
Hierarchical Reinforcement Learning Framework in Geographic Coordination for Air Combat Tactical Pursuit


Abstract
:1. Introduction
- We propose a hierarchical reinforcement learning framework in geographic coordination for the training and use of senior and basic policies to solve the MDP in air combat chase scenarios.
- We propose a meta-learning algorithm applied to the framework proposed in this paper for the complex sub-state and action space learning problem of air warfare. The reward decomposition method proposed in this paper also alleviates the problem of reward sparsity in the training process to some extent.
- We independently built a three-degrees-of-freedom air combat countermeasure environment and modeled the task as a Markov process problem. Specifically, we defined the key elements of the Markov process, such as state, behavior, and reward functions for this task.
- We established a quantitative system to evaluate the effectiveness of reinforcement learning methods for training in 3D air combat.
2. Reinforcement Learning for Air Combat
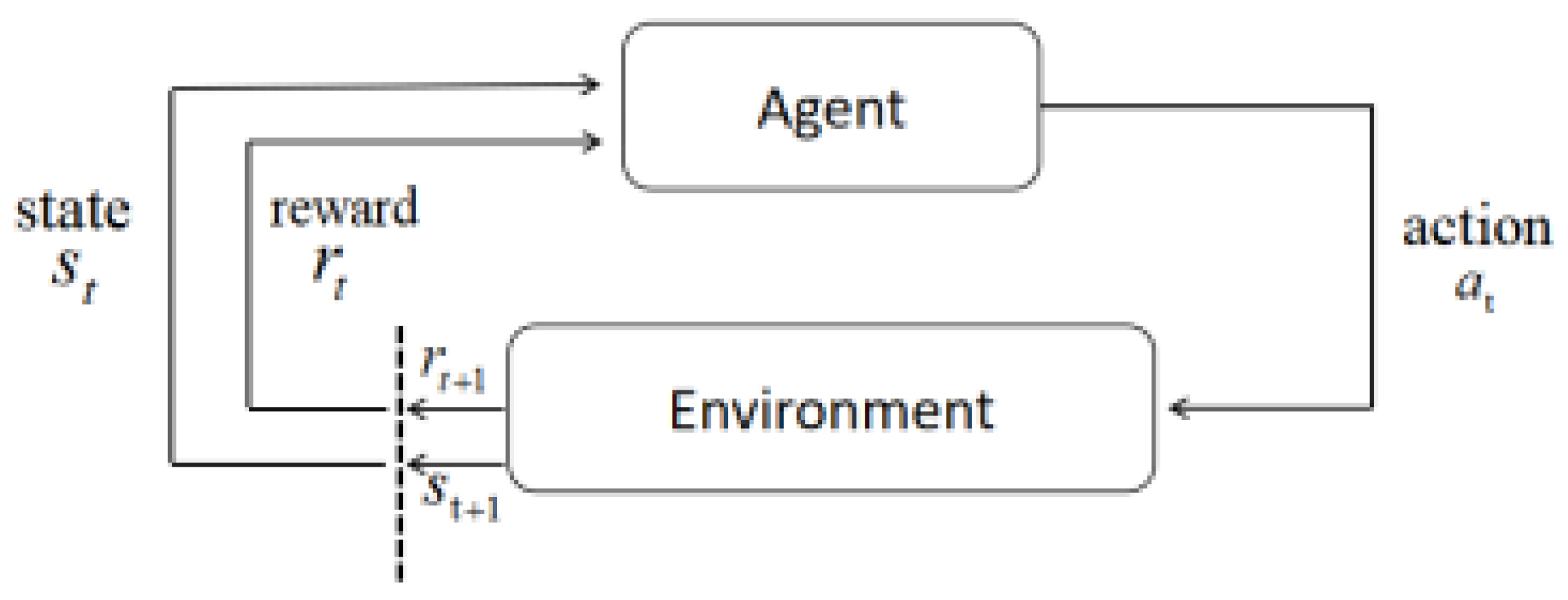
2.1. Markov Decision Process
2.2. Air Combat Environmental Model
3. Hierarchical Reinforcement Learning Design
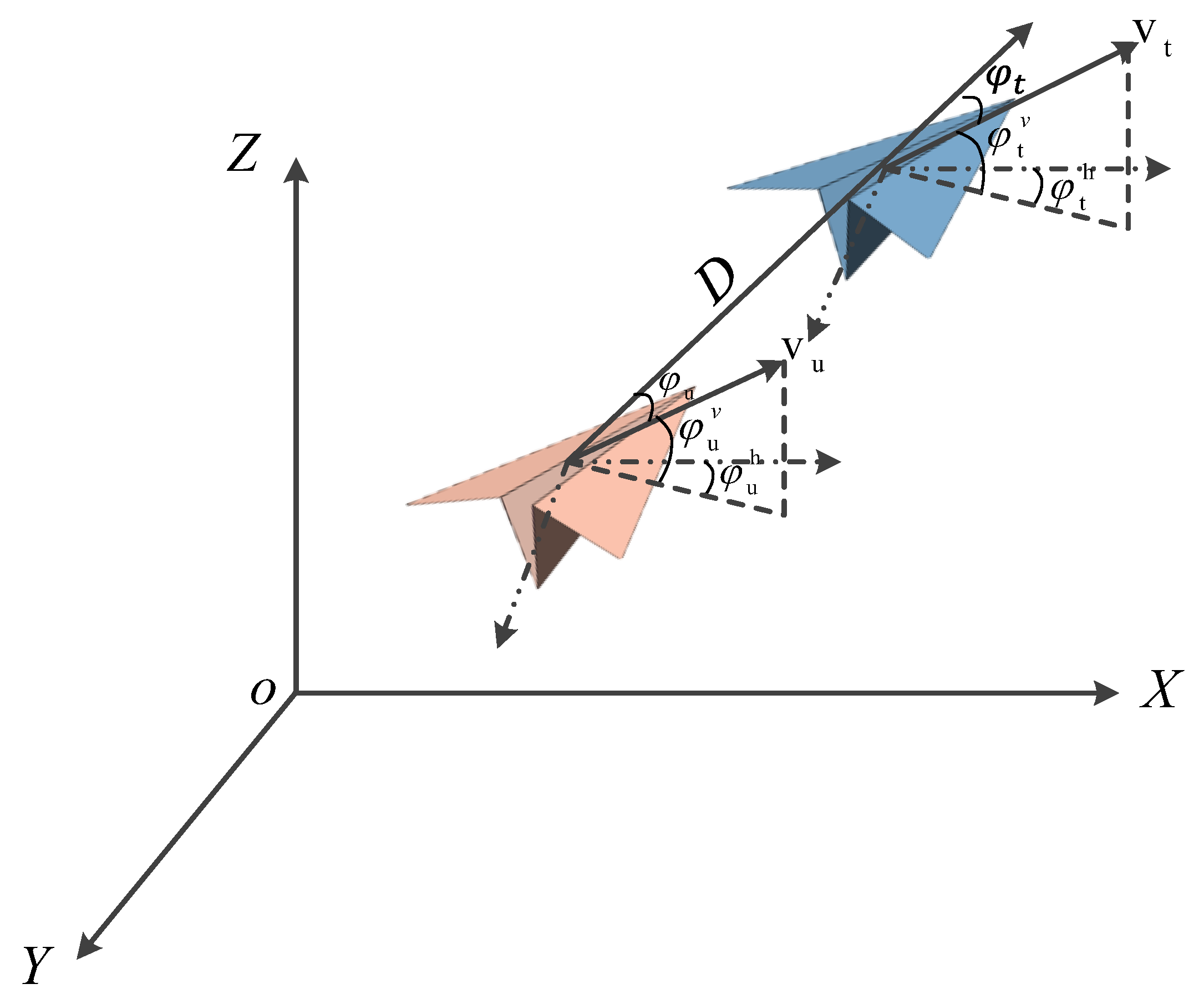
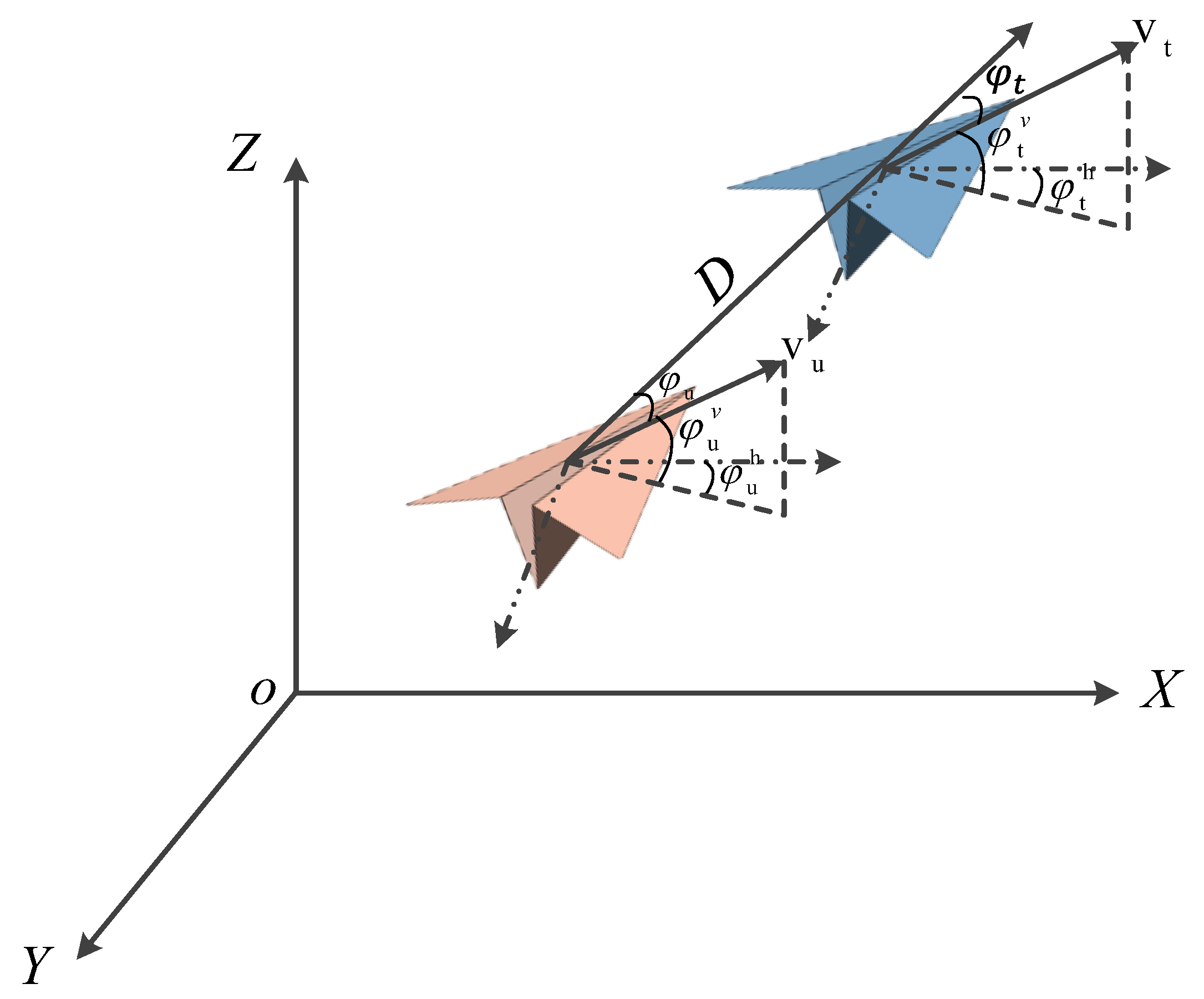
3.1. Geometric Hierarchy in the Aircombat Framework
3.2. Reward Shaping
3.3. Senior Policy Reward
3.4. Sub-Policy Reward
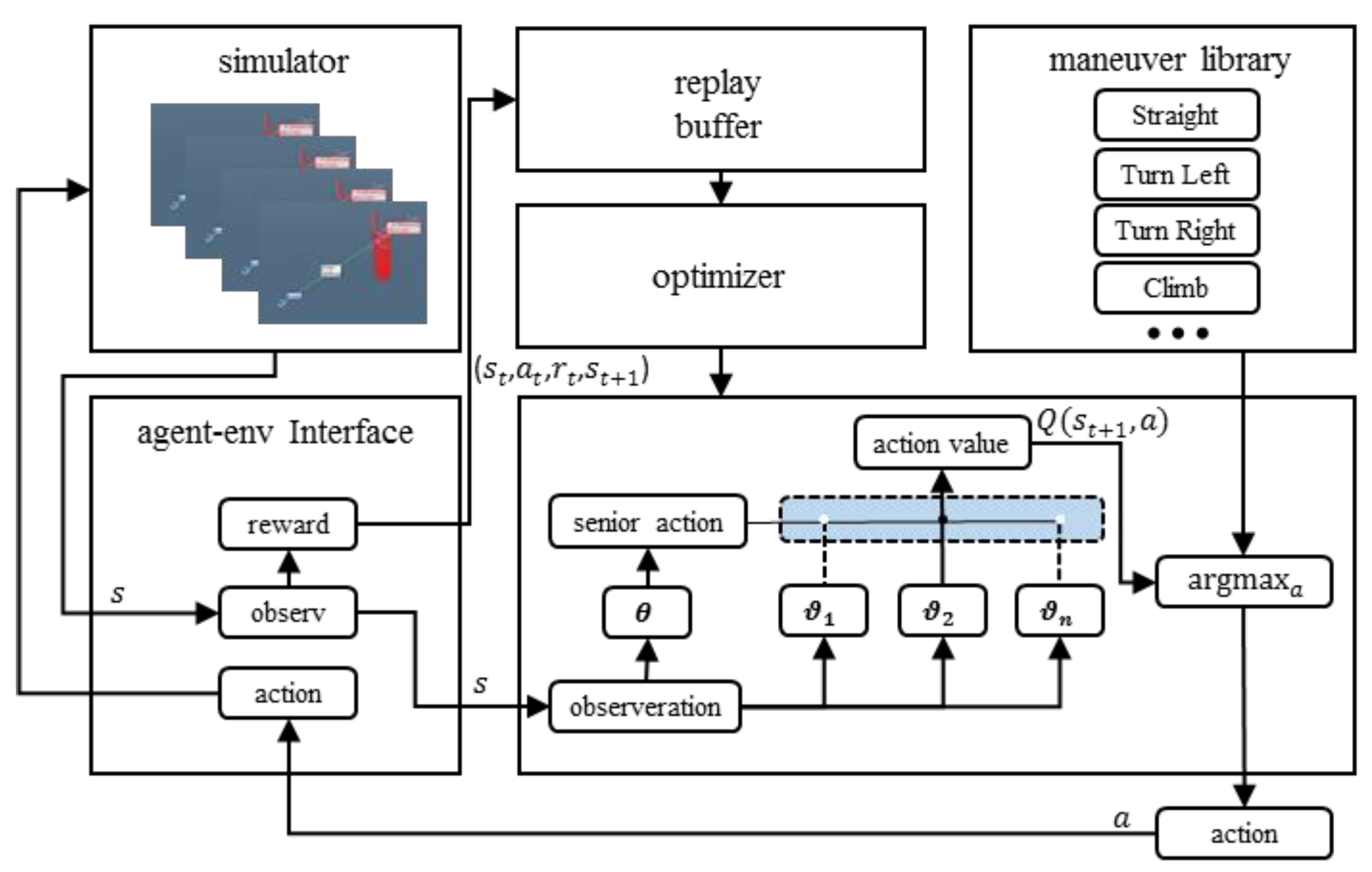
3.5. Hierarchical Training Algorithm
3.6. Hierarchical Runtime Algorithm
4. Results
4.1. Experimental Environment Setup
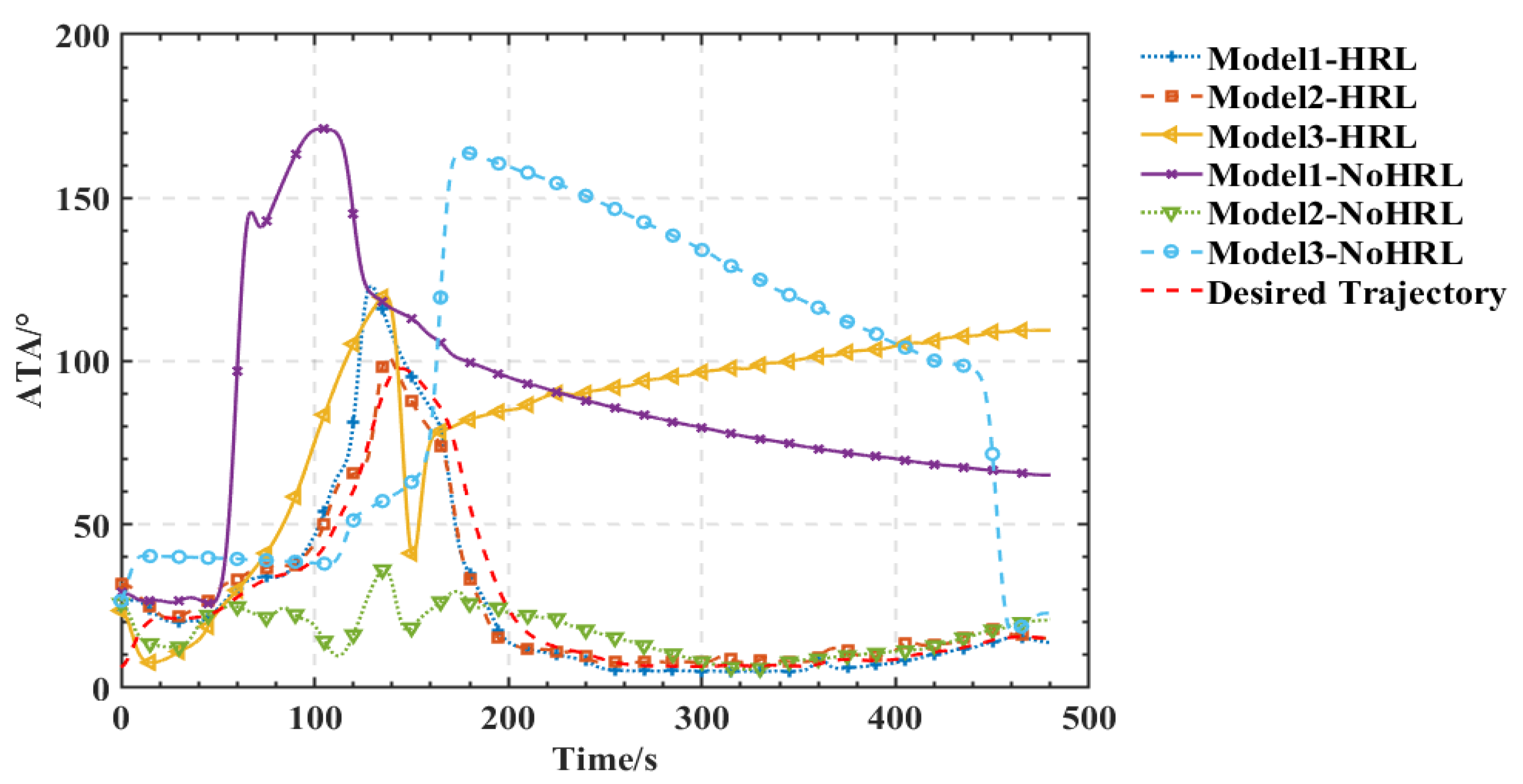
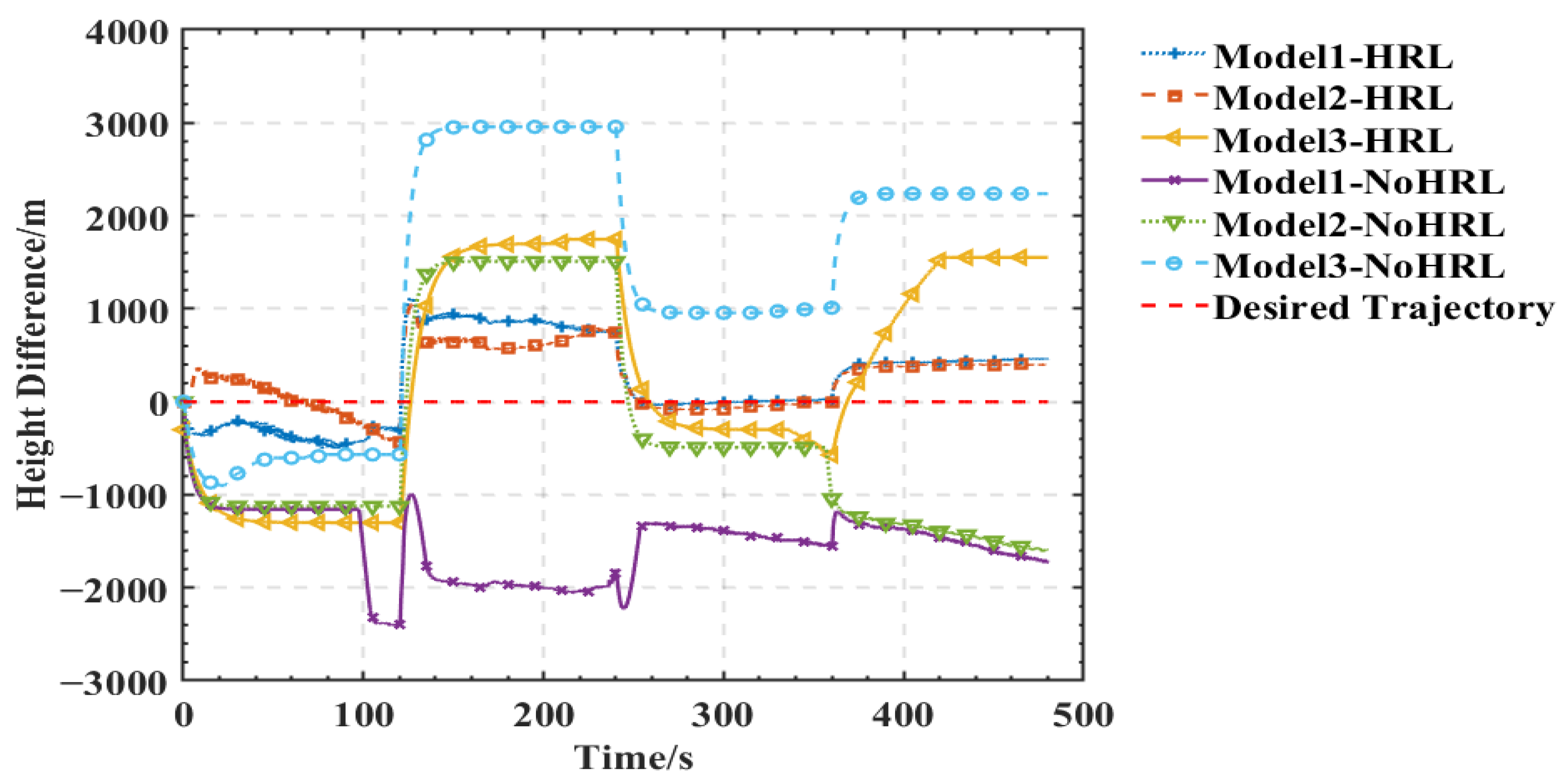
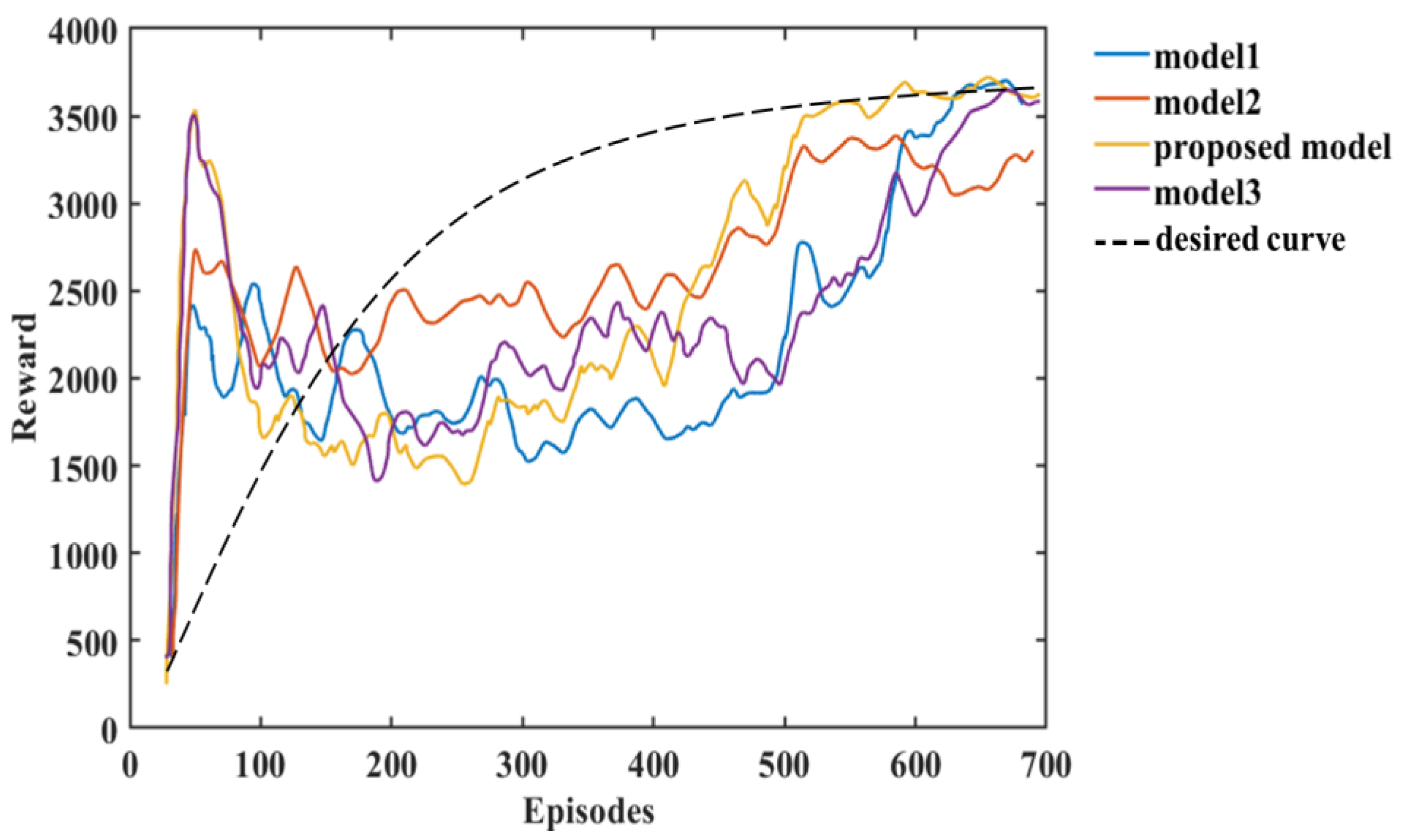
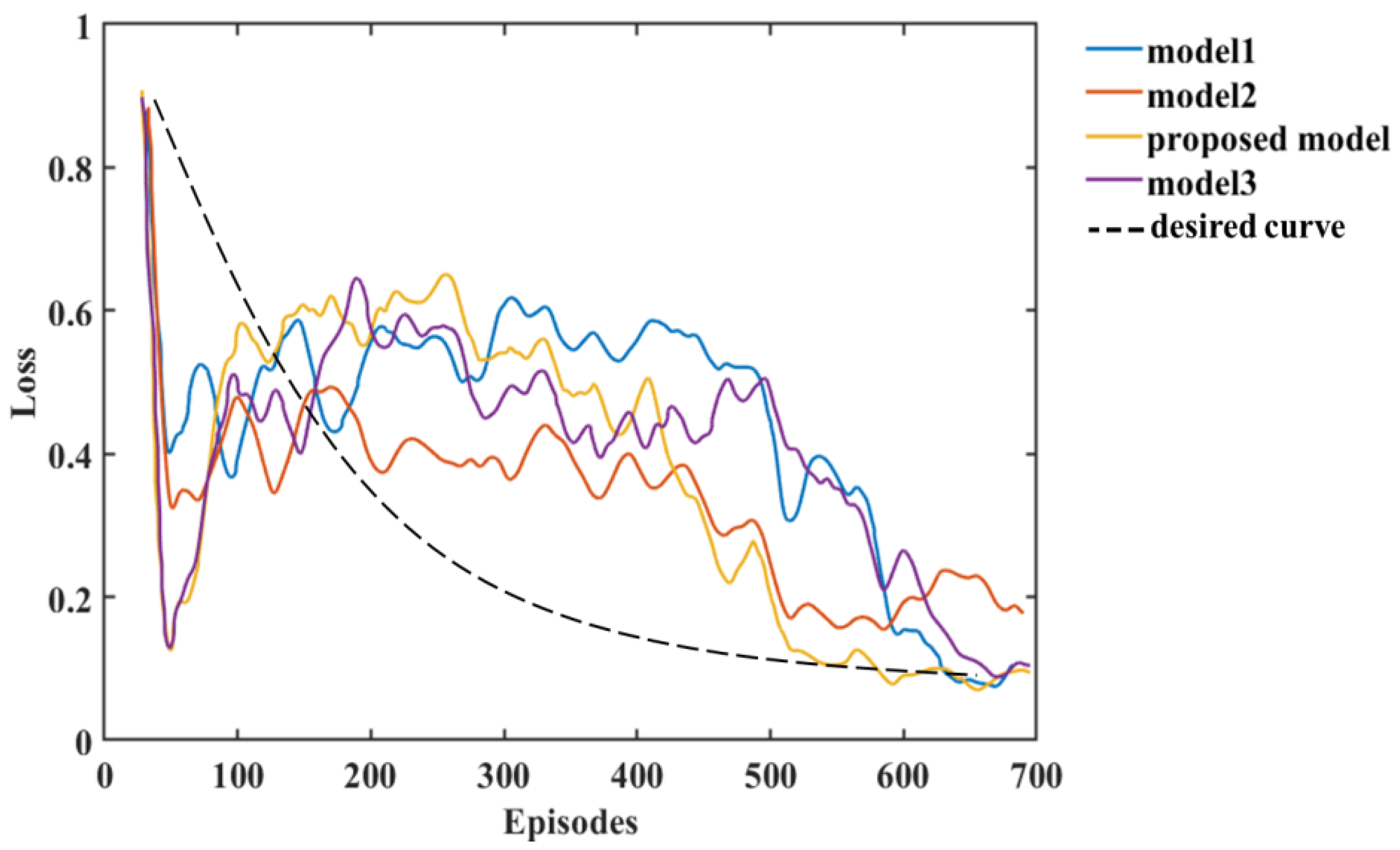
4.2. Performance Metrics during Training and Validation
4.3. Validation and Evolution of the Hierarchical Agents
5. Discussion
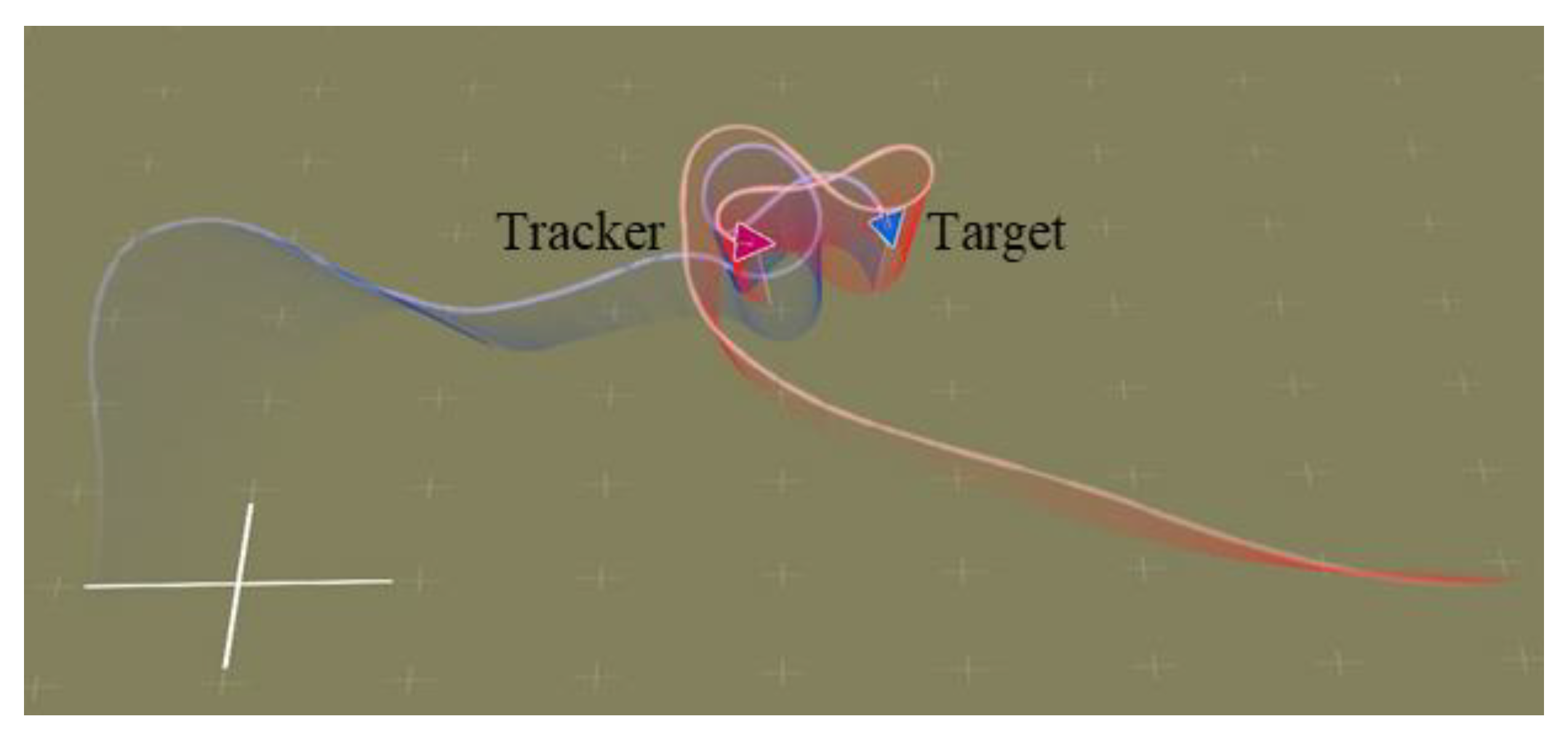
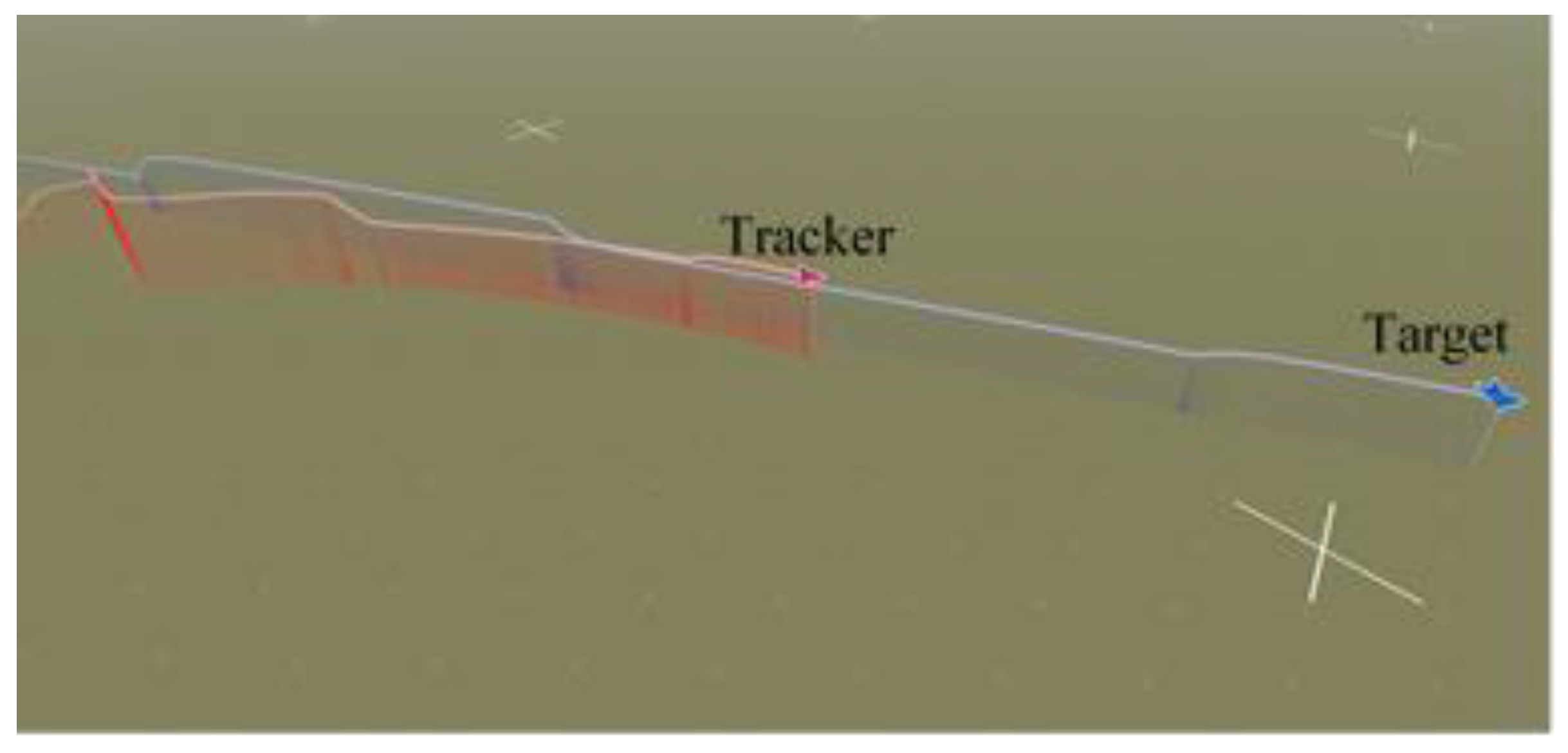
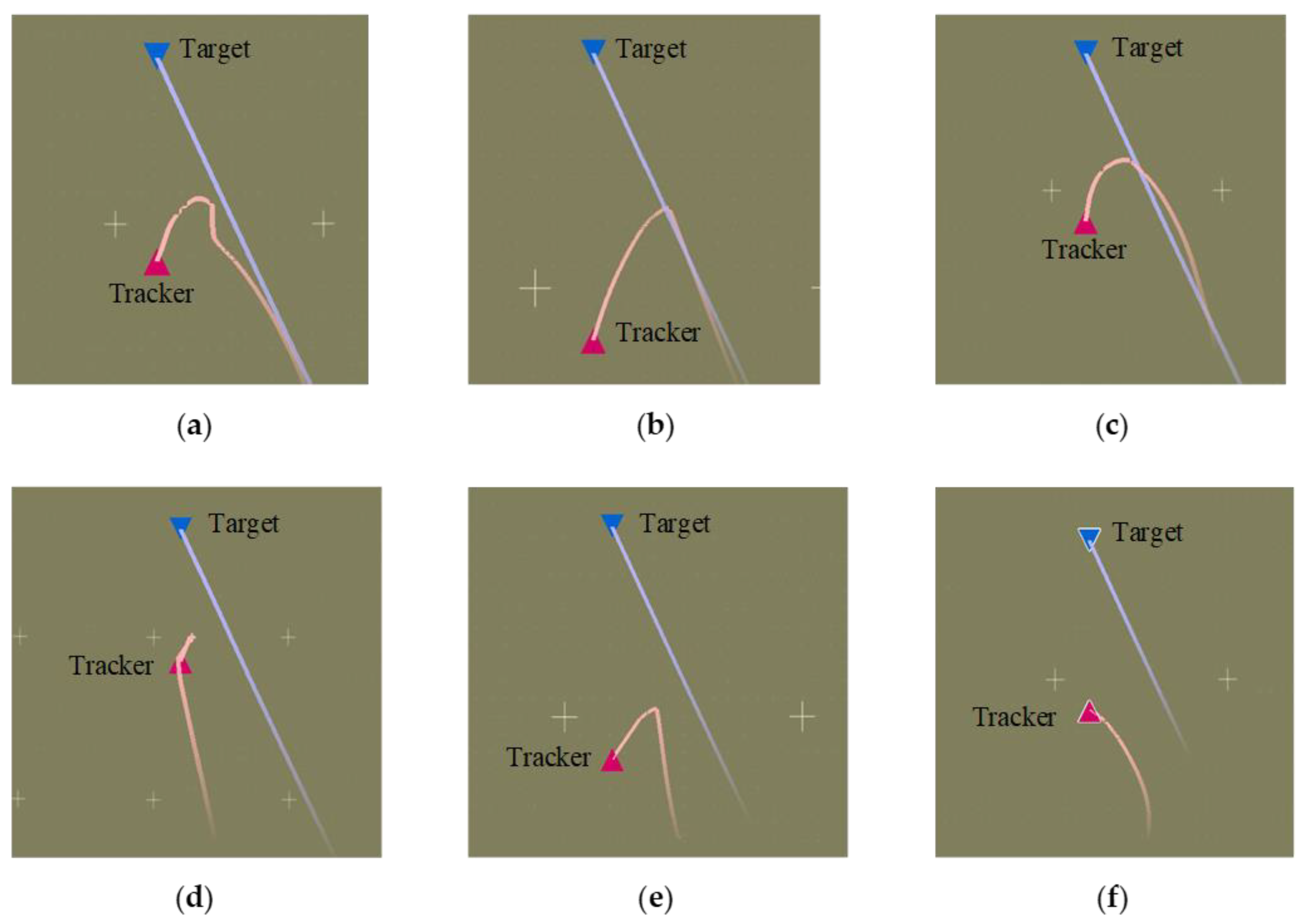
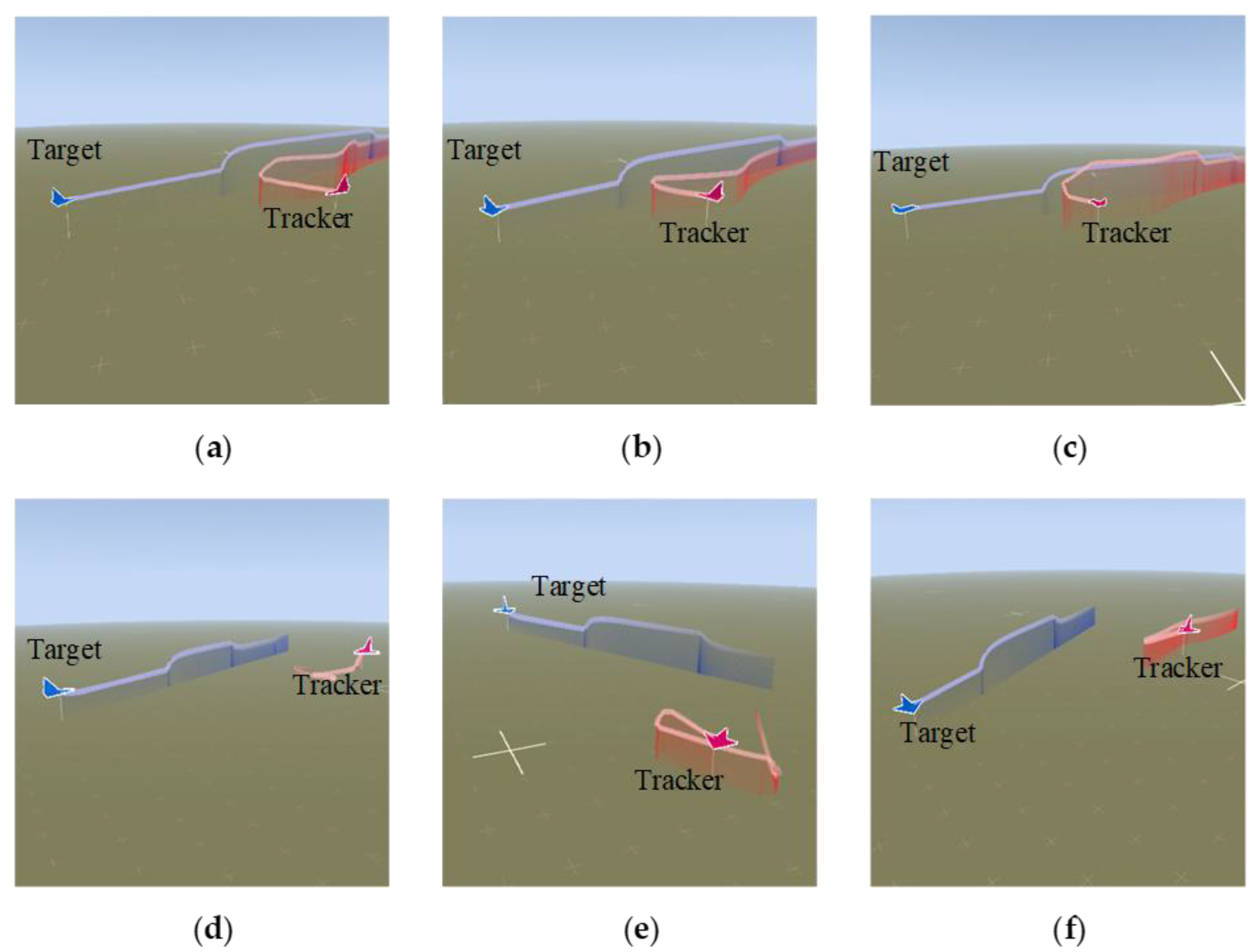
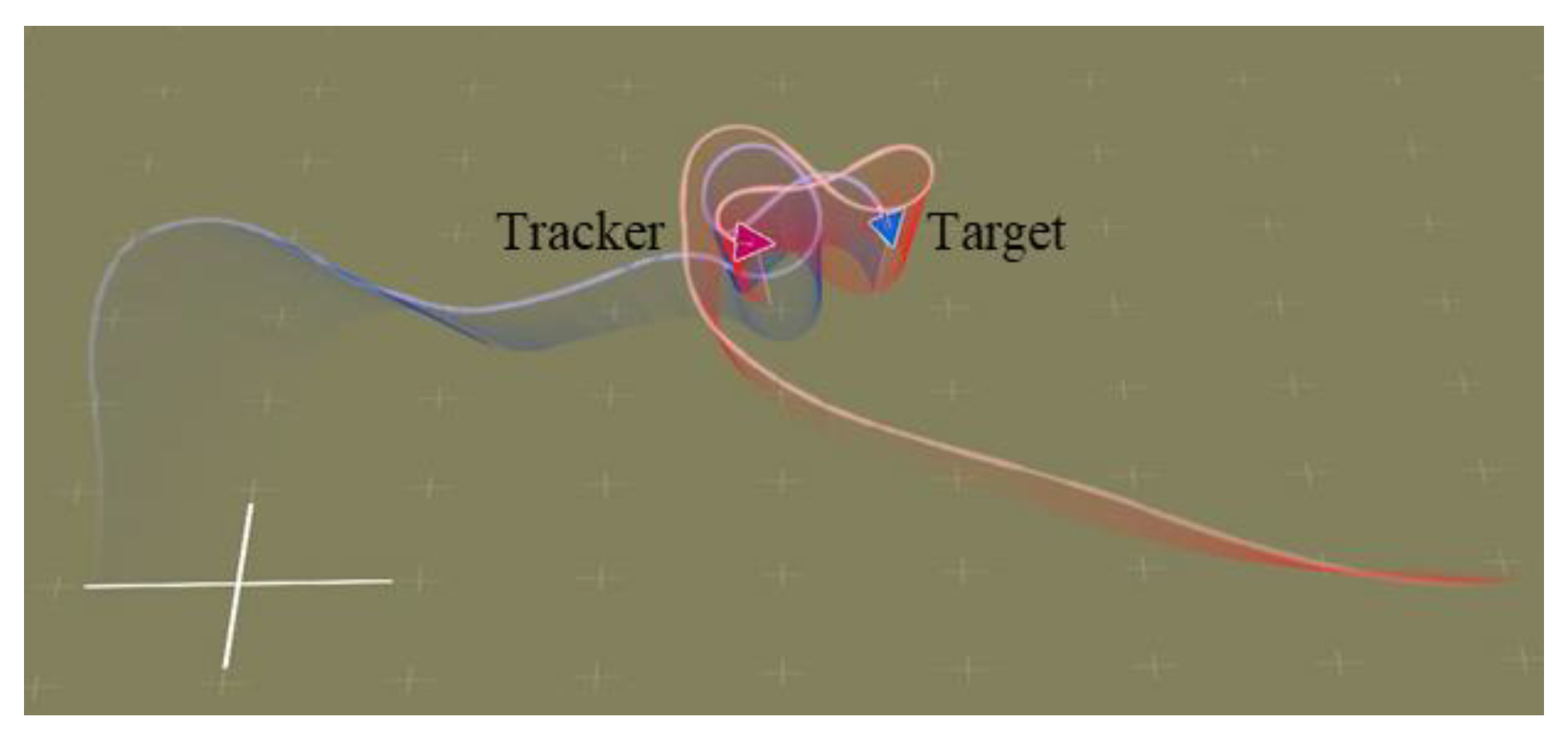
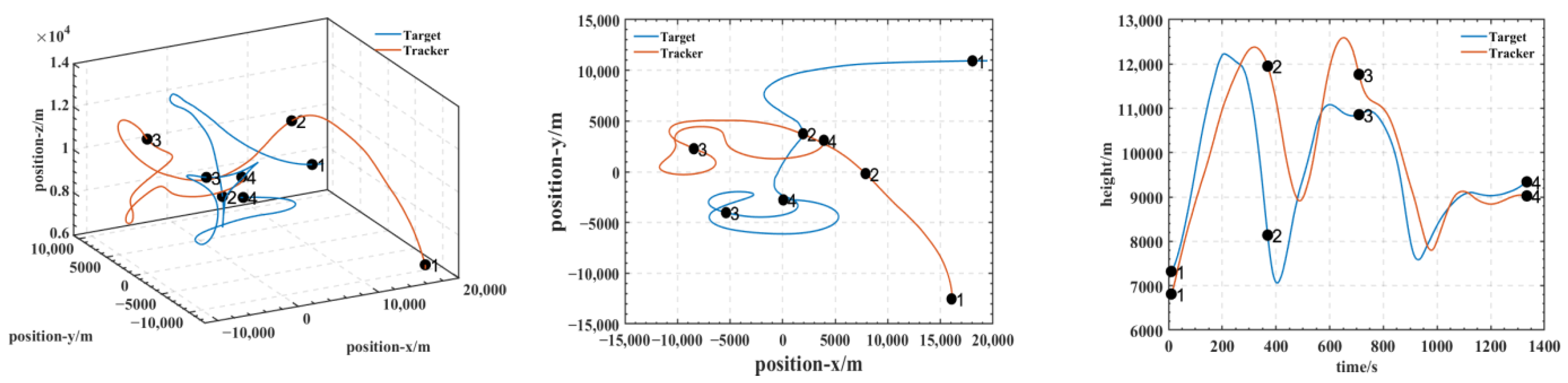
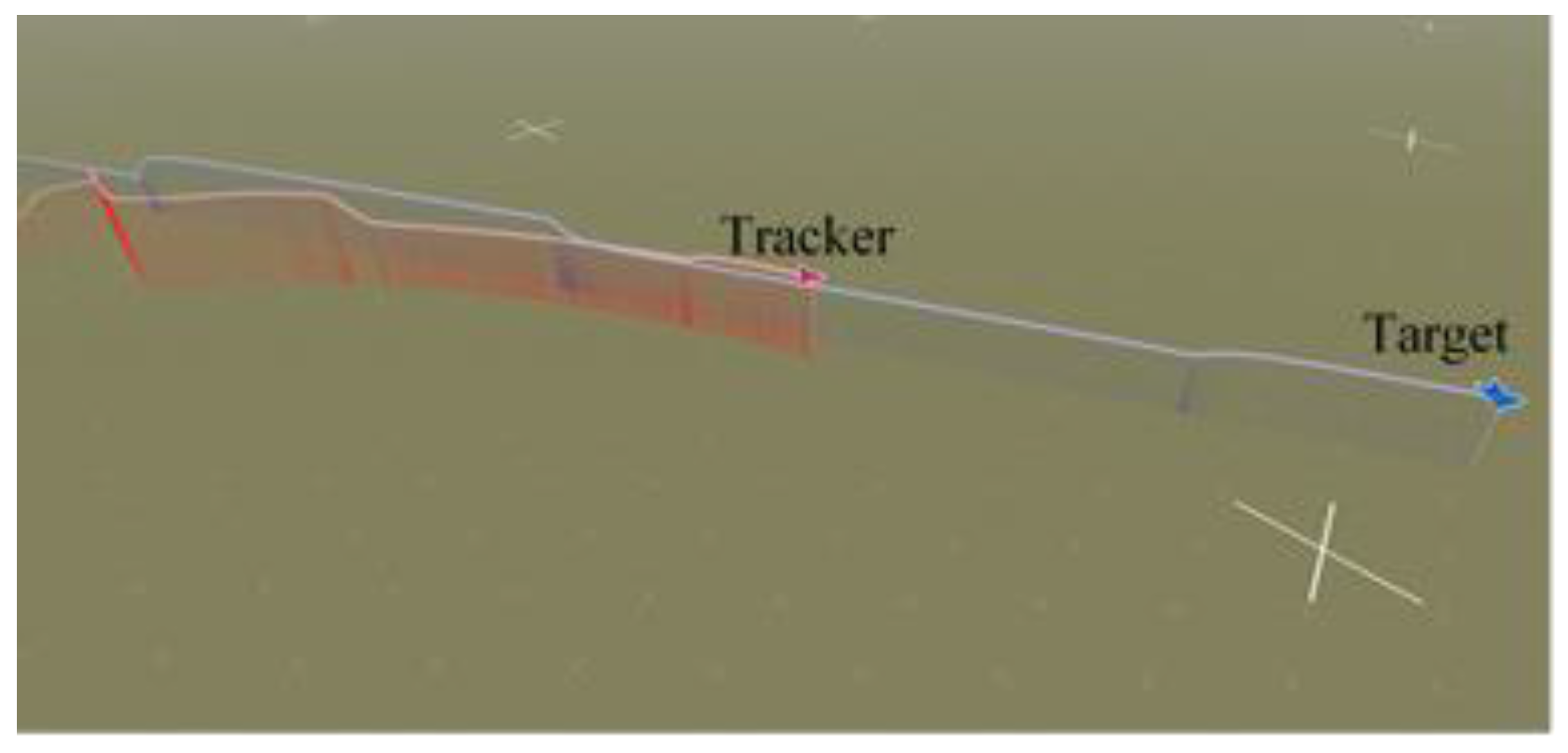
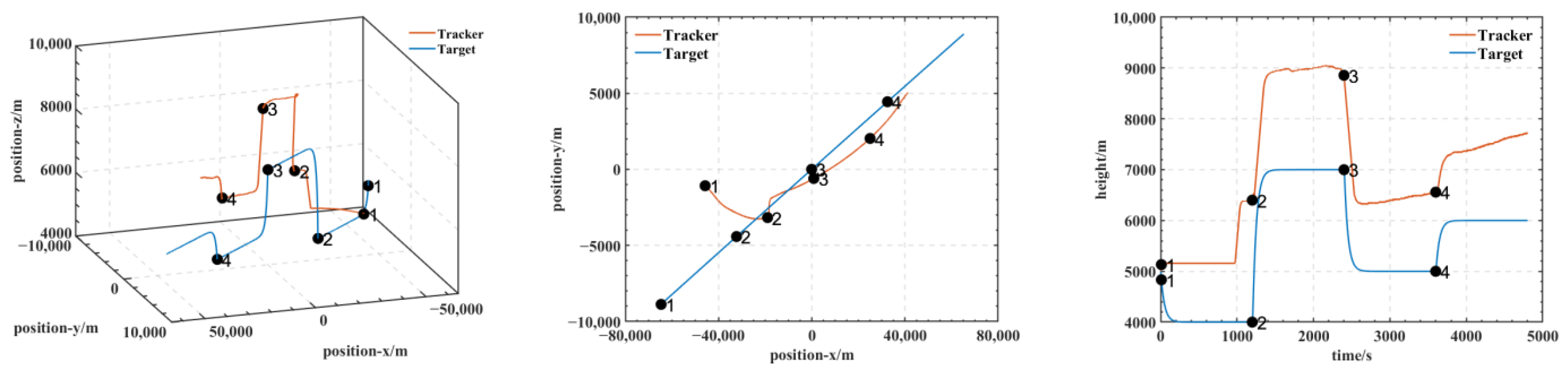
5.1. Trajectory of Air Combat Process
5.2. Training Process
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Design of Reward Functions
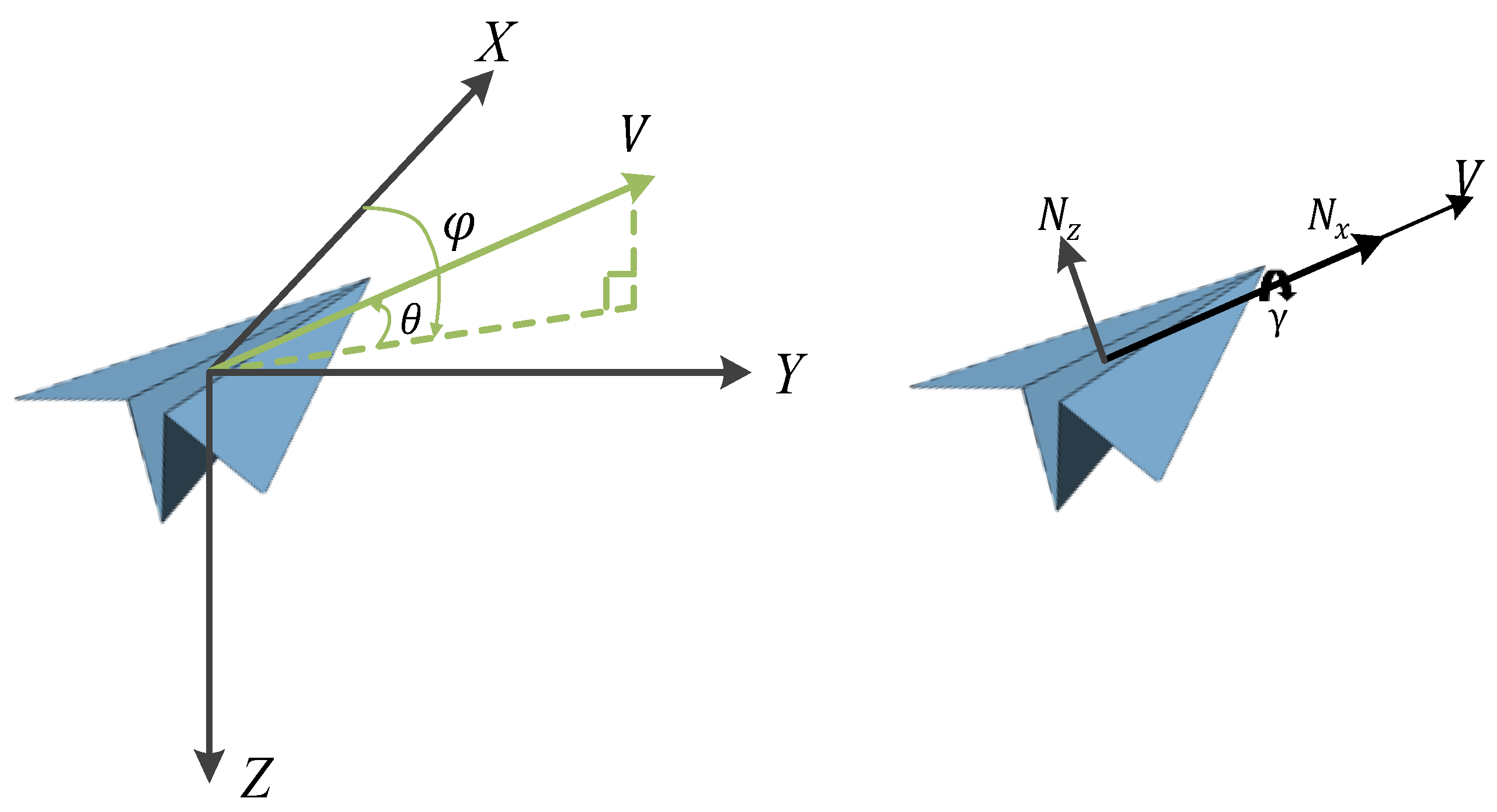
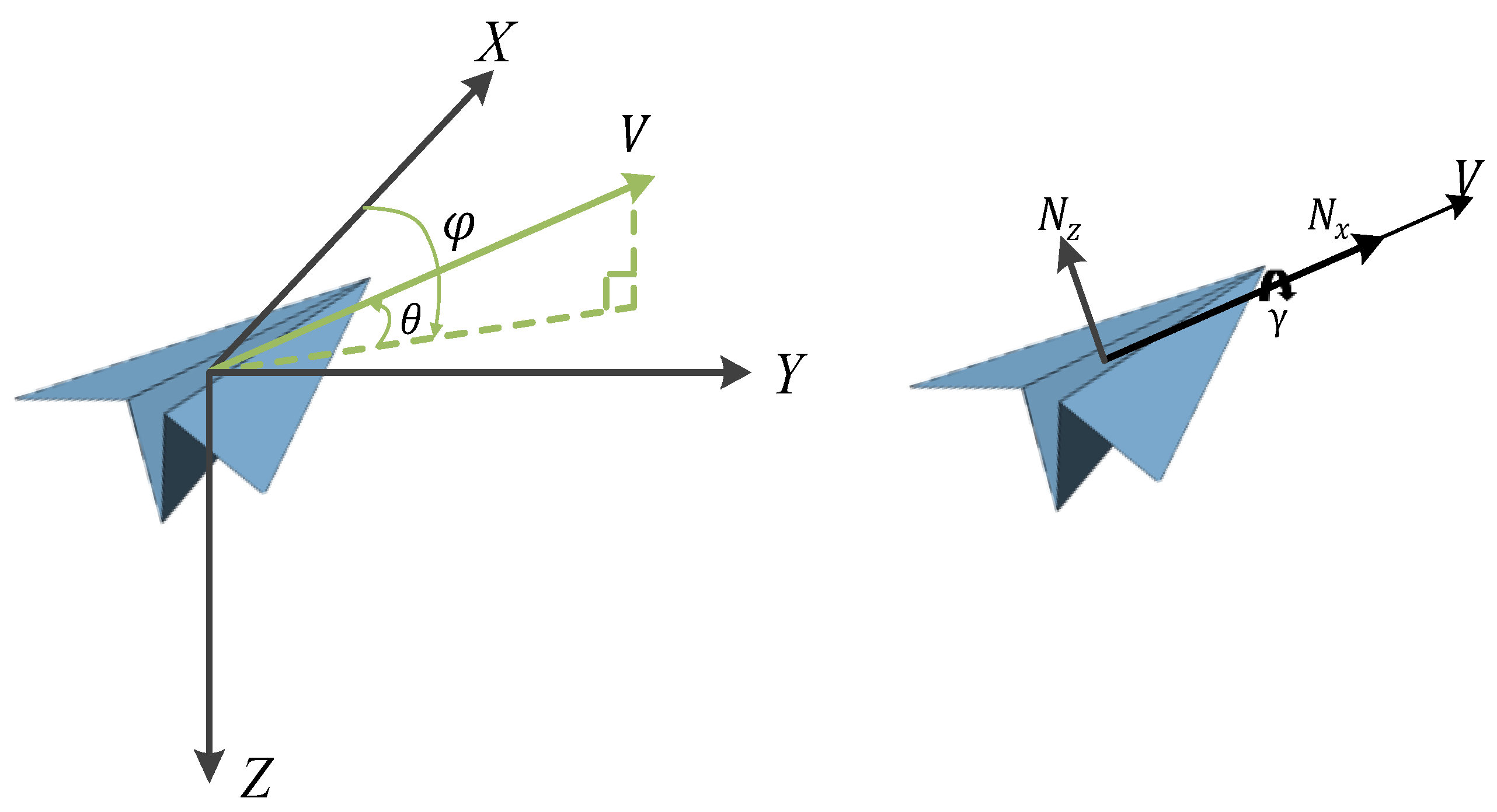
Appendix B. The Spatial Projection
Appendix C. Algorithm A1
| Algorithm A1 The hierarchical training algorithm |
| Initialize a one-on-one air combat simulation environment |
| Initialize replay buffer R1,R2 to capacity N |
| Initialize the action-value function Q with random weights |
| Initialize Agent DQN1with (Q,R1), DQN2 with (Q,R2) |
| for episode = 1, MAX do |
| = env.reset() |
| for t = 1, T do |
| using DQN1 |
| in an air combat simulation environment |
| Agent 2 samples action using DQN2 |
| in an air combat simulation environment |
| end for |
| ) into R2 |
| if the Update condition is reached, then |
| Sample random mini-batch of m from the replay buffer |
| end for |
| end for |
Appendix D. Algorithm A2
| Algorithm A2 The hierarchical running algorithm |
| ) |
| for step = 1 to max step do |
| ) do |
| is obtained according to (2) |
| is obtained according to (2) |
| end for |
| end for |
References
- Sutton, R.S.; Barto, A. Reinforcement Learning: An Introduction, Nachdruck; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2014; ISBN 978-0-262-19398-6. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Hu, D.; Yang, R.; Zuo, J.; Zhang, Z.; Wu, J.; Wang, Y. Application of Deep Reinforcement Learning in Maneuver Planning of Beyond-Visual-Range Air Combat. IEEE Access 2021, 9, 32282–32297. [Google Scholar] [CrossRef]
- Jiang, Y.; Yu, J.; Li, Q. A novel decision-making algorithm for beyond visual range air combat based on deep reinforcement learning. In Proceedings of the 2022 37th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Beijing, China, 19–20 November 2022; IEEE: New York, NY, USA, 2022; pp. 516–521. [Google Scholar] [CrossRef]
- Shi, W.; Song, S.; Wu, C.; Chen, C.L.P. Multi Pseudo Q-learning Based Deterministic Policy Gradient for Tracking Control of Autonomous Underwater Vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3534–3546. Available online: http://arxiv.org/abs/1909.03204 (accessed on 3 April 2023). [CrossRef] [PubMed]
- Byrnes, C.M.W. Nightfall: Machine Autonomy in Air-to-Air Combat. Air Space Power J. 2014, 28, 48–75. [Google Scholar]
- Kim, C.-S.; Ji, C.-H.; Kim, B.S. Development of a control law to improve the handling qualities for short-range air-to-air combat maneuvers. Adv. Mech. Eng. 2020, 12, 168781402093679. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, J.; Yang, L.; Liu, C. Autonomous decision-making for dogfights based on a tactical pursuit point approach. Aerosp. Sci. Technol. 2022, 129, 107857. [Google Scholar] [CrossRef]
- Li, W.; Shi, J.; Wu, Y.; Wang, Y.; Lyu, Y. A Multi-UCAV cooperative occupation method based on weapon engagement zones for beyond-visual-range air combat. Def. Technol. 2022, 18, 1006–1022. [Google Scholar] [CrossRef]
- Kong, W.; Zhou, D.; Du, Y.; Zhou, Y.; Zhao, Y. Hierarchical multi-agent reinforcement learning for multi-aircraft close-range air combat. IET Control Theory Appl 2022, 17, cth2.12413. [Google Scholar] [CrossRef]
- Ernest, N.; Carroll, D. Genetic Fuzzy based Artificial Intelligence for Unmanned Combat Aerial Vehicle Control in Simulated Air Combat Missions. J. Def. Manag. 2016, 06, 2167-0374. [Google Scholar] [CrossRef]
- Li, Q.; Jiang, W.; Liu, C.; He, J. The Constructing Method of Hierarchical Decision-Making Model in Air Combat. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 22–23 August 2020; IEEE: New York, NY, USA, 2020; pp. 122–125. [Google Scholar] [CrossRef]
- Mulgund, S.; Harper, K.; Krishnakumar, K.; Zacharias, G. Air combat tactics optimization using stochastic genetic algorithms. In SMC’98 Conference Proceedings, Proceedings of the 1998 IEEE International Conference on Systems, Man, and Cybernetics (Cat. No. 98CH36218), San Diego, CA, USA, 14 October 1998; IEEE: New York, NY, USA, 1998; Volume 4, pp. 3136–3141. [Google Scholar] [CrossRef]
- Lee, G.T.; Kim, C.O. Autonomous Control of Combat Unmanned Aerial Vehicles to Evade Surface-to-Air Missiles Using Deep Reinforcement Learning. IEEE Access 2020, 8, 226724–226736. [Google Scholar] [CrossRef]
- Li, Y.; Lyu, Y.; Shi, J.; Li, W. Autonomous Maneuver Decision of Air Combat Based on Simulated Operation Command and FRV-DDPG Algorithm. Aerospace 2022, 9, 658. [Google Scholar] [CrossRef]
- Cao, Y.; Kou, Y.-X.; Li, Z.-W.; Xu, A. Autonomous Maneuver Decision of UCAV Air Combat Based on Double Deep Q Network Algorithm and Stochastic Game Theory. Int. J. Aerosp. Eng. 2023, 2023, 3657814. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Wang, Y.; Ren, T.; Fan, Z. Autonomous Maneuver Decision of UAV Based on Deep Reinforcement Learning: Comparison of DQN and DDPG. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 21–23 May 2022; IEEE: New York, NY, USA, 2022; pp. 4857–4860. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, J.; Yang, Q.; Zhou, Y.; Shi, G.; Wu, Y. Design and Verification of UAV Maneuver Decision Simulation System Based on Deep Q-learning Network. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13 December 2020; IEEE: New York, NY, USA, 2020; pp. 817–823. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Z.; Chai, J.; Liu, Z.; Zhu, Y.; Yi, J. Learning Continuous 3-DoF Air-to-Air Close-in Combat Strategy using Proximal Policy Optimization. In Proceedings of the 2022 IEEE Conference on Games (CoG), Beijing, China, 21–24 August 2022; IEEE: New York, NY, USA, 2022; pp. 616–619. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.063472017. Available online: http://arxiv.org/abs/1707.06347 (accessed on 7 April 2023).
- Lu, J.; Zhao, Y.-B.; Kang, Y.; Wang, Y.; Deng, Y. Strategy Generation Based on DDPG with Prioritized Experience Replay for UCAV. In Proceedings of the 2022 International Conference on Advanced Robotics and Mechatronics (ICARM), Guilin, China, 9–11 July 2022; IEEE: New York, NY, USA, 2022; pp. 157–162. [Google Scholar] [CrossRef]
- Wei, Y.-J.; Zhang, H.-P.; Huang, C.-Q. Maneuver Decision-Making For Autonomous Air Combat Through Curriculum Learning And Reinforcement Learning With Sparse Rewards. arXiv 2023, arXiv:2302.05838. Available online: http://arxiv.org/abs/2302.05838 (accessed on 7 March 2023).
- Hu, Y.; Wang, W.; Jia, H.; Wang, Y.; Chen, Y.; Hao, J.; Wu, F.; Fan, C. Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping. Adv. Neural Inf. Process. Syst. 2020, 33, 15931–15941. [Google Scholar]
- Piao, H.; Sun, Z.; Meng, G.; Chen, H.; Qu, B.; Lang, K.; Sun, Y.; Yang, S.; Peng, X. Beyond-Visual-Range Air Combat Tactics Auto-Generation by Reinforcement Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: New York, NY, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, A.; Zhao, S.; Shi, Z.; Wang, J. Over-the-Horizon Air Combat Environment Modeling and Deep Reinforcement Learning Application. In Proceedings of the 2022 4th International Conference on Data-driven Optimization of Complex Systems (DOCS), Chengdu, China, 28–30 October 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, J.; Wang, L.; Hu, T.; Guo, C.; Wang, Y. Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics 2022, 11, 467. [Google Scholar] [CrossRef]
- Zhan, G.; Zhang, X.; Li, Z.; Xu, L.; Zhou, D.; Yang, Z. Multiple-UAV Reinforcement Learning Algorithm Based on Improved PPO in Ray Framework. Drones 2022, 6, 166. [Google Scholar] [CrossRef]
- Narvekar, S.; Sinapov, J.; Stone, P. Autonomous Task Sequencing for Customized Curriculum Design in Reinforcement Learning. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2536–2542. [Google Scholar] [CrossRef]
- Schmidhuber, J. Learning to generate subgoals for action sequences. In Proceedings of the IJCNN-91-Seattle International Joint Conference on Neural Networks, Seattle, WA, USA, 8–12 July 1991; IEEE: New York, NY, USA, 1991; Volume II, p. 453. [Google Scholar] [CrossRef]
- Rane, S. Learning with Curricula for Sparse-Reward Tasks in Deep Reinforcement Learning; Massachusetts Institute of Technology: Cambridge, MA, USA, 2020. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, USA, 24 September 2017; IEEE: New York, NY, USA, 2017; pp. 23–30. [Google Scholar] [CrossRef]
- Comanici, G.; Precup, D. Optimal Policy Switching Algorithms for Reinforcement Learning. In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems, Montreal, QC, Canada, 10–14 May 2010; Volume 1, pp. 709–714. [Google Scholar]
- Frans, K.; Ho, J.; Chen, X.; Abbeel, P.; Schulman, J. Meta Learning Shared Hierarchies. arXiv 2017, arXiv:1710.09767. Available online: http://arxiv.org/abs/1710.09767 (accessed on 20 February 2023).
- Zhao, H.; Stretcu, O.; Smola, A.J.; Gordon, G.J. Efficient Multitask Feature and Relationship Learning. PMLR 2020, 115, 777–787. [Google Scholar]
- Barto, A.G.; Mahadevan, S. Recent Advances in Hierarchical Reinforcement Learning. Discret. Event Dyn. Syst. 2003, 13, 41–77. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef]
- Eppe, M.; Gumbsch, C.; Kerzel, M.; Nguyen, P.D.H.; Butz, M.V.; Wermter, S. Intelligent problem-solving as integrated hierarchical reinforcement learning. Nat Mach Intell 2022, 4, 11–20. [Google Scholar] [CrossRef]
- Wen, Z.; Precup, D.; Ibrahimi, M.; Barreto, A. On Efficiency in Hierarchical Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 6708–6718. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. Available online: http://arxiv.org/abs/1312.5602 (accessed on 7 April 2023).
- Littman, M.L. A tutorial on partially observable Markov decision processes. J. Math. Psychol. 2009, 53, 119–125. [Google Scholar] [CrossRef]
- White, D.J. A Survey of Applications of Markov Decision Processes. J. Oper. Res. Soc. 1993, 44, 1073–1096. [Google Scholar] [CrossRef]
- Wang, L.; Wei, H. Research on Autonomous Decision-Making of UCAV Based on Deep Reinforcement Learning. In Proceedings of the 2022 3rd Information Communication Technologies Conference (ICTC), Nanjing, China, 6–8 May 2022; IEEE: New York, NY, USA, 2022; pp. 122–126. [Google Scholar] [CrossRef]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking Deep Reinforcement Learning for Continuous Control. PMLR 2016, 48, 1329–1338. [Google Scholar]
- Vogeltanz, T. A Survey of Free Software for the Design, Analysis, Modelling, and Simulation of an Unmanned Aerial Vehicle. Arch. Comput. Methods Eng. 2016, 23, 449–514. [Google Scholar] [CrossRef]
- Chandak, Y.; Theocharous, G.; Kostas, J.E.; Jordan, S.M.; Thomas, P.S. Learning Action Representations for Reinforcement Learning. PMLR 2019, 97, 941–950. [Google Scholar]
- Pope, A.P.; Ide, J.S.; Micovic, D.; Diaz, H.; Twedt, J.C.; Alcedo, K.; Walker, T.T.; Rosenbluth, D.; Ritholtz, L.; Javorsek, D. Hierarchical Reinforcement Learning for Air Combat At DARPA’s AlphaDogfight Trials. IEEE Trans. Artif. Intell. 2022. Early Access. [Google Scholar] [CrossRef]
- Chen, W.; Gao, C.; Jing, W. Proximal policy optimization guidance algorithm for intercepting near-space maneuvering targets. Aerosp. Sci. Technol. 2023, 132, 108031. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reward Type | Miss Distance (m) | Miss Angle (°) | Approach Time (s) | ||||||
| without hrl | with hrl | Ratio of Decrease | without hrl | with hrl | Ratio of Decrease | without hrl | with hrl | Ratio of Decrease | |
| Model 1 | 44,378.83 (±4020.2) | 38,900.41 (±3778.3) | 12.34% | 32.56 (±5.73) | 25.71 (±1.46) | 21.04% | 141.99 (±19.89) | 101.459 (±20.09) | 28.54% |
| Model 2 | 41,696.70 (±3692.7) | 35,797.28 (±3494.9) | 14.14% | 31.68 (±2.66) | 28.726 (±8.39) | 9.32% | 137.06 (±21.32) | 87.56 (±17.83) | 36.11% |
| Model 3 | 43,526.82 (±2332.4) | 38,427.20 (±2371.3) | 11.71% | 36.69 (±6.93) | 25.69 (±6.41) | 29.98% | 102.89 (±25.18) | 89.01 (±18.66) | 13.49% |
| Reward Type | Hold Distance Time (%) | Hold Angle Time (%) | Cost Time (ms) | ||||||
| without hrl | with hrl | Ratio of Increase | without hrl | with hrl | Ratio of Increase | without hrl | with hrl | Ratio of Increase | |
| Model 1 | 17.15% (±6.39%) | 33.14% (±3.87%) | 15.99% | 5.23% (±0.22) | 11.38% (±0.99%) | 6.15% | 0.97 | 1.427 | 47.11% |
| Model 2 | 24.79% (±4.99%) | 41.12% (±4.67%) | 16.33% | 7.2% (±0.63%) | 15.44% (±1.67%) | 8.24% | 0.94 | 1.348 | 43.40% |
| Model 3 | 19.30% (±4.61%) | 36.56% (4.51%) | 17.26% | 4.06% (±1.07%) | 14.07% (±1.72%) | 10.01% | 0.91 | 1.410 | 54.95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.; Li, H.; Yan, G.; Peng, H.; Zhang, Q. Hierarchical Reinforcement Learning Framework in Geographic Coordination for Air Combat Tactical Pursuit. Entropy 2023, 25, 1409. https://doi.org/10.3390/e25101409
Chen R, Li H, Yan G, Peng H, Zhang Q. Hierarchical Reinforcement Learning Framework in Geographic Coordination for Air Combat Tactical Pursuit. Entropy. 2023; 25(10):1409. https://doi.org/10.3390/e25101409
Chicago/Turabian StyleChen, Ruihai, Hao Li, Guanwei Yan, Haojie Peng, and Qian Zhang. 2023. "Hierarchical Reinforcement Learning Framework in Geographic Coordination for Air Combat Tactical Pursuit" Entropy 25, no. 10: 1409. https://doi.org/10.3390/e25101409
APA StyleChen, R., Li, H., Yan, G., Peng, H., & Zhang, Q. (2023). Hierarchical Reinforcement Learning Framework in Geographic Coordination for Air Combat Tactical Pursuit. Entropy, 25(10), 1409. https://doi.org/10.3390/e25101409