Abstract
For direction-of-arrival (DOA) estimation problems in a sparse domain, sparse Bayesian learning (SBL) is highly favored by researchers owing to its excellent estimation performance. However, traditional SBL-based methods always assign Gaussian priors to parameters to be solved, leading to moderate sparse signal recovery (SSR) effects. The reason is Gaussian priors play a similar role to regularization in sparsity constraint. Therefore, numerous methods are developed by adopting hierarchical priors that are used to perform better than Gaussian priors. However, these methods are in straitened circumstances when multiple measurement vector (MMV) data are adopted. On this basis, a block-sparse SBL method (named BSBL) is developed to handle DOA estimation problems in MMV models. The novelty of BSBL is the combination of hierarchical priors and block-sparse model originating from MMV data. Therefore, on the one hand, BSBL transfers the MMV model to a block-sparse model by vectorization so that Bayesian learning is directly performed, regardless of the prior independent assumption of different measurement vectors and the inconvenience caused by the solution of matrix form. On the other hand, BSBL inherited the advantage of hierarchical priors for better SSR ability. Despite the benefit, BSBL still has the disadvantage of relatively large computation complexity caused by high dimensional matrix operations. In view of this, two operations are implemented for low complexity. One is reducing the matrix dimension of BSBL by approximation, generating a method named BSBL-APPR, and the other is embedding the generalized approximate message passing (GAMB) technique into BSBL so as to decompose matrix operations into vector or scale operations, named BSBL-GAMP. Moreover, BSBL is able to suppress temporal correlation and handle wideband sources easily. Extensive simulation results are presented to prove the superiority of BSBL over other state-of-the-art algorithms.
1. Introduction
DOA estimation has advanced obviously due to several technique leaps in the last four decades, and the attained achievements are widely applied to communications, radar, sonar, and navigation. To be specific in communication [,], DOA estimation is essential in channel estimation, wireless communications, microphone localization, vehicular communications [], Reconfigurable Intelligent Surfaces (RIS), and corresponding research focuses, including the RIS-based vehicle DOA estimation method [,,].
Among the technique leaps in DOA estimation, compressed sensing (CS) and sparse recovery (SR) have played important roles in the last decade [,]. Compared with traditional algorithms based on beamforming or subspace techniques [,,,,], sparsity-based estimators have achieved technique leaps since CS and SR can mitigate the requirements for high signal-to-noise ratios (SNRs) and abundant snapshots []. Moreover, it has been proven that sparsity-based estimators have remarkable advantages, such as good robustness to correlation and high estimation accuracy.
In recent years, relevant studies on DOA estimation mainly focus on sparse array configuration [,,] or sparsity-based method innovation [,]. For the latter, three categories can be summarized out of massive documents. (i) The first is based on norm optimization [,,,,,,,,], (ii) the second is exploiting basis pursuit [,], and (iii), and the third is utilizing sparse Bayesian learning (SBL) [,,,,,,,,,,,,,,,,]. In particular, SBL-based methods are popular and highly favored owing to incomparable comprehensive performance beyond both norm optimization and basis pursuit [].
From a Bayesian perspective, sparse Bayesian learning is a probabilistic method that achieves -norm minimization by assigning sparse priors to the signal of interests for sparse signal recovery (SSR). In the single measurement vector (SMV) model, SBL can retain a desirable property of the -norm diversity measure, i.e., the global minimum is achieved at the maximally sparse solution [] and produced a more limited constellation of local minima. In practice, the most used is the MMV model, so MSBL is developed []. Theoretically, in [], the adopted empirical Bayesian prior plays an important role in estimating a convenient posterior distribution over candidate basis vectors based on the concept of automatic relevance determination. That implies that the used priors assigned to signals of interest can enforce a common sparsity profile and consistently place the prominent posterior mass on the appropriate region for sparse recovery. In other words, the adopted priors dominate the sparsity performance of SBL and indicate the ability to carry out -norm minimization. Despite this, it is still unclear which prior is the best for sparse recovery, but a hierarchical Bayesian framework representing Laplace priors has been proven to be prominent in []. Therefore, hierarchical priors are widely attractive, and many corresponding works are developed and presented. For instance, hierarchical synthesis lasso (HSL) priors for representing the same small subset of features are created for enforcing a proper sparsity profile of signal vectors [], and hierarchical priors are adopted to consider unknown mutual coupling and off-grid errors. No matter how hierarchical priors are used, SBL has to face the difficulty caused by the MMV model. To be specific, SBL needs prior assumption, i.e., the uncorrelation between different measurement vectors, while the assumption may not be satisfied in practice. Moreover, the solution of matrix form is not always easy to handle and is even prohibitive due to the large complexity during the learning process. On this basis, vectorizing the MMV model seems to be an optimal selection since the solution can be transformed into the vector form. A successful realization is developed in [], and the used block-sparse model indeed contributes much to the whole designed algorithm, although the main focus is the real-valued transformation. Regretfully, that work adopts Gaussian priors rather than hierarchical priors, so its sparsity performance is bound to be limited, no matter how impressive and excellent the running efficiency is. Recently, there have been a few documents that show the combination of SBL and deep learning (DL) [,], attracting widespread attention among numerous researchers. With big data and artificial intelligence, DL gradually arises and applies to image processing, signal processing, classification, recognition, etc. The obvious advantages of DL are its adaptability to complicated practical cases and its high running efficiency. In signal processing, many researchers use derived iterative processes to design corresponding neural networks so that the proposed algorithms operate with low complexity burdens, and the designed networks are named deep unrolled neural networks. For example, an SBL-based algorithm is unfolded into a layer-wise structure with a set of introduced trainable parameters in [], which is beneficial for channel estimation. In addition, a model-driven DL detector is developed based on variational Bayesian inference in []. Based on deep unrolled networks, the detector is able to capture channel features that may be important but neglected by model-based methods, including SBL-based methods. Although the algorithms based on both SBL and DL are not applied to DOA estimation, the disadvantages lie in the inexplicability caused by data-driven DL techniques. In fact, the lack of theoretical guarantee is always constraining the development and application of DL. Collectively, SBL-based methods face a conflict between prominent sparsity performance achieved by hierarchical priors with low computational complexity. Methods based on both SBL and DL are pending further development, especially in theoretical explicability.
In this paper, we creatively solve the contradiction between sparsity performance with complexity burdens in SBL-based methods. On the one hand, hierarchical priors are still adopted to indirectly enhance sparsity. On the other hand, the increased complexity essentially caused by the hierarchical priors in MMV models is tactfully reduced by two operations based on the transformed block-sparse model. In fact, the balance of both sparsity and complexity is the main innovation point in this paper. Not only that, but the block-sparse model provides great convenience for complexity reduction by decreasing matrix dimensions in terms of matrix operation properties, and hierarchical priors create an opportunity to embed the generalized approximate message passing (GAMB) technique for solving marginal distributions so as to reduce complexity greatly.
To be specific, as the thick and inevitable MMV model restricts the SBL to some extent, we directly vectorize the MMV model, resulting in a block-sparse model that is convenient to carry out Bayesian learning. Unluckily, the vectorization expands the model dimensions, leading to large complexity in later Bayesian learning. Despite this, block-sparse Bayesian learning, named BSBL, is still analytically derived and developed. Moreover, it is worth noting that the complexity of BSBL is reluctantly acceptable owing to our reasonable design of the iterative process. In order to further achieve complexity reduction, two operations are introduced. One is based on matrix operation properties to decrease the matrix dimensions. Specifically, we analyze the complexity of each iterative formula and select the one containing operations of large computation burdens. Later, the selected formulas of BSBL are simplified and approximated by terms of operational properties of Kronecker products and some reasonable preconditions, so the faster version is named BSBL-APPR. The other is based on the famous generalized approximate message passing (GAMB) technique. GAMP is developed to solve approximate marginal posteriors, which are exactly applicable in BSBL since BSBL is derived by iterative hyperparameters originating from marginal distributions. Therefore, the GAMP technique is able to be embedded into BSBL, and the only additional work is to derive the iterative process of GAMP so that GAMP is useful in our block-sparse model. Moreover, GAMP is able to decompose the high dimensional matrix operations into vector or scale operations, which achieves complexity reduction well. BSBL with embedded GAMP is named BSBL-GAMP. In addition, many SBL-based methods consider little about the intractable wideband cases. Since wideband sources are able to be regarded as a superposition of many narrowband sources, we extend the proposed BSBL to wideband cases. The whole algorithm for wideband cases is derived and finished. Last but not least, the temporal correlation, which is not often considered in SBL, is modeled in the block-sparse model. Therefore, all the above methods are able to suppress temporal correlation.
In summary, the contributions of this paper are as follows:
- Hierarchical priors are adopted to enhance sparsity, and a block-sparse model is generated to carry out Bayesian learning easily. Hierarchical priors play an important role in -norm optimization and outperform Gaussian priors in sparsity constraint, indirectly resulting in better sparsity performance. In the MMV case, the equivalently transformed block-sparse model laid a foundation for complexity reduction. Combining hierarchical priors with the block-sparse model allows for the balance of sparsity and complexity;
- Two operations are created to reduce complexity based on the block-sparse model. One exploits matrix operation properties to approximate high-dimension operations of derived formulas in the iterative process, while the other leverages the GAMP technique to simplify the iteration for computing marginal distributions, so that the matrix operations are decomposed into vector or scale operations;
- For wideband sources appearing in practice, the proposed BSBL is extended to be applicable in terms of the decomposition of wideband signals into narrowband ones. Moreover, the temporal correlation is considered by introducing a temporally correlated matrix into our data model. The designed iterative process of BSBL is able to be robust to temporal correlation.
The rest of this paper is organized as follows. In Section 2, the DOA estimation problem is abstracted from radar detection. Furthermore, the DOA estimation is equivalently transformed into an SSR problem based on the exploited block-sparse model. In Section 3, the traditional SBL based on our model is briefly introduced and derived, and, its defects are presented by simple analysis. In Section 4, the proposed BSBL, BSBL-APPR, BSBL-GAMP, and BSBL for wideband cases are analytically derived, and corresponding iterative processes are presented. In Section 5, the performance of the proposed methods is evaluated comprehensively. In Section 6, conclusions are drawn.
For the sake of convenience, the notations are listed in Table 1.

Table 1.
List of notations.
2. Problem Reformulation
In radar or sonar detection, for communication, localization, and navigation, the antenna array receiver can receive different signals from various directions. Taking far-field radar detection as an example, adjacent antenna sensors have the same phase difference due to the plane electromagnetic wave if every adjacent couple has the same distance. Thus, a steer vector can be abstracted as . is the direction of the source signal. is the wavelength. is the distance between adjacent sensors. is the number of sensors. For all the sources from different directions , a steer matrix is yielded as . is vital in DOA estimation because it implies the directions of all the sources based on the whole antenna array composed of sensors. Radio frequency signals were received by an antenna array, whose sensors transfer individually received signals to independent channels, in which down conversion is conducted to produce intermediate-frequency signals, i.e., baseband signals. Later, using prior signals to execute matched filtering at time , the receiver can gain a complex reflection factor of all the sources, i.e., . and are the products of complex reflection coefficients and Doppler shifts. Generally, radar takes pulse accumulation to enhance signal processing ability when the echo pulses are in the same coherent processing interval (CPI), in which little fluctuation happens between different originally received signals and processed signals. In other words, sources are motionless, and the processing signals are nearly consistent during a CPI. Last but not least, the noises of channels in a CPI are indispensable and assumed to be mutually independent. Overall, the above entire process is briefly shown in Figure 1, where the signal model is expressed as
where is the ideal data of channels in a CPI containing snapshots. is the complex reflection factor matrix of the K sources in a CPI. is the assumed noise matrix with each entry obeying an i.i.d. Gaussian distribution denoted as .
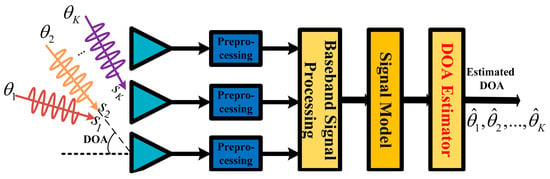
Figure 1.
Flowchart of radar signal processing for DOA estimation.
Let be M-grid sampling that covers spatial range . If sources are located on the grid exactly, (1) can be transformed into a sparse model expressed as
where is the sparsely extended manifold matrix with the angle set generated by the M-grid sampling. As holds in most cases, is the zero-padding version of , with each row representing a potential source that maps the M-grid spatial angular sampling.
Patently, processed data in a CPI are equivalently transformed into (2), which are typically sparse data in the MMV model. Now, the objective is to solute the sparse with known data and steer matrix . It is worth emphasizing two mainstream methods to handle (2). One is dealing with (2) directly, which is more difficult but has less computational complexity. The other is solving the vectorization (2), which is simple and intuitive but has large complexity caused by the vectorization. In this paper, the latter is selected because we are able to reduce the complexity tactfully. Without loss of generality, (2) is vectorized as
where , , , and . After the vectorization, a block-sparse vector is yielded since the original contains many zero rows. In addition, the matrix dimensions grow after the vectorization, leading to large complexity, but the problem will be solved by our approximation eventually. Based on the block-sparse model shown in (3), the DOA estimation is transformed into a sparse recovery problem, i.e., to solve with known and .
3. Canonical SBL Method
To solve in (3), the canonical SBL method is introduced and briefly shown as follows. According to (3), the likelihood is
The prior of p is supposed to be
where is a hyperparameter representing a potential source, and is expressed as
Based on the Bayesian formula, the posterior of p is
The posterior of (7) is rigorously solved as a Gaussian distribution with mean and covariance as follows:
The likelihood, prior, and posterior are uniquely determined by the hyperparameter set . According to the maximum a posterior (MAP) criterion, the Expectation–Maximization (EM) algorithm [] is used to maximize . Here, is treated as a hidden variable to obtain the relationship between the hyperparameter set (i.e., ) and the old one (i.e., ) by maximizing the following term.
Omitting the specific derivation, the final iteration solutions of the hyperparameters are expressed as
where and .
The canonical SBL algorithm uses (8), (9), (11), and (12) iteratively to estimate until convergence, and the final is regarded as the solved . However, recalling the whole process, two limitations are present: (i) the single Gaussian priors cannot enhance sparsity well and (ii) the computational complexity , dominated by (12), is usually unacceptable in practice. Consequently, we develop an SBL-based method to resolve (3) in this paper.
4. Proposed Methods
4.1. BSBL
Without loss of generality, the SBL-based methods are required to construct a Bayesian framework and then complete the corresponding Bayesian inference to develop an iterative algorithm.
4.1.1. Bayesian Framework
Bayesian framework is composed of prior distributions of observed data and unknown variables.
Remark 1.
According to the MAP criterion, priors are essential for SBL-based methods because the iterative process to be constructed is based on the derivatives of different variables so as to ensure the maximal posterior. Therefore, the prior distributions need to be clarified first.
In this paper, the prior distribution (i.e., likelihood) of the observed data is similar to (4), i.e.,
For better sparsity performance, we propose hierarchical priors containing Gaussian and Gamma priors. The reason for selecting Gamma priors is that the Gamma distribution is the conjugate prior to the inverse variance of the Gaussian distribution []. As usual, the prior obeys the i.i.d. complex Gaussian distribution, i.e.,
where , , and . Note that representing temporally correlated level is not equal to in the canonical SBL method. Therefore, the proposed method will be able to suppress temporal correlation, which will be tested and verified in Section 5. is generally modeled as a Toeplitz matrix, i.e.,
where is the complex correlation coefficient with the amplitude and phase .
obeys a Gamma distribution, i.e.,
where . and are the shape parameter and scale parameter. Then, a Gamma prior is applied to so that
where and are the corresponding shape and scale parameters, respectively.
It is worth emphasizing that the true prior distribution of can be solved with Student’s t-distribution, which promotes sparsity better than the traditional Gaussian distribution [].
4.1.2. Bayesian Inference
Bayesian inference is necessary for the eventual iterative algorithm, and the crux is to deduce the posterior. Unfortunately, according to our Bayesian framework, the posterior is intractable. However, we just need to maximize the posterior by maximizing the evidence procedure, regardless of the analytical closed form of the posterior. Coincidentally, OGSBI [] provides an example to maximize evidence, i.e., the marginal probability of the observed data
But, (18) is still intractable, so maximizing evidence seems to help little. However, variational inference is able to achieve it. It is necessary to explain variational inference before later derivation. Variational inference defines a function as a mapping that takes a function as the input and returns the value of the function as the output []. In the entropy field, the function is a probability distribution. When variational inference is applied to (18), the parameter vector (i.e., unknown stochastic variables) no longer appears because the parameters are absorbed into new probability distributions. Thus, (18) can be converted to an addressable form.
To be specific, we adopt variational Bayesian inference (VBI) [] to address (18) by introducing a distribution , where is the parameter set of unknown variables. The introduced can simplify (18) and allow the logarithmic form of (18) to be divided into two parts, i.e.,
where is the product of priors and is the posterior. The specific derivation from (18) to (19) is complicated [], so it is omitted here. is the lower bound of because is the Kullback–Leibler divergence between and the posterior .
The significance of (19) is transforming the intractable into an approximated tractable , so that maximizing is approximately equal to maximizing . The lower bound is a functional in terms of . In other words, is a mapping that takes as input a function and returns the value of the function as the output. Similar to the function derivative, maximizing requires some optimization over specific forms of . In Bayesian inference, the commonly used form is factorization [].
As performed in [], to achieve the maximized , is factorized into independent parts, i.e.,
where , , and correspond marginal distributions of the hidden variables , , and . is expressed as
(21) is hard to compute, but its logarithmic form is easy to obtain, i.e.,
Using (22), marginal distributions , , and can be solved.
Step 1: satisfies
Utilizing (13), (14), and (23), can be solved as a Gaussian distribution, with mean and variance given by
Please refer to Appendix A for the proof. In general, (24) and (25) are equivalently transformed into beingless complex according to the properties of the matrix in [].
Step 2: satisfies
Using (14), (16), and (28), is identified as a Gamma distribution, whose shape parameter, the scale parameters, and the element of the mean are as follows:
where is the entry of and . Please refer to Appendix B for the proof. (30) can be simplified further, i.e.,
where is the entry of , , and . Please refer to Appendix C for details of the derivation.
Step 3: satisfies
Using (13), (17), and (33), is also solved as a Gamma distribution with shape parameter , scale parameter , and mean as follows:
Please refer to Appendix D for the proof. For the convenience of iteration, (35) is further simplified as
Overall, , , and are solved, and, alternately, are updating (26), (27), (31), (36) until some convergence criterion is satisfied.
Remark 2.
According to [], maximizing the lower bound guarantees convergence of the iterative optimization since each iteration leads to a nondecreasing value of . Therefore, the proposed method must converge at some point.
4.1.3. Off-Grid Correction
Recalling (2), with angle set is yielded by spatial discretization, causing estimation errors inevitably if sources are off grid. On this basis, the array steering vector of the source is Taylor expanded around the nearest sampling grid denoted as , i.e.,
where and . Patently, the final objective is to solve . Following the above similar principle based on Taylor expansion, can be extended as
where with the element is and . To solve , (3) can be used, i.e.,
Combining (40) with (39), the following equation holds.
Using (41), is solved and is still block sparse; thus, we squeeze it as , where the element . Here, if exceeds the interval , will be assigned to it. Letting the preliminary estimated DOA value vector be , the final DOA vector, denoted as , is solved as follows:
where , is the corresponding angle compensation for . Using (42), grid errors are eliminated.
Overall, the whole BSBL algorithm is completed and summarized in Algorithm 1.
| Algorithm 1. The proposed BSBL algorithm. |
| Initialization |
| (i) set the first iterative number , . |
| (ii) assign , , and very small values (ensure uninformative distributions). |
| (iii) preset error tolerance and maximal iterative number . |
| Repetition |
| while ( or ) do |
| (i) compute and according to (26) and (27). |
| (ii) compute and according to (31) and (36). |
| (iii) Regard as . |
| (iv) . |
| end while |
| Refinement |
| (i) use the final to obtain . |
| (ii) use the final to solve according to (41). |
| (iii) obtain according to (42). |
| Output The final DOA values. |
Compared with the canonical SBL method, BSBL achieves better sparsity performance and lower computational complexity. According to the maximal number of complex multiplications, the complexity of BSBL, dominated by (26) (or rather ), is , less than of the canonical SBL method.
However, BSBL will still suffer heavy computational burdens when or is large. Therefore, we must seek some techniques to reduce computational complexity.
4.2. BSBL-APPR
Obviously, the large complexity is mainly caused by high-dimensional matrix operations that contain massive useless zero (or near-zero) operations. Automatically, the simplest perspective is to exploit some approximation to shrink the matrix dimensions, generating the first faster version called BSBL-APPR.
Recalling the entire algorithm, the high dimensions are essentially yielded by computing (26), (27), and (37). For in (26), the corresponding approximation is
where . The derivation process follows Kronecker–Product properties, i.e., , , and . The approximation exactly holds if or . To be specific, the approximation is reasonable if high SNRs or low ow correlation coefficient levels are adopted. In fact, the two conditions (or at least one) are easy to meet in practice.
Likewise, for in (27), the approximation is
Similarly, for in (37), its approximation is
After the approximation, BSBL-APPR is completed. Its concrete iterative steps are omitted here since the process is the same as BSBL, except for the calculation of , , and by (43)–(45).
Since the approximation operations have been performed, the computational complexity of BSBL-APPR, dominated by , is less than , which theoretically verifies the higher efficiency of BSBL-APPR.
Even so, the complexity of BSBL-APPR still seems to be intolerable when dense sampling is adopted, i.e., is large enough. Additionally, there exist several operations with many zero (or near-zero) elements, e.g., and . For lower complexity, the most effective method is to decompose matrix operations into vector and even scalar operations so as to selectively avoid useless computation. Fortunately, a technique, named generalized approximate message passing (GAMB), exactly achieves that.
4.3. BSBL-GAMP
GAMP is a technique developed to solve approximate marginal posteriors with low complexity based on the central limit theorem []. To briefly explain the principle of the GAMP technique, (3) is rewritten in scalar form.
where and are the entries of and . Let , , and . Given the known measurement matrix and the observed vector , the objective is to obtain the estimation of .
Each is connected to by , and vice versa. and are defined as the input node and the output node, respectively. The association between them is called an edge. Input nodes and output nodes pass messages to each other along the edges. The original message passing (MP) technique is to keep passing messages (i.e., probability distributions) with respect to until convergence. Based on MP, GAMP is the extension for low complexity since it passes only important messages that mainly affect the approximated marginal posteriors of .
Overall, the GAMP technique is selected to speed up our algorithm for two motivations. (i) It passes messages from one node to another, enforcing scalar operations with low complexity. (ii) It can also compute approximate marginal posteriors of , which allows GAMP to be embedded into the proposed BSBL.
To apply GAMP to our used block-sparse data model, we must derive it again. Along the line of the common procedures of GAMP, there are two important approximate marginal posteriors to consider. One is
for approximating , , where . and are quantities to be updated. The other is
for approximating , , where and are quantities to be updated. Given the model and priors, it is easy to obtain and , where is the row, is the column element of , and , . , . Similar to (7), (47) and (48) are easily identified as Gaussian distributions.
where and are the mean and variance of , while and are the mean and variance of . Please refer to Appendix E for details of the derivation. Then, it is required to determine two scalar functions denoted as and , where is equal to the posterior mean of , i.e.,
The corresponding posterior variance is
satisfies
The corresponding posterior variance is
So far, the derivation of GAMP is completed. Note that the variance of (52) becomes a vector (equivalent to a diagonal matrix), while of BSBL (or BSBL-APPR) is still a normal matrix. From this perspective, BSBL-GAMP is generated by the most thorough approximation, resulting in the least complexity. As shown in Algorithm 2, the GAMP algorithm is summarized.
Intuitively, only and diagonalized could be updated in the GAMP algorithm. For hyperparameter , its update process will still lead to relatively large complexity if computed by (36). Here, is rewritten as
Overall, the second faster version, called BSBL-GAMP, is eventually yielded by embedding the GAMP algorithm into BSBL. Specific steps are summarized in Algorithm 3.
| Algorithm 2. The proposed GAMP algorithm. |
| Initialization |
| , input and . |
| . |
| . |
| (iv) preset error tolerance . |
| Repetition |
| . |
| . |
| . |
| . |
| . |
| . |
| . |
| . |
| . |
| . |
| . |
| Terminate . |
| Output . |
| Algorithm 3. The proposed GAMP-BSBL algorithm. |
| Initialization. |
| (i) set the first iterative number , error tolerance , maximal iterative number . |
| (ii) set . |
| (iii) assign , , and very small values. |
| (iv) compute and with (31) and (55), respectively. |
| Repetition. |
| (i) compute and according to the above GAMP. |
| (ii) compute and according to (31) and (55), respectively. |
| (iii) update . |
| (iv) regard as . |
| Terminate or |
| Refinement |
| (i) use the final to obtain . |
| (ii) use the final to solve according to (41). |
| (iii) obtain according to (42). |
| Output the final DOA values. |
Theoretically, BSBL-GAMP contains only simple multiplication of vectors and linear operations, so it is undoubtedly the fastest algorithm. To be specific, its complexity dominated by (55) is , much less than of BSBL or of BSBL-APPR. For comparison, the computational complexity of all the narrowband algorithms involved in this paper is summarized in Table 2. Generally, holds; thus, BSBL-GAMP obviously has the least computational complexity. In contrast, BSBL-APPR seems to be also satisfactory since its complexity is smaller than others, except for IC-SPICE and RVM-DOA. Moreover, the complexity of BSBL is moderate.
Table 2.
Complexity of various algorithms.
4.4. BSBL for Wideband Sources
Although BSBL, BSBL-APPR, and BSBL-GAMP are developed, they are only applicable in the case of narrowband sources. For wideband cases, we must extend BSBL further.
A way to deal with wideband sources is to separate the wideband spectrum into independent narrowband ones. Without loss of generality, (3) can be rewritten as the special case at the frequency point , , i.e.,
In this model, it is worth emphasizing that we only care about the locations of non-zero elements in rather than the concrete values because different theoretically indicate the same location of some source. Consequently, considering all the frequency points, different can be unified as so that
where , , and . Similar to the aforementioned derivation of BSBL, (58)−(65) are yielded as follows.
To be distinguished from BSBL in narrowband cases, the diffetent parameters in wideband cases are with superscript or subscript and . In particalur, is the variance of variable , where . In wideband cases, the off-grid correction is the same as BSBL, except for (41), which is replaced by
So far, BSBL for wideband sources has been completed. The specific process is summarized in Algorithm 4.
| Algorithm 4. BSBL for wideband sources. |
| Initialization. |
| (i) set , . |
| (ii) set , , and very small values. |
| (iii) preset error tolerance and maximal iterative number . |
| Repetition |
| while ( or ) do: |
| (i) compute and according to (58) and (59). |
| (ii) compute and according to (62) and (65). |
| (iii) regard as . |
| (iv) . |
| end while |
| Refinement |
| (i) Use the final to obtain . |
| (ii) Use the final to solve according to (66). |
| (iii) Obtain according to (42). |
| Output The final DOA values. |
5. Numerical Simulation
In this section, the superiority of our proposed algorithms will be proven comprehensively through three subsections, including extensive simulations. For simplicity, the proposed BSBL, BSBL-APPR, and BSBL-GAMP are collectively referred to as BSBLs. In the first and second subsections, the narrowband and wideband estimation performance of various algorithms is evaluated comprehensively. In the third subsection, the in-depth analysis of Bayesian performance is completed by comparison with other off-grid SBL-based methods.
5.1. Estimation Performance for Narrowband Sources
In this subsection, estimation performance is evaluated by the Root-Mean-Square Error (RMSE) expressed as
where is the Monte Carlo number and is the number of sources. is the estimation value for the source in the trial and is the true angle of the source. For clarity, we introduce four canonical SMV algorithms, i.e., −SVD [], −SRACV [], IC-SPICE [], SBL [], SS-ANM [], and StrucCovMLE [], as comparisons in following simulations. Before that, unless otherwise stated, baseline simulation conditions are , temporally correlated sources with a random DOA set , the number of sensors is , the number of snapshots is , the grid interval is , the number of grids is , the Monte Carlo number is , and the temporal correlation coefficient is .
Remark 3.
and (or at least one) are provided to ensure that BSBL-APPR performs normally.
Simulation 1 tests the ability of various algorithms to suppress temporal correlation. Specifically, the amplitudes and phases of temporally correlated coefficients uniformly vary from and , respectively. The results are shown in Figure 2. Obviously, the RMSEs of BSBLs persistently remain low and fluctuate only slightly with the correlation coefficient varying, while others just struggle when the correlation coefficient is large. Particularly, IC-SPICE is able to impair the influence of temporal correlation to some extent, but it is still at a loss if the correlated level is high. Overall, the simulation results fully live up to our expectations that BSBLs are able to suppress temporal correlation effectively, which confirms that the considered temporal correlation modeled in the block-sparse model indeed plays an important role in improving the robustness of temporal correlation.
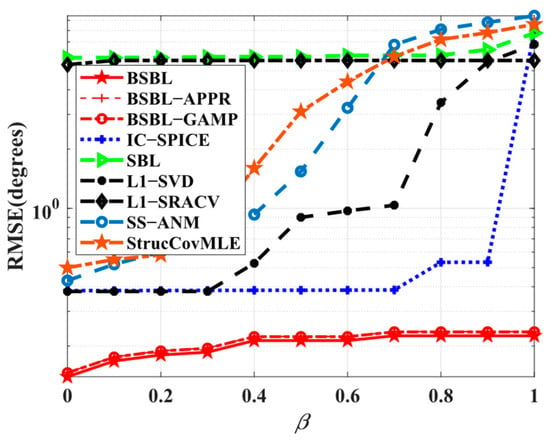
Figure 2.
RMSE versus correlation coefficient.
Simulation 2 examines the dependence on the number of snapshots. In Figure 3, all the sparsity-based algorithms are collectively robust to various snapshots. In other words, all the algorithms seem to achieve SSR with only a few snapshots. Despite this, BSBLs are still commendable due to the realized lowest RMSEs. In fact, SBL itself enables finding global minima and smoothing out numerous local minima in some cases with a few snapshots []. For SBL-based methods, BSBLs undoubtedly inherit their advantages. Additionally, the used hierarchical priors can improve sparsity performance so that BSBLs perform best. Thus, BSBLs enable high estimated precision with a few snapshots.
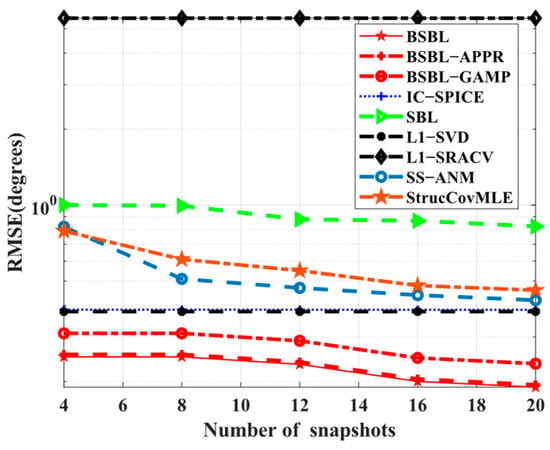
Figure 3.
RMSE versus number of snapshots.
Simulation 3 focuses on the RMSE performance with respect to SNRs. Apparently, in Figure 4, all the algorithms work well if high SNRs are adopted, while only BSBLs maintain fewer RMSEs at low SNRs. The results can be explained by the fact that the sparsity-based algorithms rely on high SNRs to some extent, but SBL can reduce the dependency. Taking IC-SPICE as an example, it can achieve efficient iterative optimization under the condition of high SNRs but cannot seek the right global minima or even trap some fixed local optima. The original reason for this is that the used covariance matrix and the updated parameters have large errors with ideal ones. However, SBL seems to work normally owing to convergence guarantee and gradual optima under the condition of existing data errors. Surprisingly, the proposed BSBLs have a similar ability in some way. On the whole, BSBLs are preferable, especially under the condition of low SNRs.
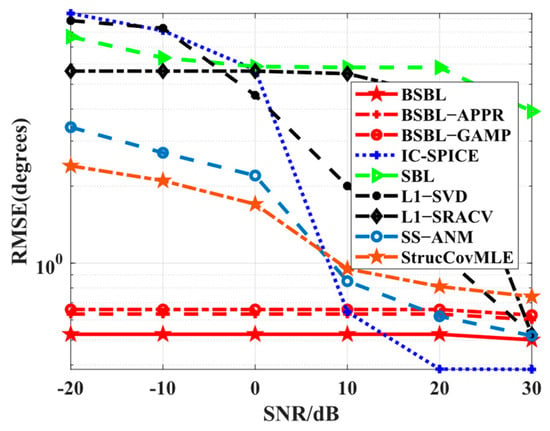
Figure 4.
RMSE versus SNR.
Simulation 4 investigates the RMSE performance with respect to the number of sensors. Here, this simulation is executed at the number of snapshots rather than since −SVD cannot work normally when the number of sensors exceeds the number of snapshots. Intuitively, in Figure 5, the RMSE performance of BSBLs is still excellent, although BSBLs are inferior to IC-SPICE at . In fact, the results are related to the ability to solve underdetermined DOA estimation problems. SBL still seems to find the sparsest solutions, although the restricted isometry property (RIP) is not satisfied []. When the number of sensors is not large enough, i.e., the solution to be solved is not sparse enough, SBL still tries its best to realize global minima. Thus, BSBLs can handle underdetermined cases efficiently. In other words, BSBLs are able to realize SSR effectively on the condition of a few sensors.
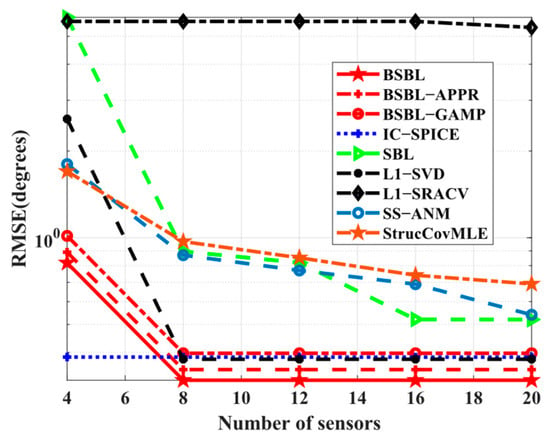
Figure 5.
RMSE versus number of sensors at .
Simulation 5 tests the adaptability to wide grid intervals. In Figure 6, the results illustrate that both BSBLs and IC−SPICE gain highly accurate estimation values at refined grids, but only BSBLs reluctantly adapt to wide grid intervals, although all the algorithms suffer hardship at coarse grids. The coarse girds compel relatively large errors of the pre-estimated values, so the refined values have a larger bias. In the proposed BSBLs, the grid refinement has an effect on reducing the bias at each iteration. Therefore, BSBLs adapt to coarse grids to some extent.
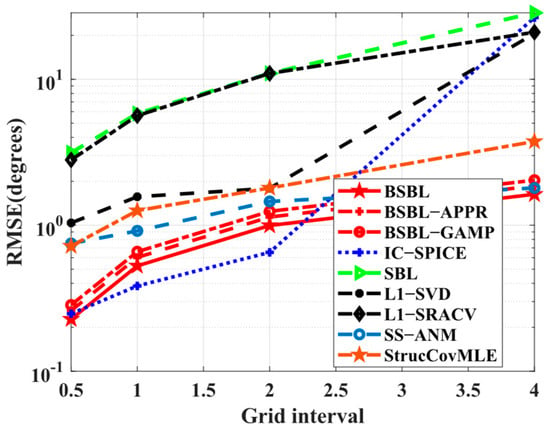
Figure 6.
RMSE versus grid interval.
Simulation 6 examines the RMSE performance with respect to the number of sources. The different conditions are as follows: the DOA sets of sources are selected from randomly, and is chosen to ensure the normal operation of −SVD. In Figure 7, all the RMSEs drop rapidly, but BSBLs seem to slow down the pace of performance degradation, which implies that BSBLs have the potential to locate more sources. In fact, the results are another proof of the excellent underdetermined DOA estimation ability of BSBLs in Simulation 4. More sources and fewer sensors play similar roles in decreasing the sparse level in sparse recovery theory, and BSBLs handle this case efficiently.
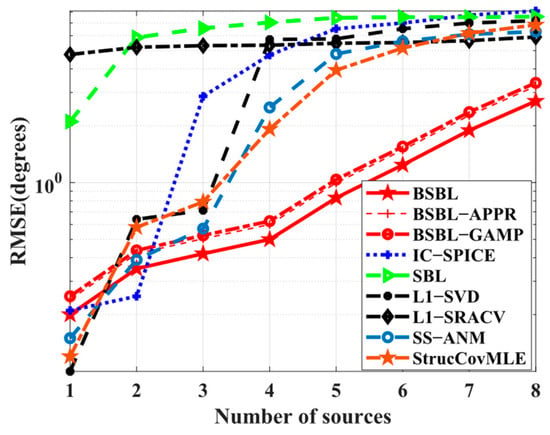
Figure 7.
RMSE versus number of sources.
5.2. Estimation Performance for Wideband Sources
For comparison, JLZA−DOA [], W−SpSF [], W−SBL [], GS−WSpSF [], and ANM [] are introduced. On behalf of BSBLs, only BSBL is adopted in the last two subsections for simplicity.
Simulation 7 tests the spectral performance of the above algorithms. Its conditions are two uncorrelated chirps with angles of and with a center frequency of 1 kHz and a bandwidth of 400 Hz from 0.8 kHz to 1.2 kHz, , the number of sensors is , the number of snapshots is , and the grid interval is . Intuitively, in Figure 8, JLZA−DOA and W−SpSF arise explicit sidelobes around their spikes, while GS−WSpSF, ANM, W−SBL, and BSBL are excellent since their spectra are almost without sidelobes and the spikes are sharp. It is worth noting that the spikes of W−SBL seem to be very low at some frequency points. Specifically, W-SBL fluctuates intensely with varied frequencies, i.e., the signal energy non-uniformly leaks between different frequencies. GS−WSpSF and ANM are better; at least their spikes are visible and apparent over the range of all the frequency points. The proposed BSBL has the highest spikes and varies little over the range of frequencies. Thus, three conclusions are drawn. (1) When sparse recovery is adopted, BSBL can ensure that equal energy is assigned between different frequency bins. (2) BSBL realizes the highest spikes and shows the best convergence effect, i.e., ensuring global minima.
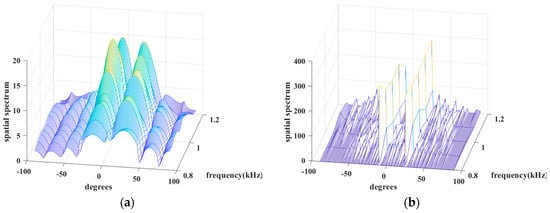
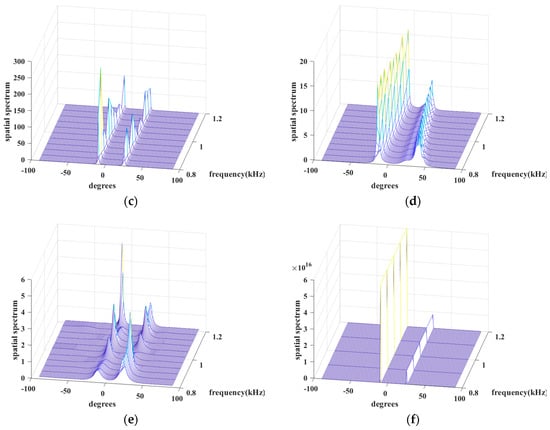
Figure 8.
Spatial spectrum versus degree and frequency of (a) JLZA−DOA, (b) W−SpSF, (c) W−SBL, (d) GS−WSpSF, (e) ANM, (f) BSBL.
Simulation 8 examines the RMSE performance with respect to the number of sensors. The condition set is the same as baseline conditions, except for wideband sources. As expected, BSBL achieves excellent RMSE performance in Figure 9. Over the whole range of the number of snapshots, BSBL shows overwhelming advantages and outperforms others patently. In fact, DOA estimation for wideband sources is difficult, and one of the main reasons is many algorithms fail to realize accuracy estimation over the whole range of frequency bins. Simulation 7 shows the special ability of BSBL to overcome this problem, and Simulation 8 seems to verify it again. On the one hand, BSBL for wideband sources maintains the superiority of narrowband BSBL, so it can obtain excellent estimation performance. On the other hand, BSBL extends the advantages of SBL to wideband sources, i.e., achieving robust sparse recovery with only a few snapshots for all the sources over the whole frequency band.
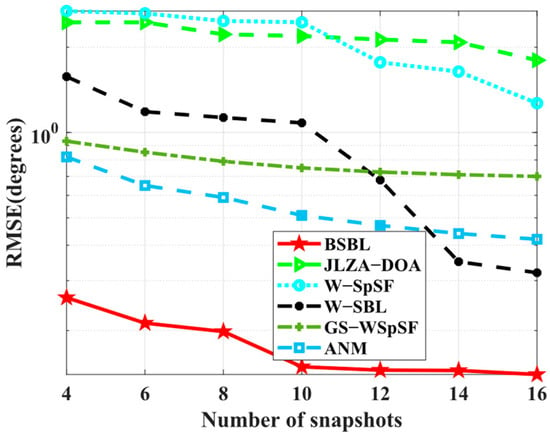
Figure 9.
RMSE versus number of snapshots.
Simulation 9 tests the RMSE performance with respect to SNRs. In Figure 10, BSBL outperforms others and improves well when SNRs increase. It is worth noting that the results are different from the narrowband ones in Simulation 2. To be specific, BSBL seems to fluctuate intensely with the varied SNRs. BSBL for wideband sources cannot work well enough compared to narrowband source cases. We carefully analyze the reasons and find that BSBL cannot realize ensuring global minima at each frequency bin for sparse recovery. Despite this, the defects cannot obscure the virtues. BSBL still achieves impressive performance for wideband sources.
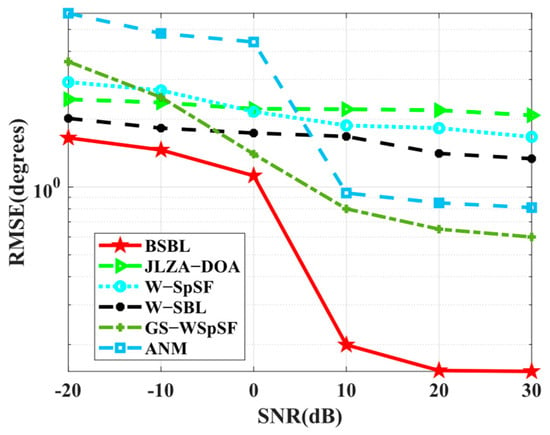
Figure 10.
RMSE versus SNR.
5.3. Analysis of Sparse Bayesian Performance
According to the common perception of SBL, the elaborate Bayesian framework with substantial priors is regarded as a characteristic to enhance sparsity well because priors play a role of regularization in sparse recovery [,]. Here, we abstract several Bayesian frameworks from several off-grid SBL-based algorithms, such as RVM−DOA [], RV−ON−SBL [], ON−SBLRVM [], SBLMC [], and HSL [], for comparison and analysis. As shown in Figure 11, RVM−DOA, RV−ON−SBL, and ON−SBLRVM are only imposed on Gaussian priors that have been proven of poor Bayesian performance. The complicated Bayesian frameworks of HSL and BSBL are the same, except for the priors assigned to the unknown variables; thus, they may perform equally well. SBLMC has the most elaborate Bayesian framework composed of sufficient priors, so its sparsity performance will be perfect theoretically.
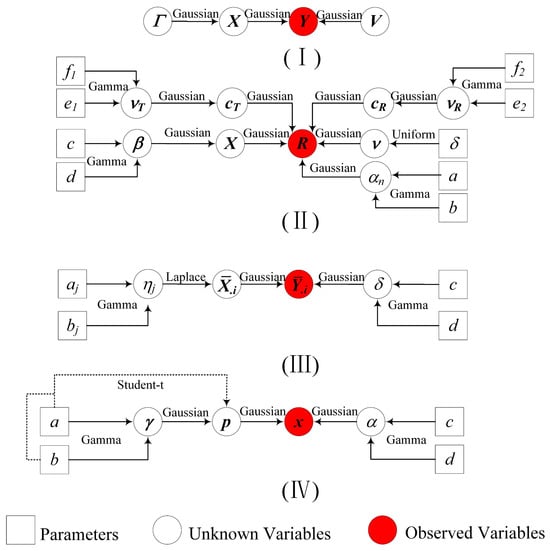
Figure 11.
Directed acyclic graph representing the Bayesian frameworks of (Ⅰ) RVM−DOA, RV−ON−SBL, ON−SBLRVM, (II) SBLMC, (III) HSL, (IV) BSBL.
To confirm the above conjectures, two more simulations are performed to test the estimation performance of these algorithms.
Simulation 10 tests the RMSE performance with respect to the number of snapshots. The conditions are the same as the baseline conditions. In Figure 12, the RMSE performance of RVM−DOA, RV−ON−SBL, and ON−SBLRVM are expectedly worse than others, but SBLMC seems to not meet our expectations, while BSBL and HSL achieve preeminent RMSE performance. BSBL and HSL with moderately elaborate Bayesian frameworks outperform others, including the SBLMC with the most elaborate one. The result seems to violate the rule of Bayesian learning, which will be explained in the following text.
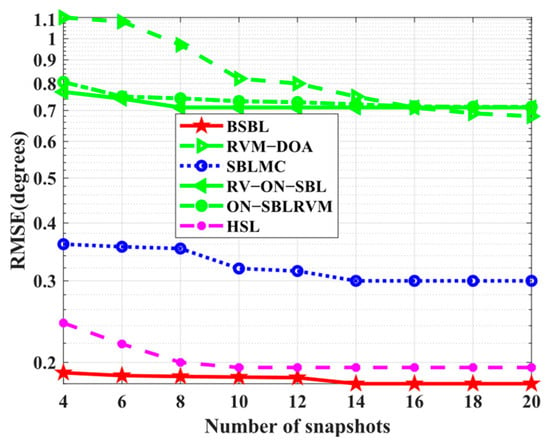
Figure 12.
RMSE versus number of snapshots.
Simulation 11 tests the RMSE performance with respect to SNRs. In Figure 13, the proposed BSBL still seems to work best. It is worth noticing that the advantages of BSBL are not obvious, especially when SNRs are low. For all the SBL-based methods, BSBL has shown no more advantages than others on the condition of low SNRs because hierarchical priors improve sparsity if, and only if, SNRs are high. To be specific, Bayesian learning is able to find global minima, even at low SNRs, but the parameters yielded by hierarchical priors seem to update well only if SNRs are high.
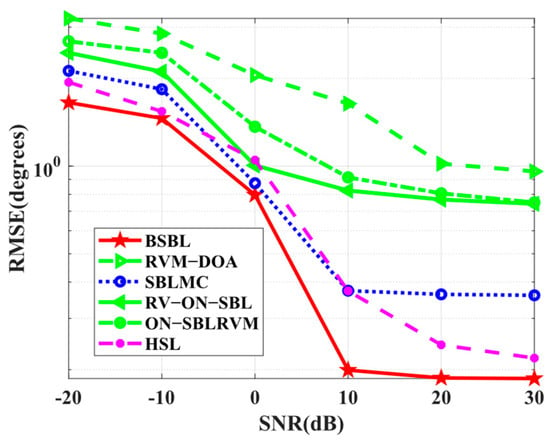
Figure 13.
RMSE versus SNR.
Based on the simulation results, it can be seen that the complicated Bayesian frameworks, i.e., Ⅱ, Ⅲ, and Ⅳ in Figure 10, indeed achieve more excellent Bayesian performance than the canonical one, i.e., Ⅰ in Figure 11. However, SBLMC with the most elaborate Bayesian framework has not met our initial expectation, which can be explained by the fact that (i) SBL belongs to machine learning, so the Bayesian framework with too many priors will yield massive iterative hyperparameters, leading to overfitting during the iterative process. (ii) SBLMC is developed in the presence of mutual coupling; thus, the involved additional hyperparameter iteration is bound to affect the key parameters related to DOA estimation.
It is worth emphasizing that BSBL achieves slightly better estimation performance than HSL. The result indicates that the indirectly induced Student’s t priors, generated by Gaussian and Gamma priors, indeed express excellent sparsity performance. In fact, Student’s t priors have preferable sparsity-inducing performance, which has been mentioned in [,].
Overall, the above three subsection simulation results sufficiently demonstrate the superiority of BSBLs. Understandably, BSBL leverages hierarchical Gaussian and Gamma priors and uses VBI to complete the Bayesian inference so as to construct the corresponding iterative algorithm. Theoretically, the superiority is guaranteed by (1) indirect Student’s t-distributions, which have an excellent sparsity-inducing ability [], and (2) variational approximation for Bayesian inference shows better performance than maximum posterior (MAP) estimation adopted in many SBL-based methods []. In addition, two approximation operations have achieved impressive running efficiency beyond many state-of-the-art methods. Moreover, BSBL still performs well in wideband cases and outperforms other algorithms in smoothing the spectrum peaks and super resolutions. Last but not least, BSBL has suppressed temporal correlation efficiently owing to its tactful algorithm design.
6. Conclusions
In this paper, we develop a DOA estimator (i.e., BSBL) based on sparse Bayesian learning with hierarchical priors. Due to the unacceptable computational complexity caused by the vectorization of the MMV model, two approximation operations are creatively introduced, thereby yielding two faster versions of BSBL, i.e., BSBL-APPR and BSBL-GAMP. As expected, all the proposed BSBLs (including BSBL, BSBL-APPR, BSBL-GAMP) achieve excellent estimation performance. For narrowband source estimation, BSBLs show perfect sparsity performance owing to the designed hierarchical priors. Further, BSBLs inherit and even extend the advantages of SBL, such as sparse signal recovery guarantee, less dependency on numerous snapshots or high SNRs, and the ability to handle underdetermined DOA estimation. Moreover, BSBLs enable robustness to temporally correlated sources and adaptability to coarse grids, which owes to the considered temporal correlation and the used grid refinement. For wideband source estimation, BSBL almost maintains huge advantages, i.e., realizing highly accurate estimation among the whole frequency band, while others suffer performance reduction to varying degrees. However, in wideband cases, BSBL cannot retain the good performance as in narrowband cases if low SNRs are adopted, which is our goal to solve in the next study. For Bayesian performance, BSBL with a moderately elaborate Bayesian framework realizes the best estimation performance. Furthermore, BSBL can balance both sparsity and complexity. Specifically, BSBL achieves sharp spectrum spikes and avoids overfitting produced by too many parameters.
Overall, the proposed BSBLs tactfully combine the hierarchical priors and the block-sparse model that contribute much to complexity reduction, which is never achieved by other SBL-based methods. Moreover, BSBLs retain and extend the advantages of SBL. Most importantly, BSBL is more practical and applicable when sources are temporally correlated or wideband. Despite this, BSBL seems not to be perfect because its performance suffers a loss at low SNRs in wideband cases to some extent. Anyway, the proposed BSBLs are worth recommendation and praise.
Author Contributions
Conceptualization, N.L. and X.Z.; methodology, N.L.; software, F.L.; validation, X.Z.; writing—original draft preparation, N.L.; writing—review and editing, N.L.; visualization, F.L.; supervision, B.Z.; project administration, X.Z.; funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by [the Natural Science Basic Research Program of Shaanxi] grant number [2023-JC-YB-488].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The terms unrelated to are absorbed into the constant. Obviously, obeys a Gaussian distribution with mean and variance , where and . Using linear transformation, (24) and (25) are yielded.
Appendix B
The terms unrelated to are absorbed into the constant. Undoubtedly, obeys a Gamma distribution with shape parameter and scale parameter .
Appendix C
Diagonal elements of affect the second-order moment of , while the off-diagonal elements only affect the mean value. Therefore, two cases are each considered for the element of .
(i)
where and and are the element of and , respectively. is the diagonal element of .
(ii)
where . Based on (i) and (ii), (32) is verified.
Appendix D
The terms unrelated to are absorbed into the constant. obeys another Gamma distribution with shape parameter and scale parameter .
Appendix E
To obtain the mean and variance of variables (i.e., and ), their distributions are transformed into logarithmic form as follows:
The final equation of (A6) is yielded based on the expansion of the Gaussian function. Patently, and can be directly abstracted and solved by simple linear transformation, so and are obtained. For (50), the logarithmic form is
Similarly, and are yielded.
References
- Liu, X.; Xu, B.; Zheng, K.; Zheng, H. Throughput maximization of wireless-powered communication network with mobile access points. IEEE Trans. Wirel. Commun. 2022, 22, 4401–4415. [Google Scholar] [CrossRef]
- Liu, X.; Lin, Z.; Zheng, K.; Yao, X.W.; Liu, J. Optimal Time Allocation for Backscatter-Aided Relay Cooperative Transmission in Wire-less-Powered Heterogeneous CRNs. IEEE Internet Things 2023, 10, 16209–16224. [Google Scholar] [CrossRef]
- Mizmizi, M.; Linsalata, F.; Brambilla, M.; Morandi, F.; Dong, K.; Magarini, M.; Nicoli, M.; Khormuji, M.N.; Wang, P.; Pitaval, R.A.; et al. Fastening the initial access in 5G NR sidelink for 6G V2X networks. Veh. Commun. 2022, 33, 100402. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, P.; Guo, Z.; Zhang, Y.; Wang, X. A RIS-based vehicle DOA estimation method with integrated sensing and communication system. IEEE Trans. Intell. Transp. Syst. 2023, 1, 1–13. [Google Scholar] [CrossRef]
- Chen, P.; Yang, Z.; Chen, Z.; Guo, Z. Reconfigurable intelligent surface aided sparse DOA estimation method with non-ULA. IEEE Signal Process. Lett. 2021, 28, 2023–2027. [Google Scholar] [CrossRef]
- Chen, P.; Chen, Z.; Zheng, B.; Wang, X. Efficient DOA estimation method for reconfigurable intelligent surfaces aided UAV swarm. IEEE Trans. Signal Process. 2022, 70, 743–755. [Google Scholar] [CrossRef]
- Shen, Q.; Liu, W.; Cui, W.; Wu, S. Underdetermined DOA estimation under the compressive sensing framework: A review. IEEE Access 2016, 4, 8865–8878. [Google Scholar] [CrossRef]
- Baraniuk, R.G. Compressive sensing [lecture notes]. IEEE Signal Proc. Mag. 2007, 24, 118–121. [Google Scholar] [CrossRef]
- Niwaria, K.; Jain, M. A Literature Survey Different Algorithms of MUSIC and MVDR DOA Estimation. IJEMR 2018, 8, 56–69. [Google Scholar]
- Li, F.; Liu, H.; Vaccaro, R. Performance analysis for DOA estimation algorithms: Unification, simplification, and observations. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 1170–1184. [Google Scholar] [CrossRef]
- Gershman, A.B.; Rübsamen, M.; Pesavento, M. One- and two-dimensional direction-of-arrival estimation: An overview of search-free techniques. Signal Process. 2010, 90, 1338–1349. [Google Scholar] [CrossRef]
- Krishnaveni, V.; Kesavamurthy, T.; Aparna, B. Beamforming for direction-of-arrival (DOA) estimation—A survey. Int. J. Comput. Appl. 2013, 61, 4–11. [Google Scholar] [CrossRef]
- Krim, H.; Viberg, M. Two decades of array signal processing research: The parametric method. IEEE Signal Proc. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Yang, Z.; Li, J.; Stoica, P.; Xie, L. Sparse methods for direction-of-arrival estimation. In Academic Press Library in Signal Processing; Academic Press: Cambridge, MA, USA, 2018; pp. 509–581. [Google Scholar]
- Aboumahmoud, I.; Muqaibel, A.; Alhassoun, M.; Alawsh, S. A Review of sparse sensor arrays for two-dimensional direction-of-arrival estimation. IEEE Access 2021, 9, 92999–93017. [Google Scholar] [CrossRef]
- Cohen, R.; Eldar, Y.C. Sparse array design via fractal geometries. IEEE Trans. Signal Process. 2020, 68, 4797–4812. [Google Scholar] [CrossRef]
- Patwari, A. Sparse linear antenna arrays: A review. In Antenna Systems; Intech Open: London, UK, 2021. [Google Scholar]
- Yang, Z.; Xie, L. On gridless sparse methods for multi-snapshot DOA estimation. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 3236–3240. [Google Scholar]
- Chung, P.J.; Viberg, M.; Yu, J. DOA estimation methods and algorithms. In Academic Press Library in Signal Processing; Elsevier: Amsterdam, The Netherlands, 2014; Volume 3, pp. 599–650. [Google Scholar]
- Malioutov, D.; Cetin, M.; Willsky, A. A sparse signal reconstruction perspective for source localization with sensor arrays. IEEE Trans. Signal Process. 2005, 53, 3010–3022. [Google Scholar] [CrossRef]
- Yin, J.; Chen, T. Direction-of-arrival estimation using a sparse representation of array covariance vectors. IEEE Trans. Signal Process. 2011, 59, 4489–4493. [Google Scholar] [CrossRef]
- Cai, S.; Wang, G.; Zhang, J.; Wong, K.-K.; Zhu, H. Efficient direction of arrival estimation based on sparse covariance fitting criterion with modeling mismatch. Signal Process. 2017, 137, 264–273. [Google Scholar] [CrossRef]
- Hyder, M.M.; Mahata, K. Direction-of-Arrival Estimation Using a Mixed l2,0 Norm Approximation. IEEE Trans. Signal Process. 2010, 58, 4646–4655. [Google Scholar] [CrossRef]
- He, Z.-Q.; Shi, Z.-P.; Huang, L.; So, H.C. Underdetermined DOA estimation for wideband signals using robust sparse covariance fitting. IEEE Signal Process. Lett. 2014, 22, 435–439. [Google Scholar] [CrossRef]
- Li, L.; Yu, C.; Li, Y.; Huang, Z.; Wu, Q. Joint squared-sine function and ANM-based DOA estimation with RIS. IEEE Trans. Veh. Technol. 2023, 72, 16856–16860. [Google Scholar] [CrossRef]
- Pote, R.R.; Rao, B.D. Maximum likelihood-based gridless doa estimation using structured covariance matrix recovery and sbl with grid refinement. IEEE Trans. Signal Process. 2023, 71, 802–815. [Google Scholar] [CrossRef]
- Wang, M.; Shen, Q.; Liu, W.; Cui, W. Wideband DOA Estimation with Frequency Decomposition via a Unified GS-WSpSF Framework. IEEE Trans. Aerosp. Electron. Syst. 2024, 1–8. [Google Scholar] [CrossRef]
- Wu, Y.; Wakin, M.B.; Gerstoft, P. Gridless DOA estimation with multiple frequencies. IEEE Trans. Signal Process. 2023, 71, 417–432. [Google Scholar] [CrossRef]
- Aich, A.; Palanisamy, P. On-grid DOA estimation method using orthogonal matching pursuit. In Proceedings of the 2017 International Conference on Signal Processing and Communication (ICSPC), Coimbatore, India, 28–29 July 2017; pp. 483–487. [Google Scholar]
- Ganguly, S.; Ghosh, I.; Ranjan, R.; Ghosh, J.; Kumar, P.K.; Mukhopadhyay, M. Compressive sensing based off-grid DOA estimation using OMP algorithm. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 772–775. [Google Scholar]
- Yang, J.; Liao, G.; Li, J. An efficient off-grid DOA estimation method for nested array signal processing by using sparse Bayesian learning strategies. Signal Process. 2016, 128, 110–122. [Google Scholar] [CrossRef]
- Dai, J.; So, H.C. Real-valued sparse Bayesian learning for DOA estimation with arbitrary linear arrays. IEEE Trans. Signal Process. 2021, 69, 4977–4990. [Google Scholar] [CrossRef]
- Zheng, R.; Xu, X.; Ye, Z.; Dai, J. Robust sparse Bayesian learning for DOA estimation in impulsive noise environments. Signal Process. 2020, 171, 107500. [Google Scholar] [CrossRef]
- Mecklenbrauker, C.F.; Gerstoft, P.; Ollila, E. DOA M-estimation using sparse Bayesian learning. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4933–4937. [Google Scholar]
- Yang, Y.; Zhang, Y.; Yang, L.; Wang, Y. Wideband Direction-of-Arrival Estimation Based on Hierarchical Sparse Bayesian Learning for Signals with the Same or Different Frequency Bands. Electronics 2023, 12, 1123. [Google Scholar] [CrossRef]
- Hu, N.; Sun, B.; Zhang, Y.; Dai, J.; Wang, J.; Chang, C. Underdetermined DOA estimation method for wideband signals using joint nonnegative sparse Bayesian learning. IEEE Signal Process. Lett. 2017, 24, 535–539. [Google Scholar] [CrossRef]
- Liu, Z.-M.; Huang, Z.-T.; Zhou, Y.-Y. An Efficient Maximum Likelihood Method for Direction-of-Arrival Estimation via Sparse Bayesian Learning. IEEE Trans. Wirel. Commun. 2012, 11, 1–11. [Google Scholar] [CrossRef]
- Wang, H.; Wan, L.; Dong, M.; Ota, K.; Wang, X. Assistant Vehicle Localization Based on Three Collaborative Base Stations via SBL-Based Robust DOA Estimation. IEEE Internet Things J. 2019, 6, 5766–5777. [Google Scholar] [CrossRef]
- Chen, P.; Cao, Z.; Chen, Z.; Wang, X. Off-Grid DOA Estimation Using Sparse Bayesian Learning in MIMO Radar With Unknown Mutual Coupling. IEEE Trans. Signal Process. 2019, 67, 208–220. [Google Scholar] [CrossRef]
- Dai, J.; So, H.C. Sparse Bayesian Learning Method for Outlier-Resistant Direction-of-Arrival Estimation. IEEE Trans. Signal Process. 2018, 66, 744–775. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, L.; Bi, G.; Wan, C.; Zhang, L.; Zhang, H. Novel Wideband DOA Estimation Based on Sparse Bayesian Learning with Dirichlet Process Priors. IEEE Trans. Signal Process. 2015, 64, 275–289. [Google Scholar] [CrossRef]
- Liu, Z.-M.; Huang, Z.-T.; Zhou, Y.-Y. Sparsity-Inducing Direction Finding for Narrowband and Wideband Signals Based on Array Covariance Vectors. IEEE Trans. Wirel. Commun. 2013, 12, 1–12. [Google Scholar] [CrossRef]
- Das, A.; Sejnowski, T.J. Narrowband and Wideband Off-Grid Direction-of-Arrival Estimation via Sparse Bayesian Learning. IEEE J. Ocean. Eng. 2017, 43, 108–118. [Google Scholar] [CrossRef]
- Jian, M.; Gao, F.; Tian, Z.; Jin, S.; Ma, S. Angle-Domain Aided UL/DL Channel Estimation for Wideband mmWave Massive MIMO Systems with Beam Squint. IEEE Trans. Wirel. Commun. 2019, 18, 3515–3527. [Google Scholar] [CrossRef]
- Wang, Q.; Zhao, Z.; Chen, Z.; Nie, Z. Grid Evolution Method for DOA Estimation. IEEE Trans. Signal Process. 2018, 66, 2374–2383. [Google Scholar] [CrossRef]
- Yang, J.; Yang, Y. Sparse Bayesian DOA Estimation Using Hierarchical Synthesis Lasso Priors for Off-Grid Signals. IEEE Trans. Signal Process. 2020, 68, 872–884. [Google Scholar] [CrossRef]
- Das, A. Real-Valued Sparse Bayesian Learning for Off-Grid Direction-of-Arrival (DOA) Estimation in Ocean Acoustics. IEEE J. Ocean. Eng. 2021, 46, 172–182. [Google Scholar] [CrossRef]
- Wipf, D.P.; Rao, B.D. Sparse Bayesian learning for basis selection. IEEE Trans. Signal Process. 2004, 52, 2153–2216. [Google Scholar] [CrossRef]
- Wipf, D.P.; Rao, B.D. An empirical Bayesian strategy for solving the simultaneous sparse approximation problem. IEEE Trans. Signal Process. 2007, 55, 3704–3716. [Google Scholar] [CrossRef]
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Bayesian compressive sensing using laplace priors. IEEE Trans. Image Process. 2009, 19, 53–63. [Google Scholar] [CrossRef] [PubMed]
- Hu, Q.; Shi, S.; Cai, Y.; Yu, G. DDPG-driven deep-unfolding with adaptive depth for channel estimation with sparse Bayesian learning. IEEE Trans. Signal Process. 2022, 70, 4665–4680. [Google Scholar] [CrossRef]
- Wan, Q.; Fang, J.; Huang, Y.; Duan, H.; Li, H. A variational Bayesian inference-inspired unrolled deep network for MIMO detection. IEEE Trans. Signal Process. 2022, 70, 423–437. [Google Scholar] [CrossRef]
- Gupta, M.R.; Chen, Y. Theory and use of the EM algorithm. Found. Trends Signal Process. 2011, 4, 223–296. [Google Scholar] [CrossRef]
- Yang, Z.; Xie, L.; Zhang, C. Off-grid direction of arrival estimation using sparse Bayesian inference. IEEE Trans. Signal Process. 2012, 61, 38–43. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Tzikas, D.G.; Likas, A.C.; Galatsanos, N.P. The variational approximation for Bayesian inference. IEEE Signal Process. Mag. 2008, 25, 131–146. [Google Scholar] [CrossRef]
- Bishop, C.M.; Tipping, M. Variational relevance vector machines. arXiv 2013, arXiv:1301.3838. [Google Scholar]
- Rangan, S. Generalized approximate message passing for estimation with random linear mixing. In Proceedings of the 2011 IEEE International Symposium on Information Theory Proceedings, St. Petersburg, Russia, 31 July–5 August 2011; pp. 2168–2172. [Google Scholar]
- Wipf, D.; Palmer, J.; Rao, B.; Kreutz-Delgado, K. Performance evaluation of latent variable models with sparse priors. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech, and Signal Processing—ICASSP ‘07, Honolulu, HI, USA, 15–20 April 2007; pp. II-453–II-456. [Google Scholar]
- Fox, C.W.; Roberts, S.J. A tutorial on variational Bayesian inference. IEEE Signal Proc. Mag. 2012, 38, 85–95. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).