
CLIP-Llama: A New Approach for Scene Text Recognition with a Pre-Trained Vision-Language Model and a Pre-Trained Language Model


Abstract
1. Introduction
2. Related Work
2.1. Language-Agnostic STR Methods
2.2. Language-Aware STR Methods
2.3. Pre-Trained Models for STR
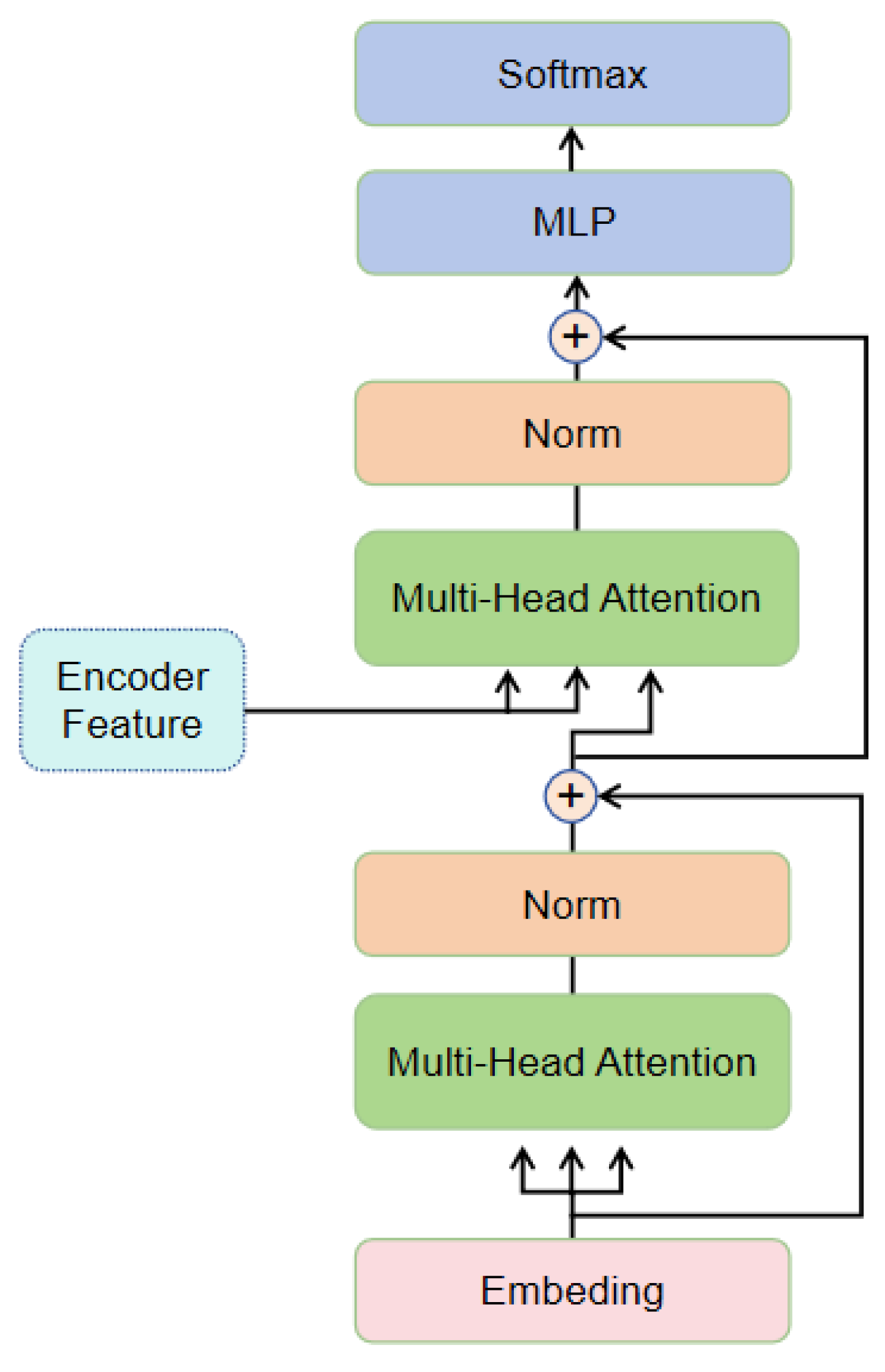
3. Method
3.1. Image Encoder and Text Encoder of CLIP
3.2. Image Decoder and Cross-Modal Decoder
3.3. Threshold Judgement and Language Model
3.4. Supervised Training Loss
4. Experiment
4.1. Dataset
4.2. Experimental Configuration
4.3. Comparison Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, D.; Li, X.; Zhang, C.; Liu, T.; Han, J.; Liu, J.; Ding, E. Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12113–12122. [Google Scholar]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 7098–7107. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision; Cornell University: Ithaca, NY, USA, 2021. [Google Scholar]
- Gao, Y.; Deng, Z.; Huo, Y.; Chen, W. Improving Non-Line-of-Sight Identification in Cellular Positioning Systems Using a Deep Autoencoding and Generative Adversarial Network Model. Sensors 2024, 24, 6494. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Liang, X.; Zhou, Z.; Zhang, B. Multitask learning for hand heat trace time estimation and identity recognition. Expert Syst. Appl. 2024, 255, 124551. [Google Scholar] [CrossRef]
- Yu, X.; Liang, X.; Zhou, Z.; Zhang, B.; Xue, H. Deep soft threshold feature separation network for infrared handprint identity recognition and time estimation. Infrared Phys. Technol. 2024, 138, 105223. [Google Scholar] [CrossRef]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. Clip4clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing 2022, 508, 293–304. [Google Scholar] [CrossRef]
- Hessel, J.; Holtzman, A.; Forbes, M.; Bras, R.L.; Choi, Y. CLIPScore: A Reference-free Evaluation Metric for Image Captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, 7–11 November 2021. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Zhao, S.; Quan, R.; Zhu, L.; Yang, Y. CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model. arXiv 2023, arXiv:2305.14014. [Google Scholar]
- Zhu, Y.; Yao, C.; Bai, X. Scene text detection and recognition: Recent advances and future trends. Front. Comput. Sci. 2016, 10, 19–36. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 2–4 May 2015. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. NeurIPS 2017. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 3–7 May 2021. [Google Scholar]
- Atienza, R. Vision transformer for fast and efficient scene text recognition. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Lausanne, Switzerland, 5 September 2021; Volume 12821, pp. 319–334. [Google Scholar]
- Pan, X.; Zhan, X.; Dai, B.; Lin, D.; Loy, C.C.; Luo, P. Exploiting deep generative prior for versatile image restoration and manipulation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7474–7489. [Google Scholar] [CrossRef] [PubMed]
- Fei, B.; Lyu, Z.; Pan, L.; Zhang, J.; Yang, W.; Luo, T.; Zhang, B.; Dai, B. Generative Diffusion Priorfor Unified Image Restoration and Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 9935–9946. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Wang, W.; Xie, E.; Liu, X.; Wang, W.; Liang, D.; Shen, C.; Bai, X. Scene text image super-resolution in the wild. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 650–666. [Google Scholar]
- Wang, Y.; Xie, H.; Fang, S.; Wang, J.; Zhu, S.; Zhang, Y. From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1–10. [Google Scholar]
- Sheng, F.; Chen, Z.; Xu, B. NRTR: A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Bautista, D.; Atienza, R. University of the Philippines, Scene text recognition with permuted autoregressive sequence models. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (ICML), Online, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Guan, T.; Shen, W.; Yang, X.; Feng, Q.; Jiang, Z.; Yang, X. Self-supervised character-to-character distillation for text recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 19473–19484. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 16000–16009. [Google Scholar]
- Aberdam, A.; Litman, R.; Tsiper, S.; Anschel, O.; Slossberg, R.; Mazor, S.; Man- matha, R.; Perona, P. Sequence-to-Sequence Contrastive Learning for Text Recognition. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 15302–15312. [Google Scholar]
- Li, M.; Lv, T.; Chen, J.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models. arXiv 2021, arXiv:2109.10282. [Google Scholar] [CrossRef]
- Lyu, P.; Zhang, C.; Liu, S.; Qiao, M.; Xu, Y.; Wu, L.; Yao, K.; Han, J.; Ding, E.; Wang, J. Maskocr: Text recognition with masked encoder-decoder pretraining. arXiv 2022, arXiv:2206.00311. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Veit, A.; Matera, T.; Neumann, L.; Matas, J.; Belongie, S.J. Cocotext: Dataset and benchmark for text detection and recognition in natural images. arXiv 2016, arXiv:1601.07140. [Google Scholar]
- Shi, B.; Yao, C.; Liao, M.; Yang, M.; Xu, P.; Cui, L.; Belongie, S.J.; Lu, S.; Bai, X. ICDAR2017 competition on reading chinese text in the wild (RCTW-17). In Proceedings of the International Conference on Document Analysis and Recognition, Kyoto, Japan, 9–15 November 2017. [Google Scholar]
- Zhang, Y.; Gueguen, L.; Zharkov, I.; Zhang, P.; Seifert, K.; Kadlec, B. Uber-text: A large-scale dataset for optical character recognition from street-level imagery. In Proceedings of the SUNw: Scene Understanding Workshop-Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chng, C.K.; Ding, E.; Liu, J.; Karatzas, D.; Chan, C.S.; Jin, L.; Liu, Y.; Sun, Y.; Ng, C.C.; Luo, C.; et al. ICDAR2019 robust reading challenge on arbitrary-shaped text - rrc-art. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Sun, Y.; Karatzas, D.; Chan, C.S.; Jin, L.; Ni, Z.; Chng, C.K.; Liu, Y.; Luo, C.; Ng, C.C.; Han, J.; et al. ICDAR 2019 competition on large-scale street view text with partial labeling—RRC-LSVT. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Nayef, N.; Liu, C.; Ogier, J.; Patel, Y.; Busta, M.; Chowdhury, P.N.; Karatzas, D.; Khlif, W.; Matas, J.; Pal, U.; et al. ICDAR2019 robust reading challenge on multi-lingual scene text detection and recognition—RRC-MLT-2019. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Zhang, R.; Yang, M.; Bai, X.; Shi, B.; Karatzas, D.; Lu, S.; Jawahar, C.V.; Zhou, Y.; Jiang, Q.; Song, Q.; et al. ICDAR 2019 robust reading challenge on reading chinese text on signboard. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Singh, A.; Pang, G.; Toh, M.; Huang, J.; Galuba, W.; Hassner, T. Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 10–25 June 2021. [Google Scholar]
- Krasin, I.; Duerig, T.; Alldrin, N.; Ferrari, V.; Abu-El-Haija, S.; Kuznetsova, A.; Rom, H.; Uijlings, J.; Popov, S.; Veit, A.; et al. Openimages: A Public Dataset for Large-Scale Multilabel and Multi-Class Image Classification. 2017. Available online: https://github.com/openimages (accessed on 21 July 2017).
- Krylov, I.; Nosov, S.; Sovrasov, V. Open images V5 text annotation and yet another mask text spotter. In Proceedings of the Asian Conference on Machine Learning, Singapore, 29 November–3 December 2021. [Google Scholar]
- Mishra, A.; Alahari, K.; Jawahar, C.V. Scene text recognition using higher order language priors. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 1 September 2012. [Google Scholar]
- Risnumawan, A.; Shivakumara, P.; Chan, C.S.; Tan, C.L. A robust arbitrary text detection system for natural scene images. Expert Syst. Appl. 2014, 41, 8027–8048. [Google Scholar] [CrossRef]
- Wang, K.; Babenko, B.; Belongie, S.J. End-to-end scene text recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Beijing, China, 27 April 2011. [Google Scholar]
- Phan, T.Q.; Shivakumara, P.; Tian, S.; Tan, C.L. Recognizing text with perspective distortion in natural scenes. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.G.i.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.; Heras, L.d. ICDAR 2013 robust reading competition. In Proceedings of the International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.K.; Bagdanov, A.D.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on robust reading. In Proceedings of the International Conference on Document Analysis and Recognition, Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Jiang, Q.; Wang, J.; Peng, D.; Liu, C.; Jin, L. Revisiting Scene Text Recognition: A Data Perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | Train Data | III5k 3000 | SVT 647 | IC13 1015 | IC15 1811 | IC15 2077 | SVTP 645 | CUTE 288 | HOST 2416 | WOST 2416 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PlugNet | V | MJ+ST | 94.4 | 92.3 | 95.0 | - | 82.2 | 84.3 | 85.0 | - | - |
| ASTER | V | MJ+ST | 93.4 | 89.5 | - | 76.1 | - | 78.5 | 79.5 | - | - |
| SRN | VL | MJ+ST | 94.8 | 91.5 | - | 82.7 | - | 85.1 | 87.8 | - | - |
| TextScanner | V | MJ+ST | 95.7 | 92.7 | 94.9 | - | 83.5 | 84.8 | 91.6 | - | - |
| SE-ASTER | V | MJ+ST | 93.8 | 89.6 | 92.8 | 80.0 | - | 81.4 | 83.6 | - | - |
| RCEED | VL | MJ+ST+B | 94.9 | 91.8 | - | - | 82.2 | 83.6 | 91.7 | - | - |
| TRBA | V | MJ+ST | 92.1 | 88.9 | - | 86.0 | - | 89.3 | 89.2 | - | - |
| VisionLAN | VL | MJ+ST | 95.8 | 91.7 | - | 83.7 | - | 86.0 | 88.5 | 50.3 70.3 | |
| ABINet | VL | MJ+ST | 96.2 | 93.5 | - | 86.0 | - | 89.3 | 89.2 | - | - |
| ViTSTR-B | V | MJ+ST | 88.4 | 87.7 | 92.4 | 78.5 | 72.6 | 81.8 | 81.3 | - | - |
| LevOCR | VL | MJ+ST | 96.6 | 92.9 | - | 86.4 | - | 88.1 | 91.7 | - | - |
| MATRN | VL | MJ+ST | 96.6 | 95.0 | 95.8 | 86.6 | 82.8 | 90.6 | 93.5 | - | - |
| PETR | V | MJ+ST | 95.8 | 92.4 | 97.0 | 83.3 | - | 86.2 | 89.9 | - | - |
| DiG-ViT-B | VL | MJ+ST | 96.7 | 94.6 | 96.9 | 87.1 | - | 91.0 | 91.3 | 74.9 | 82.3 |
| TrOCR | VL | MJ+ST+B | 94.1 | 96.1 | 97.3 | 88.1 | 84.1 | 93.0 | 95.1 | - | - |
| SIGA | VL | MJ+ST | 96.6 | 95.1 | 96.8 | 86.6 | 83.0 | 90.5 | 93.1 | - | - |
| PARSeq | VL | MJ+ST | 97.0 | 93.6 | 96.2 | 86.5 | 82.9 | 88.9 | 92.2 | - | - |
| CLIP4STR-L | VL | MJ+ST | 98.0 | 95.2 | 96.9 | 87.7 | 84.5 | 93.3 | 95.1 | 82.7 | 88.8 |
| MAERec-B | VL | Union14M-L | 98.5 | 97.8 | 98.1 | - | 89.5 | 94.4 | 98.6 | - | - |
| IGTR-PR | VL | MJ+ST | 97.6 | 95.2 | 97.6 | 88.4 | 88.4 | 91.6 | 95.5 | - | - |
| MGP-STR(Fuse) | VL | MJ+ST | 96.4 | 94.7 | 97.3 | 87.2 | 87.2 | 91.0 | 90.2 | - | - |
| CAM-Base | VL | MJ+ST | 97.4 | 96.1 | 97.2 | 87.8 | 87.8 | 90.6 | 92.4 | - | - |
| SVIPTRv2-B | VL | MJ+ST | 94.8 | 94.2 | 97.0 | 88.0 | 88.0 | 90.0 | 90.2 | - | - |
| DiG-ViT-B | VL | Real | 97.6 | 96.5 | 97.6 | 88.9 | - | 92.9 | 96.5 | 62.8 | 79.7 |
| ViTSTR-S | V | Real | 97.9 | 96.0 | 97.8 | 89.0 | 87.5 | 91.5 | 96.2 | 64.5 | 77.9 |
| ABINet | VL | Real | 98.6 | 98.2 | 98.0 | 90.5 | 88.7 | 94.1 | 97.2 | 72.2 | 85.0 |
| PARSeq | VL | Real | 99.1 | 97.9 | 98.4 | 90.7 | 89.6 | 95.7 | 98.3 | 74.4 | 85.4 |
| NRTR+DPTR | VL | Real | 99.2 | 97.8 | 98.1 | 91.8 | 90.6 | 95.7 | 98.6 | - | - |
| CLIP4STR-L | VL | Real | 99.5 | 98.5 | 98.5 | 91.3 | 90.8 | 97.4 | 99.0 | 79.8 | 89.2 |
| CLIP-Llama(Ous) | VL | Real | 99.47 | 98.45 | 98.52 | 91.99 | 91.43 | 97.67 | 98.96 | 82.33 | 90.52 |
| Method | Train Data | COCO 9825 | ArT 35,149 | Uber 80,551 |
|---|---|---|---|---|
| ViTSTR-S | MJ+ST | 56.4 | 66.1 | 37.6 |
| TRBA | MJ+ST | 61.4 | 68.2 | 38.0 |
| ABINet | MJ+ST | 57.1 | 65.4 | 34.9 |
| PARSeq | MJ+ST | 64.0 | 70.7 | 42.0 |
| MPSTR | MJ+ST | 64.5 | 69.9 | 42.8 |
| CLIP4STR-L | MJ+ST | 67.0 | 73.7 | 44.5 |
| DiG-ViT-B | Real | 75.8 | - | - |
| ViTSTR-S | Real | 73.6 | 81.0 | 78.2 |
| TRBA | Real | 77.5 | 82.5 | 81.2 |
| ABINet | Real | 76.5 | 81.2 | 71.2 |
| PARSeq | Real | 79.8 | 84.5 | 84.1 |
| MPSTR | Real | 80.3 | 84.4 | 84.9 |
| CLIP4STR-L | Real | 81.9 | 85.9 | 87.6 |
| CLIP-Llama(Ours) | Real | 83.09 | 86.85 | 87.67 |
| Threshold | Train Data | III5k 3000 | SVT 647 | IC13 1015 | IC15 1811 | IC15 2077 | SVTP 645 | CUTE 288 |
|---|---|---|---|---|---|---|---|---|
| 0.7 | Real | 99.31 | 98.12 | 98.10 | 91.12 | 91.34 | 97.69 | 98.37 |
| 0.8 | Real | 99.47 | 98.45 | 98.52 | 91.99 | 91.43 | 97.67 | 98.96 |
| 0.9 | Real | 99.35 | 98.20 | 98.27 | 91.67 | 91.54 | 97.54 | 98.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Xu, M.; Silamu, W.; Li, Y. CLIP-Llama: A New Approach for Scene Text Recognition with a Pre-Trained Vision-Language Model and a Pre-Trained Language Model. Sensors 2024, 24, 7371. https://doi.org/10.3390/s24227371
Zhao X, Xu M, Silamu W, Li Y. CLIP-Llama: A New Approach for Scene Text Recognition with a Pre-Trained Vision-Language Model and a Pre-Trained Language Model. Sensors. 2024; 24(22):7371. https://doi.org/10.3390/s24227371
Chicago/Turabian StyleZhao, Xiaoqing, Miaomiao Xu, Wushour Silamu, and Yanbing Li. 2024. "CLIP-Llama: A New Approach for Scene Text Recognition with a Pre-Trained Vision-Language Model and a Pre-Trained Language Model" Sensors 24, no. 22: 7371. https://doi.org/10.3390/s24227371
APA StyleZhao, X., Xu, M., Silamu, W., & Li, Y. (2024). CLIP-Llama: A New Approach for Scene Text Recognition with a Pre-Trained Vision-Language Model and a Pre-Trained Language Model. Sensors, 24(22), 7371. https://doi.org/10.3390/s24227371