Hands-Free User Interface for AR/VR Devices Exploiting Wearer’s Facial Gestures Using Unsupervised Deep Learning




Abstract
1. Introduction
- Implementation of an IR sensor for skin-deformation detection;
- Design of a classifier neural network for spatiotemporal data processing;
- Conception and realization of a hands-free UI for AR headsets.
2. Related works
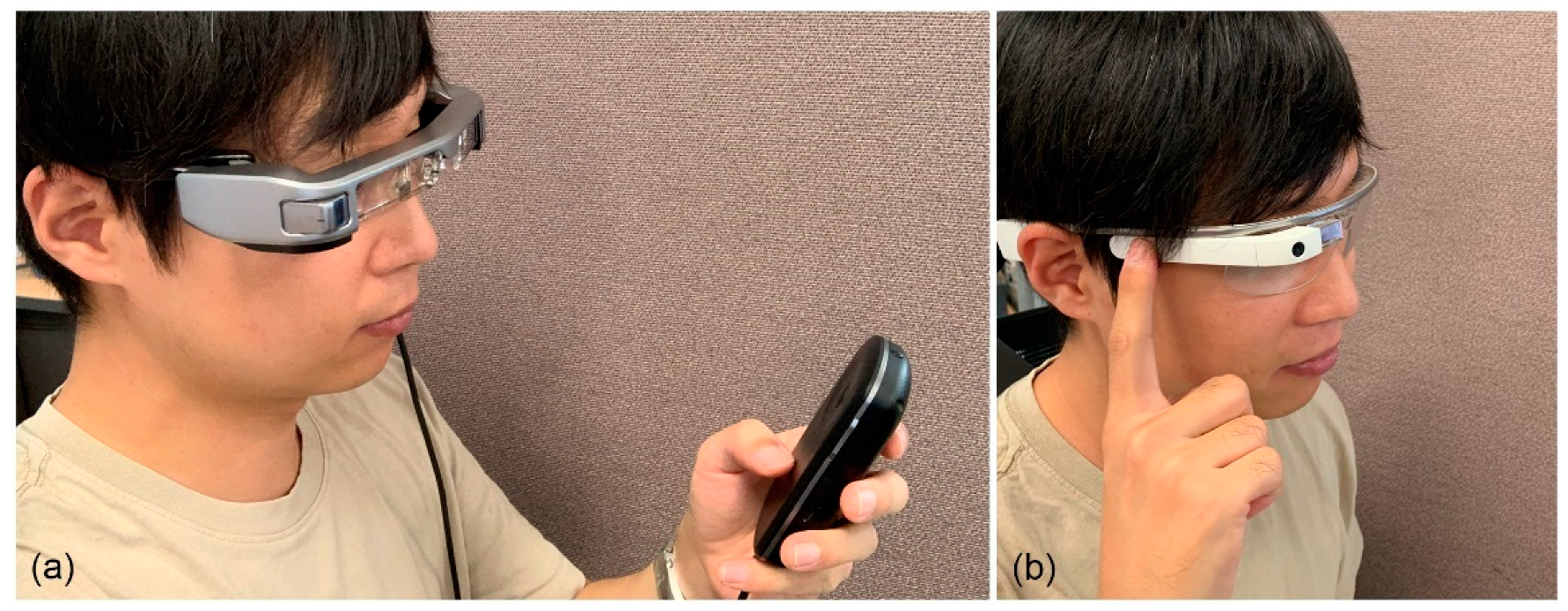
2.1. UI for Headset Environments
2.2. Facial Gesture Recognition for Headset Environments
2.2.1. Camera-Based Approaches
2.2.2. Contact-Based Approaches
2.2.3. Optical-Based Approaches
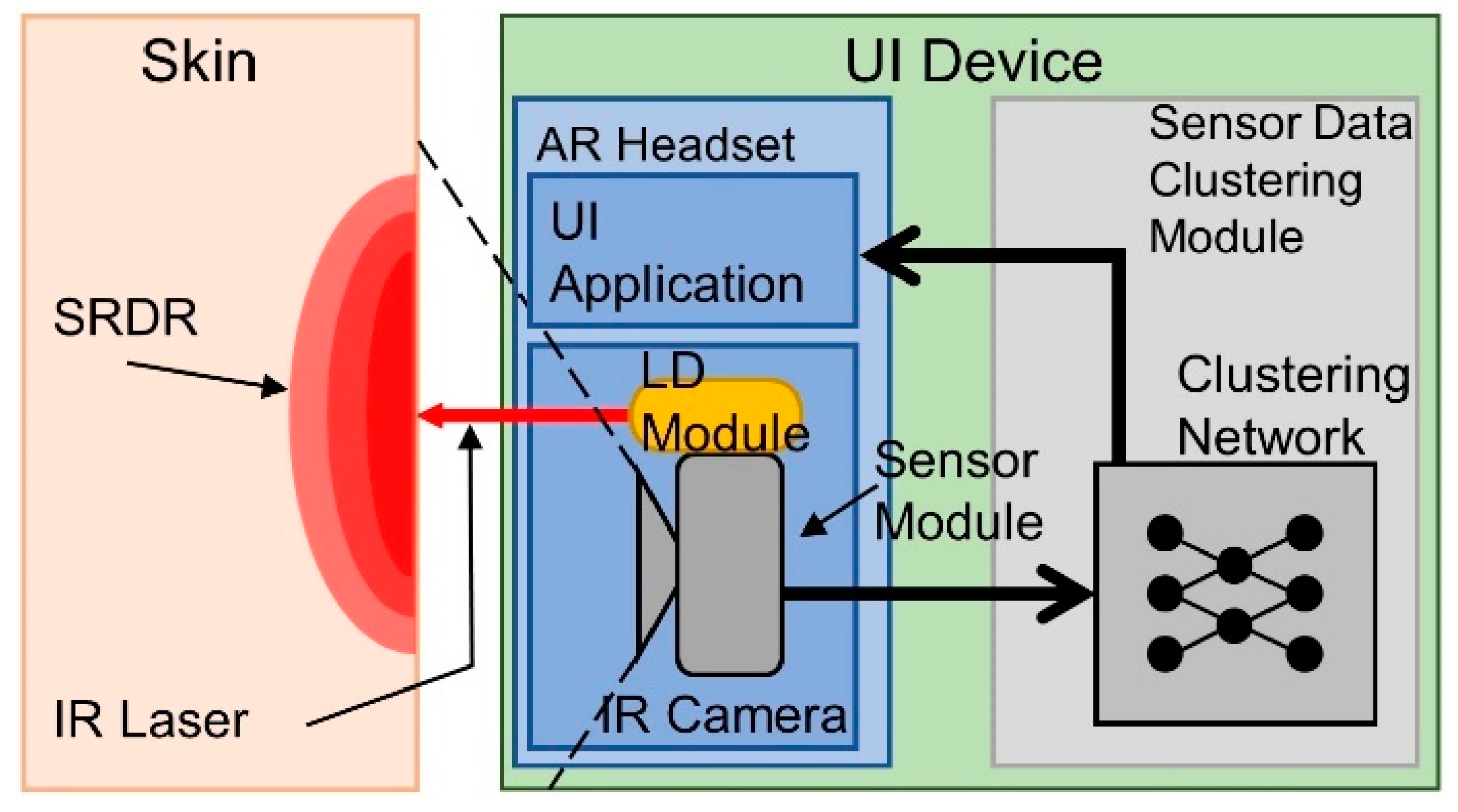
3. Sensor Implementation
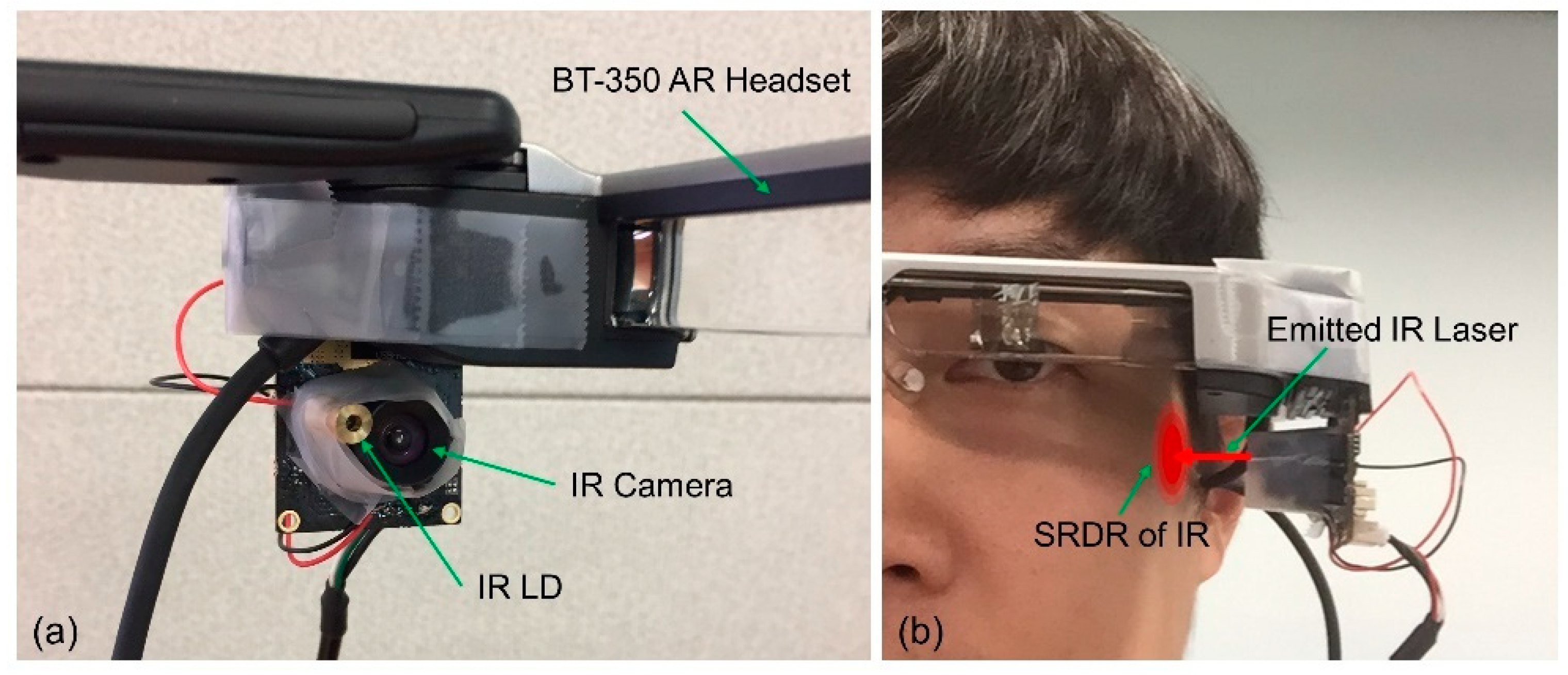
3.1. IR Diffusion in Human Skin and Skin Deformation
3.2. Target Gesture Selection for the UI Implementation
3.3. Prototyping the Sensor Module
4. Design of Sensing Data Classifier
4.1. Classifier Design and Dataset Collection
- Unsupervised learning for extracting features from the dataset using an autoencoder;
- Clustering and fine-tuning the extracted features to boost the performance of the classifier.
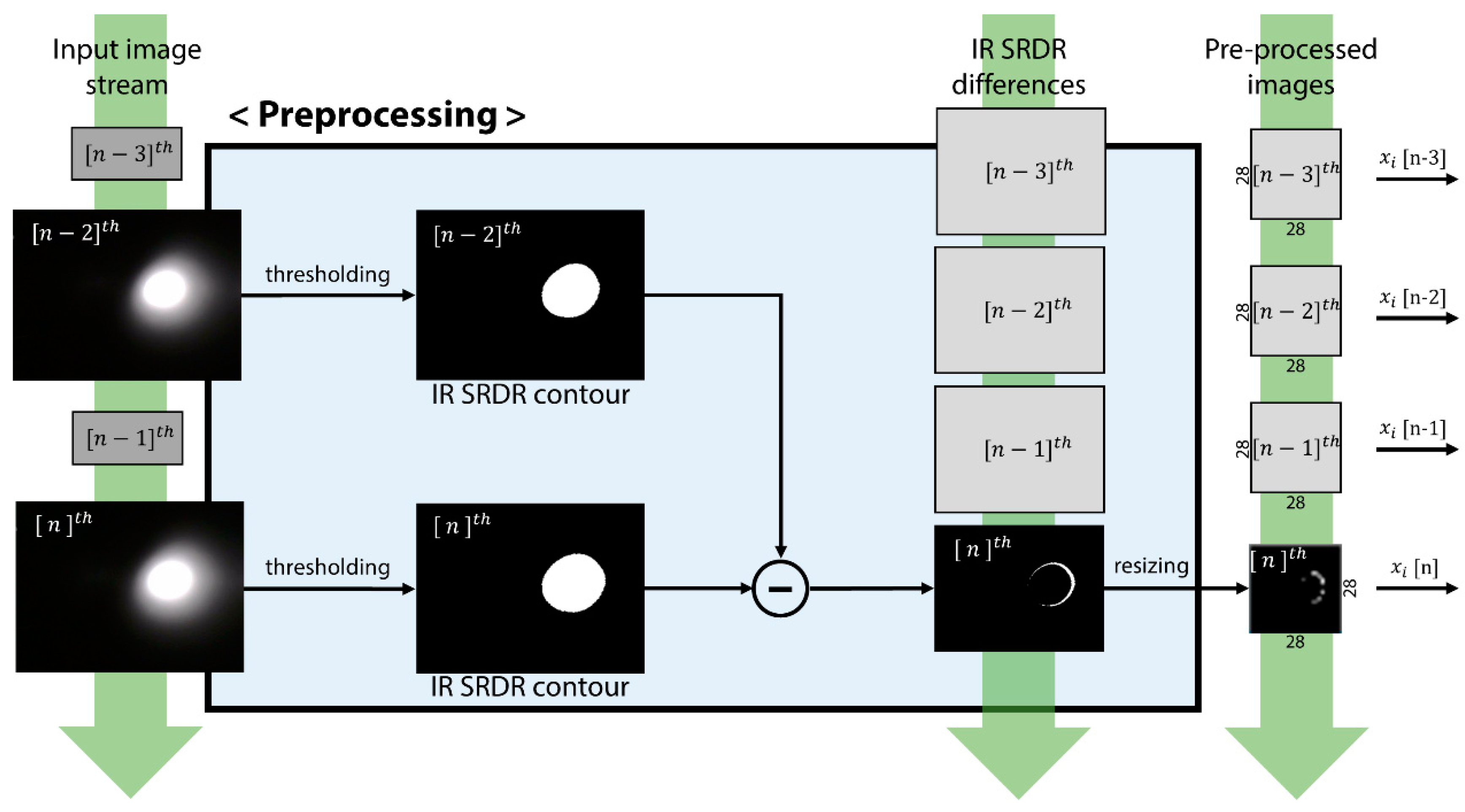
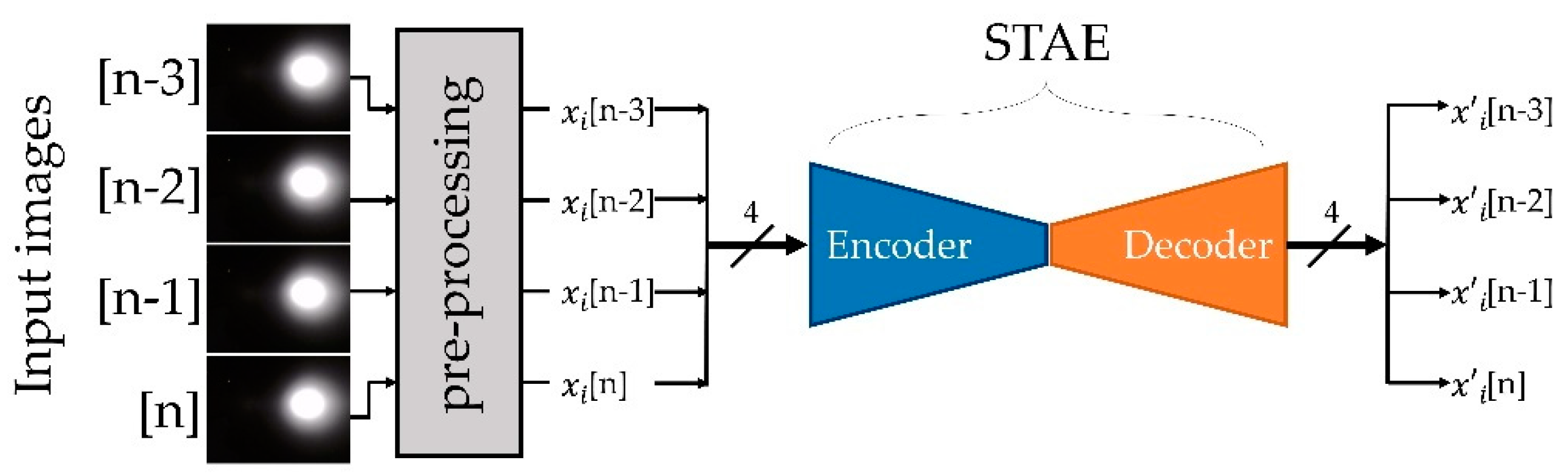
4.2. Preprocessing of SRDR Image Data
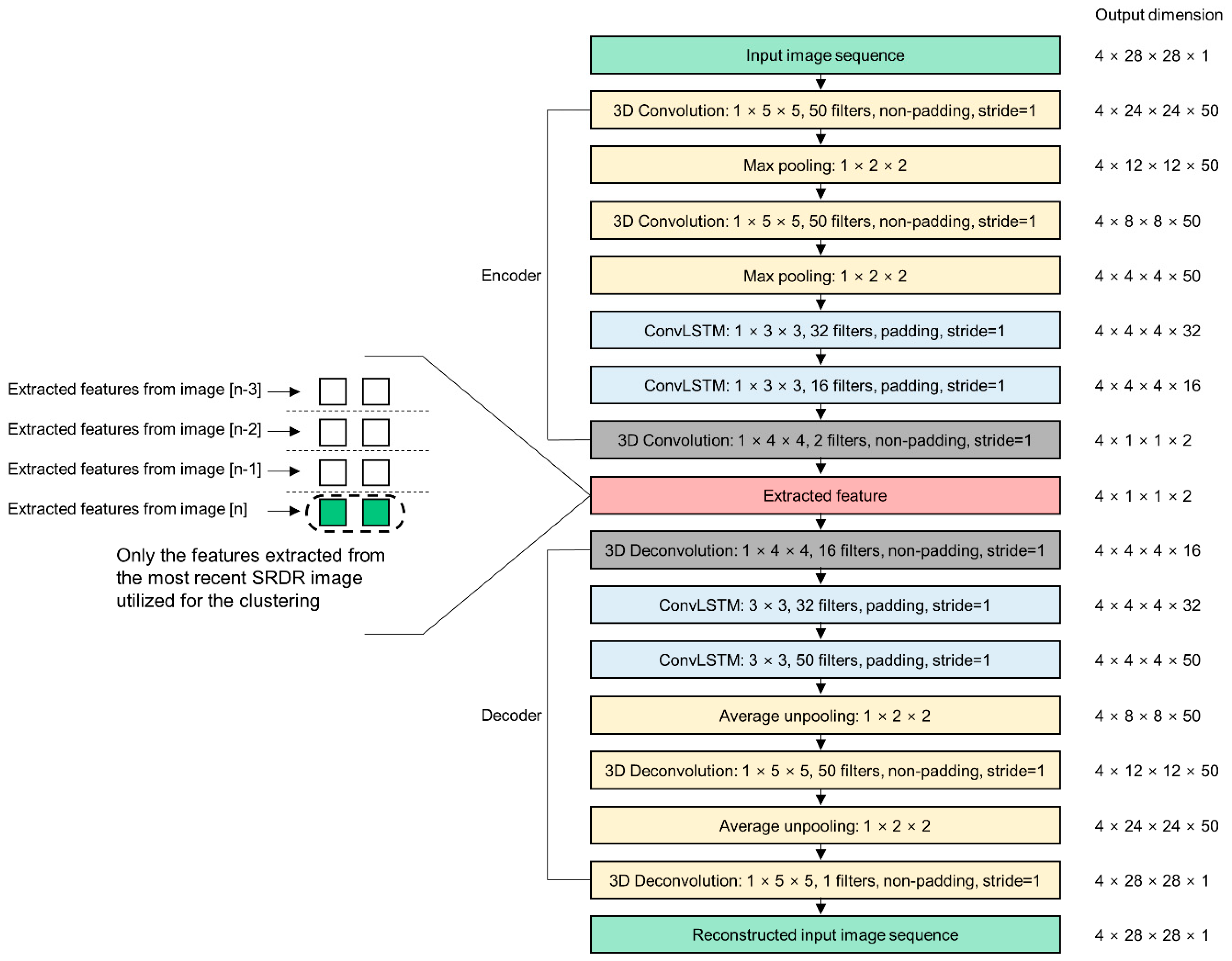
4.3. STAE for the Spatiotemporal Feature Extraction
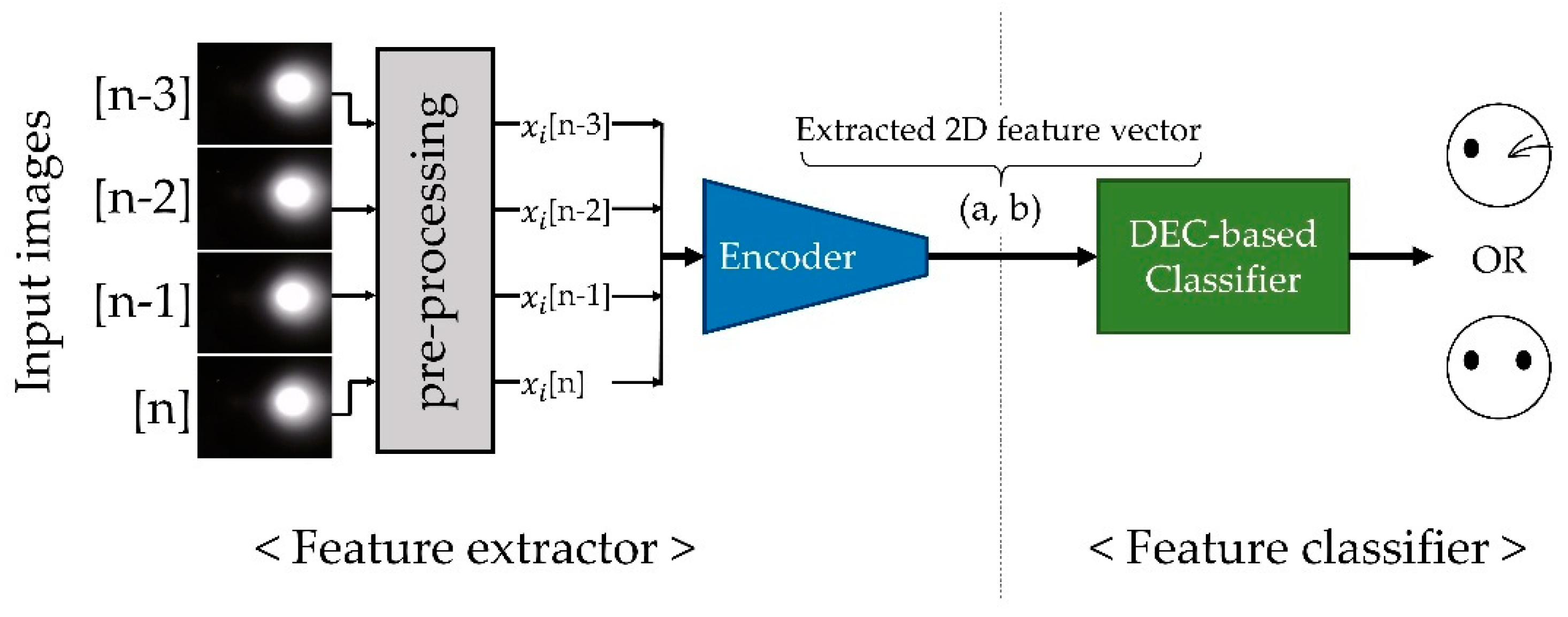
4.4. Designing and Training of the Feature Extractor
4.5. Sensor Data Feature Clustering and the Classifier Network Fine-Tuning with DEC
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Farrell, T.J.; Patterson, M.S.; Wilson, B. A diffusion theory model of spatially resolved, steady-state diffuse reflectance for the noninvasive determination of tissue optical properties in vivo. Med. Phys. 1992, 19, 879–888. [Google Scholar] [CrossRef] [PubMed]
- Kienle, A.; Wetzel, C.; Bassi, A.L.; Comelli, D.; Taroni, P.; Pifferi, A. Determination of the optical properties of anisotropic biological media using an isotropic diffusion model. J. Biomed. Opt. 2007, 12, 014026. [Google Scholar] [CrossRef] [PubMed]
- Kienle, A.; D’Andrea, C.; Foschum, F.; Taroni, P.; Pifferi, A. Light propagation in dry and wet softwood. Opt. Express 2008, 16, 9895–9906. [Google Scholar] [CrossRef] [PubMed]
- Nickell, S.; Hermann, M.; Essenpreis, M.; Farrell, T.J.; Krämer, U.; Patterson, M.S. Anisotropy of light propagation in human skin. Phys. Med. Biol. 2000, 45, 2873–2886. [Google Scholar] [CrossRef] [PubMed]
- Cha, J.; Kim, J.; Kim, S. Noninvasive determination of fiber orientation and tracking 2-dimensional deformation of human skin utilizing spatially resolved reflectance of infrared light measurement in vivo. Measurement 2019, 142, 170–180. [Google Scholar] [CrossRef]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef]
- Chong, Y.S.; Tay, Y.H. Abnormal Event Detection in Videos Using Spatiotemporal Autoencoder. International Symposium on Neural Networks; Springer: Cham, UK, 2017; pp. 189–196. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using LSTMs. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Luo, Z.; Peng, B.; Huang, D.A.; Alahi, A.; Fei-Fei, L. Unsupervised learning of long-term motion dynamics for videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, City of Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, Oakland, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Li, F.; Qiao, H.; Zhang, B. Discriminatively boosted image clustering with fully convolutional auto-encoders. Pattern Recognit. 2018, 83, 161–173. [Google Scholar] [CrossRef]
- Hong, I.; Bong, K.; Shin, D.; Park, S.; Lee, K.; Kim, Y.; Yoo, H.J. 18.1 A 2.71 nJ/pixel 3D-stacked gaze-activated object-recognition system for low-power mobile HMD applications. In Proceedings of the 2015 IEEE International Solid-State Circuits Conference-(ISSCC) Digest of Technical Papers, San Francisco, CA, USA, 22–26 February 2015; pp. 1–3. [Google Scholar]
- Lv, Z.; Feng, L.; Li, H.; Feng, S. Hand-free motion interaction on google glass. In Proceedings of the SIGGRAPH Asia 2014 Mobile Graphics and Interactive Applications, Shenzhen, China, 3–6 December 2014; p. 21. [Google Scholar]
- Lee, S.; Ha, G.; Cha, J.; Kim, J.; Lee, H.; Kim, S. CyberTouch-Touch and Cursor Interface for VR HMD. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 24–27 August 2015; pp. 503–507. [Google Scholar]
- Gugenheimer, J.; Dobbelstein, D.; Winkler, C.; Haas, G.; Rukzio, E. FaceTouch: Touch Interaction for Mobile Virtual Reality. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3679–3682. [Google Scholar]
- Lazar, J.; Feng, J.H.; Hochheiser, H. Research Methods in Human-Computer Interaction, 2nd ed.; Morgan Kaufmann: Cambridge, MA, USA, 2017; ISBN 9780128093436. [Google Scholar]
- Helander, M.G.; Landauer, T.K.; Prabhu, P.V. Handbook of Human-Computer Interaction; Elsevier: Amsterdam, The Netherlands, 1997. [Google Scholar]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812. [Google Scholar]
- Khan, M.S.L.; Réhman, S.U.; Söderström, U.; Halawani, A.; Li, H. Face-off: A face reconstruction technique for virtual reality (VR) scenarios. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 490–503. [Google Scholar]
- Olszewski, K.; Lim, J.J.; Saito, S.; Li, H. High-fidelity facial and speech animation for vr hmds. ACM Trans. Graph. 2016, 35, 221. [Google Scholar] [CrossRef]
- Hickson, S.; Dufour, N.; Sud, A.; Kwatra, V.; Essa, I. Eyemotion: Classifying facial expressions in VR using eye-tracking cameras. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Village, HI, USA, 7–11 January 2019; pp. 1626–1635. [Google Scholar]
- McFarland, D.J.; Wolpaw, J.R. Brain-computer interfaces for communication and control. Commun. ACM 2011, 54, 60. [Google Scholar] [CrossRef] [PubMed]
- Scheirer, J.; Fernandez, R.; Picard, R.W. Expression glasses: A wearable device for facial expression recognition. In Proceedings of the CHI’99 Extended Abstracts on Human Factors in Computing Systems. ACM, Pittsburgh, PA, USA, 15–20 May 1999; pp. 262–263. [Google Scholar]
- Lucero, J.C.; Munhall, K.G. A model of facial biomechanics for speech production. J. Acoust. Soc. Am. 1999, 106, 2834–2842. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Trutoiu, L.; Olszewski, K.; Wei, L.; Trutna, T.; Hsieh, P.L.; Nicholls, A.; Ma, C. Facial performance sensing head-mounted display. ACM Trans. Graph. 2015, 34, 47. [Google Scholar] [CrossRef]
- Masai, K.; Sugiura, Y.; Ogata, M.; Kunze, K.; Inami, M.; Sugimoto, M. Facial expression recognition in daily life by embedded photo reflective sensors on smart eyewear. In Proceedings of the 21st International Conference on Intelligent User Interfaces, Sonoma, CA, USA, 7–10 March 2016; pp. 317–326. [Google Scholar]
- Suzuki, K.; Nakamura, F.; Otsuka, J.; Masai, K.; Itoh, Y.; Sugiura, Y.; Sugimoto, M. Recognition and mapping of facial expressions to avatar by embedded photo reflective sensors in head mounted display. In Proceedings of the 2017 IEEE Virtual Reality (VR), Los Angeles, CA, USA, 18–22 March 2017; pp. 177–185. [Google Scholar]
- Kienle, A.; Forster, F.; Hibst, R. Anisotropy of light propagation in biological tissue. Opt. Lett. 2004, 29, 2617–2619. [Google Scholar] [CrossRef] [PubMed]
- Langer, K. On the anatomy and physiology of the skin: I. The cleavability of the cutis. Br. J. Plast. Surg. 1978, 31, 3–8. [Google Scholar] [CrossRef]
- Cha, J.; Kim, J.; Kim, S. An IR-based facial expression tracking sensor for head-mounted displays. In Proceedings of the 2016 IEEE SENSORS, Orlando, FL, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar]
- Kim, J.; Cha, J.; Lee, H.; Kim, S. Hand-free natural user interface for VR HMD with IR based facial gesture tracking sensor. In Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology, Gothenburg, Sweden, 8–10 November 2017; p. 62. [Google Scholar]
- ANSI. American National Standard for Safe Use of Lasers ANSI Z136. 1–2014; Laser Institute of America: Orlando, FL, USA, 2014. [Google Scholar]
- Barolet, D. Light-emitting diodes (LEDs) in dermatology. Semin. Cutan. Med. Surg. 2008, 27, 227–238. [Google Scholar] [CrossRef] [PubMed]
- Bellman, R.E. Adaptive Control Processes: A Guided Tour; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in Neural Information Processing Systems; MIT Press Cambridge: Cambridge, MA, USA, 2015; pp. 802–810. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of internal clustering validation measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; pp. 911–916. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Cha, J.; Kim, S.; Kim, J. A Hands-free Natural User Interface (NUI) for AR/VR Head-Mounted Displays Exploiting Wearer’s Facial Gestures, Demonstration in NeurIPS. In Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology, Gothenburg, Sweden, 8–10 November 2018. [Google Scholar]
- Ekman, P.; Rosenberg, E.L. What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: Oxford, UK, 1997. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participant IDs | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| The Number of detected gestures | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| The Number of intended gestures | 104 | 110 | 102 | 107 | 111 | 101 | 100 | 103 | 101 | 109 |
| Accuracy of gesture recognition (%) | 96.2 | 91.0 | 98.0 | 93.5 | 90.1 | 99.0 | 100 | 97.1 | 99.0 | 91.7 |
| Clustering entropy | 0.12 | 0.23 | 0.07 | 0.18 | 0.24 | 0.04 | 0 | 0.10 | 0.04 | 0.21 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, J.; Kim, J.; Kim, S. Hands-Free User Interface for AR/VR Devices Exploiting Wearer’s Facial Gestures Using Unsupervised Deep Learning. Sensors 2019, 19, 4441. https://doi.org/10.3390/s19204441
Cha J, Kim J, Kim S. Hands-Free User Interface for AR/VR Devices Exploiting Wearer’s Facial Gestures Using Unsupervised Deep Learning. Sensors. 2019; 19(20):4441. https://doi.org/10.3390/s19204441
Chicago/Turabian StyleCha, Jaekwang, Jinhyuk Kim, and Shiho Kim. 2019. "Hands-Free User Interface for AR/VR Devices Exploiting Wearer’s Facial Gestures Using Unsupervised Deep Learning" Sensors 19, no. 20: 4441. https://doi.org/10.3390/s19204441
APA StyleCha, J., Kim, J., & Kim, S. (2019). Hands-Free User Interface for AR/VR Devices Exploiting Wearer’s Facial Gestures Using Unsupervised Deep Learning. Sensors, 19(20), 4441. https://doi.org/10.3390/s19204441