Abstract
Community detection is an important and powerful way to understand the latent structure of complex networks in social network analysis. This paper considers the problem of estimating community memberships of nodes in a directed network, where a node may belong to multiple communities. For such a directed network, existing models either assume that each node belongs solely to one community or ignore variation in node degree. Here, a directed degree corrected mixed membership (DiDCMM) model is proposed by considering degree heterogeneity. An efficient spectral clustering algorithm with a theoretical guarantee of consistent estimation is designed to fit DiDCMM. We apply our algorithm to a small scale of computer-generated directed networks and several real-world directed networks.
1. Introduction
Many real-world complex networks have community structure such that nodes within the same community (also known as cluster or module) have more links than across communities. For example, in social networks, communities can be groups of students in the same department; in co-authorship networks, a community can be formed by researchers in the same field. However, community structure for a real-world network is usually not directly observable. To process this problem, community detection, also known as graph clustering, is a popular tool for uncovering a latent community structure in a network [1,2]. For decades, many community detection methods have been proposed for non-overlapping undirected networks in which each node belongs to a single community, and the interactions between two nodes are symmetric or undirected. The stochastic block model (SBM) [3] is a popular generative model for non-overlapping undirected networks. In SBM, it is assumed that each node only belongs to one community and that nodes in the same community have the same expectation degrees. Ref. [4] proposes the classical degree corrected stochastic block model (DCSBM) which extends SBM by considering variation in node degree. In recent years, numerous algorithms have been developed to estimate node community for non-overlapping undirected networks generated from SBM and DCSBM, see [5,6,7,8,9,10,11,12,13,14,15]. For recent developments about SBM, see the wonderful review paper [16].
However, in most real-world networks, a node may belong to more than one community at a time. In recent years, the problem of estimating mixed memberships for the undirected network has received a lot of attention [17,18,19,20,21,22,23,24,25,26,27,28,29], and references therein. Ref. [17] extends the SBM model from non-overlapping undirected networks to mixed membership undirected networks and designs the mixed membership stochastic block (MMSB) model. Based on the MMSB model, ref. [24] designs a model called the degree corrected mixed membership (DCMM) model by considering degree heterogeneity, where DCMM can also be seen as an extension of the non-overlapping model DCSBM, and ref. [24] also develops an efficient and provably consistent spectral algorithm. Ref. [27] presents a spectral algorithm under MMSB and establishes per-node rates for mixed memberships by sharp row-wise eigenvector deviation. Ref. [29] proposes an overlapping continuous community assignment model (OCCAM), which is also an extension of MMSB, by considering degree heterogeneity. To fit OCCAM, ref. [29] develops a spectral algorithm requiring a relatively small fraction of mixed nodes when building theoretical frameworks. Ref. [26] finds the cone structure inherent in the normalization of the eigen-decomposition of the population adjacency matrix under DCMM and develops a spectral algorithm to hunt corners in the cone structure.
Though the above works are encouraging and appealing, they focus on undirected networks. In reality, there exist substantial directed networks, such as citation networks, protein–protein interaction networks, and the hyperlink network of websites. In recent years, a lot of works with encouraging results have been developed for directed networks. Ref. [30] proposes a stochastic co-block model (ScBM) and its extension DC-ScBM by considering degree heterogeneity to model non-overlapping directed networks, where ScBM and DC-ScBM can model directed networks whose row nodes may be different from column nodes, and the number of row communities may also be different from the number of column communities. Ref. [31] studies the theoretical guarantees for the algorithm DSCORE [32] and its variants designed under DC-ScBM. Ref. [33] studies the spectral clustering algorithms designed by a data-driven regularization of the adjacency matrix under ScBM. Ref. [34] studies higher-order spectral clustering of directed graphs by designing a nearly linear time algorithm. Based on the fact that the above works only consider non-overlapping directed networks, ref. [35] develops a directed mixed membership stochastic block model (DiMMSB), which is an extension of ScBM, and models directed networks with mixed memberships. DiMMSB can also be seen as a direct extension of MMSB from an undirected network to a directed network.
Recall that DCSBM, DCMM, and DCScBM are extensions of SBM, MMSB, and ScBM by considering node degree variation, respectively, this paper aims at proposing a model as an extension of DiMMSB by considering node degree heterogeneity and building an efficient spectral algorithm to fit the proposed model. In this paper, we focus on the directed network with mixed membership. Our contributions are as follows:
- (i)
- We propose a novel generative model for directed networks with a mixed membership, the directed degree corrected mixed membership (DiDCMM) model. DiDCMM models a directed network with mixed memberships when row nodes have degree heterogeneities, while column nodes do not. We present the identifiability of DiDCMM under popular conditions which are also required by models modeling mixed membership networks when considering degree heterogeneity. Meanwhile, our results also show that modeling a directed network with mixed membership when considering degree heterogeneity for both row and column nodes needs nontrivial conditions. DiDCMM can be seen as an extension of the DCScBM model from a non-overlapping directed network to an overlapping directed network. DiDCMM also extends the DCMM model from an undirected network to a directed network and extends the DiMMSB model by considering node degree heterogeneity. For a detailed comparison of our DiDCMM with previous models, see Remark 2.
- (ii)
- To fit DiDCMM, we present a spectral algorithm called DiMSC, which is designed based on the investigation that there exists an ideal cone structure inherent in the normalized version of the left singular vectors and an ideal simplex structure inherent in the right singular vectors of the population adjacency matrix. We prove that our DiMSC exactly recovers the membership matrices for both row and column nodes in the oracle case under DiDCMM, and this also supports the identifiability of DiDCMM. We obtain the upper bounds of error rates for each row (and column) node and show that our method produces asymptotically consistent parameter estimations under mild conditions. Our theoretical results are consistent with classical results when DiDCMM degenerates to SBM and MMSB under mild conditions. Numerical results of simulated directed networks support our theoretical results and show that our approach outperforms its competitors. We also apply our algorithm to several real-world directed networks to test the existence of highly mixed nodes and asymmetric structures between row and column communities.
Notations.
We take the following general notations in this paper. For a vector x and fixed , denotes its -norm. For a matrix M, denotes the transpose of the matrix M, denotes the spectral norm, denotes the Frobenius norm, and denotes the maximum -norm of all the rows of M. Let denote the rank of matrix M. Let be the i-th largest singular value of matrix M, and denote the i-th largest eigenvalue of the matrix M ordered by the magnitude. and denote the i-th row and the j-th column of matrix M, respectively. and denote the rows and columns in the index sets and of matrix M, respectively. For any matrix M, we simply use to represent for any . For any matrix , let be the diagonal matrix whose i-th diagonal entry is . Here, and are column vectors with all entries being ones and zeros, respectively; is a column vector whose i-th entry is one, while other entries are zero. C is a positive constant that may vary occasionally.
2. The Directed Degree Corrected Mixed Membership Model
Consider a directed network , where is the set of row nodes, is the set of column nodes ( and indicate the number of row nodes and the number of column nodes, respectively), and is the set of edges. Note that when such that row nodes are the same as column nodes, is a traditional directed network [31,36,37,38,39,40,41,42]; when , is a bipartite network (also known as a bipartite graph) [30,33,35,43,44,45]; see Figure 1 for illustrations of the topological structures for a directed network and a bipartite network. Without confusion, we also call bipartite networks directed networks occasionally in this paper.
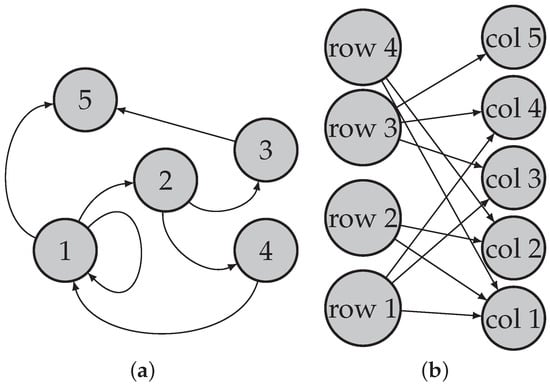
Figure 1.
Illustration for directed network and bipartite network. Panel (a): directed network; Panel (b): bipartite network.
We assume that the row nodes of the directed network belong to K perceivable communities (called row communities in this paper)
and the column nodes of the directed network belong to K perceivable communities (called column communities in this paper)
Define an row nodes membership matrix and an column nodes membership matrix such that is a probability mass function (PMF) for row node i, is a PMF for column node j, and
Call row node i ‘pure’ if is degenerate (i.e., one entry is 1, all other entries are 0) and ‘mixed’ otherwise. The same definitions hold for column nodes. Note that mixed nodes considered in this article are not the boundary nodes introduced in [46] since boundary nodes are defined based on non-overlapping networks, while mixed nodes belong to multiple communities.
Let be the bi-adjacency matrix of such that for each entry, if there is a directional edge from row node i to column node j, and otherwise. So, the i-th row of A records how row node i sends edges, and the j-th column of A records how column node j receives edges. Let P be a matrix such that
Note that since we consider a directed network in this paper, P may be asymmetric.
Without loss of generality, suppose that row nodes have degree heterogeneities, while column nodes do not i.e., row nodes have variation in degree, while column nodes do not. Note that in a directed network, if column nodes have degree heterogeneities while row nodes do not, to detect memberships of both row nodes and column nodes, we set the transpose of the adjacency matrix as input when applying our algorithm DiMSC. Meanwhile, in a directed network, if both row and column nodes have degree heterogeneity, to model such a directed network with mixed memberships, we need nontrivial constraints on the degree heterogeneities between row nodes and column nodes for model identifiability, for detail, see Remark 1.
Let be an vector whose i-th entry is the positive degree heterogeneity of row node i. For all pairs of with , DiDCMM models the entries of A such that are independent Bernoulli random variables satisfying
Equation (6) means that , i.e., the probability of generating a directional edge from row node i to column node j is , and this probability is controlled by the degree heterogeneity parameter of row node i, the connecting matrix P, and the memberships of nodes i and j. Equation (6) functions similarly to Equation (1.4) in [24], and both equations define the probability of generating an edge. For comparison, Equation (6) defines the probability of generating a directional edge under DiDCMM for a directed network, while Equation (1.4) in [24] defines the probability of generating an edge under DCMM for an undirected network, i.e., DiDCMM can be seen as an extension of DCMM from an undirected network to a directed network.
Introduce the degree heterogeneity diagonal matrix for row nodes such that
Equation (7) uses a diagonal matrix to contain all degree heterogeneities, and is useful for further theoretical analysis through Equation (8).
Definition 1.
The following conditions are sufficient for the identifiability of DiDCMM:
- (I1) , and P has unit diagonals.
- (I2) There is at least one pure node for each of the K row and K column communities.
When building statistical models for a network in which nodes can belong to multiple communities, the full rank requirement of connecting matrix P and pure nodes condition are always necessary for model identifiability, see models for an undirected network such as MMSB considered in [23,27], DCMM considered in [24,26], and OCCAM considered in [26,29]. Meanwhile, if models modeling networks with mixed memberships consider degree heterogeneity, the unit diagonals requirement on connecting matrix P is also necessary for model identifiability, see the identifiability requirement of DCMM and OCCAM considered in [24,26,29]. Furthermore, based on the fact that DiDCMM, DCMM, and OCCAM can include the well-known model SBM, letting P have unit diagonals is not a serious problem since many wonderful works study a special case of SBM when P has unit diagonals and a network has K equal size clusters (this special case of SBM is also known as a planted partition model), see [12,47,48,49,50,51,52].
Let be the expectation of the adjacency matrix A. Under DiDCMM, we have
We refer to as the population adjacency matrix. Since and by Equation (7) and Conditions (I1) and (I2), the rank of is K. Recall that K is the number of communities, and it is much smaller than network size. We see that has a low dimensional structure. The form of given in Equation (8) is powerful to build the spectral algorithm developed in this paper to fit DiDCMM. Analyzing properties of the population adjacency matrix to build a spectral algorithm fitting statistical model is a common strategy in community detection, for example, references [24,26,27,35] also use this strategy to design their algorithms fitting DCMM, MMSB, and DiDCMM.
For , let and . By Condition (I2), and are nonempty for all . For , select one row node from to construct the index set , i.e., is the indices of row nodes corresponding to K pure row nodes, one from each community, and is defined similarly. W.L.O.G., let and (Lemma 2.1 [27] has a similar setting to design their spectral algorithm under MMSB.), where is the identity matrix. The proposition below shows that the DiDCMM model is identifiable.
Proposition 1.
(Identifiability). When Conditions (I1) and (I2) hold, DiDCMM is identifiable: for eligible and , set and . If , then and .
Remark 1.
(The reason that we do not model a directed network with mixed memberships where both row and column nodes have degree heterogeneities). Suppose both row and column nodes have degree heterogeneities in a mixed membership directed network. To model such a directed network, the probability of generating an edge from row node i to column node j is
where is an vector whose j-th entry is the degree heterogeneity of column node j. Set , then , where is a diagonal matrix whose j-th diagonal entry . Set as the compact SVD of Ω. Follow similar analysis as Lemma 1, we see that and (without causing confusion, we still use here for convenience.). For model identifiability, follow similar analysis as the proof of Proposition 1, since , we see that . To obtain and from , when P has unit diagonals, we see that it is impossible to recover and unless we add a condition that . Now, suppose holds and call it Condition (I3); we have ; hence, when P has unit diagonals. However, Condition (I3) is nontrivial since it requires , and we always prefer a directed network in which there are no connections between row nodes degree heterogeneities and column nodes degree heterogeneities. For example, when all nodes are pure in a directed network, ref. [30] models such directed network using model DC-ScBM such that when all nodes are pure, and and are independent under DC-ScBM. Because Condition (I3) is nontrivial, we do not model a mixed membership directed network with all nodes having degree heterogeneities.
For DiDCMM’s identifiability, the number of row communities should equal that of column communities when both row and column nodes may belong to more than one community. However, when only row nodes have mixed memberships while column nodes do not, the number of row communities can be lesser than that of column communities, and this is also discussed in [53]. All proofs of our theoretical results are provided in the Appendix A.1.
Unless specified, we treat Conditions (I1) and (I2) as default from now on. Proposition 1 is important since it guarantees that our model DiDCMM is well-defined, and we can design efficient spectral algorithms to fit DiDCMM based on its identifiability. The reason that we do not consider degree heterogeneity for column nodes for our DiDCMM is mainly for its identifiability. As analyzed in Remark 1, considering degree heterogeneity for both row and column nodes make the model unidentifiable unless adding some nontrivial conditions on model parameters. Meanwhile, many previous statistical models in the community detection areas are identifiable, and spectral algorithms can be applied to fit them. For examples, SBM [3], DCSBM [4], MMSB [17], DCMM [24], OCCAM [29], ScBM (and DCScBM), [30], and DiMMSB [35] are identifiable. Especially, though different statistical models may have different requirements on model parameters for identifiability, the proof of identifiability enjoys a similar idea as that of Proposition 1, for instance, Proposition 1.1 [24] and Theorem 2.1 [27] build theoretical guarantees on identifiability for DCMM and MMSB, respectively.
Remark 2.
We compare our DiDCMM with some previous models in this remark.
- When for , Equation (8) gives and DiDCMM degenerates to DiMMSB [35], where ρ is known as a sparsity parameter [9,27,35]. So, DiDCMM includes DiMMSB as a special case, and the relationship between DiDCMM and DiMMSB is similar to that between DCSBM [3,4]. Meanwhile, DiDCMM considers degree heterogeneity parameter at the cost that DiDCMM requires P to have unit diagonals for model identifiability, while there is no such requirement for P on DiMMSB’s identifiability. Note that both DiDCMM and DiMMSB are identifiable only when P is a full-rank square matrix.
- When for and all nodes are pure, DiDCMM reduces to ScBM [30]. DiDCMM can model a directed network in which nodes enjoy overlapping memberships, while ScBM cannot. Meanwhile, DiDCMM enjoys this advantage at the cost of requiring for model identifiability, while ScBM is identifiable even when P is not a square matrix, i.e., ScBM can model a directed network in which the number of row communities can be different from the number of column communities. A comparison between DiDCMM and DCScBM [30] is similar.
- When and the network is undirected, DiDCMM reduces to MMSB [17]. However, DiDCMM models directed networks with mixed memberships, while MMSB only models undirected networks with mixed memberships. Again, DiDCMM enjoys its advantage at the cost of P having unit diagonals for its identifiability (not that DiDCMM allows P to be asymmetric since DiDCMM models directed networks), while MMSB is identifiable even when P has non-unit diagonals (note that P is symmetric under MMSB since it models undirected networks). Meanwhile, the identifiability of both DiDCMM and MMSB requires the square matrix P to have full rank.
- When , the network is undirected and all nodes are pure, DiDCMM reduces to SBM [3]. For comparison, DiDCMM models directed networks and allows nodes to belong to multiple communities, while SBM only models undirected networks in which a node only belongs to one community. Meanwhile, DiDCMM enjoys these advantages at the cost of requiring P to be full rank with unit diagonals for its identifiability, while SBM is identifiable even when P is not full rank and P has non-unit diagonals. Note that DiDCMM allows P to be asymmetric, while P must be symmetric for SBM since DiDCMM models directed networks, while SBM models undirected networks. Comparison between DiDCMM and DCSBM [4] is similar.
- Compared with DCMM introduced in [24] and OCCAM introduced in [29], DCMM, and OCCAM model undirected networks with mixed memberships, while DiDCMM models directed networks with mixed memberships. DiDCMM, DCMM, and OCCAM all consider degree heterogeneity for overlapping networks, and they are identifiable only when the full rank matrix P has unit diagonals. These three models are identifiable only when the square matrix P is full rank. Meanwhile, DiDCMM allows P to be asymmetric, while P must be symmetric for DCMM and OCCAM since DiDCMM models directed networks, while DCMM and OCCAM model undirected networks.
3. Algorithm
The primary goal of the proposed algorithm is to estimate the row membership matrix and column membership matrix from the observed adjacency matrix A with given K. We start by considering the ideal case when is known, and then we extend what we learn in the ideal case to the real case.
3.1. The Ideal Simplex (IS), the Ideal Cone (IC), and the Ideal DiMSC
Recall that under Conditions (I1) and (I2), and K is much smaller than . Let be the compact singular value decomposition of such that , . The goal of the ideal case is to use , and V to exactly recover and . As stated in [8,24], is one of the major nuisances, and similar to [7], we remove the effect of by normalizing each row of U to have a unit norm. Set by , and let be the diagonal matrix such that for . Then, can be rewritten as . The existences of the ideal cone (IC for short) structure inherent in and the ideal simplex (IS for short) structure inherent in V are guaranteed by the following lemma.
Lemma 1.
(Ideal Simplex and Ideal Cone). Under , there exist a unique matrix and a unique matrix such that
- , where , and wherewith being an diagonal matrix whose diagonal entries are positive. Meanwhile, if for .
- , where . Meanwhile, if for .
Lemma 1 says that the rows of V form a K-simplex in which we call the ideal simplex (IS), with the K rows of being the vertices. Such IS is also found in [24,27,35]. Lemma 1 also shows that the form of is actually the ideal cone structure mentioned in [26]. Meanwhile, we remove the influence of by normalizing each row of U to have a unit norm in this paper. Using the idea of the entry-wise ratio in [8] also works, where ref. [24] develops their spectral algorithms to fit DCMM using the idea of entry-wise ratio. Designing algorithms based on the nonnegative matrix factorization [25] to fit DiDCMM by adding some constraints on may also work. We leave the study of using these ideas to fit DiDCMM or its submodels for our future work.
For column nodes (recall that column nodes have no degree heterogeneities), since is full rank if V and are known in advance, ideally we can exactly recover by setting . For convenience, to transfer the ideal case to the real case, set . Since , we have
With given V, since it enjoys IS structure , as long as we can obtain (i.e., ), we can recover exactly. As mentioned in [24,27], for such IS, the successive projection (SP) algorithm [54] (i.e., Algorithm A2 in the Appendix E) can be applied to V with K column communities to find the column corner matrix . The above analysis gives how to recover with given and K under DiDCMM ideally.
Next, we aim to recover from U with the given K. Since , . As , the inverse of exists. Therefore, Lemma 1 also gives that
Equation (9) holds because and is a nonsingular matrix. By Lemma 1, we know that for row nodes, their membership matrix appears in the expression of Y. Therefore, we aim to use Equation (9) to find the exact expression of using , and by putting Y at the left-hand side of equality. For our next step, we aim at finding using Equation (9). Since by Lemma 1 and , using and to replace Y and in Equation (9), respectively, we have , which gives
From Equation (10), we have found the expression of as a function of , and , where we do not move to the right-hand side of Equation (10) because it is a diagonal matrix and does not influence the expression of , see our next step for details. When designing a spectral algorithm in the ideal case with given and K, we aim at recovering and by taking advantage of the singular value decomposition of . We find that though Equation (10) provides an expression for by ’s SVD, there is a term which relates to degree heterogeneity, and we aim at expressing through ’s SVD. By the proof of Lemma 1, we know that when Condition (I1) holds. Thus, substituting for in Equation (10), we obtain an expression of such that this expression is directly related to ’s SVD and two index set and . For convenience, set . By Equation (10), we have
Equation (11) looks similar to Equation (7) of [55]. However, Equation (11) is related to two index sets and , while Equation (7) of [55] is only related to one index set because Equation (11) aims at designing a spectral algorithm for directed network generated under DiDCMM and Equation (7) of [55] aims at reviewing the generation of the SVM-cone-DCMMSB algorithm proposed in [26] for undirected network generated under DCMM. Meanwhile, since is an positive diagonal matrix, we have
With given and K, we can obtain ; thus, the above analysis shows that once the two index sets and are known, we can exactly recover by Equations (11) and (12). Meanwhile, from Equation (10), we see that it is important to express as a combination of , and the two index sets and , where we successfully obtain an expression of by Condition (I1), the unit diagonal constraint on P. Otherwise, if P has no unit diagonals, we cannot obtain an expression of unless adding some nontrivial conditions on model parameters, just as analyzed in Remark 1. Similarly, references [24,26] also design their spectral algorithms to fit DCMM by using the unit diagonal constraint on P to obtain an expression of a sub-matrix of degree heterogeneity matrix, see Equations (6)–(8) of [55] as an example.
Given and K, to recover in the ideal case, we need to obtain by Equation (11), which means that the only difficulty is in finding the index set since can be obtained by SP algorithm from the IS structure . From Lemma 1, we know that forms the IC structure. In [26], their SVM-cone algorithm (i.e., Algorithm A3 in the Appendix F) can exactly obtain the row nodes corner matrix from the ideal cone as long as the Condition holds (see Lemma 2).
Lemma 2.
Under , holds.
Based on the above analysis, we are now ready to give the following four-stage algorithm which we call ideal DiMSC. Input . Output: and .
- Let be the compact SVD of such that . Let , where is an diagonal matrix whose i-th diagonal entry is for .
- Run the SP algorithm on V assuming that there are K column communities to obtain the column corner matrix (i.e.,). Run the SVM-cone algorithm on assuming that there are K row communities to obtain .
- Set and .
- Recover and by setting for , and for .
The following theorem guarantees that ideal DiMSC exactly recovers nodes memberships, and this verifies the identifiability of DiDCMM in turn. Meanwhile, it should be noted that many spectral algorithms designed to fit identifiable statistical models in the community detection area can exactly recover node memberships for the ideal case. For example, the spectral clustering for K many clusters algorithm addressed in [5] under SBM, the regularized spectral clustering designed in [7] under DCSBM, the SCORE algorithm designed in [8] under DCSBM, the two algorithms designed and studied in [9] under SBM and DCSBM, the RSC- algorithm studied in [11] under SBM, the mixed-SCORE algorithm designed in [24] under DCMM, the DI-SIM algorithm designed in [30] under DCScBM, the D-SCORE algorithm studied in [31,32] under DCScBM, the SVM-cone-DCMMSB algorithm designed in [26] under DCMM, and the SPACL algorithm designed in [27] under MMSB can exactly recover membership matrices under respective models for the ideal case by using the population adjacency matrix to replace the adjacency matrix in the input of these algorithms. The fact that ideal cases for the above spectral algorithms can return community information also supports the identifiability of the above models.
Theorem 1.
Under , the ideal DiMSC exactly recovers the row nodes membership matrix and the column nodes membership matrix .
To demonstrate that has the ideal cone structure, we drew Panel (a) of Figure 2. The simulated data used for Panel (a) is generated from with ; each row (and column) community has 120 pure nodes. For the 240 mixed row nodes, we set , where is any random number in ,
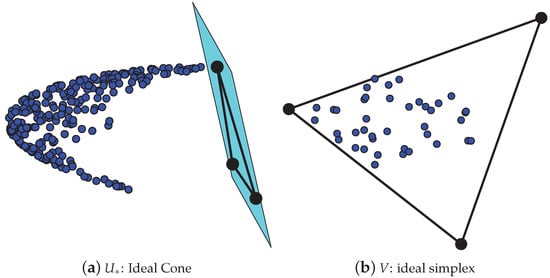
Figure 2.
Panel (a): plot of and the hyperplane formed by . Blue points denote rows respective to mixed row nodes of , and black points denote the K rows of the corner matrix . The plane in Panel (a) is the hyperplane formed by the triangle of the 3 rows of . Panel (b): plot of V and the ideal simplex formed by . Blue points denote rows respective to mixed column nodes of V, and black points denote the K rows of the corner matrix . Since , for visualization, we have projected these points from to .
and i is a mixed row node. For the 40 mixed column nodes, set ,
. For the degree heterogeneity parameter, set for all row nodes i. The matrix P is set as
Under such a setting, after computing and obtaining from , we can plot Figure 2. Panel (a) shows that all rows respective to mixed row nodes of are located at one side of the hyperplane formed by the K rows of , and this phenomenon occurs since each row of is a scaled convex combination of the K rows of guaranteed by the IC structure . Thus Panel (a) shows the existence of the ideal cone structure formed by . Similarly, to demonstrate that V has the ideal simplex structure, we drew Panel (b) of Figure 2, where Panel (b) is obtained under the same setting as Panel (a). Panel (b) shows that rows respective to mixed column nodes of V are located inside of the simplex formed by the K rows of , and this phenomenon occurs since each row of V is a convex linear combination of the K rows of guaranteed by the IS structure . Thus Panel (b) shows the existence of the ideal simplex structure formed by V.
3.2. Dimsc Algorithm
We now extend the ideal case to the real case. Set to be the top-K-dimensional SVD of A such that , and contains the top K singular values of A. Let be the row-wise normalization of such that , where is a diagonal matrix whose i-th diagonal entry is . For the real case, we use given in Algorithm 1 to estimate , respectively. Algorithm 1 called directed mixed simplex and cone (DiMSC for short) algorithm is a natural extension of the ideal DiMSC to the real case.
| Algorithm 1: Directed Mixed Simplex and Cone (DiMSC) algorithm |
| Require: The adjacency matrix of a directed network, the number of row (column) communities K. Ensure: The estimated row membership matrix and the estimated column membership matrix .
|
In the third step, we set the negative entries of as 0 by setting for the reason that weights for any row node should be nonnegative, while there may exist some negative entries of . A similar argument holds for . The flowchart of DiMSC is displayed in Figure 3. Meanwhile, in community detection, researchers often use top-K-dimensional SVD of A or its variants such as Laplacian matrix or regularized Laplacian matrix to design their spectral clustering algorithms to fit identifiable statistical models such as spectral methods designed or studied in [5,7,8,9,11,24,26,27,29,31,33,35,56]. Furthermore, as discussed in [57], the and algorithms may be used as substitutions of the SP algorithm in our DiMSC for a better estimation of . When applying the entry-wise normalization idea developed in [8] to deal with U, as analyzed in [24], we obtain a simplex structure, and we can use the SP algorithm (or the combinatorial vertex search and sketched vertex search approaches developed in [24]) to hunt for the corners. The above ideas suggest that we can design different spectral algorithms to fit our model DiDCMM. We leave them for our future work. In particular, in this paper, we apply the SVM-cone algorithm to hunt for the corners of the cone structure inherent in mainly for the theoretical convenience of the SVM-cone algorithm because ref. [26] has developed a nice theoretical framework on the performance for the SVM-cone algorithm.

Figure 3.
Flowchart of Algorithm 1.
3.3. Computational Complexity
The computing cost of DiMSC mainly comes from SVD, SP, and SVM-cone. The computational complexity of SVD is . Since the adjacency matrix A for real-world network data sets is usually sparse, using the power method discussed in [58], the computation complexity for obtaining the top-K-dimensional SVD of A is only slightly larger than [8,24]. The SP algorithm step in DiMSC has a complexity of [24]. The complexity of the one-class SVM step for SVM-cone algorithm is [26,59]. The complexity of the K-means step for SVM-cone algorithm is [60]. Since the number of communities K considered in this paper is much smaller than the network size, the total complexity of DiMSC is . Results in Section 5 show that, for a computer-generated network with 15,000 nodes under SBM, DiMSC takes hundreds of seconds to process a standard personal computer (Thinkpad X1 Carbon Gen 8) using MATLAB R2021b. Meanwhile, many spectral methods developed under models SBM, DCSBM, MMSB, ScBM, DCScBM, OCCAM, DCMM, and DiMMSB for community detection also have complexity , see spectral algorithms designed or studied in [5,7,8,9,11,24,26,27,29,30,31,33,35,61,62]. Researchers design spectral algorithms for community detection under various identifiable statistical models mainly for their convenience on building a theoretical guarantee of consistent estimation, and we also provide a theoretical guarantee on DiMSC’s estimation consistency in next section.
4. Consistency Results
In this section, we show the consistency of our algorithm for fitting the DiDCMM by proving that the sample-based estimates and concentrate around the true mixed membership matrices and . Throughout this paper, K is a known positive integer. Set and . Assume that
Assumption 1.
.
Assumption 1 means that the network cannot be too sparse, and it also means that we allow to go to zero with increasing numbers of row nodes and column nodes. When building theoretical guarantees on consistent estimation, controlling network sparsity is popular in the community detection area. For examples, Condition (2.9) of [8], Theorem 3.1 of [9], Condition (2.13) of [24], Assumption 3.1 of [27], and Assumption 2 of [31] all control network sparsity for their theoretical analysis. Especially, when DiDCMM reduces to SBM by letting , and all nodes are pure for , Assumption A1 requires that , which is consistent with the sparsity requirement in [8,9,24,31]. As analyzed in [55], we know that our requirement on network sparsity is optimal since it matches the sharp threshold of obtaining a connected Erdös–Rényi (ER) random graph [63] when SBM reduces to an ER random graph by letting .
For notation convenience, set , and , where is the row-wise singular vector deviation which can be bounded by Theorem 4.4 of [64], and measures per node clustering error of DiMSC, and measures the minimum summation of row nodes belonging to a certain row community. Increasing makes the network tend to be more balanced and vice versa. Meanwhile, row-wise singular vector deviation is important when building a theoretical guarantee of spectral methods fitting models for a network with mixed memberships, for example, refs. [24,26,27,35] also consider when building consistent estimation for their spectral methods.
The next theorem gives theoretical bounds on estimations of memberships for both row and column nodes, which is the main theoretical result for our DiMSC method.
Theorem 2.
Under , let and be obtained from Algorithm 1, when Assumption 1 holds, suppose , with probability at least , we have
In Theorem 2, the Condition is necessary when applying Theorem 4.4 [64] to obtain a theoretical upper bound of . When building a theoretical guarantee on estimation consistency for spectral methods fitting models modeling network with mixed memberships, it is necessary to have a lower bound requirement on , see [24,26,27,35]. Actually, this requirement matches with the consistent requirement on obtained from the theoretical upper bound of error rates for a balanced network, see Remark 4 for details. Meanwhile, similar to [7,11,30], we can design a spectral algorithm via an application of regularized Laplacian matrix to fit DiDCMM.
The following corollary is obtained by adding conditions on model parameters similar to Corollary 3.1 in [27], where these conditions give a directed network in which each community has the same order of size, and each node has the same order of degree, i.e., a balanced network.
Corollary 1.
Under , when conditions of Theorem 2 hold, suppose and , with probability at least , we have
Meanwhile,
- when (i.e., ), we have
- when and , we have
Consider a directed mixed membership network under the settings of Corollary 1 when for , to obtain consistent estimations for both row nodes and column nodes, by Corollary 1, should shrink slower than , where consistent estimation means that the theoretical upper bound of error rate goes to zero when increasing network size. Especially, when and , should shrink slower than . We further assume that for and let (note that for this P, we have and ). So the diagonal elements for are and non-diagonal elements are . Set as the diagonal entries of , and as the non-diagonal entries of , we have , , and . Hence, for consistent estimation, we see that should shrink slower than by Corollary 1 and should shrink slower than when and , where this result is consistent with classical separation condition for a standard network with two equal-sized clusters by applying the separation condition and sharp threshold criterion developed in [55].
Remark 3.
When the network is undirected (i.e., ) with by setting for , DiDCMM degenerates to MMSB considered in [27], the upper bound of error rate for DiMSC is when . Replacing the Θ in [24] by , their DCMM model degenerates to MMSB. Then, their conditions in Theorem 2.2 are our Assumption 1 and , where for MMSB. When , the error bound in Theorem 2.2 in [24] is , which is consistent with ours.
Remark 4.
By Lemma A5 in the Appendix D, we know . To ensure the Condition in Theorem 2 holds, we need
When and , Equation (13) gives that should shrink slower than , which matches with the consistency requirement on of Corollary 1.
For convenience, we need the following definition.
Definition 2.
Let be a special case of when , and has diagonal entries and non-diagonal entries .
denotes a special directed network such that row communities have nearly equal sizes since , and column communities also have nearly equal sizes. By Corollary 1, for consistent estimation, we need under . Since , for consistent estimation, we need
Our numerical results in Section 5 support that DiMSC can estimate memberships for both row and column nodes when the threshold holds under .
Remark 5.
When , the network is undirected (i.e., ), all nodes are pure, and each community has an equal size, reduces to the SBM case such that nodes connect with probability within clusters and across clusters. This case has been well studied in recent years, see [50] and references therein. Especially, for this case, ref. [50] finds that exact recovery is possible if and impossible if . For convenience, we use to denote this case. Our numerical results in Section 5 show that DiMSC return consistent estimation under when and are set in the impossible region of exact recovery but satisfy Equation (14).
Remark 6.
In information theory, Shannon entropy [65] quantifies the amount of information in a variable, and it is a measure of uncertainty information of a probability distribution. We use a node membership entropy (NME) derived from Shannon theory to measure the node’s uncertainty about the node and all communities [66,67]. For row node i with membership , since and can be seen as the probability that row node i belongs to row cluster k for , NME of row node i is the Shannon entropy related to :
For column node j with membership , we can also obtain its NME by Equation (15). In particular, if a node belongs to each cluster with equal probability , its NME is which is the maximum among all NME; if a node belongs to two clusters with equal probability , its NME is which is less than when . Generally, we see that recovering memberships for mixed nodes is harder than for pure nodes since NME is 0 for pure nodes, while NME is larger than 0 for mixed nodes by the definition of NME.
5. Simulations
In this section, several experiments are conducted to investigate the performance of our DiMSC under DiDCMM. We compare our DiMSC with three model-based methods that can be thought of as special cases of our model DiDCMM. Model-based methods we compare include the DISIM algorithm proposed in [30], the DSCORE algorithm studied in [31], and the DiPCA algorithm which is obtained by using the adjacency matrix A to replace the regularized graph Laplacian matrix in the DISIM algorithm. Similar to [24,27], for simulations, we measure the errors for the inferred community membership matrices instead of simply each node. We measure the performance of DiMSC and its competitors by the mixed Hamming error rate (MHamm for short) defined below
where is the set of permutation matrices.
For all simulations in this section, unless specified, we set the parameters under DiDCMM as follows: let each row community and each column community have pure nodes; let all mixed row nodes (and mixed column nodes) have membership ; for , we generate the degree parameters for row nodes as below: let such that for , where denotes the uniform distribution on , and set , where we use to control the sparsity of the network; when , P is set as
when ,
where and have non-unit diagonals, and we consider the two cases because we want to investigate DiMSC’s sensitivity when P has non-unit diagonals such that P disobeys Condition (I1).
After obtaining , similar to the five simulation steps in [8], each simulation experiment contains the following steps:
(a) Let be the diagonal matrix such that . Set .
(b) Let W be an matrix such that are independent centered-Bernoulli with parameters . Let .
(c) Set and , i.e., () is the set of row (column) nodes with 0 edges. Let A be the adjacency matrix obtained by removing rows respective to nodes in and removing columns respective to nodes in from . Similarly, update by removing nodes in and update by removing nodes in .
(d) Apply the DiMSC algorithm (and its competitors) to A. Record MHamm under investigations.
(e) Repeat (b)–(d) 50 times, and report the averaged MHamm over the 50 repetitions.
Let be the number of rows of A and be the number of columns of A. In our experiments, and are usually very close to and ; therefore we do not report the exact values of and . After providing the above steps about how to generate A numerically under DiDCMM and how to record the error rates, now we describe our experiments in detail. We consider six experiments here. In experiments 1–6, we study the influence of the fraction of pure nodes, degree heterogeneity, connectivity across communities, sparsity, phase transition, and network size on performances of these methods, respectively.
Experiment 1 (a): Fraction of pure nodes. Set and P as . Let range in . The numerical results are shown in Panel (a) of Figure 4. The results show that as the fraction of pure nodes increases for both row and column communities, all approaches perform better. Meanwhile, DiMSC performs best among all methods in Experiment 1 (a).
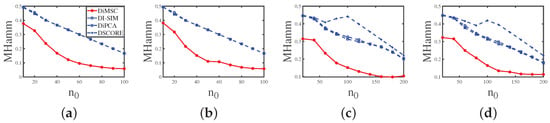
Figure 4.
Errors against increasing . y-axis: MHamm. Panel (a): Experiment 1 (a); Panel (b): Experiment 1 (b); Panel (c): Experiment 1 (c); Panel (d): Experiment 1 (d).
Experiment 1 (b): Fraction of pure nodes. All parameters are set the same as Experiment 1 (a) except that we set P as here. The numerical results are shown in Panel (b) of Figure 4. The results show that all methods perform better as increases, DiMSC outperforms its competitors, and DiMSC enjoys satisfactory performance even when P has non-unit diagonals.
Experiment 1 (c): Fraction of pure nodes. Set , , and P as . Let range in . The numerical results are shown in Panel (c) of Figure 4, and we see that all methods perform better when there are more pure nodes and our DiMSC performs best.
Experiment 1 (d): Fraction of pure nodes. All parameters are set the same as Experiment 1 (c) except that we set P as here. The numerical results are shown in Panel (d) of Figure 4, and the analysis is similar to that of Experiment 1 (b).
Experiment 2 (a): Degree heterogeneity. Set , and P as . Let z range in . A lager z generates lesser edges. The results are displayed in Panel (a) of Figure 5. The results suggest that the error rates of DiMSC for both row and column nodes tend to increase as z increases. This phenomenon happens because decreasing degree heterogeneities for row nodes lowers the number of edges in the directed network; thus the network becomes harder to be detected for both row and column nodes. Meanwhile, DiMSC outperforms its competitors in this experiment, and it is interesting to see that the error rates of DI-SIM, DiPCA, and DSCORE are almost the same for this experiment.
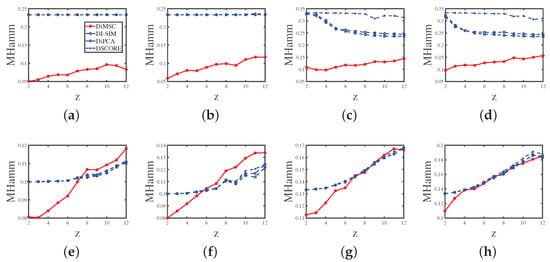
Figure 5.
Errors against increasing z. y-axis: MHamm. Panel (a): Experiment 2 (a); Panel (b): Experiment 2 (b); Panel (c): Experiment 2 (c); Panel (d): Experiment 2 (d); Panel (e): Experiment 2 (e); Panel (f): Experiment 2 (f); Panel (g): Experiment 2 (g); Panel (h): Experiment 2 (h).
Experiment 2 (b): Degree heterogeneity. All parameters are set the same as Experiment 2 (a) except that we set P as here. The results are displayed in Panel (b) of Figure 5, and we see that DiMSC performs satisfactorily when the directed network is not too sparse (i.e., a small z case) even when P has non-unit diagonals. Meanwhile, DiMSC significantly outperforms its competitors in this experiment.
Experiment 2 (c): Degree heterogeneity. Set , , and P as . Let z range in . The results are shown in Panel (c) of Figure 5 and can be analyzed similarly to Experiment 2 (a).
Experiment 2 (d): Degree heterogeneity. All parameters are set the same as Experiment 2 (c) except that we set P as here. The results are displayed in Panel (d) of Figure 5 and are similar to that of Experiment 2 (b).
Experiment 2 (e): Degree heterogeneity. All parameters are set the same as Experiment 2(a) except that we set (so there are no pure nodes in both row and column communities), and all mixed row nodes have two different memberships (0.9, 0.1) and (0.1, 0.9), each with number of row nodes, and all mixed column nodes also have the above two memberships, each with number of column nodes. Panel (e) of Figure 5 shows the results, and we see that DiMSC performs satisfactorily for a small z even for the case when there are no pure nodes for both row and column communities. Meanwhile, DiMSC performs better than its competitors when , and it perform poorer than its competitors when for this experiment. Furthermore, compared with numerical results of Experiment 2 (a), we see that DI-SIM, DiPCA, and DSCORE have better performances in Experiment 2 (e). The possible reason is the memberships and are close to and somewhat.
Experiment 2 (f): Degree heterogeneity. All parameters are set the same as Experiment 2 (b) except that we set and the same as Experiment 2 (e). The results are shown in Panel (f) of Figure 5 and are similar to that of Experiment 2 (e).
Experiment 2 (g): Degree heterogeneity. All parameters are set the same as Experiment 2 (c) except that we set , all mixed row nodes have three different memberships (0.8, 0.1, 0.1), (0.1, 0.8, 0.1), and , each with number of row nodes, and all mixed column nodes also have the above four memberships, each with number of column nodes. The results are displayed in Panel (g) of Figure 5 and are similar to that of Experiment 2 (e).
Experiment 2 (h): Degree heterogeneity. All parameters are set the same as Experiment 2 (d) except that we set and the same as Experiment 2 (g). The results are shown in Panel (h) of Figure 5 and are similar to that of Experiment 2 (e).
Experiment 3 (a): Connectivity across communities. Set , , . Set
and let range in . Decreasing increases the hardness of detecting such directed networks. Note that gives should be no larger than 1. Since may be larger than one in this experiment, after obtaining , we need to update as . The results are displayed in Panel (a) of Figure 6, and they support the arguments given after Corollary 1 such that DiMSC performs better when increases and vice versa. Meanwhile, our DiMSC outperforms its competitors in this experiment.
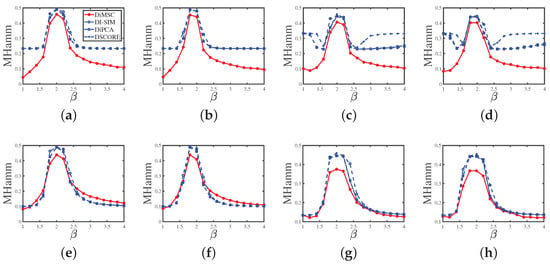
Figure 6.
Errors against increasing . y-axis: MHamm. Panel (a): Experiment 3 (a); Panel (b): Experiment 3 (b); Panel (c): Experiment 3 (c); Panel (d): Experiment 3 (d); Panel (e): Experiment 3 (e); Panel (f): Experiment 3 (f); Panel (g): Experiment 3 (g); Panel (h): Experiment 3 (h).
Experiment 3 (b): Connectivity across communities. All parameters are set the same as Experiment 3 (a) except that we set
The results are displayed in Panel (b) of Figure 6, and we see that DiMSC performs better when increases even for the case that P has non-unit diagonals.Meanwhile, our DiMSC performs better than its competitors here.
Experiment 3 (c): Connectivity across communities. Set . Set
and let range in . The results are displayed in Panel (c) of Figure 6 and can be analyzed similarly to Experiment 3 (a).
Experiment 3 (d): Connectivity across communities. All parameters are set the same as Experiment 3(c) except that we set
The results are displayed in Panel (d) of Figure 6 and can be analyzed similarly to Experiment 3 (b).
Experiment 3 (e): Connectivity across communities. All parameters are set the same as Experiment 3(a) except that we let and be the same as that of Experiment 2 (e) (so there are no pure nodes in both row and column communities.). Panel (e) of Figure 6 shows the results, and we see that DiMSC enjoys better performance when increases even in the case that there are no pure nodes for both row and column communities. Meanwhile, all methods have competitive performances for this experiment, and the possible reason that DiMSC’s competitors enjoy better performances here than in Experiment 3 (a) is analyzed in Experiment 2 (e).
Experiment 3 (f): Connectivity across communities. All parameters are set the same as Experiment 3 (b) except that we set and the same as Experiment 2 (e). The results are displayed in Panel (f) of Figure 6 and can be analyzed similarly to Experiment 3 (e).
Experiment 3 (g): Connectivity across communities. All parameters are set the same as Experiment 3 (c) except that we let and be the same as that of Experiment 2 (g) (so there are no pure nodes). Panel (g) of Figure 6 shows the results, and the analysis is similar to that of Experiment 3 (b).
Experiment 3 (h): Connectivity across communities. All parameters are set the same as Experiment 3 (d) except that we set and the same as Experiment 2 (g). Panel (h) of Figure 6 shows the results, and the analysis is similar to that of Experiment 3 (b).
Experiment 4 (a): Sparsity. Set and P as . Let range in . A larger indicates a denser network. Panel (a) in Figure 7 displays the simulation results of this experiment. We see that DiMSC performs better as the simulated directed network becomes denser, and DiMSC significantly outperforms its competitors in this experiment.
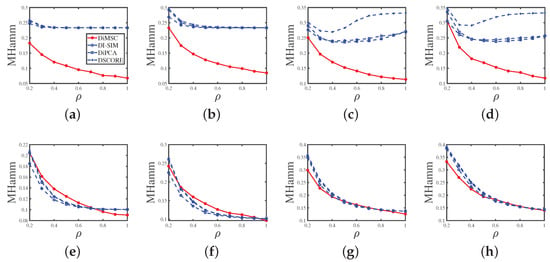
Figure 7.
Errors against increasing . y-axis: MHamm: Panel (a): Experiment 4 (a); Panel (b): Experiment 4 (b); Panel (c): Experiment 4 (c); Panel (d): Experiment 4 (d); Panel (e): Experiment 4 (e); Panel (f): Experiment 4 (f); Panel(g): Experiment 4 (g); Panel (h): Experiment 4 (h).
Experiment 4 (b): Sparsity. All parameters are set the same as Experiment 4 (a) except that P is set as . Panel (b) of Figure 7 shows the results, and the analysis is similar to that of Experiment 2 (b).
Experiment 4 (c): Sparsity. Set and P as . Let range in . Panel (c) of Figure 7 shows the results, and the analysis is similar to that of Experiment 4 (a).
Experiment 4 (d): Sparsity. All parameters are set the same as Experiment 4 (c) except that P is set as . Panel (d) of Figure 7 displays the results, and the analysis is similar to that of Experiment 4 (b).
Experiment 4 (e): Sparsity. All parameters are set the same as Experiment 4 (a) except that we let and be the same as that of Experiment 2 (e). Panel (e) of Figure 7 shows the results, and we see that DiMSC’s error rates decrease for a denser directed network even when all nodes are mixed. Meanwhile, all methods enjoy similar performances in this experiment.
Experiment 4 (f): Sparsity. All parameters are set the same as Experiment 4 (b) except that we set and the same as Experiment 2(e). Panel (f) of Figure 7 shows the results, and the analysis is similar to that of Experiment 4 (e).
Experiment 4 (g): Sparsity. All parameters are set the same as Experiment 4 (c) except that we let and be the same as that of Experiment 2 (g). Panel (g) of Figure 7 shows the results, and the analysis is similar to that of Experiment 4 (e).
Experiment 4 (h): Sparsity. All parameters are set the same as Experiment 4 (d) except that we set and the same as Experiment 2(g). Panel (h) of Figure 7 shows the results, and the analysis is similar to that of Experiment 4 (e).
Experiment 5 (a): Phase transition. Under , set . Let each row community have 100 pure nodes, each column community have 120 pure nodes, and all mixed nodes have membership . Since , and should be set in . We let and be in the range of . Panel (a) of Figure 8 displays the results. We see that DiMSC performs satisfactorily when and satisfy Equation (14), and this means that DiMSC achieves the threshold provided in Equation (14) under .
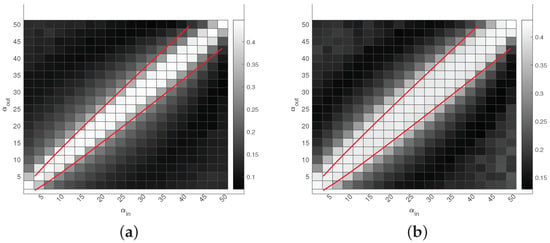
Figure 8.
Phase transition for DiMSC: darker pixels represent lower error rates. The red lines represent . Panel (a): Experiment 5 (a); Panel (b): Experiment 5 (b).
Experiment 5 (b): Phase transition. Under , set . Let each row community have 60 pure nodes, each column community have 80 pure nodes, and all mixed nodes have membership . We also let and be in the range of . Panel (b) of Figure 8 displays the results, and the analysis is similar to that of Experiment 5 (a).
For Experiments 1–5, we can conclude that DiMSC outperforms its competitors, and this supports our analysis in Remark 6 because DiMSC is designed to estimate mixed memberships, while its competitors are designed for community partition of pure nodes.
Experiment 6: Network size. Under , let and . On the one hand, we have , i.e., and locates in the impossible region of exact recovery introduced in [50]. On the other hand, we have , i.e., and satisfy Equation (14) for DiMSC’s consistent estimation. Let n range in . For each n in this experiment, we report the averaged error rate and running time of DiMSC over 10 independent repetitions. The results are shown in Figure 9. From Panel (a) of Figure 9, we see that DiMSC enjoys satisfactory performance with a small error rate for this experiment. Panels (b) of Figure 9 says that DiMSC processes computer-generated networks of up to 15,000 nodes within hundreds of seconds.
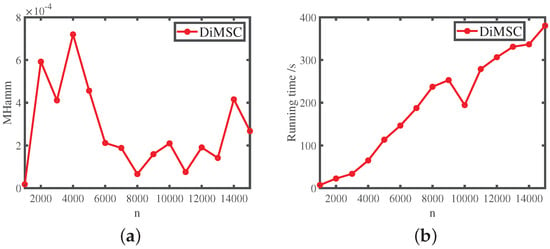
Figure 9.
Numerical results for Experiment 6. Panel (a): MHamm; Panel (b): running time.
Remark 7.


For visuality, we provide some examples of different types of directed networks generated under DiDCMM in this remark. Let for . Let each row community has pure nodes, and each column community has pure nodes. Let all mixed nodes have membership . For the setting of P, we set it as
where when P is or , and when P is or . Meanwhile, we can generate different types of directed networks under DiDCMM by considering the above six different settings of P, where these different types are also considered in Experiments 1–6, and we mainly provide the visuality for these directed networks with different structures provided in different P for this remark. Note that we allow P to have non-unit diagonals here because Condition (I1) is mainly for our theoretical buildings, and results for previous experiments show that DiMSC performs stable even when P has non-unit diagonals. We consider below eight settings.
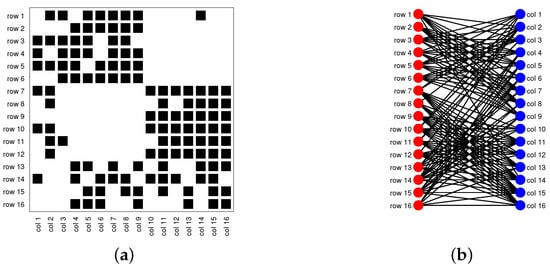
Model Setup 1: Set , and P as . For this setup, a directed network with 16 row nodes and 16 column nodes is generated from DiDCMM. Figure 10 shows a directed network generated under Model Setup 1, where we also report DiMSC’s error rate. Figure 10 says that there are more directed edges sent from row nodes 1–6 to column nodes 1–7 than from row nodes 7–12 to column nodes 1–7 for . With given adjacency matrix A and known memberships and for this setup, readers can apply our DiMSC directly to A given in Panel (a) of Figure 10 to check the effectiveness of DiMSC.
Figure 10.
Illustration for a directed network under Model Setup 1. Panel (a): Adjacency matrix of , where black square denotes 1; Panel (b): directed network , where red (blue) points indicate row (column) nodes. The error rate MHamm defined in Equation (16) of our DiSMC algorithm for this directed network is 0.0377.
Model Setup 2: All settings are the same as Model Setup 1 except that we let P be . The directed network and its adjacency matrix are shown in Figure 11. We see that there are more directed edges sent from row nodes 1–6 to column nodes 10–16 than from row nodes 7–12 to column nodes 10–16 for , which means that directed network generated using and directed network from has different structures.
Figure 11.
Illustration for a directed network under Model Setup 2. Panel (a): Adjacency matrix A; Panel (b): directed network . MHamm of DiMSC for this directed network is 0.0424.
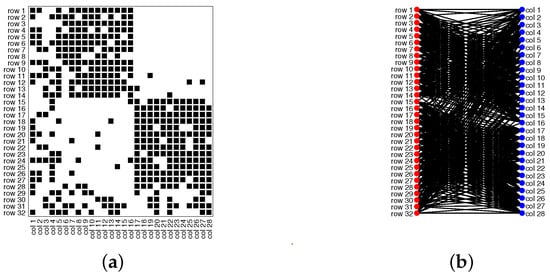
Model Setup 3: Set , and P as . For this setup, a bipartite network with 32 row nodes and 28 column nodes are generated from DiDCMM. Figure 12 shows this bipartite network and its adjacency matrix.
Figure 12.
Illustration for a bipartite network under Model Setup 3. Panel (a): Adjacency matrix A; Panel (b): bipartite network . MHamm of DiMSC for this bipartite network is 0.0313.
Model Setup 4: All settings are the same as Model Setup 3 except that we let P be . Figure 13 displays the results, and we see that the bipartite network from also has a different structure compared with the one generated from using under DiDCMM.
Figure 13.
Illustration for a bipartite network under Model Setup 4. Panel (a): Adjacency matrix A; Panel (b): bipartite network . MHamm of DiMSC for this bipartite network is 0.0320.
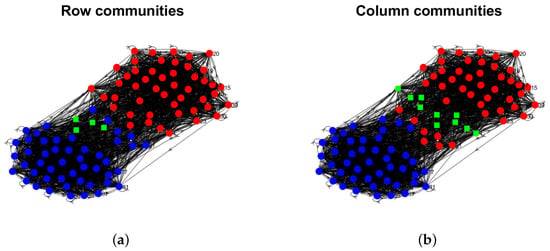
Model Setup 5: Set , and P as . Figure 14 shows the row and column communities for a directed network generated from Setup 5 under DiDCMM, where we plot the directed network directly.
Figure 14.
Illustration for a directed network under Model Setup 5. Panels (a,b) show the row and column communities, respectively. In these two panels, dots in the same color are pure nodes in the same communities, and a square indicates mixed nodes. MHamm of DiMSC for this directed network is 0.0181.
Model Setup 6: All settings are the same as Model Setup 5 except that we let P be . Figure 15 shows a directed network obtained from this setup, and we see that the structure of the directed network from in Figure 15 differs a lot from that of the directed network from shown in Figure 14.
Figure 15.
Illustration for a directed network under Model Setup 6. Panels (a,b) show the row and column communities, respectively. MHamm of DiMSC for this directed network is 0.0185.
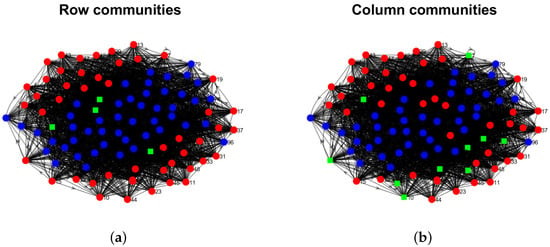
Model Setup 7: Set , and P as . Figure 16 shows a directed network generated from this setup.
Figure 16.
Illustration for a directed network under Model Setup 7. Panels (a,b) show the row and column communities, respectively. MHamm of DiMSC for this directed network is 0.0266.
Model Setup 8: All settings are the same as Model Setup 7 except that we let P be . Figure 17 displays a directed network generated from this setup, and we see that directed networks from and have different structures by comparing Figure 16 and Figure 17.
Figure 17.
Illustration for a directed network under Model Setup 8. Panels (a,b) show the row and column communities, respectively. MHamm of DiMSC for this directed network is 0.0279.
6. Application to Real-World Directed Networks
For the empirical directed networks considered here, row nodes are always the same as column nodes, so we let . For , we call node i highly mixed node if , similar for . A highly mixed node tells us whether a node has mixed memberships and belongs to multiple communities. Let be the proportion of highly mixed nodes among all nodes to measure the mixability of all row communities. Define similar to . Let be a vector such that for , where we use to denote the home base row community of node i. Define similar to . To measure the asymmetric structure of a directed network, we use
where a large means that the structure of row clusters differs a lot from that of column clusters. For , let be the number of edges sent by node i, be the number of edges received by node i, where (and ) is the out degree (in degree) of node i. Since there are many nodes with zero in degree or out degree for real-world directed network, we need the below pre-processing: for any directed network , we let be its adjacency matrix for any positive integer m such that is connected, and every node has at least m in degree and m out degree in .
We apply DiMSC to the following real-world directed networks to discover their mixability, asymmetries, and directional communities.
Political blogs: This is a directed network of hyperlinks between weblogs on US politics [68]. In this data, node means a blog, and edge means a hyperlink. This data can be downloaded from http://www-personal.umich.edu/~mejn/netdata/ (accessed on 28 August 2022). It is well-known that there are two parties, “liberal” and “conservative”, so for this data. The are 1490 nodes in the original data. After pre-processing, , where we focus on the cases when for this data here. Meanwhile, we use political blogs to denote this network when its adjacency matrix is , where every node has a degree at least m. Similar notations hold for other real-world directed networks used in this paper.
Wikipedia links (gan): This directed network consists of the Wikilinks of Wikipedia in the Gan Chinese language (gan). In this data, node means an article, and the directed edge is a Wikilink [69]. This data can be downloaded from http://konect.cc/networks/wikipedia_link_gan (accessed on 28 August 2022). There are 9189 nodes in the original data. After pre-processing, , where we study the cases for this data. The leading 20 singular values of shown in Panels (e)–(h) of Figure 18 suggest for these four adjacency matrices, where [30] also uses eigengap to estimate K.
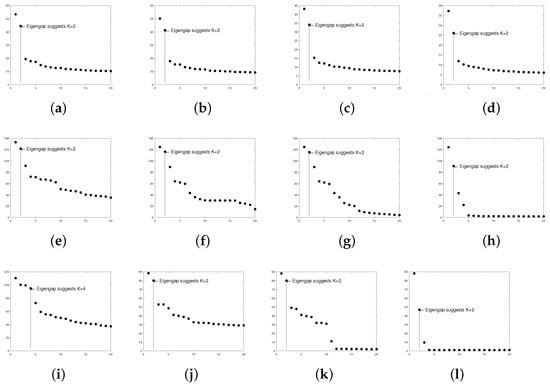
Figure 18.
Leading 20 singular values of real-world directed networks used in this paper. Panel (a): political blogs ; Panel (b): political blogs ; Panel (c): political blogs ; Panel (d): political blogs ; Panel (e): Wikipedia links (gan) ; Panel (f): Wikipedia links (gan) ; Panel (g): Wikipedia links (gan) ; Panel (h): Wikipedia links (gan) ; Panel (i): Wikipedia links (nah) ; Panel (j): Wikipedia links (nah) ; Panel (k): Wikipedia links (nah) ; Panel (l): Wikipedia links (nah) .
Wikipedia links (nah): This network consists of the Wikilinks of the N huatl language (nah) [69] and can be downloaded from http://konect.cc/networks/wikipedia_link_nah/ (accessed on 28 August 2022). The original data has 10285 nodes. After pre-processing, . Panel (i) of Figure 18 suggests for , and Panels (j)–(l) of Figure 18 suggest for , and . Note that it only takes around 4 seconds for DiMSC to estimate memberships of Wikipedia links (nah) .
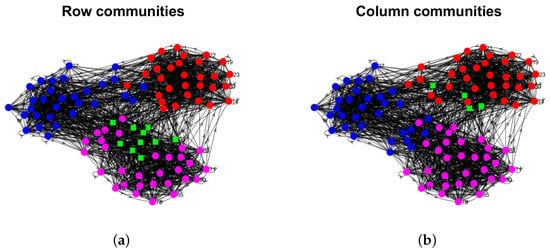
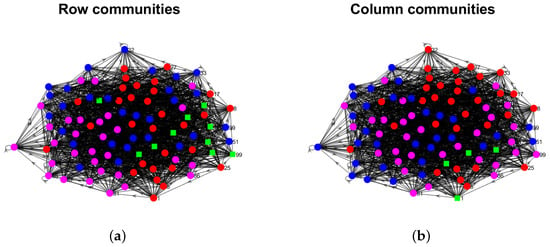
The proportions of highly mixed nodes and when applying DiMSC on the above real-world directed networks are reported in Table 1. For the political blogs network, small , and indicate that there are only a few highly mixed nodes, and the structure of row communities is similar to that of column communities, i.e., there is a slight asymmetry for this data. For Wikipedia links (gan) and Wikipedia links (nah) , they have a large proposition of highly mixed nodes in both row and column communities, and the row communities differ a lot from column communities, suggesting heavy asymmetric structure between row and column communities for these two data. For Wikipedia links (gan) , and Wikipedia links (nah) , we see that the proportion of highly mixed nodes for row (column) communities is small (large), and there is a slight asymmetric for these data. For Wikipedia links (gan) and Wikipedia links (nah) , there is no highly mixed node, and the structure of row clusters is similar to that of column clusters. For visualization, we plot the row and column communities as well as highly mixed nodes by applying DiMSC to some of these directed networks in Figure 19 and Figure 20.

Table 1.
, and obtained from DiMSC for real-world directed networks used in this paper.
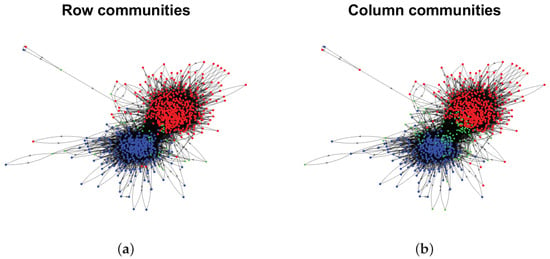
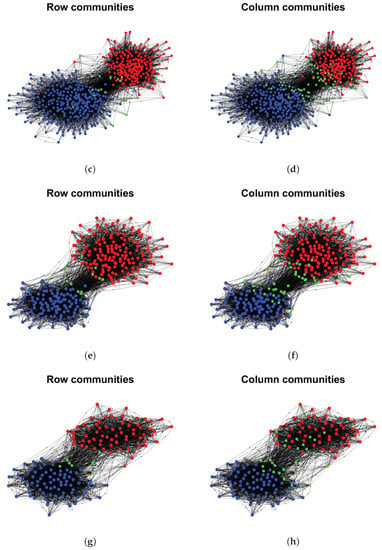
Figure 19.
Row and column communities detected by DiMSC for political blogs. Colors indicate clusters, and a green square indicates highly mixed nodes, where the row and column communities are obtained from and , respectively. Panel (a): political blogs ; Panel (b): political blogs ; Panel (c): political blogs ; Panel (d): political blogs ; Panel (e): political blogs ; Panel (f): political blogs ; Panel (g): political blogs ; Panel (h): political blogs .
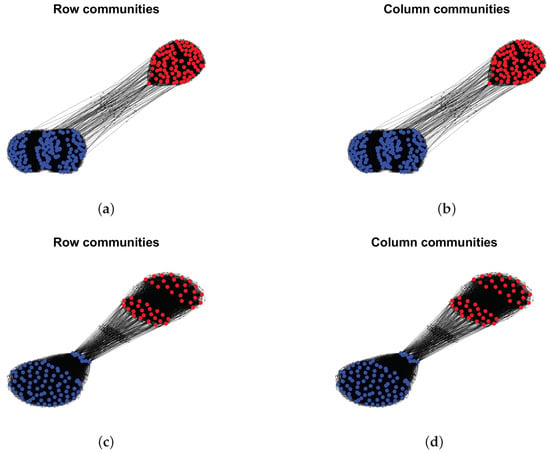
Figure 20.
Row and column communities detected by DiMSC for Wikipedia links (gan) and Wikipedia links (nah) . Colors indicate clusters, where the row and column communities are obtained from and , respectively. Panel (a): Wikipedia links (gan) ; Panel (b): Wikipedia links (gan) ; Panel (c): Wikipedia links (nah) ; Panel (d): Wikipedia links (nah) .
7. Discussion and Conclusions
In this paper, we propose a novel directed degree corrected mixed membership (DiDCMM) model. DiDCMM models a directed network with mixed memberships for row nodes with degree heterogeneities and column nodes without degree heterogeneities. DiDCMM is identifiable when the two well-used Conditions (I1) and (I2) hold. It should be mentioned that a model modeling a directed network with mixed memberships for both row and column nodes with degree heterogeneities is unidentifiable unless considering some nontrivial conditions. To fit the model, we propose a provably consistent spectral algorithm called DiMSC to infer community memberships for both row and column nodes in a directed network generated by DiDCMM. DiMSC is designed based on the SVD of the adjacency matrix, where we apply the SP algorithm to hunt for the corners in the simplex structure and the SVM-cone algorithm to hunt for the corners in the cone structure. The theoretical results of DiMSC show that it consistently recovers memberships of both row nodes and column nodes under mild conditions. Meanwhile, when DiDCMM degenerates to MMSB, our theoretical results match that of Theorem 2.2 [24] when their DCMM degenerates to MMSB under mild conditions. Experiments conducted on synthetic directed networks generated from DiDCMM verify the effectiveness and the stability of Conditions (I1) and (I2) of DiMSC. Results for real-world directed networks show that DiMSC reveals highly mixed nodes and asymmetries in the structure of row and column communities. The model DiDCMM and the algorithm DiMSC developed in this paper are useful to discover asymmetry for a directed network with mixed memberships. DiDCMM can also generate an artificially directed network with mixed memberships as a benchmark directed network for research purposes. We wish that DiDCMM and DiMSC can be widely applied in social network analysis.
The proposed model DiDCMM and the algorithm DiMSC can be extended in many ways. Similar to [24,57], we may obtain an ideal simplex from U using the idea of the entry-wise ratio proposed in [8]. Meanwhile, DiMSC is designed based on the SVD of the adjacency matrix, and similar to [5,7,11,30], we may design spectral algorithms based on the regularized Laplacian matrix under DiDCMM. Extending DiDCMM from an un-weighted directed network to a weighted directed network with an application of the distribution-free idea introduced in [62] is one of our future research directions. The SVD step of DiMSC can be accelerated by the random projection and random sampling ideas introduced in [70] to process large-scale directed networks. Instead of simply using eigengap to find K, in our future work, it is worth focusing on estimating the number of communities in a directed network generated under ScBM (and DCScBM) [30] and DiDCMM. Ref. [46] proposes an algorithm to uncover boundary nodes that spread information between communities in undirected social networks. It is an interesting topic to extend works in [46] to directed networks generated from ScBM, DCScBM, and DiDCMM. We leave them for our future work.
Funding
This research was funded by the Scientific research start-up fund of CUMT NO. 102520253, the High-level personal project of Jiangsu Province NO. JSSCBS20211218.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SBM | Stochastic Blockmodel |
| DCSBM | Degree Corrected Stochastic Blockmodel |
| MMSB | Mixed Membership Stochastic Blockmodel |
| DCMM | Degree Corrected Mixed Membership model |
| OCCAM | Overlapping Continuous Community Assignment model |
| ScBM | Stochastic co-Blockmodel |
| DC-ScBM | Degree Corrected Stochastic co-Blockmodel |
| DiMMSB | Directed Mixed Membership Stochastic Blockmodel |
| DiDCMM | Directed Degree Corrected Mixed Membership model |
| SP | Successive projection algorithm |
| SVD | Singular value decomposition |
| DiMSC | Directed Mixed Simplex & Cone algorithm |
Appendix A. Proof for Identifiability
Appendix A.1. Proof of Proposition 1
Proof.
Let be the compact singular value decomposition of . Lemma 1 gives . Since , V also equals to , which gives that .
Since by Condition (I2), we have , which gives that . From this step, we see that if P’s diagonal entries are not ones, we cannot obtain which leads to a consequence that does not equal to ; hence Condition (I1) is necessary by Condition (I1). Since , we also have , which gives that . Since also equals to , we have .
Lemma 1 gives that , where . Since , we also have . Since , we have . Since , we have . Since each row of or is a PMF, , and the claim follows. □
Appendix B. Ideal Simplex, Ideal Cone
Appendix B.1. Proof of Lemma 1
Proof.
First, we consider U and V. Since , we have since . Recall that , we have , where we set and sure it is unique. Since , we have .
Similarly, since , we have since , hence . Recall that , we have , where we set and sure it is unique. Since , we have . Meanwhile, for , we have . Hence, we have as long as .
Now, we show the ideal cone structure that appears in . For convenience, set , hence gives . Hence, we have . Therefore, , combine it with the fact that , we have
Therefore, we have
where is a diagonal matrix with for . All entries of Y are nonnegative, and since we assume that each community has at least one pure node, no row of Y is 0.
Then, we prove that when . For , we have
and the claim follows immediately. □
Appendix B.2. Proof of Lemma 2
Proof.
Since and (i.e., the inverse of exists), we have . Since , we have
Since all entries of and nonnegative and are diagonal matrices, we see that all entries of are nonnegative, and its diagonal entries are strictly positive, hence we have . □
Appendix B.3. Proof of Theorem 1
Proof.
For column nodes, Remark A1 guarantees that SP algorithm returns when the input is V with K column communities, hence ideal DiMSC recovers exactly. For row nodes, Remark A2 guarantees that SVM-cone algorithm returns when the input is with K row communities, hence ideal DiMSC recovers exactly, and this theorem follows. □
Appendix C. Equivalence Algorithm
In this subsection, we design one algorithm DiMSC-equivalence which returns the same estimations as DiMSC. Set . Set as for . is defined similarly. The next lemma guarantees that enjoys IS structure, and enjoys IC structure.
Lemma A1.
Under , we have , and .
Proof.
By Lemma 1, we know that , which gives that . For U, since by Lemma 1, we have . Set , we have . Then, follow similar proof as Lemma 1, we have , where , and are diagonal matrices whose i-th diagonal entries are , respectively. Since , we have . Since , we have . Hence, and the claim follows. □
Since and , and are singular matrix with rank K by Condition (I1), while the inverses of and exist. Therefore, Lemma A1 gives that
Since and , we see that also equals to by basic algebra.
Based on the above analysis, we are now ready to give the ideal DiMSC-equivalence. Input . Output: and .
- Obtain from .
- Run SP algorithm on with K column communities to obtain . Run SVM-cone algorithm on with K row communities to obtain .
- Set and .
- Recover and by setting for , and for .
For the real case, set . We now extend the ideal case to the real one given by Algorithm A1.
| Algorithm A1: DiMSC-equivalence |
| Require: The adjacency matrix of a directed network, the number of row communities (column communities) K. Ensure: The estimated row membership matrix and the estimated column membership matrix .
|
Lemma A2.(Equivalence). For the empirical case, we have and .
Proof.
For column nodes, Lemma 3.2 [27] gives (i.e., SP algorithm will return the same indices on both and .), which gives that , and . Therefore, we have .
For row nodes, Lemma G.1 [26] guarantees that (i.e., SVM-cone algorithm will return the same indices on both and .), so immediately we have . Since , we have and , which give that , and the claim follows immediately. □
Lemma A2 guarantees that the DiMSC and DiMSC-equivalence return same estimations for both row and column nodes’s memberships. In this article, we introduce the DiMSC-equivalence algorithm since it is helpful to build a theoretical framework for DiMSC, see Remark A3 and A4 for detail.
Appendix D. Basic Properties of Ω
Lemma A3.
Under , we have
Proof.
Since , we have
which gives that
Similarly, we have
Since for , we have
Similarly, we have
For , since , we have
Meanwhile,
□
Lemma A4.
Under , we have
Proof.
Recall that and , we have . As is full rank, we have , which gives
By the proof of Lemma 2, we know that
which gives that
Then, we have
Similarly, we have
□
Lemma A5.
Under , we have
Proof.
For , we have
where we have used the fact for any matrices , the nonzero eigenvalues of are the same as the nonzero eigenvalues of . Following a similar analysis, the lemma follows. □
Lemma A6.
Under , when Assumption A1 holds, with probability at least , we have
Proof.
Since the proof is similar to that of Lemma 7 [35], we omit most of the details. Let be an vector, where and 0 elsewhere, for row nodes , and be an vector, where and 0 elsewhere, for column nodes . Set , where . Set , for . Then, we have . For , we have
Next, we consider the variance parameter
Since
where denotes the variance of the Bernoulli random variable , we have
Since is an diagonal matrix with -th entry being one and other entries being zero, we have
Similarly, we have , which gives that
By the rectangular version of the Bernstein inequality [71], combining with
, set
for any , we have
where we have used Assumption 1 in the last inequality. Set , and the claim follows. □
Appendix E. Proof of Consistency for DiMSC
Similar to [24,26,27], for our DiMSC, the main theoretical results (i.e., Theorem 2) rely on the row-wise singular vector deviation bounds for the singular eigenvectors of the adjacency matrix.
Lemma A7.
(Row-wise singular vector deviation) Under , when Assumption 1 holds, suppose , with probability at least , we have
Proof.
Let , and be the SVD decomposition of with , where and represent, respectively, the left and right singular matrices of . Define ; is defined similarly. Since , by the proof of Lemma A6, holds by Assumption 1, where is the incoherence parameter defined as . By Theorem 4.4 [64], with high probability, we have below row-wise singular vector deviation
provided that for some sufficiently small constant , and here we set for convenience since this term has little effect on the error bounds of DiMSC, especially for the case when .
Since , we have by basic algebra. Now, we are ready to bound :
The lemma holds by following similar proof for . □
When , and DiCCMM degenerates to MMSB, the bound in Lemma A7 is . if we further assume that and , the bound is of order . Set the in [24] as , their DCMM degenerates to MMSB, their assumptions are translated to our , when , the row-wise singular vector deviation bound in the fourth bullet of Lemma 2.1 [24] is , which is consistent with ours. Meanwhile, if we further assume that , the bound is of order .
The next lemma is the cornerstone to characterizing the behaviors of DiMSC.
Lemma A8.
Under , when conditions of Lemma A7 hold, there exist two permutation matrices such that with probability at least , we have
Proof.
First, we consider column nodes. The detail of the SP algorithm is in Algorithm A2.
| Algorithm A2 Successive Projection (SP) [54] |
| Require: Near-separable matrix , where should satisfy Assumption 1 [54], the number r of columns to be extracted. Ensure: Set of indices such that (up to permutation)
|
Based on Algorithm A2, the following theorem is Theorem 1.1 in [54].
Theorem A1.
Fix and . Consider a matrix , where has a full column rank, is a nonnegative matrix such that the sum of each column is at most 1, and . Suppose has a submatrix equal to . Write . Suppose , where and are the minimum singular value and condition number of , respectively. If we apply the SP algorithm to columns of , then it outputs an index set such that and , where is the k-th column of .
Let and . By Condition (I2), has an identity submatrix . By Lemma A7, we have
By Theorem A1, there exists a permutation matrix such that
Since , where the last equality holds by Lemma A4, we have
Remark A1.For the ideal case, let and . Then, we have . By Theorem A1, SP algorithm returns when the input is V assuming there are K column communities.
Now, we consider row nodes. From Lemma 2, we see that satisfies Condition 1 in [26]. Meanwhile, since , we have , hence satisfies Condition 2 in [26]. Now, we give a lower bound for to show that is strictly positive. By the proof of Lemma A4, we have
where we set , and we have used the facts that are diagonal matrices, and by Lemma A3. Then, we have
i.e., is strictly positive. Since , we have also satisfies Conditions 1 and 2 in [26]. The above analysis shows that we can directly apply Lemma F.1 of [26] since the ideal DiMSC algorithm satisfies Conditions 1 and 2 in [26], therefore there exists a permutation matrix such that
where , and . Next, we bound as below
where the last inequality holds by Lemma A3. Then, we have . Finally, by Lemma A4, we have
Remark A2.For the ideal case, when setting as the input of the SVM-cone algorithm assuming there are K row communities, since , Lemma F.1; [26] guarantees that SVM-cone algorithm returns exactly. Meanwhile, another view to see that the SVM-cone algorithm exactly obtains when the input is (also ) is given in Appendix F, which focuses on following the three steps of SVM-cone algorithm to show that it returns with input (also ), instead of simply applying Lemma F.1. [26].
□
Lemma A9.
Under , when conditions of Lemma A7 hold, with probability at least , we have
Proof.
First, we consider column nodes. Recall that . For convenience, set . We bound when the input is in the SP algorithm. Recall that , for , we have
where we have used similar idea in the proof of Lemma VII.3 in [27] such that apply to estimate , then by Lemma A4, we have .
Now, we aim to bound . For convenience, set . We have
Remark A3.
Equation (A2) supports our statement that building the theoretical framework of DiMSC benefits a lot by introducing the DiMSC-equivalence algorithm since is obtained from DiMSC-equivalence (i.e., inputing in the SP algorithm obtains ).
Then, we have
Next, we consider row nodes. For , since , we have
Next, we consider row nodes. For , since , we have
Therefore, the bound of can be obtained as long as we bound and . We bound the four terms as below:
- We bound first. Similar as bounding , we set for convenience. We bound when the input is in the SVM-cone algorithm. For , we havewhere we have used similar idea in the proof of Lemma VII.3 in [27] such that we apply to estimate , hence (i) holds by Lemma A4.
Now, we aim to bound . For convenience, set . We have
Then, we have
- for , since , by Lemmas (A3) and (A4), we have
- for , recall that , we haveBy Lemmas (A6) and (A5), . By Lemma (A5) and Equation (A1),. By Lemma A3, , which gives (this can be seen as simply using to estimate since is the same order as ). Then, we have , which gives that .
- for , since , we have , which gives that . Thus, we have .
Combining the above results, we have
□
Appendix E.1. Proof of Theorem 2
Proof.
We bound first. Recall that , for , since
by Lemma A9, we have
For row nodes , recall that and , where and M are defined in the proof of Lemma 1 such that and , similar as the proof for column nodes, we have
Now, we provide a lower bound of as below
Therefore, by Lemma A9, we have
□
Appendix E.2. Proof of Corollary 1
Proof.
Under conditions of Corollary 1, we have
Under conditions of Corollary 1, Lemma A7 gives , which gives that
By basic algebra, this corollary follows. □
Appendix F. SVM-Cone Algorithm
For readers’ convenience, we briefly introduce the SVM-cone algorithm given in [26] and provide another view that the SVM-cone algorithm exactly recovers when the input is (or ). Let S be a matrix whose rows have unit norm, and S can be written as , where with nonnegative entries, no row of H is 0, and corresponding to K rows of S (i.e., there exists an index set with K entries such that ). Inferring H from S is called the ideal cone problem, i.e., Problem 1 in [26]. The ideal cone problem can be solved by applying one-class SVM to the rows of S, and the K rows of are the support vectors found by one-class SVM:
The solution for the ideal cone problem when is given by
For the empirical case, let be a matrix where all rows have unit norm, infer H from with given K is called the empirical cone problem, i.e., Problem 2 in [26]. For the empirical cone problem, one-class SVM is applied to all rows of to obtain and b’s estimations and . Then, apply the K-means algorithm to rows of that are close to the hyperplane into K clusters, and an estimation of the index set can be obtained from the K clusters provided. Algorithm A3 below is the SVM-cone algorithm provided in [26].
| Algorithm 3: SVM-cone [26] |
|
As suggested in [26], we can start and incrementally increase it until K distinct clusters are found.
Now, turn to our DiMSC algorithm, and focus on estimating with given , and K. By Lemmas 1 and A1, we know that and enjoy the ideal cone structure, and Lemma 2 guarantees that one-class SVM can be applied to rows of and . Set , and . Now that and are solutions of the one-class SVM in Equation (A5) by setting , and and are solutions of the one-class SVM in Equation (A5) by setting . Lemma A11 says that if row node i is a pure node, we have , and this suggests that in the SVM-cone algorithm, if the input matrix is , by setting , we can find all pure row nodes, i.e., the set contains all rows of respective to pure row nodes while including mixed row nodes. By Lemma 1, these pure row nodes belong to the K distinct row communities such that if row nodes are in the same row community, then we have , and this is the reason that we need to apply the K-means algorithm on the set obtained in Step 2 in the SVM-cone algorithm to obtain the K distinct row communities, and this is also the reason that we said the SVM-cone algorithm returns the index set exactly when the input is . These conclusions also hold when we set the input in the SVM-cone algorithm as .
Lemma A10.
Under , for , can be written as , where . Meanwhile, and if i is a pure node such that ; and if for . Similarly, can be written as , where . Meanwhile, and if ; and if for .
Proof.
Since by Lemma 1, for , we have
where we set , , and is a vector with all entries being ones.
By the proof of Lemma 1, , where . For convenience, set , and (such setting of is only for used for notation convenience for the proof of Lemma A10).
On the one hand, if row node i is pure such that for certain k among (i.e., if ), we have , and , which give that . Recall that the k-th diagonal entry of is , i.e., , which gives that and when .
On the other hand, if i is a mixed node, since , combine it with , so . The lemma follows by a similar analysis for . □
Lemma A11.
Under , for , if row node i is a pure node such that for certain k, we have
Meanwhile, if row node i is a mixed node, the above equalities do not hold.
Proof.
For the claim that holds when i is pure, by Lemma A10, when i is a pure node such that , can be written as , so holds surely. When i is a mixed node, by Lemma A10, and for any ; hence if i is mixed, which gives the result. Follow a similar analysis, we obtain the results associated with , and the lemma follows. □
References
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Karrer, B.; Newman, M.E.J. Stochastic blockmodels and community structure in networks. Phys. Rev. E 2011, 83, 16107. [Google Scholar] [CrossRef]
- Rohe, K.; Chatterjee, S.; Yu, B. Spectral clustering and the high-dimensional stochastic blockmodel. Ann. Stat. 2011, 39, 1878–1915. [Google Scholar] [CrossRef]
- Zhao, Y.; Levina, E.; Zhu, J. Consistency of community detection in networks under degree-corrected stochastic block models. Ann. Stat. 2012, 40, 2266–2292. [Google Scholar] [CrossRef]
- Qin, T.; Rohe, K. Regularized spectral clustering under the degree-corrected stochastic blockmodel. Adv. Neural Inf. Process. Syst. 2013, 26, 3120–3128. [Google Scholar]
- Jin, J. Fast community detection by SCORE. Ann. Stat. 2015, 43, 57–89. [Google Scholar] [CrossRef]
- Lei, J.; Rinaldo, A. Consistency of spectral clustering in stochastic block models. Ann. Stat. 2015, 43, 215–237. [Google Scholar] [CrossRef]
- Cai, T.T.; Li, X. Robust and computationally feasible community detection in the presence of arbitrary outlier nodes. Ann. Stat. 2015, 43, 1027–1059. [Google Scholar] [CrossRef]
- Joseph, A.; Yu, B. Impact of regularization on spectral clustering. Ann. Stat. 2016, 44, 1765–1791. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Xu, J. Convexified modularity maximization for degree-corrected stochastic block models. Ann. Stat. 2018, 46, 1573–1602. [Google Scholar] [CrossRef]
- Passino, F.S.; Heard, N.A. Bayesian estimation of the latent dimension and communities in stochastic blockmodels. Stat. Comput. 2020, 30, 1291–1307. [Google Scholar] [CrossRef]
- Li, X.; Chen, Y.; Xu, J. Convex Relaxation Methods for Community Detection. Stat. Sci. 2021, 36, 2–15. [Google Scholar] [CrossRef]
- Jing, B.; Li, T.; Ying, N.; Yu, X. Community detection in sparse networks using the symmetrized Laplacian inverse matrix (SLIM). Stat. Sin. 2022, 32, 1–22. [Google Scholar] [CrossRef]
- Abbe, E. Community detection and stochastic block models: Recent developments. J. Mach. Learn. Res. 2017, 18, 6446–6531. [Google Scholar]
- Airoldi, E.M.; Blei, D.M.; Fienberg, S.E.; Xing, E.P. Mixed Membership Stochastic Blockmodels. J. Mach. Learn. Res. 2008, 9, 1981–2014. [Google Scholar]
- Ball, B.; Karrer, B.; Newman, M.E.J. Efficient and principled method for detecting communities in networks. Phys. Rev. E 2011, 84, 36103. [Google Scholar] [CrossRef]
- Wang, F.; Li, T.; Wang, X.; Zhu, S.; Ding, C. Community discovery using nonnegative matrix factorization. Data Min. Knowl. Discov. 2011, 22, 493–521. [Google Scholar] [CrossRef]
- Gopalan, P.K.; Blei, D.M. Efficient discovery of overlapping communities in massive networks. Proc. Natl. Acad. Sci. USA 2013, 110, 14534–14539. [Google Scholar] [CrossRef]
- Anandkumar, A.; Ge, R.; Hsu, D.; Kakade, S.M. A tensor approach to learning mixed membership community models. J. Mach. Learn. Res. 2014, 15, 2239–2312. [Google Scholar]
- Kaufmann, E.; Bonald, T.; Lelarge, M. A spectral algorithm with additive clustering for the recovery of overlapping communities in networks. Theor. Comput. Sci. 2017, 742, 3–26. [Google Scholar] [CrossRef]
- Panov, M.; Slavnov, K.; Ushakov, R. Consistent estimation of mixed memberships with successive projections. In Proceedings of the International Conference on Complex Networks and their Applications, Lyon, France, 29 November–1 December 2017; Springer: Cham, Switzerland, 2017; pp. 53–64. [Google Scholar]
- Jin, J.; Ke, Z.T.; Luo, S. Mixed membership estimation for social networks. arXiv 2017, arXiv:1708.07852. [Google Scholar] [CrossRef]
- Mao, X.; Sarkar, P.; Chakrabarti, D. On Mixed Memberships and Symmetric Nonnegative Matrix Factorizations. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2324–2333. [Google Scholar]
- Mao, X.; Sarkar, P.; Chakrabarti, D. Overlapping Clustering Models, and One (class) SVM to Bind Them All. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31, pp. 2126–2136. [Google Scholar]
- Mao, X.; Sarkar, P.; Chakrabarti, D. Estimating Mixed Memberships With Sharp Eigenvector Deviations. J. Am. Stat. Assoc. 2020, 116, 1928–1940. [Google Scholar] [CrossRef]
- Wang, Y.; Bu, Z.; Yang, H.; Li, H.J.; Cao, J. An effective and scalable overlapping community detection approach: Integrating social identity model and game theory. Appl. Math. Comput. 2021, 390, 125601. [Google Scholar] [CrossRef]
- Zhang, Y.; Levina, E.; Zhu, J. Detecting Overlapping Communities in Networks Using Spectral Methods. SIAM J. Math. Data Sci. 2020, 2, 265–283. [Google Scholar] [CrossRef]
- Rohe, K.; Qin, T.; Yu, B. Co-clustering directed graphs to discover asymmetries and directional communities. Proc. Natl. Acad. Sci. USA 2016, 113, 12679–12684. [Google Scholar] [CrossRef]
- Wang, Z.; Liang, Y.; Ji, P. Spectral Algorithms for Community Detection in Directed Networks. J. Mach. Learn. Res. 2020, 21, 1–45. [Google Scholar]
- Ji, P.; Jin, J. Coauthorship and citation networks for statisticians. Ann. Appl. Stat. 2016, 10, 1779–1812. [Google Scholar] [CrossRef]
- Zhou, Z.; Amini, A.A. Analysis of spectral clustering algorithms for community detection: The general bipartite setting. J. Mach. Learn. Res. 2019, 20, 1–47. [Google Scholar]
- Laenen, S.; Sun, H. Higher-order spectral clustering of directed graphs. Adv. Neural Inf. Process. Syst. 2020, 33, 941–951. [Google Scholar]
- Qing, H.; Wang, J. Directed mixed membership stochastic blockmodel. arXiv 2021, arXiv:2101.02307. [Google Scholar]
- Wang, Y.J.; Wong, G.Y. Stochastic Blockmodels for Directed Graphs. J. Am. Stat. Assoc. 1987, 82, 8–19. [Google Scholar] [CrossRef]
- Fagiolo, G. Clustering in complex directed networks. Phys. Rev. E 2007, 76, 026107. [Google Scholar] [CrossRef] [PubMed]
- Leicht, E.A.; Newman, M.E. Community structure in directed networks. Phys. Rev. Lett. 2008, 100, 118703. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Son, S.W.; Jeong, H. Finding communities in directed networks. Phys. Rev. E 2010, 81, 016103. [Google Scholar] [CrossRef]
- Malliaros, F.D.; Vazirgiannis, M. Clustering and Community Detection in Directed Networks: A Survey. Phys. Rep. 2013, 533, 95–142. [Google Scholar] [CrossRef]
- Zhang, X.; Lian, B.; Lewis, F.L.; Wan, Y.; Cheng, D. Directed Graph Clustering Algorithms, Topology, and Weak Links. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 52, 3995–4009. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, J. Identifiability and parameter estimation of the overlapped stochastic co-block model. Stat. Comput. 2022, 32, 1–14. [Google Scholar] [CrossRef]
- Florescu, L.; Perkins, W. Spectral thresholds in the bipartite stochastic block model. In Proceedings of the Conference on Learning Theory. PMLR, New York, NY, USA, 23–26 June 2016; pp. 943–959. [Google Scholar]
- Neumann, S. Bipartite stochastic block models with tiny clusters. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Ndaoud, M.; Sigalla, S.; Tsybakov, A.B. Improved clustering algorithms for the bipartite stochastic block model. IEEE Trans. Inf. Theory 2021, 68, 1960–1975. [Google Scholar] [CrossRef]
- Mantzaris, A.V. Uncovering nodes that spread information between communities in social networks. EPJ Data Sci. 2014, 3, 1–17. [Google Scholar] [CrossRef]
- McSherry, F. Spectral partitioning of random graphs. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Newport Beach, CA, USA, 8–11 October 2001; pp. 529–537. [Google Scholar]
- Massoulié, L. Community detection thresholds and the weak Ramanujan property. In Proceedings of the Forty-Sixth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 31 May–3 June 2014; pp. 694–703. [Google Scholar]
- Mossel, E.; Neeman, J.; Sly, A. Reconstruction and estimation in the planted partition model. Probab. Theory Relat. Fields 2015, 162, 431–461. [Google Scholar] [CrossRef]
- Abbe, E.; Bandeira, A.S.; Hall, G. Exact recovery in the stochastic block model. IEEE Trans. Inf. Theory 2015, 62, 471–487. [Google Scholar] [CrossRef]
- Hajek, B.; Wu, Y.; Xu, J. Achieving exact cluster recovery threshold via semidefinite programming. IEEE Trans. Inf. Theory 2016, 62, 2788–2797. [Google Scholar] [CrossRef]
- Mossel, E.; Neeman, J.; Sly, A. A proof of the block model threshold conjecture. Combinatorica 2018, 38, 665–708. [Google Scholar] [CrossRef]
- Qing, H. Studying Asymmetric Structure in Directed Networks by Overlapping and Non-Overlapping Models. Entropy 2022, 24, 1216. [Google Scholar] [CrossRef]
- Gillis, N.; Vavasis, S.A. Semidefinite Programming Based Preconditioning for More Robust Near-Separable Nonnegative Matrix Factorization. SIAM J. Optim. 2015, 25, 677–698. [Google Scholar] [CrossRef]
- Qing, H. A useful criterion on studying consistent estimation in community detection. Entropy 2022, 24, 1098. [Google Scholar] [CrossRef] [PubMed]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Ke, Z.T.; Jin, J. The SCORE normalization, especially for highly heterogeneous network and text data. arXiv 2022, arXiv:2204.11097. [Google Scholar]
- Newman, M.E. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (Tist) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Palmer, W.R.; Zheng, T. Spectral clustering for directed networks. In Proceedings of the International Conference on Complex Networks and Their Applications, Madrid, Spain, 1–3 December 2020; Springer: Cham, Switzerland, 2020; pp. 87–99. [Google Scholar]
- Qing, H. Degree-corrected distribution-free model for community detection in weighted networks. Sci. Rep. 2022, 12, 15153. [Google Scholar] [CrossRef] [PubMed]
- Erdös, P.; Rényi, A. On the evolution of random graphs. In The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2011; pp. 38–82. [Google Scholar] [CrossRef]
- Chen, Y.; Chi, Y.; Fan, J.; Ma, C. Spectral Methods for Data Science: A Statistical Perspective. Found. Trends Mach. Learn. 2021, 14, 566–806. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Žalik, K.R.; Žalik, B. Memetic algorithm using node entropy and partition entropy for community detection in networks. Inf. Sci. 2018, 445, 38–49. [Google Scholar] [CrossRef]
- Feutrill, A.; Roughan, M. A review of Shannon and differential entropy rate estimation. Entropy 2021, 23, 1046. [Google Scholar] [CrossRef]
- Adamic, L.A.; Glance, N. The political blogosphere and the 2004 US election: Divided they blog. In Proceedings of the 3rd International Workshop on Link Discovery, Chicago, IL, USA, 21–25 August 2005; pp. 36–43. [Google Scholar]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Zhang, H.; Guo, X.; Chang, X. Randomized spectral clustering in large-scale stochastic block models. J. Comput. Graph. Stat. 2022, 31, 887–906. [Google Scholar] [CrossRef]
- Tropp, J.A. User-Friendly Tail Bounds for Sums of Random Matrices. Found. Comput. Math. 2012, 12, 389–434. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).