Abstract
Domain adaptation aims to learn a classifier for a target domain task by using related labeled data from the source domain. Because source domain data and target domain task may be mismatched, there is an uncertainty of source domain data with respect to the target domain task. Ignoring the uncertainty may lead to models with unreliable and suboptimal classification results for the target domain task. However, most previous works focus on reducing the gap in data distribution between the source and target domains. They do not consider the uncertainty of source domain data about the target domain task and cannot apply the uncertainty to learn an adaptive classifier. Aimed at this problem, we revisit the domain adaptation from source domain data uncertainty based on evidence theory and thereby devise an adaptive classifier with the uncertainty measure. Based on evidence theory, we first design an evidence net to estimate the uncertainty of source domain data about the target domain task. Second, we design a general loss function with the uncertainty measure for the adaptive classifier and extend the loss function to support vector machine. Finally, numerical experiments on simulation datasets and real-world applications are given to comprehensively demonstrate the effectiveness of the adaptive classifier with the uncertainty measure.
1. Introduction
In the field of machine learning research, supervised learning methods have already witnessed the outstanding performance in many applications. The key point of supervised learning is to collect sufficient labeled datasets for model training, which also limits the usage of supervised learning in scenarios with a lack of training data. Furthermore, data annotating is usually a time-consuming, labor-expensive, or even unrealistic task. To settle this situation, domain adaption (DA) is a promising methodology that aims to learn an adaptive classifier for the target domain tasks by making use of labeled data from source domains [1,2,3,4]. It has been applied in various fields successfully, such as object recognition [5,6], text classification [7,8], medical field [9,10], machine translation [11] and so on.
However, due to the mismatch between the source domain data and the target domain task, there is an uncertainty in DA when source domain data transfers to tasks of the target domain. As shown in Figure 1, in the target domain classification task, each source domain datum may no longer fully belong to a class in the label space of the target domain. The possibility of it being in class 1* is 0.2, and the uncertainty is 0.8, or the possibility of it being in class 1* is 0.9, and the uncertainty is 0.1. Unfortunately, the uncertainty of source domain data with respect to the target domain task is given less attention in DA. Ignoring uncertainty may result in an issue that the classifier does not fully match the target domain task, which weakens the model’s transfer performance.

Figure 1.
(a) Data distribution of source domain, (b) category distribution of source domain data in label space of the target domain.
Most DA research works adopted metric learning to minimize the data differences between the source and target domain for getting an adaptive classifier. Some works map the source and target data instances into a common feature space by minimizing the gap between the data distributions of the source and target domain, such as transfer component analysis (TCA) [12], correlation alignment (CORAL) [13], and scatter component analysis (SCA) [14]. Some works construct a loss function with the data differences as the constraint to train an adaptive classifier, such as joint adaptation network (JAN) [15], manifold embedded distribution alignment (MEDA) [16], and multi-representation adaptation network (MRAN) [17]. However, existing methods (1) cannot measure the uncertainty of source domain data about the target domain task, and (2) cannot accomplish effective training of adaptive classifiers with a data uncertainty measure.
The uncertainty is important for evaluating the adaptation degree of the source domain data about target tasks. The study of uncertainty has been successfully applied in traditional machine learning, such as bayesian-based uncertainty [18], evidence theory-based uncertainty [19], information entropy-based uncertainty [20], and granular computing-based uncertainty [21]. In particular, the evidence theory has been widely combined with machine learning methods to improve their ability to handle the uncertainty data [22,23,24,25,26].
To solve these problems, in this paper, we revisit the domain adaptation from source domain data uncertainty based on evidence theory and thereby devise a reliable adaptive classifier with the uncertainty measure. Specifically, we first construct an evidence net based on evidence theory for measuring the uncertainty of source domain data about the target domain classification task. It can calculate the proportion of uncertainty for each source domain instance in the target domain classification task. Second, we design a general loss function with the uncertainty measure for the adaptive classifier and extend the loss function to support vector machine (SVM). The contributions of this paper are summarized as follows.
- Designing an evidence net based on evidence theory to measure the uncertainty of source domain data about a target domain classification task.
- Designing a general loss function with uncertainty measure for learning of the adaptive classifier.
- Extending the SVM by the general loss function with uncertainty measure for enhancing its transferred performance.
The remainder of the paper is organized as follows. We start by reviewing related works in Section 2. Section 3 describes the evidence net that is built based on evidence theory for estimating the uncertainty. Section 4 extends the general loss function to SVM. Section 5 presents the experimental results to validate the efficiency of the proposed method. The conclusion about our exploratory work is also given in the last section.
2. Related Work
In this section, we discuss previous works on domain adaptation that minimizes the data difference between the source and target domain. In addition, we introduce the evidence theory that is most related to our work.
2.1. Domain Adaptation with Metric Learning
We will briefly introduce the domain adaptation with metric learning. These methods leverage the metric methods to reduce the data difference between two domains.
Maximum mean discrepancy (MMD) [27] takes advantage of the kernel trick, which can measure the data difference between the source domain and target domain. MMD is widely used in domain adaptation. Some state-of-the-art methods are proposed based on MMD. Pan and Yang et al. [12] propose the transfer component analysis (TCA) model based on MMD. The TCA utilizes the MMD to reduce the gap between the source domain and target domain. Long et al. [28] put forward the joint distribution adaptation (JDA) algorithm that uses the MMD to adapt both the marginal distribution and conditional distribution in domain adaptation. Muhammad Ghifary et al. [29] propose a neural network model that embeds the MMD regularization to reduce the distribution mismatch. Long et al. [30] propose a novel framework that is called adaptation regularization-based transfer learning (ARTL). The ARTL optimizes the structural risk functional, joint distribution adaptation of both the marginal, and conditional distributions by embedding the MMD regularization. Yan et al. [31] propose a weighted domain adaptation network (WDAN) by both incorporating the weighted MMD into CNN and taking into account the empirical loss on target samples.
Kullback–Leibler (KL) divergence [32] can measure data distribution differences between the source domain and target domain. Dai et al. [33,34] use the KL divergence to measure the difference between the source domain and target domain and uses the difference in co-clustering to improve the performance of transferring. Zhuang et al. [35] propose a supervised representation learning method based on a deep auto-encoder for domain adaptation. In the embedding layer, the authors use the KL divergence to keep the two distributions of source and target domains similar.
Jensen–Shannon (JS) divergence is similar to KL divergence and measures the difference between the source domain and target domain. However, the JS divergence solves the asymmetry problem of KL divergence. Joshua Giles et al. [36] use JS divergence to compare calibration trails with an electroencephalogram dataset for selecting the target user in domain adaptation. Subhadeep Dey et al. [37] employ JS divergence in Information Bottleneck clustering to find clusters in domain adaptation.
The Wasserstein distance derives from the optimal transport problem. It can be used to measure distances between two probability distributions. Shen et al. [38] reduce the discrepancy between the source domain and target domain by gradient property of the Wasserstein distance for improving transfer performance. Lee et al. [39] use the Wasserstein discrepancy between classifiers to align distributions in domain adaptation.
In summary, the core idea of most methods is to minimize the distribution difference between the source and target domain. However, they ignore the uncertainty between the source domain data and the target domain task.
2.2. Learning with Evidence Theory
Evidence theory can be considered a generalized probability [19,40]. It can represent and measure data uncertainty using mass function [41]. The evidence theory uses Dempster’s rule to finish uncertainty reasoning [42]. We will recall mass function and Dempster’s rule from evidence theory.
2.2.1. Mass Function
Let be a finite domain (set) that includes all possible answers to the decision problem, and the elements of the set are mutually exclusive and exhaustive. is called the frame of discernment. In the classification problems, the element can be regarded as the kth category, and can be considered as the sample space or label space. We denote the power-set as , and the cardinality of the power-set is .
The mass function is the Basic Belief Assignment (BBA) that represents the support degree of evidence, and is a mapping from to the interval . It satisfies the condition as follows
where measures the support degree for proposition A itself and represents that the empty set has no support degree. If , A is called a focal element. In classification problems, if , can be interpreted as a support degree (possible) that instance belongs to class . If , can be interpreted as the total ignorance degree for classification results. In this paper, can be used to reflect the instance uncertainty.
For example, we assume a classification problem that distinguishes colors. The frame of discernment is . The power-set is , and , . represents the possibility that x belong to green based on evidence E. represents that we can not determine which class the sample belongs to. It reflects the instance uncertainty.
2.2.2. Dempster’s Rule
Dempster’s rule reflects the combined effect of evidence. Let and be two mass functions induced by independent items of evidence. They can be combined using Dempster’s rule to form a new mass function defined as
for all , and (⊕ is the combination operator of Dempster’s rule). k is the degree of conflict between and ; it can be defined as
3. Uncertainty Measure in Domain Adaptation Based on Evidence Theory
In domain adaptation, the key problem of the uncertainty measure is how to evaluate the uncertainty in the target domain classification task for each source domain data. We consider that the lower uncertainty of instance represents less information loss in domain adaptation. To achieve this, we construct an evidence net based on evidence theory. It consists of two key steps (1) obtaining a trusty evidence set, and (2) designing the evidence net based on evidence theory. We describe them separately below.
3.1. Obtaining the Trusty Evidence Set
Let us consider a simple scenario with a large number of instances labeled source-domain and a small number of instances labeled target-domain .
Given a source-domain instance , its evidence set consists of similar instances from the target domain and can be formulated as a neighborhood surrounding .
in which are n target domain instances similar to the source domain instances and . To ensure the validity of the evidence set, the discrepancy between a source-domain instance and the elements of its evidence set should be small. Motivated by this, we design the objective function of obtaining an evidence set for a source domain instance as
in which the function measures the discrepancy between the of the source domain and the evidence set in a reproducing kernel Hilbert Space (RKHS) , is formulated as
where is the feature mapping, and is the number of elements in the evidence set. In this paper, we utilize the radial basis function kernel to construct the kernel Hilbert space,
in which is the Euclidean distance between two points and is a scaling parameter. Substituting into Equation (6), the function can be rewritten as
Based on the above analysis, the objective function of Equation (5) to obtain the evidence set can be specified as
The optimal evidence set in Equation (9) can be solved by a greedy search on the labeled target domain.
3.2. Constructing Evidence Net Based on Evidence Theory
In the evidence theory, suppose that is the mass function, is the label space, and is the evidence set, the mass function can represent the uncertainty of x about the classification task. In domain adaptation, comes from the label space of the target domain. In a built-up evidence set , from the target domain , for instance, , from source domain , can represent the uncertainty of the source domain instance about the target domain classification task.
In this section, motivated by evidential k-Nearest Neighbor [22] and neural network, we construct an evidence net based on Dempster’s rule to calculate . The details of the evidence net are described as follows.
According to Section 3.1, the evidence set has been generated from the labeled target domain . Given k classes, we decompose the evidence set into different classes,
where is the evidence subset in which all the target domain instances have the class label , and is the lth element in the evidence subset.
According to the decomposition of the evidence set and Dempster’s rule, the evidence net can be represented in the connectionist formalism as a network with an input layer, three evidence layers , , and , and an output layer.
As shown in Figure 2, the input layer is an instance of source domain , and the output layer is and . Each evidence layer corresponds to one step of the procedure described as follows.
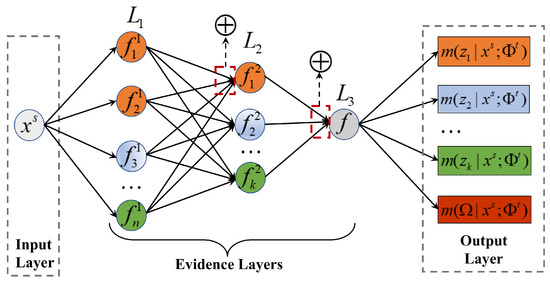
Figure 2.
Evidence net architecture.
(1) Layer contains n nodes, and we denote the node of layer as . The input of the node is an instance from source domain . At the fine-grained evidence level, given an element in an evidence subset, we compute as
in which
where is defined as follows
in which is the radial basis function kernel.
(2) Layer contains k nodes, and we denote the node as . Using Dempster’s rule to combine under single evidence , we can obtain under the evidence subset .
in which
where the orthogonal sum ⨁ represents the combination operator of Dempster’s rule.
(3) In layer , we denote the node as . can be calculated under the entire evidence set through accumulating under evidence subsets.
in which
where is a normalizing factor.
represents the proportion of uncertainty in the target domain classification task for the source domain instance . represents the possibility that source domain instance belongs to class of the target domain. In this paper, we use to measure the uncertainty of source domain data about the target domain task. Algorithm 1 summarizes the evidence net-based uncertainty measure of source domain data in domain adaptation.
| Algorithm 1 The uncertainty measure based on evidence net for source domain data |
| Input: source domain , labeled target domain . |
| Output: source domain with uncertainty . |
| 1: for all do |
| 2: Generate an evidence set for according to Equation (9). |
| 3: Estimate uncertainty of based on the evidence net . |
| 4: end for |
| 5: return with . |
4. Learning Algorithm of Adaptive Classifier with Uncertainty Measure
Section 3 has successfully solved the uncertainty measure of source domain data for target domain tasks. In domain adaptation, another key issue is how to use the uncertainty to learn an adaptive classifier. To solve this problem, we propose a general loss function with an uncertainty measure.
The learning algorithm with uncertainty measure can be transformed into a problem of regularized risk minimization with uncertainty . Thus, the general loss function of the learning algorithm with uncertainty can be written as
where instance comes from source domain , is loss function, and w is the parameter of the model. In order to verify its effectiveness, we extend the loss function with an uncertainty measure to support vector machine (SVM).
4.1. Support Vector Machine with Uncertainty Measure (SVMU)
Based on the general loss function, we propose an improved support vector machine with an uncertainty measure (SVMU), which integrates the uncertainty of the source domain instance about the target domain task to SVM. The SVM uses only one penalty factor to control the balance between margin maximization and misclassification. However, in domain adaptation, due to domain differences, the classification hyperplane controlled by only one penalty factor cannot effectively distinguish classes of the target domain. The SVMU can change the penalty factor by the uncertainty measure. It makes the instances of the source domain that are beneficial to the target domain classification task become the new support vectors and diminishes the importance of some instances that have negative effects. Thus, SVMU is more flexible and superior in domain adaptation than SVM. The details of SVMU are described as follows.
SVM maps the input points into a high-dimensional feature space and finds a separating hyperplane that maximizes the margin between two classes in this space. According to the general loss function, Equation (19), the optimization problem for SVMU is then regarded as the solution to
subject to
where parameter is the slack variable. is the penalty factor, which controls the trade-off between the slack variable penalty and the margin. denotes a fixed feature-space transformation. b is the bias parameter.
To solve this optimization problem, we construct the Lagrangian function
To find the saddle point of , the parameters satisfy the following conditions
By applying these conditions to the Lagrangian function (22), problem (20) can be transformed into
subject to
where is a kernel function
and the KKT conditions are defined as
The optimal solution of (24) can be denoted as , where corresponding to is a support vector. The support vector falls exactly on the margin boundary if . If , , then the classification is correct, and is between the boundary and the hyperplane. If and , then is on the classification hyperplane; if and , then is on the misclassified side of the classification hyperplane.
In the traditional SVM, the only penalty factor C controls the balance between margin maximization and misclassification. A larger C allows the SVM to have fewer misclassification and a narrower margin. Conversely, a smaller C makes the SVM ignore more training points and obtains a larger margin. Due to the existing uncertainty of the source domain data about the target domain task, with only one penalty factor, it is difficult to control the balance between margin maximization and misclassification in the target domain task. This may result in negative transfer when using SVM as the classifier.
Based on the above analysis, applying uncertainty to SVM, it can be found that the single penalty factor C becomes , whose number of penalty factors increases from one to the number of source domain instances. Each support vector corresponds to a penalty factor with an uncertainty measure instead of corresponding to a single constant value C. Thus, the selection of support vectors does not rely on a single penalty factor but is determined by the uncertainty of each source domain instance with respect to the target domain task. As shown in Figure 3, changing the penalty factor C by uncertainty can make the instances of the source domain that are beneficial to the target domain classification task become the new support vectors and diminish the importance of some instances that have negative effects. The classification hyperplane that is generated by these new support vectors is suited to discriminate the target data. Thus, integrating the uncertainty to SVM can adjust the classification hyperplane to suit the target domain task.
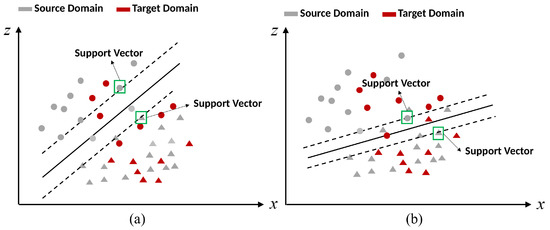
Figure 3.
Schematic diagram: (a) Classification hyperplane is generated by SVM. (b) Classification hyperplane is generated by SVM with uncertainty.
5. Experiments
In the experiments, we evaluate the adaptive classifier with an uncertainty measure on various kinds of data, including texts and images. The descriptions of the datasets are listed below.
Amazon product reviews dataset [43] is the benchmark text corpora widely used for domain adaptation evaluation. The reviews are about four product domains: books (denoted as B), dvds (denoted as D), electronics (denoted as E), and kitchen appliances (denoted as K). Each review is assigned to a sentiment label, (negative review) or +1 (positive review), based on the rating score given by the review author. In each domain, there are 1000 positive reviews and 1000 negative reviews. In this dataset, we construct 12 cross-domain sentiment classification tasks: , , , , , , , , , , , , where the word before an arrow corresponds to the source domain and the word after an arrow corresponds with the target domain. In each cross-domain classification task, we extract the features of the texts by using the word2vec tool.
Office+Caltech dataset [44] is commonly used for the task of visual object recognition in domain adaptation. It includes four domains: Amazon (denoted as A, images downloaded from online merchants), Webcam (denoted as W, low-resolution images from a web camera), DSLR (denoted as D, high-resolution images from a digital SLR camera), and Caltech-256 (denoted as C). The dataset includes 10 classes: backpack, touring bike, calculator, head Caltech, phones, computer keyboard, laptop-101, computer monitor, computer mouse, coffee mug, and video projector. There are 8 to 151 samples per category per domain and 2533 images in total. In this dataset, we construct 12 cross-domain multi-classification tasks: , , , , , , , , , , , and .
In the experiment, for each domain adaptation classification task, we use the classification accuracy of the target domain as the evaluation criterion. Suppose is the target domain dataset,
where y is the ground truth label of x, and is the label predicted by the classifier.
5.1. Comparative Studies
To evaluate the transfer performance of SVM with the uncertainty measure (SVMU), we compared it with 9 domain adaptation methods on Amazon product reviews dataset and Office+Caltech datasets, respectively. The methods of comparison include transfer component analysis (TCA) [12], correlation alignment (CORAL) [13], geodesic flow kernel (GFK) [44], joint distribution adaptation (JDA) [28], kernel mean matching (KMM) [45], metric transfer learning (MTLF) [46], scatter component analysis (SCA) [14], practically easy transfer learning (EasyTL) [47], and Wasserstein distance-guided representation learning (WDGAL) [38].
- (1)
- Testing on Amazon product reviews dataset
In this testing, we evaluate SVM with an uncertainty measure (SVMU) on the Amazon product reviews dataset. The classification accuracies of the comparative study are listed in Table 1.

Table 1.
Cross-domain sentiment classification accuracies of Amazon product reviews generated by SVMU and baseline methods.
As shown in Table 1, the average classification accuracy of SVMU on the 12 tasks is . The performance improvement is 6.17%, 12.77%, 9.28%, 6.04%, 5.19%, 12.47%, 2.70%, 3.33%, and 0.9% compared to baseline method. The average classification accuracy of TCA, CORAL, GFK, JDA, and KMM are , , , , and on Amazon product reviews. These methods aim to minimize the different between the source and target domains, while ignoring the uncertainty of the instances in the source domain with respect to the task. Although they can find a representation space with the greatest commonality between the source and target domains, they cannot determine whether the source domain instance is suitable for the target domain task. This limits the performance of these methods. The performance improvement of our method is , , , , and compared to them. In results of text classification, since these results are obtained from a larger number of datasets, it can convincingly verify that SVMU is reliable and effective for classifying cross-domain text accurately.
- (2)
- Testing on Office+Caltech datasets
In this testing, we evaluate SVM with an uncertainty measure (SVMU) on Office+Caltech datasets. In each cross-domain classification task, we extract the features of images by speeded up robust features (SURF). The classification accuracies of the comparative study are listed in Table 2.
Table 2.
Cross-domain classification accuracies on Office+Caltech image datasets (SURF features) generated by SVMU and baseline methods.
It is obvious that SVMU achieves better performance than the methods of comparison on Office+Caltech datasets. Specifically, the average classification accuracy of SVMU on 12 cross-domain classification tasks is 50.60%, which gains significant performance improvements of 4.16%, 4.1%, 5.22%, 4.04%, 4.55%, 4.63%, 3.23%, and 2.93% compared to the baseline methods. The experimental results reveal that the improved SVM with the uncertainty measure is reliable and effective in cross-domain image classification tasks.
5.2. Effectiveness Verification of Uncertainty Measure
In this experiment, we verify the effectiveness of the uncertainty measure from three views: (1) Testing on synthetic data, visualizing the classification hyperplane of an adaptive classifier with and without an uncertainty measure. (2) Testing on real-world datasets, comparing the performance of SVM with and without an uncertainty measure. (3) Case study, explaining the role of uncertainty measure.
5.2.1. Testing on Synthetic Data
In order to demonstrate the effectiveness of the adaptive classifier with an uncertainty measure in domain adaptation, we visualize the classification hyperplane of an adaptive classifier on a synthetic dataset. The synthetic dataset is generated from a Gaussian distribution , where and are the mean and standard deviation, respectively. We apply different and to generate the data from the source domain and target domain. In the dataset, the source domain and target domain consist of two-dimensional data points under two classes, and each class has 500 data points. The source domain is marked by a pentagram, and the target domain is marked by a triangle. Class 1 is marked in orange, and Class 2 is marked in dark slate-gray.
In Figure 4, (a) and (b) show the classification hyperplanes that are generated based on the source domain by SVM and SVMU, respectively. Due to the difference in data distribution between the source and target domains, the classification hyperplane generated by SVM cannot accurately distinguish the categories of the target domain and cannot satisfy the domain adaptation task. In contrast, the classification hyperplane generated by SVMU can accurately classify the target domain categories, and the classification results are shown in (a) and (b). The experimental results are consistent with the conclusions about SVMU in Section 4.1. Therefore, the uncertainty measure is effective and can improve the transfer performance of the adaptive classifier.

Figure 4.
Results on synthetic data: (a) Classification hyperplane is generated by SVM. (b) Classification hyperplane is generated by SVM with uncertainty.
5.2.2. Testing on Real-World Datasets
To further explain the effectiveness of the adaptive classifier with uncertainty, we compare the SVM with and without uncertainty on the Amazon product reviews dataset.
Figure 5 shows the result of SVM with and without uncertainty on the Amazon product reviews dataset; it is obvious that in all the cross-domain text tasks, SVMU achieves better performance than SVM. SVMU improves the transfer accuracy over SVM on the 12 subtasks by , , , , , , , , , , , and . Comparing the average classification accuracy, SVMU improves the average classification accuracy by over SVM. The above results show that it is effective at enhancing the transfer performance of the adaptive classifier by introducing the uncertainty between the source domain data and target domain task.
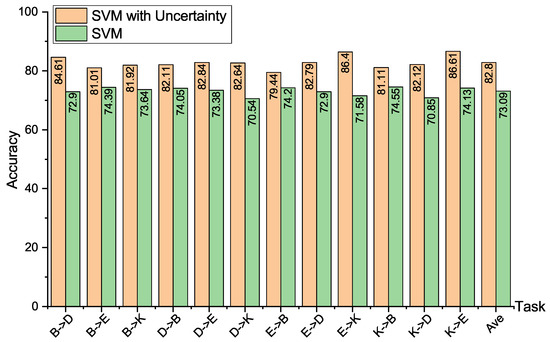
Figure 5.
Cross-domain sentiment classification accuracies on Amazon product reviews generated by SVM with and without uncertainty.
5.2.3. Case Study
Based on the above sub-experiments, it can be verified that the uncertainty measure is able to enhance adaptive classifier transfer performance. To explain the role of the uncertainty measure on the transfer process for an adaptive classifier, we use the Caltech-256 image data (complex background) as the source domain and the Amazon image data (no background) as the target domain. When the Caltech-256 dataset transfers to the Amazon dataset, the uncertainty values of some instances in the backpack and bicycle categories in the Caltech-256 dataset are shown.
As shown in Figure 6, for images (a1) to (a6) in the Caltech-256 dataset, it can be found that (a1) and (a2) are cartoon images of a backpack, and (a5) and (a6) are bicycles with obscure features. These instances are not significantly helpful for the target domain classification task. On the contrary, in (a3) and (a4), the features of the backpack and bicycle are obvious and beneficial for the target domain classification task.

Figure 6.
The uncertainty of the category ’backpack’ and ’bike’ in source domain C about the target domain A classification task.
We use the evidence net to calculate the uncertainty between (a1)–(a6) and the target domain task; as shown in Figure 6, we can find that the uncertainties of (a1), (a2), (a5), and (a6) calculated by the evidence network are high; , , , and , respectively. The uncertainties of (a3) and (a4) are low, at and , respectively. When the Caltech-256 dataset transfers to the Amazon dataset, the images (a1)–(a6) no longer fully belong to the category of backpack and bicycle. (a1), (a2), and (a3) belong to the backpack category with the possibilities , , and , and , , and are the uncertainties. (a4), (a5), and (a6) belong to the bicycle category with the possibilities , , and , and , , and are the uncertainties. Based on the above results, it can be found that our proposed uncertainty measure is consistent with people’s cognition. Therefore, the uncertainty can accurately measure the adaptability of instances with respect to the target domain task.
6. Conclusions
In this article, based on evidence theory, we revisited the domain adaptation from source domain data uncertainty and thereby devised a reliable adaptive classifier with the uncertainty measure. Specifically, for solving the uncertainty measure between the source domain data and target domain tasks, we designed an evidence net based on evidence theory. To solve the problem of model learning with a data uncertainty measure, we proposed a general loss function with an uncertainty measure for an adaptive classifier and extended the loss function to support vector machine. Experiments on the text dataset and image dataset validate that the proposed uncertainty measure is effective at improving the transfer performance of an adaptive classifier. In the future, we plan to extend the classifier with the uncertainty measure to handle the domain adaptation with multiple source domains and the domain adaptation on open sets.
Author Contributions
Conceptualization, Y.L. and B.Z.; Data curation, Z.X. and H.L.; Methodology, Y.L. and G.Z.; Writing—original draft, Y.L.; Writing-review and editing, B.Z. and X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key R&D Program of China grant number 2017YFC09 07505.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Zhang, L. Transfer adaptation learning: A decade survey. arXiv 2019, arXiv:1903.04687. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Ye, H.; Tan, Q.; He, R.; Li, J.; Ng, H.T.; Bing, L. Feature adaptation of pre-trained language models across languages and domains for text classification. arXiv 2020, arXiv:2009.11538. [Google Scholar]
- Guo, H.; Pasunuru, R.; Bansal, M. Multi-Source Domain Adaptation for Text Classification via DistanceNet-Bandits. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 7830–7838. [Google Scholar]
- Apostolopoulos, I.D.; Mpesiana, T.A. COVID-19: Automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef] [Green Version]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 3347–3357. [Google Scholar]
- Zhao, H.; Hu, J.; Risteski, A. On learning language-invariant representations for universal machine translation. arXiv 2020, arXiv:2008.04510. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Ghifary, M.; Balduzzi, D.; Kleijn, W.B.; Zhang, M. Scatter Component Analysis: A Unified Framework for Domain Adaptation and Domain Generalization. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1414–1430. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Wang, J.; Feng, W.; Chen, Y.; Yu, H.; Huang, M.; Yu, P.S. Visual domain adaptation with manifold embedded distribution alignment. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 402–410. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-representation adaptation network for cross-domain image classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef]
- Bielza, C.; Larranaga, P. Discrete Bayesian network classifiers: A survey. ACM Comput. Surv. (CSUR) 2014, 47, 1–43. [Google Scholar] [CrossRef]
- Shafer, G. A mathematical theory of evidence turns 40. Int. J. Approx. Reason. 2016, 79, 7–25. [Google Scholar] [CrossRef]
- Principe, J.C.; Xu, D.; Fisher, J.; Haykin, S. Information theoretic learning. Unsupervised Adapt. Filter. 2000, 1, 265–319. [Google Scholar]
- Zadeh, L.A.; Klir, G.J.; Yuan, B. Fuzzy Sets, Fuzzy Logic, and Fuzzy Systems: Selected Papers; World Scientific: Singapore, 1996; Volume 6. [Google Scholar]
- Denoeux, T. A k-nearest neighbor classification rule based on Dempster-Shafer theory. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; pp. 737–760. [Google Scholar]
- Su, Z.; Hu, Q.; Denaeux, T. A distributed rough evidential K-NN classifier: Integrating feature reduction and classification. IEEE Trans. Fuzzy Syst. 2020, 29, 2322–2335. [Google Scholar] [CrossRef]
- Quost, B.; Denœux, T.; Li, S. Parametric classification with soft labels using the evidential EM algorithm: Linear discriminant analysis versus logistic regression. Adv. Data Anal. Classif. 2017, 11, 659–690. [Google Scholar] [CrossRef] [Green Version]
- Denoeux, T. Logistic regression, neural networks and Dempster–Shafer theory: A new perspective. Knowl.-Based Syst. 2019, 176, 54–67. [Google Scholar] [CrossRef] [Green Version]
- Denoeux, T.; Sriboonchitta, S.; Kanjanatarakul, O. Evidential clustering of large dissimilarity data. Knowl.-Based Syst. 2016, 106, 179–195. [Google Scholar] [CrossRef] [Green Version]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain adaptive neural networks for object recognition. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, 1–5 December 2014; pp. 898–904. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Pan, S.J.; Philip, S.Y. Adaptation regularization: A general framework for transfer learning. IEEE Trans. Knowl. Data Eng. 2013, 26, 1076–1089. [Google Scholar] [CrossRef]
- Yan, H.; Ding, Y.; Li, P.; Wang, Q.; Xu, Y.; Zuo, W. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2272–2281. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Dai, W.; Xue, G.R.; Yang, Q.; Yu, Y. Co-clustering based classification for out-of-domain documents. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, VA, USA; 2007; pp. 210–219. [Google Scholar]
- Dai, W.; Yang, Q.; Xue, G.R.; Yu, Y. Self-taught clustering. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 200–207. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning: Transfer learning with deep autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Giles, J.; Ang, K.K.; Mihaylova, L.S.; Arvaneh, M. A Subject-to-subject Transfer Learning Framework Based on Jensen-shannon Divergence for Improving Brain-computer Interface. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3087–3091. [Google Scholar]
- Dey, S.; Madikeri, S.; Motlicek, P. Information theoretic clustering for unsupervised domain-adaptation. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2016; pp. 5580–5584. [Google Scholar]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lee, C.Y.; Batra, T.; Baig, M.H.; Ulbricht, D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10285–10295. [Google Scholar]
- Dempster, A.P. Upper and lower probabilities generated by a random closed interval. Ann. Math. Stat. 1968, 39, 957–966. [Google Scholar] [CrossRef]
- Walley, P. Belief function representations of statistical evidence. Ann. Stat. 1987, 15, 1439–1465. [Google Scholar] [CrossRef]
- Denœux, T. Reasoning with imprecise belief structures. Int. J. Approx. Reason. 1999, 20, 79–111. [Google Scholar] [CrossRef]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 440–447. [Google Scholar]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Huang, J.; Gretton, A.; Borgwardt, K.M.; Schölkopf, B.; Smola, A.J. Correcting Sample Selection Bias by Unlabeled Data. Adv. Neural Inf. Process. Syst. 2006, 19, 601–608. [Google Scholar]
- Xu, Y.; Pan, S.J.; Xiong, H.; Wu, Q.; Luo, R.; Min, H.; Song, H. A Unified Framework for Metric Transfer Learning. IEEE Trans. Knowl. Data Eng. 2017, 29, 1158–1171. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Yu, H.; Huang, M.; Yang, Q. Easy Transfer Learning By Exploiting Intra-Domain Structures. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1210–1215. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).