Two-Way Affective Modeling for Hidden Movie Highlights’ Extraction


Abstract
1. Introduction
2. Our Motivations and Contributions
- The cognitive psychology research framework should produce more reasonable results.
- In the bottom-up processing within the framework, a simple prototype approach-based local feature should be adopted instead of superposition of the features’ values.
- To enable top-down processing, the global expectation and sensitivity of the film should be estimated.
- A hybrid cognitive psychology model in combing bottom-up and top-down processing is proposed to mimic the excitement time curve of a film;
- A set of new global and local features measures the average sensitivity and abnormality of low-level features;
- A sensitivity adaptive algorithm to extract the excitement time curve of a film.
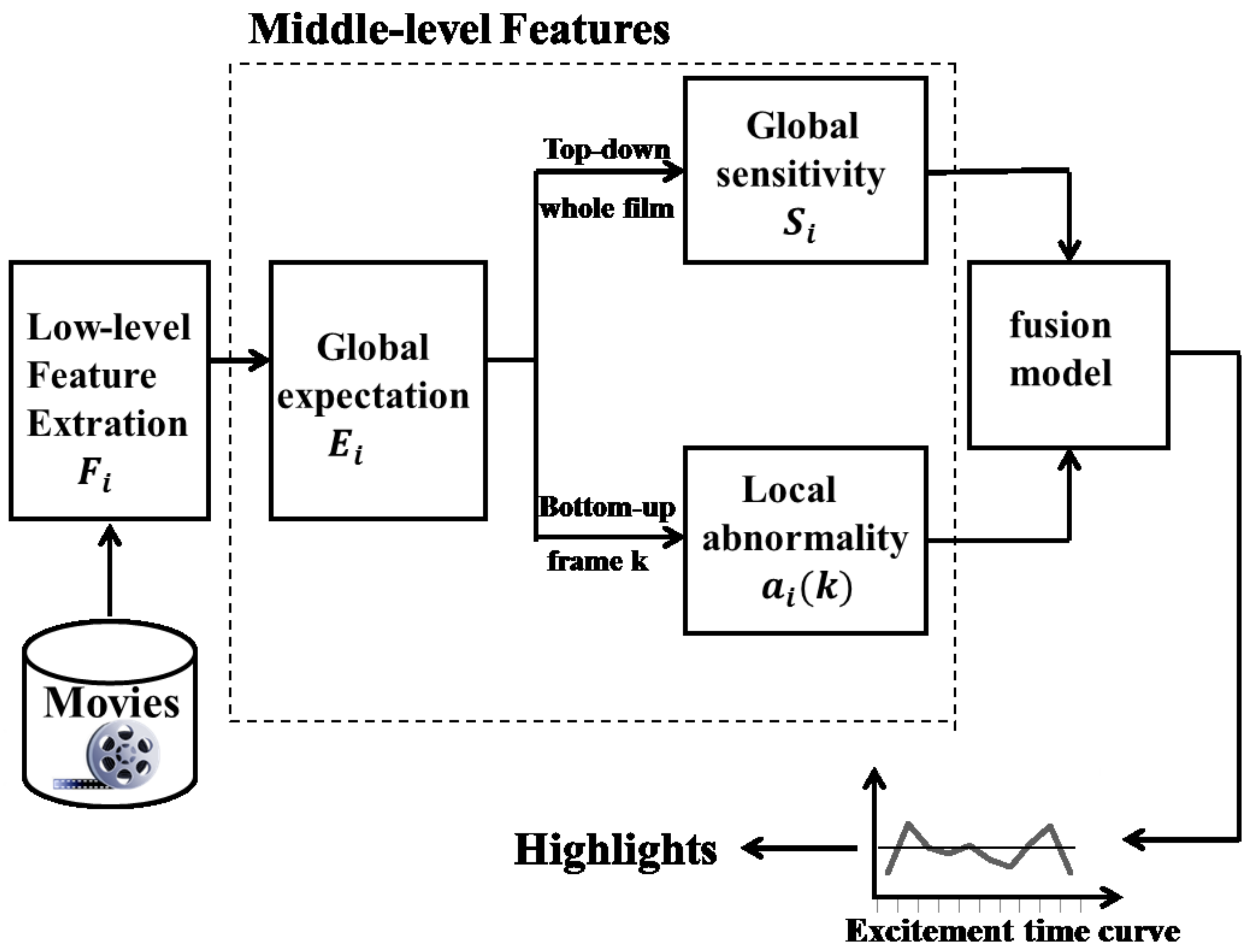
3. Overall Methodology
3.1. Criteria for Developing Middle-Level Features
3.2. Feature Selection
3.3. Model for the Excitement Time Curve
3.3.1. Low-Level Features
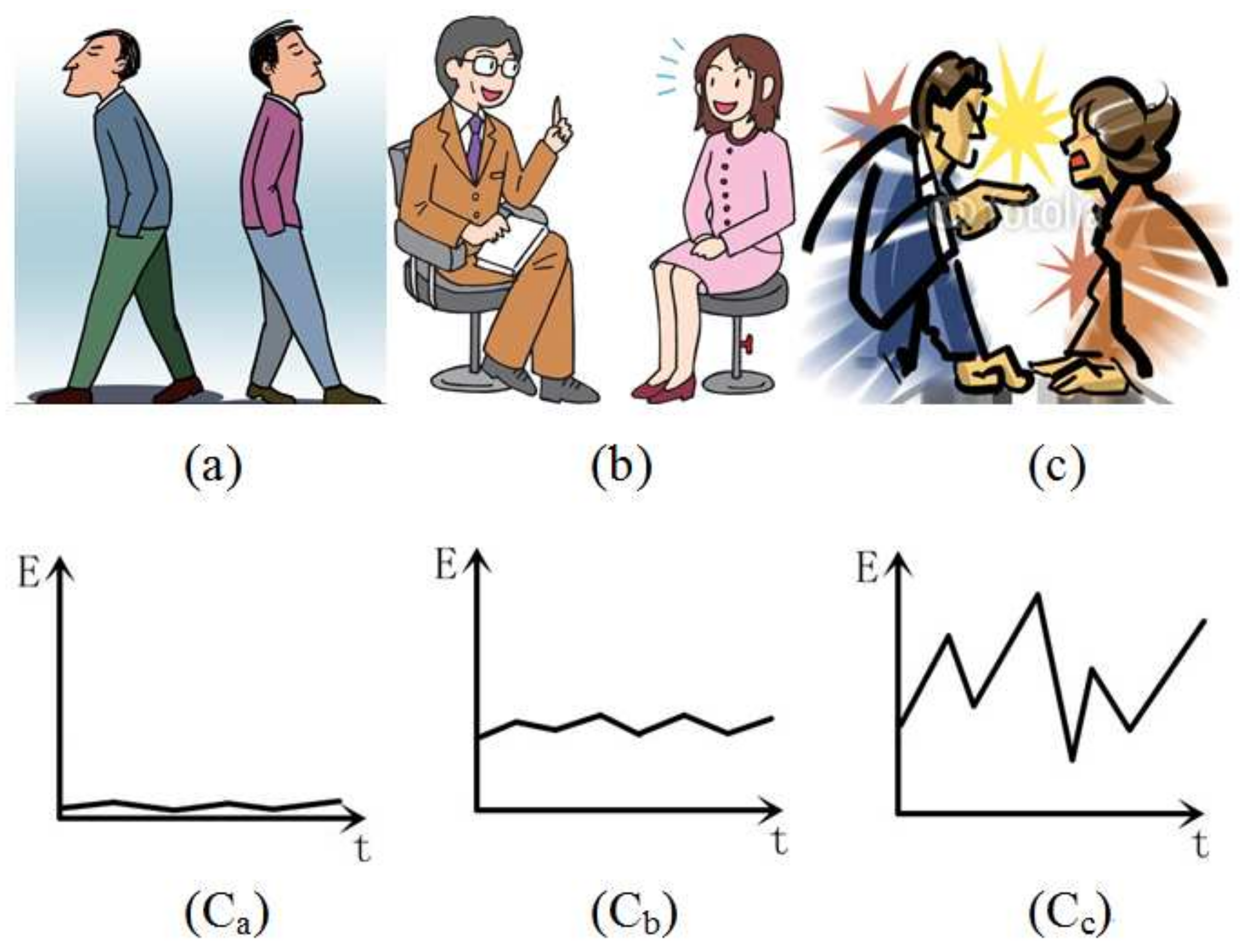
3.3.2. Global Expectation and Sensitivity Features
3.3.3. Local Abnormality Feature
3.3.4. Excitement Model
- Considering the time stamp k, compute the values of the components computed at that time stamp;
- Compute the local abnormality , as in Equation (8);
- Using the fusion model to obtain a excitement time curve, the model is defined as followswhere:and:The parameter is the spread factor determining the steepness of the curve. The weighting function Equation (10) ensures that any event that is abnormal and whose audio-visual effects are very sensitive for the user will be detected. On the contrary, normal events will be ignored.
- After obtaining the filtered time curves , we fuse them as follows to obtain the excitement time curve .Parameters are weighting factors of fusion with .
- To make the curve smooth, the excitement time curve is filtered by a Kaiser window , as shown in the following.
- By applying a cutoff line to the excitement time curve , only those segments whose values are higher than the value of cutoff line will be extracted as highlights.
4. Experiment
4.1. Data Collection and Experiment Setup
4.2. Case Study
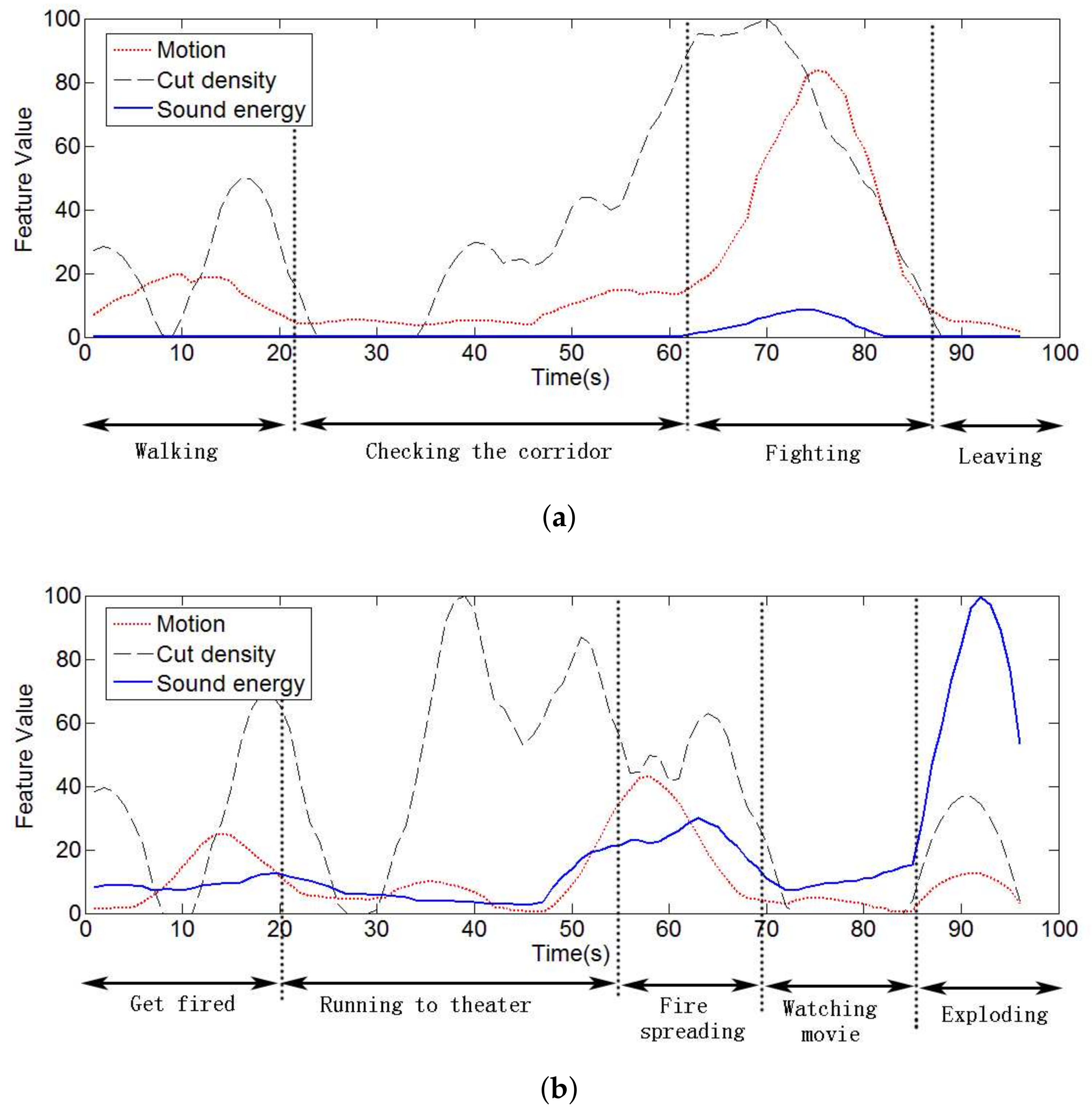
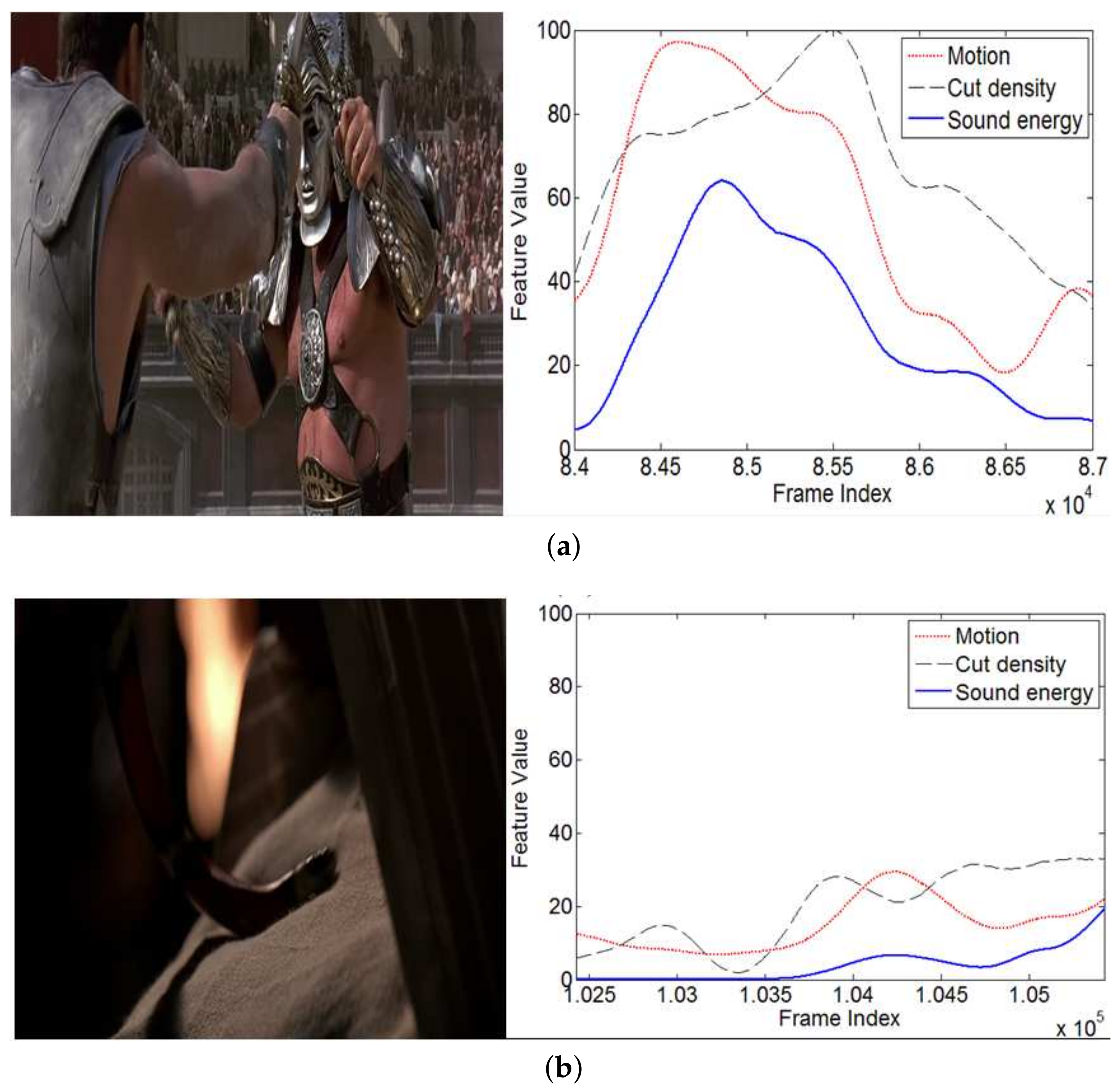
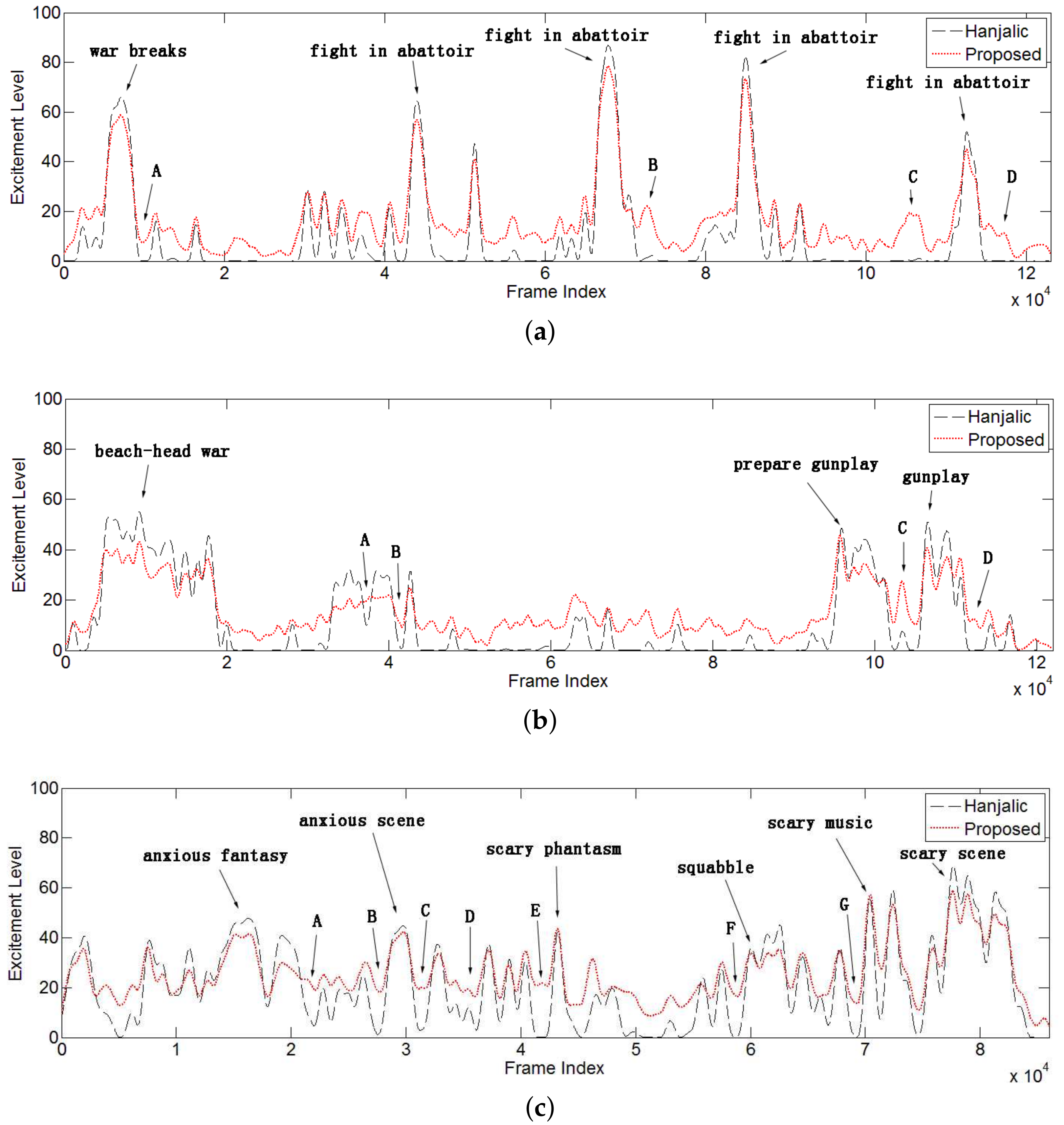
4.2.1. Detecting Violent Events
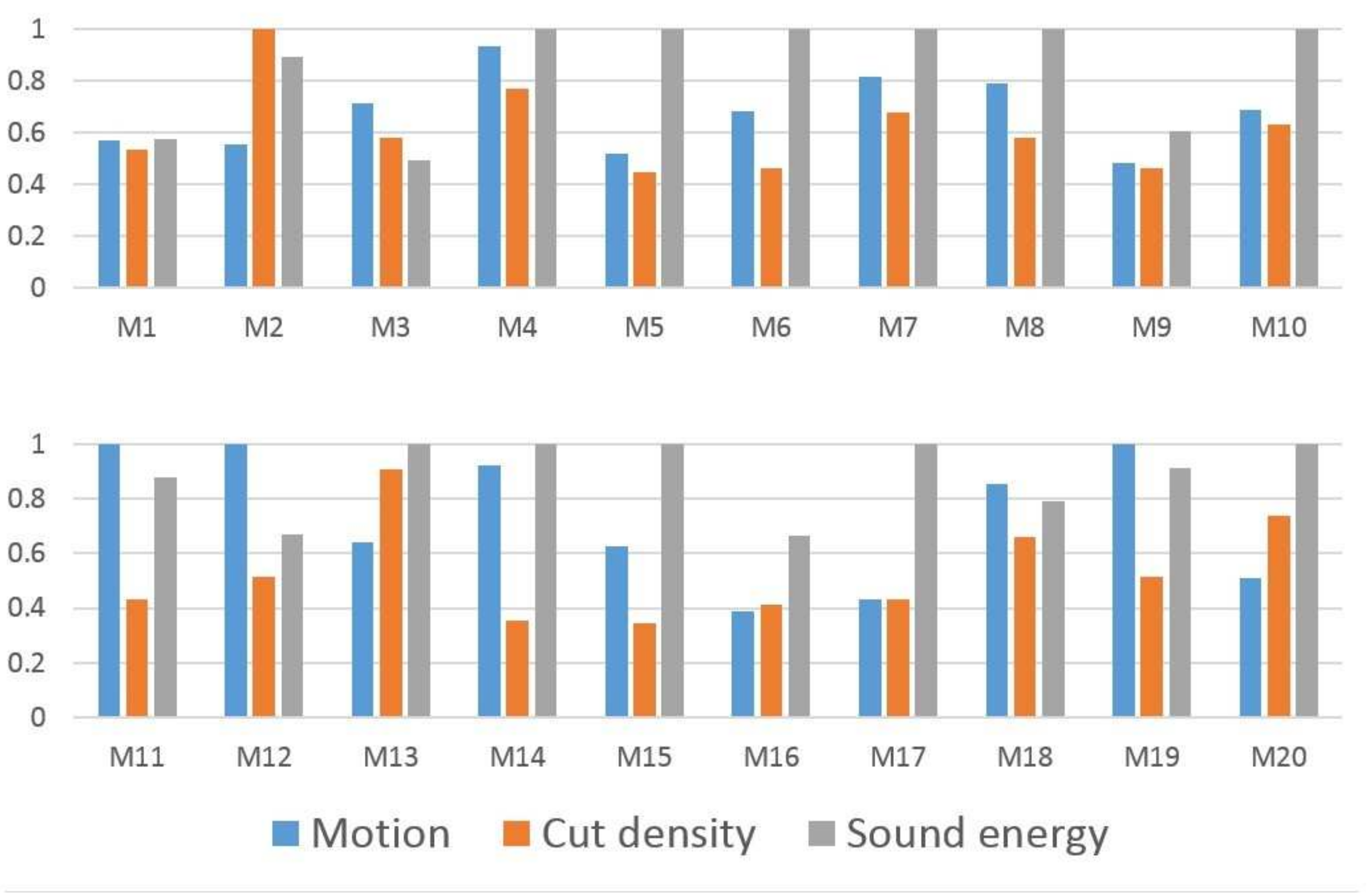
4.2.2. Detecting Exciting Events with Low Feature Values
4.2.3. Curve Continuity Discussion
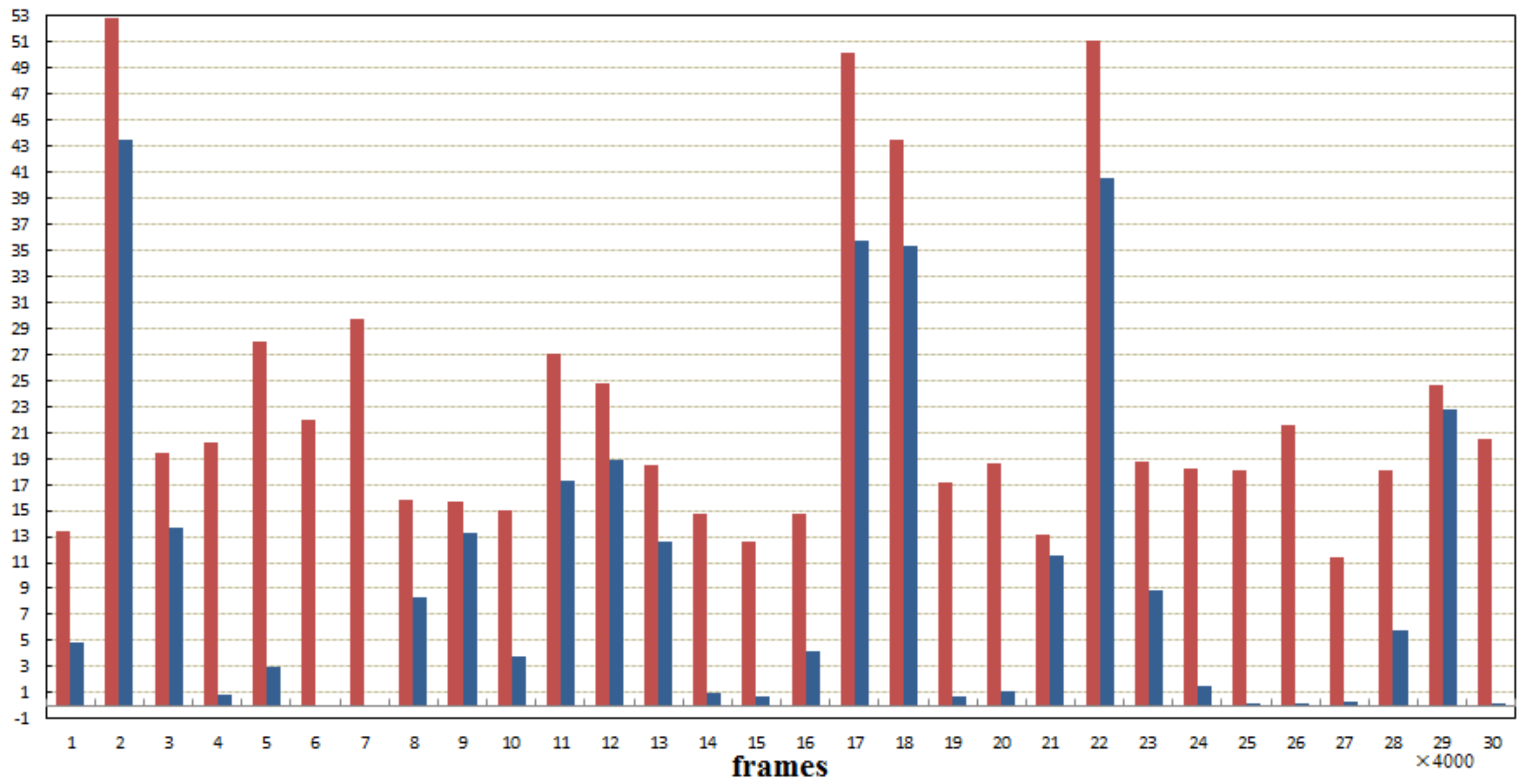
4.2.4. Comparison Result
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Reference
- Taşdemir, K.; Cetin, A.E. Content-based video copy detection based on motion vectors estimated using a lower frame rate. Signal Image Video Process. 2014, 8, 1049–1057. [Google Scholar] [CrossRef]
- Chang, S.F.; Vetro, A. Video adaptation: Concepts, technologies, and open issues. Proc. IEEE 2005, 93, 148–158. [Google Scholar] [CrossRef]
- Canini, L.; Benini, S.; Leonardi, R. Affective recommendation of movies based on selected connotative features. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 636–647. [Google Scholar] [CrossRef]
- Arijon, D. Grammar of the Film Language; Hastings House Publishers: New York, NY, USA, 1976. [Google Scholar]
- Darwin, C.; Prodger, P. The Expression of the Emotions in Man and Animals; Oxford University Press: Cary, NC, USA, 1998. [Google Scholar]
- Arnold, M.B. Emotion and Personality; Columbia University Press: New York, NY, USA, 1960. [Google Scholar]
- Gaikwad, R.; Neve, J.R. A comprehensive study in novel content based video retrieval using vector quantization over a diversity of color spaces. In Proceedings of the International Conference on Global Trends in Signal Processing, Information Computing and Communication, Jalgaon, India, 22–24 December 2017; pp. 38–42. [Google Scholar]
- Mittal, A.; Cheong, L.F. Framework for synthesizing semantic-level indices. Multimed. Tools Appl. 2003, 20, 135–158. [Google Scholar] [CrossRef]
- Yeh, M.C.; Tsai, Y.W.; Hsu, H.C. A content-based approach for detecting highlights in action movies. Multimed. Syst. 2016, 22, 1–9. [Google Scholar] [CrossRef]
- Irie, G.; Satou, T.; Kojima, A.; Yamasaki, T.; Aizawa, K. Affective audio-visual words and latent topic driving model for realizing movie affective scene classification. IEEE Trans. Multimed. 2010, 12, 523–535. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Poria, S.; Peng, H.; Hussain, A.; Howard, N.; Cambria, E. Ensemble application of convolutional neural networks and multiple kernel learning for multimodal sentiment analysis. Neurocomputing 2017, 261, 217–230. [Google Scholar] [CrossRef]
- Paul, S.; Saoda, N.; Rahman, S.M.M.; Hatzinakos, D. Mutual information-based selection of audiovisual affective features to predict instantaneous emotional state. In Proceedings of the International Conference on Computer and Information Technology, Dhaka, Bangladesh, 18–20 December 2017; pp. 463–468. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning Affective Features with a Hybrid Deep Model for Audio-Visual Emotion Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3030–3043. [Google Scholar] [CrossRef]
- Omidyeganeh, M.; Ghaemmaghami, S.; Shirmohammadi, S. Group-based spatio-temporal video analysis and abstraction using wavelet parameters. Signal Image Video Process. 2013, 7, 787–798. [Google Scholar] [CrossRef]
- Xu, M.; Chia, L.T.; Jin, J. Affective content analysis in comedy and horror videos by audio emotional event detection. In Proceedings of the IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; pp. 622–625. [Google Scholar]
- Zhalehpour, S.; Akhtar, Z.; Erdem, C.E. Multimodal emotion recognition based on peak frame selection from video. Signal Image Video Process. 2016, 10, 827–834. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; He, X.; Jin, J.S.; Luo, S.; Lu, H. A three-level framework for affective content analysis and its case studies. Multimed. Tools Appl. 2014, 70, 757–779. [Google Scholar] [CrossRef]
- Hanjalic, A. Adaptive extraction of highlights from a sport video based on excitement modeling. IEEE Trans. Multimed. 2005, 7, 1114–1122. [Google Scholar] [CrossRef]
- Hu, W.; Xie, N.; Li, L.; Zeng, X.; Maybank, S. A survey on visual content-based video indexing and retrieval. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 41, 797–819. [Google Scholar]
- Geetha, P.; Narayanan, V. A Survey of Content-Based Video Retrieval. J. Comput. Sci. 2008, 4, 474–486. [Google Scholar] [CrossRef]
- Del Bimbo, A. Visual Information Retrieval; Morgan and Kaufmann: Burlington, NJ, USA, 1999. [Google Scholar]
- Hanjalic, A.; Langelaar, G.; Van Roosmalen, P.; Biemond, J.; Lagendijk, R. Image and Video Databases: Restoration, Watermarking and Retrieval; Elsevier: Amsterdam, The Netherlands, 2000; Volume 8. [Google Scholar]
- Lew, M.S. Principles of Visual Information Retrieval; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Feng, W.; Jia, J.; Liu, Z. Self-Validated Labeling of Markov Random Fields for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1871–1887. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Ji, Q. Video Affective Content Analysis: A Survey of State-of-the-Art Methods. IEEE Trans. Affect. Comput. 2015, 6, 410–430. [Google Scholar] [CrossRef]
- Yang, H.; Wang, B.; Lin, S.; Wipf, D.; Guo, M.; Guo, B. Unsupervised Extraction of Video Highlights via Robust Recurrent Auto-Encoders. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4633–4641. [Google Scholar]
- Xu, Y.; Han, Y.; Hong, R.; Tian, Q. Sequential Video VLAD: Training the Aggregation Locally and Temporally. IEEE Trans. Image Process. 2018, 27, 4933–4944. [Google Scholar] [CrossRef]
- Zhao, S.; Yao, H.; Sun, X. Video classification and recommendation based on affective analysis of viewers. In Proceedings of the ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1473–1476. [Google Scholar]
- Zhao, S.; Yao, H.; Sun, X.; Jiang, X.; Xu, P. Flexible Presentation of Videos Based on Affective Content Analysis. In Proceedings of the International Conference on Multimedia Modeling, Huangshan, China, 7–9 January 2013; pp. 368–379. [Google Scholar]
- Hanjalic, A.; Xu, L.Q. Affective video content representation and modeling. IEEE Trans. Multimed. 2005, 7, 143–154. [Google Scholar] [CrossRef]
- Wang, H.L.; Cheong, L.F. Affective understanding in film. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 689–704. [Google Scholar] [CrossRef]
- Kang, H.B. Affective content detection using HMMs. In Proceedings of the Eleventh ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 259–262. [Google Scholar]
- Rasheed, Z.; Sheikh, Y.; Shah, M. On the use of computable features for film classification. IEEE Trans. Circuits Syst. Video Technol. 2005, 15, 52–64. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, Q.; Jiang, S.; Gao, W.; Tian, Q. Affective visualization and retrieval for music video. IEEE Trans. Multimed. 2010, 12, 510–522. [Google Scholar] [CrossRef]
- Zhu, G.; Xu, C.; Huang, Q.; Rui, Y.; Jiang, S.; Gao, W.; Yao, H. Event tactic analysis based on broadcast sports video. IEEE Trans. Multimed. 2009, 11, 49–67. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage: Newcastle upon Tyne, UK, 2012. [Google Scholar]
- Xu, G.; Ma, Y.F.; Zhang, H.J.; Yang, S. A HMM based semantic analysis framework for sports game event detection. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003. [Google Scholar]
- Xu, M.; Jin, J.S.; Luo, S.; Duan, L. Hierarchical movie affective content analysis based on arousal and valence features. In Proceedings of the 16th ACM international conference on Multimedia, Vancouver, BC, Canada, 26–31 October 2008; pp. 677–680. [Google Scholar]
- Lin, J.C.; Wu, C.H.; Wei, W.L. Error weighted semi-coupled hidden Markov model for audio-visual emotion recognition. IEEE Trans. Multimed. 2012, 14, 142–156. [Google Scholar] [CrossRef]
- Rui, H.; Wei, F.; Jizhou, S. Color feature reinforcement for co-saliency detection without single saliency residuals. IEEE Signal Process. Lett. 2017, 24, 569–573. [Google Scholar]
- Qing, G.; Sun, S.; Ren, X.; Dong, F.; Gao, B.; Feng, W. Frequency-tuned active contour model. Neurocomputing 2018, 275, 2307–2316. [Google Scholar]
- Han, J.; Cheng, G.; Li, Z.; Zhang, D. A Unified Metric Learning-Based Framework for Co-saliency Detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2473–2483. [Google Scholar] [CrossRef]
- Han, J.; Chen, H.; Liu, N.; Yan, C.; Li, X. CNNs-Based RGB-D Saliency Detection via Cross-View Transfer and Multiview Fusion. IEEE Trans. Cybern. 2018, 48, 3171–3183. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2018, 28, 256–278. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Han, J.; Zhao, L.; Meng, D. Leveraging Prior-Knowledge for Weakly Supervised Object Detection under a Collaborative Self-Paced Curriculum Learning Framework. Int. J. Comput. Vis. 2018. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Time Periods | Description | Affect |
|---|---|---|---|
| A | 0:11:30–0:12:28 | A very horrifying battle scene is shown with slow motion and deep music. | Horrifying |
| B | 1:38:11–1:38:57 | Hero is hiding an arrow head in his hand and wants to kill the evil king. | Tension |
| C | 2:24:19–2:26:11 | Enemy put a snake in a bed to assassinate target quietly. | Dangerous |
| D | 2:38:07–2:42:58 | When hero killed the evil king, all the audience turns to quiet suddenly, and the hero sees a vision of his family, then dies. | Happy, anxious, and very sad |
| No. | Time Periods | Description | Affect |
|---|---|---|---|
| A | 0:51:04–0:53:03 | Teammate is shot by sniper, and all soldiers are hiding without movement and sound. | Dangerous |
| B | 0:55:10–0:56:20 | Our sniper killed enemy the sniper covertly and quietly. | Tension |
| C | 2:21:56–2:26:54 | A soldier is too scared to speak and walk and cries when an enemy passes him. | Dangerous |
| D | 2:35:12–2:37:15 | Hero is dying and leaving his last words. | Sad |
| No. | Time Periods | Description | Affect |
|---|---|---|---|
| A | 0:28:32–0:30:22 | The kid is riding a bike along an empty long corridor. | Strange |
| B | 0:36:19–0:38:16 | The kid sees a terrible phantom, and he cannot cry or run away. | Scared |
| C | 0:42:58–0:44:15 | The kid is playing in an empty hall alone; suddenly, a door is opened, but is nobody there. | Dangerous |
| D | 0:48:32–0:51:45 | The leading man dropped into the illusion that he is drinking in a bar, and he is talking to himself. | Strange |
| E | 0:56:48–1:00:36 | The leading man is kissing a beauty, but he catches a glimpse that she is a zombie. | Horrible |
| F | 1:20:24–1:23:45 | The leading man wants to get close to the leading lady quietly and kill her. | Dangerous |
| G | 1:35:19–1:37:28 | The kid is holding a dagger and standing beside the sleeping leading lady. | Horrible |
| No. | Movie Names | GT | Our | Hanjalic |
|---|---|---|---|---|
| M1 | Gladiator | 15 | 13 | 11 |
| M2 | Titanic | 12 | 10 | 9 |
| M3 | The Perfect Storm | 17 | 13 | 13 |
| M4 | Silent Hill | 18 | 16 | 10 |
| M5 | The Shining | 16 | 14 | 9 |
| M6 | Troy | 29 | 24 | 24 |
| M7 | Brave heart | 20 | 18 | 16 |
| M8 | Saving Private Ryan | 27 | 25 | 24 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Yan, X.; Jiang, W.; Sun, M. Two-Way Affective Modeling for Hidden Movie Highlights’ Extraction. Sensors 2018, 18, 4241. https://doi.org/10.3390/s18124241
Wang Z, Yan X, Jiang W, Sun M. Two-Way Affective Modeling for Hidden Movie Highlights’ Extraction. Sensors. 2018; 18(12):4241. https://doi.org/10.3390/s18124241
Chicago/Turabian StyleWang, Zheng, Xinyu Yan, Wei Jiang, and Meijun Sun. 2018. "Two-Way Affective Modeling for Hidden Movie Highlights’ Extraction" Sensors 18, no. 12: 4241. https://doi.org/10.3390/s18124241
APA StyleWang, Z., Yan, X., Jiang, W., & Sun, M. (2018). Two-Way Affective Modeling for Hidden Movie Highlights’ Extraction. Sensors, 18(12), 4241. https://doi.org/10.3390/s18124241