1. Introduction
In today’s era of rapid technological development, intelligent agriculture has become an important trend in the field of agriculture. Castañeda-Miranda et al. and Chatterjee et al. utilize IoT technology to achieve smart agriculture [
1,
2]. Castañeda-Miranda et al. employ IoT technology and artificial neural networks to monitor and collect environmental data in real time, enabling intelligent frost control and irrigation management [
1]. Chatterjee et al. have developed an IoT-based livestock health monitoring framework that can identify the health status of dairy cows and analyze changes in their behavior to predict various dairy cow diseases [
2]. IoT technology has significantly improved the efficiency of agricultural systems. Animal husbandry, as a pillar industry of agriculture, is being promoted by the Internet of Things (IoT), artificial intelligence, and other technologies for precise and intelligent management. Zhang et al. discussed the application of Wearable Internet of Things (W-IoT) technology in smart farms to realize precision livestock breeding, where accurate identification of individual animals is the key to realizing precision management [
3]. Many scholars have used deep learning technology to perform facial recognition on pigs and cattle to achieve accurate individual identification [
4,
5]. Deep learning-driven animal facial recognition technology (such as individual identification of livestock, such as pigs and cattle) is driving the livestock industry toward a paradigm shift toward individual precision management, intelligent health monitoring, and automated behavioral analysis, providing core technological support for agricultural intelligence. For sheep, as a widely farmed livestock species worldwide, the accurate identification of its individual animals is of great significance to improve farming efficiency and ensure product safety.
Traditional identification of individual sheep relies mainly on physical marking and manual observation: ear tags are easily removed, branding can cause infection, and spray paint fails as the wool grows; the Radio Frequency Identification (RFID) [
6] technology allows for electronic identification but suffers from the risk of tag damage and high cost, while empirical body observation methods are inefficient and difficult to scale up. These methods have significant limitations in terms of durability, automation, and affordability. In contrast, biometric technologies are more adaptable: DNA detection is difficult to scale up due to the lack of real-time performance and high cost, iris recognition is limited by equipment investment and animal cooperation, and facial recognition can analyze sheep’s facial features using deep learning technology to identify individuals, which can simultaneously meet the demand for accurate management and tracking of health data, providing an efficient and reliable solution for modern agriculture.
With the rapid development of deep learning technology, sheep face recognition shows important application value in intelligent animal husbandry. The existing research mainly focuses on four directions: Convolutional Neural Networks (CNNs), Vision Transformer (ViT), Metric Learning, and model lightweighting. Although each method has made significant progress in specific scenarios, there is still room for improvement in terms of model efficiency, feature representation capability, and complex scene adaptation. Early research focused on building end-to-end recognition frameworks using CNNs. Almog et al. collected 81 Assaf goat facial images, first localized the goat face with Faster R-CNN, and then classified it with ResNet50V2 model embedded with ArcFace loss function, with an average accuracy of 95% on the two datasets, but the number of parameters was 40.4 M [
7]. Billah et al. used a YOLOv4 model to recognize the key parts of a goat’s face; the accuracy of face, eyes, ears, and nose was 93%, 83%, 92%, and 85%; however, global facial features are not used, and there may be missed detections [
8]. Zhang et al. used the YOLOv4 model, incorporating the CBAM attention mechanism to recognize the sheep’s face trained by migration learning; the mAP@50 was 91.58% and 90.61% in the two datasets, respectively, demonstrating the importance of the attention mechanism in screening key features. However, the number of parameters and floating-point operations of YOLOv4 are extremely large, which makes it difficult to meet the requirements of mobile deployment [
9]. Zhang et al. incorporated the SE attention mechanism into the AlexNet model and used the Mish activation function. The recognition accuracy on the validation set reached 98.37%, and the accuracy on the validation set was about 96.58% after 100 days of tracking and collection. It demonstrates the long-term stability of the model, but its shallow network structure limits the ability to handle complex occlusion scenarios [
10]. Guo et al. collected 10 types of sheep facial images as a dataset. They used knowledge distillation to migrate the knowledge from YOLOv5x to YOLOv5s to enhance the feature extraction capability, with a model accuracy of 92.75%, mAP@50:95 of 94.67%, and an inference time of 12.63 ms. However, the number of model parameters is 7.2 M, and the model size is 14.065 MB, which is still far from the lightweight model [
11]. Pang et al. proposed the Attention Residual Module (ARM) on a self-constructed dataset containing 4490 images of 38 sheep with VGG16, GoogLeNet, and ResNet50, combined with 10.2%, 6.65%, and 4.38% accuracy improvement, respectively. However, the number of ARM module references is 1.6 M, which may not satisfy the lightweight requirement in combination with other models [
12].
Many other researchers have used the algorithm based on the Vision Transformer architecture to achieve good results in sheep face recognition. Li et al. combined MobileNetV2 with ViT. They achieved 97.13% accuracy on a dataset of 7434 images containing 186 sheep, with the number of parameters and floating-point operations reduced by 5 times compared to that of ResNet-50 [
13]. Zhang et al. improved the ViT model by introducing the LayerScale module and migration learning method, achieving 97.9% accuracy on a self-built dataset of 16,000 images containing 160 sheep [
14]. Zhang et al. designed a multiview image acquisition device by adopting the T2T-ViT method and introducing the SE attention mechanism, the LayerScale module, and ArcFace loss function. The improved T2T-ViT model achieves a recognition accuracy of 95.9% and an F1-Score of 95.5%. The ViT model is a heavyweight model with a huge number of parameters, making it difficult to meet lightweight requirements [
15].
In addition, some scholars have conducted research based on the Siamese network. Zhang et al. constructed two datasets and designed RF_Block and EI_Block. They introduced a 3D attention mechanism to construct SAM_Block; the accuracies on 100 little-tailed cold sheep datasets were 97.2% and 90.5%, and the accuracies on small sample training were 92.1% and 86.5%, respectively. However, the size of the model is 112.2 MB, and the average recognition time is 49.7 ms [
16].
Some scholars have also conducted research on model lightweighting. Zhang et al. lighten the model based on the YOLOv5s model. On the self-constructed dataset containing 63 small-tailed frigid sheep, the parameters and computational complexity of LSR-YOLO is 4.8 M and 12.3 GFLOPs, which are 25.5% and 33.4% lower than that of YOLOv5s, respectively, and the model size is only 9.5 MB when the mAP@50 reaches 97.8%, but there is still some room for compression in the number of model parameters and FLOPs [
17]. Zhang et al. made improvements based on the YOLOv7-tiny module. Finally, they obtained the YOLOv7-SFR algorithm through knowledge distillation, with the number of parameters, model size, and average recognition time of 5.9 M, 11.3 MB, and 3.6 ms, respectively, on the self-constructed sheep face dataset; mAP@50 was 96.9%. However, with the introduction of the Dyhead module, the parameter and model sizes increased by 3.3 M and 6.5 MB, respectively [
18].
The current research on lightweight sheep face recognition faces four core challenges: the number of model parameters and computational volume are too large, the number of parameters and FLOPs of traditional CNNs (e.g, ResNet50V2, YOLOv4) and Transformer architectures (e.g, ViT) are far more than the upper limit of the deployment of the mobile terminal, and the attention modules, such as CBAM, ARM, and so on, have introduced additional parameter overheads while improving the accuracy; Complex scene robustness is insufficient, and shallow networks (e.g, AlexNet) are poorly adapted to occluded scenes; it is difficult to balance lightweighting and accuracy, and although existing methods (e.g, LSR-YOLO, YOLOv7-SFR) compress parameters, the FLOPs and model size still affect the ultimate lightweighting, so it is necessary to optimize the parameter and computation volume in depth while guaranteeing the accuracy.
Facing these challenges, in this paper, the PFL-YOLO model is proposed, which aims to fill the gap in lightweight sheep face recognition and provide a new solution. The model is lightweight based on YOLOv8n, and by optimizing the model structure and parameter configurations, the number of parameters and computational complexity are significantly reduced to make it more adaptable to mobile devices or devices with limited computational resources while ensuring higher recognition accuracy. The main contributions of this study include the following:
In this study, a dataset of sheep facial images was constructed through multi-angle image acquisition of 60 Australian and Lake hybrid sheep (bred from Australian White Sheep and Hu Sheep) in the Linxia Hui Autonomous Prefecture, Gansu Province, China.
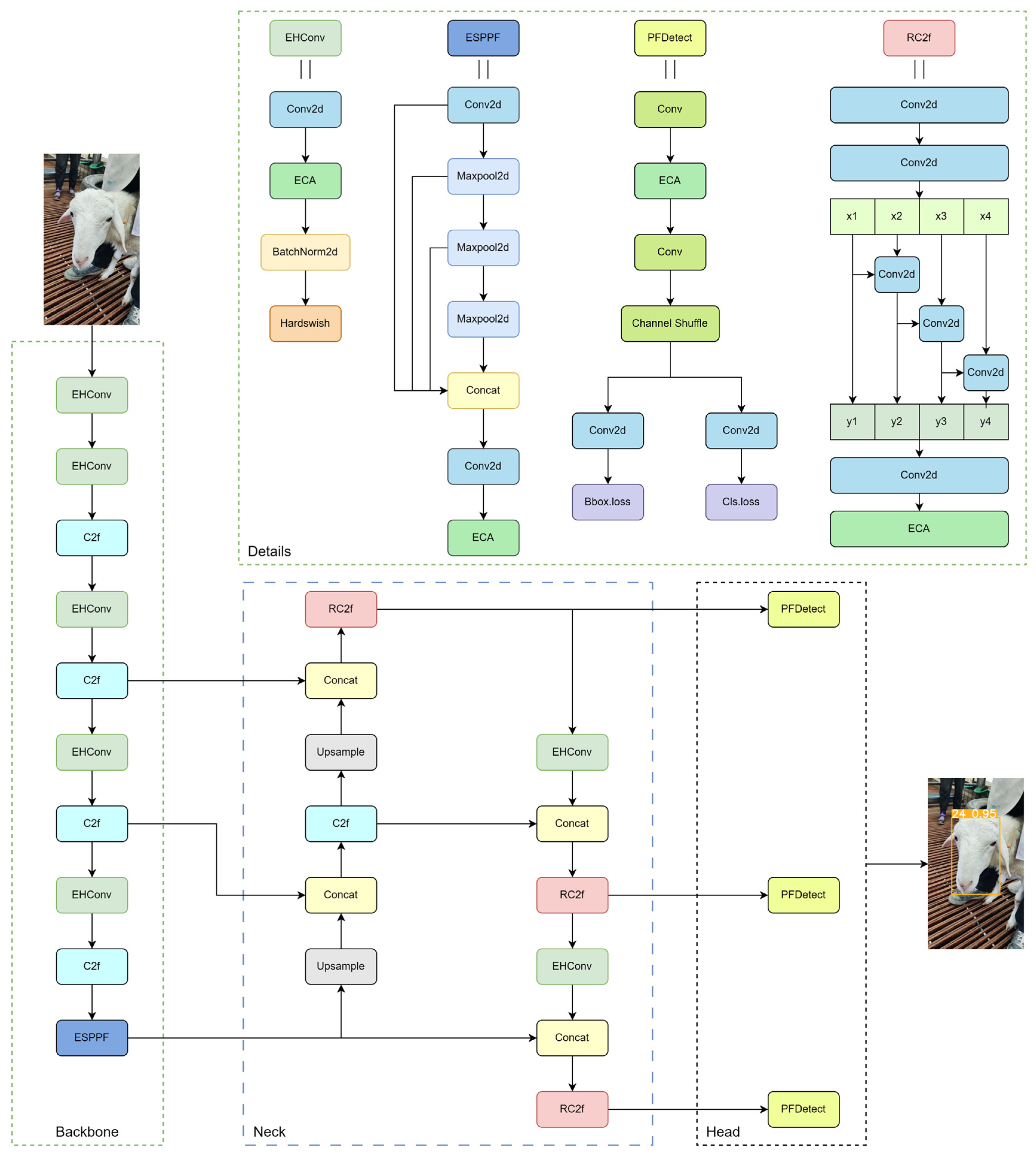
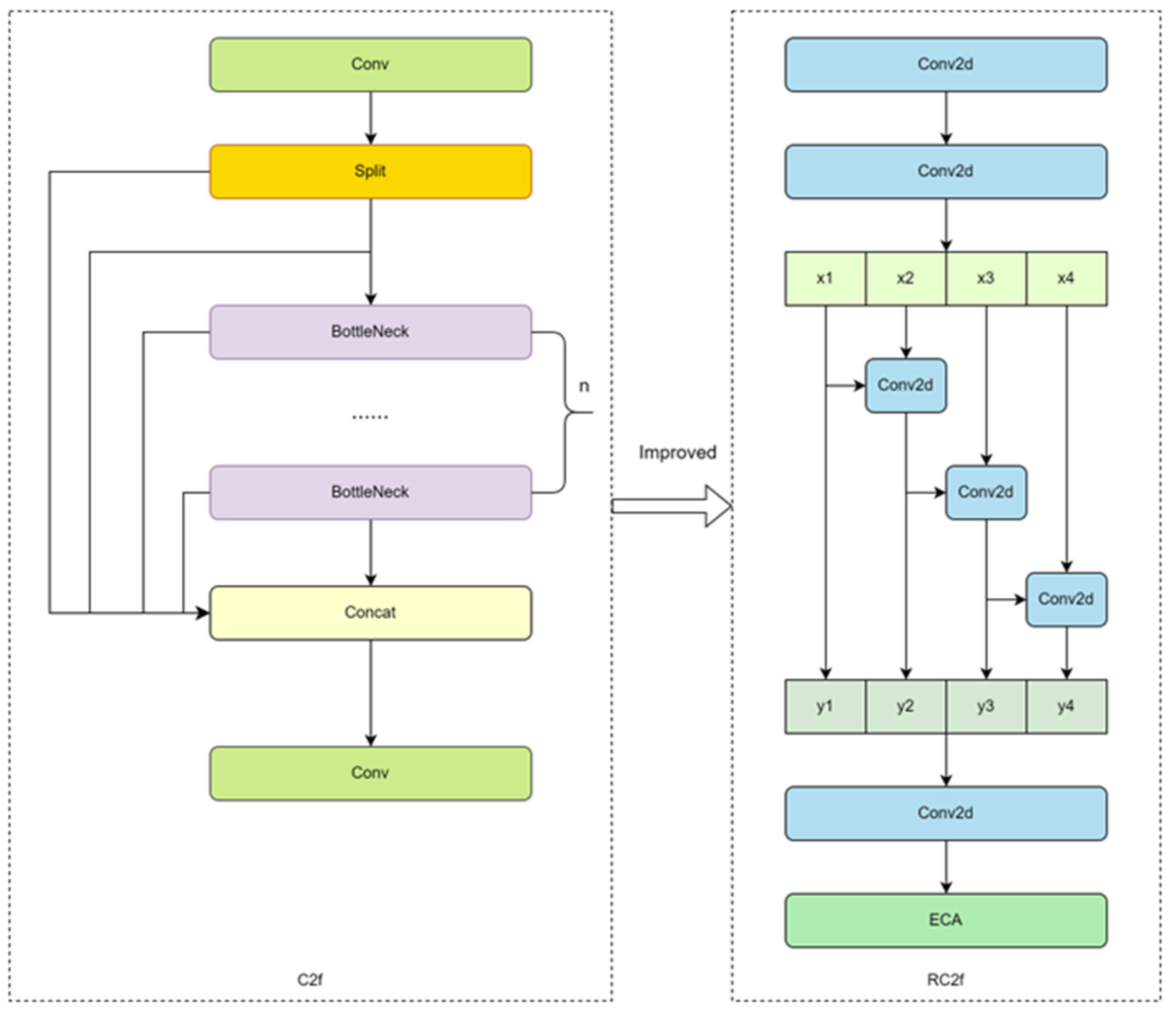
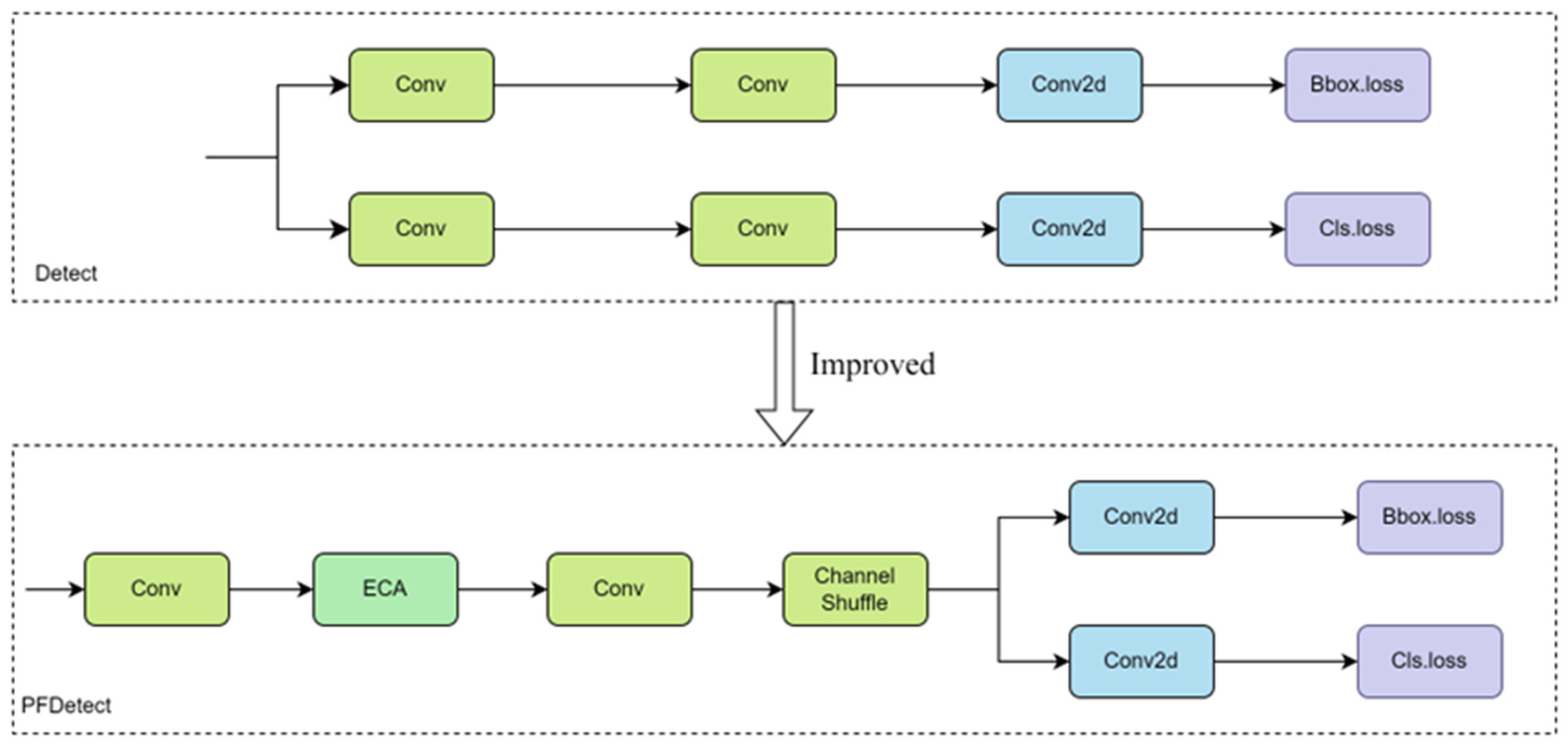
To meet the requirements of lightweight sheep face recognition, this study proposes the PFL-YOLO model. The EHConv module is embedded in the backbone network, which greatly reduces the number of parameters and computations while maintaining the receptive field and enhances the ability to extract local fine features such as wool texture and horn shape. The RC2f module is designed to realize the efficient interaction between shallow detail features and deep semantic features through the residual ladder network structure. The ESPPF module is proposed to fuse features of different scales and enhance the semantic information of the sheep face feature map through adaptive spatial pyramid pooling. The PFDetect module is constructed, which greatly reduces the number of parameters and the computation of the detection head through cross-layer parameter sharing and an attention mechanism.
The PFL-YOLO model maintains an extremely low level of parameter number, computational complexity, and model size while being able to recognize a single sheep face efficiently and accurately. In addition, the PFL-YOLO model is superior to mainstream object recognition models in recognizing the positive features of sheep faces and is suitable for use in mobile devices, embedded devices, and surveillance systems.
3. Results
3.1. Results and Analysis of Ablation Experiments
In order to understand the impact of the improved module on the model, ablation experiments were designed in this study. The ablation experiments were conducted with the same server configuration and the same hyperparameters. The results of the ablation experiments are shown in
Table 5 and
Table 6, where √ indicates the use of the module and is left blank if it is not used.
The introduction of the ESPPF module into the YOLOv8n model alone reduced the number of parameters by 5.3% (0.16 M) but resulted in a 0.7% decrease in recall and a 0.2% decrease in mAP@50; this suggests that the ESPPF module has a role in lightweighting the model but has an impact on the model’s detection performance, especially on the recall metrics.
On the basis of YOLOv8n+ESPPF, the introduction of the EHConv module alone can increase the precision by 0.1%, reduce the number of parameters by 23.8% (0.72 M), and compress the FLOPs by 14.8% (1.2 G), but it can lead to a decrease in the recall rate by 0.2%. This suggests that the EHConv module excels in improving model accuracy and lightweighting, with relatively little impact on recall. The introduction of the RC2f module alone reduces the number of parameters by 24.8% (0.75 M), FLOPs by 13.5% (1.1 G), and model size by 25% (1.5 MB), but it results in a 0.2% decrease in the recall rate and a 0.4% decrease in mAP@50:95. While the RC2f module has a significant effect in terms of model compression, it has an acceptable impact on detection performance. The introduction of the PFDetect module alone can increase precision by 0.1%, reduce the number of parameters by 28.4% (0.86 M), FLOPs by 33.3% (2.7 G), and model size by 28.3% (1.7 MB) while decreasing mAP@50:95 by 0.4%. This suggests that the PFDetect module effectively improves accuracy while compressing the model with relatively little effect on mAP@50:95.
Based on the YOLOv8n+ESPPF model, the EHConv, RC2f, and PFDetect modules were combined in pairs to explore the influence of the combination effect of these modules on the model. When EHConv is combined with the RC2f module, the mAP@50:95 is reduced by 0.9%, but the parameters are reduced by 43.6% (1.31 M), the model size is reduced by 41.2% (2.6 M), and the FLOPs are reduced by 27.1% (2.2 G). Recall is improved by 0.2%. When EHConv is combined with the PFDetect module, the recall rate is reduced by 0.5%, but the number of parameters is reduced by 47% (1.42 M), the model size is reduced by 45% (2.7 MB), and the FLOPs are reduced by 46.9% (3.8 G). When RC2f is combined with the PFDetect module, the recall rate is reduced by 1.1%, but the number of parameters is reduced by 48% (1.45 M), the model size is reduced by 46.7% (2.8 MB), and FLOPs are reduced by 45.6% (3.7 G).
After the integration of the four modules, the number of model parameters was compressed to 33.4% (1.01 M) of the original size, and the FLOPs were reduced by 59.3% (4.8 G); the core detection accuracy (mAP@50 99.5%) was maintained, but the mAP@50:95 index decreased by 1.0%. The results show that the combination of the four modules achieves an effective balance between model lightness (model parameter number 1.01 M, model size 2.1 MB) and high accuracy.
3.2. Comparison Experiment
In this comparison experiment, to comprehensively evaluate the model performance, several lightweight versions of the YOLO series are selected for comparison. Specifically, these include YOLOv5n, YOLOv7-tiny [
24], YOLOv8n, YOLOv9-t [
25], and YOLO11n, the most lightweight models within their respective series. In addition to investigating the effect of the lightweight model further, this study carries out a series of innovative lightweight improvements based on YOLOv8n. The backbone layer of YOLOv8n was modified with the help of Hugging Face’s timm library. Specifically, several layers before the SPPF module were replaced with a more lightweight model architecture, which includes the mobilenetv3_small_050, mobilenetv4_conv_small_035, ghostnet_050, and lcnet_035 models. The interpretation of the above models is as follows: mobilenetv3_small_050 adopts the miniature model of MobileNetV3 [
26] with a model width of 0.5; mobilenetv4_conv_small_035 selects the small convolutional model of MobileNetV4 [
27], a small convolutional model with the same model width of 0.5; ghostnet_050 uses the GhostNet [
28] model with the model width kept at 0.5; and lcnet_035 employs the LCNet [
29] model, which also has a model width of 0.5. In this paper, the transformed models are named V3-YOLOv8n, V4-YOLOv8n, LCNet-YOLOv8n, and Ghost-YOLOv8n for the subsequent analysis and comparison of model performance.
3.2.1. PFL-YOLO: Optimal Balance of Performance and Efficiency
In a comprehensive analysis of the performance of various YOLO series models and their improved versions, the PFL-YOLO model demonstrated distinct advantages. First, in terms of key performance metrics, the results are shown in
Table 7. PFL-YOLO achieved 98.5% precision, 98.8% recall, 99.5% mAP@50, 87.4% mAP@50:95, and 98.65% F1-Score. These results indicate that although PFL-YOLO did not achieve the highest score across all evaluation criteria, it maintained a consistently competitive level across all major performance indicators, particularly excelling in mAP@50 and F1-Score, which reflects an excellent balance between detection accuracy and efficiency. From the perspective of model performance efficiency, the results are shown in
Table 8. The PFL-YOLO model requires only 1.01 M parameters, 3.3 GFLOPs of computational complexity, and a model size of 2.1 MB to achieve an average detection time of 11.2 ms and a detection speed of approximately 89.4 images per second. Compared to other models such as YOLOv5n and YOLOv7-tiny, PFL-YOLO significantly reduces computational resource requirements and model size while maintaining similar or even superior detection performance, making it especially suitable for deployment on resource-constrained devices.
Further comparison shows that although some models, such as YOLOv9-t, are slightly higher than PFL-YOLO in terms of precision and recall, they tend to require more parameters, higher computational complexity, and larger model sizes, e.g., YOLOv9-t has 3.51 million parameters and 15.3 GFLOPs, which results in a much slower inference than PFL-YOLO. In addition, the modified backbone networks like V3-YOLOv8n and Ghost-YOLOv8n, although similar to PFL-YOLO in terms of the number of parameters and model size, are inferior to PFL-YOLO in terms of detection performance metrics, which once again demonstrates that PFL-YOLO does a particularly good job of optimizing the balance between model efficiency and performance.
In summary, PFL-YOLO not only excels in detection performance but also demonstrates significant advantages in computational efficiency and model size. This high performance and low resource consumption make PFL-YOLO particularly suitable for applications in scenarios with high real-time and computational resource requirements, such as target detection tasks in mobile devices or edge computing environments.
3.2.2. Balance of High Precision and Low Parameters
The PFL-YOLO model substantially reduces the number of parameters and complexity while maintaining high accuracy, reducing the demand for computational resources; it can be deployed on resource-constrained devices to recognize sheep faces in different scenarios effectively, and it provides a highly efficient and lightweight solution for sheep individual recognition.
Figure 10 shows the relationship between the accuracy of the ten target detection models and the number of parameters, from which it can be seen that the closer to the point in the upper left corner, it proves that the model has a high recognition accuracy while having a low number of parameters. The mAP@50:95 accuracy of the PFL-YOLO model is 87.4%; among the other target detection models, the index of YOLOv8n is the highest, amounting to 88.4%, and compared with YOLOv8n, the PFL-YOLO model loses only 1%, but the number of parameters is reduced by 2M. The PFL-YOLO model achieves a balance between high accuracy and lightweight.
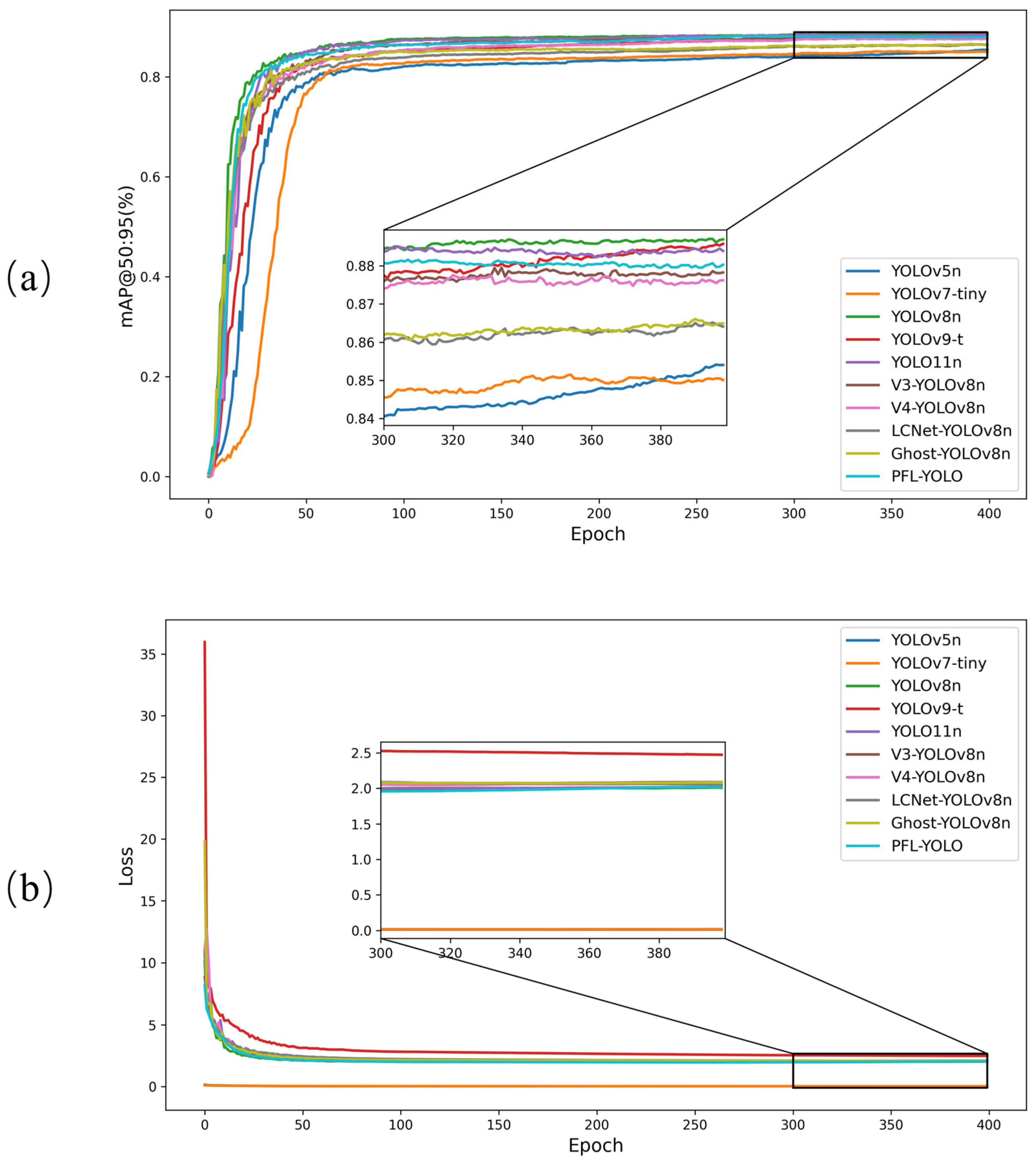
3.2.3. Comparison of Accuracy and Loss Curves for Different Models
Figure 11 shows the mAP@50:95 accuracy curves and the validation set loss curves of the ten object detection models in the validation set. In
Figure 11a, the mAP@50:95 of PFL-YOLO is slightly lower than that of YOLOv8n and YOLOv9-t but better than that of other models with modified backbones. The lower accuracy of YOLOv5n and YOLOv7-tiny indicates their limitations in complex tasks. In the later training phase (300–400 epochs), mAP@50:95 is basically stable for all models. In
Figure 11b, the loss values of all models decrease with an increasing number of training epochs, indicating that the models gradually converge during the training process. In addition, the loss of most models tends to be stable around 100 epochs. The loss of PFL-YOLO fluctuates slightly around 300 epochs but eventually stabilizes around 380–400 epochs.
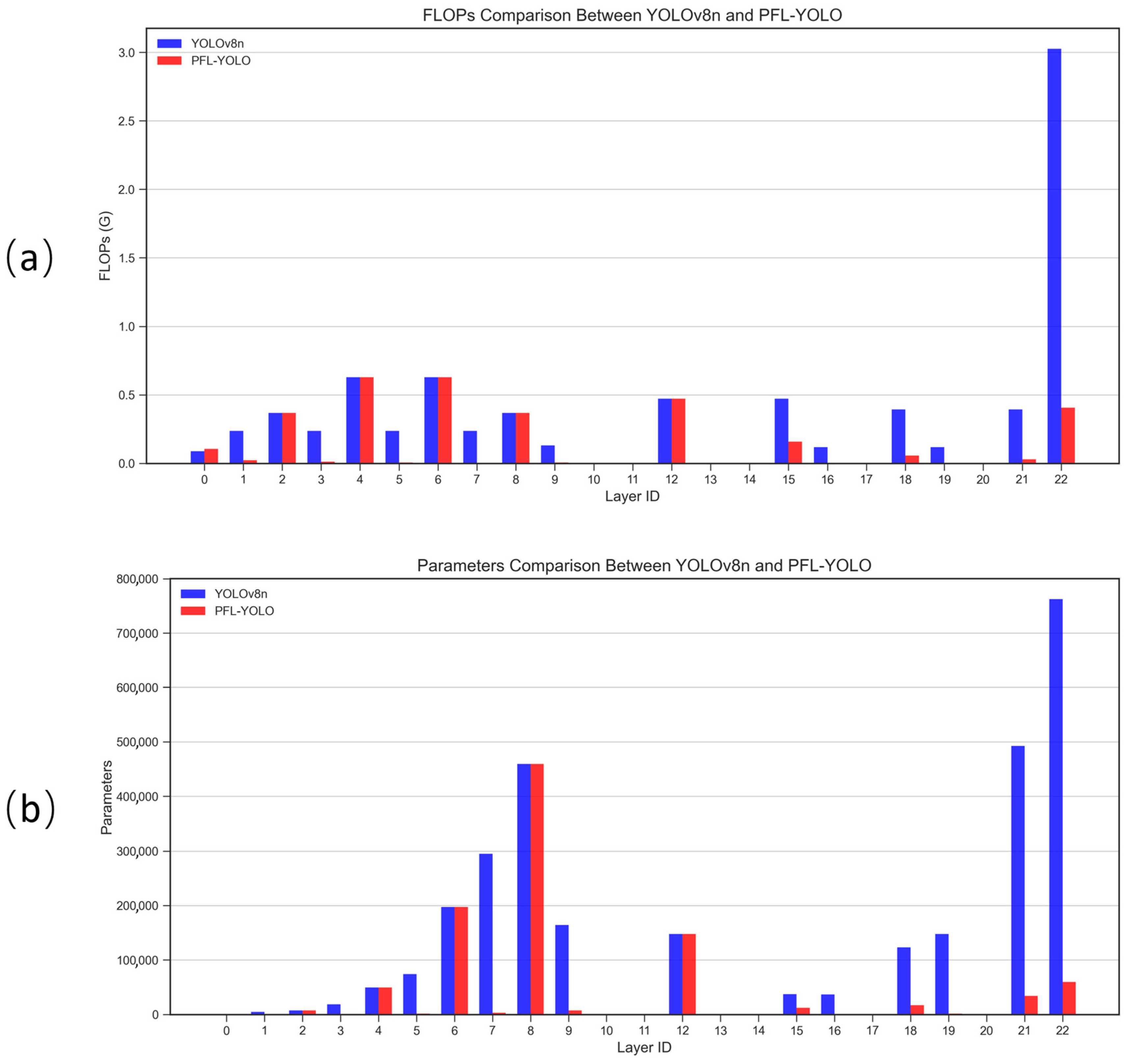
3.2.4. Comparison of Parameter Counts and FLOPs for Models
Figure 12 illustrates the histogram comparison of the number of parameters and FLOPs for the YOLOv8n and PFL-YOLO models. In
Figure 12a, the FLOPs of PFL-YOLO in most layers are significantly lower than those of YOLOv8n, especially in the 22nd layer, where the FLOPs of YOLOv8n is 3.025 G, while PFL-YOLO is only 0.405 G, indicating that PFL-YOLO has more advantages in computational efficiency. In
Figure 12b, the number of parameters of PFL-YOLO is significantly lower than that of YOLOv8n in the 22nd layer, where the number of parameters of YOLOv8n is 762,244 while that of PFL-YOLO is only 59,861, which further proves the lightweight advantage of PFL-YOLO.
PFL-YOLO outperforms YOLOv8n in terms of FLOPs and the number of parameters, which makes it more suitable for use in resource-constrained environments.
Table 9 shows the statistical results of the PFL-YOLO model with the lightweight detection model. The number of PFL-YOLO parameters is only 1.01 M (33.4% of YOLOv8n and 54.8% of YOLOv5n), the FLOPs are only 3.3 G (40.7% of YOLOv8n), and the model size is compressed to 2.1 MB (55.2% of YOLOv5n). Compared with YOLOv7-tiny, the number of parameters is reduced by 83.6%, and the computation amount is reduced by 75.5%, but it can still maintain high accuracy with very low resource consumption (mAP@50:95 87.4%). In terms of precision–efficiency balance, the PFL-YOLO model achieves a mAP@50 of 99.5% (equal to YOLOv9-t and YOLO11n), which is only 0.1% lower than YOLOv7-tiny (99.6%), and the mAP@50:95 (87.4%) is slightly worse than YOLOv8n (88.4%). However, it approaches the performance of mainstream models with 33.4% parameters and 40.7% computation, which is more suitable for resource-constrained scenarios.
3.2.5. Comparison of Heatmap Effects of Different Models
Heatmaps can effectively visualize the region of concern of the algorithm through the change of color shades to intuitively present the model’s determination of the likelihood of the existence of different regions and targets in the image. The Gradient-weighted Class Activation Mapping (Gradient-CAM) [
30] technique has been used in this study to visualize the effect of sheep face recognition.
As shown in
Figure 13, in images (a) and (b), the heatmap area of the PFL-YOLO model was significantly superior to that of YOLOv8n and other lightweight models. It shows that it can capture the key information of the image more comprehensively, especially when dealing with the frontal features of the sheep’s face, and can make full use of the large effective area to improve the recognition accuracy.
To deepen the comparison, the heatmap area of interest was calculated through a process involving grayscale conversion, binarization, contour extraction, and area computation of the contour-surrounded region.
Table 10 lists the pixel area of the area of interest for the different models. In image (a), PFL-YOLO’s heatmap concern area (20,066 pixels) far exceeded that of other models. In image (b), its area reached 38,888.5 pixels, again surpassing others. In image (c), although PFL-YOLO’s 27,417.5 pixels were lower than YOLOv8n’s 29,417 pixels, it still outperformed other lightweight models. In image (d), its 13,686 pixels were lower than YOLOv8n (17,062.5 pixels) and V3-YOLOv8n (17,556 pixels) but higher than some lightweight models.
PFL-YOLO demonstrated a larger focus area across all images, indicating its ability to comprehensively capture key information during detection. In contrast, models such as YOLOv8n, V3-YOLOv8n, V4-YOLOv8n, LCNet-YOLOv8n, and Ghost-YOLOv8n exhibited smaller focus areas in certain images, suggesting incomplete capture of key areas in specific scenes.
3.2.6. Comparison of Prediction Results of Different Models
To evaluate the performance of different target detection models in the sheep individual recognition task, two images from the test set were randomly selected for sheep face recognition in this study.
Figure 14 displays the prediction results of ten target detection models. In image (a), most models present relatively balanced recognition abilities, with prediction probabilities roughly centered at 90%. Notably, PFL-YOLO shows the lowest prediction probability of 85%, a 5% reduction compared to YOLOv8n, revealing its limitations in dealing with the lateral features of sheep faces, which impacts its generalization ability in this specific scenario. Conversely, in image (b), PFL-YOLO achieves the highest prediction probability of 95%, reflecting a 4% improvement over YOLOv8n. These findings highlight PFL-YOLO’s distinct advantage in capturing the frontal features of sheep faces, enabling robust recognition for sheep faces with prominent frontal characteristics. Although PFL-YOLO demonstrates suboptimal performance in some scenarios, its strengths in identifying the frontal features of sheep faces remain significant.
4. Discussion
Many scholars have carried out related research on lightweight sheep face recognition. For example, Zhang et al. based their work on the lightweight YOLOv5s model and achieved some results on the self-built dataset; the number of parameters, FLOPs, and model size of LSR-YOLO were reduced to a certain extent, and the mAP@50 also had good performance [
17]. Zhang et al. based their work on the improved YOLOv7-tiny module. The obtained YOLOv7-SFR algorithm also shows good performance on the self-built sheep face dataset [
18]. Compared with the sheep face recognition models proposed by these two scholars, the PFL-YOLO model in this study has greatly improved in terms of parameter quantity and mAP@50 indicators; the PFL-YOLO model maintains a higher mAP@50 (99.5%) while further reducing the number of parameters to 1.01 M and is also competitive in terms of average detection time and FPS. This indicates that the lightweight strategy in this study is more efficient in balancing model performance and resource consumption and can be better adapted to sheep face recognition in resource-constrained environments.
The data collection method in this study is manual, and this method is suitable for small farms. However, the manual collection method is time-consuming and labor-intensive for large farms. An automated acquisition scheme can be considered to solve this problem. Expressly, a 3m×3m fenced area can be set up on a large farm, and one sheep at a time can be guided into the area and allowed to move freely. Four video cameras are installed around the fence to take footage of the sheep. Image frames were extracted from the video at a frequency of 30 frames per second by video processing techniques. The extracted image frames are then processed using a sheep face detection model (which is only used to locate sheep faces and not to identify individuals) to filter out images containing sheep faces and assign a unique ID number to each sheep. This automated acquisition method effectively reduces the reliance on human resources, significantly improves work efficiency, and gives reuse value to the acquired data. Compared with the manual collection method, the automated scheme demonstrates higher efficiency and greater scalability, providing strong technical support for the intelligent management of large-scale farms.
The sheep face dataset constructed in this study contains only a single breed (Australian–Hu crossbred sheep) at this stage, and all the samples were collected in the sheep house environment. Although the robustness of the sheep face dataset has been improved by a series of data enhancement techniques, it lacks images of sheep faces from other breeds and complex scenes (high occlusion and low light), and we will work on expanding the dataset in the future to include images of sheep faces of multiple breeds and age groups in complex scenes to improve the generalization and generalization ability of the dataset. Robustness testing will be conducted on the expanded complex dataset to evaluate sheep face recognition capabilities, providing a new option for a high-precision, low-parameter general sheep face recognition model.
The mAP@50 and mAP@50:95 of PFL-YOLO on the self-built sheep face dataset are 99.5% and 87.4%, respectively, which is a 0.1% improvement over YOLOv8n on the mAP@50 metric, while the number of model parameters is compressed by 66.5%, and the computational complexity is reduced by 59.2%. It is worth noting that the average inference time of the model is 11.2 ms, which is mainly due to the extra computational overhead introduced by the bidirectional feature fusion structure of the RC2f module. Future research will focus on structured pruning and knowledge distillation, which can greatly reduce the number of parameters and FLOPs while maintaining accuracy. In addition, they can be applied in livestock breeding scenarios, accurately and stably play the individual identification function, and provide strong support for the intelligent management of the livestock industry.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}