
Study of the Applicability Domain of the QSAR Classification Models by Means of the Rivality and Modelability Indexes


Abstract
1. Introduction
2. Results
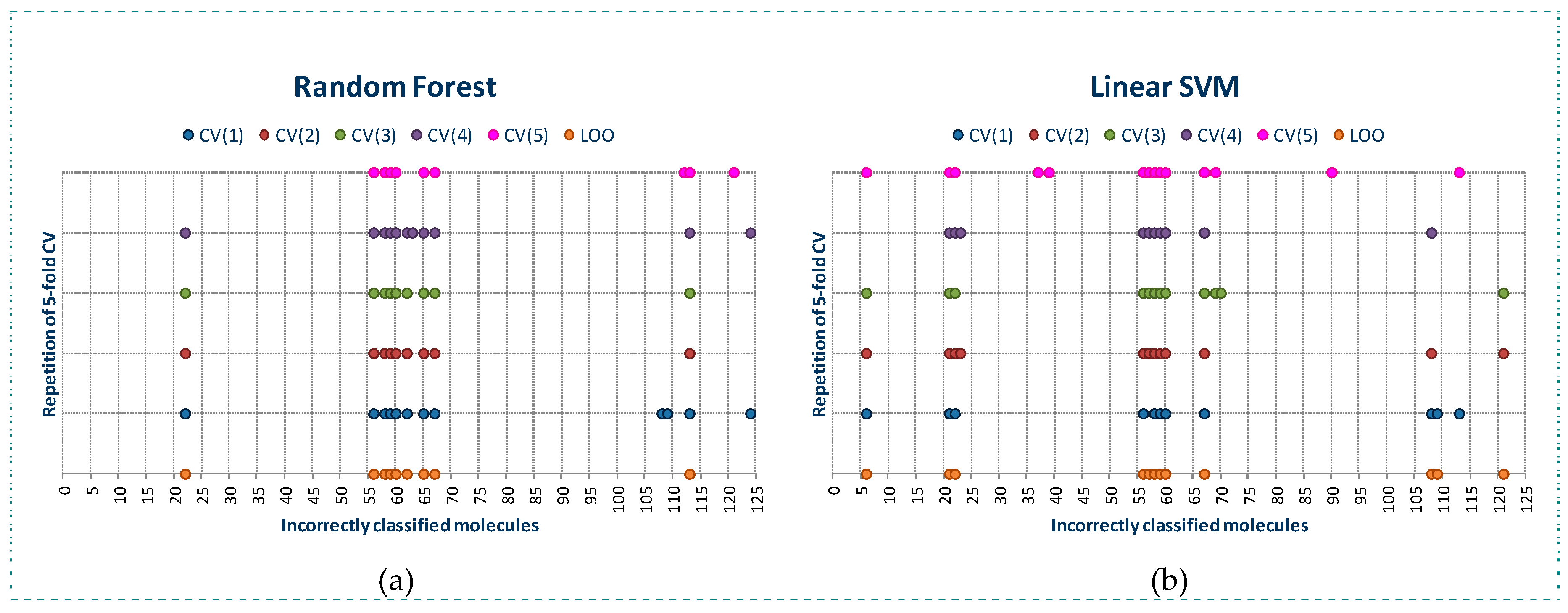
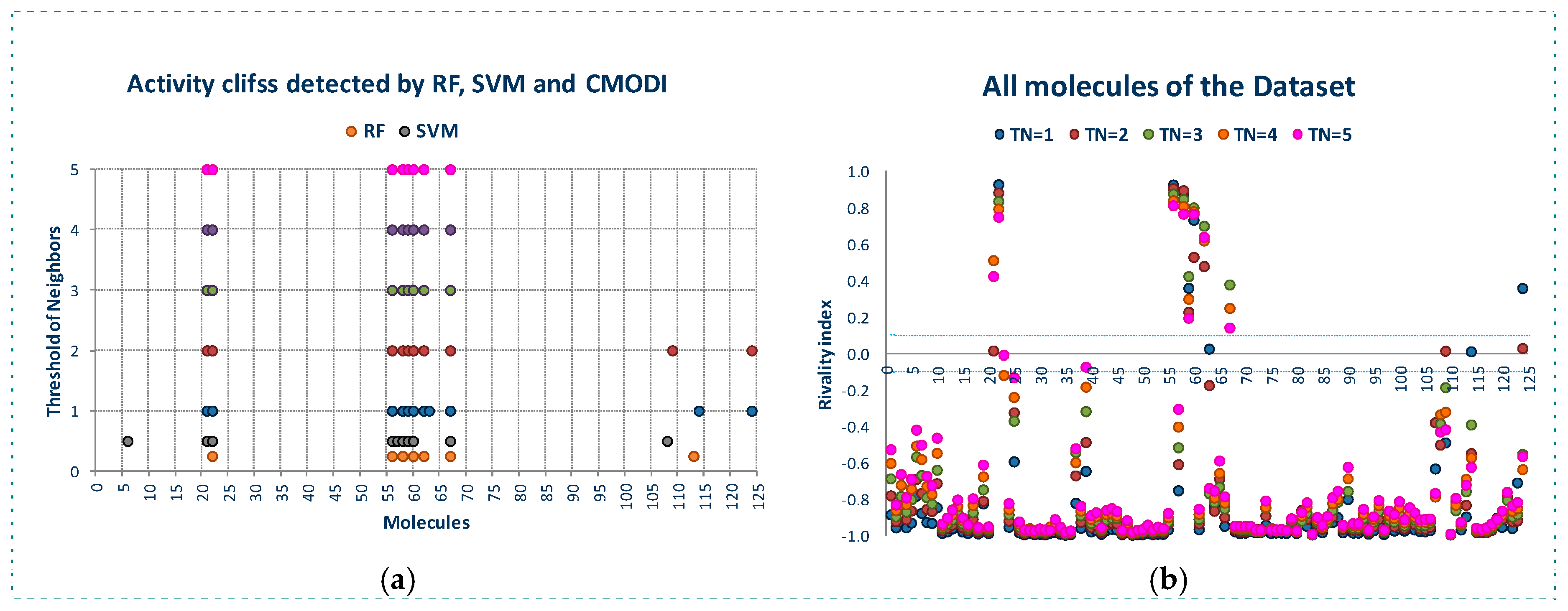
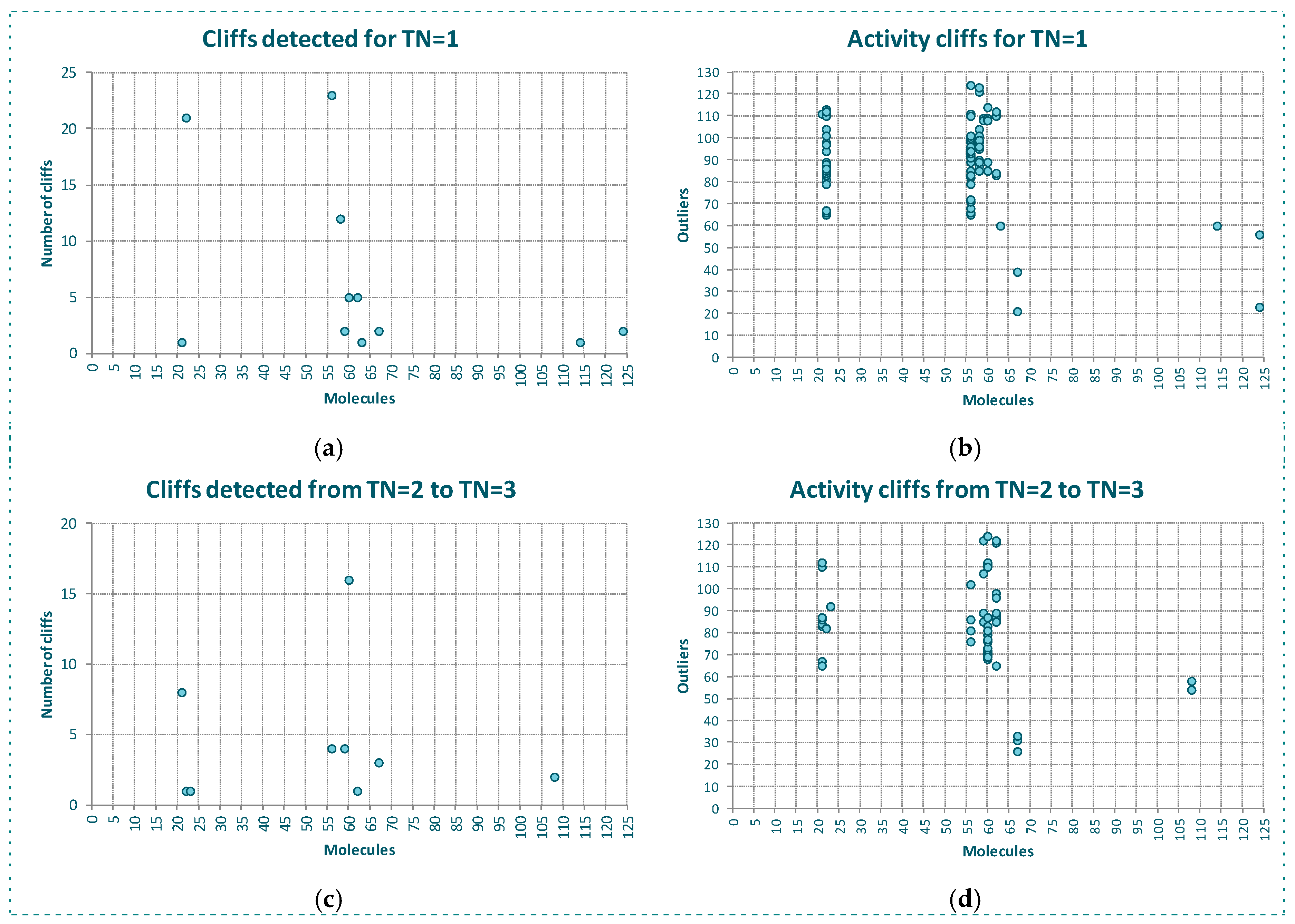
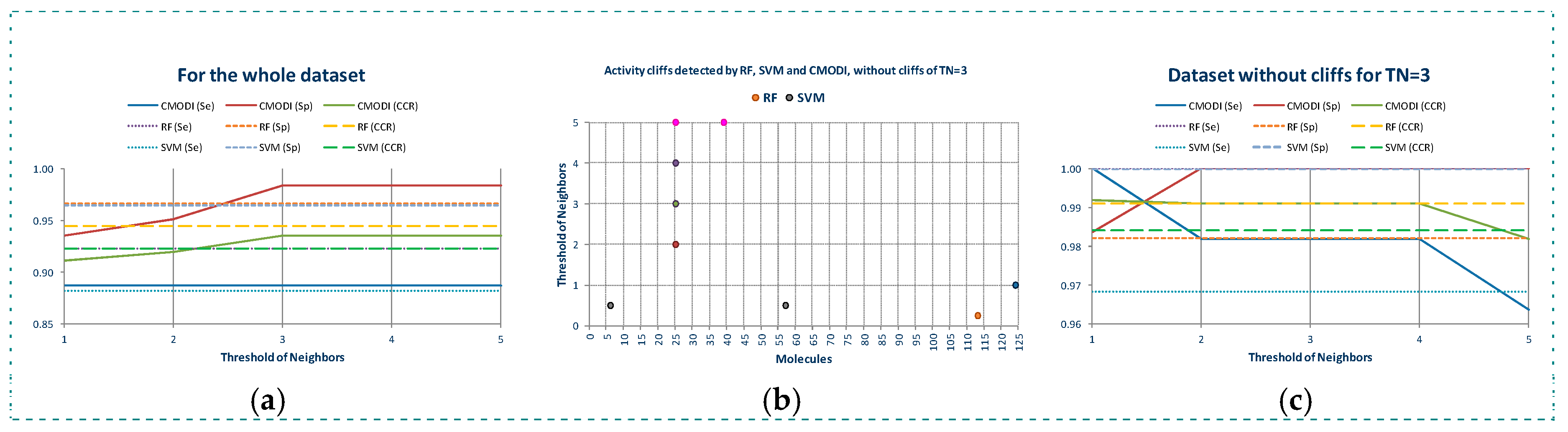
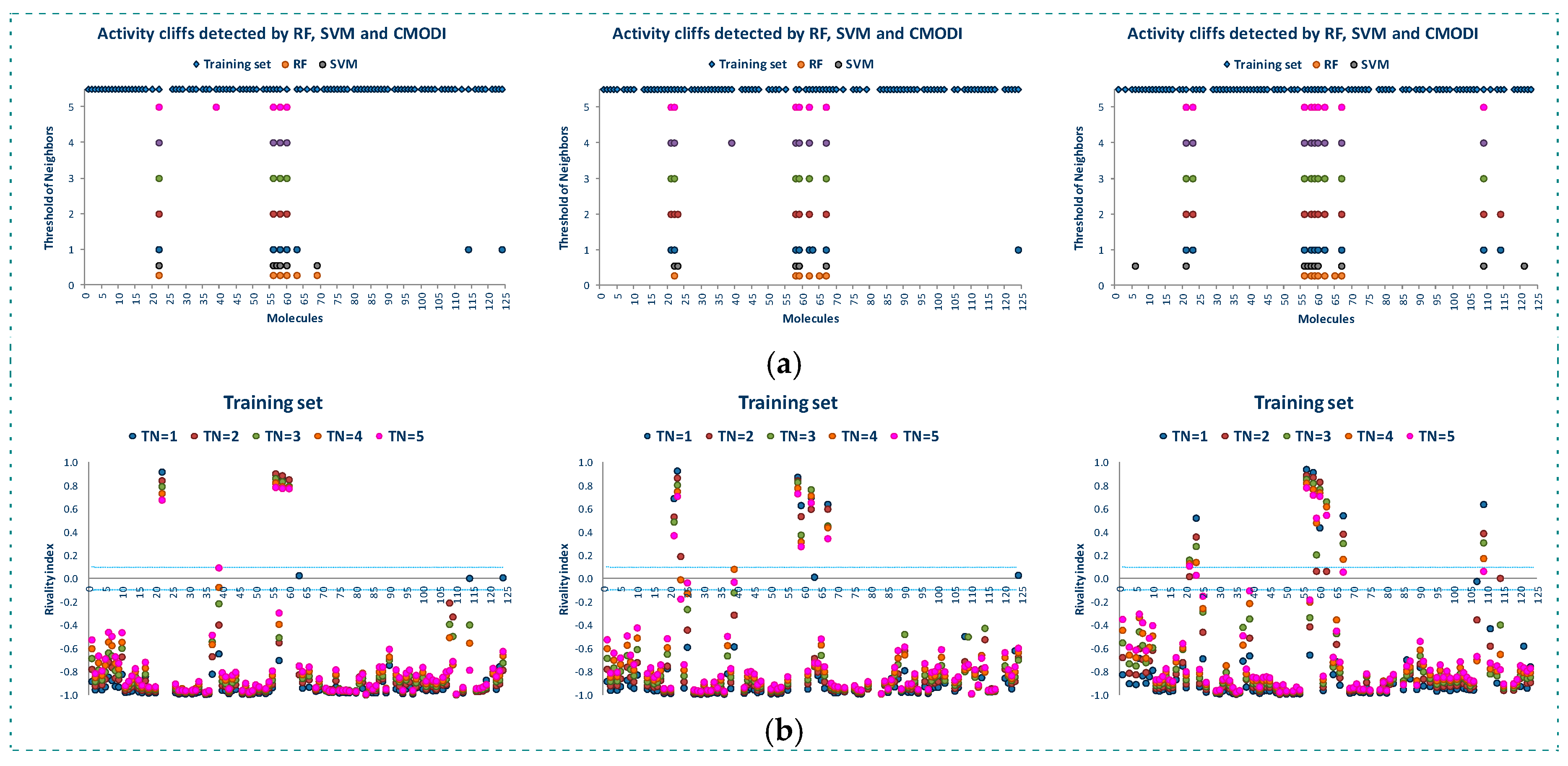
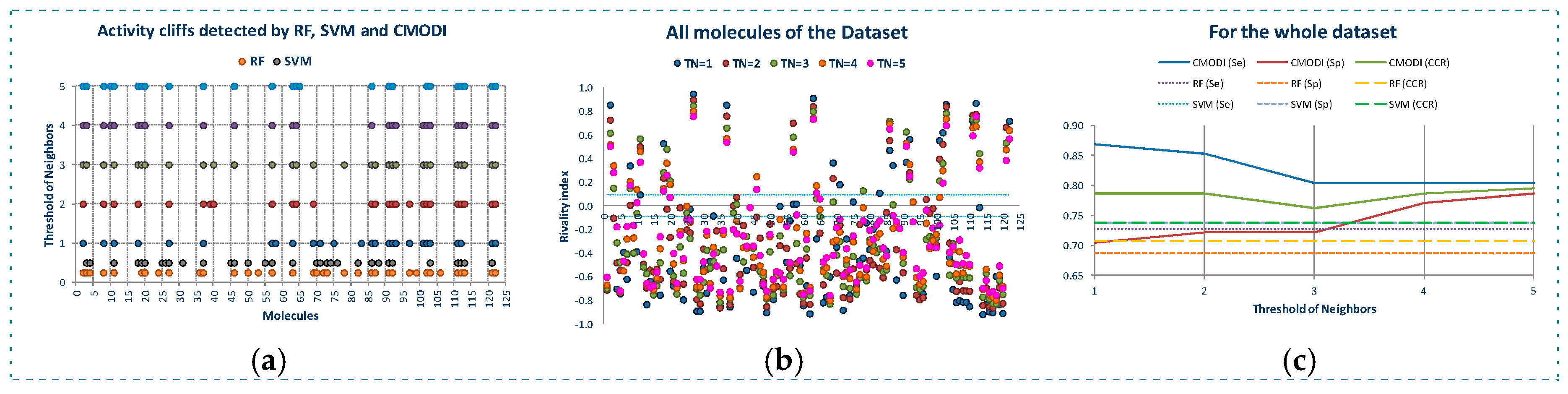
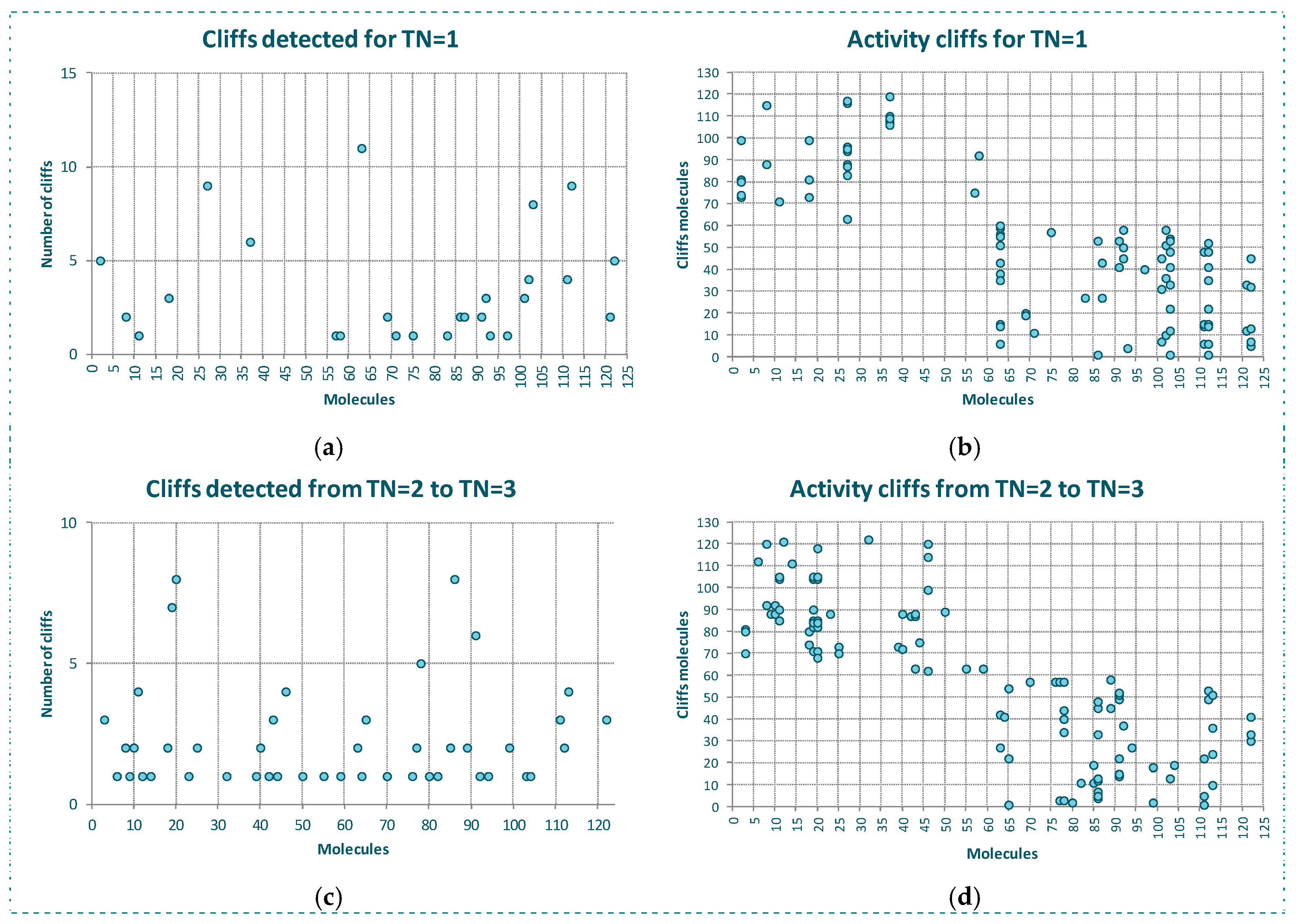
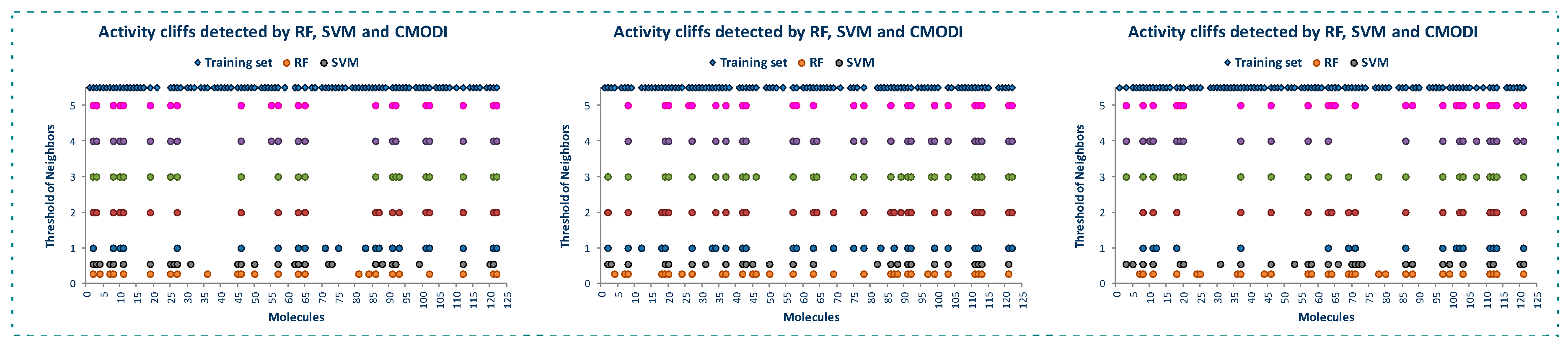
2.1. Behavior of RI and CMODI Indexes, and RF and SVM Algorithms with the YES1 Dataset
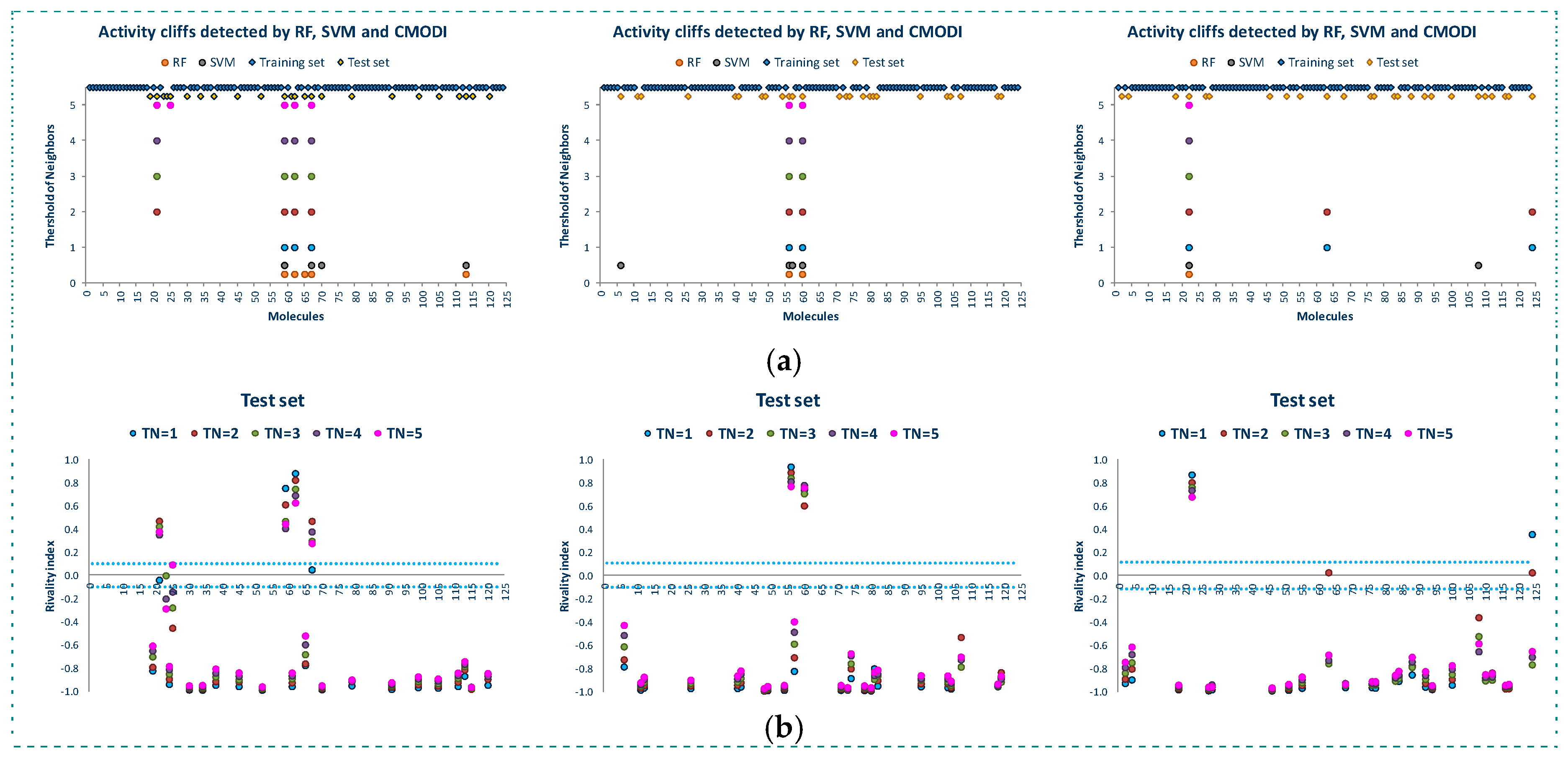
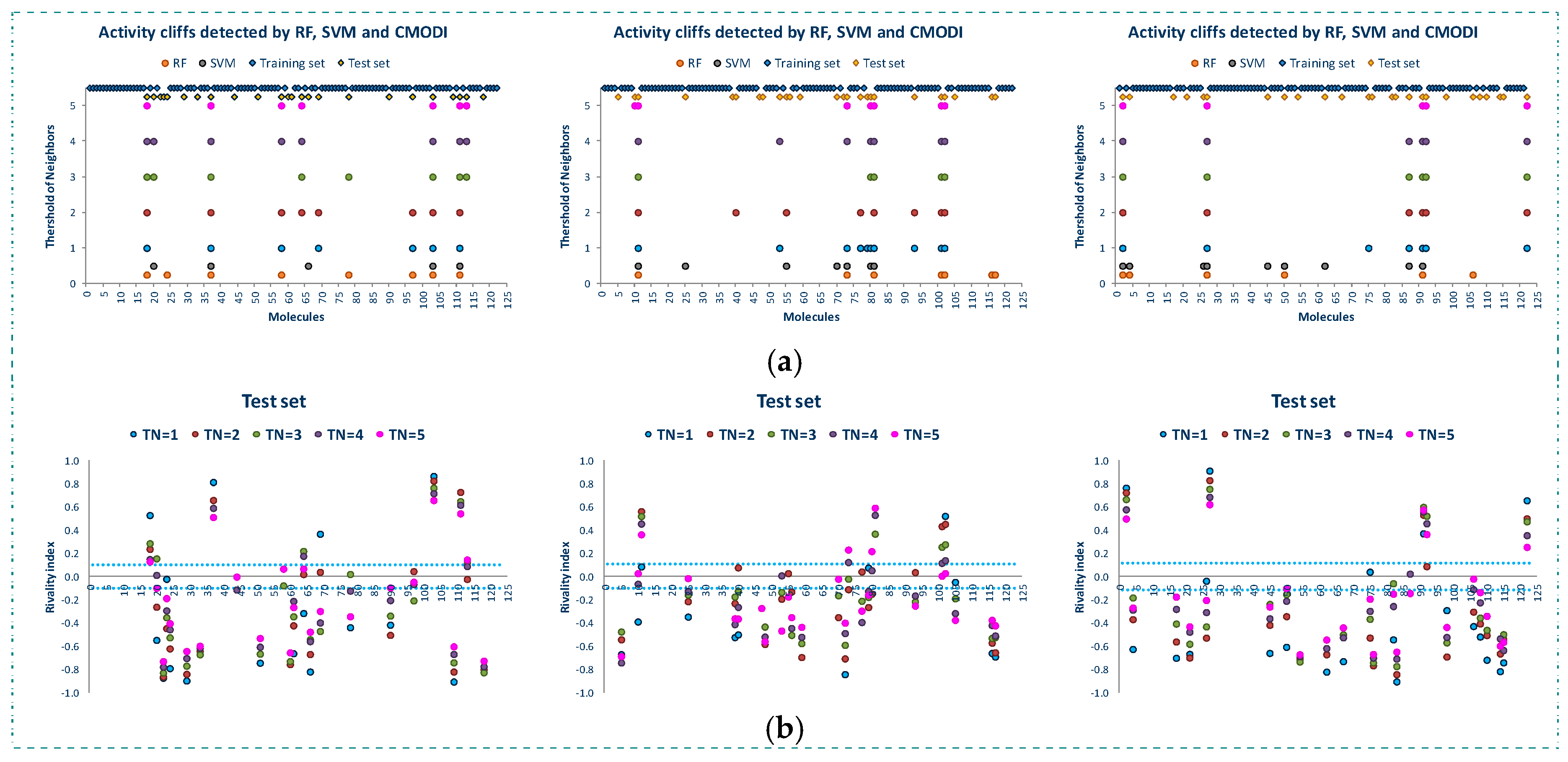
2.2. Analysis of the Applicability Domain of the Classification Models for the YES1 Dataset
- YES1 dataset was randomly partitioned (80/20). This process was performed three times obtaining three sets for training (TRS) and three sets for external validations (TES). Thus, we can reproduce the behavior of the algorithms, the rivality and modelability indexes in the external validation process of the classification models, and to study the applicability domain of those models.
- Using the training sets (TRS), the classification models were built using RF and SVM algorithms and LOO technique. In this way, the results are reproducible and they are independent of the partitions generated when CV technique is used. For each of the models built, the values of sensitivity (SE), specificity (SP), accuracy (ACC) and CCR were stored.
- Values of the rivality index and CMODI were calculated for each one of the three TRS, and the activity cliffs detected were also stored.
- External validations were performed for each one of the three TES for each of the models built using RF and SVM.
- Finally, the analysis of the AD for the three TES was performed.
2.3. Application to Datasets with Low Modelability
3. Discussion
4. Materials and Methods
4.1. Datasets Description and Representation
4.2. Experimental Method
4.3. Rivality Index
4.4. Weighted Rivality Index
4.5. Modelability Index
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Weaver, S.; Gleeso, M.P. The importance of the domain of applicability in QSAR modeling. J. Mol. Graph. Model. 2008, 26, 1315–1326. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Wallqvist, A. Merging applicability domains for in silico assessment of chemical mutagenicity. J. Chem. Inf. Model. 2014, 54, 793–800. [Google Scholar] [CrossRef] [PubMed]
- Dimitrov, S.; Dimitrova, G.; Pavlov, T.; Dimitrova, N.; Patlewicz, G.; Niemela, J.; Mekenyan, O. A stepwise approach for defining the applicability domain of SAR and QSAR models. J. Chem. Inf. Model. 2005, 45, 839–849. [Google Scholar] [CrossRef] [PubMed]
- Schroeter, T.B.; Schwaighofer, A.; Mika, S.; Laak, A.T.; Suelzle, D.; Ganzer, U.; Heinrich, N.; Muller, K.R. Estimating the domain of applicability for machine learning QSAR models: A study on aqueous solubility of drug discovery molecules. J. Comput. Aided. Mol. Des. 2007, 21, 651–664. [Google Scholar] [CrossRef] [PubMed]
- Bassan, A.; Worth, A.P. Computational Toxicology: Risk Assessment for Pharmaceutical and Environmental Chemicals; Ekins, S., Ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2007; Volume 3, pp. 751–775. [Google Scholar]
- Hanser, T.; Barber, C.; Marchaland, J.F.; Werner, S. Applicability domain: towards a more formal definition. SAR QSAR Environ. Res. 2016, 17, 865–881. [Google Scholar] [CrossRef] [PubMed]
- Dragos, H.; Gilles, M.; Varnek, A. Predicting the predictability: A unified approach to the applicability domain problem of QSAR models. J. Chem. Inf. Model. 2009, 49, 1762–1776. [Google Scholar] [CrossRef] [PubMed]
- Sheridan, R.P. Three useful dimensions for domain applicability in QSAR models using random forest. J. Chem. Inf. Model. 2012, 52, 814–823. [Google Scholar] [CrossRef] [PubMed]
- Organization for Economic Co-operation and Development. OECD Principles for the Validation, for Regulatory Purposes of (Quantitative) Structure-Activity Relationship Models. Available online: http://www. oecd.org/chemicalsafety/risk-assessment/37849783.pdf (accessed on 3 September 2018).
- European Commission. QSAR Model Reporting Format (QMRF). Available online: https://ec.europa.eu/jrc/en/scientific-tool/qsar-modelreporting-format-qmrf (accessed on 3 September 2018).
- Netzeva, T.I.; Worth, A.; Aldenberg, T.; Benigni, R.; Cronin, M.T.D.; Gramatica, P.; Jaworska, J.S.; Kahn, S.; Klopman, G.; Marchant, C.A.; et al. Current status of methods for defining the applicability domain of (quantitative) structure-activity relationships. ATLA 2005, 33, 155–173. [Google Scholar] [PubMed]
- Nikolova, N.; Jaworska, J. Approaches to measure chemical similarity: A review. QSAR Comb. Sci. 2003, 22, 1006–1026. [Google Scholar] [CrossRef]
- Eriksson, L.; Jaworska, J.; Worth, A.P.; Cronin, M.T.D.; McDowell, R.M.; Gramatica, P. Methods for reliability and uncertainty assessment and for applicability evaluations of classification and regression-based QSARs. Environ. Health Perspect. 2003, 111, 1361–1375. [Google Scholar] [CrossRef] [PubMed]
- Kaneko, H. A new measure of regression model accuracy that considers applicability domains. Chemometr. Intell. Lab. 2017, 171, 1–8. [Google Scholar] [CrossRef]
- Patel, M.; Chilton, M.L.; Sartini, A.; Gibson, L.; Barber, C.; Covey-Crump, L.; Przybylak, K.R.; Cronin, M.T.D.; Madden, J.C. Assessment and reproducibility of quantitative structure—Activity relationship models by the nonexpert. J. Chem. Inf. Model. 2018, 58, 673–682. [Google Scholar] [CrossRef] [PubMed]
- Keefer, C.E.; Kauffman, G.W.; Gupta, R.R. Interpretable, probability-based confidence metric for continuous quantitative structure—Activity relationship models. J. Chem. Inf. Model. 2013, 53, 368–383. [Google Scholar] [CrossRef] [PubMed]
- Polishchuk, P. Interpretation of Quantitative Structure−Activity Relationship Models: Past, Present, and Future. J. Chem. Inf. Model. 2017, 57, 2618–2639. [Google Scholar] [CrossRef] [PubMed]
- Sushko, I.; Novotarskyi, S.; Körner, R.; Pandey, A.K.; Cherkasov, A.; Li, J.; Gramatica, P.; Hansen, K.; Schroeter, T.; Müller, K.R.; et al. Applicability domains for classification problems: benchmarking of distance to models for ames mutagenicity set. J. Chem. Inf. Model. 2010, 50, 2094–2111. [Google Scholar] [CrossRef] [PubMed]
- Carrió, P.; Pinto, M.; Ecker, G.; Sanz, F.; Pastor, M. Applicability domain analysis (ADAN): A robust method for assessing the reliability of drug property predictions. J. Chem. Inf. Model. 2014, 54, 1500–1511. [Google Scholar] [CrossRef] [PubMed]
- Yun, Y.H.; Wua, D.M.; Li, G.Y.; Zhang, Q.Y.; Yang, X.; Li, Q.F.; Cao, D.S.; Xu, Q.S. A strategy on the definition of applicability domain of model based on population analysis. Chemom. Intell. Lab. 2017, 170, 77–83. [Google Scholar] [CrossRef]
- Roy, K.; Kar, S.; Ambure, P. On a simple approach for determining applicability domain of QSAR models. Chemom. Intell. Lab. 2015, 145, 22–29. [Google Scholar] [CrossRef]
- Roy, K.; Ambure, P.; Aher, R.B. How important is to detect systematic error in predictions and understand statistical applicability domain of QSAR models? Chemom. Intell. Lab. 2017, 162, 44–54. [Google Scholar] [CrossRef]
- Manallack, D.T.; Tehan, B.G.; Gancia, E.; Hudson, B.D.; Ford, M.G.; Livingstone, D.J.; Whitley, D.C.; Pitt, W.R. A Consensus neural network-based technique for discriminating soluble and poorly soluble compounds. J. Chem. Inf. Comput. Sci. 2003, 43, 674–679. [Google Scholar] [CrossRef] [PubMed]
- Sahigara, F.; Mansouri, K.; Ballabio, D.; Mauri, A.; Consonni, V.; Todeschini, R. Comparison of Different Approaches to Define the Applicability Domain of QSAR Models. Molecules 2012, 17, 4791–4810. [Google Scholar] [CrossRef] [PubMed]
- Sheridan, R.P. Using random forest to model the domain applicability of another random forest model. J. Chem. Inf. Model. 2013, 53, 2837–2850. [Google Scholar] [CrossRef] [PubMed]
- Luque Ruiz, I.; Gómez-Nieto, M.A. Study of the datasets modelability: modelability, rivality and weighted modelability indexes. J. Chem. Inf. Model. 2018, 58, 1798–1814. [Google Scholar] [CrossRef] [PubMed]
- Chembench website. Carolina Exploratory Center for Cheminformatics Research (CECCR). Available online: https://chembench.mml.unc.edu/ (accessed on 6 August 2018).
- The Chemistry Development Kit (CDK). Available online: https://cdk.github.io/ (accessed on 1 August 2018).
- Matlab and Simulink. Version 2017Rb. The MathWorks, Inc.: Natick, MA, USA. Available online: https://www.mathworks.com/products/matlab.html (accessed on 4 September 2018).
- Statistics and Machine Learning Toolbox. Version 2017Rb. The MathWorks, Inc.: Natick, MA, USA. Available online: https://www.mathworks.com/products/statistics.html (accessed on 4 September 2018).
- Ballabio, D.; Grisoni, F.; Todeschini, R. Multivariate Comparison of Classification Performance Measures. Chemom. Intell. Lab. 2018, 174, 33–44. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| All Molecules of the Dataset | Erasing Cliffs for TN = 3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | TN | SE | SP | ACC | CMODI | CCR | SE | SP | ACC | CMODI | CCR |
| 1 | 0.887 | 0.935 | 0.911 | 0.911 | 1.000 | 0.984 | 0.991 | 0.992 | |||
| 2 | 0.887 | 0.952 | 0.919 | 0.919 | 0.982 | 1.000 | 0.991 | 0.991 | |||
| 3 | 0.887 | 0.984 | 0.935 | 0.935 | 0.982 | 1.000 | 0.991 | 0.991 | |||
| 4 | 0.887 | 0.984 | 0.935 | 0.935 | 0.982 | 1.000 | 0.991 | 0.991 | |||
| 5 | 0.887 | 0.984 | 0.935 | 0.935 | 0.964 | 1.000 | 0.983 | 0.982 | |||
| RF | 0.923 | 0.966 | 0.944 | 0.945 | 1.000 | 0.982 | 0.991 | 0.991 | |||
| SVM | 0.882 | 0.964 | 0.919 | 0.923 | 0.968 | 1.000 | 0.983 | 0.984 | |||
| All Molecules of the Dataset | Erasing Cliffs for TN = 3 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | TN | SE | SP | ACC | CMODI | CCR | SE | SP | ACC | CMODI | CCR | |
| Training set TRS-01 | ||||||||||||
| 1 | 0.918 | 0.941 | 0.930 | 0.930 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| 2 | 0.918 | 1.000 | 0.960 | 0.959 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| 3 | 0.918 | 1.000 | 0.960 | 0.959 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| 4 | 0.918 | 1.000 | 0.960 | 0.959 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| 5 | 0.898 | 1.000 | 0.950 | 0.949 | 0.978 | 1.000 | 0.990 | 0.989 | ||||
| RF | 0.925 | 0.957 | 0.940 | 0.941 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| SVM | 0.909 | 0.978 | 0.940 | 0.943 | 0.980 | 0.978 | 0.979 | 0.979 | ||||
| Training set TRS-02 | ||||||||||||
| 1 | 0.900 | 0.939 | 0.919 | 0.919 | 1.000 | 0.979 | 0.989 | 0.990 | ||||
| 2 | 0.880 | 0.980 | 0.929 | 0.930 | 0.978 | 1.000 | 0.989 | 0.989 | ||||
| 3 | 0.900 | 0.980 | 0.939 | 0.940 | 0.978 | 1.000 | 0.989 | 0.989 | ||||
| 4 | 0.880 | 0.980 | 0.929 | 0.930 | 0.978 | 1.000 | 0.989 | 0.989 | ||||
| 5 | 0.900 | 0.980 | 0.939 | 0.940 | 0.978 | 1.000 | 0.989 | 0.989 | ||||
| RF | 0.922 | 0.958 | 0.939 | 0.940 | 1.000 | 0.978 | 0.989 | 0.989 | ||||
| SVM | 0.923 | 0.979 | 0.949 | 0.951 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| Training set TRS-03 | ||||||||||||
| 1 | 0.868 | 0.935 | 0.899 | 0.901 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| 2 | 0.868 | 0.935 | 0.899 | 0.901 | 1.000 | 1.000 | 1.000 | 1.000 | ||||
| 3 | 0.868 | 0.957 | 0.909 | 0.912 | 0.978 | 1.000 | 0.989 | 0.989 | ||||
| 4 | 0.868 | 0.957 | 0.909 | 0.912 | 0.978 | 1.000 | 0.989 | 0.989 | ||||
| 5 | 0.868 | 0.957 | 0.909 | 0.912 | 0.957 | 1.000 | 0.978 | 0.978 | ||||
| RF | 0.898 | 0.960 | 0.929 | 0.929 | 1.000 | 0.979 | 0.989 | 0.989 | ||||
| SVM | 0.860 | 0.939 | 0.899 | 0.899 | 0.957 | 1.000 | 0.978 | 0.978 | ||||
| All Molecules of the Training Sets | Erasing Cliffs for TN = 3 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | TN | SE | SP | ACC | CMODI | CCR | SE | SP | ACC | CMODI | CCR | |
| Test set TES-01 | ||||||||||||
| 1 | 0.846 | 0.909 | 0.875 | 0.878 | 0.769 | 0.909 | 0.833 | 0.838 | ||||
| 2 | 0.769 | 0.909 | 0.833 | 0.839 | 0.692 | 0.909 | 0.792 | 0.801 | ||||
| 3 | 0.769 | 0.909 | 0.833 | 0.839 | 0.692 | 0.909 | 0.792 | 0.801 | ||||
| 4 | 0.769 | 0.909 | 0.833 | 0.839 | 0.692 | 0.909 | 0.792 | 0.801 | ||||
| 5 | 0.692 | 0.909 | 0.792 | 0.801 | 0.692 | 0.909 | 0.792 | 0.801 | ||||
| RF | 0.846 | 0.727 | 0.792 | 0.787 | 0.846 | 0.818 | 0.833 | 0.832 | ||||
| SVM | 0.923 | 0.727 | 0.833 | 0.825 | 0.923 | 0.909 | 0.917 | 0.916 | ||||
| Test set TES-02 | ||||||||||||
| 1 | 0.833 | 1.000 | 0.920 | 0.917 | 0.833 | 1.000 | 0.917 | 0.920 | ||||
| 2 | 0.833 | 1.000 | 0.920 | 0.917 | 0.833 | 1.000 | 0.917 | 0.920 | ||||
| 3 | 0.833 | 1.000 | 0.920 | 0.917 | 0.833 | 1.000 | 0.917 | 0.920 | ||||
| 4 | 0.833 | 1.000 | 0.920 | 0.917 | 0.833 | 1.000 | 0.917 | 0.920 | ||||
| 5 | 0.833 | 1.000 | 0.920 | 0.917 | 0.833 | 1.000 | 0.917 | 0.920 | ||||
| RF | 0.833 | 1.000 | 0.920 | 0.917 | 0.833 | 1.000 | 0.920 | 0.917 | ||||
| SVM | 0.667 | 1.000 | 0.840 | 0.833 | 0.667 | 1.000 | 0.840 | 0.833 | ||||
| Test set TES-03 | ||||||||||||
| 1 | 0.889 | 0.875 | 0.880 | 0.882 | 0.889 | 0.938 | 0.920 | 0.913 | ||||
| 2 | 0.889 | 0.875 | 0.880 | 0.882 | 0.889 | 0.938 | 0.920 | 0.913 | ||||
| 3 | 0.889 | 1.000 | 0.960 | 0.944 | 0.889 | 1.000 | 0.960 | 0.944 | ||||
| 4 | 0.889 | 1.000 | 0.960 | 0.944 | 0.889 | 1.000 | 0.960 | 0.944 | ||||
| 5 | 0.889 | 1.000 | 0.960 | 0.944 | 0.889 | 1.000 | 0.960 | 0.944 | ||||
| RF | 0.889 | 1.000 | 0.960 | 0.944 | 0.889 | 1.000 | 0.960 | 0.944 | ||||
| SVM | 0.889 | 0.938 | 0.920 | 0.913 | 0.889 | 1.000 | 0.960 | 0.944 | ||||
| All Molecules of the Dataset | Erasing Cliffs for TN = 3 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | TN | SE | SP | ACC | CMODI | CCR | SE | SP | ACC | CMODI | CCR | |
| Training set TRS-01 | ||||||||||||
| 1 | 0.904 | 0.733 | 0.825 | 0.819 | 0.977 | 0.970 | 0.974 | 0.973 | ||||
| 2 | 0.885 | 0.733 | 0.814 | 0.809 | 0.953 | 0.909 | 0.934 | 0.931 | ||||
| 3 | 0.827 | 0.733 | 0.784 | 0.780 | 0.977 | 0.909 | 0.947 | 0.943 | ||||
| 4 | 0.808 | 0.756 | 0.784 | 0.782 | 0.977 | 0.818 | 0.908 | 0.897 | ||||
| 5 | 0.827 | 0.644 | 0.742 | 0.736 | 0.977 | 0.758 | 0.882 | 0.867 | ||||
| RF | 0.707 | 0.714 | 0.711 | 0.711 | 0.882 | 0.929 | 0.908 | 0.905 | ||||
| SVM | 0.714 | 0.727 | 0.722 | 0.721 | 0.848 | 0.884 | 0.868 | 0.866 | ||||
| Training set TRS-02 | ||||||||||||
| 1 | 0.735 | 0.708 | 0.722 | 0.722 | 0.947 | 0.969 | 0.957 | 0.958 | ||||
| 2 | 0.776 | 0.667 | 0.722 | 0.721 | 0.947 | 0.906 | 0.929 | 0.927 | ||||
| 3 | 0.776 | 0.667 | 0.722 | 0.721 | 0.947 | 0.969 | 0.957 | 0.958 | ||||
| 4 | 0.796 | 0.688 | 0.742 | 0.742 | 0.868 | 0.969 | 0.914 | 0.919 | ||||
| 5 | 0.776 | 0.729 | 0.753 | 0.752 | 0.868 | 0.969 | 0.914 | 0.919 | ||||
| RF | 0.868 | 0.694 | 0.691 | 0.691 | 0.964 | 0.881 | 0.914 | 0.923 | ||||
| SVM | 0.735 | 0.750 | 0.742 | 0.742 | 0.903 | 0.897 | 0.900 | 0.900 | ||||
| Training set TRS-03 | ||||||||||||
| 1 | 0.869 | 0.705 | 0.787 | 0.787 | 0.959 | 0.977 | 0.968 | 0.968 | ||||
| 2 | 0.852 | 0.721 | 0.787 | 0.787 | 0.939 | 0.977 | 0.957 | 0.958 | ||||
| 3 | 0.803 | 0.721 | 0.762 | 0.762 | 0.959 | 0.977 | 0.968 | 0.968 | ||||
| 4 | 0.803 | 0.770 | 0.787 | 0.787 | 0.939 | 0.977 | 0.957 | 0.958 | ||||
| 5 | 0.803 | 0.787 | 0.795 | 0.795 | 0.939 | 0.955 | 0.946 | 0.947 | ||||
| RF | 0.712 | 0.698 | 0.705 | 0.705 | 0.860 | 0.977 | 0.914 | 0.918 | ||||
| SVM | 0.746 | 0.763 | 0.754 | 0.754 | 0.840 | 0.953 | 0.892 | 0.897 | ||||
| All Molecules of the Training Sets | Erasing Cliffs for TN = 3 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | TN | SE | SP | ACC | CMODI | CCR | SE | SP | ACC | CMODI | CCR | |
| Test set TES-01 | ||||||||||||
| 1 | 0.769 | 0.636 | 0.708 | 0.703 | 0.692 | 0.545 | 0.625 | 0.619 | ||||
| 2 | 0.769 | 0.545 | 0.667 | 0.657 | 0.692 | 0.545 | 0.625 | 0.619 | ||||
| 3 | 0.769 | 0.545 | 0.667 | 0.657 | 0.692 | 0.636 | 0.667 | 0.664 | ||||
| 4 | 0.692 | 0.636 | 0.667 | 0.664 | 0.692 | 0.636 | 0.667 | 0.664 | ||||
| 5 | 0.769 | 0.636 | 0.708 | 0.703 | 0.615 | 0.545 | 0.583 | 0.580 | ||||
| RF | 0.692 | 0.636 | 0.667 | 0.664 | 0.385 | 0.455 | 0.417 | 0.420 | ||||
| SVM | 0.846 | 0.727 | 0.792 | 0.787 | 0.692 | 0.636 | 0.667 | 0.664 | ||||
| Test set TES-02 | ||||||||||||
| 1 | 0.833 | 0.385 | 0.600 | 0.609 | 0.667 | 0.692 | 0.680 | 0.679 | ||||
| 2 | 0.750 | 0.615 | 0.680 | 0.683 | 0.667 | 0.769 | 0.720 | 0.718 | ||||
| 3 | 0.917 | 0.682 | 0.800 | 0.804 | 0.583 | 0.615 | 0.600 | 0.599 | ||||
| 4 | 0.833 | 0.615 | 0.720 | 0.724 | 0.583 | 0.538 | 0.560 | 0.561 | ||||
| 5 | 0.833 | 0.615 | 0.720 | 0.724 | 0.583 | 0.538 | 0.560 | 0.561 | ||||
| RF | 0.917 | 0.538 | 0.720 | 0.728 | 0.917 | 0.615 | 0.760 | 0.766 | ||||
| SVM | 0.750 | 0.692 | 0.720 | 0.721 | 0.750 | 0.692 | 0.720 | 0.721 | ||||
| Test set TES-03 | ||||||||||||
| 1 | 0.778 | 0.688 | 0.720 | 0.723 | 0.778 | 0.750 | 0.760 | 0.764 | ||||
| 2 | 0.778 | 0.750 | 0.760 | 0.764 | 0.778 | 0.750 | 0.760 | 0.764 | ||||
| 3 | 0.778 | 0.750 | 0.760 | 0.764 | 0.778 | 0.750 | 0.760 | 0.764 | ||||
| 4 | 0.778 | 0.750 | 0.760 | 0.764 | 0.778 | 0.750 | 0.760 | 0.764 | ||||
| 5 | 0.778 | 0.813 | 0.800 | 0.795 | 0.778 | 0.750 | 0.760 | 0.764 | ||||
| RF | 0.556 | 0.875 | 0.760 | 0.715 | 0.556 | 0.875 | 0.760 | 0.715 | ||||
| SVM | 0.333 | 0.813 | 0.640 | 0.573 | 0.333 | 0.688 | 0.560 | 0.510 | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luque Ruiz, I.; Gómez-Nieto, M.Á. Study of the Applicability Domain of the QSAR Classification Models by Means of the Rivality and Modelability Indexes. Molecules 2018, 23, 2756. https://doi.org/10.3390/molecules23112756
Luque Ruiz I, Gómez-Nieto MÁ. Study of the Applicability Domain of the QSAR Classification Models by Means of the Rivality and Modelability Indexes. Molecules. 2018; 23(11):2756. https://doi.org/10.3390/molecules23112756
Chicago/Turabian StyleLuque Ruiz, Irene, and Miguel Ángel Gómez-Nieto. 2018. "Study of the Applicability Domain of the QSAR Classification Models by Means of the Rivality and Modelability Indexes" Molecules 23, no. 11: 2756. https://doi.org/10.3390/molecules23112756
APA StyleLuque Ruiz, I., & Gómez-Nieto, M. Á. (2018). Study of the Applicability Domain of the QSAR Classification Models by Means of the Rivality and Modelability Indexes. Molecules, 23(11), 2756. https://doi.org/10.3390/molecules23112756