Moving Object Detection in Freely Moving Camera via Global Motion Compensation and Local Spatial Information Fusion


Abstract
1. Introduction
- (1)
- (2)
- A novel method for local spatial information fusion is proposed, which utilizes several types of local spatial boundary information, to effectively handle challenges such as foreground false alarms, hollow foreground objects, and unclear contours.
- (3)
- An end-to-end MOD method is proposed through the collaborative work of the two modules mentioned above. The proposed approach is validated on three datasets, and a comparison is made with existing methods. The results show state-of-the-art performance and confirm the efficacy of the proposed method. Furthermore, the method covers a wide variety of camera motions, which increases its practical utility.
2. Related Works
2.1. Model-Based Algorithms
2.2. Motion-Based Algorithms
2.3. Hybrid Algorithms
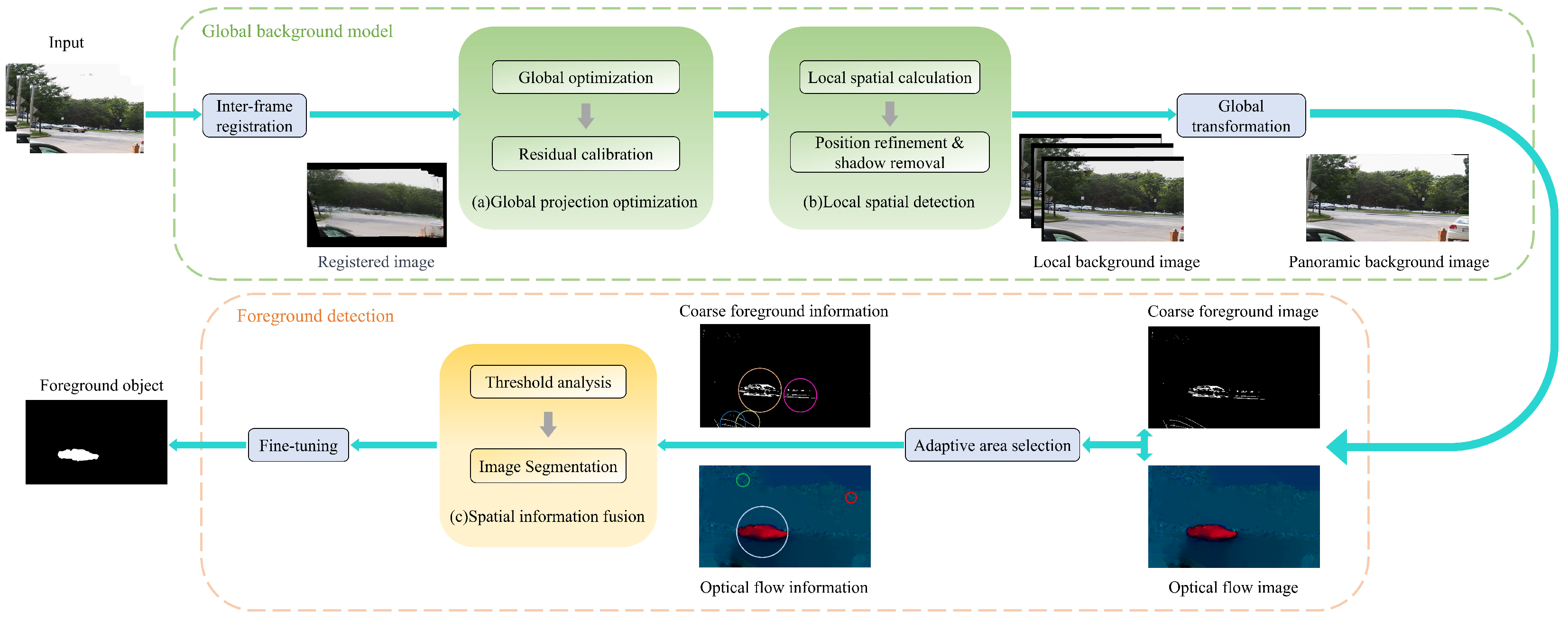
3. Method
3.1. Inter-Frame Registration
3.2. Global Projection Optimization
3.3. Local Spatial Detection
3.4. Spatial Information Fusion
4. Experiments
4.1. Dataset and Metrics
4.2. Experimental Analysis of MOD under Fixed and Jittered Cameras
4.2.1. Quantitative Analysis
4.2.2. Qualitative Analysis
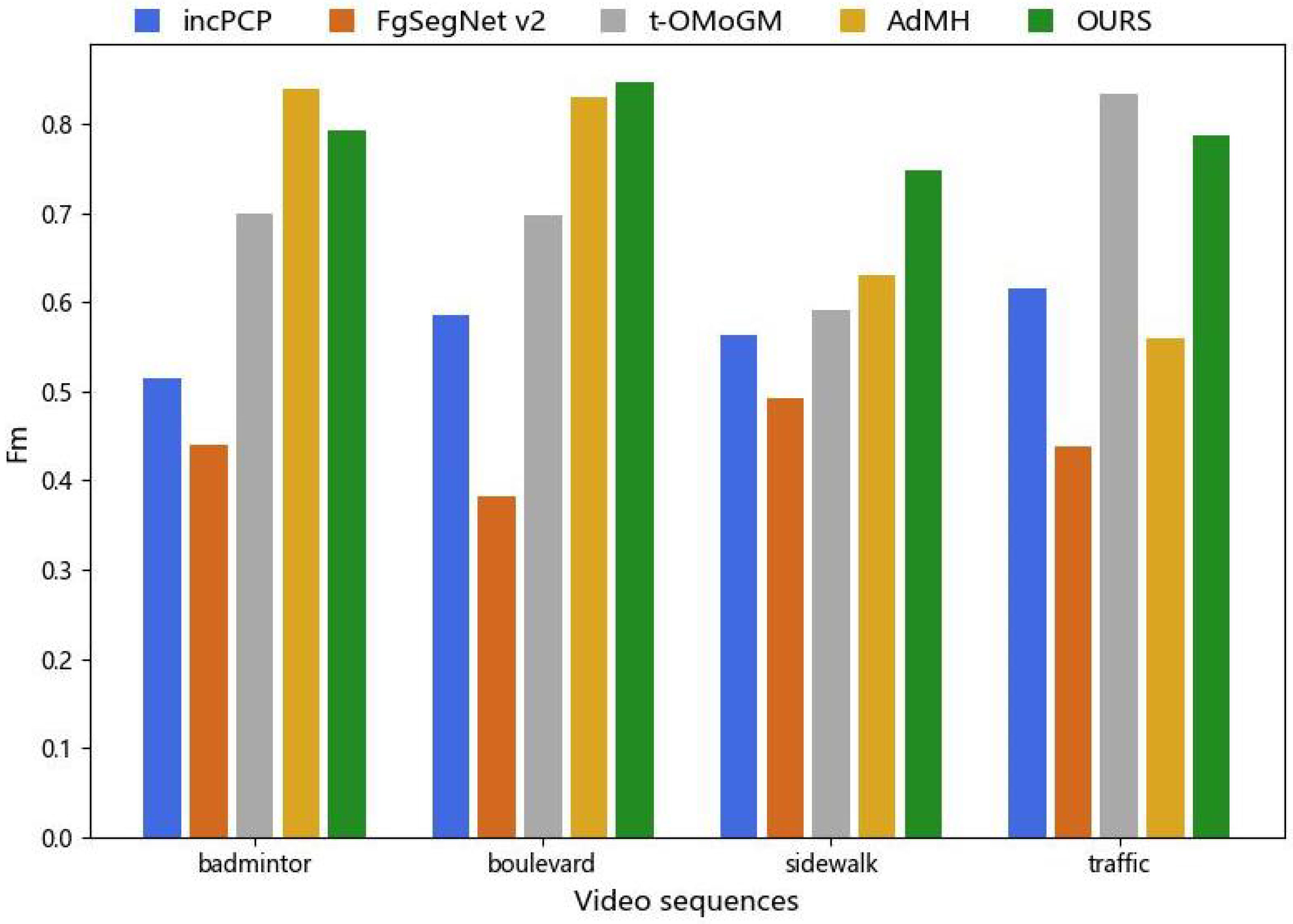
4.3. Experimental Analysis of MOD under Freely Moving Cameras
4.4. Analysis of Spatial Fusion Threshold and Ablation Study
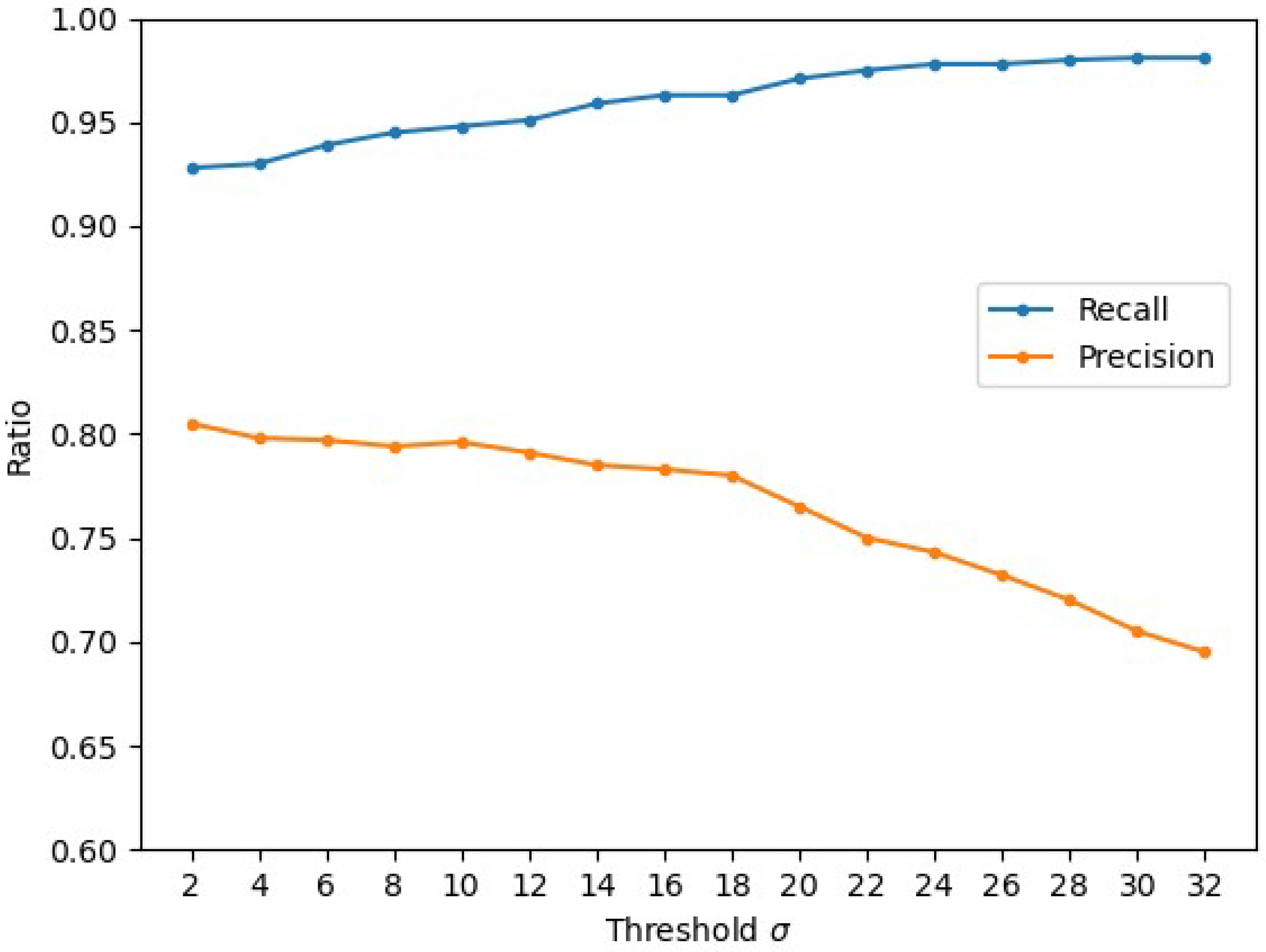
4.4.1. Analysis of Threshold for Spatial Information Fusion
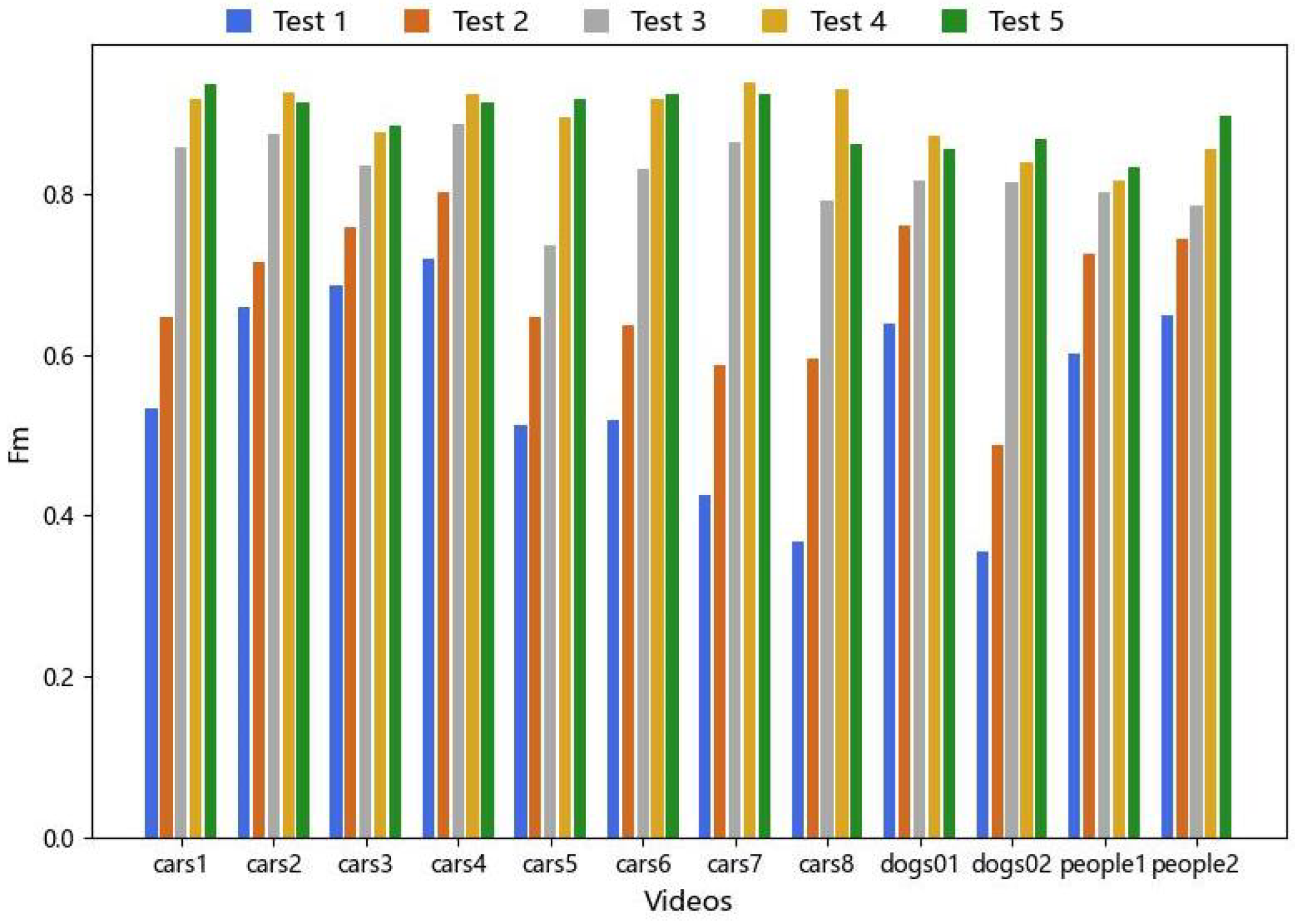
4.4.2. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chapel, M.N.; Bouwmans, T. Moving objects detection with a moving camera: A comprehensive review. Comput. Sci. Rev. 2020, 38, 100310. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Gu, S.; Ma, J.; Hui, G.; Xiao, Q.; Shi, W. STMT: Spatio-temporal memory transformer for multi-object tracking. Appl. Intell. 2023, 53, 23426–23441. [Google Scholar] [CrossRef]
- Bideau, P.; Learned-Miller, E. It’s moving! a probabilistic model for causal motion segmentation in moving camera videos. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 433–449. [Google Scholar]
- Yong, H.; Meng, D.; Zuo, W.; Zhang, L. Robust online matrix factorization for dynamic background subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1726–1740. [Google Scholar] [CrossRef]
- Montero, V.J.; Jung, W.Y.; Jeong, Y.J. Fast background subtraction with adaptive block learning using expectation value suitable for real-time moving object detection. J. Real-Time Image Process. 2021, 18, 967–981. [Google Scholar] [CrossRef]
- Rodriguez, P.; Wohlberg, B. Incremental principal component pursuit for video background modeling. J. Math. Imaging Vis. 2016, 55, 1–18. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, Y.; Zhang, K.; Wang, Q.; Li, X. Spatio-temporal online matrix factorization for multi-scale moving objects detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 743–757. [Google Scholar] [CrossRef]
- Işık, Ş.; Özkan, K.; Günal, S.; Gerek, Ö.N. SWCD: A sliding window and self-regulated learning-based background updating method for change detection in videos. J. Electron. Imaging 2018, 27, 023002. [Google Scholar] [CrossRef]
- He, W.; Li, W.; Zhang, G.; Tu, B.; Kim, Y.K.; Wu, J.; Qi, Q. Detection of moving objects using adaptive multi-feature histograms. J. Vis. Commun. Image Represent. 2021, 80, 103278. [Google Scholar] [CrossRef]
- Huang, Y.; Jiang, Q.; Qian, Y. A novel method for video moving object detection using improved independent component analysis. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2217–2230. [Google Scholar] [CrossRef]
- Delibasoglu, I. Real-time motion detection with candidate masks and region growing for moving cameras. J. Electron. Imaging 2021, 30, 063027. [Google Scholar] [CrossRef]
- Chen, C.; Song, J.; Peng, C.; Wang, G.; Fang, Y. A novel video salient object detection method via semisupervised motion quality perception. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2732–2745. [Google Scholar] [CrossRef]
- An, Y.; Zhao, X.; Yu, T.; Guo, H.; Zhao, C.; Tang, M.; Wang, J. ZBS: Zero-shot Background Subtraction via Instance-level Background Modeling and Foreground Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6355–6364. [Google Scholar]
- Mondal, A.; R, S.; Giraldo, J.H.; Bouwmans, T.; Chowdhury, A.S. Moving object detection for event-based vision using graph spectral clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 876–884. [Google Scholar]
- Giraldo, J.H.; Javed, S.; Werghi, N.; Bouwmans, T. Graph CNN for moving object detection in complex environments from unseen videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 225–233. [Google Scholar]
- Tezcan, O.; Ishwar, P.; Konrad, J. BSUV-Net: A fully-convolutional neural network for background subtraction of unseen videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2774–2783. [Google Scholar]
- Lim, L.A.; Keles, H.Y. Learning multi-scale features for foreground segmentation. Pattern Anal. Appl. 2020, 23, 1369–1380. [Google Scholar] [CrossRef]
- He, J.; Zhang, D.; Balzano, L.; Tao, T. Iterative Grassmannian optimization for robust image alignment. Image Vis. Comput. 2014, 32, 800–813. [Google Scholar] [CrossRef]
- Eltantawy, A.; Shehata, M.S. An accelerated sequential PCP-based method for ground-moving objects detection from aerial videos. IEEE Trans. Image Process. 2019, 28, 5991–6006. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, X.; Li, Y.; Wei, Y.; Ye, L. Enhanced semantic feature pyramid network for small object detection. Signal Process. Image Commun. 2023, 113, 116919. [Google Scholar] [CrossRef]
- Shakeri, M.; Zhang, H. Moving object detection under discontinuous change in illumination using tensor low-rank and invariant sparse decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7221–7230. [Google Scholar]
- Sahoo, S.; Nanda, P.K. Adaptive feature fusion and spatio-temporal background modeling in KDE framework for object detection and shadow removal. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1103–1118. [Google Scholar] [CrossRef]
- Moore, B.E.; Gao, C.; Nadakuditi, R.R. Panoramic robust pca for foreground–background separation on noisy, free-motion camera video. IEEE Trans. Comput. Imaging 2019, 5, 195–211. [Google Scholar] [CrossRef]
- Nakaya, Y.; Harashima, H. Motion compensation based on spatial transformations. IEEE Trans. Circuits Syst. Video Technol. 1994, 4, 339–356. [Google Scholar] [CrossRef]
- Liu, F.; Gleicher, M. Learning color and locality cues for moving object detection and segmentation. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 320–327. [Google Scholar]
- Zamalieva, D.; Yilmaz, A.; Davis, J.W. A multi-transformational model for background subtraction with moving cameras. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 803–817. [Google Scholar]
- Lezki, H.; Ahu Ozturk, I.; Akif Akpinar, M.; Kerim Yucel, M.; Berker Logoglu, K.; Erdem, A.; Erdem, E. Joint exploitation of features and optical flow for real-time moving object detection on drones. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8 September 2018. [Google Scholar]
- Beauchemin, S.S.; Barron, J.L. The computation of optical flow. ACM Comput. Surv. (CSUR) 1995, 27, 433–466. [Google Scholar] [CrossRef]
- Shen, J.; Peng, J.; Shao, L. Submodular trajectories for better motion segmentation in videos. IEEE Trans. Image Process. 2018, 27, 2688–2700. [Google Scholar] [CrossRef]
- Sugimura, D.; Teshima, F.; Hamamoto, T. Online background subtraction with freely moving cameras using different motion boundaries. Image Vis. Comput. 2018, 76, 76–92. [Google Scholar] [CrossRef]
- Rosen, D.M.; Carlone, L.; Bandeira, A.S.; Leonard, J.J. SE-Sync: A certifiably correct algorithm for synchronization over the special Euclidean group. Int. J. Robot. Res. 2019, 38, 95–125. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Zhang, W.; Sun, X.; Yu, Q. Moving object detection under a moving camera via background orientation reconstruction. Sensors 2020, 20, 3103. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Wright, J.; Candes, E.; Ma, Y. Stable principal component pursuit. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1518–1522. [Google Scholar]
- Yu, Y.; Kurnianggoro, L.; Jo, K.H. Moving object detection for a moving camera based on global motion compensation and adaptive background model. Int. J. Control. Autom. Syst. 2019, 17, 1866–1874. [Google Scholar] [CrossRef]
- Chelly, I.; Winter, V.; Litvak, D.; Rosen, D.; Freifeld, O. JA-POLS: A moving-camera background model via joint alignment and partially-overlapping local subspaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12585–12594. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM (JACM) 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Cui, X.; Huang, J.; Zhang, S.; Metaxas, D.N. Background subtraction using low rank and group sparsity constraints. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part I 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 612–625. [Google Scholar]
- Ochs, P.; Malik, J.; Brox, T. Segmentation of moving objects by long term video analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1187–1200. [Google Scholar] [CrossRef]
- Keuper, M.; Andres, B.; Brox, T. Motion trajectory segmentation via minimum cost multicuts. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3271–3279. [Google Scholar]
- Mandal, M.; Kumar, L.K.; Vipparthi, S.K. Mor-uav: A benchmark dataset and baselines for moving object recognition in uav videos. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2626–2635. [Google Scholar]
- Elqursh, A.; Elgammal, A. Online moving camera background subtraction. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part VI 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 228–241. [Google Scholar]
- Zhang, W.; Sun, X.; Yu, Q. Accurate moving object segmentation in unconstraint videos based on robust seed pixels selection. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420947273. [Google Scholar] [CrossRef]
- Singh, S.; Deshmukh, S.V.; Sarkar, M.; Krishnamurthy, B. LOCATE: Self-supervised Object Discovery via Flow-guided Graph-cut and Bootstrapped Self-training. In Proceedings of the 34th British Machine Vision Conference 2023, BMVC 2023, Aberdeen, UK, 20–24 November 2023; BMVA: London, UK, 2023. [Google Scholar]
- Dave, A.; Tokmakov, P.; Ramanan, D. Towards segmenting anything that moves. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Zhang, J.; Xu, C.; Gao, Z.; Rodrigues, J.J.; de Albuquerque, V.H.C. Industrial pervasive edge computing-based intelligence IoT for surveillance saliency detection. IEEE Trans. Ind. Inform. 2020, 17, 5012–5020. [Google Scholar] [CrossRef]
- Liu, J.; Wang, J.; Wang, W.; Su, Y. DS-Net: Dynamic spatiotemporal network for video salient object detection. Digit. Signal Process. 2022, 130, 103700. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, L.; Wang, Z.; Liu, Y.; Cheng, M.M.; Lu, S.P. Pyramid constrained self-attention network for fast video salient object detection. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10869–10876. [Google Scholar] [CrossRef]
- Zhang, Y.P.; Chan, K.L. Saliency detection with moving camera via background model completion. Sensors 2021, 21, 8374. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Lai, J.; Wang, G.; Zhou, H. Confidence-guided adaptive gate and dual differential enhancement for video salient object detection. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Dong, G.; Zhao, C.; Pan, X.; Basu, A. Learning Temporal Distribution and Spatial Correlation Towards Universal Moving Object Segmentation. IEEE Trans. Image Process. 2024, 33, 2447–2461. [Google Scholar] [CrossRef] [PubMed]
- Delibaşoğlu, İ. Moving object detection method with motion regions tracking in background subtraction. Signal Image Video Process. 2023, 17, 2415–2423. [Google Scholar] [CrossRef]
- Cui, Z.; Jiang, K.; Wang, T. Unsupervised Moving Object Segmentation from Stationary or Moving Camera Based on Multi-frame Homography Constraints. Sensors 2019, 19, 4344. [Google Scholar] [CrossRef]
- Sajid, H.; Cheung, S.C.S.; Jacobs, N. Motion and appearance based background subtraction for freely moving cameras. Signal Process. Image Commun. 2019, 75, 11–21. [Google Scholar] [CrossRef]
- Makino, K.; Shibata, T.; Yachida, S.; Ogawa, T.; Takahashi, K. Moving-object detection method for moving cameras by merging background subtraction and optical flow methods. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 383–387. [Google Scholar]
- Zhu, Y.; Elgammal, A. A multilayer-based framework for online background subtraction with freely moving cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5132–5141. [Google Scholar]
- Zhao, C.; Sain, A.; Qu, Y.; Ge, Y.; Hu, H. Background subtraction based on integration of alternative cues in freely moving camera. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1933–1945. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. Lect. Notes Comput. Sci. 2006, 3951, 404–417. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Detlefsen, N.S.; Freifeld, O.; Hauberg, S. Deep diffeomorphic transformer networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4403–4412. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. In Foundations and Trends® in Machine Learning; Stanford University: Stanford, CA, USA, 2011; Volume 3, pp. 1–122. [Google Scholar]
- Peng, Z.; Qu, S.; Li, Q. Interactive image segmentation using geodesic appearance overlap graph cut. Signal Process. Image Commun. 2019, 78, 159–170. [Google Scholar] [CrossRef]
- Deshpande, A.; Dahikar, P.; Agrawal, P. An Experiment with Random Walks and GrabCut in One Cut Interactive Image Segmentation Techniques on MRI Images. In Computational Vision and Bio-Inspired Computing: ICCVBIC 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 993–1008. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Goyette, N.; Jodoin, P.M.; Porikli, F.; Konrad, J.; Ishwar, P. A novel video dataset for change detection benchmarking. IEEE Trans. Image Process. 2014, 23, 4663–4679. [Google Scholar] [CrossRef] [PubMed]
- Narayana, M.; Hanson, A.; Learned-Miller, E. Coherent motion segmentation in moving camera videos using optical flow orientations. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1577–1584. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Videos | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BW | BL | CJ | DB | IOM | LF | NV | PTZ | SH | TH | TU | Overall | |
| incPCP [7] | 0.7324 | 0.8287 | 0.5684 | 0.6844 | 0.5691 | 0.5767 | 0.4736 | 0.6514 | 0.7154 | 0.7436 | 0.6247 | 0.6524 |
| SWCD [9] | 0.8233 | 0.9214 | 0.7411 | 0.8645 | 0.7092 | 0.7374 | 0.5807 | 0.4545 | 0.8779 | 0.8581 | 0.7735 | 0.7583 |
| AdMH [10] | 0.5600 | 0.7900 | 0.7150 | 0.7750 | 0.4900 | 0.4500 | 0.2600 | 0.0900 | 0.6900 | 0.6900 | 0.6325 | 0.5584 |
| FBS-ABL [6] | 0.8106 | 0.8649 | 0.5298 | 0.7424 | 0.7232 | 0.6328 | 0.5272 | 0.3267 | 0.8671 | 0.6619 | 0.5564 | 0.6585 |
| t-OMoGM [5] | 0.7649 | 0.8027 | 0.7060 | 0.7126 | 0.7348 | 0.7418 | 0.5413 | 0.5843 | 0.6143 | 0.7346 | 0.5466 | 0.6789 |
| FgSegNet v2 [18] | 0.3277 | 0.6926 | 0.4266 | 0.3634 | 0.2002 | 0.2482 | 0.2800 | 0.3503 | 0.5295 | 0.6038 | 0.0643 | 0.3715 |
| BSUV-Net [17] | 0.8713 | 0.9693 | 0.7743 | 0.7967 | 0.7499 | 0.6797 | 0.6987 | 0.6282 | 0.9233 | 0.8581 | 0.7051 | 0.7868 |
| OURS | 0.8873 | 0.8724 | 0.7962 | 0.8759 | 0.6751 | 0.7618 | 0.6584 | 0.8032 | 0.9376 | 0.7791 | 0.7825 | 0.8027 |
| Methods | Videos | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cars1 | cars2 | cars3 | cars4 | cars5 | cars6 | cars7 | cars8 | dogs01 | dogs02 | people1 | people2 | Overall | |
| MLBS [57] | 0.9204 | 0.9016 | 0.9316 | 0.9155 | 0.8662 | 0.9223 | 0.9117 | 0.8593 | 0.8200 | 0.8200 | 0.8138 | 0.9434 | 0.8855 |
| IFB [58] | 0.6700 | 0.8167 | 0.6900 | 0.8267 | 0.7333 | 0.6267 | 0.7482 | 0.7103 | 0.7837 | 0.9200 | 0.5626 | 0.7315 | 0.7350 |
| JA-POLS [37] | 0.5325 | 0.6587 | 0.6851 | 0.7189 | 0.5126 | 0.5178 | 0.4548 | 0.3671 | 0.6376 | 0.3149 | 0.6012 | 0.6493 | 0.5542 |
| Sugimura [31] | 0.9010 | 0.9020 | 0.9550 | 0.8740 | 0.9090 | 0.8790 | 0.9150 | 0.9210 | 0.8143 | 0.8285 | 0.8020 | 0.8820 | 0.8819 |
| CAG-DDE [51] | 0.9312 | 0.9186 | 0.6605 | 0.9110 | 0.4358 | 0.8634 | 0.8946 | 0.9371 | 0.8154 | 0.8146 | 0.8738 | 0.8454 | 0.8251 |
| DS-Net [48] | 0.8922 | 0.7268 | 0.4965 | 0.9089 | 0.9154 | 0.8639 | 0.9146 | 0.8814 | 0.7548 | 0.8459 | 0.9074 | 0.8154 | 0.8269 |
| LOCATE [45] | 0.8742 | 0.7589 | 0.8473 | 0.6146 | 0.9018 | 0.8356 | 0.8842 | 0.8174 | 0.7732 | 0.7958 | 0.8092 | 0.8467 | 0.8132 |
| LTS [52] | 0.7598 | 0.5178 | 0.6734 | 0.5489 | 0.8067 | 0.7256 | 0.5874 | 0.6793 | 0.7421 | 0.7972 | 0.8126 | 0.8298 | 0.7067 |
| OURS | 0.9359 | 0.9225 | 0.8846 | 0.9231 | 0.9168 | 0.9384 | 0.9389 | 0.9293 | 0.8530 | 0.8661 | 0.8358 | 0.8965 | 0.9034 |
| Methods | Videos | |||||
|---|---|---|---|---|---|---|
| Drive | Forest | Parking | Store | Traffic | Overall | |
| MLBS [57] | 0.6595 | 0.7220 | 0.8366 | 0.8628 | 0.4819 | 0.7126 |
| JA-POLS [37] | 0.2101 | 0.1584 | 0.1456 | 0.2876 | 0.3487 | 0.2301 |
| Sugimura [31] | 0.8880 | 0.8300 | 0.8110 | 0.7590 | 0.5580 | 0.7690 |
| CAG-DDE [51] | 0.0765 | 0.8507 | 0.4123 | 0.2458 | 0.5714 | 0.4313 |
| DS-Net [48] | 0.2654 | 0.8546 | 0.1769 | 0.1137 | 0.0624 | 0.2946 |
| LOCATE [45] | 0.6813 | 0.7139 | 0.4661 | 0.6764 | 0.5312 | 0.6138 |
| LTS [52] | 0.3488 | 0.6795 | 0.2746 | 0.5163 | 0.3867 | 0.4224 |
| OURS | 0.7968 | 0.8159 | 0.8566 | 0.8743 | 0.6381 | 0.7963 |
| Method | GraphCut [63] | OneCut [64] | GrabCut [65] | MLBS [57] | JA-POLS [37] | Sugimura [31] | LOCATE [45] |
| Time (ms) | 7101.96 | 1369.52 | 2847.61 | 6856.73 | 16,913.64 | 5178.46 | 411.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhao, R.; Guo, X.; Xie, J.; Han, X. Moving Object Detection in Freely Moving Camera via Global Motion Compensation and Local Spatial Information Fusion. Sensors 2024, 24, 2859. https://doi.org/10.3390/s24092859
Chen Z, Zhao R, Guo X, Xie J, Han X. Moving Object Detection in Freely Moving Camera via Global Motion Compensation and Local Spatial Information Fusion. Sensors. 2024; 24(9):2859. https://doi.org/10.3390/s24092859
Chicago/Turabian StyleChen, Zhongyu, Rong Zhao, Xindong Guo, Jianbin Xie, and Xie Han. 2024. "Moving Object Detection in Freely Moving Camera via Global Motion Compensation and Local Spatial Information Fusion" Sensors 24, no. 9: 2859. https://doi.org/10.3390/s24092859
APA StyleChen, Z., Zhao, R., Guo, X., Xie, J., & Han, X. (2024). Moving Object Detection in Freely Moving Camera via Global Motion Compensation and Local Spatial Information Fusion. Sensors, 24(9), 2859. https://doi.org/10.3390/s24092859