
Detection and Recognition of Tilted Characters on Railroad Wagon Wheelsets Based on Deep Learning


Abstract
:1. Introduction
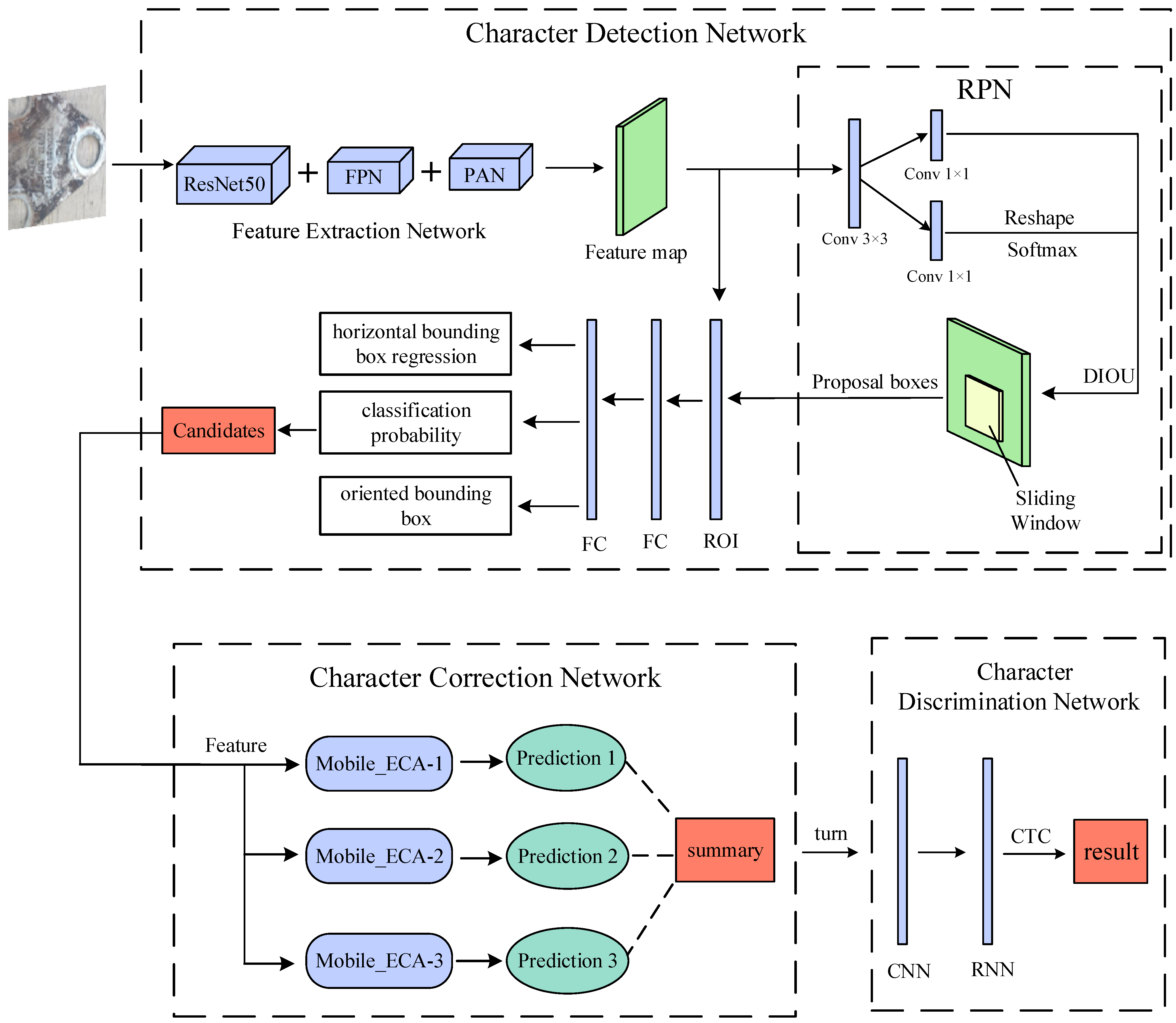
- We construct a tilted character detection network based on Faster RCNN. To increase detection speed, adding an architecture combining the feature pyramid network (FPN) and path aggregation network (PAN) performs feature extraction, using a two-branch structure to process horizontal and oriented boxes. Using the distance-IOU (DIOU) in the region proposal network (RPN) enhances the accuracy of the candidate box.
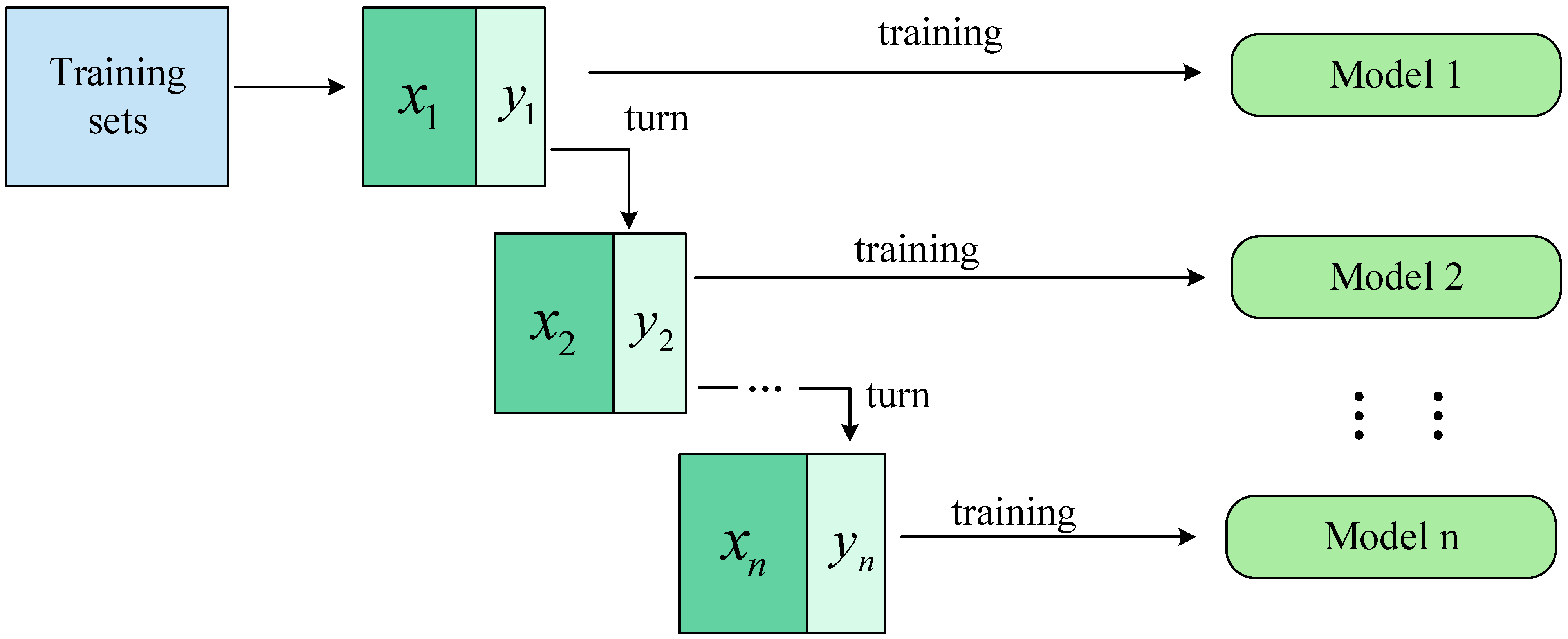
- A lightweight network is designed to perform character orientation classification and correction; the MobileNet_ECA network, a combination of MobileNetV2 and efficient channel attention (ECA), is constructed as an individual learner with ensemble learning, and the Bagging algorithm is used to train it on different datasets to improve the accuracy of the network.
- A network that recognizes characters has been constructed based on CRNN, using MobileNetV2_ECA as a feature extraction network to improve network speed and accuracy. The extracted features are fed into the bidirectional long short-term memory network (BLSTM) to remove the sequence information further. Finally, the connectionist temporal classification (CTC) is used to output the corresponding sequence of characters to realize the recognition of wheel–pair characters.
2. Related Work
2.1. Conventional Methods
2.2. Deep Learning Methods
3. The Proposed Approach
3.1. Tilted Character Detection Network
3.1.1. Feature Extraction Network
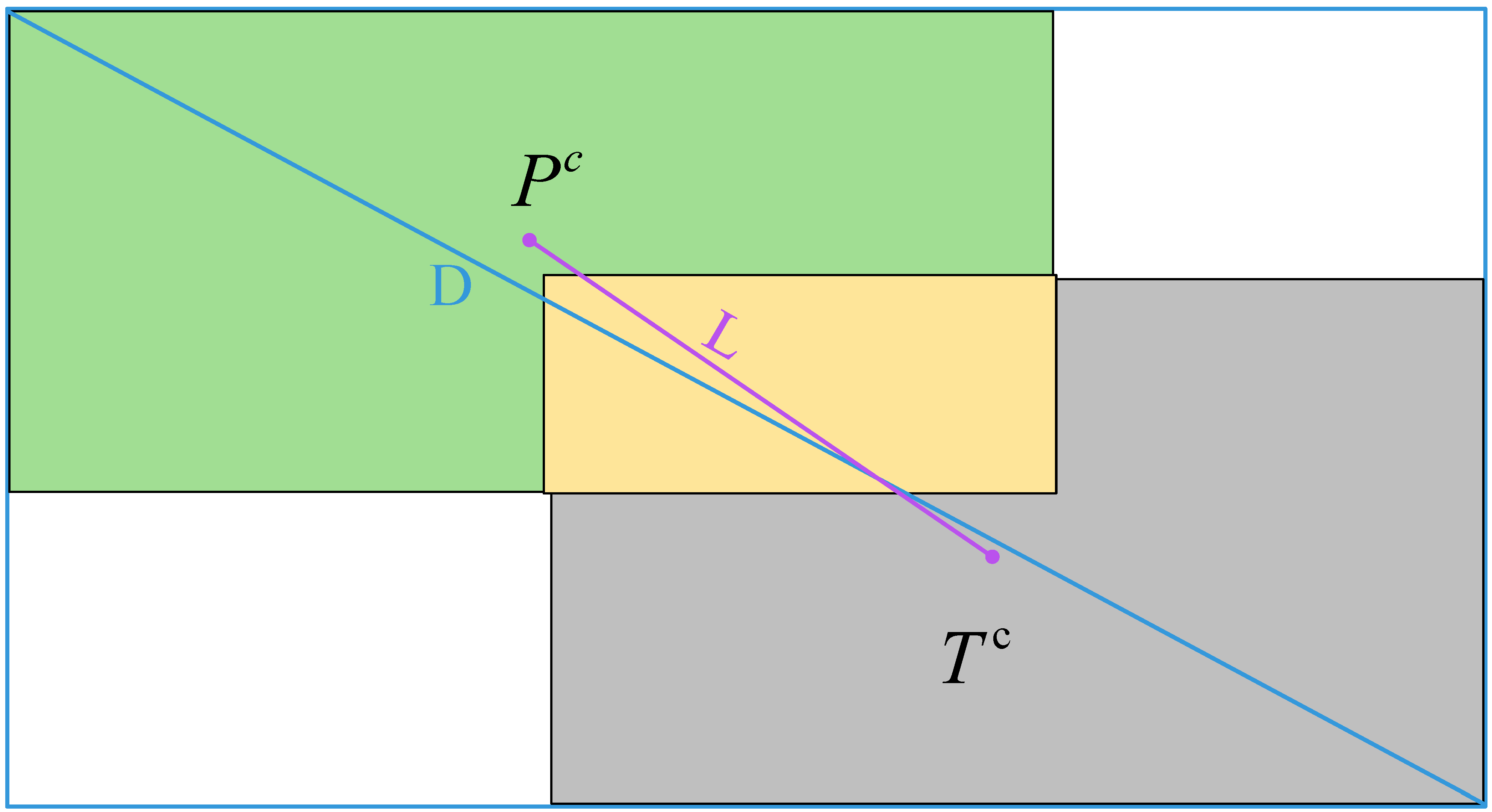
3.1.2. Region Proposal Network (RPN)
3.1.3. Region of Interest (ROI)
3.2. Tilted Character Correction Network
3.3. Character Recognition Network
4. Experiments and Result
4.1. Experimental Configuration
4.2. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dziadak, B.; Kucharek, M.; Starzyński, J. Powering the WSN Node for Monitoring Rail Car Parameters, Using a Piezoelectric Energy Harvester. Energies 2022, 15, 1641. [Google Scholar] [CrossRef]
- Opala, M. Analysis of Safety Requirements for Securing the Semi-Trailer Truck on the Intermodal Railway Wagon. Energies 2021, 14, 6539. [Google Scholar] [CrossRef]
- Mikhailov, E.; Semenov, S.; Shvornikova, H.; Gerlici, J.; Kovtanets, M.; Dižo, J.; Blatnický, M.; Harušinec, J. A Study of Improving Running Safety of a Railway Wagon with an Independently Rotating Wheel’s Flange. Symmetry 2021, 13, 1955. [Google Scholar] [CrossRef]
- Muradian, L.; Pitsenko, I.; Shaposhnyk, V.; Shvets, A.; Shvets, A. Predictive model of risks in railroad transport when diagnosing axle boxes of freight wagons. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2023, 237, 528–532. [Google Scholar] [CrossRef]
- Jwo, J.-S.; Lin, C.-S.; Lee, C.-H.; Zhang, L.; Huang, S.-M. Intelligent System for Railway Wheelset Press-Fit Inspection Using Deep Learning. Appl. Sci. 2021, 11, 8243. [Google Scholar] [CrossRef]
- Liu, Z.; Li, L.; Zhang, D.; Liu, L.; Deng, Z. A Parallel Text Recognition in Electrical Equipment Nameplate Images Based on Apache Flink. J. Circuits Syst. Comput. 2023, 32, 2350109. [Google Scholar] [CrossRef]
- Yang, P.; Zhang, F.; Yang, G. A Fast Scene Text Detector Using Knowledge Distillation. IEEE Access 2019, 7, 22588–22598. [Google Scholar] [CrossRef]
- Wang, B.; Xiao, H.; Zheng, J.; Yu, D.; Chen CL, P. Character Segmentation and Recognition of Variable-Length License Plates Using ROI Detection and Broad Learning System. Remote Sens. 2022, 14, 1560. [Google Scholar] [CrossRef]
- Xiao, L.; Zhou, P.; Xu, K.; Zhao, X. Multi-Directional Scene Text Detection Based on Improved YOLOv3. Sensors 2021, 21, 4870. [Google Scholar] [CrossRef]
- Li, C. Research on Methods of English Text Detection and Recognition Based on Neural Network Detection Model. Sci. Program. 2021, 2021, 6406856. [Google Scholar] [CrossRef]
- Guo, Z.; Yang, J.; Qu, X.; Li, Y. Fast Localization and High Accuracy Recognition of Tire Surface Embossed Characters Based on CNN. Appl. Sci. 2023, 13, 6560. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, X.; Fu, B.; Zhan, Z.; Sun, H.; Li, L.; Zhang, G. Evaluation and Recognition of Handwritten Chinese Characters Based on Similarities. Appl. Sci. 2022, 12, 8521. [Google Scholar] [CrossRef]
- Boukharouba, A. A new algorithm for skew correction and baseline detection based on the randomized Hough Transform. J. King Saud Univ.-Comput. Inf. Sci. 2017, 29, 29–38. [Google Scholar] [CrossRef]
- Sun, Y.; Mao, X.; Hong, S.; Xu, W.; Gui, G. Template Matching-Based Method for Intelligent Invoice Information Identification. IEEE Access 2019, 7, 28392–28401. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Tang, Q.; Xin, J.; Yang, C.; Zhang, Z.; Yang, X. A Rapid Identification Technique of Moving Loads Based on MobileNetV2 and Transfer Learning. Buildings 2023, 13, 572. [Google Scholar] [CrossRef]
- Vieira, N. Quaternionic Convolutional Neural Networks with Trainable Bessel Activation Functions. Complex Anal. Oper. Theory 2023, 17, 82. [Google Scholar] [CrossRef]
- Antonello, M.; Chiesurin, S.; Ghidoni, S. Enhancing semantic segmentation with detection priors and iterated graph cuts for robotics. Eng. Appl. Artif. Intell. 2020, 90, 103467. [Google Scholar] [CrossRef]
- Yang, S.; Pei, Z.; Zhou, F.; Wang, G. Rotated Faster R-CNN for Oriented Object Detection in Aerial Images. In Proceedings of the 2020 3rd International Conference on Robot Systems and Applications, Chengdu, China, 14–16 June 2020; pp. 35–39. [Google Scholar]
- Sheng, W.; Yu, X.; Lin, J.; Chen, X. Faster RCNN Target Detection Algorithm Integrating CBAM and FPN. Appl. Sci. 2023, 13, 6913. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Huang, S.Y.; An, W.J.; Zhang, D.S.; Zhou, N.R. Image classification and adversarial robustness analysis based on hybrid quantum–classical convolutional neural network. Opt. Commun. 2023, 533, 129287. [Google Scholar] [CrossRef]
- Zhang, X.S.; Wang, Y. Industrial character recognition based on improved CRNN in complex environments. Comput. Ind. 2022, 142, 103732. [Google Scholar]
- Biró, A.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, L.; Szilágyi, S.M. Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Appl. Sci. 2023, 13, 4419. [Google Scholar] [CrossRef]
- Li, W.; Sun, W.; Zhao, Y.; Yuan, Z.; Liu, Y. Deep Image Compression with Residual Learning. Appl. Sci. 2020, 10, 4023. [Google Scholar] [CrossRef]
- Wang, C.; Zhong, C. Adaptive Feature Pyramid Networks for Object Detection. IEEE Access 2021, 9, 107024–107032. [Google Scholar] [CrossRef]
- Hu, J.F.; Sun, J.; Lin, Z.; Lai, J.H.; Zeng, W.; Zheng, W.S. APANet: Auto-Path Aggregation for Future Instance Segmentation Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3386–3403. [Google Scholar] [CrossRef]
- Dong, C.; Duoqian, M. Control Distance IoU and Control Distance IoU Loss for Better Bounding Box Regression. Pattern Recognit. 2023, 137, 109256. [Google Scholar] [CrossRef]
- Geng, F.; Ding, Q.; Wu, W.; Wang, X.; Li, Y.; Sun, J.; Wang, R. Light-efficient channel attention in convolutional neural networks for tic recognition in the children with tic disorders. Front. Comput. Neurosci. 2022, 16, 1047954. [Google Scholar] [CrossRef]
- Chadha, G.S.; Panambilly, A.; Schwung, A.; Ding, S.X. Bidirectional deep recurrent neural networks for process fault classification. ISA Trans. 2020, 106, 330–342. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Versions |
|---|---|
| CPU | 12th Gen Intel (R) Core (TM) i5-12500H |
| RAM | 16.0 GB |
| Operating system | Windows 11 |
| Language | Python 3.10 |
| Framework | Pytorch 1.11.0 |
| Net | Training Sets (Base) | Validation Sets (Base) | Batch Size | Learning Rate |
|---|---|---|---|---|
| Detection | 700 | 300 | 50 | 0.0001 |
| Correction | 700 | 300 | 50 | 0.0001 |
| Discriminate | 700 | 300 | 50 | 0.0001 |
| Model | Accuracy (%) | mAP (%) | Inference Time (ms) |
|---|---|---|---|
| Template matching | 82.95 | - | 203 |
| Faster (ResNet) | 92.33 | 72.6 | 30.6 |
| Faster + FPN-PAN | 93.21 | 73.4 | 32.7 |
| Faster + DIOU | 93.19 | 73.1 | 32.3 |
| Faster + FPN-PAN + DIOU | 94.69 | 74.6 | 34.6 |
| Model | Accuracy (%) | Parameters (M) | Inference Time (ms) |
|---|---|---|---|
| MobileNetV2 | 90.13 | 3.5 | 5.7 |
| MobileNetV2_ECA | 92.34 | 3.5 | 6.5 |
| Ensemble | 94.62 | 11.6 | 8.2 |
| Model | Accuracy (%) | Model Size (Mb) | Inference Time (ms) |
|---|---|---|---|
| CRNN (ResNet) | 94.73 | 27 | 23.11 |
| CRNN (MobileNetV2) | 94.12 | 11 | 15.89 |
| CRNN (MobileNetV2_ECA) | 96.36 | 13 | 16.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Xu, Z.; Lu, Z.; Peng, C.; Yan, S. Detection and Recognition of Tilted Characters on Railroad Wagon Wheelsets Based on Deep Learning. Sensors 2023, 23, 7716. https://doi.org/10.3390/s23187716
Xu F, Xu Z, Lu Z, Peng C, Yan S. Detection and Recognition of Tilted Characters on Railroad Wagon Wheelsets Based on Deep Learning. Sensors. 2023; 23(18):7716. https://doi.org/10.3390/s23187716
Chicago/Turabian StyleXu, Fengxia, Zhenyang Xu, Zhongda Lu, Chuanshui Peng, and Shiwei Yan. 2023. "Detection and Recognition of Tilted Characters on Railroad Wagon Wheelsets Based on Deep Learning" Sensors 23, no. 18: 7716. https://doi.org/10.3390/s23187716
APA StyleXu, F., Xu, Z., Lu, Z., Peng, C., & Yan, S. (2023). Detection and Recognition of Tilted Characters on Railroad Wagon Wheelsets Based on Deep Learning. Sensors, 23(18), 7716. https://doi.org/10.3390/s23187716