a comprehensive set of experiments to evaluate and demonstrate the effectiveness of our approach. Finally, Section 5 offers concluding remarks and discusses potential future directions.
2. Related Work
2.1. Adversarial Attacks
DNNs have demonstrated remarkable performance in various machine learning applications, such as image recognition, natural language processing, and autonomous driving. However, despite their success, DNNs remain vulnerable to adversarial attacks. These attacks involve adding small, carefully crafted perturbations to input samples that cause DNNs to make incorrect predictions. The vulnerability of DNNs to imperceptible perturbations was first discovered by Szegedy et al. [17], sparking significant interest in the study of adversarial attacks. Since then, a wide range of attack methods have been proposed [5,18,19,20], which can be broadly categorized into two types: white-box attacks and black-box attacks, depending on the adversary’s level of knowledge about the target model.
White-box attacks assume full access to the target model, including its architecture, parameters, and gradients. This enables precise, gradient-based adversarial example generation. For example, the Fast Gradient Sign Method (FGSM) [5] perturbs the input in the direction of the loss gradient. Its iterative variant, Iterative FGSM (I-FGSM) [18], applies multiple small-step updates to produce stronger perturbations. Projected Gradient Descent (PGD) [8], a widely adopted attack, extends I-FGSM by incorporating a projection step to ensure that the perturbed sample remains within the allowed -norm constraint, thereby enhancing attack strength and stability. The Carlini & Wagner (C&W) attack [19] formulates adversarial generation as an optimization problem, aiming to minimize perturbation magnitude while enforcing misclassification with high confidence. More recently, AutoAttack [20] has emerged as a robust and reliable evaluation suite. It is a parameter-free ensemble of attacks, combining complementary strategies such as APGD and the Square Attack [21] to produce a comprehensive robustness assessment.
Black-box attacks, in contrast, assume no internal access to the model and rely solely on input–output behavior. These attacks are typically divided into two categories: query-based and transfer-based. Query-based attacks [21,22,23] iteratively generate adversarial examples by probing the model with carefully designed inputs and observing the outputs. Although they can be effective, these methods often come with substantial computational costs, as they require a large number of queries. Transfer-based attacks [24,25,26] exploit the transferability property of adversarial examples, where inputs generated to fool a surrogate model can also mislead an unseen target model. Despite their computational efficiency, the effectiveness of transfer-based methods often diminishes when the target model is robust or architecturally different from the surrogate model. To improve transferability, recent research has proposed strategies such as input diversity [27], feature alignment between models [28] and the use of ensemble surrogates [29] to better approximate the decision boundaries of the target model. In summary, the growing sophistication of adversarial attacks, summarized in Table 1, continues to challenge the reliability of deep learning systems. This underscores the importance of developing robust defense strategies and standardized evaluation protocols to assess model resilience under various adversarial threat models.

Table 1.
Summary of major adversarial attack methods and their characteristics.
2.2. Adversarial Defense
Defending against adversarial attacks has become an increasingly critical problem, drawing substantial attention from the research community [30]. Among various defense mechanisms, adversarial training is widely regarded as one of the most effective and commonly adopted proactive defense strategies [8,30]. This method enhances model robustness by explicitly incorporating adversarial examples into the training process. By optimizing the model to correctly classify both clean and adversarial inputs, adversarial training encourages the learning of smoother loss landscapes and more robust feature representations, thereby improving resistance to worst-case perturbations.
Although adversarial training significantly improves robustness, it often introduces substantial computational overhead and leads to a reduction in clean-data accuracy [14,15]. To address these limitations, numerous improved variants have been developed. For instance, Liu et al. [31] proposed Collaborative Adversarial Training (CAT), an ensemble-based method where multiple models are trained under diverse adversarial objectives, enabling mutual knowledge transfer and enhanced robustness. Yin et al. [32] introduced Logit-Oriented Adversarial Training (LOAT), which incorporated Fisher-Rao norm regularization to refine the decision boundaries, effectively mitigated the robustness–accuracy trade-off. More recently, Bai et al. [33] presented Wasserstein distributional adversarial training (WAT), a Wasserstein-based adversarial training method grounded in optimal transport theory, enabling better alignment between clean and adversarial distributions to improve generalization across threat models.
Beyond deterministic defenses, randomization-based methods have emerged as a promising alternative approach. These techniques introduced stochasticity at various stages of training or inference to obscure gradients and hinder adversarial optimization. For example, Parametric Noise Injection (PNI) [34] introduced learnable Gaussian noise into weights or activations, effectively enhancing model robustness while preserving its representational capacity. Jin et al. [35] proposed weight-level noise guided by first-order Taylor approximations, effectively flattening the loss landscape to suppress adversarial sensitivity. Liu et al. [36] designed a selective neuron-level noise injection strategy that targets non-critical pathways, balancing robustness with computational cost.
Recent works further reinforce the potential of randomized defenses. Pinot et al. [37] demonstrated the limitations of deterministic classifiers and showed that stochastic ensembles could achieve improved adversarial robustness under specific conditions. Subsequently, certified defenses such as randomized smoothing [38] offered probabilistic robustness guarantees by leveraging the expected prediction of noise-injected models, marking a rigorous advancement in verifiable defense mechanisms.
Despite significant advancements, randomization-based defenses encounter several key challenges. First, the incorporation of stochasticity often destabilizes training and slows convergence, particularly when applied to large-scale datasets. Furthermore, the lack of a unified theoretical framework for determining critical noise parameters results in a reliance on empirical tuning and heuristics. Additionally, current methods exhibit limited scalability and generalization across diverse architectures and data domains. Consequently, understanding the complex interplay between randomness, optimization dynamics, and generalization remains an open problem and a dynamic area of ongoing research.
3. Methodology
As illustrated in Figure 1, the proposed DSGN introduces learnable stochasticity into both feature representations and classifier weights, followed by geometric normalization on a unit hypersphere. This section provides the implementation details of the DSGN framework.
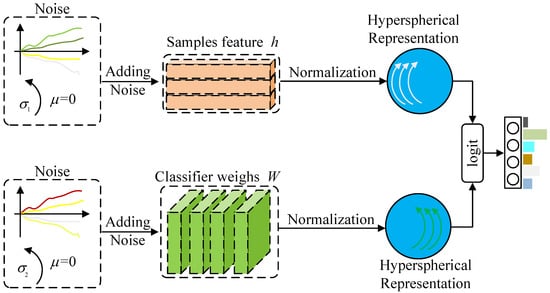
Figure 1.
Overview of the DSGN framework. To model uncertainty, the DSGN framework injects zero-mean Gaussian noise into both feature representations and classifier weights. The noise is modeled as a zero-mean Gaussian distribution with a variance that increases progressively over the course of training. The resulting noisy features and classifier weights are then normalized via -normalization to produce unit vectors, which are used in the final logit computation.
3.1. Random Feature
Our approach injects stochastic noise directly into the feature representations at the penultimate layer of the feature extractor. The key idea is to progressively increase the noise variance throughout training, starting with small stochastic noises and gradually amplifying them. This progressive noise injection acts as an implicit regularizer, encouraging the model to learn decision boundaries that are robust to both adversarial attack.
We provide a theoretical framework that explains how stochastic noise induces implicit regularization against input perturbations. Given a mini-batch of training samples , we inject stochastic noise into the activations at the penultimate layer of the neural network to improve model robustness. Specifically, When Gaussian noise , with zero mean and variance , is introduced, the activation is rewritten as
Let denote the standard loss on clean input. After noise injection, the modified loss becomes
Using the exponential shift operator identity
We can compute the average batch loss by
Expanding the exponential operator with Taylor series, we obtain
where denotes the average loss on clean inputs, are batch-averaged derivatives of the loss function with respect to the preactivations at the noise-injected layer, and we have
For zero-mean Gaussian noise, the first two terms can be simplified as
where and denote the gradient and Hessian of the loss with respect to the activations at the penultimate layer, correspondingly.
When the noise level is small, the first-order term becomes the dominant effect, serving as a mild regularizer that stabilizes gradient fluctuations and helps mitigate overfitting. As the noise level increases, the second-order term becomes more influential, penalizing directions in the loss landscape with high curvature. This progressive effect leads to a smoother optimization surface, thereby enhancing the model’s robustness to both adversarial attacks.
3.2. Random Weight
To improve the model’s generalization and robustness, we introduce stochasticity at the level of the classifier’s weight matrix. Specifically, instead of using a deterministic weight matrix , we introduce noise , each element following zero-mean Gaussian distribution, and variance to randomize the weights. This noisy weight matrix, denoted as , is expressed as
Let the logit output before softmax be defined as . After adding the noise, the noisy logit becomes
Let denote the standard loss computed from logits and ground truth labels. The loss becomes
Using the exponential shift operator in the logit space:
We can expand the loss as
where is the clean loss, and higher-order terms represent the influence of weight noise.
Taking the expectation over the Gaussian noise, the first-order term vanishes (due to symmetry), and the leading contribution comes from the second-order term:
This simplifies to
This shows that weight noise introduces an implicit curvature-aware regularizer that penalizes the sensitivity of the loss with respect to logits, scaled by the energy of the input features. Similar to feature noise, the second-order term acts as a smoothing constraint on the loss landscape, but now in the weight (parameter) space. As the model is trained with increasing noise levels, it learns to avoid regions with sharp logit sensitivity, resulting in improved generalization and robustness.
3.3. Hyperspherical Geometry via Dual Normalization
To reduce instability caused by magnitude variations and enforce geometric consistency, we apply normalization to both feature vectors and classifier weights. Given a feature vector , we normalize it to lie on the unit hypersphere:
Similarly, each class weight vector is normalized as
This transforms the conventional linear classifier into a cosine classifier:
where is the angle between the normalized feature and class weight. The model predicts based solely on angular similarity, discarding scale information.
Normalization simultaneously removes magnitude bias in both features and weights and induces an angular decision boundary geometry, providing several advantages. Without normalization, the classifier is sensitive to feature norm , biasing training toward easy examples with large norms; normalization enforces fair gradient flow across samples of all difficulty levels. Weight normalization restricts all classes to lie on a hypersphere, ensuring uniform decision geometry and reducing inter-class bias caused by class imbalance or perturbations. Furthermore, under normalization, adversarial examples must induce angular deviation to succeed, making magnitude-based attacks ineffective, as the logits are only influenced by the angular relationship between the feature and the weight vectors.
Considering a small perturbation added to , the normalized adversarial feature is
Assuming , a first-order approximation yields
which bounds logit changes by the angular shift , making the model more resistant to norm-based adversarial manipulation.
3.4. Overall Loss
As previously mentioned, enhancing uncertainty estimation during training is essential. Directly specifying parameter variances is infeasible because the required uncertainty depends on the model architecture and dataset, which are typically unknown. To address this, we initialize the Gaussian variance with a non-informative uniform prior. Throughout training, the variance gradually increases in small increments. Moreover, the variance remains bounded because its gradient is inversely proportional to the variance. As the variance increases, the gradient magnitude decreases, preventing further escalation.
The overall loss is formulated as
where denotes the standard cross-entropy loss. Here, the feature noise variance is parameterized per element of the feature vectore of size D, and the weight noise variance is parameterized per element of the classifier weight matrix of size . The negative log terms serve as entropy regularizers on the noise variances, preventing them from growing excessively. The training procedure of the proposed DSGN method is summarized in Algorithm 1.
| Algorithm 1 Training procedure of the proposed DSGN |
|
4. Experiments
4.1. Experiment Setup
Datasets: We evaluate our method on seven widely used benchmark datasets: MNIST [39], SVHN [40], CIFAR-10 [41], CIFAR-100 [41], Tiny ImageNet [40], Imagenette [42], and ImageNet [43]. MNIST consists of 60,000 training and 10,000 testing grayscale images of handwritten digits, each with a resolution of . SVHN contains 73,257 training and 26,032 testing RGB images of street-view house numbers at resolution, spanning 10 digit classes. CIFAR-10 and CIFAR-100 both comprise natural color images, with CIFAR-10 covering 10 general object categories, while CIFAR-100 offers a more challenging setting with 100 fine-grained classes. Tiny ImageNet contains 200 categories, each with 500 training images resized to resolution. Imagenette is a curated subset of ImageNet consisting of approximately 13,000 images from 10 selected classes, with all images uniformly resized to . ImageNet (ILSVRC 2012) is a large-scale benchmark dataset comprising over 1.2 million labeled training images and 50,000 validation samples across 1000 object categories, providing a realistic and challenging evaluation setting for high-capacity models.
Adversarial Attacks: To evaluate the robustness of the proposed framework, we test it against a range of adversarial attacks, including FGSM [5], PGD [8], C&W [19], MIFGSM [29], DeepFool [44], and AutoAttack [45]. All attacks are implemented following widely adopted settings. For FGSM, PGD, MIFGSM, and AutoAttack, the perturbation limit is . The step size for PGD and MIFGSM is , with 20 and 5 steps, respectively. For the C&W attack, we set the learning rate to 0.01 and run it for 1000 steps. DeepFool uses 50 steps and an overshoot of 0.02. On the ImageNet dataset, the perturbation bound is reduced to , with attack steps set to 10 and 50.
Baseline: To ensure a fair and comprehensive evaluation, we compare our method with a diverse set of baselines, including both randomized and non-randomized adversarial defenses. For randomized defenses, We consider Additive Noise [13] and its multiplicative noise injection variant, as well as Random Bits [46], RPF [47], CTRW [48], and RN [36] as baseline methods. For non-randomized baselines, we include several adversarial training-based methods such as RobustWRN [49], AWP [50], SAT [51], LLR [52], and RobNet [53]. These baselines cover a broad range of defense strategies and enable rigorous comparison across different threat models.
4.2. Results on CIFAR
To demonstrate the effectiveness of our proposed method, we first performed evaluations under six different adversarial attacks. Beyond the standard baseline of a deterministic classifier with adversarial training (denoted as AT), we included two additional noise-based baselines: additive noise injection and a stronger baseline, multiplicative noise injection, which simply fuses the feature maps via multiplying the noise. Additive noise is sampled from a standard Gaussian distribution , while multiplicative noise is sampled from . Furthermore, we also compared our results with the latest defense algorithms, including RPF, CTRW and RN. Although these noise-based baselines are simple, they can achieve satisfactory adversarial robustness within our defense scheme. The results are summarized in Table 2.
Table 2.
Comparison with noise injection techniques using ResNet-18 on CIFAR-10 and CIFAR-100.
On the CIFAR-10 dataset, the analysis of noise injection methods reveals clear gains over the AT baseline. Additive Noise achieves a 5.45% increase in PGD20 robustness over AT (from 52.16% to 57.61%), while Multiplicative Noise further improves this to 59.49% under PGD20 and 63.78% under AutoAttack, accompanied by modest gains in clean accuracy. The RPF method, leveraging geometric constraints, elevates PGD20 robustness to 61.27% and AutoAttack accuracy to 64.38%, signaling the advantage of structured randomness. The CTRW method achieves a significant PGD20 robustness of 69.48% and an AutoAttack accuracy of 73.56%, marking an important advance in robustness. The RN method demonstrates strong resistance to multi-step attacks, achieving 74.55% robustness against PGD20. Our proposed approach, DSGN, consistently surpasses all prior competitors. DSGN achieves a superior clean accuracy of 92.21% and attains 80.43% robust accuracy against PGD20, representing a 5.88% improvement over the strongest prior competitor RN (74.55%). Furthermore, under the AutoAttack benchmark, DSGN achieves an impressive 84.52% robustness, which is a remarkable 20.14% improvement compared to RPF (64.38%). Crucially, our model uniquely maintains over 80% robustness consistently across multiple attack types, including FGSM (82.32%), PGD20 (80.43%), and MIFGSM (80.54%), while simultaneously maintaining superior clean accuracy, effectively mitigating the common trade-off between robustness and accuracy.
The performance disparity becomes even more pronounced on the more challenging CIFAR-100 dataset, highlighting the limitations of prior work in high-complexity settings. The AT baseline struggles significantly, achieving only 28.71% robustness under PGD20 and 24.48% under AutoAttack. Both Additive and Multiplicative noise injection methods yield moderate improvements, yet their AutoAttack accuracies remain below 39%. The RPF method pushes the robustness envelope further, reaching 42.88% AutoAttack accuracy. The CTRW method achieves 42.01% for PGD20 and 45.58% for AutoAttack. The RN method provides a PGD20 robustness of 47.70%, but its AutoAttack robustness drops to 39.01%. However, our method, DSGN, sets a new standard with 56.34% precision under AutoAttack and 48.23% robustness under PGD20, representing a significant improvement of over 10% compared to RPF under AutoAttack. Equally important is the clean accuracy, where DSGN attains 67.71%, substantially outperforming all prior baselines, such as RPF (56.88%). This result underscores our model’s ability to circumvent the traditional robustness–accuracy trade-off even on complex datasets with higher class cardinality. Collectively, these findings robustly validate the superiority of our DSGN method across all evaluated metrics and datasets, demonstrating its effectiveness in achieving state-of-the-art performance in both clean accuracy and adversarial robustness.
We further evaluate the adversarial robustness of our method on CIFAR-10 using the WideResNet-34-10 architecture, and compare it against a variety of randomized baselines, as summarized in Table 3. Consistent with the observations on ResNet-18, our method outperforms all competing baselines across four commonly used adversarial attacks. Compared with the AT, our method achieves significantly higher robust accuracy, with a 27.18% improvement under PGD20 and a 29.68% gain under AutoAttack. Similarly, when compared to the additive noise injection, which achieves 60.55% accuracy under AutoAttack, our method improves the robustness by 21.37%. This suggests that our approach provides more stable and effective defense even under stronger attack settings. In addition, our method also surpasses advanced randomized defenses such as Random Bits, Multiplicative Noise, RPF, and CTRW, demonstrating both higher clean and robust accuracy. For instance, compared to CTRW, which achieves 74.23% robust accuracy under AutoAttack, our method improves robust accuracy by 7.69%. Furthermore, even against the most competitive recent baseline RN, our method achieves a consistent improvement across all attack scenarios. Specifically, we observe a 1.36% improvement under AutoAttack and a 1.25% boost under PGD20.
Table 3.
Adversarial robustness evaluation of randomized techniques with WideResNet on CIFAR-10.
4.3. Evaluate with Stronger Attacks
In addition to the standard evaluation of adversarial robustness presented in Table 2, we further evaluate the performance of various defense methods under stronger attack settings on CIFAR-10 and CIFAR-100, as shown in Figure 2. We mainly consider two scenarios: increasing the number of PGD attack steps (from ) and increasing the magnitude of the perturbation (with ). We compare our method with Overfit (denoted as AT), RPF (denoted as RPF), Additive Noise (denoted as Add), and Multiplicative Noise (denoted as Mult). In the scenario with increased PGD steps, Figure 2a,c demonstrate the robustness of different methods on CIFAR-10 and CIFAR-100, respectively. Unlike the deterministic adversarial training baseline, randomized methods exhibit stronger resilience against the increasing number of attack iterations. Among these, Ours consistently achieves the highest robust accuracy, maintaining 80.0% on CIFAR-10 and 48.0% on CIFAR-100 under PGD100. In contrast, RPF attains 60.6% and 39.0%, while Additive and Multiplicative noise injection methods perform even lower.
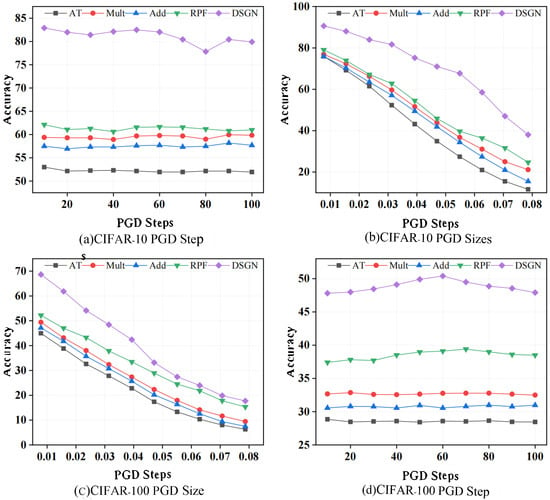
Figure 2.
The evaluation of stronger PGD attacks with ResNet-18 on CIFAR-10 and CIFAR-100.
Although all methods experience performance degradation as the perturbation size increases, our method consistently maintains the highest robust accuracy across all settings, as shown in Figure 2b,d. On CIFAR-10, our method achieves 58.4% robust accuracy at , clearly outperforming RPF (36.2%) as well as additive and multiplicative noise baselines. Even under stronger perturbations (e.g., ), our method still reaches 36.6% accuracy, the best among all evaluated methods. A similar trend is observed on CIFAR-100: at , our method maintains 18.6% robust accuracy, surpassing RPF (16.6%) and other baselines.
4.4. State-of-the-Art Comparison
We also compare our proposed DSGN with leading defense methods to highlight its effectiveness. The evaluation is conducted on two widely used benchmarks: WideResNet-34-10 for CIFAR-10 and ResNet-50 for ImageNet. The results are summarized in Table 4. Specifically, we report robust accuracies on CIFAR-10 under PGD20 and AA, and on ImageNet under PGD10 and PGD50. Our method consistently outperforms all existing approaches across both datasets and evaluation settings. On CIFAR-10, it achieves robust accuracies of 83.31% under PGD20 and 84.92% under AA, surpassing the previously strongest baseline RN by 0.32% and 16.22%, respectively. On ImageNet, our method attains robust accuracies of 74.26% and 72.27% under PGD10 and PGD50, representing clear improvements over both CTRW and RN. In particular, our method outperforms RPF by 17.70% under PGD10 and 16.86% under PGD50. These results demonstrate the strong robustness and scalability of our method, especially under more challenging attack scenarios and on large-scale datasets.
Table 4.
Comparison with SOTA defense algorithms on CIFAR-10 and ImageNet.
4.5. Inspection of Generalization
We conduct comprehensive experiments on diverse datasets and network architectures to assess the generalization capability of the proposed method. The experimental results are summarized in Table 5 and Table 6. In Table 5, we focus on evaluating the robustness of our method across six widely used image classification datasets: MNIST, SVHN, CIFAR-10, CIFAR-100, Tiny-ImageNet and Imagenette. All experiments are conducted using ResNet-18 as the backbone, except for MNIST, which uses LeNet. We report accuracy under clean, FGSM, and PGD20 attack settings. Compared to the baseline (no defense), our method achieves significantly improved robustness across all datasets, particularly under strong PGD attacks. For instance, on SVHN and CIFAR-10, our method achieves over 80% accuracy under PGD20 attacks, while the baseline model suffers severe degradation. These results indicate that our method maintains strong generalization capability across datasets of varying complexity and scale. In Table 6, we investigate the impact of different network architectures on our method. We evaluate the performance of our method on several mainstream models, including VGG19, GoogLeNet, DenseNet121, and various ResNet variants (ResNet-32/44/56). As shown in the results, our method consistently outperforms the baseline under adversarial settings for all architectures. Notably, our method maintains high robustness even on deeper networks such as ResNet-56, achieving 69.1% accuracy under PGD20, compared to only 1.2% for the no defense. This suggests that our method generalizes effectively across networks of varying depths and design paradigms. In summary, we evaluate the generalization ability of our method from two perspectives: datasets and architectures. For datasets, our method demonstrates strong robustness across a wide range of data distributions. For architectures, we confirm that our method adapts well to different network types, as well as varying widths and depths. These results validate that our method is a highly generalizable defense method for adversarial robustness.
Table 5.
Generalization study on different datasets. All results are reported using ResNet-18 as the backbone (except MNIST). Accuracy (%) under clean and adversarial (FGSM, PGD20) settings is shown.
Table 6.
Generalization study on different network architectures. Results show that our method consistently improves robustness across mainstream architectures.
4.6. TSNE Visualization
We visualize the classification results on the CIFAR-10 dataset using a ResNet-18 model (Figure 3). In our experiments, we sampled 1000 data points and observed that DSGN effectively enhances intra-class compactness while increasing inter-class separability. This indicates that our method maintains a high level of uncertainty and adaptively learns deeper feature representations. Such uncertainty helps the network avoid local minima and explore global optima, ultimately boosting both robustness and classification accuracy.
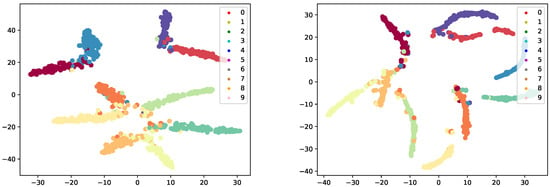
Figure 3.
t-SNE visualization of classification results on CIFAR-10 trained with ResNet-18. No defense (Left) DSGN (Right).
4.7. Inspection of Gradient Obfuscation
Athalye et al. [55] pointed out that certain stochastic defense methods merely obscure gradient information to create the illusion of improved robustness, and as such, are considered “false defenses.” While these methods may temporarily impede gradient-based attacks, they are ultimately vulnerable to targeted attacks. To validate the list proposed by Athalye, we conduct a series of experiments following the experimental setup of Jeddie et al. [56] to evaluate these defenses. To verify that our proposed approach does not rely on gradient obfuscation, we conduct a series of diagnostic evaluations following the criteria proposed by Athalye and in accordance with the experimental protocol of Jeddi et al. [56].
4.7.1. Criterion 1: One-Step Attacks Outperform Iterative Attacks
Refutation: It is well established that PGD attack is an iterative method, while the FGSM constitutes a single-step variant. As observed in Table 2 and Table 3, the DSGN model consistently attains higher accuracy against FGSM attacks compared with PGD attacks. This empirical evidence confirms that iterative attacks are indeed more potent than one-step methods, thereby refuting the characteristic behavior of gradient-obfuscated defenses.
4.7.2. Criterion 2: Black-Box Attacks Outperform White-Box Attacks
Refutation: From Table 2 and Table 7, the white-box PGD attack demonstrates significantly stronger adversarial effectiveness than the 1- and 2-pixel black-box attacks. This outcome indicates that the defense remains vulnerable under full gradient access, reaffirming that the observed robustness does not stem from gradient masking or stochastic shielding.
Table 7.
Comparison of state-of-the-art methods for black-box n-Pixel attack on CIFAR-10 with a ResNet-18 backbone.
4.7.3. Criterion 3: Unbounded Attacks Fail to Achieve Complete Success
Refutation: In accordance with He et al. [34], we progressively increased the perturbation bound during evaluation. As shown in Figure 2 (left), the classification accuracy converges to nearly 0% under unbounded perturbations. This behavior is consistent with standard, non-obfuscated models, suggesting that our defense does not rely on deceptive gradient properties.
4.7.4. Criterion 4: Random Sampling Can Independently Discover Adversarial Examples
Refutation: As discussed by He et al. [34], random sampling should only succeed when gradient-based attacks fail. However, Figure 4 (right) clearly illustrates that as the perturbation bound increases, the proposed method remains susceptible to gradient-based attacks such as PGD. Therefore, the model’s robustness is not a byproduct of stochastic randomness or gradient discontinuities.
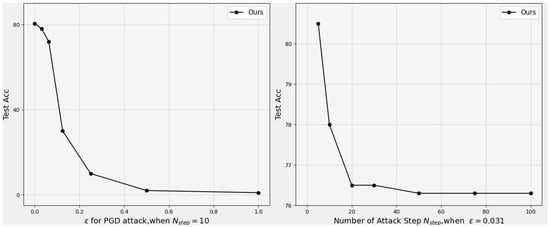
Figure 4.
On the CIFAR-10 test set, the perturbed-data accuracy of ResNet-18 under PGD attack: (Left) versus attack bound , and (Right) versus the number of attack steps .
4.7.5. Criterion 5: Increasing the Distortion Bound Does Not Improve the Attack Success Rate
Refutation: The empirical trend depicted in Figure 4 (left) shows that larger distortion bounds consistently lead to higher attack success rates (i.e., lower classification accuracy). This monotonic degradation aligns with the theoretical expectations of adversarial robustness under increasing perturbation magnitude, and further invalidates the possibility of gradient obfuscation.
4.7.6. EOT-Based Evaluation
Athalye [55] also emphasized that defenses based on stochastic transformations are ineffective when gradients are estimated through the Expectation over Transformation (EOT) framework. Following Jeddi et al. [56] and Pinot et al. [57], we employ a Monte Carlo approximation of the gradient expectation over 80 random transformations on the CIFAR-10 dataset using a ResNet-18 backbone.
The results reveal that RPF, CTRW and RN achieve robustness levels of 59.32%, 66.74%, and 71.35%, respectively, while the proposed DSGN attains 78.32% robustness—substantially surpassing competing methods. This demonstrates that the proposed DSGN mechanism provides genuine robustness rather than relying on gradient obfuscation. To ensure gradient stability, we further apply 15 Monte Carlo samples during the testing phase, which produces consistent and reproducible performance across multiple evaluations.
4.8. Ablation Study
4.8.1. The Effectiveness of Our Proposed Method
To evaluate the effectiveness and necessity of each core component of the proposed DSGN framework, we conduct a detailed ablation study on the CIFAR-10 dataset using ResNet-18 backbone under both FGSM and PGD attack settings. As illustrated in Figure 5, we progressively integrate the three core components of DSGN: Random Feature, Random Weight, and Normalize of both feature and weight, to assess their individual and combined contributions to adversarial robustness.The baseline model, lacking any defense, exhibits extreme vulnerability, achieving only 21.3% and 2.3% robust accuracy against FGSM and PGD, respectively. Introducing the Random Feature (+RF) module yields the most substantial initial robustness gain, increasing accuracy to 77.3% (FGSM) and 75.2% (PGD). This highlights its critical role in learning perturbation-invariant feature representations. Subsequently, the addition of the Random Weight (+RFW) module further enhances robustness to 79.2% (FGSM) and 77.2% (PGD), confirming that stochasticity in the weight space improves generalization across diverse adversarial directions. Finally, the integration of all modules (All Module), including feature and weight normalization, achieves the best performance with 82.3% robust accuracy against FGSM and 80.4% against PGD. The final gain of approximately 3% is crucial because, in the highly competitive regime of adversarial defense against strong attacks like PGD, such incremental improvements are difficult to obtain and indicate that the normalization mechanism, by enforcing a geometric regularization that promotes inter-class separation on a hypersphere, is necessary to reach the highest level of adversarial resilience for the DSGN framework.
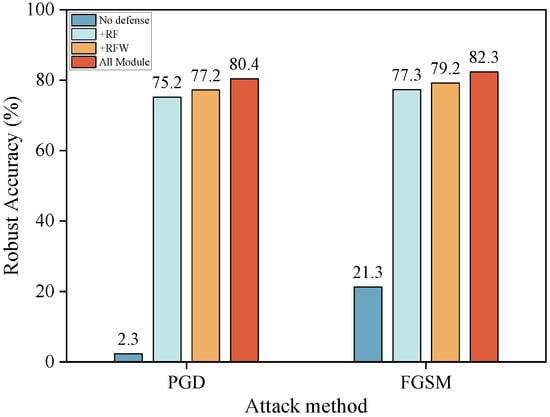
Figure 5.
Ablation study of DSGN components.
4.8.2. Sensitivity of Hyper-Parameter
To investigate the effect of the hyperparameters and on the experimental results, we conducted an ablation study, with the results shown in Figure 6. Specifically, Figure 6a,c display the results on the CIFAR-10 dataset using the ResNet-18 model, while Figure 6b,d show the results on the CIFAR-100 dataset using the ResNet-18 model. First, we explored the impact of on the performance of random features. As shown in Figure 6a,b, the optimal value was achieved when . Subsequently, with fixed, we investigated the effect of on eight randomness. The results indicate that the best performance was obtained when . Furthermore, we can observe that weights are more sensitive to noise compared to features.
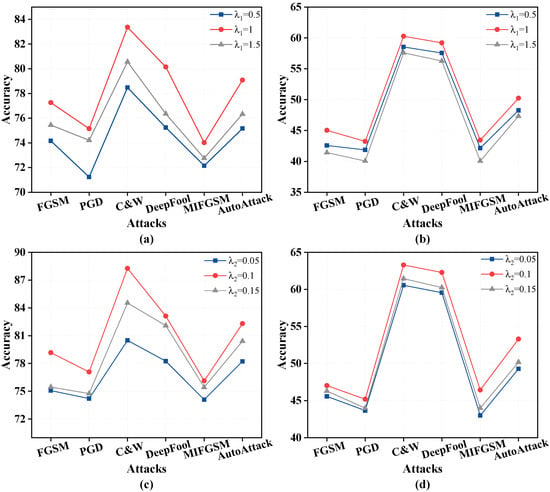
Figure 6.
The evaluation of stronger PGD attacks with ResNet-18 on CIFAR-10 and CIFAR-100. (a) Impact of on experimental results using CIFAR-10; (b) Impact of on experimental results using CIFAR-100; (c) Impact of on experimental results using CIFAR-10; (d) Impact of on experimental results using CIFAR-100.
5. Conclusions and Future Work
In this work, DSGN, a unified stochastic regularization framework designed to improve adversarial robustness, was proposed. By integrating input-dependent noise with geometric normalization, predictive uncertainty is effectively modeled and smoother decision boundaries are encouraged. Our results indicate that DSGN achieves a robust accuracy improvement of approximately 1% to 6% over the State of the arts baseline model under PGD and a 17% improvement under AutoAttack, demonstrating its effectiveness in enhancing adversarial robustness while maintaining high clean accuracy While the current results are encouraging, several promising directions remain for future research. These include extending the theoretical analysis to deeper, non-linear architectures to gain a deeper understanding of DSGN’s impact on generalization and the geometry of the loss landscape, designing adaptive noise mechanisms that dynamically adjust variance during training, and exploring the applicability of DSGN to alternative architectures such as Transformers and graph neural networks to assess its generalizability. Advancing these directions will further solidify the theoretical foundation of DSGN and broaden its practical utility across diverse real-world tasks. It is believed that this study offers a novel perspective on integrating stochastic and geometric principles for building reliable and robust deep learning systems.
Author Contributions
Conceptualization, X.W.; methodology, X.W.; software, X.W.; validation, X.W.; data curation, X.W. and G.H.; writing original draft preparation, X.W.; writing—review and editing, All; visualization, G.H.; funding acquisition, G.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 62101504).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study are available and can be provided upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, Y.; Guan, C.; Wei, Z.; Wang, X.; Zhu, W. Metadelta: A meta-learning system for few-shot image classification. In Proceedings of the AAAI Workshop on Meta-Learning and MetaDL Challenge, Virtual, 9 February 2021; AAAI: Palo Alto, CA, USA, 2021; pp. 17–28. [Google Scholar]
- Zhu, W.; Wang, X.; Gao, W. Multimedia intelligence: When multimedia meets artificial intelligence. IEEE Trans. Multimed. 2020, 22, 1823–1835. [Google Scholar] [CrossRef]
- Wu, C.; Chen, J.; Li, J.; Xu, J.; Jia, J.; Hu, Y.; Feng, Y.; Liu, Y.; Xiang, Y. Profit or Deceit? Mitigating Pump and Dump in DeFi via Graph and Contrastive Learning. IEEE Trans. Inf. Forensics Secur. 2025, 20, 8994–9008. [Google Scholar] [CrossRef]
- Ozbulak, U.; Vandersmissen, B.; Jalalvand, A.; Couckuyt, I.; Van Messem, A.; De Neve, W. Investigating the significance of adversarial attacks and their relation to interpretability for radar-based human activity recognition systems. Comput. Vis. Image Underst. 2021, 202, 103111. [Google Scholar] [CrossRef]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; ICLR: San Diego, CA, USA, 2015. [Google Scholar]
- Wu, C.; Cao, H.; Xu, G.; Zhou, C.; Sun, J.; Yan, R.; Liu, Y.; Jiang, H. It’s All in the Touch: Authenticating Users With HOST Gestures on Multi-Touch Screen Devices. IEEE Trans. Mob. Comput. 2024, 23, 10006–10030. [Google Scholar] [CrossRef]
- Deng, Z.; Guo, Y.; Han, C.; Ma, W.; Xiong, J.; Wen, S.; Xiang, Y. AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways. ACM Comput. Surv. 2025, 57, 1557–7341. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; ACM: New York, NY, USA, 2017; pp. 506–519. [Google Scholar]
- Yang, H.; Wang, M.; Yu, Z.; Zhou, Y. Weight-based regularization for improving robustness in image classification. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1775–1780. [Google Scholar]
- Yang, H.; Wang, M.; Wang, Q.; Yu, Z.; Jin, G.; Zhou, C.; Zhou, Y. Non-informative noise-enhanced stochastic neural networks for improving adversarial robustness. Inf. Fusion 2024, 108, 102397. [Google Scholar] [CrossRef]
- Yang, H.; Wang, M.; Yu, Z.; Zeng, Z.; Lao, M.; Zhou, Y. Maximizing feature distribution variance for robust neural networks. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; ACM: New York, NY, USA, 2024; pp. 9943–9951. [Google Scholar]
- Liu, X.; Cheng, M.; Zhang, H.; Hsieh, C.J. Towards robust neural networks via random self-ensemble. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 369–385. [Google Scholar]
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.; Ghaoui, L.E.; Jordan, M. Theoretically principled trade-off between robustness and accuracy. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 7472–7482. [Google Scholar]
- Zhang, J.; Xu, X.; Han, B.; Niu, G.; Cui, L.; Sugiyama, M.; Kankanhalli, M. Attacks which do not kill training make adversarial learning stronger. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 11278–11287. [Google Scholar]
- Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Improving the generalization of adversarial training with domain adaptation. arXiv 2018, arXiv:1810.00740. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Ren, H.; Huang, T. Adversarial example attacks in the physical world. In Proceedings of the Machine Learning for Cyber Security, Guangzhou, China, 8–10 October 2020; Springer: Cham, Switzerland, 2020; pp. 572–582. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 39–57. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 2206–2216. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square attack: A query-efficient black-box adversarial attack via random search. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 484–501. [Google Scholar]
- Zhou, C.; Shi, X.; Wang, Y.G. Query-Efficient Hard-Label Black-Box Attack against Vision Transformers. arXiv 2024, arXiv:2407.00389. [Google Scholar] [CrossRef]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 2484–2493. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into transferable adversarial examples and black-box attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar] [CrossRef]
- Wang, X.; He, K. Enhancing the transferability of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1924–1933. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2730–2739. [Google Scholar]
- Inkawhich, N.; Liang, K.J.; Carin, L.; Chen, Y. Transferable perturbations of deep feature distributions. arXiv 2020, arXiv:2004.12519. [Google Scholar] [CrossRef]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 9185–9193. [Google Scholar]
- He, Z.; Liu, W.; Huang, Z.; Chen, Y.; Zhang, S. A3GT: An Adaptive Asynchronous Generalized Adversarial Training Method. Electronics 2024, 13, 4052. [Google Scholar] [CrossRef]
- Liu, X.; Kuang, H.; Lin, X.; Wu, Y.; Ji, R. CAT: Collaborative adversarial training. arXiv 2023, arXiv:2303.14922. [Google Scholar] [CrossRef]
- Yin, X.; Ruan, W. Boosting adversarial training via fisher-rao norm-based regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 24544–24553. [Google Scholar]
- Bai, X.; He, G.; Jiang, Y.; Obloj, J. Wasserstein distributional adversarial training for deep neural networks. arXiv 2025, arXiv:2502.09352. [Google Scholar] [CrossRef]
- He, Z.; Rakin, A.S.; Fan, D. Parametric noise injection: Trainable randomness to improve deep neural network robustness against adversarial attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 588–597. [Google Scholar]
- Jin, G.; Yi, X.; Wu, D.; Mu, R.; Huang, X. Randomized adversarial training via taylor expansion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 16447–16457. [Google Scholar]
- Liu, Z.; Gagnon, G.; Venkataramani, S.; Liu, L. Enhance DNN adversarial robustness and efficiency via injecting noise to non-essential neurons. arXiv 2024, arXiv:2402.04325. [Google Scholar] [CrossRef]
- Pinot, R.; Ettedgui, R.; Rizk, G.; Chevaleyre, Y.; Atif, J. Randomization matters how to defend against strong adversarial attacks. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 7717–7727. [Google Scholar]
- Rekavandi, A.M.; Farokhi, F.; Ohrimenko, O.; Rubinstein, B.I.P. Certified adversarial robustness via randomized α-smoothing for regression models. In Proceedings of the Thirty-eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024; NeurIPS: New Orleans, LA, USA, 2024. [Google Scholar]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. In Handbook of Systemic Autoimmune Diseases; Elsevier: Munich, Germany, 2009; Volume 1, pp. 1–4. [Google Scholar]
- Li, X.; Chen, Y.; Zhu, Y.; Wang, S.; Zhang, R.; Xue, H. Imagenet-e: Benchmarking neural network robustness via attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 20371–20381. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2574–2582. [Google Scholar]
- Carbone, G.; Wicker, M.; Laurenti, L.; Patane, A.; Bortolussi, L.; Sanguinetti, G. Robustness of bayesian neural networks to gradient-based attacks. Adv. Neural Inf. Process. Syst. 2020, 33, 15602–15613. [Google Scholar]
- Fu, Y.; Yu, Q.; Li, M.; Chandra, V.; Lin, Y. Double-Win Quant: Aggressively Winning Robustness of Quantized Deep Neural Networks via Random Precision Training and Inference. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 3492–3504. [Google Scholar]
- Dong, M.; Xu, C. Adversarial robustness via random projection filters. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4077–4086. [Google Scholar]
- Ma, Y.; Dong, M.; Xu, C. Adversarial robustness through random weight sampling. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; NeurIPS: New Orleans, LA, USA, 2023; pp. 37657–37669. [Google Scholar]
- Huang, H.; Wang, Y.; Erfani, S.; Gu, Q.; Bailey, J.; Ma, X. Exploring architectural ingredients of adversarially robust deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 5545–5559. [Google Scholar]
- Wu, D.; Xia, S.T.; Wang, Y. Adversarial weight perturbation helps robust generalization. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 2958–2969. [Google Scholar]
- Xie, C.; Tan, M.; Gong, B.; Yuille, A.; Le, Q.V. Smooth adversarial training. arXiv 2020, arXiv:2006.14536. [Google Scholar]
- Qin, C.; Martens, J.; Gowal, S.; Krishnan, D.; Dvijotham, K.; Fawzi, A.; De, S.; Stanforth, R.; Kohli, P. Adversarial robustness through local linearization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Guo, M.; Yang, Y.; Xu, R.; Liu, Z.; Lin, D. When nas meets robustness: In search of robust architectures against adversarial attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 631–640. [Google Scholar]
- Rice, L.; Wong, E.; Kolter, Z. Overfitting in adversarially robust deep learning. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 8093–8104. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; PMLR: New York, NY, USA, 2018; pp. 1–10. [Google Scholar]
- Jeddi, A.; Wong, A.; Scharfenberger, C.; Karg, M.; Shafiee, M.J. Learn2Perturb: An end-to-end feature perturbation learning to improve adversarial robustness. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2034–2046. [Google Scholar]
- Pinot, R.; Meunier, L.; Araujo, A.; Kashima, H.; Yger, F.; Gouy-Pailler, C.; Atif, J. Theoretical evidence for adversarial robustness through randomization. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; NeurIPS: Vancouver, BC, Canada, 2020; pp. 1234–1245. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).