
Probabilistic Semantic Mapping for Autonomous Driving in Urban Environments
 , , , , and
, , , , and
Abstract
1. Introduction
2. Related Work
2.1. Semantic Segmentation
2.2. Semantic Mapping
2.3. HD Map Generation
2.4. Probabilistic Map
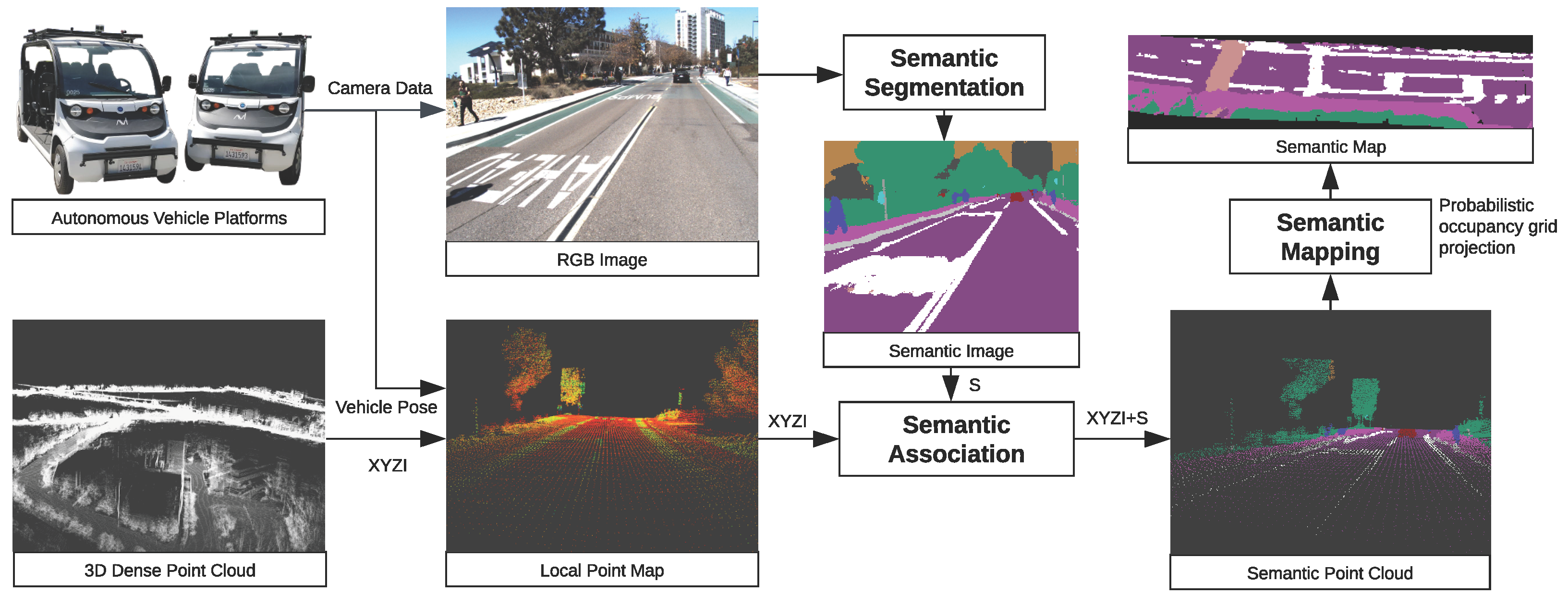
3. Materials and Methods
3.1. Image Semantic Segmentation
3.2. Point Cloud Semantic Association
3.3. Semantic Mapping
4. Experiments
4.1. Platform
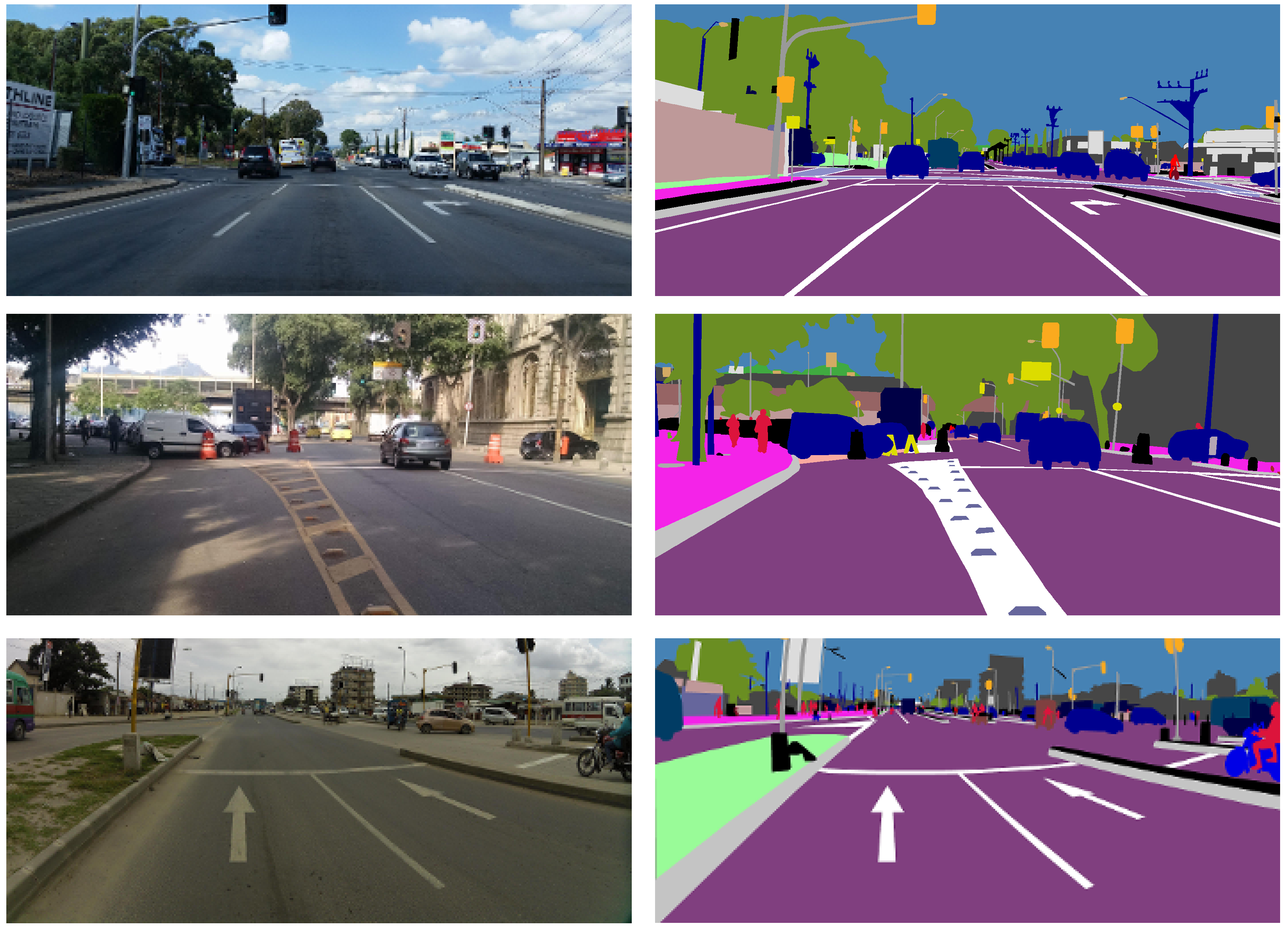
4.2. Image Semantic Segmentation
4.2.1. MScale HRNet+OCR Configuration
4.2.2. DeepLabV3Plus Training Dataset
4.2.3. DeepLabV3Plus Hyperparameters
4.2.4. Comparison of Semantic Segmentation
4.3. Semantic Mapping
4.3.1. Metric for Semantic Mapping
4.3.2. Modeling of Observation Uncertainty
4.3.3. Integration with LiDAR Intensity
4.3.4. Effect of Clipping Range
4.3.5. Mapping Results
4.4. Comparison with Different Depth Association Approach
4.4.1. Comparison to Sparse LiDAR Scan
4.4.2. Comparison to Planar Assumption
5. Discussion
5.1. IoU and Localization Error
5.2. Semantic Segmentation
5.3. Mapillary Inconsistency
5.4. Disappearing Lanes and Discretization
6. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiao, J. Machine Learning Assisted High-Definition Map Creation. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 367–373. [Google Scholar] [CrossRef]
- Douillard, B.; Fox, D.; Ramos, F.; Durrant-Whyte, H. Classification and Semantic Mapping of Urban Environments. Int. J. Robot. Res. 2011, 30, 5–32. [Google Scholar] [CrossRef]
- Sengupta, S.; Sturgess, P.; Ladický, L.; Torr, P.H.S. Automatic dense visual semantic mapping from street-level imagery. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 857–862. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation; Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef]
- Homayounfar, N.; Ma, W.C.; Lakshmikanth, S.K.; Urtasun, R. Hierarchical Recurrent Attention Networks for Structured Online Maps. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3417–3426. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Maturana, D.; Chou, P.W.; Uenoyama, M.; Scherer, S. Real-Time Semantic Mapping for Autonomous Off-Road Navigation. In Field and Service Robotics; Hutter, M., Siegwart, R., Eds.; Springer: Cham, Switzerland, 2018; Volume 5, pp. 335–350. [Google Scholar] [CrossRef]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper: Extracting road topology from aerial images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3458–3466. [Google Scholar] [CrossRef]
- Homayounfar, N.; Ma, W.C.; Liang, J.; Wu, X.; Fan, J.; Urtasun, R. DAGMapper: Learning to Map by Discovering Lane Topology. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2911–2920. [Google Scholar] [CrossRef]
- Zhou, Y.; Takeda, Y.; Tomizuka, M.; Zhan, W. Automatic Construction of Lane-level HD Maps for Urban Scenes. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 6649–6656. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, T.; Wang, Y.; Wang, Y.; Zhao, H. VectorMapNet: End-to-end Vectorized HD Map Learning. arXiv 2023, arXiv:2206.08920. [Google Scholar]
- Liao, B.; Chen, S.; Wang, X.; Cheng, T.; Zhang, Q.; Liu, W.; Huang, C. MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction. arXiv 2023, arXiv:2208.14437. [Google Scholar]
- Li, T.; Chen, L.; Geng, X.; Wang, H.; Li, Y.; Liu, Z.; Jiang, S.; Wang, Y.; Xu, H.; Xu, C.; et al. Topology Reasoning for Driving Scenes. arXiv 2023, arXiv:2304.05277. [Google Scholar]
- Can, Y.B.; Liniger, A.; Paudel, D.P.; Van Gool, L. Topology Preserving Local Road Network Estimation from Single Onboard Camera Image. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 17242–17251. [Google Scholar] [CrossRef]
- Tao, A.; Sapra, K.; Catanzaro, B. Hierarchical Multi-Scale Attention for Semantic Segmentation. arXiv 2020, arXiv:2005.10821. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Rota Bulò, S.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar] [CrossRef]
- Paz, D.; Zhang, H.; Li, Q.; Xiang, H.; Christensen, H.I. Probabilistic Semantic Mapping for Urban Autonomous Driving Applications. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2059–2064. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic Object Classes in Video: A High-Definition Ground Truth Database. Pattern Recognit. Lett. 2008, 30, 88–97. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar] [CrossRef]
- Heinzler, R.; Piewak, F.; Schindler, P.; Stork, W. CNN-Based Lidar Point Cloud De-Noising in Adverse Weather. IEEE Robot. Autom. Lett. 2020, 5, 2514–2521. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, T.; Yun, P.; Tai, L.; Liu, M. PointSeg: Real-Time Semantic Segmentation Based on 3D LiDAR Point Cloud. arXiv 2018, arXiv:1807.06288. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar] [CrossRef]
- Jain, J.; Li, J.; Chiu, M.; Hassani, A.; Orlov, N.; Shi, H. OneFormer: One Transformer to Rule Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 2989–2998. [Google Scholar]
- Dwivedi, I.; Malla, S.; Chen, Y.T.; Dariush, B. Bird’s Eye View Segmentation Using Lifted 2D Semantic Features. In Proceedings of the British Machine Vision Conference (BMVC), Virtually, 22–25 November 2021; pp. 6985–6994. [Google Scholar]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Wolf, D.F.; Sukhatme, G.S. Semantic Mapping Using Mobile Robots. IEEE Trans. Robot. 2008, 24, 245–258. [Google Scholar] [CrossRef]
- Sengupta, S.; Greveson, E.; Shahrokni, A.; Torr, P.H.S. Urban 3D semantic modelling using stereo vision. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 580–585. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Wilson, B.; Qi, W.; Agarwal, T.; Lambert, J.; Singh, J.; Khandelwal, S.; Pan, B.; Kumar, R.; Hartnett, A.; Pontes, J.K.; et al. Argoverse 2: Next Generation Datasets for Self-driving Perception and Forecasting. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021), Virtually, 7–10 December 2021. [Google Scholar]
- Lambert, J.; Hays, J. Trust, but Verify: Cross-Modality Fusion for HD Map Change Detection. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021), Virtually, 7–10 December 2021. [Google Scholar]
- Wang, H.; Li, T.; Li, Y.; Chen, L.; Sima, C.; Liu, Z.; Wang, Y.; Jiang, S.; Jia, P.; Wang, B.; et al. OpenLane-V2: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving. arXiv 2023, arXiv:2304.10440. [Google Scholar]
- Li, Q.; Wang, Y.; Wang, Y.; Zhao, H. HDMapNet: An Online HD Map Construction and Evaluation Framework. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4628–4634. [Google Scholar] [CrossRef]
- Büchner, M.; Zürn, J.; Todoran, I.G.; Valada, A.; Burgard, W. Learning and Aggregating Lane Graphs for Urban Automated Driving. arXiv 2023, arXiv:2302.06175. [Google Scholar]
- Thrun, S.; Fox, D.; Burgard, W. Probabilistic mapping of an environment by a mobile robot. In Proceedings of the 1998 IEEE International Conference on Robotics and Automation (Cat. No.98CH36146), Leuven, Belgium, 16–20 May 1998; Volume 2, pp. 1546–1551. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; M. Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Levinson, J.; Thrun, S. Robust vehicle localization in urban environments using probabilistic maps. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; pp. 4372–4378. [Google Scholar] [CrossRef]
- Shao, Y.; Toth, C.; Grejner-Brzezinska, D.A.; Strange, L.B. High-Accuracy vehicle localization using a pre-built probability map. In Proceedings of the IGTF 2017—Imaging & Geospatial Technology Forum 2017, Baltimore, MD, USA, 12–16 March 2017. [Google Scholar]
- Wu, J.; Ruenz, J.; Althoff, M. Probabilistic Map-based Pedestrian Motion Prediction Taking Traffic Participants into Consideration. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1285–1292. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings Part VI 16. Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Volume 12351, pp. 173–190. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paz, D.; Lai, P.J.; Harish, S.; Zhang, H.; Chan, N.; Hu, C.; Binnani, S.; Christensen, H. Lessons Learned from Deploying Autonomous Vehicles at UC San Diego; Field and Service Robotics; Ishigami, G., Yoshida, K., Eds.; Springer: Singapore, 2019; Volume 16, pp. 427–441. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An accurate O(n) solution to the PnP problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving Semantic Segmentation via Video Propagation and Label Relaxation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8848–8857. [Google Scholar] [CrossRef]
- Wu, Q.; Shi, S.; Wan, Z.; Fan, Q.; Fan, P.; Zhang, C. Towards V2I Age-aware Fairness Access: A DQN Based Intelligent Vehicular Node Training and Test Method. Chin. J. Electron. 2022, 32, 1–15. [Google Scholar] [CrossRef]
- Paz, D.; Zhang, H.; Christensen, H.I. TridentNet: A Conditional Generative Model for Dynamic Trajectory Generation; Intelligent Autonomous Systems 16; Ang, M.H., Jr., Asama, H., Lin, W., Foong, S., Eds.; Springer: Cham, Switzerland, 2022; Volume 412, pp. 403–416. [Google Scholar] [CrossRef]
- Paz, D.; Xiang, H.; Liang, A.; Christensen, H.I. TridentNetV2: Lightweight Graphical Global Plan Representations for Dynamic Trajectory Generation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9265–9271. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Config | Road | Crosswalks | Lane Marks | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision * | Recall * | IoU | Precision * | Recall * | IoU | Precision * | Recall * | IoU | ||
| 4*DeepLabV3+ | Vanilla | 0.975 | 0.786 | 0.678 | 0.990 | 0.687 | 0.567 | 0.762 | 0.498 | 0.186 |
| Vanilla+I | 0.975 | 0.784 | 0.674 | 0.990 | 0.677 | 0.552 | 0.757 | 0.576 | 0.213 | |
| CFN | 0.985 | 0.760 | 0.641 | 0.954 | 0.745 | 0.622 | 0.730 | 0.833 | 0.335 | |
| CFN+I | 0.985 | 0.759 | 0.640 | 0.954 | 0.741 | 0.616 | 0.727 | 0.835 | 0.335 | |
| 4*MScale-HRNet | Vanilla | 0.983 | 0.771 | 0.674 | 0.911 | 0.658 | 0.519 | 0.725 | 0.451 | 0.191 |
| Vanilla+I | 0.984 | 0.770 | 0.670 | 0.909 | 0.646 | 0.502 | 0.720 | 0.522 | 0.207 | |
| CFN | 0.989 | 0.758 | 0.647 | 0.897 | 0.697 | 0.547 | 0.752 | 0.807 | 0.320 | |
| CFN+I | 0.989 | 0.757 | 0.645 | 0.892 | 0.690 | 0.537 | 0.749 | 0.810 | 0.321 | |
| Range | Road | Crosswalks | Lane Marks | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision * | Recall * | IoU | Precision * | Recall * | IoU | Precision * | Recall * | IoU | |
| 30 | 0.985 | 0.847 | 0.702 | 0.695 | 0.760 | 0.495 | 0.555 | 0.567 | 0.182 |
| 15 | 0.989 | 0.836 | 0.706 | 0.823 | 0.766 | 0.560 | 0.683 | 0.761 | 0.270 |
| 10 | 0.989 | 0.757 | 0.645 | 0.892 | 0.690 | 0.537 | 0.750 | 0.810 | 0.321 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Venkatramani, S.; Paz, D.; Li, Q.; Xiang, H.; Christensen, H.I. Probabilistic Semantic Mapping for Autonomous Driving in Urban Environments. Sensors 2023, 23, 6504. https://doi.org/10.3390/s23146504
Zhang H, Venkatramani S, Paz D, Li Q, Xiang H, Christensen HI. Probabilistic Semantic Mapping for Autonomous Driving in Urban Environments. Sensors. 2023; 23(14):6504. https://doi.org/10.3390/s23146504
Chicago/Turabian StyleZhang, Hengyuan, Shashank Venkatramani, David Paz, Qinru Li, Hao Xiang, and Henrik I. Christensen. 2023. "Probabilistic Semantic Mapping for Autonomous Driving in Urban Environments" Sensors 23, no. 14: 6504. https://doi.org/10.3390/s23146504
APA StyleZhang, H., Venkatramani, S., Paz, D., Li, Q., Xiang, H., & Christensen, H. I. (2023). Probabilistic Semantic Mapping for Autonomous Driving in Urban Environments. Sensors, 23(14), 6504. https://doi.org/10.3390/s23146504