1. Introduction
Graph Neural Networks (GNNs) [
1,
2,
3,
4] are of pivotal importance for the advancement of AI in structural domains such as molecular chemistry, social-network analysis [
5], and even algorithmic reasoning [
6,
7]. GNNs are
node-centric, since they exploit adjacency information to learn latent spaces where the nodal features are encoded for node classification and graph classification. Link/edge prediction, however, does usually rely on the latent representations of the nodes supposed to form an edge.
So far, capturing the latent spaces of edges has been an elusive problem. For instance, HOPE [
8] exploits the powers of the adjacency matrix to assign asymmetric roles (source and target) to the nodes via a double embedding. This leads to edge prediction, but the resulting long-range similarity tends to diffuse local contexts, which results in poor node classification. The NERD method [
9] overcomes the latter limitation by using alternating random walks, a standard method for estimating node centrality in directed graphs [
10]. These walks provide, again, two embeddings: one for the source role of the node and another for its target role. The product of these embeddings provides a good performance in link prediction and graph reconstruction, and the concatenation of the embeddings is also competitive with node-centered methods in node-classification.
However, the issues derived from addressing edge-related tasks such as link prediction from a node-centric angle have not been recognized until recently [
11]. The degree distribution of most social networks follows a power law: a small number of nodes has a large number of neighbors, whereas most of the nodes have a small degree, and they are in the tail of the degree distribution. This is the so-called
long-tail effect: link prediction of GNNs is greatly hindered by the tail node pairs since they share few neighbors. See, for instance,
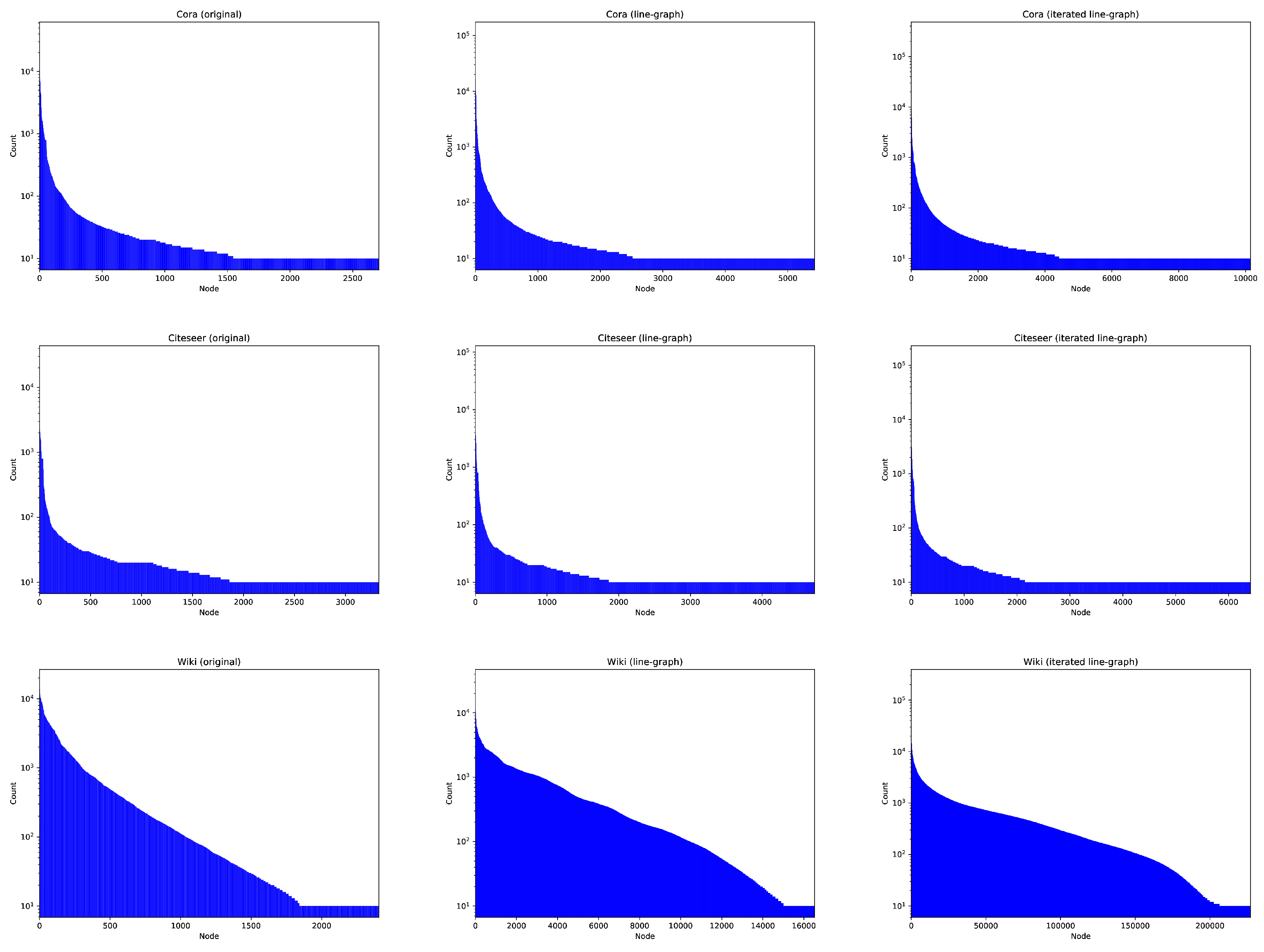
Figure 1-Left, where we plot the probabilities of reaching each node from a bunch of random walks for three social networks. Therein, the tail effect is quite visible: half of the nodes are unreached. However, in the Center and Right columns of
Figure 1 we present more entropic distributions, thereby mitigating the long-tail effect to some extent, but how do we construct these distributions?
Maximum Entropy Latent Spaces. Instead of modifying the structure to increase the number of neighbors among under-represented nodes, as done in [
11], we propose a more principled approach in this paper. In particular, we
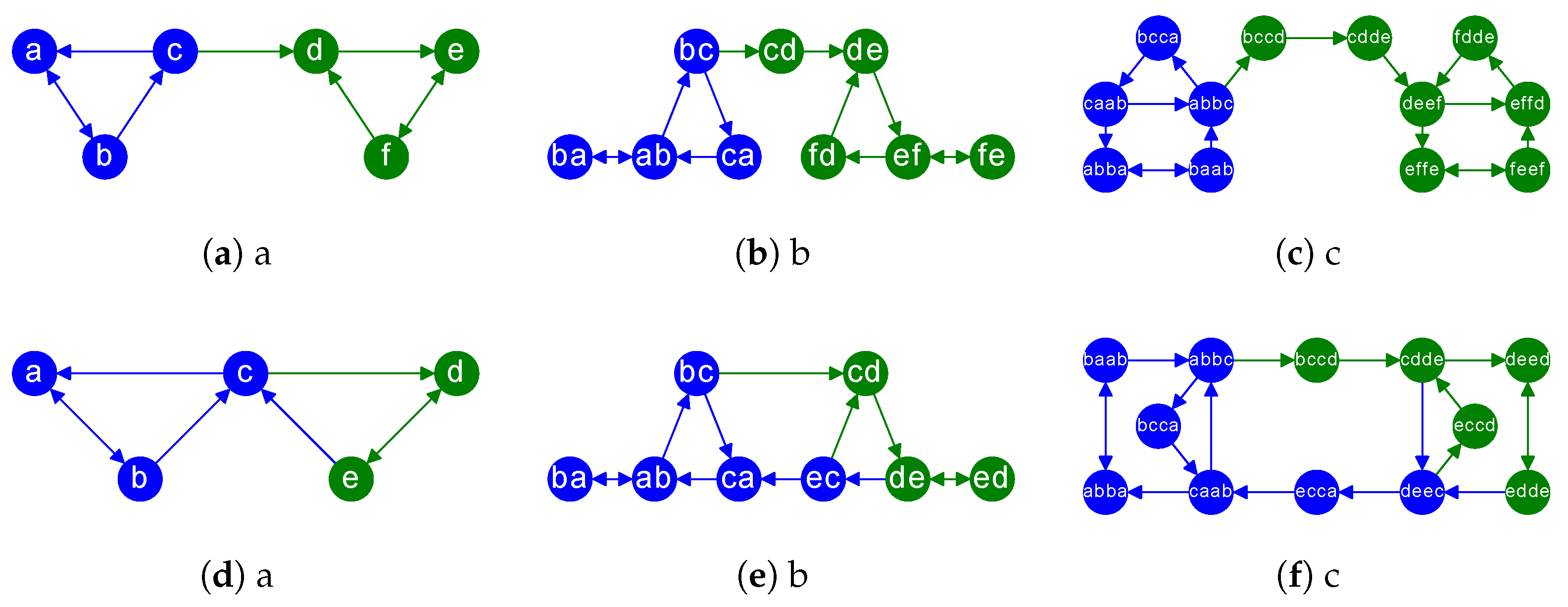
turn our attention to the latent spaces of edges themselves. Such spaces must produce similar codes for the edges having a similar structural role in the network. This requirement is even stronger when the networks encode causal relationships via directed edges. We show a couple of examples in
Figure 2-Left column
(a),
(d), where there are two distinct roles: intra-community edges and inter-community edges. The nodes of intra-community edges have the same color (blue and green, respectively), whereas inter-communities have different colors in their nodes.
Then, in
Figure 2-Center column
(b),
(e), we show a graph, say
, where the nodes are the edges of the original graph
, i.e.,
. There is an edge
iff
and
. In other words, edges in
, the so-called
line graph of
G, encode transitive relationships in
G. As a result, paths and loops are shortened in the line graph. Since the edges of
G are now the nodes of
, we can apply a node-centric approach to
in order to uncover the properties of the latent spaces of the edges in
G. Independently of whether we use a node2vec-like embedding [
12,
13,
14,
15,
16] or the embedding resulting from a state-of-the-art (SOTA) or more recent GNN [
17,
18,
19,
20,
21], the subsequent latent space relies on how the structure constrains the random walks exploring it.
For instance, the Center and Right columns of
Figure 2, show the line graphs of the graphs in the previous columns. A brief observation reveals that the line graph produces denser communities while preserving inter-class edges. Thus, shortening the paths and loops is respectful of the community structure of the graph: communities become redundant, but the inter-community information flow is preserved. In other words, random walks launched inside a given community visit it faster, but their probability of visiting another community is preserved with respect to the one in the original graph.
Main Contribution. Considering the above observations, and pointing out that has nodes instead of , in this paper we give spectral arguments showing that line graphs lead naturally to quasi-maximum entropy embeddings.
Thus, this paper goes beyond the previous (instrumental) uses of line graphs. For instance, in the LGNN (line graph NN) model [
22], line graph features complement node-based features for community detection. Similarly, in PRUNE [
23] line graphs are implicitly computed via second-order proximity (considering the respective direct predecessors and successors of node pairs). Second-order proximity was introduced in LINE [
14]. However, in [
24] second-order proximity is used to bridge the microscopic scale of nodes with the mesoscopic community structure. This is interpreted in PRUNE via tri-factorization. Finally, GNNs have recently incorporated convolutions on both nodes and edges [
25], and transfer learning [
26] has been applied to node-centric approaches. In this latest regard, node-centric embeddings fail to capture transferable edges since they infer edges in a node-centric way and they are subject to the long-tail effect. We conjecture that modeling edges themselves would help to better transfer structural information.
Organization of the paper. The remainder of the paper is organized as follows. In
Section 2, we introduce the main properties of line digraphs and uncover the formal relationship between nodal embeddings and the embedding of edges/paths. This relationship is linked to the rank property of the line digraph (the rank of a line digraph is the number of nodes of the original digraph), and this makes the difference in classification and clustering. Actually, large rank is an algebraic interpretation of maximum entropy [
27]. In
Section 3, we present our experimental results (edge classification and clustering), both in node2vec-like methods and GNNs, where we compute a proxy of the nodes classification/clustering. We show that this proxy not only outperforms the original (node-centric) classification and clustering but also has stable performance at different levels of sparsification. Finally, in
Section 4, we sketch our conclusions and future work.
2. Method
2.1. Embedding Edges and Paths
This section presents the main theoretical contribution of this paper: the linearity theorem and its corollary, namely the rank-preservation property. We commence by defining line digraphs and introducing some of their formal properties. We focus our attention on two complementary concepts: (a) The preservation of the non-zero spectrum of the original digraph; (b) The relative density and diameter.
Given an input graph G, its line digraph tends to shorten the cycles in G, and this results in holding a small degree and diameter with respect to G. When we translate these facts to the respective transition matrices, we find out that running random walks in (instead of in G) results in the following: (a) Sampling a larger number of nodes; (b) Doing the sampling in a more efficient way (lower probability of returning to the origin); (c) Getting less oversampled nodes, which makes the representation less biased towards notable nodes, i.e., more entropic, thus reducing the long-tail effect.
With the above properties at hand, we prove (linearity theorem) that the similarity between two edges (entry of the r—the power of the transition matrix of ) is a linear combination of the similarities between several pairs of nodes (entries of the transition matrix of G). Since the respective embeddings of the nodes of G and those of (the edges of G) rely on the weighted sums of these powers, we have that the matrix-to-factorize for tends to preserve its rank much better than that for G (rank-preservation corollary). This corollary explains why embedding the line digraph and using the labels of the destination nodes provides better classification and clustering performances than embedding the nodes of the original graph (we test this hypothesis in the experimental section).
Therefore, we contribute with theoretical results having important practical implications beyond explaining the link between the embedding of edges and that of nodes. In general, due to the iterative property of line digraphs, our rationale is extensible to line digraphs of line digraphs (path embedding), provided that there are enough computational resources to compute and store the iterated digraph. In this regard, we rely on digraph sparsification techniques to make this method scalable.
2.2. Line and Iterated Line Digraphs
Similarity of G and . Let
be a digraph with
n nodes
V and
m edges
E. Its line digraph
is a graph where the nodes
are the edges of
G and there is an edge between two nodes of
if
, i.e., if the edges
share the node
. Then,
G and
are encoded by their respective adjacency matrices which are related as follows:
where
is the
incidence matrix of heads with
if the node
i is the head of the edge
j and
otherwise, and
is the
incidence matrix of tails, with
if the node
i is the tail of the edge
j and
otherwise.
Example. Consider the Top-Left digraph (directed graph) in
Figure 2. We have
and
. The edges are ordered in lexicographic order:
. Then, we have the following matrix product
:
Note that the rows of
correspond to the edges in
G and the respective columns contain the target node of each edge. The first edges in
are given by
and
:
and
respectively. Then, we have
leading to
and
and
leading respectively to
and
. Then, we obtain 12 edges in
: the nodes of the digraph in
Figure 2b.
An
iterated line digraph , with
is
. For instance, in
Figure 2 we have that the digraph
(c) is
, that is, the line graph of
: see digraph
(c) with 12 nodes. Definitively, computing iterated line graphs allows us to understand the
latent spaces of directed paths encoding causal chains.
Coding Intuition: The Rank Property. As shown in the example above, we have highlighted (in bold) the rows that are
unique, i.e., those defining the algebraic rank of
. We will build our
linearity theorem on a result from [
28]: rank
. However, at this point in the paper, the intuition that there are as many
different connectivity patterns in as nodes in G is quite useful for the reader. Actually, this fact reveals the coding properties of
wrt
G. We highlight two basic consequences:
- (a)
We have that . Note that node2vec-like latent spaces are rooted in a SVD factorization (PCA) involving the adjacency matrix. As a result, the latent spaces of are, at least, as entropic as those of G: exactly codewords are needed to explain the ways of linking the nodes of .
- (b)
When it comes to GNNs, we observe a similar result. The foundational mechanism of a GNN is message passing: (i) Nodes are endowed with feature vectors; (ii) These vectors are propagated using the adjacency; (iii) The vectors received by each node are combined and projected on a learnable matrix. Having implies that of the nodes in integrate their neighboring information in a different and orthogonal way. As a result, the subsequent latent spaces the nodes in are at least as entropic as those of the nodes in G. These spaces are actually less prone to the over-smoothing problem (hindering of the performance by decreasing the entropy of the coding due to repeated aggregation).
2.3. The Spectral Argument
The rank property is transferred to random walks as follows.
Preservation of the spectrum of G in . The line digraph
is somewhat redundant with respect to
G: the respective adjacencies
and
are called
Flanders pair in [
29]; they have the same non-zero eigenvalues, with the same multiplicities, and also have the same number of distinct eigenvectors and generalized eigenvectors in each case associated with these non-zero eigenvalues (see also [
30]). The transition matrices
and
also share the same non-zero spectrum. This is key for understanding how random walks sample both
G and
. In particular, we have [
31]:
(equal traces for all powers of
).
Transport Efficiency. The condition
leads to the following expected probabilities of returning to the starting node:
and
, where
and
. Borrowing the terminology from continuous-time random walks,
and
quantify the
efficiency of the respective random walks in terms of diffusing far from the origin (the smaller, the more efficient) [
32]. Thus,
is more efficient than
G, and to some extent this mitigates the long-tail effect, as we show in
Figure 1.
Quasi-Maximum Entropy. Maximal Entropy Random Walks [
33] require that paths of a given length
r are equiprobable. The condition
for all
r, leads to
, i.e.,
. Then, the denser
G we have
and
(maximal efficiency). Under these conditions, we have Maximal Entropy for any cycle of any length. This is consistent with envision the
as a quasi-entropy maximizers with respect to
G: it maximizes the entropy of
G subject to preserving the spectrum. Since the transition matrices
and
share the same non-zero spectrum, they have an identical asymptotic behavior (same maximal eigenvalue).
Density and diameter of G vs. . Line digraphs hold small degree and diameter in relation to their large number of nodes
m [
28]. This means that when we are forced to place
m nodes in
with respect to the
n nodes of
G,
(loosely) works as a complete digraph without forcing each node to be adjacent to all the others [
34]. More formally, some line graphs are
almost Moore graphs. For instance, if the order (sum of all nodes that can be reached from any node) of
G is upper bounded [
35] by
, then the order of
is upper bounded by
, where
D is the diameter of
G, and
is the leading eigenvalue of
(and
since both matrices share the non-zero spectrum). Therefore, we have
vs.
bounds. These bounds control, respectively, the reachability of the nodes in both graphs. Again, the largest reachability bound of
allows us to mitigate the long-tail effect.
2.4. The Rank Property of LDEs
Since node-centric graph embeddings can be seen as factorizing a matrix
relying on the powers of
, the transition matrix [
36], the above properties suggest a deeper analysis of
vs.
. (The respective
matrices-to-factorize for
G and
). In particular, the preservation of the non-zero spectrum in
with respect to that of
for
suggests a link between both matrices to factorize and, consequently, between their respective embeddings. Therefore, uncovering this link allows us to understand (and then characterize) the structural differences between the respective latent spaces of nodes and edges (or even paths) for the same graph.
More precisely, the standard factorization approach for network embedding [
36] states that the latent representations for nodes of
are obtained from the SVD of
, where
is the Pointwise Mutual Information (PMI) matrix. More recently, Qiu et al. [
15] showed that
can be posed in the following terms:
where
is the transition matrix of
G. This emphasizes the role of the random walks (RWs) in the resulting embedding. In particular, Qiu et al. show that the negative spectrum of
is filtered out (zeroed) even for moderate values of the
window size T. In practice, this leads to bound the singular values of
by its eigenvalues (The formal proof is only correct when the
average matrix is symmetric.). Since the eigenvalues of
decay exponentially, one should expect small optimal embedding dimensions for locally dense graphs, due to their small spectral gap [
37,
38]. In addition, the factorization of
provides a loss function (quality of the
K-rank approximation) for quantifying the relative distortion of the current embedding with respect to that of an ideal one [
39].
Herein, we extend the above analysis to link nodal embeddings with the embedding of higher-order entities (edges, paths, etc.). To that end, we compare the factorizaton of
with that of
or
. This is particularly interesting when considering directed networks (digraphs), where the following conditions apply: (a) We have a more flexible/general model; (b) There is solid mathematical machinery linking the ranks of
G,
, and
[
28,
31], as well as emphasizing the optimal diameter, degree preservation, and density of line graphs and their iterations [
35,
40].
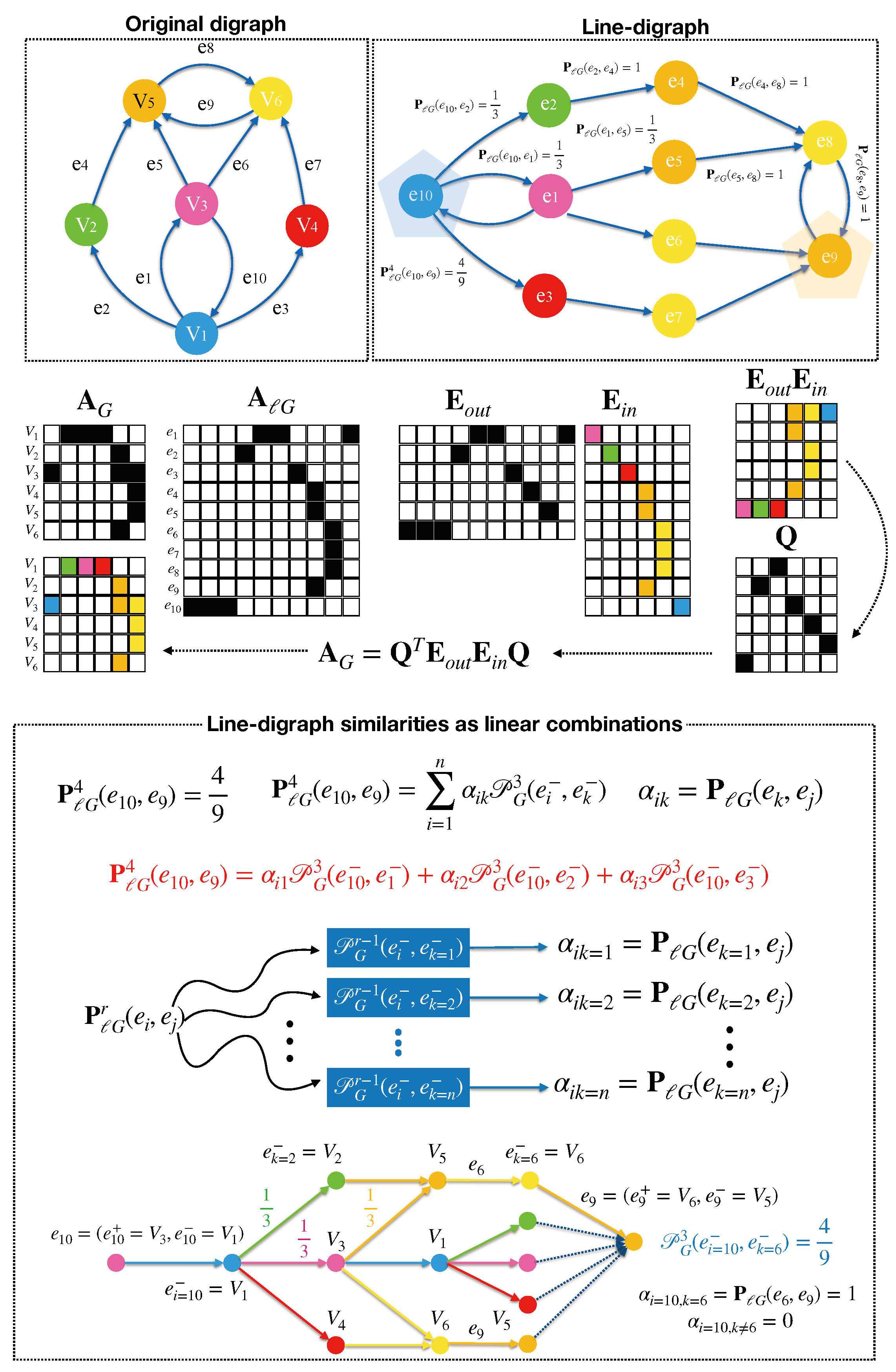
Here follows our main formal result in this paper. The intuition behind the following theorem is that random walks of length
r in
are linear combinations of
random walks in
G of length
for any length
(see
Figure 3).
Theorem 1 (Linearity)
. Embedding edges can be posed concerning the linear combination of node embeddings. For a strongly connected digraph , i.e., without sinks and sources, and with line digraph , we have the following relationship between edge similarity and node similarity:where is the transition matrix of , is a permutation of , the transition matrix of G and denotes the directed edges (“out-of” and “into” components) of E (the nodes of ). Proof. If
is strongly connected, then we have that rank
, with
(see Lemma 4.2 in [
28]). In addition, following the characterization theorem for the adjacency matrices of line graphs (Theorem 10 in [
31]), we have that given two of the
rows of
, they are either orthogonal or identical. As a result, there are only
n different rows or
prototypes in
, say
, each one representing a
class of equivalence (see
Figure 3). Therefore,
can be factorized as follows:
, where
is a
indicator matrix with
, if
belongs to the class of
and 0 otherwise; on the other hand,
is the
matrix containing the different rows of
(characteristic patterns of linkage of the line graph).
Interestingly, the prototypes
, are defined by the “into” node
since edges ending in the same node
in
G exhibit the same pattern of linkage in
. As a result,
, where
is a
permutation matrix where
if
and 0 otherwise, with
. In addition, the transition matrices of both
G and
store the same probabilities in the non-zero positions and we have
and
, where
. Then, we have
where
is the permuted
. Then, we obtain
, which is an
matrix. Since
is a rank-
n indicator matrix, the resulting
matrix has only
n distinct rows, i.e., many edges have the same probabilistic pattern of linkage. This is why the
matrix
retains only the different rows of
and it is the matricial version of Equation (
4). □
The proof of the linearity theorem uncovers the differences between the structure of
(see Equation (
3)) and that of
. These differences lead to the rank preservation property of
. This property is summarized by the following corollary:
Corollary 1 (Rank Preservation). The structure of preserves better the rank than it does for values of T (window size) closer to the mixing time of .
The proof is in
Appendix A, where we refer the reader for a deeper understanding of the link between rank preservation and random walks.
2.5. Implications of Using Line Digraphs
In light of the formal analysis above, line digraphs and their embeddings have several pros and cons.
Implications of Rank Preservation. This is a key property for LDEs (Line Digraphs Embeddings) since the rank of the similarity matrix (and therefore that of the embedding) is closely related to the optimal dimension of the embedding. Following [
41], a too-low dimensionality discards too much signal power, and this leads to a high bias (many vectors in the embedding collapse). On the other hand, a very large dimensionality leads to a high variance (the embedding becomes a noisy subspace). The optimal dimensionality is upper bound by the rank of the embedding. Thus, if we set a given dimensionality
, LDEs (Line Digraph embeddings) hold a rank close to
, whereas DEs (Digraph embeddings) do not generally reach this rank. As a result, LDEs retain naturally the most informative part of the signal (which reduces the bias) with respect to DEs.
Finally, Theorem 1 and its corollary lead to the following definition of the component-wise similarity for the line digraph:
Therefore, factorizing allows us to classify edges in . Since herein the label of the edge is that of the destination node, we thus obtain a proxy to classify nodes in G. As a result, the differences in node-classification performance between and are due to the following:
- (a)
The flexibility of combining linearly many probabilities (actually n terms) for defining a single probability of linking any pair of edges in the line digraph.
- (b)
The better rank preservation for the line digraph embedding with respect to its nodal counterpart. The rank of is even for large values of the window size T. Since edges with the same destination nodes are hashed to nearly the same embedding vector (see the proof of Theorem 1), this enforces the coherent classification of these destination nodes.
Implications in Edge Mining. As an additional result, the component-wise Katz similarity (used in HOPE [
8]) with
is
, where
is a permutation of
, and we down weight the number of paths between each pair of nodes in
(edges in
G). Such paths are linear combinations of the corresponding paths in
G. This can be used to predict links in
(second-order paths in
G), to quantify the centrality of an edge (apply [
42] to the line digraphs embeddings). We may also identify edge-hubs and authorities (applying HITS [
43] to the line digraph, see
Figure 3).
The Need for Sparsification. Computing the line digraph of a realistic (i.e., large) digraph is very challenging since we have
nodes in the line digraph (the worst case arises with dense digraphs). To overcome this limitation, we must rely on
digraph sparsification to
filter out non-critical edges before embedding the line digraph. Although graph sparsification theory is mostly developed for non-directed graphs [
44,
45], there are recent approaches focused on asymmetric adjacency matrices, i.e., designed for digraphs. Herein, we follow Cohen et al.’s notion of matrix approximation:
two adjacency matrices and are similar if their symmetrizations hold good spectral properties. They are spectrally similar [
46]. With this notion to hand, we have that a good approximation (sparsification)
should preserve the in-degrees and out-degrees of
(Lemma 3.13 of [
46]). As a result, the node
in
(edges in
will be sampled with probability
:
where
and
are, respectively, the out-degree of
i and the in-degree of
j. The probability of keeping the error of the approximation below
with probability
p is achieved with sampling independently
edges (see Theorem 3.9 in [
46]).
In our experiments, we will analyze how competitive is the line digraph embedding in terms of classifying and clustering nodes with a decreasing number of sampled edges. Therefore, our approach is consistent with analyzing the robustness of the embedding to attacks (graph poisoning) [
39]. Since edges are removed according to not linking good hubs with good authorities, both hubs and authorities are preserved as much as possible (hubs visit many authorities, and authorities are visited from many hubs). However, the singular gap (difference between the main singular value and the second best) may be reduced. Thus, we interpret the performance stability as evidence of the preservation of the singular gaps [
47].
3. Experimental Results
3.1. Experimental Setup
In this paper, we analyze the following networks:
(a)
Directed single-label citation networks: Cora [
48]—Citation network containing 2708 scientific publications with 5278 links between them. Each publication is classified into one of 7 categories. CiteSeer for Document Classification [
48]—Citation network containing 3312 scientific publications with 4676 links between them. Each publication is classified into one of 6 categories. Wiki—Contains a network of 2405 web pages with 17,981 links between them. Each page is classified into one of 19 categories.
https://github.com/thunlp/MMDW/ (accessed on 10 March 2025). Citeseer and Cora have been retrieved from LINQS (
https://linqs.soe.ucsc.edu/data, accessed on 10 March 2025). See
Table 1 for details.
(b)
Originally undirected multi-label networks: Protein-Protein Interactions (PPI)—Subgraph from PPI corresponding to Homo Sapiens.
https://downloads.thebiogrid.org/BioGRID (accessed on 10 March 2025) [
49]. Wikipedia Part-of-Speech (POS)—Co-occurrence of words appearing in the first million bytes of the Wikipedia dump. The categories correspond to the Part-of-Speech (POS) labels inferred by the Stanford POS-Tagger. Facebook social circles [
50] that are treated as directed by adding bidirectional edges. These datasets have been retrieved from SNAP (
https://snap.stanford.edu/node2vec/, accessed on 10 March 2025) [
51]. See
Table 2.
All the experiments were run on an Intel Xeon(R) W-2123 CPU @ 3.60 GHz , equipped with a GeForce RTX 2080 Ti and 32 Gb RAM. Regarding the hyper-parameters of node2vec and NetMF, we have used window size , rw-path length , 10 walks per node, and dimension of the embedding vectors . The down-weighting parameter for the HOPE algorithm is . The obtained results are quite invariant to changes in these settings.
3.2. Classification Experiments
Protocol. The classification experiments are performed by training a logistic regression classifier with the embedding vectors corresponding to 50% of the nodes and tested with the remaining vectors, using the OpenNE framework (
https://github.com/thunlp/OpenNE, accessed on 10 March 2025). Some cells in the results tables have been left blank due to computational limitations. Concerning the sparsification level, for the
inverse degree of sparsification IDS
, we sample
edges with probability
given in Equation (
7). A descending IDS illustrates better than a pair
the robustness of the embedding.
Then, we proceed to embed edges and use these embeddings for edge classification and/or clustering. Since edges inherit their labels from nodes, the latter process returns a proxy representation for node classification or clustering.
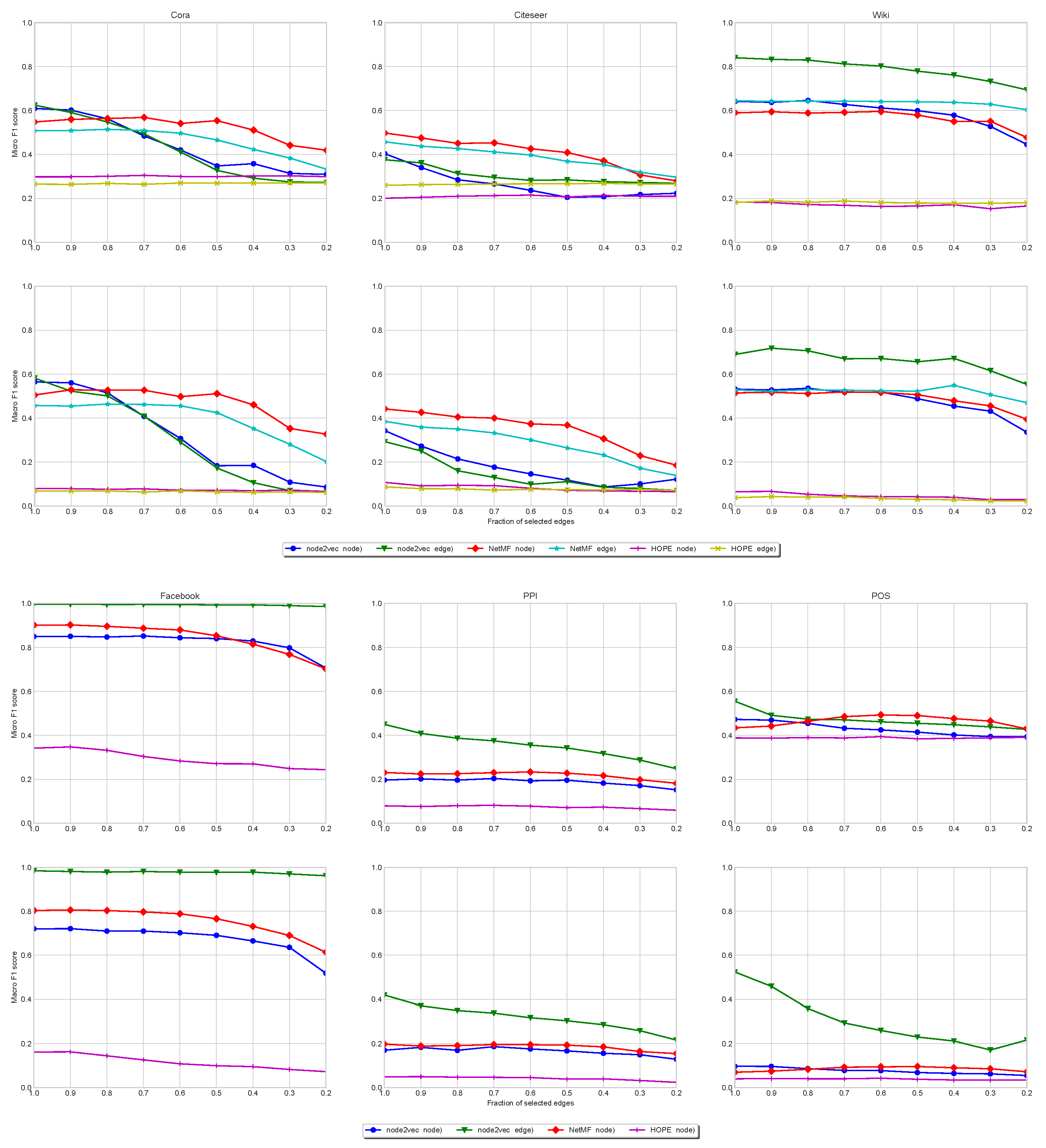
Citation Networks. In
Figure 4-Top, we show the stability of node classification for Cora, Citeseer, and Wiki. In all cases, the node and edge (line digraph) versions of NetMF are quite stable, even for small values of IDS (very sparse). However, the reachability patterns of Cora and Citeseer follow a power law with respect to the visiting of nodes in random walks (see
Figure 1), which does not change when we apply the line graph (see their large numbers of sources and sinks in
Table 2). Under these conditions, the random walks running on the line digraphs cannot reach many more different (contextual) nodes than when they run on the original graphs. This leads to very redundant embeddings. In addition, they have a low edge density. As a result, the LDE (node2vec(edge)) is not always the best alternative (especially in Citeseer).
However, for the Wiki network, the reachability pattern does not follow a power law (see
Figure 1). In addition, the reachability pattern of the line digraph is even more entropic than that of the original graph. This is consistent with having much less sinks than Cora and Citeseer. It also has less sources than these networks but the higher density of the network allows the random walks exploring the line digraph to reach many different nodes. This leads to less redundant embeddings for the nodes of the line digraph. The node2vec(edges) algorithm works better because it reduces the redundancy with respect to the NetMF factorization.
In all cases, HOPE is stable but its performance is the lowest. It is only competitive with NetMF and node2vec in Cora and Citeseer because of their power laws. This is consistent with some findings showing that Katz similarity is competitive for networks with high-degree node coverage [
52].
Undirected Multi-label Networks. Regarding PPI, Facebook, and POS, in
Figure 4-Bottom, we show that in all cases the line digraph improves significantly the classification scores of the alternatives. It is worth mentioning that in all the cases in which the line digraph presents a significant improvement, it corresponds to datasets with a large edge/node ratio (i.e., cases in which the size of the line digraph presents a drastic growth with respect to the original graph). This is also the case of Wiki, in the citation networks.
Stability Under Sparsification. Concerning the citation networks, we do not observe significant differences between the magnitudes and the evolutions of their average singular gaps. However, Wiki has larger gaps than Cora and Citeseer for large values IDS (a small fraction of removed edges). Additionally, the most stable network (Facebook) has the largest average singular gap for the line digraph representation: (line digraph) vs. (original graph).
Summarizing, the line digraph embedding improves the alternatives when it is possible to reduce the redundancy. This is explained by the rank property of the line digraph. In general, line digraphs are more robust than original graphs with respect to increasing levels of sparsification, especially when their average singular gap is large (Facebook).
3.3. Clustering Experiments
Protocol. We evaluate the performance of the obtained embeddings for community detection problems, by applying agglomerative clustering on the embedding vectors. The total number of classes
C is set to the number of labels. We analyze both the Adjusted Rand Index (ARI) and the modularity, which is defined for digraphs with adjacency matrix
, volume
W, and proposed partition:
, as
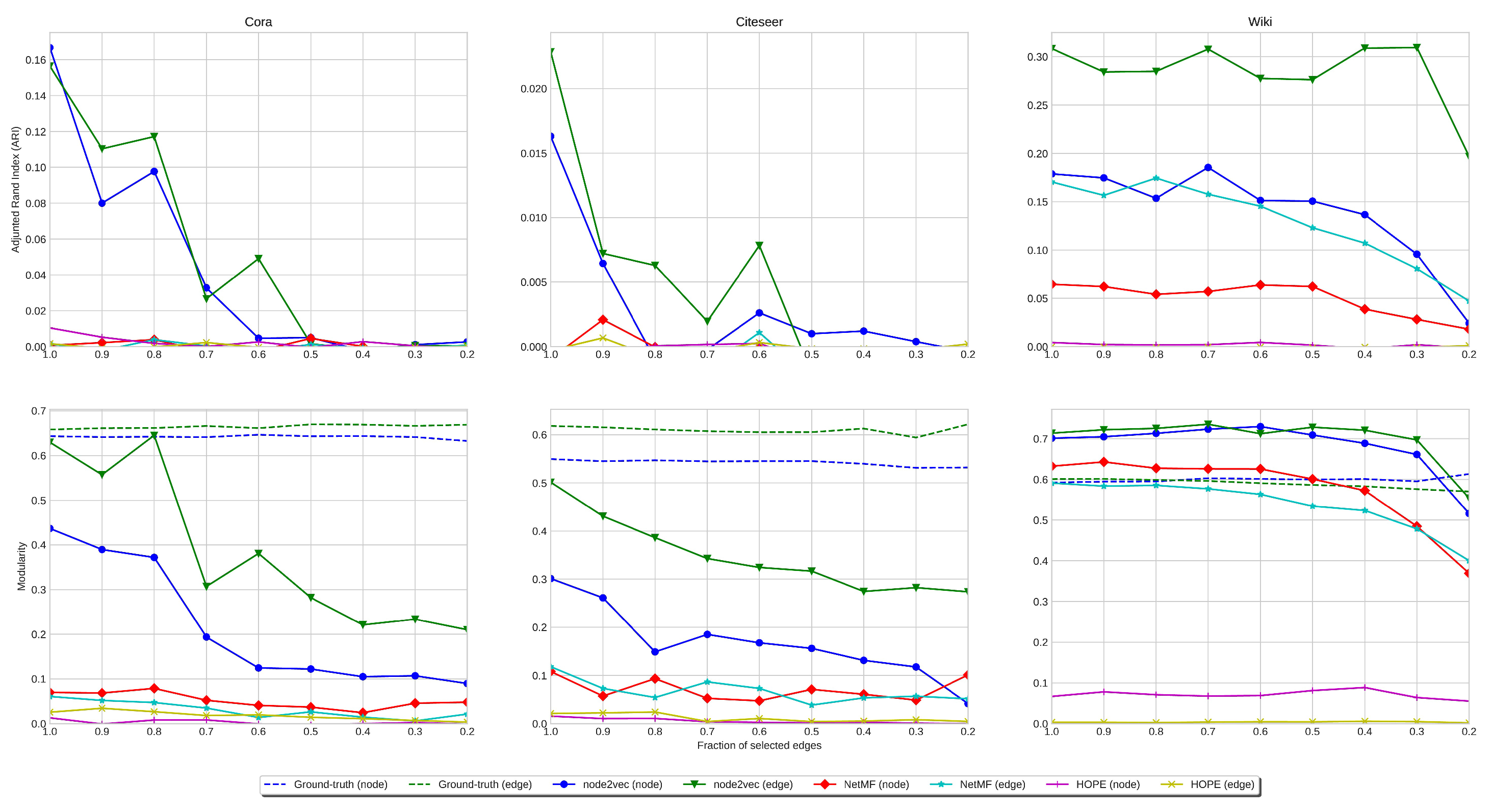
ARI Analysis. We run clustering experiments on all our single-label datasets: Cora, Citeseer, and Wiki. In
Figure 5, we show the ARI values obtained by clustering the embedding of the original graph and the line digraph corresponding to the citation datasets. In the case of Cora, the results with the original graph, the line digraph, and the iterated line digraph are similar, but in the other cases, the line digraph outperforms the results obtained with the original graph.
Modularity Analysis. Regarding modularity, we have obtained both the modularity of the partition given by the original labeling of the graphs (ground truth), and the modularity of the partition provided by the clustering. Consistently with the ARI values, the modularity obtained with the line digraph outperforms the results of the original graph. In addition, we can observe that the modularity of the ground truth is almost the same in the original digraph and the line digraph. Interestingly, in Wiki we outperform the clustering obtained with the ground truth labeling.
Stability under Sparsification. The performance of clustering is less stable than that of classification for increasing levels of sparsification (decreasing IDS). This is due to the multi-modality of the labelled communities. Summarizing, the performance of clustering is less stable than that of classification, but still the best results are obtained with the line digraph representation.
3.4. GNN Experiments
To further validate our theoretical findings about line digraphs and their stability under sparsification, we extended our analysis to modern Graph Neural Networks (GNNs). While our previous experiments focused on node2vec-like embeddings, here we evaluate whether the maximum entropy properties of line digraphs translate to improved performance with GNN architectures as well.
GNNs have emerged as powerful tools for learning graph-structured data by iteratively updating node representations through neighborhood aggregation schemes [
1]. In their simplest form, vanilla GNNs follow a message-passing framework where each node aggregates feature vectors from its neighbors and then applies a learnable transformation to update its own representation [
53,
54]. This process can be expressed as follows:
where
is the feature vector of node
v at layer
l,
represents the neighbors of
v,
is a learnable weight matrix, and
is a non-linear activation function.
We evaluated four state-of-the-art GNN architectures [
55] that extend this basic framework in different ways:
Graph Convolutional Networks (GCN) [
1]: Uses a simple weighted average of neighbor features with spectral motivation.
Graph Attention Networks (GAT) [
2]: Employs attention mechanisms to weight neighbor contributions differently.
GraphSAGE (SAGE) [
4]: Samples a fixed number of neighbors and learns how to aggregate their features.
Approximate Personalized Propagation of Neural Predictions (APPNP) [
3]: Separates feature transformation from propagation using personalized PageRank.
Following standard practice in the literature, we used the established split of 60% training, 20% validation, and 20% testing sets for all datasets. For each architecture and dataset, we implemented two different sparsification strategies:
The fraction of selected edges varied from 0.0 to 1.0 in steps of 0.1, allowing us to assess model robustness across different sparsification levels.
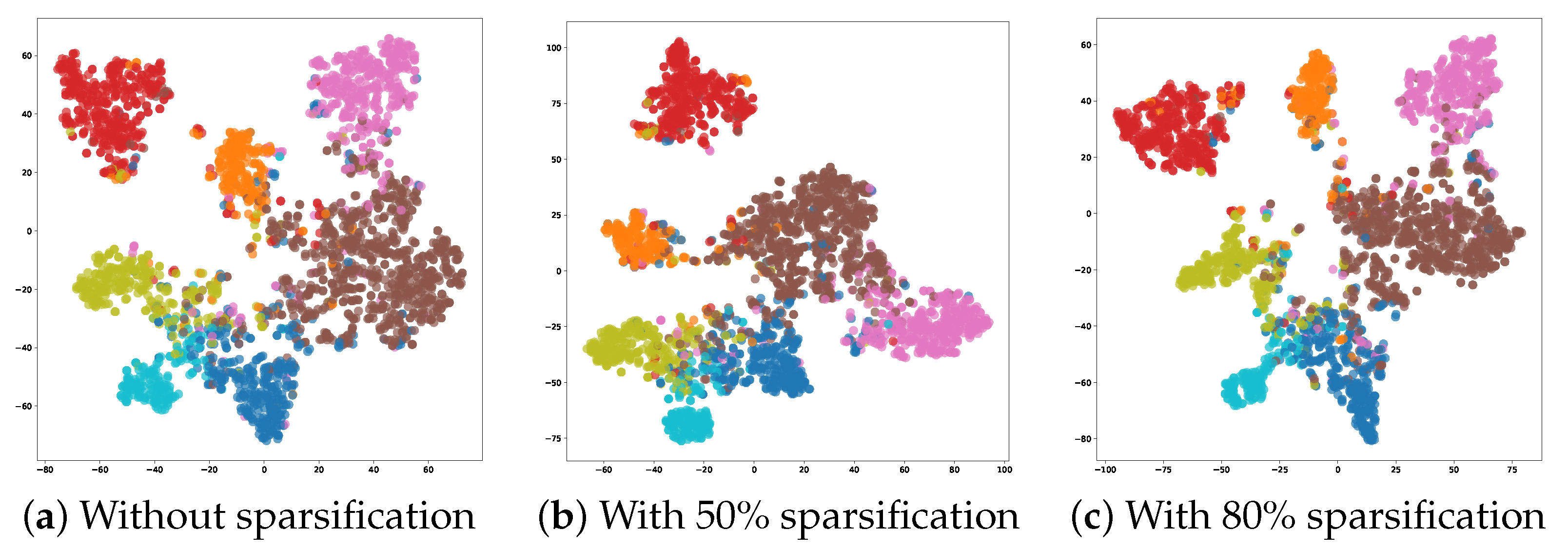
Figure 6 visualizes the learned edge embeddings from the line digraph of Cora using t-SNE dimensionality reduction at different sparsification levels. Remarkably, even with significant sparsification (80% of edges removed), the embedding space preserves clear community structures with well-defined boundaries between different classes. This visual evidence supports our theoretical claim that line digraphs maintain high entropy between communities even under aggressive sparsification, preserving the essential topological structure needed for node classification.
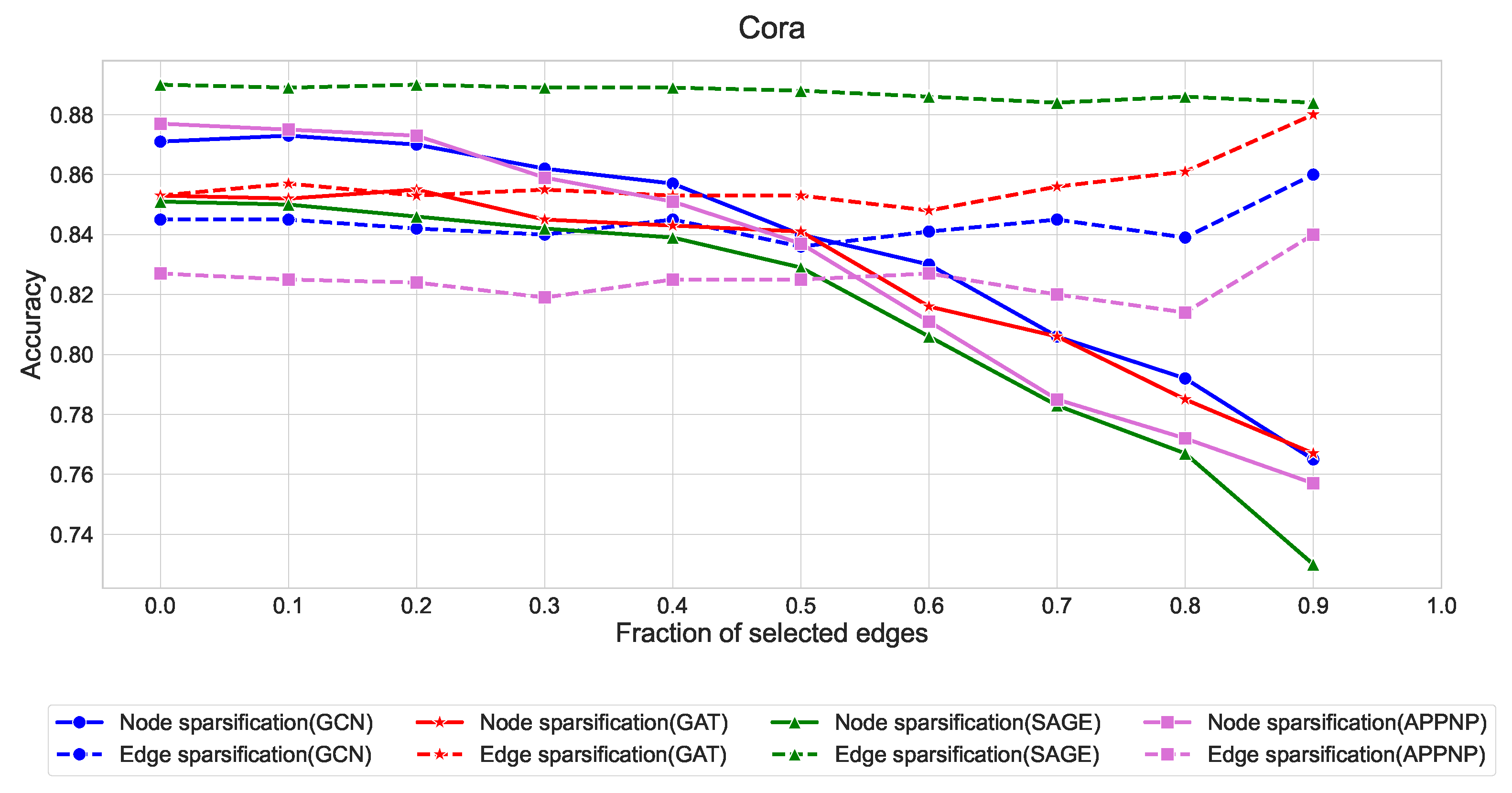
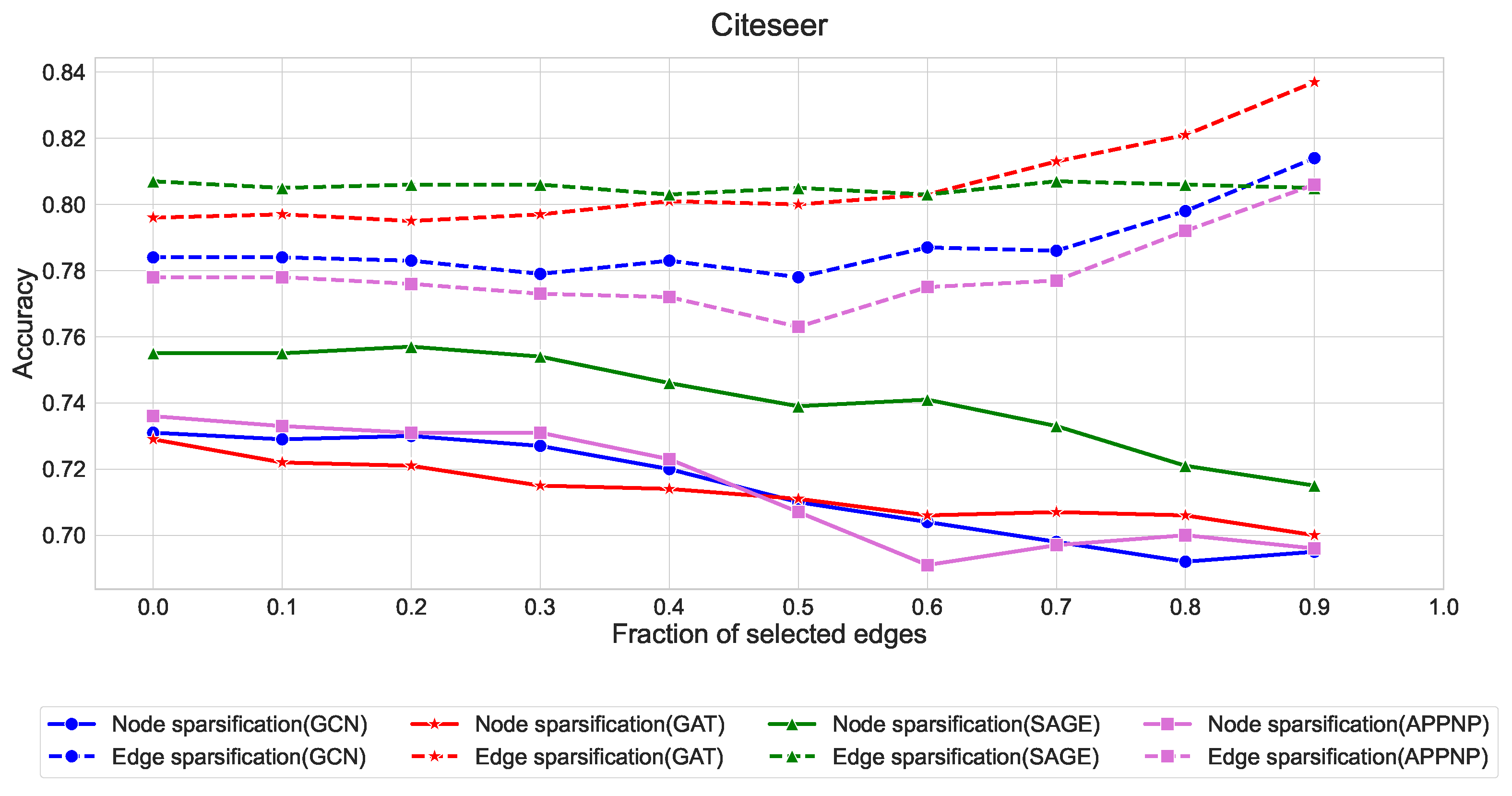
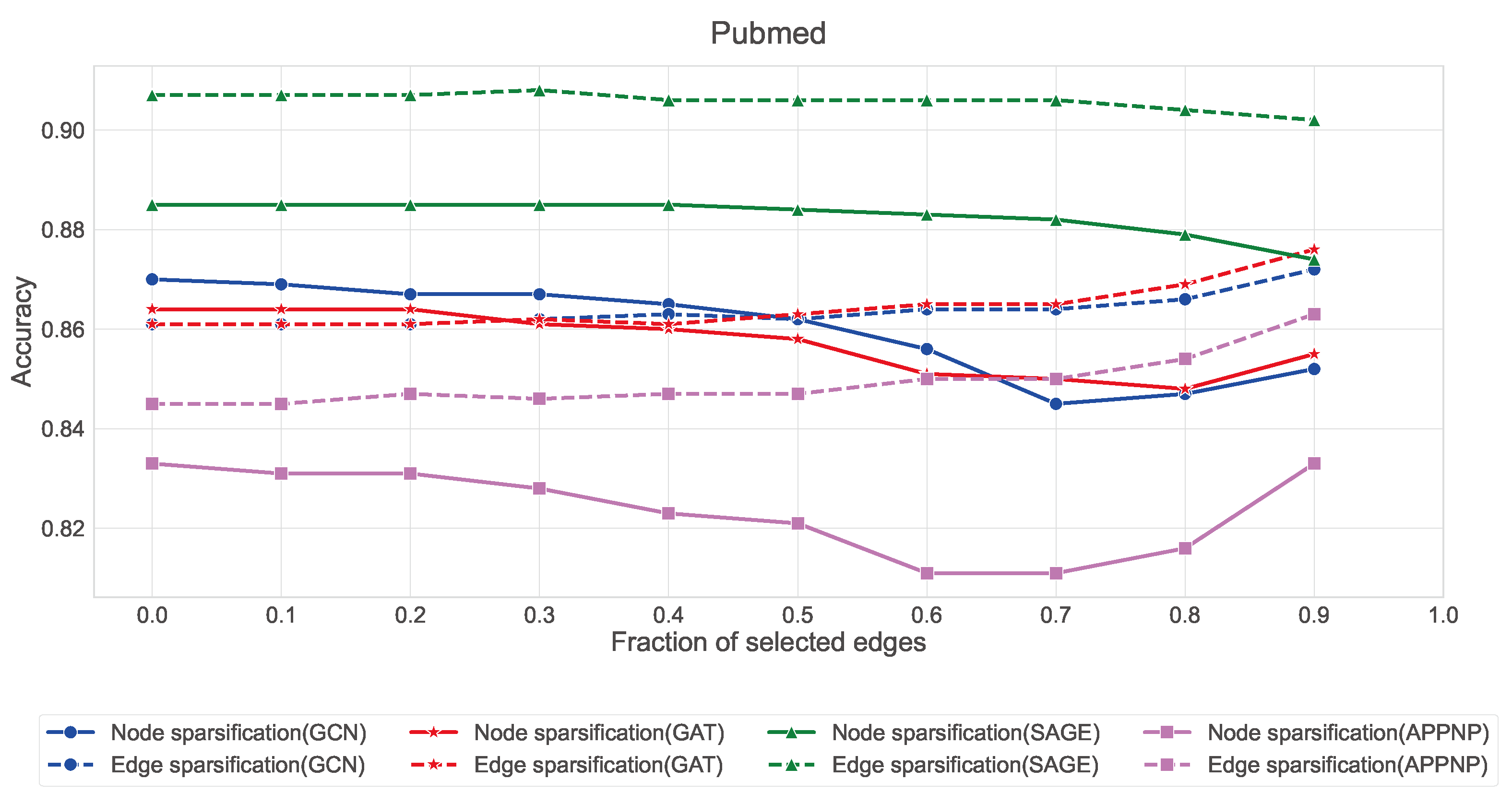
Edge sparsification consistently outperforms node sparsification across all three datasets, with the effect being most pronounced in Citeseer and Pubmed. This aligns with our theory that strategic edge sampling preserves more of the graph’s spectral properties than node-based approaches.
GraphSAGE exhibits remarkable stability under edge sparsification, maintaining accuracy above 88% in Cora, 80% in Citeseer, and 90% in Pubmed even with only 10% of edges. This robustness can be attributed to its neighborhood sampling strategy, which naturally accommodates sparser structures.
GCN and GAT show similar patterns, with edge sparsification providing better performance than node sparsification when the fraction of selected edges is below 0.5.
APPNP demonstrates higher sensitivity to sparsification compared to other architectures, suggesting its personalized PageRank-based propagation mechanism benefits from denser graph structures.
These findings complement our earlier analysis of node2vec-like embeddings, providing additional evidence that the line digraph representation can maintain high classification performance even under significant edge reduction. The consistency of these results across both traditional embedding approaches and modern GNN architectures validates our theoretical framework regarding the entropy-maximizing properties of line digraphs and their stability under sparsification.
4. Conclusions
In this paper, we have proposed an edge-centric embedding: embedding the line digraph instead of the original digraph. Our motivation is that node-centric approaches do not model edge directionality. We have uncovered a formal link between the embedding of edges and that of nodes. This link leads to the ranking property, which allows us to (a) better classify and cluster nodes of the original graph, when we use their respective directed-edges embeddings as proxies, and (b) better understand the latent spaces of both nodes and edges, which may explain the success of their co-embedding. In addition, we filter out in advance the non-critical edges of the original graph to make the line digraph computation scalable. Our experiments show that line digraphs are stable under increasing levels of sparsification. These experiments are performed from two different angles: for node2vec-like latent spaces, where our nodes do not have attributes (only topology), and GNNs, where each node is attributed and the combination between topology and aggregation determines the latent spaces. In both cases, the entropy-maximization margin of line graphs is key.
Future work is motivated by the scalability problems arising in dense graphs, but this is inherent to investigating the role of an edge in a graph. This requires the development of more powerful and even
learnable sparsifiers. In addition, the rank-preservation property (which is congruent with determinantal point processes) suggests that edge-embeddings could be more powerful than node-based ones for classifying graphs themselves through deep sets [
56]. Finally, we will test to what extent LDEs contribute to structural transfer learning [
26].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}