1. Introduction
The study of deletion/insertion correcting codes, which originated in the 1960s, has made a great progress in recent years, encouraged by their application to DNA-based data storage. One of the basic problems in this area is construction of codes with low redundancy and low encoding/decoding complexity, where the redundancy of a
q-ary
code
of length
n is defined as
, measured in
q-ary symbols, or
, measured in bits (in this paper, for simplicity, for any real
, we write
). The optimal redundancy of a
q-ary
t-deletion correcting code of length
n was proved to be asymptotically between
and
[
1]. In general, codes with a redundancy matching the upper bound can be constructed by graph-coloring method. However, the encoding complexity of such a construction is exponential in
n. In practice, the construction of codes with polynomial encoding complexity (also called explicit construction) and low redundancy is an interesting research problem.
The famous VT codes were proved to be a family of single-deletion correcting binary codes, and are asymptotically optimal in redundancy [
2]. The VT construction was generalized to nonbinary single-deletion correcting codes in [
3] and, recently, a different version of nonbinary VT codes was proposed in [
4] using differential vector, with asymptotically optimal redundancy and efficient encoding/decoding. Works on binary and nonbinary codes for correcting multiple deletions can be found in [
5,
6,
7,
8,
9,
10,
11,
12,
13] and the references therein.
Burst deletions and insertions, which means that deletions and insertions occur at consecutive positions in a string, are a class of error that can be found in many applications, such as DNA-based data storage and file synchronization. For the binary case, the maximal cardinality of a
t-burst-deletion correcting code (i.e., a code that can correct a burst of
exactly t deletions) is proved to be asymptotically upper bounded by
[
14], so its redundancy is asymptotically lower bounded by
. Several constructions of binary codes correcting a burst of exactly
t deletions were reported in [
15,
16], where the construction in [
16] achieves an optimal redundancy of
. A more general class, i.e., codes correcting a burst of
at most t deletions, were also constructed in the same paper [
16], and this construction was improved in [
17] to achieve a redundancy of
for some constant
that only depends on
t. In [
18], by using VT constraint and shifted VT constraint in the so-called
-dense strings, binary codes correcting a burst of at most
t deletions were constructed, with an optimal redundancy of
, where
is a constant depending only on
t.
In recent parallel works [
12,
19],
q-ary codes correcting a burst of at most
t deletions were constructed for even integer
, with redundancy
or, more specifically,
bits for some constant
that only depends on
t. The basic techniques in [
12,
19] are to represent each
q-ary string as a binary matrix whose columns are the binary representation of the entries of the corresponding
q-ary string. Strings of length
n are constructed such that the first row of their matrix representation is
-dense. Then, the first row of their matrix representation is protected by a binary burst deletion correcting code of length
n and the other rows are protected by binary burst deletion correcting codes of length not greater than
, which results in a construction with
bits of redundancy. A different construction of
q-ary codes correcting a burst of at most
t deletions was reported in a more recent work [
4], which has redundancy
.
A relaxed model of error correction, called sequence reconstruction, also received great attention from researchers (e.g., see [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]). Unlike the classical error correcting codes, in the sequence reconstruction model, the receiver is allowed to reconstruct the original transmitted sequence from multiple noisy reads (channel outputs). This model is suitable for DNA data storage because current synthesis and sequencing technologies can generate many (possibly erroneous) reads for each DNA strand, and so each stored DNA strand can be recovered by its many erroneous copies. Sequence reconstruction for deletion, insertion, transposition, and substitution was first studied in [
20,
21], where the minimum number of reads for exact reconstruction of uncoded sequence was computed. Coded sequence reconstruction for deletion channel was considered recently in [
23], where it was assumed that a codeword of a single-deletion-correcting code is transmitted over the
t-deletion channels, and the minimum number of distinct reads required to uniquely reconstruct the transmitted sequence was computed. The more general problem, i.e., the minimum number of reads for reconstruction of a codeword of an
-deletion-correcting code of length
n transmitted over the
t-deletion channels for some
, was solved in [
27]. The dual problem, i.e., designing codes (called reconstruction codes) for reconstruction of a sequence with fixed number of reads for deletion channel, was also considered in recent years. A construction of binary reconstruction codes for two reads and with
bits of redundancy under single-deletion channel was presented in [
24], and this construction was generalized in [
28] to
q-ary single-edit channel for
. Binary reconstruction codes under 2-deletion channel were constructed in [
29,
30]. It was shown in [
30] that
bits of redundancy is sufficient for two reads, and
bits of redundancy is sufficient for five reads. Reconstruction codes under single-burst-insertion/deletion/edit channel were considered in [
31], where for the channel suffering from a single burst of at most
t deletions, a family of
q-ary codes for two reads with
bits of redundancy were constructed.
In this paper, we propose some new constructions of
q-ary codes for correcting a burst of at most
t deletions for any fixed positive integers
t and
. We consider both the classical error correcting codes and the reconstruction codes. In our constructions, we consider
q-ary
-dense strings (sequences), which are generalization of the binary
-dense strings defined in [
18], and give an efficient algorithm for encoding and decoding of
q-ary
-dense strings. For the classical burst-deletion correcting codes, a VT-like function is used to locate the deletions within an interval of length not greater than
, which results in
bits of redundancy. In addition, two functions are used to recover the substring destroyed by deletions, which results in
bits of redundancy (in this paper, the term
may depends on
q and
t. However, since
q and
t are assumed to be fixed positive integers, they are omitted). Thus, the total redundancy of our construction is
bits. Compared to previous works, the redundancy of our new construction is independent of
q and
t in the second term. An explicit encoding function is given, which is simpler than previous works and has complexity
. The decoding complexity is
.
We also construct reconstruction codes for correcting a burst of at most
t deletions from two reads and with redundancy
bits, which is lower than the construction in [
31]. We give an explicit encoding function for such codes with encoding complexity
and decoding complexity
.
In
Section 2, we introduce related notations and concepts, and present some basic constructions that will be used in our new constructions. In
Section 3, we study
-dense
q-ary strings. A new construction of classical
q-ary burst-deletion correcting codes is given in
Section 4, and
q-ary codes for correcting burst deletions from two reads is given in
Section 5. Finally, the paper is concluded in
Section 6.
2. Preliminaries
Let for any two integers m and n, such that , and call an interval. If , then let . For simplicity, we denote for any positive integer n. The size of a set S is denoted by .
Given any integer , let . For any sequence (also called a string or a vector) , n is called the length of , and denote . We will denote or . For any set such that , denote , and call a subsequence of . If for some such that , then is called a substring of . We say that contains or is contained in if is a substring of . For any and , we use to denote their concatenation, i.e., . We also use notations such as to denote substrings of a sequence . For example, the notation means that the sequence consists of k substrings .
Let be a nonnegative integer. For any , let denote the set of subsequences of of length , and let denote the set of subsequences of that can be obtained from by a burst of t deletions, that is, for some interval of length (i.e., for some . Moreover, let , i.e., is the set of subsequences of that can be obtained from by a burst of at most t deletions. Clearly, and for .
A code is said to be a t-deletion correcting code if, for any codeword , given any , can be uniquely recovered from ; the code is said to be capable of correcting a burst of at most t deletions if, for any , given any , can be uniquely recovered from . More generally, let and N be a positive integer. A code is said to be an -reconstruction code if, for any codeword , can be uniquely recovered from any given N distinct sequences in . In this case, we also say that can be uniquely recovered from N reads in . If , then an -reconstruction code degenerates to the classical error correcting code for the error pattern .
For any code , the redundancy of is defined as measured in q-ary symbols or measured in bits. Clearly, if there is an encoding function that maps each length-k sequence (message) to a length-n codeword in , then the redundancy of is . In this paper, we will always assume that q and t are fixed (i.e., q and t are constant with respect to .
A convenient way for constructing deletion correcting codes is to construct some sketches such that for sufficiently many sequences, each can be recovered from its (known) sketches and one of its subsequence obtained by (a burst of) at most
t deletions. The VT syndrome is a sketch for correcting a single deletion, which is defined as follows. For each
, the VT syndrome of
is defined as
It was proved in [
2] that for any
, given
and any
, one can uniquely recover
.
Suppose
. For each
, let
be such that, for each
,
if
and
if
. Moreover, let
for all
one can also let
for all
. Then, there are
q-ary codes constructed in [
3] for correcting a single deletion.
Lemma 1. [3] For any , given , and any , one can uniquely recover , where and 2.1. A Construction of q-ary Burst-Deletion Codes
For codes correcting burst deletions, the following lemma gives a
q-ary version the construction in [
33] to
q-ary codes
, and will be used in our new construction.
Lemma 2. For any positive integer m, there exists a functioncomputable in time , such that for any distinct with . Proof. The function
can be constructed by the syndrome compression technique developed in [
33].
For each
, let
be the set of all
, such that
. By simple counting, we have
We first construct a function
satisfying: 1)
; and 2)
for any
and any
. Specifically,
is constructed as follows: For each
and
, let
where
and
. Then, let
Clearly,
and so, when represented as a binary sequence, the length
of
satisfies the following (throughout this paper, for any given
, if needed, we will view a positive integer
m as a
q-ary sequence which is the
q-base representation of
m, and conversely, we also view a
q-ary sequence
as a positive integer whose
q-base representation is
):
Hence, viewed as a positive integer, we have for any . Moreover, for each , if , then we have for each , where . By Lemma 1, can be recovered from and , and so can be recovered from and . Equivalently, for any , we have .
For each
, let
be the set of all positive integers
j such that
j is a divisor of
for some
. By the same discussions as in the proof of [
33] (Lemma 4), we can obtain
. (Note that
q and
t are assumed to fixed integers and, by (
1),
. So, by brute force search, one can find, in time
, a positive integer
such that
. Let
. Then, we have
for all
. Equivalently,
for any distinct
with
.
Finally, since
is a positive integer, and by (
1),
, so viewed as a
q-ary sequence, we have
. □
Clearly, for any , given and any , one can uniquely recover . This is because for any such that , we have , so and by Lemma 2, we have . Thus, is uniquely determined by and .
2.2. Bounded Burst-Deletion Correction
We give a construction for correcting a single burst-deletion given the knowledge that the location of the deleted symbols are within an interval of length .
Given a positive integer
, we define a collection of intervals
such that
The following remark is easy to see.
Remark 1. The intervals in satisfy the following:
- 1)
For any interval of length , there is a (not necessarily unique) , such that .
- 2)
for all , such that .
Construction 1: Let
be a function for any positive integer
m, where
is a positive integer depending on
and
t, such that
for any distinct
with
. Let
, such that each
is defined by (
2). For each
and each
, let
The modular operation
in (
3) is performed on the result of the summation, but not on each
.
Lemma 3. Suppose . Suppose there exists an interval of length and two intervals of size , such that . Then, we have for some .
Proof. By (
2), for each
, the length
of
satisfies
. So, for any
, the length
of
(as a
q-ary sequence) satisfies
, which implies that (as an integer),
Since
, by 1) of Remark 1, there is a
, such that
. Let
be such that
, and let
Then, by 2) of Remark 1,
for all
. Further, by assumption of
and
L, we have
and
for all
. Therefore, we have
and
By the above discussions, and by Construction 1, we can obtain that , which completes the proof. □
Remark 2. Let h be the function constructed in Lemma 2. Then, we have . Moreover, by Lemma 2, h is computable in time .
3. Pattern Dense Sequences
The concept of
-dense sequences was introduced in [
18], and was used to construct binary codes with redundancy
for correcting a burst of at most
t deletions, where
n is the message length and
is a constant only depending on
t. In this section, we generalize the
-density to
q-ary sequences and derive some important properties for these sequences that will be used in our new construction in the next section.
The q-ary -dense sequences can be defined similarly to the binary -dense sequences as follows.
Definition 1. Let be three positive integers and called a pattern.
A sequence is said to be -dense
if each substring of of length δ contains at least one . The indicator vector of with respect to is a vectorsuch that, for each , if , and otherwise. In this section, we will always let
and view
for any
. Moreover, from Definition 1, we have the following simple remark.
Remark 3. Each sequence can be written as the form for some , such that each , , is a (possibly empty) string that does not contain . Moreover, is -dense if and only if it satisfies the following: (1) the lengths of and are not greater than ; and (2) the length of each , , is not greater than .
In [
18], the VT syndrome of
was used to bound the location of deletions for
-dense
, where
is a vector of length
, whose
i-th entry is the distance between positions of the
i-th and
-st 1 in the string
, and
is the number of 1s in
. In this paper, we prove that the VT syndrome of
plays the same role. Specifically, for each
, let
and
where
is the indicator vector of
with respect to
, as defined in Definition 1. Then, we have the following lemma.
Lemma 4. Suppose is -dense. For any and any , given and , one can find, in time , an interval of length , such that for some interval of size (in fact, we can require that the length of L is at most δ. However, the proof for needs more careful discussions).
Proof. Let
and
. Then, by Remark 3,
and
can be written as the following form:
and
where
and
do not contain
for each
and
. We denote
and
Additionally, let
. Clearly, for each
, we have
and
. Moreover, for each
, each
and
, we have
Note that a burst of deletions may destroy at most two ps or create at most one , so and can be computed from . We need to consider the following four cases according to .
Case 1: . Then, and there is an such that and can be obtained from by deleting a substring for some , such that . More specifically, . Clearly, we have and . It is sufficient to let , but we still need to find .
Consider
and
. By Definition 1,
can be obtained from
by
insertions and two substitutions in the substring
: inserting
0s and substituting two 0s by two 1s. Then, by (
5), we can obtain
where
are the locations of the two substitutions. To find
, we define a function
as follows: for every
, let
Then, for each
, we can obtain
, where the first inequality comes from (
6). So, for each
, we have
where the last inequality comes from the simple observation that
.
By definition of
and
, we can obtain
where (i) holds because
, and (ii) is obtained from (
6). On the other hand, by (
7),
(noticing that
. Hence, we can obtain
By (
8) and (
9),
and
L can be found as follows: Compute
and
for
i from 0 to
. Then, we can find an
such that
, where
. Let
. Note that
and
is
-dense, so by Remark 3, the length of
L satisfies
, where the last inequality holds because
.
Case 2:
. Then,
and, similarly to Case 1, there is an
such that
can be obtained from
by deleting
symbols and the pattern
is destroyed. Clearly,
, and it is sufficient to let
. To find
, consider
and
. By Definition 1,
can be obtained from
by
insertions and one substitution in the substring
: inserting
0s and substituting a 0 by a 1. By (
5), we can obtain
where
is the location of the substitution. For every
, let
Then, for each
, we have
, and so we can further obtain
By definition of
and
, we can obtain
. On the other hand, by (
10),
. Hence, we can obtain
By (
11) and (
12),
L can be found as follows: Compute
and
for
i from 0 to
. Let
be such that
. Then, let
, where
. Note that
and
is
-dense, so by Remark 3,
.
Case 3:
. Then,
. For every
, let
Note that
contains
m copies of
, so we have
. Therefore, for each
, we can obtain
As , there are two ways to obtain from :
- 1)
There is an
such that
can be obtained from
by a burst of
deletions. Correspondingly, by Definition 1,
can be obtained from
by inserting
0s into
. Therefore, we have
- 2)
There is an
such that
for some
, such that
, and
is obtained from
by deleting the substring
. By Definition 1,
can be obtained from
by inserting
0s in
and
0s in
. Therefore, we have
By definition of
, we have
and
. So, we can obtain
For both cases, if
, then we can
; if
, then we can let
. Note that
and
, and since
is
-dense, then by Remark 3, we have
or
. Moreover, by (
13), (
14), and (
15),
(and so
can be found as follows: Compute
and
for
i from 0 to
m. Then, we can always find an
, such that
, which is what we want.
Case 4:
. Then,
and there is an
such that
or
, where
,
and
, and
can be obtained from
by deleting
. In this case, we can let
, and can obtain
. To find
, we consider
and
. By Definition 1,
can be obtained from
by inserting
0s into
and substituting
by a 0. Therefore, we have
For every
, let
Then, for each
, we have
, where the inequality is obtained from (
6). Moreover, we have
and
. So, for each
, we can obtain
By (
16), and by the definition of
, we have
. So, by (
17),
(and so
can be found by the following process: For
i from 0 to
, compute
. Then, we can always find an
such that
, which is what we want.
Thus, one can always find the expected interval . From the above discussions, it is easy to see that the time complexity for finding such L is . □
In the rest of this section, we will use the so-called sequence replacement (SR) technique to construct
q-ary
-dense strings with only one symbol of redundancy for
. The SR technique, which has been widely used in the literature (e.g., see [
19,
34,
35,
36]), is an efficient method for constructing strings with or without some constraints on their substrings. In this paper, to apply the SR technique to construct
-dense strings, each length-
string that does not contain
needs to be compressed to a shorter sequence, which can be realized by the following lemma.
Lemma 5. Let and be the set of all sequences of length δ that do not contain . For , there exists an invertible functionsuch that g and are computable in time . Proof. The proof follows the same idea of Proposition 1 of [
19], and is replicated here for completeness.
As each
has length
and does not contain
, then
can be viewed as a subset of
, and we have
where (i) comes from the fact that
for
, and (ii) holds when
, i.e.,
. Thus, each sequence in
can be represented by a
q-ary sequence of length
, which gives an invertible function
.
The computation of g and involve conversion of integers in between -base representation and q-base representation, so have time complexity . □
In the rest of this section, we will always let
As we are interested in large n, we will always assume that . The following lemma gives a function for encoding q-ary strings to -dense strings.
Lemma 6. There exists an invertible function, denoted by , such that for every , is -dense. Both and its inverse, denoted by , are computable in time.
Proof. Let g be the function constructed in Lemma 5. The functions and are described by Algorithms 1 and 2, respectively, where each integer is also viewed as a q-ary string of length which is the q-base representation of i.
The correctness of Algorithm 1 can be proved as follows:
- 1)
In the initialization step, if
contains
then, clearly,
has length
n. If
does not contain
, then
and so
, where
, and by Lemma 5,
. So, at the end of the initialization step,
has length
n. Moreover,
, and the substring
has length
.
- 2)
In each round of the replacement step, if does not contain for some , then by Lemma 5, , so by replacement, the length of the appended string equals to the length of the deleted substring, and hence the length of keeps unchanged.
- 3)
At the beginning of each round of the replacement step, we have , so for , the substring contains . Equivalently, if does not contain for some , then it must be that . In this case, , so by replacement, the length of the appended string equals to the length of the deleted substring, and hence the length of keeps unchanged.
- 4)
By 1), 2) and 3), the substring is always of the form , where all substrings have a length not greater than . So, by Remark 3, for each , the substring contains .
- 5)
At the end of each round of the replacement step, the value of strictly decreases, so the While loop will end after at most n rounds, and at this time, for each , the substring contains , which combining with 4) implies that is -dense.
The correctness of Algorithm 2 can be easily seen from Algorithm 1, so is the inverse of .
Note that Algorithms 1 and 2 have at most n rounds of replacement, and in each round, (resp. needs to be computed, which has time complexity by Lemma 5, so the total time complexity of Algorithms 1 and 2 is . □
| Algorithm 1: The function for encoding to -dense sequence |
- 1:
Input: - 2:
Output: such that is -dense - 3:
(Initialization Step:) - 4:
Let . - 5:
if contains then - 6:
let be the smallest such that , and let ; - 7:
else - 8:
let and . - 9:
end if - 10:
(Replacement Step:) - 11:
while there exists an such that does not contain do - 12:
if then - 13:
delete from and append to ; let . - 14:
end if - 15:
if then - 16:
delete from and append to , where satisfying ; let . - 17:
end if - 18:
end while - 19:
Return .
|
| Algorithm 2: The function for decoding of -dense sequence |
- 1:
Input: - 2:
Output:
- 3:
while for some do - 4:
let be obtained from by deleting the last symbols; delete the last symbols of and insert at the position i of such that . - 5:
end while - 6:
if
then - 7:
let be obtained from by deleting the last 0s and let . - 8:
end if - 9:
if
then - 10:
let . - 11:
end if - 12:
Return .
|
The Algorithm 1 is obtained by modifying the Algorithm 2 of [
19], which is for binary sequences but for our purpose we need apply it to
q-ary sequences.
4. Burst-Deletion Correcting -ary Codes
In this section, we still let
Based on
-dense sequences, for any fixed positive integers
t and
, we will construct a family of
q-ary codes that can correct a burst of at most
t deletions. The basic idea of our construction is as follows: For each
-dense sequence
, use the sketches
and
(defined by (
4) and (
5), respectively) to locate the deletions within an interval of length
. Then, use the functions
constructed in Construction 1 to uniquely recover
.
Let
be a sketch function for any positive integer
m, where
is a positive integer depending on
and
t, such that
for any distinct
with
. For each
, let
such that
is defined by (
4),
is defined by (
5),
and
are obtained by Construction 1 with
.
Lemma 7. Let f be the function given by (18). If is -dense, then given and any , one can uniquely recover . Proof. First, since is -dense, then by Lemma 4, given and , one can find an interval L of length , such that for some interval of size . Moreover, suppose , such that for some interval of size . Then, by Lemma 3, we have for some . Thus, given and any , one can uniquely recover . □
Using the function f, we can give an encoding function of a q-ary code that can correct a burst of at most t deletions.
Lemma 8. Let f be the function given by (18) and be the q-ary representation of . Letsuch that and . Then, for each , given any , one can uniquely recover (and so . Proof. Let . Suppose is an interval such that . If there is more than one interval D such that , then we consider the D with the smallest . Clearly, we have . If , then ; if , then . So, we have the following two cases.
Case 1: . Then, . We need further to consider the following three subcases.
Case 1.1: . In this case, it must be that . Therefore, we have and . By Lemma 7, can be recovered from and correctly.
Case 1.2: There is a such that and . In this case, it must be that . Therefore, and . By Lemma 7, can be recovered from and correctly.
Case 1.3: and . In this case, it must be that . Therefore, .
Case 2: . Then, we have and .
Thus, one can always uniquely recover from . □
Theorem 1. There exists a q-ary code of length n capable of correcting a burst of at most t deletions, which has redundancy bits, encoding complexity and decoding complexity .
Proof. In Construction 1, let h be the function given by Lemma 2 and let be the code with the encoding function constructed in Lemma 8. Then, is a code capable of correcting a burst of at most t deletions.
The redundancy of
is
in
q-ary symbols. We now evaluate
. By Lemma 2, we have
. Moreover, since
, then for
, by (
3) and Remark 2, the length
of
(as a
q-ary string) satisfies
So, by (
4) and (
5), the length
of
(as a
q-ary string) satisfies
Thus, the redundancy of , measured in bits, is .
Consider the encoding complexity of
. Note that, by (
3) and Remark 2,
and
are computable in time
. Then, by (
4), (
5), and (
18),
is computable in time
. Moreover, by Lemma 6, the mapping
is computable in
time, so by (
19), the encoding complexity of
is
.
For the decoding complexity of
, by Lemma 6, the inverse of
is computable in
time, so by the proof of Lemma 8, we only need to consider the complexity of recovering
from
and any given
. By Lemma 4 and 1) of Remark 1, one can locate the deletions within an interval
in time
using
and
. Then,
can be recovered by brute force searching in time
. In fact, there are
candidate sequences for
, and for each candidate sequence
, we need to verify whether
, which takes time
by Lemma 2. Hence, the time of brute force searching is
where the inequality holds because
. Thus, the decoding complexity of
is
. □
5. Correcting Burst-Deletion with Two Reads
In this section, we construct a family of codes correcting a burst of at most
t deletions with 2 reads. Our construction improves the construction in [
31] in redundancy. We first recall the concept of period of a sequence.
Suppose are two positive integers and . We say that T is a period of if for any .
The following two simple observations are easy to see and will be used in our construction.
Observation 1: Let
and
. Suppose
such that
. Then,
if and only if the following holds:
Observation 2: Let and . Suppose is an interval such that and the substring of has period . Then, for any and , we have .
Our construction will use
-dense sequences for
. To apply Lemma 6 to construct
-dense sequences, we need to let
. Then, by Lemma 6, there exists an invertible function
, such that
is
-dense for every
. Moreover, both
and its inverse
are computable in
time. Thus, in this section, we always assume that
Suppose is -dense and is an interval of length . By Definition 1, there exists an such that and . For any positive integer , let if , and let if . Then, and . Thus, T is not a period of . In other words, we have the following remark.
Remark 4. Suppose is -dense, where and . Then, the length of any substring of of period is at most δ.
Lemma 9. Suppose are both -dense. If , then there exists an interval of length and two intervals of size , such that .
Proof. Suppose
and
. Then,
for some intervals
of size
, and
for some intervals
of size
. For convenience in the discussions, we denote
If for some , then let , and such that and . Clearly, J, D, and satisfy the desired conditions. So, in the following, we assume that for each .
By the symmetry of
and
and
, we can assume
Since
, where
,
and
, we can obtain from Observation 1 that
Similarly, since , where and , we have
If
, then according to Observation 1,
If
, then according to Observation 1,
Let
where
and
. Then, by (
20), (
21), and (
22), we can easily obtain the following claim.
Claim 1: For all , we have .
Since , by Claim 1, we have . If then, clearly, satisfies the desired conditions. So, in the following, we only need to consider . We have the following two cases.
Case 1: . Then, and , and so and , where and . We need to further divide this case into the following two subcases.
Case 1.1:
. Let
and
. Then,
and
. Note that by Claim 1,
for every
, and by (
20),
for every
. So, according to Observation 1, we can obtain
Moreover, by (
20) and (
21),
for every
. So,
has period
, and by Remark 4,
. Hence, we have
Case 1.2:
. We will prove that this case is impossible by contradiction. Without loss of generality, assume
. Since
, then
and
, where
. By (
20) and (
21), we have
for every
, i.e.,
has period
. So, we can obtain
(according to Observation 2), which contradicts to the assumption that
.
Case 2:
. In this case,
and we have
, where
and
. Let
and
. Then,
and
. Note that by Claim 1,
for every
, and by (
20),
for every
. So, according to Observation 1, we can obtain
Moreover, by (
20) and (
22), we can obtain
for every
. Hence,
is a substring of
of period
. By Remark 4,
, so
. □
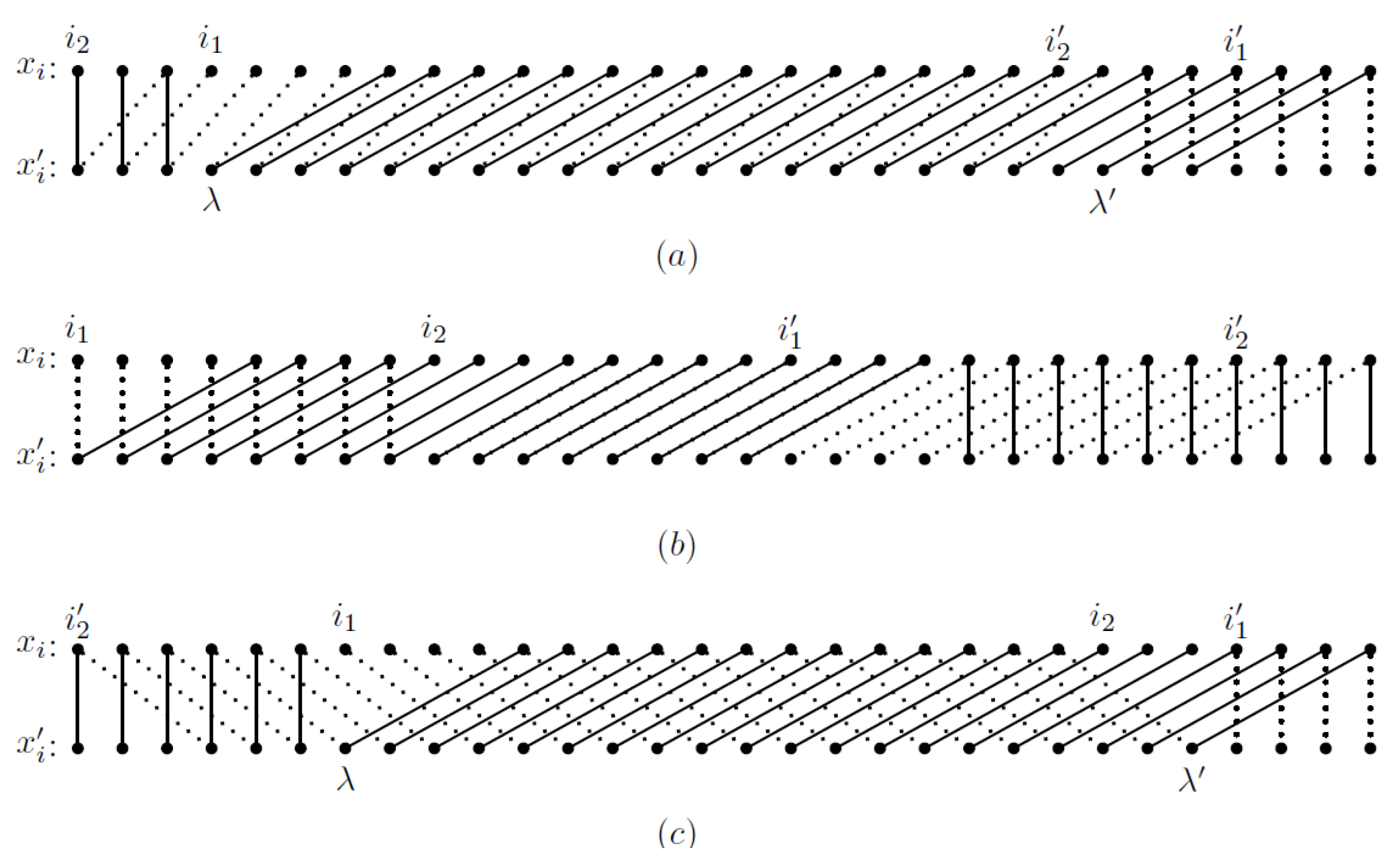
For , we give three examples of and , satisfying conditions of the different cases in the proof of Lemma 9.
Example 1. Suppose and , where , , and . Here, we have and ; and . Then, conditions of Case 1.1 are satisfied, and . Figure 1a is an illustration of this case. We can easily find that for every and for every . So, by Observation 1, . Moreover, for every , so the substring of has period 2. Example 2. Suppose and , where , , and . Here, we have , and . Then, conditions of Case 1.2 are satisfied. Figure 1b is an illustration of this case. We can find that for every , i.e., has period 4. So, by Observation 2, we have . Example 3. Suppose and , where , , and . Here, we have and ; and . Then, conditions of Case 2 are satisfied and . Figure 1c is an illustration of this case. We can easily find that for every , and for every . So by Observation 1, . Moreover, for every , i.e., has period 7. In the following, we give a construction of
q-ary codes for correcting a burst of at most
t deletions with two reads. Let
and
be defined by (
2). For each
, let the function
be obtained from Construction 1 by letting
h be the function
given by Lemma 2. Then, let
Lemma 10. For each , the function is computable in time , and when viewed as a binary string, the length of satisfies Moreover, if is -dense, then given and any two distinct , one can uniquely recover .
Proof. Note that
for each
j. Then, by (
3) and by Remark 2, the functions
and
are computable in time
Hence, by (
23),
is computable in time
.
Again by (
3) and by Remark 2, the length of
(viewed as a binary string) satisfies
where the last equality comes from the assumption that
.
Finally, we prove that if
is
-dense, then given
and any two distinct
, one can uniquely recover
. It suffices to prove that for any
-dense
, if
, then
. This can be proved as follows. By Lemma 9, there exists an interval
of length
and two intervals
of size
, such that
. Then, by Lemma 3, we have
for some
. Therefore, by (
23), we have
. □
Theorem 2. Let be the code with the encoding functionwhere , , and . Then, is an -reconstruction code with redundancy bits, encoding complexity and decoding complexity . Proof. We first prove that is an -reconstruction code. We need to prove that for each codeword , given any distinct , one can uniquely recover .
Let , where is an interval of size . By the same discussions as in the proof of Lemma 8, exactly one of the following three cases holds:
Case 1: . In this case, we have .
Case 2: There exists a such that . In this case, and . So, .
Case 3: . In this case, we have and .
Similarly, for
, either
can be recovered from
or
for some interval
of size
. Suppose
and
for some intervals
. Then,
and
. Moreover, we must have
, because otherwise, from (
24), we will obtain
, which contradicts to the assumption that
. By Lemma 10,
can be uniquely recovered from
and
.
Thus, we proved that, given any distinct , one can uniquely recover (and so , which implies that is an -reconstruction code.
By (
24), the redundancy of
is
in
q-ary symbols, which is at most
bits by Lemma 10.
The encoding complexity of comes from the complexity of computing , which is by Lemma 10. The decoding complexity of by brute force searching is at most . □



{kind=link}