Abstract
Link prediction plays an important role in the research of complex networks. Its task is to predict missing links or possible new links in the future via existing information in the network. In recent years, many powerful link prediction algorithms have emerged, which have good results in prediction accuracy and interpretability. However, the existing research still cannot clearly point out the relationship between the characteristics of the network and the mechanism of link generation, and the predictability of complex networks with different features remains to be further analyzed. In view of this, this article proposes the corresponding link prediction indexes Reg, DFPA and LW on a regular network, scale-free network and small-world network, respectively, and studies their prediction properties on these three network models. At the same time, we propose a parametric hybrid index HEM and compare the prediction accuracies of HEM and many similarity-based indexes on real-world networks. The experimental results show that HEM performs better than other Birnbaum–Saunders. In addition, we study the factors that play a major role in the prediction of HEM and analyze their relationship with the characteristics of real-world networks. The results show that the predictive properties of factors are closely related to the features of networks.
1. Introduction
The network represents the relationship between entities in the form of connections, which is an effective and popular abstraction of the complex real world. Network science has been involved in biological, social, communication and economic fields and has had many fruitful achievements [1,2]. In the study of complex networks, the research on the formation and the evolution mechanism of networks has attracted more and more attention. These studies aim to understand the root causes of changes in network structure and function by studying the connection mode and the evolution rules of networks.
The research on the mechanism of network evolution has gone through a long process. The proposal of the Erds–Rényi model [3] realized the explanation of some of the randomness of the network, but the model cannot explain other characteristics of the network. Then, after the Watts–Strogatz (WS) small-world model [4] and the Barabási–Albert (BA) scale-free model [5] were proposed, the small-world and scale-free characteristics of complex networks were discovered, which led to important progress in the study of the network evolution mechanism. In the subsequent research on the network connection mechanism, there has been a fitness model [6], a local world model [7], a hierarchical structure model [8], a node replication model [9] and other models which also promoted the development of network science [10].
As an interesting and challenging research direction in network science, link prediction has attracted more and more attention. Link prediction aims to predict missing links and new links in the network through existing structural information in the network. At present, link prediction has been applied widely in recommendation systems [11,12,13,14,15], mining biological information [16,17,18,19], reconstructing network information [20,21], and evaluating network evolution models [22,23]. Moreover, link prediction also helps us to understand and infer the connection mechanism of complex networks. Link prediction is essentially a guess regarding the network evolution mechanism. A good link prediction algorithm can more accurately reveal the evolution behavior of a network [24]. Current link prediction methods mainly include methods based on structural similarity, network embedding, matrix completion, ensemble learning and neural network methods, etc. [13,25,26,27]. These methods calculate the connection probability between nodes in the network and express the network connection mechanism to some extent. Through the study of the network evolution mechanism, if we can deeply grasp the relationship between nodes in network evolution and deeply understand the basis of connections in the network, we are more likely to propose an excellent link prediction algorithm. Based on this idea, this article proposes a link prediction algorithm via the evolution characteristics of the network.
Among all the link prediction algorithms, the similarity-based algorithms are favored in many fields because of their simplicity and good interpretability. The link prediction algorithms based on structural similarity aim to predict links by calculating the similarity score between each pair of nodes. The higher the similarity score, the more likely the links are to be generated. Among the similarity Birnbaum–Saunders, the simplest and most intuitive index is the “common neighbor” (CN) [28,29]. CN assumes that the more common the neighbors between two nodes, the more likely they are to be connected. CN performs very well in the prediction on social networks. Many of the other local similarity Birnbaum–Saunders are based on common neighbors and taking into account the contribution of the degree of both ends of the nodes, such as Satlon, Jaccard, Sorensen, HPI, HDI, LHN1, etc. [28,30]. They are suitable for different network characteristics. In other local similarity Birnbaum–Saunders, AA and RA consider the influence of the degree of common neighbor nodes [28,31]. In recent years, some Birnbaum–Saunders that consider the local community paradigm (LCP) are integrated into the local similarity index [32], such as CAR, CRA and CH Birnbaum–Saunders [25,32,33]. These Birnbaum–Saunders believe that nodes within the community are more likely to have connections than nodes that are not in the same community. In addition to the local similarity Birnbaum–Saunders, there are some Birnbaum–Saunders that consider wider information, such as the LP index, which considers the information of higher-order paths, such as three-order and above [28,29]. Moreover, LRW and SRW calculate the similarity between nodes using random walk [26,34]. Similarly, global similarity Birnbaum–Saunders take into account information about the entire network, such as Katz, LHN2 and LO [29,30,35]. The more information is considered, the better the performance will be, but it also leads to a higher computational cost.
The research of link prediction and complex networks is developing rapidly, but it also faces many challenges. Firstly, the existing similarity algorithms often perform well in the face of a few networks, but they are no longer effective when dealing with a wider range of real-world networks, including directed networks, weighted networks, heterogeneous edge networks and other complex situations [36,37,38]. Secondly, there is a strong correlation between the link prediction algorithm, the network structure characteristics and the link predictability of the network in theory [39,40]. However, how to describe and express the relationship between them is a challenging task. In addition, through link prediction, the evolution characteristics of the network can be reproduced to a certain extent, and the research on the evolution behavior of complex networks can be promoted, but the research on this aspect is still relatively lacking; on the other hand, link prediction needs to face large-scale real data at the application level, and our algorithm needs stronger adaptability and more efficient calculations [41].
Therefore, starting from these challenges, this paper attempts to study through the following aspects. Firstly, this paper studies the characteristics of regular networks, scale-free networks and small-world networks. According to these characteristics, we propose the corresponding link prediction Birnbaum–Saunders Reg, DFPA and LW. Through these Birnbaum–Saunders, we aim to verify the following: link prediction Birnbaum–Saunders are often related to the characteristics of the network when predicting, a single index often cannot cope with many networks and Birnbaum–Saunders that fit a certain network characteristics will always be better for the network. After that, we propose a parametric hybrid index HEM. We hope that through this hybrid index, we can obtain a better generalization performance index that integrates the characteristics of different networks. This index has better adaptability and a more accurate prediction effect on complex real-world networks.
This article focuses on proposing link prediction algorithms according to the evolution mechanism of the network. Firstly, we experiment with the prediction ability of the link prediction Birnbaum–Saunders on some networks that are generated by some simple network evolution rules. Then, we experiment and compare the prediction accuracies of our hybrid index and some similarity-based Birnbaum–Saunders on some real-world networks.
The main contributions of this article can be summarized as follows:
- (1)
- This article proposes corresponding link prediction algorithms on regular networks, scale-free networks and small-world networks, respectively, and studies their prediction properties on these three network models.
- (2)
- This article proposes a parametric hybrid index, which has a higher prediction accuracy than many similarity-based Birnbaum–Saunders on real-world networks.
- (3)
- This article studies the main predictors in the hybrid index, and analyzes and summarizes their relationship with the network features.
In this article, we first introduce some basic network evolution models, then introduce the evaluation metrics of link prediction and some representative similarity-based algorithms. Finally, we introduce our proposed Birnbaum–Saunders based on the network evolution mechanism.
2. Network Model and Link Prediction
In this section, we will briefly introduce some network evolution models, link prediction evaluation metrics and similarity-based Birnbaum–Saunders.
2.1. Network Evolution Model
The study of complex networks plays an increasingly important role in mathematics, statistical physics, computer science and other fields [42,43,44,45,46]. Many biological, sociological and information systems can be represented by graphs, where nodes represent individuals and links represent relationships between individuals. Facts have proved that most complex networks are not random. Many complex networks have small-world property, scale-free property, community structure and other characteristics [4,5,47,48]. Therefore, many complex networks can be constructed using some simple rules.
In order to study the connection mechanism of networks, models such as the random graphs model, small-world model, scale-free model and hierarchical network model have been proposed [1,8,10]. These models can simulate the overall structure of the real network according to the potential network connection mechanism, so as to reproduce the observed attribute characteristics in the real network. This article will introduce the evolution characteristics of a regular network, small-world network and scale-free network.
2.1.1. Regular Network
In the regular network, each node has the same number of neighbors, that is, the degree of each node is equal. Many crystal networks or protein networks in the field of chemistry can be regarded as regular networks.
2.1.2. Scale-Free Network
Many observed networks have the characteristics of power–law degree distribution. In the power–law distribution, the degree of most of the nodes is very small, whereas the degree of a few of the nodes is very large. Networks with power–law distribution are also called scale-free networks [49]. For many complex networks in the real world, such as the Internet and social networks, they have the properties of scale-free networks.
At present, there are many mechanisms that can generate scale-free networks, such as the rich-get-richer mechanism [5], optimal design-driven mechanism [50], merging, regeneration mechanism [51] and so on [41]. In order to study scale-free networks, Albert-László Barabás and Réka Alber proposed a model for generating scale-free networks [5], which is the most classical BA model. The BA model explains the power–law distribution of the network through network growth and preferential attachment. The model is introduced below.
The BA model contains two important steps: growth and preferential attachment. Growth: new nodes are added to the initial network at each time point. Due to the addition of new nodes, the scale of the network is growing. Preferential attachment: when a new node is connected to the initial network, the probability of connection with the existing node is proportional to the degree of the node. Therefore, new nodes tend to be connected to nodes with a high degree. In the BA model, when a new node generates a connection, the probability of selecting a node with a degree of is:
The remarkable feature of the network generated by the BA model is the power–law distribution.
2.1.3. Small-World Network
The small-world network depicts the phenomenon of the large clustering coefficient and the small average short path length in the real world network. The famous six-degrees of separation theory, Kevin Bacon game and Erdős number all reveal the universality of small-world characteristics in the real world [52,53]. Social networks, protein networks, food chain networks, cultural networks and so on have been proved to have the characteristics of small-world networks.
In the study of the mechanism of small-world networks, the WS model is a more classic small-world construction model [4]. The construction algorithm includes two steps:
- (1)
- Starting from the regular network, consider a regular network consisting of N nodes, circled in a ring. Each node is connected to its closest left neighbors and right neighbors in the ring, where K is an even number;
- (2)
- Randomly reconnect each link in the network with probability p (one endpoint of the link remains unchanged, while the other endpoint is a randomly selected node from the network). Note that there can be at most one link between any two different nodes, and each node cannot have a link connected to itself.
According to the WS model, corresponds to the regular network, and corresponds to the completely random network (see in Figure 1). Therefore, by adjusting the value of the p, we can control the transition from the regular network to the completely random graph. Network generated by WS model is a network between regular network and random network.
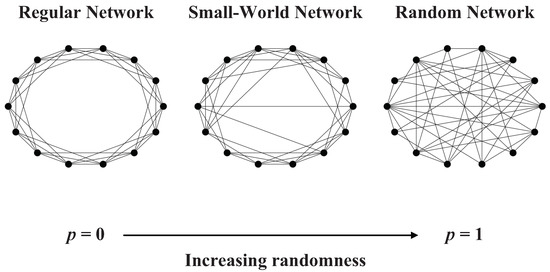
Figure 1.
Illustration of the WS model.
Similarly, the NW model is also a classic small-world network construction model [54]. The NW model simply changes the “randomized reconnecting” in the WS model to “randomized adding links”. The difference between the NW model and WS model is that the randomization process in the WS model may destroy the connectivity of the network, while NW does not cut off the original link in the regular network, but adds a link with probability p. The network constructed in this way has both a large clustering coefficient and small average distance.
2.2. Link Prediction Evaluation Metrics
Define as an undirected graph without multiple edges or self-connections, where V is the set of vertices and E is the set of edges. Define U as the universal set of edges, so U contains edges. The task of link prediction is to find missing edges or possible edges in the future. These edges exist in the set . Generally, link prediction algorithms are unsupervised learning methods and we usually do not know which edges need to be predicted.
In order to test the accuracy of the link prediction algorithm, it is common to divide the known edges E into training set and test set , with and . The edges in are the known information in the graph. Meanwhile, the edges in need to be predicted, which can be used to evaluate the accuracy of the link prediction algorithms. The and are randomly divided from the original data set. In order to overcome the statistical bias, this article uses the 10-fold cross-validation method [55,56].
Reference [26] proposed two methods to evaluate the accuracy of link prediction algorithms, namely AUC (area under the receiver operating characteristic curve) and Precision. They are introduced below.
AUC measures the accuracy of the algorithm by focusing on the whole link list, including the missing links (i.e., ) and the nonexistent links (i.e., ). Link prediction algorithms calculate the score of each pair of nodes. The greater the score the greater the probability of the existence of links between nodes. The AUC metric evaluates the accuracy of the algorithms by comparing the score of missing links and the nonexistent links.
Suppose there are n independent comparisons in total. Among these comparisons, there are times the missing link having a greater score and times the missing link and nonexistent link have the same score. Then, the AUC value can be calculated as:
When AUC is equal to 0.5, the prediction accuracy of the algorithm is equivalent to that of a random prediction. The closer the AUC value is to 1, the better the prediction accuracy of the algorithm is.
The Precision metric sorts the scores of missing links and nonexistent links in descending order. We take the sorted top-L links as the predicted ones. Among these L links, N links belong to the test set. Then, the Precision can be calculated as:
Compared with AUC, the Precision only focuses on whether the top L links are predicted accurately.
2.3. Link Prediction Similarity-Based Algorithms
The similarity-based algorithms for link prediction compute a score for each pair of nodes x and y, which is directly defined as the similarity between x and y. The algorithms consider that nodes with a high similarity score are more likely to connect. The similarity-based algorithms can be classified into two categories: local similarity Birnbaum–Saunders and global similarity Birnbaum–Saunders. Here, we choose some representative Birnbaum–Saunders to introduce (these Birnbaum–Saunders are similar to the Birnbaum–Saunders proposed in this paper in terms of expression, so they are chosen to better analyze and explain the differences. We ignore some Birnbaum–Saunders that are not comparable). The details are as follows.
2.3.1. Local Similarity Birnbaum–Saunders
- (1)
- Common Neighbor (CN) [28]:
denotes the set of neighbors of the node x. In the CN index, the more common neighbors two nodes have, the more likely they are to connect.
- (2)
- Salton Index [28]:
and denote the degree of nodes x and y, respectively. The Satlon index is also known as cosine similarity.
- (3)
- Resource Allocation Index (RA) [28]:
This index considers the dynamic resource allocation between x and y nodes. The resources that x sends to y are equally distributed among their common neighbors. So, the RA index defines the amount of resources x allocates to y, which represents the similarity score between the two nodes.
- (4)
- Cannistraci–Hebb Index (CH) [33]:where denotes the number of links of z with other common neighbors of x and y, and denotes the number of links between z and nodes other than x and y or their common neighbors.
- (5)
- Local Path Index (LP) [28]:
is a free parameter. The LP index contains more information and performs better than the neighbor-based Birnbaum–Saunders. Obviously, when , this index degenerates to CN. LP index can be extended to include higher-order path information, as
where n is the maximum order. The increase in n allows higher-order paths to be considered, but the computational complexity is also higher.
2.3.2. Global Similarity Birnbaum–Saunders
- (1)
- Katz Index [29]:
This index considers all path sets. It calculates all the paths and assigns less weight to long paths in an exponential decay. Katz can be expressed as:
is the free parameter. The contribution of a higher order path can be controlled by adjusting . Katz can also be written as
I is the identity matrix. must be small enough to ensure convergence.
- (2)
- Linear Optimization Index (LO) [35]:
is a free parameter. I is the identity matrix and A is the adjacency matrix. When is small enough, LO degenerates to the index that calculates only the three3-hop paths .
3. Link Prediction Based on Network Evolution Mechanism
According to the characteristics of regular networks, scale-free networks and small-world networks, this article proposes link prediction Birnbaum–Saunders for these three networks, and proposes a hybrid index for complex networks based on the three Birnbaum–Saunders. Note that all the link prediction results in this article are obtained by using the 10-fold cross-validation method on test networks.
3.1. Index Based on Regular Networks
According to the characteristics of regular networks, this article proposes a link prediction index called Reg. Reg is expressed as follows:
and represent the degree of nodes x and y, respectively. In the formula, the nodes with larger degree are less likely to be connected. Small nodes are more likely to generate connections. By suppressing the connection probability of large degree nodes and promoting the connection probability of small degree nodes, the degree balance is achieved to a certain extent.
In order to study the performance of the Reg index, we compared the link prediction accuracies of the Reg index, CN index and Salton index on a random regular network (see results in Table 1).

Table 1.
Accuracies of regular networks.
We can see that the Reg index is significantly better than other Birnbaum–Saunders. Due to the randomness of the regular network, the CN index has an AUC value of only 0.5, while the Satlon index shows random results even with the same computational factor (i.e., ) as the Reg index. As the degree of each node increases, the prediction performance of the Reg index will gradually decrease.
3.2. Index Based on Scale-Free Networks
In reference to the article [28], a link prediction index PA corresponding to the preferential attachment principle is proposed. The expression of PA is as follows.
This article also proposes a link prediction algorithm called DFPA (Difference Preferential Attachment) for scale-free networks. The expression is as follows.
Compared with the PA index, the DFPA index pays more attention to the connection between nodes with a large degree and nodes with a small degree. Nodes with a similar degree are more stable and less likely to connect with each other. Therefore, small degree nodes and large degree nodes develop faster according to the DFPA index. Moreover, the connection probability between nodes with a large degree is smaller than PA.
We compare the link prediction accuracies of PA and DFPA on scale-free networks constructed by the BA model. The results are shown in Figure 2. Note that accuracies are measured by the AUC value. The number of nodes of the networks are all 2000. Based on the BA model, the new nodes generate 1, 2, 4, 8, 16, 32 and 64 links, respectively. Thus, there are seven kinds of scale-free networks.
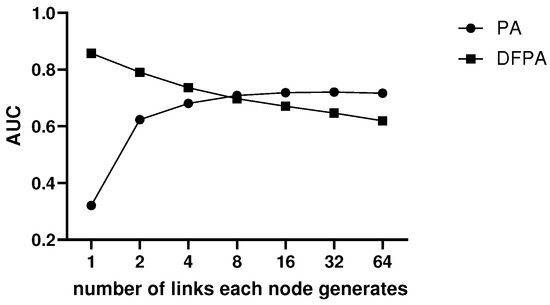
Figure 2.
Accuracies of PA and DFPA on scale-free networks.
According to the prediction results of PA and DFPA in these scale-free networks, DFPA performs better when the network is sparse. As the degree of each node increases, the performance of PA gradually becomes better, while that of DFPA shows a downward trend. However, DFPA has a higher upper limit than PA in prediction.
There is a definition of degree assortativity in article [57]: when it is greater than 0, nodes with similar degrees tend to connect with each other. When it is less than 0, nodes with different degrees are more likely to connect with each other. DFPA considers the latter case. In theory, the DFPA index also accurately predicts disassortative networks.
3.3. Index Based on Small-World Networks
In the first step of the WS model, each node is connected to the nearest k nodes. Based on that, this article proposes the LW (local world) index. The LW index considers that when two nodes have paths with a length less than k or , it is possible for the two nodes to have a connection. The expression of the LW index is as follows.
k is the free parameter, A is the adjacency matrix of the network and calculates the number of paths with length k between each pair of nodes. The paths calculated by may go back and forth on some edges. For example, there are three cases that takes into consideration (see in Figure 3). In Case 1 and Case 2, there is a path of length 2 between x and y, but there is no path of length 4. The calculation of includes round trips on some edges, including round trips on the direct path and on the branch. Here, we have . In the third Case, there is only a path of length 4 between x and y, then and . So, contains the information for , In order to consider both odd-order paths and even-order paths, LW calculates the sum of and .

Figure 3.
Example of the calculation of . (a) Round trip on the branch; (b) round trip on direct path; (c) a four-order path.
k in the LW represents the breadth and scope of information, which is similar to n in the LP index. Compared with LP and Katz Birnbaum–Saunders, the LW index does not consider that the lower order path has a higher weight. The weight of the path is related to the size of k and the network structure. Moreover, the LW index has a small computational complexity.
To facilitate the comparison of the LP and LW Birnbaum–Saunders, we define the LPK index as:
LPK is the case where the parameter of the LP is set to 1 and the order n of the LP is set to . We define LP2, LP4 and LP8 as the cases where the k value of LPK takes 2, 4 and 8, respectively. Similarly, define LW2, LW4 and LW8 as the cases where the k value of the LW index takes 2, 4 and 8, respectively.
We select , and then compare the prediction performance of CN, Katz, LPK and LW Birnbaum–Saunders on the networks generated by WS model (see result in Figure 4). Note that accuracies are measured according to the AUC value. The number of nodes of the networks are all 2000. According to the WS model, each node is set to connect to the nearest 8 and 16 neighbors and they are denoted as WS_8 and WS_16, respectively. The probabilities of link reconnection are set to 0.0, 0.25, 0.50 and 0.75 and they are denoted as r00, r25, r50 and r75, respectively. So, eight kinds of networks in total were generated here.
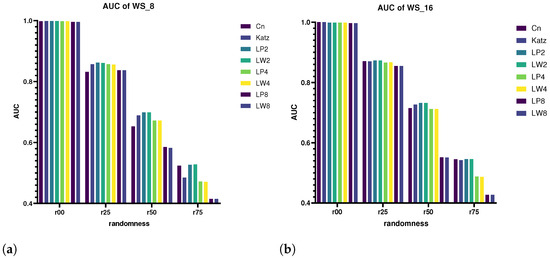
Figure 4.
Accuracies of small-world networks with different randomness. (a) Accuracies of WS networks; (b) accuracies of WS networks.
When , all Birnbaum–Saunders perform very well, and the prediction accuracies basically reached 100%. On the whole, the more neighbors each node has, the better the performance of the Birnbaum–Saunders. With the increase in randomness, the prediction accuracies of all Birnbaum–Saunders decrease accordingly. It can be seen that the performance of LW2 and LP2, LW4 and LP4 and LW8 and LP8 are basically the same, which proves that compared to the LPK index, the LW does not lose much information on the link prediction in small-world networks.
3.4. Hybrid Index Based on Complex Network
Among the above three Birnbaum–Saunders, Reg and DFPA are Birnbaum–Saunders based on degree distribution, and LW is the index based on network topology. According to the three link prediction Birnbaum–Saunders proposed by different network models, this article proposes a hybrid index called HEM (Hybrid Evolution Mechanism). The expression of HEM is as follows.
There are two free parameters and k in the HEM index. The parameter is used to balance the degree distribution. The role of the k parameter is the same as in the LW, representing the range of paths included.
By adjusting the parameter, we can achieve the optimal balance of the HEM index in the link prediction of the mixed networks of regular networks and disassortative networks. When is close to 1, the HEM index tends to predict regular networks; when is close to 0, the HEM index tends to predict disassortative networks. The k parameter represents the path range considered in the prediction of the LW index. If the k value is set too small, some high-order paths may not be taken into account for prediction. If it is too large, the paths that should not be considered will be involved. Therefore, the and k parameters need to be adjusted simultaneously during the experiment.
In order to test the link prediction accuracy of the HEM index, this article selects the following network data sets (see in Table 2). The multiple edges are regarded as one single edge, and the directed edge is regarded as an undirected edge. The self-connections are not taken into account. In addition, we only consider the giant component when one network is not well connected.
Table 2.
The features of 11 real-world networks.
PPI is a protein–protein interaction network [58]. NS is a network of co-authorships in the area of network science [59]. Grid contains information about the power grid of the Western States of the United States of America [4]. INT represents the router-level topology of the Internet [60]. PB is a network of hyperlinks between political blogs about politics in the United States of America [61]. Yeast is a protein–protein interaction network in budding yeast [62]. FB consists of “friends lists” from Facebook, whose data were collected from survey participants using the Facebook app [63]. HSS represents the network of friendships between users of the website hamsterster.com [64]. GrQc is the collaboration network from the e-print arXiv and covers scientific collaborations between authors whose papers are submitted to the General Relativity and Quantum Cosmology category [65]. AS is the network of autonomous systems of the Internet that are connected with each other [64,65]. ER is the international E-road network, a road network located mostly in Europe [66].
There are many similarity Birnbaum–Saunders in link prediction. This paper only selects some Birnbaum–Saunders that are similar to the Birnbaum–Saunders proposed in this paper in terms of expression. On the one hand, it is better to control variables and understand the factors that cause the difference in accuracies between indexes. On the other hand, some Birnbaum–Saunders are quite different from the indicators in this paper in terms of predictive properties and computational performance, so that the predictive differences of the indicators cannot be accurately grasped, and the interpretability is also poor.
So, this article compares the prediction accuracies of the HEM index and other similarity-based Birnbaum–Saunders such as CN, Salton, PA, RA, CH, LPK, Katz and LO on these networks. In these 11 networks, we calculate the AUC value and Precision value of these link prediction algorithms (see results in Table 3 and Table 4).
Table 3.
The algorithms’ accuracies quantified using AUC.
Table 4.
The algorithms’ accuracies quantified using Precision.
According to the results of AUC, the HEM performs much better than the other indexes in the Grid, INT, AS and ER networks. In the PPI, PB, Yeast, HSS, GrQc and NS networks, the prediction accuracies of HEM is also higher than other indexes. For the FB network, the HEM and many other indexes perform very well, and the prediction accuracies are basically reaching 100%.
According to the results of Precision, the performance of the HEM index in the PPI, FB and HSS networks is much better than in other indexes, especially in the PPI and FB networks, the Precision values of the HEM index are almost 1. The HEM also has a better improvement on the PB and GrQC networks compared to the classic indexes. In contrast, for the AUC results, the HEM index outperforms in the Grid, INT and AS networks, but underperforms in Precision compared to other indexes, which indicates that most of the correct predictions from the HEM index for these networks come from the second half of the lists of links.
Moreover, in the tables we see that the parameters of the HEM index differ when taking the maximum AUC and Precision values. Therefore, we need to study the role of parameters in the HEM index and their relationship with network characteristics.
4. Analysis of HEM Index
In order to understand the influence of different parameters, study which factor, including Reg, DFPA and LW, plays a major role in the prediction. Here, we propose two methods.
- (1)
- Calculate the prediction accuracies of different factors separately, and choose two factors with the highest accuracies.
- (2)
- Sample and k, then choose the top five combinations of the and k parameters from where the HEM index has the highest prediction accuracy. The main influencing factors are determined by the chosen and k parameters, where takes the average value and k takes the mode.
The first method discusses the performance of individual factors and the second method calculates the parameters that have a greater impact on the prediction. In practical considerations, the second method is used as the main reference and the results obtained by the first method can help us have a better understanding of the characteristics of the network.
Here, we discuss the situation when the prediction accuracy is measured using the AUC value. The results of two methods may be different when measured by the Precision value, but they are performed in the same manner. In this article we consider five factors; they are Reg, DFBA, LW2, LW4 and LW8.
We calculate the prediction results of the individual factors on the above 11 networks using method 1 (see results in Table 5). Through method 2, we calculate the prediction results of the HEM index under different parameters and then choose the top five results and record the combinations of parameters. Among all the sampling parameters, the values are 0.0, 0, 25, 0.5, 0.75 and 1.0, and the k values are 2, 4 and 8 (see results in Table 6).
Table 5.
Accuracies of individual factors.
Table 6.
The top five combinations of and k.
As is known from the formula of the HEM index, when is greater than 0.5, the impact of Reg is greater than that of DFPA and vice versa. When is 0.5, it means that both factors have little effect on the prediction. So, in method 2, if is equal to 0.5, we do not consider the Reg or DFPA factor. In method 1, if both maximum AUC values are produced by LW, only the LW factor with the largest AUC value is taken.
We compare the main factors of the 11 networks obtained by the two methods and the results are shown in Table 7.
Table 7.
The main factors of 11 networks obtained using method 1 and method 2.
It can be seen that the results obtained by the two methods are basically the same except for the three networks, Yeast, GrQc and NS. In Yeast, the main factors calculated by method 2 has DFPA, while in method 1, DFPA in Yeast performs better than Reg. In the GrQc and NS networks, the main factors obtained by method 2 have Reg, while according to method 1, the Reg factor performs worse than the DFPA factor. Therefore, the influencing factors cannot be simply determined by the individual prediction accuracy.
Observe the several networks with a high clustering coefficient: NS, FB, PB and GrQc. They have LW2 as their main factors based on the first method. LW2 performs very well on these networks, especially on FB. The FB network is a dense network, with a high clustering coefficient, and the prediction accuracies of the LW indexes basically reach 1. So, we guess that the LW index may be related to the clustering coefficient of the network. In addition, we can also observe that the density of the network has a certain influence on the prediction of LW. For example, although the NS network has the highest clustering coefficient, the average degree of the network is only 3.75, far sparser than the FB network, and the LW2 and LW4 indexes perform less well than on the FB network. Moreover, the main factors in the NS network obtained by the second method are Reg and LW4, indicating that due to the sparsity, a wider k in LW and additional consideration of regularity are needed to have a better prediction performance in the NS network. In addition, although the clustering coefficient of the HSS network is low, the network is denser and the performance of the LW index on the network is as good as that on the PPI and PB networks, whose clustering coefficient are much larger.
Both the Grid and ER networks are sparse, and the diameter of the two networks is very large compared to other networks. Therefore, the LW index needs to consider wider paths to predict the links. The main factors obtained in method 1 and method 2 are both LW8. The degree of assortativity of the INT and AS networks is observed to be negative, indicating that the networks have a tendency towards a differential connection. Thus, in these two networks, DFPA as their main factor performs the best among all the factors.
Moreover, the maximum degree of the network AS is 1485, indicating that the degree distribution is very unbalanced and the preferential attachment is more obvious. So, the prediction performance of the DFPA factor alone on the AS network is also better. The maximum degree ofthe GrQc, ER and NS networks is relatively small, indicating that the degree distribution of the network is relatively balanced. So, in these three networks, the corresponding results obtained in the second method indicate that Reg is their main factor. Although the Yeast network also has a small maximum degree, the degree assortativity is negative, indicating that connections on the network are still difference preferential. Correspondingly, in the second method, DFPA is the main factor in the Yeast network.
In summary, the Reg factor often acts on networks with relatively balanced degree distribution; that is, when the maximum degree is relatively small, we can take the Reg index into account to predict links. The DFPA index is usually more effective in networks with negative degree assortativity. The prediction performance of LW index is determined by clustering coefficient, average degree and network diameter. When clustering coefficient is higher and the network is denser, the link prediction of LW index is always more accurate. The size of the k of the LW index depends largely on the diameter and average distance of the network.
By arranging the above results, we compare the prediction results (measured using the AUC value) of individual factors and the hybrid index using tabular statistics (see in Table 8).
Table 8.
Results of individual factors and hybrid index.
So, we can see that the main factor largely determines the upper limit of the prediction accuracy of the hybrid index.
In general, the hybrid index always has a better prediction performance than the single index. The prediction performance is mainly determined by the main factor, and other factors may have some influence to the prediction, which will help to improve the overall result.
If we can determine the factors that have a greater impact in the link prediction of different networks, then we can save the sampling of the parameters of the HEM index that have little impact and reduce the computational complexity. Depending on the upper limit of the main factors, we can also have some idea of the upper limit of the HEM index. Determining the main factors can also give us some insight into the characteristics of the network.
5. Conclusions and Future Work
The link prediction indexes in this article, including the prediction indexes for specific networks and the hybrid indexes for complex networks, are based on the idea of simulating the evolution mechanism of complex networks through simple rules. This method can simplify our research on the mechanism of network evolution, so as to understand the intrinsic properties of the network more deeply.
Firstly, this article constructs regular networks, scale-free networks and small-world networks and proposes our link prediction algorithms based on the properties of these networks. We perform link prediction on these networks to understand the advantages and limitations of different link prediction algorithms.
Secondly, we propose an algorithm that combines the above three indexes. The hybrid index sets two parameters for the prediction factors. In this article, we sample the parameters and perform predictions on some real-world networks. The results show that the hybrid index performs better in those complex networks than many classical similarity-based indexes.
Finally, we analyze the dominant factors of the hybrid index using two methods. Experiments show that the prediction results of the hybrid index are often determined by one or two main factors, and the upper limit of the prediction of the main factors often determines the upper limit of the prediction of the hybrid index to some extent. In addition, we find that the main factors in the real world network are always related to the characteristics of the network, which coincides with the prediction properties of the indexes proposed by different network models.
In the experiment, we see that the computational complexity of the hybrid index increases with the frequency of the parameter sampling. If we can use simple parameter sampling to outline the prediction accuracy curve of the hybrid index, it will greatly optimize our algorithm. When performing predictions, we often pay attention to the best results, and parameter sampling should also be oriented to the upper limit of the index. The two methods of determining the main factors proposed in this article solve the problem of parameter sampling and determining the upper limit to some extent. However, our goal is still to draw a prediction curve, through which we can better understand the predictive properties of the hybrid index.
In future work, we will further refine the link prediction algorithms according to the network evolution mechanism. Firstly, we will refine the algorithms based on degree distribution. This article only considers the mixed degree distribution of the regular network and the disassortativitive network. Therefore, in future research, it is necessary to consider the complete degree distribution to propose a more comprehensive link prediction algorithm. Secondly, we need to refine the link prediction algorithms based on topology structure. The algorithm in this article only considers the paths of specific range. In the face of more complex situations, we need more effective topology information to predict links.
Author Contributions
Conceptualization, D.K. and J.P.; methodology, D.K.; software, D.K.; validation, D.K. and J.P.; formal analysis, D.K.; investigation, D.K.; resources, J.P.; data curation, J.P.; writing—original draft preparation, D.K.; writing—review and editing, D.K. and J.P.; visualization, D.K.; supervision, J.P.; project administration, J.P.; funding acquisition, J.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (NSFC), under grant no.62272088 and U19A2078, and a grant no.230298 from a joint technical development project from a research institution.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://www.konect.cc/networks/.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (NSFC), under grant no.62272088 and U19A2078, and a grant No. 230298 from a joint technical development project from a research institution. We would like to thank all the participants involved in the studies for their valuable feedback, and the anonymous reviewers for their valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mark, N. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Albert-László, B. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Erdos, P.L.; Rényi, A. On the evolution of random graphs. Trans. Am. Math. Soc. 1984, 286, 257. [Google Scholar]
- Duncan, W.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar]
- Barabási, A.-L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Ginestra, B.; Barabási, A.-L. Bose-Einstein condensation in complex networks. Phys. Rev. Lett. 2001, 86, 5632. [Google Scholar]
- Xiang, L.; Chen, G. A local-world evolving network model. Phys. Stat. Mech. Its. Appl. 2003, 328, 274–286. [Google Scholar]
- Aaron, C.; Moore, C.; Newman, M.E.J. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98–101. [Google Scholar]
- Simkin Mikhail, V.; Roychowdhury, V.P. Stochastic modeling of citation slips. Scientometrics 2005, 62, 367–384. [Google Scholar] [CrossRef]
- Shuaizong, S.I. Link Prediction Method for Network Evolution and Connection Mechanism. Ph.D. Dissertation, Northeastern University, Boston, MA, USA, 2019. (In Chinese). [Google Scholar]
- Aiello, L.M.; Barrat, A.; Schifanella, R.; Cattuto, C.; Markines, B.; Menczer, F. Friendship prediction and homophily in social media. ACM Trans. Web (TWEB) 2012, 6, 1–33. [Google Scholar] [CrossRef]
- Lü, L.; Medo, M.; Yeung, C.H.; Zhang, Y.C.; Zhang, Z.K.; Zhou, T. Recommender systems. Phys. Rep. 2012, 519, 1–49. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef]
- Hakan, B.; Karagoz, P. Context-aware friend recommendation for location based social networks using random walk. In Proceedings of the 25th International Conference Companion on World Wide Web, Montreal, QC, Canada, 11–15 April 2016. [Google Scholar]
- Nikos, P.; Pitoura, E.; Tsaparas, P. Centrality-aware link recommendations. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016. [Google Scholar]
- Csermely, P.; Korcsmaros, T.; Kiss, H.J.; London, G.; Nussinov, R. Structure and dynamics of molecular networks: A novel paradigm of drug discovery: A comprehensive review. Pharmacol. Ther. 2013, 138, 333–408. [Google Scholar] [CrossRef]
- Ding, H.; Takigawa, I.; Mamitsuka, H.; Zhu, S. Similarity-based machine learning methods for predicting drug–target interactions: A brief review. Briefings Bioinform. 2014, 15, 734–747. [Google Scholar] [CrossRef]
- Fakhraei, S.; Huang, B.; Raschid, L.; Getoor, L. Network-based drug-target interaction prediction with probabilistic soft logic. IEEE/ACM Trans. Comput. Biol. Bioinform. 2014, 11, 775–787. [Google Scholar] [CrossRef] [PubMed]
- Dhanya, S.; Fakhraei, S.; Getoor, L. A probabilistic approach for collective similarity-based drug–drug interaction prediction. Bioinformatics 2016, 32, 3175–3182. [Google Scholar]
- Squartini, T.; Caldarelli, G.; Cimini, G.; Gabrielli, A.; Garlaschelli, D. Reconstruction methods for networks: The case of economic and financial systems. Phys. Rep. 2018, 757, 1–47. [Google Scholar] [CrossRef]
- Tiago, P.P. Reconstructing networks with unknown and heterogeneous errors. Phys. Rev. X 2018, 8, 041011. [Google Scholar]
- Wen-Qiang, W.; Zhang, Q.; Zhou, T. Evaluating network models: A likelihood analysis. EPL (Europhys. Lett.) 2012, 98, 28004. [Google Scholar]
- Zhang, Q.M.; Xu, X.K.; Zhu, Y.X.; Zhou, T. Measuring multiple evolution mechanisms of complex networks. Sci. Rep. 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Lin, W.; Chao, S. Research on Link Prediction Problem in Scale-free Network. Comput. Eng. 2012, 38, 67–70. [Google Scholar]
- Tao, Z. Progresses and challenges in link prediction. iScience 2021, 24, 103217. [Google Scholar]
- Linyuan, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. Stat. Mech. Its. Appl. 2011, 390, 1150–1170. [Google Scholar]
- Mutlu Ece, C.; Oghaz, T.A. Review on graph feature learning and feature extraction techniques for link prediction. arXiv 2019, arXiv:1901.03425. [Google Scholar]
- Tao, Z.; Lü, L.; Yi, Z. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar]
- Linyuan, L.; Jin, C.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar]
- Elizabeth, L.A.; Holme, P.; Newman, M.E.J. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar]
- Lada, A.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar]
- Vittorio, C.C.; Alanis-Lobato, G.; Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 2013, 3, 1–14. [Google Scholar]
- Alessandro, M.; Abdelhamid, I.; Cannistraci, C.V. Local-community network automata modelling based on length-three-paths for prediction of complex network structures in protein interactomes, food webs and more [Preprint]. bioRxiv 2018, 346916. [Google Scholar] [CrossRef]
- Weiping, L.; Lü, L. Link prediction based on local random walk. EPL (Europhys. Lett.) 2010, 89, 58007. [Google Scholar]
- Pech, R.; Hao, D.; Lee, Y.L.; Yuan, Y.; Zhou, T. Link prediction via linear optimization. arXiv 2018, arXiv:abs/1804.00124. [Google Scholar] [CrossRef]
- Linyuan, L.; Zhou, T. Link prediction in weighted networks: The role of weak ties. EPL (Eur. Lett.) 2010, 89, 18001. [Google Scholar]
- Jure, L.; Huttenlocher, D.; Kleinberg, J. Predicting positive and negative links in online social networks. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Tsuyoshi, M.; Moriyasu, S. Link prediction of social networks based on weighted proximity measures. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’07), Fremont, CA, USA, 2–5 November 2007. [Google Scholar]
- Lü, L.; Pan, L.; Zhou, T.; Zhang, Y.C.; Stanley, H.E. Toward link predictability of complex networks. Proc. Natl. Acad. Sci. USA 2015, 112, 2325–2330. [Google Scholar] [CrossRef]
- Suo-Yi, T.; Ming-Ze, Q.; Jun, W.; Xin, L. Link predictability of complex network from spectrum perspective. Acta Phys. Sin. Chin. Ed. 2020, 69, 088901. [Google Scholar]
- Lin-Yuan, L. Link Prediction on Complex Networks. J. Univ. Electron. Sci. Technol. China 2010, 7, 253–278. [Google Scholar]
- Albert, R.; Jeong, H.; Barabási, A.L. Error and attack tolerance of complex networks. Nature 2000, 406, 378–382. [Google Scholar] [CrossRef] [PubMed]
- Albert, R.; Barabási, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Wang, X.F. Complex networks: Topology, dynamics and synchronization. Int. J. Bifurc. Chaos 2002, 12, 885–916. [Google Scholar] [CrossRef]
- Hou, L.; Lao, S.Y.; Xiao, Y.D.; Bai, L. Recent progress in controllability of complex network. Wuli Xuebao/Acta Phys. Sin. 2015, 64, 0188901. [Google Scholar]
- Newman, M.E.J. Detecting community structure in networks. Eur. Phys. J. B 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Linyuan, L.; Xiaolong, R.; Tao, Z. Network Link Prediction: Concepts and Frontiers. China Comput. Fed. Newsl. 2016, 12, 12–19. (In Chinese) [Google Scholar]
- Caldarelli, G. Scale-Free Networks: Complex Webs in Nature and Technology; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Sergi, V.R.; Cancho, F.; Sole, R.V. Scale-free networks from optimal design. EPL (Europhys. Lett.) 2002, 60, 512. [Google Scholar]
- Kim, B.J.; Trusina, A.; Minnhagen, P.; Sneppen, K. Self organized scale-free networks from merging and regeneration. Eur. Phys. J. Condens. Matter Complex Syst. 2005, 43, 369–372. [Google Scholar] [CrossRef][Green Version]
- John, G.; Sandrich, J.; Loewenberg, S.A. Six Degrees of Separation; LA Theatre Works: Los Angeles, CA, USA, 2000. [Google Scholar]
- Goffman, C. And what is your Erdös number? Am. Math. Mon. 1969, 76, 791. [Google Scholar]
- Newman, M.E.J.; Watts, D.J. Renormalization group analysis of the small-world network model. Phys. Lett. A 1999, 263, 341–346. [Google Scholar] [CrossRef]
- Leo, B.; Spector, P. Submodel selection and evaluation in regression. The X-random case. Int. Stat. Rev. Int. Stat. 1992, 60, 291–319. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. Int. Jt. Conf. Artif. Intell. 1995, 14, 1137–1145. [Google Scholar]
- Newman, M.E.J. Assortative mixing in networks. Phys. Rev. Lett. 2002, 89, 208701. [Google Scholar] [CrossRef]
- Von Mering, C.; Krause, R.; Snel, B.; Cornell, M.; Oliver, S.G.; Fields, S.; Bork, P. Comparative assessment of large-scale data sets of protein-protein interactions. Nature 2002, 417, 399–403. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. Stat. Nonlinear Soft Matter Phys. 2006, 74 Pt 2, 036104. [Google Scholar] [CrossRef]
- Mahajan, R.; Spring, N.; Wetherall, D.; Anderson, T. Inferring link weights using end-to-end measurements. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet Measurment, Marseille, France, 6–8 November 2002. [Google Scholar]
- Adamic, L.A.; Glance, N.S. The Political Blogosphere and the 2004 U.S. Election: Divided They Blog. In Proceedings of the LinkKDD ’05, Chicago, IL, USA, 21–25 August 2005. [Google Scholar]
- Jeong, H.; Mason, S.P.; Barabasi, A.L.; Oltvai, Z.N. Lethality and centrality in protein networks. Nature 2001, 411, 41–42. [Google Scholar] [CrossRef] [PubMed]
- Mcauley, J.J.; Leskovec, J. Learning to Discover Social Circles in Ego Networks; Neural Information Processing Systems Curran Associates Inc.: Lake Tahoe, NV, USA, 2012. [Google Scholar]
- Kunegis, J. KONECT: The Koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph Evolution: Densification and Shrinking Diameters. Acm Trans. Knowl. Discov. Data 2007, 1, 2. [Google Scholar] [CrossRef]
- Šubelj, L.; Bajec, M. Robust network community detection using balanced propagation. Eur. Phys. J. 2011, 81, 353–362. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).