Abstract
We consider a constructive definition of the multivariate Pareto that factorizes the random vector into a radial component and an independent angular component. The former follows a univariate Pareto distribution, and the latter is defined on the surface of the positive orthant of the infinity norm unit hypercube. We propose a method for inferring the distribution of the angular component by identifying its support as the limit of the positive orthant of the unit p-norm spheres and introduce a projected gamma family of distributions defined through the normalization of a vector of independent random gammas to the space. This serves to construct a flexible family of distributions obtained as a Dirichlet process mixture of projected gammas. For model assessment, we discuss scoring methods appropriate to distributions on the unit hypercube. In particular, working with the energy score criterion, we develop a kernel metric that produces a proper scoring rule and presents a simulation study to compare different modeling choices using the proposed metric. Using our approach, we describe the dependence structure of extreme values in the integrated vapor transport (IVT), data describing the flow of atmospheric moisture along the coast of California. We find clear but heterogeneous geographical dependence.
1. Introduction
The statistical analysis of extreme values focuses on inferences for rare events that correspond to the tails of probability distributions. As such, it is a key ingredient in the risk assessment of phenomena that can have strong societal impacts like floods, heat waves, high concentration of pollutants, crashes in the financial markets, among others. The fundamental challenge of extreme value theory (EVT) is to use information, collected over limited periods of time, to extrapolate to long time horizons. This sets EVT apart from most of statistical inference, where the focus is on the bulk of the distribution. Extrapolation to the tails of the distributions is possible thanks to theoretical results that give asymptotic descriptions of the probability distributions of extreme values.
Inferential methods for the extreme values of univariate observations are well established, and software is widely available; see, for example, [1]. For variables in one dimension, the application of EVT methods considers the asymptotic distribution of either the maxima calculated for regular blocks of data, or the values that exceed a certain threshold. The former leads to a generalized extreme value (GEV) distribution that depends on three parameters. The latter leads to a generalized Pareto (GP) distribution, which depends on a shape and a scale parameter. Likelihood-based approaches to inference can be readily implemented in both cases. In the multivariate case, the GEV theory is well developed; see, for example, [2], but the inferential problem is complicated by the fact that there is no parametric representation of the GEV. This problem is inherited by the peaks over threshold (PoT) approach and compounded by the fact that there is no unique definition of an exceedance of a multivariate threshold, as there is an obvious dependence on the norm that is used to measure the size of a vector.
During the last decade or so, much work has been done in the exploration of the definition and properties of an appropriate generalization of the univariate GP distribution to a multivariate setting. To mention some of the papers on the topic, the work of [3] defines the generalized Pareto distribution, with further analysis of these classes of distributions presented in [4,5]. A recent review of the state of the art in multivariate peaks over threshold modeling using generalized Pareto is provided in [6] while [7] provides insight on the theoretical properties of possible parametrizations. These are used in [8] for likelihood-based models for PoT estimation. A frequently used method for describing dependence in multivariate distributions is to use a copula. Refs. [9,10] provide successful examples of this approach in an EVT framework.
Ref. [11] presents a constructive definition of the Pareto process, which generalizes the GP to an infinite-dimensional setting. It consists of decomposing the process into independent radial and angular components. Such an approach can be used in the finite-dimensional case, where the angular component contains information pertaining to the dependence structure of the random vector. Based on this definition, we present a novel approach for modeling the angular component with families of distributions that provide flexibility and can be applied in a moderately large dimensional setting. Our focus on the angular measure is similar to that in [12,13,14], which consider Bayesian non-parametric approaches. Yet, our approach differs in that it is established in the peaks-over-threshold regime and uses a constructive definition of the multivariate GP based on the infinity norm. The approach proposed in this paper adds to the growing literature on Bayesian models for multivariate extreme value analysis (see, for example, [12,13,14,15]), providing a model that has strong computational advantages due its structural simplicitly, achieves flexibility using a mixture model, and scales well to moderately large dimensions.
The remainder of this paper is outlined as follows. Section 2 comprises a brief review of multivariate PoT, detailing the separation of the radial measure from the angular measure. Section 3 details our approach for estimating the angular measure, based on transforming an arbitrary distribution supported in onto unit hyper-spheres defined by p-norms. Section 4 develops criteria for model selection in the support of the angular measure. Section 5 explores the efficacy of the proposed approach on a set of simulated data, and, acknowledging the relevance of extreme value theory to climatological events [16,17,18], estimates the extremal dependence structure for a measure of water vapor flow in the atmosphere, used for identifying atmospheric rivers. Finally, Section 6 presents our conclusions and discussion.
Throughout the paper, we adopt the operators ∧ to denote minima and the ∨ to denote maxima. Thus , and . These operators can also be applied component-wise between vectors such as . Similarly, we apply inequality and arithmetic operators operators to vectors. For example, , and interpret them component-wise. We use uppercase to indicate random variables, lowercase to indicate points, and bold-face to indicate vectors or matrices thereof.
2. A Multivariate PoT Model
To develop a multivariate PoT model for extreme values, consider a d-dimensional random vector with cumulative distribution F. A common assumption on is that it is in the so-called domain of attraction of a multivariate max-stable distribution, G. Thus, following [7], assume that there exists sequences of vectors and , such that . G is a d-variate generalized extreme value distribution. Notice that, even though the univariate marginals are obtained from a three-parameter family, there is no parametric form to represent G. Taking logarithms and expanding, we have that
such that . It follows that
where indicates element-wise inversion, and denotes the set where at least one coordinate is above the corresponding component of . H is a multivariate Pareto distribution. It corresponds to a joint distribution conditional on exceeding a multivariate threshold. H is defined by a non-parametric function governing the multivariate dependence and two d-dimensional vectors of parameters that control the shapes and scales of the marginals. We denote these as for the shapes and for the scales. Ref. [7] provides a number of stochastic representations for H. In this paper, we focus on a particular one that is proposed in [11]. To this end, we denote as Z a random variable with distribution H where and . Then, where R and are independent. is distributed as a standard Pareto random variable, and is a random vector in , the positive orthant of the unit sphere under norm, with distribution . This representation is central to the methods proposed in this paper. R and are referred to, respectively, as the radial and angular components of H. The angular measure controls the dependence structure of in the tails. In view of this, to obtain a PoT model, we seek a flexible model for the distribution of , based on a Bayesian non-parametric model.
The approach considered in [6] focuses on the limiting conditional distribution H. An alternative approach to obtaining a limiting PoT distribution consists of assuming that regular variation (see, for example, [19]) holds for the limiting distribution of , implying that
for some measure that is referred to as the exponent measure. has the homogeneity property . Letting and , define , which is referred to as the angular measure. After some manipulations, we obtain that
Thus, a model for the exponent measure induces a model for the limiting distribution conditional on the observations being above a threshold defined with respect to their p-norm. The constraint that all marginals of correspond to a standard Pareto distribution leads to the so-called moment constraints on , consisting of
Inference for the limiting distribution of the exceedances needs to account for the normalizing constant in Equation (1) as well as the moment constraints. Because of these issues, in this paper, we prefer to follow the limiting conditional distribution approach. An example of the application of the regular variation approach using is developed in [13].
3. Estimation of the Angular Measure
To infer the PoT distribution, we consider two steps: First we estimate the shape and scale parameters for the multivariate Pareto distribution, using the univariate marginals; then we focus on the dependence structure in extreme regions by proposing a flexible model for the distribution of . Consider a collection of realizations of . We start by setting a large threshold for the ℓ-th marginal, . Then, the distribution of , conditional on exceeding the threshold, can be approximated with a generalized univariate Pareto. Thus,
where indicates the positive part function. We set , the empirical -quantile. We then estimate and , for each ℓ, using likelihood-based methods. To estimate the angular distribution, we standardize each of the marginals. The standardization yields
Note that implies that , meaning that the observation is extreme in the ℓ-th dimension. Thus, implies that at least one dimension has an extreme observation and corresponds to a very extreme observation when t is large. We focus on the observations that are such that . These provide a sub-sample of the standardized original sample. We define . These vectors are used for the estimation of .
3.1. Projected Gamma Family
At the core of our PoT method is the development of a distribution on , where, for , is the -norm of a vector , defined as
The absolute and Euclidean norms are obtained for and respectively, and the norm can be obtained as a limit:
To obtain a distribution on , we start with a vector in and normalize it to obtain . Figure 1a shows the progression of asymptotically towards as p increases; Figure 1b shows the relative positions of data points normalized to for selected p. A natural distribution to consider in is given by a product of independent univariate Gamma distributions. Let . and are the shape and scale parameters, respectively. For any finite , letting , the transformation
is invertible with
The Jacobian of the transformation takes the form
The normalization provided by T maps a vector in onto . With a slight abuse of terminology, we refer to it as a projection. Using Equations (3)–(5), we have the joint density
Integrating out r yields the resulting Projected Gamma density
defined for and for any finite . To avoid identifiability problems when estimating the shape and scale parameters, we set . Ref. [20] obtain the density in Equation (7) for as a multivariate distribution for directional data using spherical coordinates. For and for all ℓ, the density in Equation (7) corresponds to that of a Dirichlet distribution.
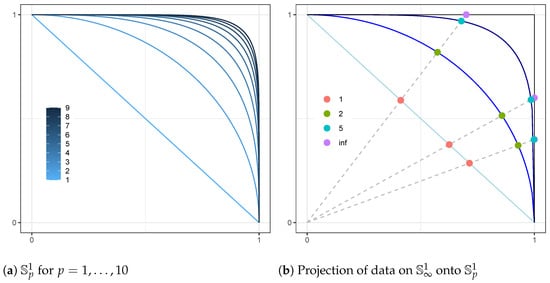
Figure 1.
The positive orthant of the p-norm sphere for .
The projected gamma family is simple to specify and has very tractable computational properties. Thus, we use it as a building block for the angular measure models. To build a flexible family of distributions in , we consider mixtures of projected gamma densities defined as
where . Following a Bayesian non-parametric approach [21,22,23], we assume that G is drawn from a random measure. In particular, assuming a Dirichlet process prior for G, we have a hierarchical formulation of the mixture model that, for a vector of observations , is given by
where denotes a Dirichlet process, is the precision parameter, and is the centering distribution.
Unfortunately, in the limit when , the normalizing transformation is not differentiable. Thus, a closed-form expression like Equation (7) for the projected gamma density on is not available. Instead, we observe that for a sufficiently large p, will approach . With that in mind, our strategy consists of describing the angular distribution using a sample-based approach with the following steps: (i) Apply the transformation in Equation (2) to the original data; (ii) Obtain the subsample of the standardized observations that satisfy ; (iii) Take a finite p and project the observations onto ; (iv) Fit the model in Equation (8) to the resulting data and obtain samples from the fitted model; (v) project the resulting samples onto . For step (iv), we use a Bayesian approach that is implemented using a purposely developed Markov chain Monte Carlo sampler described in the next section.
3.2. Tail Probabilities for the PoT Model
A measure that is used to characterize the strength of the dependence in the tail for two random variables, and , with marginal distributions and is given by [1]
provides information about the distribution of extremes for the variable given that is very large. When , and are said to be asymptotically dependent; otherwise, they are asymptotically independent. The following result provides the asymptotic dependence coefficient between two components of for our proposed PoT model.
Proposition 1.
Suppose that with , and exists, for , then
Proof.
Denote as the marginal distribution of . To obtain , we need , where . Using the fact that almost surely, we have that the former is equal to
where the second identity is justified by the fact that is bounded and . The proof is completed by noting that □
Equation (10) implies that , and so, no asymptotic independence is possible under our proposed model. For the analysis of extreme values, it is of interest to calculate the multivariate conditional survival function. The following result provides the relevant expression as a function of the angular measure.
Proposition 2.
Assume the same conditions as Proposition 1. Let be a collections of indexes. Then
The proof uses a similar approach to the proof of Proposition 1.
Equations (10) and (11) provide relevant tools for inference on the tail behavior of the joint distribution of the observations. The expressions can be readily calculated within a sample-based inferential approach like the one considered in the following section.
Inference for the Projected Gamma Mixture Model
To perform inference for our proposed PoT model, we develop an iterative sample-based approach. We implement a Markov chain Monte Carlo method that, for a given iteration, groups observations into stochastically assigned clusters, where members of a cluster share distributional parameters [23,24]. Building out the methods of inference for Equation (9), let be the number of observations in cluster j, not including observation i. Let be the number of extant clusters, not including any singleton containing observation i. Under this model, the probability of cluster membership for a given observation is proportional to
where the top case is iterating over extant clusters , and the bottom case is for a new cluster. If is not a conjugate prior for the kernel density, the integral in the above formula may not be available in closed form. We sidestep this using Algorithm 8 from [25]: by Monte Carlo integration, we draw m candidate clusters, for from . Then, we sample the cluster indicator from extant or candidate clusters, where the probability of cluster membership is proportional to
Again, the top case is iterating over extant clusters, and now the bottom case is iterating over new candidate clusters. If a candidate cluster is selected, then , and the associated cluster parameters are saved.
A key feature of the the projected Gamma distribution is its computational properties. We augment by introducing a latent radial component , for each observation. Using Equation (6) we observe that the full conditional of is easy to sample from, as it is given as
Moreover, the full conditional for is then proportional to
Note that the ordering of the products can be reversed in Equation (14), indicating that with appropriate choice of centering distribution, the full conditionals for can become separable by dimension, and thus inference on can be done in parallel for all j, ℓ. We first consider a centering distribution given by a product of independent Gammas:
This model is completed with independent Gamma priors on , , , and . We also assume a Gamma prior on , which is updated via the procedure outlined in [26]. We refer to this model as the projected gamma-gamma (PG-G) model. An advantage of the PG-G model is that, thanks to conjugacy, the rate parameters can easily be integrated out for inference on . Then, the full conditional for takes the form
for . For , as , the full conditional takes the simpler form
Samples of can thus be obtained using a Metropolis step. In our analysis, we first transform to the log scale and use a normal proposal density. The full conditional for is
for . Updating is done via a Gibbs step. The hyper-parameters follow similar gamma-gamma update relationships. We also explore a restricted form of this model, where for all ℓ. Under this model, we use the full conditional in Equation (17) for all ℓ and omit inference on . We refer to this model as the projected restricted gamma-gamma (PRG-G) model.
The second form of centering distribution we explore is a multivariate log-normal distribution on the shape parameters with independent gamma rate parameters.
This model is completed with a normal prior on , an inverse Wishart prior on , and Gamma priors on , , and . This model is denoted as the projected gamma-log-normal (PG-LN) model. We also explore a restricted Gamma form of this model as above, where for all ℓ. This is denoted as the projected restricted gamma-log-normal (PRG-LN) model. Updates for can be accomplished using a joint Metropolis step, where for have been integrated out of the log-density. That is,
The inferential forms for and its priors are the same as for PG-G. The normal prior for is conjugate for the log-normal and can be sampled via a Gibbs step. Finally, the inverse Wishart prior for is again conjugate to the log-normal , implying that it can also be sampled via a Gibbs step.
To effectively explore the sample space with a joint Metropolis step, as well as to speed convergence, we implement a parallel tempering algorithm [27] for the log-normal models. This technique runs parallel MCMC chains at ascending temperatures. That is, for chain s, the posterior density is exponentiated by the reciprocal of temperature . For the cold chain, . Let be the log-posterior density under the current parameter state for chain s. Then states between chains are exchanged via a Metropolis step with probability
Higher temperatures serve to flatten the posterior distribution, meaning hotter chains have a higher probability of making a given transition or will make larger transitions. As such, they will more quickly explore the parameter space and share information gained through state exchange.
4. Scoring Criteria for Distributions on the Infinity-Norm Sphere
In order to assess and compare the estimation of a distribution on , we consider the theory of proper scoring rules developed in [28]. As mentioned in Section 3.1, our approach does not provide a density on , restricting our ability to construct model selection criteria to sample-based approaches. To this end, we employ the energy score criterion introduced therein.
The energy score criterion, defined for a general probability distribution P with a finite expectation, is developed as
where g is a kernel function. The score defined in Equation (20) can be evaluated using samples from P with the help of the law of large numbers. Moreover, Theorem 4 in [28] states that if is a negative definite kernel, then is a proper scoring rule. Recall that a real valued function g is a negative definite kernel if it is symmetric in its arguments, and for all positive integers n and any collection such that .
In a Euclidean space, these conditions are satisfied by the Euclidean distance [29]. However, for observations on different faces of , the Euclidean distance will under-estimate the geodesic distance, the actual distance required to travel between the two points. Let
comprise the ℓth face. For points on the same face, the Euclidean distance corresponds to the length of the shortest possible path in . For points on different faces, the Euclidean distance is a lower bound for that length.
For a finite p, the shortest connecting path between two points in is the minimum geodesic; its length satisfying the definition of a distance. Thus its length can be used as a negative definite kernel for the purpose of defining an energy score. Unfortunately, as , the resulting surface is not differentiable, implying that routines to calculate geodesics are not readily available. However, as is a portion of a d-cube, we can borrow a result from geometry [30] stating that the length of the shortest path between two points on a geometric figure corresponds to the length of a straight line drawn between the points on an appropriate unfolding, rotation, or net of the figure from a d-dimensional to a -dimensional space. The optimal net will have the shortest straight line between the points, as long as that line is fully contained within such a net. As has d faces—each face pairwise adjacent, there are possible nets. However, we are only interested in nets that begin and end on the source and destination faces, respectively, reducing the number of nets under consideration to . This is still computationally burdensome for a large number of dimensions. However, we can efficiently establish an upper bound on the geodesic length. We use this upper bound on geodesic distance as the kernel function for the energy score.
To calculate the energy score, we define the kernel
where , and for . Evaluating g as described requires the solution of a -dimensional optimization problem. The following proposition provides a straightforward approach.
Proposition 3.
Let , and , for . For , the transformation required to rotate the 𝚥th face along the ℓth axis produces the vector , where
Then .
Proof.
Notice that for , . We then have that
The last equality is due to the fact that and belong to the same hyperplane. □
Using the rotation in Proposition 3, we obtain the following result.
Proposition 4.
g is a negative definite kernel.
Proof.
For a given n, consider an arbitrary set of points , and , such that . Then
where is defined as in Proposition 3. The last equality holds as is negative definite [28] □
Proposition 3 provides a computationally efficient way to evaluate the proper scoring rule defined on for each observation. For the purpose of model assessment and comparison, we report the average taken across all observed data and notice that the smaller the score, the better.
5. Data Illustrations
We apply the aforementioned models to simulated angular data. We then consider the analysis of atmospheric data. To tackle the difficult problem of assessing the convergence an MCMC chain for a large-dimensional model, we monitor the log-posterior density. In all the examples considered, MCMC samples produced stable traces of the log-posterior in less than 40,000 iterations. We use that as a burn-in and thereafter sample 10,000 additional iterations. We then thin the chain by retaining one every ten samples, to obtain 1000 total samples. These are used to generate samples from the posterior predictive densities. We used two different strategies to implement the MCMC samplers. For the models whose DP prior is centered around a log-normal distribution, we used parallel tempering. This serves to overcome the very slow mixing that we observed in these cases. The temperature ladder was set as for . This was set empirically in order to produce acceptable swap probabilities both for the simulated data and real data. Parallel tempering produces chains with good mixing properties but has a computational cost that grows linearly with the number of temperatures. Thus, for the gamma-centered models, we used a single chain. We leverage the fast speed of each iteration to obtain a large number of samples, which are appropriately thinned to deal with a mild autocorrelation. In summary, the strategy for log-normal centered models is based on a costly sampler with good mixing properties. The strategy for the gamma-centered models is based on a cheap sampler that can be run for a large number of iterations.
Our hyperprior parameters are set as follows: For the gamma-centered models (PG-G, PRG-G), the shape parameter for the centering distribution , and rate parameter . For the log-normal centered models (PG-LN, PRG-LN), the centering distribution’s log-mean , and covariance matrix . These values are intended such that draws from the prior for will weakly tend towards the identity matrix. For models learning rate parameters (PG-G, PG-LN), the centering distribution’s shape parameter and rate parameter . The choice of the for rate parameters places little mass near 0 in order to draw estimates for the value away from 0 for numerical stability.
5.1. Simulation Study
The challenging problem in multivariate EVT is to capture the dependence structure of the limiting distribution. To this end, we focus our simulation study specifically on the angular component. To evaluate our proposed approach for angular measure estimation, we consider simulated datasets on for values of d ranging from 2 to 32. We generated each dataset as a mixture of multivariate log-normal distributions projected onto . The generation procedure is detailed in Algorithm 1. We produced ten replicates of each configuration. We consider two gamma-centered and two log-normal-centered DP mixture models, with and without restrictions in each case. To perform a comparative analysis, we fitted the pairwise betas model proposed in [31]. We chose this model for comparison, as it similarly works to capture a complex dependence structure on an sphere, albeit with , and is implemented in the readily available package BMAmevt in R [32], which can provide samples from the posterior predictive distribution. These samples are needed for the calculation of the energy scores that are at the basis of our comparison. In addition, BMAmevt can be fitted to moderately large multivariate observations. For the DP mixture models, the data are projected onto . For the other two models, they are projected onto . We sampled each model for 50,000 iterations, dropping the first 40,000 as burn-in and thinning to keep every 10th iteration after. These settings were intended to provide a consistent sampling strategy that would work with every model, even if inefficient for some.
| Algorithm 1 Simulated Angular Dataset Generation Routine. , are the parameters of the mixture component distribution; is the probability vector assigning weight mixture components; is the mixture component identifier for each simulated observation. |
|
Figure 2 shows the average rise over baseline in energy score, as calculated on using the kernel metric described in Proposition 3, for models trained on simulated data. After training a model, a posterior predictive dataset is generated, and the energy score is calculated as a Monte Carlo approximation of Equation (20). In our analysis, after burn-in and thinning, we had 1000 replicates from the posterior distribution and generated 10 posterior predictive replicates per iteration. The baseline value is the energy score of a new dataset from the same generating distribution as the training dataset evaluated against the training dataset. For the simulated data, we observe that the projected gamma models dominate the other two options considered, regardless of the choice of centering distribution. The projected restricted gamma models with a multivariate log-normal centering distribution appear to be dominated by the models based on the alternative centering distributions. Moreover, the performance deteriorates with the increase in dimensionality. Additionally, models centered around the log-normal distribution incur the computational cost of multivariate normal evaluation and parallel tempering, taking approximately six times longer to sample relative to the gamma models. We also note that the computational cost of the pairwise betas model grows combinatorially, with a sample space of dimension . By comparison, the sample space for PG-G and PRG-G are and , respectively, where J is the number of extant clusters, with much of that inference able to be done in parallel. In our testing, for low-dimensional problems, BMAmevt was substantially faster than any of our proposed DP mixture models. However, for examples with high numbers of dimensions, the computational time for BMAmevt was greater than that for PG-G. We compare computing times in our data analysis in Table 1b.
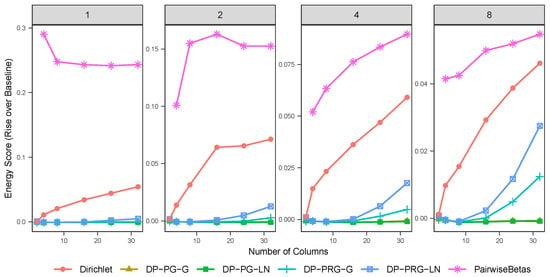
Figure 2.
Average energy score rise over baseline (on ) for various models fitted to simulated data, with ascending count of mixture components (indicated by plot heading) and number of dimensions (indicated by horizontal axis). Note that pairwise betas is a moment-restricted model.

Table 1.
Model fit assessment and computation time on ERA-Interim and ERA5 data. (a) Energy score criterion from fitted models against the IVT data. Lower is better. (b) Time to sample (in minutes) 50,000 iterations for various models.
5.2. Integrated Vapor Transport
The integrated vapor transport (IVT) is a two-component vector that tracks the flow of the total water volume in a column of air over a given area [33]. IVT is increasingly used in the study of atmospheric rivers because of its direct relationship with orographically induced precipitation [34]. Atmospheric rivers (AR) are elongated areas of high local concentration of water vapor in the atmosphere that transport water from the tropics around the world. AR can cause extreme precipitation, something that is usually associated with very large values of the IVT magnitude over a whole geographical area. In spite of this, AR are fundamental for the water supply of areas like California. Thus, the importance of understanding the extreme behavior of IVT includes extreme tail dependence. We consider datasets that correspond to IVT estimated at two different spatial resolutions. The coarse-resolution dataset is obtained from the European Centre for Medium-Range Weather Forecasts (ECMWF) Interim reanalysis (ERA-Interim) [35,36]. The high-resolution dataset corresponds to the latest ECMWF observational product, ERA5 [37].
Our data correspond to daily average values for the IVT magnitude along the coast of California. The ERA-Interim data used cover the time period 1979 through 2014 (37 years), omitting leap days, and eight grid cells that correspond to the coast of California. The ERA5 data cover the time period 1979 through 2019 (42 years) with the same restriction and 47 grid cells for the coast of California. This gives us the opportunity to illustrate the performance of our method in multivariate settings of very different dimensions. Figure 3 provides a visual representation of the area these grid cells cover.
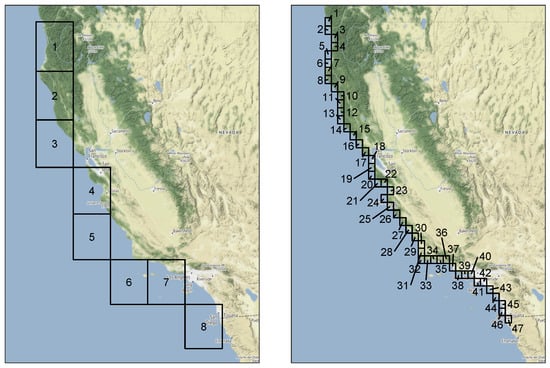
Figure 3.
Grid cell locations for ERA-Interim (left) and ERA5 (right).
Fitting our models to the IVT data requires some pre-processing. First, we subset the data to the rainy season, which in California runs roughly from November to March. Following the approach described in Section 3, we estimate the shape and scale parameters of a univariate GP in each dimension, using maximum likelihood. We set the threshold in each dimension ℓ as , where is the empirical CDF and , which corresponds to the 95 percentile. We then use the transformation in Equation (2) to standardize the observations. Dividing each standardized observation by its norm, we obtain a projection onto . As the data correspond to a daily time series, the observations are temporally correlated. For each group of consecutive standardized vectors such that , we retain only the vector with the largest norm. The complete procedure is outlined in Algorithm 2.
After subsetting the ERA-Interim data to the rainy season, we have 5587 observations. After the processing and declustering described in Algorithm 2, this number reduces to 511 observations. A pairwise plot of the transformed data after processing and declustering is presented in Figure 4. From this, we note that the marginal densities display strong similarities, with a large spike near 0 and a small spike near 1. A value of 1 in a particular axis indicates that the standardized threshold exceedance was the largest in that dimension. The off-diagonal plots correspond to pairwise density plots. We observe that some site pairs, such as , , and especially , have the bulk of their data concentrated in a small arc along the ; in other site combinations, such as , , or , the data is split, favoring one side or the other of the line. For the ERA5 data, after subsetting, we have 6342 observations, which reduces to 532 observations after processing and declustering. We fit the PG-G, PRG-G, PG-LN, and PRG-LN models to both datasets.
| Algorithm 2 Data preprocessing to isolate and transform data exhibiting extreme behavior. represents the radial component, and the angular component. The declustering portion is relevant for data correlated in time. |
|
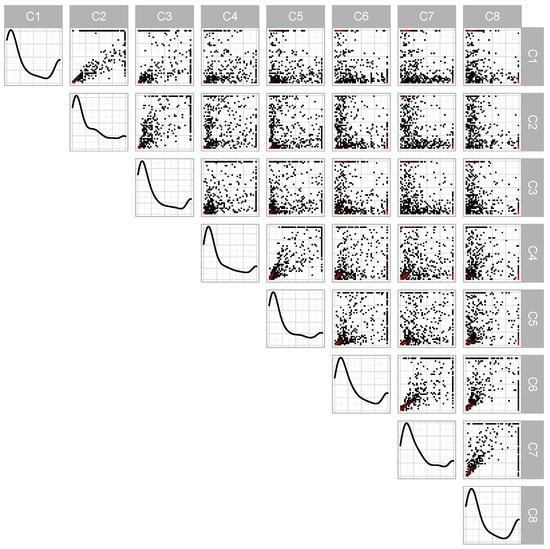
Figure 4.
Pairwise plots from ERA-Interim data after transformation and projection to . Down the diagonal are marginal kernel densities with two-dimensional histograms on the off-diagonal. In those plots, red indicates a higher density. All data are between 0 and 1.
Table 1a shows the values of the estimated energy scores for the different models considered. We observe that, contrary to the results in the simulation study in Figure 2, the preferred model is the projected restricted gamma models, though for the lower-dimensional ERA-Interim data, all models perform comparably. Table 1b shows the computing times needed to fit the different models to the two datasets. We see the effect of dimensionality on the various models; for gamma-centered models, it grows linearly; for the log-normal centered model, it will grow superlinearly as matrix inversion becomes the most costly operation. For BMAmevt, its parameter space grows combinatorially with the number of dimensions, and thus so does computational complexity and sampling time.
We consider an exploration of the pairwise extremal dependence using Monte Carlo estimates of the coefficients in Equation (10). For this, we use samples obtained from the PRG-G model. Figure 5 provides a graphical analysis of the results. The coefficients achieve values between and for the ERA-Interim data and between and for the ERA5 data. The greater range in dependence scores observed in the ERA5 data versus ERA-Interim speaks to the greater granularity of the ERA5 data, indicating that distance between locations is a strong contributor to the strength of the pairwise asymptotic dependence. The highest coefficients are for locations 4 and 5 in the ERA-Interim data and for locations 1 and 2 in the ERA5 data. Clearly, pairwise asymptotic dependence coefficients tell a limited story, as a particular dependence may include more than two locations. We can, however, glean some information from the patterns that emerge in two dimensions. For the ERA-Interim data, we observe a possible cluster between cells 5–8, indicating a strong dependence among these cells. Analogously, for the ERA5 data, we observe three possible groups of locations.
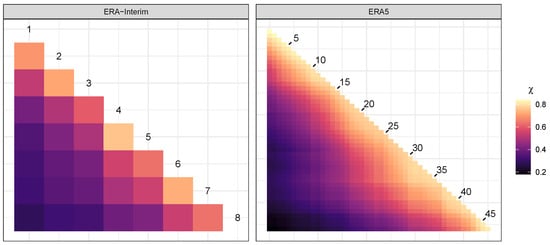
Figure 5.
Pairwise extremal dependence coefficients for IVT data using the PRG-G model.
Figure 6 shows, for the ERA-Interim data under the PRG-G model, the conditional survival curve defined in Equation (11) for one dimension conditioned on all other dimensions being greater than their (fitted) 90th percentile. Figure 7 presents the bi-variate conditional survival function, conditioning on all other dimensions. These results illustrate quantitatively how extremal dependence affects the shape of the conditional survival curves. The two top panels represent the joint survival function between grid locations 4 and 5, which are shown in Figure 5 to exhibit strong extremal dependence. We observe that the joint survival surface is strongly convex. The bottom panels represent the joint survival surface between grid locations 1 and 5, which exhibited low extremal dependence. In this case, the shape of the contours tends to be concave, quite different from the shapes observed in the top panels.
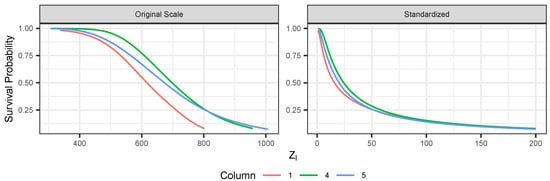
Figure 6.
Conditional survival curves for selected locations using ERA-Interim and PRG-G model conditioning on all other dimensions at greater than 90th percentile (fitted). The left panel uses original units. Right panel uses standardized units.
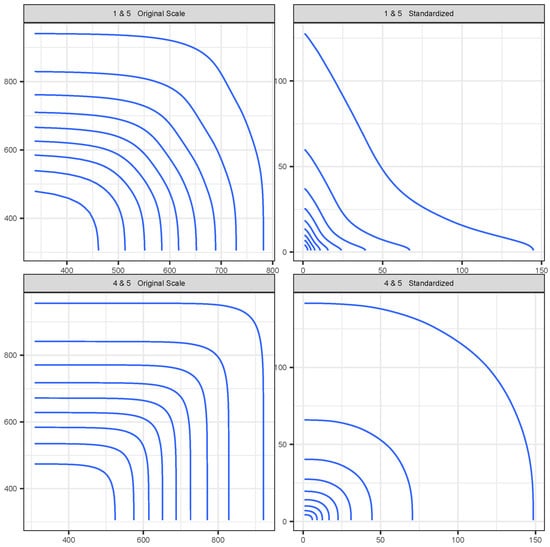
Figure 7.
Pairwise conditional survival curves for selected locations, using ERA-Interim and PRG-G models, conditioning on all other dimensions at greater than the 90th percentile (fitted).
Using our proposed scoring criteria, we explored the effect of the choice of p on the final results. Using the simulated data, generated from a mixture of projected gammas, we were unable to observe sizeable differences in the scores for p ranging between 1 and 15. However, for the IVT data, we observed a drop in the energy score associated with higher p, with a diminishing effect as p increased. We observed no significant differences in the performance of the model that uses , which corresponds to the analysis presented, relative to the one that uses .
6. Conclusions
In this paper, we have built upon the definition of the multivariate Pareto described in [11] to establish a useful representation of its dependence structure through the distribution of its angular component, which is supported on the positive orthant of the unit hypersphere under the norm, . Due to the inherent difficulty of obtaining the likelihood of distributions with support on , our method transforms the data to , fits then using mixtures of products of independent gammas, then transforms the predictions back to . As converges to as , we expect the proposed resampling to be efficient for large enough p. In fact, our exploration of the simulated and real data indicates that the procedure is robust to the choice of moderately large values of p. Our method includes two inferential steps. The first consists of the estimation of the marginal Pareto distributions; the second consists of the estimation of the angular density. Parameter uncertainty incurred in the former is not propagated to the latter. Conceptually, an integrated approach that accounts for all the estimation uncertainty is conceivable. Unfortunately, this leads to posterior distributions with complex data-dependent restrictions that are very difficult to explore, especially in large dimensional settings. In fact, our attempts to fit a simple parametric model for the marginals and the angular measures jointly in several dimensions were not successful.
In this paper, we have focused on a particular representation of the multivariate Pareto distribution for PoT inference on extreme values. To this end, our model provides a computationally efficient and flexible approach. An interesting extension of the proposed model is to consider regressions of extreme value responses, due to extreme value inputs following the ideas in [38]. This will produce PoT-based Bayesian non-parametric extreme value regression models. More generally, models that allow for covariate-dependent extremal dependence [39] could be considered. In addition, we notice that our approach is based on flexibly modeling angular distributions for any p-norm. As such, it can be applied to other problems focused on high-dimensional directional statistics constrained to a cone of directions.
Developing an angular measure specifically in provides two benefits over . First, the transformation to is unique. Recall that Equation (4) gives as a function of . An analogous expression can be obtained for any . This indicates that there are d equivalent transformations, each yielding a different Jacobian and, for , potentially resulting in a different density. Second, the evaluation of geodesic distances on is not straightforward. However, we have demonstrated a computationally efficient upper bound on geodesic distance on . Accepting these foibles, it would be interesting to explore the distribution of ,
The computations in this paper were performed on a desktop computer with an AMD Ryzen 5000 series processor. The program is largely single-threaded, so computation time is not dependent on the available core count. In each case, we run the MCMC chain for 50,000 iterations, with a burn-in of 40,000 samples. Fitting the PG-G model on the ERA5 dataset took approximately 15 min. Work is in progress to optimize the code and explore parallelization where possible. We are also exploring alternative computational approaches that will make it feasible to tackle very high dimensional problems, such as variational Bayes. In fact, to elaborate on the study of IVT, there is a need to consider several hundreds, if not thousands, of grid cells over the Pacific Ocean in order to obtain a good description of atmospheric events responsible for large storm activity over California.
Author Contributions
Conceptualization, methodology, visualization, writing, P.T.; Supervision, editing, B.S. All authors have read and agreed to the published version of the manuscript.
Funding
This material is based on work supported by the National Science Foundation under Grant No. SES-2050012 and DMS-2153277.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Coles, S.G. An Introduction to Statistical Modelling of Extreme Values; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar] [CrossRef]
- De Haan, L.; Ferreira, A. Extreme Value Theory: An Introduction; Springer: Berlin/Heidelberg, Germany, 2006; Volume 21. [Google Scholar] [CrossRef]
- Rootzén, H.; Tajvidi, N. Multivariate generalized Pareto distributions. Bernoulli 2006, 12, 917–930. [Google Scholar] [CrossRef]
- Falk, M.; Guillou, A. Peaks-over-Threshold stability of multivariate generalized Pareto distributions. J. Multivar. Anal. 2008, 99, 715–734. [Google Scholar] [CrossRef]
- Michel, R. Some notes on multivariate generalized Pareto distributions. J. Multivar. Anal. 2008, 99, 1288–1301. [Google Scholar] [CrossRef]
- Rootzén, H.; Segers, J.; Wadsworth, J.L. Multivariate peaks over thresholds models. Extremes 2018, 21, 115–145. [Google Scholar] [CrossRef]
- Rootzén, H.; Segers, J.; Wadsworth, J.L. Multivariate generalized Pareto distributions: Parametrizations, representations, and properties. J. Multivar. Anal. 2018, 165, 117–131. [Google Scholar] [CrossRef]
- Kiriliouk, A.; Rootzén, H.; Segers, J.; Wadsworth, J.L. Peaks Over Thresholds Modeling With Multivariate Generalized Pareto Distributions. Technometrics 2019, 61, 123–135. [Google Scholar] [CrossRef]
- Renard, B.; Lang, M. Use of a Gaussian copula for multivariate extreme value analysis: Some case studies in hydrology. Adv. Water Resour. 2007, 30, 897–912. [Google Scholar] [CrossRef]
- Falk, M.; Padoan, S.A.; Wisheckel, F. Generalized Pareto copulas: A key to multivariate extremes. J. Multivar. Anal. 2019, 174, 104538. [Google Scholar] [CrossRef]
- Ferreira, A.; de Haan, L. The generalized Pareto process; with a view towards application and simulation. Bernoulli 2014, 20, 1717–1737. [Google Scholar] [CrossRef]
- Boldi, M.O.; Davison, A.C. A mixture model for multivariate extremes. J. R. Stat. Soc. Ser. Stat. Methodol. 2007, 69, 217–229. [Google Scholar] [CrossRef]
- Sabourin, A.; Naveau, P. Bayesian Drichlet mixture model for multivariate extremes: A re-parametrization. Comput. Stat. Data Anal. 2014, 71, 542–567. [Google Scholar] [CrossRef]
- Hanson, T.E.; de Carvalho, M.; Chen, Y. Bernstein polynomial angular densities of multivariate extreme value distributions. Stat. Probab. Lett. 2017, 128, 60–66. [Google Scholar] [CrossRef]
- Guillotte, S.; Perron, F.; Segers, J. Non-parametric Bayesian inference on bivariate extremes. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2011, 73, 377–406. [Google Scholar] [CrossRef]
- Jentsch, A.; Kreyling, J.; Beierkuhnlein, C. A new generation of climate-change experiments: Events, not trends. Front. Ecol. Environ. 2007, 5, 365–374. [Google Scholar] [CrossRef]
- Vousdoukas, M.I.; Mentaschi, L.; Voukouvalas, E.; Verlaan, M.; Jevrejeva, S.; Jackson, L.P.; Feyen, L. Global probabilistic projections of extreme sea levels show intensification of coastal flood hazard. Nat. Commun. 2018, 9, 2360. [Google Scholar] [CrossRef]
- Li, C.; Zwiers, F.; Zhang, X.; Chen, G.; Lu, J.; Li, G.; Norris, J.; Tan, Y.; Sun, Y.; Liu, M. Larger increases in more extreme local precipitation events as climate warms. Geophys. Res. Lett. 2019, 46, 6885–6891. [Google Scholar] [CrossRef]
- Resnick, S. Extreme Values, Regular Variation, and Point Processes; Applied Probability; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Núñez-Antonio, G.; Geneyro, E. A multivariate projected Gamma model for directional data. Commun. Stat.-Simul. Comput. 2021, 50, 2721–2742. [Google Scholar] [CrossRef]
- Ferguson, T.S. Prior Distributions on Spaces of Probability Measures. Ann. Stat. 1974, 2, 615–629. [Google Scholar] [CrossRef]
- Antoniak, C.E. Mixtures of Dirichlet Processes with Applications to Bayesian Nonparametric Problems. Ann. Stat. 1974, 2, 1152–1174. [Google Scholar] [CrossRef]
- Müller, P.; Quintana, F.A.; Jara, A.; Hanson, T. Bayesian Nonparametric Data Analysis; Springer: Berlin/Heidelberg, Germany, 2015; Volume 1. [Google Scholar]
- Ascolani, F.; Lijoi, A.; Rebaudo, G.; Zanella, G. Clustering consistency with Dirichlet process mixtures. Biometrika 2022, 110, 551–558. [Google Scholar] [CrossRef]
- Neal, R.M. Markov Chain Sampling Methods for Dirichlet Process Mixture Models. J. Comput. Graph. Stat. 2000, 9, 249–265. [Google Scholar] [CrossRef]
- Escobar, M.D.; West, M. Bayesian density estimation and inference using mixtures. J. Am. Stat. Assoc. 1995, 90, 577–588. [Google Scholar] [CrossRef]
- Earl, D.J.; Deem, M.W. Parallel tempering: Theory, applications, and new perspectives. Phys. Chem. Chem. Phys. 2005, 7, 3910–3916. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly Proper Scoring Rules, Prediction, and Estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Berg, C.; Christensen, J.P.R.; Ressel, P. Harmonic Analysis on Semigroups: Theory of Positive Definite and Related Functions; Springer: Berlin/Heidelberg, Germany, 1984; Volume 100. [Google Scholar]
- Pappas, T. The Joy of Mathematics: Discovering Mathematics All Around You; Wide World Pub Tetra: Frederick, MD, USA, 1989. [Google Scholar]
- Cooley, D.; Davis, R.A.; Naveau, P. The pairwise beta distribution: A flexible parametric multivariate model for extremes. J. Multivar. Anal. 2010, 101, 2103–2117. [Google Scholar] [CrossRef]
- Sabourin, A. BMAmevt: Multivariate Extremes: Bayesian Estimation of the Spectral Measure, R Package Version 1.0.5; 2023. Available online: https://CRAN.R-project.org/package=BMAmevt (accessed on 10 April 2024).
- Ralph, F.M.; Iacobellis, S.; Neiman, P.; Cordeira, J.; Spackman, J.; Waliser, D.; Wick, G.; White, A.; Fairall, C. Dropsonde observations of total integrated water vapor transport within North Pacific atmospheric rivers. J. Hydrometeorol. 2017, 18, 2577–2596. [Google Scholar] [CrossRef]
- Neiman, P.J.; White, A.B.; Ralph, F.M.; Gottas, D.J.; Gutman, S.I. A water vapour flux tool for precipitation forecasting. In Proceedings of the Institution of Civil Engineers-Water Management; Thomas Telford Ltd.: London, UK, 2009; Volume 162, pp. 83–94. [Google Scholar] [CrossRef]
- Berrisford, P.; Kållberg, P.; Kobayashi, S.; Dee, D.; Uppala, S.; Simmons, A.; Poli, P.; Sato, H. Atmospheric conservation properties in ERA-Interim. Q. J. R. Meteorol. Soc. 2011, 137, 1381–1399. [Google Scholar] [CrossRef]
- Dee, D.P.; Uppala, S.; Simmons, A.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.; Balsamo, G.; Bauer, P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- de Carvalho, M.; Kumukova, A.; Dos Reis, G. Regression-type analysis for multivariate extreme values. Extremes 2022, 25, 595–622. [Google Scholar] [CrossRef]
- Mhalla, L.; de Carvalho, M.; Chavez-Demoulin, V. Regression-type models for extremal dependence. Scand. J. Stat. 2019, 46, 1141–1167. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).