FedeAMR-CFF: A Federated Automatic Modulation Recognition Method Based on Characteristic Feature Fine-Tuning


Abstract
1. Introduction
- To highlight the more effective federate learning in AMR, this paper proposes FedeAMR-CFF, an innovative federated automatic modulation recognition framework that uniquely integrates parameter aggregation with characteristic feature fine-tuning.
- To address the data privacy issue, we propose a distance metric-based feature selection method at the client level to extract the most representative features of each modulation type.
- To address the distribution discrepancy issue, we propose a targeted fine-tuning method on the classification layer at the server level using the selected representative features based on FedAvg, significantly enhancing the generalization capability across clients with heterogeneous data distributions.
- Extensive experiments on the RML2016.10A dataset validate our model’s superior performance, indicating that FedAMR-CFF outperforms the best local model by 3.43% in recognition accuracy.
2. Related Work
2.1. Automatic Modulation Recognition
2.2. Federated Learning
3. Methodology
3.1. Signal Model and Dataset
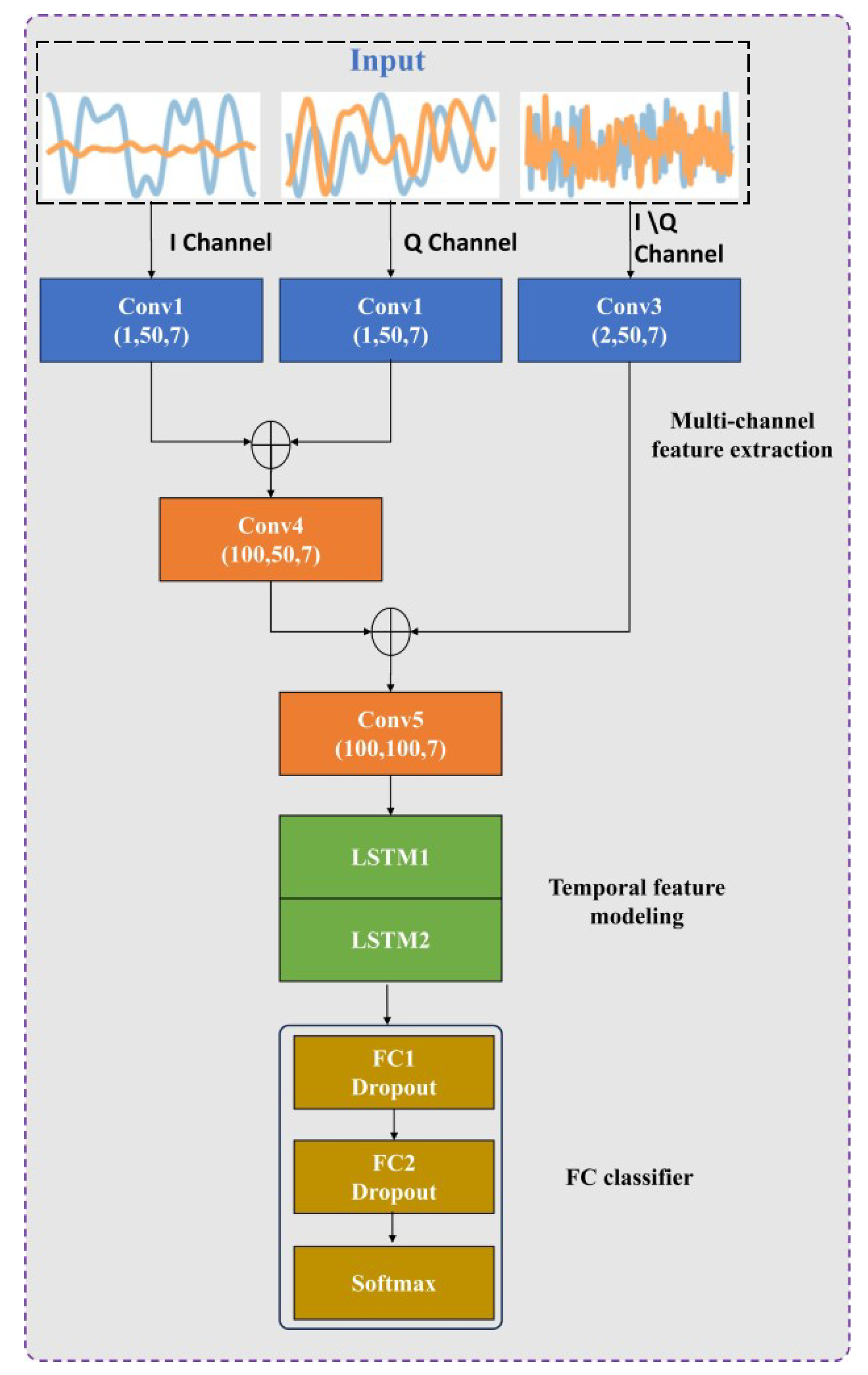
3.2. Multi-Channel Temporal Feature Extraction
3.3. Model Aggregation Method
3.4. Distance-Based Feature Selection Method
3.5. FedeAMR with Feature Fine-Tuning
| Algorithm 1 FedeAMR-CFF: |
|
4. Experiment and Analysis
4.1. Training Details
4.2. Evaluation Metrics
- (1)
- Recognition accuracy measures the proportion of correctly classified samples out of all samples, reflecting the overall prediction performance.
- (2)
- Precision represents the proportion of true positive samples among those predicted as positive.High precision indicates a low false positive rate, meaning the model’s positive predictions are highly reliable.
- (3)
- Recall measures the proportion of actually positive samples that are correctly predicted as positive by the model. It reflects the model’s ability to comprehensively identify positives and minimize false negatives. A high recall denotes strong coverage of true positives with minimal missed detections.
- (4)
- F1-score is the harmonic mean of precision and recall, balancing both metrics:
- (5)
- Specificity denotes the model’s ability to correctly exclude negative samples, i.e., the portion of truly negative samples that are correctly rejected:High specificity indicates that the model has few false positives.
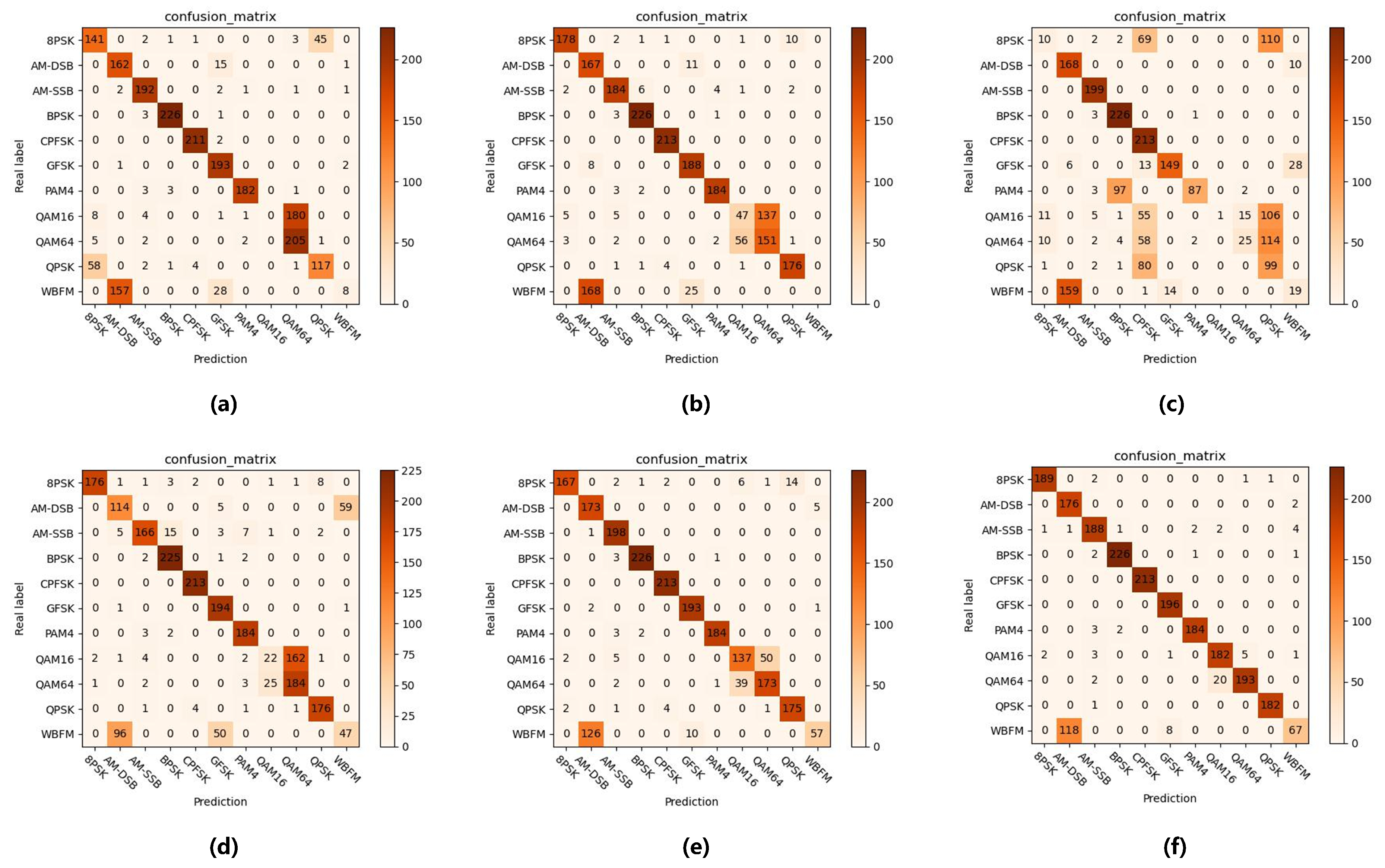
4.3. Experimental Result
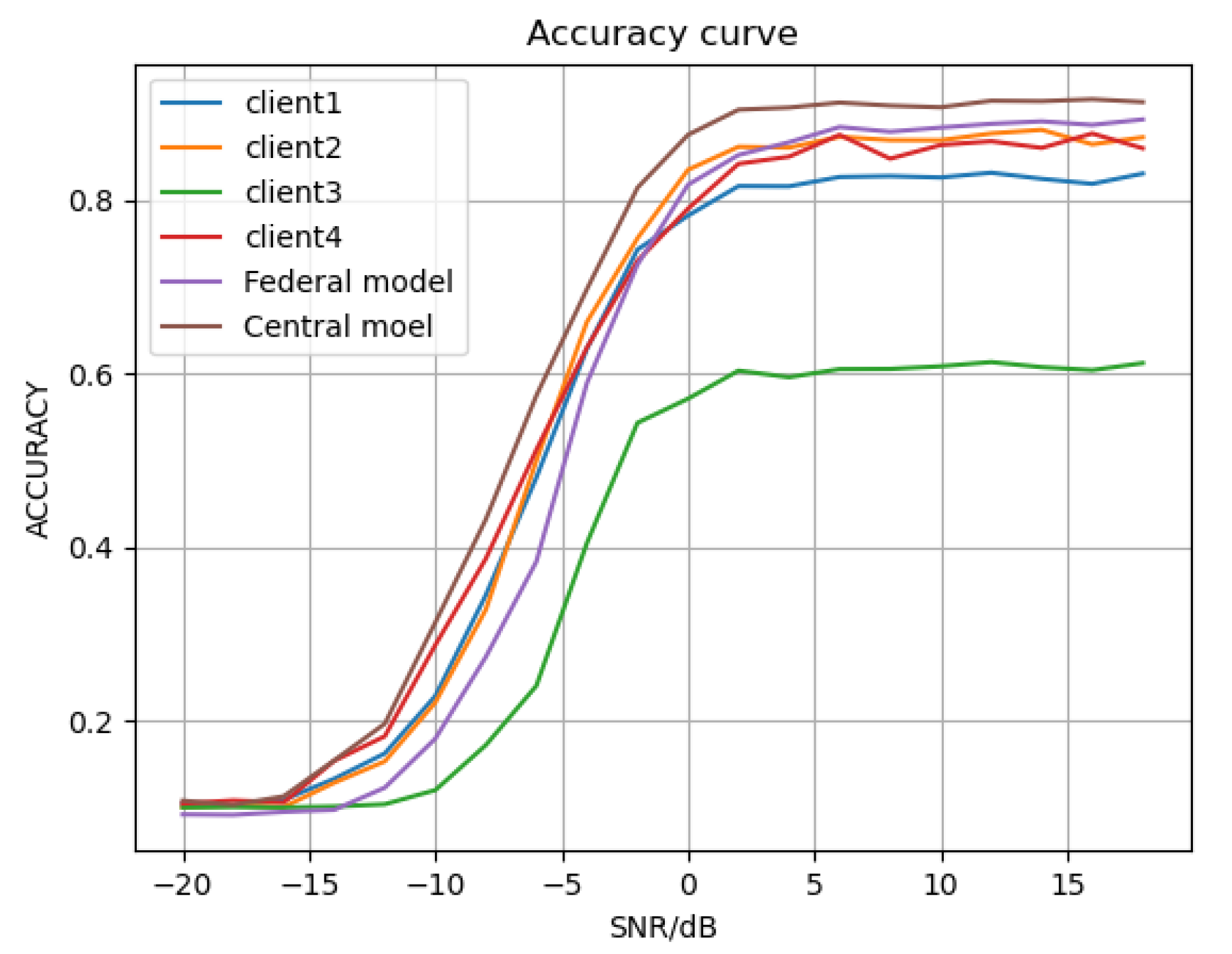
4.3.1. Comparison with Local Client Result
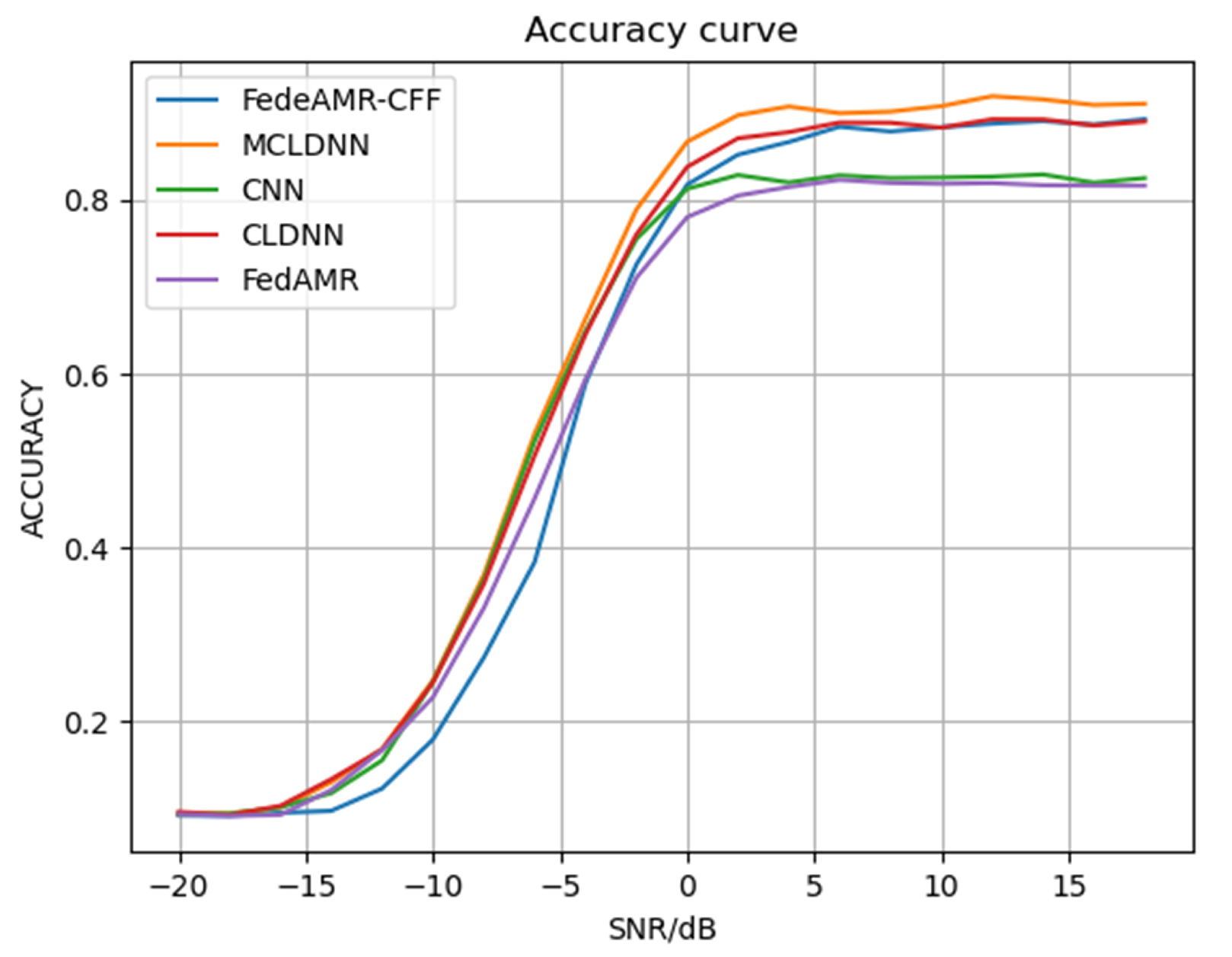
4.3.2. Comparison with Centralized Full Data Training
4.3.3. Ablation Study for Feature Fine-Tuning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, Z.; Nandi, A.K. Automatic Modulation Classification: Principles, Algorithms and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Lin, Y.; Tu, Y.; Dou, Z. An improved neural network pruning technology for automatic modulation classification in edge devices. IEEE Trans. Veh. Technol. 2020, 69, 5703–5706. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, Z.; Li, Y.; Shi, X.; Wang, L.; Yang, X.; Zhou, F. PASS-Net: A Pseudo Classes and Stochastic Classifiers-Based Network for Few-Shot Class-Incremental Automatic Modulation Classification. IEEE Trans. Wirel. Commun. 2024, 23, 17987–18003. [Google Scholar] [CrossRef]
- Huang, S.; Chai, L.; Li, Z.; Zhang, D.; Yao, Y.; Zhang, Y.; Feng, Z. Automatic modulation classification using compressive convolutional neural network. IEEE Access 2019, 7, 79636–79643. [Google Scholar] [CrossRef]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Park, C.S.; Choi, J.H.; Nah, S.P.; Jang, W.; Kim, D.Y. Automatic modulation recognition of digital signals using wavelet features and SVM. In Proceedings of the 2008 10th International Conference on Advanced Communication Technology, Gangwon, Republic of Korea, 17–20 February 2008; IEEE: New York, NY, USA, 2008; Volume 1, pp. 387–390. [Google Scholar]
- Zeng, C.; Jia, X.; Zhu, W. Modulation classification of communication signals. Commun. Technol. 2015, 48, 252–257. [Google Scholar]
- Tan, H.; Zhang, Z.; Shi, X.; Yang, X.; Li, Y.; Bai, X.; Zhou, F. Few-Shot SAR ATR via Multilevel Contrastive Learning and Dependence Matrix-Based Measurement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 8175–8188. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Zhang, Z.; Bai, D.; Fan, W.; Shi, X.; Tan, H.; Du, J.; Bai, X.; Zhou, F. A Time-frequency Aware Hierarchical Feature Optimization Method for SAR Jamming Recognition. IEEE Trans. Aerosp. Electron. Syst. 2025, 1–16. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y.; Zheng, F.C. Deep learning based automatic modulation recognition: Models, datasets, and challenges. Digit. Signal Process. 2022, 129, 103650. [Google Scholar] [CrossRef]
- O’shea, T.J.; West, N. Radio machine learning dataset generation with gnu radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 6 September 2016; Volume 1. [Google Scholar]
- Chang, S.; Huang, S.; Zhang, R.; Feng, Z.; Liu, L. Multitask-learning-based deep neural network for automatic modulation classification. IEEE Internet Things J. 2021, 9, 2192–2206. [Google Scholar] [CrossRef]
- Kumar, A.; Satija, U.; Satija, U. Residual stack-aided hybrid CNN-LSTM-based automatic modulation classification for orthogonal time-frequency space system. IEEE Commun. Lett. 2023, 27, 3255–3259. [Google Scholar] [CrossRef]
- Ghasemi, A.; Sousa, E.S. Spectrum sensing in cognitive radio networks: Requirements, challenges and design trade-offs. IEEE Commun. Mag. 2008, 46, 32–39. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, G.; Gacanin, H.; Adebisi, B.; Sari, H.; Adachi, F. Federated learning for automatic modulation classification under class imbalance and varying noise condition. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 86–96. [Google Scholar] [CrossRef]
- Rahman, R.; Nguyen, D.C. Improved Modulation Recognition Using Personalized Federated Learning. IEEE Trans. Veh. Technol. 2024, 73, 19937–19942. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Hosseinalipour, S.; Love, D.J.; Pathirana, P.N.; Brinton, C.G. Latency optimization for blockchain-empowered federated learning in multi-server edge computing. IEEE J. Sel. Areas Commun. 2022, 40, 3373–3390. [Google Scholar] [CrossRef]
- Sills, J.A. Maximum-likelihood modulation classification for PSK/QAM. In Proceedings of the MILCOM 1999. IEEE Military Communications. Conference Proceedings (Cat. No. 99CH36341), Atlantic City, NJ, USA, 31 October–3 November 1999; IEEE: New York, NY, USA, 1999; Volume 1, pp. 217–220. [Google Scholar]
- Wei, W.; Mendel, J.M. Maximum-likelihood classification for digital amplitude-phase modulations. IEEE Trans. Commun. 2000, 48, 189–193. [Google Scholar] [CrossRef]
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; IEEE: New York, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Hong, L.; Ho, K. Identification of digital modulation types using the wavelet transform. In Proceedings of the MILCOM 1999. IEEE Military Communications. Conference Proceedings (Cat. No. 99CH36341), Atlantic City, NJ, USA, 31 October–3 November 1999; IEEE: New York, NY, USA, 1999; Volume 1, pp. 427–431. [Google Scholar]
- Liu, L.; Xu, J. A novel modulation classification method based on high order cumulants. In Proceedings of the 2006 International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 22–24 September 2006; IEEE: New York, NY, USA, 2006; pp. 1–5. [Google Scholar]
- O’shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y.D. Modulation classification based on signal constellation diagrams and deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 718–727. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-air deep learning based radio signal classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Pham, Q.V.; Kim, D.S. MCNet: An efficient CNN architecture for robust automatic modulation classification. IEEE Commun. Lett. 2020, 24, 811–815. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, Z.; Li, Y.; Shi, X.; Zhou, F. Multi-Scale Feature Fusion and Distribution Similarity Network for Few-Shot Automatic Modulation Classification. IEEE Signal Process. Lett. 2024, 31, 2890–2894. [Google Scholar] [CrossRef]
- West, N.E.; O’shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; IEEE: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Xu, J.; Luo, C.; Parr, G.; Luo, Y. A spatiotemporal multi-channel learning framework for automatic modulation recognition. IEEE Wirel. Commun. Lett. 2020, 9, 1629–1632. [Google Scholar] [CrossRef]
- Kong, W.; Jiao, X.; Xu, Y.; Zhang, B.; Yang, Q. A transformer-based contrastive semi-supervised learning framework for automatic modulation recognition. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 950–962. [Google Scholar] [CrossRef]
- Zhou, H.; Tian, C.; Zhang, Z.; Huo, Q.; Xie, Y.; Li, Z. Multispectral fusion transformer network for RGB-thermal urban scene semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7507105. [Google Scholar] [CrossRef]
- Cai, J.; Gan, F.; Cao, X.; Liu, W. Signal modulation classification based on the transformer network. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1348–1357. [Google Scholar] [CrossRef]
- Zhai, L.; Li, Y.; Feng, Z.; Yang, S.; Tan, H. Learning Cross-Domain Features With Dual-Path Signal Transformer. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 3863–3869. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 12. [Google Scholar] [CrossRef]
- Ang, F.; Chen, L.; Zhao, N.; Chen, Y.; Wang, W.; Yu, F.R. Robust federated learning with noisy communication. IEEE Trans. Commun. 2020, 68, 3452–3464. [Google Scholar] [CrossRef]
- Boughorbel, S.; Jarray, F.; Venugopal, N.; Moosa, S.; Elhadi, H.; Makhlouf, M. Federated uncertainty-aware learning for distributed hospital ehr data. arXiv 2019, arXiv:1910.12191. [Google Scholar]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Distributed federated learning for ultra-reliable low-latency vehicular communications. IEEE Trans. Commun. 2019, 68, 1146–1159. [Google Scholar] [CrossRef]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A joint learning and communications framework for federated learning over wireless networks. IEEE Trans. Wirel. Commun. 2020, 20, 269–283. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR (dB) | Local Client1 | Local Client2 | Local Client3 | Local Client4 | FedeAMR-CFF | Central Model |
|---|---|---|---|---|---|---|
| −18 | 10.24% | 10.22% | 10.04% | 10.80% | 9.13% | 10.29% |
| −12 | 16.22% | 15.30% | 10.36% | 18.19% | 12.27% | 19.64% |
| −6 | 48.03% | 49.99% | 24.02% | 51.22% | 38.34% | 57.48% |
| 0 | 78.22% | 83.51% | 57.11% | 79.02% | 81.78% | 87.54% |
| 6 | 82.68% | 87.31% | 60.52% | 87.53% | 88.44% | 91.26% |
| 12 | 83.17% | 87.69% | 61.34% | 86.79% | 88.81% | 91.47% |
| 18 | 83.07% | 87.25% | 61.22% | 85.99% | 89.31% | 91.32% |
| All | 50.93% | 53.03% | 36.20% | 53.28% | 56.71% | 61.18% |
| Metric | Local Client1 | Local Client2 | Local Client3 | Local Client4 | FedeAMR-CFF | Central Model |
|---|---|---|---|---|---|---|
| Precision | 70.28% | 72.63% | 62.69% | 74.96% | 88.42% | 92.66% |
| Recall | 74.18% | 78.24% | 54.17% | 77.29% | 86.68% | 91.33% |
| Specificity | 97.50% | 97.85% | 95.48% | 97.79% | 98.69% | 99.14% |
| F1-score | 68.49% | 74.36% | 47.74% | 74.96% | 85.61% | 90.44% |
| SNR (dB) | FedeAMR- CFF | Other Model | |||
|---|---|---|---|---|---|
| MCLDNN [31] | CNN [25] | CLDNN [30] | FedeAMC [17] | ||
| −18 | 9.13% | 10.29% | 9.37% | 9.22% | 9.13% |
| −12 | 12.27% | 19.64% | 15.52% | 16.76% | 16.69% |
| −6 | 38.34% | 57.48% | 52.26% | 50.60% | 45.66% |
| 0 | 81.78% | 87.54% | 81.29% | 83.82% | 78.03% |
| 6 | 88.44% | 91.26% | 82.85% | 88.92% | 82.32% |
| 12 | 88.81% | 91.47% | 82.95% | 89.30% | 81.96% |
| 18 | 89.31% | 91.32% | 82.00% | 88.59% | 81.76% |
| All | 56.71% | 61.18% | 56.70% | 59.39% | 54.95% |
| Fedavg | Feature Fine-Tuning | Accuracy |
|---|---|---|
| × | × | 53.28% |
| ✓ | × | 54.54% |
| ✓ | ✓ | 56.71% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Ma, J.; Zhang, Z.; Zhou, F. FedeAMR-CFF: A Federated Automatic Modulation Recognition Method Based on Characteristic Feature Fine-Tuning. Sensors 2025, 25, 4000. https://doi.org/10.3390/s25134000
Zhang M, Ma J, Zhang Z, Zhou F. FedeAMR-CFF: A Federated Automatic Modulation Recognition Method Based on Characteristic Feature Fine-Tuning. Sensors. 2025; 25(13):4000. https://doi.org/10.3390/s25134000
Chicago/Turabian StyleZhang, Meng, Jiankun Ma, Zhenxi Zhang, and Feng Zhou. 2025. "FedeAMR-CFF: A Federated Automatic Modulation Recognition Method Based on Characteristic Feature Fine-Tuning" Sensors 25, no. 13: 4000. https://doi.org/10.3390/s25134000
APA StyleZhang, M., Ma, J., Zhang, Z., & Zhou, F. (2025). FedeAMR-CFF: A Federated Automatic Modulation Recognition Method Based on Characteristic Feature Fine-Tuning. Sensors, 25(13), 4000. https://doi.org/10.3390/s25134000