Abstract
We study statistical dependence in the frequency domain using the integral probability metric (IPM) framework. We propose the uniform Fourier dependence measure (UFDM) defined as the uniform norm of the difference between the joint and product-marginal characteristic functions. We provide a theoretical analysis, highlighting key properties, such as invariances, monotonicity in linear dimension reduction, and a concentration bound. For the estimation of the UFDM, we propose a gradient-based algorithm with singular value decomposition (SVD) warm-up and show that this warm-up is essential for stable performance. The empirical estimator of UFDM is differentiable, and it can be integrated into modern machine learning pipelines. In experiments with synthetic and real-world data, we compare UFDM with distance correlation (DCOR), Hilbert–Schmidt independence criterion (HSIC), and matrix-based Rényi’s -entropy functional (MEF) in permutation-based statistical independence testing and supervised feature extraction. Independence test experiments showed the effectiveness of UFDM at detecting some sparse geometric dependencies in a diverse set of patterns that span different linear and nonlinear interactions, including copulas and geometric structures. In feature extraction experiments across 16 OpenML datasets, we conducted 160 pairwise comparisons: UFDM statistically significantly outperformed other baselines in 20 cases and was outperformed in 13.
1. Introduction
The estimation of statistical dependence plays an important role in various statistical and machine learning methods (e.g., hypothesis testing [1], feature selection and extraction [2,3], causal inference [4], self-supervised learning [5], representation learning [6], interpretation of neural models [7], among others). In recent years, various authors (e.g., [1,8,9,10,11,12,13,14]) have suggested different approaches to measuring statistical dependence.
In this paper, we focus on the estimation of statistical dependence using characteristic functions (CFs) and integral probability metric (IPM) framework. We propose and investigate a novel IPM-based statistical dependence measure, defined as the uniform norm of the difference between the joint and product-marginal CFs. After introducing core concepts, we conduct a short review of the previous work (Section 2). In Section 3, we formulate the proposed measure and its empirical estimator and perform their theoretical analysis. Section 4 is devoted to empirical investigation. Finally, in Section 5 we discuss results, limitations, and future work. Appendix A contains technical details, such as mathematical proofs, and auxiliary tables. The main contributions of this paper are the following:
- Theoretical and methodological contributions. We propose a new IPM-based statistical dependence measure (UFDM) and derive its properties. The main theoretical result of this paper is the structural characterisation of UFDM, which includes invariance under linear transformations and augmentation with independent noise, monotonicity under linear dimension reduction, vanishing under independence, and a concentration bound for its empirical estimator. We additionally propose a gradient-based estimation algorithm with an SVD warm-up to ensure numerical stability.
- Empirical analysis. We conduct an empirical study demonstrating the practical effectiveness of UFDM in permutation-based independence testing across diverse linear, nonlinear, and geometrically structured patterns, as well as in supervised feature-extraction tasks on real datasets.
In addition, we provide the accompanying code repository https://github.com/povidanius/UFDM (accessed on 4 December 2025).
1.1. IPM Framework
In the context of estimation of statistical dependence, the IPM is a class of metrics between two probability distributions and , defined for a function class :
where , and [15].
1.2. Characteristic Functions
Let , , and be random vectors defined on a common probability space . Let us recall that their characteristic functions are given by
where , , and . Having n i.i.d. realisations , the corresponding empirical characteristic functions (ECFs) are given by
The uniqueness theorem states that X and Y have the same distribution if and only if their CFs are identical [16]. Therefore, CFs can be considered a description of a distribution. Alternatively, a CF can be represented as a real vector , where ℜ and ℑ denote real and imaginary components [17]. This viewpoint avoids explicit reliance on the imaginary unit i and makes the geometric structure of CFs more transparent.
For convenience, let us define , and let be its empirical counterpart. In our study, we will utilise IPM framework for investigation of the statistical dependence via
and its empirical counterpart
2. Previous Work
Various theoretical instruments have been employed for statistical dependence estimation. For example, weighted spaces and CFs (e.g., distance correlation, [13]), reproducing kernel Hilbert spaces (RKHS) (HSIC [1], DIME [18]), information theory (mutual information [19], and generalisations such as MEF [20,21]) and copula theory ([10,22]), among others. Since our work is rooted in the CF-based line of research and IPM framework, and it is empirically evaluated for independence testing and representation learning, let us consider DCOR, HSIC, and MEF, because these three measures form the compact set of high-performing baselines that span CFs, IPMs, and information-theoretic methods, which are widely used in representation learning tasks.
- Distance correlation. DCOR [13] is defined as
- HSIC. For reproducing kernel Hilbert spaces (RKHS) and with kernels k and l, it is defined as
- MEF. Shannon mutual information is defined by [19]. The neural estimation of mutual information (MINE, [26]) uses its variational (Donsker–Varadhan) representation , since it allows avoiding density estimation (here is a neural network with parameters ). In this case, the optimisation is performed over the space of neural network parameters, which often leads to unstable training and biased estimates due to the unboundedness of the objective and the difficulty of balancing the exponential term. The matrix-based Rényi’s -order entropy functional (MEF) [20,21,27] provides a kernel version of mutual information that avoids both density estimation and neural optimization. For random variables X and Y with distributions , , and , it is defined as
Motivation
The motivation of our work stems from the theoretical observation that applying the norm to Equation (4) yields a novel, structurally simple IPM with some advantageous properties, such as the ability to detect arbitrary statistical dependencies, invariance under full-rank linear transformations and coordinate augmentation with independent noise, and monotonicity under linear dimension reduction (Theorem 1).
Since the norm isolates the most informative frequencies where dependence concentrates, we hypothesise that its empirical estimator could extract important structure from that may be diluted by weighted or other global approaches such as DCOV, HSIC, and MEF.
3. Proposed Measure
Given two random vectors X and Y of dimensions and , and assuming possibly unknown joint distribution , we define our measure via IPM with function class , which corresponds to the following.
Definition 1.
Uniform Fourier Dependence Measure.
Since CF is a Fourier transform of a probability distribution, and the norm in is called a uniform norm, we refer to it as Uniform Fourier Dependence Measure (UFDM).
Theorem 1.
has the following properties:
- .
- .
- if and only if (⊥ denotes statistical independence).
- For Gaussian random vectors , with cross-covariance matrix we have .
- Invariance under full-rank linear transformation: for any full-rank matrices , and vectors , .
- Linear dimension reduction does not increase .
- If , for any continuous function , , if has a density.
- If X and Y have densities, then , where is mutual information.
- Invariance to augmentation with independent noise: let be random vectors such that . Then .
Proof.
See Appendix A.1. □
- Interpretation of UFDM via canonical correlation analysis (CCA). In the Gaussian case, the UFDM objective reduces analytically to CCA via a closed-form expression (Theorem 1, Property 4): after whitening (setting and ), it becomes , where . By von Neumann’s inequality, the maximizers align with the leading singular vectors of K, corresponding to the top CCA pair. Note that since Gaussian independence is equivalent to the vanishing of the leading canonical correlation (as all remaining correlations , must also vanish), UFDM’s focus on the leading canonical correlation entails no loss of discriminatory power.
- Interpretation of UFDM via cumulants. Let us recall that , , . For general distributions, writing offers a cumulant-series factorization, with , where are cross-cumulants and are the -order tensors formed by the tensor product of p copies of and q copies of . The leading term, corresponding to , is (with for centered variables), which aligns with the CCA interpretation, while higher-order terms capture non-Gaussian deviations, interpreting UFDM as a frequency-domain approach that aligns with cross-cumulant directions under marginal damping by .
- Remark on the representations of CFs. Since , the UFDM objective naturally operates on the real two-dimensional vector formed by the real and imaginary parts of . This aligns with recent work on real-vector representations of characteristic functions [17] and shows that UFDM does not rely on any special algebraic role of the imaginary unit.
3.1. Estimation
Having i.i.d. observations , , we define and discuss empirical estimators of UFDM. Recall that (Section 1.2) that and let , and be CFs of X, Y, and , respectively (, , and ). Let us also denote norms , , for and multivariate .
- Empirical estimator. Let us define the empirical estimator of for a fixed :
3.2. Estimator Convergence
The ECF is a uniformly consistent estimator of CF in each bounded subset [28] (i.e., almost surely for any fixed ) [28]. By the triangle inequality, this implies the following:
Proposition 1.
For a fixed , , almost surely.
Theorem 2
([29]). If and , as , then almost surely for any and corresponding .
- This implies the convergence of the empirical estimator Equation (12):
Proposition 2.
If and , as , then , almost surely.
Proof.
See Appendix A.1. □
Note that ECF does not converge to CF [28,29] uniformly in the entire space. Therefore, to ensure the convergence of the empirical estimator of UFDM, we need to bound the norm by slowly growing balls as in Theorem 2. The finite–sample analysis of the convergence of empirical UFDM Equation (12) to its truncated population counterpart () yields the following concentration inequality.
Theorem 3.
Let us assume that , . Let us define , , and . Then there exists a constant C, such that for every fixed , :
where , and .
Proof.
See Appendix A.2. □
3.3. Estimator Computation
In practice, UFDM can be estimated iteratively using Algorithm 1. Since it depends on initial parameters and , the complementary Algorithm 2 is designed for their data-driven initialisation. According to our experience with UFDM applications, Algorithm 2 is very important, since without it we often encountered stability issues, and initially had to rely on various heuristics, such as parameter normalisation to the unit sphere. In our opinion, this is because is a highly nonlinear optimisation surface (especially in larger dimensions), which complicates the finding of the corresponding maxima.
| Algorithm 1 UFDM estimation |
| Require: Number of iterations N, batch size , initial . for to N do Sample batch . Standardise to zero mean and unit variance. . end for return , , |
| Algorithm 2 SVD warm-up |
| Require:
Batch size . Sample batch . Compute cross-covariance . Decompose: . . return , |
The computational complexity of Algorithm 2 consists of cross-covariance computation and finding its SVD a complexity of . Having initialisation of and , the complexity of Algorithm 1 is . Hence, the total computational complexity of the sequential application of Algorithm 2 and Algorithm 1 is . Finally, having the optimal and computed by Algorithm 1, the evaluation of empirical has computational complexity linear in sample size.
4. Experiments
For UFDM, we used SVD warm-up (Algorithm 2) for parameter initialisation and fixed truncation parameter t to . For kernel measures, HSIC and MEF, we used Gaussian kernels for both X and Y, with a bandwidth selected using median heuristics [30]. For MEF measure was set to , as in [21].
4.1. Permutation Tests
- Permutation tests with UFDM. We compared , DCOR, HSIC, and MEF in permutation-based statistical independence testing ( versus the alternative ) using a set of multivariate distributions. We investigated scenarios with a sample size of and data dimensions (). To ensure valid finite-sample calibration, permutation p-values were computed with the Phipson–Smyth correction [31].
- Hyperparameters. We used 500 permutations per p-value. The number of iterations in UFDM estimation Algorithm 1 was set to 100. The batch size equaled the sample size (). We used a learning rate of . Due to the high computation time (permutation tests took days on five machines with Intel i7 CPU, 16GB of RAM, and Nvidia GeForce RTX 2060 12 GB GPU), we relied on 500 p-values for each test in the scenario and on 100 p-values for each test in the scenario.
- Distributions analysed. In the case, X was sampled from multivariate uniform, Gaussian, and Student distributions (corresponding to no-tail, light-tail, and heavy-tail scenarios, respectively), and Y was independently sampled from the same set of distributions. Afterwards, we examined the uniformity of the p-values obtained from permutation tests using different statistical measures, through QQ-plots and Kolmogorov–Smirnov (KS) tests.
In the case, X and Y were related through statistical dependencies described in Table A2. These dependencies include structured dependence patterns, where X was sampled from the same set of distributions (multivariate uniform, Gaussian, and Student ), and Y was generated as , with denoting additive Gaussian noise independent of X. We also examined more complex dependencies (Table A2), where the relationship between X and Y was modeled using copulas, bimodal, circular, and other nonlinear patterns. Using this setup, we evaluated the empirical power of the permutation tests based on the same collection of statistical measures.
- Results for . As shown in Figure 1, UFDM, DCOR, HSIC, and MEF exhibited approximately uniform permutation p-values across all distribution pairs and dimensions, with empirical false rejection rates (FRR) remaining close to the nominal level. Isolated low KS p-values below occurred in only two cases: one for MEF in the Gaussian/Gaussian pair at dimension 5 (p-value of ) and one for UFDM in the Gaussian/Student-t pair at dimension 5 (p-value of ), suggesting minor sampling variability rather than systematic deviations from uniformity. These results show that UFDM remained comparably stable to DCOR, HSIC and MEF, in terms of type-I error control under .
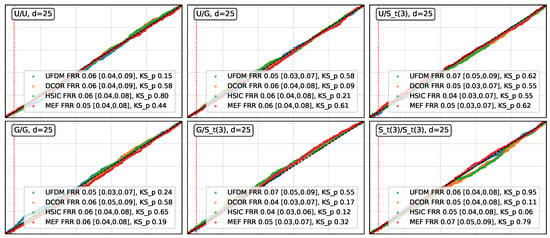
 Figure 1. Empirical QQ-plots of p-values under . The dashed vertical line corresponds to the nominal significance level . The empirical FRR and its Wilson confidence interval, p-values of KS test are reported in the legend.
Figure 1. Empirical QQ-plots of p-values under . The dashed vertical line corresponds to the nominal significance level . The empirical FRR and its Wilson confidence interval, p-values of KS test are reported in the legend. - Results for . The empirical power and its -Wilson confidence intervals (CIs) are presented in Table 1 and Table 2. These results show that, in most cases, the empirical power of UFDM, DCOR, HSIC, and MEF was approximately equal to . However, Table 2 also reveals that for the sparse Circular and Interleaved Moons patterns (), MEF exhibited a noticeable decrease in empirical power. We conjecture that this reduction may stem from MEF’s comparatively higher sensitivity to kernel bandwidth selection in these specific, geometrically structured patterns. On the other hand, UFDM’s robustness in these settings may also be explained by its invariance to augmentation with independent noise (Theorem 1, Property 9), which helps to preserve the detectability of sparse geometric dependencies embedded within high-dimensional noise coordinates.
 Table 1. Empirical power and Wilson CIs for the dependent data (structured dependence patterns) at .
Table 2. Empirical power with 95% Wilson confidence intervals for dependent data (complex dependence patterns) at .
Table 1. Empirical power and Wilson CIs for the dependent data (structured dependence patterns) at .
Table 2. Empirical power with 95% Wilson confidence intervals for dependent data (complex dependence patterns) at . - Ablation experiment. The necessity of the SVD warm-up (Algorithm 2) is empirically demonstrated in Table A1, where the p-values obtained without SVD warm-up systematically fail to reveal dependence in many nonlinear patterns.
- Remark on the stability of the estimator. Since the UFDM objective is non-convex, different random initialisations may potentially lead to distinct local optima. To assess the impact of this issue, we investigated the numerical stability of the UFDM estimator. We computed the mean and standard deviation of the statistic across 50 independent runs for each distribution pattern and dimension (Table 1 and Table 2), as well as for the corresponding permuted patterns in which dependence is destroyed, as reported in Table 3. The obtained results align with the permutation test findings. While a slight upward shift is observed under independent (permuted) data, the proposed estimator retained consistent separation between dependent and independent settings and exhibited stable behaviour across random restarts.
Table 3. UFDM statistic (mean ± std) under true dependence/permuted independence.
4.2. Supervised Feature Extraction
Feature construction is often a key initial step in machine learning with tabular data. These methods can be roughly classified into feature selection and feature extraction. Feature selection identifies a subset of relevant inputs, either incrementally (e.g., via univariate filters) or through other strategies, and feature extraction transforms inputs into lower-dimensional, informative representations. In our experiments, we used the latter approach because of its computational effectiveness. The total computational time for these experiments was h on single Intel i7 CPU, 16GB of RAM, and Nvidia GeForce RTX 2060 12 GB GPU machine.
Let be a classification dataset consisting of n pairs of -dimensional inputs , and -dimensional one-hot encoded outputs . In our experiments, we used a collection of OpenML classification datasets [32], which cover different domains, input and output dimensionalities. We randomly split the data into training, validation, and test sets using the proportions , respectively. We followed the dependence maximisation scheme (e.g., [3,33]) by seeking
where . To evaluate the obtained features , we used logistic regression’s [34] accuracy, measured on the test set. For each baseline method, we selected the dimensions of the features that correspond to the maximal validation accuracy of the investigated method, checking all dimensions starting from 1 with a step of of . Similarly, we selected . The feature extraction loss Equation (13) was optimised via Algorithm 1 for 100 epochs, with the learning rate set to , as in permutation testing experiments (Section 4.1).
- Baselines. We compared the following baselines: unmodified inputs (denoted as RAW); and Equation (13) scheme with dependence measures: UFDM, DCOR, MEF, and HSIC. We also included the neighbourhood component analysis (NCA) [35] baseline, which is specially tailored for classification.
- Evaluation metrics. Let us denote , if for r runs on the dataset d the average test set accuracy of baseline b is statistically significantly higher than that of with p-value threshold p. For statistical significance assessment, we used Wilcoxon’s signed-rank test [36]. We computed the win ranking (WR) and loss ranking (LR) as
- Based on these metrics, Table 4 includes full information on how many cases each baseline method statistically significantly outperformed the other method.
Table 4. Pairwise wins matrix: entry is the number of cases where the method in row i outperformed the method in column j (Wilcoxon’s signed-rank test, 25 runs, p-value threshold ).
- Results. Using 18 datasets, we conducted 80 feature efficiency evaluations (excluding the RAW baseline) and 160 feature efficiency comparisons, of which 97 (∼60%) were statistically different. The results of the feature extraction experiments are presented in Table 4 and Table 5. They reveal that, although MEF showed best WR, UFDM also performed comparable to other measures: it statistically significantly outperformed them in cases (listed in Table 6), and was outperformed in cases (Table 4).
Table 5. Classification accuracy comparison. n denotes dataset size, is input dimensionality, and is the number of classes. Best-performing method that is also statistically significant when compared with all other methods (Wilcoxon’s signed-rank test, 25 runs, p-value threshold ) is indicated in bold (otherwise, best-performing method is underlined).
Table 6. Twenty cases (Measures Outperformed) where UFDM outperformed the other baselines.
In addition to pairwise statistical comparisons using Wilcoxon’s test, we also conducted statistical analysis to clarify whether some method is globally better or worse over multiple datasets using the methodology described in [37]. In this analysis, the Friedman/Iman–Davenport test () showed a global significant difference between the five methods. The Nemenyi post hoc test (, critical difference ) revealed that RAW was significantly outperformed by the other methods; however, it also showed the absence of a global best-performing method.
5. Conclusions
- Results. We proposed and analysed an IPM-based statistical dependence measure, , defined as the norm of the difference between the joint and product-marginal characteristic functions. applies to pairs of random vectors of possibly different dimensions and can be integrated into modern machine learning pipelines. In contrast to global measures (e.g., DCOR, HSIC, MEF), which aggregate information across the entire frequency domain, identifies spectrally localised dependencies by highlighting frequencies where the discrepancy is maximised, thereby offering potentially interpretable insights into the structure of dependence. We theoretically established key properties of , such as invariance under linear transformations and augmentation with independent noise, monotonicity under dimension reduction, and vanishing under independence. We also showed that UFDM’s objective aligns with the vectorial representation of CFs. In addition, we investigated the consistency of the empirical estimator and derived a finite-sample concentration bound. For practical estimation, we proposed a gradient-based estimation algorithm with SVD warm-up, and this warm-up was found to be essential for stable convergence.
We evaluated on simulated and real data in permutation-based independence testing and supervised feature extraction. The permutation test experiments (, ) indicated that in this regime performed comparably to established baseline measures, exhibiting similar empirical power and calibration across diverse dependence structures. Notably, maintained high power on the Circular and Interleaved Moons datasets, where some other measures displayed reduced sensitivity under these geometrically structured dependencies. These findings suggest that provides a complementary addition to the family of widely used dependence measures (DCOR, HSIC, and MEF).
Further experiments with real data demonstrated that, in dependence-based supervised feature extraction, often performed on par with the well-established alternatives (HSIC, DCOR, MEF) and with NCA, which is specifically designed for classification. Across 16 datasets and 160 pairwise comparisons, statistically significantly outperformed other baselines in 20 cases and was outperformed in 13. To facilitate reproducibility, we provide an open-source repository.
- Limitations. Computing UFDM requires maximising a highly nonlinear objective, which makes the estimator sensitive to initialisation and optimisation settings. Although the proposed SVD warm-up substantially improves numerical stability, estimation may still become more challenging as dimensionality d increases or sample size n decreases. From the perspective of the effective , our empirical evaluation covers two different tasks. First, in independence testing with synthetic data and and , UFDM maintained effectiveness across diverse dependence structures. Our preliminary experiments with , and indicate a reduction in power for several dependency patterns, whereas DCOR, HSIC, and MEF remained comparatively stable. Nonetheless, UFDM preserved its performance for sparse geometrically structured dependencies (e.g., Interleaved Moons), where alternative measures often show more pronounced loss of sensitivity. Due to the high computational cost of UFDM permutation tests, we omitted systematic exploration of these regimes, leaving it to future work. On the other hand, in supervised feature extraction on real datasets, we examined substantially broader ranges, including high-dimensional settings such as USPS, Micro-Mass, and Scene. UFDM outperformed one or more baselines on several such datasets (Table 6), suggesting that it may be effective in some larger-dimensional machine learning tasks.
- Future work and potential applications. Identifying the limit distribution of the empirical could enable faster alternatives to permutation-based statistical tests, which would also facilitate the systematic analysis of previously mentioned settings. However, since the empirical is not a U- or V-statistic like HSIC or distance correlation, this would require a non-trivial analysis of the extrema of empirical processes. Possible extensions of UFDM include multivariate generalisations [23] and weighted or normalised variants to enhance empirical stability. From an application perspective, may prove useful in causality, regularisation, representation learning, and other areas of modern machine learning where statistical dependence serves as an optimisation criterion.
Author Contributions
Conceptualization, P.D.; methodology, P.D.; software, P.D., S.J., L.K., V.M.; validation, P.D., and V.M.; formal analysis, P.D.; writing—original draft preparation, P.D., and V.M.; writing—review and editing, P.D.; funding acquisition, P.D., and V.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. The APC was funded by Vytautas Magnus University and Vilnius University.
Data Availability Statement
All synthetic data were generated as described in the manuscript; real datasets were obtained from OpenML (https://www.openml.org (accessed on 4 December 2025)). Code to reproduce the experiments is available at https://github.com/povidanius/UFDM (accessed on 4 December 2025). No additional unpublished data were used.
Acknowledgments
We sincerely thank Dominik Janzing for pointing out the possible theoretical connection between UFDM and HSIC, Marijus Radavičius for a remark that the convergence of empirical UFDM in the entire space requires special investigation, and Iosif Pinelis for [38]. We also acknowledge Pranas Vaitkus, Mindaugas Bloznelis, Linas Petkevičius, Aleksandras Voicikas, Osvaldas Putkis, and colleagues from Neurotechnology for discussions. We feel grateful to Neurotechnology, Vytautas Magnus University, and the Institute of Data Science and Digital Technologies, Vilnius University, for supporting this research. We also thank the anonymous reviewers for their valuable feedback.
Conflicts of Interest
Povilas Daniušis is employee of Neurotechnology. The paper reflects the views of the scientists and not the company. The other authors declare no conflict of interest.
Appendix A
Appendix A.1. Proofs
In the proofs, we interchangeably abbreviate with , with , and with , where .
Proof of Theorem 1.
Property 1. By Cauchy–Schwarz inequality.
Recall that for complex numbers z and we have , where is complex conjugate of z. Therefore by plugging and from the definition of CF we obtain
and similarly . Since the absolute value of CF is bounded by 1, we have that Equation (A1) is also bounded by 1.
Property 2.
Property 3. Let us assume that . Then . Therefore, . On the other hand, if then for all ,. Let and be two independent random vectors, having the same distributions as X and Y, respectively. Therefore . The uniqueness of CF [16] implies that distributions of and coincide, from what directly follows that .
Property 4. Let be cross-covariance matrix of X and Y. Since X and Y are Gaussian, we have , , . Therefore, by Equation (11)
Property 5. Since , and , , we have
Since both A and B are full-rank matrices, and , , the maximization of the last equation is equivalent to the maximization of , which by definition is .
Property 6. If , , , are parameters of linear dimension reduction, where , and , we have
for any of the same dimensions (defined as in Property 5), because maximisation of LHS is conducted in smaller space than that of RHS. By Property 5, it follows that .
Property 7. The independence of X and implies that
which converges to 0, since by multivariate Riemann–Lebesgue lemma [39] the common term , when . The multivariate Riemann–Lebesgue lemma can be applied since has a density.
Property 8. Recall that the total variation distance between joint probability measure and product measure is given by
where is joint density, and , are marginal ones. Recall that Pinsker’s inequality for total variation states that , where is mutual information between X and Y. Therefore,
By taking the supremum we have by Property 1 and Pinsker’s inequality.
Property 9. Independence condition gives
Since and , we have Therefore, . □
Proof of Proposition 2.
Let . Since ECF is CF, and a product of two CFs also is CF, by Theorem 2 and triangle inequality, we can find natural number such that : , almost surely. From the inverse triangle inequality for norms we have , almost surely. On the other hand, along with the definition of , this implies that will be arbitrarily small almost surely, when n is sufficiently large. □
Appendix A.2. Proof of Theorem 3
Proof of Theorem 3.
Finally, the stated bound follows from the inverse triangle inequality for norms. □
Recall that , with and
Step 1. Lipschitz continuity. First, we will prove that and are Lipschitz continuous. For the population version, consider
Since , by inequality ,
Similarly,
since , . Therefore,
Thus,
so is Lipschitz with constant . For the empirical version,
where
and
Define , so is Lipschitz with random constant . Recall that , are finite because of bounded second moment assumption. concentrates around L, and by Cantelli’s inequality, we have
Step 2. Construct a -net and bound the deviation on the -net. For , construct a -net such that every is within of some . The cardinality satisfies [40].
For fixed , bound . Changing one to alters by at most , and by at most each, and by at most . Thus, . By McDiarmid’s inequality,
Compute the bias: , and so
Thus,
Step 3. Extend to the entire frequency ball. For any , choose with . Then we have
Thus, . Then by union bound
Recall that in Equation (A4) we showed that . Choosing implies
For the max term, by the union bound,
where .
Appendix A.3. Ablation Experiment on SVD Warm-Up
Table A1.
p-value means and standard deviations of the analysed dependence patterns in permutation tests for UFDM without SVD warm-up (Algorithm 2), uniformly initialising parameters and from interval. Here .
Table A1.
p-value means and standard deviations of the analysed dependence patterns in permutation tests for UFDM without SVD warm-up (Algorithm 2), uniformly initialising parameters and from interval. Here .
| Distribution of Y | |||
|---|---|---|---|
| Linear (1.0) | 0.002 ± 0.000 | 0.002 ± 0.000 | 0.002 ± 0.000 |
| Linear (0.3) | 0.002 ± 0.000 | 0.002 ± 0.000 | 0.002 ± 0.000 |
| Logarithmic | 0.035 ± 0.097 | 0.192 ± 0.251 | 0.387 ± 0.297 |
| Quadratic | 0.023 ± 0.061 | 0.298 ± 0.291 | 0.285 ± 0.145 |
| Polynomial | 0.002 ± 0.000 | 0.062 ± 0.134 | 0.056 ± 0.078 |
| LRSO (0.05) | 0.002 ± 0.001 | 0.041 ± 0.066 | 0.026 ± 0.040 |
| Heteroscedastic | 0.004 ± 0.006 | 0.002 ± 0.001 | 0.003∗ ± 0.003 |
Appendix A.4. Dependency Patterns
Table A2.
Dependence structures. denotes uniform linear spacing over given interval , , , and d is dimension. Fixed parameters , , . By ⊙ we denote element-wise product.
Table A2.
Dependence structures. denotes uniform linear spacing over given interval , , , and d is dimension. Fixed parameters , , . By ⊙ we denote element-wise product.
| Type | Formula |
|---|---|
| Structured dependence patterns () | |
| Linear(p) | , |
| Logarithmic | |
| Quadratic | |
| Cubic | |
| LRSO(p) | |
| Heteroscedastic | , |
| Complex dependence patterns | |
| Bimodal | |
| Sparse bimodal | , |
| Sparse circular | |
| Gaussian copula | Marginals . |
| Clayton copula | |
| Interleaved Moons | |
We used sklearn.datasets.make_moons.
References
- Gretton, A.; Bousquet, O.; Smola, A.; Schölkopf, B. Measuring statistical dependence with Hilbert-Schmidt norms. In Proceedings of the 16th International Conference on Algorithmic Learning Theory (ALT), Singapore, 8–11 October 2005. [Google Scholar]
- Daniušis, P.; Vaitkus, P.; Petkevičius, L. Hilbert–Schmidt component analysis. Lith. Math. J. 2016, 57, 7–11. [Google Scholar] [CrossRef]
- Daniušis, P.; Vaitkus, P. Supervised feature extraction using Hilbert-Schmidt norms. In Proceedings of the 10th International Conference on Intelligent Data Engineering and Automated Learning (IDEAL), Burgos, Spain, 23–26 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 25–33. [Google Scholar]
- Hoyer, P.; Janzing, D.; Mooij, J.M.; Peters, J.; Schölkopf, B. Nonlinear causal discovery with additive noise models. In Proceedings of the Advances in Neural Information Processing Systems 21 (NeurIPS 2008), Vancouver, BC, Canada, 8–11 December 2008. [Google Scholar]
- Li, Y.; Pogodin, R.; Sutherland, D.J.; Gretton, A. Self-Supervised Learning with Kernel Dependence Maximization. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Ragonesi, R.; Volpi, R.; Cavazza, J.; Murino, V. Learning unbiased representations via mutual information backpropagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Virtual, 19–25 June 2021; pp. 2723–2732. [Google Scholar]
- Zhen, X.; Meng, Z.; Chakraborty, R.; Singh, V. On the Versatile Uses of Partial Distance Correlation in Deep Learning. In Proceedings of the 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Chatterjee, S. A New Coefficient of Correlation. J. Am. Stat. Assoc. 2021, 116, 2009–2022. [Google Scholar] [CrossRef]
- Feuerverger, A. A consistent test for bivariate dependence. Int. Stat. Rev. 1993, 61, 419–433. [Google Scholar] [CrossRef]
- Póczos, B.; Ghahramani, Z.; Schneider, J.G. Copula-based kernel dependency measures. arXiv 2012, arXiv:1206.4682. [Google Scholar] [CrossRef]
- Puccetti, G. Measuring linear correlation between random vectors. Inf. Sci. 2022, 607, 1328–1347. [Google Scholar] [CrossRef]
- Shen, C.; Priebe, C.E.; Vogelstein, J.T. From Distance Correlation to Multiscale Graph Correlation. J. Am. Stat. Assoc. 2020, 115, 280–291. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Tsur, D.; Goldfeld, Z.; Greenewald, K. Max-Sliced Mutual Information. In Proceedings of the Advances in Neural Information Processing Systems 36 (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; Curran Associates, Inc.: Red Hook, NY, USA, 2023; pp. 80338–80351. [Google Scholar]
- Sriperumbudur, B.K.; Fukumizu, K.; Gretton, A.; Schölkopf, B.; Lanckriet, G.R.G. On the empirical estimation of integral probability metrics. Electron. J. Stat. 2012, 6, 1550–1599. [Google Scholar] [CrossRef]
- Jacod, J.; Protter, P. Probability Essentials, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Richter, W.-D. On the vector representation of characteristic functions. Stats 2023, 6, 1072–1081. [Google Scholar] [CrossRef]
- Zhang, W.; Gao, W.; Ng, H.K.T. Multivariate tests of independence based on a new class of measures of independence in Reproducing Kernel Hilbert Space. J. Multivar. Anal. 2023, 195, 105144. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Yu, S.; Giraldo, L.G.S.; Jenssen, R.; Príncipe, J.C. Multivariate Extension of Matrix-Based Rényi’s α-Order Entropy Functional. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2960–2966. [Google Scholar] [CrossRef]
- Yu, S.; Alesiani, F.; Yu, X.; Jenssen, R.; Príncipe, J.C. Measuring Dependence with Matrix-based Entropy Functional. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI 2021), Virtual, 2–9 February 2021; pp. 10781–10789. [Google Scholar]
- Lopez-Paz, D.; Hennig, P.; Schölkopf, B. The Randomized Dependence Coefficient. In Proceedings of the Advances in Neural Information Processing Systems 26 (NeurIPS 2013), Lake Tahoe, NV, USA, 5–8 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Böttcher, B.; Keller-Ressel, M.; Schilling, R. Distance multivariance: New dependence measures for random vectors. arXiv 2018, arXiv:1711.07775. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L. Partial distance correlation with methods for dissimilarities. Ann. Stat. 2014, 42, 2382–2412. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual Information Neural Estimation. In Proceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Sanchez Giraldo, L.G.; Rao, M.; Principe, J.C. Measures of Entropy From Data Using Infinitely Divisible Kernels. IEEE Trans. Inf. Theory 2015, 61, 535–548. [Google Scholar] [CrossRef]
- Ushakov, N.G. Selected Topics in Characteristic Functions; De Gruyter: Berlin, Germany, 2011. [Google Scholar]
- Csörgo, S.; Totik, V. On how long interval is the empirical characteristic function uniformly consistent. Acta Sci. Math. (Szeged) 1983, 45, 141–149. [Google Scholar]
- Garreau, D.; Jitkrittum, W.; Kanagawa, M. Large sample analysis of the median heuristic. arXiv 2017, arXiv:1707.07269. [Google Scholar]
- Phipson, B.; Smyth, G.K. Permutation p-values should never be zero: Calculating exact p-values when permutations are randomly drawn. Stat. Appl. Genet. Mol. Biol. 2010, 9, 39. [Google Scholar] [CrossRef]
- Vanschoren, J.; van Rijn, J.N.; Bischl, B.; Torgo, L. OpenML: Networked Science in Machine Learning. SIGKDD Explor. 2013, 15, 49–60. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Z.H. Multilabel Dimensionality Reduction via Dependence Maximization. ACM Trans. Knowl. Discov. Data 2010, 4, 14:1–14:21. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models, 2nd ed.; Chapman and Hall/CRC Monographs on Statistics and Applied Probability Series, Chapman & Hall; Routledge: Oxfordshire, UK, 1989. [Google Scholar]
- Goldberger, J.; Hinton, G.E.; Roweis, S.; Salakhutdinov, R.R. Neighbourhood components analysis. In Proceedings of the Advances in Neural Information Processing Systems 17 (NeurIPS 2004), Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Euclidean Norm of Sub-Exponential Random Vector is Sub-Exponential? MathOverflow. Version: 2025-05-06. Available online: https://mathoverflow.net/q/492045 (accessed on 10 April 2025).
- Bochner, S.; Chandrasekharan, K. Fourier Transforms (AM-19); Princeton University Press: Princeton, NJ, USA, 1949. [Google Scholar]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).