
Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction

Abstract
:1. Introduction
2. Notations and Preliminary
2.1. Notations and Description of Dataset
- Let or 0 denote two treatments for comparison. For patient , let and represent the potential outcomes of treatment and , respectively; let , , and denote the observed survival time, baseline vector comprising covariates, and the actual treatment patient has received, respectively; let and denote that and are corresponding to an actual treatment (i.e., the observed survival time and the baseline of patient who has received a treatment , or ). For the case where we do not need to refer to the specific value of , we also use and for short.
- Considering the censoring problem, let denote the observed censoring time when is censored, which is defined as “the time up to which we are certain that the event has not occurred” according to [4], where the event refers to death here. To denote and in a unified way, like reference [9], let denote the observed time, which equals when it is available, and is set at when is censored. Similar to the meaning of , we use to denote the observed time of patient who has received an actual treatment . Let indicate that survival time is (is not) censored.
- Let denote the historical dataset of all patients and let represent the historical dataset for patients who have received treatments , with or , where and are the subsets of , with .
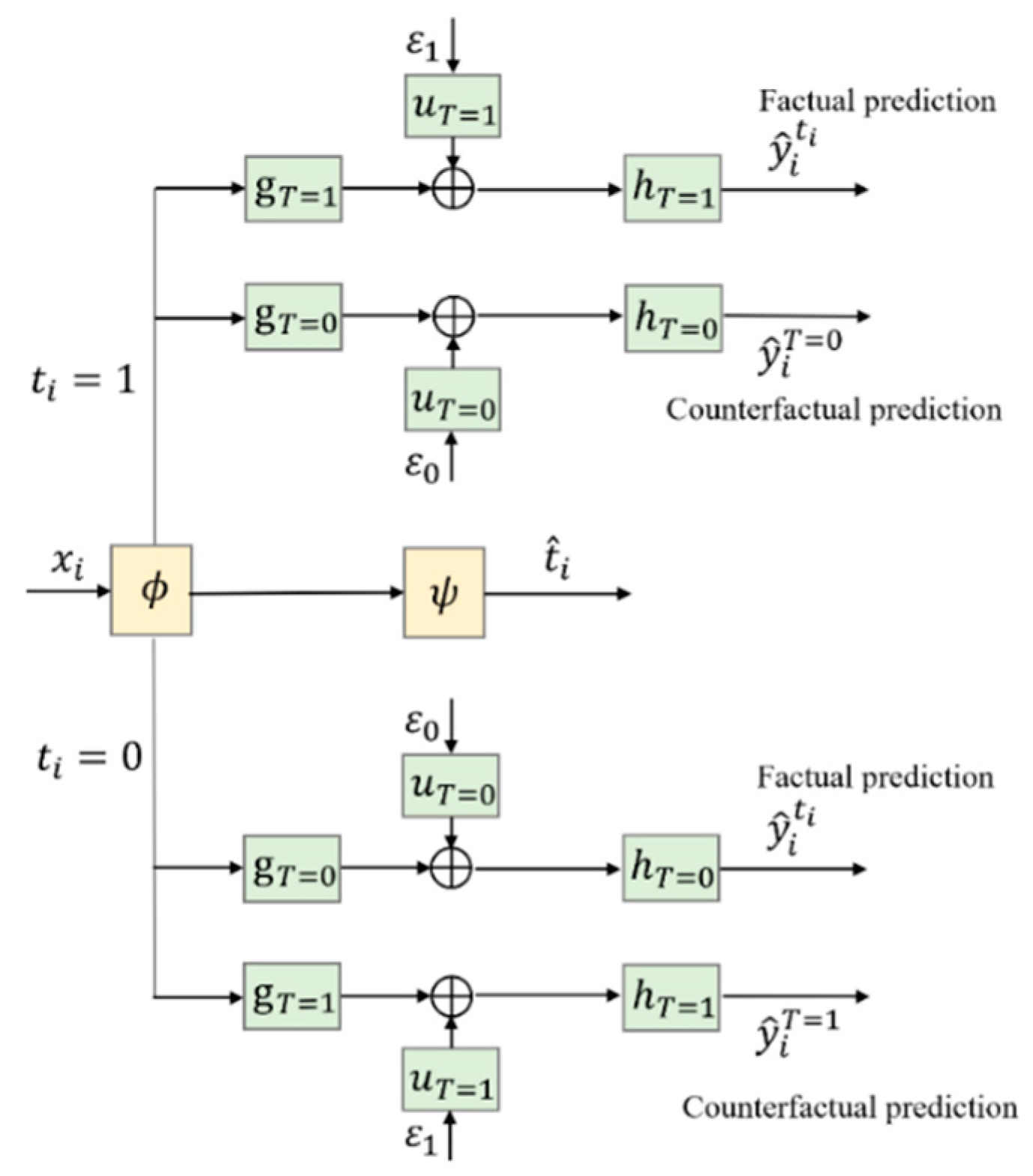
- Let denote the prediction of based on and denote the prediction of survival time based on , with or , which is also called factual prediction. While on the contrary, we use to represent a counterfactual prediction, which uses (for a patient who has received ) to predict what will happen if the contrary treatment is adopted (please see Section 4.2 for details).
- Let represent the potential outcome of (with or and call the Individual Treatment Effect of relative to [1]. In this paper, suppose we have historical datasets , , and , and some prior knowledge which can be expressed by for and for (please refer to Section 4.1 for details).
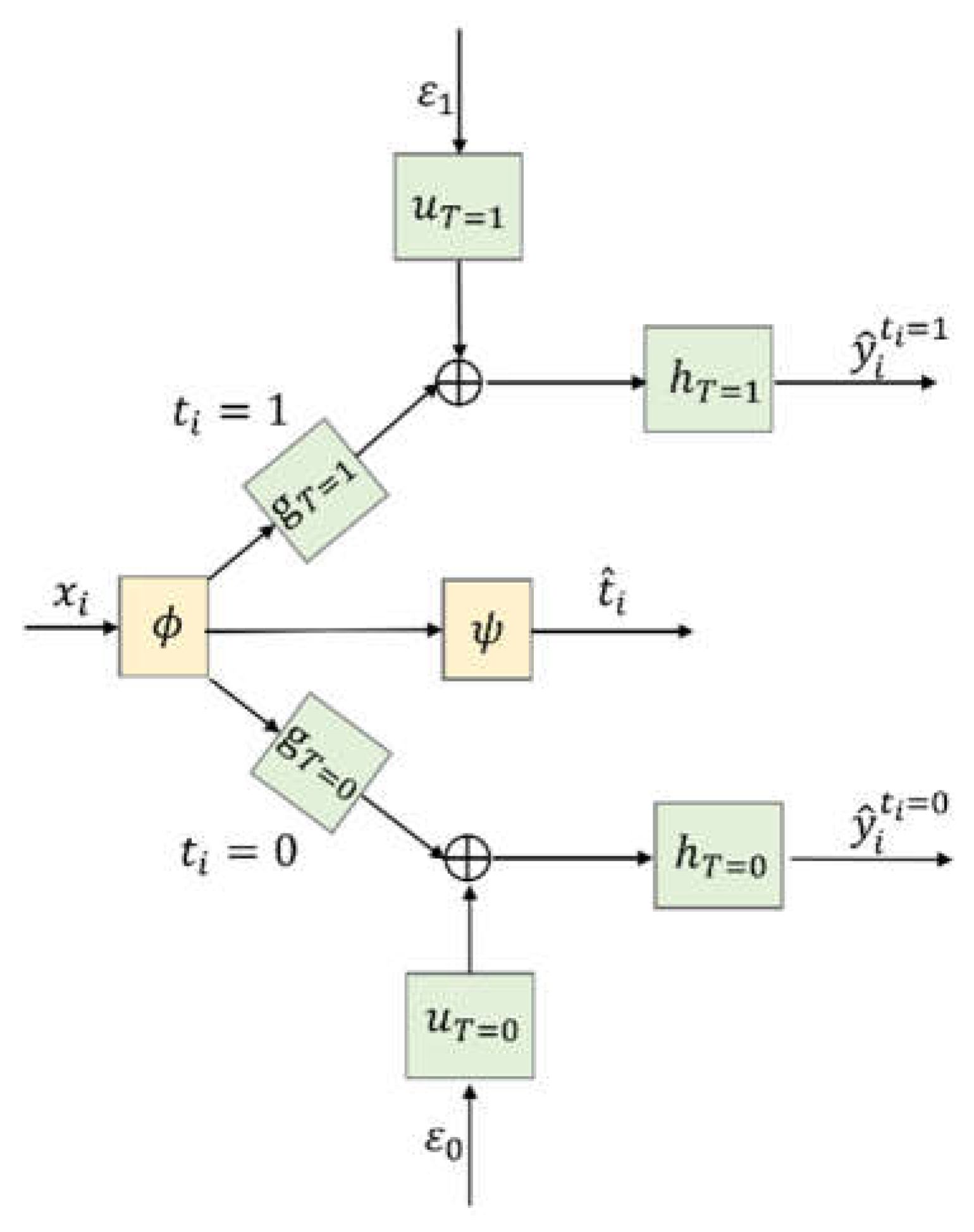
2.2. A Brief Introduction to CSA and Dragonnet
3. CSA–Dragonnet
4. CSA–Dragonnet with Embedded Prior Knowledge (CDNEPK)
4.1. A Unified Expression of the Prior Knowledge Yielded by RCTs and RCSs
4.2. Importance of Counterfactual Prediction
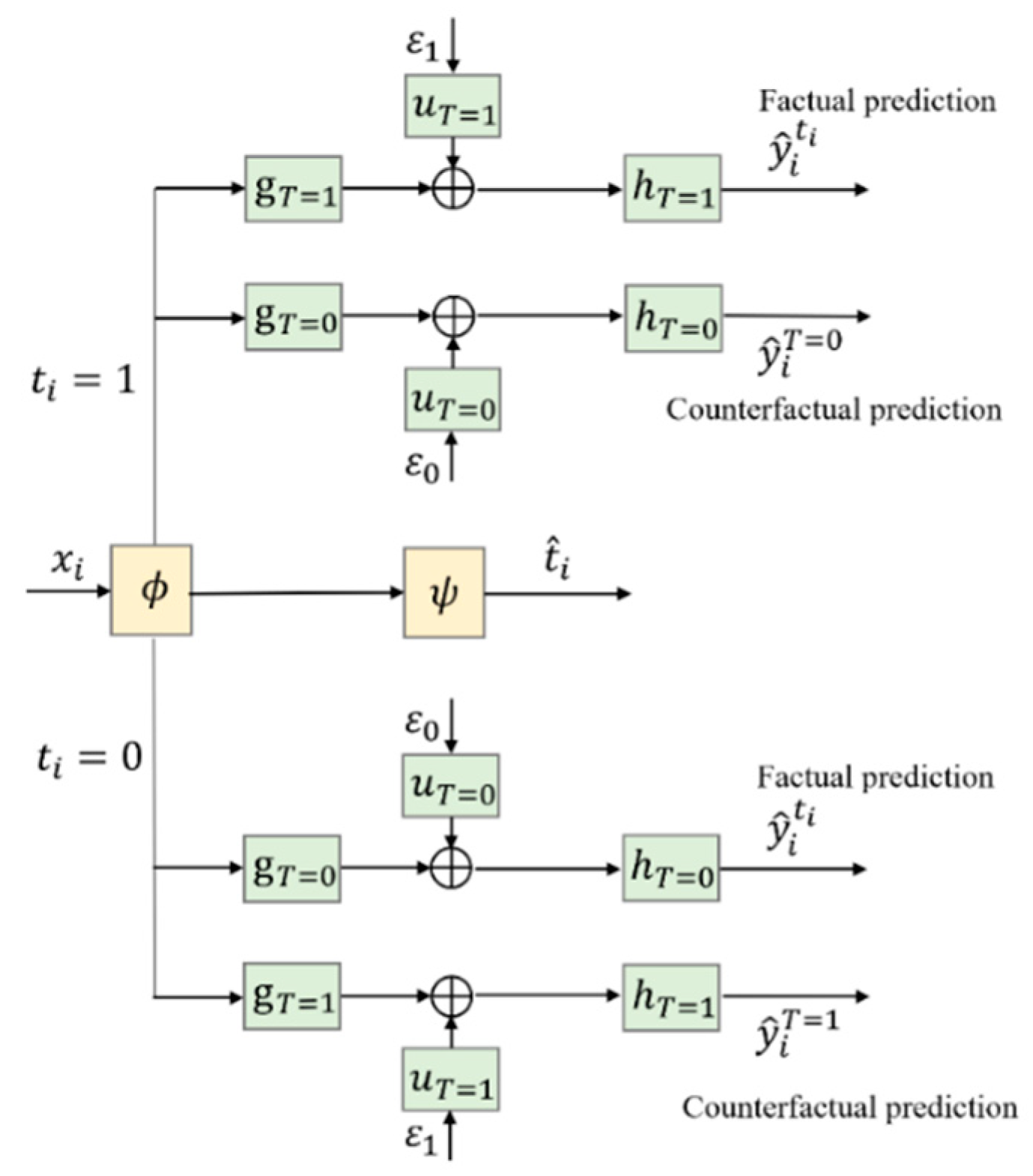
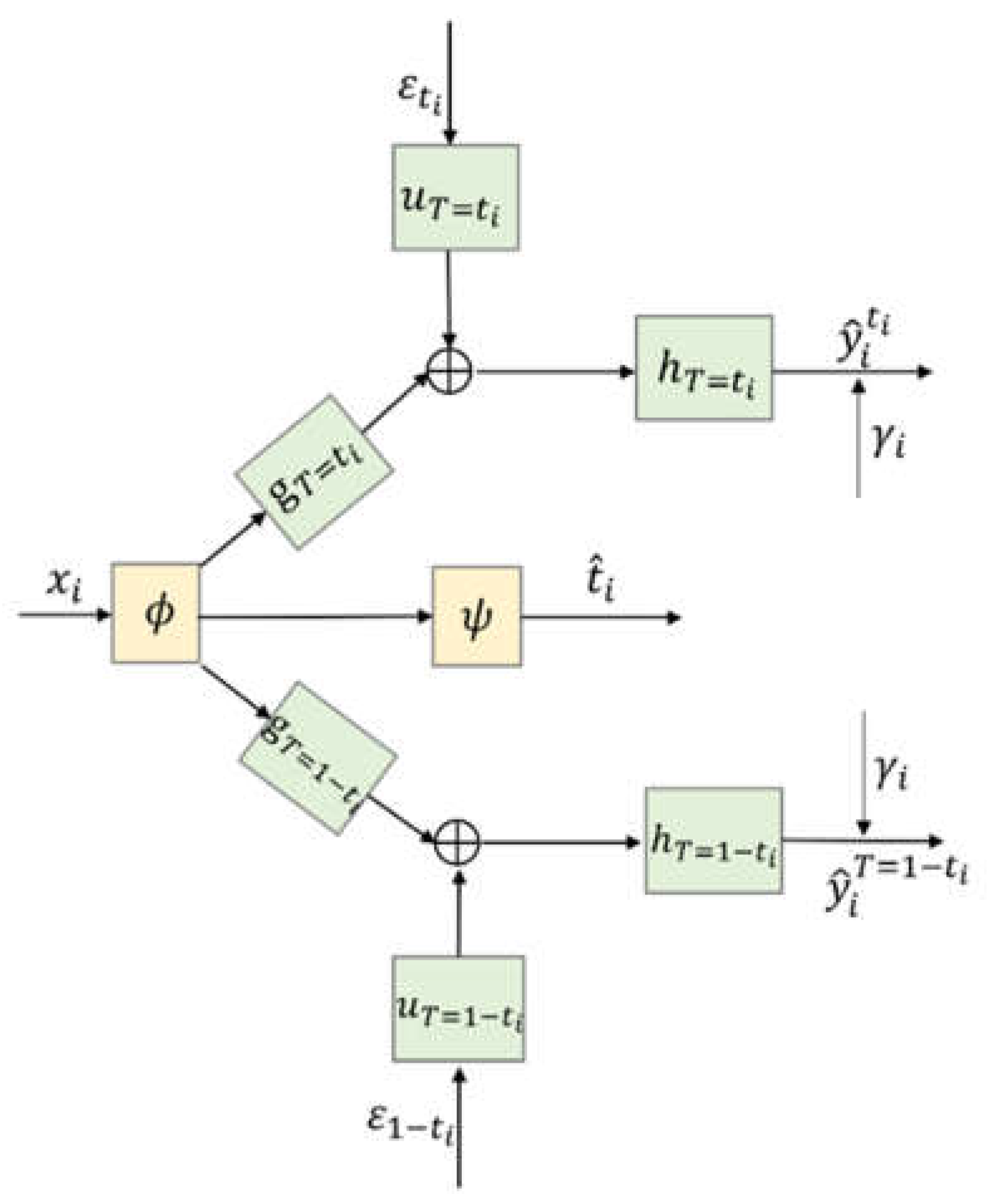
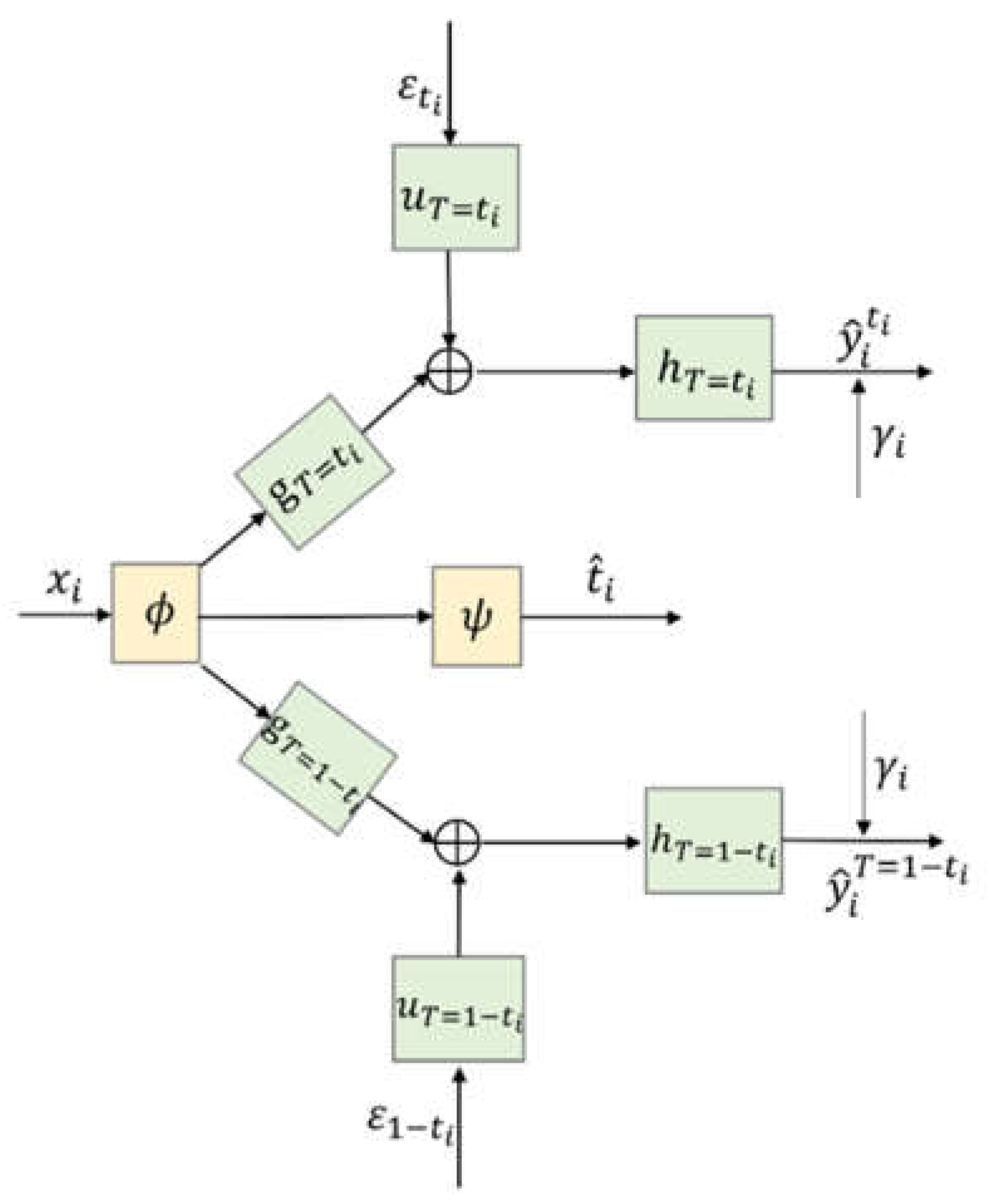
4.3. Architecture of CDNEPK with Incorporated Counterfactual Prediction Branches
4.4. Loss Items of CDNEPK with Incorporated Prior Knowledge
- Patients with prior knowledge ()
- (i)
- , and .
- (ii)
- , and .
- (iii)
- and .
- (iv)
- , and .
- 2.
- Patients with prior knowledge )
- (i)
- or , and .
- (ii)
- or , and .
4.5. Training Algorithm for CDNEPK
| Algorithm 1: Training algorithm of CDNEPK. |
| Input: Dataset Dall, weighting factors α,β, iteration time c1, batch number c2, batch size b, learning rate r, initial weights of network W; |
| Output: Trained CDNEPK model |
| 1: for i = 1 to c1 do |
| 2: |
| 3: |
| 4: Calculate loss function of jth batch Dj according to Formula (15): |
| 5: Update W by descending its gradient |
| 6: end for |
| 7: end for |
5. Experiments Based on Semi-Synthetic Data
5.1. Data Generating and Experiment Setup
5.2. Experimental Results
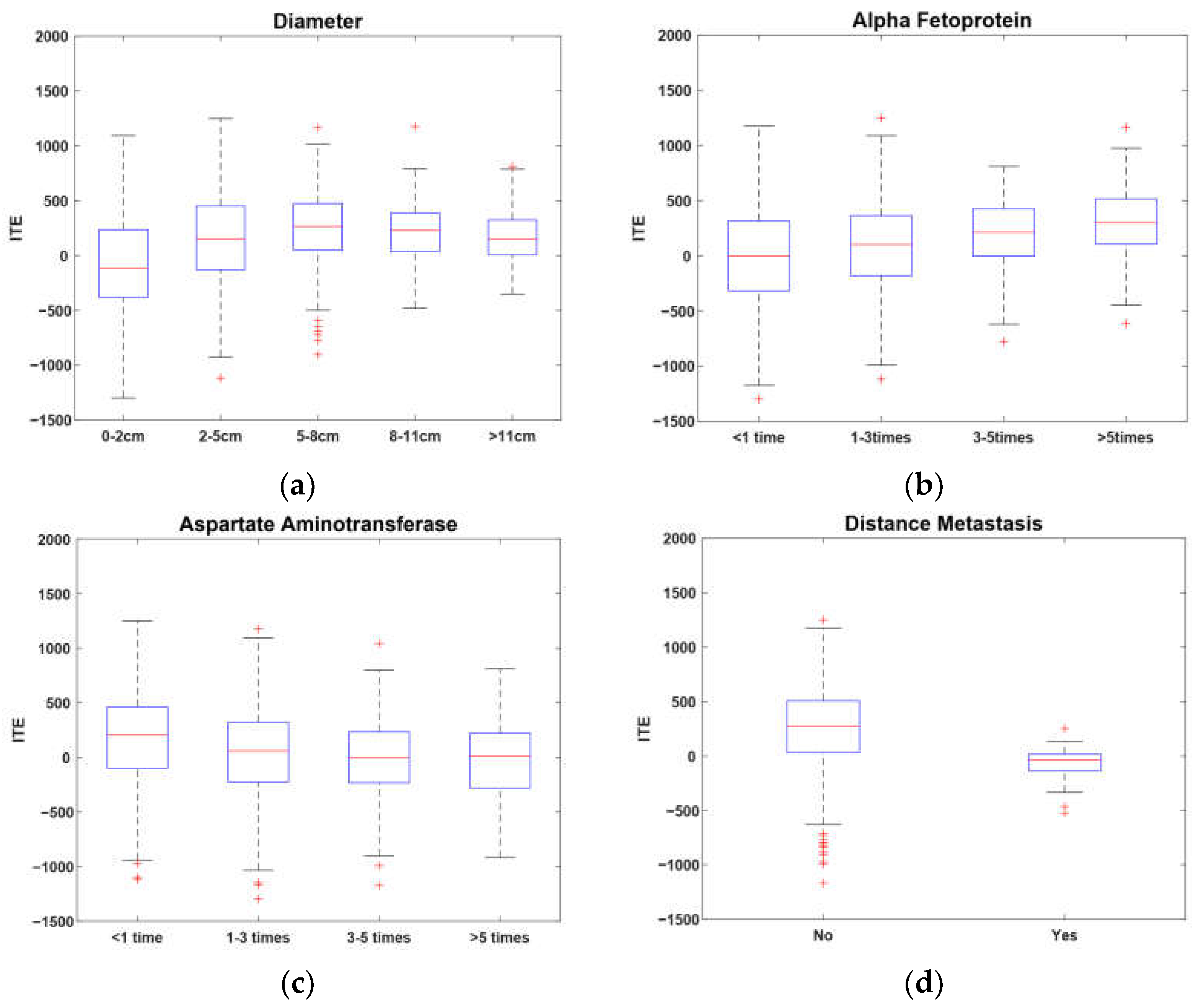
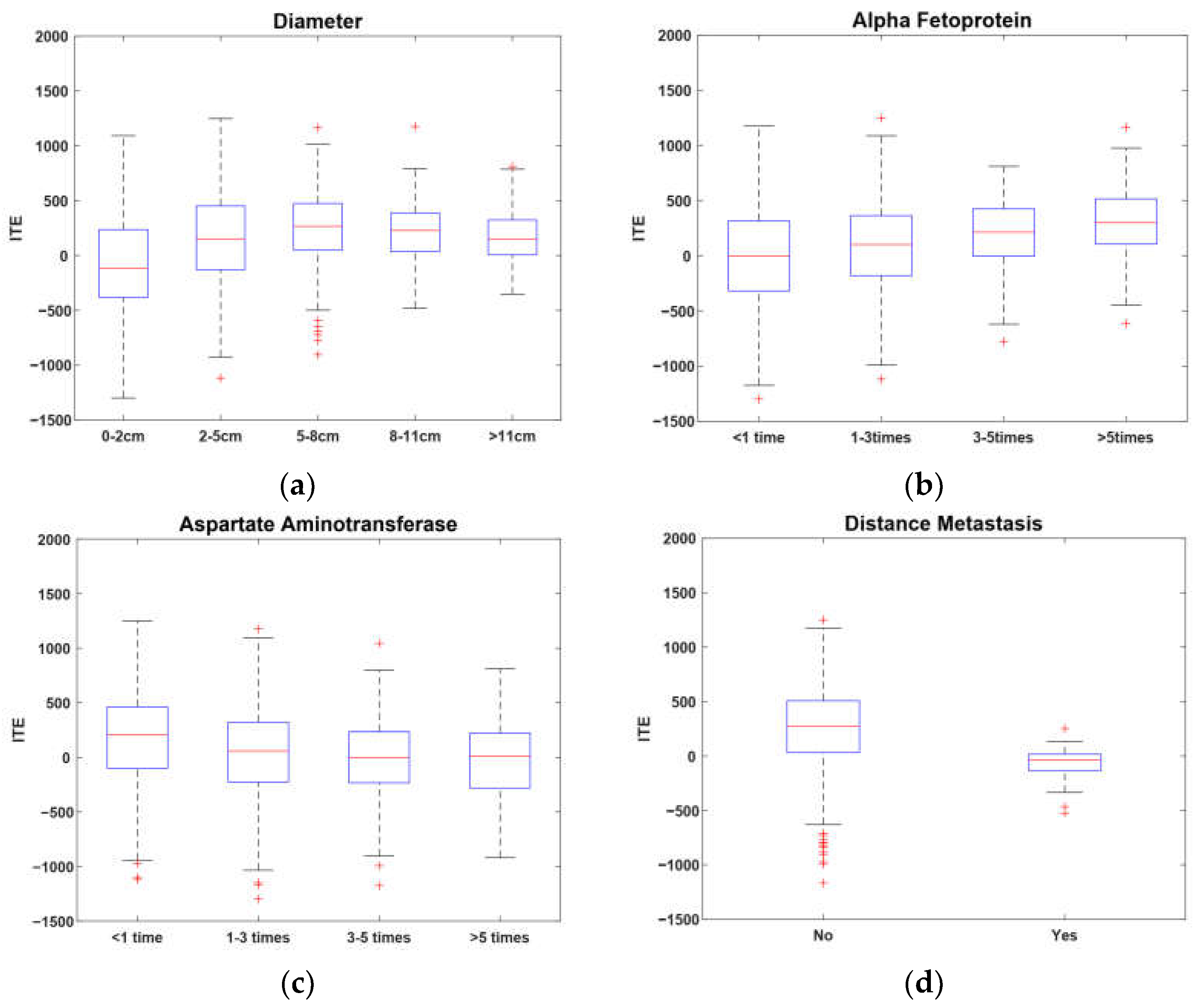
6. Real-World Experiment on Hepatocellular Carcinoma
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yao, L.; Chu, Z.; Li, S.; Li, Y.; Gao, J.; Zhang, A. A survey on causal inference. ACM Trans. Knowl. Discov. Data 2021, 15, 1–46. [Google Scholar] [CrossRef]
- Hernán, M.; Robins, J. Causal Inference: What If; Chapman & Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Shalit, U.; Johansson, F.D.; Sontag, D. Estimating individual treatment effect: Generalization bounds and algorithms. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3076–3085. [Google Scholar]
- Chapfuwa, P.; Assaad, S.; Zeng, S.; Pencina, M.J.; Carin, L.; Henao, R. Enabling counterfactual survival analysis with balanced representations. In Proceedings of the Conference on Health, Inference, and Learning, Virtual Event, 8–9 April 2021; pp. 133–145. [Google Scholar]
- Wu, A.; Yuan, J.; Kuang, K.; Li, B.; Wu, R.; Zhu, Q.; Zhuang, Y.; Wu, F. Learning Decomposed Representations for Treatment Effect Estimation. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Imbens, G.; Rubin, D. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Hassanpour, N.; Greiner, R. CounterFactual Regression with Importance Sampling Weights. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 5880–5887. [Google Scholar]
- Prinja, S.; Gupta, N.; Verma, R. Censoring in clinical trials: Review of survival analysis techniques. Indian J. Community Med. Off. Publ. Indian Assoc. Prev. Soc. Med. 2010, 35, 217. [Google Scholar] [CrossRef] [PubMed]
- Jenkins, S.P. Survival Analysis; Institute for Social and Economic Research, University of Essex: Colchester, UK, 2005; Volume 42, pp. 54–56, Unpublished Manuscript. [Google Scholar]
- Shi, C.; Blei, D.; Veitch, V. Adapting neural networks for the estimation of treatment effects. In Advances in Neural Information Processing Systems 32; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2019. [Google Scholar]
- Fox, J.; Weisberg, S. Cox Proportional-Hazards Regression for Survival Data. Appendix to an R and S-PLUS Companion to Applied Regression. Available online: https://socialsciences.mcmaster.ca/jfox/Books/Companion-2E/appendix/Appendix-Cox-Regression.pdf (accessed on 23 February 2011).
- Saikia, R.; Barman, M.P. A review on accelerated failure time models. Int. J. Stat. Syst. 2017, 12, 311–322. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Hariton, E.; Locascio, J.J. Randomised controlled trials—The gold standard for effectiveness research. BJOG Int. J. Obstet. Gynaecol. 2018, 125, 1716. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Shen, Q.; Bai, H.X.; Wu, J.; Ma, C.; Shang, Q.; Hunt, S.J.; Karakousis, G.; Zhang, P.J.; Zhang, Z. Comparison of radiofrequency ablation and hepatic resection for the treatment of hepatocellular carcinoma 2 cm or less. J. Vasc. Interv. Radiol. 2018, 29, 1218–1225.e1212. [Google Scholar] [CrossRef]
- Mariani, A.W.; Pego-Fernandes, P.M. Observational studies: Why are they so important? Sao Paulo Med. J. 2014, 132, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Cartwright, N. Are RCTs the gold standard? BioSocieties 2007, 2, 11–20. [Google Scholar] [CrossRef] [Green Version]
- Concato, J.; Shah, N.; Horwitz, R.I. Randomized, controlled trials, observational studies, and the hierarchy of research designs. N. Engl. J. Med. 2000, 342, 1887–1892. [Google Scholar] [CrossRef] [Green Version]
- Sauer, B.C.; Brookhart, M.A.; Roy, J.; VanderWeele, T. A review of covariate selection for non-experimental comparative effectiveness research. Pharmacoepidemiol. Drug Saf. 2013, 22, 1139–1145. [Google Scholar] [CrossRef] [PubMed]
- Bloniarz, A.; Liu, H.; Zhang, C.-H.; Sekhon, J.S.; Yu, B. Lasso adjustments of treatment effect estimates in randomized experiments. Proc. Natl. Acad. Sci. USA 2016, 113, 7383–7390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sriperumbudur, B.K.; Fukumizu, K.; Gretton, A.; Schölkopf, B.; Lanckriet, G.R. On the empirical estimation of integral probability metrics. Electron. J. Stat. 2012, 6, 1550–1599. [Google Scholar] [CrossRef]
- Le, P.B.; Nguyen, Z.T. ROC Curves, Loss Functions, and Distorted Probabilities in Binary Classification. Mathematics 2022, 10, 1410. [Google Scholar] [CrossRef]
- McNamara, M.G.; Slagter, A.E.; Nuttall, C.; Frizziero, M.; Pihlak, R.; Lamarca, A.; Tariq, N.; Valle, J.W.; Hubner, R.A.; Knox, J.J. Sorafenib as first-line therapy in patients with advanced Child-Pugh B hepatocellular carcinoma—A meta-analysis. Eur. J. Cancer 2018, 105, 1–9. [Google Scholar] [CrossRef]
- Turcotte, J.G.; Child III, C.G. Portal Hypertension: Pathogenesis, Management and Prognosis. Postgrad. Med. 1967, 41, 93–102. [Google Scholar] [CrossRef]
- Christensen, E.; Schlichting, P.; Fauerholdt, L.; Gluud, C.; Andersen, P.K.; Juhl, E.; Poulsen, H.; Tygstrup, N. Prognostic value of Child-Turcotte criteria in medically treated cirrhosis. Hepatology 1984, 4, 430–435. [Google Scholar] [CrossRef]
- Wang, J.-H.; Wang, C.-C.; Hung, C.-H.; Chen, C.-L.; Lu, S.-N. Survival comparison between surgical resection and radiofrequency ablation for patients in BCLC very early/early stage hepatocellular carcinoma. J. Hepatol. 2012, 56, 412–418. [Google Scholar] [CrossRef]
- Nathan, S.D. Lung transplantation: Disease-specific considerations for referral. Chest 2005, 127, 1006–1016. [Google Scholar] [CrossRef] [Green Version]
- Russo, M.J.; Iribarne, A.; Hong, K.N.; Davies, R.R.; Xydas, S.; Takayama, H.; Ibrahimiye, A.; Gelijns, A.C.; Bacchetta, M.D.; D’Ovidio, F. High lung allocation score is associated with increased morbidity and mortality following transplantation. Chest 2010, 137, 651–657. [Google Scholar] [CrossRef] [Green Version]
- Kutikov, A.; Uzzo, R.G. The RENAL nephrometry score: A comprehensive standardized system for quantitating renal tumor size, location and depth. J. Urol. 2009, 182, 844–853. [Google Scholar] [CrossRef] [PubMed]
- Sisul, D.M.; Liss, M.A.; Palazzi, K.L.; Briles, K.; Mehrazin, R.; Gold, R.E.; Masterson, J.H.; Mirheydar, H.S.; Jabaji, R.; Stroup, S.P. RENAL nephrometry score is associated with complications after renal cryoablation: A multicenter analysis. Urology 2013, 81, 775–780. [Google Scholar] [CrossRef] [PubMed]
- Hammer, S.M.; Katzenstein, D.A.; Hughes, M.D.; Gundacker, H.; Schooley, R.T.; Haubrich, R.H.; Henry, W.K.; Lederman, M.M.; Phair, J.P.; Niu, M. A trial comparing nucleoside monotherapy with combination therapy in HIV-infected adults with CD4 cell counts from 200 to 500 per cubic millimeter. N. Engl. J. Med. 1996, 335, 1081–1090. [Google Scholar] [CrossRef]
- Yin, L.; Li, H.; Li, A.-J.; Lau, W.Y.; Pan, Z.-Y.; Lai, E.C.; Wu, M.-C.; Zhou, W.-P. Partial hepatectomy vs. transcatheter arterial chemoembolization for resectable multiple hepatocellular carcinoma beyond Milan Criteria: A RCT. J. Hepatol. 2014, 61, 82–88. [Google Scholar] [CrossRef]
- Kaneko, K.; Shirai, Y.; Wakai, T.; Yokoyama, N.; Akazawa, K.; Hatakeyama, K. Low preoperative platelet counts predict a high mortality after partial hepatectomy in patients with hepatocellular carcinoma. World J. Gastroenterol. WJG 2005, 11, 5888. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, H.-C.; Wang, Z.; Cong, W.-M.; Wang, J.-H.; Zeng, M.-S.; Yang, J.-M.; Bie, P.; Liu, L.-X.; Wen, T.-F. Guidelines for diagnosis and treatment of primary liver cancer in China (2017 Edition). Liver Cancer 2018, 7, 235–260. [Google Scholar] [CrossRef] [PubMed]
- Abdi, H.; Williams, L.J.; Valentin, D. Multiple factor analysis: Principal component analysis for multitable and multiblock data sets. Wiley Interdiscip. Rev. Comput. Stat. 2013, 5, 149–179. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Covariates | Conditions for Covariate Score = 1 | Conditions for Covariate Score = 2 | Conditions for Covariate Score = 3 |
|---|---|---|---|
| hepatic encephalopathy grade | 0 | 1, 2 | 3, 4 |
| ascites grade | 0 | 1 | 2, 3 |
| total bilirubin (g/L) | >0 and <34 | 34~51 | >51 |
| albumin (g/L) | >35 | 28~35 | >0 and <28 |
| prothrombin time (s) | >0 and <4 | 4~6 | >6 |
| COX | 375.33 | 144.65 |
| AFT | 342.71 | 180.08 |
| RSF | 292.78 | 127.29 |
| CSA | 291.49 | 80.34 |
| CSA–Dragonnet | 271.23 | 73.24 |
| CDNEPK | 264.59 | 67.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhou, H.; Gu, J.; Ye, H. Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction. Entropy 2022, 24, 975. https://doi.org/10.3390/e24070975
Zhao Y, Zhou H, Gu J, Ye H. Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction. Entropy. 2022; 24(7):975. https://doi.org/10.3390/e24070975
Chicago/Turabian StyleZhao, Yijie, Hao Zhou, Jin Gu, and Hao Ye. 2022. "Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction" Entropy 24, no. 7: 975. https://doi.org/10.3390/e24070975
APA StyleZhao, Y., Zhou, H., Gu, J., & Ye, H. (2022). Estimating the Individual Treatment Effect on Survival Time Based on Prior Knowledge and Counterfactual Prediction. Entropy, 24(7), 975. https://doi.org/10.3390/e24070975