5.1. Statistical Analysis for the Identification of Differences in Feature Representations Extracted from Smartwatch Data
The nature of the long-term study conducted in the e-Prevention project required a different data processing approach than previous studies. For this reason, we conducted a rigorous statistical analysis in order to identify the most suitable representations in conjunction with our large dataset. Thus, inspired by traditional signal processing techniques, we extracted common and more complex features using short-time analysis and we studied them through their descriptive statistics in order to obtain a rough estimate of how they differentiate between healthy controls and patients with psychotic disorders.
The statistical analysis presented next has offered a high degree of certainty that some of both the more common and the novel nonlinear features differ extensively between the two groups, and are thus of major importance to clinical practitioners, as well as for the next steps of our experimental evaluations. Therefore, we could claim that it constitutes a vital step towards developing a method that can leverage informative and interpretable physiological and behavioral data from sensors that could act as diagnostic tools with the aim of timely prediction of relapses.
Data Collection: For this statistical analysis, we used data from twenty-three (23) healthy control volunteers and 24 patients with a disorder in the psychotic spectrum (12 with Schizophrenia, 8 with Bipolar Disorder I, 2 with Schizoaffective disorder, 1 with Brief Psychotic Episode, and 1 with Schizophreniform Disorder). Due to limitations on the number of available devices, each subject was recruited at a different date—controls were recruited between June 2019 and October 2019, whereas patients have been continuously recruited from November 2019 up to March 2021, when this first statistical analysis was conducted. Controls were continuously monitored for at least 90 days and then they returned the watches, whereas the monitoring of patients has been an ongoing process. In the analysis presented here, we use data up to September 2020 to ensure that the analyzed data for each group are approximately balanced. Furthermore, to mitigate the effect of the COVID-19 Pandemic quarantine in Greece (15 March 2020–10 May 2020), since only patients were monitored at the time, we exclude data collected during this period.
Table 3 contains information on the demographics of the two groups, as well as the collected data at the time of conducting the analysis. We also include the BMI and the PANSS scale rating at the time of recruitment for the two groups (note that PANSS is only applicable to patients).
Data Preprocessing: Short-time analysis of signals using windowing is a traditional signal processing method. In short-time analysis, we assume the process under which the data are generated to be stationary. Drawing power from these techniques, but largely increasing the time scale, we proceeded to perform “short-time’’ analysis in windows of 5 min for both movement and HRV data. Five (5) min intervals have been found to hold important information for distinguishing short-term patterns in a previous study [
100].
Preprocessing of Heart-Rate Variability: The heart rate variability (HRV) sequence from the 5 Hz signal was obtained by dropping identical consecutive values. We also removed RR intervals larger than 2000 ms and smaller than 300 ms, considered artifacts, and replaced possible non-detected pulses with linear interpolation. After preprocessing, we extract features from the first 4.5 min () of the RR intervals sequence, dropping subsequent values so that each interval has the same length.
Preprocessing of Accelerometer and Gyroscope Data: In data collected from the accelerometer and gyroscope, we first dropped all intervals with more than 50 missing values. Then, existing missing values were filled via nearest-neighbor interpolation and features were extracted from the first 5940 (
) samples of the interval. Note also that we applied high-frequency wavelet denoising [
101] in order to smooth out the intrinsic noise from the sensors. The mean and standard deviation of the number of 5-min intervals for each user is reported in
Table 3.
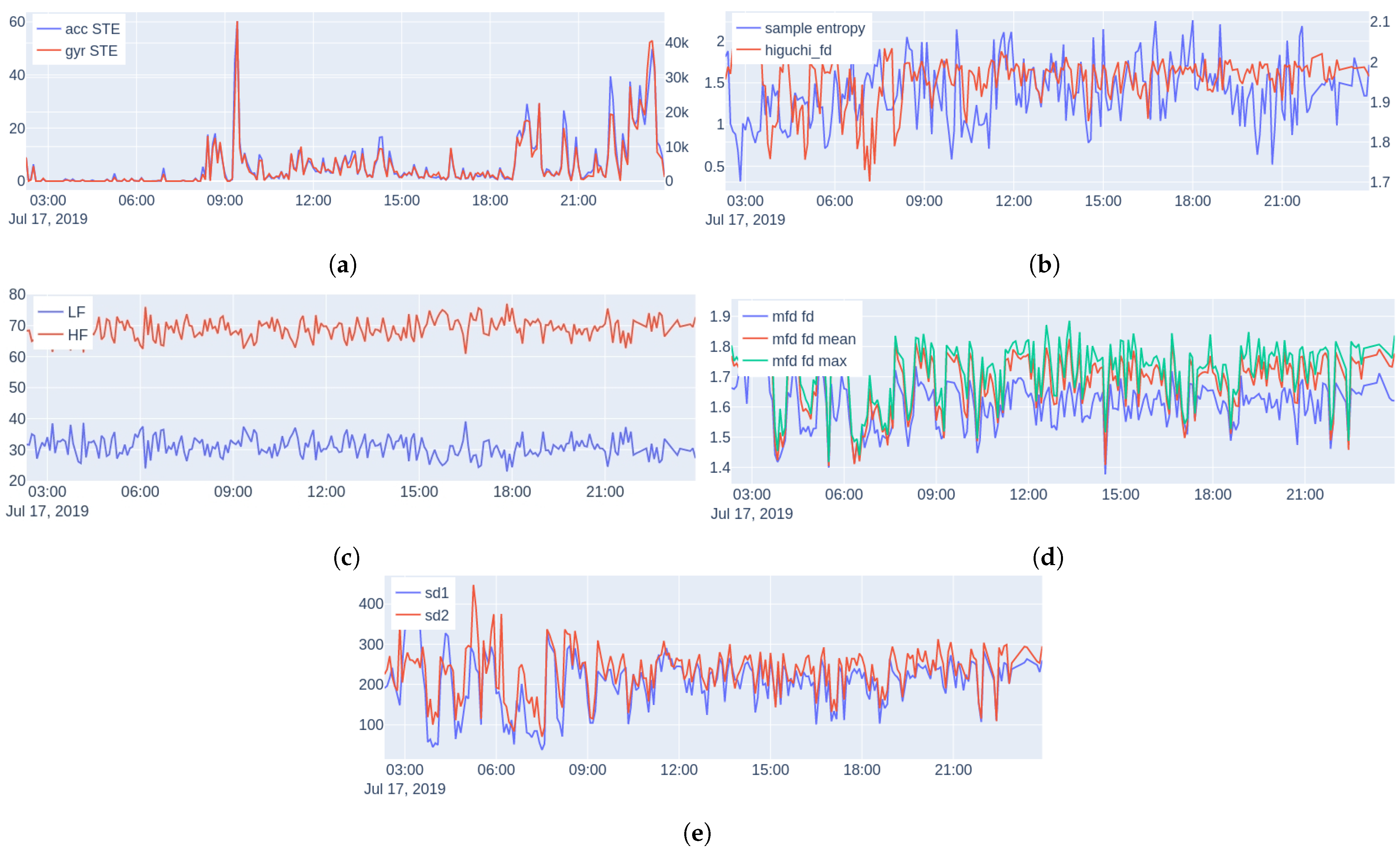
Feature Extraction: We consider the following features, examples are shown in
Figure 6 (during one day of monitoring a subject):
Energy: The short-time energy (STE) of the euclidean norm of the accelerometer (acc) and gyroscope (gyr) signals is extracted (since they are measured triaxially). We use these features as an objective measure of physical activity and general movement behavior.
Spectral features: Power Spectral Density (PSD) is a common and powerful frequency-domain method for analysis of HRV describing the relative energy of the signal’s cyclic fluctuations, managing to decompose the HRV signal to the sum of its sine and cosine components; allowing this way superimposed periodicities to be unraveled. Medical studies split the HRV spectrum into four frequency bands: ultra-low-frequency (ULF
Hz), very-low-frequency (VLF
–
Hz), low-frequency (LF
–
Hz), and high-frequency (HF
–
Hz) [
102]. Since HRV is, by definition, a non-uniformly sampled signal, we perform spectral analysis using the Lomb–Scargle (LS) periodogram [
103].
The Lomb–Scargle periodogram is a method of power spectrum estimation that can be directly applied to non-uniformly sampled signals, and as a result, it is appropriate for HRV measurements. The periodogram is defined as:
where
is given by:
and
is the angular frequency (rad/s),
the time (s) at which the signal was sampled, and
the value of the signal at time
. Using the LS periodogram, we extract for each interval the normalized power in two bands: LF and HF, as well as the ratio LF-to-HF.
Sample Entropy: Nonlinear methods treat the extracted time series as the output of a nonlinear system. A typical characteristic of a nonlinear system is its complexity. The first measure of complexity we consider is the sample entropy (SampEn). Sample entropy is a measure of the rate of information generated by the system and it has been considered to be an improved version of the approximate entropy [
104], due to its unbiased nature.
Higuchi Fractal Dimension: Multiple algorithms have been proposed for measuring the fractal dimension of time series. Here, we use the Higuchi fractal dimension [
105], which has been used extensively in neurophysiology due to its simplicity and computational speed [
106,
107,
108].
Multiscale Fractal Dimension: Multiscale Fractal Dimension (MFD) is an efficient algorithm [
109] that measures the short-time fractal dimension based on the Minkowski–Bouligand dimension [
63]. In more detail, the algorithm measures the short-time fractal dimension using nonlinear multiscale morphological filters that can create geometrical covers around the graph of a signal, whose fractal dimension
D can be found by:
As is known,
D is between 1 and 2 for one-dimensional signals, and the larger the
D is the larger the degree of geometrical fragmentation of the signal. In practice, real-world signals do not have the same structure over different scales; hence,
D is computed by fitting a line to the log–log data of Equation (
3) over a small scale window that can move along the
s axis creating a profile of local multiscale fractal dimensions (MFDs)
at each time location
t of the signal frame; thus, we are able to examine the complexity and fragmentation of the signals at multiple scales. In general, the short-time fractal dimension at the smallest discrete scale
has been found to provide some discrimination among various events. At higher scales, the MFD profile can also offer additional information that could help further the discrimination; more details about the algorithm can be found in [
109]. For this reason, we summarized the short-time measured MFD profiles by taking the following statistics: fd[1] (the fractal dimension), min, max, mean, and std for each 5-min HRV interval.
Poincare Plot Measures: The Poincare plot [
61] is a recurrence plot, where each sample of a time series is plotted against the previous, and then an ellipse is fitted on the scatter plot. The width of the ellipse (SD1) is a measure of short-term HRV, whereas the length (SD2) is a measure of long-term HRV.
Feature Aggregation: Using the information from the sleep schedule of each subject, we split the intervals into two groups; one corresponding to intervals during sleep and one during wakefulness. We then calculated the mean and standard deviation (std) over all individual intervals, resulting in two values for each subject and feature type and a total of 28 features. Significance tests using the Student’s
t-test showed no significant differences between the recorded movement and HRV intervals for each group and state (i.e., sleeping and awake). Normality was tested with the Shapiro–Wilk test [
110].
Sleep/Wake Ratio and Steps: In addition to the above features, we also extracted for each subject the mean and standard deviation of his/her sleep/wake ratio and the mean number of steps per day. Since the number of recorded hours each day fluctuates, for these features, we use only days with at least 20 recorded hours (no significant difference found between the number of days for controls and patients using Mann–Whitney U testing [
111], since the normality assumption was violated).
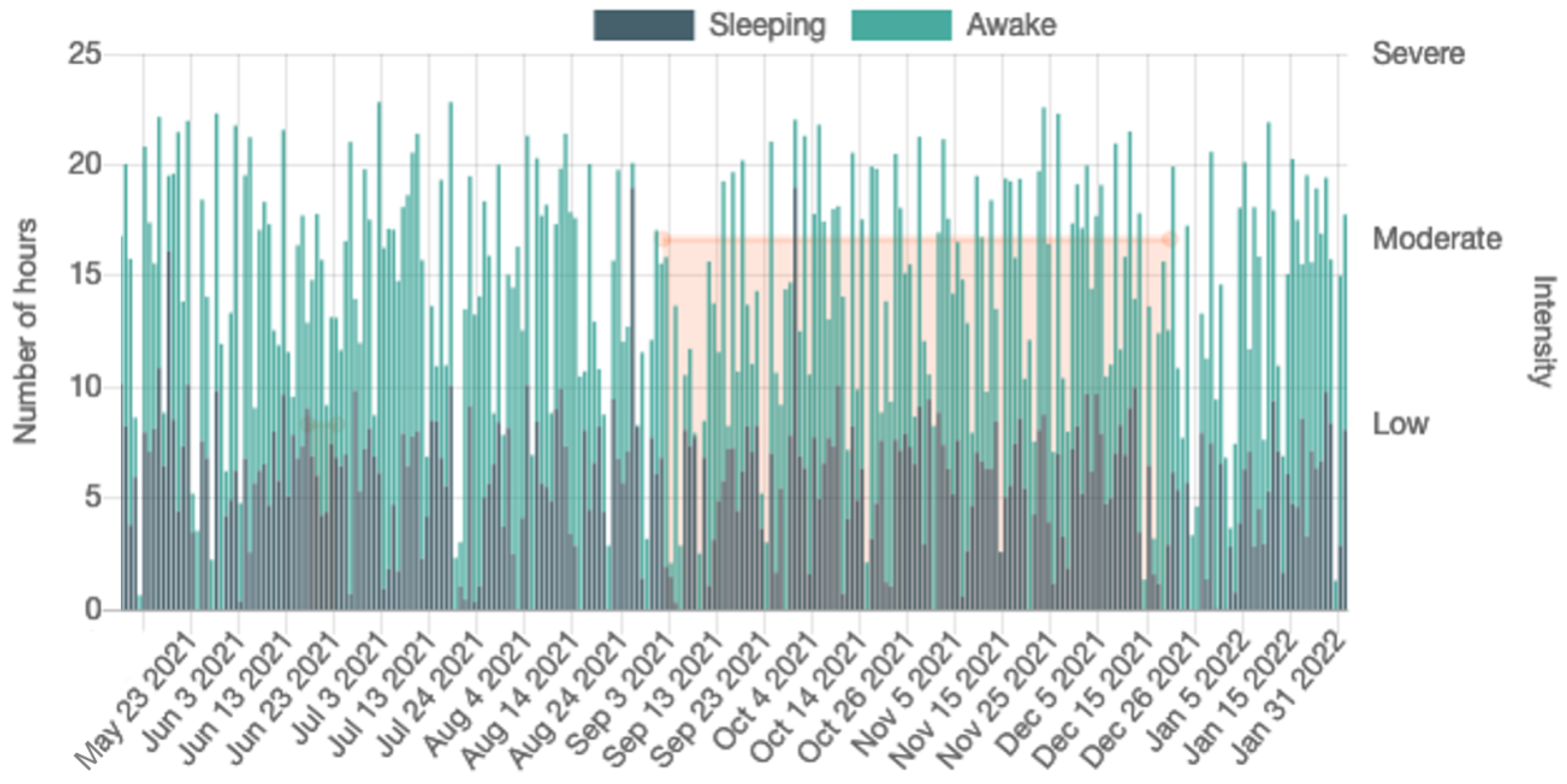
Figure 7 shows the steps per day and sleep/wake cycle during one month of monitoring.
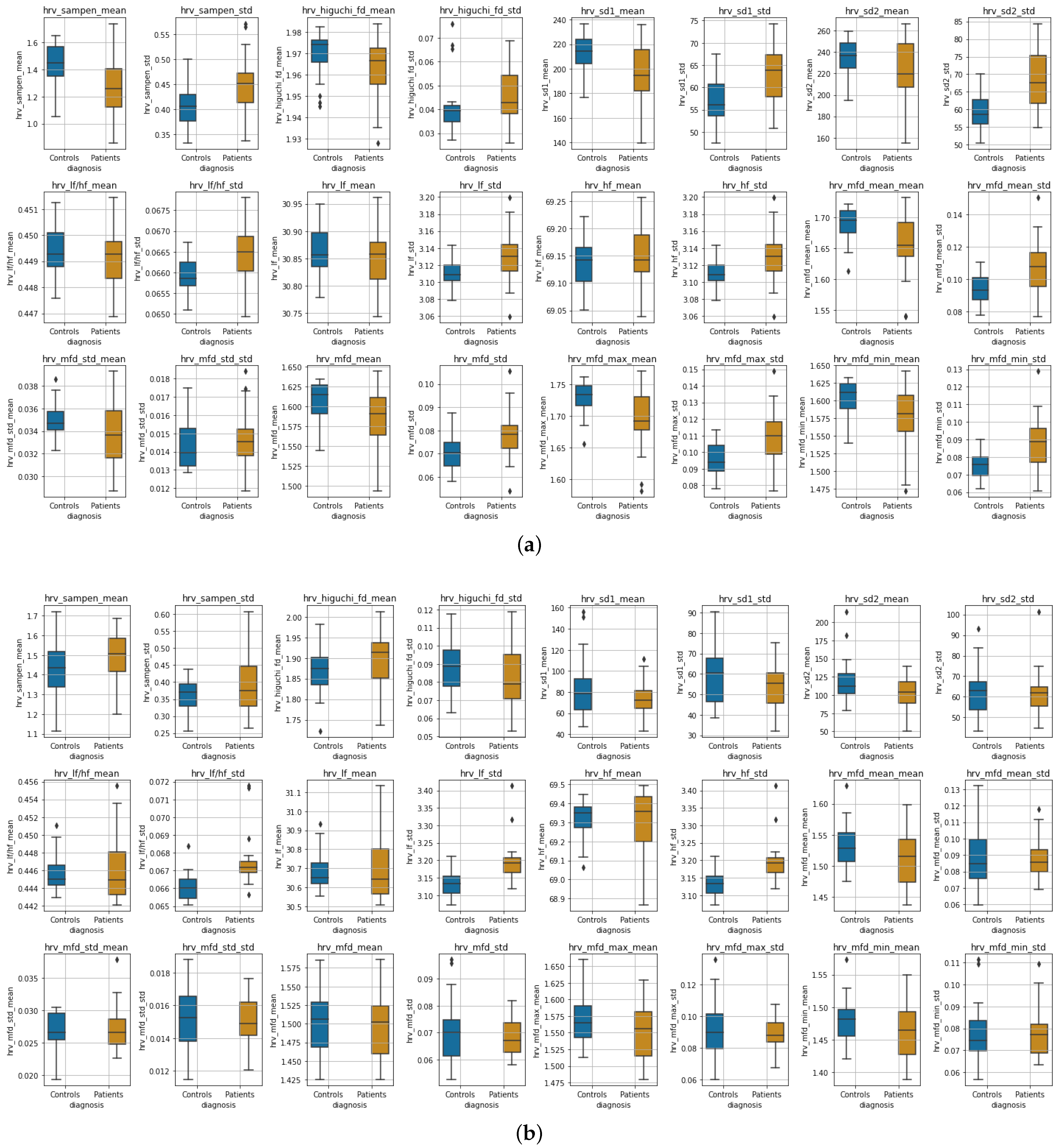
Experimental Results:Figure 8 shows boxplots of the features extracted from the accelerometer and gyroscope data during wakefulness and sleeping, whereas in
Figure 9, boxplots of the HRV features are presented for the two states, respectively. Due to the differences observed perceptually between the distributions in most features, we tested for significant differences between distributions (the null hypothesis being that the two distributions are the same) using two-tailed non-parametric Mann–Whitney U tests [
111]. We adjusted for
p-values using the Benjamini–Hochberg (BH) procedure [
112]. Due to the nature of our study, BH was preferred over the more strict Family-Wise Error Rate methods [
113].
Table 4 shows the results of Mann–Whitney U tests for all features.
Wakefulness Comparison: During wakefulness, the features that pertain to movements appear to present more variability in the patient group compared to the controls, as shown in
Figure 8 (top row). The same appears to also be valid for some nonlinear HRV features, for instance, SampEn mean, Higuchi mean and std, SD1 and SD2, various statistics extracted from the MFD profile, and some of the frequency domain features, as can be seen in
Figure 9 (three top rows). Additionally, the significance testing presented in
Table 4 showed significant distribution differences in the
std of
acc and
gyr short-time energy, the
mean and
std of SampEn, the
std of SD1 and SD2, the
std of LF, HF and LF-to-HF ratio as well as the MFD statistics related to
std as well as to
mean,
max and
min std. The other features failed to reject the null hypothesis.
Sleep Comparison: Similarly,
Figure 8 (bottom row) presents the accelerometer and gyroscope feature distributions for each group during sleeping, whereas
Figure 9 (three top rows) shows the distributions of HRV features. It is evident that especially the movement-related features present a significant difference, which is also verified in the Mann–Whitney U test results shown in
Table 4. The mean of the sample entropy among others also appears to be different (large variations); however, the null hypothesis could not be rejected, possibly due to
p-value adjustments for multiple testing. From the rest of the features, the
std of LF, HF, and their ratio were found to differ significantly.
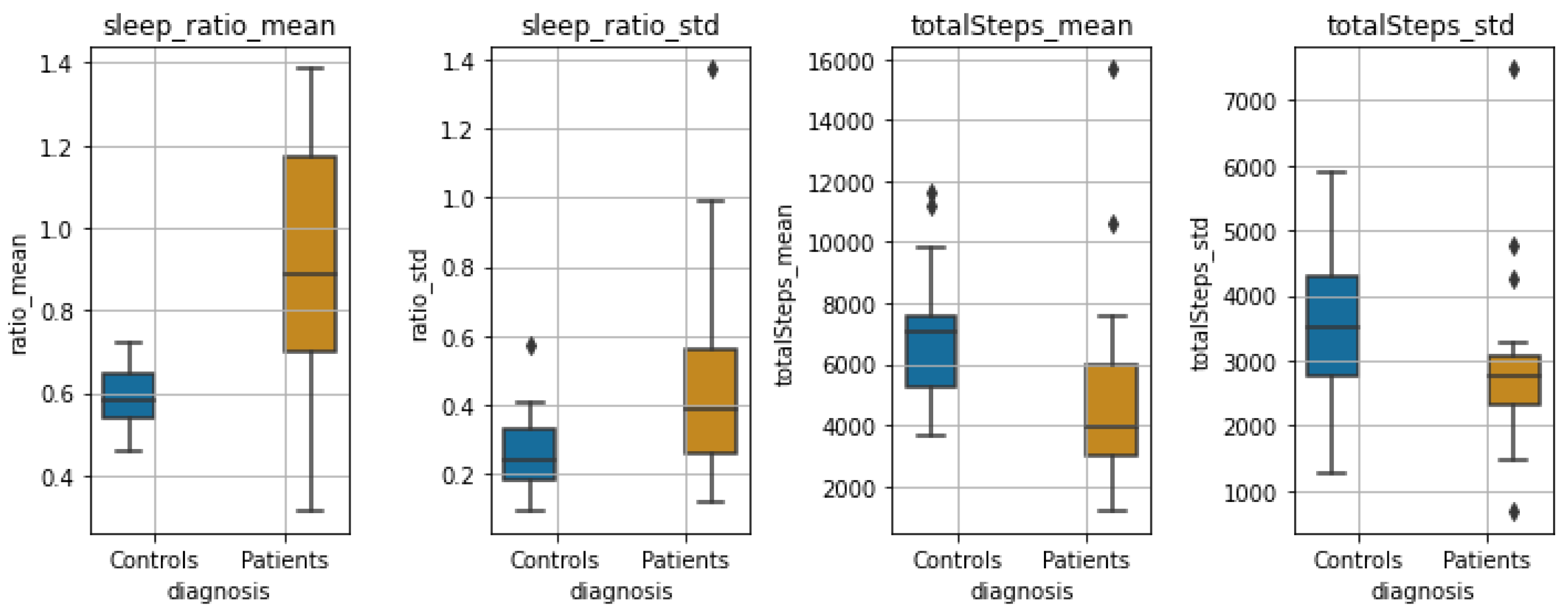
Sleep-wake Ratio and Total Steps: Finally,
Figure 10 shows the boxplots of the statistics of steps per day and sleep/wake ratio for the two groups. We observe a large significant difference between both the distributions of the
mean and
std of the sleep/wake ratio (
and
, respectively), as well as the mean and std of total steps per day (
and
, respectively).
Discussion: Our goal with the statistical analysis is to exploit various traditional but also less-known and, at the same time, more novel signal processing techniques to identify common markers/features that differ drastically when a person has a psychotic disorder. These markers could prove useful in predicting potential relapses in these patients.
Our findings have shown that patients tend to behave with greater variability and present large outliers—some behave close to controls, whereas others might show extreme values. During wakefulness, even though the mean energy did not differ when compared to controls, the standard deviation showed a significant difference, indicating that patients tend to depict large variations in their movement behavior. On the contrary, during sleeping, the patients presented a small mean and standard deviation of the energy in each of their sleeping intervals compared to the controls. We should note, however, that the observed differences in sleep between the two groups could be attributed to medication administered to patients, which possibly causes variability in sleep duration.
Some of the nonlinear features that were measured for the HRV data showed significant differences in the distributions between controls and patients, i.e., during wakefulness; as seen in
Table 4, such features are the mean and standard deviation of the sample entropy, as well as various statistics derived from the MFD analysis. Furthermore, the standard deviation of the normalized low- and high-frequency bands of the HRV, as well as their ratio, were found to differ significantly both during wakefulness and sleeping. During sleeping, we did not find any other measurements of HRV to differ significantly. Finally, the sleep ratio of the two groups, as well as the mean and std of the number of steps per day, presented significant variation between the two groups.
The main merits of this statistical analysis are two-fold: First, compared to previous similar studies, which have mostly lasted for a few weeks, our study, at the point that was conducted, had already been going on for more than a year. To do this, we employed a commercial off-the-shelf smartwatch that had been acknowledged by our volunteers to be comfortable, and patients are willing to insert it into their daily lives routine. Second, we show how traditional short-time analysis combined with common but also more complex and novel features, such as the MFD features that depicted significant differences in wakefulness data, can be employed to identify biomarkers and present large inter-group variabilities between healthy controls and patients, paving the way towards both acquiring clinical insights on psychotic disorders, but also exploring the capabilities of these markers to predict relapses. In the next
Section 5.2, we present our work on relapse detection, using some of the features found statistically significant in this analysis.
5.2. Relapse Detection Using Smartwatch Data and Autoencoder Architectures
In order to detect relapses in patients with psychotic disorders using the physiological signals collected by the smartwatch, we followed an anomaly detection approach [
89,
114]. In particular, we examined four different autoencoder architectures based on Transformers, Fully connected Neural Networks (FNN), Convolution Neural Networks (CNN) and Gated Recurrent Units (GRU) [
115,
116], with our models implemented using both a personalized and a global scheme. For this task, we used time-scaled data of 1569 days, segmented into five-minute intervals, from ten patients, obtaining encouraging results. We also conducted an analysis using the best-performing models to examine the ability to estimate the severity level of a relapse among patients who relapsed multiple times with different severity levels, providing important evidence as well [
91].
Data Collection: At the time that this study was performed 24 patients with a disorder in the psychotic spectrum had already been recruited; however, after the preprocessing of the raw data (and taking under consideration missing data that could not be recovered), we were able to process only data from 10 patients, of which 2 with Schizoaffective Disorder, 4 with Bipolar I Disorder, 1 with Brief Psychotic Episode, 1 with Schizophreniform Disorder and 2 with Schizophrenia; see
Table 5 for demographics. Specifically, the data were collected from November 2019 to September 2021, with the exact period varying for each patient due to the differences in time of recruitment; after preprocessing, the data amounted to a total of 1569 days. Depending on the clinician annotations, as described in
Section 4, we split the data into three categories: normal data, where the patient was stable; relapse data corresponding to time periods when a relapse had occurred; and near-relapse data, thus data recorded up to 21 days prior to the appearance of each relapse. For this study, we discard near-relapse data and keep data corresponding to stable and relapsing periods.
Feature Extraction and Data Preprocessing: As the first step in our analysis, and based on the statistically significant representations as described in
Section 5.1, we performed feature extraction, including in our experiments the following features: the mean energy of the accelerometer and gyroscope norm, the mean heart rate and R-R interval, the normalized energy in the LF and HF bands of the heart rate (0.04–0.15 Hz and 0.15–0.40 Hz, respectively), and the value of the width of the ellipse in the Poincare recurrence plot. Moreover, three additional features were included to model the chronological order of the time-series and how well the patient was wearing the watch, specifically, the sine and cosine representations of the corresponding seconds (over a daily period) and the percentage of correctly identified pulses in the given interval.
Afterwards, the features were aggregated into a dense representation of 5-min intervals, since as shown in [
100] such intervals are able to capture micro-scale patterns, something that also allowed us to have an adequate amount of data for the deep learning architectures that we implemented. These intervals were then stacked temporally into tensors, each covering 24 h of physiological activity. In cases of missing data up to 10 consecutive hours (e.g., when the patient was charging or did not wear the watch), we filled the data with the median values of the missing feature over a temporal window; when more than 10 consecutive hours of data were missing, we completely disregarded the specific interval.
Methodology: We implemented four different architectures based on autoencoders that learn to reconstruct an input time series; specifically, Transformers, Fully connected Neural Networks (FNN), Convolutional Neural Networks (CNN) and Gated Recurrent Unit (GRU), see also [
91].
In the Transformer model, the input sequence is first imported into a positional encoding layer followed by four stacked transformer encoder layers, which are made up of two sub-layers. Both sub-layers are followed by a normalization layer. The input sequence after the encoding is reversed and piped into the decoder, which consists of four decoder layers, with similar architecture to the encoder. At the end, a linear layer is applied.
For the Gated Recurrent Unit (GRU) sequence-to-sequence model with attention, a subsequence of data is fed into the encoding layer of the GRU with a specified hidden unit of size 100. Afterwards, we pass the weighted average of all encoded outputs (attention vectors) from all time-steps as inputs into the GRU decoder layer that reconstructs the subsequence.
The Fully connected Neural Network autoencoder (FNN) encompasses 2 fully connected encoder and decoder layers that compress an input subsequence to a lower dimension in order to reconstruct the initial subsequence. A ReLU nonlinearity follows after each fully connected layer and the last layer also contains a dropout layer in order to avoid over-fitting.
The CNN-based autoencoder follows an encoder-decoder scheme, with the encoder mapping the input to a low-dimensional latent representation, and then the decoder trying to reconstruct the original input. We build the decoder using 4 downsampling blocks which consist of an 1D Convolutional layer, batch normalization, and a LeakyReLU activation. In a similar manner, we build the decoder using 4 successive upsampling convolutional blocks, mirroring the blocks of the encoder. Finally, we apply a linear layer at the top.
Training and Evaluation of Anomalies: Models were trained using both a personalized and a global scheme. In the
personalized scheme the evaluation is performed for each patient separately, which is a common and proposed procedure for such tasks [
46]. However, we wanted to explore the generalization capabilities of our methods, so we evaluated them using a
global scheme, as well; thus, we train our models on data corresponding to all patients. For each case, we separated the respective normal data into three sets, i.e., the train (60%), validation (20%) and test (20%) set, following a 5-fold cross-validation scheme; the validation set was internally split into two equal subsets. All data were normalized in the
range, apart from the sine and cosine time representations, which were already in
. The train and validation sets, as usually performed in such anomaly detection tasks, contained only data with no anomalies (i.e., “normal” data), whereas the test set contained data both without and with anomalies (thus, relapses). Consequently, the performance of all models was evaluated to “unseen” normal and relapse data.
For the architecture’s implementation, we used Pytorch and the Mean Square Error (MSE) between the reconstructed and input time-series as a loss function for training (batch size of 64). For the Transformer and the FNN AE, the Adam optimizer [
117] was used, whereas the RMSprop optimizer was used for CNN AE and GRU AE. All models had a learning rate equal to
, with the exception of the Transformer having
. The training took place for 50 epochs, and early stopping was applied to monitor the model’s performance, using the validation loss of the first validation subset.
The mean absolute error (MAE) between the predictions
and the given data
was calculated in order to obtain the reconstruction error vector with size
of each point
i. The error vectors
in the second validation subset are used to compute the mean (
) and covariance (
) of a multivariate normal distribution that is the expected error distribution. Afterwards, the “anomaly score” was computed as the Mahalanobis distance between the predicted points in the test set and the Gaussian distribution that was calculated in the respective validation subset as in [
118]:
The per-point anomaly scores are day-averaged similarly to [
48]. The performance of each architecture was evaluated by the Receiver Operating Characteristic Area Under Curve (ROC AUC) and Precision-Recall Area Under Curve (PR AUC) metrics. Since we utilize 5-fold cross-validation, the median metric over all folds is reported as the final score. Concerning the evaluation of global models, we evaluated them either
globally (global scheme, tested to all patients) or
individually (global scheme evaluated individually, thus per patient).
Experimental Results and Discussion: In order to obtain baseline results, we implemented a random classifier (referred to as Random in
Table 6,
Table 7 and
Table 8), where we classified the data without training the models. Specifically, we directly calculated the mean and the covariance of the features in the validation set and then the anomaly scores in the test set.
Table 6 and
Table 7 show the results of our experiments for the personalized scheme for all patients and models. The best results for each patient are shown in bold. We observe that the best overall performance is obtained by the CNN AE model, with a PR-AUC equal to
, whereas all personalized models’ results surpass the baseline.
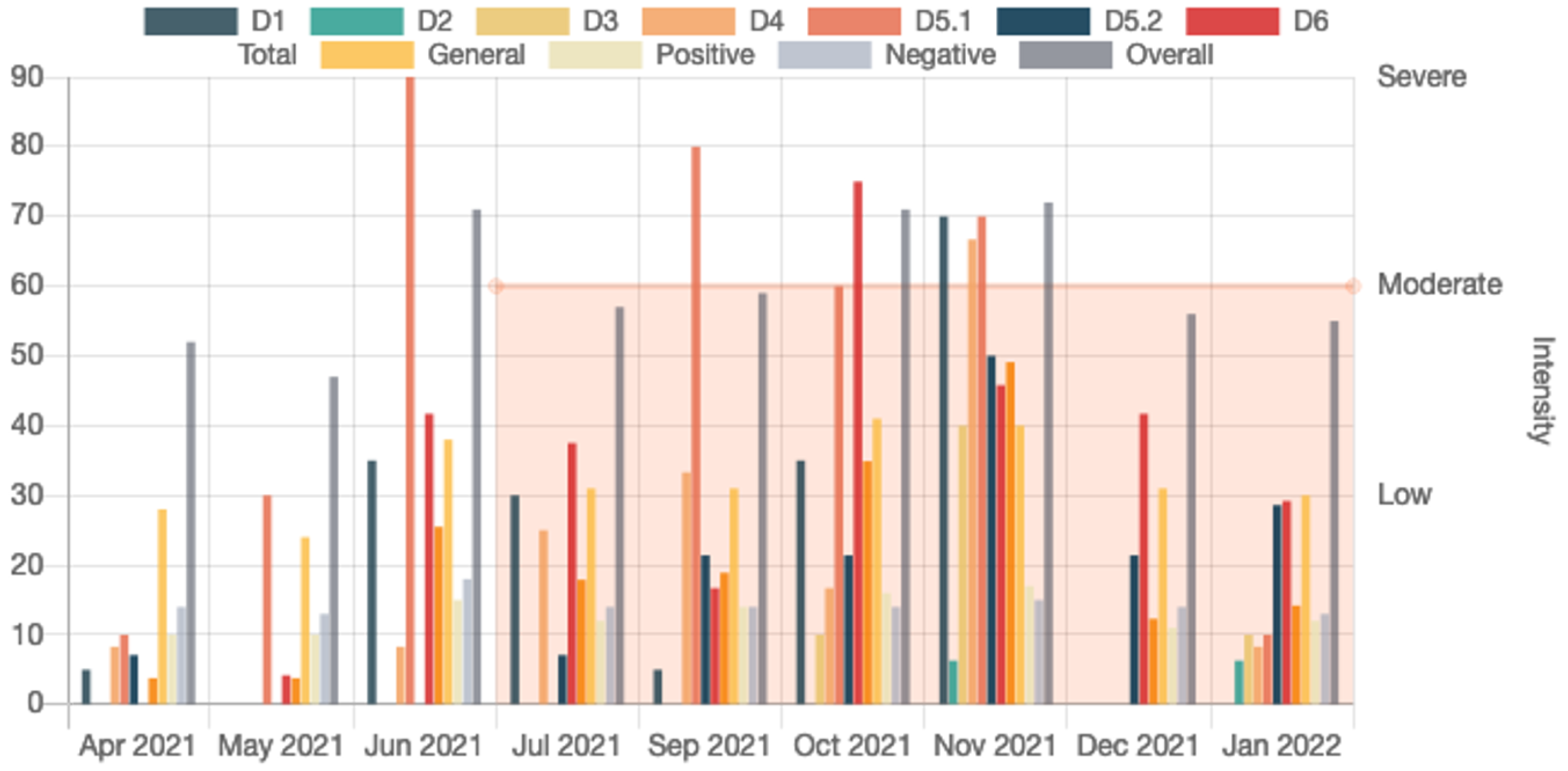
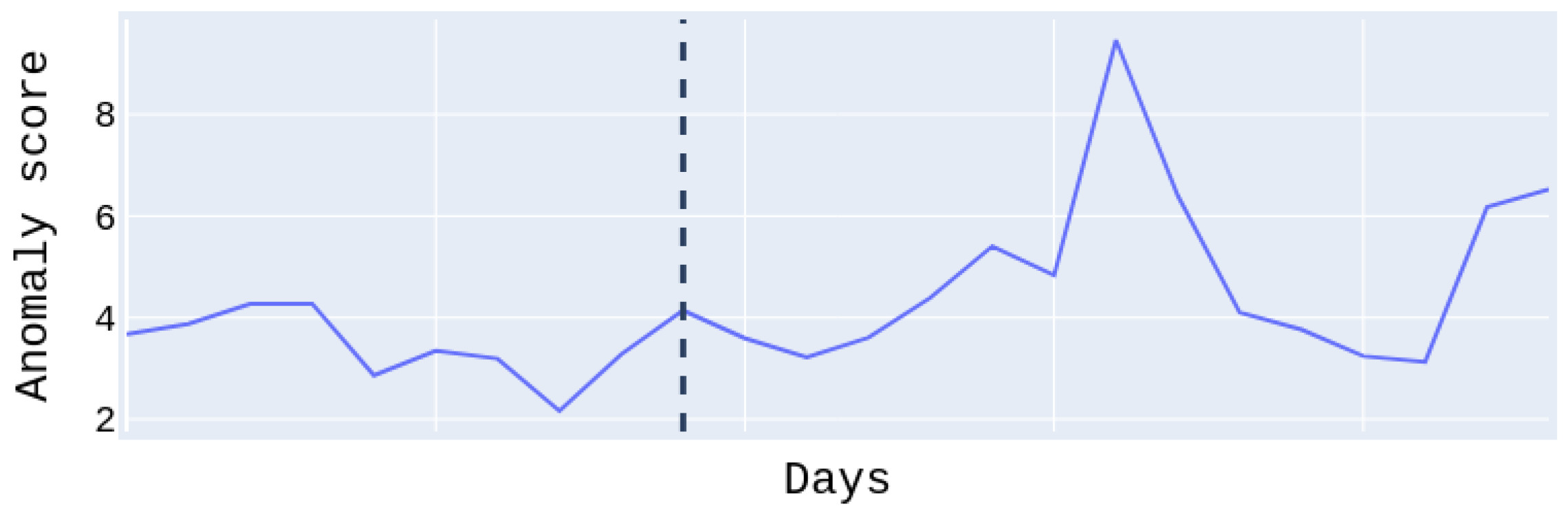
Figure 11, shows the anomaly score of the test set for patient
, who suffered a moderate relapse of about 11 days. The anomaly score to the right of the dividing line regards the relapse days and to the left the normal days. We easily notice that the anomaly score during relapse days is higher than on normal days. Note that the days on the
x-axis are not continuous. For this patient, we obtained the best PR and ROC AUC scores at
with the Transformer model. We have to emphasize at this point, that for some patients the performance is low. This is due to the fact that there was only a low amount of available relapse data (in some cases only a few days or hours after preprocessing); nonetheless, they were not excluded (as possible outliers), in order to maintain an adequate amount of data for the experiments. However, the conducted
t-tests showed statistically significant improvement for six out of ten patients over the random baseline, with a
p-value lower than
, whereas patients with more relapse days and data, i.e., patients
and
had better results related to the tests.
A number of ablations were performed on the best-performing architecture, namely the CNN AE, concerning the type of features utilized as well as the temporal dimension of the input tensors. Particularly, in
Table 9, we present the median per-patient ROC-AUC and PR-AUC scores obtained by discarding either the features from the accelerometer and the gyroscope or those related to the heart rate. We observe that both types of features are necessary to achieve a good performance; using only the heart-rate-based features, we obtain a similar ROC-AUC score but a lower PR-AUC, whereas the drop in the PR-AUC is more noticeable when using only features from the accelerometer and the gyroscope.
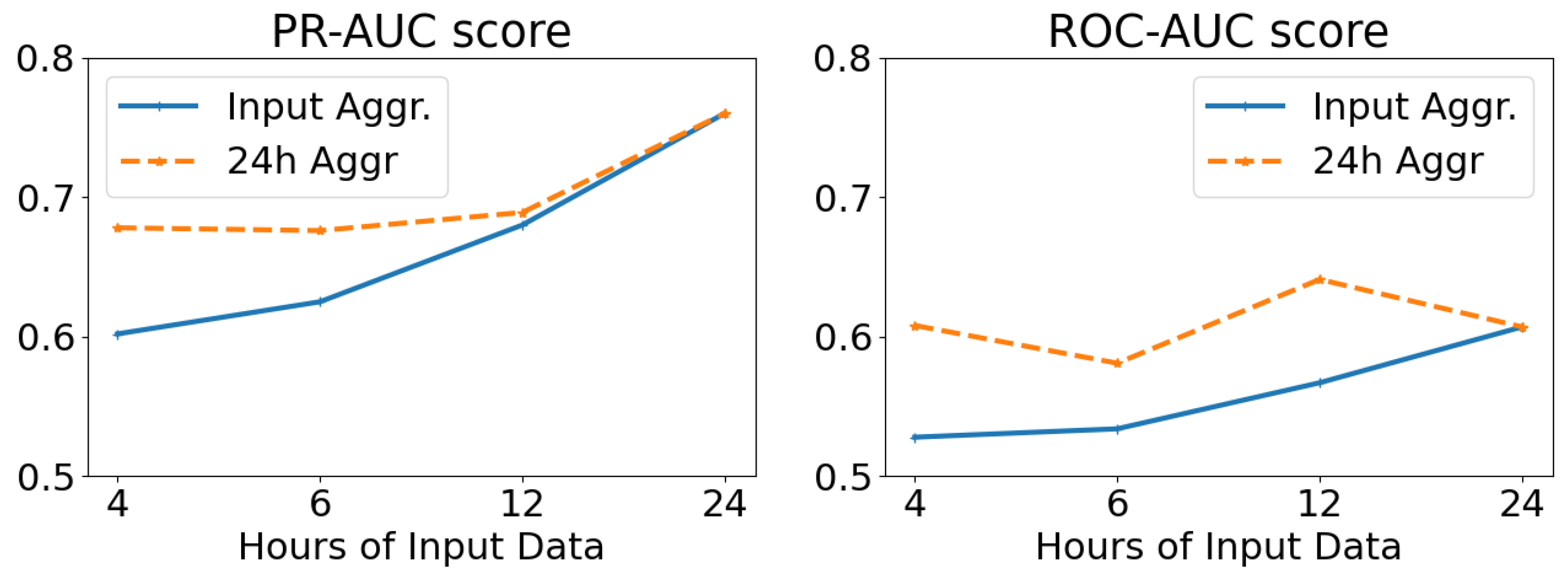
The results of altering the length (in hours) of the network input, while keeping the temporal resolution stable (and equal to 5-min intervals), are displayed in
Figure 12. We examine averaging the results at the temporal window of each input tensor (Input Aggr., ranging from 4 to 24 h), as well as on a daily basis irrespective of the input length (24 h Aggr.). From these results, we deduce that the larger the length of the network input, and thus the temporal window of analysis, the better the overall predicting ability of our model. We also note that per-day aggregation of the anomaly scores yields better results than using the temporal dimension of the input as a scale.
Table 8 presents the results for the global scheme and the global scheme evaluated individually. In this case, the FNN AE model, which was evaluated individually (denoted as Median), had the best performance with PR and ROC AUC of
and
, respectively, whereas the global scheme (denoted as Global) in general presents lower performance than the models that were evaluated individually, possibly due to the fact that several of the relapses had “low” severity, thus making their detection harder. Another important observation that we draw is that patients with moderate and severe relapses yielded better PR and ROC AUC results than the others.
Finally, using the best-performing models we experimentally evaluated the importance of relapse severity, using data from three patients that relapsed multiple times with different severity levels (Low and Moderate), while also examining the differences presented between low, moderate and severe relapses across all patients and severity level. For the former, we observed that for patients with adequate data the reconstruction error for moderate relapses was higher than the one recorded for the low-severity relapses, whereas for the latter, as intuitively expected, we noted that there was a gradual increase in the reconstruction error in relation to the severity of the relapse.
5.3. Relapse Detection and Prediction from Spontaneous Speech
Apart from physiological data, we investigated the extent excerpts from the spontaneous speech of the patients can be used to either detect relapses or predict their appearance. We opted for an unsupervised learning approach since it provides the advantage that models can be trained without necessarily having access to data from relapsing periods. Experiments conducted in a database with a total of 16 patients, containing over 38,000 s of total speech, yielded encouraging results for both classical Convolutional Autoencoders (CAEs) and Convolutional Variational Autoencoders (CVAEs) in a personalized setting, in agreement to our previous results derived from smaller subsets of this database [
86,
119]. Moreover, CVAEs can reach the performance of personalized models in a global (patient-independent) setup, especially when per-person normalization is applied to the input features [
119]. Finally, we experimented with a decision-level fusion between audio and physiological data, with the results indicating that physiological signals can act as a complementary modality to audio.
Data Collection and Preprocessing: For the purposes of this set of experiments, we utilized the short interviews between the patients and the clinicians, recorded through the e-Prevention app. Since not all patients recorded interviews, for the subsequent experiments we used interview data from 16 patients (1 with Schizoaffective disorder, 1 with Schizophreniform disorder, 1 with Bipolar II disorder, 8 with Schizophrenia and 5 with Bipolar I disorder), collected between May 2020 and December 2021. Patient demographics used in this work are presented in
Table 10. Eight (8) out of the sixteen patients had experienced a relapse during the duration of this study, whereas the rest were selected according to the total duration of their interviews. Each interview was annotated, according to the condition of the patient at the time it was conducted. In particular, interviews were split into clean data (C), where no relapse had been detected by the clinicians, relapse data (R), including interviews where the patient’s condition was denoted as relapsing, and pre-relapse data (P), which correspond to time periods up to 30 days prior to the appearance of a relapse. For the purposes of this work, both relapsing and pre-relapsing data were considered anomalous. Note that in contrary to the work described in
Section 5.2, using only smartwatch data, the period for pre-relapse data is different by 9 days; however, both duration of pre-relapse days that were selected are valid and were dictated by the clinicians of the e-Prevention project.
These interview videos were then preprocessed, in order to facilitate the feature extraction. In particular, the audio excerpts were extracted from the interviews and downsampled to 16 kHz. In order to isolate the utterances corresponding to patients from the complete audio excerpts, the x-vector [
120] diarization recipe from kaldi [
121] was used. This process resulted in a total of 14,562 utterances (38,066 s), about which we present detailed statistics in
Table 10. For each utterance, the log mel-spectrogram was computed, using a frame length of 512 samples (approx. 30 ms), an overlap of 256 samples (approx. 15 ms), and 128 mel bands. Finally, these spectrograms were cut off along the time axis in slices of 64 frames (approx. 1 s), thus yielding a
representation for each second of speech.
For the experiments examining the effect of fusion between audio and physiological information in detecting and predicting relapses, it was necessary to produce day-aligned pairs of interviews and physiological data. To ensure the availability of an adequate amount of paired data for each patient, these experiments were conducted with a reduced set of 12 patients (1 with Schizoaffective disorder, 1 with Schizophreniform disorder, 7 with Schizophrenia, 2 with Bipolar I disorder and 1 with Bipolar II disorder), out of whom 6 had experienced a relapse during the course of this study. Thus, taking into account the coupling of modalities, 164 interview sessions, containing 5623 utterances with an overall duration of 14,534 s, and 2233 h of physiological data were used. In order to deal with the reduced amount of physiological data, compared to
Section 5.2, the respective features (in this case, the mean heart rate and R-R interval, the peaks of the high frequency (HF, 0.15–0.4 Hz) and low frequency (LF, 0.04–0.15 Hz) bands of the Welch periodogram, and the ellipse width of the Poincare recurrence plot) were averaged over 2-min intervals, and then stacked temporally into a
representation, covering one hour of physiological activity.
Architectural Details: In the case of the CAE model, the encoder contains 4 convolutional blocks, which progressively reduce the dimensionality of the input mel-spectrograms to produce a low-dimensional embedding. Each block consists of a 2D-Convolution layer with an increasing number of filters at each block, a ReLU activation function, and a 2D Max Pooling layer. In turn, the decoder restores the latent embedding into its original dimensionality by applying a series of 4 upsampling convolutional blocks upon it. These blocks alternate upsampling layers with 2D-Convolution layers, followed by ReLU activations with the exception of the last layer. The reconstruction objective was enforced through an MSE loss () between the true and estimated spectrograms.
The CVAE is built upon the CAE architecture presented above, but instead of compressing its input into an intermediate latent representation, the encoder of the CVAE learns a
Gaussian distribution, from which embeddings are sampled and decoded through the decoder. To this end, the last convolutional block of the encoder is replaced by a pair of parallel convolutional blocks, which estimate the parameters of the latent Gaussian distribution. This distribution is encouraged to align with the spherical isotropic Gaussian,
, through the imposition of a Kullback–Liebler divergence loss (
) in the bottleneck of the network. For more details about the developed architectures, we refer the reader to [
86,
119].
Experimental Protocol: Concerning relapse detection and prediction from audio data, we trained models for both the personalized and the global case. In the personalized case, a separate model is trained for each patient who had experienced a relapse during the course of the study, using their respective speech segments. On the other hand, in the global case, a single model is trained for all patients, regardless of whether they had undergone any relapses, using the whole set of interview data. In both cases, we followed a 5-fold cross-validation training protocol, where the networks were trained only using clean data, and evaluated on a mixture of clean and anomalous data. In particular, for each fold, the clean data were split into training (60%), validation (20%) and testing (20%) data. The clean testing data were then merged with the anomalous (corresponding to pre-relapsing or relapsing states) data, in order to form the evaluation set. We further note that to avoid session-wise overfitting, data were split so that spectrograms corresponding to the same interview belong in the same fold. All networks were trained for a maximum of 200 epochs, with early stopping being applied with a patience of 10 epochs. The networks were optimized using Adam [
117] with a learning rate equal to
and a batch size equal to 8, and the loss weights for the case of the CVAE were set as
and
, respectively. We also note that to ensure the robustness of the results, each experiment was repeated five times, and we report on the average of the results over all repetitions.
The performance of both architectures is evaluated on a per-session basis. Each spectrogram provides an anomaly score; in the case of the CAE, it is derived by the reconstruction error, whereas in the case of the CVAE, we investigate the suitability of both the reconstruction error of the spectrogram and the KL divergence of its projected representation. A single value of the anomaly score for each session is then computed by temporal aggregation of the per-spectrogram scores. We utilize as our evaluation metrics the median anomaly score over all sessions, according to the state of the patient and the mean ROC-AUC score over all folds, applied to the per-session anomaly scores. We also perform an ablation study on the temporal pooling functions used to aggregate the per-spectrogram anomaly scores into a single anomaly score for each session. Finally, we investigate the effect of per-patient normalization of the features in the global case, as opposed to global feature normalization.
Experiments concerning the fusion of audio and physiological signals were only conducted for the global case. In this case, a pair of unimodal neural networks were trained independently and then evaluated individually in coupled speech from interview sessions and physiological signals from the day the interview was conducted. The unimodal anomaly scores were temporally aggregated, similar to above, on a per-session basis and a daily basis, respectively, and then combined using decision-level fusion. To this end, we experimented with two fusion mechanisms, namely additive (Add.) and multiplicative (Mult.) fusion.
Personalized Experiments: In
Table 11, we present the medians of the per-session anomaly scores for each patient, depending on the state of the patient during the interview session (clean, pre-relapsing or relapsing) and the network configuration used for deriving the anomaly score. We observe that for the majority of patients, interviews corresponding to either pre-relapsing or relapsing states record higher anomaly scores compared to those conducted when the patient’s condition was annotated as stable. Interestingly, this trend appears to be more profound for interviews conducted in pre-relapse periods, than during relapses. We finally note that when the KL divergence was used as an anomaly measure, the anomaly scores exhibit lower variability among different patients compared to the reconstruction error, implying its potential scalability to a subject-independent setting.
In
Table 12, we report on the macro-average of the ROC-AUC score for each network configuration, according to the pooling function used to aggregate the per-spectrogram anomaly scores into a single measure, and considering both pre-relapsing and relapsing states as anomalous. With regard to the temporal pooling function, we compare average pooling (AP), max pooling (MP) and norm pooling (NP) [
122] using the fixed value
. No statistically significant deviations between the evaluated models were found at the
level, after using the Bonferroni-corrected Mann–Whitney U-Test. We observe that when using the reconstruction error as the anomaly score, average pooling performs best, whereas comparatively better results are acquired when using the norm pooling for temporal aggregation of the KL divergence scores of the CVAE. Finally, the per-patient ROC-AUC scores when using the best performing pooling function for each model are presented in
Table 13, where we observe that for five out of the eight patients, a ROC-AUC score higher than 0.7 is achieved.
Global Experiments:
In
Table 14, we present the medians of the per-session anomaly scores for all patients, depending on their state during the interview and the network configuration used, as well as the application of global or per-patient normalization. We observe that when using global feature normalization, pre-relapsing sessions record only slightly higher anomaly scores than sessions conducted under stable patient conditions, whereas lower scores are acquired from sessions corresponding to relapsing states. On the other hand, per-patient normalization leads to better discriminability between clean sessions and sessions corresponding to both anomalous states in the case of the CVAE. The trend observed in the personalized case, regarding the higher anomaly scores yielded by pre-relapsing sessions compared to ones recorded during relapsing periods, is noticeable in this case as well.
The ROC-AUC scores depending on (i) whether features were normalized globally or per-patient, and (ii) the temporal pooling function used to aggregate the per-spectrogram anomaly scores are presented in
Table 15. These results support the qualitative claims deduced from the median anomaly scores presented above. Namely, when the input spectrograms are normalized per patient, and the KL divergence is used as the anomaly score, the global CVAE-based model reaches comparable performance to the personalized models, outperforming the original CAE. On the other hand, the application of global normalization to the spectrograms does not lead to performance improvements over random chance, irrespective of the model used. The necessity of per-patient normalization as a means to reach the performance of a personalized model is also consistent with [
72].
Concerning the suitability of the temporal aggregators evaluated, in contrast to the personalized case, average pooling yields the worst performance, whereas a global ROC-AUC score of approximately 0.7 is reached when using norm pooling as the aggregator, in conjunction with the KL divergence of the CVAE as a scoring function. Indeed, application of the Mann–Whitney U-Test to the ROC-AUC scores (over all folds and experiment repetitions,
) indicates the superior performance of the KL-CVAE over the other two configurations at a
statistical significance level post-Bonferroni correction, irrespective of the temporal pooling function and the normalization protocol used. The superior performance shown by the CVAE, compared to the CAE, in the global setup is in agreement with [
123], where VAE-based models were used to successfully extract speaker-invariant features from speech signals, indicating decreased dependency on person-specific speech properties.
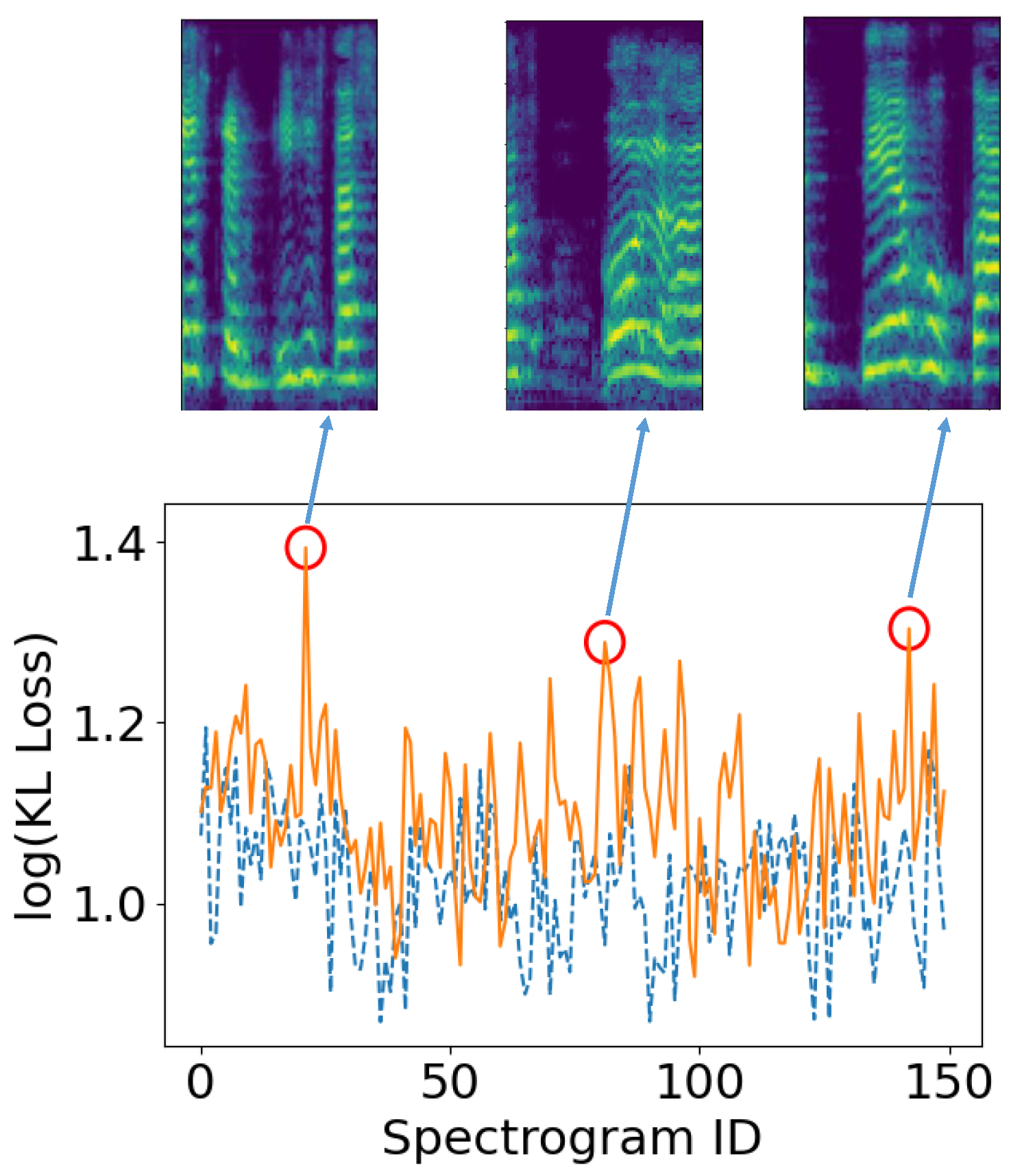
In
Figure 13, we present the per-spectrogram KL loss for two interview sessions corresponding to the same patient. We observe that the spectrograms that correspond to stable (dashed blue) patient conditions do not exhibit consistently higher anomaly scores compared to those comprising the interview recorded during a relapse (orange). However, a number of peaks appear in the anomaly scores of the relapsing session, denoted with red circles. Upon examination of the speech excerpts, whose spectrograms are also displayed in
Figure 13, we observe that they correspond to segments with abrupt pauses in the patient’s flow of speech.
Multimodal Fusion: Before presenting the results on the fusion between audio and physiological data, we evaluate a number of modifications to the CNN-AE architecture presented in
Section 5.2 operating on the physiological data to make it suitable for a global (patient-independent) setup. Since the results presented above indicate that, in conjunction with a per-patient feature normalization scheme, CVAEs can scale in a global relapse detection and prediction setting from audio better than CAEs, we examine the effect of those adjustments to the CNN-AE using physiological signals. In particular, we adapt the CNN-AE architecture into a 1D-CVAE following a similar procedure to the one used for the speech-based architecture, while also examining the effect of per-patient normalization on the input physiological tensors. Concerning the per-instance anomaly score, we investigate as potential probe points either the Mahanalobis distance between the predicted error distribution and the error distribution of the validation set [
118], denoted as EMD, or the KL-divergence of the input embeddings.
The results are provided in
Table 16, leading to similar conclusions to those acquired from the speech segments. Namely, the per-patient normalization appears to positively affect the performance of the network, irrespective of the architecture used, whereas using the 1D-CVAE with the KL divergence as an anomaly score of the HRV tensors leads to improved performance compared to the original CNN-AE. Thus, based on these results in conjunction with those of the previous sections, networks for both modalities are realized as appropriately designed CVAEs, with the input features of the respective modality being normalized per subject and the anomaly scores, for both modalities, being derived from the KL divergence of the respective embeddings.
The results acquired from combining audio and physiological data using this configuration are presented in
Table 17; apart from the two fusion mechanisms we examine, we present the results acquired by only using a single modality. We observe that using both modalities with either fusion mechanism yields higher results than using only a single modality, indicating that physiological signals can be utilized as auxiliary information in speech-based relapse detection and prediction. Concerning the fusion mechanisms, additive (Add.) fusion appears to provide slightly improved results compared to multiplicative (Mult.) fusion.
We also examine the effect of the temporal pooling mechanism used to aggregate the anomaly scores for each modality; we report on the results in
Table 18. Similar to the unimodal audio dataset, norm pooling provides the best results concerning the per-session aggregation of the anomaly scores for each spectrogram. However, regarding the physiological data, we found that daily averaging of the per-hour scores resulted in the best performance. In fact, usage of the other two potential temporal aggregation functions negated the benefits of the multimodal relapse detection scheme, resulting in performance lower than the one of the unimodal audio CVAE.
5.4. Evaluating Mental Conditions Utilizing Facial Cues from Videos
Finally, in this section, we describe our work in trying to predict PANSS indicators related to facial cues, using both handcrafted and learned features, extracted from the videos of the unstructured interviews conducted between patients and clinicians. Indeed, facial expressions of patients could be a key indicator towards the quantification of cognitive impairments [
124], and recent advancements in computer vision, machine and deep learning allow the evaluation and recognition of such temporal emotional status, through facial expressions. For that reason, we try to assess the degree of symptoms severity in patients with mental disorders based on their social behavior and cognitive functioning, while they are conducting the weekly interviews with the clinicians. Specifically, we aim to automatically recognize the alterations in psychopathology, which are determined through the Positive and Negative Syndrome Scale (PANSS) [
40], using features extracted from the patients’ facial expressions [
125].
Data Collection: PANSS is one of the most well-established procedures to assess symptoms’ severity. Through the monthly in-person assessments with the patients (
Section 4), the clinicians are evaluating three types of symptoms, the positive ones that refer to the excessive occurrence of normal functions, and the negative ones which correspond to the limited occurrence of normal functions, as well as general psychopathology symptoms. Overall, 30 symptoms are rated on a scale from 1–7, resulting in a maximum score of 210 points. Due to their association with facial expressions, 10 PANSS elements were chosen to constitute the ground truth for our model, namely: excitement, hostility (positive items) anxiety, poor impulse, motor retardation, depression, tension (general items), blunted effect, poor rapport, lack of spontaneity, and flow of conversation (negative items).
To ensure the correlation between the recorded interview videos and the PANSS values, annotated by the clinicians, we only used videos that were recorded up to two weeks or closer to the assessments that the patients undergo each month. Thus, at the time that this work was conducted, the number of such videos was 167, collected up to early October 2020, (with a duration of up to 1141 seconds) corresponding to 22 patients (2 with Schizoaffective disorder, 1 with Schizophreniform disorder, 1 with Bipolar II disorder, 12 with Schizophrenia and 6 with Bipolar I disorder). Patient demographics are presented in
Table 19.
Methodology and Data Preprocessing: In order to predict PANSS values from facial cues detected in the interview videos, we followed a pipeline consisting of the following steps: (i) detection of the facial area from the video sessions, (ii) frame-wise feature extraction, (iii) aggregation of the frame-wise features into a single feature vector for each session and finally (iv) prediction of the value of the PANSS from the extracted session-wise feature representations.
In more detail, we first subsample the RGB videos, using a sampling rate of one frame per second. Afterwards, in order to extract the face region for each frame, we utilize a pre-trained Multiple Task Cascaded Neural Network (MTCNN) model [
126] to detect the facial area, and then crop each frame accordingly.
For the representation of each frame, we compared two methodologies for feature extraction. In the first case, we utilized the widely used Bag of Visual Words (BOVW) method. In particular,
n keypoints are detected in each frame using the Speeded Up Robust Features (SURF) algorithm [
127]; for each detected keypoint, a feature vector with 64 elements is computed. Afterwards, by using the k-means algorithm, the collection of feature vectors calculated over all videos and all frames is segmented into
k clusters, with each cluster centroid corresponding to a visual word. The final descriptor computed for each frame is a histogram of
k values, denoting the number of occurrences for each visual word in the frame. On the other hand, the second approach we evaluated is based on transfer learning. In more detail, we utilize the convolutional front-end of an EfficientNet-B0 [
128], that has been pre-trained on ImageNet [
129]; the frame-wise representation we obtain at the output of the front-end as a feature vector contains a total of
elements.
By this point, we have acquired an feature representation for each interview session, where m corresponds to the number of extracted frames per session video and n to the feature dimensionality ( for the BOVW-based feature extraction and for the EfficientNet-based methodology). In order to aggregate them into a single feature vector, we repeat the BOVW procedure on the whole set of n-dimensional frame descriptors, acquiring thus centroids and assigning a centroid to each frame via k-means. Afterwards, we again form a histogram of values for each session video, which contains the relative appearance frequency of each visual word in the interview. Finally, the extracted representations for each interview are classified into the respective PANSS class. To this end, we experiment with three widely-used machine learning models: XGBoost (XGB), Random Forests (RF) and Support Vector Machines (SVM) with a radial basis function (RBF) kernel.
Experimental Protocol and Results: Based on the pipeline presented above, for each video, we first extract the facial region from the sampled frames, then obtain a low-level feature representation corresponding to each video frame, and finally fuse the frame-level representations into a high-level feature representation for each video. Thus, the following configurations were evaluated: (i)
(Bag of Visual Words (BOVW) for both low-level and high-level representations) and (ii) EfficientNet to BOVW (EfficientNet features for the low-level representation and BOVW for the high-level representation). The data were divided into two subsets, with 70% of the videos used for training and the rest for testing, whereas the optimal number of clusters for each PANSS item was determined by grid search. The results are presented in
Table 20, using the balanced accuracy and the top-2 accuracy as metrics; next to each PANSS element, we also denote the number of values (classes) the respective element takes in the dataset. In terms of balanced accuracy and the
configuration, the best results concern predictions of tension, hostility and poor impulse control recording values up to
, while anxiety and poor rapport cannot be successfully estimated by either configuration. Additionally, some PANSS items such as poor impulse control, poor rapport, tension and excitement exceed in terms of the top-2 accuracy barrier of 80%, deviating significantly from the balanced accuracy scores, potentially because of the subjectivity of PANSS questionnaire scoring. Finally, we note that contrary to our assumptions, the features extracted from the pretrained EfficientNet (used in the EfficientNet to BOVW configuration) perform worse than those computed by the SURF algorithm (utilized in the
configuration).




 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}