Abstract
In resistive polymer humidity sensors, the quality of the resistor chips directly affects the performance. Detecting chip defects remains challenging due to the scarcity of defective samples, which limits traditional supervised-learning methods requiring abundant labeled data. While few-shot learning (FSL) shows promise for industrial defect detection, existing approaches struggle with mixed-scene conditions (e.g., daytime and night-version scenes). In this work, we propose a crossed wavelet convolution network (CWCN), including a dual-pipeline crossed wavelet convolution training framework (DPCWC) and a loss value calculation module named ProSL. Our method innovatively applies wavelet transform convolution and prototype learning to industrial defect detection, which effectively fuses feature information from multiple scenarios and improves the detection performance. Experiments across various few-shot tasks on chip datasets illustrate the better detection quality of CWCN, with an improvement in mAP ranging from 2.76% to 16.43% over other FSL methods. In addition, experiments on an open-source dataset NEU-DET further validate our proposed method.
1. Introduction
As the critical component of resistive polymer humidity sensors, the humidity-sensitive resistor chips sense environmental humidity through the change in resistance value. Defects as shown in Figure 1a can directly affect the reliability, where “disconnection” and “blotchy surface” cause open and short circuits, respectively, and “scratches” disable the polymer material on the surface. In this case, defect detection has always been a key research topic in sensor manufacturing. Recently, Automatic Visual Inspection (AVI) based on computer vision and object detection techniques has replaced traditional manual visual inspection. Representative algorithms, such as RCNN-based method [1], SSD variant [2], and YOLO series [3], as well as ViT [4] and SwinT [5] based on the transformer architecture [6], have significantly boosted detection accuracy and efficiency.
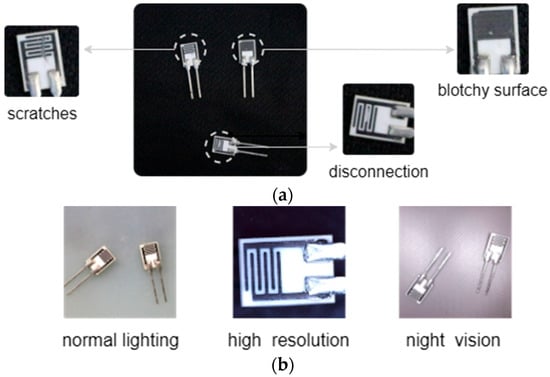
Figure 1.
Industrial chip samples. (a) Types of defects and (b) multiple scenarios of samples.
Unfortunately, industrial defect samples are usually scarce and scattered. In addition to the sensor manufacturing mentioned in this paper, this situation is common in other precision electronics assembly and high-end component production. Although every production stage is under strict monitoring for high-quality standards, defects caused by unforeseen circumstances would be rare but deadly. Traditional supervised-learning methods relying on abundant labeled samples are ineffective. As a result, few-shot learning (FSL) methods have gained widespread attention and research interest.
Recent years have witnessed impressive progress in FSL for visual tasks and image processing problems, including meta-learning methods (e.g., Meta-AdaM [7], Metadiff [8]), pretraining-finetuning frameworks like Ppt [9], and cross-domain approaches such as CGDM [10]. To improve performance on downstream tasks such as image classification, object detection, and segmentation, researchers attempt to extract highly transferable feature representations from limited annotated samples.
Nonetheless, existing FSL applications in industrial detection still underperform in multi-scene conditions. As illustrated in Figure 1b, defect samples of chips exhibit variations across different conditions. The feature extraction modules struggle to maintain feature consistency for the same defect category in these diverse scenarios, leading to suboptimal detection quality. Our experimental results reveal that, compared to a single-scene dataset, there is a substantial 20–30% performance gap in Mean Average Precision (mAP) when evaluating on a mixed-scene dataset. The detailed analysis will be presented in Section 4.4.1.
To address these limitations, we propose a novel network that introduces two key innovations. First, we develop a dual-pipeline crossed wavelet convolution training mechanism (DPCWC). This module enables parallel feature extraction and cross-pipeline information fusion, effectively capturing discriminative features across multiple scenarios. Second, we design a loss computation module, ProSL, that incorporates feature information from prototypes. This module minimizes the feature distance between identical defect categories across different scenarios, significantly improving the model’s scenario adaptation capability.
The main contributions of our work are summarized below:
- To address performance degradation in industrial chip defect detection under mixed-scene condition (relative to single-scene data), we propose a dual-pipeline feature extractor.
- Our work uses wavelet transform convolution in industrial defect detection. We also adopt a selective strategy to ensure effective but not excessive fusion.
- Unlike existing methods of processing dual-pipeline features, our work employs prototype information to calculate loss value, effectively aligning the features from two pipelines.
2. Related Work
2.1. Cross-Domain Few-Shot Object Detection
By transferring knowledge from source domain datasets, which contain abundant labeled samples, cross-domain few-shot learning (CD-FSL) aims to address the challenge of data scarcity in target domain.
Compared to image classification [11,12,13,14,15], research on CD-FSL focusing on object detection is relatively limited, but there have been notable works in related fields recently. The work of [16] presents FSCE to learn contrastive-aware object proposal encodings, introducing Contrastive Proposal Encoding (CPE) to improve the performance of few-shot detection. Another approach, Detic [17], trains on detection data and image-labeled data, decoupling classification and localization tasks while developing efficient classification loss functions. In addition, a ViT-based variant [18] demonstrates that a plain Vision Transformer (ViT) without hierarchical structures can achieve competitive detection performance, challenging the conventional reliance on hierarchical backbones.
Particularly in industrial defect detection, the following methods have been of great assistance. (1) The two-stage Fine-tuning Approach (TFA) [19] establishes a classic “pretraining + fine-tuning” paradigm, providing a framework for many CD-FSL applications in industrial detection; (2) DeFRCN [20] addresses the inherent conflict between multi-stage (RPN and RCNN in Faster R-CNN) and multi-task (classification and localization); (3) DE-ViT [21] based on a region-propagation mechanism for localization employs fixed-ratio expansion of proposals, propagated region masks, and the construction of a feature subspace to improve the model’s robustness; (4) CD-ViTO [22] quantifies domain differences across three dimensions: style discrepancy, inter-class variance, and indefinable boundaries. The method achieves superior performance on various datasets.
However, these methods lack specific designs to align defect samples from different scenarios. Insufficient feature interaction manifests poor detection quality in mixed-scene data.
2.2. Wavelet Transform
Compared to Fourier Transform, which sacrifices time (or spatial) information to obtain frequency domain information, wavelet transform [23] achieves a good balance between the time (or spatial) and frequency domains. It decomposes signals into wavelet components that simultaneously contain information from both domains above. Therefore, as stated in [24], the unique advantages of the wavelet transform have made it an important tool in the field of signal processing, and it has been widely used in areas such as image processing and industrial supervision.
Research on wavelet transforms and wavelet convolutions has established a solid theoretical foundation and provided practical references for subsequent studies. Notably, Wavelet Compressed Convolution (WCC) [25] demonstrates the viability of the framework “wavelet transforms + neural networks”. Ref. [26] introduces a dual-episode sampling mechanism and breaks new ground to apply wavelet in CD-FSL. In industrial defect detection, ref. [27] presents a dynamic weights-based wavelet attention neural network (DWWA-Net) and achieves remarkable performance improvement.
However, these works addressed a critical challenge in neural network development: the computational inefficiency caused by over-parameterization in traditional CNNs and ViTs when obtaining the global receptive field. In one study [28], the Wavelet Transform Convolution layer (WTConv) effectively resolved this issue while maintaining model performance, representing a significant step forward in efficient feature extraction architectures.
2.3. Prototype Learning
The concept of prototype learning was originally introduced in Prototypical Networks [29] and applied to FSL. It establishes class prototypes by computing the mean feature of all samples within each category, and then calculates the distance metric between the query samples and these prototypes for classification.
Subsequent research has significantly enhanced prototype learning through various innovations. For instance, refs. [21,22] extract features through deep convolutional models and develop advanced prototype representations by statistical computations. In [30], the CPLAE model based on self-supervised learning uses category prototypes as anchors for contrastive training. These prototype variants and enhancements have collectively addressed key challenges in prototype learning while expanding its applicability across diverse computer vision tasks.
3. Method
3.1. Problem Setting
In cross-domain few-shot object detection (CD-FSOD), the source domain dataset and target domain dataset are defined, where , i.e., the categories of the two are different. contains numerous labeled data with diverse categories, while has fewer categories and only a small amount of labeled data for each category. The label information includes, but is not limited to, category labels and the coordinates of bounding boxes.
Currently, there are two mainstream approaches to solve the CD-FSOD problem, one is “meta-learning”, and the other is “pretraining + fine-tuning”. Our model adopts the latter, and the main processes are as follows: Firstly, a base model is trained in a supervised-learning way using large-scale , and subsequently fine-tunes using to obtain the specialized . The fine-tuning process employs an n-way-k-shot sampling strategy from , as outlined below:
- The support set for tuning contains k annotated samples for each of n categories.
- The query set for testing comprises unlabeled samples from the same n categories.
- Critical constraints are and .
This methodology enables effective adaptation of ’s parameters to novel categories on the target domain while maintaining its fundamental detection capabilities. The limited annotated samples (k per category) in provide sufficient supervisory signals for this specialized adaptation, while the disjoint query set ensures a proper evaluation of the model’s generalization performance on unseen target domain instances.
Our research addresses defect detection of a specific type of chip, presenting unique challenges beyond conventional “cross-domain” difficulties. The problem’s complexity manifests through two distinct dimensions: one is significant distributional discrepancies between and , and the other is intrinsic variations within the target domain itself arising from illumination changes, and imaging device diversity. Such multi-faceted scenario variations impose stringent demands on model generalization capabilities.
3.2. Preliminaries: Wavelet Transform Convolution in Image Field
For an input image X, four specific filters (Equation (1)) based on the 2D Haar wavelet transform [31] are employed to conduct image decomposition and reconstruction. The forward wavelet transform (Equation (2)) decomposes the image into multiple components, while the inverse wavelet transform (Equation (3)) enables image reconstruction. The decomposition yields representing the low-frequency approximation component that preserves the image’s primary structural information, along with three high-frequency detail components, (horizontal), (vertical), and (diagonal), which collectively capture the image’s edge and texture characteristics.
3.3. Overview of CWCN
The framework of the crossed wavelet convolution network (CWCN) proposed is shown in Figure 2, which is divided into three parts, including “data preprocessing”, “feature extraction and fusion”, and “detection and loss computation”.
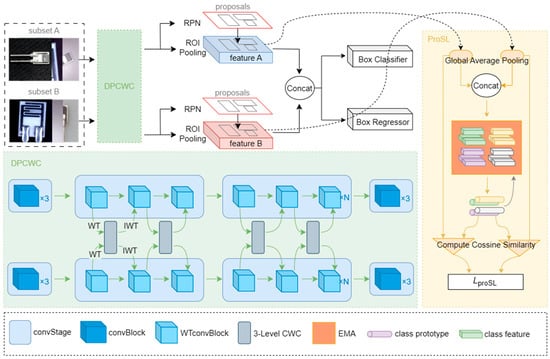
Figure 2.
Overall framework of CWCN.
(1) Data preprocessing. Since our network employs a dual-pipeline feature extraction and fusion mechanism, the dataset requires special processing during model training. Specifically, the original dataset is divided into two subsets, Subset A and Subset B, both of which should contain complete and category-balanced samples. Within the same input batch, images from the two pipelines share the same category labels but exhibit different scenes. This preprocessing strategy facilitates the network in aligning features. Without such alignment, training instability may arise, potentially leading to non-convergence of the model.
(2) Feature extraction and fusion. CWCN employs a novel dual-pipeline crossed wavelet convolution training mechanism, which utilizes wavelet transform convolution (WTConv) instead of conventional convolution for feature extraction. The module also incorporates 3-level crossed wavelet convolution modules (3-Level CWC) to fuse features. The technical details are elaborated in Section 3.4.
(3) Detection and loss computation. CWCN adopts the Region Proposal Network (RPN) and ROI Pooling from Faster R-CNN [32] to process dual-pipeline feature maps. The RPN generates target proposal boxes through an anchor mechanism, while ROI Pooling maps the proposals of varying scales onto the feature maps for subsequent classification and regression. During training, the RPN loss function is computed as follows:
where and are the number of anchors, and is a balancing weight. is the classification loss term, and represent the predicted probability and ground -truth label of the anchor, respectively. is the regression loss term, where and are the predicted and ground-truth bounding box corresponding to the anchor.
Subsequently, our network concatenates the outputs from two ROI Pooling streams and employs fully connected layers to construct the predictor (consisting of a box classifier and box regressor). This process generates the classification loss and regression loss during training:
where and are the number of proposal regions, denotes the predicted class probability of ROI, and represents the ground-truth class label. The indicator function ensures the loss is computed only for foreground samples . The is applied to the bounding box parameters, where and correspond to the predicted and ground-truth bounding box of foreground samples.
Additionally, we design a Prototype Similarity Learning (ProSL) module to process the dual-pipeline ROI Pooling outputs, with detailed implementation described in Section 3.5.
3.4. DPCWC Module
The dual-pipeline crossed wavelet convolution (DPCWC) training framework proposed employs a WTConv variant as a backbone. The backbone is structured with four ConvStages, each of which contains several ConvBlocks or WTConvBlocks that perform wavelet transform (WT) and inverse wavelet transform (IWT) operations (theoretical details in Section 3.2). Compared to conventional convolution, our backbone simultaneously captures both low-frequency and high-frequency components of data features, thereby enhancing the model’s ability to perceive both global structures and local details. Unlike single-path designs, this module takes the preprocessed datasets Subset A and Subset B as dual inputs, with features being synchronously extracted through a weight-shared backbone. Consequently, our feature extraction module not only effectively decomposes global contour and local detail information of samples, but also enables the model to capture features from different scenes within the same training phase.
The dual-pipeline feature fusion follows a fundamental principle. Each pipeline preserves its global information through low-frequency components while exchanging local details via high-frequency components. Our implementation employs an alternating fusion strategy across network blocks: after performing WT in the previous block, the high-frequency components from Pipeline B are replaced by the corresponding components of Pipeline A, followed by IWT. In the subsequent block, Pipeline A’s high-frequency components are replaced by Pipeline B’s. This alternating fusion scheme continues iteratively across subsequent WTConvBlocks, where high-frequency components from Pipeline A and Pipeline B are alternately exchanged.
Based on the strategy above, we developed several implementation variants as illustrated in Figure 3.
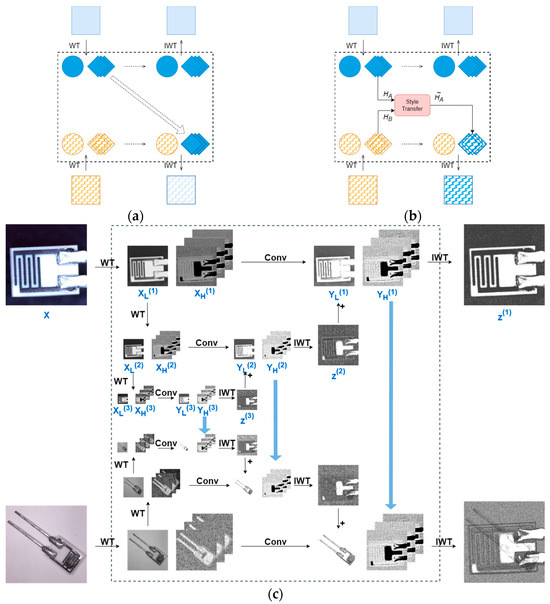
Figure 3.
Schematic diagram of dual-pipeline feature fusion. Only the process “A to B” is shown, including (a) direct replacement, (b) style-transfer-based method, and (c) 3-level crossed wavelet convolution.
For wavelet component processing in the dual-pipeline framework, Figure 3a demonstrates the direct replacement approach where one pipeline’s high-frequency components are simply substituted from the other. Figure 3b presents our enhanced method, building upon prior works [26,33], which performs style transfer between the high-frequency components using Equation (7) before component substitution:
where and denote the mean and variance, respectively, while and represent the high-frequency components before and after processing, respectively.
However, we explore that the two methods above fail to adequately account for the importance of multi-scale feature fusion, resulting in significant performance disparities in detecting objects of different sizes (see Section 4.5.1 for detailed experimental results). To alleviate this impact, DPCWC adopts the 3-Level CWC method illustrated in Figure 3c. Our approach modifies the cascaded wavelet transform from [28] by implementing the following operations:
- Multi-level Wavelet Decomposition:
- ■
- The input feature map X undergoes 1-level WT, yielding high-frequency component and low-frequency component .
- ■
- is further decomposed via 2-level WT to produce and .
- ■
- undergoes 3-level WT to generate and .
- Convolution in Wavelet Domain:
- ■
- Each level’s components perform convolutional operations in wavelet domain using Equation (8), yielding transformed components and , denotes the learnable weight tensor at the level .
- Hierarchical Reconstruction:
- ■
- and undergo 3-level IWT to reconstruct .
- ■
- is combined with through element-wise addition to form the composite low-frequency component at the level
- ■
- Feature maps at each level are reconstructed by applying IWT to the composite low-frequency components and corresponding , as formalized in Equation (9).
- Cross-pipeline Feature Fusion:
- ■
- During synchronous dual-pipeline processing, high-frequency components (, , and ) from one pipeline replace their corresponding counterparts in the other.
- ■
- The modified components then undergo cascaded IWT operations.
We also develop a stage-wise fusion strategy, enabling the 3-Level CWC to carry out more effective multi-scale feature fusion and information interaction. Specifically, when applied to shallower network layers, 3-Level CWC excels at integrating fine-grained features, while its application in deeper layers facilitates the fusion of coarse-grained features. However, DPCWC does not employ this fusion operation across all four ConvStages of the backbone but rather selectively implements 3-Level CWC in the second and third ConvStages. This strategic design is based on three key considerations: First, it simultaneously addresses fusion requirements for both shallow and deep network features, ensuring comprehensive multi-scale representation throughout the network hierarchy. Second, it prevents excessive cross-pipeline interference and maintains distinctive feature characteristics in each pipeline, reducing the risk of feature homogenization. Third, it avoids unnecessary parameter proliferation to control model complexity. As evidenced by the experimental results in Section 4.5.2, our selective fusion approach achieves an optimal balance between representation learning capability and computational efficiency.
3.5. ProSL Module
For the cross-scene features from the two pipelines, a dedicated loss computation module is needed to establish and reinforce feature correlations, thereby guiding the model to learn more generalizable feature representations. If our loss computation module appropriately processes the dual ROI Pooling outputs, which contain both categorical and spatial coordinate information from multi-scene, the model can be optimized for category classification and object localization simultaneously.
Inspired by the contrastive learning framework of SimCLR [34], we initially designed a self-supervised loss computation module. As illustrated in Figure 4, the module first applies global average pooling (GAP) to reduce dimension and computational complexity. The low-dimensional feature vectors are then used to compute cosine similarity by Equation (10):
where the numerator represents the dot product of the two feature vectors and the denominator is the product of their Euclidean norms. To promote similar feature distributions between the two pipelines, the model optimization aims to minimizes the loss value in Equation (11).
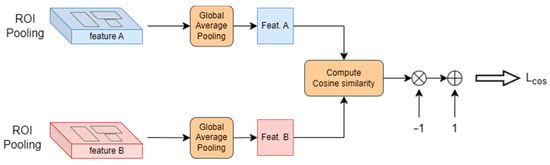
Figure 4.
Self-supervised loss computation module.
However, this loss computation is inherently limited to contrastive learning between the dual-pipeline features. While the trained model achieves cross-scene feature alignment and effectively determines whether samples from Subset A and B belong to the same category, the inter-class feature clustering relies solely on the Faster R-CNN’s loss computations (Equations (4)–(6)), which leads to insufficient discriminative capability between different categories. In our chip defect detection tasks, this limitation manifests defect misclassification with similar visual characteristics, ultimately failing to address the practical requirements of defect detection.
Building upon the aforementioned loss computation module, we propose Prototype Similarity Learning (ProSL) as illustrated in Figure 2. ProSL incorporates category label information as prior knowledge to guide model learning, so it falls under the supervised learning (SL) paradigm. The computational details of this module are presented in Algorithm 1.
In ProSL module, the dual-pipeline features from ROI Pooling undergo dimensionality reduction and concatenation, resulting in which contains features of all ROIs from both Subset A and B. is then utilized to construct prototypes through the following procedure: features are grouped according to category labels and Intersection over Union (IoU), yielding class-specific features, and then the mean features are computed as prototypes. All the category prototypes including background type are refined using Exponential Moving Average (EMA) as shown in Equation (12):
where and denote prototypes of the previous and current batch. In the first batch, (i.e., ) is constructed by a pre-trained model and all the support samples. is an initial model created by the current . is the momentum coefficient, whose initial value is 0.1 during the “warm-up” phase and decreases to 0.01. This momentum-based update strategy establishes robust prototypes during initial training epochs while subsequently smoothing the prototype evolution, mitigating excessive fluctuations caused by distribution shifts within individual training batch.
| Algorithm 1. ProSL |
| created by pretrained model and all support samples |
| //Concatenate feature maps to dimension (NA+NB, D) |
| //Group features by annotations for each category, containing background type |
| // Compute the final prototypes for current batch to dimension (K, D) |
| //Dimension is (Nj, K) |
Subsequently, the dual-pipeline features and are computed similarity with the prototypes using Equation (10) to obtain and , respectively. The final loss objective of ProSL is to minimize the value in Equation (13), where is 0.1 as a scaling factor, is the similarity of positive sample and denotes the similarity for each category.
The loss value is combined with the base losses from Equations (4)–(6) to form the total optimization objective , which is backpropagated to jointly optimize the entire model.
We conducted ablation studies evaluating the effectiveness of different loss functions to identify the optimal module for CWCN (results shown in Section 4.5.3). Based on the special design of DPCWC, we ultimately adopt the ProSL loss module to strengthen the model’s ability to learn inter-pipeline feature correlations while preserving category discriminability. This option enables the model to better adapt to cross-domain few-shot chip defect detection tasks under multi-scene conditions.
4. Results and Discussion
4.1. Datasets
In our work, we use COCO2014 [35] as the source domain dataset, and the dataset processing approach is based on [19] as a reference, where 98,459 images covering 60 classes are used for model pretraining.
Our method focuses on industrial chips of a humidity sensor. Two customized chip datasets are collected for performance comparison: ChipNormal (single-scene) and ChipMix (multi-scene). ChipNormal contains images captured solely under normal lighting conditions, while ChipMix incorporates multiple scenarios, as shown in Figure 1b. High-resolution images are captured by a CCD camera with a resolution of 5120 × 2880, while the other two scenes have a resolution of 1920 × 1080. Night-vision images are captured by an infrared camera with a wavelength of 840 nm. The two datasets have the same defect categories, as shown in Figure 1a, both being divided by the same strategy, including 3-way-1-shot, 3-way-5-shot, and 3-way-10-shot support sets for fine-tuning. We use data augmentation (e.g., rotation, cropping, etc.) to create the query set, obtaining 150 images for each scene. The types of defects in each scene are relatively balanced. Incidentally, ChipNormal uses only 150 images captured under normal lighting conditions, whereas ChipMix consists of a total of 450 images.
To further validate our method, we also use an open-source dataset NEU-DET [36] as the target domain dataset for comparison experiments. This dataset focuses on steel surface defects, including six common defect types, and we refer to [22] to create 6-way-1-shot, 6-way-5-shot and 6-way-10-shot support sets, along with 360 images as a query set.
4.2. Evaluation Metric
In object detection, Average Precision (AP) serves as a key evaluation index for assessing model performance. AP calculation involves fundamental concepts:
True Positives (TPs) represent correctly detected positive samples, False Positives (FPs) denote incorrectly identified positive samples, and False Negatives (FNs) indicate missed positive samples. IoU is short for “Intersection over Union”, and A and B correspond to the areas of predicted bounding boxes and ground truth boxes, respectively.
AP is computed as the area under the Precision–Recall curve (PR curve), which comprehensively reflects the model’s precision performance across varying recall rates. Our work employs mean Average Precision (mAP) as the primary evaluation metric, computed according to the COCO standard [35]. For individual categories, the AP value is calculated across multiple IoU thresholds (ranging from 0.5 to 0.95 with a step size of 0.05, totaling 10 thresholds) and then averaged to obtain . The mAP is subsequently derived as the mean of across all categories (as formulated in Equation (18)).
Additionally, following the PASCAL VOC standard [37], we adopt single-IoU-threshold precision metrics AP50 and AP75, where detections are considered correct if their IoU with ground truth exceeds 50% or 75%, respectively. To assess the performance on multi-scale objects, the evaluation also includes APs (Small Object AP), APm (Medium Object AP), and APl (Large Object AP).
To specifically evaluate the model’s cross-scene performance in chip defect detection, we introduce a novel index, , defined as the mAP gap between models trained on different datasets (ChipNormal versus ChipMix), i.e., a smaller indicates superior model adaptability across diverse scenarios.
4.3. Experimental Setup
To make a fair comparison, the pretraining settings of all implementations followed [19] and our method employ one pipeline without ProSL for pretraining.
In the fine-tuning phase, all implementations adopt full-parameter fine-tuning. The learning rate schedule follows a warm-up and decay strategy: 10% of the total epochs are “warm-up” trained at a learning rate of 1 × 10−5, followed by 55% epochs at a base learning rate (BASE_LR). The learning rate is then decayed to 10% BASE_LR for 30% epoch training, and finally reduced to 1% for the remaining epochs. For all k-shot tasks on the chip datasets, we set around 80 training epochs, with a BASE_LR of 0.001; for the open-source dataset, the settings followed the work of [22], tuning on 1-shot tasks around 80 epochs and on 5/10-shot tasks around 40 epochs, with the BASE_LR of 0.002. All experiments are conducted on a GeForce RTX 3090.
It should be noted that in certain cases, such as 1-shot tasks, dividing the data into two subsets may not be feasible. To ensure both pipelines process the same categories for effective feature alignment, we employ only one pipeline for the first epoch, and thereafter utilize components of the previous epoch into pipeline B of the current epoch.
4.4. Results and Analyses
4.4.1. Results on Chip Datasets
Table 1, Table 2 and Table 3 present the results of different algorithms on both ChipNormal and ChipMix datasets. The vertical comparison among algorithms demonstrates that our method consistently outperforms others across various k-shot tasks, achieving superior performance in both single-IoU-threshold metrics (AP50, AP75) and the more rigorous mAP criterion. Horizontal analysis across datasets reveals that our approach exhibits smaller values compared to other methods. This strongly validates the enhanced scenario adaptability of our proposed method.

Table 1.
Results of 1-shot detection task on chip datasets. The best indicators are shown in bold, and the down arrow means that lower scores have better quality.
Table 2.
Results of 5-shot detection task on chip datasets. The best indicators are shown in bold, and the down arrow means that lower scores have better quality.
Table 3.
Results of 10-shot detection task on chip datasets. The best indicators are shown in bold, and the down arrow means that lower scores have better quality.
Figure 5 and Figure 6 visualize the prediction results (confidence threshold is 0.5). The comparative visualizations reveal that all comparison methods perform consistently on single-scene datasets. As for ChipMix, while other methods exhibit either false positives or missed detections, our method demonstrates significantly enhanced robustness when handling defect samples across different scenarios.

Figure 5.
Visual comparison of prediction results. Three-way-ten-shot detection on ChipNormal is shown.

Figure 6.
Visual comparison of prediction results. Three-way-ten-shot detection on ChipMix is shown.
Analyzing theoretically, existing methods face two fundamental challenges when processing mixed-scene data: one is ineffective fusion of cross-scene semantic information, and the other is inter-scenario interference that makes it harder to learn feature representations from any individual scene. In contrast, our method addresses these limitations through dual-pipeline feature extraction and wavelet-based component fusion, further enhanced by the ProSL module to strengthen feature consistency.
4.4.2. Results on NEU-DET
To comprehensively evaluate models’ performance, we conducted comparative experiments on the open-source NEU-DET dataset from two perspectives: (1) comparison among different methods and (2) comparison across backbones of varying scales.
The results in Table 4 demonstrate that our method achieves superior mAP across all few-shot configurations, with performance improvement observed as the backbone scale increases. This means that larger backbones in CWCN possess enhanced feature extraction capabilities. Table 4 also reports the frames per second (FPS) for 10-shot tasks, demonstrating that our method achieves competitive inference speed, with the lightweight variant exhibiting superior efficiency. Furthermore, Figure 7 shows the AP50 of the comparison methods in each category, and the results demonstrate that our method performs relatively steadily in inter-class detection.
Table 4.
Results of k-shot detection task on NEU-DET. The best indicators are shown in bold.
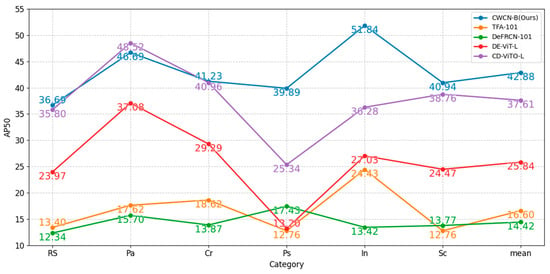
Figure 7.
AP50 results for all the categories on NEU-DET. Six-way-ten-shot detection is shown. The best indicators are shown in bold.
Unlike conventional CNNs or Transformers, our WTConv-enhanced backbone conducts convolutions in the wavelet domain rather than direct spatial convolution or attention mechanism, gradually expanding receptive fields without over-parameterization via multi-level cascaded wavelet blocks [28]. As evidenced by the experiments, the whole CWCN architecture, integrating this advanced backbone with dual-pipeline design and specialized loss computation, demonstrates generalizability beyond industrial chips. This method exhibits potential to defect inspection tasks across various industrial workpieces.
4.5. Ablation Study
4.5.1. Analysis of Feature Fusion Modules
To validate the 3-Level CWC, we conducted an ablation study in Table 5, which reveals significant limitations in two initial approaches. Direct Replacement achieves only 29.75% mAP overall, particularly deficient in small object detection (APs = 19.82%). The Style-Transfer-Based Method shows moderate improvement but still exhibits substantial scale imbalance with the gap between 51.98% APl and 22.26% APs.
Table 5.
Verification of feature fusion module. Based on 3-way-10-shot on ChipMix. The best indicators are shown in bold.
In contrast, our 3-Level CWC demonstrates consistent performance gains across all evaluation metrics. This advancement primarily stems from its multi-scale fusion mechanism, which better accommodates varying object sizes through hierarchical wavelet decomposition and adaptive cross-pipeline component interaction.
4.5.2. Analysis of Selective Staged Fusion Strategy
Regarding the question of which ConvStage the 3-Level CWC should be applied in DPCWC, we conducted relevant experiments. Empirically, the crossed wavelet transform needs to be applied in both shallower and deeper layers to fuse multi-scale information. Thus, we conduct several schemes as shown in Table 6. The results show that excessive fusion (Scheme 2) leads to performance degradation, as frequent cross-pipeline interactions introduce feature interference that compromises each pipeline’s distinctive feature representations. Additionally, although Scheme 3 achieves precision comparable to our method, it does so at more complicated training parameters.
Table 6.
Verification of selective staged fusion strategy. Based on 3-way-10-shot on ChipMix. The best indicators are shown in bold, and the down arrow means that lower scores have better quality.
To further evaluate the rationality of our selective scheme, the results of AP50 at the category level are shown in Figure 8. Among them, over-fusion schemes may confuse more visual characteristics in shallower ConvStages. It increases the difficulty of training, manifesting performance degradation and fluctuation across categories. Properly integrating encoded features rather than visual features avoids these situations.
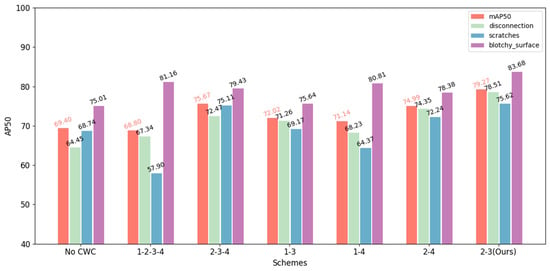
Figure 8.
Category AP50 of different selective schemes. Based on 3-way-10-shot on ChipMix.
The proposed 2nd-3rd-ConvStage scheme emerges as the optimal solution, effectively balancing multi-scale feature fusion with computational efficiency. This selective fusion strategy successfully captures both local textures and global structures while preserving pipeline-specific characteristics without significantly increasing computational overhead.
4.5.3. Analysis of Loss Calculation Modules
To evaluate different loss computation modules, we conducted a comparative visualization experiment. The same query samples were processed through feature extractors equipped with different loss modules to obtain high-dimensional representations, which were then projected into a 2D space using t-SNE dimensionality reduction. The visualization results in Figure 9 depict feature points of three scenarios (represented by triangles, circles, and squares, respectively) and three defect categories (colored coral, green, and blue). As our study focuses on two key aspects:
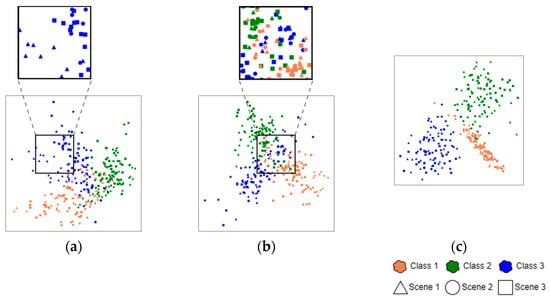
Figure 9.
T-SNE visualization. (a) Baseline, (b) SSL module, and (c) ProSL (ours).
- The overlap between different geometric markers indicates cross-scene adaptability. More overlap suggests better scenario-invariant feature learning.
- The separation between color-coded clusters reflects category discriminability. Clearer boundaries mean stronger classification capability.
When solely on Faster R-CNN’s original loss functions, it is difficult to adapt to CWCN’s dual-pipeline design, as shown in Figure 9a, due to insufficient inter-class discrimination and poor cross-scene feature alignment. The visualization result proves the necessity of a specialized loss computation module. Figure 9b displays the feature distribution obtained using the self-supervised loss module, with substantial overlapping areas between different-colored points. While this approach achieves partial success in clustering feature points from different scenarios, it still suffers from inter-class confusion. This limitation stems from the module’s inherent design flaw, it focuses exclusively on inter-pipeline feature comparison while lacking explicit category discrimination guidance. It remains dependent on Faster R-CNN’s original loss functions for classification and localization.
In contrast, the model employing the ProSL module (Figure 9c) demonstrates superior distribution characteristics. The features show tighter intra-class clustering and clearer inter-class separation boundaries while effectively aligning same-class samples across different scenarios. This distribution pattern visually confirms ProSL’s dual advantage in maintaining both scenario consistency and category specificity.
4.6. Discussion
Our method has successfully achieved cross-domain, multi-scene industrial chip defect detection under few-shot conditions.
However, the results of APs, APm, and Apl reveal notable performance fluctuations when detecting defects of different sizes. Taking the 10-shot task on ChipMix as an example, Table 3 reports that our method achieves 67.28% in Apl, while showing lower performance in APm (41.64%). Although these indicators show improvement over the baselines, the size-dependent performance gap appears more pronounced in our method than in others.
The potential reasons for this limitation are as follows: our backbone only ensures multi-scale feature fusion between the two pipelines. But it neglects the importance of the pipeline itself in multi-scale feature extraction. CWCN’s single pipeline does not use technologies such as FPN, which is an idea worth exploring in the future.
Additionally, our method is currently limited to the two-stage object detection framework (Faster R-CNN) and it satisfies offline batch processing but falls short of real-time demands in online detection. Thus, adapting our approach to one-stage frameworks is a key focus of our ongoing research.
5. Conclusions
Our work focuses on defect detection in industrial chips, thoroughly investigating the challenges of cross-domain few-shot learning under multi-scene conditions. We propose the crossed wavelet convolution network (CWCN), whose core components include (1) a novel dual-pipeline crossed wavelet convolution (DPCWC) training mechanism that achieves multi-scene feature alignment through wavelet component extraction and a selective fusion strategy; (2) a Prototype Similarity Learning (ProSL) module that employs class prototypes and pipeline features similarity calculation, enforcing scenario consistency while enhancing feature discriminability. Comprehensive comparative experiments and ablation studies confirm the effectiveness of our method in improving both cross-scene adaptability and detection accuracy. However, limitations remain: the approach shows room for improvement in handling multi-scale defects, and its performance in online industrial detection requires further investigation.
Our work expands the application boundaries of wavelet transform. While wavelet transform has been extensively studied and applied in signal processing, its exploration in computer vision and image processing remains relatively limited. Our work not only provides a novel case for applying wavelet transform in image processing but also represents a successful example of introducing wavelet transform convolution into few-shot learning, particularly for cross-domain few-shot object detection.
Author Contributions
Conceptualization, Z.S., Y.L. (Yiyu Lin) and Y.L. (Yan Li); Methodology, Y.L. (Yiyu Lin); Software, Y.L. (Yiyu Lin); Validation, Z.S., Y.L. (Yiyu Lin), Y.L. (Yan Li) and Z.L.; Formal analysis, Y.L. (Yan Li); Investigation, Z.S., Y.L. (Yiyu Lin), Y.L. (Yan Li) and Z.L.; Resources, Z.S. and Y.L. (Yan Li); Data curation, Y.L. (Yiyu Lin) and Z.L.; Writing—original draft, Z.S. and Y.L. (Yiyu Lin); Writing—review & editing, Z.S.; Visualization, Z.L.; Supervision, Z.S.; Funding acquisition, Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Project (NO. 62073145).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Currently, the datasets in this work are part of ongoing research and they will be available upon request from the corresponding author.
Acknowledgments
The humidity sensor chips for this work are supported by Guangzhou Haigu Electronic Technology Co. in China.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, Y.; Wang, X.; Hao, R.; Lu, B.; Huang, B. Metal surface defect detection method based on improved cascade r-cnn. J. Comput. Inf. Sci. Eng. 2023, 24, 041002. [Google Scholar] [CrossRef]
- Qiu, J.; Shen, Y.; Lin, J.; Qin, Y.; Yang, J.; Lei, H.; Li, M. An enhanced method for surface defect detection in workpieces based on improved MobileNetV2-SSD. Expert Syst. 2024, 42, e13567. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, arXiv:1706.0376230. [Google Scholar]
- Sun, S.; Gao, H. Meta-AdaM: A meta-learned adaptive optimizer with momentum for few-shot learning. Adv. Neural Inf. Process. Syst. 2023, 36, 65441–65455. [Google Scholar]
- Zhang, B.; Luo, C.; Yu, D.; Li, X.; Lin, H.; Ye, Y.; Zhang, B. Metadiff: Meta-learning with conditional diffusion for few-shot learning. Proc. AAAI Conf. Artif. Intell. 2024, 38, 16687–16695. [Google Scholar] [CrossRef]
- Gu, Y.; Han, X.; Liu, Z.; Huang, M. Ppt: Pre-trained prompt tuning for few-shot learning. arXiv 2021, arXiv:2109.04332. [Google Scholar]
- Du, Z.; Li, J.; Su, H.; Zhu, L.; Lu, K. Cross-domain gradient discrepancy minimization for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Tseng, H.Y.; Lee, H.Y.; Huang, J.B.; Yang, M.H. Cross-domain few-shot classification via learned feature-wise transformation. arXiv 2020, arXiv:2001.08735. [Google Scholar]
- Wu, K.; Tan, J.; Liu, C. Cross-domain few-shot learning approach for lithium-ion battery surface defects classification using an improved Siamese network. IEEE Sensors J. 2022, 22, 11847–11856. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Xie, J.; Yang, X.; Xue, J.-H.; Ma, Z. Self-reconstruction network for fine-grained few-shot classification. Pattern Recognit. 2024, 153, 110485. [Google Scholar] [CrossRef]
- Bai, S.; Zhou, W.; Luan, Z.; Wang, D.; Chen, B. Improving Cross-domain Few-shot Classification with Multilayer Perceptron. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Li, X.; He, Z.; Zhang, L.; Guo, S.; Hu, B.; Guo, K. CDCNet: Cross-domain few-shot learning with adaptive representation enhancement. Pattern Recognit. 2025, 162, 111382. [Google Scholar] [CrossRef]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Zhou, X.; Girdhar, R.; Joulin, A.; Krähenbühl, P.; Misra, I. Detecting twenty-thousand classes using image-level supervision. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. Defrcn: Decoupled faster r-cnn for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Zhang, X.; Liu, Y.; Wang, Y.; Boularias, A. Detect everything with few examples. arXiv 2023, arXiv:2309.12969. [Google Scholar]
- Fu, Y.; Wang, Y.; Pan, Y.; Huai, L.; Qiu, X.; Shangguan, Z.; Liu, T.; Fu, Y.; Van Gool, L.; Jiang, X. Cross-domain few-shot object detection via enhanced open-set object detector. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024. [Google Scholar]
- Akujuobi, C.M. Wavelets and Wavelet Transform Systems and Their Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Othman, G.; Zeebaree, D.Q. The applications of discrete wavelet transform in image processing: A review. J. Soft Comput. Data Min. 2020, 1, 31–43. [Google Scholar]
- Finder, S.E.; Zohav, Y.; Ashkenazi, M.; Treister, E. Wavelet feature maps compression for image-to-image CNNs. Adv. Neural Inf. Process. Syst. 2022, 35, 20592–20606. [Google Scholar]
- Fu, Y.; Xie, Y.; Fu, Y.; Chen, J.; Jiang, Y.G. Wave-san: Wavelet based style augmentation network for cross-domain few-shot learning. arXiv 2022, arXiv:2203.07656. [Google Scholar]
- Liu, J.; Zhao, H.; Chen, Z.; Wang, Q.; Shen, X.; Zhang, H. A dynamic weights-based wavelet attention neural network for defect detection. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 16211–16221. [Google Scholar] [CrossRef]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet convolutions for large receptive fields. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Gao, Y.; Fei, N.; Liu, G.; Lu, Z.; Xiang, T. Contrastive prototype learning with augmented embeddings for few-shot learning. In Uncertainty in Artificial Intelligence, Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence, Online, 27–30 July 2021; PMLR: Cambridge, MA, USA, 2021. [Google Scholar]
- Zaynidinov, H.; Juraev, J.; Juraev, U. Digital image processing with two-dimensional haar wavelets. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2016, arXiv:1506.0149728. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2020. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part v 13. Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).