4.3. Evaluation Metrics
To objectively evaluate the model’s detection performance, the following evaluation metrics were used: Precision, Recall, mean Average Precision (mAP), parameters, Giga Floating-Point Operations Per Second (GFLOPS), and Frames Per Second (FPS).
Precision measures the proportion of true positive samples among all samples predicted as positive by the model; recall measures the proportion of true positive samples among all actual positive samples correctly predicted by the model; Precision and Recall have a trade-off, where increasing precision may reduce recall, which is typically quantified by the F1-score; and mAP is used to measure the model’s accuracy. The calculation formulas for the evaluation metrics are as follows.
GFLOPS was used to estimate the execution time of the model, and the parameters measured the size and complexity of the model.
4.4. Experimental Results and Analysis
4.4.1. Experimental Comparison of Attention Modules and Feature Extraction Networks
To verify the performance advantage of the constructed PEFNet, a comparison was performed with other mainstream attention modules on the GRDDC2022 Chinese subset under the same experimental conditions. The bottlenecks of the Conv and C2f modules were replaced with improvements at the same location. The experimental results are listed in
Table 4.
In the table, YOLOv8n is the baseline model, and “+” indicates that the corresponding module improvements were made based on YOLOv8n. The experimental results show that the computational load with the PEFNet backbone network increases by only 0.7 GFLOPS, and mAP50 improves by 1.9% compared with the baseline. The results demonstrate the effectiveness of using RFCBAMConv to improve the convolution and bottleneck in the original backbone and C2f modules.
4.4.2. Verification of GDSFPN Feature Fusion Structure
To validate the effectiveness of the GDSFPN, a performance comparison experiment was conducted between the original feature fusion structure PAFPN in YOLOv8 and the proposed GDSFPN. The experimental results are listed in
Table 5. The experimental results showed that when YOLOv8n used the GDSFPN structure for feature fusion, the parameter and computational loads increased by only 0.25 M and 0.2 G, and mAP50 increases by 1.7%. This indicates that the GDSFPN structure achieves better feature fusion and significantly improves average detection accuracy.
To intuitively demonstrate the improvement of the GDSFPN structure in feature fusion performance, Grad-CAM [
16] technology is used for visualization analysis, generating detection heatmaps of the feature fusion structures of GDSFPN and PAFPN, as shown in
Figure 10. Visualization results for defects show that: for tiny longitudinal cracks, the heatmap of GDSFPN has higher attention weights in the edge regions of the cracks, indicating that it more accurately focuses on defect details; for reticular cracks with complex shapes, the attention distribution of GDSFPN’s heatmap is more concentrated and less affected by background interference.
It can be clearly observed from the heatmaps that the PAFPN structure is prone to interference from the background (such as vehicles, shadows), and its attention tends to focus on areas outside the target, which affects detection accuracy. In contrast, the proportion of attention of the GDSFPN structure to pavement defect areas has significantly increased, and its attention to pothole areas is significantly higher than that of PAFPN. This further confirms that GDSFPN has optimized the multi-scale feature fusion effect, enhanced the model’s targeted attention to defect areas, and provided a clearer interpretability basis for model decision-making.
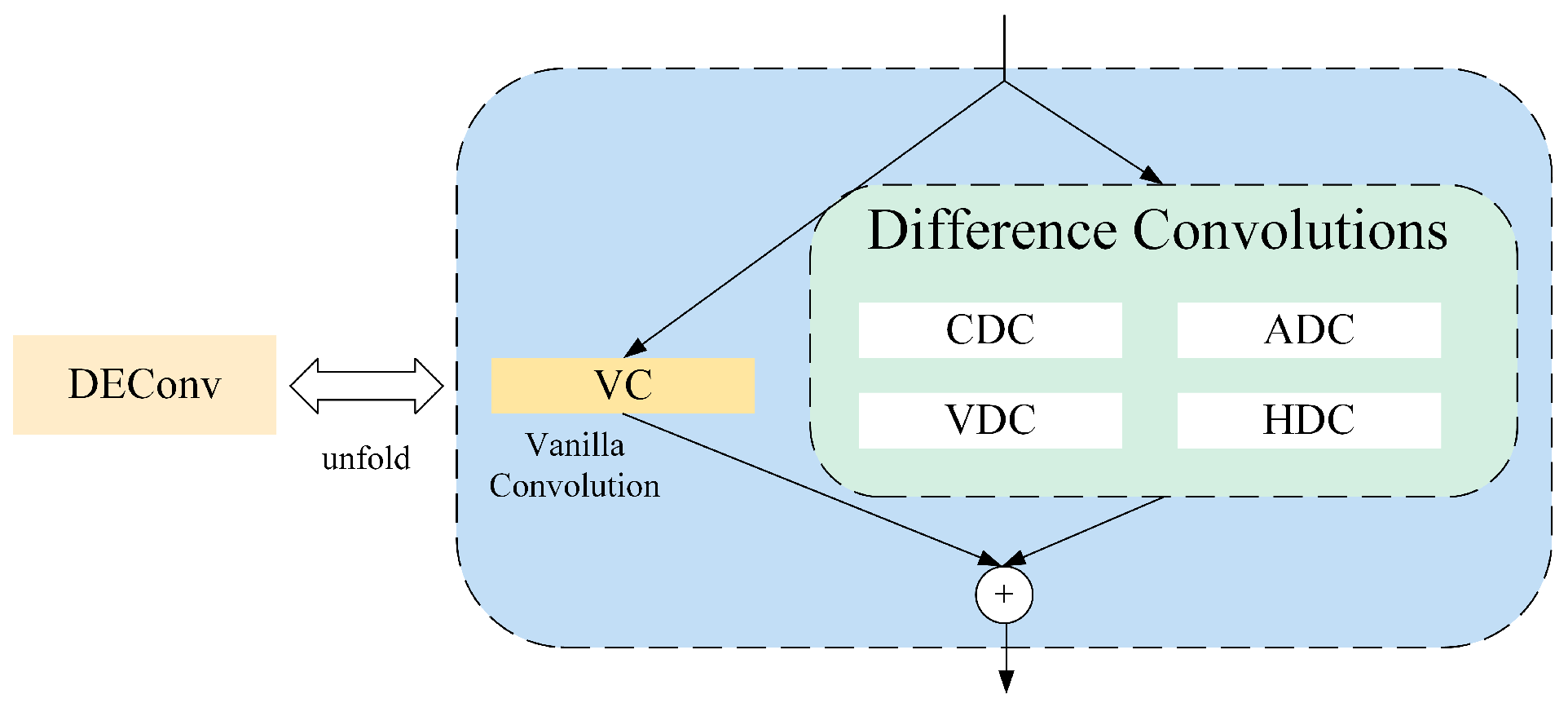
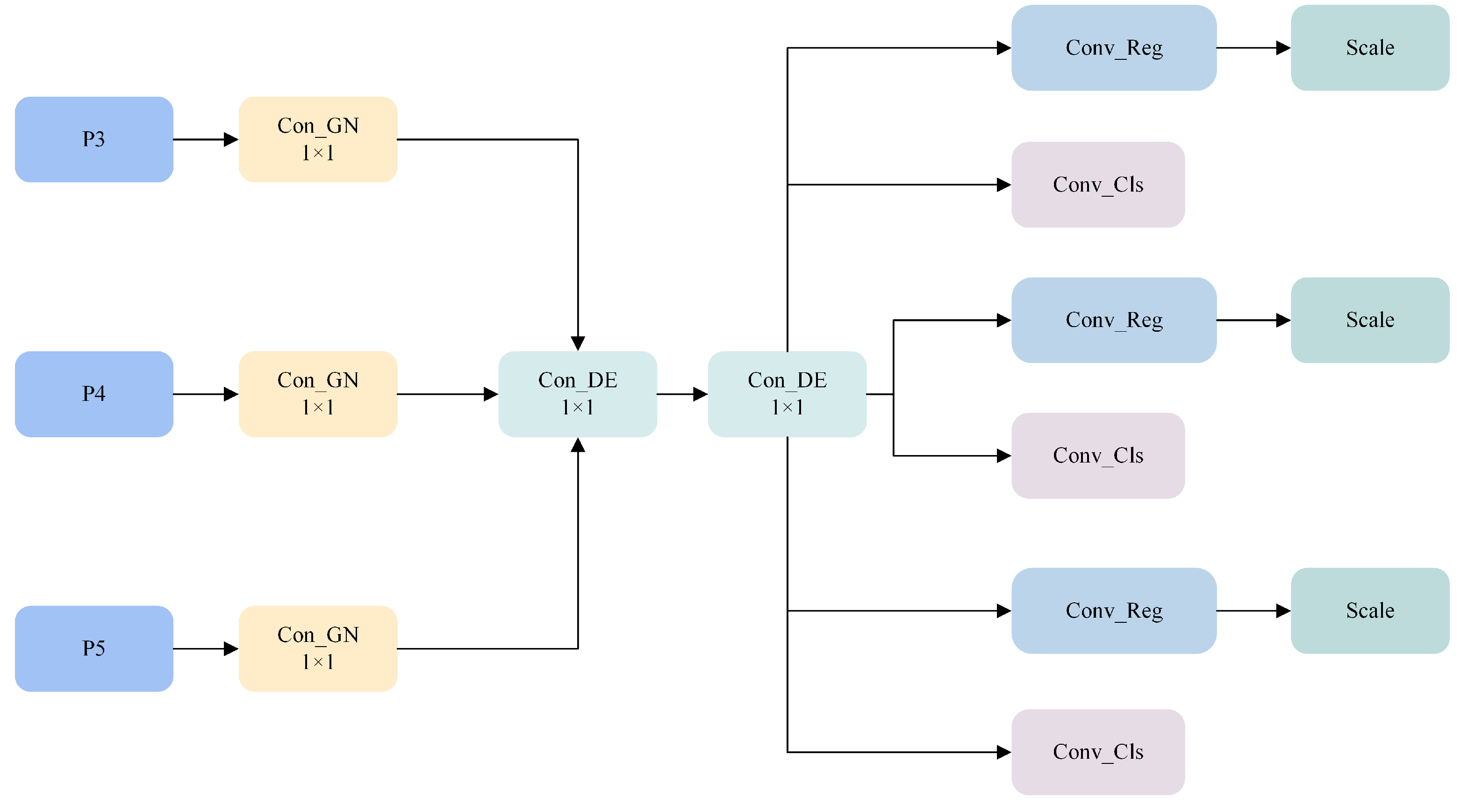
4.4.3. Verification of SDCLD Lightweight Detection Head Effectiveness
The computation load of the YOLOv8 detection head accounts for 40% of the total; therefore, lightweight processing of the YOLOv8 model’s detection head is key to reducing the overall model size. To verify the lightweight advantage of the designed SDCLD detection head, it was compared experimentally with the original detection head and the RSCD lightweight detection head proposed by Cao et al. [
17]. The experimental results are listed in
Table 6.
The experimental results show that compared to the baseline model, the SDCLD detection head improves the detection accuracy for the D00 and D10 classes, which mostly consist of small cracks, by 2.7% and 2.1%, respectively. This proves that DEConv effectively enhances the ability of the model to capture small target details, with mAP50 improving by 1.5%, and the number of parameters and computation were significantly reduced by 21.6% and 19.8%, respectively. Compared with the RSCD detection head, SDCLD exhibits significant advantages in all aspects.
4.4.4. Validation of WIoU Effectiveness
To verify the effectiveness of Wise-IoU compared with traditional loss functions, comparative experiments are conducted on the Chinese subset of GRDDC2022, using CIoU, DIoU, and WIoUv3 as loss functions respectively, with the remaining experimental conditions kept consistent. The experimental results are shown in
Table 7.
The experimental results show that for small targets such as longitudinal cracks (D00) and transverse cracks (D10), the AP% of WIoU reaches 86.2 and 84.5, which is an increase of 2.1% and 2.6% compared with CIoU, and 1.8% and 1.3% compared with DIoU. For large targets including reticular cracks (D20) and potholes (D40), the AP% of WIoU reaches 76.1% and 75.3%, showing an increase of 1.7% and 2.6% compared with CIoU, and 1.2% and 1.5% compared with DIoU.
Wise-IoUv3 dynamically adjusts gradient gain through a non-monotonic focusing mechanism, assigning larger gradient weights to anchor boxes with low matching degrees and reducing gradient interference for anchor boxes with high matching degrees. This enables the model to more accurately optimize bounding box regression during training.In contrast, although CIoU takes into account the overlap degree of bounding boxes, center point distance, and aspect ratio, it has insufficient gradient optimization for low-quality anchor boxes; DIoU focuses on center point distance optimization but neglects the dynamic adjustment of anchor box quality.The experimental results show that in the detection of different types of defects, the mAP50 of Wise-IoUv3 is consistently higher than that of CIoU (1.5%) and DIoU (1.1%), demonstrating its stability and superiority in improving detection accuracy and further optimizing the training effect of the model.
4.4.5. Ablation Experiment
To verify the effectiveness of the proposed improvement modules, ablation experiments were designed to compare the impacts of different module combinations on the performance of the pavement defect detection algorithm. YOLOv8n was used as the baseline model for the ablation experiment, and the validation was performed on the validation set under the same experimental conditions. The results are presented in
Table 8.
As shown in the table, compared to the baseline model, when using the Perception Enhanced Feature Extraction Network (PEFNet) as the model’s feature extraction module, the detection accuracy for complex and large-scale defects in the D20 and D40 categories improves by 2.9% and 3.7%, respectively. The number of parameters and computations increased slightly by 4% and 8%, respectively. When the redesigned GDSFPN is used as the feature fusion module, the detection performance for D20 and D40 defects is also improved, with the detection accuracy increasing by 3.7% and 2.9%, and the parameters and computation increased by only 8% and 2%, respectively. Using SDCLD improves the detection accuracy for small cracks in the D00 and D10 categories by 2.7% and 2.1%, respectively, while reducing the number of parameters and computations by 21.6% and 19.8%, respectively. When using WIoUv3 to replace the original loss function, the detection accuracy for D00 and D10 defects, which mainly consist of small targets, improved by 2.4% and 1.5%, respectively. For D20 defects, which have large-scale variations, the detection accuracy improves by 0.7%, and mAP50 increases by 0.9%, proving that WIoUv3 can dynamically optimize small target loss weights and enhance the localization capability. When PEFNet and GDSFPN are used together, the detection accuracy for D20 and D40 defects, which are complex in shape and have large-scale variations, improves by 2.9% and 2.3%, respectively, and mAP50 improves by 1.9%. The parameters and computation increase by only 11% and 8%, respectively, proving that the feature information processed by PEFNet is better fused by the GDSFPN without adding extra computational burden. Finally, when PEFNet, GDSFPN, and the lightweight detection head SDCLD were used together, the detection capability for various defects improved, with the mAP50 increasing by 2.4%, and the parameters and computation were reduced by 10.3% and 9.9%, respectively. The improved PGS-YOLO model, with WIoUv3, achieved the highest average detection accuracy of 82.3%, with mAP50 improving by 2.9% compared to the baseline model, and FPS reaching 69 frames per second, meeting real-time detection requirements. It balances model complexity and detection accuracy, while further improving accuracy and reducing parameters and computation.
4.4.6. Comparison of Different Algorithms
To comprehensively evaluate the performance of the PGS-YOLO model, it was compared with the current mainstream object detection algorithms and lightweight algorithms. The comparison of mAP_0.5 and mAP_0.5:0.95 curves of different models is shown in
Figure 11. Additionally, lightweight pavement defect detection algorithms, YOLOv5s+Ghost+CA and LE-YOLOv5, were also compared. The experiments were conducted under the same conditions, and all models converged. The results are presented in
Table 9.
The experimental results show that, in terms of accuracy, PGS-YOLO performs best on evaluation metrics, such as Precision, Recall, mAP50, and F1-score, with mAP50 being the highest at 82.3%. In terms of model complexity, PGS-YOLO also performs excellently, with parameters and computation of 2.7M and 7.3G, respectively, which is only higher than those of YOLOv5n, YOLOv9t, YOLOv10n, and YOLOv11n. However, the detection accuracy improved by 4.7, 4.5, 4.6, and 3.7%, respectively. Compared to YOLOv8n, the number of parameters and computations are reduced by 10.3% and 9.9%, respectively.
Compared to YOLOv5s+Ghost+CA and LE-YOLOv5, which are also used in pavement defect detection, the mAP50 of PGS-YOLO was 1.3% and 0.5% higher, respectively. The number of parameters and computation is reduced by 27.6% and 21.5%, respectively, and the detection frame rate is improved by 20.3% and 11.6%, respectively, reaching 69 frames per second. This indicates that PGS-YOLO achieves a better balance between real-time performance and accuracy through a reasonable module design, while pursuing higher precision. The experiments prove that PGS-YOLO has advantages in terms of model complexity, detection accuracy, and speed, and achieves a better balance between detection accuracy and model complexity.
4.4.7. Comparison Across Different Datasets
To verify the cross-dataset generalization ability of the algorithm and its applicability in pavement defect detection, comparative experiments were conducted on the complete GRDDC2022 [
15] dataset and the CRACK500 dataset proposed by Yang et al. [
27] with current mainstream object detection algorithms.
The GRDDC2022 dataset includes 47,420 road images from Japan, India, the Czech Republic, Norway, the United States, and China, covering four categories: longitudinal cracks (D00), transverse cracks (D10), network cracks (D20), and potholes (D40). As a large number of images in it did not have required annotations, 23,767 images were screened for comparative experiments. The dataset was divided into training, validation, and test sets using a random division method at a ratio of 8:1:1, and the experimental results are shown in
Table 10.
The experimental results show that PGS-YOLO outperforms other detection models in evaluation metrics such as P%, R%, mAP50, and F1 score.In terms of detection speed, its FPS reaches 64 frames per second, which is lower than that of YOLOv10n (85FPS) but higher than that of RT-DETR (36FPS) and YOLOv11 (44FPS). Considering the large scale and diverse scenarios of the complete GRDDC2022 dataset, the FPS of PGS-YOLO fully meets the real-time detection requirements in practical engineering.Meanwhile, compared with YOLOv8n, its GFLOPs are reduced by 20%, and mAP50 is increased by 2.8%, reaching 58.0%, the highest among all compared models. This indicates that PGS-YOLO maintains high efficiency while improving accuracy. This result demonstrates that PGS-YOLO has good generalization ability and excellent applicability in pavement defect detection.
The initial Crack500 dataset includes 500 road crack images, with each image generally having a resolution of 1440 × 2560 or 2560 × 1440. Due to the limited number of images, large size of each image, and limited computing resources, the original images are cropped into 16 non-overlapping sub-regions according to a 4 × 4 grid. Only sub-regions with more than 1000 crack pixels are retained, while regions with no cracks or too few cracks are discarded. Finally, rotation or cropping is used to ensure the final sub-regions have a resolution of 640 × 360. Since the original labels of this dataset are not suitable for pavement defect detection, the LabelImg tool is used for manual annotation. Following the annotation specifications of the GRDDC2022 dataset, defects are classified into four categories: D00 (longitudinal cracks), D10 (transverse cracks), D20 (reticular cracks), and D40 (potholes). Finally, 3368 road crack images meeting the annotation requirements for object detection are obtained. The dataset is randomly divided into a training set, validation set, and test set in an 8:1:1 ratio, and the experimental results are shown in
Table 11.
The experimental results show that, compared with current mainstream object detection algorithms, PGS-YOLO also performs excellently on the processed CRACK500 dataset, with its P%, R%, and mAP50 reaching 68.0%, 38.8%, and 45.2% respectively, all being the highest values.Compared with the YOLOv8n model, the detection accuracy is improved by 2.3%, and the FPS reaches 72 frames per second, which is higher than that of RT-DETR (38FPS) and YOLOv11 (58FPS), and close to that of YOLOv10n (86FPS). Its GFLOPs remain at a low level, ensuring efficient computation in the fine-grained crack detection required by CRACK500. This experimental result demonstrates that PGS-YOLO has good cross-dataset generalization ability and achieves a balance between detection accuracy and efficiency.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}