Abstract
We develop a novel framework for fiducial inference in linear mixed-effects (LME) models, with the standard deviation of random effects reformulated as coefficients. The exact fiducial density is derived as the equilibrium measure of a reversible Markov chain over the parameter space. The density is equivalent in form to a Bayesian LME with noninformative prior, while the underlying fiducial structure adds new benefits to unify the inference of random effects and all other parameters in a neat and simultaneous way. Our fiducial LME needs no additional tests or statistics for zero variance and is more suitable for small sample sizes. In simulation and empirical analysis, our confidence intervals (CIs) are comparable to those based on Bayesian and likelihood profiling methods. And our inference for the variance of random effects has competitive power with the likelihood ratio test.
MSC:
62F99
1. Introduction
The linear mixed-effects (LME) model is very popular in many fields like physics, biology and social sciences [1], where both within-subject and between-subject variations are studied. There have been a wealth of LME-based methodologies developed in the past decades, such as model selection [2], model averaging [3], semiparametric [4] and nonparametric [5] estimations, etc. Large-sample asymptotics of likelihood-based LME models are well studied [6]. Bayesian LME models also perform well under medium-to-large samples. For small samples, the inference based on the maximum likelihood needs finite-sample corrections or approximations [7], and Bayesian models rely much more on the prior.
The analysis of variance (ANOVA) and t-test summaries are two common ways of statistical inference in LME models. For fixed effects, F statistics in ANOVA and t statistics are available in most software. However, testing zero-variance components in random effects is challenging for small samples and has not been well resolved in the statistical literature. When some of the within-subject variances are zero or close-to-zero, Bayesian estimations may encounter issues [8]. And the inference of zero variance involves additionally constructed statistics like the profiling restricted maximum likelihood (REML) ratio test [9] or posterior evidence ratio with properly built prior [10]. Comparisons among multiple nested models are often unskippable.
From a frequentist viewpoint, aside from asymptotic approximations, the inference can be facilitated by nonparametric approaches [11,12], which are also known to be performant in LME models for small sample sizes. According to a comparative study [13] on various bootstrap methods in LME models, a nonparametric bootstrap with resampling on subjects is recommended [11].
Fiducial inference, initiated by Fisher [14] and revitalized in the 21st century [15], has unique advantages in small-sample inference in parametric statistical models, despite its limits in nonparametric statistics and computing cost [16]. Unlike Bayesian posterior built upon prior, fiducial distribution derived from data generation equations thus relieves the need for prior. For LME, Li et al. [17] proposed a fiducial test for within-subject variances, but they did not consider other parameters. Hari et al. [18] studied a two-component LME with partially known structures on covariances. Hannig et al. [19] developed a generalized fiducial inference (GFIlmm) for interval data. Although GFIlmm can be adapted to non-interval cases by artificially adding the intervals, the estimations vary with the interval widths. And its numerical algorithm in practice is inefficient on models with more than nine parameters.
In this study, we propose a new framework for non-asymptotic inference in LME models via a fiducial approach, which reduces computational burden and does not require duplicates within each group. Moreover, our approach naturally incorporates the zero-variance inference, thus cutting the labor of extra tests and calculation.
2. Fiducial Distribution in LME
We assume the data is generated as
where is a vector of fixed coefficients; is a random coefficient vector; is the response of the ith subject; and are the and covariate matrix of fixed and random effects, respectively; and is independent of , , , . In this study, we assume a diagonal .
2.1. Conditional Fiducial Distribution
Let , and , then model (1) can be rewritten as
It can be further specified in matrix form as
with , , , and . The in random effects are formulated as a coefficient vector in Equation (2). This brings two benefits: 1. The inference of random effects can be realized by a general fiducial recipe [16] like all other parameters, avoiding extra tests and statistics like the LR tests. 2. We do not need . The model can still be estimated even if . So, our method can handle inadequate within-subject measures.
Let , and , then model (2) given can be reformed as
For observed , the conditional fiducial density of and given u, denoted as and , respectively, could be derived from the conditional fiducial quantities [17] below:
where , independently, irrespective of any parameters in an LME model. Let , then the conditional fiducial density of given u is
Here, and is the likelihood function of (2) given .
U is invisible in reality. But, it is easy to see that with
. We denote the conditional density of U as hereinafter.
2.2. Gibbs Sampler and the Final Fiducial Distribution
With both and available, the fiducial distribution could be realized by a Gibbs sampler. Let . By Equations (5) and (6), we have
where and is the likelihood function with U integrated out. Obviously, is symmetric and satisfies the detailed balance below:
The final fiducial density, as the stationary distribution of , can be derived by the reversibility [20] of the Markov chain on :
which is equivalent to a Bayesian LME with uniform prior on and and prior on .
In practice, once a u sampled by Equation (6) makes close to y, the in Equation (3) also becomes close to 0, making in Equation (4) nearly constant and the Monte Carlo Markov Chain (MCMC) degenerated. So, we restrict ’s parameter space away from zero by a small so that and use the constrained fiducial quantity by a trimmed as follows:
where is the cumulative distribution function, is its inverse, and is a uniform random variable on . In this paper, we set . The Gibbs sampling algorithm is given in Algorithm 1.
| Algorithm 1: Gibbs sampling for |
Remark 1.
We can also start with Equation (9) by setting corresponding prior in ready-made Bayesian packages that employ algorithms with better quality like HMC or NUTS [21]. However, HMC is time consuming and loses the advantages of direct inference for . The histogram of a Gibbs sample on δ can directly reflect how much the distribution is concentrated around zero. So, we mainly use Gibbs in this study and leave HMC for future research.
Remark 2.
When D is non-diagonal, becomes , where R is the correlation matrix. And becomes . Given , the fiducial density of R, say , is also available [22]. The Gibbs sampler turns into iterations among three parts: , and . The fiducial density here is no longer equivalent to Equation (9) and cannot be readily implemented by Bayesian packages. We also leave this for future research.
3. Fiducial Inference for LME
Given the observed y, the fiducial distribution of a parameter of interest can be given as
3.1. Interval Estimation
A fiducial interval for parameter is formed by the and quantiles of , denoted as and , respectively, which are the solutions of
Then, the equal-tailed fiducial interval is .
Once we find a numerical sample of as Section 2.2 described, the fiducial interval of can be obtained from the empirical distribution of , which is given in Algorithm 2.
| Algorithm 2: Interval estimation for |
|
Noting that is conventionally nonnegative, we use its zero-truncated distribution to construct the CI such that the left end is . According to remark 2.1 and theorem 2.2 in [17], a truncated fiducial quantity uniquely solved from the fiducial structural equations has the same theoretical property as the untruncated one for inference in a restricted parameter space.
3.2. Fiducial p-Value
For a hypothesis test : with a two-sided alternative, the fiducial p-value is
Given a significance level , is rejected when . The computing procedure is given in Algorithm 3.
| Algorithm 3: Fiducial p-value for : |
|
Remark 3.
Algorithms 2 and 3 are routine constructions of the CI and p value in unimodal distributions. All the histograms of δ that we have plotted so far are unimodal in a Gibbs sampler, probably because the sign of δ and that of U are interdependent in model (2) while Gibbs updates δ largely based on U. But, this does not mean the bimodal shape will not occur for δ in other algorithms bypassing the sampling of since δ in Equation (9) is symmetric at about 0. For a bimodal distribution, routine p value and CI are not applicable but a histogram or density curve can directly tell.
4. Simulation
4.1. Confidence Intervals
We compare the coverages and lengths of CIs constructed by our method (Fiducial), the profiling method (Profiling) in R package lme4 [9], the Bayesian LME (Bayeisan) with default prior in R package brms (version 2.22.0) [10], and the nonparametric bootstrap (Bootstrap) in [13]. We generate a chain over 6000 in length, with the first 300 as a warmup, and select every 3 steps to gather a sample size N = 2000 for the Gibbs sampler in Algorithm 1. We also try the HMC in Remark 1 by setting a uniform prior for and , and is approximated by an inverse gamma prior IG(0.001, 0.001) in brms (The density of IG(a, b) is , . thus can be approximated by IG(a,b) with a and b close to 0.) Bootstrap CIs are constructed by percentiles of 2000 replicates resampled among subjects, and each replicate is estimated by REML (lmer in package lme4). All MCMCs are set as a single chain with a sample size of 2000. Coverages (nominal level ) are annotated in figures and tables, averaged over 1000 runs.
Example 1.
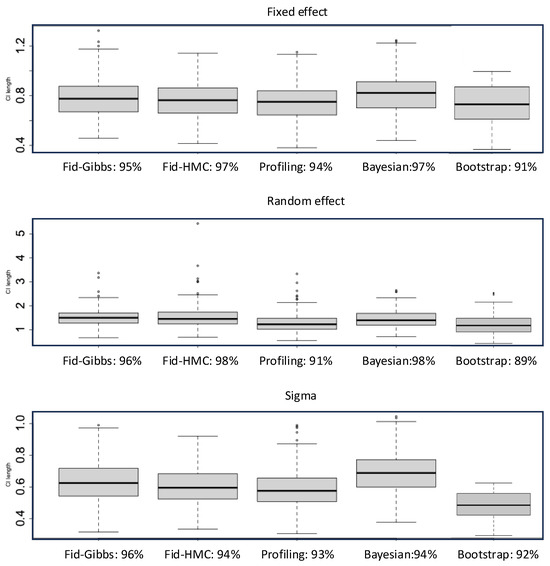
with , , , , , , , . In general, the Profiling CIs are narrower but susceptible to low coverages (Figure 1). Fiducial CIs are comparable to the Bayesian except those on are often wider. This can be improved by HMC yet it is much slower. We use Gibbs for our method afterward. Bayesian LME is time-consuming yet performs well, partly due to its advantages in small samples and partly due to the suitability of the default prior for this parameter setting. Bootstrap has the lowest coverages; perhaps the sample size here is too small for it to take effect. The relative CPU time for model fit plus CI construction in fiducial (Gibbs), profiling, Bayesian, and bootstrap is about 2:1:30:40. Given the underperformance of bootstrap in coverage and computation efficiency, we do not discuss it in later examples. The variations in CI length are similar across different methods. So, we summarize the median length in the table hereinafter.
Figure 1.
Confidence intervals in example 1.
Example 2.

with , , and the others the same as example 1. That is, we add a false random effect . Bayesian LME is unable to directly detect zero variance (coverage = 0 for , Table 1). Profiling CIs can have zero end points to keep reasonable coverages, but other parameters are affected, especially σ. Also, of ’s output contains NA or ∞ when . This is not a big issue when , but σ’s coverage is still lower. In contrast, fiducial CIs capture both zero and nonzero variances in random effects and have stable coverages (Table 1).
Table 1.
Coverage (length) of CIs in example 2.
Example 3.
with , , all from , , , a longitudinal setting with , so . does not work in this scenario, which makes profiling and bootstrap inapplicable. Bayesian CIs, overall, are wider with lower coverages than fiducial CIs (Table 2).
Table 2.
Coverage (length) of CIs in example 3.
4.2. Zero-Variance Test for Random Effects
We plot the histograms of fiducial samples on zero and nonzero . They are indeed different (Figure 2). Negative generated by Equation (4) helps in measuring the significance of the random effect. We further compare p value distributions under null (=0) and alternative (≠0) hypotheses by treating example 2 as with and others unchanged. Frequentist p values are calculated by the package lmerTest [23] with fixed effects based on Satterthwaite-approximated t tests and random effects based on likelihood ratio (LR) tests. Fiducial p values are calculated simultaneously as described in Section 3. The type I error and power at a significance level are annotated in Figure 3. The Satterthwaite p value has a higher type I error than the fiducial test (Figure 3). The type I errors of the fiducial and LR tests do not differ much, but the power of the fiducial test is higher. Moreover, the LR p value has a weird peak near 1 under alternative hypothesis (Figure 3), which is an obvious drawback in small data analysis. From this perspective, we think our fiducial approach can contribute to the inference in LME for small samples.
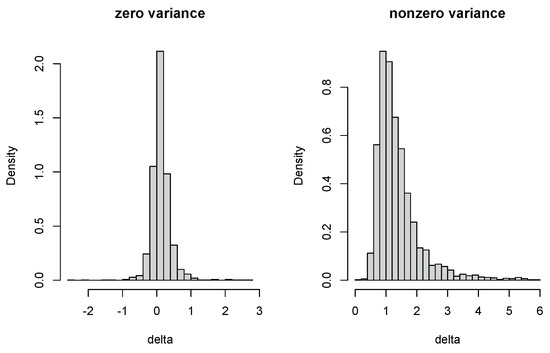
Figure 2.
Fiducial density for and .
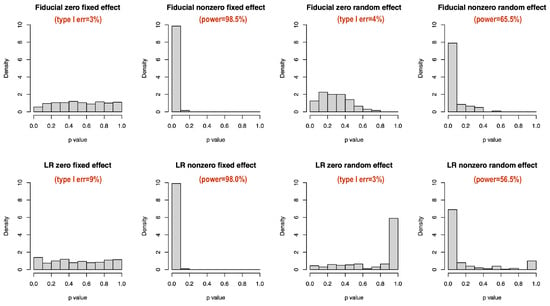
Figure 3.
p value comparison for fixed and random effects, n = 20.
4.3. Comparison with GFIlmm
For the GFIlmm in [19] (simplified as GFI hereinafter), we set a simpler scenario that their R package gfilmm (version 2.0.5) can run for comparsion: . Here, , , , and , j = 1, 2; . Intervals are added as . Performances on both zero and nonzero are compared (Table 3). The CIs in the nonzero case are comparable, and GFI is better in the zero case. We also plot histograms of the two fiducial p values. At a significance level, our method has lower type I error and higher power than GFI (Figure 4).
Table 3.
Coverages (length) of CIs in comparison with GFI.
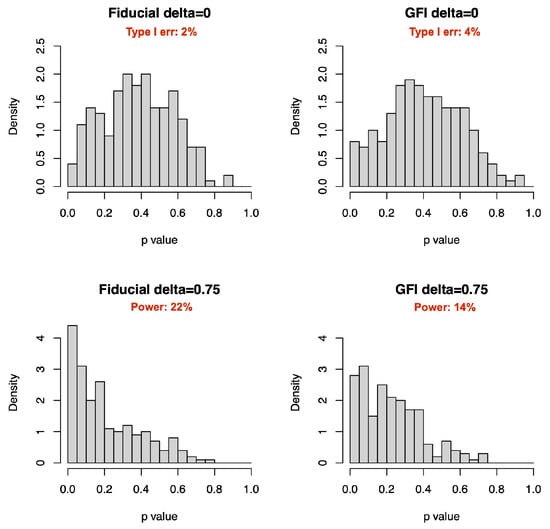
Figure 4.
p value distributions on zero and nonzero random effects (, m = 10).
5. Empirical Analysis
We use the sleepstudy data in R package lme4 as an illustration, which contains a sleep-deprived group of 18 subjects for 10 days of the study in [24]. Day0 and Day1 were adaptation and training, so altogether observations. The reaction time of the ith subject on after sleep deprivation is modeled as
with , , and . Both the fixed and random effects are significant [9]. We resample of the data for a subset with to see how much the inference based on a smaller sample agrees with that on the whole dataset. We conduct resampling 50 times and plot the CI lengths of , , , and in Figure 5. Different from the simulation, the Bayesian intervals are much wider this time since the default prior does not well suit the real data. We annotate the percentage of CIs excluding 0 in Figure 5 as an estimated power, on which the fiducial LME are generally higher. We further try a combination of and , retaining n = 36, but neither lmer nor brms can fit all the cases successfully this time. Our fiducial LME still works. The percentages of significance are on , on , on , and on , respectively.
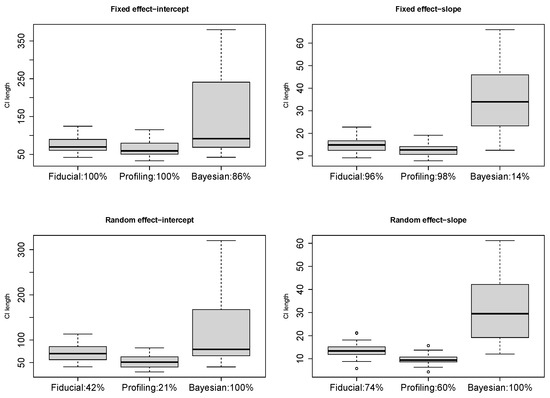
Figure 5.
CI length in resampled sleep data.
6. Conclusions
We study the fiducial inference in LME with the group-level variation innovatively modeled as coefficients. We derive the fiducial density by the stationary theory of Markov chains and demonstrate its advantages in small sample sizes by using simulation and real data. Our study facilitates the inference of zero variance in random effects and reveals a deep relationship between fiducial and Bayesian inference. On one hand, it confirms the rationality of the commonly used noninformative prior in Bayesian LME. On the other, the equivalence to a Bayesian LME is only for independent random effects. It is difficult to make a direct inference of zero variance in random effects if we simply treat the final density as a posterior distribution with a flat prior. But, from the perspective of fiducial structural equations, it turns out to be feasible.
We compare four inferential methods on , , and respectively. Our approach outperforms others on . This is helpful in prescreening random effects since q can easily exceed when we test if all the predictors have random effects. The minimal sample size on which our fiducial LME can work stably is much smaller than other methods. We also tried the parametric bootstrap in lme4. But, its improvement over nonparametric bootstrap is quite limited regarding coverage under the scenarios in Section 4.1.
There is also much space for improvement. The Gibbs algorithm is not fine enough. More advanced numerical algorithms can also be considered and will be studied in the future. The theoretical property of the truncated in the fiducial sample and the inference for correlated random effects (non-diagonal D) also need further investigation.
Author Contributions
C.Z. designed and conducted the research. X.L. provided theoretical support and edited the article. J.Y. participated in the simulation. H.G. provided resources, study materials and financial support. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Grants 11901328, 11871294 and 72171126 from the National Natural Science Foundation of China and Systems Science Plus Joint Research Program of Qingdao University (XT2024301).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jiang, J. Linear and Generalized Linear Mixed Models and Their Applications; Springer: New York, NY, USA, 2007. [Google Scholar]
- Buscemi, S.; Plaia, A. Model selection in linear mixed-effect models. Asta-Adv. Stat. Anal. 2019, 104, 1–47. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, G.; Liang, H. Model averaging and weight choice in linear mixed-effects models. Biometrika 2014, 101, 205–218. [Google Scholar] [CrossRef]
- Waterman, M.J.; Birch, J.B.; Abdel-Salam, A.-S.G. Several nonparametric and semiparametric approaches to linear mixed model regression. J. Stat. Comput. Simul. 2015, 85, 956–977. [Google Scholar] [CrossRef]
- Dion, C. New adaptive strategies for nonparametric estimation in linear mixed models. J. Stat. Plan. Inference 2014, 150, 30–48. [Google Scholar] [CrossRef]
- Jiang, J. Asymptotic Analysis of Mixed Effects Models: Theory, Applications, and Open Problems; Chapman and Hall/CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- Breslow, N.E.; Clayton, D.G. Approximate inference in generalized linear mixed models. J. Am. Stat. Assoc. 1993, 88, 9–25. [Google Scholar] [CrossRef]
- Chung, Y.; Rabe-Hesketh, S.; Dorie, V.; Gelman, A.; Liu, J. A non-degenerate estimator for variance parameters in multilevel models via penalized likelihood estimation. Psychometrika 2013, 78, 685–709. [Google Scholar] [CrossRef] [PubMed]
- Bates, D. Fitting linear mixed-effects models using lme4. arXiv 2014, arXiv:1406.5823. [Google Scholar]
- Burkner, P.-C. brms: An r package for bayesian multilevel models using stan. J. Stat. Softw. 2017, 80, 1–28. [Google Scholar] [CrossRef]
- Das, S.; Krishen, A. Some bootstrap methods in nonlinear mixed-effect models. J. Stat. Plan. Inference 1999, 75, 237–245. [Google Scholar] [CrossRef]
- Flores-Agreda, D.; Cantoni, E. Bootstrap estimation of uncertainty in prediction for generalized linear mixed models. Comput. Stat. Data Anal. 2019, 130, 1–17. [Google Scholar] [CrossRef]
- Thai, H.-T.; Mentre, F.; Holford, N.; Veyrat-Follet, C.; Comets, E. A comparison of bootstrap approaches for estimating uncertainty of parameters in linear mixed-effects models. Pharm. Stat. 2013, 12, 129–140. [Google Scholar] [CrossRef]
- Fisher, R.A. On a point raised by m. s. bartlett on fiducial probability. Ann. Hum. Genet. 1937, 7, 370–375. [Google Scholar] [CrossRef]
- Hannig, J.; Iyer, H.; Lai, R.C.S.; Lee, T.C.M. Generalized fiducial inference: A review and new results. J. Am. Stat. Assoc. 2016, 111, 1346–1361. [Google Scholar] [CrossRef]
- Martin, R.; Liu, C. Inferential models: A framework for prior-free posterior probabilistic inference. J. Am. Stat. Assoc. 2013, 108, 301–313. [Google Scholar] [CrossRef]
- Li, X.; Su, H.; Liang, H. Fiducial generalized p-values for testing zero-variance components in linear mixed-effects models. Sci. China Math. 2018, 61, 1–16. [Google Scholar] [CrossRef]
- Lidong, E.; Hannig, J.; Iyer, H.K. Fiducial intervals for variance components in an unbalanced two-component normal mixed linear model. J. Am. Stat. Assoc. 2008, 103, 854–865. [Google Scholar]
- Cisewski, J.; Hannig, J. Generalized fiducial inference for normal linear mixed models. Ann. Stat. 2012, 40, 2102–2127. [Google Scholar] [CrossRef]
- Grimmett, G.R.; Stirzaker, D.R. Probability and Random Processes; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Betancourt, M. A Conceptual Introduction to Hamiltonian Monte Carlo. arXiv 2017, arXiv:1701.02434. [Google Scholar] [CrossRef]
- Shi, W.J.; Hannig, J.; Lai, R.C.S.; Lee, T.C.M. Covariance estimation via fiducial inference. Stat. Theory Relat. Fields 2021, 5, 316–331. [Google Scholar] [PubMed]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest package: Tests in linear mixed effects models. J. Stat. Softw. 2017, 82, 1–26. [Google Scholar] [CrossRef]
- Belenky, G.; Wesensten, N.; Thorne, D.; Thomas, M.; Sing, H.; Redmond, D.; Russo, M.; Balkin, T. Patterns of performance degradation and restoration during sleep restriction and subsequent recovery: A sleep dose-response study. J. Sleep Res. 2003, 12, 1–12. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).