
SAAQ: A Characterization Method for Distributed Servers in Ubicomp Environments




Abstract
1. Introduction
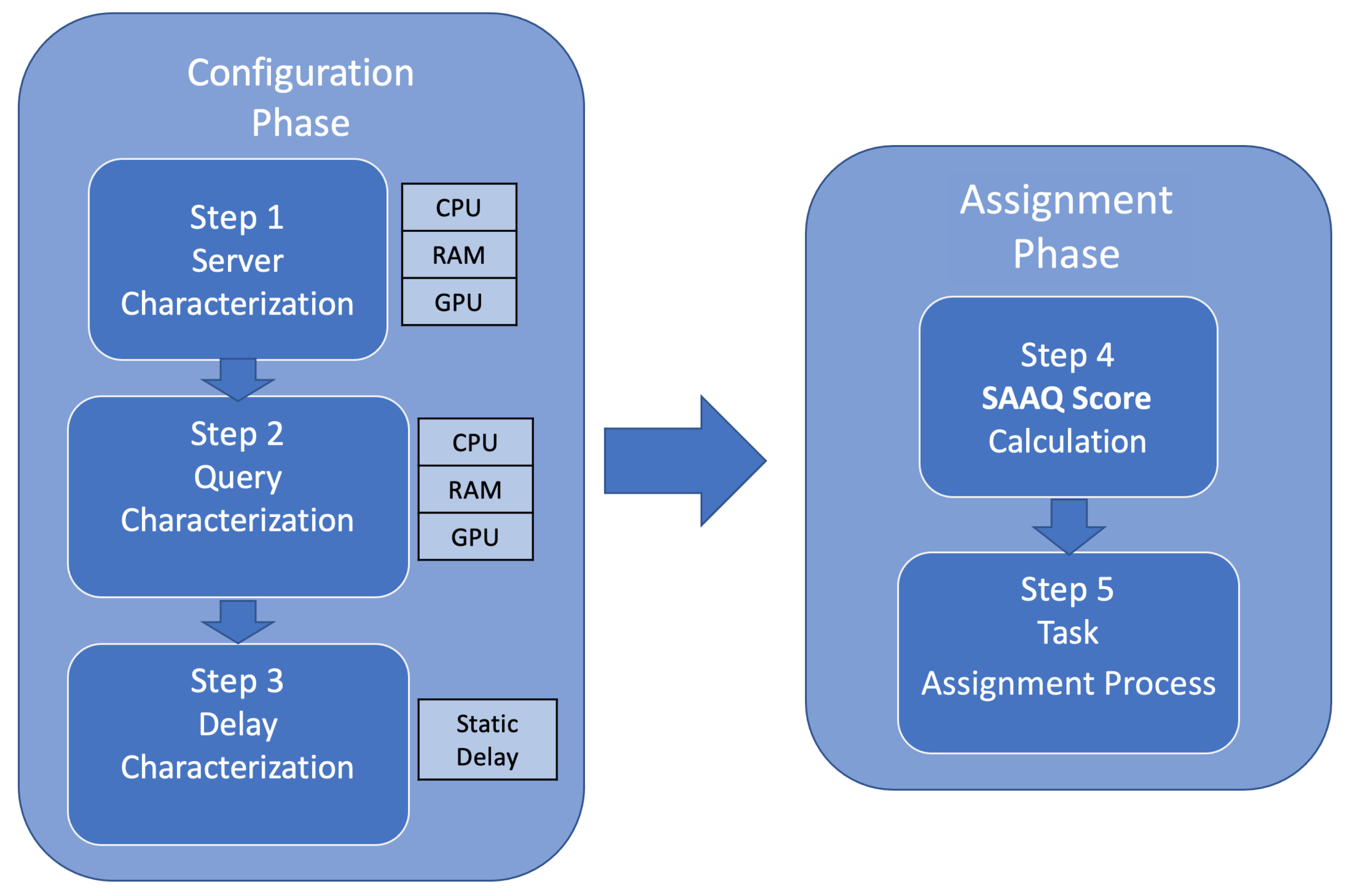
- The configuration phase comprised of characterization methods to represent: (i) servers, considering CPU, RAM, and GPU capabilities; (ii) queries, considering CPU, RAM, and GPU requirements; and (iii) the network delay.
- The assignment phase which manages: (i) an SAAQ score, that represents the result of calculating capabilities of servers with respect to queries and network delay; and (ii) a distribution query process, considering the SAAQ score values.
2. Motivating Scenario
- A semi-centralized architecture, where a master medium-high server is able to distribute the requests. The heterogeneity of servers and local-client devices that can become servers for particular cases require a central powerful coordinator to reduce the complexity of the architecture with respect to a fully distributed one, where all entities determine their computational capabilities, wasting resources, especially for low-performance servers.
- Characterization methods for servers and requests to determine which servers are the most adequate to attend to a specific type of request based on:
3. Related Work
- Location awareness to allow Ubicomp servers closer to end users to respond to their queries and thus reduce the communication costs.
- Energy awareness to distribute the queries and tasks to devices without energy consumption restrictions, as much as possible.
- Consider the query cost (service characterization) and the capabilities of servers and the network state (hardware characterization) to ensure an efficient management of computational resources, therefore providing the operation of large-scale Ubicomp networks.
4. SAAQ-Based Methodology: Our Proposal
4.1. Configuration Phase
4.1.1. Step 1: Sever Characterization Method (Computational Capabilities)
- The objective: in our case the goal is to calculate the overall performance of the servers.
- The practice: represent the actions to measure the server performance.
- The resources to evaluate: in this study are CPU, RAM, and GPU.
- The measurement in terms of consumption and execution time of a task.
4.1.2. Step 2: Query Characterization Method (Computational Cost)
- Multimedia services, referred to all binary format data like images, videos, and voice recording.
- Localization services, such as services like devices Geo localization, GPS, places description, and environment recognition.
- Web services, meaning all services that allow accessing web applications, webpages, API (Application Programming Interfaces), and cloud platforms.
- Information Management services that manage all personal data, devices metadata and place information stored in DB (Data Bases); therefore, it defines how these data are shared, saved, and transmitted through the middleware.
4.1.3. Step 3: Delay Characterization (Network Cost)
4.2. Assignment Phase
4.2.1. Step 4: Calculation of the SAAQ Score
4.2.2. Step 5: Assignment Query Process
5. Experimental Evaluation
5.1. Query Implementation
- Images Processing query: Client sends a 1.8 MB picture as query data and receives the same image as response from the server.
- Web query: The text of the Uniform Resource Locater type (URL) “www.rutas.com.pe” (accessed on 1 March 2021) is received as a response.
- Word Processing: A text about a historical review of the city of Arequipa, Peru, of 1842 bytes is sent, and the same text is received as response data once it is processed.
- Synchronization query: The Linux “date” command is executed on the assigned server system, and the date and time information extracted from the system are stored in a 29-byte text that is sent as response data to the client.
- Localization by Images: A 1.6 MB image is sent and a random geographic location is received in response.
- Localization by IP address: In this type of query, the client sends its IP address and receives a random geographic location as a response.
5.2. Architecture Implementation: Servers
5.3. Architecture Implementation: Protocol and Configuration
5.3.1. Communication Protocol
5.3.2. Configuration
- Thread numbers: The first parameter to be defined is the number of threads in the threads pool of each server in the communication socket programmed in C language. This pool of threads establishes the number of simultaneous connections that servers can handle. It was determined by experimentation, obtaining the best performance with 250 threads for the Master Server and 150 threads for the other servers, since the Master Server has better hardware than the other ones.
- File descriptors: The number of file descriptors defined by default (1024) is insufficient when it is required to process thousands of queries and processes simultaneously; thus, to avoid the known error too many file opens, it is pertinent to set a number greater than the default value. It was experimentally determined for this scenario that the optimal number of file descriptors to allow servers to process thousands of queries simultaneously without producing errors is 8192; this parameter is set with the Linux command “ulimit -n 8192”.
- Libraries: Library “netinet/sctp.h” must be installed to run the server sockets under the SCTP, and include all the data handling and connection characteristics of this communication protocol. Its installation was carried out through the command “sudo apt install libsctp-dev” and is executed in the following way “gcc mysocket.c –o mysocket.out –lsctp”. Library “pthread.h” is necessary to run the C program, from the multithreaded client or server socket, using command “gcc mysocket.c –o mysocket.out –lpthread”. Additionally, tool “glxinfo”, by the command “apt-get install mesa-utils” was executed, where the MESA library was installed, which provides a generic implementation of OpenGL, which is an Application Programming Interface (API) cross-platform graphics that specifies a standard software interface for three-dimensional (3D) graphics processing hardware [61,62]. In this sense, to extract the information from the computer’s graphic card, the command “glxinfo ∣ grep OpenGL”, when the first connection of each SE with the SM was established.
5.4. Experiments and Results
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Poslad, S. Ubiquitous Computing: Smart Devices, Environments and Interactions; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- IERC. Internet of Things Research. 2016. Available online: http://www.internet-of-things-research.eu/ (accessed on 25 January 2021).
- Soldatos, J.; Kefalakis, N.; Hauswirth, M.; Serrano, M.; Calbimonte, J.P.; Riahi, M.; Aberer, K.; Jayaraman, P.P.; Zaslavsky, A.; Zarko, I.; et al. OpenIoT: Open Source Internet-of-Things in the Cloud. Lect. Notes Comput. Sci. 2015, 9001, 13–25. [Google Scholar] [CrossRef]
- Chianese, A.; Piccialli, F. Designing a Smart Museum: When Cultural Heritage Joins IoT. In Proceedings of the 2014 Eighth International Conference on Next Generation Mobile Apps, Services and Technologies, Oxford, UK, 10–12 September 2014; pp. 300–306. [Google Scholar] [CrossRef]
- Das, A.; Patterson, S.; Wittie, M. EdgeBench: Benchmarking Edge Computing Platforms. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018. [Google Scholar] [CrossRef]
- Premsankar, G.; Di Francesco, M.; Taleb, T. Edge Computing for the Internet of Things: A Case Study. IEEE Internet Things J. 2018, 5, 1275–1284. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Sengupta, M.; Maiti, S.; Dutta, S. Role of Middleware for Internet of Things: A Study. Int. J. Comput. Sci. Eng. Surv. 2011, 2, 94–105. [Google Scholar] [CrossRef]
- Consortium, O. Open Source Cloud Solution for the Internet of Things. 2019. Available online: https://www.openiot.eu/ (accessed on 22 December 2020).
- OpenRemote Inc. OpenRemote. 2009. Available online: https://openremote.io/ (accessed on 22 December 2020).
- Technologies, K. Kaa IoT platform. 2021. Available online: https://www.kaaiot.com/ (accessed on 22 December 2020).
- Sinha, N.; Pujitha, K.; Alex, J.S.R. Xively based sensing and monitoring system for IoT. In Proceedings of the 2015 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 8–10 January 2015; pp. 1–6. [Google Scholar]
- Almeida, R.; Blackstock, M.; Lea, R.; Calderon, R.; Prado, A.; Guardia, H. Thing broker: A twitter for things. In Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8–12 September 2013; pp. 1545–1554. [Google Scholar]
- Zgheib, R. SeMoM, a Semantic Middleware for IoT Healthcare Applications. Ph.D. Thesis, Université Paul Sabatier—Toulouse III, Toulouse, France, 2017. [Google Scholar]
- Neumann, G.B.; Almeida, V.P.d.; Endler, M. Smart Forests: Fire detection service. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC), Natal, Brazil, 25–28 June 2018; pp. 01276–01279. [Google Scholar]
- Ji, Z.; Ganchev, I.; O’Droma, M.; Zhao, L.; Zhang, X. A Cloud-Based Car Parking Middleware for IoT-Based Smart Cities: Design and Implementation. Sensors 2014, 14, 22372–22393. [Google Scholar] [CrossRef]
- Elias, A.R.; Golubovic, N.; Krintz, C.; Wolski, R. Where’s the Bear?—Automating Wildlife Image Processing Using IoT and Edge Cloud Systems. In Proceedings of the 2017 IEEE/ACM Second International Conference on Internet-of-Things Design and Implementation (IoTDI), Pittsburgh, PA, USA, 18–21 April 2017; pp. 247–258. [Google Scholar]
- Zaqout, I. Diagnosis of Skin Lesions Based on Dermoscopic Images Using Image Processing Techniques. In Pattern Recognition: Selected Methods and Applications; BoD–Books on Demand: Norderstedt, Germany, 2019. [Google Scholar] [CrossRef]
- Solutions, C. High End CPUs—Intel vs. AMD. 2021. Available online: https://www.cgdirector.com/cinebench-r20-scores-updated-results/ (accessed on 23 April 2021).
- Yousefpour, A.; Ishigaki, G.; Jue, J.P. Fog Computing: Towards Minimizing Delay in the Internet of Things. In Proceedings of the 2017 IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 17–24. [Google Scholar] [CrossRef]
- Noordally, R.; Nicolay, X.; Anelli, P.; Lorion, R.; Tournoux, P.U. Analysis of Internet Latency: The Reunion Island Case. In Proceedings of the 12th Asian Internet Engineering Conference, Bangkok, Thailand, 30 November–2 December 2016. [Google Scholar] [CrossRef]
- Othman, O.; Schmidt, D. Optimizing Distributed System Performance via Adaptive Middleware Load Balancing. In Proceedings of the Workshop on Optimization of Middleware and Distributed Systems, Snowbird, UT, USA, 18 June 2001. [Google Scholar]
- Huo, C.; Chien, T.C.; Chou, P.H. Middleware for IoT-Cloud Integration Across Application Domains. IEEE Design Test 2014, 31, 21–31. [Google Scholar] [CrossRef][Green Version]
- Zhang, J.; Ma, M.; Wang, P.; Sun, X.d. Middleware for the Internet of Things: A survey on requirements, enabling technologies, and solutions. J. Syst. Archit. 2021, 117, 102098. [Google Scholar] [CrossRef]
- Atlam, H.F.; Walters, R.J.; Wills, G.B. Fog Computing and the Internet of Things: A Review. Big Data Cogn. Comput. 2018, 2, 10. [Google Scholar] [CrossRef]
- Mahmoud, H.; Thabet, M.; Khafagy, M.H.; Omara, F.A. An efficient load balancing technique for task scheduling in heterogeneous cloud environment. Clust. Comput. 2021, 24, 3405–3419. [Google Scholar] [CrossRef]
- Kashani, M.H.; Mahdipour, E. Load Balancing Algorithms in Fog Computing: A Systematic Review. IEEE Trans. Serv. Comput. 2022. [Google Scholar] [CrossRef]
- Sriram, G. Challenges of cloud compute load balancing algorithms. Int. Res. J. Mod. Eng. Sci. 2022, 4, 1186–1190. [Google Scholar]
- Singh, S.P.; Kumar, R.; Sharma, A.; Nayyar, A. Leveraging energy-efficient load balancing algorithms in fog computing. Concurr. Comput. Pract. Exp. 2022, 34, e5913. [Google Scholar] [CrossRef]
- Cruz Huacarpuma, R.; De Sousa Junior, R.T.; De Holanda, M.T.; De Oliveira Albuquerque, R.; García Villalba, L.J.; Kim, T.H. Distributed Data Service for Data Management in Internet of Things Middleware. Sensors 2017, 17, 977. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Cai, Q.; Lou, Y. Optimal data placement strategy considering capacity limitation and load balancing in geographically distributed cloud. Future Gener. Comput. Syst. 2022, 127, 142–159. [Google Scholar] [CrossRef]
- Oliner, A.J.; Iyer, A.P.; Stoica, I.; Lagerspetz, E.; Tarkoma, S. Carat: Collaborative energy diagnosis for mobile devices. In Proceedings of the 11th ACM Conference on Embedded Networked Sensor Systems, Roma Italy, 11–15 November 2013; pp. 1–14. [Google Scholar]
- Behrouz, R.J.; Sadeghi, A.; Garcia, J.; Malek, S.; Ammann, P. Ecodroid: An approach for energy-based ranking of android apps. In Proceedings of the IEEE/ACM 4th International Workshop on Green and Sustainable Software, Florence, Italy, 18 May 2015; pp. 8–14. [Google Scholar]
- Ibrahim, N. Ranking energy-aware services. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 575–580. [Google Scholar]
- Saxena, D.; Singh, A.K. Energy aware resource efficient-(eare) server consolidation framework for cloud datacenter. In Advances in Communication and Computational Technology; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1455–1464. [Google Scholar]
- Kaur, M.; Aron, R. An Energy-Efficient Load Balancing Approach for Scientific Workflows in Fog Computing. Wirel. Pers. Commun. 2022, 125, 3549–3573. [Google Scholar] [CrossRef]
- Korzun, D.; Marchenkov, S.; Vdovenko, A.; Petrina, O. A Semantic Approach to Designing Information Services for Smart Museums. Int. J. Embed. -Real-Time Commun. 2016, 7, 15–34. [Google Scholar] [CrossRef]
- Pang, W.C.; Wong, C.Y.; Seet, G. Exploring the Use of Robots for Museum Settings and for Learning Heritage Languages and Cultures at the Chinese Heritage Centre. Presence Teleoper. Virtual Environ. 2018, 26, 420–435. [Google Scholar] [CrossRef]
- Papadakis, P.; Lohr, C.; Lujak, M.; Karami, A.; Kanellos, I.; Lozenguez, G.; Fleury, A. System Design for Coordinated Multi-robot Assistance Deployment in Smart Spaces. In Proceedings of the 2018 Second IEEE International Conference on Robotic Computing (IRC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 324–329. [Google Scholar] [CrossRef]
- Damelio, R. Los Fundamentos del Benchmarking; Panorama: Caracas, Venezuela, 1997. [Google Scholar]
- Kayande, D.; Shrawankar, U. Performance analysis for improved RAM utilization for Android applications. In Proceedings of the 2012 CSI Sixth International Conference on Software Engineering, Madhay Pradesh, India, 5–7 September 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Santos, J.; Wauters, T.; Volckaert, B.; De Turck, F. Towards Network-Aware Resource Provisioning in Kubernetes for Fog Computing Applications. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 351–359. [Google Scholar] [CrossRef]
- Rodriguez-Gil, L.; Orduña, P.; Garcia-Zubia, J.; López-de Ipiña, D. Interactive live-streaming technologies and approaches for web-based applications. Multimed. Tools Appl. 2018, 77, 6471–6502. [Google Scholar] [CrossRef]
- Zyrianoff, I.; Heideker, A.; Silva, D.; Kleinschmidt, J.; Soininen, J.P.; Salmon Cinotti, T.; Kamienski, C. Architecting and Deploying IoT Smart Applications: A Performance–Oriented Approach. Sensors 2020, 20, 84. [Google Scholar] [CrossRef]
- UserBenchmark. Best User Rate GPU. 2021. Available online: https://gpu.userbenchmark.com/ (accessed on 25 January 2021).
- Bhargav Pandya, S.; Hasmukhbhai Patel, R.; Sudhir Pandya, A. Evaluation of Power Consumption of Entry-Level and Mid-Range Multi-Core Mobile Processor. In Proceedings of the 4th International Conference on Electronics, Communications and Control Engineering, ICECC 2021, New York, NY, USA, 16–21 June 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 32–39. [Google Scholar] [CrossRef]
- Gupta, K.; Sharma, T. Changing Trends in Computer Architecture: A Comprehensive Analysis of ARM and x86 Processors. Int. J. Sci. Res. Comput. Eng. Inf. Technol. 2021, 7, 619–631. [Google Scholar] [CrossRef]
- Iio, T.; Satake, S.; Kanda, T.; Hayashi, K.; Ferreri, F.; Hagita, N. Human-Like Guide Robot that Proactively Explains Exhibits. Int. J. Soc. Robot. 2020, 12, 549–566. [Google Scholar] [CrossRef]
- Pereira, R.; Couto, M.; Ribeiro, F.; Rua, R.; Cunha, J.; Fernandes, J.; Saraiva, J. Energy efficiency across programming languages: How do energy, time, and memory relate? In Proceedings of the 10th ACM SIGPLAN International Conference on Software Language Engineering, Vancouver, BC, Canada, 23–24 October 2017; pp. 256–267. [Google Scholar] [CrossRef]
- Firdhous, M.; Ghazali, O.; Hassan, S. Fog Computing: Will it be the Future of Cloud Computing? In Proceedings of the Third International Conference on Informatics & Applications (ICIA2014), Kuala Terengganu, Malaysia, 6–8 October 2014.
- Máttyus, G.; Fraundorfer, F. Aerial image sequence geolocalization with road traffic as invariant feature. Image Vis. Comput. 2016, 52, 218–229. [Google Scholar] [CrossRef][Green Version]
- Merhej, J.; Demerjian, J.; Fares, K.; Bou abdo, J.; Makhoul, A. Geolocalization in Smart Environment. In Proceedings of the International Conference on Sensor Networks, Prague, Czech Republic, 26 February 2019; pp. 108–115. [Google Scholar] [CrossRef]
- Rafi, M.R.; Ferdous, M.S.; Sibli, S.A.; Shafkat, A. Reduction of Processing Time to Improve Latency in Wireless Communication Network. Int. J. Res. Publ. 2019, 39, 5. [Google Scholar]
- Wang, J.; Wu, W.; Liao, Z.; Sangaiah, A.K.; Simon Sherratt, R. An Energy-Efficient Off-Loading Scheme for Low Latency in Collaborative Edge Computing. IEEE Access 2019, 7, 149182–149190. [Google Scholar] [CrossRef]
- Aldebara. Pepper—2D Cameras. 2020. Available online: http://doc.aldebaran.com/2-0/family/juliette_technical/video_juliette.html (accessed on 21 May 2021).
- DigitalOcean. About. 2021. Available online: https://www.digitalocean.com/about/ (accessed on 1 June 2021).
- Hassan, H.; Moussa, A.; Farag, I. Performance vs. Power and Energy Consumption: Impact of Coding Style and Compiler. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef]
- Gn, V.; Reddy, P. Performance evaluation of TCP, UDP, and SCTP in manets. ARPN J. Eng. Appl. Sci. 2018, 13, 3087–3092. [Google Scholar]
- Nor, S.; Alubady, R.; Kamil, W.A. Simulated performance of TCP, SCTP, DCCP and UDP protocols over 4G network. Procedia Comput. Sci. 2017, 111, 2–7. [Google Scholar]
- Wheeb, A. Performance evaluation of UDP, DCCP, SCTP and TFRC for different traffic flow in wired networks. Int. J. Electr. Comput. Eng. 2017, 7, 3552. [Google Scholar] [CrossRef]
- Lavania, G.; Sharma, P.; Upadhyay, R. Comparative Analysis of TCP, SCTP and MPTCP in Transport Layer of Wireless Sensor Networks. In Proceedings of the International Conference on Emerging Trends in Expert Applications & Security (2018), Maharashtra, India, 16–18 December 2018; Volume 2, pp. 22–29. [Google Scholar] [CrossRef]
- Mesa. Debian. Available online: https://wiki.debian.org/Mesa (accessed on 16 April 2021).
- Developers. OpenGL ES. Available online: https://developer.android.com/guide/topics/graphics/opengl?hl=es-419 (accessed on 20 February 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU Example | CPU Score | Raking | Reference Architecture CPU | |
|---|---|---|---|---|
| CPU Score | Server | |||
| AMD Threadripper 3990X | > 10,000 | 10 | 35,225 | Remote Server I |
| AMD Threadripper 3970X | 6000 < ≤ 10,000 | 9 | ||
| Procesador Intel Xeon Platino 8160 | 2000 < ≤ 6000 | 8 | ||
| Intel Core i9-9900x | 700 < ≤ 2000 | 7 | 880 | Master Server |
| Intel i7 8700 | 281 < ≤ 700 | 6 | ||
| Intel i7 7800X | 115 < ≤ 281 | 5 | 202 | Remote Server II |
| AMD Ryzen 5 1400 | 100 < ≤ 115 | 4 | ||
| AMD A10-9700 | 90 < ≤ 100 | 3 | 91.2 | Local Server |
| Intel Core i7-8650U (2.7 GHz) | 83.2 < ≤ 90 | 2 | ||
| Intel i3 2330 M | ≤ 83.2 | 1 | 30.56 | Robot A and B |
| RAM Score | Ranking | Reference Architecture RAM | |
|---|---|---|---|
| RAM Score | Server | ||
| 10 | 128 GB | Remote Server I | |
| 100 < < 128 | 9 | ||
| 64 < ≤ 100 | 8 | 64 GB | Master Server |
| 32 < ≤ 64 | 7–6 | ||
| 16 < ≤ 32 | 5 | 16 GB | Remote Server II |
| 8 < ≤ 16 | 4 | ||
| 4 < ≤ 8 | 3 | 4 GB | Local Server |
| 2 < ≤ 4 | 2 | 2 GB | Robot A and B |
| ≤ 2 | 1 | ||
| GPU Example | GPU Score | Ranking | Reference Architecture GPU | |
|---|---|---|---|---|
| GPU Score | Server | |||
| Nvidia RTX 3090 | < 40.8 | 10 | 40.80 | Remote Server I |
| Nvidia GTX 950 | 28.8 ≤ < 40.8 | 9 | - | - |
| AMD RX 590 | 12 ≤ < 28.8 | 8 | 12 | Master Server |
| Nvidia GeForce MX250 | 6.4 ≤ < 12 | 7 | - | - |
| AMD Radeon HD 6670 | 1.2 ≤ < 6.4 | 6 | - | - |
| Nvidia GeForce GTX 280 | 0.64 ≤ <1.2 | 5 | 0.64 | Remote Server II |
| Nvidia Quadro FX 880M | 0.56 ≤ < 0.63 | 4 | - | - |
| Intel HD 5500 (Mobile 0.95 GHz) | 0.51 ≤ < 0.56 | 3 | 0.52 | Local Server |
| ATI Mobility FireGL V5700 | 0.15 ≤ < 0.51 | 2 | - | - |
| NVIDIA GeForce 7150M + nForce 630M or Rendering processes appointed to MESA Library | < 0.15 | 1 | 0 | Robot I and II |
| Server | Characterization Score |
|---|---|
| Remote Server I | <10, 10, 10> |
| Master Server | <7, 8, 8> |
| Remote Server II | <5, 5, 5> |
| Local Server | <3, 3, 3> |
| Robot I and Robot II | <1, 2, 1> |
| Service | Type of Query | Query Characterization Score () |
|---|---|---|
| Multimedia Service | (1) Image Processing | |
| Web Service | (2) Webiste and Apps Accessing | |
| Information Management Service | (3) Words Processing (4) Syncronization (updating data) | |
| Localization Service | (5) Localization by Images (6) Localization by IP address |
| Delay Network Score (ms) | Ranking () | Reference Architecture |
|---|---|---|
| 0– 20 | 0 | Master Server |
| 21–40 | 1 | Robot I/Robot II/Local Server |
| 41–60 | 2 | - |
| 61–80 | 3 | - |
| 81–100 | 4 | - |
| 101–120 | 5 | - |
| 121–140 | 6 | - |
| 141–160 | 7 | - |
| 161–180 | 8 | Remote Server I |
| 181–200 | 9 | Remote Server II |
| 200+ | 10 | - |
| Server Score | Remote Server I [10, 10, 10] | Master Server [7, 8, 8] | Remote Server II [5, 5, 5] | Local Server [3, 3, 3] | Robots [1, 2, 1] |
| Query Cost | |||||
| Images Processing [6, 5, 6] | 73 | 33 | −12 | −58 | −75 |
| Server Score | Remote Server I [10, 10, 10] | Master Server [7, 8, 8] | Remote Server II [5, 5, 5] | Local Server [3, 3, 3] | Robots [1, 2, 1] |
| Query Cost | |||||
| Images Processing [6, 5, 6] | 10 | 7.290 | 4.250 | 1.140 | 0 |
| Server Score | Remote Server I [10, 10, 10] | Master Server [7, 8, 8] | Remote Server II [5, 5, 5] | Local Server [3, 3, 3] | Robots [1, 2, 1] |
| Query Cost | |||||
| Images Processing [6, 5, 6] | 9.072 | 7.645 * | 2.860 | 2.053 | 0 |
| Syncronization [1, 1, 1] | 5.821 | 6.725 | 4.559 | 5.734 | 5.380 * |
| Localization by Images [6, 4, 5] | 9.072 | 7.928 | 3.568 | 3.044 | 1.203 |
| Localization by IP address [3, 2, 1] | 7.166 | 7.504 | 4.842 | 5.592 * | 4.884 |
| Web Query [6, 4, 4] | 9.007 | 8 * | 3.851 | 3.469 | 1.769 |
| Words processing [6, 5, 2] | 8.511 | 7.645 * | 3.709 | 3.185 | 1.981 |
| Type of Query | Query Data Type | Size of Query Data (Bytes) | Response Data Type | Size of Response Data (Bytes) |
|---|---|---|---|---|
| Image processing | Image | 1.800.000 | Image | 1.800.000 |
| Web query | Text | 1 | Text | 15 |
| Words processing | Text | 1.842 | Text | 1.842 |
| Syncronization | Text | 1 | Text | 29 |
| Localization by images | Image | 1.668.636 | Text | 30 |
| Localization by IP address | Text | 1 | Text | 30 |
| Role | CPU State | Location | CPU Core N° | RAM Memory | Price Per Month | Server Characteri. Score () |
|---|---|---|---|---|---|---|
| Master Server | Share | San Francisco | 8 | 16 GB | 80$ | [7, 5, 8] |
| Local Server | Share | San Franciso | 1 | 2 GB | 10$ | [5, 1, 1] |
| Remote Server I | Share | Frankfurt | 1 | 2 GB | 10$ | [5, 1, 1] |
| Remote Server II | Share | Singapore | 1 | 2 GB | 10$ | [5, 1, 1] |
| Client 1 | Dedicated | New York | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 2 | Dedicated | Toronto | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 3 | Dedicated | London | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 4 | Dedicated | San Francisco | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 5 | Dedicated | Amsterdam | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 6 | Dedicated | Frankfurt | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 7 | Dedicated | Bangalore | 8 | 16 GB | 160$ | [7, 5, 1] |
| Client 8 | Dedicated | Singapore | 8 | 16 GB | 160$ | [7, 5, 1] |
| From (Client 1) | To | Delay (ms) |
|---|---|---|
| New York | San Francisco (Master Server) | 75.7600 |
| New York | San Francisco (Local Server) | 75.5479 |
| New York | Frankfurt (Remote Server I) | 84.2000 |
| New York | Singapore (Remote Server II) | 247.7850 |
| Server | Master | Remote I | Remote II | Local | Renamed |
|---|---|---|---|---|---|
| Query | |||||
| Images processing | 7.645 | −0.055 | −0.455 | 0 | Type 1 |
| Web and apps | 6.725 | 1.785 | 1.385 | 1.769 | Type 2 |
| Word processing | 7.928 | 1.219 | 0.819 | 1.203 | Type 3 |
| Synchronization | 7.504 | 5.500 | 5.600 | 5.380 | Type 4 |
| Localization by images | 8 | 1.219 | 0.819 | 1.203 | Type 5 |
| Localization by Ip address | 7.645 | 5.500 | 5.600 | 5.380 | Type 6 |
| Scenario | Client Location | Most Suitable Server |
|---|---|---|
| O1 | Client 2 (San Francisco—USA) | Local Server (San Francisco—USA) |
| O2 | Client 3 (Toronto—Canada) | Local Server (San Francisco—USA) |
| O3 | Client 4 (Frankfurt—Germany) | Remote Server 1 (Frankfurt—Germany) |
| O4 | Client 5 (London—United Kingdom) | Remote Server I (Frankfurt—Germany) |
| O5 | Client 6 (Amsterdam—Netherlands) | Remote Server I (Frankfurt—Germany) |
| O6 | Client 7 (Singapore—Singapore) | Remote Server II (Singapore—Singapore) |
| O7 | Client 8 (Bangalore—India) | Remote Server II (Singapore—Singapore) |
| Server | Master | Remote I | Remote II | Local |
|---|---|---|---|---|
| Query | ||||
| Images processing | 7.645 | −0.055 | −0.455 | 0 |
| Web and apps | 6.725 | 1.785 | 1.385 | 1.769 |
| Word processing | 7.928 | 1.219 | 0.819 | 1.203 |
| Synchronization | 7.504 | 7.600 | 7.700 | 5.380 |
| Localization by images | 8 | 1.219 | 0.819 | 1.203 |
| Localization by Ip address | 7.645 | 7.700 | 7.750 | 5.380 |
| Server | Master | Remote I | Remote II | Local |
|---|---|---|---|---|
| Query | ||||
| Images processing | 7.645 | −0.055 | −0.455 | 0 |
| Web and apps | 6.725 | 1.785 | 1.385 | 1.769 |
| Word processing | 7.928 | 1.219 | 0.819 | 1.203 |
| Sync | 7.504 | 5.380 | 7.700 | 7.600 |
| Localization by images | 8 | 1.219 | 0.819 | 1.203 |
| Localization by Ip address | 7.645 | 5.380 | 7.750 | 7.700 |
| Server | Master | Remote I | Remote II | Local |
|---|---|---|---|---|
| Query | ||||
| Images processing | 7.645 | −0.055 | −0.455 | 0 |
| Web and apps | 6.725 | 1.785 | 1.385 | 1.769 |
| Word processing | 7.928 | 1.219 | 0.819 | 1.203 |
| Sync | 7.504 | 7.700 | 5.380 | 7.600 |
| Localization by images | 8 | 1.219 | 0.819 | 1.203 |
| Localization by Ip address | 7.645 | 7.750 | 5.380 | 7.700 |
| Client Location | Average Response Time (ms) | Client- Master Server Network Delay (ms) | Master- Nearest Suitable Server Network Delay (ms) | Client- Nearest Suitable Server Network Delay (ms) |
|---|---|---|---|---|
| San Francisco | 19.1 | 0.6578 | 0.5980 | 0.6016 |
| Toronto | 2602.3 | 59.0250 | 0.5611 | 59.1670 |
| Frankfurt | 5654.6 | 157.4379 | 158.5471 | 0.5799 |
| London | 5074.5 | 144.6109 | 158.5580 | 13.5938 |
| Amsterdam | 8624.4 | 193.2961 | 158.5583 | 18.6036 |
| Singapore | 6533.0 | 186.0983 | 186.5254 | 0.4039 |
| Bangalore | 7518.7 | 173.2195 | 186.5140 | 33.6762 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferere, D.; Dongo, I.; Cardinale, Y. SAAQ: A Characterization Method for Distributed Servers in Ubicomp Environments. Sensors 2022, 22, 6688. https://doi.org/10.3390/s22176688
Ferere D, Dongo I, Cardinale Y. SAAQ: A Characterization Method for Distributed Servers in Ubicomp Environments. Sensors. 2022; 22(17):6688. https://doi.org/10.3390/s22176688
Chicago/Turabian StyleFerere, David, Irvin Dongo, and Yudith Cardinale. 2022. "SAAQ: A Characterization Method for Distributed Servers in Ubicomp Environments" Sensors 22, no. 17: 6688. https://doi.org/10.3390/s22176688
APA StyleFerere, D., Dongo, I., & Cardinale, Y. (2022). SAAQ: A Characterization Method for Distributed Servers in Ubicomp Environments. Sensors, 22(17), 6688. https://doi.org/10.3390/s22176688