
Prediction of Preterm Delivery from Unbalanced EHG Database



Abstract
:1. Introduction
2. Related Works
3. Methods
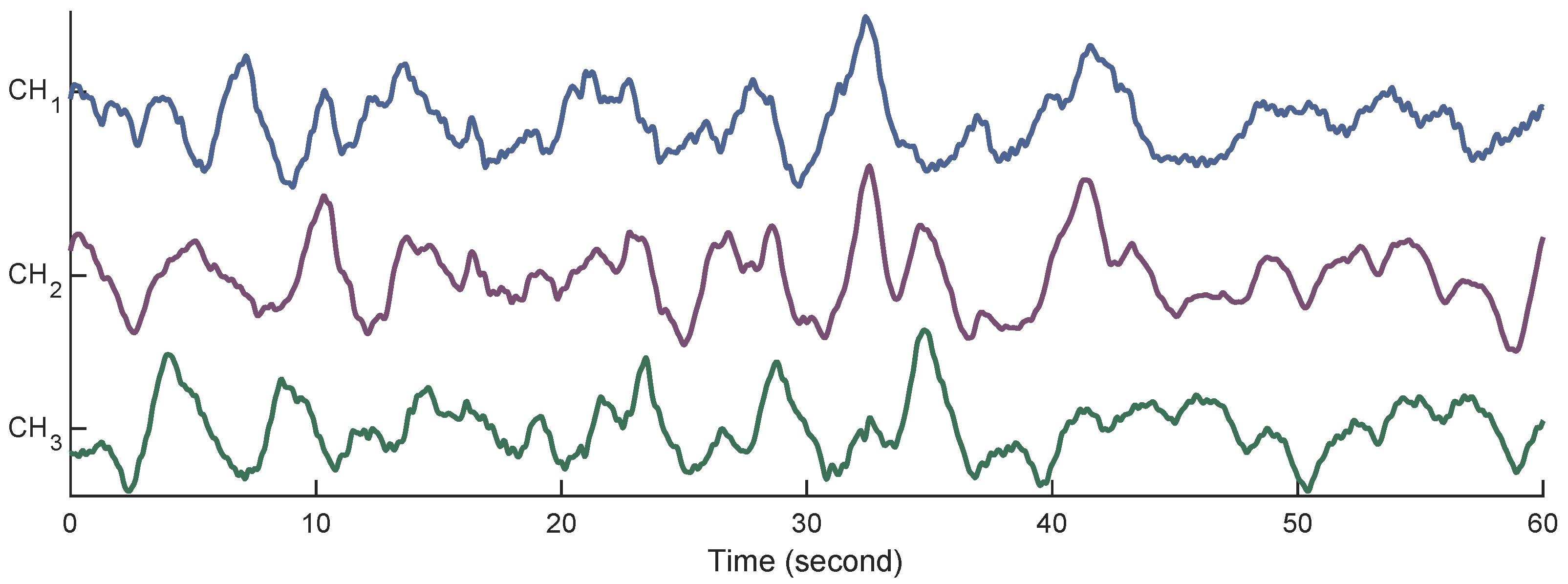
3.1. The Proposed Method
3.2. Empirical Mode Decomposition
- In the whole data set, the number of extrema and zero-crossings must either be equal or differ at most by one;
- At any point, the mean value of the envelope defined by the local maxima and the envelope defined by the local minima is zero.
- Extract the local minima and local maxima from ;
- Create the upper and lower signal’s envelopes using cubic spline;
- Compute the local mean signal, , by averaging the upper and lower signal’s envelopes;
- Subtract from to obtain the first possible IMF candidate .
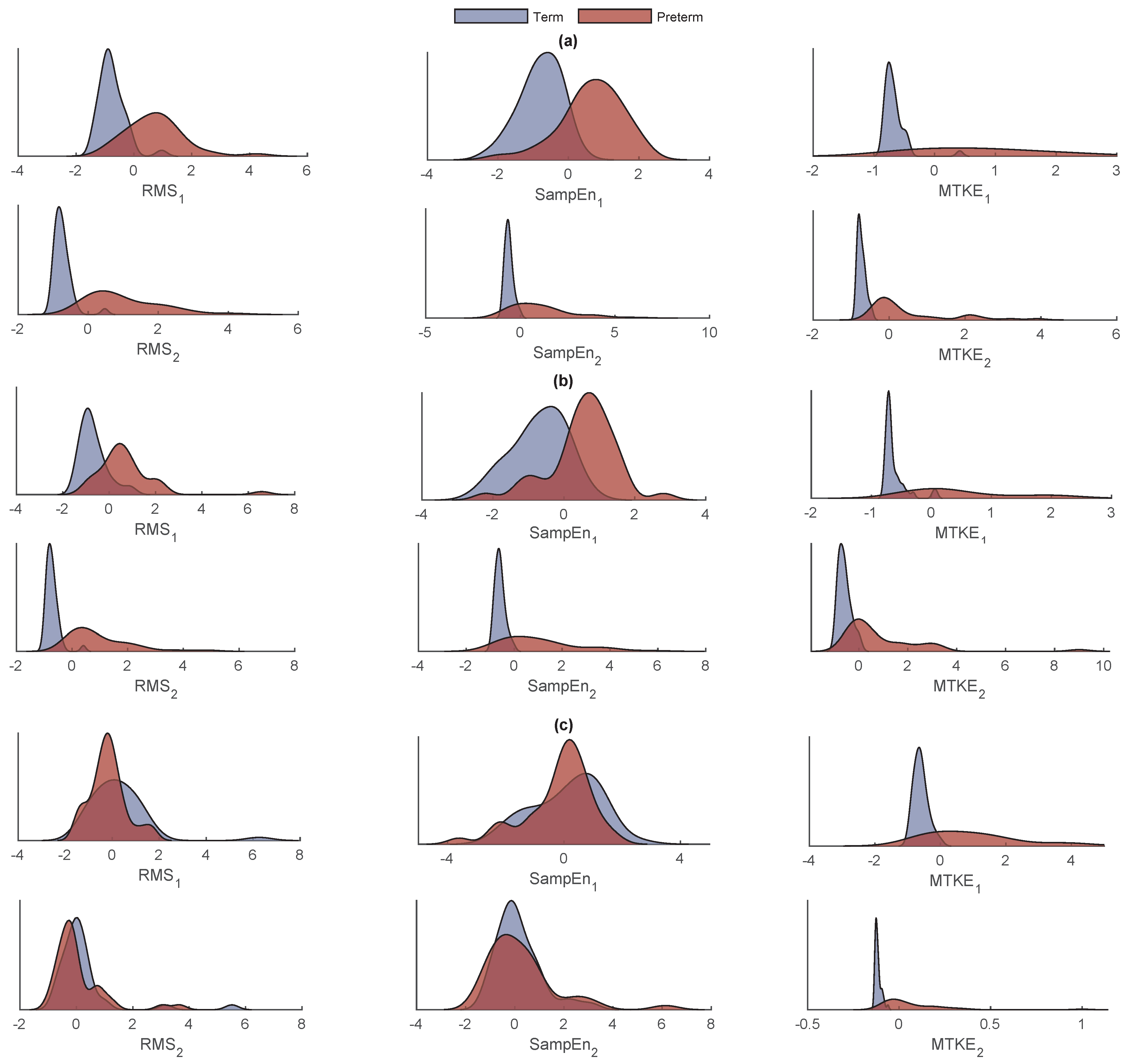
3.3. Feature Extraction
3.4. Classifiers
3.4.1. k-Nearest Neighbors
3.4.2. Support Vector Machine
3.4.3. Decision Tree
4. Evaluation
4.1. Data
4.2. Imbalanced Database Issue
4.3. Evaluation Metrics
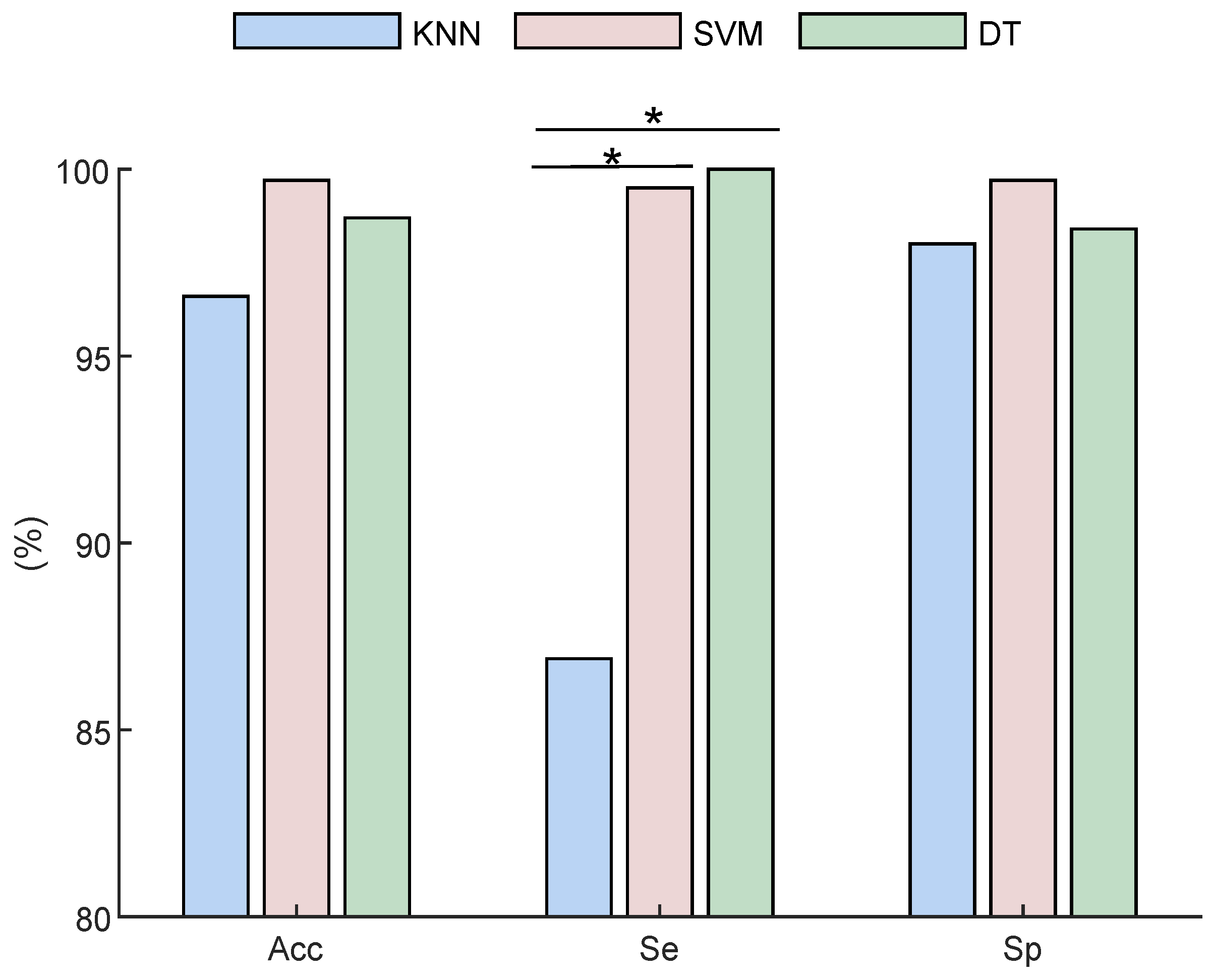
5. Results and Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| EHG | electrohysterogram |
| EMD | empirical mode decomposition |
| IMF | intrinsic mode functions |
| SampEn | sample entropy |
| RMS | root mean square |
| MTKE | mean Teager–Kaiser energy |
| kNN | k-nearest neighbors |
| SVM | support vector machine |
| LDA | linear discriminant analysis |
| Acc | accuracy |
| Se | sensitivity |
| Sp | specificity |
| AUC | area under the curve |
| SMOTE | synthetic minority oversampling technique |
| ADASYN | adaptive synthetic sampling approach |
| GBC | gradient boosting classifier |
References
- Frey, H.A.; Klebanoff, M.A. The epidemiology, etiology, and costs of preterm birth. Semin. Fetal Neonatal Med. 2016, 21, 68–73. [Google Scholar] [CrossRef]
- Schleußner, E. The prevention, diagnosis and treatment of premature labor. Dtsch. Arztebl. Int. 2013, 110, 227–235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iams, J.D.; Goldenberg, R.L.; Mercer, B.M.; Moawad, A.H.; Meis, P.J.; Das, A.F.; Caritis, S.N.; Miodovnik, M.; Menard, M.K.; Thurnau, G.R.; et al. The preterm prediction study: Can low-risk women destined for spontaneous preterm birth be identified? Am. J. Obstet. Gynecol. 2001, 184, 652–655. [Google Scholar] [CrossRef] [PubMed]
- Available online: www.who.int (accessed on 15 September 2019).
- Nieto-del-Amor, F.; Beskhani, R.; Ye-Lin, Y.; Garcia-Casado, J.; Diaz-Martinez, A.; Monfort-Ortiz, R.; Diago-Almela, V.J.; Hao, D.; Prats-Boluda, G. Assessment of Dispersion and Bubble Entropy Measures for Enhancing Preterm Birth Prediction Based on Electrohysterographic Signals. Sensors 2021, 21, 6071. [Google Scholar] [CrossRef]
- Horoba, K.; Wrobel, J.; Jezewski, J.; Kupka, T.; Roj, D.; Jezewski, M. Automated detection of uterine contractions in tocography signals-comparison of algorithms. Biocybern. Biomed. Eng. 2016, 36, 610–618. [Google Scholar] [CrossRef]
- Barber, M.A.; Eguiluz, I.; Plasencia, W.; Medina, M.; Valle, L.; Garcia, J.A. Preterm delivery and ultrasound measurement of cervical length in Gran Canaria, Spain. Int. J. Gynecol. Obstet. 2010, 108, 58–60. [Google Scholar] [CrossRef]
- Mourguesa, C.; Rossic, A.; Favrec, N.; Delabaereb, A.; Roszykd, L.; Sapind, V.; Debost-Legrandb, A.; Gallot, D. Fetal fibronectin test for threatened preterm delivery 48 h after admission: Cost-effectiveness study. Eur. J. Obstet. Gynecol. Reprod. Biol. 2019, 234, 75–78. [Google Scholar] [CrossRef] [PubMed]
- Euliano, T.Y.; Darmanjian, M.T.N.M.T.S.; Mcgorray, S.P.; Euliano, N.; Onkala, A.; Gregg, A.R. Monitoring uterine activity during labor: A comparison of 3 methods. Am. J. Obstet. Gynecol. 2013, 208, 66.e1–66.e6. [Google Scholar] [CrossRef] [Green Version]
- Hao, D.; Qiu, Q.; Zhou, X.; An, Y.; Peng, J.; Yang, L.; Zheng, D. Application of decision tree in determining the importance of surface electrohysterography signal characteristics for recognizing uterine contractions. Biocybern. Biomed. Eng. 2019, 39, 806–813. [Google Scholar] [CrossRef]
- Jager, F.; Geršak, K.; Vouk, P.; Pirnar, Ž.; Trojner-Bregar, A.; Lucovnik, M.; Borovac, A. Assessing velocity and directionality of uterine electrical activity for preterm birth prediction using EHG surface records. Sensors 2020, 20, 7328. [Google Scholar] [CrossRef]
- Mas-Cabo, J.; Prats-Boluda, G.; Ye-Lin, Y.; Alberola-Rubio, J.; Perales, A.; Garcia-Casado, J. Characterization of the effects of Atosiban on uterine electromyograms recorded in women with threatened preterm labor. Biomed. Signal Process. Control 2019, 52, 198–205. [Google Scholar] [CrossRef]
- Mas-Cabo, J.; Ye-Lin, Y.; Garcia-Casado, J.; Alberola-Rubio, J.; Perales, A.; Prats-Boluda, G. Uterine contractile efficiency indexes for labor prediction: A bivariate approach from multichannel electrohysterographic records. Biomed. Signal Process. Control 2018, 46, 238–248. [Google Scholar] [CrossRef]
- Xu, J.; Chen, Z.; Lou, H.; Shen, G.; Pumir, A. Review on EHG signal analysis and its application in preterm diagnosis. Biomed. Signal Process. Control 2022, 71, 103231. [Google Scholar] [CrossRef]
- Batista, A.G.; Cebola, R.; Esgalhado, F.; Russo, S.; Reis, C.R.P.d.; Serrano, F.; Vassilenko, V.; Ortigueira, M. The contractiongram: A method for the visualization of uterine contraction evolution using the electrohysterogram, Biomed. Signal Process. Control 2021, 67, 102531. [Google Scholar] [CrossRef]
- Babu, A.; Kumar, R. Optimized feature selection for the classification of uterine magnetomyography signals for the detection of term delivery. Biomed. Signal Process. Control 2020, 58, 101880. [Google Scholar]
- Khalil, M.; Duchene, J. Uterine EMG analysis: A dynamic approach for change detection and classification. IEEE Trans. Biomed. Eng. 2000, 47, 748–756. [Google Scholar] [CrossRef]
- Moslem, B.; Khalil, M.; Marque, C.; Diab, M.O. Complexity analysis of the uterine electromyography. In Proceedings of the 32nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC’10), Buenos Aires, Argentina, 31 August–4 September 2010; pp. 2802–2805. [Google Scholar]
- Diab, A.; Hassan, M.; Marque, C.; Karlsson, B. Quantitative performance analysis of fourmethods of evaluating signal nonlinearity: Application to uterine EMG signals. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC’12), Doha, Qatar, 12–15 November 2012; pp. 1045–1048. [Google Scholar]
- Fele-Zorz, G.; Kavsek, G.; Novak-Antolic, Z.; Jager, F. A comparison of various linear and non-linear signal processing techniques to separate uterine EMG records of term and preterm delivery groups. Med. Biol. Eng. Comput. 2008, 46, 911–922. [Google Scholar] [CrossRef]
- Alamedine, D.; Khalil, M.; Marque, C. Parameters extraction and monitoring in uterine EMG signals. Detection of preterm deliveries. IRBM 2013, 34, 322–325. [Google Scholar] [CrossRef]
- Ahmed, M.U.; Chanwimalueang, T.; Thayyil, S.; Mandic, D.P. A Multivariate Multiscale Fuzzy Entropy Algorithm with Application to Uterine EMG Complexity Analysis. Entropy 2016, 19, 2. [Google Scholar] [CrossRef] [Green Version]
- Horoba, K.; Jezewski, J.; Matonia, A.; Wrobel, J.; Czabanski, R.; Jezewski, M. Early predicting a risk of preterm labour by analysis of antepartum electrohysterograhic signals. Biocybern. Biomed. Eng. 2016, 36, 574–583. [Google Scholar] [CrossRef]
- Hoque, N.; Singh, M.; Bhattacharyya, D.K. EFS-MI: An ensemble feature selection method for classification. Complex Intell. Syst. 2018, 4, 105–118. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Fergus, P.; Cheung, P.; Hussain, A.; Al-Jumeily, D.; Dobbins, C.; Iram, S. Prediction of preterm deliveries from EHG signals using machine learning. PLoS ONE 2013, 8, e77154. [Google Scholar] [CrossRef]
- Hussain, A.J.; Fergus, P.; Al-Askar, H.; Al-Jumeily, D.; Jager, F. Dynamic neural network architecture inspired by the immune algorithm to predict preterm deliveries in pregnant women. Neurocomputing 2015, 151, 963–974. [Google Scholar] [CrossRef]
- Smrdel, A.; Jager, F. Separating sets of term and preterm uterine EMG records. Physiol. Meas. 2015, 36, 341–355. [Google Scholar] [CrossRef] [PubMed]
- Fergus, P.; Idowu, I.; Hussain, A.; Dobbins, C. Advanced artificial neural network classification for detecting preterm births using EHG records. Neurocomputing 2016, 188, 42–49. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Hao, D.; Yang, L.; Dua, M.; Song, X.; Jiang, H.; Zhang, Y.; Zheng, D. Evaluation of electrohysterogram measured from different gestational weeks for recognizing preterm delivery: A preliminary study using random Forest. Biocybern. Biomed. Eng. 2020, 40, 352–362. [Google Scholar] [CrossRef] [PubMed]
- Degbedzui, D.K.; Eminyüksel, M. Accurate diagnosis of term–preterm births by spectral analysis of electrohysterography signals. Comput. Biol. Med. 2020, 119, 103677. [Google Scholar] [CrossRef]
- Nieto-del-Amor, F.; Prats-Boluda, G.; Martinez-De-Juan, J.L.; Diaz-Martinez, A.; Monfort-Ortiz, R.; Diago-Almela, V.J.; Ye-Lin, Y. Optimized Feature Subset Selection Using Genetic Algorithm for Preterm Labor Prediction Based on Electrohysterography. Sensors 2021, 21, 3350. [Google Scholar] [CrossRef]
- Xu, J.; Chen, Z.; Zhang, J.; Lu, Y.; Yang, X.; Pumir, A. Realistic preterm prediction based on optimized synthetic sampling of EHG signal. Comput. Biol. Med. 2021, 136, 104644. [Google Scholar] [CrossRef]
- Zhang, J.X.M.W.J.; Huang, Z.C.W.; Shen, G.; Zhang, M. Network theory based EHG signal analysis and its application in preterm prediction. IEEE J. Biomed. Health Inform. 2022. (early access). [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the hilbert spectrum for nonlinear and nonstationary Time Series Analysis. Proc. R. Soc. Lond. A 1971, 454, 903–995. [Google Scholar] [CrossRef]
- Ren, P.; Yao, S.; Li, J.; Valdes-Sosa, P.A.; Kendrick, K.M. Improved prediction of preterm delivery using empirical mode decomposition analysis of uterine electromyography signals. PLoS ONE 2015, 10, e0132116. [Google Scholar] [CrossRef] [Green Version]
- Sadi-Ahmed, N.; Kacha, B.; Taleb, H.; Kedir-Talha, M. Relevant features selection for automatic prediction of preterm deliveries from pregnancy electroHysterograhic (EHG) records. J. Med. Syst. 2017, 41, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Sudarshan, V.K.; Rong, S.Q.; Tan, Z.; Min, L.C.; Koh, J.E.; Nayak, S.; Bhandary, S.V. Automated detection of premature delivery using empirical mode and wavelet packet decomposition techniques with uterine electromyogram signals. Comput. Biol. Med. 2017, 85, 33–42. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.U.; Sajid, Z.; Sohail, M.; Aziz, S.; Ibraheem, S.; Naavi, S.Z.H. Electrohysterogram based Term and Preterm Delivery Classification System. In Proceedings of the 2020 First International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 3–5 November 2020; pp. 83–88. [Google Scholar]
- Bhavsara, R.; Heliana, N.; Suna, Y.; Daveya, N.; Steffertb, T.; Mayor, D. Efficient Methods for Calculating Sample Entropy in Time Series Data Analysis. Procedia Comput. Sci. 2018, 145, 97–104. [Google Scholar] [CrossRef]
- Boudraa, A.O.; Salzenstein, F. Teager–Kaiser energy methods for signal and image analysis: A review. Digit. Signal Process. 2018, 78, 338–375. [Google Scholar] [CrossRef]
- Parsian, M. Data Algorithms; O’Reilly Media, Inc.: Newton, MA, USA, 2015. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer: New York, NY, USA, 2008. [Google Scholar]
- Smith, C.; Koning, M. Decision Trees and Random Forests: A Visual Introduction For Beginners: A Simple Guide to Machine Learning with Decision; Blue Windmill Media: Sheffield, UK, 2017. [Google Scholar]
- Jager, F.; Libenšek, S.; Geršak, K. Characterization and automatic classification of preterm and term uterine records. PLoS ONE 2018, 13, e0202125. [Google Scholar] [CrossRef] [Green Version]
- Shahrdad, M.; Amirani, M.C. Detection of preterm labor by partitioning and clustering the EHG signal. Biomed. Signal Process. Control 2018, 45, 109–116. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of K | Channel | Se | Sp | Acc |
|---|---|---|---|---|
| 2 | CH1 | 81.2 % | 95.1 % | 93.9 % |
| CH2 | 78.9 % | 94.0 % | 91.8 % | |
| CH3 | 77.3 % | 95.4 % | 93.2 % | |
| 4 | CH1 | 86.1 % | 97.8 % | 96.3 % |
| CH2 | 86.9 % | 98.0 % | 96.6 % | |
| CH3 | 82.9 % | 97.6 % | 96.7 % | |
| 8 | CH1 | 82.1 % | 98.7 % | 96.6 % |
| CH2 | 80.0 % | 98.0 % | 95.8 % | |
| CH3 | 81.3 % | 99.6 % | 97.2 % | |
| 10 | CH1 | 79.2 % | 98.8 % | 96.2 % |
| CH2 | 79.0 % | 98.3 % | 95.9 % | |
| CH3 | 80.0 % | 99.6 % | 97.1 % | |
| 12 | CH1 | 77.1 % | 98.9 % | 96.0 % |
| CH2 | 76.7 % | 98.2 % | 95.4 % | |
| CH3 | 78.0 % | 99.6 % | 96.8 % |
| Kernel | Channel | Se | Sp | Acc |
|---|---|---|---|---|
| Linear | CH1 | 77.5 % | 98.4 % | 95.8 % |
| CH2 | 78.9 % | 98.5 % | 96.0 % | |
| CH3 | 85.0 % | 99.6 % | 97.7 % | |
| RBF | CH1 | 82.8 % | 98.8 % | 96.7 % |
| CH2 | 83.7 % | 98.3 % | 96.4 % | |
| CH3 | 76.8 % | 100 % | 97.0 % | |
| Poly | CH1 | 99.5 % | 99.7 % | 99.7 % |
| CH2 | 93.6 % | 99.6 % | 98.9 % | |
| CH3 | 88.4 % | 99.0 % | 97.7 % |
| MLS | Channel | Se | Sp | Acc |
|---|---|---|---|---|
| 10 | CH1 | 93.4 % | 96.4 % | 96.1 % |
| CH2 | 87.8 % | 92.8 % | 92.1 % | |
| CH3 | 89.7 % | 94.8 % | 94.5 % | |
| 20 | CH1 | 100 % | 98.4 % | 98.7 % |
| CH2 | 91.0 % | 96.9 % | 96.2 % | |
| CH3 | 91.7 % | 96.8 % | 96.2 % | |
| 30 | CH1 | 100% | 97.7 % | 98.2 % |
| CH2 | 94.1% | 96.7 % | 96.2 % | |
| CH3 | 91% | 97.0 % | 96.2 % | |
| 40 | CH1 | 97.2 % | 96.8 % | 96.8 % |
| CH2 | 97.1 % | 96.8 % | 96.9 % | |
| CH3 | 100 % | 97.3 % | 97.6 % | |
| 50 | CH1 | 100% | 93.2 % | 94.1 % |
| CH2 | 100% | 93.3 % | 94.1 % | |
| CH3 | 100% | 93.2 % | 94.0 % |
| blackWork | Data Balancing | Channel | No. Data | Classifier | Acc | Se | Sp | AUC |
|---|---|---|---|---|---|---|---|---|
| black [27] | Yes (SMOTE) | CH3 | 262 term; 38 preterm | polynomial | – | 96% | 90% | 0.95 |
| [28] | Yes (Min–Max) | CH3 | 150 term; 19 preterm | SONIA | 92.7% | 91.2% | 94.5% | 0.93 |
| [29] | Yes (SMOTE) | CH3 | 262 term; 38 preterm | SVM | 87% | 96% | 79% | – |
| [30] | Yes (SMOTE) | CH3 | 262 term; 38 preterm | Combined * | – | 91% | 84% | 0.94 |
| [31] | Yes (ADASYN) | CH1-3 | 143 term; 19 preterm | RF * | 93% | 89% | 97% | 0.962 |
| [32] | Yes (ADASYN) | CH1 | 262 term; 38 preterm | SVM | 99.72% | 99.48% | 99.96% | – |
| [37] | Yes (SMOTE) | CH3 | 262 term; 38 preterm | Adaboost | – | – | – | 0.986 |
| [38] | No | CH1-2 | 26 term; 26 preterm | SVM * | 95.70% | 98.40% | 93% | 0.95 |
| [39] | Yes (ADASYN) | CH1-3 | 262 term; 38 preterm | SVM * | 96.25% | 95.08% | 97.33% | – |
| [33] | Yes (SMOTE) | CH1-3 | 275 term; 51 preterm | Ensemble * | 91.64% | 96.23% | 87.04% | 98.13 |
| [5] | Yes (SMOTE) | CH1-3 | 275 term; 51 preterm | LDA * | 89.2% | 98.4% | 79.9% | 0.936 |
| [34] | Yes (SMOTE) | CH1-3 | 262 term; 38 preterm | GBC | 85% | - | - | 0.91 |
| [35] | Yes (Partition-Synthesis) | CH1-3 | 275 term; 51 preterm | SVM * | 91% | 89.0% | 93% | 0.97 |
| [40] | Yes (ADASYN) | CH1-3 | 262 term; 38 preterm | SVM * | 98.5% | 98.4% | 98.4% | - |
| Ours | No | CH1 | 262 term; 38 preterm | SVM | 99.7% | 99.5% | 99.7% | 0.999 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammadi Far, S.; Beiramvand, M.; Shahbakhti, M.; Augustyniak, P. Prediction of Preterm Delivery from Unbalanced EHG Database. Sensors 2022, 22, 1507. https://doi.org/10.3390/s22041507
Mohammadi Far S, Beiramvand M, Shahbakhti M, Augustyniak P. Prediction of Preterm Delivery from Unbalanced EHG Database. Sensors. 2022; 22(4):1507. https://doi.org/10.3390/s22041507
Chicago/Turabian StyleMohammadi Far, Somayeh, Matin Beiramvand, Mohammad Shahbakhti, and Piotr Augustyniak. 2022. "Prediction of Preterm Delivery from Unbalanced EHG Database" Sensors 22, no. 4: 1507. https://doi.org/10.3390/s22041507
APA StyleMohammadi Far, S., Beiramvand, M., Shahbakhti, M., & Augustyniak, P. (2022). Prediction of Preterm Delivery from Unbalanced EHG Database. Sensors, 22(4), 1507. https://doi.org/10.3390/s22041507