Abstract
Due to the rapid development of sensor technology and the popularity of the Internet, not only has the amount of digital information transmission skyrocketed, but also its acquisition and dissemination has become easier. The study mainly investigates audio security issues with data compression for private data transmission on the Internet or MEMS (micro-electro-mechanical systems) audio sensor digital microphones. Imperceptibility, embedding capacity, and robustness are three main requirements for audio information-hiding techniques. To achieve the three main requirements, this study proposes a high-quality audio information-hiding technology in the wavelet domain. Due to the fact that wavelet domain provides a useful and robust platform for audio information hiding, this study applies multi-coefficients of discrete wavelet transform (DWT) to hide information. By considering a good, imperceptible concealment, we combine signal-to-noise ratio (SNR) with quantization embedding for these coefficients in a mathematical model. Moreover, amplitude-thresholding compression technology is combined in this model. Finally, the matrix-type Lagrange principle plays an essential role in solving the model so as to reduce the carrying capacity of network transmission while protecting personal copyright or private information. Based on the experimental results, we nearly maintained the original quality of the embedded audio by optimization of signal-to-noise ratio (SNR). Moreover, the proposed method has good robustness against common attacks.
1. Introduction
The uses of digital information transmission in Internet applications, artificial intelligence, and data sensing [1,2,3,4,5,6,7,8,9,10] are more frequent. In many cases, without permission from the legal owner, the digital information is often stolen, copied, or even turned into profit by criminal individuals. In general, an audio information-hiding technique should possess three properties: make the piece of hidden information imperceptible in the embedded audio, provide a signal-to-noise ratio (SNR) of 20 dB or more, and maintain the embedding capacity of at least 20 bps (bits per second) [11,12]. Moreover, hidden information is resistant to most attacks, which include re-sampling, MP3 compression, filtering, amplitude modification, time scaling, and so on [12,13,14,15].
Audio information-hiding techniques are classified according to their domain. These algorithms are categorized as time-domain techniques and transform-domain techniques. Discrete wavelet transform (DWT) is one practical transform domain for hiding audio information [13,14,15,16,17,18,19,20,21,22,23,24,25,26,27]. In the literature, several earlier procedures embedded watermarks into DWT low-frequency coefficients using the quantization-based technique so that they could obtain adaptive performance [15,20,24]. Chen et al. [15,24] proposed an optimization quantization approach to fixed-weighting DWT coefficients to gain high-quality modified audio and high robustness against many common attacks. Li et al. [27] proposed a new audio watermarking technique. They performed the norm ratio on fixed-scaling DWT coefficient quantization without considering the signal compression in the implementation. In addition, the quality of modified audio worsens with weighting variation, and hidden information is inadequately robust to time-scaling attacks.
This study proposes an optimization model to integrate optimization-based signal steganography [24] with threshold-based compression in the wavelet domain. Firstly, we utilized binary digits to store data and represent information. We modified the signal-to-noise ratio (SNR) and the amplitude-quantization rules in the wavelet domain as performance index and constraints. At the same time, to reduce the amount of the embedded audio data signal, we also employed threshold-based compression technology in the constrictions. Then, we obtained an optimization model that enhanced the audio quality in the information-hiding and compression processes. Secondly, the optimization model was solved by the matrix-type Lagrange principle and graphic illustration Accordingly, we performed information hiding and data compression on each audio signal for private information transmission on the Internet or MEMS (micro-electro-mechanical systems) audio sensor digital microphones. On the other end of the transmission process, the hidden information was extracted smoothly without either the original audio or the recovery of the compressed audio signal adopting a cubic spline. To demonstrate the quality of the proposed performance, we measured the appropriate threshold ε and embedding strength Q in our experiment. The proposed algorithm reduces the amount of carried network transmission but preserves the original audio signals and protects personal privacy.
The rest of this study is as follows: Section 2 presents the proposed method and introduces the embedding technique, optimization model, and compressions. The illustrations of the optimization model, presentation of the recovery method, and the extraction technique are in Section 3. Section 4 contains discissions of experimental results, and some remarks and conclusions are in Section 5.
2. Proposed Method
This section introduces the embedding technique, the extraction technique, and the compression of the proposed method. Figure 1 shows the block diagram of the proposed algorithm; further detailed introduction will appear in Section 2.1 and Section 2.2.
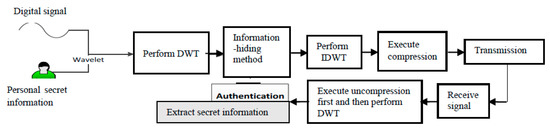
Figure 1.
The block diagram of the proposed algorithm.
2.1. Embedding Technique
To embed the private information into the lowest DWT coefficients, we implemented DWT using the single prototype function . This function is regulated by a scaling parameter and a shift parameter [28,29]. The discrete normalized scaling and wavelet basis function was defined as
where and are the dilation and translation parameters, and and denote low-pass and high-pass filters. Orthogonal wavelet basis functions provide simple calculation of coefficient expansion and easily express audio signals as a series expansion of orthogonal scaling functions and wavelets. Throughout this study, we used the host digital audio signal , , to denote samples of the original audio signal at the nth sample time, and each piece of audio signal was cut into segments on which DWT was performed. As a result, the signal-to-noise ratio (SNR)
can be rewritten as
where is the modified digital audio signal and the vector form consists of the unknown absolute values of DWT coefficients with respect to the original DWT coefficient vector in each segment.
For convenience, the secret information is usually stored as a binary sequence. To embed the binary bit “” or “” as shown in Figure 1, we performed DWT and then determined unknown values of DWT coefficients, . Accordingly, an optimization-based model for embedding the binary bit was proposed as follows.
We determined the vector such that the is maximized. Due to the fact that all logarithmic functions are one-to-one, that is, for all and in the domain of logarithmic function, if , then . We defined a performance index of the form so that the binary sequence with binary bit “” or “” can be embedded by the proposed optimization model described below:
- If the bit “” is embedded into , then is quantized by(b) Compression constraint;
- If the bit “” is embedded into , then is quantized by(b) Compression constraint;
where is the floor function; is the quantization size or embedding strength which is adopted as the secret key ; the compression constraint is described in Equations (6)–(8) in Section 2.2.
2.2. Compression Constraint
Solving the optimization models (4) and (5), the watermarked audio signal with optimal SNR is obtained after applying the IDWT. To reduce the amount of data when transmitting on the Internet, we compressed the embedded audio signal using the threshold compression method formulated as follows:
where represents the threshold.
To recover the signal from the compressed signal , we used the cubic function, which is formulated as . We found the N cloud-gauge line collection of functions to describe the entire set of data, where must satisfy
To ensure the recovery quality, we adjusted the compression threshold while considering Q to better fit the optimal SNR.
3. Proposed Optimization Solution in Embedding and Extraction Method
In this section, we solve the optimization problem described in models (4) and (5) in two steps. Since the optimization problems (4) and (5) are similar, we first solve (4) and then apply the optimal solution to (5) using the same method.
3.1. First Step in Finding the Optimal Solution
Applying Theorems A1 and A2 introduced in Appendix A, the Lagrange multiplier is utilized to combine (4a) and (4b) into a function F without any constraints,
where setting . The necessary conditions for minimizing are
Multiplying (10a) by to observe that
Since , Equation (11) can be rewritten as
Hence, the optimal solution of is
Moreover, by substituting (13) into (10a), the optimal DWT coefficients are
where the superscript denotes the optimal result with respect to the corresponding variable.
3.2. Audio Recovery and Information Extraction
To extract the hidden confidential data, we first recover the signal from the compressed signal using the cubic function, which is formulated as . We found that the N cloud gauge line collection of functions to describe the entire set of data, where must satisfy .
Next, we extract the hidden information from the DWT coefficients of the recovered audio signal according to the following steps:
Split the test audio into segments and perform DWT on each segment. If presents consecutive DWT lowest-frequency coefficients, the binary sequence is extracted from by the following proposed extraction technique:
- If
- If
then the extracted value is .
Finally, the hidden information is recovered from the binary sequence. In addition, to closely monitor the accuracy of the extracted private data, its ratio of bit errors (BER) is measured to check if an attack occured. The BER is usually expressed as a percentage and can be formulated as , where and denote the numbers of error binary bits and total binary bits during a tested period.
3.3. Application Scenarios of Our Proposal
The model and techniques proposed in this study combine information hiding and data compression of audio signals. During network transmission, if the amount of data (including the hidden private information) is large and the network speed is slow, the compression ratio can be increased to save transmission time; on the contrary, if the amount of data is small or the network speed is fast, one can just perform information hiding without performing data compression to improve the accuracy of the data transmission. This is the biggest difference between the proposed method and other methods.
4. Experimental Results
This section presents experimental results from testing the proposed algorithm. Without loss of generality, we investigate various forms of audio signals, such as love songs, symphonies, and dance and folkloric music. Ten songs per audio were averaged to evaluate the performance of the proposed method. These mono-type signals achieved a sampling rate of 44.1 kHz, which means there were 512,000 samples in each piece of selected information. They all came with a bit depth of 16 bits and 11.6 s in length. In the embedding procedure, each audio signal with 512,000 samples was initially cut into four segments of equal length; an 8-level discrete wavelet transform was performed on each evenly cut piece. This process ensured each piece of data had the total number of lowest-frequency coefficients . The values for Q are 13,000 and 26,000 for n = 2 and 4, respectively. To show a better comparison, we also implemented the two methods listed in references [24,27]; the experimental results are shown to compare with our algorithm.
4.1. Embedding Capacity and Averaged SNR
As listed in Table 1, the embedding capacities for n = 2 and 4 are 1000 and 500 bits, which satisfy the IFPI requirement—providing at least 20 bps (200 bits/10 s) embedding capacity. However, if the group size is greater than 16, this requirement is violated. Since we aim to present an optimization model for DWT multi-coefficients in this study, the resulting SNR of the proposed method clearly shows our SNR is much better than those SNRs using the methods in [24,27].

Table 1.
Embedding capacity and SNR.
4.2. Robustness Measurement
We used five types of common attacks: re-sampling, low-pass filtering, amplitude scaling, time scaling, and MP3 compression, to evaluate how robust the proposed algorithm is. The performance quality is measured according to the averaged BER and its standard deviation (SD). A detailed discussion is illustrated below.
- (1)
- Re-sampling: In the re-sampling process, the sampling rate of an audio signal can be increased (up-sample) or decreased (down-sample) in three stages: (i) down-sample, (ii) interpolation, and (iii) up-sample. We down-sampled the sampling rate of embedded audios from 44.1 kHz to 22.05 kHz, then up-sampled them from 22.05 kHz back to 44.1 kHz with a linear interpolation filter. A similar approach allowed the sampling rates to change from 44.1 kHz to 11.025 kHz and 8 kHz and regain the original rate of 44.1 kHz. Table 2 shows the BER of testing re-sampling on audio signals. One can see that when the re-sampling rate is 8 kHz, the proposed embedding method has lower BER than those from implementations in [24,27]. In those cases when the re-sampling rates are 22.05 kHz and 11.025 kHz, the proposed method shows comparable robustness.
Table 2. BER of Testing Re-sampling.
- (2)
- Low-pass filtering: Table 3 presents the BER while testing low-pass filters with cutoff frequencies of 3 kHz and 5 kHz. The BER results show that models in [24,27] have slightly higher robustness. Since both references [24,27] also adopted quantization-based embedding technique, the BER evaluation of the proposed method gives extremely similar results to theirs during the process of low-pass filtering.
Table 3. BER of Testing Low-pass Filtering.
- (3)
- MPEG Audio Layer-3 (MP3) compression: Table 4 shows the BER from testing MP3 compression with different bit rates on the embedded audio data. The BER values reflect that the proposed model has similar robustness to that in references [24,27].
Table 4. BER of Testing MP3 compression.
- (4)
- Amplitude scaling: Since the amplitude-scaling attack usually results in saturation, in this study, we selected four distinct values for the amplitude-scaling factor: 0.5, 0.8, 1.1, and 1.2. The experimental results in Table 5 confirm that the proposed algorithm is much more robust than the methods in references [24,27].
Table 5. BER of Testing Amplitude Scaling.
- (5)
- Time scaling: Table 6 lists the BER from testing time-scaling attacks with a ±2% and ±5% range. The BER results show that our method has comparable robustness to those in references [24,27].
Table 6. BER of Testing Time Scaling.
Based on the experimental outcomes and aforementioned discussions, the proposed method generally achieves high SNR and is almost zero-error against the amplitude-scaling attacks. However, it shows slightly lower robustness against low-pass filtering attacks and poor robustness against time-scaling attacks.
4.3. Compression Measurement
The purpose of compression is to have maximal compression ratio (CR) under maximal SNR, where CR is defined by
The threshold and the embedding strength Q directly affect compression ratio (CR) and SNR, respectively. As shown in Figure 2, it can be said that the larger the threshold and the embedding strength, the larger the compression ratio CR, that is, the better the compression effect, but the worse the SNR before and after compression.
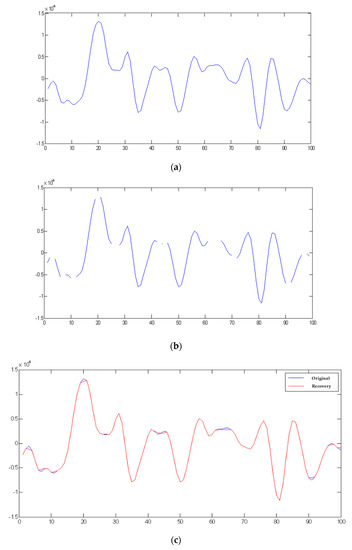
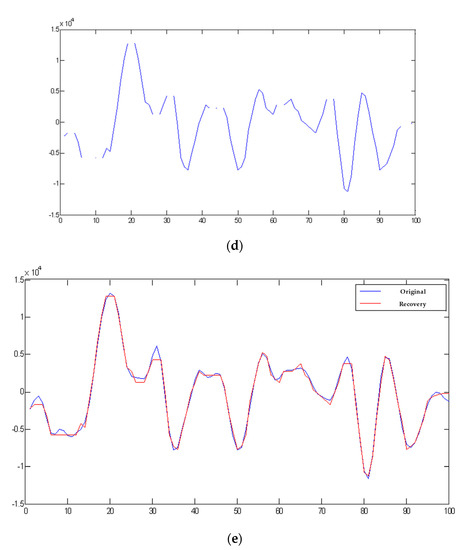
Figure 2.
Comparison among the original audio, compressed audio, and decompressed audio in 1 and 100 audio samples with a threshold value of 500 and with/without embedding private information. (a) Original audio. (b) Compressed audio with threshold value of 500. (c) Recovering the compressed audio in (b). (d) Compressed audio with threshold value of 500 and embedding private information of embedding strength Q = 1000. (e) Recovering the compressed audio in (d).
Data in Table 7 show that the CR and SNR obtained without embedding information (denoted by N) vary under distinct threshold values. Such a result is consistent with the fact that when CR increases, SNR worsens. While signals are embedded, the result of the investigation of the relationship between the two is also in Table 7. From the experimental outcomes, we observed two noteworthy findings. First, with the same threshold value, if the embedding strength is higher, the overall audio values vary less. Though SNR seems worse, it demonstrates a more powerful embedding strength and a better compression effect. Second, in cases where threshold values change, we see that if the threshold value is greater than the embedding strength, the CR value becomes higher. That is to say, the compression effect enhancesand the relative decompression effect worsens, but the total effectiveness remains almost unchanged.
Table 7.
Relationship between CR and SNR with and without embedding private information (N).
Moreover, to better understand the relationship between CR and SNR, we used the graph in Figure 3 to find appropriate values of threshold ε and embedding strength Q. We changed the threshold ε to obtain the relationship between CR and SNR using different markers by keeping green and blue fixed to include all the Q values obtained in Table 7. By doing this, we made sure the effect between CR and SNR remained optimized.
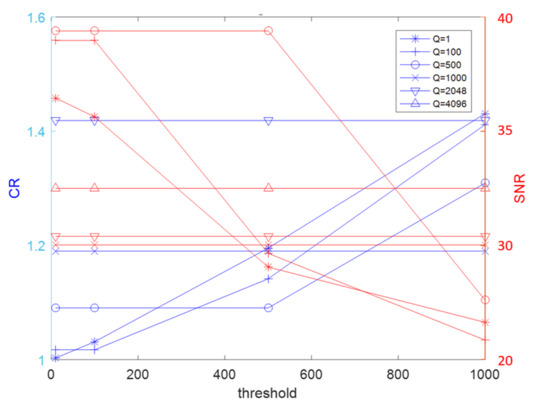
Figure 3.
Changing the threshold ε to obtain the relationship between CR and SNR using different markers by keeping green and blue fixed to include all the Q values in Table 7.
5. Conclusions
This study proposes a method to seek the integration between the information-hiding process and data compression for five types of commonly seen audio signals. Under the proposed model, simulation results demonstrated that each piece of hidden audio signal attains high SNR and showed strong robustness. SNRs of most hidden audios were more than 35, and some were even higher than 40. On the other hand, most BERs were as low as 5% or less. In addition, we obtained the relationship between CR and SNR with embedded private information and observed two critical outcomes. First, with a fixed threshold value, a high embedding strength makes the differences between the overall audio values smaller. Such an algorithm shows better embedding strength and enhanced compression effects but reflects worse SNR values. Second, when playing with distinct threshold values, we found that if the threshold value ε is set higher than the embedding strength Q, the CR value drops. That means the compression effect becomes better and the relative decompression effect worsens, but the total effectiveness remains almost unchanged.
Author Contributions
Conceptualization: S.-T.C.; methodology: S.-T.C.; software: S.-T.C.; validation: S.-Y.T. and M.Z.; Writing—review and editing: S.-T.C. and S.-Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Theorem A1.
Let A be a matrix of size n × n. If and X are n × 1 column vectors, then the following statement holds [30,31]:
Theorem A2.
Suppose that g is a continuously differentiable function of X on a subset of the domain of a function f. If X0minimizes (or maximizes) f(X) subjected to the constraint g(X) = 0, then
∇f(X0) and
∇g(X0) are parallel and one is a constant multiple of another. That is, if
∇g(X0) ≠ 0, then there exists a non-zero scalar λ such that
Based on Theorem A2, if an augmented function is defined as
then an optimal solution of the optimization problem is to compute the extreme of the unconstraint function H(X, λ). The necessary conditions to ensure the existence of the extreme of H are [30,31]
References
- Chang, C.-L.; Chang, C.-Y.; Tang, Z.-Y.; Chen, S.-T. High-Efficiency Automatic Recharging Mechanism for Cleaning Robot Using Multi-Sensor. Sensors 2018, 18, 11. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-L.; Chen, C.-J.; Lee, H.-T.; Chang, C.-Y.; Chen, S.-T. Bounding the Sensing Data Collection Time with Ring-based Routing for Industrial Wireless Sensor Networks. J. Internet Technol. 2020, 21, 673–680. [Google Scholar]
- Zuo, Z.; Liu, L.; Zhang, L.; Fang, Y. Indoor Positioning Based on Bluetooth Low-Energy Beacons Adopting Graph Optimization. Sensors 2018, 18, 3736. [Google Scholar] [CrossRef]
- Chang, C.-L.; Chen, S.-T.; Chang, C.-Y.; Jhou, Y.-C. The Application of Machine Learning in Air Hockey Interactive Control System. Sensors 2020, 18, 7233. [Google Scholar] [CrossRef]
- Lin, S.-J.; Chen, S.-T. Enhance the perception of easy-to-fall and apply the Internet of Things to fall prediction and protection. J. Healthc. Commun. 2020, 5, 52. [Google Scholar]
- Zhang, X.; Zhang, S.; Huai, S. Low-Power Indoor Positioning Algorithm Based on iBeacon Network. Hindawi Complex. 2021, 2021, 8475339. [Google Scholar] [CrossRef]
- Zhou, C.; Yuan, J.; Liu, H.; Qiu, J. Bluetooth indoor positioning based on RSSI and Kalman filter. Wirel. Pers. Commun. 2017, 96, 4115–4130. [Google Scholar] [CrossRef]
- Song, W.; Lee, H.M.; Lee, S.H.; Choi, M.H.; Hong, M. Implementation of android application for indoor positioning system with estimote BLE beacons. J. Internet Technol. 2018, 19, 871–878. [Google Scholar]
- Cui, L.; Yang, S.; Chen, F.; Ming, Z.; Lu, N.; Qin, J. A survey on application of machine learning for Internet of Things. Int. J. Mach. Learn. Cyber. 2018, 9, 1399–1417. [Google Scholar] [CrossRef]
- Baldini, G.; Dimc, F.; Kamnik, R.; Steri, G.; Giuliani, R.; Gentile, C. Identification of mobile phones using the built-in magnetometers stimulated by motion patterns. Sensors 2017, 17, 783. [Google Scholar] [CrossRef]
- IFPI (International Federation of the Phonographic Industry). Available online: http://www.ifpi.org (accessed on 10 January 2021).
- Katzenbeisser, S.; Petitcolas, F.A.P. (Eds.) Information Hiding Techniques for Steganography and Digital Watermarking; Artech House, Inc.: Norwood, MA, USA, 2000. [Google Scholar]
- Al-Haj, A.; Mohammad, A.A.; Bata, L. DWT-based audio watermarking. Int. Arab. J. Inf. Technol. 2011, 8, 326–333. [Google Scholar]
- Xiang, S. Robust audio watermarking against the D/A and A/D conversions. EURASIP J. Adv. Signal Processing 2011, 3, 29. [Google Scholar] [CrossRef]
- Chen, S.-T.; Wu, G.-D.; Huang, H.-N. Wavelet-Domain Audio Watermarking Scheme Using Optimization-Based Quantization. IET Signal Processing 2010, 4, 720–727. [Google Scholar] [CrossRef]
- Noriega, R.M.; Nakano, M.; Kurkoski, B.; Yamaguchi, K. High Payload Audio Watermarking: Toward Channel Characterization of MP3 Compression. J. Inf. Hiding Multimed. Signal Process. 2011, 2, 91–107. [Google Scholar]
- Mishra, J.; Patil, M.V.; Chitode, J.S. An Effective Audio Watermarking using DWT-SVD. Int. J. Comput. Appl. 2013, 70, 6–11. [Google Scholar] [CrossRef]
- Zhao, M.; Pan, J.-S.; Chen, S.-T. Entropy-Based Audio Watermarking via the Point of View on the Compact Particle Swarm Optimization. J. Internet Technol. 2015, 16, 485–495. [Google Scholar]
- Darabkh, A.K. Imperceptible and Robust DWT-SVD-Based Digital Audio Watermarking Algorithm. J. Softw. Eng. Appl. 2014, 7, 859–871. [Google Scholar] [CrossRef]
- Chen, S.-T.; Guo, Y.-J.; Huang, H.-N.; Kung, W.-M.; Tseng, K.-K.; Tu, S.-Y. Hiding Patients Confidential Data in the ECG Signal via a Transform-Domain Quantization Scheme. J. Med. Syst. 2014, 38, 54. [Google Scholar] [CrossRef]
- Zear, A.; Singh, A.K.; Kumar, P. A proposed secure multiple watermarking technique based on DWT, DCT and SVD for application in medicine. Multimed. Tools Appl. 2016, 77, 4863–4882. [Google Scholar] [CrossRef]
- Wu, Q.; Wu, M. A Novel Robust Audio Watermarking Algorithm by Modifying the Average Amplitude in Transform Domain. Appl. Sci. 2018, 8, 723. [Google Scholar] [CrossRef]
- Karajeh, H.; Khatib, T.; Rajab, L.; Maqableh, M. A robust digital audio watermarking scheme based on DWT and Schur decomposition. Multimed. Tools Appl. 2019, 78, 18395–18418. [Google Scholar] [CrossRef]
- Chen, S.-T.; Huang, H.-N. Optimization-Based Audio Watermarking with Integrated Quantization Embedding. Multimed. Tools Appl. 2016, 75, 4735–4751. [Google Scholar] [CrossRef]
- Shankar, T.; Yamuna, G. Optimization Based Audio Watermarking using Discrete Wavelet Transform and Singular Value Decomposition. Int. J. Electron. Electr. Comput. Syst. 2017, 6, 375–379. [Google Scholar]
- Dhar, P.K.; Shimamura, T. Blind Audio Watermarking in Transform Domain Based on Singular Value Decomposition and Exponential-Log Operations. Radio Eng. 2017, 26, 552–561. [Google Scholar] [CrossRef]
- Li, J.-F.; Wang, H.-X.; Wu, T.; Sun, X.-M.; Qian, Q. Norm ratio-based audio watermarking scheme in DWT domain. Multimed. Tools Appl. 2018, 77, 14481–14497. [Google Scholar] [CrossRef]
- Mallat, S. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intel. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Burrus, C.S.; Gopinath, R.A.; Gao, H. Introduction to Wavelet Theory and Its Application; Prentice-Hall: Hoboken, NJ, USA, 1998. [Google Scholar]
- Lewis, F.L. Optimal Control; John Wiley and Sons: New York, NY, USA, 1986. [Google Scholar]
- Bartle, R.G. The Elements of Real Analysis, 2nd ed.; Wiley: New York, NY, USA, 1976. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).