1. Introduction
In the sustainable management of marine resources, the accurate detection and localization of underwater resources are crucial. Remotely operated vehicles (ROVs) and autonomous underwater vehicles (AUVs) play an irreplaceable role in locating marine life, mapping the seabed, and other underwater tasks. The scope of these applications extends from monitoring marine species [
1] to underwater archaeology [
2] and aquaculture [
3]. However, designing a fully functional AUV requires the integration of advanced technologies such as target detection [
4,
5], tracking [
5,
6,
7,
8], grasping [
9], human–machine interaction [
10], autonomous control [
8], and multimodal sensor integration [
11]. ROVs and AUVs play a central role in the development of underwater target detection technology. They assist in mapping the seabed and locating potential obstacles by identifying the terrain and biological categories of the seabed, and they are also used to inspect underwater facilities. Although existing target detection technologies perform well in extracting low-level features such as shapes, outlines, and textures [
12,
13,
14], the recognition of these features often lacks precision and is slow in complex underwater environments.
Underwater target detection faces numerous challenges. Firstly, the absorption and scattering of light by water cause unstable lighting conditions, significantly reducing the contrast between targets and their backgrounds [
15]. Secondly, factors such as water currents, suspended particles, and foam can cause image blurring and distortion, thereby reducing the recognition accuracy [
16]. Moreover, the diversity of the targets in underwater environments, with significant differences in appearance, size, and shape among marine organisms, adds complexity to detection tasks [
17]. Finally, various noise and disturbances such as water waves, bubbles, and floating debris further interfere with the detection and identification processes [
18]. To address these challenges, researchers have proposed several improvement strategies, including expanding the receptive field, enhancing the feature expression capabilities, implementing multi-scale information fusion, and facilitating comprehensive information interaction [
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29].
Firstly, increasing the receptive field helps to better capture the contextual information and environmental characteristics of targets, which is crucial in making accurate predictions in complex underwater environments. Deep convolutional neural networks (CNNs) have demonstrated their exceptional processing capabilities across various domains in recent years. Numerous studies have shown that by adjusting the depth of the CNN and the size of the convolutional kernels, the network’s receptive field can be effectively expanded [
19]. These strategies are particularly beneficial in tasks requiring dense predictions, such as semantic image segmentation [
20,
21], stereo vision [
22], and optical flow estimation [
23]. Ensuring that each output pixel is influenced by an adequate receptive field enhances the accuracy and robustness of the algorithm.
Additionally, the adoption of nonlinear activation functions, the integration of attention mechanisms, and the application of data augmentation techniques [
24] can significantly enhance the network’s ability to process the input data, thereby improving the accuracy in recognition, classification, or localization tasks. Techniques such as feature pyramid networks [
25], multi-scale fusion modules [
19], and Atrous Spatial Pyramid Pooling (ASPP) [
26] enable the generation of feature maps at various resolutions, effectively integrating feature information from different scales to enhance the system’s recognition capabilities. Advanced architectures such as standard Transformers and their variants [
27,
28] and DenseNet [
29] further boost the model’s performance and adaptability by managing complex data structures.
In summary, in the field of underwater target detection, existing research has been conducted on the aforementioned improvement strategies. However, there are still significant shortcomings in considering the complex underwater environment comprehensively and achieving higher precision. To address this, this paper introduces the improved YOLOv8-MU model, which integrates advanced computer vision technologies such as large kernel blocks (LarK blocks) [
30], C2fSTR, and Spatial Pyramid Pooling Fully Connected Spatial Pyramid Convolution (SPPFCSPC) [
31] with attention mechanisms to enhance the model’s receptive field, multi-scale fusion capabilities, and feature expression abilities. Furthermore, by incorporating a fusion block [
32], we have further enhanced the model’s performance in multi-scale feature fusion, optimizing the feature aggregation process and thus improving the flow of gradient information and network performance at various levels. Additionally, the model has been optimized to accommodate resource-limited edge devices, with an improved loss function (MPDIOU) [
33] that enhances the precision of localization for targets with unclear boundaries.
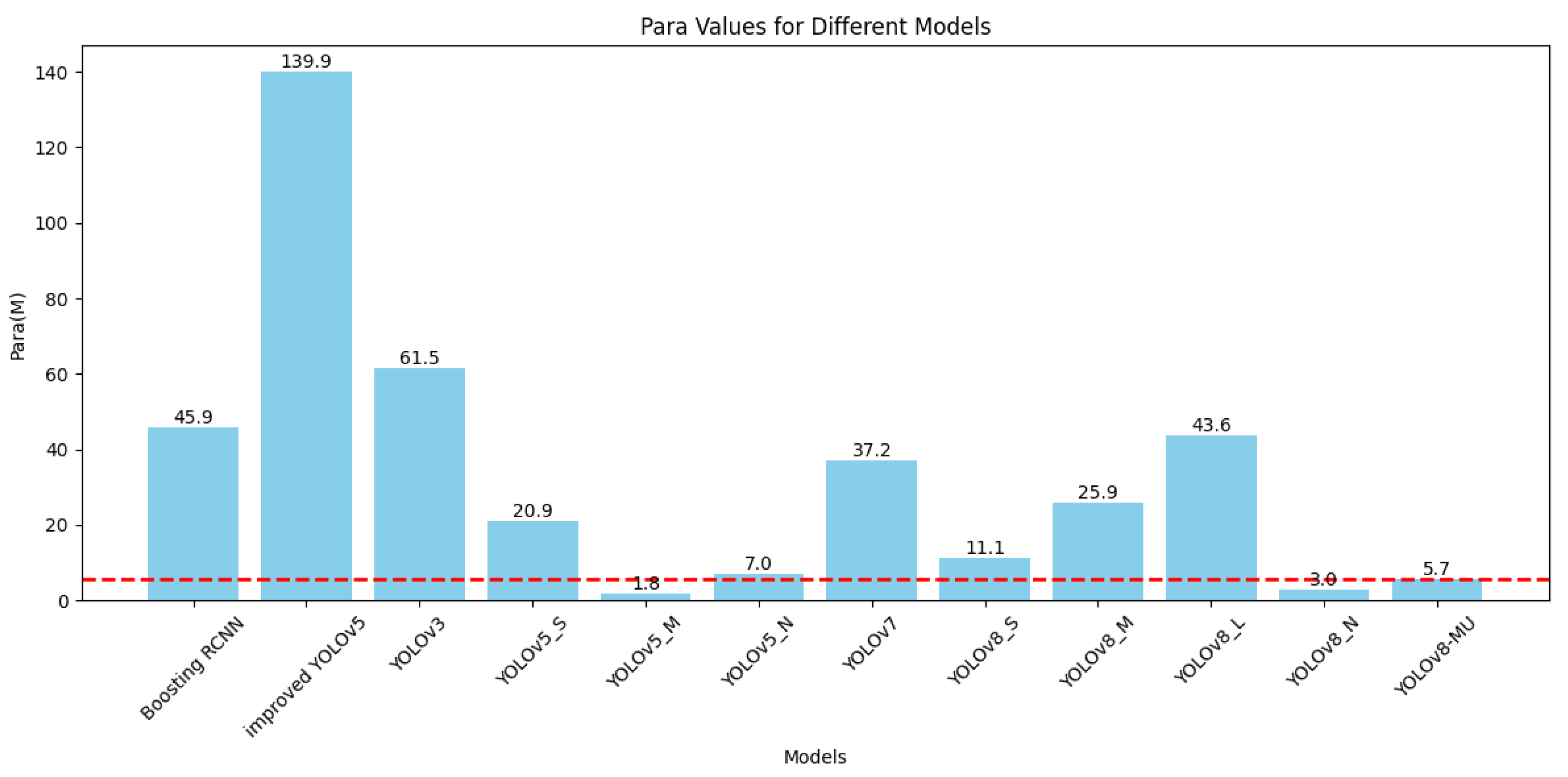
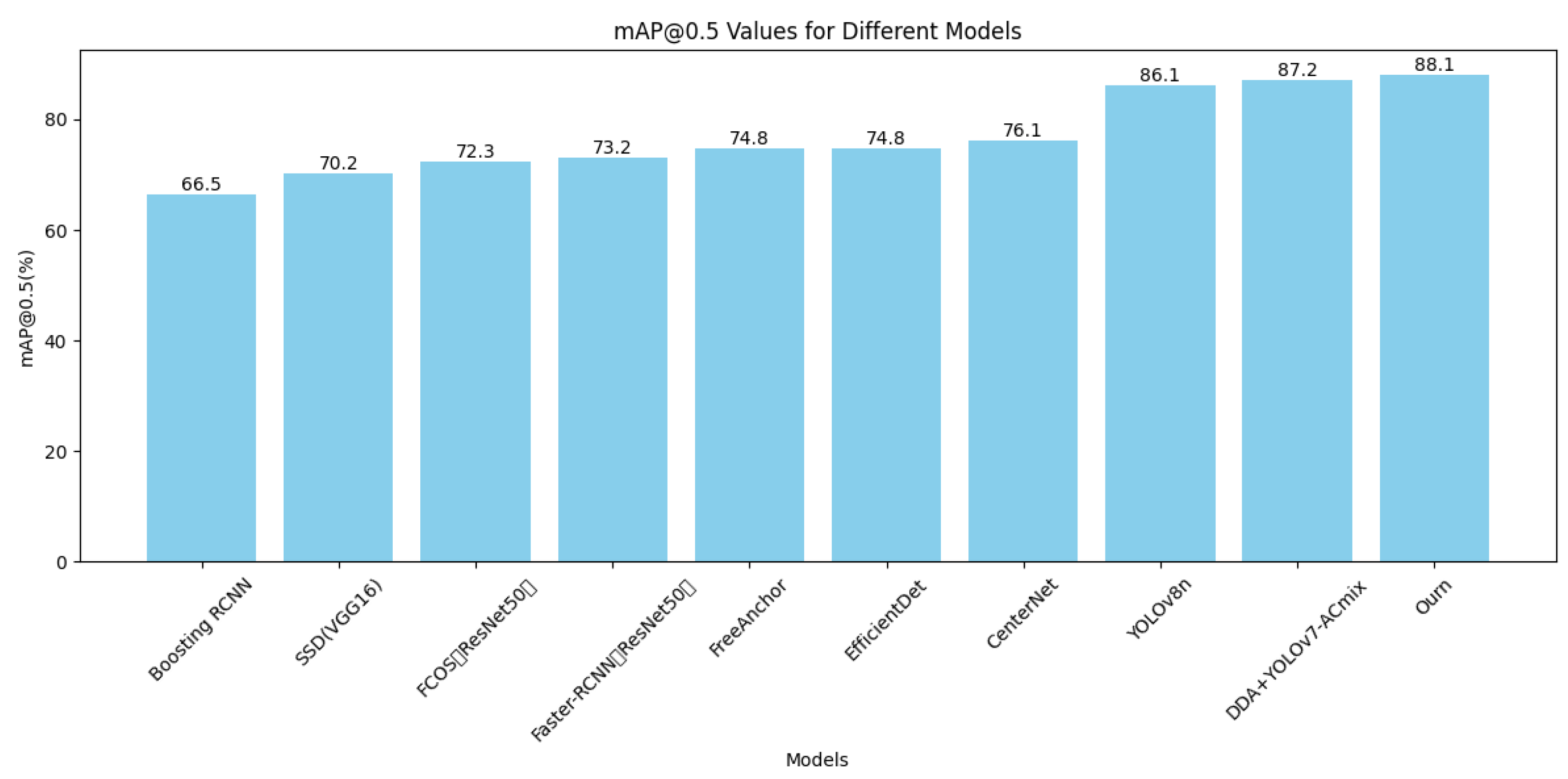
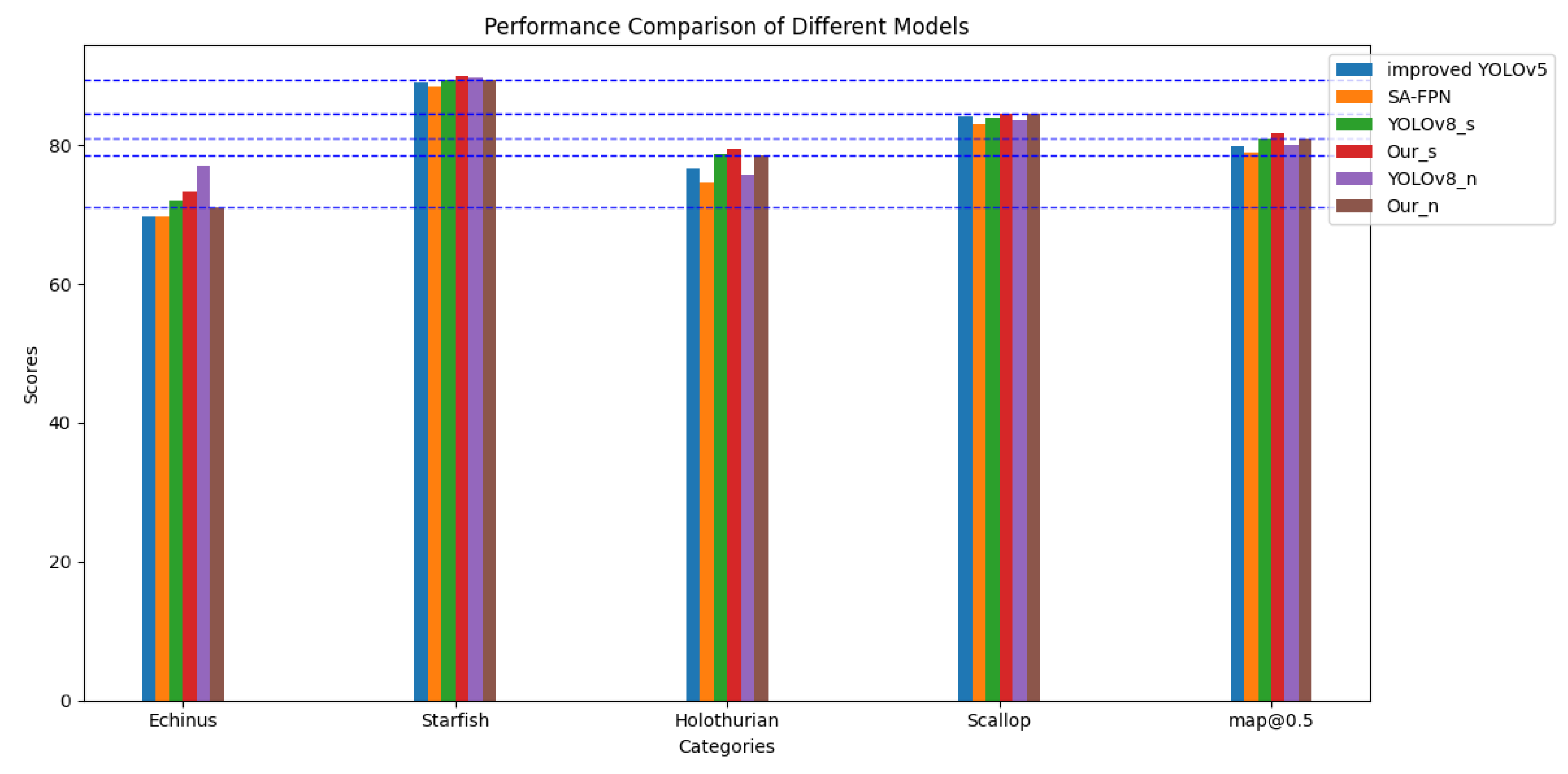
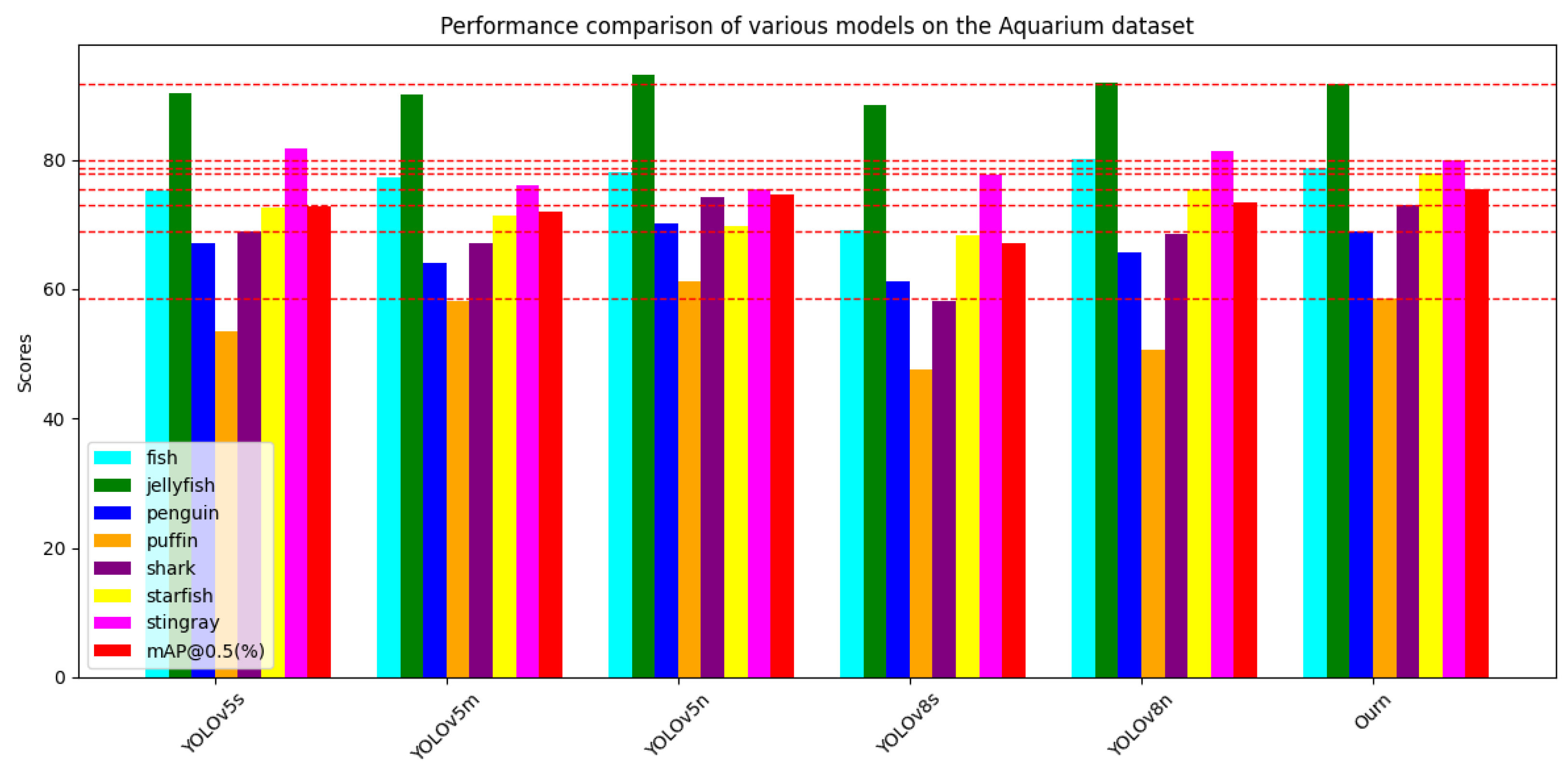
The experimental results on the URPC2019 dataset demonstrate that the YOLOv8-MU model achieved an mAP@0.5 of 78.4%, which represents a 4.0% improvement over the original YOLOv8 model. Additionally, the model reached an mAP@0.5 of 80.9% on the URPC2020 dataset and 75.5% on the Aquarium dataset, surpassing other models such as YOLOv5 and YOLOv8n, thereby confirming the broad applicability and generalization capabilities of our proposed improved model architecture. Additionally, evaluations on the refined URPC2019 dataset demonstrated leading performance, achieving an mAP@0.5 of 88.1%, which further confirms its superior performance on this dataset. These results highlight the model’s extensive applicability and generalization across various underwater datasets and provide valuable insights and contributions to future research in underwater target detection.
The structure of this document is as follows.
Section 2 provides a review of the literature relevant to this field. The YOLOv8-MU model proposed in this study, along with the experimental analysis, is detailed in
Section 3 and
Section 4, respectively. Finally,
Section 5 summarizes the contributions of this paper and outlines areas for future research.
3. Methodology
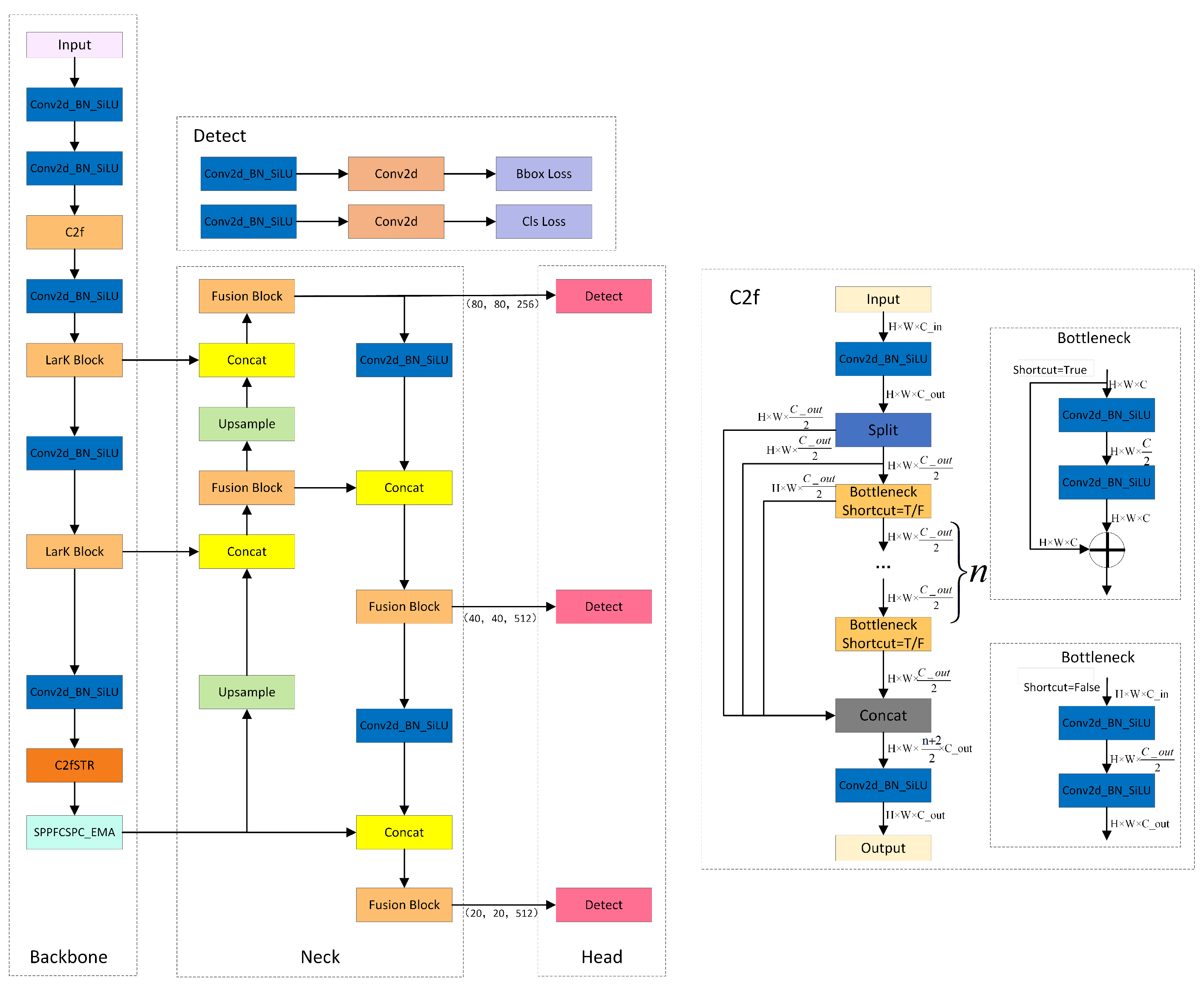
While the YOLOv8 model has achieved significant progress in the field of object detection, it still exhibits certain limitations. Firstly, it adopts a larger network architecture, resulting in slower processing speeds compared to other models within the YOLO family. Secondly, for objects with limited feature information, the localization accuracy may not be sufficiently high. Furthermore, the absence of the consideration of inter-object relationships during the prediction process may lead to issues such as overlapping bounding boxes. Additionally, the utilization of fixed-scale anchor boxes may struggle to accommodate objects with varying aspect ratios, potentially resulting in object deformation. To address these issues, we designed YOLOv8-MU, as shown in
Figure 1.
3.1. LarK Block
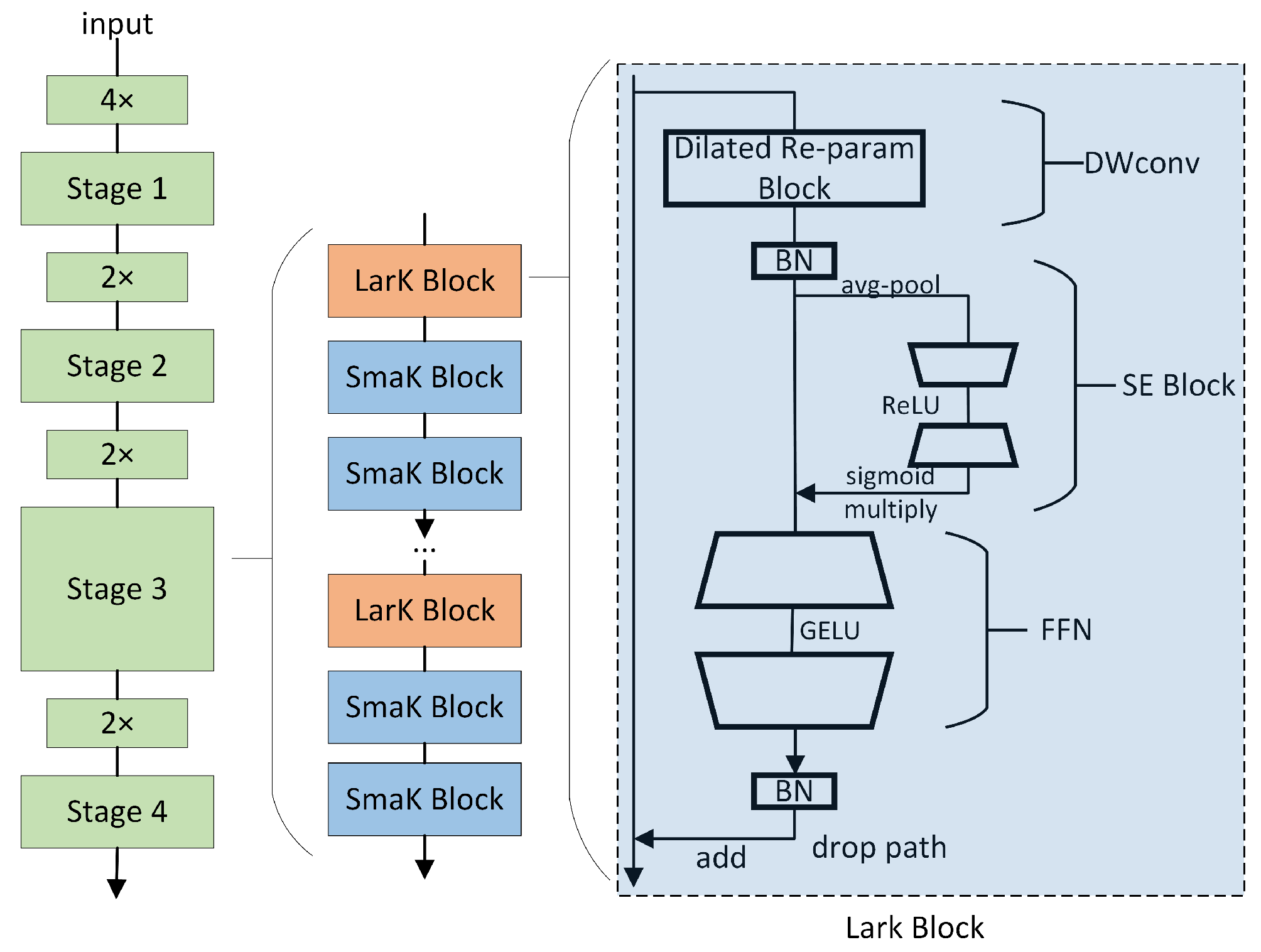
The convolutional neural network (ConvNet) with large kernels has shown remarkable performance in capturing sparse patterns and generating high-quality features, but there is still considerable room for exploration in its architectural design. While the Transformer model has demonstrated powerful versatility across multiple domains, it still faces some challenges and limitations in terms of computational efficiency, memory requirements, interpretability, and optimization. To address these limitations, we introduce the LarK block from UniRepLKNet into our model [
30], as depicted in
Figure 2. This block leverages the advantages of large kernel convolution to achieve a wider receptive field. By employing larger convolutional kernels, the LarK block can capture more contextual information without necessitating additional network layers. This represents a key advantage of large kernel convolution, enabling the network to capture richer features.
As illustrated in
Figure 2, the block utilizing the dilated reparam block is referred to as the large kernel block (LarK block), while the block employing DWconv 3 × 3 is termed the small kernel block (SmaK block). The dilated reparam block is proposed based on equivalent transformations, with its core idea being the utilization of a non-sparse large kernel block (kernel size K = 9), combined with multiple sparse small kernel blocks (kernel sizes k are 5, 3, 3, 3), to enhance the feature extraction effectiveness. The sparsity rate r determines the distribution of non-zero elements within the convolution kernel, where a higher sparsity rate implies more zero elements within the kernel, aiding in reducing the computational complexity while maintaining the performance. For instance, to accommodate larger input sizes, when the large kernel K is increased to 13, the corresponding adjustment of the small kernel sizes and sparsity rates is made to be k = (5, 7, 3, 3, 3) and r = (1, 2, 3, 4, 5). This adjustment allows us to simulate an equivalent large convolutional layer with a kernel size of (5, 13, 7, 9, 11), effectively enhancing the feature extraction by integrating large kernel layers in this manner. We observe that, apart from capturing small-scale patterns, the ability to enhance a large kernel capturing sparse patterns may yield higher-quality features, aligning perfectly with the mechanism of dilated convolution [
30]. From the perspective of sliding windows, dilated convolution layers with a dilation rate of d scan the input channels to capture spatial patterns, where the distance between each pixel of interest and its neighboring pixels is d − 1. Therefore, we adopt dilated convolution layers parallel to the large kernels and sum their outputs.
The large kernel block is primarily integrated into the middle and upper layers of the model to enhance the depth and expressive capability of the model when using large kernel convolutional layers. This enhancement is achieved by stacking multiple SE blocks to deepen the model. The squeeze-and-excitation (SE) block compresses all channels of the feature map into a single vector through a global compression operation, which contains global contextual information about the features. Then, this vector is activated through a fully connected layer and a sigmoid activation function to restore the number of channels to match the input features. This activation vector is multiplied element-wise with the original feature map, thereby enhancing or suppressing certain channels in the feature map. The SE block can enhance the model’s feature expression capability, especially in the early stages, particularly when there is a lack of sufficient contextual information.
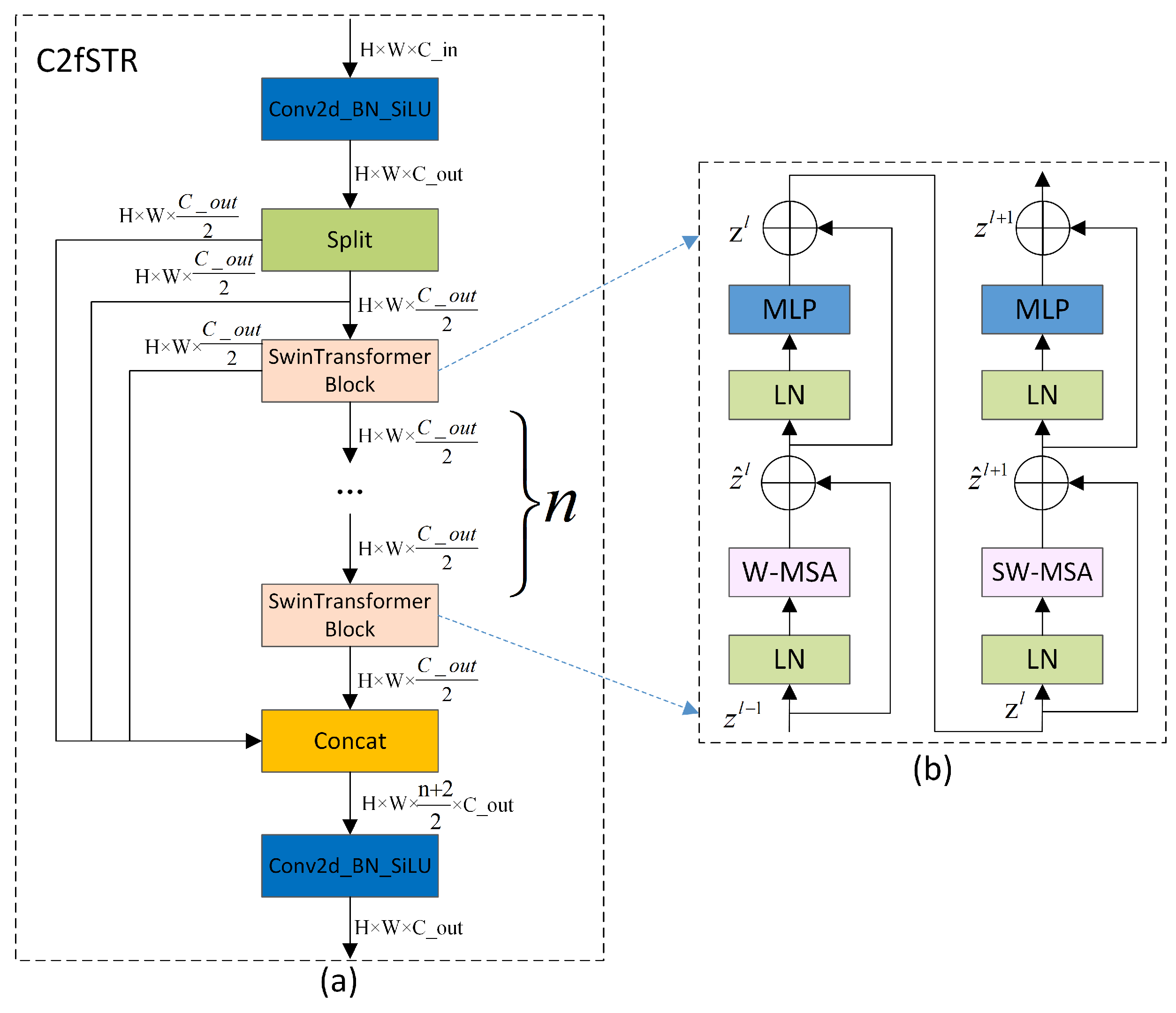
3.2. C2fSTR
The proposed C2fSTR in this paper modifies the original YOLOv8 architecture’s C2f module using the Swin Transformer block [
28]. Compared to the original C2f module, the modified C2fSTR module facilitates better interactions between strong feature maps and fully utilizes the target background information, thereby enhancing the accuracy and robustness of object detection under complex background conditions.
Figure 3a illustrates the structure of the C2fSTR.
The C2fSTR consists of two modules. One is the Conv module, which consists of a Conv2d with a kernel size of 1 × 1 and a stride of 1, followed by batch normalization and the Silu activation function. The role of the convolution module is to reduce the length and width of the feature map while expanding the dimensionality. The other module is the Swin Transformer block, which comprises a linear layer (LN), a shifted window multi-head self-attention (SW-MSA), and a feed-forward MLP (MLP). The structure includes some Swin Transformer modules. The function of the Swin Transformer block is to expand the scope of the information interaction without increasing the number of parameters by restricting the attention computations to be within each window. Its structure is illustrated in
Figure 3b.
Traditional Transformers typically compute the attention globally, leading to high computational complexity. The computational complexity of the multi-head attention mechanism is proportional to the square of the size of the feature map. To reduce the computational complexity of the multi-head attention mechanism and expand the range of the information interaction, in the Swin Transformer, the feature map is divided into windows. Each window undergoes window-based multi-head self-attention computation followed by shifted window-based multi-head self-attention computation, enabling mutual communication between windows [
65]. The computation of consecutive Swin Transformer blocks is shown in Equation (
1):
where
and
represent the output features of the (S)W-MSA and MLP modules of block
l, respectively, and W-MSA and SW-MSA represent window-based multi-head self-attention using regular and shifted window partitioning configurations, respectively.
When employing the window-based multi-head self-attention (W-MSA) module, self-attention calculations are conducted solely within individual windows, thereby preventing information exchange between separate windows. To address this limitation, the model incorporates the shifted window multi-head self-attention (SW-MSA) module, which is an offset adaptation of the W-MSA. However, the shifted window partitioning approach introduces another issue: it results in the proliferation of windows, and some of these windows are smaller than standard windows. For instance, a window comprising 2 × 2 patches may expand to encompass 3 × 3 patches, more than doubling the number of windows, which may consequently lead to an increase in parameters. To resolve this issue, a cyclic shift along the top-left direction is proposed. This method involves cyclically shifting the input features, enabling the windows within a batch to consist of discontinuous sub-windows, thereby maintaining a constant number of windows. Thus, although the shifted window strategy intrinsically increases the number of windows, the cyclic shift approach effectively mitigates this issue by ensuring the stability of the window count.
In this way, by confining the attention computations to each window, the Swin Transformer enhances the model’s focus on local features, thereby augmenting its ability to model local details. However, object recognition and localization in images depend on the feature information of the global background. The information interaction in the Swin Transformer is limited to individual windows and shifted windows, capturing only local details of the target, while global background information is difficult to obtain [
66]. To achieve a more extensive information interaction and simultaneously obtain both global background and local detail information, we apply the Swin Transformer block to C2f, replacing the Darknet bottleneck and forming the C2fSTR feature backbone system. This combined strategy enables a comprehensive information interaction, effectively capturing rich spatial details and significantly improving the model’s accuracy in object detection in complex backgrounds.
3.3. SPPFCSPC_EMA
As shown in
Figure 4, YOLOv8-MU replaces the SPPF module in YOLOv8 with the SPPFCSPC module and introduces multiple convolutions and concatenation techniques to extract and fuse features at different scales, expanding the receptive field of the model and thereby improving the model’s accuracy. Additionally, we have introduced the EMA module, whose parallel processing and self-attention strategy significantly improve the model’s performance and optimize the feature representation [
67]. By combining the SPPFCSPC and EMA modules to form the SPPFCSPC_EMA module, not only are the model’s accuracy, efficiency, and robustness enhanced, but the model’s performance is further improved while maintaining its efficiency.
The SPPFCSPC module integrates two submodules: SPP and fully connected spatial pyramid convolution (FCSPC) [
69]. SPP, as a pooling layer, can handle input feature maps of different scales, effectively detecting both small and large targets. FCSPC is an improved convolutional layer aimed at optimizing the representation of the feature maps to enhance the detection performance. By performing multi-scale spatial pyramid pooling on the input feature map, the SPP module captures information about targets and scenes at different scales [
55]. Subsequently, the FCSPC module convolves the feature maps of different scales output by the SPP module and divides the input feature map into blocks. These blocks are pooled and concatenated, followed by convolution operations, to enhance the model’s receptive field and retain key feature information, thereby improving the model’s accuracy [
69]. The SPPFCSPC module is an optimization of SPPCSPC based on the SPPF concept, reducing the computational requirements for the pooling layer’s output by connecting three independent pooling operations and improving the speed and detection accuracy of dense targets without changing the receptive field [
68]. The results produced using this pooling method are comparable to those obtained using larger pooling kernels, thus optimizing the training and inference speeds of the model. The calculation formula for the pooling part is shown in Equation (
2):
where
R represents the input feature layer,
represents the pooling layer result of the smallest pooling kernel,
represents the pooling layer result of the medium-sized pooling kernel,
represents the pooling layer result of the largest pooling kernel,
represents the final output result, and ⊛ represents tensor concatenation.
The EMA [
67] mechanism employs three parallel pathways, including two 1 × 1 branches and one 3 × 3 branch, to enhance the processing capability for spatial information. In the 1 × 1 branches, global spatial information is extracted through two-dimensional global average pooling, and the softmax function is utilized to ensure computational efficiency. The output of the 3 × 3 branch is directly adjusted to align with the corresponding dimensional structure before the joint activation mechanism, which combines channel features, as shown in Equation (
3). An initial spatial attention map is generated through matrix dot product operations, integrating spatial information of different scales within the same processing stage. Furthermore, the 2D global average pooling embeds global spatial information into the 3 × 3 branch, producing a second spatial attention map that preserves precise information on the spatial location. Finally, the output feature maps within each group are further processed through the sigmoid function [
70]. As illustrated in
Figure 5, the design of EMA aims to assist the model in capturing the interactions between features at different scales, thereby enhancing the performance of the model.
Here, represents the output related to the c-th channel. The primary purpose of this output is to encode global information, thereby capturing and modeling long-range dependencies.
Therefore, the overall formula for the SPPFCSPC_EMA module is as shown in Equation (
4):
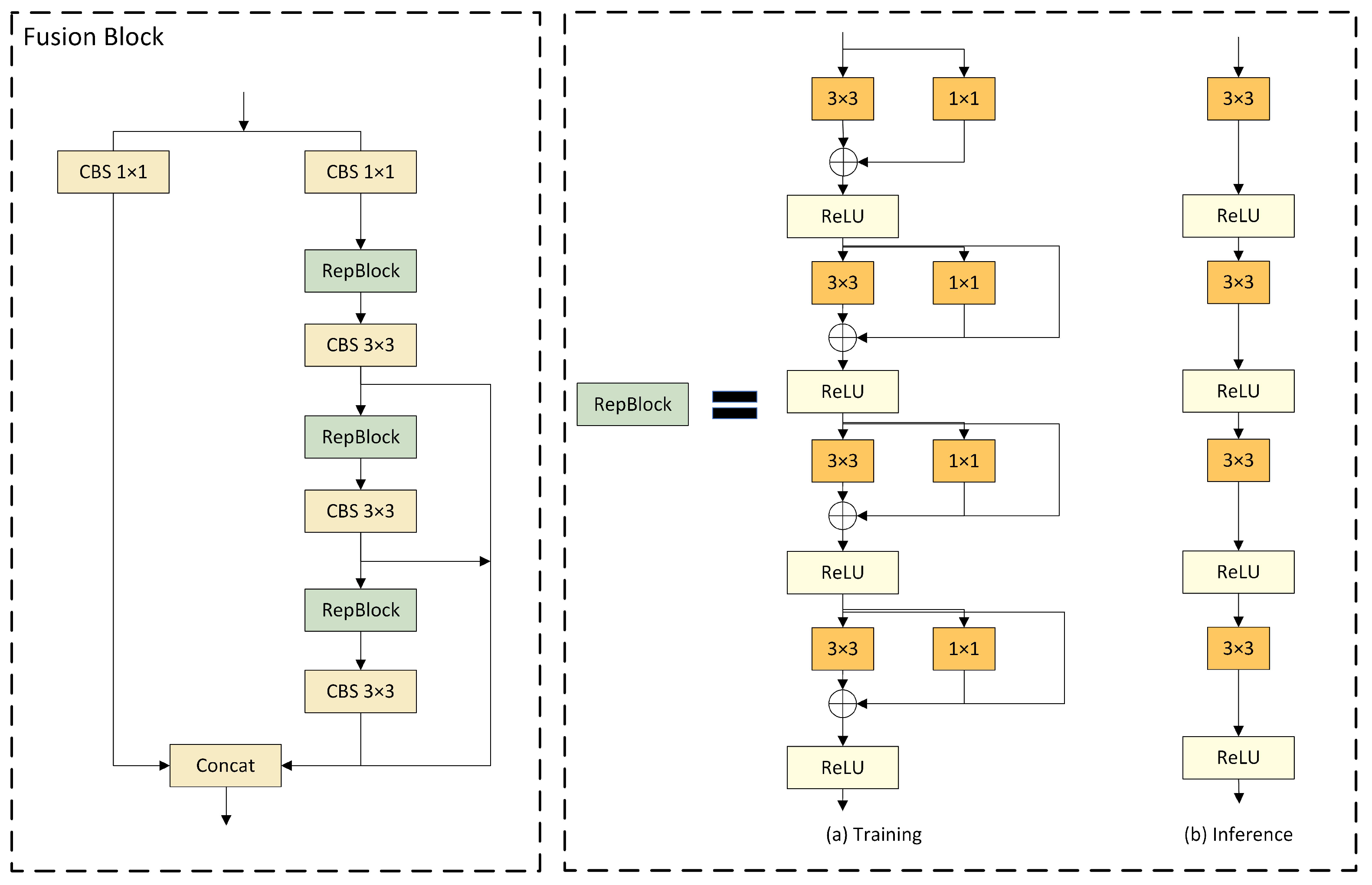
3.4. Fusion Block
DAMO-YOLO has improved the efficiency of node stacking operations and optimized feature fusion by introducing a specially designed fusion block. Inspired by this, we replaced the C2f module in the neck network with the fusion block to enhance the fusion capability for multi-scale features. As illustrated in
Figure 6, the architecture of the fusion block commences with channel number adjustment on two parallel branches through 1 × 1 CBS, followed by the incorporation of the concept of feature aggregation from the efficient layer aggregation network (ELAN) [
71] into the subsequent branch, composed of multiple RepBlocks and 3 × 3 CBS. This design leverages strategies such as CSPNet [
72], the reparameterization mechanism, and multi-layer aggregation to effectively promote rich gradient flow information at various levels. Furthermore, the introduction of the reparameterized convolutional module significantly enhances the performance.
Four gradient-path fusion blocks are utilized in the model, each splitting the input feature map into two streams. One stream is directly connected to the output, while the other undergoes channel reduction, cross-level edge processing, and convolutional reparameterization before further dividing into three gradient paths from this stream. Ultimately, all paths are merged into the output feature map. This design segments the gradient flow paths, introducing variability in the gradient information as it moves through the network, effectively facilitating a richer flow of gradient information.
As for
Figure 6, the RepBlock is designed to employ different network structures during the training and inference phases through the use of reparameterization techniques, thereby achieving efficient model training and rapid inference speeds [
73]. Following the recommendations of RepVGG, we optimized the parameter structure, clearly segregating the multi-branch used during the training phase from the single branch used during the inference phase. During the training process, the RepBlock adopts a complex structure containing multiple parallel branches, which extract features through 3 × 3 convolutions, 1 × 1 convolutions, and batch normalization (BN). This design is intended to enhance the representational capacity of the model. During inference, these multi-branch structures are converted into a single, more streamlined 3 × 3 convolutional layer through structural reparameterization, eliminating the branch structure to increase the inference speed and reduce the memory consumption of the model.
The conversion from a multi-branch to a single-branch architecture is primarily motivated by three considerations. Firstly, from the perspective of speed, the models reparameterized for inference demonstrate a significant acceleration in inference speed. This not only expedites the model inference process but also enhances the practicality of model deployment. Secondly, regarding memory consumption, the multi-branch model necessitates the allocation of memory individually for each branch to store its computational results, leading to substantial memory usage. Adopting a single-path model significantly reduces the demand for memory. Lastly, in terms of model flexibility, the multi-branch model is constrained by the requirement that the input and output channels for each branch remain consistent, posing challenges to model modification and optimization. In contrast, the single-path model is not subject to such limitations, thereby increasing the flexibility of model adjustments.
3.5. MPDIOU
Although they consider multiple factors, existing boundary box regression loss functions, such as CIoU, may still exhibit inaccurate localization and blurred boundary issues when dealing with complex scenarios where the target boundary information is unclear, affecting the regression accuracy. Given the intricate underwater environment and limited lighting conditions, the boundary information of target objects is often inadequate, posing challenges that prevent traditional loss functions from adapting effectively. Inspired by the geometric properties of a horizontal rectangle, Ma et al. [
33] designed a novel boundary box regression loss function based on the minimum point distance
. We incorporated this function, referred to as MPDIoU, into our model to evaluate the similarity between the predicted and ground truth boundary boxes. Compared to existing loss functions, MPDIoU not only better accommodates blurred boundary scenarios and enhances the object detection accuracy but also accelerates the model’s convergence and reduces the redundant computational overhead, thereby improving the localization and boundary precision for underwater organism detection.
The calculation process of MPDIoU is as follows. Assume that and represent the coordinates of the top-left and bottom-right points of the ground truth box, respectively, and and represent the coordinates of the top-left and bottom-right points of the predicted box, respectively. Parameters w and h represent the width and height of the input image, respectively. The formulas for the ground truth box and the predicted box are and , respectively.
Subsequently, the final
can be calculated using Equations (
5) and (
6) based on
and
.
The MPDIoU loss function optimizes the similarity measurement between two bounding boxes, enabling it to adapt to scenarios involving both overlapping and non-overlapping bounding box regression. Moreover, all components of the existing bounding box regression loss functions can be represented using four-point coordinates, as shown in Equations (
7)–(
9).
where
represents the area of the smallest bounding rectangle encompassing both the ground truth and predicted boxes. The center coordinates of the ground truth and predicted boxes are denoted by
and
, respectively, while their widths and heights are also represented. Through Equations (
7)–(
9), we can calculate the non-overlapping area, the distance between the center points, and the deviation in width and height. This method not only ensures comprehensiveness but also simplifies the computational process. Therefore, in the localization loss part of the YOLOv8-MU model, we choose to use the MPDIoU function to calculate the loss, to enhance the model’s localization accuracy and efficiency.















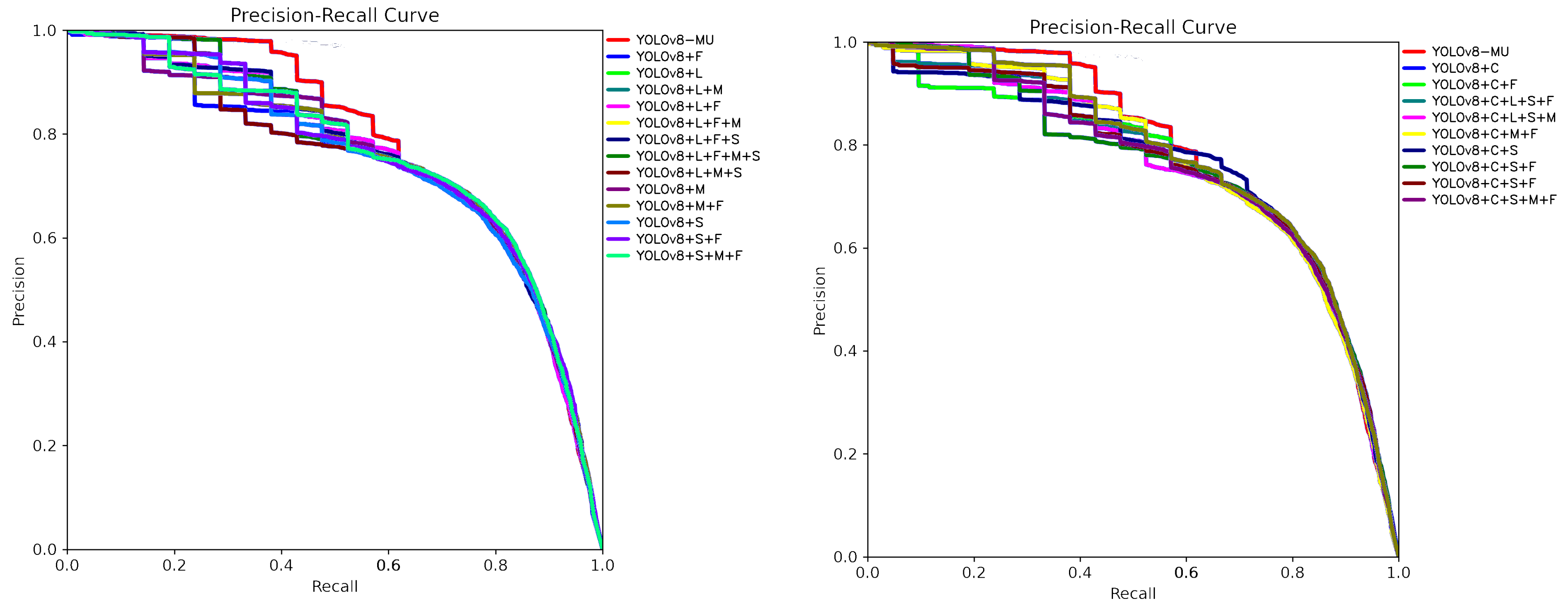

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}