1. Introduction
The automatic generation and recognition of the face dynamics that allow people to perform facial expressions has a strong theoretical and practical interest in a broad range of disciplines. It is well recognized that facial expressions as well as more subtle facial movements represent important visual cues that can support machine-based approaches aimed at the analysis of the human emotional state. In turn, this has a lot of potential applications such as monitoring for fatigue detection, gaming, deception recognition, or Human Computer Interaction, to cite a few.
From a physiological point of view, facial expressions can be seen as resulting from the contraction of facial muscles that deform the visible skin tissue. Usually, the type and intensity of facial expressions depend in a complex way on the level of activation of several muscles and their combined effect. Looking to the deformation of individual muscles or combination of them, Ekman and Friesen defined the Facial Action Coding System (FACS) [
1] that relates facial expressions with the activation of Action Units (AUs), i.e., deformations of individual muscles. Both expression recognition and AU detection have been addressed in the literature using either RGB images or 3D data. The most common solution is that of recognizing and classifying the facial movements by analyzing the variation between neutral and expressive faces of some face features. In case of RGB imagery, these are extracted from the texture and are meant to describe appearance changes as induced by the facial deformations. In 3D, they instead capture changes occurring in the geometrical structure of the face surface. In both the cases, it is possible to use those features to discriminate between deformations that induced specific appearance changes. In other words, given a sample face, either in the form of RGB image or 3D data, we can observe the sample and decide which process, i.e., muscular movement, generated the particular appearance. However, operating this way we do not gather knowledge on the generative process itself, and so cannot replicate it. A way of addressing this problem would be that of directly analyzing the motions induced by AUs rather than what changes they determine on the face. Clearly, using 3D data is necessary to this aim, and would allow a direct evaluation of geometric deformations in the 3D space where they actually take place, rather than from their 2D projection in RGB images [
2].
In this paper, we address the problem from the latter point of view, and we propose a method for AU detection in 3D using a 3D Morphable Model (3DMM) of the face. Given the local nature of action units, we developed on a particular variant of the 3DMM, called Sparse and Locally Coherent (SLC) 3DMM [
3], which has the capability of modeling local deformations of the face. The SLC-3DMM can reproduce both structural face deformations related to the identity, and facial expressions. In fact, differently from most existing 3DMMs, its training data include neutral as well as expressive scans, which enables the 3DMM to reproduce also expression-like deformations. In addition, thanks to its particular learning formulation, the deformation components derived by the SLC solution capture quite well local deformations of the face. All of the above make it particularly suitable for our purposes.
This 3DMM can be efficiently fit to a target 3D scan using an iterative process that results into a 3D reconstructed model of the target subject, which is semantically consistent, i.e., in dense correspondence, with the 3DMM. In doing so, a set of deformation coefficients (weights) balancing the contribution of each atom are identified. In the most general case, such coefficients encode both structural deformations of the shape, commonly related to the identity of the subject, and other deformations that are instead related to expressions. In our case, we are interested in extrapolating the information related to the facial motions caused by the activation of AUs. In order to decouple the two, the proposed approach first adapts an average face to a 3D scan of an arbitrary individual in neutral expression. In this way, we account for the identity component. Then, the fitted neutral scan is used in place of the generic face to fit an expressive 3D face scan of the same subject. This two-step process allows us to disentangle the identity traits and the ones related to AUs activation. Once all these coefficients are collected from a training set of subjects, we look for recurrent patterns that identify facial motions related to AUs activation, and we use them to train a SVM and perform AU detection. In addition, with the proposed solution, we can easily recover AU-specific coefficients that can be used to deform a generic 3D model in neutral expression and synthesize a corresponding model with AU activation. This is achieved by simply averaging over all the collected coefficients that correspond to a particular AU, which demonstrates the effectiveness of the proposed two-step fitting solution.
A conceptually similar solution to learn expression-specific 3DMM coefficients and synthesize expressive face images appeared in [
4]. There are yet several differences with respect to [
4], the main one being that the above method dealt with 2D images rather than 3D faces. The 3DMM fitting was based on a set of sparse landmarks, and it aimed at modeling prototypical macro-expressions such as happiness or anger using the global DL-3DMM of [
5]. These two characteristics prevented the method in [
4] to account for smaller face motions. We instead perform here a way finer task that is modeling, classifying, and reproducing each muscular movement separately and directly in the 3D space. A set of sparse landmarks would result ineffective to this aim; being designed for coarsely localizing a sparse set of key-points on the face, they would not provide sufficiently detailed information. For this reason, the solution we present here uses a 3DMM, which is capable of accounting for such finer deformations using a dense 3D-3D fitting approach.
In summary, the novel contributions of this work are as follows:
We propose a framework for learning the 3DMM deformation coefficients that control fine-grained, AU-specific deformations;
We successfully apply them to the task of 3D AU detection in a challenging cross-database scenario, and we report competitive performance with respect to methods relying on carefully designed surface descriptors;
We demonstrate the effectiveness and versatility of this solution by synthesizing realistic 3D faces with AUs activation using the learned coefficients.
The remainder of the paper is organized as follows: In
Section 2, we revise and discuss works in the literature that are most closely related to our proposal. In
Section 3, we summarize the characteristics of the SLC-3DMM used in this work, and we describe the method employed to perform the 3D-3D fitting. In
Section 4, we present the proposed solution to learn AU-specific deformation coefficients from a set of raw 3D scans. These coefficients are then used to detect AUs and also to synthesize AUs from a generic 3D face model. Both a quantitative and a qualitative evaluation of AUs detection and synthesis are reported in
Section 5. Finally, discussion and conclusions are given in
Section 6 and
Section 7.
3. 3D Morphable Model
In the literature on 3DMM construction, there are some aspects that emerge quite evidently and that have a relevant impact on the modeling capabilities of the resulting tool. The first aspect that is worth mentioning is related to the set of scans used for learning the model. It is quite evident that the variability of the human face captured by the 3DMM is a direct consequence of the number of scans included in the training data and their heterogeneity. The second observation descends from the fact facial expressions and action units correspond to local deformations of the face due to the contraction of individual muscles or combinations of few of them. So, in order to include such local deformations among those that can be modeled, it is very important that scans with variegated local deformations of the face are observed in the training.
The two characteristics mentioned above are not commonly exposed jointly by the 3DMM existing in the literature. To the best of our knowledge, the Sparse and Locally-Coherent (SLC)-3DMM proposed by Ferrari et al. [
3] shows the unique characteristic of having a large spectrum of variability in the generated models, including gender, ethnicity and expression, combined with the capability of modeling local deformations of the face. Based on this, we propose to use the SLC-3DMM for AUs detection from 3D scans. To this end, in the remaining parts of this section, we present the main solutions for constructing the model (
Section 3.1) and fitting it in a dense way to a target scan (
Section 3.2). These solutions were originally presented in [
3], and are summarized here with the aim to make the paper as self-contained as possible. A full description of the SLC-3DMM method with all the details can be found in [
3].
3.1. SLC-3DMM Construction
As we have mentioned above, the set of scans used to train the 3DMM is of great importance for determining its final modeling and generative power. In the construction of the SLC-3DMM, the scans of the Binghamton University 3D facial expression dataset (BU-3DFE) were used. One interesting aspect of this dataset is that it includes sufficient variability in terms of gender, ethnicity, and age, also providing neutral and expressive scans. In particular, expressive scans are given for the six prototypical expressions (i.e., angry, disgust, fear, happy, sad, and surprise), with four different levels of intensity, from small to exaggerated, that also include topological variations, like for open/closed mouth. In order to compute the average model it is necessary that such training scans are posed in dense semantic correspondence. This means that all the scans should have the same number of points, and corresponding points should have the same semantic meaning. For the SLC-3DMM this has been obtained by exploiting the solution first proposed in [
5,
30]. The idea is to start from the facial landmarks that are annotated for each scan of the BU-3DFE (i.e., 83 landmarks per scan). Such landmarks provide initial points of correspondence across all the scans that are then used to partition the face surface in a set of non-overlapping regions. Each region is re-sampled internally so that the same regions for different scans have the same number of sampling points. Overall this results in scans that have been re-sampled according to a common semantic.
Relying on such set of scans in dense semantic correspondence, the geometry of a generic 3D face in the training set is represented as a vector
that contains the linearized
coordinates of the
m vertices. Let
be the matrix of the
N training scans, each with
m vertices arranged column-wise. Then, the difference between each training scan and the average 3D face is computed as
Each
represents the set of directions that transform the average model
into a training model
. Such
form the training matrix
.
The peculiar characteristic of the SLC-3DMM is that it changes the way we look at the training data. Instead of using each as a separate training sample, as in the “standard” 3DMM approach, each vertex coordinate is treated independently, that is, the displacements of each coordinate across the N scans are used as training samples. So, each sample becomes an N-dimensional data point representing the statistics of variation each vertex coordinate is subject to, for a total of training samples. Practically, this is obtained by simply transposing the training matrix . The estimation of the primary directions and expansion coefficients is formulated as a sparse-coding problem, in which the goal is to find a set of directions that can be sparsely combined to reconstruct the training data. This procedure is summarized in the following.
Let
be the transposed training matrix. We wish to find a set of
k (
) primary directions
and sparse expansion coefficients
that allow optimally reconstructing the input data, i.e., such that
is minimized and
is sparse. To obtain realistic deformations, the coefficients should also be smooth enough to prevent discontinuities. The problem is formulated as
This formulation is known as Elastic-net, and it has some properties that make it particularly suitable for this task. In particular, the
regularization encourages the grouping effect [
31], that is when the coefficients of a regression method associated with highly correlated variables tend to be equal. This correlation is in terms of displacement direction, and it is caused by the local consistency of motion induced by facial muscles. Together, these two characteristics result in deformations that are both sparse and spatially localized. Finally, it is worth noting that in addition to learn the vertex motions, a positivity constraint is also forced in (
2), which induces additional sparsity to the solution by promoting the complementarity of each learned atom [
32].
The sparse components
, the average model
, and the weight vector
constitute the Sparse and Locally-Coherent (SLC)-3DMM. For a more detailed description on the SLC-3DMM construction procedure, the reader can refer to [
3].
3.2. Fitting the SLC-3DMM to Target Scans
Fitting a 3DMM to a 3D face scan allows a coarse 3D reconstruction of the face, which is obtained by a different parameterization established by the vertex association between the 3DMM and the target. The process is started by a preliminary ICP alignment. Then, the following steps are iterated until a stopping condition is reached (more details can be found in [
3]):
A vertex correspondence is established between vertices in the 3DMM and the target.
A transformation accounting for rotation, scale, and translation is estimated between the average 3DMM
and the target
:
where
is the 3D translation, and
contains the 3D rotation and scale parameters.
is found in closed-form solving the following least-squares problem:
A solution to (
4) is given by
, where
is the pseudo-inverse of
. The translation is then recovered as
. Rotation and scale matrices
can be retrieved applying QR decomposition to
. Using
and
, we re-align both
and
to
prior to performing the deformation:
To deform
, we need to find the optimal set of deformation coefficients
so that the per-vertex distance between the two point sets is minimized. Similar to other works using a morphable model [
5,
33,
34], we formulate the problem as a regularized least-squares:
where
is the regularization parameter that allows balancing between the fitting accuracy and smoothness of the deformation. Here we regularize the deformation using the inverse
so that the contribution of each component is weighed with respect to its average intensity. By pre-computing
, the solution is found in closed form:
In the equation above, the symbol is used to denote a diagonal matrix with the vector on its main diagonal. is then deformed applying Finally, we estimate the per-vertex error of the deformed model as the average Euclidean distance between each vertex of and its nearest-neighbor in .
The procedure reported above is performed in an iterative way. The stopping criteria are reached when the error between two subsequent iterations falls under a predefined threshold
, or after a maximum number of iterations. When the stopping condition is reached, the 3DMM is fit to the target shape. A more detailed description of the fitting procedure is reported in [
3].
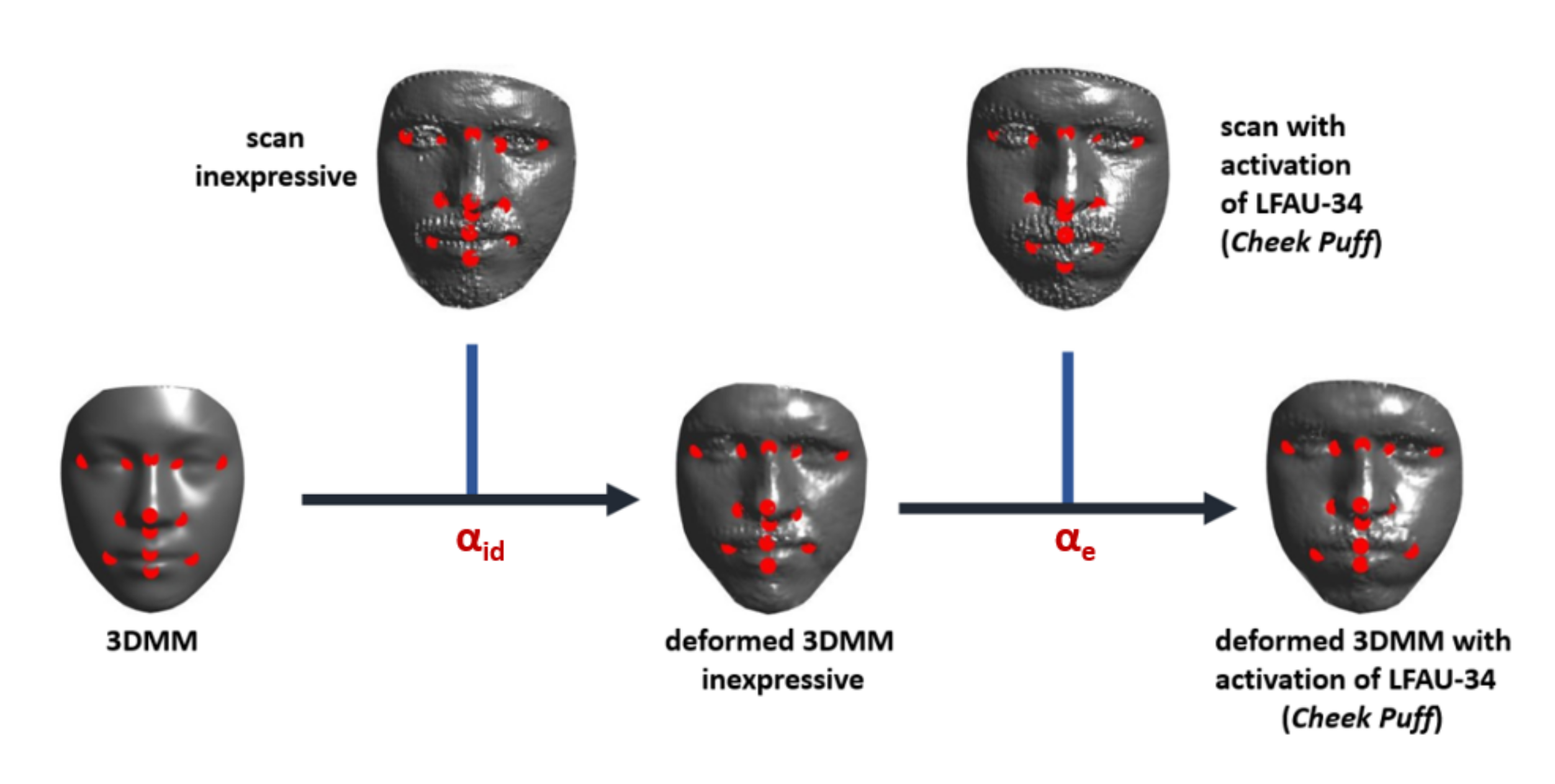
Figure 1 illustrates a fitting example, where the SLC-3DMM has been fit to a target scan using the procedure discussed above. It is possible to observe the SLC-3DMM fitting is quite accurate.
4. Learning AU-Specific 3DMM Coefficients
The proposed method to extract the deformation coefficients related to the activation of single AUs is rather simple yet effective. Considering a raw target face
, the deformation coefficients
resulting from the fitting process expounded in
Section 3.2 encode both global shape variations (i.e., the identity) along with other motions (i.e., action units activation). In order to extract only the information related to the activation of the AUs, we decouple the two by defining a two-step process. First, the average model
is deformed with the procedure expounded in
Section 3.2 to fit the scan in neutral expression
of an individual, so as to model morphological traits related to the identity and retrieve the related coefficients
. The fitted 3DMM results in a neutral model
that has the same topology of
. However, it still represents an approximation of the target face. In order to ameliorate it and improve the subsequent steps, we map each vertex of
to its nearest-neighbor vertex in
. In doing so, we obtain a neutral model
that still has the same topology of
, but each point is sampled from
, thus representing the actual target surface. Then,
is used in place of
to fit raw scans
of the same subject with action units activation. In order to reduce the impact of possible misalignment that could impair the estimation of the coefficients, we first align the nose-tips of
and
, and perform a rigid ICP to account for slight rigid roto-translations. Then, we again apply the fitting of
Section 3.2. In this way, we obtain a set of coefficients
that encode the deformation associated with a particular AU. The process is illustrated in
Figure 1.
Differently from [
4] where the process is guided by a sparse set of landmarks, thus limiting the possible deformations that can be captured, here the fitting is iterative and optimizes the shape with respect to the whole point-cloud. Hence, for each non-neutral scan we obtain a variable number
of coefficients
, which depends on the iterations. Optimizing with respect to the point-cloud has the advantage of capturing finer deformations of the face surface; on the other hand, minor deformations due to slight misalignment or sensor-noise could be captured while estimating the coefficients
. To remove such information from the coefficients, we experimented with a few solutions, which include (i) Taking the maximum of the coefficients across the iterations, (ii) setting a threshold to remove the effect of minor deformations, (iii) taking the coefficients of the first iteration only, and (iv) averaging the coefficients across the iterations. The latter solution resulted in the best performance. This is because such smaller deformations account for very small vertex displacements, and they can be well approximated by a zero-mean Gaussian noise. So, by taking the average we cancel their effect to a great extent. The magnitude of the deformation needed to compensate slight shape differences are also relatively smaller than those associated with the AU modeling. Ultimately, in this way we are able to associate a single vector of coefficient to each sample.
For each subject, we now have a set of coefficients
with the corresponding AU label. We use these to train a Support Vector Machine (SVM) classifier. In particular, we chose the C-Support Vector Classification. To address the multi-class problem, where each of the
C classes is one AU, we employ the standard One-vs-Rest strategy, which splits a multi-class problem into one binary classification for each class, for a total of
C classifiers. We train the SVM with the RBF kernel, which is in the form of a Gaussian function, defined as
where
is a free parameter, and
x and
represent a feature vectors in some input space, i.e.,
vectors in our case.
5. Experimental Results
We conducted experiments using the Bosphorus database, that includes 105 subjects performing 24 facial AUs activation (not every subject has all the 24 action units), for a total of 1879 scans. All the 24 AUs were employed for training and testing the SVM classifier. For training and testing, we used the Leave-One-subject-Out Cross Validation, or LOOCV. In particular, the scans of each subject are used once as a test set (Singleton), while the remaining subjects form the training set. The final results are the average over all the test subjects. Features were normalized to unitary -norm and standardized by removing the mean and scaling to unit variance prior to training the SVM. The centering and the scaling were done independently on each feature by computing the relevant statistics on the samples in the training set. Features were further processed by applying a dimensionality reduction based on PCA, retaining a number of dimensions carrying the 95% of the variance.
In the experiments, we compared the AU detection accuracy obtained as a result of performing the fitting with the SLC-3DMM described in
Section 3 and the standard PCA-3DMM. We chose the configurations that were reported to perform best in [
3], which are SLC with 50 components (also named SLC-50), SLC with 300 components (SLC-300), and PCA with 50 components (PCA-50). After that, we also tested whether the two could bring complementary information, and we performed an early fusion of the
coefficients among SLC-50 with PCA-50 (SLC-PCA-50) and SLC-50 with SLC-300 (SLC-50-300). The fusion was performed by concatenating the vectors from the two modalities. Following the standard convention, results are reported in terms of confusion matrices, F1-score, accuracy, and Area Under the Receiver Operating Characteristic (ROC) Curve (AUC). The former are widely used in facial expression analyses to understand the distribution of the classifier predictions and the properties of the features. F1-score, instead, represents the harmonic mean of precision and recall, while the AUC provides an aggregate measure of a classifier performance for all possible decision thresholds.
Previous works in the literature reported results on Bosphorus only in terms of AUC. So, in the following, we first report a comparison between the PCA-50 and SLC-50 methods in terms of accuracy and F1-score, and we discuss the relevant differences. Then, we provide a more comprehensive evaluation of the general performance of the proposed framework in comparison with the literature using the AUC measure.
5.1. Comparing SLC and PCA Deformation Components
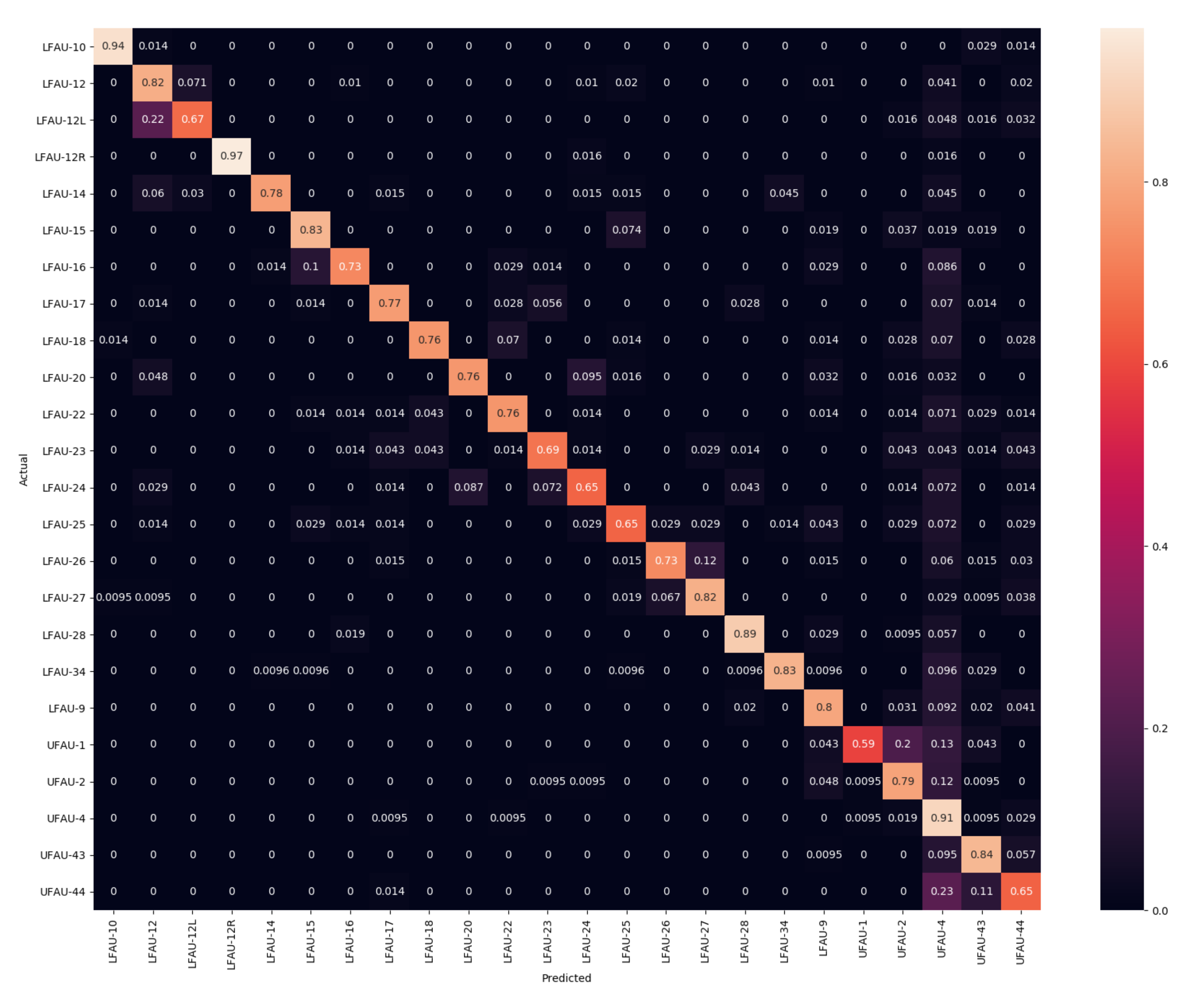
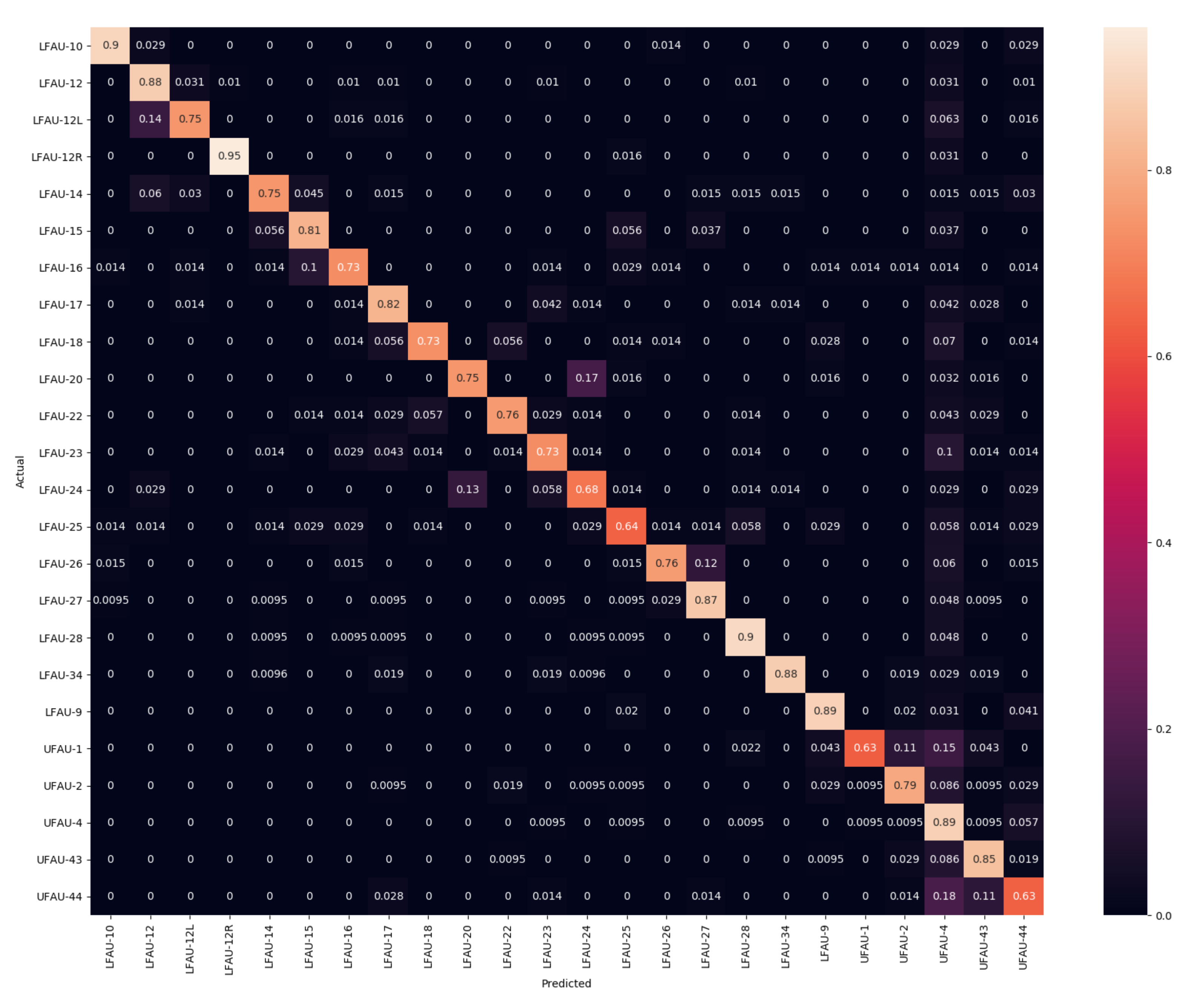
In this section, we evaluate the differences between the SLC and PCA components, which significantly differ in terms of type of deformation; SLC applies sparse and localized deformation, while PCA has global support on the face, and each component moves all the vertices of the 3DMM. Confusion matrices for PCA-50 and SLC-50 are reported in
Figure 2 and
Figure 3, respectively. Each row of the confusion matrix represents instances in the actual class, while each column represents instances of the predicted class. Therefore, a more accurate classification is represented by a confusion matrix with the diagonal line that has the higher percentages, but it can provide useful information on the behavior of the classifier. For example, tests indicate that LFAU-12L gets a little confused with the LFAU-12, which is plausible as both concern the lip corner puller, the first one being the asymmetric left lip corner. It turns out in this case that the SLC components, thanks to their sparse nature, better capture such slight difference and provide more accurate detection. The same occurs for UFAU-1, or Inner Brow Raiser, and UFAU-2, or Outer Brow Raiser, which get less confused when using the SLC components. We finally note a generally lower accuracy for the UFAU-44, or Squint. For this particular action unit, we find the absence of surface details in the eyes region of the 3DMM a potential source of error in this case. Examples of these are shown in
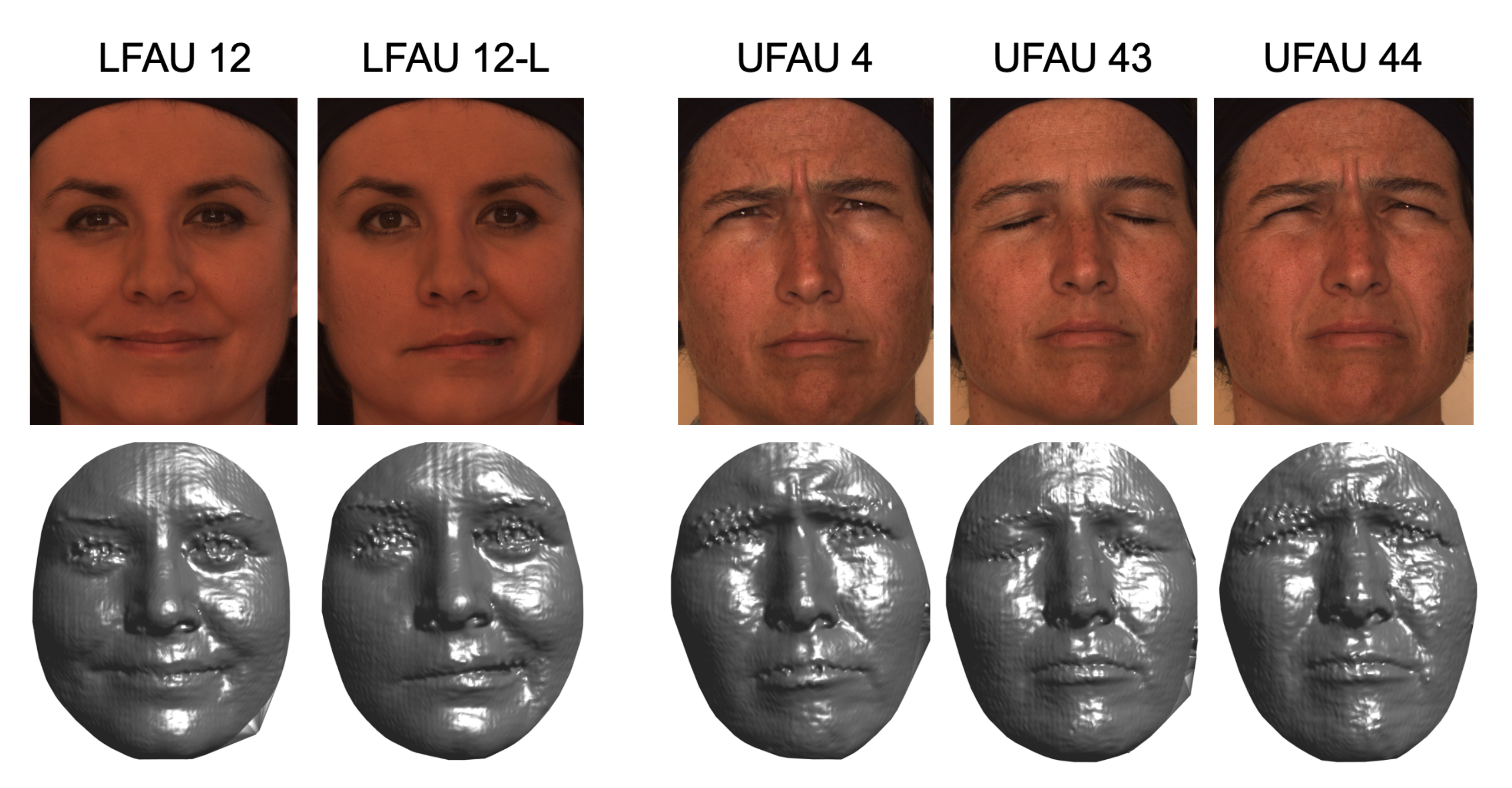
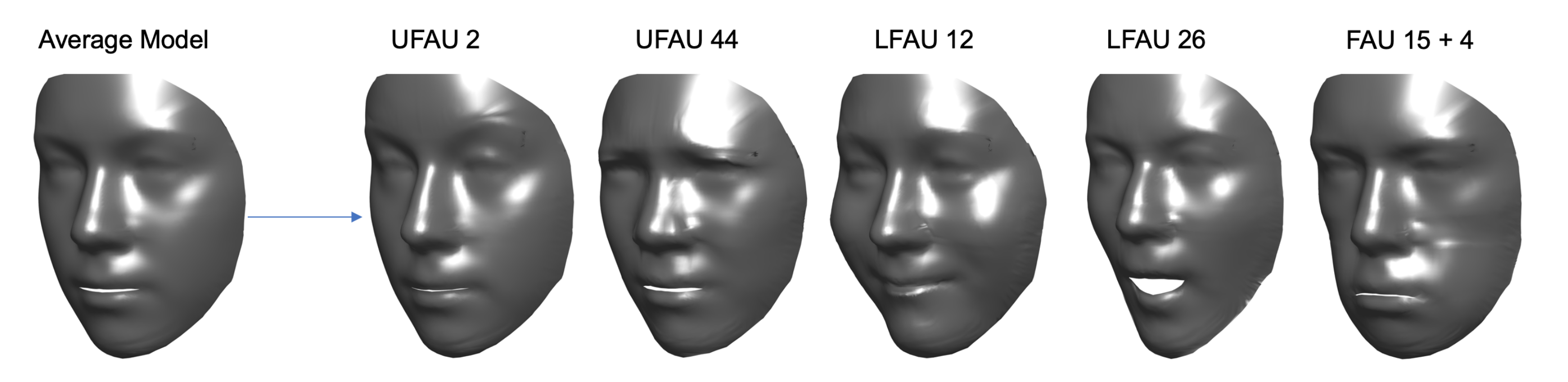
Figure 4. In particular, the reader can appreciate the very slight differences occurring between the set of action units involving the eyebrows, which is most evident for the sole 3D shape.
A similar behavior comes out from the results in
Table 1, where F1 and accuracy scores are reported. They show an excellent level for the most of the action units. Again, the worst cases are related to LFAU-12L, UFAU-1, and UFAU-44 in all the cases, which get confused with other very similar action units, as evidenced by the confusion matrices. SLC components perform generally slightly better than PCA ones, mostly for those AUs that involve the movement of smaller face areas. This represents a piece of evidence that modeling facial deformations locally can be beneficial. Indeed, we observe the largest accuracy increase being related to such action units (e.g., LFAU-12L for which there is an accuracy improvement of 8%). Overall, the proposed framework to detect the activation of action units in 3D faces provides accurate results. There are yet some problematic action units that are more difficult to detect. However, we will see in the next section that the approach is rather robust and provides a good recall on all the action units compared to other previous methods. A noticeable aspect of this solution is that these outcomes are a direct result of the fitting process and so derive from the analysis of the vertices’ motion, eliminating the need to design, choose, and compute any surface descriptors.
The Bosphorus database also includes some annotations of multiple action units activation and prototypical expressions, which can be viewed as the result of the activation of multiple action units. We performed an additional experiment on these samples aimed at verifying the behavior of the proposed method in case of more complex facial deformations. To this aim, we applied the method described in
Section 4 to recover the deformation coefficients. Just the same as for the AUs, we cast this learning problem as a single-label multi-class problem; thus, we trained the SVM to classify either the one of the six expressions, i.e., Anger, Disgust, Fear, Happy, Surprise, Sadness, or the two available AU combinations. Recognizing the expression in terms of a single action unit would have required to change the learning problem into a multi-label, multi-class, which was not the scope of this work. Results are reported in
Table 2 and show macro-expressions are fairly accurately recognized, again with the SLC solution performing slightly better in most of the cases. It is interesting to observe that the expression where the most significant improvement occurred was “disgust”, which is heavily related to the activation of AU9, that is “nose wrinkler”. Incidentally, that is one AU where a larger gap between PCA and SLC occurred (see
Table 1). The opposite happened for “Anger”, which is instead related to AU4 (eyebrow lowerer) and partially to AU44 (squint).
5.2. Comparison with the State-of-the-Art
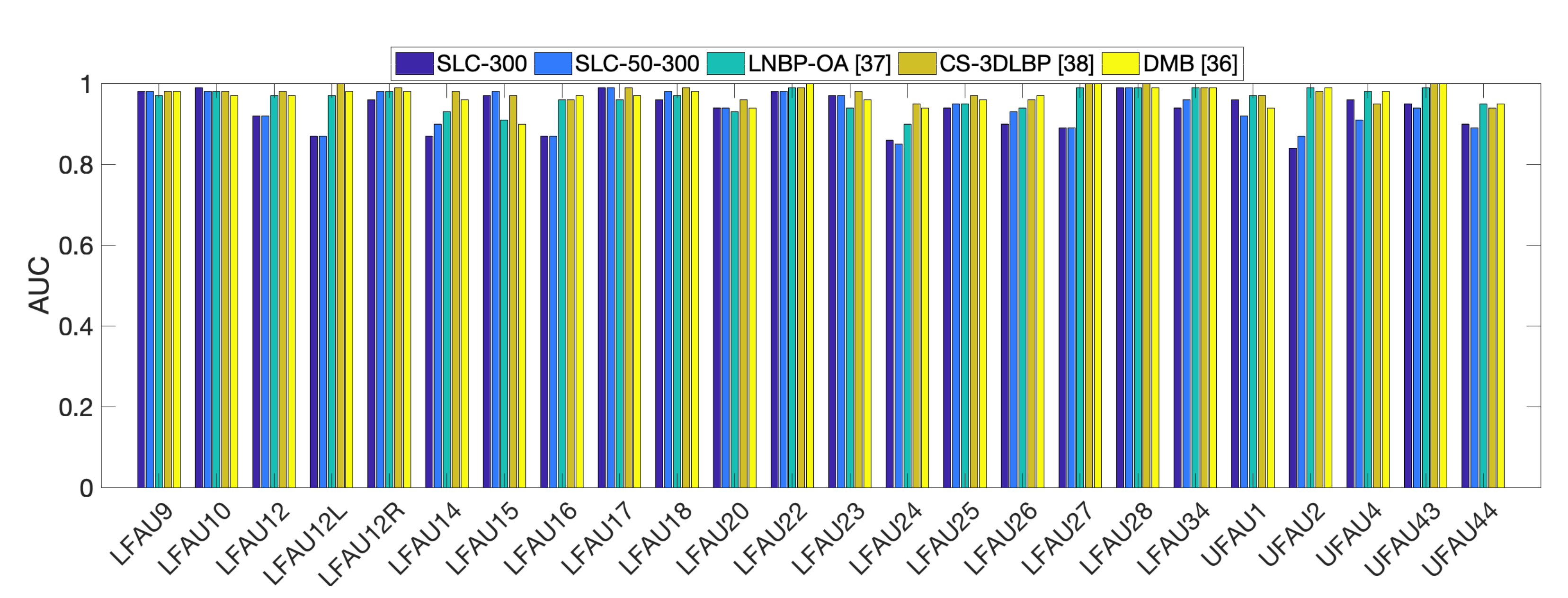
In this section, we report a comparison with state-of-the-art methods on the Bosphorus database. All the previous works report results in terms of Area Under the Receiver Operating Characteristic Curve (ROC-AUC), which is a fundamental tool for diagnostic accuracy evaluation, and so we compared in terms of this measure. We computed and reported AUC values for each action unit separately. Results for the compared approaches have been collected from the original papers and are reported in
Table 3 and
Figure 5. It is relevant here to comment about a significant difference between the proposed approach and the compared works. The 3DMM that is used to fit the raw scans of the Bosphorus and retrieve AU-specific deformation coefficients as described in
Section 4 was built from the fully registered scans of a different database, that is the BU-3DFE [
35]. So, despite the SVM classifier being trained on Bosphorus training splits, we argue that, in a way, this represents a challenging cross-dataset setting. This because the relevant statistics of face variations captured by the deformation components are learned on a different set of 3D faces; these are carried by the 3DMM and transferred to the Bosphorus faces so to encode the deformations. Note that the BU-3DFE database contains completely different subjects, only prototypical expressions, and does not include single action units activation. In the compared approaches, all the surface descriptors, e.g., 3DLBP, Cs-3DLB, that are used to train the classifiers are directly computed on the Bosphorus scans. We argue this can impair the generalization ability of the classification inasmuch as scans collected from different devices, i.e., from different datasets, present very different surface characteristics in terms of resolution, noise, and topology. Unfortunately, no previous works report cross-database results on Bosphorus; however, in [
36], a cross-database experiment was conducted by training the classifiers with descriptors computed on Bosphorus and testing on a different database (D3DFACS). In this case, AUC measures dropped around 10%, demonstrating the difficulty of generalizing to shapes from different databases, which the authors in [
36] ascribe to the diverse levels of mesh smoothness that inevitably affect the generalization performance. Our solution, instead, relies on deformation coefficients that encode 3D motion of points.
In
Table 3, we also report results obtained with SLC-300 and the two early fusion solutions. The general trend is similar to that of the previous measurements, both in the best and worst cases. Results show our method performed competitively with respect to state-of-the-art approaches. The best performance was obtained using SLC-300 and the early fusion between SLC-50 and SLC-300. As reported in [
3], increasing the number of SLC-components induces an indirect effect on the deformation extent. Practically, when more components are used, the area of the deformation is reduced. The higher general performance can be ascribed to this fact, being the activation of facial action units related to the movement of localized face regions.
Figure 5 reports also a graphical representation of the results (only best configurations as from
Table 3 are reported for clarity of visualization). It turns out evidently that some AUs were more critical, e.g., LFAU-12L, LFAU-14, LFAU-16, while some others were very accurately recognized, e.g., LFAU-10, LFAU28, LFAU-17. We argue this is likely due to the difficulty of reproducing some particular movements when performing the 3DMM fitting. These include asymmetric motions (LFAU-12L), or subtle and peculiar movements like dimpler (LFAU-14) or lip presser (LFAU-24). A different aspect that could represent a concurrent cause of this behavior is the possible bias induced by the characteristics of the BU-3DFE scans, from which our 3DMM is built. As discussed previously, the BU-3DFE contains only prototypical expressions. In this regard, it is possible that some action units that are less correlated to facial expressions are being recognized with more difficulty. This suggests that performance could be improved using a more descriptive 3DMM. Indeed, those AU that instead are more related to expressions, get very good detection results, even superior to the compared approaches. Finally, the strong level of noise of many Bosphorus scans, as for example those subjects with the beard, further complicated the problem.
5.3. Generating Action Units Activation
In this section we show that by applying the process described in
Section 4, the estimated deformation coefficients
effectively encode the information related to the activation of specific action units, and they can be used to generate 3D faces with synthetic action units activation. For each action unit, we accumulated all the related coefficients across all the
M subjects, and we estimated a set of AU-specific coefficients as
. We used these coefficients to deform the average model as
, and we generated new shapes with a specific action unit. Some examples are shown in
Figure 6. Each set of coefficients
accurately reproduced the motion induced by different action units, resulting in realistic and smooth 3D faces. In addition, note that regions of the face that were not involved in the motion were deformed to a very small extent. For example, reproducing the UFAU 2, which corresponds to raising the outer eyebrows, just slightly modified the mouth region, but it left the structural traits of the face unchanged, e.g., nose shape.
Event though the SLC components are meant to apply localized deformations, when performing the fitting as expounded in
Section 3.2, all the 3DMM vertices were involved in the deformation; thus, it is likely that some residual information resulting from the fitting leads to smaller deformations being performed overall the face. It is evident from
Figure 6 that these are yet very slight. The complementary nature of action units also allows us to fuse coefficients
of different action units so to generate combined samples. Obviously, it would be pointless to combine action units involving the same face region, e.g., UFAU 2 and UFAU 4, which both control the eyebrows motion but in opposite directions. The rightmost example of
Figure 6 corresponds to a face generated by combining the coefficients of UFAU 4 (eyebrow lowerer) and LFAU 15 (lip corner depressor). To obtain it, we simply computed the average of the two without any further processing. This is evidence that the proposed two-step fitting process allows us to extrapolate AU-specific deformation coefficients, disentangling the identity and expressions components.
To further demonstrate the retrieved coefficients effectively encode particular action units deformation and are independent of the identity, we applied some AU-specific coefficients
as described above, to neutral models
instead of the average model
. In
Figure 7 an example is shown for one subject. Similarly to
Figure 6, the reader can appreciate the fact the neutral model
is deformed in a way that the action units are activated, but still the identity does not change. To explicitly show this is not simply a particular case but instead applies to arbitrary subjects, we applied the
related to a specific AU (LFAU-12) to different identities.
Figure 8 shows that, irrespective of the subject, we obtained a natural deformation, while maintaining stable morphological traits.
Finally, in order to showcase the versatility of the proposed approach and the high generalization of the learned coefficients, we applied the fitting approach described in
Section 3.2 to some raw scans of the FRGCv2.0 dataset [
39] and obtained the corresponding neutral models
. Then, we used the
coefficients described above obtained from the Bosphorus scans to apply AU-deformations to the FRGC ones.
Figure 9 shows that even changing the target dataset, the applied deformations were realistic and well maintained the identity of the subject. Furthermore, from the examples in
Figure 9, we observe that the neutral models
actually did not necessarily need to be in neutral expression. For example, the second and third columns show neutral models with puffed up cheeks, while the scan in the rightmost column is smiling; this fact does not prevent to apply additional facial movements and generate even more complex shapes.
6. Discussion
The proposed framework for AU detection on 3D faces showed both advantages and limitations. As observed in
Section 5.1, the information carried out by the 3DMM deformation coefficients cannot completely capture very slight differences occurring in the activation of AUs involving highly overlapping face regions. We argue that the surface noise as induced by scanners represents a concurrent cause of this behavior. The sparse SLC formulation was more effective than the standard PCA in these cases, being specifically designed to apply localized deformations. On the other hand, we reported results that are comparable with that of approaches relying on multiple features extracted from the face surface. We find being independent from any surface descriptor represents a valuable advantage of our solution. This because different capturing devices result in 3D faces that are highly variable in terms of, for example, number and disposition of vertices, surface granularity, noise, and general topology. Even though descriptors such as 3DLBP and variants are usually computed after converting the shape into a 2D depth representation, the above differences could still negatively impact the computation of the descriptors, as also discussed in [
36]. Finally, we showed that, other than being able to precisely classify the different AUs, we jointly learn AU-specific deformation coefficients by decoupling identity and expression from the 3D faces. This property allows us to control the learned coefficients and generate new faces with arbitrary AUs. This opens a lot of possible applications, from data augmentation to animation.
Another evident limitation of the current learning approach is that at least one sample in the neutral expression of each subject is required to perform the first step of the fitting process, so to account for the identity component. On the other hand, we showed in
Section 5.3 that AU-specific representative sets of coefficients are easily computed from the available samples and are used to replicate AU deformations. The same process could be applied to the identity part, i.e.,
, so to retrieve another representative set of coefficients, this time modeling the general identity component. It would be then possible, given a non-neutral target scan, to perform the fitting and separate the identity and expression components a posteriori, provided the two representative sets. As we did not address this issue in the current work, we aim at further developing the method to remove the two-step constraint.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}