
Heuristic Attention Representation Learning for Self-Supervised Pretraining



Abstract
:1. Introduction
- We introduce a new self-supervised learning framework (HARL) that maximizes the similarity agreement of object-level latent embedding on vector space across different augmented views. The framework implementation is available in the Supplementary Material section.
- We utilized two heuristic mask proposal techniques from conventional computer vision and unsupervised deep learning methods to generate a binary mask for the natural image dataset.
- We construct the two novel heuristic binary segmentation mask datasets for the ImageNet ILSVRC-2012 [24] to facilitate the research in the perceptual grouping for self-supervised visual representation learning. The datasets are available to download in the Data Availability Statement section.
- Finally, we demonstrate that adopting early visual attention provides a diverse set of high-quality semantic features that increase more effective learning representation for self-supervised pretraining. We report promising results when transferring HARL’s learned representation on a wide range of downstream vision tasks.
2. Related Works
3. Methods
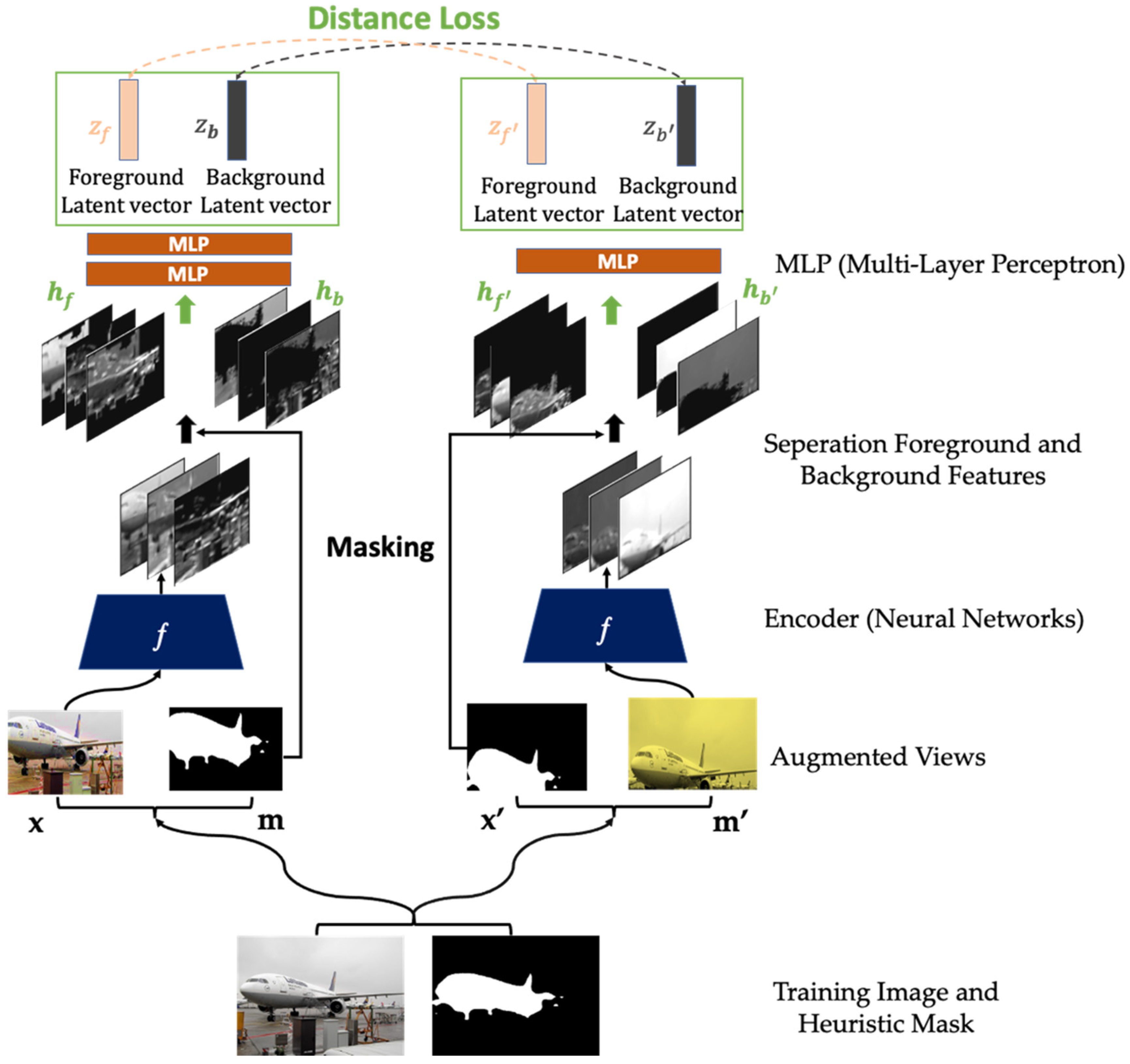
3.1. HARL Framework
| Algorithm 1: HARL: Heuristic Attention Representation Learning |
| Input: : set of images, mask and distributions of transformations initial online parameters, encoder, projector, and predictor ; // initial target parameters, target encoder, and target projector Optimizer; //optimizer, updates online parameters using the loss gradient and ; //total number of optimization steps and batch size ; //target network update schedule and learning rate schedule
|
3.2. Heuristic Binary Mask
4. Experiments
4.1. Self-Supervised Pretraining Implementation
4.2. Evaluation Protocol
4.2.1. Linear Evaluation and Semi-Supervised Learning on the ImageNet Dataset
4.2.2. Transfer Learning to Other Downstream Tasks
5. Ablation and Analysis
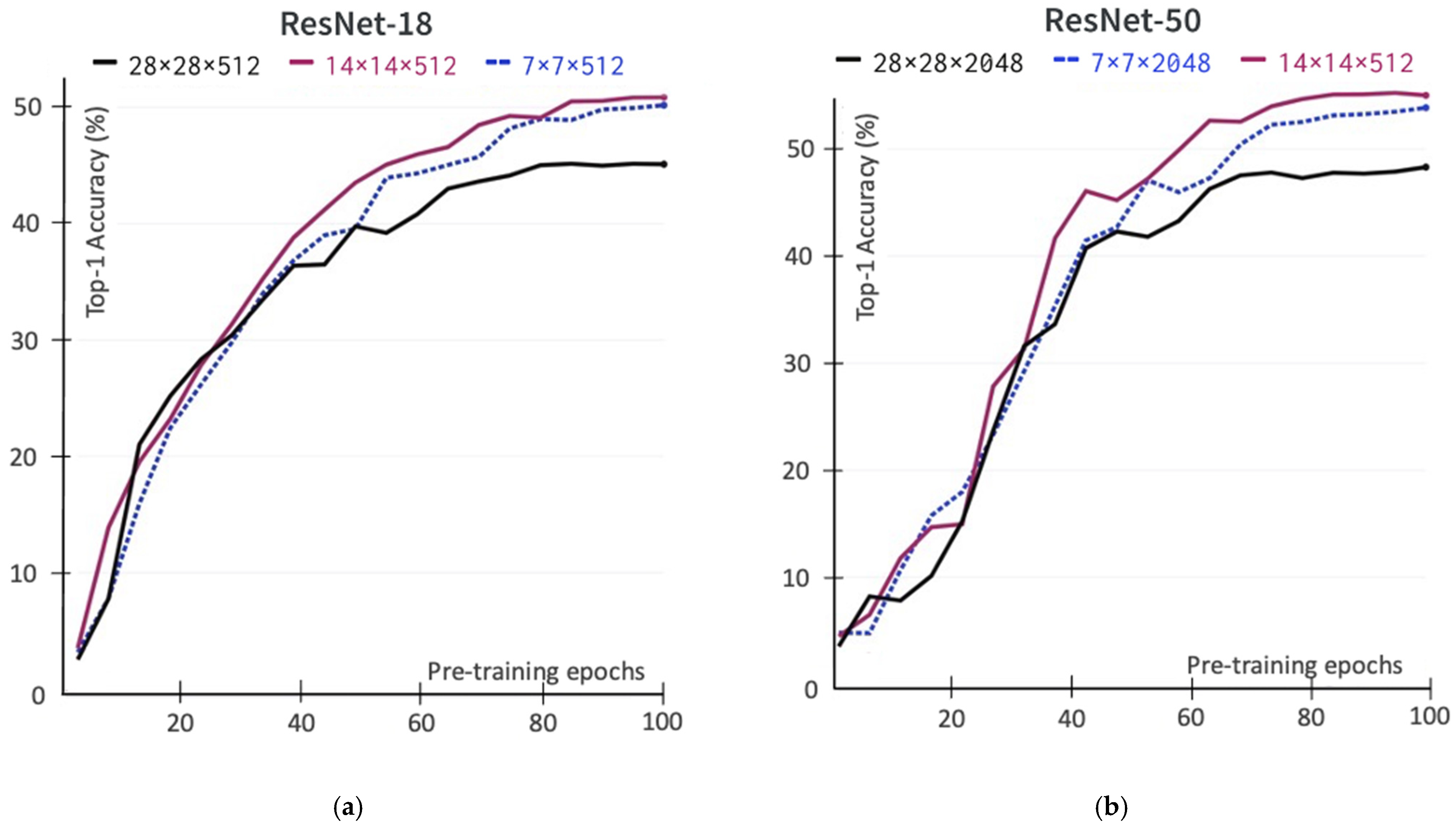
5.1. The Output of Spatial Feature Map (Size and Dimension)
5.2. Objective Loss Functions
5.2.1. Mask Loss
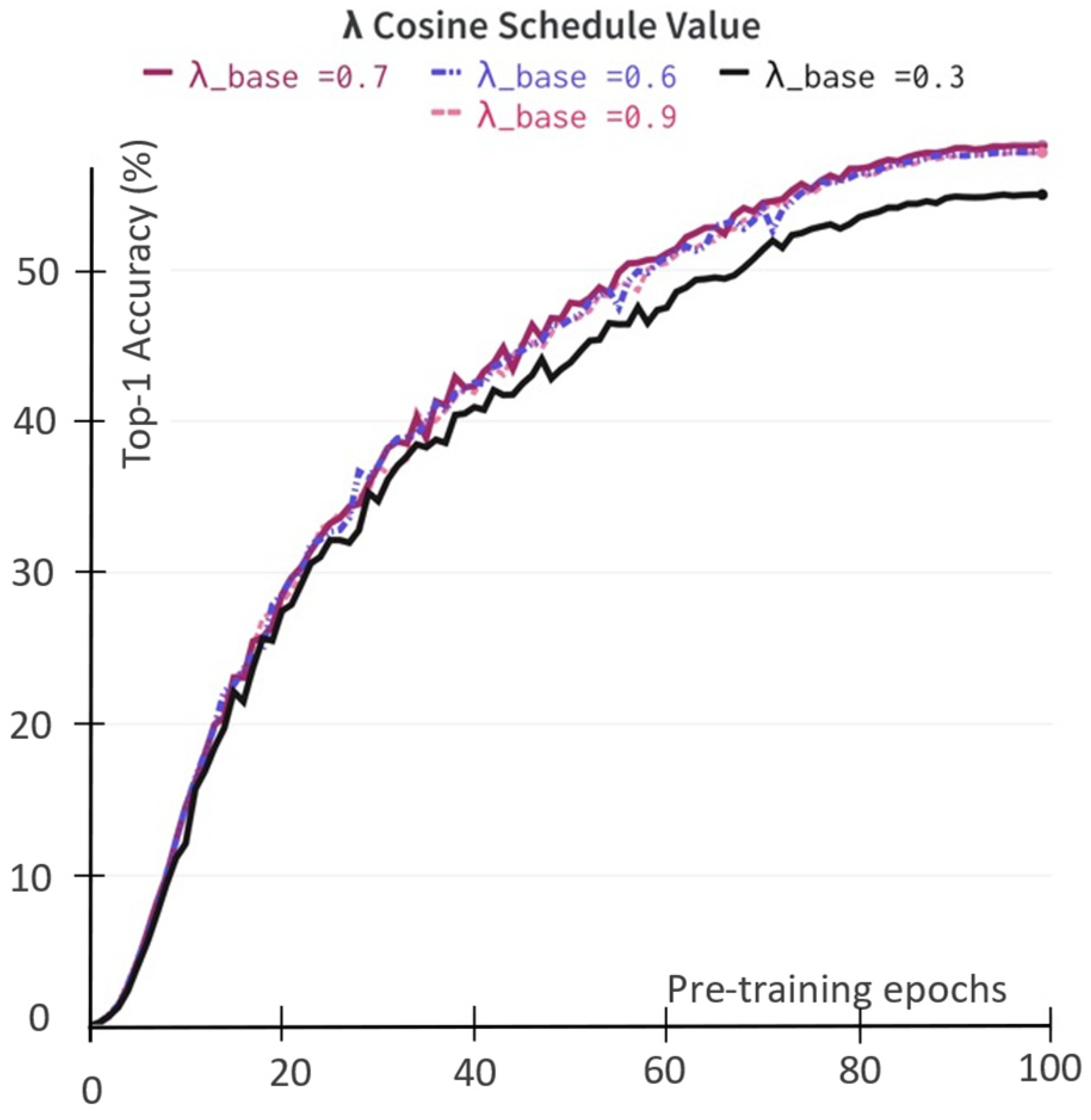
5.2.2. Hybrid Loss
5.2.3. Mask Loss versus Hybrid Loss
5.3. The Impact of Heuristic Mask Quality
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Implementation Detail
Appendix A.1. Implementation Data Augmentation
- Random cropping with resizes: a random patch of the image is selected. In our pipeline, we use the inception-style random cropping [62], whose area crop is uniformly sampled in [0.08 to 1.0] of the original image, and the random aspect ratio is logarithmically sampled in [3/4, 4/3]. The patch is then resized to 224 × 224 pixels using bicubic interpolation;
- Optional horizontal flipping (left and right);
- Color jittering: the brightness, contrast, saturation and hue are shifted by a uniformly distributed offset;
- Optional color dropping: the RGB image is replaced by its greyscale values;
- Gaussian blurring with a 224 × 224 square kernel and a standard deviation uniformly sampled from [0.1, 2.0];
- Optional solarization: a point-wise color transformation for pixel values in the range [0–1].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | T | T′ | M | M′ |
|---|---|---|---|---|
| Inception-style random crop probability | 1.0 | 1.0 | 1.0 | 1.0 |
| Flip probability | 0.5 | 0.5 | 0.5 | 0.5 |
| Color jittering probability | 0.8 | 0.8 | - | - |
| Brightness adjustment max intensity | 0.4 | 0.4 | - | - |
| Contrast adjustment max intensity | 0.4 | 0.4 | - | - |
| Saturation adjustment max intensity | 0.2 | 0.2 | - | - |
| Hue adjustment max intensity | 0.1 | 0.1 | - | - |
| Color dropping probability | 0.2 | 0.2 | - | - |
| Gaussian blurring probability | 1.0 | 0.1 | - | - |
| Solarization probability | 0.0 | 0.2 | - | - |
Appendix A.2. Implementation Masking Feature
Appendix B. Evaluation on the ImageNet and Transfer Learning
Appendix B.1. Implementation Masking Feature Linear Evaluation Semi-Supervised Protocol on ImageNet
| Dataset | Classes | Original Training Examples | Training Examples | Validation Examples | Test Examples | Accuracy Measure | Test Provided |
|---|---|---|---|---|---|---|---|
| Food101 | 101 | 75,750 | 68,175 | 7575 | 25,250 | Top-1 accuracy | - |
| CIFAR-10 | 10 | 50,000 | 45,000 | 5000 | 10,000 | Top-1 accuracy | - |
| CIFAR-100 | 100 | 50,000 | 44,933 | 5067 | 10,000 | Top-1 accuracy | - |
| Sun397 (split 1) | 397 | 19,850 | 15,880 | 3970 | 19,850 | Top-1 accuracy | - |
| Cars | 196 | 8144 | 6494 | 1650 | 8041 | Top-1 accuracy | - |
| DTD (split 1) | 47 | 1880 | 1880 | 1880 | 1880 | Top-1 accuracy | Yes |
- Top-1: We compute the proportion of correctly classified examples.
- AP, AP50 and AP75: We compute the average precision as defined in [56].
Appendix B.2. Transfer via Linear Classification and Fine-Tuning
Appendix B.3. Transfer Learning to Other Vision Tasks
Appendix C. Heuristic Mask Proposal Methods
Appendix C.1. Heuristic Binary Mask Generates Using DRFI
Appendix C.2. Heuristic Binary Mask Generates Using Unsupervised Deep Learning
References
- Shu, Y.; Kou, Z.; Cao, Z.; Wang, J.; Long, M. Zoo-tuning: Adaptive transfer from a zoo of models. arXiv 2021, arXiv:2106.15434. [Google Scholar]
- Yang, Q.; Zhang, Y.; Dai, W.; Pan, S.J. Transfer Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- You, K.; Kou, Z.; Long, M.; Wang, J. Co-Tuning for Transfer Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 17236–17246. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch Networks for Multi-task Learning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Li, X.; Xiong, H.; Xu, C.; Dou, D. SMILE: Self-distilled mixup for efficient transfer learning. arXiv 2021, arXiv:2103.13941. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jeju Island, Korea, 11–15 October 2015; pp. 1–5. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Amjad, R.A.; Geiger, B.C. Learning representations for neural network-based classification using the information bottleneck principle. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2225–2239. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Goyal, P.; Caron, M.; Lefaudeux, B.; Xu, M.; Wang, P.; Pai, V.; Singh, M.; Liptchinsky, V.; Misra, I.; Joulin, A.; et al. Self-supervised Pretraining of Visual Features in the Wild. arXiv 2021, arXiv:2103.01988. [Google Scholar]
- Misra, I.; Maaten, L.v.d. Self-supervised learning of pretext-invariant representations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6706–6716. [Google Scholar]
- Ermolov, A.; Siarohin, A.; Sangineto, E.; Sebe, N. Whitening for self-supervised representation learning. In Proceedings of the International Conference on Machine Learning ICML, Virtual, 18–24 July 2021. [Google Scholar]
- Grill, J.-B.; Strub, F.; Altch’e, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.v.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; J’egou, H.e.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. arXiv 2021, arXiv:2104.14294. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. arXiv 2020, arXiv:2006.09882. [Google Scholar]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a “Siamese” time delay neural network. In Proceedings of the 13th International Joint Conference on Artificial Intelligence, Chambéry, France, 28 August–3 September 1993. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9726–9735. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hayhoe, M.M.; Ballard, D.H. Eye movements in natural behavior. Trends Cogn. Sci. 2005, 9, 188–194. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; SihiteDicky, N.; Itti, L. Quantitative analysis of human-model agreement in visual saliency modeling. IEEE Trans. Image Process. 2013, 22, 55–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benois-Pineau, J.; Callet, P.L. Visual content indexing and retrieval with psycho-visual models. In Multimedia Systems and Applications; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Awh, E.; Armstrong, K.M.; Moore, T. Visual and oculomotor selection: Links, causes and implications for spatial attention. Trends Cogn. Sci. 2006, 10, 124–130. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Chen, X.; Ganguli, S. Understanding self-supervised learning dynamics without contrastive Pairs. arXiv 2021, arXiv:2102.06810. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning ICML, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Bojanowski, P.; Joulin, A. Unsupervised learning by predicting noise. arXiv 2017, arXiv:1704.05310. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Colorization as a proxy task for visual understanding. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 840–849. [Google Scholar]
- Iizuka, S.; Simo-Serra, E. Let there be color!: Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Trans. Graph. (ToG) 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Pathak, D.; Krähenbühl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of the European Conference on Computer Vision ECCV, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 645–654. [Google Scholar]
- Mundhenk, T.N.; Ho, D.; Chen, B.Y. Improvements to context based self-supervised learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9339–9348. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2017, arXiv:1605.09782. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative adversarial nets. In Proceedings of the Neural Information Processing Systems NIPS, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Donahue, J.; Simonyan, K. Large scale adversarial representation learning. In Proceedings of the Neural Information Processing Systems NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Bansal, V.; Buckchash, H.; Raman, B. Discriminative auto-encoding for classification and representation learning problems. IEEE Signal Process. Lett. 2021, 28, 987–991. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big Self-supervised models are strong semi-supervised learners. arXiv 2020, arXiv:2006.10029. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Van Gansbeke, W.; Vandenhende, S.; Georgoulis, S.; Gool, L.V. unsupervised semantic segmentation by contrasting object mask proposals. arXiv 2021, arXiv:2102.06191. [Google Scholar]
- Zhang, X.; Maire, M. Self-Supervised visual representation learning from hierarchical grouping. arXiv 2020, arXiv:2012.03044. [Google Scholar]
- Jiang, H.; Yuan, Z.; Cheng, M.-M.; Gong, Y.; Zheng, N.; Wang, J. Salient object detection: A discriminative regional feature integration approach. Int. J. Comput. Vis. 2013, 123, 251–268. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- You, Y.; Gitman, I.; Ginsburg, B. Scaling SGD batch size to 32K for imageNet training. arXiv 2017, arXiv:1708.03888. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.B.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large Minibatch SGD: Training ImageNet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Kolesnikov, A.; Zhai, X.; Beyer, L. Revisiting self-supervised visual representation learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1920–1929. [Google Scholar]
- Ye, M.; Zhang, X.; Yuen, P.; Chang, S.-F. Unsupervised embedding learning via invariant and spreading instance feature. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6203–6212. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2019, arXiv:1808.06670. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.B.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet models transfer better? In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2656–2666. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.M.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Zhang, S.; Liew, J.H.; Wei, Y.; Wei, S.; Zhao, Y. Interactive object segmentation with inside-outside guidance. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12231–12241. [Google Scholar]
- Xie, Z.; Lin, Y.; Zhang, Z.; Cao, Y.; Lin, S.; Hu, H. Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16679–16688. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning ICML, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Gool, L.V. Food-101-mining discriminative components with random forests. In Proceedings of the European Conference on Computer Vision ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 8 April 2009).
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for fine-grained categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- HÈnaff, O.J.; Srinivas, A.; Fauw, J.D.; Razavi, A.; Doersch, C.; Eslami, S.M.A.; Oord, A.R.V.D. Data-efficient image recognition with contrastive predictive coding. arXiv 2020, arXiv:1905.09272. [Google Scholar]
- Borji, A.; Cheng, M.-M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H. Salient object detection in the deep learning era: An in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3239–3259. [Google Scholar] [CrossRef]
- Zou, W.; Komodakis, N. HARF: Hierarchy-associated rich features for salient object detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 406–414. [Google Scholar]
- Zhang, J.; Zhang, T.; Dai, Y.; Harandi, M.; Hartley, R.I. Deep unsupervised saliency detection: A multiple noisy labeling perspective. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9029–9038. [Google Scholar]





| Method | Linear Evaluation | Semi-Supervised Learning | ||||
|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | |||
| 1% | 10% | 1% | 10% | |||
| Supervised | 76.5 | - | 25.4 | 56.4 | 48.4 | 80.4 |
| PIRL [11] | 63.6 | - | - | - | 57.2 | 83.8 |
| SimCLR [9] | 69.3 | 89.0 | 48.3 | 65.6 | 75.5 | 87.8 |
| MoCo [17] | 60.6 | - | - | - | - | - |
| MoCo v2 [54] | 71.1 | - | - | - | - | - |
| SimSiam [18] | 71.3 | - | - | - | - | - |
| BYOL [13] | 74.3 | 91.6 | 53.2 | 68.8 | 78.4 | 89.0 |
| HARL (ours) | 74.0 | 91.3 | 54.5 | 69.5 | 79.2 | 89.3 |
| Method | Food101 | CIFAR10 | CIFAR100 | SUN397 | Cars | DTD |
|---|---|---|---|---|---|---|
| Linear evaluation: | ||||||
| HARL (ours) | 75.0 | 92.6 | 77.6 | 61.4 | 67.3 | 77.3 |
| BYOL [13] | 75.3 | 91.3 | 78.4 | 62.2 | 67.8 | 75.5 |
| MoCo v2 (repo) | 69.2 | 91.4 | 73.7 | 58.6 | 47.3 | 71.1 |
| SimCLR [9] | 68.4 | 90.6 | 71.6 | 58.8 | 50.3 | 74.5 |
| Fine-tuned: | ||||||
| HARL (ours) | 88.0 | 97.6 | 85.6 | 64.1 | 91.1 | 78.0 |
| BYOL [13] | 88.5 | 97.4 | 85.3 | 63.7 | 91.6 | 76.2 |
| MoCo v2 (repo) | 86.1 | 97.0 | 83.7 | 59.1 | 90.0 | 74.1 |
| SimCLR [9] | 88.2 | 97.7 | 85.9 | 63.5 | 91.3 | 73.2 |
| Method | Object Detection | Instance Segmentation | |||||||
|---|---|---|---|---|---|---|---|---|---|
| VOC07 + 12 Detection | COCO Detection | COCO Segmentation | |||||||
| AP50 | AP | AP75 | AP50 | AP | AP75 | ||||
| Supervised | 81.3 | 53.5 | 58.8 | 58.2 | 38.2 | 41.2 | 54.7 | 33.3 | 35.2 |
| SimCLR-IN [18] | 81.8 | 55.5 | 61.4 | 57.7 | 37.9 | 40.9 | 54.6 | 33.3 | 35.3 |
| MoCo [17] | 82.2 | 57.2 | 63.7 | 58.9 | 38.5 | 42.0 | 55.9 | 35.1 | 37.7 |
| MoCo v2 [54] | 82.5 | 57.4 | 64.0 | - | 39.8 | - | - | 36.1 | - |
| SimSiam [18] | 82.4 | 57.0 | 63.7 | 59.3 | 39.2 | 42.1 | 56.0 | 34.4 | 36.7 |
| BYOL [13] | - | - | - | 40.4 | - | - | 37.0 | - | |
| BYOL (repo) | 82.6 | 55.5 | 61.9 | 61.2 | 40.2 | 43.9 | 58.2 | 36.7 | 39.5 |
| HARL (ours) | 82.7 | 56.3 | 62.4 | 62.1 | 40.9 | 44.5 | 59.0 | 37.3 | 40.0 |
| Method | Top-1 Accuracy | Top-5 Accuracy |
|---|---|---|
| Mask Loss | ||
| α_base = 0.3 | 51.3 | 77.4 |
| α_base = 0.5 | 53.9 | 79.4 |
| α_base = 0.7 | 54.6 | 79.8 |
| Hybrid Loss | ||
| λ_base = 0.3 | 55.0 | 79.4 |
| λ_base = 0.5 | 57.8 | 81.7 |
| λ_base = 0.7 | 58.2 | 81.8 |
| Method | Object Detection | Instance Segmentation | |||||||
|---|---|---|---|---|---|---|---|---|---|
| VOC07 + 12 Detection | COCO Detection | COCO Segmentation | |||||||
| AP50 | AP | AP75 | AP50 | AP | AP75 | ||||
| HARL (DRFI Masks) | 82.3 | 55.4 | 61.2 | 44.2 | 24.6 | 24.8 | 41.8 | 24.3 | 25.1 |
| HARL (Deep Learning Masks) | 82.1 | 55.5 | 61.7 | 44.7 | 24.7 | 25.3 | 42.3 | 24.6 | 25.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, V.N.; Liu, S.-H.; Li, Y.-H.; Wang, J.-C. Heuristic Attention Representation Learning for Self-Supervised Pretraining. Sensors 2022, 22, 5169. https://doi.org/10.3390/s22145169
Tran VN, Liu S-H, Li Y-H, Wang J-C. Heuristic Attention Representation Learning for Self-Supervised Pretraining. Sensors. 2022; 22(14):5169. https://doi.org/10.3390/s22145169
Chicago/Turabian StyleTran, Van Nhiem, Shen-Hsuan Liu, Yung-Hui Li, and Jia-Ching Wang. 2022. "Heuristic Attention Representation Learning for Self-Supervised Pretraining" Sensors 22, no. 14: 5169. https://doi.org/10.3390/s22145169
APA StyleTran, V. N., Liu, S.-H., Li, Y.-H., & Wang, J.-C. (2022). Heuristic Attention Representation Learning for Self-Supervised Pretraining. Sensors, 22(14), 5169. https://doi.org/10.3390/s22145169