Abstract
While there are many works on the applications of machine learning, not so many of them are trying to understand the theoretical justifications to explain their efficiency. In this work, overfitting control (or generalization property) in machine learning is explained using analogies from physics and biology. For stochastic gradient Langevin dynamics, we show that the Eyring formula of kinetic theory allows to control overfitting in the algorithmic stability approach—when wide minima of the risk function with low free energy correspond to low overfitting. For the generative adversarial network (GAN) model, we establish an analogy between GAN and the predator–prey model in biology. An application of this analogy allows us to explain the selection of wide likelihood maxima and ab overfitting reduction for GANs.
1. Introduction
Analogies from physics and other fields, particularly population genetics, are of interest when studying problems in machine learning theory. Analogies between machine learning theory and Darwinian evolution theory were discussed already by Alan Turing [1]. Biological analogies in computing were discussed by John von Neumann [2]. Physical models in relation to computing were discussed by Yuri Manin [3]. Such analogies allow physical intuition to be used in learning theory. Among the well-known examples are genetic [4] and evolutionary algorithms [5], models of neural networks and physical systems with emergent collective computational abilities and content-addressable memory [6], a parallel search learning method based on statistical mechanics and Boltzmann machines that mimic Ising spin chains [7]. A phenomenological model of population genetics, the Lotka–Volterra model with mutations, related to generative adversarial network (GAN) was introduced in [8]. Analogies between evolution operator in physics and transformers (an artificial intelligence model) were discussed in [9]. Ideas of thermodynamics in application to learning were considered in [10,11] and in relation to the evolution theory in [12,13]. GANs have found many applications in physics, e.g., for designing the process of electromagnetically induced transparency metasurfaces [14], etc. Physics-informed neural networks were developed for solving the optima quantum control of open quantum systems [15]. Beyond that, the theory of open systems inspired the development of quantum reinforcement learning, where states of the agent are quantum states of some quantum system and the dynamic environment is a quantum environment surrounding the manipulated system to optimize the reward [16,17], which is connected to the general incoherent quantum control paradigm [18]. Various approaches to quantum machine learning were proposed, e.g., [19]. Open quantum systems were suggested to be applied to spin glasses [20], network science [21], and finance [22]. Quantum neural networks were proposed to be applied for some problems, e.g., to work with encrypted data to protect the privacy of users’ data and models [23].
Within the framework of such analogies, it is natural to discuss biological analogs for various models of the machine learning theory. In this work, two analogies are considered, between the stochastic gradient Langevin dynamics (SGLD) in machine learning and the Eyring formula in the kinetic theory [24], and between the GAN model [25] and the mathematical predator–prey model in biology, where we suggest to consider the discriminator and generator in GAN playing the role of prey and predator, respectively. The proposed analogies allow us to explain the efficiency of controlling overfitting, which is the lack of generalization abilities for a machine learning approach. It is known that for stochastic gradient descent (SGD), overfitting is reduced; for the GAN, this effect of reducing overfitting is even more significant. We propose to explain overfitting control in these processes within the framework of the algorithmic stability approach by suppressing narrow minima of the empirical risk function.
In Section 2, we consider the stochastic gradient Langevin dynamics (SGLD) using a stochastic differential equation (SDE). We show that the reduction of overfitting in such a model follows from ideas used in chemical kinetics such as the Eyring formula, which states that the reaction rate (the rate of the transition between two potential wells due to diffusion) is determined by free energy of the transition state (the saddle between two potential wells) and the free energy of the initial state of the reaction (optimization of quantities involving entropy-dependent Helmholtz free energy also appears in quantum optimization, e.g., [26]).
In Section 3, we describe the minimax problem for the GAN model by a system of two stochastic differential equations (one is for the discriminator and another is for the generator). In this sense, the GAN model is a two-body generalization of the SGLD model considered in Section 2. However, this generalization significantly changes the behavior of the learning system, as demonstrated by the simulations below. We show that this model implements a selection of wide maxima of the likelihood function, leading to a reduction of overfitting. A biological interpretation of the GAN model is provided in terms of the interaction between a predator and a prey (the predator is the generator, the prey is the discriminator). Learning for GANs by solving a system of ordinary differential equations was considered in [27,28,29].
In Section 4, we introduce a generalization of the GAN for a type of population genetics model. We consider a branching random process with diffusion for two types of particles (discriminators and generators), in which discriminators and generators can replicate. In this case, the rates of replication and death of particles depend on the contributions to the functional, minimax, which is defined by the GAN model.
In Section 5, we provide the numerical simulations illustrating the behavior of the stochastic gradient descent and the predator–prey model of the minimax problem for the GAN for a simple potential with two wells. We observe the following two regimes: pushing out of the narrower well and oscillations in the wider well. One parameter of the interaction allows to control the transition between these two regimes. The third regime, when escape out of the both wells occurs, is possible; however, this regime can be avoided by adjusting the parameters.
Some relevant notions from the theory of random processes are provided in Appendix A. Section 6 summarizes the results.
2. Stochastic Gradient Descent and the Eyring Formula
2.1. Stochastic Gradient Descent
Let , (with the elements belonging to ), a loss function for the l-th sample object, and hypothesis x (we assume that the hypothesis space is ). Minimization of the empirical risk is the following problem:
Gradient descent algorithm for this problem, when the loss function belongs to the space of continuously differentiable functions , is defined by the solution of the differential equation , which is numerically described by the iterative process starting from some initial guess , such that
where is a gradient step [which is also often called as learning rate (lr)] at the kth iteration. There are different methods for introducing stochasticity in training for the problem (1), such as mini-batch learning or dropout. In this paper, we consider a method based on adding Gaussian noise to (2), which is related to stochastic gradient Langevin dynamics.
Stochastic gradient Langevin dynamics encompasses the modification of the above procedure where small independent random perturbations are added at each step of gradient descent, such that
where the set of all is a set of independent Gaussian random vectors.
This procedure can be considered as a discrete-time version of the stochastic equation
where is the stochastic differential of the Wiener process (factor is used for convenience to have unit instead of in front of in Equation (5) below).
The stochastic gradient Langevin dynamics procedure with an equation of the form (4) was discussed in [30,31,32,33].
Diffusion equation in the potential is the partial differential equation
where , is the distribution function, is the potential, , and is the temperature.
Equivalently, this diffusion equation can be rewritten as (where is the inverse temperature)
Gibbs distribution is a stationary solution of this equation. The solution converges to the Gibbs distribution under certain conditions on f, as discussed in [34].
Diffusion Equation (5) is the Fokker–Planck equation (see (A2) in Appendix A) for stochastic gradient Langevin dynamics (4).
We would like to highlight the following: The well-known stable diffusion neural network and, in general latent, diffusion models [35,36] do use diffusion described by a stochastic differential equation (as in SGLD). However, the general formulation of the problem is different there, where a special type of diffusion is used for generating objects (particularly images), while we are considering the diffusion (SGLD) for learning in a potential.
2.2. Overfitting Control for Stochastic Gradient Descent
Overfitting is the lack of ability to generalize for the solution of the learning problem (i.e., high likelihood on the training sample and low likelihood for the validation sample). One approach to overfitting control is based on the algorithmic stability, i.e., on the stability of the solution obtained by a learning algorithm to perturbations of the training sample [37,38,39]. In this case, narrow (sharp) minima of the empirical risk functional (in the hypothesis space) are associated with overfitting, and wide (flat) minima correspond to solutions of the learning algorithm without overfitting [40].
Introducing noise into the gradient descent procedure, i.e., considering SDE (4) and diffusion (5), is related to the problem of overfitting as follows: The Eyring formula, which is a generalization of the Arrhenius formula, describes the reaction rate (the rate of transition between two potential wells due to diffusion of the form (5)) in the kinetic theory: the reaction rate is proportional to
where is the free energy of the transition state (the saddle between two potential wells), and is the free energy of the initial state of the reaction (the potential well from which the transition occurs). The free energy of a state is , where E is the energy and S is the entropy of the state. In general, free energy of a set U (say a potential well) is defined as
The connection between the Arrhenius and Eyring formulas and the spectral asymptotics for the Schrödinger operator corresponding to the subbarrier (tunnel) transition between two potential wells was discussed in [34].
Let us emphasize that we do not assume any minimization procedure—stochastic gradient Langevin dynamics (4) generate the Gibbs distribution according to diffusion Equation (5), and this Gibbs distribution will be concentrated in potential wells with low free energy. In the view of the above discussion, learning with stochastic gradient Langevin dynamics is a search for a potential well that gives the global minimum of free energy. The influence of the temperature is important when comparing the entropy and the energy parts of free energy. For the effect of particle capture by a well (i.e., learning) to take place, it is important that the temperature should be significantly (e.g., by several times) less than the difference in the free energies of the well and the saddle; hence, the temperature is important for the SGLD. Thus, for successful learning, the temperature should be low enough to make the capture of the particle by a potential well possible.
The Eyring formula (6) implies that, for equal free energies of the transition state and equal energies of the initial state, the transition rate will be lower (the free energy of the initial state will be lower) for potential wells with higher entropy (wider ones). Thus, stochastic gradient Langevin dynamics (4) will correspond to a regime in which wider wells (with higher entropy) more effectively capture the learning system, i.e., algorithmically stable solutions to the learning problem will be selected during stochastic gradient optimization (here, we consider the SGLD procedure but we believe the same effect will hold for other forms of SGD, such as mini-batch procedure).
The validity of the proposed approach is limited by the assumptions for the Eyring formula. The Eyring formula describes transitions for a diffusion equation in the potential and might be applied to various complicated high-dimensional landscapes having clear minima and saddles between them. Its validity under quite general conditions has been justified in [41]. For landscapes which might not exhibit clear minima and saddles between them, the proposed approach based on the Eyring formula may not work.
Physical analogies in machine learning, particularly the application of free energy, were discussed in [10]. In [11], the following procedure was considered: the empirical risk functional (depending on the hypothesis x) was replaced by the so called “local entropy” functional, which looks like minus free energy of some vicinity of x (where energy is the empirical risk). In this way, the wider empirical risk minima will correspond to deeper minima of the new “local entropy” functional. Relation to the generalization property in the approach of [40] (flat minima) was discussed (although the authors of this paper do not discuss the Eyring formula).
3. The GAN Model and Overfitting
3.1. Stochastic Gradient Langevin Dynamic for GAN
The generative adversarial network (GAN) model is a minimax problem, such that [25]
is a sample, where , and are parametric families of probability distributions on the space Z, called the discriminator and the generator, with parameters x and y from statistical manifolds X and Y (which we will assume to be real vector spaces).
In [25], the generator was considered as a parametric family of mappings from some auxiliary space to Z. These mappings transferred the probability distribution on the auxiliary space to Z. The discriminator was described by a distribution on the same space as the data, and the interpretation was as follows: the discriminator outputs binary variable “one” or “zero” given the data and given the generator according to this distribution (i.e., outputs “one” if the discriminator considers these inputs as correct).
The first contribution to in (8) is the log-likelihood function. The second contribution behaves qualitatively as the minus inverse of the Kullback–Leibler distance (Kullback–Leibler divergence, KL distance, or KLD) between the distributions of the discriminator and the generator (that is, this contribution is negative, large in magnitude for small KL–distances, and grows to zero for large KL–distances), as was mentioned in [25].
Here
where the Kullback–Leibler distance between probability distributions p and q is defined as
The minimax for over x, y is obtained from the local maximum of over x. Transitions between the local maxima of generate transitions between local minimaxes of (the generator follows the discriminator) as shown below.
The stochastic gradient Langevin dynamics optimization for the problem (7), (8) can be described by a system of SDEs defining random walks , , , on statistical manifolds X and Y of the discriminator and generator,
Here, and are derivatives of V with respect to the first and second arguments, respectively; and are Wiener processes on the parameter spaces of the discriminator and generator. This system of stochastic equations follows directly from the minimax condition and is independent from the KL distance formulation. However, the KLD formulation is used later for analyzing the behavior of the solution. In this system of SDEs, the discriminator seeks to maximize the function (8) with respect to x, and the generator seeks to minimize this function with respect to y.
Example 1.
Let us consider one-dimensional parameters x and y for the discriminator and for the generator, respectively, and functional with minimax located at the origin. The noiseless GAN equation system is
Its solution is
with oscillations around the minimax.
In [27,28,29], the convergence of the optimization of the GAN model by the gradient descent method with respect to the parameters of the discriminator and generator in the neighborhood of the functional’s local minimax was studied, and oscillations of the parameters were discussed.
3.2. Overfitting Control for GAN
If we ignore the presence of the generator, then the dynamics of the discriminator (9) for optimization with noise will correspond to the diffusion in the potential generated by the data. Thus, the arguments of Section 2 will be applicable. Therefore, overfitting can be reduced according to the Eyring formula.
The presence of the generator will further suppress overfitting. The minimax problem for the GAN (7) can be described as follows. The discriminator (9) tries to reach regions of the parameter x with high values of . The generator (10) tries to reach regions of the parameter y with low values of . In this case, the contribution to (8) from the likelihood function depends only on the parameters of the discriminator, i.e., the discriminator tries to increase both contributions to (8), and the generator tries to decrease only the second contribution. The second contribution to (8) decreases at small Kullback–Leibler distances between the discriminator and the generator.
Therefore, the compromise between the optimization problems for the discriminator and the generator will be achieved when they are located at maxima of the contribution from the likelihood function to (8) which are sufficiently wide in the space of the parameters (where the average KL–distance between the discriminator and the generator is not too small). Selecting wide maxima, in accordance with the algorithmic stability approach, will reduce the effect of overfitting.
Here, we propose a biological prey–predator interpretation for the GAN model, which is completely different from the interpretation used in [25]. In our interpretation, the discriminator is herbivore (prey), the generator is predator, and the data are grass. Then, the minimax problem (7) describes the situation when the discriminator searches for grass (the maximum of the likelihood function; this corresponds to an increase in the first contribution in (8)) and also runs away from the predator (this corresponds to an increase in the second contribution to (8)), while the predator chases the prey (and hence decreases this contribution). In our interpretation, the discriminator (herbivore)—as a distribution—tries to get closer to the data distribution (grass) and farther from the generator (predator) as a distribution (in the KL distance sense), and the generator tries to be closer to the discriminator. As a result of this interaction, the generator also moves toward the data (grass) because herbivores (discriminator) are likely to be found there; however, this does not mean that the predator tries to imitate grass (this is a mixture of the two interpretations of the GAN). Minimization in (7) for the generator forces the predator to move to fields (or meadows, likelihood maxima) where the discriminator is present. The interaction of the two contributions to (8) forces the discriminator to search for sufficiently wide meadows (likelihood maxima) where the average KL–distance from the predator is not too small. In general, the predator pushes out the prey from narrow fields of grass, and both the prey and predator move to wide grass fields. Thus, the GAN model implements the selection of wide likelihood maxima, which reduces overfitting.
Simulations illustrating the discussed above behavior are considered in Section 5 below.
4. Branching Random Process for GAN
In this section, a branching random process with diffusion and particle interactions describing the populations of discriminators and generators in a generalization of the GAN model is introduced.
The theory of branching random processes and its connection with population genetics have been actively discussed in the literature, for example, in [42,43]. Previously, in [8], a generalization of the GAN model related to population genetics (a Lotka–Volterra-type model with mutations), was discussed. In this model, discriminators and generators could reproduce and form populations. The phenomenological equations of population dynamics were considered, and the suppression of overfitting was discussed.
Consider a generalization of the GAN to the case of several discriminators (particles in the hypothesis space of the discriminator with parameter x, particles are indexed by a) and generators (particles in the hypothesis space of the generator with parameter y, particles are indexed by b). The analog of the SDE system (9) and (10) will take the form
where each particle is associated with its own independent Wiener process , on the right-hand side of the equation in the discriminator and generator spaces, respectively, and the terms with interaction on the right-hand sides of the equations have the form
Here, is the likelihood function for the discriminator x.
This corresponds to a GAN-type model with functional for discriminator x and functional for generator y. Equations (11) and (12) describe optimization by the stochastic gradient Langevin dynamics. Each discriminator interacts with a set of generators and similarly, each generator interacts with a set of discriminators. Here, and are sets of discriminators and generators, respectively. The second contribution and the function contain sums from contributions that behave qualitatively as , where is the Kullback–Leibler distance between discriminators and generators with parameters x and y.
Let us define a model which mimics the population genetics, defined by a branching random process with diffusion and interaction with particles of two types , (discriminators and generators), which can perform random walks in accordance with Equations (11) and (12), and have the ability to replicate and die, with the probabilities of such processes depending on the functionals (13) and (14). The replication of a particle consists of replacing it with two particles of the same type with the same coordinates (which can then perform random walks in accordance with (11) and (12)).
We propose to use the following branching rates (as related to Lotka–Volterra-type model discussed in [8]): the death rate of generators is considered as fixed, while the replication rates of the generators are proportional to (recall that both W and are negative)
the replication rates of discriminators are proportional to
the rate of death of the discriminator is proportional to
Thus, discriminators replicate depending on the data and die depending on the generators. Generators replicate depending on the discriminators and die at a constant rate.
The biological interpretation of the proposed model is the following. The data are the distribution of grass, the discriminators are herbivores (prey), the generators are predators; herbivores reproduce on grass, and predators hunt herbivores. The effect of suppressing overfitting on narrow likelihood maxima looks as follows: if the discriminator has replicated on the likelihood maximum (on its statistical manifold X), the generator will tend to go there and replicate there (the generator will tend to the corresponding regions of its statistical manifold Y, such that the KL–distance between and is small). In this case, for a narrow likelihood maximum, the average KL–distance will be small, i.e., the predator will eat the prey more effectively (and then suffer from hunger) than for a wide maximum. This is how the effect of selective suppression of narrow population maxima in X and Y corresponding to narrow likelihood maxima is realized. For the case of the population genetics model for the GAN (where discriminators and generators can replicate), the effect of overfitting control is more pronounced than for the standard GAN model (without replication).
5. Simulations
In this section, the results of the numerical simulation of the SGLD procedure and the simulation of the predator–prey model for the GAN are provided.
5.1. Objective Function
Let be an objective function for optimization, . We consider as a sum of non-normalized Gaussians of the following form:
where and are some real-value positive constants, . For visualization, we use . Constant can be interpreted as a characteristic width of the extremum. We consider the case when for all , so that has n separated extrema.
This objective function has two hills around the two extrema (or wells for the minimization of ; for definiteness, we call them below as wells).
5.2. Stochastic Gradient Langevin Dynamics
For objective function (15), we consider , , , for (here and in similar places below, T means transpose of the vector, not temperature). Thermal plot of the function and its gradient field are shown on Figure 1. As the starting point, set . Note that has positive coordinates. Therefore, standard gradient descent procedure starting from the point will converge to , which is the well with a smaller width. Consider standard stochastic gradient procedure
where are two-dimensional independent random variables,
where is the normal distribution with center at the origin and with variance , T is temperature parameter, and is a fixed learning rate. The scaling is introduced to ensure convergence of the SGLD process.
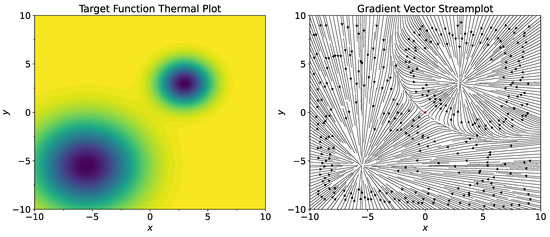
Figure 1.
Thermal plot of the function (left) and its gradient field (right). Red dot in the center of the gradient field plot shows the starting point .
We consider 15 values of temperature T uniformly spanned on . For each value of T, we run the SGLD starting from the same initial point with a maximal number of iterations and select those runs which in no more than K iterations converge to one or another well (in their -vicinities). Then, we compute the fraction of the runs which converge to the wider well. For , all runs converge to the well with a smaller width. According to the Eyring formula (6), we expect an increase in the fraction of the SGLD’s runs from the starting point with increasing temperature T, which converge to the well with a larger width. Figure 2 confirms this behavior.
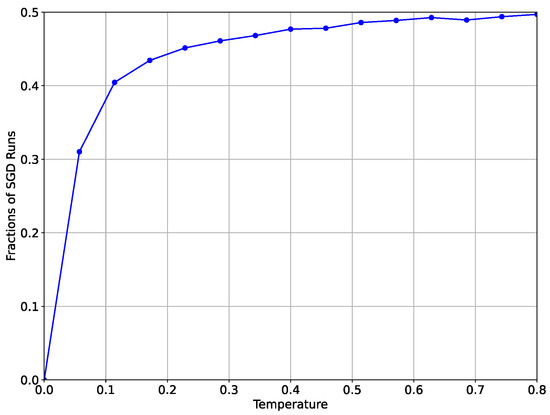
Figure 2.
Fraction of the runs of the SGLD starting at the point , which converge to the well with greater width.
The efficiency of SGLD depends on such hyperparameters as temperature and learning rate, which influence both the convergence behavior and the stability of the solution SGLD. Since our analysis is limited to the use of a stochastic differential equation, we just use a sufficiently low learning rate value without a detailed analysis and tuning of its value. The conditions on the learning rate are that it should be sufficiently small to guarantee not escaping the target well and also it should be not very small, since if it is very small, it will require a large number of iterations. Temperature is relevant for our consideration. An increase in the temperature affects the convergence and stability of the SGLD because if the temperature is too high, fluctuations can throw the trajectory beyond the minimum. To demonstrate this, we plot the dependence of the trajectories’ fractions on Figure 3 that converge to one of the two extrema on the number of iterations for different temperatures and for a single learning rate.
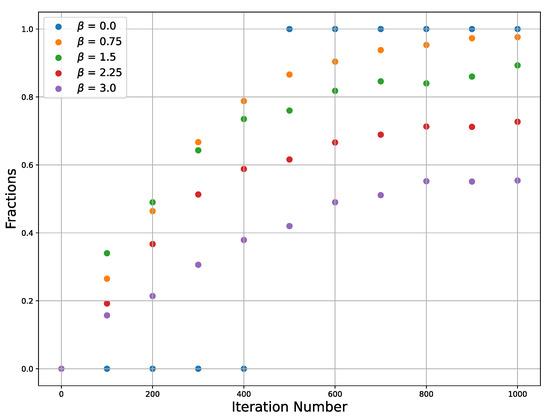
Figure 3.
Fraction of the points which converge to extrema vs. iteration number plotted for several inverse temperatures .
5.3. Predator–Prey Model
For the predator–prey model, we consider a more general dynamical system than the system defined by Equations (9) and (10). Let be position of the prey and be position of the predator at time t. In simulations for visualization, we consider . We consider their joint evolution as governed by the system of equations
where V and W are some vector functions (forces) describing the interaction between the prey and the predator (in this subsection, they are not the same as functions V and W considered in the previous sections). Informally speaking, tries to evolve in a way to simultaneously maximize the objective function and the distance to the predator, while tries to evolve in a way to minimize the distance to the prey. For W, we choose
which defines the motion of y with a constant speed towards x.
A key point in our analysis is to find suitable conditions on the vector function , which depends on the difference . Let be the distance between and . We suggest the potentials to have the following general behavior at various distances:
- At short distances, , where is an estimate of the minimum acceptable width of the well (i.e., some width from which we do not consider the well to be narrow). For this distance, we assume to allow a predator to push the prey out of the well.
- At intermediate distances, , where is the estimate from above of the width of the well of . For these distances, we assume . This condition is introduced to have oscilations in sufficiently wide wells.
- At long distances, , we assume to guarantee convergence to some well of .
As an explicit potential which satisfies these conditions, we take
with some parameters . It contains the Yukawa potential as a summand. The parameter l can be interpreted as a characteristic intermediate distance and A as a mid-range predator, as shown in Figure 4. The norm of the interaction vector function V along with its characteristic points for the parameter values described below is plotted in Figure 4.
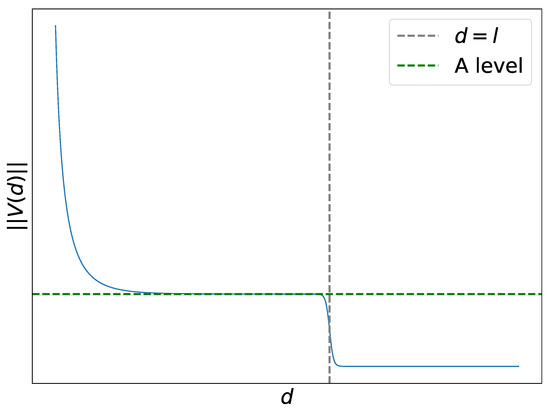
Figure 4.
Absolute value of the norm of the vector function and its characteristic points: l and A.
We assume that by tuning the parameters of the interaction vector functions V, we can push the system out of narrow wells of . To estimate these parameters, we consider the case of limiting oscillations around a radially symmetric well. Schematically, such oscillations can be represented in Figure 5. Note that this behavior is not stable for small values of due to the discreteness of the step also known as learning rate. Let and be distances between the extremum and x or y, respectively, and let be the angle between the predator–prey line and the radial line. In our simulations, the smallest, critical angle value is about . For this behavior with limiting oscillations and radially symmetric structure, we have the following relation:
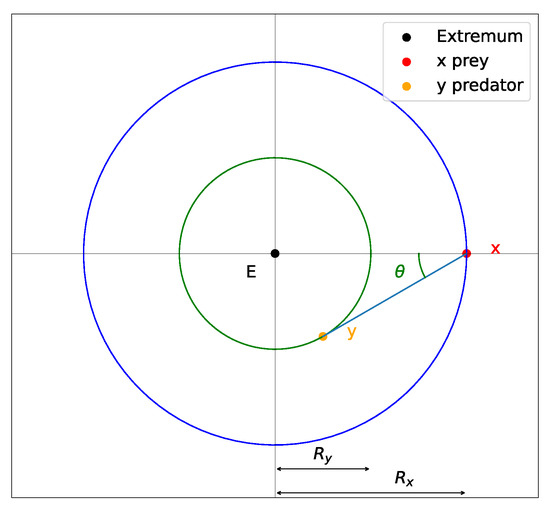
Figure 5.
The limiting unstable oscillations around the extremum point for the predator–prey model.
To enable pushing out of narrow wells and oscillations inside sufficiently wide wells, the constants should satisfy the following heuristic conditions:
- The constant A should be small enough not to generate a too strong pushing-out potential; otherwise, the prey would escape all the wells.
- The constant A should satisfy , so that x can keep at some distance from y.
- The constant l should correspond to a sufficient width of the well. If l is too large, the non-convergence to any well can occur because x will enter the regime of running away from y. If l is too small, the dynamics will not have oscillations in the wider well.
- The constant in Equation (18) determines the minimal width of a well. The width of the well from which there will be pushout due to the short-range Yukawa potential is defined as ∼ (up to some constant).
- The constant C must be chosen to be large enough so that the Yukawa potential creates a repulsion stronger than the attraction of the gradient near the narrow well.
- The parameter c characterizes the rate of the transition from intermediate to long distances; its value is taken to be large enough. With increasing c, the norm of the vector function tends to be more step-like with a gap at .
A typical evolution is shown in Figure 6 (Video S1 available in Supplementary Material). The model parameters for this simulation are the following. Centers of the two Gaussian extrema in (15) () are , widths , and amplitudes . The parameters of the function V defined by Equation (18) are the following: , , , , . Starting points for the prey and for the predator are , , respectively.
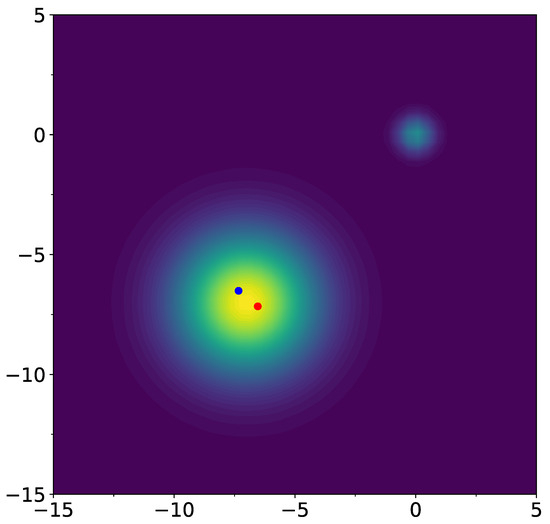
Figure 6.
Simulation of the GAN process for the potentials V and W with two extrema of having different widths (Video S1 available in Supplementary Material). The red dot shows the prey and the blue dot the predator. We observe two regimes: first, the prey escapes of the narrow well and moves to the wider well (first regime), where it starts to oscillate (second regime).
We observe the possibility of having the following two regimes: pushing out of the narrower well and oscillations in a wider well. One of the parameters of the interaction vector functions controls the transition between these two regimes. It has the meaning of maximal width of the well from which pushout is expected. The third regime, when escape out of the both wells occurs, is possible, but we were able to overcome this regime by adjusting the parameters.
5.4. Application to Wine Recognition Dataset
In Section 5, we applied the predator–prey model to some synthetic conditions to reveal the desired behavior. While the application of the method to real big datasets is a separate complex task, here we investigate the improvement achieved by the suggested method on an educational small dataset. As an example, we consider the Wine recognition dataset from scikit-learn library (https://scikit-learn.org/stable/datasets/toy_dataset.html#wine-recognition-dataset, accessed on 10 October 2024). This dataset consists on 178 instances with 13 numeric attributes. Target is class attribute which is encoded by numbers . To make the overfitting process more visible and for simplicity of having overfitting, we consider this dataset as a regression task. Linear regression is a good solution for this dataset; however, to create an overfitting situation, we consider quadratic regression with ordinary gradient descent and compare it with the predator–prey model. We randomly split the dataset on train and test sets (train is ) and run gradient descent for linear and quadratic regression and predator–prey model for quadratic regression. The obtained results, summarized in Table 1, show that the predator–prey model allows to improve the learning results. Running with other random splittings of the dataset into train and test subsets, which show similar results in general. However, several differences may occur. First, linear regression sometimes shows better results than quadratic regression. Second, at first, iteration gradient descent sometimes occurs faster that the predator–prey model convergence to some minimum, but then GD goes up and starts overfitting, while the predator–prey model oscillates around the minimum that avoids overfitting. Thus, in general, our finding on this example is that the predator–prey model works better and sometimes much better to reduce the effect of overfitting.

Table 1.
Results of the work of linear and quadratic regression with gradient descent, as well as the predator–prey model on the Wine recognition dataset. MSE loss is mean squared error; accuracy is ratio of the corrected predicted class in percent.
6. Conclusions
Various mimics of physical or biological behavior do appear in machine learning, e.g., in evolutionary and genetic algorithms. In this work, we discuss a possible justification, based on some models appearing in physics and biology, for the ability to control overfitting in SGLD and the GAN. For SGLD, we show that the Eyring formula of the kinetic theory allows to control overfitting in the algorithmic stability approach, when wide minima of the risk function with low free energy correspond to low overfitting. We also establish a relation between the GAN and the predator–prey model in biology, which allows us to explain the selection of wide likelihood maxima and overfitting reduction for the GAN (the predator pushes the prey out of narrow likelihood maxima). We performed numerical simulations and suggested conditions on the potentials which would imply such behavior.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/e26121090/s1, Video S1: Simulation of the predator-prey model with two extrema of different widths.
Author Contributions
Conceptualization, S.V.K.; investigation, S.V.K., I.A.L. and A.N.P.; software, I.A.L.; writing—review and editing, S.V.K., I.A.L. and A.N.P.; visualization, I.A.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Higher Education of the Russian Federation, grant number 075-15-2024-529.
Data Availability Statement
All the input data used during this study and all the computed data during this study are written or shown in the figures in this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| GD | Gradient descent |
| SGD | Stochastic gradient descent |
| GAN | Generative adversarial network |
| SDE | Stochastic differential equation |
| SGLD | Stochastic gradient Langevin dynamics |
| lr | learning rate |
Appendix A
Here, we provide some relevant notions from the theory of random processes [44].
Fokker–Planck equation. Consider a diffusion with a generator
and the adjoint operator
Then, the transition diffusion probability density satisfies the Fokker–Planck equation
References
- Turing, A. Computing machinery and intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- von Neumann, J. The Computer and the Brain, 1st ed.; Yale University Press: New Haven, CT, USA, 1958. [Google Scholar]
- Manin, Y.I. Complexity vs. energy: Theory of computation and theoretical physics. J. Phys. Conf. Ser. 2014, 532, 012018. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Vikhar, P.A. Evolutionary algorithms: A critical review and its future prospects. In Proceedings of the International Conference on Global Trends in Signal Processing, Information Computing and Communication, Jalgaon, India, 22–24 December 2016. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar]
- Kozyrev, S.V. Lotka–Volterra Model with Mutations and Generative Adversarial Networks. Theor. Math. Phys. 2024, 218, 276–284. [Google Scholar] [CrossRef]
- Kozyrev, S.V. Transformers as a Physical Model in AI. Lobachevskii J. Math. 2024, 45, 710–717. [Google Scholar] [CrossRef]
- LeCun, Y.; Chopra, S.; Hadsell, R.; Ranzato, M.A.; Huang, F.J. A Tutorial on Energy-Based Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Chaudhari, P.; Choromanska, A.; Soatto, S.; LeCun, Y.; Baldassi, C.; Borgs, C.; Chayes, J.; Sagun, L.; Zecchina, R. Entropy-SGD: Biasing Gradient Descent Into Wide Valleys. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Katsnelson, M.I.; Wolf, Y.I.; Koonin, E.V. Towards physical principles of biological evolution. Phys. Scr. 2018, 93, 043001. [Google Scholar] [CrossRef]
- Vanchurin, V.; Wolf, Y.I.; Katsnelson, M.I.; Koonin, E.V. Towards a theory of evolution as multilevel learning. Proc. Natl. Acad. Sci. USA 2022, 119, e2120037119. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, C.; Dong, L.; Rong, M.; Gong, J.; Meng, F. Inverse design of electromagnetically induced transparency (EIT) metasurface based on deep convolutional Generative Adversarial Network. Phys. Scr. 2023, 98, 105501. [Google Scholar] [CrossRef]
- Norambuena, A.; Mattheakis, M.; González, F.J.; Coto, R. Physics-informed neural networks for quantum control. Phys. Rev. Lett. 2024, 132, 010801. [Google Scholar] [CrossRef]
- Dong, D.; Chen, C.; Tarn, T.-J.; Pechen, A.; Rabitz, H. Incoherent Control of Quantum Systems With Wavefunction-Controllable Subspaces via Quantum Reinforcement Learning. IEEE Trans. Syst. Man. Cybern. B Cybern. 2008, 38, 957–962. [Google Scholar] [CrossRef] [PubMed]
- Dong, D.; Chen, C.; Li, H.; Tarn, T.-J. Quantum Reinforcement Learning. IEEE Trans. Syst. Man. Cybern. B Cybern. 2008, 38, 1207–1220. [Google Scholar] [CrossRef] [PubMed]
- Pechen, A.; Rabitz, H. Teaching the environment to control quantum systems. Phys. Rev. A 2006, 73, 062102. [Google Scholar] [CrossRef]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum Machine Learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef]
- Sieberer, L.M.; Buchhold, M.; Diehl, S. Keldysh field theory for driven open quantum systems. Rep. Prog. Phys. 2016, 79, 096001. [Google Scholar] [CrossRef]
- Nokkala, J.; Piilo, J.; Bianconi, G. Complex quantum networks: A topical review. J. Phys. A Math. Theor. 2024, 57, 233001. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, J.-W.; Guo, H. Quantum Brownian motion model for the stock market. Physica A 2016, 452, 281–288. [Google Scholar] [CrossRef]
- Sun, W.; Chang, Y.; Wang, D.; Zhang, S.; Yan, L. Delegated quantum neural networks for encrypted data. Phys. Scr. 2024, 99, 05510. [Google Scholar] [CrossRef]
- Eyring, H. The Activated Complex in Chemical Reactions. J. Chem. Phys. 1935, 3, 107–115. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the NIPS, Montréal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Morzhin, O.V.; Pechen, A.N. Control of the von Neumann Entropy for an Open Two-Qubit System Using Coherent and Incoherent Drives. Entropy 2023, 26, 36. [Google Scholar] [CrossRef]
- Qin, C.; Wu, Y.; Springenberg, J.T.; Brock, A.; Donahue, J.; Lillicrap, T.P.; Kohli, P. Training Generative Adversarial Networks by Solving Ordinary Differential Equations. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Khrulkov, V.; Babenko, A.; Oseledets, I. Functional Space Analysis of Local GAN Convergence. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Nagarajan, V.; Kolter, J.Z. Gradient descent GAN optimization is locally stable. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Parisi, G. Correlation functions and computer simulations. Nucl. Phys. B 1981, 180, 378–384. [Google Scholar] [CrossRef]
- Parisi, G. Correlation functions and computer simulations II. Nucl. Phys. B 1982, 205, 337–344. [Google Scholar] [CrossRef]
- Geman, S.; Hwang, C.-R. Diffusions for Global Optimization. SIAM J. Control Optim. 1986, 24, 1031–1043. [Google Scholar] [CrossRef]
- Welling, M.; Teh, Y.W. Bayesian Learning via Stochastic Gradient Langevin Dynamics. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, DC, USA, 28 June–2 July 2011. [Google Scholar]
- Kozyrev, S.V.; Volovich, I.V. The Arrhenius formula in kinetic theory and Witten’s spectral asymptotics. J. Phys. A 2011, 44, 215202. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv 2022, arXiv:2112.10752. [Google Scholar]
- Chang, Z.; Koulieris, G.A.; Shum, H.P.H. On the Design Fundamentals of Diffusion Models: A Survey. arXiv 2023, arXiv:2306.04542. [Google Scholar]
- Bousquet, O.; Elisseeff, A. Stability and Generalization. J. Mach. Learn. Res. 2002, 2, 499–526. [Google Scholar]
- Kutin, S.; Niyogi, P. Almost-everywhere algorithmic stability and generalization error. In Proceedings of the 18th Conference on Uncertainty in Artificial Intelligence, Edmonton, AB, Canada, 1–4 August 2002. [Google Scholar]
- Poggio, T.; Rifkin, R.; Mukherjee, S.; Niyogi, P. General conditions for predictivity in learning theory. Nature 2004, 428, 419–422. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Flat Minima. Neural Comput. 1997, 9, 1–42. [Google Scholar] [CrossRef]
- Avelin, B.; Julin, V.; Viitasaari, L. Geometric Characterization of the Eyring–Kramers Formula. Commun. Math. Phys. 2023, 404, 401–437. [Google Scholar] [CrossRef]
- Sevastyanov, B.A. Branching Processes, 1st ed.; Nauka: Moscow, Russia, 1971. [Google Scholar]
- Haccou, P.; Jagers, P.; Vatutin, V.A. Branching Processes: Variation, Growth, and Extinction of Populations; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Wentzell, A.D. A Course in the Theory of Stochastic Processes; McGraw-Hill International: New York, NY, USA, 1981. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).