
LM-CycleGAN: Improving Underwater Image Quality Through Learned Perceptual Image Patch Similarity and Multi-Scale Adaptive Fusion Attention

Abstract
1. Introduction
2. Related Work
2.1. Physical Model-Based Methods
2.2. Non-Physical Model-Based Methods
2.3. Deep Learning-Based Methods
3. Materials and Methods
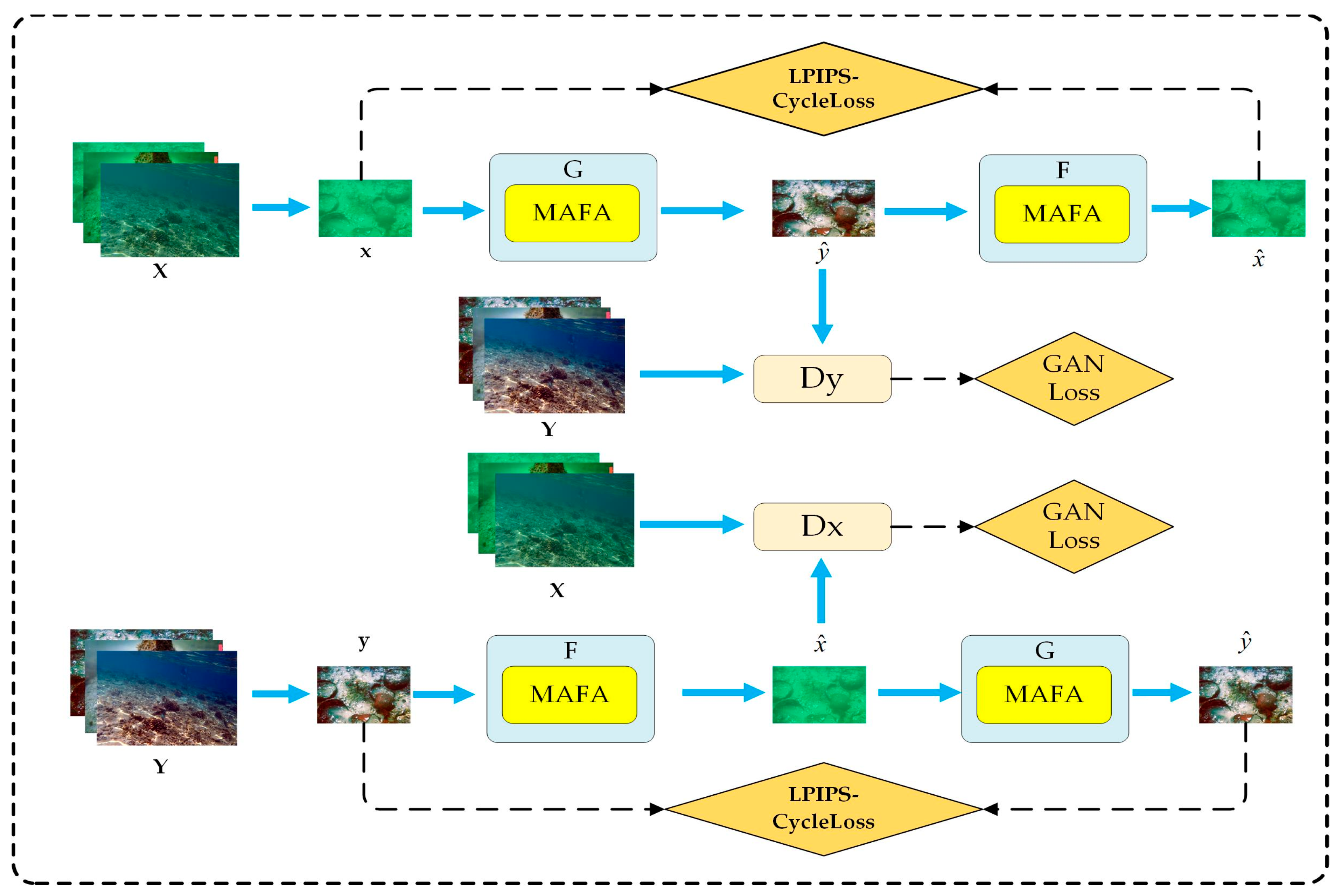
3.1. Architecture of LM-CycleGAN
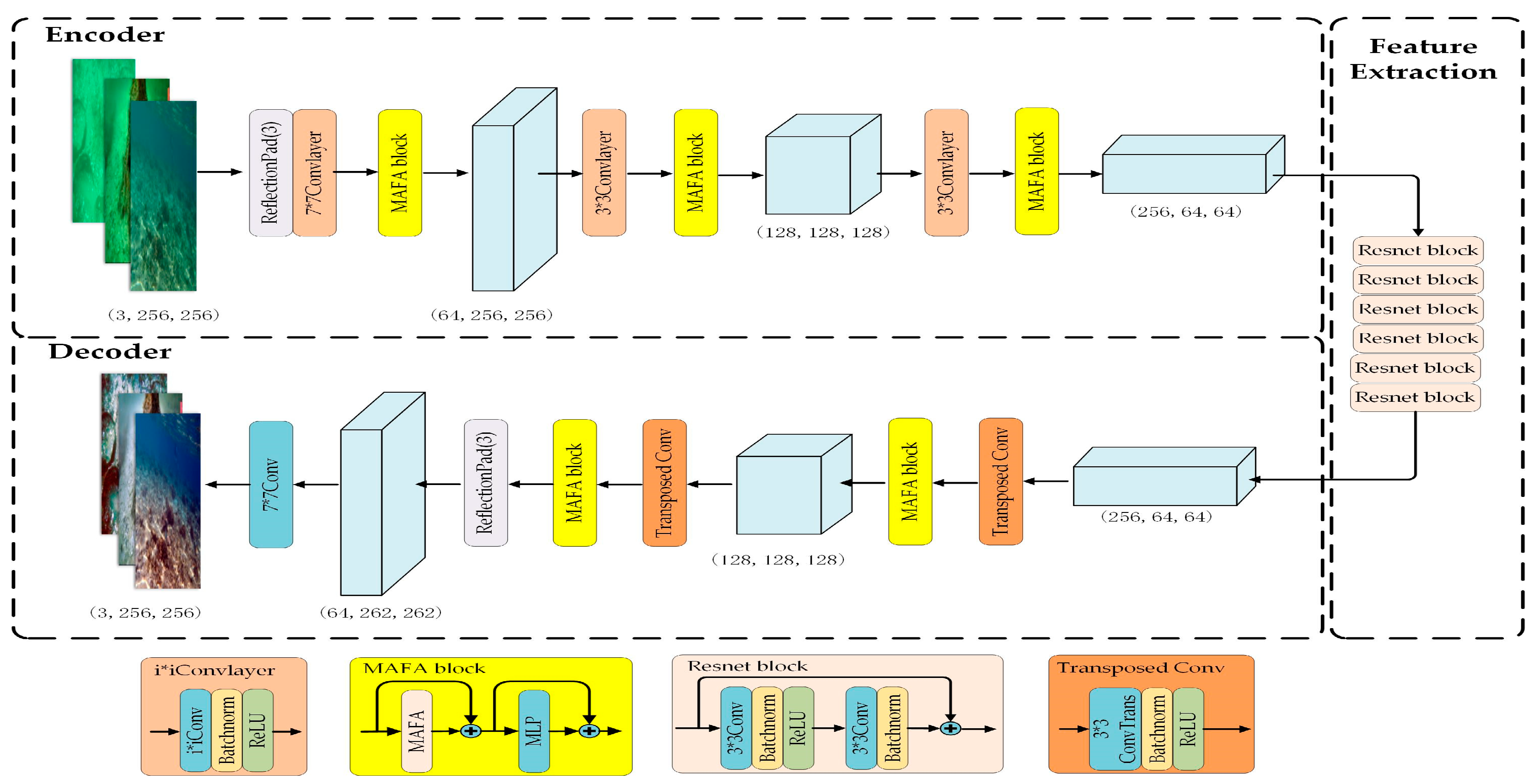
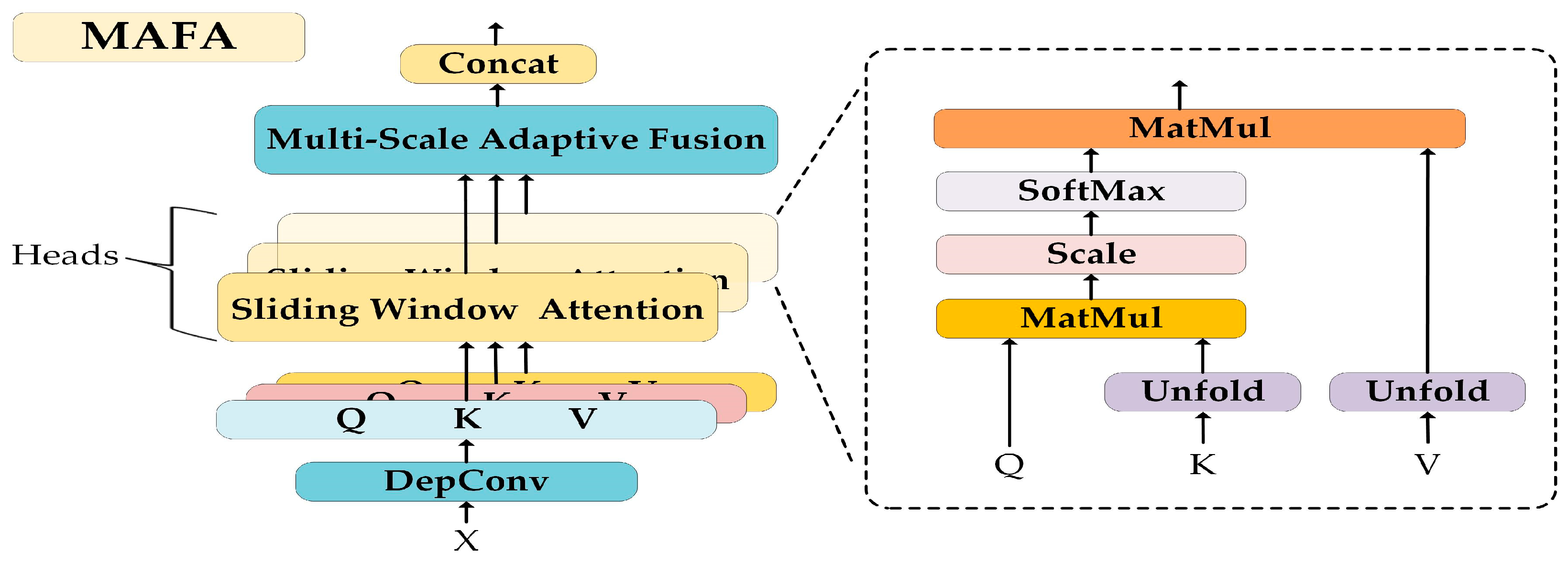
3.2. Generator Structure Based on MAFA
3.3. Discriminator Network Structure
3.4. Loss Function
- (1)
- GAN Loss
- (2)
- Cycle Loss
- (3)
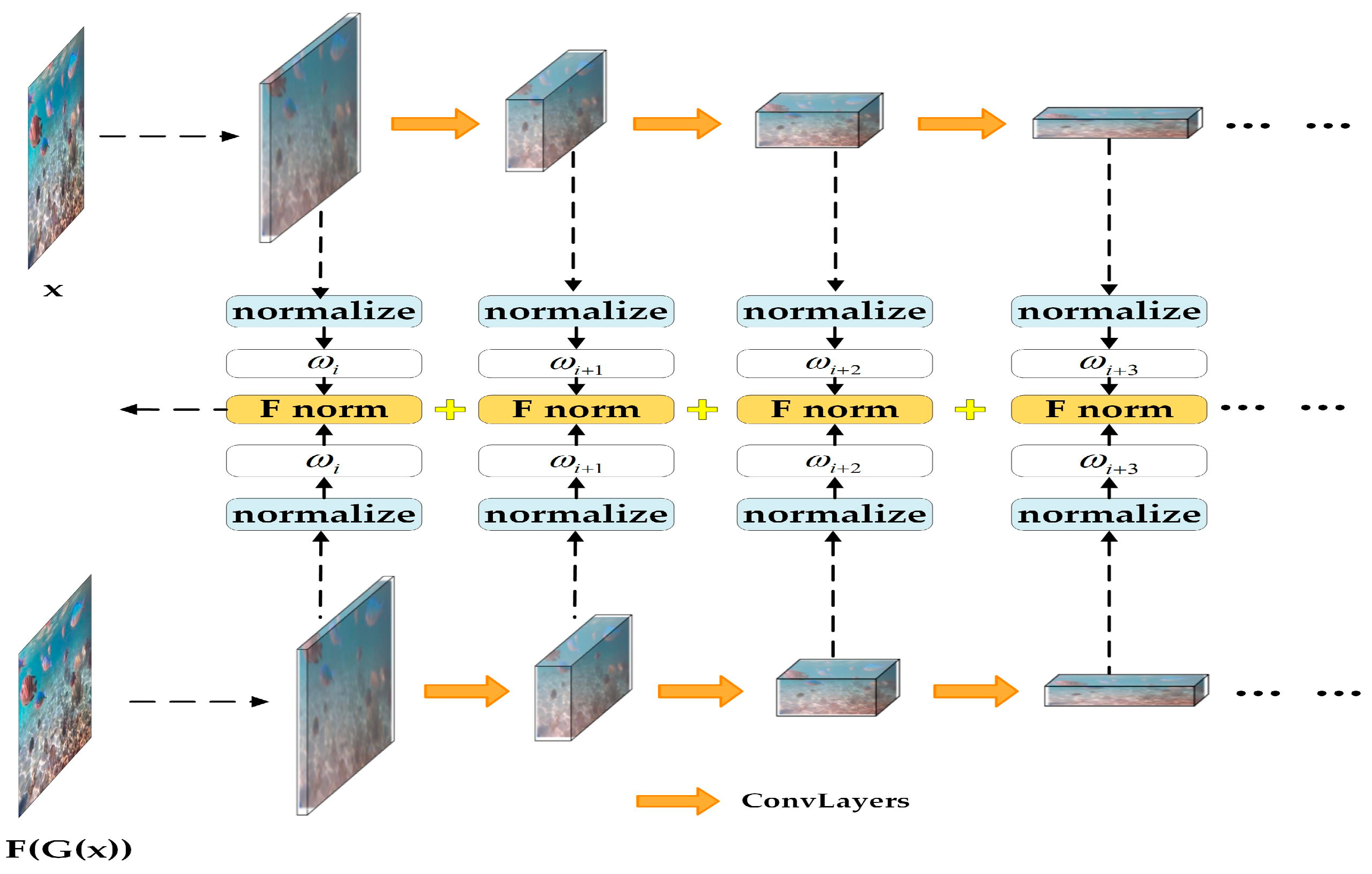
- LPIPS Loss
- (4)
- Total loss function of LM-CycleGAN
4. Experimental Results and Analysis
4.1. Dataset Introduction
4.2. Experimental Settings
4.3. Evaluation Indicators
4.4. Visual Comparison with Other Methods
4.5. Objective Comparison with Other Methods
4.6. Ablation Experiment
4.7. Real-Time Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Xu, W.; Deng, L.; Xiao, Y.; Han, Z.; Zheng, H. Deep learning for visual recognition and detection of aquatic animals: A review. Rev. Aquac. 2023, 15, 409–433. [Google Scholar] [CrossRef]
- Guyot, A.; Lennon, M.; Thomas, N.; Gueguen, S.; Petit, T.; Lorho, T.; Cassen, S.; Hubert-Moy, L. Airborne Hyperspectral Imaging for Submerged Archaeological Mapping in Shallow Water Environments. Remote Sens. 2019, 11, 2237. [Google Scholar] [CrossRef]
- Lee, D.; Kim, G.; Kim, D.; Myung, H.; Choi, H.-T. Vision-based object detection and tracking for autonomous navigation of underwater robots. Ocean Eng. 2012, 48, 59–68. [Google Scholar] [CrossRef]
- Bell, K.L.; Chow, J.S.; Hope, A.; Quinzin, M.C.; Cantner, K.A.; Amon, D.J.; Cramp, J.E.; Rotjan, R.D.; Kamalu, L.; de Vos, A.; et al. Low-cost, deep-sea imaging and analysis tools for deep-sea exploration: A collaborative design study. Front. Mar. Sci. 2022, 9, 873700. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, T.; Zhang, W. Underwater vision enhancement technologies: A comprehensive review, challenges, and recent trends. Appl. Intell. 2023, 53, 3594–3621. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Li, C.; Hu, E.; Zhang, X.; Zhou, H.; Xiong, H.; Liu, Y. Visibility restoration for real-world hazy images via improved physical model and Gaussian total variation. Front. Comput. Sci. 2024, 18, 181708. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-purpose oriented single nighttime image haze removal based on unified variational retinex model. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1643–1657. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Chao, L.; Wang, M. Removal of water scattering. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Technology, Chengdu, China, 16–18 April 2010; pp. V2–V35. [Google Scholar]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2011, 21, 1756–1769. [Google Scholar] [CrossRef] [PubMed]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 1–8 December 2013; pp. 825–830. [Google Scholar]
- Garg, D.; Garg, N.K.; Kumar, M. Underwater image enhancement using blending of CLAHE and percentile methodologies. Multimed. Tools Appl. 2018, 77, 26545–26561. [Google Scholar] [CrossRef]
- Hu, H.; Xu, S.; Zhao, Y.; Chen, H.; Yang, S.; Liu, H.; Zhai, J.; Li, X. Enhancing Underwater Image via Color-Cast Correction and Luminance Fusion. IEEE J. Ocean. Eng. 2023, 49, 15–29. [Google Scholar] [CrossRef]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; p. 27. [Google Scholar]
- Anwar, S.; Li, C.; Porikli, F. Deep underwater image enhancement. arXiv 2018, arXiv:1807.03528. [Google Scholar]
- Saleh, A.; Sheaves, M.; Jerry, D.; Azghadi, M.R. Adaptive uncertainty distribution in deep learning for unsupervised underwater image enhancement. arXiv 2022, arXiv:2212.08983. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Li, Q.Z.; Bai, W.X.; Niu, J. Underwater image color correction and enhancement based on improved cycle-consistent generative adversarial networks. Acta Autom. Sin. 2020, 46, 1–11. [Google Scholar]
- Chen, B.; Zhang, X.; Wang, R.; Li, Z.; Deng, W. Detect concrete cracks based on OTSU algorithm with differential image. J. Eng. 2019, 23, 9088–9091. [Google Scholar] [CrossRef]
- Bakht, A.B.; Jia, Z.; Din, M.U.; Akram, W.; Saoud, L.S.; Seneviratne, L.; Lin, D.; He, S.; Hussain, I. MuLA-GAN: Multi-Level Attention GAN for Enhanced Underwater Visibility. Ecol. Inform. 2024, 81, 102631. [Google Scholar] [CrossRef]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.-L.; Huang, Q.; Kwong, S. Pugan: Physical model-guided underwater image enhancement using gan with dual-discriminators. IEEE Trans. Image Process. 2023, 32, 4472–4485. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Jiao, J.; Tang, Y.M.; Lin, K.Y.; Gao, Y.; Ma, A.J.; Wang, Y.; Zheng, W.-S. Dilateformer: Multi-scale dilated transformer for visual recognition. IEEE Trans. Multimed. 2023, 25, 8906–8919. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Iandola, F.N. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; He, W.; Gao, H.; Yue, H.; Zhang, Z.; Li, C. Is underwater image enhancement all object detectors need? IEEE J. Ocean. Eng. 2024, 49, 606–621. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model/Method | UCIQE ↑ | UIQM ↑ | SSIM ↑ | PSNR ↑ | AG ↑ |
|---|---|---|---|---|---|
| UDCP | 0.5230 | 1.3371 | 0.6439 | 28.2402 | 9.8035 |
| CLAHE | 0.4429 | 1.0293 | 0.7190 | 28.2846 | 10.5692 |
| UCM | 0.4927 | 1.0138 | 0.7177 | 28.6008 | 10.9695 |
| UWCNN | 0.3707 | 0.5164 | 0.7066 | 28.0678 | 6.7591 |
| UDnet | 0.3554 | 0.4492 | 0.7665 | 28.1062 | 7.5259 |
| CycleGAN | 0.4504 | 0.7244 | 0.7554 | 28.2691 | 11.1365 |
| SSIM-CycleGAN | 0.4618 | 0.8319 | 0.7717 | 28.9576 | 11.3564 |
| SESS-CycleGAN | 0.4608 | 0.8330 | 0.7593 | 28.8892 | 11.3594 |
| MuLA-GAN | 0.4542 | 0.8325 | 0.7759 | 28.8459 | 10.0260 |
| PUGAN | 0.4628 | 0.7921 | 0.7714 | 28.9979 | 9.2452 |
| ours | 0.4842 | 0.8936 | 0.7933 | 29.2120 | 11.6876 |
| Model/Method | UCIQE ↑ | UIQM ↑ | SSIM ↑ | PSNR ↑ | AG ↑ |
|---|---|---|---|---|---|
| UDCP | 0.5204 | 1.1924 | 0.5799 | 28.0624 | 7.3796 |
| CLAHE | 0.4597 | 1.0586 | 0.7295 | 28.3214 | 8.3591 |
| UCM | 0.4745 | 0.9554 | 0.7573 | 28.6456 | 8.6528 |
| UWCNN | 0.3958 | 0.5329 | 0.7437 | 28.0347 | 6.0778 |
| UDnet | 0.3649 | 0.4618 | 0.7535 | 28.1286 | 6.0875 |
| CycleGAN | 0.4457 | 0.7643 | 0.7635 | 28.2800 | 9.0708 |
| SSIM-CycleGAN | 0.4482 | 0.7989 | 0.7771 | 28.4973 | 9.5739 |
| SESS-CycleGAN | 0.4454 | 0.7775 | 0.7747 | 28.6656 | 9.4611 |
| MuLA-GAN | 0.4571 | 0.7819 | 0.7730 | 28.4388 | 9.9494 |
| PUGAN | 0.4495 | 0.8178 | 0.7647 | 28.8436 | 9.0193 |
| ours | 0.4669 | 0.8358 | 0.7883 | 29.1524 | 10.7343 |
| Model/Method | UCIQE ↑ | UIQM ↑ | AG ↑ |
|---|---|---|---|
| UDCP | 0.4227 | 0.9736 | 6.1208 |
| CLAHE | 0.3409 | 0.4619 | 7.8120 |
| UCM | 0.3932 | 0.7004 | 8.6002 |
| UWCNN | 0.3707 | 0.5164 | 6.7591 |
| UDnet | 0.3275 | 0.3614 | 4.5951 |
| CycleGAN | 0.3618 | 0.5765 | 7.8345 |
| SSIM-CycleGAN | 0.3638 | 0.6150 | 8.2624 |
| SESS-CycleGAN | 0.3627 | 0.6209 | 8.4896 |
| MuLA-GAN | 0.3688 | 0.6394 | 8.3231 |
| PUGAN | 0.3715 | 0.6288 | 8.7618 |
| ours | 0.3890 | 0.6569 | 8.9634 |
| Experiments | MSDA | MAFA | LPIPS | UCIQE ↑ | UIQM ↑ | SSIM ↑ | PSNR ↑ | AG ↑ |
|---|---|---|---|---|---|---|---|---|
| T1 | — | — | — | 0.4504 | 0.7244 | 0.7554 | 28.2691 | 11.1365 |
| T2 | √ | — | — | 0.4534 | 0.7708 | 0.7661 | 28.6008 | 11.3141 |
| T3 | — | √ | — | 0.4587 | 0.8491 | 0.7765 | 29.0604 | 11.4885 |
| T4 | — | — | √ | 0.4629 | 0.8501 | 0.7839 | 28.9574 | 11.4448 |
| T5 | √ | — | √ | 0.4784 | 0.8763 | 0.7896 | 29.9013 | 11.5635 |
| T6 | — | √ | √ | 0.4842 | 0.8936 | 0.7933 | 29.2120 | 11.6876 |
| Model/Method | Params (M) ↓ | FLOPs (G) ↓ | FPS (Hz) ↑ |
|---|---|---|---|
| UDCP | — | — | 142.3 |
| CLAHE | — | — | 154.2 |
| UCM | — | — | 128.4 |
| UWCNN | 1.1 | 3.08 | 42.3 |
| UDnet | 16.1 | 96.3 | 54.3 |
| CycleGAN | 11.4 | 58.2 | 99.2 |
| SSIM-CycleGAN | 13.6 | 63.3 | 89.4 |
| SESS-CycleGAN | 13.1 | 62.7 | 90.9 |
| MuLA-GAN | 17.3 | 30.2 | 117.8 |
| PUGAN | 95.7 | 72.5 | 62.5 |
| ours | 12.6 | 60.1 | 94.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Zhang, G.; Fan, Y. LM-CycleGAN: Improving Underwater Image Quality Through Learned Perceptual Image Patch Similarity and Multi-Scale Adaptive Fusion Attention. Sensors 2024, 24, 7425. https://doi.org/10.3390/s24237425
Wu J, Zhang G, Fan Y. LM-CycleGAN: Improving Underwater Image Quality Through Learned Perceptual Image Patch Similarity and Multi-Scale Adaptive Fusion Attention. Sensors. 2024; 24(23):7425. https://doi.org/10.3390/s24237425
Chicago/Turabian StyleWu, Jiangyan, Guanghui Zhang, and Yugang Fan. 2024. "LM-CycleGAN: Improving Underwater Image Quality Through Learned Perceptual Image Patch Similarity and Multi-Scale Adaptive Fusion Attention" Sensors 24, no. 23: 7425. https://doi.org/10.3390/s24237425
APA StyleWu, J., Zhang, G., & Fan, Y. (2024). LM-CycleGAN: Improving Underwater Image Quality Through Learned Perceptual Image Patch Similarity and Multi-Scale Adaptive Fusion Attention. Sensors, 24(23), 7425. https://doi.org/10.3390/s24237425