
Clustering Cities over Features Extracted from Multiple Virtual Sensors Measuring Micro-Level Activity Patterns Allows One to Discriminate Large-Scale City Characteristics


Abstract
1. Introduction
- 1.
- Can meaningful city categories (clusters) be detected based on micro-level city activity patterns derived from individual citizen activity data?
- 2.
- Is there any relationship between the clusters obtained and large-scale city characteristics such as the City Innovation Index [12]?
2. Background and Related Work
2.1. Large-Scale Urban Characteristics, Innovation and Public Policies
2.2. Data-Driven Policy-Making Using Digital Traces
3. Data Description
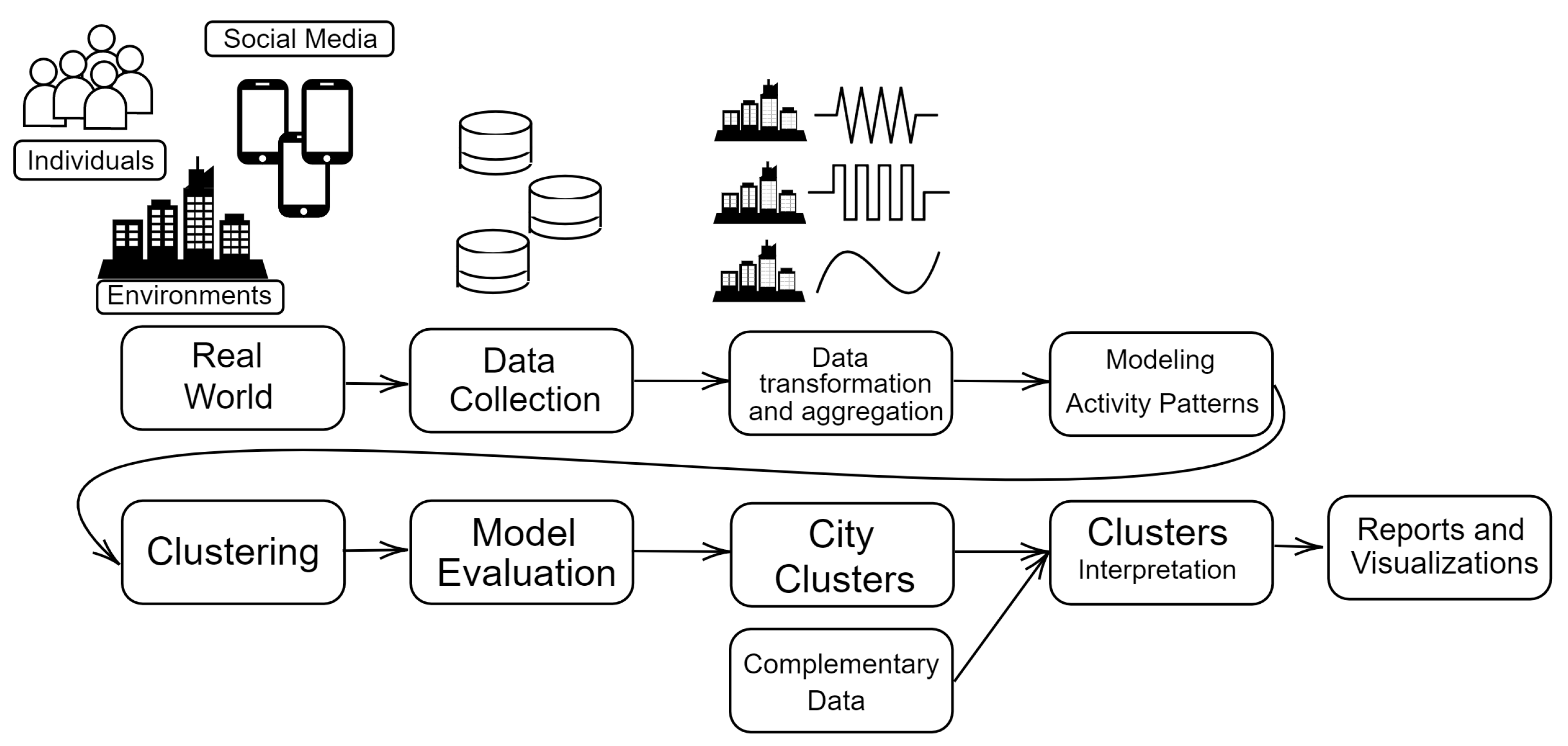
4. Methodology and Experimental Setup
Data Preprocessing
5. Experimental Setup
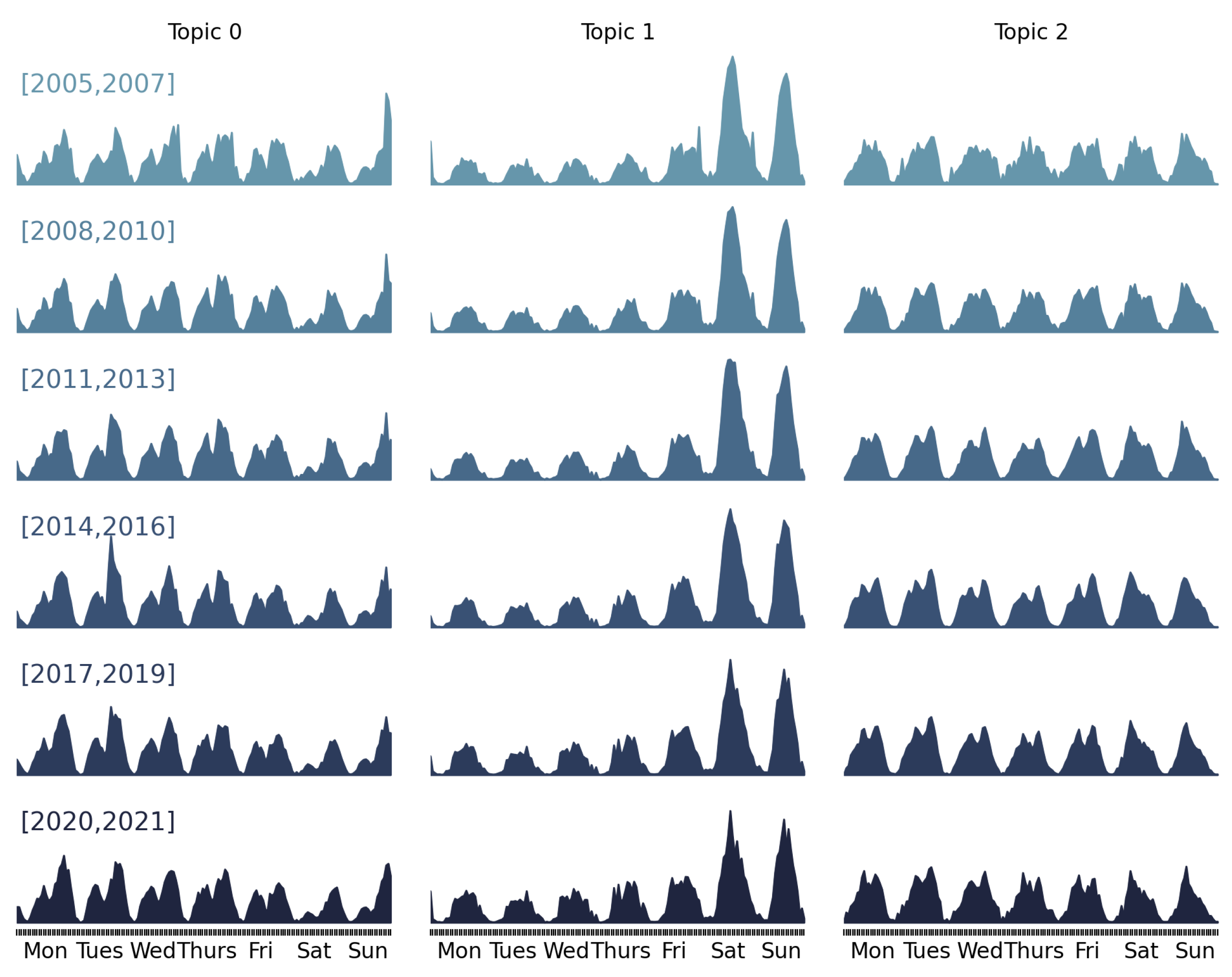
- The first step computes city features as the average and standard deviation of the coefficients of the linear decomposition of the weekly activity patterns and sorts them into the topic representative activity patterns extracted from each time slice of the dataset; thus, each city would be described by features, where is the optimal number of topics selected as described elsewhere [44] and is the number of time slices. These features are further compressed by averaging over the time slices. Therefore, each city is described by features for the ensuing clustering experiments.
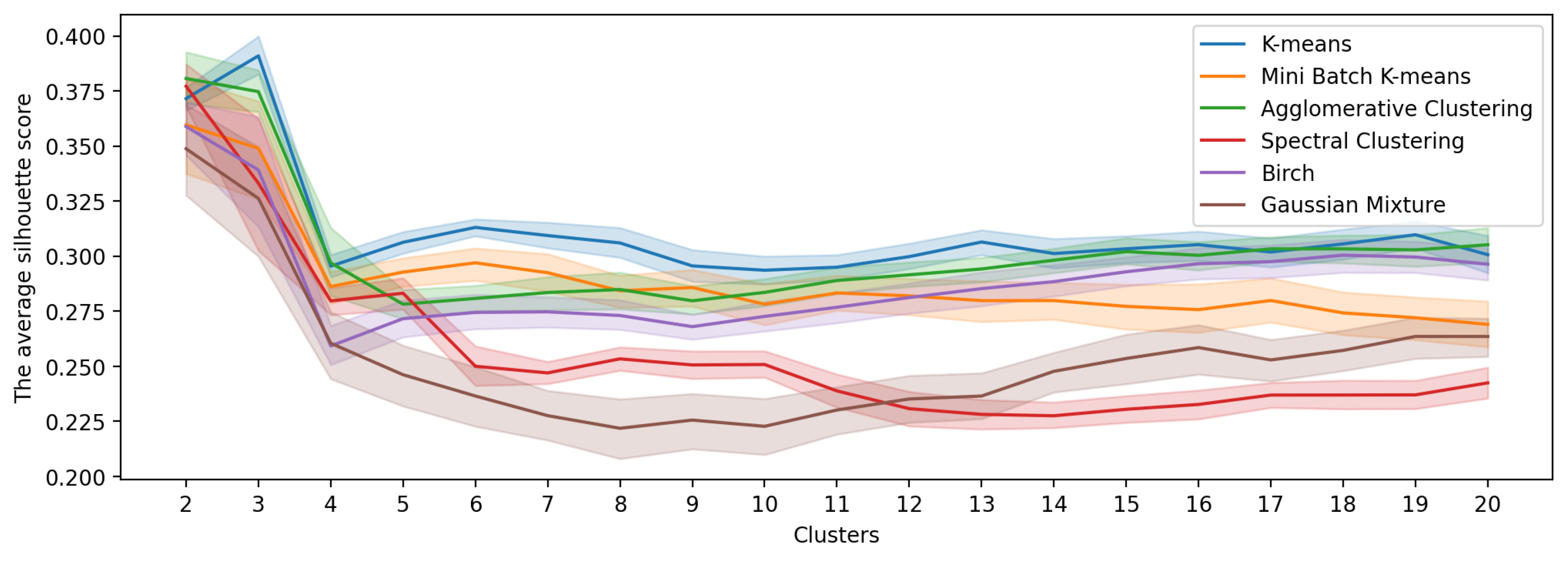
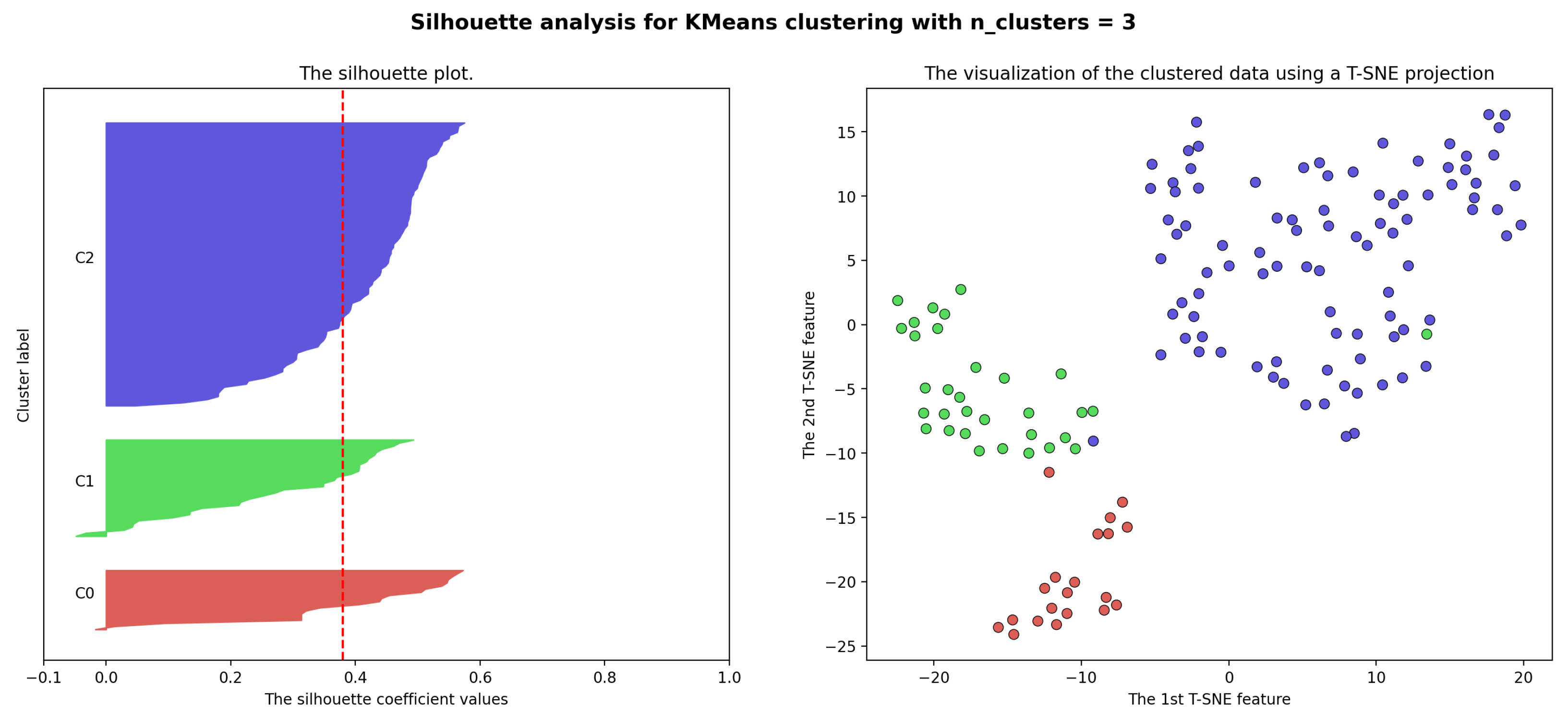
- The second step is the comparison among state-of-the-art clustering algorithms, namely K-Means, Mini Batch K-Means, Agglomerative Clustering, Spectral Clustering, BIRCH and Gaussian Mixture model. Clustering is repeated 30 time with each algorithm and the number of clusters is set in the range between 2 and 20. The best clustering algorithm and optimal number of clusters are selected using the Silhouette Score over the 30 repetitions. The optimal number of clusters corresponds to the maximum of the average Silhouette Score. The best clustering algorithm is selected based on paired comparisons using the non-parametric Wilcoxon test over the Silhouette Scores achieved along the number of cluster explorations.
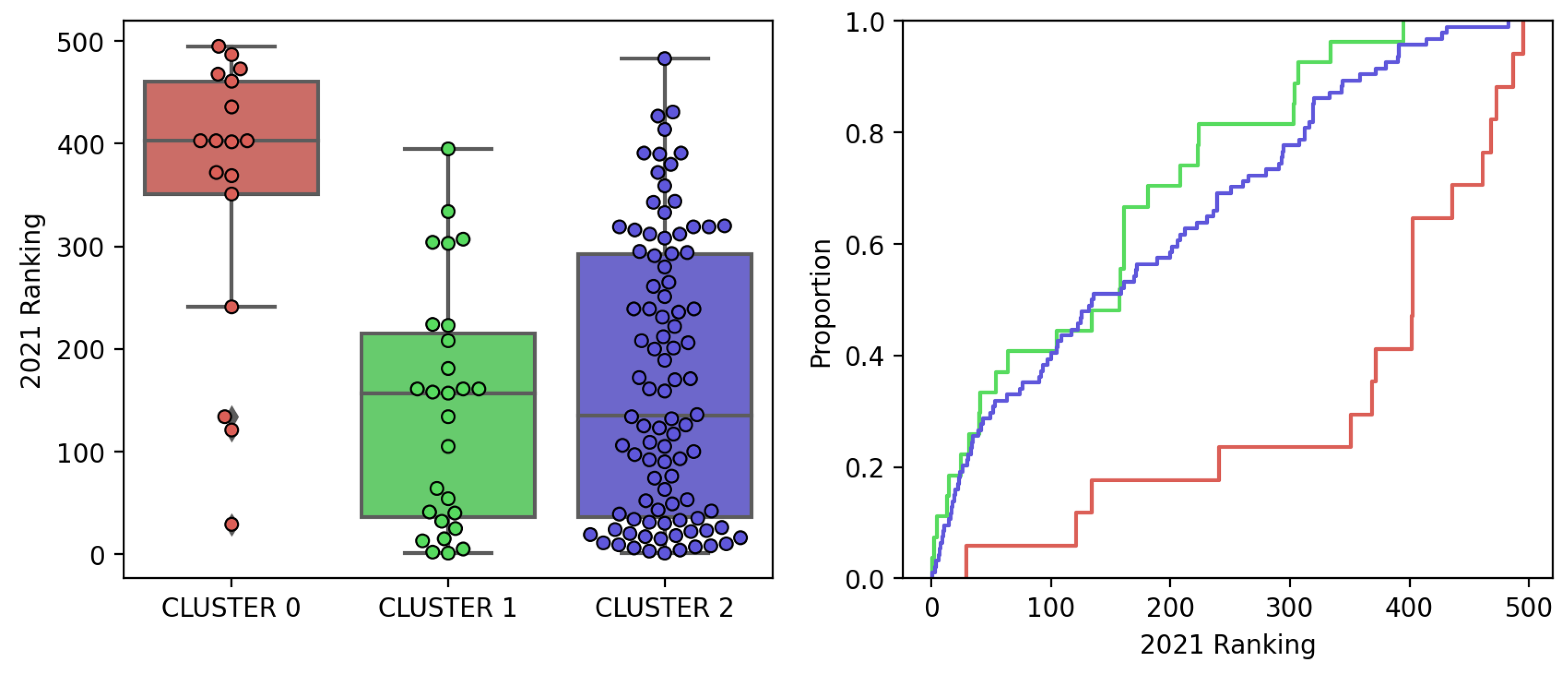
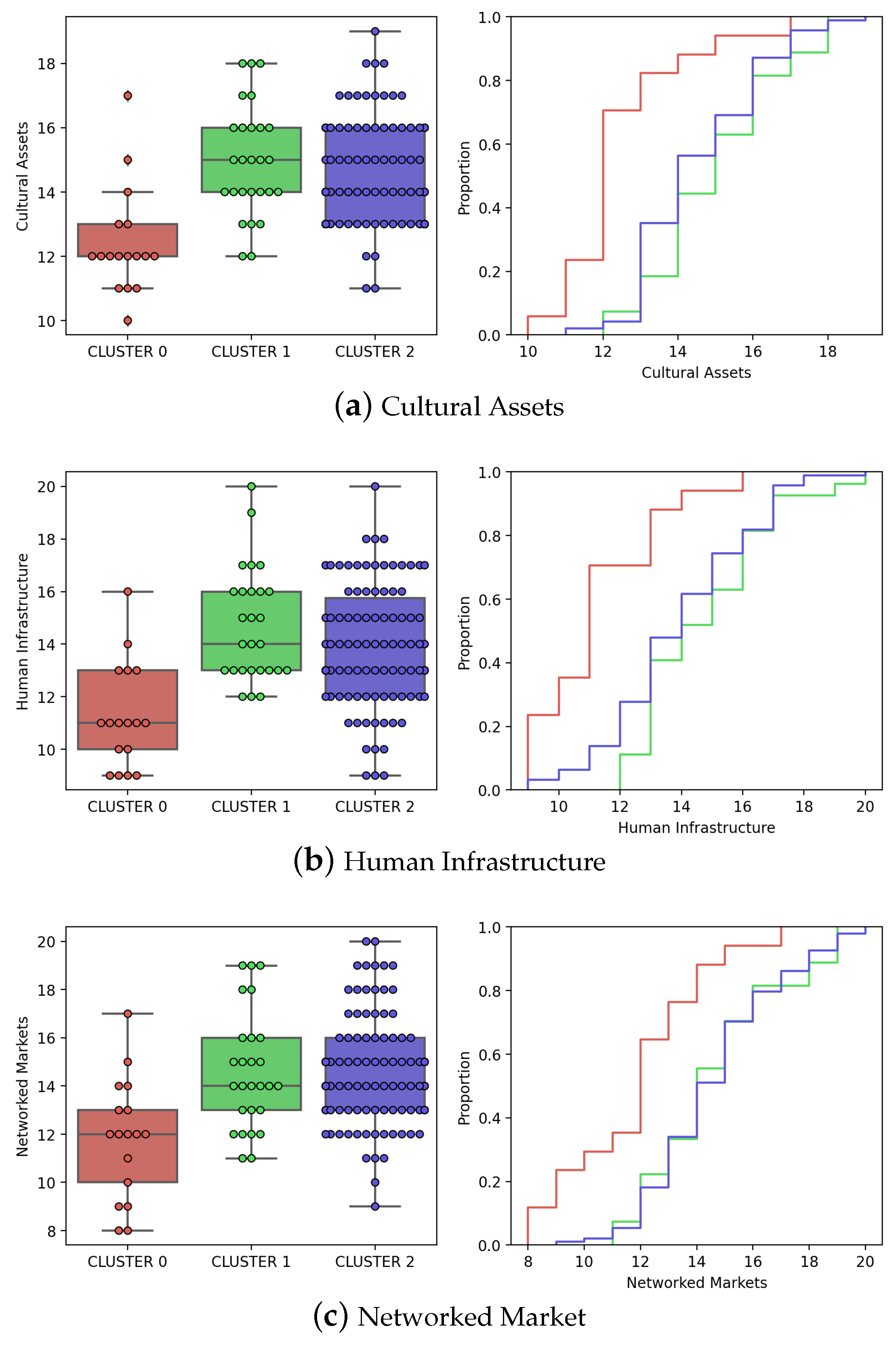
- The third step is the computation of the distribution of the City Innovation Index and other large-scale urban indices over the cities included in each cluster of the optimal clustering solution found above. The boxplot visualization of the distribution per cluster shows that the clusters effectively discriminate between cities according to large-scale city indices.
6. Results
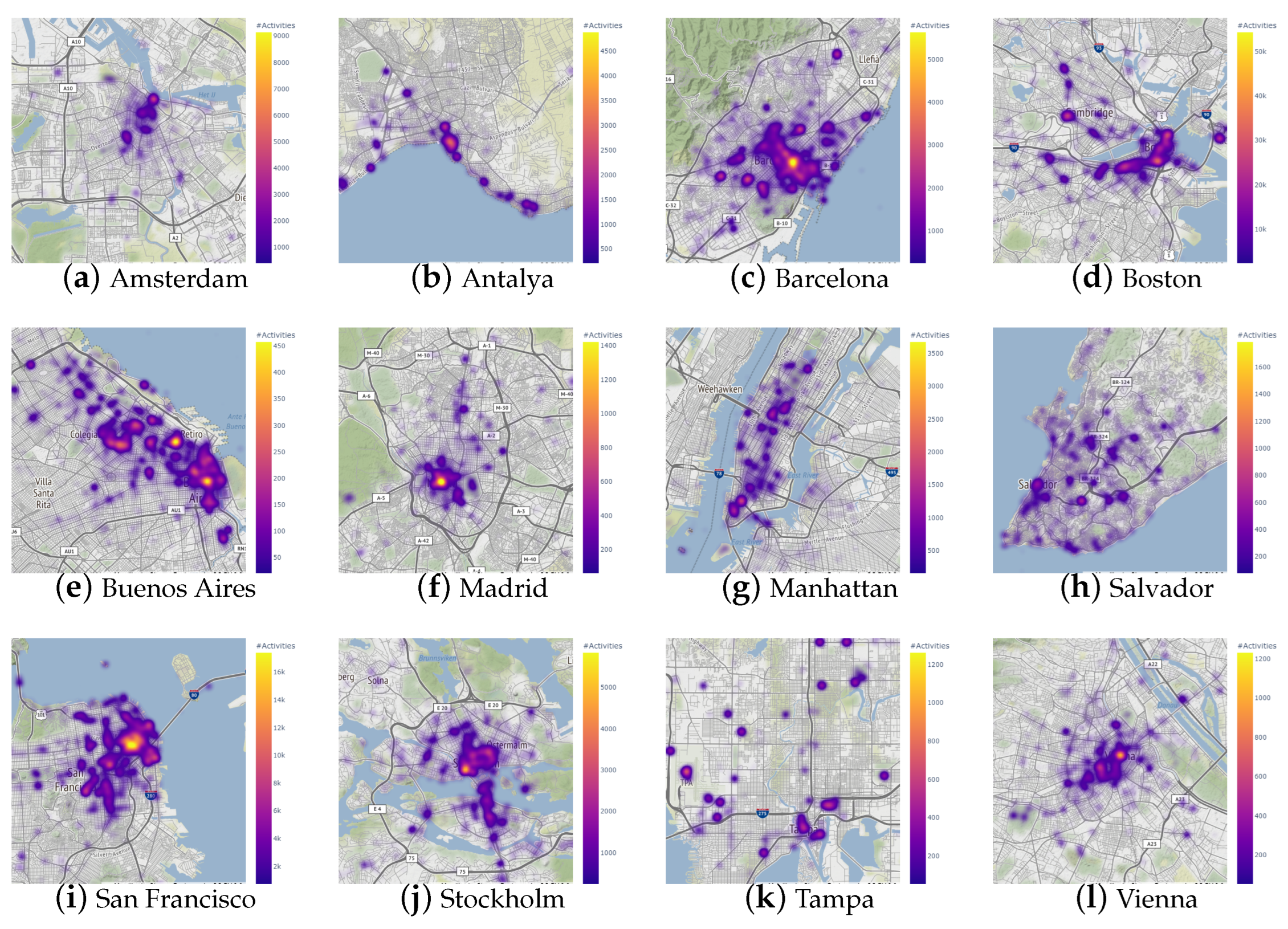
6.1. Data Exploration
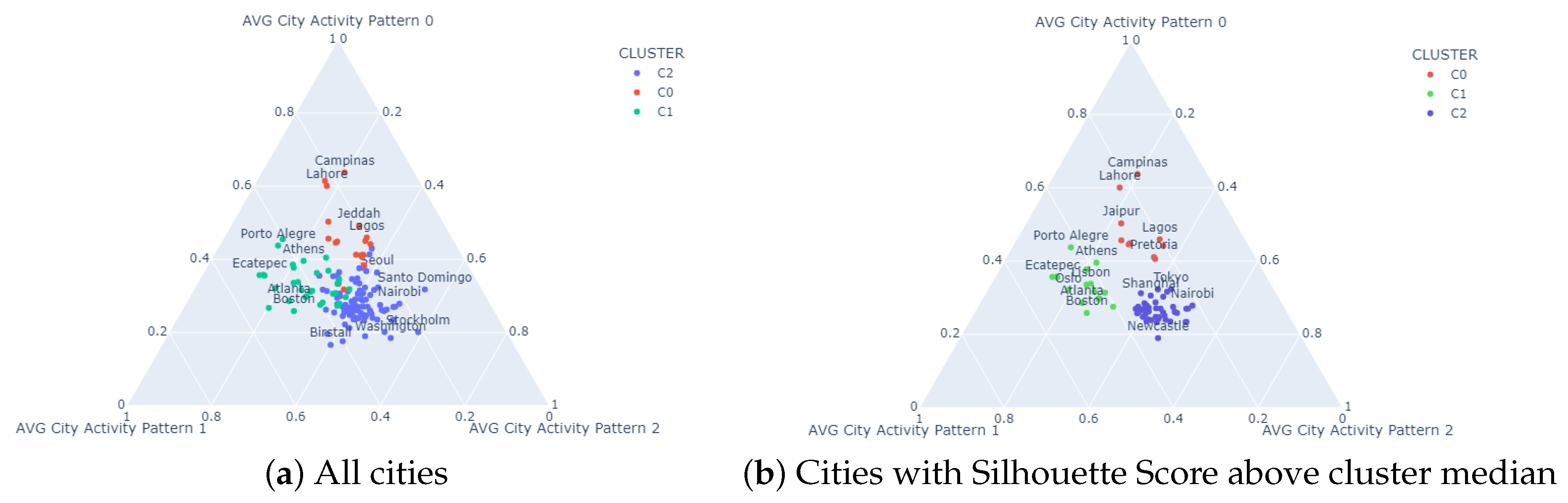
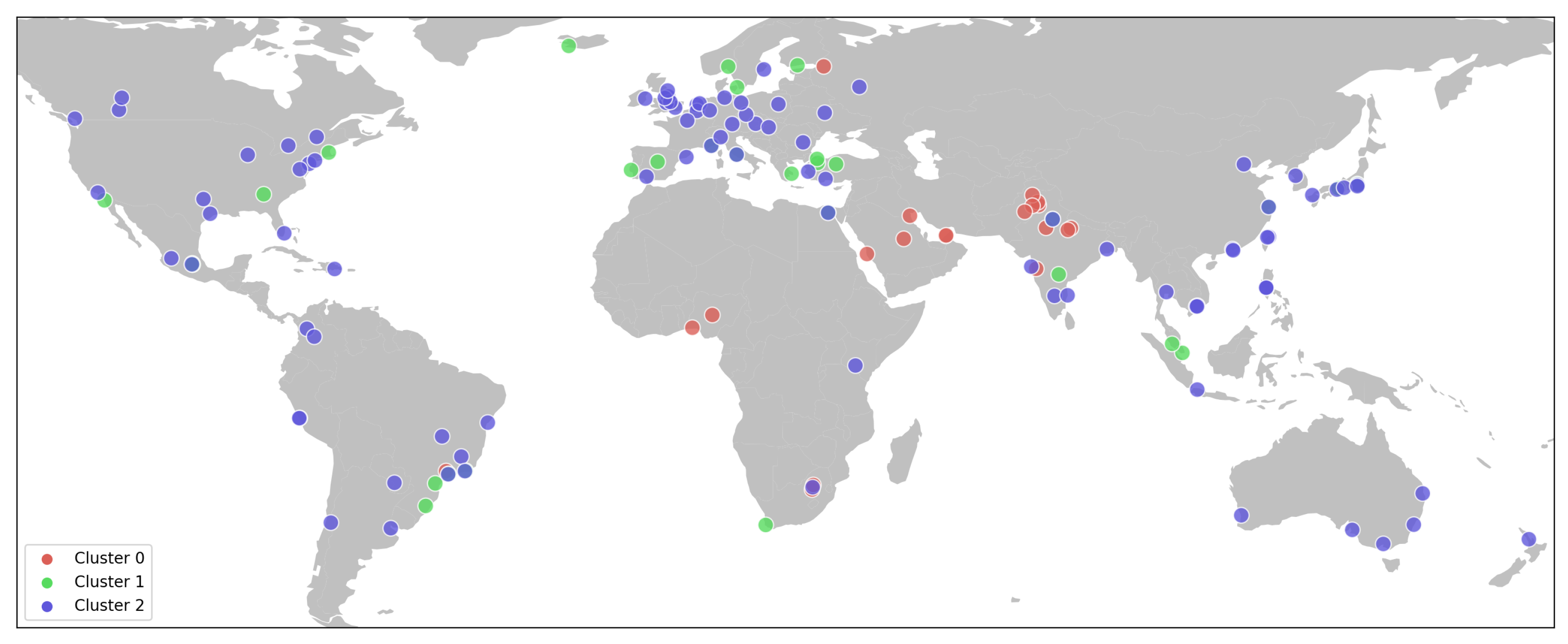
6.2. City Clustering
6.3. City Clusters
6.4. City Clusters and The City Innovation Index
7. Discussion
8. Conclusions and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Johnson, B. Cities, systems of innovation and economic development. Innovation 2008, 10, 146–155. [Google Scholar] [CrossRef]
- Appio, F.P.; Lima, M.; Paroutis, S. Understanding Smart Cities: Innovation ecosystems, technological advancements, and societal challenges. Technol. Forecast. Soc. Chang. 2019, 142, 1–14. [Google Scholar] [CrossRef]
- Guvensan, M.A.; Dusun, B.; Can, B.; Turkmen, H.I. A Novel Segment-Based Approach for Improving Classification Performance of Transport Mode Detection. Sensors 2018, 18, 87. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Cao, G.; Yan, Y.; Wang, J. Does high-speed rail stimulate cross-city technological innovation collaboration? Evidence from China. Transp. Policy 2022, 116, 119–131. [Google Scholar] [CrossRef]
- Borrego-Jaraba, F.; Garrido, P.C.; Garcia, G.C.; Ruiz, I.L.; Gomez-Nieto, M.A. A Ubiquitous NFC Solution for the Development of Tailored Marketing Strategies Based on Discount Vouchers and Loyalty Cards. Sensors 2013, 13, 6334–6354. [Google Scholar] [CrossRef]
- Schröder, P.; Vergragt, P.; Brown, H.S.; Dendler, L.; Gorenflo, N.; Matus, K.; Quist, J.; Rupprecht, C.D.; Tukker, A.; Wennersten, R. Advancing sustainable consumption and production in cities-A transdisciplinary research and stakeholder engagement framework to address consumption-based emissions and impacts. J. Clean. Prod. 2019, 213, 114–125. [Google Scholar] [CrossRef]
- Bencardino, M.; Greco, I. Smart Communities. Social Innovation at the Service of the Smart Cities. TeMA-J. Land Use Mobil. Environ. 2014, 40–51. [Google Scholar] [CrossRef]
- Leckel, A.; Veilleux, S.; Dana, L.P. Local Open Innovation: A means for public policy to increase collaboration for innovation in SMEs. Technol. Forecast. Soc. Chang. 2020, 153, 119891. [Google Scholar] [CrossRef]
- Marasco, A.; Errichiello, L. The role of networking in the development of new city services-A framework for exploring smart public-private service innovation networks. Rev. Eur. d’Écon. Manag. Serv. 2016, 2016, 65–100. [Google Scholar]
- Vrana, V.; Das, S. Dynamic Restructuring of Digital Media and Entertainment Sector: Role of Urbanization, Industrial Innovation, and Technological Evolution. In Digital Entertainment as Next Evolution in Service Sector: Emerging Digital Solutions in Reshaping Different Industries; Springer Nature: Singapore, 2023; pp. 15–34. [Google Scholar] [CrossRef]
- Granell, C.; Ostermann, F.O. Beyond data collection: Objectives and methods of research using VGI and geo-social media for disaster management. Comput. Environ. Urban Syst. 2016, 59, 231–243. [Google Scholar] [CrossRef]
- 2thinknow Innovation Cities Index 2021. Innovation Cities Index 2021: Top 100 World’s Most Innovative Cities. 2021. Available online: https://innovation-cities.com/worlds-most-innovative-cities-2021-top-100/25477/ (accessed on 23 October 2021).
- Acs, Z.J. Innovation and the Growth of Cities. In Urban Dynamics and Growth: Advances in Urban Economics; Contributions to Economic Analysis; Elsevier: Amsterdam, The Netherlands, 2004; Volume 266, pp. 635–658. [Google Scholar] [CrossRef]
- Roessner, J.D. Incentives to innovate in public and private organizations. Adm. Soc. 1977, 9, 341–365. [Google Scholar] [CrossRef]
- Qi, Y.; Peng, W.; Xiong, N.N. The effects of fiscal and tax incentives on regional innovation capability: Text extraction based on python. Mathematics 2020, 8, 1193. [Google Scholar] [CrossRef]
- Naphade, M.; Banavar, G.; Harrison, C.; Paraszczak, J.; Morris, R. Smarter cities and their innovation challenges. Computer 2011, 44, 32–39. [Google Scholar] [CrossRef]
- Zygiaris, S. Smart city reference model: Assisting planners to conceptualize the building of smart city innovation ecosystems. J. Knowl. Econ. 2013, 4, 217–231. [Google Scholar] [CrossRef]
- Capdevila, I. Co-working spaces and the localised dynamics of innovation in Barcelona. Int. J. Innov. Manag. 2015, 19, 1540004. [Google Scholar] [CrossRef]
- Berbegal-Mirabent, J. What do we know about co-working spaces? Trends and challenges ahead. Sustainability 2021, 13, 1416. [Google Scholar] [CrossRef]
- Engel, J.S.; Berbegal-Mirabent, J.; Pique, J.M. The renaissance of the city as a cluster of innovation. Cogent Bus. Manag. 2018, 5, 1532777. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Yi, P. Evaluation of city innovation capability using the TOPSIS-based order relation method: The case of Liaoning province, China. Technol. Soc. 2020, 63, 101330. [Google Scholar] [CrossRef]
- Wigginton, C.; Curran, M.; Brodeur, C. Global Mobile Consumer Trends: Second Edition. 2017. Available online: https://www2.deloitte.com/us/en/pages/technology-media-and-telecommunications/articles/global-mobile-consumer-trends.html (accessed on 29 April 2023).
- BankMyCell. How Many Smartphones Are in the World? 2022. Available online: https://www.bankmycell.com/blog/how-many-phones-are-in-the-world (accessed on 13 October 2022).
- Datareportal. Global Social Media Statistics. 2023. Available online: https://datareportal.com/social-media-users (accessed on 29 April 2023).
- DemandSage. Social Media Users in the World—(2023 Demographics). 2023. Available online: https://www.demandsage.com/social-media-users/ (accessed on 29 April 2023).
- Noulas, A.; Scellato, S.; Mascolo, C.; Pontil, M. Exploiting Semantic Annotations for Clustering Geographic Areas and Users in Location-based Social Networks. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5, pp. 32–35. [Google Scholar] [CrossRef]
- Frias-Martinez, V.; Soto, V.; Hohwald, H.; Frias-Martinez, E. Characterizing Urban Landscapes Using Geolocated Tweets. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust, PASSAT 2012, and 2012 International Conference on Social Computing, SocialCom 2012, Amsterdam, The Netherlands, 3–5 September 2012; pp. 239–248. [Google Scholar] [CrossRef]
- Fujisaka, T.; Lee, R.; Sumiya, K. Exploring urban characteristics using movement history of mass mobile microbloggers. In Proceedings of the Eleventh Workshop on Mobile Computing Systems & Applications, HotMobile ′10, Annapolis, MD, USA, 22–23 February 2010; ACM: New York, NY, USA, 2010; pp. 13–18. [Google Scholar] [CrossRef]
- Wakamiya, S.; Lee, R.; Sumiya, K. Urban area characterization based on semantics of crowd activities in Twitter. In Proceedings of the 4th International Conference on GeoSpatial Semantics, GeoS 2011, Brest, France, 12–13 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 108–123. [Google Scholar]
- Ríos, S.A.; Muñoz, R. Land Use detection with cell phone data using topic models: Case Santiago, Chile. Comput. Environ. Urban Syst. 2017, 61, 39–48. [Google Scholar] [CrossRef]
- Madhawa, K.; Lokanathan, S.; Maldeniya, D.; Samarajiva, R. Land use classification using call detail records. In Proceedings of the NetMob 2015 (Fourth Conference on the Scientific Analysis of Mobile Phone Datasets), MIT Media Lab, Cambridge, MA, USA, 8–10 April 2015. [Google Scholar] [CrossRef]
- Soto, V.; Frías-Martínez, E. Robust Land Use Characterization of Urban Landscapes Using Cell Phone Data. 2011. Available online: https://www.researchgate.net/publication/228923406_Robust_Land_Use_Characterization_of_Urban_Lanscapes_using_Cell_Phone_Data (accessed on 29 April 2023).
- Lenormand, M.; Picornell, M.; Cantú-Ros, O.G.; Tugores, A.; Louail, T.; Herranz, R.; Barthelemy, M.; Frías-Martínez, E.; Ramasco, J.J. Cross-Checking Different Sources of Mobility Information. PLoS ONE 2014, 9, 1–10. [Google Scholar] [CrossRef]
- Lenormand, P.; Cantú-Ros, O.G.; Tugores, A.; Louail, T.; Herranz, R.; Barthelemy, M.; Frías-Martínez, E.; Ramasco, J.J. Influence of sociodemographic characteristics on human mobility. Sci. Rep. 2015, 5, 10075. [Google Scholar] [CrossRef] [PubMed]
- Crandall, D.J.; Backstrom, L.; Huttenlocher, D.; Kleinberg, J. Mapping the world’s photos. In Proceedings of the 18th International Conference on World Wide Web, WWW 2009, Madrid, Spain, 20–24 April 2009; ACM: New York, NY, USA, 2009; pp. 761–770. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Tsou, M.H.; Li, H.; Jiang, W.; Guo, F. Mapping Dynamic Urban Land Use Patterns with Crowdsourced Geo-Tagged Social Media (Sina-Weibo) and Commercial Points of Interest Collections in Beijing, China. Sustainability 2016, 8, 1202. [Google Scholar] [CrossRef]
- Du, H.; Mulley, C. The short-term land value impacts of urban rail transit: Quantitative evidence from Sunderland, UK. Land Use Policy 2007, 24, 223–233. [Google Scholar] [CrossRef]
- Dong, H.; Wu, M.; Ding, X.; Chu, L.; Jia, L.; Qin, Y.; Zhou, X. Traffic zone division based on big data from mobile phone base stations. Transp. Res. Part C Emerg. Technol. 2015, 58, 278–291. [Google Scholar] [CrossRef]
- Dasgupta, A. Floods and poverty traps: Evidence from Bangladesh. Econ. Political Wkly. 2007, 42, 3166–3171. [Google Scholar]
- Hong, L.; Lee, M.; Mashhadi, A.; Frias-Martinez, V. Towards Understanding Communication Behavior Changes During Floods Using Cell Phone Data. In Proceedings of the Social Informatics—10th International Conference, SocInfo 2018, Proceedings, Part II, St. Petersburg, Russia, 25–28 September 2018; Staab, S., Koltsova, O., Ignatov, D.I., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 97–107. [Google Scholar]
- Darabi, H.; Choubin, B.; Rahmati, O.; Haghighi, A.T.; Pradhan, B. Urban flood risk mapping using the GARP and QUEST models: A comparative study of machine learning techniques. J. Hydrol. 2019, 569, 142–154. [Google Scholar] [CrossRef]
- Gao, S.; Rao, J.; Kang, Y.; Liang, Y.; Kruse, J. Mapping county-level mobility pattern changes in the United States in response to COVID-19. SIGSpatial Spec. 2020, 12, 16–26. [Google Scholar] [CrossRef]
- Muñoz-Cancino, R.; Rios, S.A.; Goic, M.; Graña, M. Non-Intrusive Assessment of COVID-19 Lockdown Follow-Up and Impact Using Credit Card Information: Case Study in Chile. Int. J. Environ. Res. Public Health 2021, 18, 5507. [Google Scholar] [CrossRef]
- Muñoz-Cancino, R. On the Use of Multi-Sensor Digital Traces to Discover Spatio-Temporal Human Behavioral Pattems. Ph.D. Thesis, University of Basque Country, San Sebastián, Spain, 2023. [Google Scholar]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and Mobility: User Movement in Location-Based Social Networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’11, San Diego, CA, USA, 21–24 August 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1082–1090. [Google Scholar] [CrossRef]
- Le Falher, G.; Gionis, A.; Mathioudakis, M. Where is the Soho of Rome? Measures and algorithms for finding similar neighborhoods in cities. In Proceedings of the Ninth International Conference on Web and Social Media, ICWSM 2015, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Yang, D.; Zhang, D.; Zheng, V.W.; Yu, Z. Modeling User Activity Preference by Leveraging User Spatial Temporal Characteristics in LBSNs. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 129–142. [Google Scholar] [CrossRef]
- Mousselly-Sergieh, H.; Watzinger, D.; Huber, B.; Döller, M.; Egyed-Zsigmond, E.; Kosch, H. World-Wide Scale Geotagged Image Dataset for Automatic Image Annotation and Reverse Geotagging. In Proceedings of the Multimedia Systems Conference 2014, MMSys ′14, Singapore, 19–21 March 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 47–52. [Google Scholar] [CrossRef]
- Cheng, Z.; Caverlee, J.; Lee, K. You Are Where You Tweet: A Content-Based Approach to Geo-Locating Twitter Users. In Proceedings of the 19th ACM Conference on Information and Knowledge Management, CIKM 2010, Toronto, ON, Canada, 26–30 October 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 759–768. [Google Scholar] [CrossRef]
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2021, 51, 2790–2804. [Google Scholar] [CrossRef]
- Kejriwal, M.; Melotte, S. A Geo-Tagged COVID-19 Twitter Dataset for 10 North American Metropolitan areas over a 255-day period. Data 2021, 6, 64. [Google Scholar] [CrossRef]
- Yelp Open Dataset. 2021. Available online: https://www.yelp.com/dataset (accessed on 26 October 2021).
- Simple Maps. Basic World Cities Database. 2021. Available online: https://simplemaps.com/data/world-cities (accessed on 3 September 2021).
- Starczewski, A.; Krzyżak, A. Performance Evaluation of the Silhouette Index. In Proceedings of the Artificial Intelligence and Soft Computing—14th International Conference ICAISC 2015, Proceedings, Part II, Zakopane, Poland, 14–28 June 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 49–58. [Google Scholar]
- Markatou, M.; Alex, R.E. Urban System of Innovation: Main Agents and Main Factors of Success. Procedia-Soc. Behav. Sci. 2015, 195, 240–250. [Google Scholar] [CrossRef]
- Zhang, R.; Ji, C.; Tan, L.; Sun, Y. Evaluation and construction of the capacities of urban innovation chains based on efficiency improvement. PLoS ONE 2022, 17, E0274092. [Google Scholar] [CrossRef] [PubMed]
- Straccamore, M.; Bruno, M.; Monechi, B.; Loreto, V. Urban economic fitness and complexity from patent data. Sci. Rep. 2023, 13, 3655. [Google Scholar] [CrossRef]
- Pugliese, E.; Cimini, G.; Patelli, A.; Zaccaria, A.; Pietronero, L.; Gabrielli, A. Unfolding the innovation system for the development of countries: Coevolution of Science, Technology and Production. Sci. Rep. 2019, 9, 16440. [Google Scholar] [CrossRef]
- Miao, L.; Murray, D.; Jung, W.S.; Larivière, V.; Sugimoto, C.R.; Ahn, Y.Y. The latent structure of global scientific development. Nat. Hum. Behav. 2022, 6, 1206–1217. [Google Scholar] [CrossRef]
- Bonaventura, M.; Aiello, L.M.; Quercia, D.; Latora, V. Predicting urban innovation from the US Workforce Mobility Network. Humanit. Soc. Sci. Commun. 2021, 8, 10. [Google Scholar] [CrossRef]
- Ball, P.A.; Jara-Figueroa, C.; Petralia, S.G.; Steijn, M.P.; Rigby, D.L.; Hidalgo, C.A. Complex economic activities concentrate in large cities. Nat. Hum. Behav. 2020, 4, 248–254. [Google Scholar] [CrossRef]
- Dubrovina, E. Concentrated cities. Nat. Phys. 2020, 16, 123. [Google Scholar] [CrossRef]
- Zhang, J.X.; Cheng, J.W.; Philbin, S.P.; Ballesteros-Perez, P.; Skitmore, M.; Wang, G. Influencing factors of urban innovation and development: A grounded theory analysis. Environ. Dev. Sustain. 2023, 25, 2079–2104. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Dataset Reference | Events |
|---|---|---|
| Brightkite checkins | [45] | 1,639,399 |
| Foursquare checkins | [46] | 7,515,201 |
| [47] | 1,099,826 | |
| Geotagged Images | [48] | 4,998,865 |
| Geotagged Tweets | [49] | 2,041,262 |
| [50] | 187,802 | |
| [51] | 47,337 | |
| [50] (Exact Location) | 184,547 | |
| [50] (Inferred Location) | 2,604,233 | |
| Gowalla checkins | [45] | 1,992,082 |
| Weeplaces checkins | [45] | 4,176,673 |
| Yelp checkins | [52] | 5,695,209 |
| Algorithm | k | p-Value | Difference (%) |
|---|---|---|---|
| Mini Batch K-Means | 3 | 12.0% | |
| Agglomerative Clustering | 3 | 4.3% | |
| Spectral Clustering | 3 | 17.4% | |
| BIRCH | 3 | 15.3% | |
| Gaussian Mixture | 3 | 19.8% | |
| K-Means | 2 | 5.2% | |
| Mini Batch K-Means | 2 | 8.7% | |
| Agglomerative Clustering | 2 | 2.7% | |
| Spectral Clustering | 2 | 3.7% | |
| BIRCH | 2 | 9.0% | |
| Gaussian Mixture | 2 | 12.1% |
| CLUSTER C0 | CLUSTER C1 | CLUSTER C2 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| City | Ranking | T0 | T1 | T2 | City | Ranking | T0 | T1 | T2 | City | Ranking | T0 | T1 | T2 |
| Campinas (Brazil) | 134 | 0.63 | 0.16 | 0.19 | Saitama (Japan) | 1 | 0.31 | 0.40 | 0.28 | Tokyo (Japan) | 1 | 0.32 | 0.24 | 0.43 |
| Vereeniging (South Africa) | 372 | 0.40 | 0.23 | 0.35 | Boston (USA) | 2 | 0.25 | 0.47 | 0.26 | New York (USA) | 3 | 0.32 | 0.27 | 0.40 |
| Lahore (Pakistan) | 403 | 0.60 | 0.22 | 0.17 | Atlanta (USA) | 13 | 0.28 | 0.47 | 0.24 | Sydney (Australia) | 4 | 0.23 | 0.29 | 0.46 |
| Pune (India) | 436 | 0.45 | 0.29 | 0.24 | Oslo (Norway) | 25 | 0.32 | 0.48 | 0.19 | Dallas (USA) | 6 | 0.28 | 0.29 | 0.41 |
| Pretoria (South Africa) | 461 | 0.41 | 0.24 | 0.34 | Helsinki (Finland) | 41 | 0.33 | 0.43 | 0.22 | Houston (USA) | 8 | 0.24 | 0.31 | 0.44 |
| Lagos (Nigeria) | 468 | 0.45 | 0.20 | 0.33 | Copenhagen (Denmark) | 54 | 0.29 | 0.42 | 0.27 | Chicago (USA) | 9 | 0.24 | 0.31 | 0.44 |
| Jaipur (India) | 473 | 0.50 | 0.27 | 0.22 | Guarulhos (Brazil) | 134 | 0.37 | 0.41 | 0.20 | London (UK) | 11 | 0.24 | 0.33 | 0.41 |
| Lucknow (India) | 487 | 0.44 | 0.28 | 0.27 | Lisbon (Portugal) | 158 | 0.33 | 0.42 | 0.23 | Shanghai (China) | 15 | 0.30 | 0.30 | 0.39 |
| Cawnpore (India) | 495 | 0.44 | 0.27 | 0.27 | Ecatepec (Mexico) | 161 | 0.35 | 0.50 | 0.13 | Los Angeles (USA) | 20 | 0.23 | 0.33 | 0.42 |
| City Innovation Ranking | |||||
|---|---|---|---|---|---|
| Cluster | City Population | (0, 41] | (41, 161] | (161, 311] | (311, 500] |
| C0 | (0–1508] | - | 5.9% | 5.9% | 11.8% |
| (1508–3002] | 5.9% | - | - | 17.6% | |
| (3002–8154] | - | 5.9% | - | 35.3% | |
| (8154–37,977] | - | - | - | 11.8% | |
| C1 | (0–1508] | 11.1% | 25.9% | 7.4% | 3.7% |
| (1508–3002] | - | 7.4% | 7.4% | - | |
| (3002–8154] | 18.5% | - | 3.7% | - | |
| (8154–37,977] | 3.7% | - | 7.4% | 3.7% | |
| C2 | (0–1508] | 3.2% | 6.4% | 7.4% | 2.1% |
| (1508–3002] | 2.1% | 10.6% | 5.3% | 9.6% | |
| (3002–8154] | 8.5% | 5.3% | 5.3% | 3.2% | |
| (8154–37,977] | 12.8% | 4.3% | 7.4% | 6.4% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muñoz-Cancino, R.; Ríos, S.A.; Graña, M. Clustering Cities over Features Extracted from Multiple Virtual Sensors Measuring Micro-Level Activity Patterns Allows One to Discriminate Large-Scale City Characteristics. Sensors 2023, 23, 5165. https://doi.org/10.3390/s23115165
Muñoz-Cancino R, Ríos SA, Graña M. Clustering Cities over Features Extracted from Multiple Virtual Sensors Measuring Micro-Level Activity Patterns Allows One to Discriminate Large-Scale City Characteristics. Sensors. 2023; 23(11):5165. https://doi.org/10.3390/s23115165
Chicago/Turabian StyleMuñoz-Cancino, Ricardo, Sebastián A. Ríos, and Manuel Graña. 2023. "Clustering Cities over Features Extracted from Multiple Virtual Sensors Measuring Micro-Level Activity Patterns Allows One to Discriminate Large-Scale City Characteristics" Sensors 23, no. 11: 5165. https://doi.org/10.3390/s23115165
APA StyleMuñoz-Cancino, R., Ríos, S. A., & Graña, M. (2023). Clustering Cities over Features Extracted from Multiple Virtual Sensors Measuring Micro-Level Activity Patterns Allows One to Discriminate Large-Scale City Characteristics. Sensors, 23(11), 5165. https://doi.org/10.3390/s23115165