Using Temporal Covariance of Motion and Geometric Features via Boosting for Human Fall Detection




Abstract
1. Introduction
2. Related Work
2.1. Classification Based on Input Data Types
2.1.1. Sensor-Based
2.1.2. Audio-Based
2.1.3. Image and Video-Based
2.2. Classification Based on Classifier Types
2.2.1. Thresholding-Based
2.2.2. Machine Learning-Based
3. Proposed Fall Detection System
3.1. Foreground Detection
3.2. Temporal and Spatial Variance for Falling Person Detection
3.2.1. Temporal Variance of the Aspect Ratio
3.2.2. Temporal Variation of the Person Angle
3.2.3. Temporal Variation of the Motion Vector
3.2.4. Temporal Variation of Shape Deformations
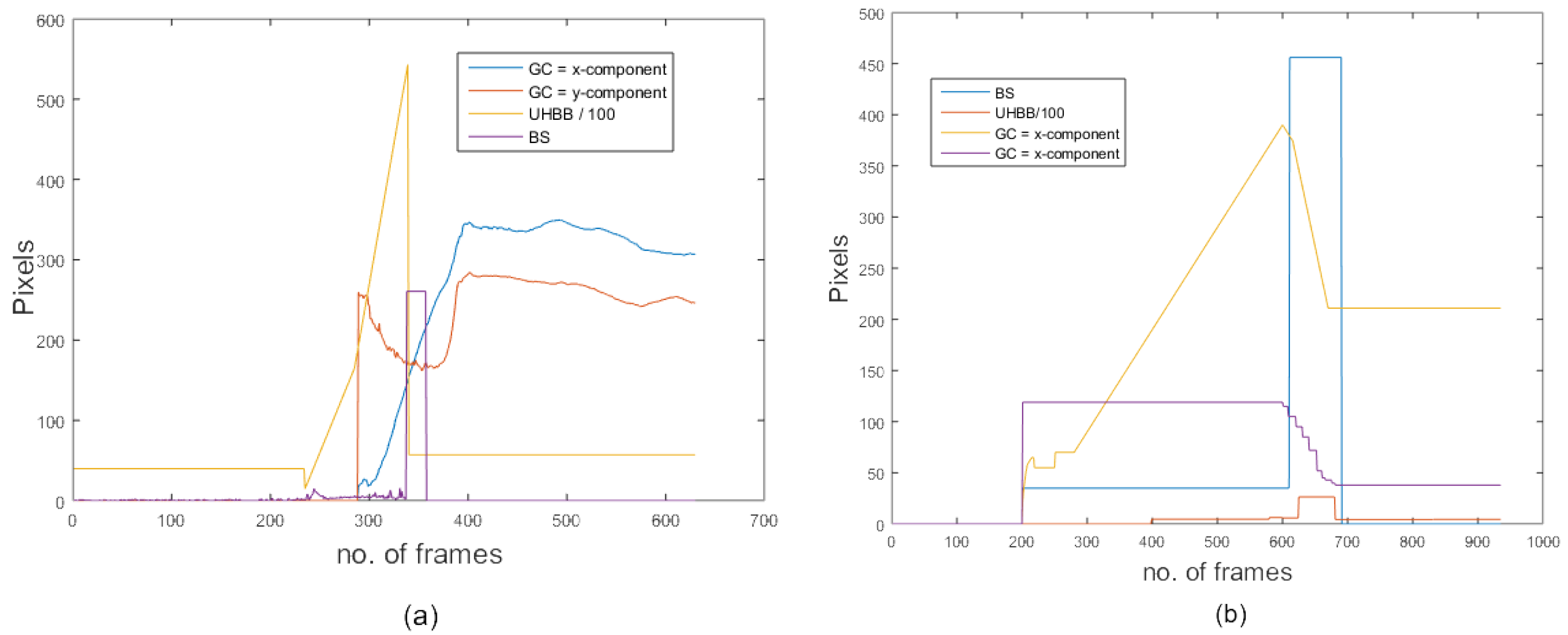
3.2.5. Temporal Variation in the Geometric Center Position
3.2.6. Temporal Variation of the Ellipse Ratio
3.3. Training Boosted J48 Classifier
4. Experiments and Results
4.1. Datasets
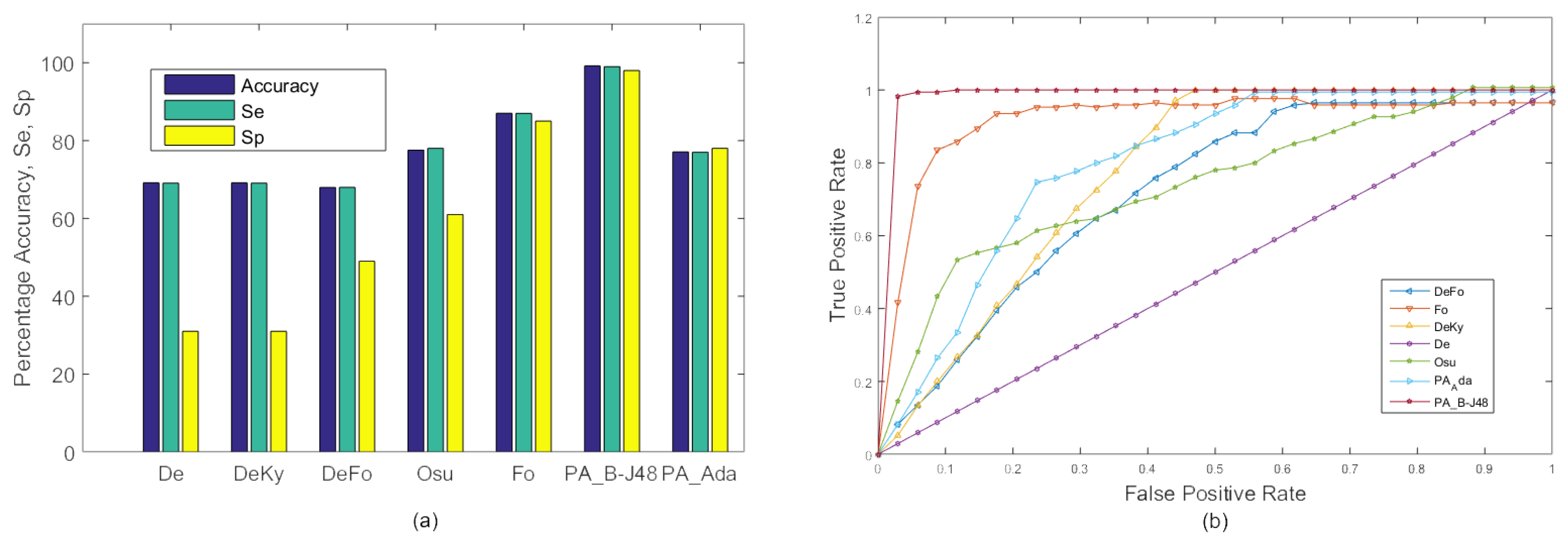
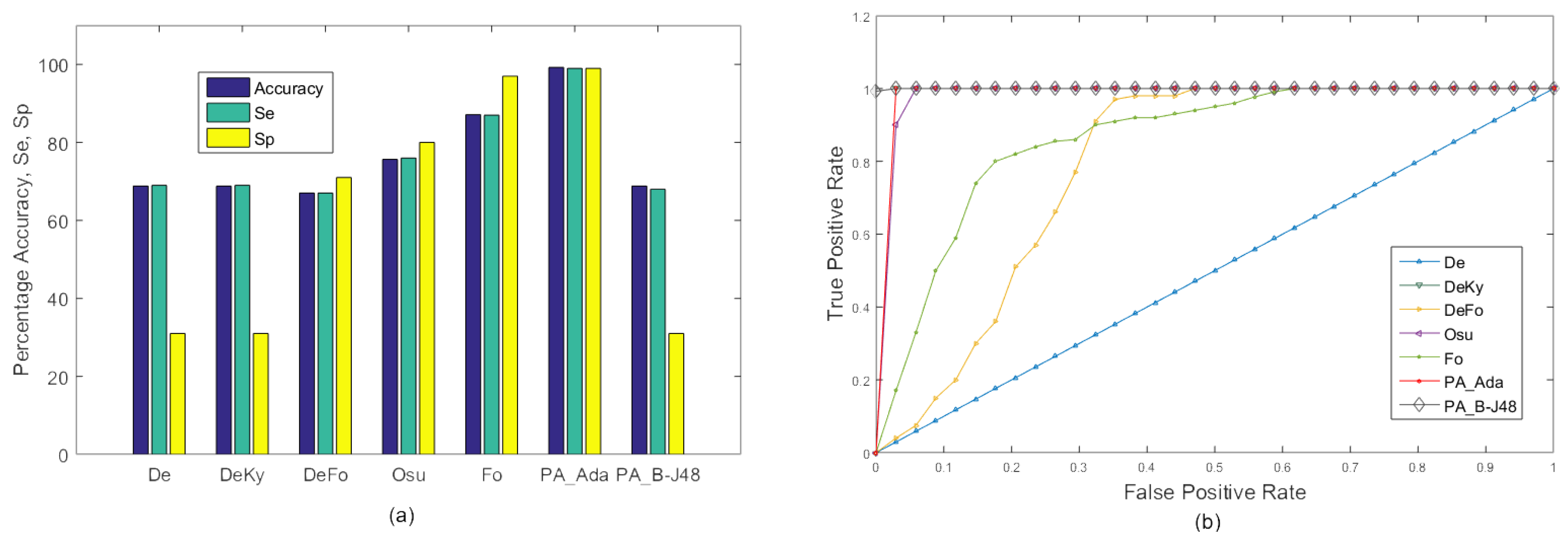
4.2. Comparison with Existing Approaches
4.3. Performance Measures
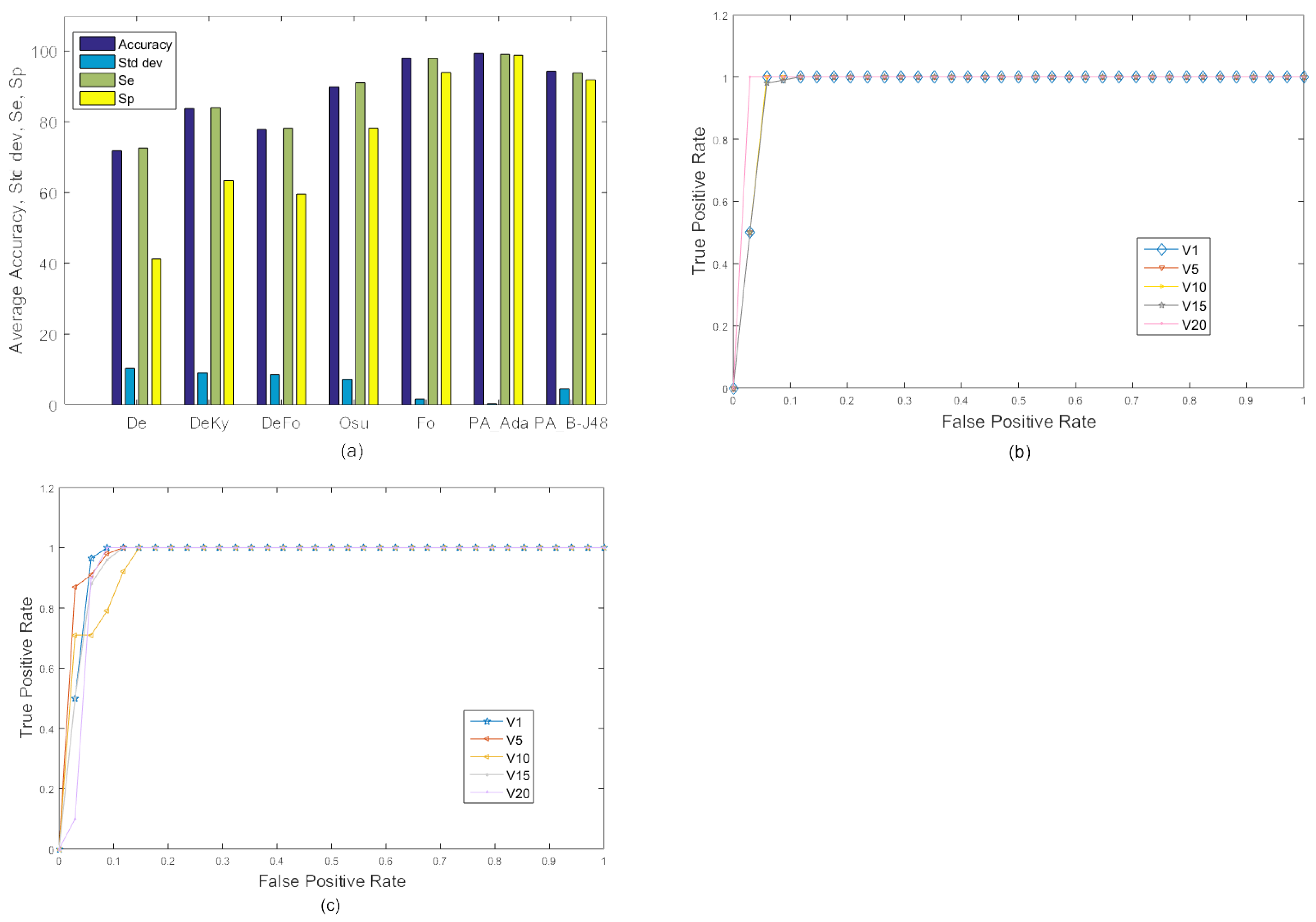
4.4. Experiments on the MFC Dataset
4.4.1. Experiment 1
4.4.2. Experiment 2
4.4.3. Experiment 3
4.5. Experiments on the URFD Dataset
4.6. Execution Time Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lmberis, A.; Dittmar, A. Advanced wearable health systems and applications-research and development efforts in the European union. IEEE Eng. Med. Biol. Mag. 2007, 26, 29–33. [Google Scholar] [CrossRef]
- Rahmani, H.; Mahmood, A.; Huynh, D.; Mian, A. Histogram of oriented principal components for cross-view action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2430–2443. [Google Scholar] [CrossRef] [PubMed]
- Tazeem, H.; Farid, M.S.; Mahmood, A. Improving security surveillance by hidden cameras. Multimedia Tools Appl. 2017, 76, 2713–2732. [Google Scholar] [CrossRef]
- Rimmer, J.H. Health promotion for people with disabilities: The emerging paradigm shift from disability prevention to prevention of secondary conditions. Phys. Ther. 1999, 79, 495–502. [Google Scholar] [PubMed]
- Tinetti, M.E. Preventing falls in elderly persons. N. Engl. J. Med. 2003, 2003, 42–49. [Google Scholar] [CrossRef] [PubMed]
- Gutta, S.; Cohen-Solal, E.; Trajkovic, M. Automatic System for Monitoring Person Requiring Care and His/Her Caretaker. U.S. Patent 6,968,294, 22 November 2005. [Google Scholar]
- Darwish, A.; Hassanien, A.E. Wearable and implantable wireless sensor network solutions for healthcare monitoring. Sensors 2011, 11, 5561–5595. [Google Scholar] [CrossRef] [PubMed]
- Mac Donald, C.L.; Johnson, A.M.; Cooper, D.; Nelson, E.C.; Werner, N.J.; Shimony, J.S.; Snyder, A.Z.; Raichle, M.E.; Witherow, J.R.; Fang, R.; et al. Detection of blast-related traumatic brain injury in US military personnel. N. Engl. J. Med. 2011, 364, 2091–2100. [Google Scholar] [CrossRef] [PubMed]
- Luo, S.; Hu, Q. A dynamic motion pattern analysis approach to fall detection. In Proceedings of the 2004 IEEE International Workshop on Biomedical Circuits and Systems, Singapore, 1–3 December 2004; pp. 1–5. [Google Scholar]
- Bourke, A.; O’brien, J.; Lyons, G. Evaluation of a threshold-based tri-axial accelerometer fall detection algorithm. Gait Posture 2007, 26, 194–199. [Google Scholar] [CrossRef] [PubMed]
- Makhlouf, A.; Nedjai, I.; Saadia, N.; Ramdane-Cherif, A. Multimodal System for Fall Detection and Location of person in an Intelligent Habitat. Procedia Comput. Sci. 2017, 109, 969–974. [Google Scholar] [CrossRef]
- Casilari, E.; Santoyo-Ramón, J.A.; Cano-García, J.M. UMAFall: A Multisensor Dataset for the Research on Automatic Fall Detection. Procedia Comput. Sci. 2017, 110, 32–39. [Google Scholar] [CrossRef]
- Zigel, Y.; Litvak, D.; Gannot, I. A method for automatic fall detection of elderly people using floor vibrations and sound—Proof of concept on human mimicking doll falls. IEEE Trans. Biomed. Eng. 2009, 56, 2858–2867. [Google Scholar] [CrossRef] [PubMed]
- Doukas, C.N.; Maglogiannis, I. Emergency fall incidents detection in assisted living environments utilizing motion, sound, and visual perceptual components. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 277–289. [Google Scholar] [CrossRef] [PubMed]
- Foroughi, H.; Aski, B.S.; Pourreza, H. Intelligent video surveillance for monitoring fall detection of elderly in home environments. In Proceedings of the 11th International Conference on Computer and Information Technology (ICCIT 2008), Khulna, Bangladesh, 24–27 December 2008; pp. 219–224. [Google Scholar]
- Miaou, S.G.; Sung, P.H.; Huang, C.Y. A customized human fall detection system using omni-camera images and personal information. In Proceedings of the 1st Transdisciplinary Conference on Distributed Diagnosis and Home Healthcare (D2H2 2006), Arlington, VA, USA, 2–4 April 2006; pp. 39–42. [Google Scholar]
- Lee, T.; Mihailidis, A. An intelligent emergency response system: Preliminary development and testing of automated fall detection. J. Telemed. Telecare 2005, 11, 194–198. [Google Scholar] [CrossRef] [PubMed]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. Robust video surveillance for fall detection based on human shape deformation. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 611–622. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. Fall detection from human shape and motion history using video surveillance. In Proceedings of the 21st International Conference on Advanced Information Networking and Applications Workshops (AINAW’07), Niagara Falls, ON, Canada, 21–23 May 2007; Volume 2, pp. 875–880. [Google Scholar]
- Doulamis, A.; Doulamis, N.; Kalisperakis, I.; Stentoumis, C. A real-time single-camera approach for automatic fall detection. In ISPRS Commission V, Close Range Image Measurements Techniques; John Wiley & Sons: Hoboken, NJ, USA, 2010; Volume 38, pp. 207–212. [Google Scholar]
- Nait-Charif, H.; McKenna, S.J. Activity summarisation and fall detection in a supportive home environment. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 23–26 August 2004; Volume 4, pp. 323–326. [Google Scholar]
- Tao, J.; Turjo, M.; Wong, M.F.; Wang, M.; Tan, Y.P. Fall incidents detection for intelligent video surveillance. In Proceedings of the 2005 Fifth International Conference on Information, Communications and Signal Processing, Bangkok, Thailand, 6–9 December 2005; pp. 1590–1594. [Google Scholar]
- Mundher, Z.A.; Zhong, J. A real-time fall detection system in elderly care using mobile robot and kinect sensor. Int. J. Mater. Mech. Manuf. 2014, 2, 133–138. [Google Scholar] [CrossRef]
- Sumiya, T.; Matsubara, Y.; Nakano, M.; Sugaya, M. A mobile robot for fall detection for elderly-care. Procedia Comput. Sci. 2015, 60, 870–880. [Google Scholar] [CrossRef]
- Foroughi, H.; Rezvanian, A.; Paziraee, A. Robust fall detection using human shape and multi-class support vector machine. In Proceedings of the Sixth Indian Conference on Computer Vision, Graphics & Image Processing (ICVGIP’080), Bhubaneswar, India, 16–19 December 2008; pp. 413–420. [Google Scholar]
- Debard, G.; Karsmakers, P.; Deschodt, M.; Vlaeyen, E.; Van den Bergh, J.; Dejaeger, E.; Milisen, K.; Goedemé, T.; Tuytelaars, T.; Vanrumste, B. Camera based fall detection using multiple features validated with real life video. In Workshop Proceedings of the 7th International Conference on Intelligent Environments; IOS Press: Amsterdam, The Netherlands, 2011; Volume 10, pp. 441–450. [Google Scholar]
- Yu, M.; Yu, Y.; Rhuma, A.; Naqvi, S.M.R.; Wang, L.; Chambers, J.A. An online one class support vector machine-based person-specific fall detection system for monitoring an elderly individual in a room environment. IEEE J. Biomed. Health Inform. 2013, 17, 1002–1014. [Google Scholar] [PubMed]
- Bosch-Jorge, M.; Sánchez-Salmerón, A.J.; Valera, Á.; Ricolfe-Viala, C. Fall detection based on the gravity vector using a wide-angle camera. Expert Syst. Appl. 2014, 41, 7980–7986. [Google Scholar] [CrossRef]
- Ni, B.; Nguyen, C.D.; Moulin, P. RGBD-camera based get-up event detection for hospital fall prevention. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 1405–1408. [Google Scholar]
- Kyrkou, C.; Theocharides, T. A flexible parallel hardware architecture for AdaBoost-based real-time object detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2011, 19, 1034–1047. [Google Scholar] [CrossRef]
- Kerdegari, H.; Samsudin, K.; Ramli, A.R.; Mokaram, S. Evaluation of fall detection classification approaches. In Proceedings of the 2012 4th International Conference on Intelligent and Advanced Systems (ICIAS), Kuala Lumpur, Malaysia, 12–14 June 2012; Volume 1, pp. 131–136. [Google Scholar]
- Gjoreski, H.; Lustrek, M.; Gams, M. Accelerometer placement for posture recognition and fall detection. In Proceedings of the 2011 7th International Conference on Intelligent environments (IE), Nottingham, UK, 25–28 July 2011; pp. 47–54. [Google Scholar]
- Kansiz, A.O.; Guvensan, M.A.; Turkmen, H.I. Selection of time-domain features for fall detection based on supervised learning. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 23–25 October 2013; pp. 23–25. [Google Scholar]
- Kaur, R.; Gangwar, R. A Review on Naive Baye’s (NB), J48 and K-Means Based Mining Algorithms for Medical Data Mining. Int. Res. J. Eng. Technol. 2017, 4, 1664–1668. [Google Scholar]
- Kapoor, P.; Rani, R.; JMIT, R. Efficient Decision Tree Algorithm Using J48 and Reduced Error Pruning. Int. J. Eng. Res. Gen. Sci. 2015, 3, 1613–1621. [Google Scholar]
- Shi, G.; Zhang, J.; Dong, C.; Han, P.; Jin, Y.; Wang, J. Fall detection system based on inertial mems sensors: Analysis design and realization. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Shenyang, China, 8–12 June 2015; pp. 1834–1839. [Google Scholar]
- Guvensan, M.A.; Kansiz, A.O.; Camgoz, N.C.; Turkmen, H.; Yavuz, A.G.; Karsligil, M.E. An Energy-Efficient Multi-Tier Architecture for Fall Detection on Smartphones. Sensors 2017, 17, 1487. [Google Scholar] [CrossRef] [PubMed]
- Kepski, M.; Kwolek, B. Embedded system for fall detection using body-worn accelerometer and depth sensor. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Warsaw, Poland, 24–26 September 2015; Volume 2, pp. 755–759. [Google Scholar]
- Javed, S.; Mahmood, A.; Bouwmans, T.; Jung, S.K. Background-Foreground Modeling Based on Spatiotemporal Sparse Subspace Clustering. IEEE Trans. Image Process. 2017, 26, 5840–5854. [Google Scholar] [CrossRef] [PubMed]
- Javed, S.; Mahmood, A.; Bouwmans, T.; Jung, S.K. Spatiotemporal Low-rank Modeling for Complex Scene Background Initialization. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 1315–1329. [Google Scholar] [CrossRef]
- Javed, S.; Mahmood, A.; Bouwmans, T.; Jung, S.K. Superpixels-based Manifold Structured Sparse RPCA for Moving Object Detection. In Proceedings of the British Machine Vision Conference (BMVC 2017), London, UK, 4–7 September 2017. [Google Scholar]
- Mahmood, A. Structure-less object detection using adaboost algorithm. In Proceedings of the International Conference on Machine Vision (ICMV 2007), Islamabad, Pakistan, 28–29 December 2007; pp. 85–90. [Google Scholar]
- Mahmood, A.; Khan, S. Early terminating algorithms for Adaboost based detectors. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1209–1212. [Google Scholar]
- Kaur, G.; Chhabra, A. Improved J48 classification algorithm for the prediction of diabetes. Int. J. Comput. Appl. 2014, 98, 13–17. [Google Scholar] [CrossRef]
- Tanwani, A.K.; Afridi, J.; Shafiq, M.Z.; Farooq, M. Guidelines to select machine learning scheme for classification of biomedical datasets. In Proceedings of the European Conference on Evolutionary Computation, Machine Learning and Data Mining in Bioinformatics, Tübingen, Germany, 15–17 April 2009; pp. 128–139. [Google Scholar]
- Devasena, C.L. Comparative Analysis of Random Forest REP Tree and J48 Classifiers for Credit Risk Prediction. In Proceedings of the International Conference on Communication, Computing and Information Technology (ICCCMIT-2014), Chennai, India, 12–13 December 2015. [Google Scholar]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Foroughi, H.; Naseri, A.; Saberi, A.; Yazdi, H.S. An eigenspace-based approach for human fall detection using integrated time motion image and neural network. In Proceedings of the 9th International Conference on Signal Processing (ICSP 2008), Beijing, China, 26–29 October 2008; pp. 1499–1503. [Google Scholar]
- Lv, T.; Yan, J.; Xu, H. An EEG emotion recognition method based on AdaBoost classifier. In Proceedings of the Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 6050–6054. [Google Scholar]
- Wang, S.; Chen, L.; Zhou, Z.; Sun, X.; Dong, J. Human fall detection in surveillance video based on PCANet. Multimedia Tools Appl. 2016, 75, 11603–11613. [Google Scholar] [CrossRef]
- Dietterich, T.; Bishop, C.; Heckerman, D.; Jordan, M.; Kearns, M. Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA; London, UK.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
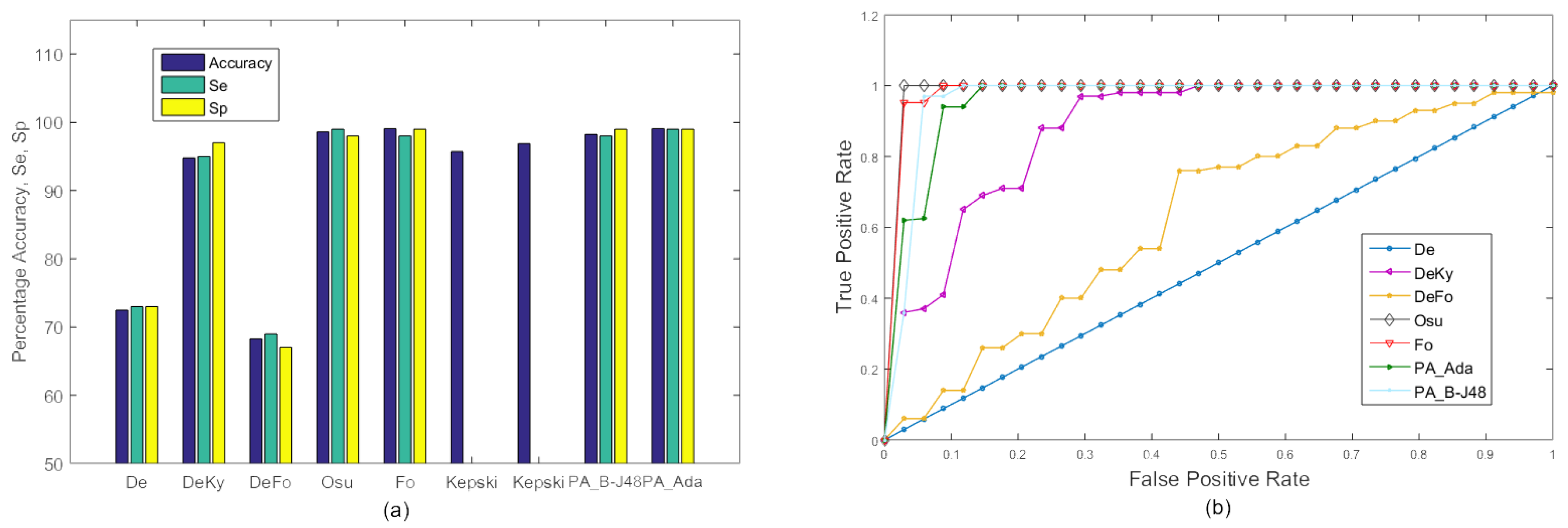{kind=link}
| Videos | Total Frames | Fall | No Fall | Videos | Total Frames | Fall | No Fall |
|---|---|---|---|---|---|---|---|
| Video 1 | 1411 | 314 | 1097 | Video 11 | 1486 | 608 | 878 |
| Video 2 | 756 | 331 | 425 | Video 12 | 1041 | 420 | 621 |
| Video 3 | 883 | 272 | 611 | Video 13 | 1240 | 360 | 880 |
| Video 4 | 1033 | 409 | 624 | Video 14 | 970 | 385 | 585 |
| Video 5 | 600 | 266 | 334 | Video 15 | 1007 | 367 | 640 |
| Video 6 | 1203 | 513 | 690 | Video 16 | 1023 | 320 | 703 |
| Video 7 | 912 | 290 | 622 | Video 17 | 992 | 432 | 560 |
| Video 8 | 700 | 240 | 460 | Video 18 | 1217 | 627 | 590 |
| Video 9 | 905 | 360 | 545 | Video 19 | 1155 | 390 | 765 |
| Video 10 | 813 | 230 | 583 | Video 20 | 2328 | 90 | 2238 |
| Existing Approaches | Proposed Approaches | |||||||
|---|---|---|---|---|---|---|---|---|
| De [26] | DeKy [30] | DeFo [48] | Osu [27] | Fo [48] | PA_B-J48 | PA_Ada | ||
| Cam3 (V3) | A | 73.23 | 77.09 | 78.37 | 93.47 | 98.39 | 92.4 | 99.14 |
| Existing Approaches | Proposed Approaches | |||||||
|---|---|---|---|---|---|---|---|---|
| Video | De [26] | DeKy [30] | DeFo [48] | Osu [27] | Fo [48] | PA_B-J48 | PA_Ada | |
| V1 | A | 88.65 | 93.76 | 90.50 | 99.23 | 99.86 | 99.65 | 98.99 |
| Se | 89.00 | 94.00 | 91.00 | 98.00 | 99.00 | 99.00 | 99.00 | |
| Sp | 69.00 | 95.00 | 86.00 | 97.00 | 99.00 | 99.00 | 99.00 | |
| V2 | A | 61.83 | 91.76 | 71.24 | 93.03 | 99.74 | 99.08 | 99.34 |
| Se | 62.00 | 92.00 | 71.00 | 98.00 | 99.00 | 99.00 | 99.00 | |
| Sp | 49.00 | 85.00 | 61.00 | 97.00 | 99.00 | 99.00 | 99.00 | |
| V3 | A | 72.79 | 92.86 | 74.94 | 99.88 | 99.89 | 99.89 | 100.00 |
| Se | 73.00 | 93.00 | 75.00 | 99.00 | 99.00 | 99.00 | 100.00 | |
| Sp | 42.00 | 91.00 | 71.00 | 99.00 | 99.00 | 99.00 | 100.00 | |
| V4 | A | 68.41 | 82.95 | 70.45 | 87.40 | 98.35 | 99.42 | 88.85 |
| Se | 68.00 | 83.00 | 70.00 | 87.00 | 98.00 | 99.00 | 89.00 | |
| Sp | 31.00 | 55.00 | 64.00 | 77.00 | 98.00 | 99.00 | 70.00 | |
| V5 | A | 63.42 | 89.38 | 90.12 | 92.03 | 95.72 | 98.82 | 94.99 |
| Se | 63.00 | 89.00 | 90.00 | 92.00 | 96.00 | 99.00 | 95.00 | |
| Sp | 65.00 | 98.00 | 98.00 | 87.00 | 93.00 | 99.00 | 98.00 | |
| V6 | A | 91.51 | 89.33 | 94.01 | 95.34 | 99.58 | 99.67 | 98.17 |
| Se | 91.00 | 90.00 | 94.00 | 95.00 | 100.00 | 99.00 | 98.00 | |
| Sp | 85.00 | 89.00 | 87.00 | 91.00 | 100.00 | 99.00 | 98.00 | |
| V7 | A | 68.09 | 85.42 | 79.17 | 95.39 | 99.23 | 99.45 | 98.90 |
| Se | 68.00 | 85.00 | 79.00 | 95.00 | 99.00 | 99.00 | 98.00 | |
| Sp | 32.00 | 62.00 | 76.00 | 89.00 | 99.00 | 99.00 | 98.00 | |
| V8 | A | 65.57 | 83.86 | 72.57 | 89.14 | 99.00 | 99.29 | 98.42 |
| Se | 66.00 | 84.00 | 73.00 | 89.00 | 99.00 | 99.00 | 98.00 | |
| Sp | 32.00 | 61.00 | 78.00 | 72.00 | 98.00 | 99.00 | 98.00 | |
| V9 | A | 70.50 | 85.19 | 77.46 | 91.60 | 97.13 | 99.45 | 96.46 |
| Se | 71.00 | 85.00 | 78.00 | 92.00 | 97.00 | 99.00 | 97.00 | |
| Sp | 52.00 | 90.00 | 74.00 | 97.00 | 95.00 | 99.00 | 76.00 | |
| V10 | A | 77.74 | 80.93 | 80.07 | 91.39 | 98.40 | 99.02 | 95.69 |
| Se | 78.00 | 81.00 | 81.00 | 91.00 | 98.00 | 99.00 | 96.00 | |
| Sp | 65.00 | 52.00 | 52.00 | 84.00 | 94.00 | 99.00 | 93.00 | |
| V11 | A | 59.02 | 59.02 | 65.75 | 84.86 | 98.92 | 99.53 | 87.35 |
| Se | 59.00 | 59.00 | 66.00 | 85.00 | 99.00 | 99.00 | 87.00 | |
| Sp | 41.00 | 70.00 | 55.00 | 84.00 | 99.00 | 99.00 | 95.00 | |
| V12 | A | 63.01 | 83.19 | 74.54 | 93.28 | 98.85 | 99.33 | 95.58 |
| Se | 79.00 | 79.00 | 79.00 | 93.00 | 99.00 | 99.00 | 96.00 | |
| Sp | 21.00 | 21.00 | 21.00 | 89.00 | 99.00 | 99.00 | 97.00 | |
| V13 | A | 78.93 | 78.93 | 78.93 | 78.93 | 95.24 | 99.11 | 89.26 |
| Se | 79.00 | 79.00 | 79.00 | 93.00 | 95.00 | 99.00 | 89.00 | |
| Sp | 21.00 | 21.00 | 21.00 | 6.00 | 84.00 | 97.00 | 74.00 | |
| V14 | A | 64.08 | 64.29 | 68.84 | 79.81 | 96.58 | 98.96 | 89.64 |
| Se | 64.00 | 64.00 | 68.00 | 80.00 | 97.00 | 99.00 | 90.00 | |
| Sp | 36.00 | 39.00 | 51.00 | 57.00 | 95.00 | 98.00 | 92.00 | |
| V15 | A | 63.72 | 90.85 | 72.56 | 91.65 | 96.02 | 99.50 | 86.18 |
| Se | 63.00 | 91.00 | 73.00 | 92.00 | 96.00 | 99.00 | 86.00 | |
| Sp | 40.00 | 70.00 | 72.00 | 96.00 | 95.00 | 99.00 | 87.00 | |
| V16 | A | 69.60 | 85.92 | 69.60 | 74.19 | 94.33 | 99.41 | 89.34 |
| Se | 79.00 | 86.00 | 70.00 | 74.00 | 94.00 | 99.00 | 75.00 | |
| Sp | 30.00 | 67.00 | 30.00 | 42.00 | 90.00 | 99.00 | 89.00 | |
| V17 | A | 72.53 | 83.13 | 75.46 | 78.30 | 97.46 | 98.83 | 93.26 |
| Se | 72.00 | 81.00 | 76.00 | 78.00 | 98.00 | 99.00 | 93.00 | |
| Sp | 27.00 | 70.00 | 47.00 | 49.00 | 93.00 | 98.00 | 86.00 | |
| V18 | A | 65.24 | 79.79 | 78.14 | 90.30 | 99.06 | 99.18 | 92.76 |
| Se | 65.00 | 90.00 | 78.00 | 98.00 | 99.00 | 99.00 | 99.00 | |
| Sp | 37.00 | 72.00 | 88.00 | 99.00 | 99.00 | 99.00 | 100.00 | |
| V19 | A | 76.19 | 78.79 | 77.06 | 93.42 | 97.84 | 99.48 | 93.42 |
| Se | 76.00 | 79.00 | 77.00 | 93.00 | 99.00 | 99.00 | 93.00 | |
| Sp | 48.00 | 52.00 | 56.00 | 88.00 | 55.00 | 99.00 | 92.00 | |
| V20 | A | 96.09 | 96.09 | 96.06 | 98.58 | 99.87 | 99.87 | 99.83 |
| Se | 96.00 | 96.00 | 96.00 | 99.00 | 100.00 | 100.00 | 100.00 | |
| Sp | 3 | 3 | 3 | 65.00 | 96.00 | 99.00 | 96.00 | |
| Existing Approach | Proposed Approach | ||||
|---|---|---|---|---|---|
| Experiment | DeFo | Osu | Fo | PA_B-J48 | PA_Ada |
| Experiment 1 | 16.5 s | 135.19 s | 49.65 s | 28.63 s | 1.82 s |
| Experiment 3 | 13.05 s | 113.28 s | 48.98 s | 21.6 s | 3.05 s |
| URFD (average) | 0.12 s | 0.01 s | 0.32 s | 0.01 s | 0.025 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, S.F.; Khan, R.; Mahmood, A.; Hassan, M.T.; Jeon, M. Using Temporal Covariance of Motion and Geometric Features via Boosting for Human Fall Detection. Sensors 2018, 18, 1918. https://doi.org/10.3390/s18061918
Ali SF, Khan R, Mahmood A, Hassan MT, Jeon M. Using Temporal Covariance of Motion and Geometric Features via Boosting for Human Fall Detection. Sensors. 2018; 18(6):1918. https://doi.org/10.3390/s18061918
Chicago/Turabian StyleAli, Syed Farooq, Reamsha Khan, Arif Mahmood, Malik Tahir Hassan, and Moongu Jeon. 2018. "Using Temporal Covariance of Motion and Geometric Features via Boosting for Human Fall Detection" Sensors 18, no. 6: 1918. https://doi.org/10.3390/s18061918
APA StyleAli, S. F., Khan, R., Mahmood, A., Hassan, M. T., & Jeon, M. (2018). Using Temporal Covariance of Motion and Geometric Features via Boosting for Human Fall Detection. Sensors, 18(6), 1918. https://doi.org/10.3390/s18061918