Abstract
While deep learning models have demonstrated superior performance in cryptocurrency forecasting, their deployment is often hindered by a lack of interpretability and trustworthiness. To bridge this gap, this paper proposes the Cryptocurrency Counterfactual Explanation (CryptoForecastCF) model. Recognizing the inherent volatility and complex non-linear dynamics of cryptocurrency markets, we argue that understanding the sensitivity of model outputs to slight variations in historical conditions is fundamental to robust risk management. CryptoForecastCF employs a gradient-based optimization strategy to generate meaningful counterfactual explanations. Specifically, it identifies minimal modifications, defined as the optimal perturbations to historical market features such as price constrained by or norms, that are sufficient to steer the model’s future predictions into user-specified target intervals. This approach not only elucidates the key driving factors and decision boundaries of opaque models but also equips traders and risk managers with actionable insights, enabling them to identify the specific market shifts required to navigate high-stakes scenarios and mitigate unfavorable predictive outcomes.
1. Introduction
The cryptocurrency market constitutes a highly dynamic financial ecosystem characterized by pronounced stochastic volatility, complex non-linear dynamics, and heterogeneous information-driven behaviors [1,2]. Its price trajectories and risk profiles are governed by an intricate interplay of internal market mechanisms, such as order book depth and trading volume, and on-chain activities, while remaining acutely sensitive to multidimensional external factors, including macroeconomic indicators, regulatory shifts, and social media sentiment [3].
To navigate this complexity, deep learning architectures have emerged as the dominant paradigm, evolving from fundamental recurrent units to sophisticated hybrid frameworks that significantly outperform traditional statistical models in forecasting tasks [4,5,6,7]. Early approaches, such as the Long Short-Term Memory (LSTM) models utilized by Hoa et al. [8], demonstrated effectiveness in regression tasks, specifically for closing price prediction using daily OHLCV data. To capture more intricate local and temporal patterns, subsequent research has pivoted toward hybrid architectures. For instance, Amirshahi et al. [9] integrated Convolutional Neural Networks (CNNs) with LSTMs and Multi-Layer Perceptrons (MLPs) to classify high-frequency trends. Similarly, mixed recurrent architectures combining LSTM and Gated Recurrent Unit (GRU) modules, as proposed by Kaur et al. [10], have proven capable of handling multi-time window predictions and modeling complex interdependencies. Furthermore, the incorporation of attention mechanisms into CNN-LSTM structures, as demonstrated by Peng et al. [11], has significantly enhanced the capacity to process multi-frequency and multi-currency data for robust trend forecasting. By automatically extracting latent feature patterns from high-dimensional data, these models effectively integrate information across related assets, thereby enhancing both modeling efficiency and predictive accuracy [12].
However, the superior performance of these deep models comes at the cost of transparency. Their inherent opacity, resulting from complex internal non-linear mappings, renders decision-making processes inaccessible to human reasoning, posing severe challenges to interpretability [13]. In the high-stakes domain of cryptocurrency trading and risk management, this “black-box” nature directly undermines trustworthiness [14,15]. Stakeholders, ranging from institutional investors to regulatory authorities, require more than accurate point predictions; they urgently need to comprehend the key drivers behind model outputs and the boundary conditions under which models may fail. Trust, built upon deep understanding, is a prerequisite for integrating these predictive tools into decision-making workflows.
To enhance model transparency, the research community has developed various post-hoc explanation methods, including gradient-based saliency maps [16], local surrogate models like LIME, and game theoretic approaches such as SHAP. While these methods effectively quantify feature importance [17], they primarily address the question of “attribution”, explaining why a model made a specific prediction in the past. Crucially, they lack “actionability,” failing to provide guidance on how to intervene to alter an unfavorable outcome. For instance, when a model forecasts a high-risk market state, users derive limited utility from a static heatmap of feature importance; rather, they require identification of the minimal, realistic modifications to historical conditions that would have averted such a prediction.
Counterfactual Explanations [18,19] offer a promising avenue to address this limitation by providing actionable recourse. The core objective of a counterfactual explanation is to answer “what-if” questions: what is the minimal, constraint-compliant perturbation to the original input that shifts the model’s output to a predefined target state? This paradigm has been successfully applied in image recognition [20] and natural language processing [21] and is beginning to be explored in time series classification [22]. Its primary advantage lies in its model-agnostic nature and the provision of intuitive recommendations that reveal model sensitivities and decision boundaries [23,24].
Despite these advancements, a significant gap remains in applying counterfactuals to financial time series. As categorized in the comprehensive survey by Guidotti et al. [25], existing methods predominantly rely on generic optimization strategies [26,27] or heuristic search algorithms [28] tailored for static tabular data. Although recent works such as ForecastCF [29] and CounTS [30] have extended these concepts to the time-series domain, they function primarily as general-purpose tools. Consequently, they fail to address the unique challenges inherent to the cryptocurrency market, specifically its extreme volatility and the critical requirement for actionable, interval-based risk thresholds rather than precise point targets.
To bridge this gap, inspired by ForecastCF [29], this study proposes CryptoForecastCF, a novel counterfactual explanation framework specifically designed for cryptocurrency risk prediction. Our work distinguishes itself from existing approaches through three key dimensions. First, unlike standard optimization methods (e.g., WACH [26]) that target precise point-wise decision flips, CryptoForecastCF introduces a novel interval-based optimization objective. This aligns with practical trading needs such as steering predictions into a safe “non-liquidation” range rather than achieving an arbitrary specific value. Second, in contrast to methods prioritizing explanation diversity (e.g., DiCE [27]), we prioritize economic feasibility. By enforcing strict norm constraints, we ensure that generated counterfactuals represent minimal, realistic market shifts rather than theoretical statistical artifacts. Finally, unlike self-interpretable frameworks like CounTS [30] that require specific Bayesian architectures, our approach is model-agnostic and post-hoc. This allows it to provide interpretability for the wide array of pre-trained, high-performance deep learning models currently deployed in quantitative finance.
As illustrated in Figure 1, we envision a scenario where counterfactual explanations enhance the trustworthiness of volatility predictions. Suppose a model predicts an unfavorable 12-day price trend based on a 14-day history. The counterfactual explanation method generates a modified historical price sequence that is very close to the original history but contains targeted perturbations. When the prediction model uses this counterfactual history as input, its generated prediction results successfully fall within the user-predefined desired target interval. This provides insights beyond simple attribution, clearly indicating which temporal dynamics were pivotal in driving the unfavorable forecast.
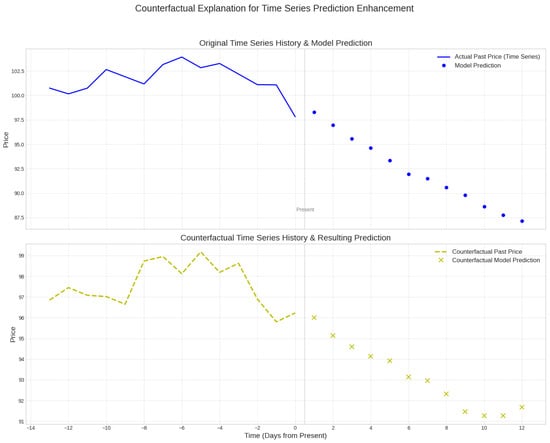
Figure 1.
Cryptocurrency Counterfactual Example. The framework generates a modified historical sequence (counterfactual) that shifts the future prediction into a user-defined safe interval.
Based on this analysis, this research addresses the core question: How can we design effective counterfactual explanation methods for cryptocurrency prediction models that provide actionable interpretability guidance? We focus on three sub-problems: (1) defining a counterfactual framework suitable for high-dimensional, multivariate cryptocurrency data; (2) designing generation algorithms that guide predictions toward specific desired intervals; and (3) ensuring the economic feasibility of the recommended interventions. The core contributions of this paper are summarized as follows:
- Problem Formalization: We systematically define the problem of counterfactual explanations for cryptocurrency prediction, demonstrating its critical value in enhancing model transparency and providing actionable decision support in high-risk financial environments.
- The CryptoForecastCF Framework: We propose a universal, gradient-optimization-based framework capable of generating counterfactuals for complex black-box models. It uniquely incorporates interval-based constraints (upper and lower bounds) to align with practical risk management strategies.
- Empirical Evaluation: We conduct extensive experiments on representative cryptocurrency datasets across multiple mainstream deep learning architectures, systematically validating the capability of CryptoForecastCF to generate effective, meaningful, and minimally modified counterfactual explanations.
2. Problem Definition
The inherent volatility and non-linear complexity of cryptocurrency markets render accurate forecasting a non-trivial task. While deep learning models have achieved superior performance, their “black-box” nature often obscures the decision-making process, limiting their trustworthiness in high-stakes financial applications. To bridge the gap between predictive performance and interpretability, this study addresses a fundamental question: How can we generate counterfactual explanations that elucidate the specific conditions under which a model yields a desired prediction outcome?
Formally, the objective is to identify minimal yet plausible perturbations to the historical input data such that the model’s output, over a specified future horizon, conforms to user-defined interval constraints. These counterfactual explanations not only enhance model transparency but also provide actionable insights for risk management and strategic investment.
2.1. Mathematical Formulation
Let denote a multivariate time series, where represents an F-dimensional feature vector at time step t. Consider a pre-trained predictive model , which maps a historical lookback window of length d to a prediction sequence of length T. The prediction process at time n is defined as:
where denotes the input matrix from the lookback window, and is the predicted value at future time step i.
To incorporate user intent, we define lower and upper bound constraint vectors, , which delineate the acceptable range for the prediction trajectory. These bounds can be dynamically generated via functions and , instantiated based on statistical properties, technical indicators (e.g., support/resistance levels), or risk thresholds.
2.2. Problem Statement
Based on the aforementioned notation, we formally define the Interval-based Cryptocurrency Counterfactual Prediction problem.
Definition 1
(Counterfactual Generation). Given a time series , a predictive model f, and target constraints , the goal is to synthesize a counterfactual input sequence that satisfies the following criteria:
- Locality: Perturbations are strictly confined to the lookback window, i.e., , ensuring historical integrity outside the relevant context.
- Validity: The modified input generates a valid counterfactual prediction .
- Constraint Adherence: The counterfactual prediction must lie within the target interval for all , such that .
- Minimality: The counterfactual input must remain proximal to the original input to ensure plausibility. This is achieved by minimizing a distance metric .
We formulate this task as a regularized optimization problem. To facilitate gradient-based solutions, we express the objective function as:
where represents the candidate input, is a penalty function enforcing interval constraints, is a regularization coefficient balancing validity and proximity, and denotes the feasible domain of the input space.
3. Proposed Method: CryptoForecastCF
To address the interpretability deficit in cryptocurrency forecasting, we propose CryptoForecastCF, a gradient-based counterfactual generation framework. In contrast to conventional attribution methods that are limited to identifying feature importance, CryptoForecastCF reframes the explanation task as a constrained optimization problem within the input feature space. The framework is engineered to synthesize counterfactual inputs that satisfy three critical criteria: (1) validity, ensuring the model’s predictive output shifts into a user-specified target interval; (2) proximity, minimizing deviation from the original data manifold to preserve realism; and (3) actionability, providing feasible guidance for risk mitigation.
3.1. Objective Function Formulation
The optimization objective involves iteratively perturbing the historical lookback window to satisfy predefined prediction constraints. A composite objective function is defined to balance the trade-off between constraint satisfaction and perturbation minimization:
where represents the candidate counterfactual input, and is a regularization hyperparameter governing the strength of the penalty term.
3.1.1. Boundary Constraint Loss
To constrain the prediction output within the target interval , a rectified boundary loss is employed. This loss function penalizes predictions exclusively when they violate the specified upper or lower bounds:
where . This formulation effectively functions as a dynamic mask, contributing to the gradient calculation only at time steps j where the prediction falls outside the feasible region . Consequently, the optimization process is directed solely toward correcting violated constraints, thereby enhancing convergence efficiency.
3.1.2. Proximity Regularization
To ensure that the generated counterfactuals adhere to the principle of minimal change and remain within the data manifold, a distance penalty term is introduced. Two norm-based regularization strategies are provided to tailor the properties of the perturbation:
- Norm (Euclidean Distance): . This formulation encourages smooth, dense perturbations distributed across multiple features, minimizing the aggregate magnitude of change.
- Norm (Manhattan Distance): . This formulation promotes sparsity, modifying only a subset of critical features, which facilitates the generation of more interpretable and concise explanations.
3.2. Optimization Strategy
Given that the predictive model f is differentiable (e.g., a deep neural network), gradient descent is utilized to minimize Equation (3). The optimization process updates the input while holding the model parameters constant. The update rule at iteration k is defined as:
where denotes the learning rate. The gradient is computed via backpropagation through the model f to the input layer. The iterative procedure terminates when either the boundary constraints are fully satisfied (i.e., ) or upon reaching a maximum iteration count. This end-to-end optimization renders CryptoForecastCF model-agnostic, making it applicable to any differentiable architecture, including RNNs, CNNs, and Transformers.
3.3. Constraint Instantiation Protocols
The definition of semantically meaningful target boundaries and is critical for generating actionable explanations. Four instantiation protocols are proposed to address diverse analytical objectives:
- Statistical Trend Constraints: Designed to explore scenarios where predictions deviate from historical norms. Boundaries are derived from the statistics of the lookback window (mean , standard deviation ):where s is a shift factor, k controls the interval width, and represents the expected trend slope. Intermediate bounds are generated via interpolation.
- Technical Analysis Levels: Incorporates domain knowledge by setting boundaries based on key support and resistance levels, enabling traders to simulate “breakout” or “rebound” scenarios.
- Risk Thresholds: For risk management, is set to a maximum acceptable Value-at-Risk (VaR) or volatility index, identifying conditions that would trigger risk alerts.
- ROI Objectives: Tailored for quantitative trading, where boundaries define a minimum return on investment (ROI) or maximum drawdown, facilitating strategy backtesting and stress testing.
4. Experimental Evaluation
4.1. Data Preparation
To rigorously evaluate the efficacy of the proposed CryptoForecastCF framework, this study utilizes a comprehensive suite of cryptocurrency time series datasets. The primary data sources include daily 18 cryptocurrencies, acquired from major exchanges (e.g., Binance, Coinbase) via robust data aggregators such as CoinMarketCap and CryptoCompare. The temporal scope of the dataset extends from 22 September 2020 to 12 March 2024, comprising approximately 1263 daily observations based on closing prices. The dataset incorporates Open, High, Low, Close, and Volume (OHLCV) features, thereby adequately capturing the fundamental stochastic dynamics of the cryptocurrency market.
The hyperparameters for the lookback window d and the prediction horizon T were established based on standard quantitative trading analysis cycles. Specifically, for daily resolution scenarios, the parameters were set to (representing a 30-day historical context) and (forecasting the subsequent weekly trajectory). This configuration strikes an optimal balance between providing sufficient historical context for feature extraction and maintaining the temporal relevance necessary for actionable trading decisions. Data preprocessing adhered to rigorous protocols for time series forecasting. To preserve temporal continuity and ensure a realistic evaluation environment, the dataset was chronologically partitioned into training (70%), validation (15%), and test (15%) subsets. Furthermore, Min-Max normalization was applied to all features to mitigate scale discrepancies and facilitate stable model convergence. In the experimental formulation, denotes the original test set samples, while represents the generated counterfactual samples, serving as the basis for the subsequent quantitative performance assessment.
The 18 cryptocurrencies selected for this study (detailed in Table 1) constitute a representative cross-section of the digital asset ecosystem, encompassing market leaders (BTC, ETH), exchange utility tokens (BNB), DeFi governance tokens (UNI, LINK), stablecoins (USDT), and prominent altcoins (SOL, ADA, DOT, AVAX). This diverse portfolio is designed to reflect the complex internal correlations and systemic risks inherent in the market. For instance, BTC functions as the market bellwether, exerting significant influence over broader asset classes; ETH, as the premier smart contract platform, serves as a proxy for the utility of the decentralized ecosystem; while USDT liquidity dynamics are critical indicators of overall capital flow.

Table 1.
Nomenclature of Selected Cryptocurrencies.
The descriptive statistics presented in Table 2 reveal significant heterogeneity in the risk return profiles across these assets. First, dominant assets such as BTC and ETH are characterized by high valuations and substantial volatility. BTC’s negative kurtosis (−0.66) suggests a platykurtic distribution with a broad fluctuation range, whereas ETH approximates a normal distribution. Second, assets like BCH and SOL demonstrate elevated relative volatility; notably, BCH’s high kurtosis (3.88) indicates a leptokurtic distribution, implying significant tail risk. Third, the majority of non-stablecoins (e.g., DOGE, AVAX, LTC, ADA) exhibit distinct positive skewness, suggesting a right-tailed distribution likely driven by speculative trading behavior. DOGE is particularly notable for its extreme skewness (1.86) and kurtosis (4.69), reflecting acute sensitivity to market sentiment. Finally, while USDT confirms its stability with a mean approximating 1.0, its extreme kurtosis (67.52) and skewness (5.11) underscore rare but critical de-pegging risks. In summary, the market is characterized by high volatility in large-cap assets, fat tails in altcoins, and tail risks in stablecoins, providing a robust and challenging data foundation for time-series modeling and risk management.
Table 2.
Descriptive Statistics of the Cryptocurrency Portfolio.
4.2. Prediction Models
The CryptoForecastCF framework was evaluated across a diverse set of deep learning architectures, representing the classic method in time series forecasting. To guarantee a rigorous comparative analysis, model-specific architectural hyperparameters were initialized according to standard configurations found in the literature [31,32], while common training hyperparameters were optimized via grid search on the validation set. The selected architectures include:
- GRU: As a quintessential Recurrent Neural Network (RNN), the Gated Recurrent Unit excels at capturing long-term temporal dependencies. The optimal configuration identified consists of two stacked GRU layers, each comprising 100 hidden units.
- Seq2seq [33]: Leveraging an encoder–decoder framework, this model is adept at handling variable-length sequences for multi-step forecasting. The optimized architecture employs RNN blocks coupled with fully connected layers of 256 units.
- WaveNet [34]: This architecture utilizes causal dilated convolutions to capture patterns across varying temporal scales. Superior performance was achieved using a WaveNet structure with residual skip connections and a filter size of 256.
- N-Beats [31]: A pure deep neural architecture based on backward and forward residual links and a very deep stack of fully-connected layers. We employed a doubly residual stacked architecture with 256 hidden units.
The lookback window d was fixed as a multiple of the prediction horizon T (specifically ), adhering to established practices [32]. All models were trained using the Adam optimizer. Hyperparameter tuning on the validation set yielded an optimal learning rate of , a batch size of 128, and a maximum of 100 training epochs. An early stopping strategy with a patience of 10 epochs was implemented to prevent overfitting. The Mean Absolute Error (MAE) served as the objective function for training.
4.3. Counterfactual Method Evaluation
In this study, the counterfactual explanations generated by CryptoForecastCF are benchmarked against two baseline methods. The core hyperparameters for CryptoForecastCF were set to a learning rate of and a maximum iteration count of 100. The regularization coefficient was fine-tuned on the validation set to ensure the stability and convergence of the optimization process. The baseline methods include:
- Input Gradient (Grad) [35]: A gradient-based attribution method that identifies input features or time steps with the highest sensitivity regarding the prediction output. Although it is not strictly a generative counterfactual approach, it serves as a baseline for assessing model sensitivity.
- BaseShift [36]: A heuristic baseline that employs a naive shifting strategy, applying fixed shift factors (e.g., the average expected change) to the entire input lookback window to generate “modified” inputs.
4.4. Evaluation Metrics
To rigorously evaluate the performance of the proposed framework, we adopt a two-tiered validation strategy focusing on both predictive fidelity and the quality of the counterfactual explanations.
4.4.1. Predictive Performance Metrics
To assess forecasting accuracy, we employ the symmetric Mean Absolute Percentage Error (sMAPE) and the Mean Absolute Scaled Error (MASE) as primary indicators. To ensure statistical robustness, all reported results represent the mean performance derived from five independent experimental trials across the entire test set.
4.4.2. Counterfactual Evaluation Metrics
The quality of the generated counterfactual explanations is evaluated across three distinct dimensions: (1) Effectiveness, quantifying the extent to which the counterfactual predictions satisfy the desired target constraints; (2) Proximity, measuring the deviation of the counterfactual samples from the original input space to ensure minimal alteration; and (3) Plausibility, assessing the realistic feasibility and statistical alignment of the generated perturbations with the underlying data manifold.
Effectiveness Metrics
To quantify effectiveness, we utilize the Validity Ratio and the Stepwise Validity AUC. The Validity Ratio computes the mean proportion of time steps within a generated counterfactual sequence that successfully satisfy the target constraints:
where denotes an indicator function that returns 1 if the prediction falls within the specified bounds , and 0 otherwise.
Complementing this, we introduce the Stepwise Validity AUC to assess the temporal continuity of valid predictions. This metric calculates the Area Under the Curve (AUC) for the function , which represents the proportion of counterfactuals that maintain validity for at least t consecutive time steps:
where is derived from a cumulative validity check , enforcing the strict condition that a time step is considered valid only if all preceding steps also satisfy the constraints. For both metrics, values approaching 1 denote superior performance.
Proximity and Plausibility Metrics
To evaluate the minimal alteration and realistic nature of the counterfactuals, we employ the following metrics: Proximity [22] (the average Euclidean distance between the original and counterfactual samples, where lower values are preferred); Compactness [22] (measuring the sparsity of modifications, where higher values indicate more focused changes).
4.5. Experimental Results and Discussion
This section presents a comparative evaluation of the proposed CryptoForecastCF method against the BaseNN and BaseShift baselines across four deep learning architectures. The experiments utilize 18 cryptocurrencies daily closing prices from 22 September 2020 to 12 March 2024. Table 3 summarizes the performance across prediction quality, counterfactual effectiveness, and counterfactual quality. Bold entries denote the optimal performance for each model-metric pair.
Table 3.
Performance Comparison of Counterfactual Explanation Methods under Different Deep Learning Models.
4.5.1. Multi-Horizon Results
Table 4 reports the aggregated multi-horizon performance over the 18-cryptocurrency test set for . Two consistent patterns emerge. First, forecasting difficulty increases with horizon: both sMAPE and MASE generally rise as T grows, reflecting the compounding uncertainty in longer-range cryptocurrency prediction. Second, counterfactual effectiveness remains high at moderate horizons (e.g., and ), but degrades for specific architectures at long horizons (notably Seq2Seq at ), indicating that certain model classes can be substantially harder to steer into the desired interval when the forecast window becomes long.
Table 4.
Multi-horizon performance comparison (aggregated over the 18-cryptocurrency test set). Results are reported for different forecasting horizons days.
Notably, the Step-AUC values for the 1-day setting are reported as 0.000 across methods. This is expected because the stepwise validity curve becomes degenerate when (there is no multi-step continuity to accumulate), so the resulting AUC does not provide meaningful discrimination in the single-step case. Therefore, Step-AUC should be interpreted primarily for multi-step horizons () where temporal consistency is non-trivial.
4.5.2. Asset-Level Results
Table 5 provides an asset-level breakdown under the default setting (). The results highlight strong cross-asset heterogeneity: large-cap assets (e.g., BTC, ETH) typically exhibit higher counterfactual validity under N-BEATS/WaveNet/GRU, while more volatile altcoins (e.g., SOL, AVAX) often show substantially lower validity and Step-AUC, indicating that steering predictions into a target interval can be considerably harder in high-volatility regimes. In addition, the per-asset view makes clear that model choice interacts with asset characteristics: for example, Seq2Seq shows severe instability on some assets (e.g., extreme sMAPE for BTC), suggesting that its learned dynamics may be less robust for certain price processes and horizons in this experimental setup.
Table 5.
Per-cryptocurrency (asset-level) performance for the default setting (). The table is organized into two parallel sections with horizontal separators for each asset.
4.5.3. Prediction Performance Analysis
sMAPE Metric Analysis: The CryptoForecastCF framework exhibits exceptional capability in preserving prediction fidelity across all evaluated architectures. Specifically, the sMAPE on the N-BEATS model was reduced to 9.8%, representing a 40.2% improvement over BaseShift (16.4%) and a 28.5% improvement over BaseNN (13.7%). This substantial reduction underscores the capability of CryptoForecastCF to preserve the fidelity of the underlying predictive model while generating counterfactual samples through end-to-end optimization. Notably, the method not only preserves prediction performance during counterfactual generation but also appears to positively influence the prediction accuracy of the underlying models, likely due to the deep utilization of model internal structures during the optimization process.
MASE Metric Analysis: In terms of the Mean Absolute Scaled Error, CryptoForecastCF consistently outperformed the baselines. MASE values for all models were maintained below 0.731, significantly surpassing the naive prediction baseline (MASE = 1.0). For the N-BEATS model, the MASE value of 0.672 represents a 28.7% improvement over BaseShift (0.943). These findings corroborate the efficacy of the gradient-based optimization strategy, which systematically navigates the feature space to avoid the accuracy degradation often associated with the heuristic perturbations employed by traditional methods.
4.5.4. Counterfactual Effectiveness Evaluation
Validity Metric Analysis: CryptoForecastCF demonstrated superior performance in counterfactual effectiveness. The validity on the N-BEATS model reached 92.4%, indicating that 92.4% of the generated counterfactual samples successfully satisfied the target constraints. This performance significantly surpasses BaseNN (74.3%) and BaseShift (65.1%), yielding improvements of 24.4% and 41.9%, respectively. These results validate the robustness of the gradient-guided optimization, demonstrating its ability to reliably steer predictions across decision boundaries to meet user-defined objectives.
Step-AUC Metric Analysis: The Stepwise Validity analysis reveals that CryptoForecastCF excels in maintaining the temporal continuity of valid predictions. The Step-AUC on the Seq2Seq model reached 83.2%, indicating high target consistency across the entire prediction horizon. With an average improvement exceeding 20% compared to baseline methods, this metric highlights the method’s stability in long-sequence forecasting tasks. The superior Step-AUC scores reflect the efficiency of CryptoForecastCF in progressively achieving targets, underscoring the continuity and coherence of its optimization trajectory.
4.5.5. Counterfactual Quality Analysis
Proximity Metric Analysis: Regarding the minimization of input modifications, CryptoForecastCF achieved significant optimization. The Proximity value on the Seq2Seq model was 0.159, indicating that only a 15.9% deviation from the original input was required to achieve the expected targets. This represents a 46.6% reduction in perturbation magnitude compared to BaseShift (29.8%) and a 27.4% reduction compared to BaseNN (21.9%). This advantage in identifying minimal necessary changes aligns with the principle of sparsity in counterfactual explanations, thereby enhancing their interpretability and trustworthiness for end-users.
Compactness Metric Analysis: The analysis of change concentration demonstrates that CryptoForecastCF effectively localizes modifications to critical temporal segments. The Compactness value on the N-BEATS model reached 87.1%, implying that 87.1% of the modifications were concentrated in a few key positions. This significantly outperforms BaseShift (68.7%) and BaseNN (75.6%). Such a highly concentrated modification pattern improves the actionability of the counterfactual explanations, enabling users to pinpoint the specific temporal events that most significantly influence the model’s predictive outcome.
4.6. Ablation Study Analysis
4.6.1. Sensitivity to Desired Change Magnitude
Table 6 indicate that the optimal values for the desired change parameter (desired_change) are predominantly concentrated within the (i.e., ) interval. Within this range, the majority of models achieve a superior equilibrium between counterfactual effectiveness and quality. For instance, the N-BEATS model attains a Validity of 0.848, Step-AUC of 0.697, Compactness of 0.715, and an optimal Proximity of 0.083 when desired_change is set to 0.1. Similarly, GRU and WaveNet exhibit peak performance at desired_change = −0.1. It is noteworthy that while Proximity and Compactness remain exceptional within the interval, the Seq2Seq model demonstrates diminished Validity (e.g., 0.008), suggesting that insufficient perturbation magnitudes may fail to drive certain architectures to generate effective counterfactuals. Conversely, as the absolute value of desired change increases (), Validity and Compactness decline across all models, while Proximity increases significantly. This trend suggests that excessive prediction targets compromise the plausibility of the generated counterfactual explanations by necessitating unrealistic input perturbations.
Table 6.
Ablation Study Results of Desired Change Parameter on CryptoForecastCF Method Performance.
These findings reflect the inherent trade-offs in counterfactual generation: smaller desired_change values favor proximity and plausibility while maintaining adequate effectiveness, whereas larger values disrupt this balance. N-BEATS, WaveNet, and GRU display distinct performance peaks, indicating sensitivity to this parameter, while Seq2Seq’s consistent underperformance suggests limited applicability for this specific method under low-magnitude changes. Given that prediction quality metrics (sMAPE, MASE) reflect inherent model properties unaffected by post hoc counterfactual generation, the optimal desired_change should be selected to maximize counterfactual effectiveness and quality.
Based on this analysis, we recommend an optimal parameter interval of for the CryptoForecastCF method. Within this range, the framework consistently achieves optimal or near-optimal comprehensive performance. From an optimization perspective, this interval provides a balanced constraint that facilitates the search for solutions sufficiently close to the original inputs while satisfying the counterfactual objectives.
4.6.2. Impact of Standard Deviation Fraction
Table 7 elucidates the impact of the standard deviation fraction () parameter on the performance of CryptoForecastCF. This parameter defines the permissible search space for counterfactual generation relative to the intrinsic variability of the data. The experimental results reveal a distinct trade-off between effectiveness and counterfactual quality.
Table 7.
Ablation Study Results of Standard Deviation Fraction Parameter on CryptoForecastCF Method Performance.
Across all four prediction models, setting consistently yields the optimal balance for predictive accuracy and validity. For instance, the N-BEATS model achieves its lowest sMAPE (9.8%) and highest Validity (92.4%) at this threshold. This finding suggests that aligning the search space with the natural volatility of the data (i.e., one standard deviation) provides sufficient flexibility for the algorithm to identify feasible counterfactuals that satisfy the target constraints without introducing excessive noise.
However, the data also highlights a divergence in optimization objectives. While maximizes effectiveness, lower parameter values (0.25) result in superior Proximity and Compactness scores. For example, at , N-BEATS achieves a Proximity of 0.089 and Compactness of 0.934, significantly outperforming the values at (0.145 and 0.871, respectively). This indicates that tighter constraints force the model to make smaller, more concentrated changes, albeit at the cost of reduced Validity (dropping to 75.6% for N-BEATS). Conversely, increasing beyond 1.0 (to 1.5–2.0) degrades both predictive quality and counterfactual sparsity, as the expanded search space allows for larger, less realistic perturbations.
Consequently, we identify as the robust default configuration for practical applications where high validity is paramount. It ensures high counterfactual effectiveness (>88% across models) while maintaining acceptable similarity to original inputs. However, for scenarios strictly prioritizing minimal modification, a lower fraction may be preferable, provided the associated reduction in validity is acceptable.
5. Conclusions
This paper addresses the critical imperative for interpretability in deep learning-based cryptocurrency forecasting by introducing CryptoForecastCF, a rigorous interval-constrained counterfactual explanation framework. By formalizing the problem through the core principles of input modification, prediction validity, constraint satisfaction, and modification minimization, and leveraging a gradient-based optimization strategy with dynamic masking, the proposed method efficiently generates actionable, high-fidelity explanations. Empirical evaluations substantiate the framework’s superiority, demonstrating a greater than 20% improvement in counterfactual effectiveness and a reduction of over 30% in input perturbations compared to baselines. These technical advancements translate into substantial practical utility for the fintech industry: empowering traders to validate algorithmic signals, facilitating precise stress testing via “what-if” simulations, and providing transparent audit trails for regulatory compliance. While the current reliance on white-box gradient access and structured OHLCV data presents certain limitations regarding proprietary systems and multi-modal market drivers, these constraints delineate clear pathways for future investigation. Prospective research will focus on integrating unstructured sentiment data to enable comprehensive market analysis, extending the architecture to Graph Neural Networks to capture systemic risk contagion, and exploring model-agnostic reinforcement learning approaches to eliminate gradient dependencies. Ultimately, CryptoForecastCF establishes a foundational paradigm for trustworthy, transparent, and actionable AI within the high-stakes domain of financial decision-making.
Author Contributions
Conceptualization, X.L.; methodology, X.L.; software, X.L.; investigation, X.L.; writing—original draft preparation, X.L.; visualization, X.L.; writing—review and editing, W.Y.; supervision, W.Y.; funding acquisition, W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Social Science Fund of China Program, grant number 24BJY093.
Data Availability Statement
The original data presented in the study are openly available on GitHub at https://github.com/xinxinluo123 (accessed on 3 December 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Fang, F.; Ventre, C.; Basios, M.; Kanthan, L.; Martinez-Rego, D.; Wu, F.; Li, L. Cryptocurrency trading: A comprehensive survey. Financ. Innov. 2022, 8, 13. [Google Scholar] [CrossRef]
- Katsiampa, P. Volatility estimation for Bitcoin: A comparison of GARCH models. Econ. Lett. 2017, 158, 3–6. [Google Scholar] [CrossRef]
- McNally, S.; Roche, J.; Caton, S. Predicting the price of Bitcoin using machine learning. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 339–343. [Google Scholar]
- Cheng, D.; Yang, F.; Xiang, S.; Liu, J. Financial time series forecasting with multi-modality graph neural network. Pattern Recognit. 2022, 121, 108218. [Google Scholar] [CrossRef]
- Feng, F.; He, X.; Wang, X.; Luo, C.; Liu, Y.; Chua, T.S. Temporal relational ranking for stock prediction. ACM Trans. Inf. Syst. 2019, 37, 27. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In KDD ’20: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; Association for Computing Machinery: San Diego, CA, USA, 2020; pp. 753–763. [Google Scholar]
- Zhou, Y.; Xie, C.; Wang, G.J.; Gong, J.; Zhu, Y. Forecasting cryptocurrency volatility: A novel framework based on the evolving multiscale graph neural network. Financ. Innov. 2025, 11, 87. [Google Scholar] [CrossRef]
- Hoa, T.T.; Le, T.M.; Nguyen-Dinh, C.H. Hybrid model of 1D-CNN and LSTM for forecasting Ethereum closing prices: A case study of temporal analysis. Int. J. Inf. Technol. 2025, 17, 3999–4011. [Google Scholar] [CrossRef]
- Amirshahi, B.; Lahmiri, S. Investigating the effectiveness of Twitter sentiment in cryptocurrency close price prediction by using deep learning. Expert Syst. 2025, 42, e13428. [Google Scholar] [CrossRef]
- Kaur, R.; Uppal, M.; Gupta, D.; Juneja, S.; Arafat, S.Y.; Rashid, J.; Kim, J.; Alroobaea, R. Development of a cryptocurrency price prediction model: Leveraging GRU and LSTM for Bitcoin, Litecoin and Ethereum. PeerJ Comput. Sci. 2025, 11, e2675. [Google Scholar] [CrossRef]
- Peng, P.; Chen, Y.; Lin, W.; Wang, J.Z. Attention-based CNN–LSTM for high-frequency multiple cryptocurrency trend prediction. Expert Syst. Appl. 2024, 237, 121520. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From principles to practices. ACM Comput. Surv. 2023, 55, 177. [Google Scholar] [CrossRef]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy artificial intelligence: A review. ACM Comput. Surv. 2022, 55, 39. [Google Scholar] [CrossRef]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Gajcin, J.; Dusparic, I. Redefining counterfactual explanations for reinforcement learning: Overview, challenges and opportunities. ACM Comput. Surv. 2024, 56, 219. [Google Scholar] [CrossRef]
- Prado-Romero, M.A.; Prenkaj, B.; Stilo, G.; Giannotti, F. A survey on graph counterfactual explanations: Definitions, methods, evaluation, and research challenges. ACM Comput. Surv. 2024, 56, 171. [Google Scholar] [CrossRef]
- Goyal, Y.; Wu, Z.; Ernst, J.; Batra, D.; Parikh, D.; Lee, S. Counterfactual visual explanations. Proc. Mach. Learn. Res. 2019, 97, 2376–2384. [Google Scholar]
- Feder, A.; Keith, K.A.; Manzoor, E.; Pryzant, R.; Sridhar, D.; Wood-Doughty, Z.; Eisenstein, J.; Grimmer, J.; Reichart, R.; Roberts, M.E.; et al. Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Trans. Assoc. Comput. Linguist. 2022, 10, 1138–1158. [Google Scholar] [CrossRef]
- Delaney, E.; Greene, D.; Keane, M.T. Instance-based counterfactual explanations for time series classification. In Case-Based Reasoning Research and Development. ICCBR 2021; Springer: Salamanca, Spain, 2021; pp. 32–47. [Google Scholar]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual explanations for machine learning: A review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Karimi, A.H.; Schölkopf, B.; Valera, I. Algorithmic recourse: From counterfactual explanations to interventions. ACM SIGKDD Explor. Newsl. 2021, 23, 49–61. [Google Scholar]
- Guidotti, R. Counterfactual explanations and how to find them: Literature review and benchmarking. Data Min. Knowl. Discov. 2024, 38, 2770–2824. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841–887. [Google Scholar] [CrossRef]
- Mothilal, R.K.; Sharma, A.; Tan, C. Explaining machine learning classifiers through diverse counterfactual explanations. In FAT* ’20: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; Association for Computing Machinery: Barcelona, Spain, 2020; pp. 607–617. [Google Scholar]
- Gilo, D.; Markovitch, S. A general search-based framework for generating textual counterfactual explanations. In AAAI’24/IAAI’24/EAAI’24: Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI Press: Vancouver, Canada, 2024; Volume 38, pp. 18073–18081. [Google Scholar]
- Wang, Z.; Miliou, I.; Samsten, I.; Papapetrou, P. Counterfactual explanations for time series forecasting. In Proceedings of the 2023 IEEE International Conference on Data Mining (ICDM), Shanghai, China, 1–4 December 2023; pp. 1391–1396. [Google Scholar]
- Yan, J.; Wang, H. Self-interpretable time series prediction with counterfactual explanations. In ICML’23: Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; JMLR.org: Honolulu, HI, USA, 2023; pp. 39110–39125. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2019, arXiv:1905.10437. [Google Scholar]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Peng, C.; Li, Y.; Yu, Y.; Zhou, Y.; Du, S. Multi-step-ahead host load prediction with gru based encoder-decoder in cloud computing. In Proceedings of the 2018 10th International Conference on Knowledge and Smart Technology (KST), Chiang Mai, Thailand, 31 January–3 February 2018; pp. 186–191. [Google Scholar]
- Dorado Rueda, F.; Durán Suárez, J.; del Real Torres, A. Short-term load forecasting using encoder-decoder wavenet: Application to the french grid. Energies 2021, 14, 2524. [Google Scholar] [CrossRef]
- Finlay, C.; Oberman, A.M. Scaleable input gradient regularization for adversarial robustness. Mach. Learn. Appl. 2021, 3, 100017. [Google Scholar] [CrossRef]
- Tang, C.; Chen, X.; Yao, H.; Yin, H.; Ma, X.; Jin, M.; Lu, X.; Wang, Q.; Meng, K.; Yuan, Q. Enhanced oral absorption of icaritin by using mixed polymeric micelles prepared with a creative acid-base shift method. Molecules 2021, 26, 3450. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.