Abstract
Unlike traditional control systems that rely on physical input devices, facial gesture-based interaction offers a contactless and intuitive method for operating autonomous systems. Recent advances in computer vision and deep learning have enabled the use of facial expressions and movements for command recognition in human–robot interaction. In this work, we propose a lightweight, real-time facial gesture recognition method, GhostNet-BiLSTM-Attention (GBA), which integrates GhostNet and BiLSTM with an attention mechanism, is trained on the FaceGest dataset, and is integrated with a 3D robot simulation in Unity. The system is designed to recognize predefined facial gestures such as head tilts, eye blinks, and mouth movements with high accuracy and low inference latency. Recognized gestures are mapped to specific robot commands and transmitted to a Unity-based simulation environment via socket communication across machines. This framework enables smooth and immersive robot control without the need for conventional controllers or sensors. Real-time evaluation demonstrates the system’s robustness and responsiveness under varied user and lighting conditions, achieving a classification accuracy of 99.13% on the FaceGest dataset. The GBA holds strong potential for applications in assistive robotics, contactless teleoperation, and immersive human–robot interfaces.
1. Introduction
The use of robots, both mobile and stationary, in fields such as industrial automation, assistive technology, telepresence, entertainment, and scientific research has significantly increased in recent years [1]. With the rapid progress of Artificial Intelligence (AI) and computer vision, interactions between humans and robots have become increasingly common [2]. Among emerging methods, Intelligent Human–Robot Interaction (HRI) techniques are gaining attention as alternatives to conventional control systems [3]. Traditional approaches often rely on physical input devices such as joysticks or keyboards [4]. However, unlike these hardware-based interfaces, facial gesture-based HRI allows users to operate robots through intuitive and contactless expressions, making interaction more natural and accessible even for inexperienced users [5].
HRI research aims to create innovative designs and intuitive interfaces, typically grouped into four categories: wearable sensors, speech recognition, gesture-based systems, and user-friendly remote controls [6]. Table 1 summarizes the common advantages and disadvantages of typical HRI systems. In recent years, facial gesture-based recognition (FGR) systems have attracted growing interest due to the expressive and intuitive nature of facial movements as a means of communication [7,8]. Unlike hand gestures, facial gestures such as head tilts, eye blinks, or mouth movements can be performed with minimal effort, require no additional hardware, and remain effective even when the user’s hands are occupied, making them particularly suitable for contactless robot control [9].
Facial gesture recognition systems utilize various data sources, generally divided into two categories: sensor-based facial gesture recognition (S-FGR) [10] and vision-based facial gesture recognition (V-FGR) [11]. These categories differ primarily in their data acquisition techniques, data types, and training methodologies [12]. Sensor-based FGR typically employs specialized wearable devices or electrodes that capture muscle activity and subtle facial movements through electromyography (EMG) or inertial measurement units (IMUs) [13,14]. Such sensor data tends to be robust against external variations like lighting and background noise, and often requires less computational effort since the signals are directly obtained without complex image processing [15]. In contrast, vision-based FGR analyzes 2D images or video sequences captured by cameras, which makes it more accessible and cost-effective, as no additional hardware beyond a camera is needed [6,16]. Consequently, the majority of recent research has concentrated on V-FGR due to its simplicity and scalability [17].
Vision-based methods generally follow two approaches: extracting hand-crafted features [15] or employing deep learning to automatically learn features [10,18]. Hand-crafted methods typically utilize predefined facial landmarks, geometric features, or texture descriptors to recognize gestures [19]. Although these traditional approaches can be computationally efficient, they often lack adaptability to varying facial expressions and environmental conditions [20,21]. On the other hand, deep learning methods, particularly convolutional neural networks (CNNs), automatically learn hierarchical features from raw data, leading to superior accuracy and robustness [10,22]. However, these methods generally impose higher computational requirements and demand large annotated datasets for effective training [8,12,13].
Facial gestures can also be classified as either static or dynamic [12]. Static gestures involve holding a specific facial expression or pose for a certain duration [23], such as raising eyebrows or blinking, whereas dynamic gestures consist of a sequence of movements over time, like nodding or mouth movements [19]. While deep learning techniques have demonstrated excellent performance in recognizing static gestures due to their consistent visual patterns, dynamic gesture recognition remains more challenging [24]. The temporal nature of dynamic gestures adds complexity, resulting in an increased computational load and often lower accuracy compared to static gestures [25]. To address the temporal dimension of dynamic facial gestures, tracking algorithms combined with deep learning have been employed [9,26]. For instance, some works integrate pose estimation frameworks with tracking methods such as Kalman filters or DeepSORT [27] to extract and maintain consistent facial landmarks over video frames, facilitating temporal gesture classification. While these methods improve recognition robustness, they further increase computational complexity, which can hinder real-time performance [28].
Despite the advances in facial gesture recognition, many state-of-the-art methods [17,26,29,30] still struggle with balancing accuracy and efficiency. Real-time human–robot interaction systems require lightweight, fast, and reliable models that can operate under resource constraints without sacrificing safety or user experience [31]. To this end, several CNN and 3D CNN architectures [7,30,32] have been proposed, offering improved feature extraction and temporal modeling capabilities. However, these approaches typically entail high computational costs, motivating the search for efficient alternatives that maintain competitive performance [28,33].
To address these gaps, we propose GBA, a lightweight and efficient facial gesture recognition network that leverages the GhostNet feature extractor [34] and incorporates a BiLSTM with an attention mechanism [35]. This system accurately recognizes both static and dynamic facial gestures while maintaining low computational overhead. Furthermore, we developed a 3D robot simulation environment in Unity, enabling smooth and intuitive robot control through socket communication. This setup offers a faster and more user-friendly interface compared to previous approaches.
Overall, our novel approach leverages a streamlined set of facial gestures combined with a 3D simulation environment for remote robot operation. By integrating socket communication, the system functions as a virtual simulation platform, laying the groundwork for more advanced and contactless control methods. Compared to traditional joystick controllers and sensor-based interaction systems [3,12,21,31], our proposed solution offers improved speed, reliability, and user-friendliness. We summarize our main contributions in this work as follows:
- GhostNet-based spatial features achieve 99.13% accuracy (↑4.3%) at 30 FPS with only 1.1 GFLOPs, proving suitable for real-time use on embedded GPUs.
- Incorporated LSTM networks capture sequential dependencies in gesture patterns, improving robustness to temporal variations.
- Integrated spatial and temporal attention modules to focus on the most salient facial regions and critical time frames, boosting classification accuracy.
- Designed a Unity3D-based virtual environment where recognized facial gestures are converted into robot control commands via socket communication for interactive operation.
- Developed a fully trainable architecture that unifies spatial feature extraction, temporal modeling, and attention in a single efficient framework for human–robot interaction.
Furthermore, the related work on facial gesture recognition is reviewed in Section 2, followed by a detailed description of our proposed method in Section 3. The experimental setup, results, and analysis are presented in Section 4 with further discussion in Section 5. Finally, Section 6 concludes the paper and outlines future research directions.

Table 1.
Human–robot interaction systems can be classified into several types, as outlined in [3,12,21,31].
Table 1.
Human–robot interaction systems can be classified into several types, as outlined in [3,12,21,31].
| HRI Method | Pros | Cons |
|---|---|---|
| Remote Control Devices | Familiar interface Low latency Precise control | Requires physical devices Limited mobility |
| Wearable Tracking Sensors | Accurate motion tracking Enables continuous monitoring | Intrusive Costly hardware User discomfort |
| Voice-Based Interaction | Hands-free interaction Intuitive for commands | Sensitive to noise Language dependent |
| Facial Gesture Interface | Contactless Intuitive and expressive No additional hardware needed | Sensitive to lighting Limited gesture vocabulary Computationally intensive |
2. Related Work
Various methods have been proposed for facial gesture-based interaction in autonomous system control, employing different sensing modalities to improve recognition accuracy, responsiveness, and robustness in real time [36]. Sensor-assisted systems utilize data from IMUs, depth sensors, or motion capture devices to capture and localize subtle facial movements precisely [37,38]. Vision-based approaches, on the other hand, leverage RGB data from standard cameras, while some hybrid frameworks integrate both sensor and vision modalities to enhance recognition under challenging conditions [39,40]. In general, facial gesture recognition methods can be categorized into two main types: sensor-assisted facial gesture recognition (S-FGR) and vision-based facial gesture recognition (V-FGR).
2.1. Sensor-Assisted Facial Gesture Recognition
S-FGR techniques often employ wearable or external sensors to track head orientation, facial muscle activation, or eye movement patterns. In some approaches, inertial measurement units (IMUs) mounted on headgear or eyeglass frames record orientation changes to detect gestures such as nods or tilts [41]. Similarly, depth and 3D facial scanning devices can capture high-fidelity geometric changes in facial expressions, enabling more precise gesture classification [37]. Motion capture systems have also been employed to track facial landmarks in three dimensions, providing robustness against lighting changes and partial occlusions [42,43].
Machine learning algorithms such as support vector machines (SVMs) [44], decision trees (DTs), and k-nearest neighbors (KNNs) have been used extensively with sensor-based features to perform the classification of facial gestures. These methods are computationally efficient and can perform well in constrained environments; however, they typically require specialized hardware and are less suitable for unconstrained, everyday usage. More recent studies have explored hybrid approaches, combining electromyography (EMG) sensors with visual data to capture both muscle activity and external appearance changes [45], although these systems face challenges such as user discomfort and calibration requirements.
2.2. Vision-Based Facial Gesture Recognition
In vision-based FGR, facial gestures are detected directly from camera images or video streams, which can be considered a specialized case of facial expression recognition [40,46]. These approaches generally fall into handcrafted feature-based and deep feature-based categories. Handcrafted methods rely on manually designed descriptors such as local binary patterns (LBPs) or the histogram of oriented gradients (HOG) applied to facial regions [39], whereas deep learning-based automatically approaches extract discriminative features using convolutional or recurrent neural networks.
Deep feature-based methods have recently achieved state-of-the-art performance in FGR, with architectures including 2D CNNs [29,47], 3D CNNs for spatiotemporal modeling [12,48], recurrent models such as LSTMs for temporal dynamics [17,49], and hybrid transfer learning models leveraging pretrained networks such as VGG19, ResNet-50, and MobileNet [50,51,52]. Vision Transformers (ViTs) have also been explored for facial expression and gesture recognition [18,53], although their high computational cost currently limits their adoption in low-latency applications. For example, Aouayeb et al. [54] proposed a ViT enhanced with a squeeze-and-excitation (SE) block for facial expression recognition, achieving 99.8% accuracy on the CK+ dataset. While this demonstrates the strong discriminative capacity of transformer-based models, the evaluation on a relatively small and controlled dataset suggests potential challenges in generalizing to more diverse, in-the-wild scenarios. Building on this line of work, Wasi et al. [55] introduced ARBEx, a framework for facial expression learning that leverages Vision Transformers. The framework combines several strategies to mitigate common challenges in facial expression learning, including class imbalance, bias, and uncertainty, highlighting the potential of transformer-based approaches to enhance robustness in expression recognition tasks.
More recently, Li et al. [56] proposed FER-former, a Transformer-based architecture for facial expression recognition in the wild that employs multifarious supervision. The model integrates multi-granularity embeddings, a hybrid self-attention mechanism, and domain-steering supervision to improve feature learning. By combining features from both CNNs and Transformers through a hybrid stem, FER-former achieves enhanced representation for FER tasks. Experiments across multiple benchmarks demonstrate that this approach outperforms several state-of-the-art methods, highlighting the benefits of hybrid CNN-Transformer designs for in-the-wild expression recognition. Similarly, Xue et al. [57] proposed TransFER, which integrates Multi-Attention Dropping and Multi-head Self-Attention mechanisms to capture rich, relation-aware local features for FER. While effective, it was slightly outperformed by FER-former [56] across multiple benchmarks but still surpassed other state-of-the-art methods.
Finally, Huang et al. [58] proposed a CNN-based framework with a dual attention mechanisms: grid-wise attention for low-level feature extraction and a visual Transformer for high-level semantic representation. It achieved up to 99.0% accuracy on CK+ but has not been validated extensively on larger, diverse datasets or optimized for lightweight, real-time deployment.
In summary, while these Transformer- and attention-based methods achieve high accuracy, they often suffer from high computational cost, limited generalization to unconstrained environments, and challenges for real-time HCI deployment. Significant progress has been made in both sensor-assisted and vision-based FGR. Still, real-time deployment in interactive systems, especially in immersive environments, remains challenging due to factors such as varying lighting, diverse user characteristics, and the need for low-latency inference [3,6,26]. To advance the state of the art in practical applications, we propose GBA, a lightweight vision-based FGR system integrated into a 3D Unity simulation environment for real-time robot control. The system operates without specialized sensors, mapping recognized facial gestures to control commands transmitted over network sockets between machines, enabling a seamless and contactless human–robot interaction experience.
3. Methodology
This section presents an integrated 3D virtual environment system for controlling a ground robot, which communicates in real-time with the GBA (FGR module) via TCP/IP sockets. The two modules, the GBA and the 3D Unity simulation, are connected through network protocols, enabling intuitive and interactive robot control using facial gestures, as illustrated in Figure 1.
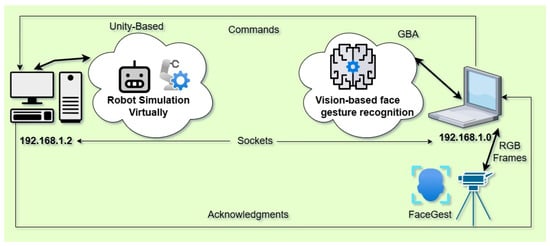
Figure 1.
Gesture-based robot control: Real-time facial gesture recognition for interactive robot navigation in a unity simulation via sockets.
3.1. Problem Formulation
Given a video sequence of face images , where is the face image at time step t, the goal is to classify the sequence into one of K discrete face gesture classes.
Formally, the task is to learn a mapping
that accurately predicts the gesture label y based on spatiotemporal patterns.
3.2. Spatial Feature Extraction with GhostNet
Each frame is passed through a GhostNet convolutional backbone to extract a compact spatial feature vector .
3.2.1. GhostNet Backbone
GhostNet is designed to generate efficient feature maps by combining intrinsic features with cheap linear transformations, reducing computational cost. Formally, GhostNet computes the feature maps as
where each is generated by a standard convolution and refined from intrinsic features using efficient linear operations. The GhostNet module performs spatial feature extraction, which is enhanced with spatial attention. These features are then processed by a BiLSTM for temporal modeling, followed by a temporal attention mechanism. Figure 2 illustrates this pipeline: (a) shows the GhostNet bottlenecks with strides 1 and 2; and (b) shows the attention heads.
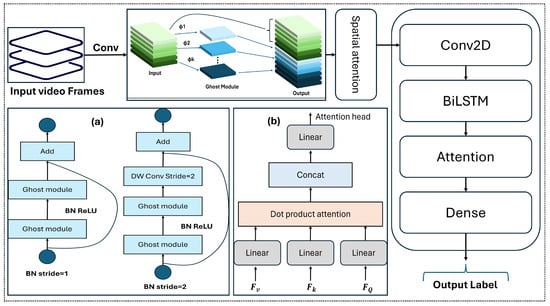
Figure 2.
Architecture of the proposed GhostNet-BiLSTM with attention (GBA) model, illustrating spatial feature extraction with GhostNet, spatial and temporal attention mechanisms, and temporal modeling via BiLSTM. Panel (a) shows GhostNet bottlenecks with strides 1 and 2; and panel (b) depicts the attention heads.
3.2.2. Spatial Attention Module
To enhance the representational capacity, a spatial attention mechanism is integrated after the GhostNet backbone to focus on the most informative facial regions.
The spatial attention map is computed as
where is a convolutional layer followed by a sigmoid activation , and is the spatial feature map tensor before pooling.
The attended feature is then
where ⊙ denotes element-wise multiplication.
Finally, global average pooling is applied to get the spatial feature vector:
3.3. Temporal Modeling with Bidirectional LSTM and Attention
The extracted spatial features from each frame are concatenated into a sequence:
which is input to a Bidirectional Long Short-Term Memory (BiLSTM) network to model temporal dependencies in face gestures.
3.3.1. Bidirectional LSTM
A standard LSTM cell computes hidden state and cell state at time step t as
In a bidirectional setting, two LSTM layers process the sequence forwards and backwards, and their outputs are concatenated:
3.3.2. Temporal Attention Mechanism
To emphasize important time steps in the gesture sequence, a temporal attention mechanism is applied over the BiLSTM outputs .
The attention weights are computed as
where , , are learnable parameters.
The context vector representing the entire sequence is
3.4. Classification Layer
The context vector is passed through fully connected layers with nonlinearities to predict the gesture class probabilities:
where represents the predicted class probabilities.
The predicted label is
3.5. Robot Control via Unity Simulation with Socket Communication
To realize interactive robot control in a metaverse-like environment, the predicted gesture is converted to a control command and sent in real-time to the Unity 3D simulation via socket communication. The messaging protocol, key parameters, and gesture–command associations are summarized in Table 2 and Table 3.
Table 2.
Implementation details and considerations for the socket communication module used in real-time robot control.
Table 3.
Distribution of training and testing samples per gesture class on an average of 1100 samples per gesture.
The proposed method’s simulation environment is implemented in Unity Engine. Figure 3 provides screenshots of this 3D environment and the graphical user interface (GUI) of GBA, which delivers a real-time user experience for ground robot control. The simulator runs on a separate PC and receives commands from the FGR module (GBA) via TCP/IP sockets, as illustrated in Figure 2. The simulator module operates independently, connected over an IP network, and provides constant feedback to the FGR module for each executed command. Robot maneuvers such as moving forward, backward, turning, picking, and dropping objects are performed accurately according to the mapped commands listed in Table 3 and Table 4.

Figure 3.
Simulation environment for gesture-based robot control. (a) GUI of the FGR (GBA) system showing Subject A performing a ‘raise eyebrows’ gesture. (b) Robots receive and execute the corresponding command. (c) Subject B is performing a different facial gesture. (d) Robot executing the corresponding command, demonstrating real-time interaction.
Table 4.
Mapped commands and accuracy for each class in the proposed facial gesture recognition model.
To mimic real-world dynamics, Unity’s physics engine handles inertia, collisions, and force vectors, with each behavior applied according to the specific command. Figure 3 shows example scenarios in the simulator. Figure 3 also illustrates subjects interacting with the remote VR robot using facial gestures. Panel (a) shows the GUI of the FGR (GBA) system, where Subject A is performing a “raise eyebrows” gesture, and the corresponding command is sent to the robot. Panel (b) displays the robot receiving and executing this command. Similarly, Subject B performs a different facial gesture in panel (c), and the robot’s response is shown in panel (d), demonstrating real-time interaction between users and the simulated environment.
3.6. Socket Communication
In our proposed system, the 3D Unity simulator acts as the server, while the FGR (GBA) module functions as the client, as shown in Figure 4. For each command, the client establishes a connection and sends a request to the server. The messaging protocol and key parameters are detailed in Table 2. Upon receiving a command from the FGR module, the server sends an acknowledgment and forwards the command to the robot for execution, ensuring accurate and real-time operation.
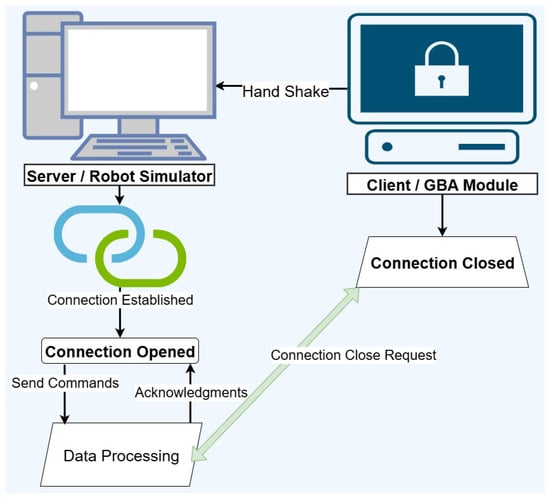
Figure 4.
Communication between GBA-Module and the 3D simulator module via sockets.
3.7. Dataset
Most existing benchmarks for facial gesture recognition focus primarily on static images for emotion recognition and typically offer only a small number of gesture categories [4,36,38]. This limitation reduces their suitability for human–computer interaction (HCI) applications, where dynamic, video-based gesture data is essential for capturing temporal variations. To address this gap, we utilize FaceGest [59], a publicly available large-scale dynamic facial gesture dataset specifically designed for interaction-oriented research.
The dataset comprises 13 gesture classes with labeled video samples, collected under diverse lighting conditions and environmental settings to ensure robustness. Each sample captures dynamic sequences rather than single frames, making it suitable for temporal modeling with deep learning architectures. In addition, FaceGest provides pre-extracted deep feature representations to facilitate rapid experimentation.
In our experiments, 10 facial gesture classes were considered, with a total of approximately 15,000 video samples, averaging around 1100 samples per gesture. For each class, 80% of the samples (approximately 880 videos) were used for training, while the remaining 20% (approximately 220 videos) were allocated for testing/validation. Following standard evaluation protocols, we employed a five-fold cross-validation approach, ensuring balanced class distributions across all folds. Table 3 and Table 4 summarize the dataset and command mapping information. Specifically, Table 3 presents the number of training and test samples for each gesture class, while Table 4 lists the gesture class names along with their mapped control commands and class abbreviations.
4. Experimental Evaluation
Experiments for the proposed system were conducted to evaluate the performance of vision-based dynamic facial gesture recognition, computational efficiency, and real-time applicability for interactive control tasks. The evaluation was carried out using the publicly available FaceGest [59] dataset, which provides 13 distinct facial gesture classes recorded under diverse conditions. Our focus was on assessing classification accuracy, robustness across different gesture categories, and inference speed in comparison with existing baseline methods.
4.1. System Setup and Configuration
The proposed system was evaluated using a cross-platform client–server configuration. The Unity-based 3D simulation environment acted as the server and was deployed on a Windows 11 Home workstation (HP Pavilion Gaming Desktop TG01-1xxx, HP Inc., Palo Alto, CA, USA) equipped with an Intel® Core™ i5-10400F CPU at 2.90 GHz, 32 GB of RAM, and a Realtek Gaming GbE network interface. This server maintained a TCP socket connection to receive gesture commands from the remote client, acknowledged each command, and updated the virtual environment in real time, enabling responsive simulation control. The client consisted of the FGR module (GBA), which was trained and executed on an Ubuntu 22.04.5 LTS workstation with a 3.50 GHz Intel Core i9-10920X CPU, dual NVIDIA GeForce RTX 3090 GPUs, and 32 GB of RAM. The model was trained for 350 epochs with early stopping enabled. Categorical cross-entropy was used as the loss function, and the Adam optimizer was employed for optimal weight updates. The tanh activation function was used in the BiLSTM layers, while softmax activation was applied at the final output layer for gesture classification.
Fifteen subjects participated in testing the proposed system. The FGR (GBA) module was installed on one machine, and the Unity 3D simulator on another, connected through IP addresses as shown in Figure 4. The communication mechanism is illustrated in Figure 3. To evaluate real-world applicability, the simulation was replaced with a physical ground robot and interfaced via an ATmega32U4 microcontroller, enabling the direct execution of commands predicted by the FGR system.
Experimental averaged test results for each class were recorded and are presented in Table 4 and Table 5. Comparisons with existing methods are reported in Table 6 and Table 7. Each subject performed the gestures listed in Table 4. Unlike systems based on wearable gloves or aided sensors, the vision-based gesture recognition allowed subjects to perform gestures naturally without maintaining strict distances or requiring extensive training.
Table 5.
Performance metrics of the proposed facial gesture recognition model on the FaceGest dataset.
Table 6.
Comparison of the proposed GBA method for dynamic facial gesture recognition with baseline algorithms.
Table 7.
Performance comparison of ViT-based dynamic and facial gesture-based HCI control systems.
4.2. Evaluation of Vision-Based Face Gesture Classification
The proposed GBA pipeline integrates GhostNet for lightweight spatial feature extraction, followed by bidirectional LSTM layers with temporal attention for dynamic gesture sequence modeling. To quantitatively assess performance, we computed classification metrics on the test split of the FaceGest dataset, including precision, recall, F1-score, and overall accuracy (Table 5).
The confusion matrix (Figure 5) demonstrates the ability of our model to distinguish between eye-based, mouth-based, head-based, and combined gestures, with minimal inter-class confusion. Classes with visually subtle differences, such as blink versus double blink, were also accurately recognized due to the temporal attention mechanism highlighting key frames.
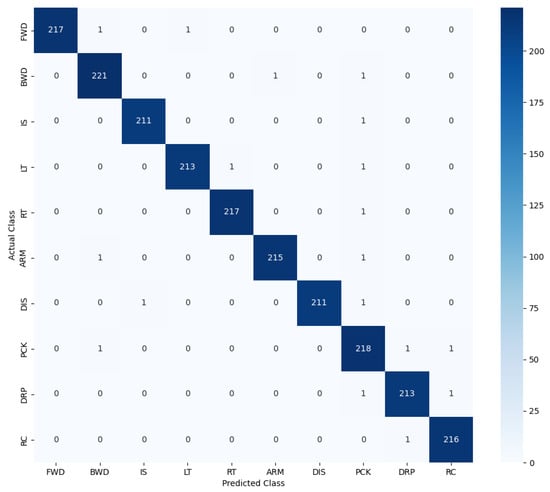
Figure 5.
Confusion matrix for vision-based facial gesture recognition trained model based on the test data.
To further evaluate the training behavior of the proposed model, we analyzed the variation in accuracy and loss over epochs. As shown in Figure 6, the training and validation accuracy (Figure 6a) steadily increases, while the training and validation loss (Figure 6b) decreases consistently, indicating smooth convergence without overfitting. These curves confirm the stability of the model training process and support the effectiveness of the proposed architecture for dynamic facial gesture recognition.
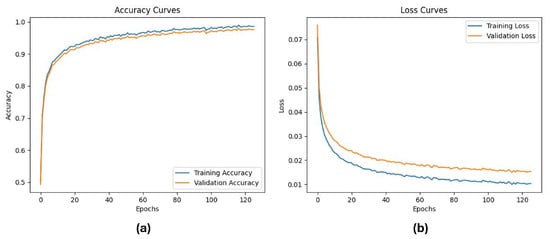
Figure 6.
The training and validation curves of the proposed model: (a) Accuracy over epochs for training and validation sets; (b) Loss value variation over epochs for training and validation sets, showing stable convergence.
In comparison with baseline dynamic gesture recognition methods from the literature, our approach consistently achieved higher accuracy and significantly reduced the computational cost, making it suitable for deployment on resource-constrained systems. The evaluation confirmed that the integration of attention modules into GhostNet and LSTM layers improved the model’s robustness in varying lighting conditions and across different subjects.
4.3. Evaluation Based on Lap Time
One of the standard performance indicators in gesture-based control systems is the lap time [60,61], which measures the total time taken from the initiation of a gesture to the completion of the corresponding action. The primary objective of the proposed system is to provide a natural, safe, and intuitive interface for controlling robots and UAVs, particularly for users with no prior control experience. Therefore, lap time was selected as a key evaluation metric.
A total of 15 participants took part in the experiments, performing the complete set of facial gestures defined in the FaceGest dataset. The system was evaluated in a virtual simulation environment implemented in Unity3D 6.0. For each participant, the time required to execute the control commands using all gestures was measured and averaged to obtain the lap time (shown in Table 7 and Table 8).
Table 8.
Performance comparison of Hybrid CNN-based dynamic and facial gesture-based HCI control systems.
The results demonstrated that the proposed GBA architecture, enhanced with spatial and temporal attention mechanisms, enabled faster and more responsive control compared to existing vision-based gesture recognition systems. The lap times achieved by our system were significantly lower, confirming its suitability for non-expert users. Additionally, the consistently low detection time ensured that commands were processed and executed with minimal delay, resulting in a smoother and more intuitive interaction experience.
Overall, these findings validate that the proposed GBA approach not only improves recognition accuracy but also enhances real-time responsiveness, making it highly applicable to hands-free HCI scenarios such as robotics, UAV navigation, and immersive metaverse applications.
5. Discussion
This study presents a vision-based facial gesture recognition framework for the real-time remote control of robotic systems in both virtual environments. The compact gesture set, combined with the system’s low-latency response, enables intuitive operation with minimal cognitive load for users, even those without prior experience. This was achieved by designing a concise set of 10 easily distinguishable gestures, balancing functional coverage with operational simplicity. Such a design ensures reliable control in challenging or time-sensitive scenarios, avoiding the pitfalls of overly complex gesture vocabularies that may overwhelm operators, or overly simplistic ones that limit task execution [68,69].
Compared to existing vision-based interaction systems, the proposed method is characterized by its simplicity, adaptability, and extensibility. While the core command set is intentionally minimal, it can be expanded depending on application-specific needs, which makes the system flexible for deployment across different domains. Furthermore, the integration of socket-based communication enables seamless remote operation within metaverse-style environments, extending the scope of traditional gesture-based control systems. The recognition engine is built on a hybrid GhostNet-BiLSTM backbone, augmented with spatial and temporal attention mechanisms. This architecture combines the efficiency of lightweight convolutional feature extraction with the temporal modeling capacity of recurrent networks, enabling the robust detection of dynamic facial gestures with minimal computational overhead. The model’s responsiveness and temporal pattern recognition capabilities make it readily transferable to other vision-based HCI applications, from robotic teleoperation to immersive VR/AR interaction.
Limitations
Despite its promising results, the system has certain limitations. The current implementation uses a fixed set of 10 base gestures to ensure ease of use and reduce cognitive burden. While this constraint improves user experience, it may limit control granularity in highly complex scenarios, such as multiple robot operations, where additional derived commands would be necessary. Expanding the gesture set, however, must be approached carefully to maintain usability.
Another limitation lies in the scope of evaluation. The reported results are primarily based on the FaceGest dataset and a real-world pilot study with 15 participants. While the high accuracy values and live testing results are encouraging, they may not fully capture the model’s generalization capability across different datasets or unseen subjects. A cross-dataset evaluation was not conducted in this work due to dataset availability and compatibility constraints, and we explicitly recognize this as a direction for future research.
In addition, while several baselines were included for comparison, not all were re-trained under identical experimental conditions. Some results were adopted directly from prior publications, as shown in Table 6. This distinction may affect the fairness of comparisons, although care was taken to ensure that all baseline results are reported accurately and from reputable sources.
Finally, the current implementation assumes stable computational resources and controlled environmental conditions. Deployment in highly dynamic or resource-constrained settings may require further optimization and robustness checks to ensure consistent performance.
6. Conclusions
In this paper, we proposed a lightweight and efficient vision-based facial gesture recognition system for the intuitive remote control of robots in a virtual environment. Leveraging a hybrid GhostNet-BiLSTM architecture with spatial and temporal attention, our method achieves high accuracy and low latency on the FaceGest dataset, demonstrating robust performance across varied lighting and user conditions. The integration with a Unity3D-based simulation environment via socket communication enables seamless, real-time command transmission, offering a novel approach to contactless human–robot interaction.
The compact gesture vocabulary designed in this work strikes a balance between functionality and user cognitive load, making it suitable for both expert and novice users. Experimental evaluations, including gesture classification accuracy and lap time metrics, validate the system’s superiority over existing vision-based control methods in terms of responsiveness and usability.
Future work will focus on extending the gesture set to support more complex control scenarios, including multi-robot coordination. Additionally, we plan to explore adaptive learning techniques to personalize gesture recognition and improve robustness under diverse real-world conditions. Beyond these directions, we also aim to conduct cross-dataset and unseen subject evaluations to better assess the generalization capabilities of the framework. This will help identify potential dataset biases and ensure reliability across different user groups and environments. Another important direction is optimizing the framework for deployment in resource-constrained platforms, such as mobile or embedded systems, where real-time performance and energy efficiency are critical.
Overall, the proposed system paves the way for accessible, immersive, and reliable vision-based interfaces in assistive robotics, teleoperation, and metaverse applications.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were waived for this study as the FaceGest dataset is publicly available and all data were collected with prior informed consent from the individuals involved.
Informed Consent Statement
The FaceGest dataset used in this study is publicly available. Written informed consent was obtained from all individuals who participated in the data collection.
Data Availability Statement
Project source code is available on request.
Conflicts of Interest
The author declares no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| GBA | GhotNet-BiLSTM-Attention |
| FGR | Facial Gesture Recognition |
| BiLSTM | Bidirectional Long Short-Term Memory |
| HRI | Human–Robot Interaction |
References
- Cruz, P.J.; Vásconez, J.P.; Romero, R.; Chico, A.; Benalcázar, M.E.; Álvarez, R.; Barona López, L.I.; Valdivieso Caraguay, Á.L. A Deep Q-Network based hand gesture recognition system for control of robotic platforms. Sci. Rep. 2023, 13, 7956. [Google Scholar] [CrossRef]
- Mardiyanto, R.; Utomo, M.F.R.; Purwanto, D.; Suryoatmojo, H. Development of Hand Gesture Recognition Sensor Based on Accelerometer and Gyroscope for Controlling Arm of Underwater Remotely Operated Robot. In Proceedings of the 2017 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2017; pp. 329–333. [Google Scholar]
- Zhang, S.; Zhang, S. A novel human-3DTV interaction system based on free hand gestures and a touch-based virtual interface. IEEE Access 2019, 7, 165961–165973. [Google Scholar] [CrossRef]
- Saha, A.; Rajak, S.; Saha, J.; Chowdhury, C. A survey of machine learning and meta-heuristics approaches for sensor-based human activity recognition systems. J. Ambient. Intell. Humaniz. Comput. 2024, 15, 29–56. [Google Scholar] [CrossRef]
- Noh, D.; Yoon, H.; Lee, D. A Decade of Progress in Human Motion Recognition: A Comprehensive Survey from 2010 to 2020. IEEE Access 2024, 12, 5684–5707. [Google Scholar] [CrossRef]
- Diwan, A.; Sunil, R.; Mer, P.; Mahadeva, R.; Patole, S.P. Advancements in Emotion Classification via Facial and Body Gesture Analysis: A Survey. Expert Syst. 2025, 42, e13759. [Google Scholar] [CrossRef]
- Yu, J.; Qin, M.; Zhou, S. Dynamic gesture recognition based on 2D convolutional neural network and feature fusion. Sci. Rep. 2022, 12, 4345. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Biswas, S.; Nandy, A.; Naskar, A.K.; Saw, R. MediaPipe with LSTM Architecture for Real-Time Hand Gesture Recognization. In Proceedings of the International Conference on Computer Vision and Image Processing, Jammu, India, 3–5 November 2023; pp. 422–431. [Google Scholar]
- Wang, Y.; Yan, S.; Liu, Y.; Song, W.; Liu, J.; Chang, Y.; Mai, X.; Hu, X.; Zhang, W.; Gan, Z. A Survey on Facial Expression Recognition of Static and Dynamic Emotions. arXiv 2024, arXiv:2408.15777. [Google Scholar] [CrossRef]
- Wang, F.; Liu, Z.; Lei, J.; Zou, Z.; Han, W.; Xu, J.; Li, X.; Feng, Z.; Liang, R. Dynamic-Static Graph Convolutional Network for Video-Based Facial Expression Recognition. In Proceedings of the International Conference on Multimedia Modeling, Amsterdam, The Netherlands, 29 January–2 February 2024; pp. 42–55. [Google Scholar]
- Diao, H.; Jiang, X.; Fan, Y.; Li, M.; Wu, H. 3D face reconstruction based on a single image: A review. IEEE Access 2024, 12, 59450–59473. [Google Scholar] [CrossRef]
- Sun, B.; Cao, S.; He, J.; Yu, L. Affect recognition from facial movements and body gestures by hierarchical deep spatio-temporal features and fusion strategy. Neural Netw. 2018, 105, 36–51. [Google Scholar] [CrossRef]
- Bian, S.; Liu, M.; Zhou, B.; Lukowicz, P.; Magno, M. Body-area capacitive or electric field sensing for human activity recognition and human–computer interaction: A comprehensive survey. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2024, 8, 1–49. [Google Scholar] [CrossRef]
- Li, H.; Sun, J.; Xu, Z.; Chen, L. Multimodal 2D+ 3D facial expression recognition with deep fusion convolutional neural network. IEEE Trans. Multimed. 2017, 19, 2816–2831. [Google Scholar] [CrossRef]
- Karthikeyan, P.; Kirutheesvar, S.; Sivakumar, S. Facial Emotion Recognition for Enhanced Human–Computer Interaction Using Deep Learning and Temporal Modeling with BiLSTM. In Proceedings of the 2024 5th International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 18–20 September 2024; pp. 1791–1797. [Google Scholar]
- Febrian, R.; Halim, B.M.; Christina, M.; Ramdhan, D.; Chowanda, A. Facial expression recognition using bidirectional LSTM-CNN. Procedia Comput. Sci. 2023, 216, 39–47. [Google Scholar] [CrossRef]
- Kim, S.; Nam, J.; Ko, B.C. Facial expression recognition based on squeeze vision transformer. Sensors 2022, 22, 3729. [Google Scholar] [CrossRef]
- Sun, Y.; Huang, J.; Cheng, Y.; Zhang, J.; Shi, Y.; Pan, L. High-accuracy dynamic gesture recognition: A universal and self-adaptive deep-learning-assisted system leveraging high-performance ionogels-based strain sensors. SmartMat 2024, 5, e1269. [Google Scholar] [CrossRef]
- Hax, D.R.T.; Penava, P.; Krodel, S.; Razova, L.; Buettner, R. A Novel Hybrid Deep Learning Architecture for Dynamic Hand Gesture Recognition. IEEE Access 2024, 12, 28761–28774. [Google Scholar] [CrossRef]
- Singh, R.D.; Mittal, A.; Bhatia, R.K. 3D convolutional neural network for object recognition: A review. Multimed. Tools Appl. 2019, 78, 15951–15995. [Google Scholar] [CrossRef]
- Li, C.; Li, S.; Gao, Y.; Zhang, X.; Li, W. A two-stream neural network for pose-based hand gesture recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 1594–1603. [Google Scholar] [CrossRef]
- Hu, Z.; Qiu, F.; Sun, H.; Zhang, W.; Ding, Y.; Lv, T.; Fan, C. Learning a compact embedding for fine-grained few-shot static gesture recognition. Multimed. Tools Appl. 2024, 83, 79009–79028. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, S.L.; Kuruoglu, E.E. HGR Correlation Pooling Fusion Framework for Recognition and Classification in Multimodal Remote Sensing Data. Remote Sens. 2024, 16, 1708. [Google Scholar] [CrossRef]
- Reddy, S.P.T.; Karri, S.T.; Dubey, S.R.; Mukherjee, S. Spontaneous Facial Micro-Expression Recognition Using 3D Spatiotemporal Convolutional Neural Networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- López, L.I.B.; Ferri, F.M.; Zea, J.; Caraguay, Á.L.V.; Benalcázar, M.E. CNN-LSTM and post-processing for EMG-based hand gesture recognition. Intell. Syst. Appl. 2024, 22, 200352. [Google Scholar]
- Kassab, M.A.; Ahmed, M.; Maher, A.; Zhang, B. Real-time human-UAV interaction: New dataset and two novel gesture-based interacting systems. IEEE Access 2020, 8, 195030–195045. [Google Scholar] [CrossRef]
- Yoo, M.; Na, Y.; Song, H.; Kim, G.; Yun, J.; Kim, S.; Moon, C.; Jo, K. Motion estimation and hand gesture recognition-based human–UAV interaction approach in real time. Sensors 2022, 22, 2513. [Google Scholar] [CrossRef]
- Kohli, A.; Gupta, A. Detecting deepfake, faceswap and face2face facial forgeries using frequency CNN. Multimed. Tools Appl. 2021, 80, 18461–18478. [Google Scholar] [CrossRef]
- Ramachandra, R.; Vetrekar, N.; Venkatesh, S.; Nageshker, S.; Singh, J.M.; Gad, R.S. VoxAtnNet: A 3D Point Clouds Convolutional Neural Network for Generalizable Face Presentation Attack Detection. In Proceedings of the 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), Istanbul, Turkey, 27–31 May 2024; pp. 1–9. [Google Scholar]
- Kwon, O.J.; Kim, J.; Lee, J.; Ullah, F. Vision-Based Gesture-Driven Drone Control in a Metaverse-Inspired 3D Simulation Environment. Drones 2025, 9, 92. [Google Scholar]
- Sharma, K.; Singh, G.; Goyal, P. IPDCN2: Improvised Patch-based Deep CNN for facial retouching detection. Expert Syst. Appl. 2023, 211, 118612. [Google Scholar] [CrossRef]
- Ferrari, C.; Berretti, S.; Pala, P.; Del Bimbo, A. The Florence multi-resolution 3D facial expression dataset. Pattern Recognit. Lett. 2023, 175, 23–29. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Hao, X.; Liu, Y.; Pei, L.; Li, W.; Du, Y. Atmospheric temperature prediction based on a BiLSTM-Attention model. Symmetry 2022, 14, 2470. [Google Scholar] [CrossRef]
- Li, B.; Lima, D. Facial expression recognition via ResNet-50. Int. J. Cogn. Comput. Eng. 2021, 2, 57–64. [Google Scholar] [CrossRef]
- Ulrich, L.; Marcolin, F.; Vezzetti, E.; Nonis, F.; Mograbi, D.C.; Scurati, G.W.; Dozio, N.; Ferrise, F. CalD3r and MenD3s: Spontaneous 3D facial expression databases. J. Vis. Commun. Image Represent. 2024, 98, 104033. [Google Scholar] [CrossRef]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; PietikäInen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Dhall, A.; Ramana Murthy, O.; Goecke, R.; Joshi, J.; Gedeon, T. Video and Image Based Emotion Recognition Challenges in the Wild: Emotiw 2015. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 423–426. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A Complete Dataset for Action Unit and Emotion-Specified Expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG Facial Expression Database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services WIAMIS 10, Desenzano del Garda, Italy, 12–14 April 2010; pp. 1–4. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training Deep Networks for Facial Expression Recognition with Crowd-Sourced Label Distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar]
- Jiang, X.; Zong, Y.; Zheng, W.; Tang, C.; Xia, W.; Lu, C.; Liu, J. Dfew: A Large-Scale Database for Recognizing Dynamic Facial Expressions in the Wild. In Proceedings of the 28th ACM international Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2881–2889. [Google Scholar]
- Wang, Y.; Sun, Y.; Huang, Y.; Liu, Z.; Gao, S.; Zhang, W.; Ge, W.; Zhang, W. Ferv39k: A Large-Scale Multi-Scene Dataset for Facial Expression Recognition in Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20922–20931. [Google Scholar]
- Taha, B.; Hatzinakos, D. Emotion Recognition from 2D Facial Expressions. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4. [Google Scholar]
- Hu, Q. Enhancing American Sign Language Communication with Virtual Reality: A Gesture Recognition Application on Oculus Quest 2. Ph.D. Thesis, Carleton University, Ottawa, ON, Canada, 2024. [Google Scholar]
- Mohana, M.; Subashini, P.; Krishnaveni, M. Emotion recognition from facial expression using hybrid CNN–LSTM network. Int. J. Pattern Recognit. Artif. Intell. 2023, 37, 2356008. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Mishra, R.K.; Urolagin, S.; Jothi, J.A.A.; Gaur, P. Deep hybrid learning for facial expression binary classifications and predictions. Image Vis. Comput. 2022, 128, 104573. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chaudhari, A.; Bhatt, C.; Krishna, A.; Mazzeo, P.L. ViTFER: Facial emotion recognition with vision transformers. Appl. Syst. Innov. 2022, 5, 80. [Google Scholar] [CrossRef]
- Aouayeb, M.; Hamidouche, W.; Soladie, C.; Kpalma, K.; Seguier, R. Learning vision transformer with squeeze and excitation for facial expression recognition. arXiv 2021, arXiv:2107.03107. [Google Scholar] [CrossRef]
- Wasi, A.T.; Šerbetar, K.; Islam, R.; Rafi, T.H.; Chae, D.K. Arbex: Attentive feature extraction with reliability balancing for robust facial expression learning. arXiv 2023, arXiv:2305.01486. [Google Scholar] [CrossRef]
- Li, Y.; Wang, M.; Gong, M.; Lu, Y.; Liu, L. Fer-former: Multimodal transformer for facial expression recognition. IEEE Trans. Multimed. 2024, 27, 2412–2422. [Google Scholar] [CrossRef]
- Xue, F.; Wang, Q.; Guo, G. Transfer: Learning Relation-Aware Facial Expression Representations with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3601–3610. [Google Scholar]
- Huang, Q.; Huang, C.; Wang, X.; Jiang, F. Facial expression recognition with grid-wise attention and visual transformer. Inf. Sci. 2021, 580, 35–54. [Google Scholar] [CrossRef]
- Yaseen; Jamil, S. FaceGest: A Comprehensive Facial Gesture Dataset for Human—Computer Interaction. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 10–17 June 2025; pp. 337–347. [Google Scholar]
- Kang, J.; Chen, J.; Xu, M.; Xiong, Z.; Jiao, Y.; Han, L.; Niyato, D.; Tong, Y.; Xie, S. Uav-assisted dynamic avatar task migration for vehicular metaverse services: A multi-agent deep reinforcement learning approach. IEEE/CAA J. Autom. Sin. 2024, 11, 430–445. [Google Scholar] [CrossRef]
- Sharmila, P.; Maheswaran, M.; Mohanraj, T.; Verma, R.; Malviya, B.; SubbaRao, S. A Way of Safe Wireless Networks using IMU/UWB/Vision Through Sensor Networks. In Proceedings of the 2024 4th International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 14–15 May 2024; pp. 266–271. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef] [PubMed]
- Ming, Z.; Xia, J.; Luqman, M.M.; Burie, J.C.; Zhao, K. Dynamic multi-task learning for face recognition with facial expression. arXiv 2019, arXiv:1911.03281. [Google Scholar] [CrossRef]
- Serengil, S.I.; Ozpinar, A. Hyperextended Lightface: A Facial Attribute Analysis Framework. In Proceedings of the 2021 International Conference on Engineering and Emerging Technologies (ICEET), Istanbul, Turkey, 27–28 October 2021; pp. 1–4. [Google Scholar]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Ji, W.; Zong, M.; Wong, W.K.; Lai, Z.; Lv, H. Discriminative deep multi-task learning for facial expression recognition. Inf. Sci. 2020, 533, 60–71. [Google Scholar] [CrossRef]
- Antoniadis, P.; Filntisis, P.P.; Maragos, P. Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Dang, T.L.; Pham, T.H.; Dao, D.M.; Nguyen, H.V.; Dang, Q.M.; Nguyen, B.T.; Monet, N. DATE: A video dataset and benchmark for dynamic hand gesture recognition. Neural Comput. Appl. 2024, 36, 17311–17325. [Google Scholar] [CrossRef]
- Nayan, N.; Ghosh, D.; Pradhan, P.M. A multi-modal framework for continuous and isolated hand gesture recognition utilizing movement epenthesis detection. Mach. Vis. Appl. 2024, 35, 86. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).