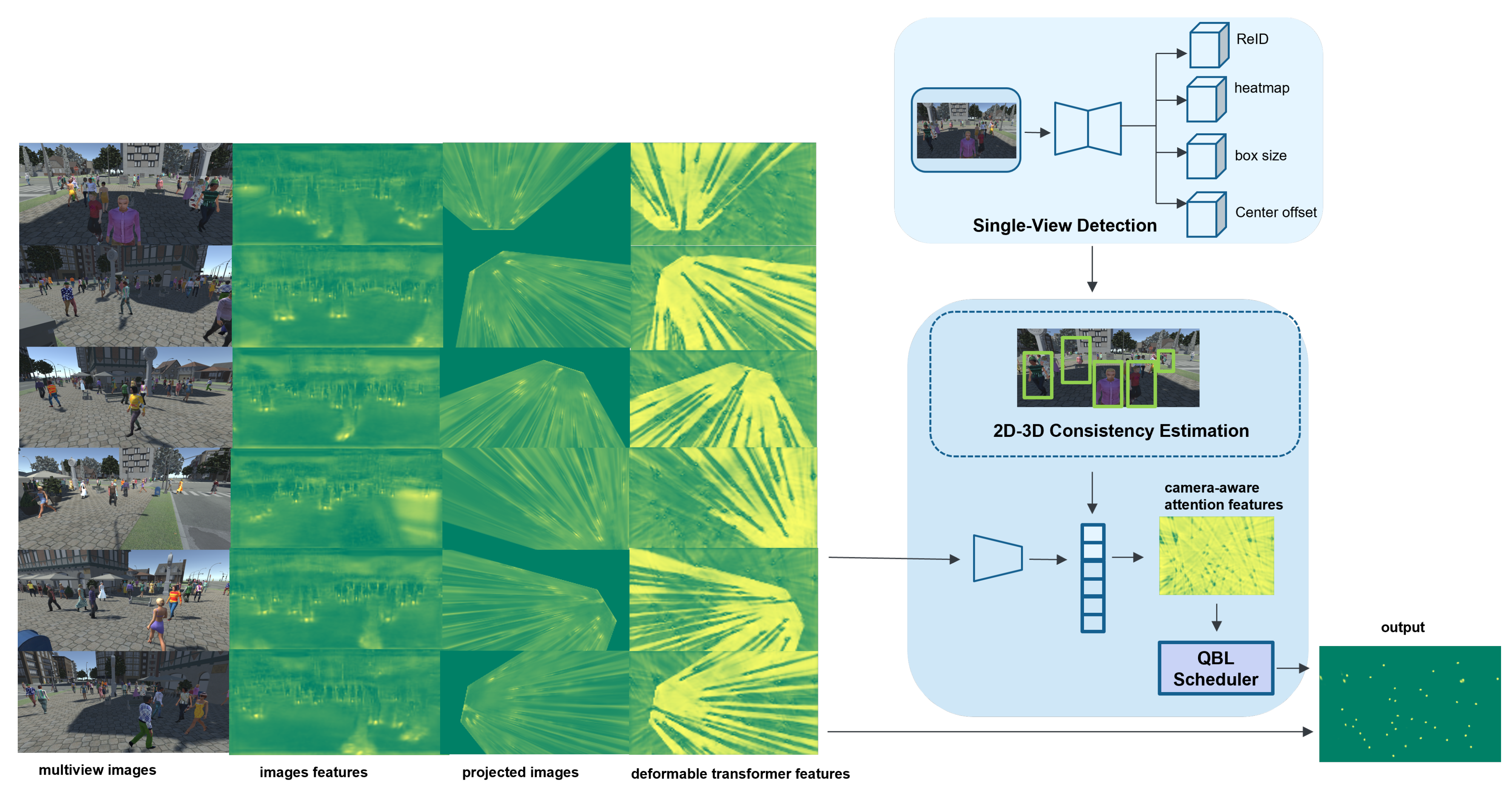
Our framework aims to determine the 3D coordinates of each individual using images captured from multiple cameras. With a set of images and their corresponding camera parameters, we seek to detect pedestrian locations within the overlapping fields of view while maintaining 2D–3D consistency constraints. To accomplish this, we introduce a 2D–3D consistency constraint that jointly optimizes the proposed QMVDet and the 2D single-view detection network using consistency and mimic losses. Although QMVDet inherently maintains consistency, the 2D single-view detection network may not always ensure strict 2D–3D consistency, potentially leading to inaccuracies in QMVDet’s results. To address this, we use inconsistent 2D–3D projection results as an attention mechanism to generate distributions based on the inconsistency, weighting the importance of each camera for multiview aggregation. We model learnable latent codes with the conditional probability of 2D–3D detection inconsistency through a 2D–3D consistency estimation.
Next, we will introduce the 2D single-view detection network in
Section 3.1, which is followed by a discussion of our QMVDet in
Section 3.2. Finally, we will explain how we establish the 2D–3D consistency mechanism based on these two networks in
Section 3.3.
Figure 2 presents the proposed QMVDet framework with further details provided in Algorithm 1.
| Algorithm 1: QMVDet Algorithm |
![Sensors 24 04773 i001]() |
3.1. Two-Dimensional (2D) Single-View Detection Network
To evaluate the consistency between 2D and 3D, it is essential to have a 2D single-view detection network. To ensure more accurate 2D detection results, we utilize the detection-by-tracking approach, which leverages tracklet association and interpolation to compensate for missed detections. This is crucial for 2D–3D consistency estimation, as 2D detection performance is often impacted by occlusions present in 2D images. Therefore, we employ a multiple object tracking (MOT) network as our single-view detection component.
Our single-view detection setup follows the configuration of FairMOT [
24], utilizing an anchor-free detector. We use DLA-34 [
37] to predict heatmaps, object center offsets, and bounding box sizes, and we incorporate 3 × 3 convolutional layers to generate output features. The final layer is a 1 × 1 convolutional layer that produces the final output. The single-view detection branch includes two heads: a heatmap head and a box head. The loss functions are defined as follows:
where
represents the heatmap, and
and
are the parameters of the focal loss. The heatmap head is responsible for estimating the centers of pedestrians, ideally producing a value of one when it aligns with the ground truth. Conversely, the box offset and size loss functions are employed to enhance the accuracy of pedestrian locations. The single-view detection branch is based on the CenterNet framework [
37], which is widely adopted in many anchor-free methods. For each bounding box
i,
denotes the corresponding offset, and
represents its size. The predicted offset and size are denoted by
and
, respectively.
is a weighting parameter set to 0.1, following the original CenterNet [
37].
3.2. QMVDet
In this section, we describe the method for leveraging 2D–3D consistency to create an attention mechanism across multiple cameras. We propose a query-based learning framework for multiview detection, wherein the 2D single-view detection network directs the 3D multiview detection network.
A multiview detection system involves two primary steps: projecting feature maps and aggregating multiview data. The first step projects the feature maps from multiple views onto a ground plane (bird’s eye view) through perspective transformation. This is accomplished by extracting feature maps from a 2D single-view detection network and applying perspective transformation [
1] to achieve anchor-free representations. This transformation process translates between 2D image pixel coordinates
and 3D locations
. Using the 2D image pixel coordinates, the corresponding 3D world coordinates on the ground plane (where
) are calculated to generate the projected feature maps.
where
denotes a scaling factor, and
P represents the perspective transformation matrix, which is derived from the intrinsic parameter
I and the extrinsic parameter, consisting of the rotation–translation matrix
.
The second step in multiview detection is the anchor-free aggregation of feature maps. In our framework, we use the encoder from the deformable transformer as our feature extractor to produce aggregated multiview projected feature maps in accordance with the principles of MVDetr [
2].
where
p denotes the position, and
c represents the camera ID.
is the set of position offsets for the deformable reference point, with
k indicating the number of reference points.
and
are the transformations for multi-head
m.
In this context, treating all camera views with equal weighting for multiview projected feature map aggregation is not optimal due to varying occlusion levels and different visibilities from each camera. Therefore, we propose a query-based learning framework that allows the network to learn attention weights for each camera, enabling adjustable weighted feature map aggregation. This method leverages 2D–3D consistency to guide the learning of the 3D multiview detection network using a 2D single-view detection network.
where
represents the trained camera-aware attention vector based on query-based learning. To determine
, we start by inferring the 3D foot point
from the multiview detection network. Using perspective transformation, we convert these to 2D foot point coordinates
. This allows us to measure the discrepancy
between
and the 2D foot point coordinates
predicted by the 2D single-view detection network, as defined in Equation (
6). We then calculate the average discrepancy for all pedestrians
p in Equation (
7) for each camera
c, resulting in
. This serves as the 2D–3D consistency-based camera-aware attention to aid in training the multiview detection network. It is worth noting that projecting 2D detection results into 3D space to compare with predicted 3D coordinates is an alternative method; however, it is less reliable than the 3D to 2D projection approach used in Equation (
6).
Within the camera-aware attention model, we apply attention-weighted averaging to a sequence of image features. The concept of camera-aware attention for aggregating multiview data is defined as follows:
The network responsible for generating attention processes a sequence of image-level deformable transformer features
and produces
C attention scores. Our attention mechanism involves two key steps: “spatial convolution” and “cross-camera convolution”. First, a spatial convolution layer is applied to each frame from every camera, resulting in a
d-dimensional feature for each frame. Next, a cross-camera convolution layer combines these frame-level features from all cameras to create temporal attentions
. The attention scores
are then multiplied by
, and a softmax function is applied to produce the final camera-aware attention vector
.
Due to the computational intensity involved in the 2D–3D consistency estimation, substantial computational resources are needed. Therefore, we introduced a query-based learning (QBL) scheduler to manage the frequency of guiding the multiview detection learning process. When there are significant changes in the distribution of the camera-aware attention vector, meaning the relative weights of the cameras shift, the QBL scheduler adjusts by providing the camera-aware attention vector to generate the final attention vector
to steer the learning of multiview detection. Ultimately, a pedestrian occupancy map is employed to generate the multiview detection results via ground plane convolution. In
Figure 3, we illustrate how to use weight order to monitor the changes in the distribution of the camera-aware attention vector. If the weight order changes, the QBL scheduler will be activated immediately.
3.3. Training Scheme
Multiview detection essentially involves detecting key points with the objective of multiview systems being to estimate pedestrian occupancy on the ground plane [
1,
6]. We employ a heatmap regression method to predict the likelihood of pedestrian occupancy, which is inspired by the approach used in CornerNet [
38]. In the QMVDet framework, we also train a single-view detection network to produce 2D detection results. These results are then used for 2D–3D consistency estimation, which in turn guides the training of the camera-aware attention mechanism.
Training Scheme for Single-view Detection. We train the 2D MOT by combining multiple loss functions, including the re-identification (ReID) loss in our single-view detection branch. This is necessary to use tracklet association for obtaining reliable 2D detections for 2D–3D consistency estimation. Drawing inspiration from uncertainty losses, we automatically balance these losses using Equation (
11).
where
,
, and
are learnable parameters. Our loss for 2D MOT is inspired by FariMOT [
24], and the re-identification (ReID) loss
is cross-entropy loss.
N denotes the total number of samples.
K denotes the total number of classes.
represents the actual distribution (typically a one-hot encoded vector) for the
i-th sample in the
K-th class.
represents the predicted probability of the
K-th class by the model. For
, we use another cross-entropy loss to learn the camera classification.
C means the number of cameras.
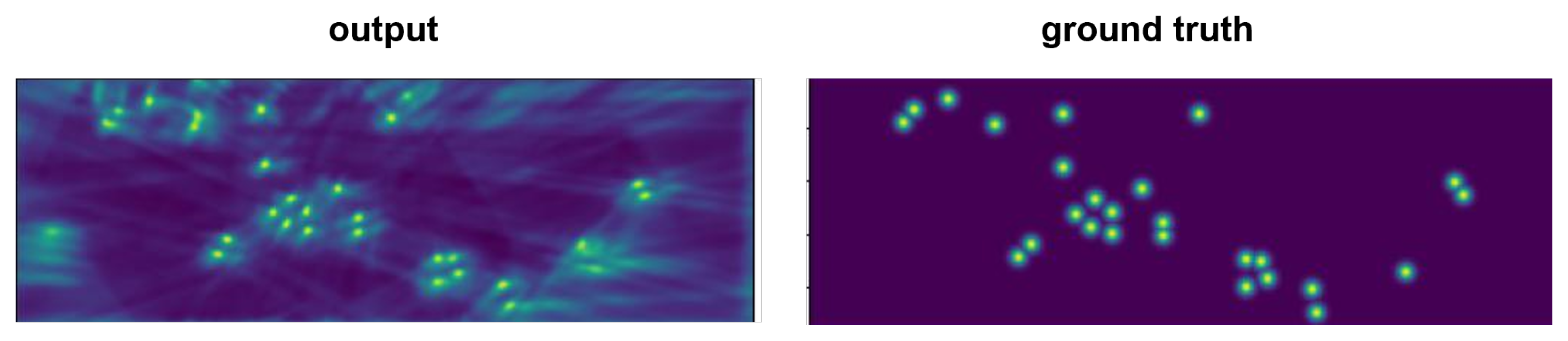
Training Scheme of Multiview Detection. The goal of the multiview detection network is to generate a heatmap that represents the pedestrian occupancy likelihood score
for each position
p on the ground plane. Inspired by the focal loss [
39] and using a Gaussian-smoothed target
s, the loss function for multiview detection can be formulated as follows:
where
N represents the total number of pedestrians on the ground plane and
indicates the ground truth position of the target
s. Similar to the approach in MVDetr [
2], we also predict an offset to account for the lower resolution of the output heatmap compared to the ground truth, allowing us to adjust for the missing decimal precision.
where
represents the positional offset and
r is the downsampling parameter. Additionally, we incorporate a bounding box regression loss based on the L1 distance into our final loss function. Hence, the complete loss function is as follows:
, and represent the image-level loss for a specific camera c.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}