1. Introduction
Financial market data are often correlated with each other and need to be analyzed together. If two or more financial data belong to the same category or reveal a similar pattern with strong correlation, the bivariate or multivariate datasets should be modeled simultaneously by an appropriate multivariate time series model to obtain good performance. Multivariate financial data with characteristics such as strong correlation and long memory have attracted much attention from econometricians and statisticians. Among various time series models, one of the most popular and powerful models capturing such financial features is the heterogenous autoregressive realized-volatility (HAR-RV) model [
1]. Based on the HAR model, this paper considers a multivariate model to analyze joint time series data with strong cross-correlation.
The HAR-RV model has been originally proposed and widely used to explore the predictability of realized volatility [
2,
3,
4,
5]. In particular, Anderson et al. [
2] used the HAR models for volatility prediction of stock prices, foreign exchange rates, and bond prices. Corsi et al. [
3] discussed the volatility of the realized volatility based on HAR models with non-Gaussianity and volatility clustering. McAleer and Medeiros [
4] proposed an extension of the HAR model with a multiple-regime smooth transition which contains long memory and nonlinearity, and incorporates sign and size asymmetries. Hillebrand and Medeiros [
5] considered log–linear and neural network HAR models of realized volatility. Tang and Chi [
6] found that the HAR model showed better predictive ability than the ARFIMA-RV model. Clements et al. [
7], Bollerslev et al. [
8], Bianco et al. [
9], and Asai et al. [
10] investigated successful uses of the HAR models for risk management with VaR measures, risk-return tradeoff, serial correlation, implied volatility, and realized volatility errors. Luo et al. [
11] incorporated jumps, leverage effects, and speculation effects into the realized volatility modeling and showed that the portfolio using infinite hidden Markov regime-switching HAR model achieves higher portfolio returns than benchmark HAR model. Meanwhile, as an application of the HAR-RV model to various financial data such as oil, gold, and bitcoin realized volatility [
12,
13,
14,
15], we considered extensions of the model incorporating with an associated-uncertainty index to obtain high forecasting gains.
Along with the success of univariate HAR models as above, a multivariate HAR model has been adopted for financial analysis due to its usefulness with multivariate data. Many researchers discussed the superiority of the multivariate HAR model. Busch et al. [
16] used a vector HAR model to control possible endogeneity issues. Taylor [
17] demonstrated that the multivariate HAR-RV model improved forecast accuracy of the realized volatility in the international stock market. The claim in [
17] was also verified by Hwang and Hong [
18], who dealt with the multivariate HAR-RV model with heteroskedastic errors. Cech and Barunik [
19] showed the generalized HAR model offers better predictability than univariate models in commodity markets. Tang et al. [
20,
21] showed that the multivariate HAR-RV model is more accurate in out-of-sample forecasting and outperforms the univariate models.
In addition, the multivariate HAR model represents strong correlations between the multiple assets data and examines cross-market spillover effects. For instance, Bubak et al. [
22] used a multivariate extension of the HAR model to analyze volatility transmission between currencies and foreign exchange rates, whereas Bauer and Vorkink [
23] adopted a multivariate setting of the HAR model and showed how to ensure positive covariance matrix without parameter restrictions. Soucek and Todorova [
24] found instantaneous correlation between equity and energy futures by proposing a vector HAR model. Cubadda et al. [
25] studied a vector HAR index model for detecting the presence of commonalities in a set of realized volatility measures, whereas Bollerslev et al. [
26] proposed a model for a scalar version of vectorized HAR model for the variances and correlations separately. Luo and Ji [
27] combined the HAR model with other models to identify time-varying volatility connectedness. Luo and Chen [
28] employed matrix log transformation method to ensure the positive definiteness of covariance matrices and developed a Bayesian random compressed multivariate HAR model to forecast the realized covariance matrices of stock returns. Wilms et al. [
29] showed that cross-market spillover effects embedded in the multivariate HAR models have long-term forecasting power.
Even though the HAR model is widely used for volatility forecasting based on the realized volatility of intraday prices, it is not restricted to the realized volatility but can be applied to various time series data such as the stock price itself or other economics index, because the HAR model is theoretically a linear AR model. Stock market forecasting techniques were surveyed in [
30,
31,
32], including stock returns, stock prices, and volatility via conventional time series methods and soft computing methods. Stock price modelings are mostly based on efficient market hypothesis (EMH), random walk theory and machine learning techniques as in [
33,
34,
35,
36]. According to the EMH, the only relevant information on the stock is its current values. A promising application of the HAR model could be the stock price movement. A reason why the HAR model is expected to perform well on the stock price modeling is that the current value itself and the current averages make its future value in the model.
In this work, we propose a multivariate time series model for strongly correlated data and study its statistical inference of hypothesis test and estimation, with empirical analysis on joint data of financial assets. More specifically, we focus on the multivariate HAR model with exponentially decaying coefficients for the application to stock prices in the stock market. Because two or more financial data exhibit a similar pattern with strong correlation, a multivariate model should be adopted for the multiple assets, instead of univariate models for each asset. However, when the multivariate HAR model is employed to analyze the multiple data, there are many parameters to be estimated. For example, even with two assets, a bivariate HAR(3) model has 14 parameters including two intercept terms. For better performance, we need to make some efforts to reduce errors along with fewer parameters in the model. As a trial for this, we consider the exponentially weighted multivariate HAR model that has exponentially decaying coefficients. If decay rates can be imposed in the multivariate HAR model, the number of parameters substantially decreases and the proposed model might outperform the existing models, reducing the errors as well. This is one of the motivations for this work in the spirit of a principle of parsimony. Moreover, the decay rates not only serve as the long-memory effect as seen in [
37], but also represent the commonality of the joint data, as we expect a common structure in multiple assets with strong correlation.
In order to employ the proposed model for joint time series data, the data need to be tested before fitting the model. To this end, we deal with a test problem based on the CUSUM test to identify the presence of decay coefficients in the multivariate HAR model of the fitted data. In general, the CUSUM test is a change-point test and would be reasonable if parameter changes are expected within the time series. For example, Refs. [
38,
39] dealt with CUSUM(SQ) tests for mean and variance change-detection in univariate HAR(
∞) models and [
40] proposed a CUSUM test for parameter change in dynamic panel models. However, the idea of the CUSUM tests can be applied to detect other dynamic structures. In this work, we suggest the use of such an idea to detect coefficient structure by generating pseudo-time series of residuals in two versions. In other words, by applying the idea of the tests to the difference series of two types of residuals, but not to the original data, the coefficient structure can be identified. That is, the CUSUM(SQ) tests of mean and variance change-detection in [
38,
39] are used for the pseudo-time series generated by two residuals. The key point is that under the null hypothesis, the mean or variance of the difference series are not changed over time, whereas under the alternative hypothesis there exist change-points in mean or variance of the difference series of two residuals. This idea is a novel attempt in that the CUSUM tests are used for other test problems in time series analysis, not limited to the conventional change-point detection of the raw data.
This work proposes two CUSUM-based tests to detect whether the underlying model has exponentially decaying coefficients. The first test is conducted to test whether the model has an exponential decay rate for each asset, and the second tests whether the exponentially weighted multivariate HAR model has a common decay rate for all the multiple assets. The null limiting distributions are developed as the standard Brownian bridge, and the theoretical results are proven by means of a modified version of a martingale central limit theorem. Additionally, easy-to-implement estimators of the decay rates are discussed.
A Monte Carlo experiment is carried out to see the sample paths of our model and to validate the proposed statistical methods. The sample paths depict the long-memory feature as well as strong cross-correlation of the simulated data. Furthermore, various related series such as difference series and test statistics are depicted to justify our proposed tests under the null and alternative hypotheses. The simulation study not only strongly supports the proposed CUSUM tests with reasonable performances of size and power, but also shows consistency in estimates of decay rates. To compare with the conventional HAR model, root mean squared error (RMSE), mean absolute error (MAE), AIC, and BIC are evaluated in the models with several values of fitting parameters as well as efficiency of the exponentially weighted HAR model, relative to the benchmark HAR model, is computed by using two metrics of RMSE and MAE. It is reported that our proposed model with fewer parameters can reduce the residual errors, compared to the existing HAR models.
As an empirical application of this work, financial market stock prices with similar patterns are selected to suit the multivariate HAR model. It is interesting that the exponentially weighted multivariate HAR model is shown to be suitable for the joint data of U.S. stock prices, rather than the volatility. Our proposed CUSUM tests favor the existence of the decay rates in the multivariate HAR model of the stock prices, based on the computed test statistics. The decay-rate estimators for the stock prices are evaluated as well. The stock prices are well-matched to the exponentially weighted multivariate HAR model. To compare performance of the proposed model, RMSE, MAE, AIC, and BIC are evaluated along with those of the conventional univariate and multivariate HAR models via OLSE and LASSO. The exponentially weighted multivariate HAR model outperforms others in the chosen datasets of U.S. stock prices.
We summarize main benefits of the exponentially weighted multivariate HAR model according to the following points: fewer number of parameters, reduction of the model-fitting errors, representation of the common structure with decay rates, and an appropriate model for joint datasets of stock prices with similar patterns. Our proposed model is suitable for strongly cross-correlated multivariate (bivariate) data with similar patterns because the decay rates yield a common structure in the joint data. Along with the high applicability of the HAR model, the proposed model can be used to analyze and forecast the joint data with strong correlation and long memory as well as its extension can be considered with an exogenous variable such as associated-uncertainty index, as in [
12,
13,
14,
15]. The proposed model would help analysts provide simpler and more efficient models by producing smaller errors in predictions in financial time series. Furthermore, it has the potential to extend to dynamic time series models with error terms of heteroscedasticity, time-varying variance, non-Gaussianity, or heavy-tailed distribution, which are more practical in real-world financial markets.
The remainder of the paper is organized as follows. In
Section 2 we describe the model and develop main results of the tests, and in
Section 3 a simulation study is performed. In
Section 4, empirical examples are given. Concluding remarks are stated in
Section 5, and proofs are drawn in the
Appendix A.
2. Model and Main Results
We consider a multivariate HAR(
) model
of order
p with
q multiple assets, given by
where
with positive integers
satisfying
,
are parameters to be estimated, and
are independent random variables with mean zero and finite variance.
In this work, we are particularly concerned with the multivariate HAR model with exponentially decaying coefficients in order to account for the lesser weights on the farther past values. In the conventional HAR model, regressors are previous value, weekly average and monthly average of consecutive data, which are assigned with coefficients in a decreasing order to represent the long-memory features. For example, see [
37], which introduced the (univariate) HAR
model with coefficients decaying exponentially to capture the genuine long-memory. They showed that exponentially decaying coefficients make algebraic decreasing autocovariance functions under appropriate lag conditions in the HAR(
∞) model. Likewise, we consider the exponentially weighted coefficient version of model (
1) with multiple assets, called exponentially weighted multivariate HAR(
) model. In our proposed model, coefficients are assumed to be
for
and
. The
is the first coefficient for the previous value of the
kth asset,
, at the first lag
, and the
is the decay rate for the next coefficients. The exponentially weighted multivariate HAR model has long memory as seen in
Figure 1 and
Figure 2 in the next section, where autocovariance functions as well as the sample paths of the model with decay rates are observed. The decay rates
not only clearly represent the long-memory feature but also reduce the number of parameters to estimate. In this work, we mainly focus on detecting the existence of the decay rates in model (
1) and additionally deal with estimating the decay rates.
In the multivariate HAR model, we first study the hypothesis test problem whether the underlying model is an exponentially weighted multivariate HAR model with decay rates, and secondly we handle easy-to-implement estimators of the decay rates.
For the hypothesis test problem, we consider two tests in (i) and (ii) as follows:
- (i)
whether or not, in the multivariate HAR model, the jth asset has a decay rate satisfying for some for each j;
- (ii)
whether or not the exponentially weighted multivariate HAR model has a common rate for all multiple assets, i.e., for some for all .
In test (i), each asset is first individually analyzed. Once test (i) has been conducted to favor the null, test (ii) is performed to detect a common rate. For test (i), the null hypothesis
and the alternative hypothesis
are, for each
j, stated as
In order to introduce a test statistic, we adopt the ordinary least squares estimator (OLSE) of the multivariate HAR model. Suppose that we have observed
of sample size
n. Let the OLSE of
be denoted by
The asymptotic property of OLSE
in the multivariate HAR model is derived theoretically by Hong et al. [
41]. From the OLSE, we first choose an estimate of
by
, and then consider a regression model with the decay rates as its coefficients under the null hypothesis as in (
2) and (
4). To describe the regression model, we let
Note that under the null hypothesis,
We rewrite
as follows:
where
, for
. Let
and consider the following regression in (
4) with coefficients
, which is a similar form to (
2) but replaced by observable quantities
and
,
:
From this regression we compute OLSE
of the parameters
by
Note that under the null hypothesis with
, it follows that
Thus, to construct a test statistic, two types of residuals
and
are respectively defined by
To construct a test statistic, we use the difference series of the two types of residuals, (not the original time series). Let
Let
where
is a consistent estimator of
, for example,
noting that
as
under the null hypothesis. Now we define a CUSUM test statistic
as follows: for
,
The following theorem states asymptotic distribution of both statistics. It provides critical values of the test for .
Theorem 1. We assume for some , for all . If the multivariate HAR() model has exponential decay rate with for some for each j, then we have, as ,where is the standard Brownian bridge with the Brownian motion . Remark 1. In order to test vs. , we adopt the CUSUM test statistics , rather than , and the null hypothesis is rejected if is large. The reason is as follows: The difference series has coefficients in the linear combination of . Note that the pseudo-time series is a triangular array and under the null hypothesis the coefficients are asymptotically zeros whereas under the alternative hypothesis the coefficients are changed over the time without vanishing asymptotically, which makes a change-point in mean or variance of the difference series. This idea is the reason why we adopt the CUSUM-based test for our goal that is to detect the exponentially decay rates. Sample paths of the series and under both and can be seen in Figure 3 and Figure 4 along with values of . In Figure 3 and Figure 4, it is shown that the difference series under the null is an asymptotical constant due to the asymptotical zeros of the coefficients, whereas under the alternative, it fluctuates with large variance; that is, it indicates that there are change-points in mean or variance. On the other hand, we might use the full sum as a test statistic in a view of theoretical insight. However, as seen in Figure 3 and Figure 4, even under , the sum is not evaluated as small values because of the following reason: can be expressed as a linear combination of and thus as a linear combination of . Note that for each k, converges to the normal distribution with asymptotic mean zero. Thus makes an asymptotic bias of the form in a finite sample. Because the asymptotic bias is not negligible even though tends to normal distribution with mean zero under the null hypothesis, the sum has somewhat large values and thus cannot distinguish significantly the two hypotheses. Therefore, this work adopts the test statistic to resolve our problem. Now we would further like to test whether or not the exponential weighted multivariate HAR model has a common exponential decay rate
for all multiple assets. That is, in the exponentially weighted multivariate HAR(
) model with
for some
for all
, after the first test has been performed, we test the null hypothesis
versus the alternative hypothesis
as follows:
Similar to the above, under the null
, for all
j we have
instead of (
2), but we use a consistent estimate
of
for
. For the estimation of the rates
,
, we discuss below in Remark 2. By using the estimate
we compute residuals
for each
j. Now, we let
and let
,
where
. Also, let
. We construct a test statistic for testing if the HAR model has common rate as follows:
For
, let
which is rewritten as
where
is a consistent estimator of
such as
The following theorem provides the null limiting distribution of the test statistic.
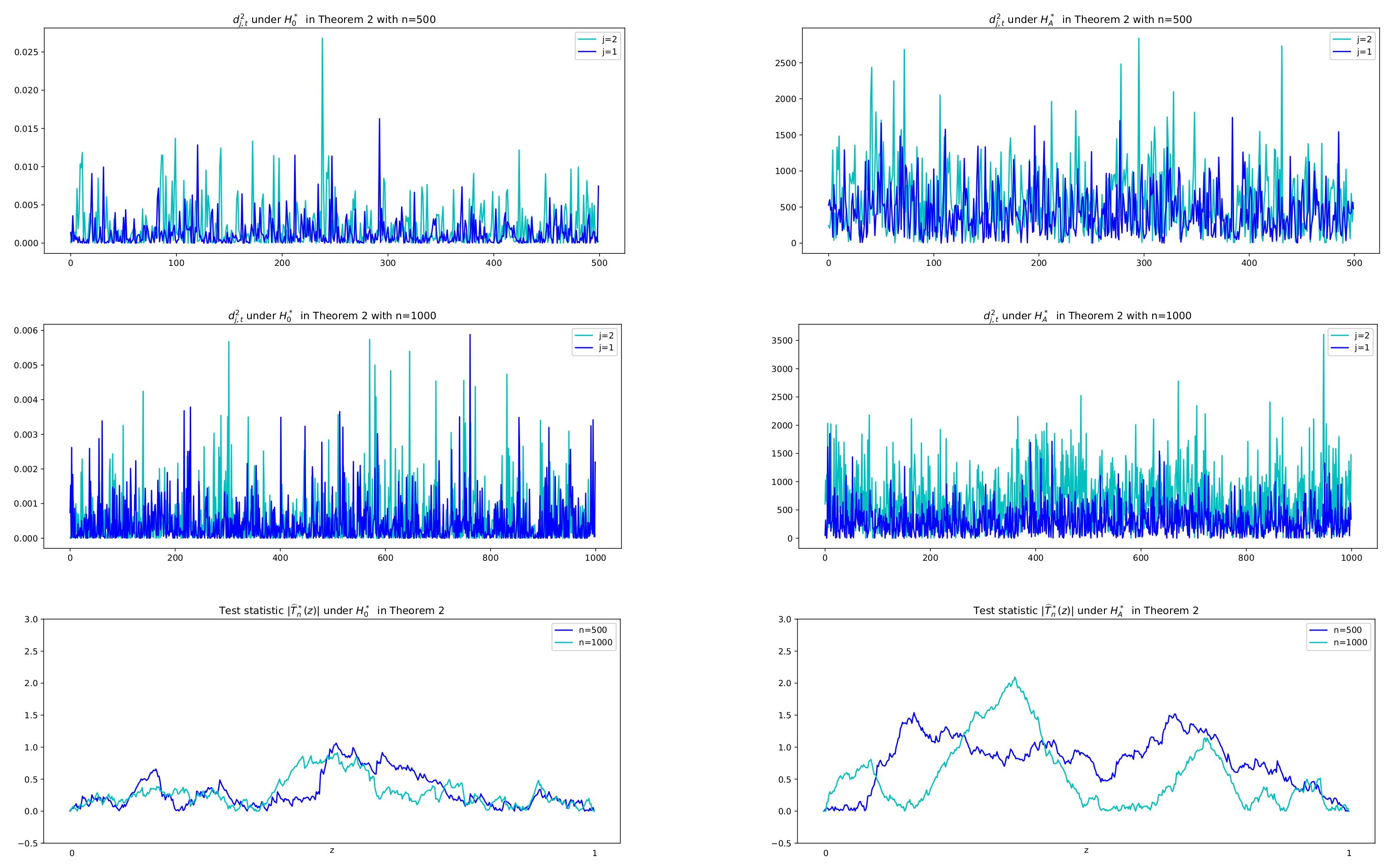
Theorem 2. We assume for some , for all . If the multivariate HAR() model has a common exponential decay rate λ with for some for all , then we have, as , Note that under the null hypothesis , the difference series are evaluated as small values and are characterized with small variance, but under the alternative hypothesis , they have large values with dynamic variance over the time. Thus we use the CUSUMSQ test for the difference series (not the original data) to see the change-point of the variance. Justification of suitability of the CUSUMSQ test can be seen in the next section, where sample paths of the difference squared, , and the values of test statistics in absolute, , under both hypotheses are depicted.
Once the first test in Theorem 1 has been conducted to datasets of multiple assets, we obtain estimates of the decay rates by using (
9), and then the second test in Theorem 2 is conducted to see whether the datasets have a common rate. Finally, the estimate (
10) is used to find the common rate.
Remark 2. The following concerns the estimation of the decay rates. In the exponentially weighted multivariate HAR model (1) with coefficients , estimators of the decay rates can be obtained in a simple way. From the OLSEs of parameter vector , we construct an easy-to-implement estimator of as follows:Furthermore, in case of the common rate with , the common rate λ is estimated byIn the estimates of the decay rates in (9) and (10), only the first and the second coefficients estimates, i.e., and , are used. This is because these two estimates have comparatively fewer standard errors than others. To see their performances, sample means and standard errors of the estimates in (9) and (10) are computed and compared in the next section. In the conventional multivariate HAR(
) model there are a total of
coefficient parameters to estimate, whereas in the exponential weighted multivariate HAR
model the number of parameters is decreased to
. Each
,
has one intercept, and
q coefficients of the previous lag values of
q assets and one decay rate. For a simple case with
and
, the number of parameters is reduced from 14 to 8. This implies that some measures of statistical models such as AIC and BIC might be improved considerably. This improvement can be shown in the following sections with simulated data and real data examples. In the multivariate HAR
) model, the asymptotic normality for the OLSE
of
has been established by Hong et al. [
41]:
as
, where
is some
covariance matrix.
Remark 3. The following concerns the bias adjustment for a finite sample. In our exponential weighted multivariate HAR model with , which are components of , we construct an estimator of , called the rate-adopted estimator (RE), as follows: wherewith in (9). It is obvious that as . Here we need to observe the residuals on behalf of the empirical analysis for a finite sample. We rewrite model (1) as , where Let and be residuals by the OLSE and the RE, respectively:Note thatLet , and then by the asymptotic normality of with asymptotic mean zero and by noticing that we haveEven though under the null hypothesis, is not negligible in a small finite sample. Thus we need the bias adjustment for a fitting model in a finite sample. When we fit the exponentially weighted HAR model to real datasets, especially ones with small sample size, the error performances can be improved by means of the bias adjustment. For instance, one way is that the fitted model is shifted by the residual mean , which is a constant. An alternative way is that the model is shifted by a moving average of residuals, which is a time-varying process, as we define in the following. For a positive integer m and , letwhere and , (j is omitted in for notational simplicity). The time-varying process determines the error performances of the fitting model shifted by . The fitted model with exponential decay rates is now determined bywhere and . Note that . Effects of m, called the fitting parameter, on the error performances of (12) will be discussed in the next section. 3. Monte Carlo Simulation
In this section, we first see the plots of sample paths of the proposed model and their autocorrelation coefficient functions (ACFs). Secondly, finite sample validity of the proposed tests is investigated along with the plots of various related series for the justification of the tests. Thirdly, the estimates of the decay rates are computed, and finally comparisons with conventional HAR models are addressed in terms of measures such as RMSE, MAE, AIC, and BIC. Moreover, efficiency of the proposed model vs. the benchmark HAR model is discussed.
In the simulation experiment, to see the plots of the proposed model, simulated data are generated by bivariate exponentially weighted HAR models of order
, HAR(3,2) models, with lag structure
, by using i.i.d. standard normal distributed
-errors
and size
. In order to avoid the effect of selected initial value in the models, data of size 600 are generated and the first 200 data are deleted to obtain
.
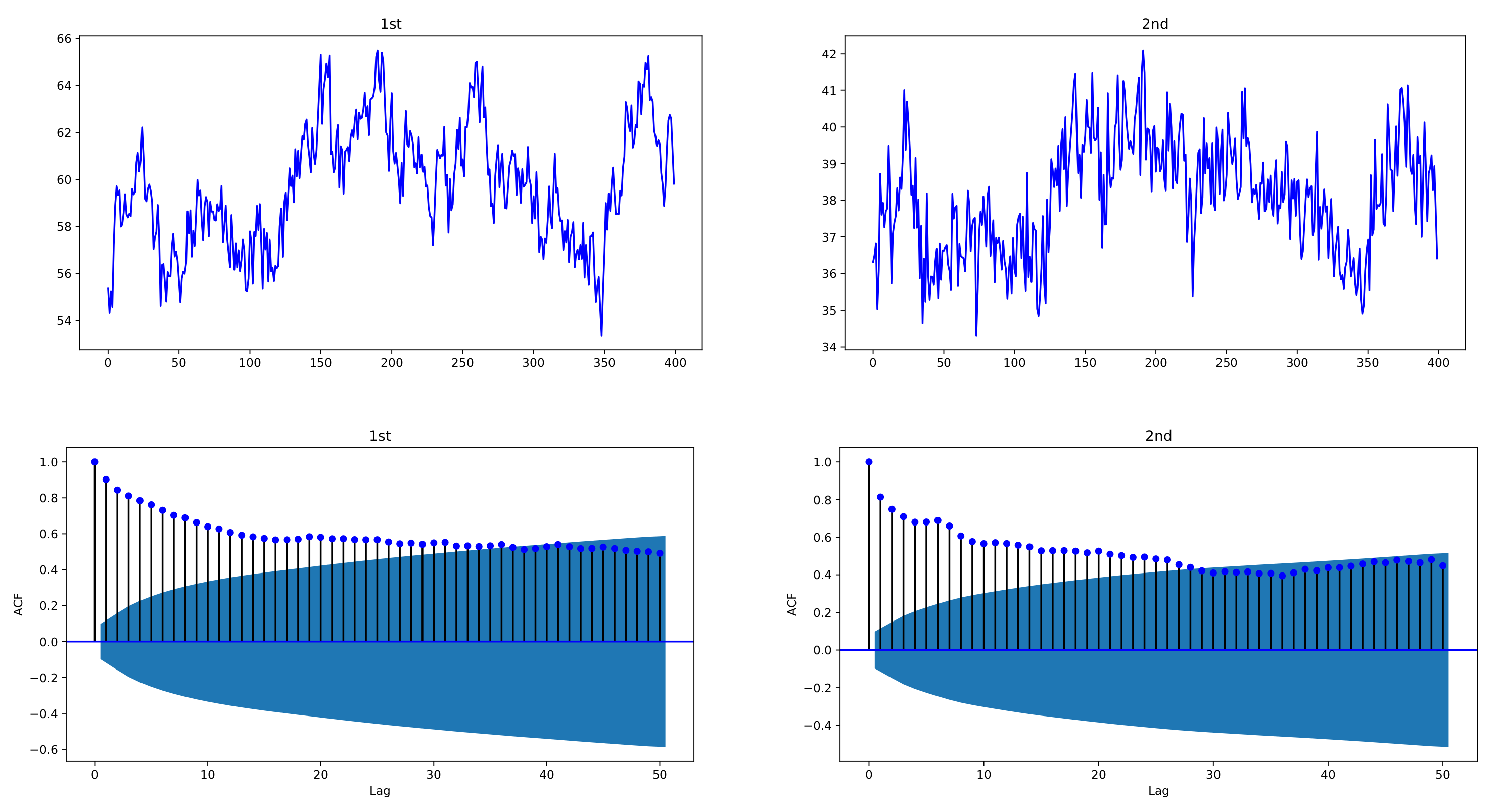
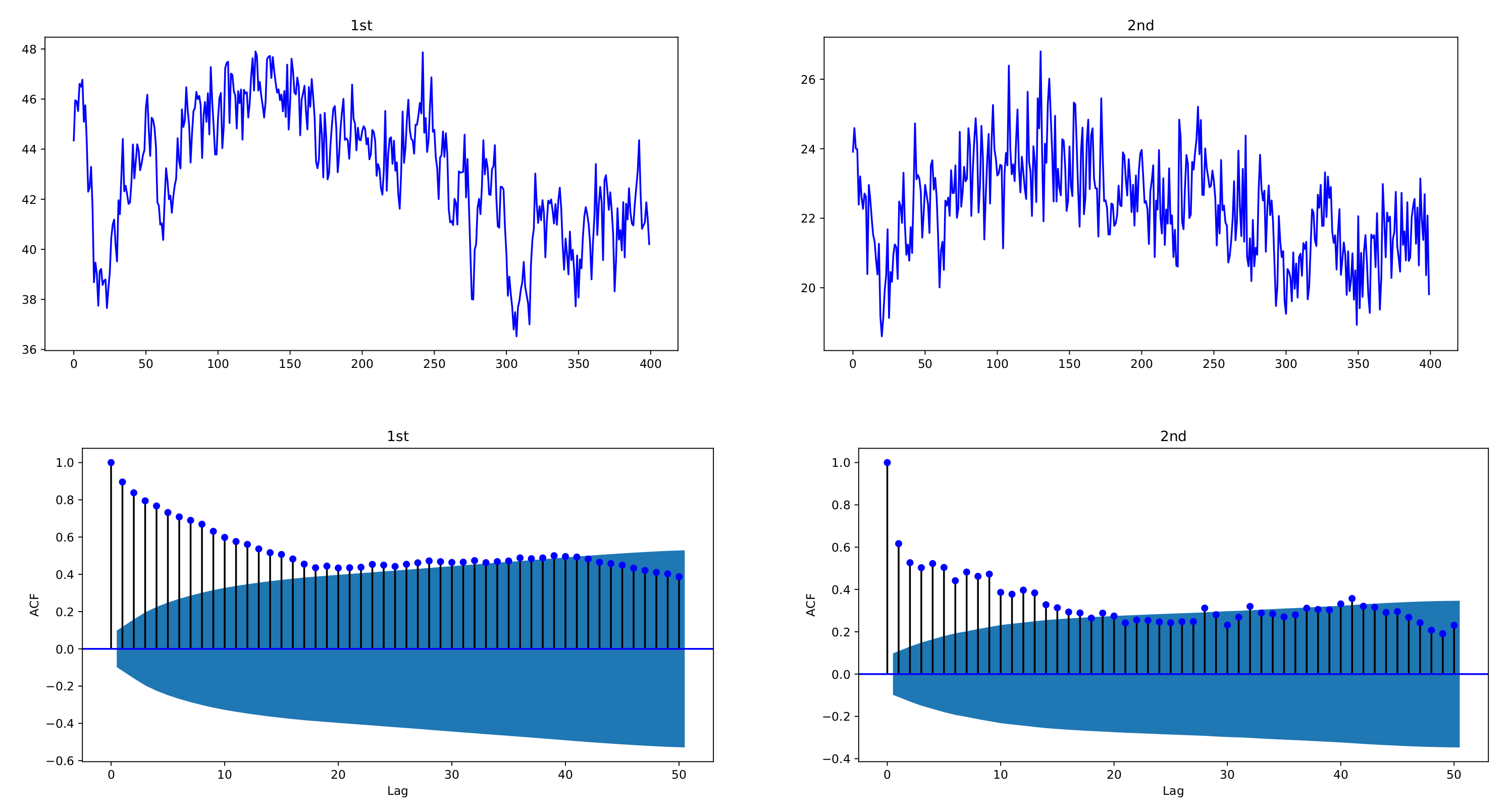
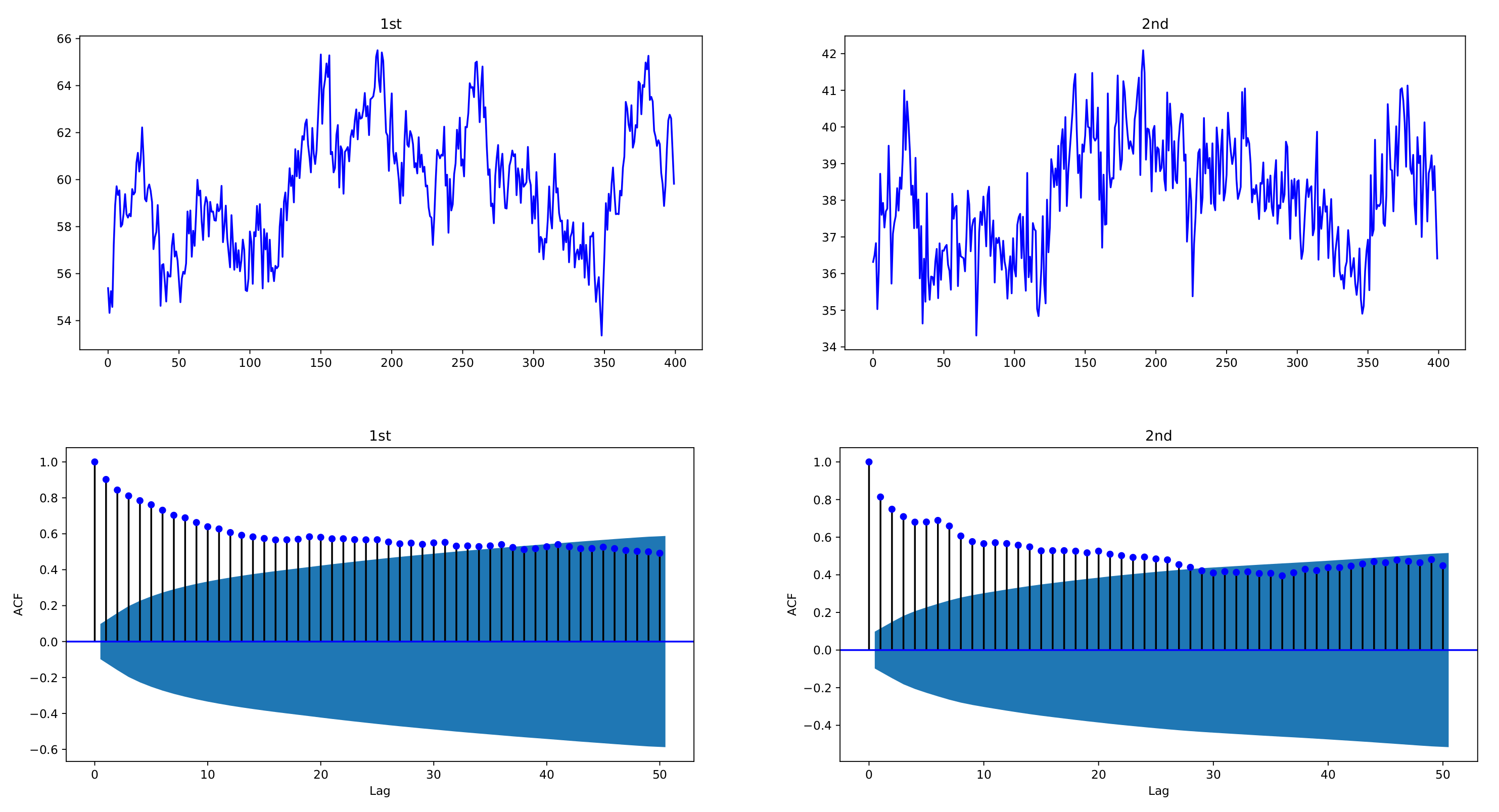
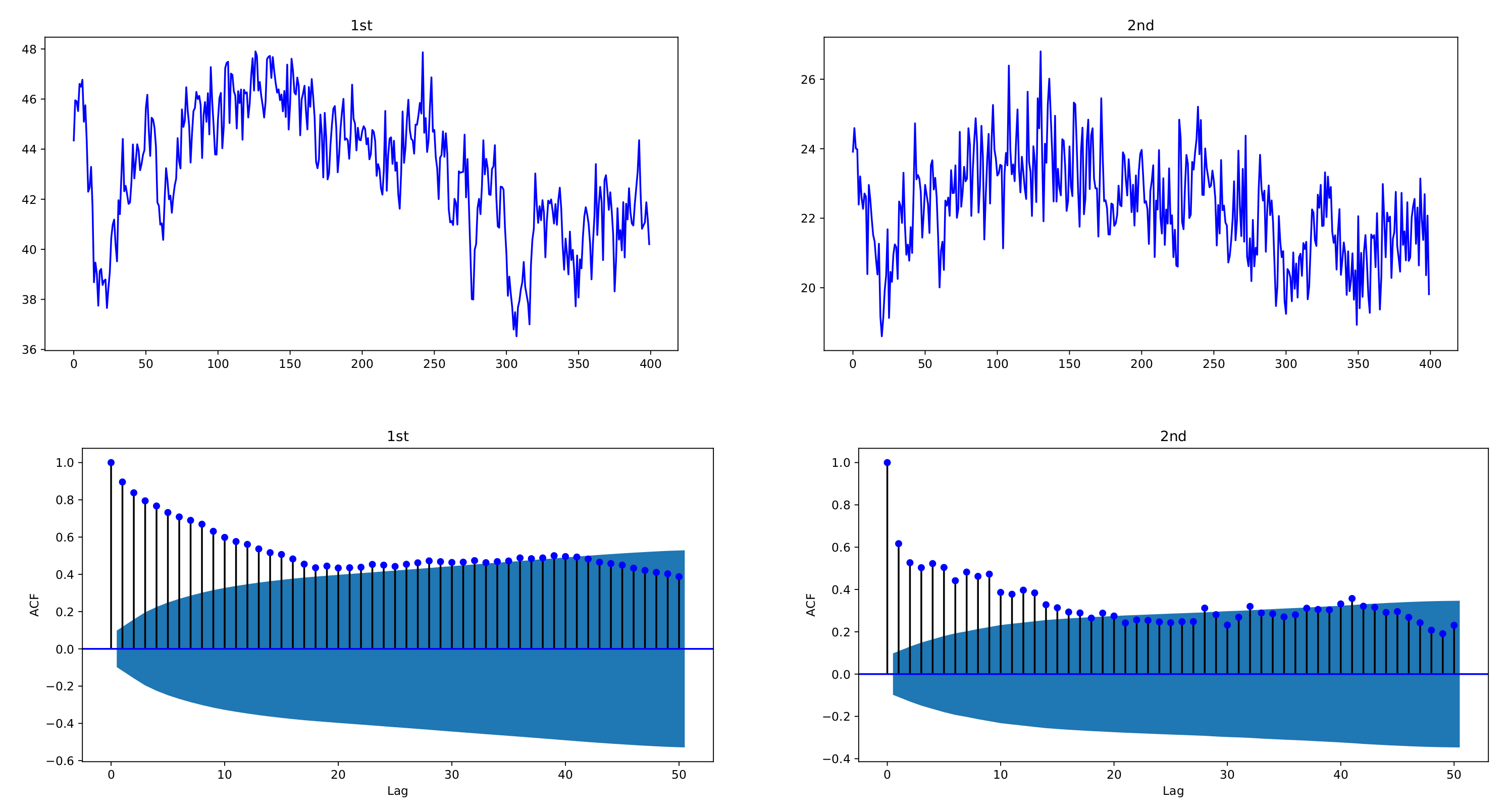
Figure 1 and
Figure 2 depict sample paths with parameters
,
, together with their ACFs;
Figure 1 uses individual decay rates
,
whereas
Figure 2 uses common rate
. We see that the simulated data are strongly correlated with each other and reveal the long-memory feature. In
Figure 1, two datasets have a correlation coefficient of 0.7856, and in
Figure 2, the correlation coefficient is 0.6748.
Figure 1.
Sample paths of exponentially weighted bivariate HAR model and their ACFs, with decay rates , ; , ; . The simulated data of the exponentially weighted bivariate HAR model are characterized with strong cross-correlation and long memory.
Figure 1.
Sample paths of exponentially weighted bivariate HAR model and their ACFs, with decay rates , ; , ; . The simulated data of the exponentially weighted bivariate HAR model are characterized with strong cross-correlation and long memory.
Figure 2.
Sample paths of exponentially weighted bivariate HAR model and their ACFs, with common decay rate ; , ; . The simulated data of the exponentially weighted bivariate HAR model are characterized with strong cross-correlation and long memory.
Figure 2.
Sample paths of exponentially weighted bivariate HAR model and their ACFs, with common decay rate ; , ; . The simulated data of the exponentially weighted bivariate HAR model are characterized with strong cross-correlation and long memory.
To verify Theorems 1 and 2, we compute the test statistics in the HAR(3,2) model and report their rejection rates in
Table 1 and
Table 2, respectively. To see the validation of Theorem 1, four combinations of two datasets are assumed as follows:
- •
Case I: Both are exponentially weighted models with and .
- •
Case II: The first data set follows an exponentially weighted model with whereas the second is not.
- •
Case III: The second is an exponentially weighted model with whereas the first is not.
- •
Case IV: None of them are exponentially weighted models.
For the null hypothesis of Cases I, II, and III, are used. For Case IV, there are total 14 (irregular) parameters, and thus their presentation with so many parameters, including those under the alternative hypothesis in Cases II and III, are omitted here, but are available upon request.
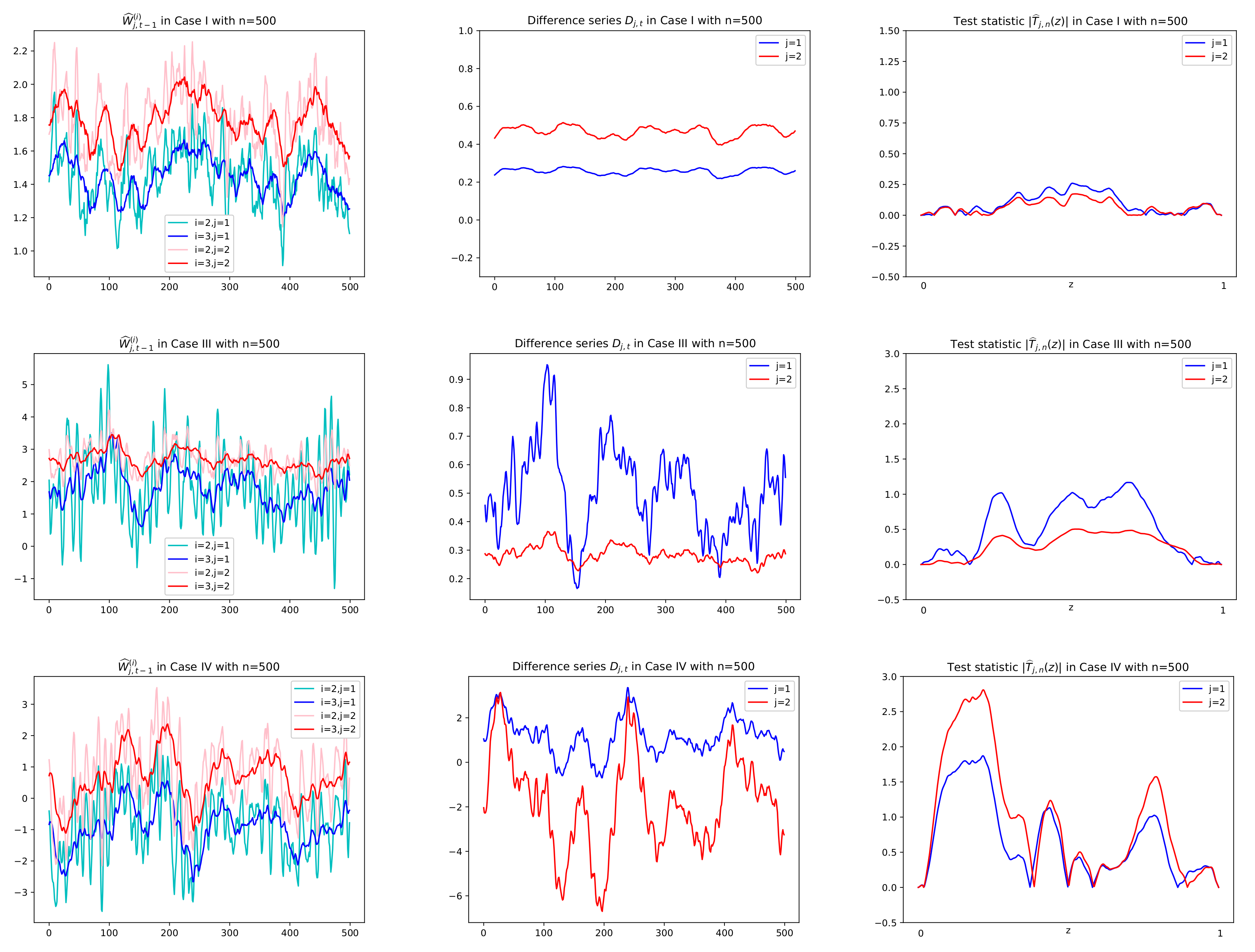
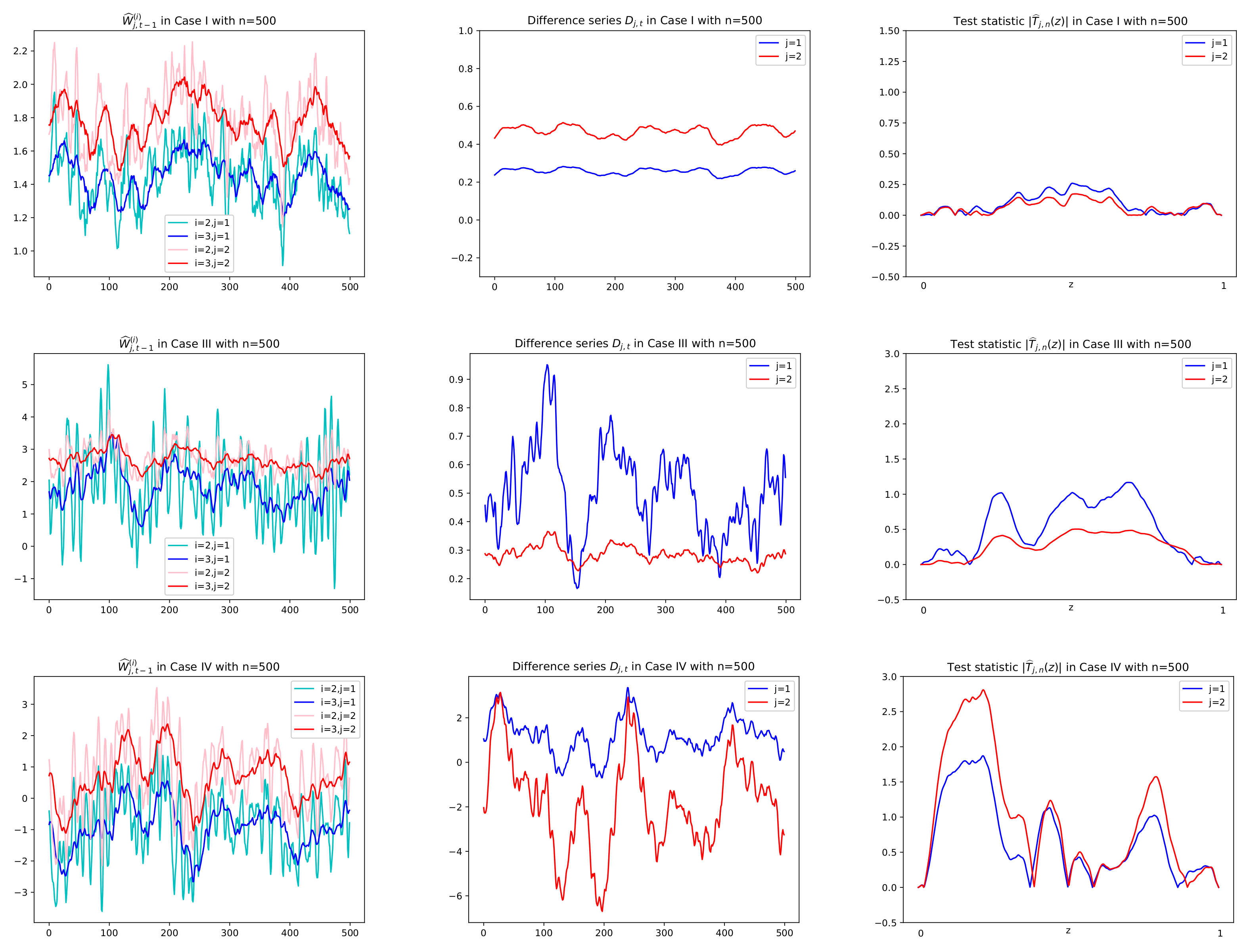
Prior to reporting the test results, some plots of related series are illustrated in order to justify the suitability of the CUSUM tests. In particular, for Cases I, III, and IV, sample paths of
,
and
in (
3), (
6), and (
8), respectively, are depicted with
in
Figure 3 and
Figure 4, where values of
in
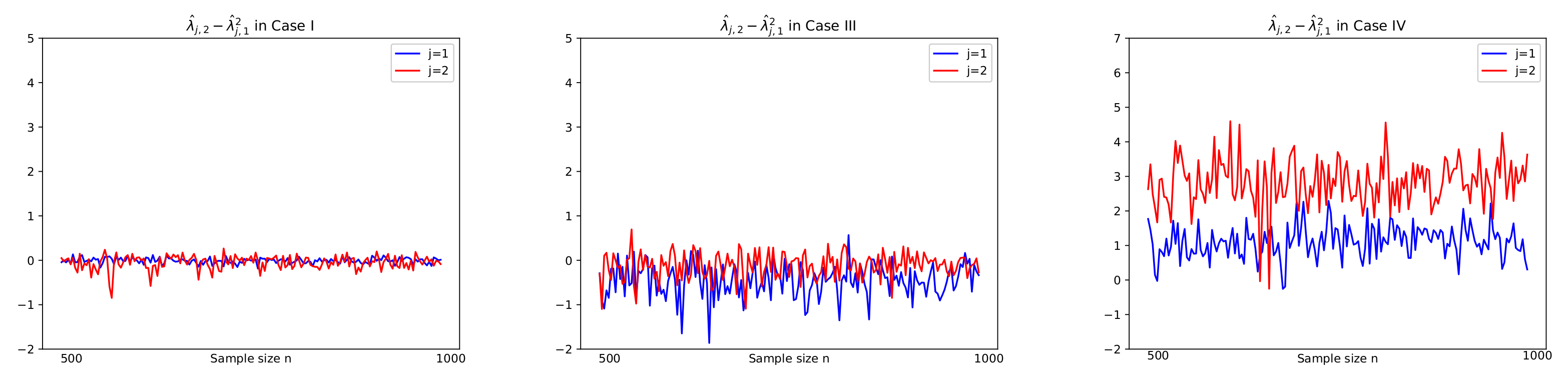
Figure 5 are used to compute
together with using
. In
Figure 5, we see that
tends to zero in Case I (
) and Case III (
) as its theory indicates as in (
5) under the null hypothesis. However, it is shown in
Figure 5 that Case III (
) and Case IV (
have the deviation from zeros under the alternative. In
Figure 3 and
Figure 4, under the null hypothesis with decay rates, the difference series
does not fluctuate due to the asymptotic zero of
, which can be interpreted as constant coefficients in the linear combination of
, whereas under the alternative, plots of
are dynamic with large variance because of nonzero
, (see Equation (
6)). This fact yields higher values of the CUSUM test statistic in absolute,
, as seen in the third columns of
Figure 3 and
Figure 4.
Figure 3.
Sample paths of and , in Cases I, III, IV in Theorem 1 with . Difference series in the second column are obtained by multiplying in the first column by given in Figure 5. Test statistics in absolute , , are computed using the difference series in the second column. In the first row of Case I with both and , has no change in mean and thus small values of for all z. In the second row of Case III with , (in red), the same interpretation is given.
Figure 3.
Sample paths of and , in Cases I, III, IV in Theorem 1 with . Difference series in the second column are obtained by multiplying in the first column by given in Figure 5. Test statistics in absolute , , are computed using the difference series in the second column. In the first row of Case I with both and , has no change in mean and thus small values of for all z. In the second row of Case III with , (in red), the same interpretation is given.
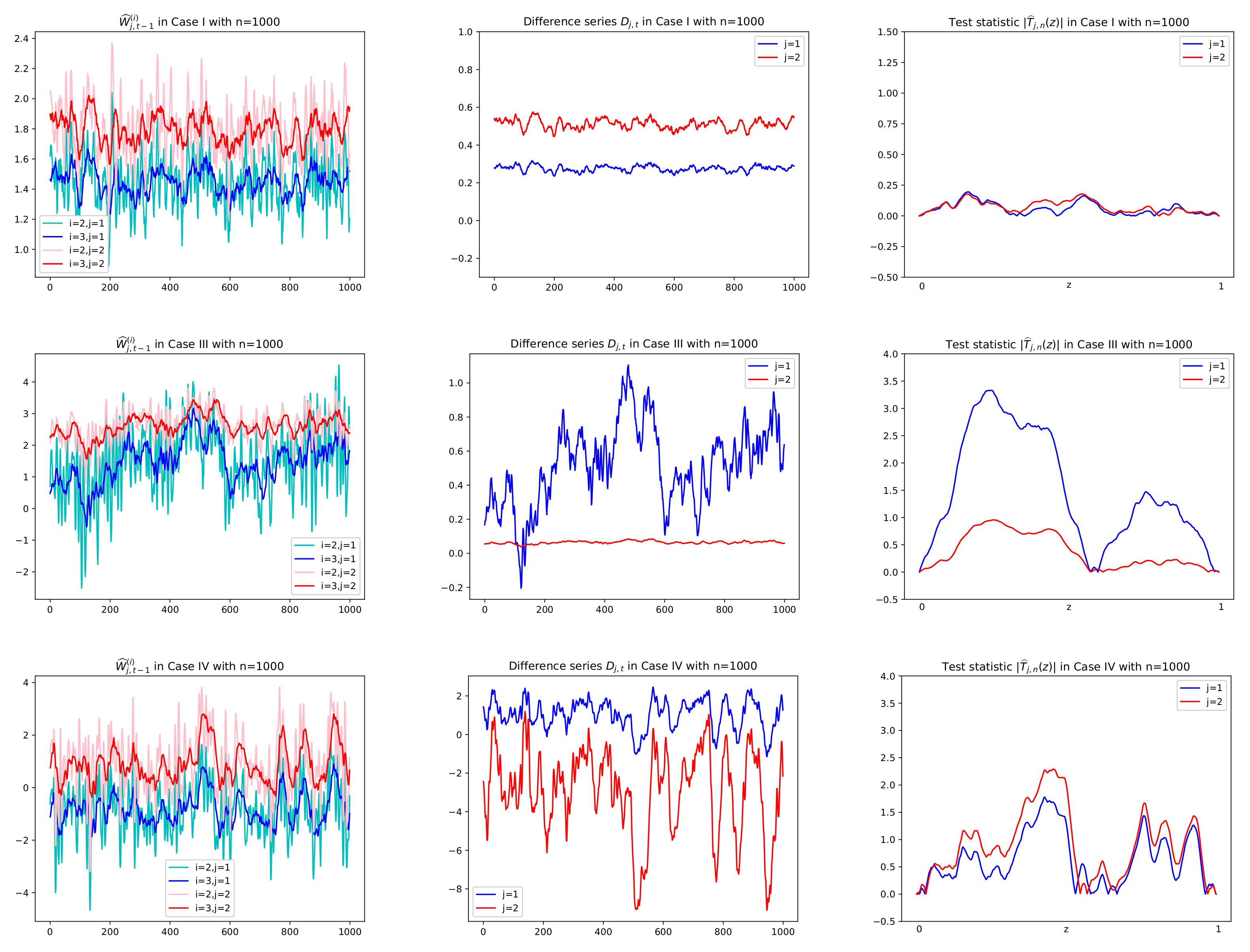
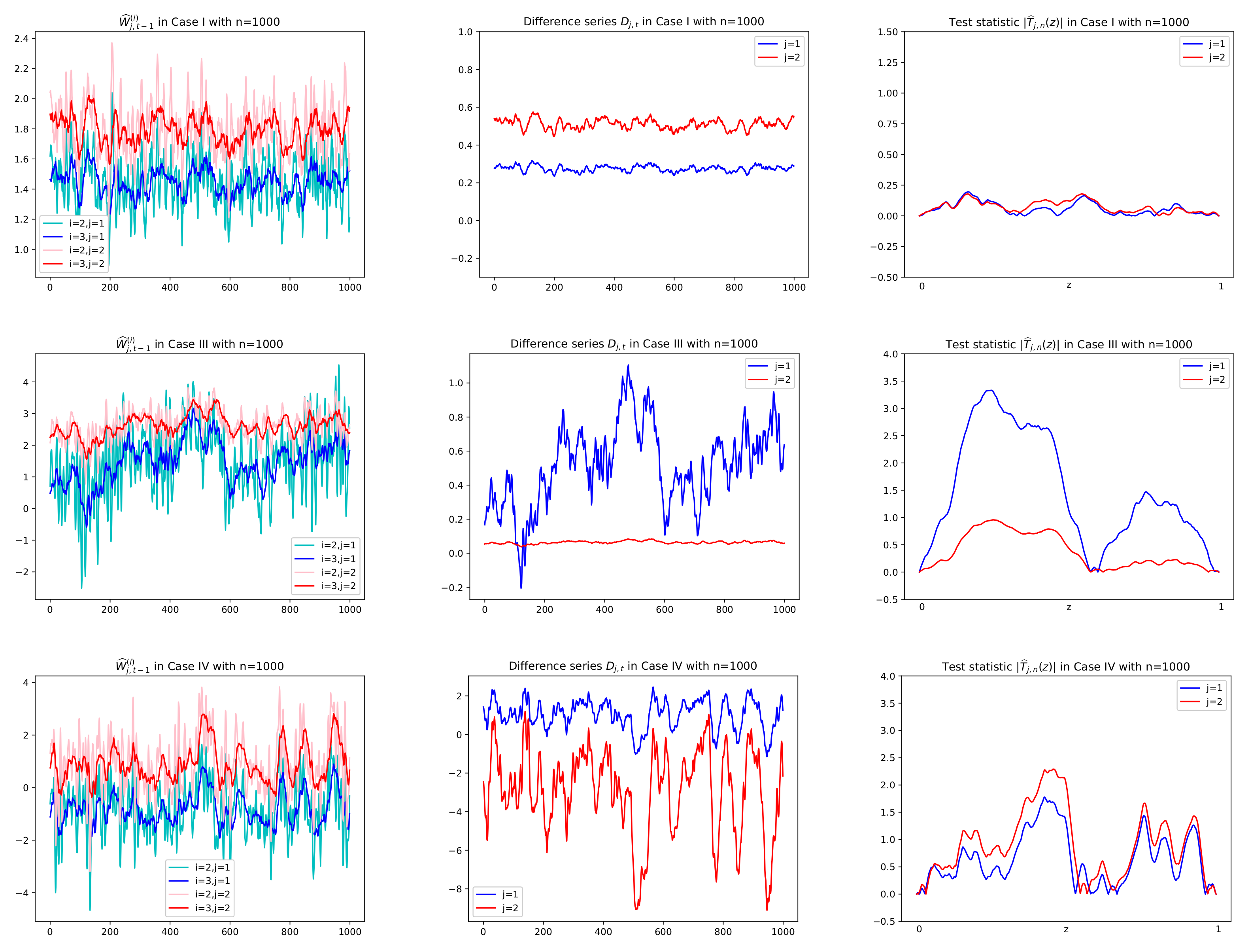
Figure 4.
Sample paths of
and
,
in Cases I, III, IV in Theorem 1 with
. Difference series
in the second column are obtained by multiplying
in the first column by
given in
Figure 5. Test statistics in absolute
,
, are computed using the difference series
in the second column. In the first row of Case I with both null hypotheses
and
,
has no change in mean and thus small values of
for all
z. In the second row of Case III with
,
(in red), the same interpretation is given.
Figure 4.
Sample paths of
and
,
in Cases I, III, IV in Theorem 1 with
. Difference series
in the second column are obtained by multiplying
in the first column by
given in
Figure 5. Test statistics in absolute
,
, are computed using the difference series
in the second column. In the first row of Case I with both null hypotheses
and
,
has no change in mean and thus small values of
for all
z. In the second row of Case III with
,
(in red), the same interpretation is given.
Figure 5.
, , with sample size on horizontal axis, in Case I, III, IV in Theorem 1. In Case I() and Case III() with the null hypothesis , tends to zero as .
Figure 5.
, , with sample size on horizontal axis, in Case I, III, IV in Theorem 1. In Case I() and Case III() with the null hypothesis , tends to zero as .
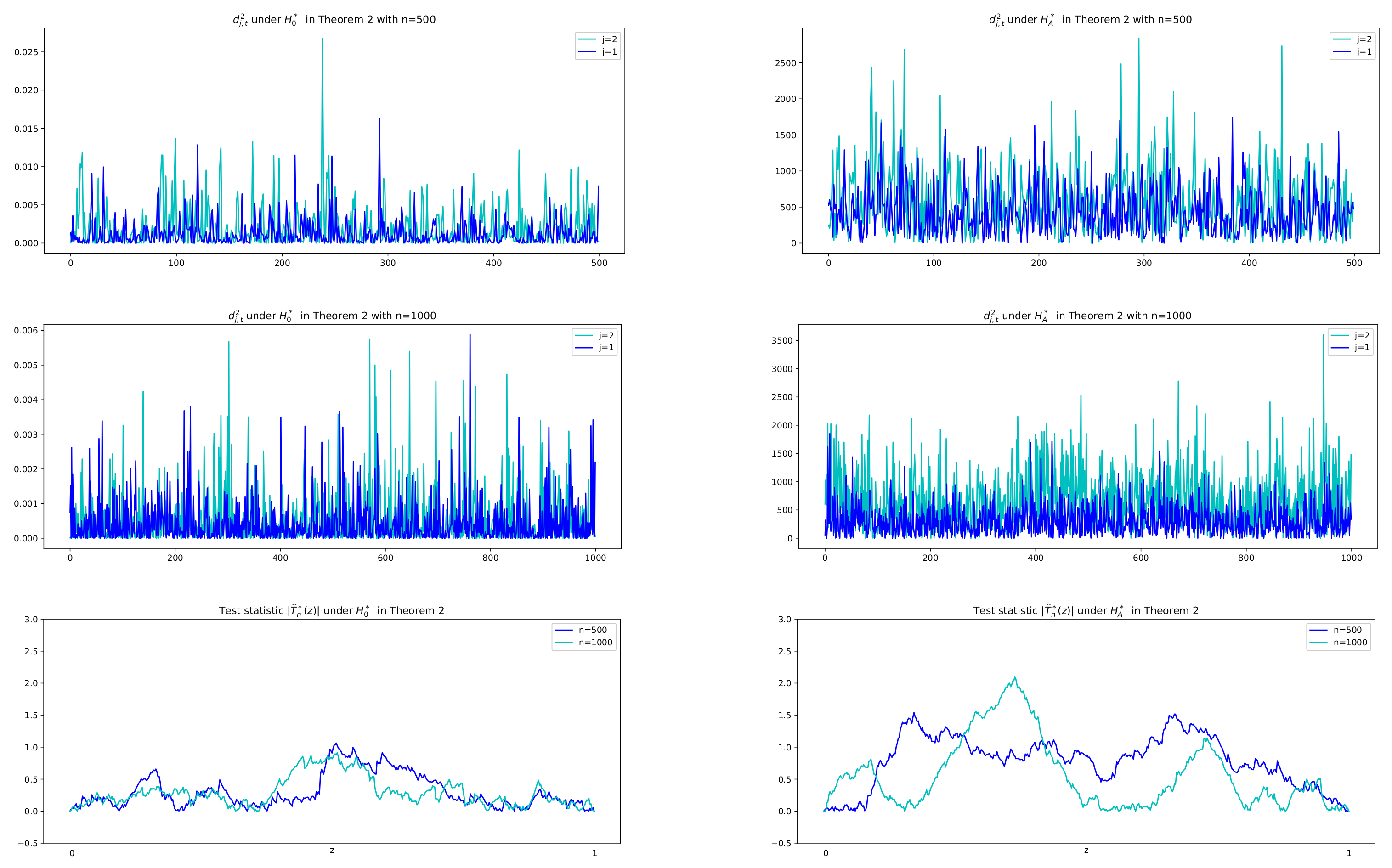
As for the CUSUMSQ test in Theorem 2,
Figure 6 describes series of difference squared,
, and test statistic values in absolute,
, under the two hypotheses with
, respectively. It is shown that under
, the difference series
has small variance with small values whose squares are less than 0.025 for
and 0.006 for
, whereas under
it has large values with their squares between 0 and 2500. Therefore we adopt the idea of change-point test of variance to the difference series
, which yields a solution of the existence of the exponential decay rate.
Throughout the simulation study of the CUSUM tests, replication number 1000, significant level , and sample size and 1000 are used.
Table 1 and
Table 2 display the evaluated rejection rates in Theorems 1 and 2, respectively. In
Table 1, results of rejection rates of two tests
,
, in Theorem 1 for the four cases are addressed. To compute the test statistic
in Theorem 1, a consistent estimate
of the standard deviation should be found. Recall two of
in (
7), which are estimators of
. Because
as
due to
under the null hypothesis
, we may use both in (
7) for
. However, the use of the estimates incurs slow convergence rates because of the bias problem, as seen in the argument in Remark 1. If the mean has a large bias, the convergence rate tends to be slow, as affected by the bias. Thus we adopt the two estimates partially to adjust the convergence rate. In particular, so as to visualize the convergence to the nominal level with increasing
n, we here take partially the second sample variance in (
7) of the form:
, where
, which converges to zero in probability along with
as
. To use it partially, we construct a consistent estimator with the following threshold:
, where
with an indicator function
and a threshold
. In other words, we use either the first one or the second one in (
7), depending on the magnitude of the mean
. By doing this, we can adjust the convergence rate by adopting the following threshold: setting the value
of the indicator function to zero in case of the large bias. In this simulation, threshold
is chosen empirically such that
; that is, if
with probability 0.95, then the first in (
7) is used and otherwise with probability 0.05, the second in (
7) is used for the estimate
. This is because the probability of having the bias is high as seen in Remark 1. In
Table 1, results of rejection rates are given by using the estimate
with the chosen threshold
and are seen with the convergence to the nominal level
as
n increases under the null hypothesis. For
Table 2 with Theorem 2, a similar argument can be given.
Table 1.
Validation of Theorem 1. Rejection rate for hypotheses and of level , in exponentially weighted bivariate HAR models of order ; h = ; in the null hypothesis of Cases I, II, III; replication number =1000. (Other parameter values used are available upon request ).
Table 1.
Validation of Theorem 1. Rejection rate for hypotheses and of level , in exponentially weighted bivariate HAR models of order ; h = ; in the null hypothesis of Cases I, II, III; replication number =1000. (Other parameter values used are available upon request ).
| n | Case I | Case II | Case III | Case IV |
|---|
| | | | | | | |
| 100 | 0.066 | 0.056 | 0.083 | 0.198 | 0.547 | 0.058 | 0.640 | 0.776 |
| 200 | 0.053 | 0.058 | 0.057 | 0.236 | 0.767 | 0.054 | 0.789 | 0.897 |
| 500 | 0.051 | 0.050 | 0.057 | 0.313 | 0.946 | 0.053 | 0.826 | 0.920 |
| 1000 | 0.050 | 0.050 | 0.052 | 0.408 | 0.985 | 0.054 | 0.823 | 0.936 |
Table 2.
Validation of Theorem 2. Rejection rate for hypotheses and of level in exponentially weighted bivariate HAR models of order ; h = , with decay rates , ; , ; replication number =1000.
Table 2.
Validation of Theorem 2. Rejection rate for hypotheses and of level in exponentially weighted bivariate HAR models of order ; h = , with decay rates , ; , ; replication number =1000.
| n | | | |
|---|
| | | | | |
| | | | | |
| 100 | 0.027 | 0.301 | 0.021 | 0.340 | 0.028 | 0.326 |
| 200 | 0.033 | 0.288 | 0.032 | 0.299 | 0.043 | 0.274 |
| 500 | 0.050 | 0.284 | 0.045 | 0.266 | 0.048 | 0.258 |
| 1000 | 0.048 | 0.285 | 0.051 | 0.265 | 0.049 | 0.270 |
It is shown from
Table 1 that Case I favors two of the null hypotheses in Theorem 1; i.e., the models are exponentially weighted with small rejection numbers of the null hypothesis. Moreover,
Table 2 depicts reasonable rejection rates of the test in Theorem 2 for a large sample size under both null and alternative hypotheses. Note that in
Table 2, the null hypothesis
indicates that both
and
are the same values; i.e., the common rate
, where small rejection rates are reported. The rejection rates in
Table 1 and
Table 2 tend to the nominal level
as
n increases under the null hypothesis.
Next, we observe the size and power properties of our proposed CUSUM test in Theorem 1. To assess the performance of the test, we use bivariate HAR models of orders
. We set
,
if
, and
,
if
. The sizes of the proposed test in the HAR(
) models with
, are illustrated in
Table 3. Most cases indicate very small values of type I errors, consistent with the size of the test. Also, the powers of the CUSUM test are displayed in
Table 4, where we see comparatively reasonable power results.
In
Table 5, estimates of the decay rates in (
9) and (
10) are computed to obtain sample means and standard errors. Cases I–III have the same parameters as those in
Table 1 whereas Cases IV
–VI
use common rates given as follows:
- •
Case IV: Common rate .
- •
Case V: Common rate .
- •
Case VI: Common rate .
Table 5 reports that estimate results are consistent in the sample sizes, whereas for Cases IV
, V
and VI
, estimates
in (
9) are used for
,
, and estimates
in (
10) are used for
. We notice that in the common rate cases, Equation (
10) gives smaller standard errors of the estimates.
Table 3.
Size of the CUSUM test in Theorem 1 for HAR, ; , ; Replication number = 1000, .
Table 3.
Size of the CUSUM test in Theorem 1 for HAR, ; , ; Replication number = 1000, .
| p | h | n | | |
|---|
| | | |
| | | | | | | |
| (1, 5, 22) | 100 | 0.087 | 0.078 | 0.080 | 0.067 | 0.091 | 0.090 | 0.094 | 0.078 |
| | | 200 | 0.071 | 0.071 | 0.074 | 0.059 | 0.071 | 0.075 | 0.061 | 0.061 |
| | | 500 | 0.054 | 0.058 | 0.050 | 0.054 | 0.052 | 0.054 | 0.051 | 0.050 |
| | | 1000 | 0.050 | 0.050 | 0.050 | 0.053 | 0.051 | 0.052 | 0.050 | 0.050 |
| (1, 5, 7, 9, 14, 22) | 100 | 0.098 | 0.089 | 0.108 | 0.078 | 0.076 | 0.065 | 0.054 | 0.053 |
| | | 200 | 0.064 | 0.084 | 0.058 | 0.071 | 0.058 | 0.053 | 0.052 | 0.052 |
| | | 500 | 0.054 | 0.076 | 0.049 | 0.069 | 0.051 | 0.056 | 0.051 | 0.050 |
| | | 1000 | 0.049 | 0.055 | 0.045 | 0.058 | 0.047 | 0.056 | 0.050 | 0.051 |
| (1, 7, 14) | 100 | 0.112 | 0.091 | 0.105 | 0.081 | 0.099 | 0.093 | 0.095 | 0.076 |
| | | 200 | 0.070 | 0.064 | 0.060 | 0.061 | 0.071 | 0.072 | 0.069 | 0.059 |
| | | 500 | 0.054 | 0.051 | 0.052 | 0.053 | 0.052 | 0.056 | 0.050 | 0.053 |
| | | 1000 | 0.050 | 0.051 | 0.052 | 0.053 | 0.050 | 0.050 | 0.050 | 0.052 |
| (1, 7, 14, 19, 22, 25) | 100 | 0.091 | 0.090 | 0.077 | 0.076 | 0.071 | 0.064 | 0.057 | 0.053 |
| | | 200 | 0.076 | 0.076 | 0.073 | 0.069 | 0.061 | 0.053 | 0.056 | 0.050 |
| | | 500 | 0.053 | 0.065 | 0.065 | 0.055 | 0.048 | 0.048 | 0.047 | 0.049 |
| | | 1000 | 0.054 | 0.062 | 0.055 | 0.051 | 0.048 | 0.052 | 0.050 | 0.051 |
Table 4.
Power of the CUSUM test in Theorem 1 for HAR, p = 3,6; Replication number = 1000, . (Parameter values used in Power Models 1 & 2 are available upon request).
Table 4.
Power of the CUSUM test in Theorem 1 for HAR, p = 3,6; Replication number = 1000, . (Parameter values used in Power Models 1 & 2 are available upon request).
| n | Power Model 1 | Power Model 2 |
|---|
| | | |
| | | |
| | | | | | | |
| 100 | 0.664 | 0.807 | 0.716 | 0.518 | 0.812 | 0.727 | 0.691 | 0.722 |
| 200 | 0.794 | 0.906 | 0.849 | 0.642 | 0.901 | 0.823 | 0.679 | 0.771 |
| 500 | 0.850 | 0.967 | 0.948 | 0.806 | 0.937 | 0.863 | 0.738 | 0.852 |
| 1000 | 0.907 | 0.987 | 0.976 | 0.841 | 0.948 | 0.887 | 0.802 | 0.952 |
Finally, we discuss the fitting problem of the exponentially weighted HAR models in (
12) and compare with the conventional HAR model fitted by OLSEs. The simulated data in
Figure 1 are used to compute the OLSEs
of coefficients and the estimates
of the decay rates in (
9). From the estimated rates
, the rate-adopted estimators (REs)
of the coefficients are evaluated as a further step. To compare the fitted models by the OLSEs and REs,
Table 6 presents some criteria such as the root mean square error (RMSE), mean absolute error (MAE), AIC, and BIC. In the case of the exponential weighted bivariate HAR models, the fitting parameter
m is used with
. Because the conventional bivariate HAR model has 14 parameters whereas our proposed model has 8 parameters, the AIC and BIC of the latter are smaller values than those of the former. Intuitively, the small choice of
m yields small errors in RMSEs and MAEs because the average
in (
11) for interval
is closer to
for smaller
m, and thus this fact makes the error term
in (
12) smaller. In the latter case, (
12) is applied with
for the bias adjustment. RMSE and MAE of the OLSE residuals in fitting the conventional HAR model are 0.9971, 0.8253 for
and 0.9644, 0.7596 for
, and those of the RE residuals in fitting our proposed model are 0.9424, 0.7805 for
and 0.9226, 0.7381 for
.
Table 5.
Sample means and standard errors (s.e.) of estimates for the decay rates
of exponentially weighted HAR (3, 2) models, Replication number = 1000. Note that in common rate cases with *, Cases IV
, V
and VI
, estimates
in (
9) are used for
,
, while estimates
in (
10) are used for
.
Table 5.
Sample means and standard errors (s.e.) of estimates for the decay rates
of exponentially weighted HAR (3, 2) models, Replication number = 1000. Note that in common rate cases with *, Cases IV
, V
and VI
, estimates
in (
9) are used for
,
, while estimates
in (
10) are used for
.
| | | | | |
|---|
| | | Sample Mean | (s.e.) | Sample Mean | (s.e.) | Sample Mean | (s.e.) |
| Case I | | 0.458 | (0.038) | 0.493 | (0.017) | 0.528 | (0.008) |
| | | 0.418 | (0.022) | 0.452 | (0.012) | 0.419 | (0.005) |
| Case II | | 0.764 | (0.143) | 0.625 | (0.021) | 0.505 | (0.007) |
| | - | | - | | - | | - |
| Case III | - | | - | | - | | - |
| | | 0.497 | (0.034) | 0.445 | (0.014) | 0.413 | (0.006) |
| Case IV | | 0.188 | (0.037) | 0.121 | (0.019) | 0.104 | (0.011) |
| | | −0.022 | (0.164) | 0.101 | (0.011) | 0.103 | (0.007) |
| | | 0.118 | (0.014) | 0.084 | (0.009) | 0.095 | (0.006) |
| Case V | | 0.684 | (0.044) | 0.579 | (0.019) | 0.525 | (0.012) |
| | | 0.556 | (0.019) | 0.526 | (0.012) | 0.518 | (0.008) |
| | | 0.507 | (0.015) | 0.511 | (0.010) | 0.506 | (0.007) |
| Case VI | | 0.768 | (0.652) | 0.934 | (0.021) | 0.921 | (0.014) |
| | | 0.983 | (0.021) | 0.928 | (0.014) | 0.922 | (0.010) |
| | | 0.930 | (0.018) | 0.888 | (0.011) | 0.900 | (0.008) |
Table 6.
Comparison of exponential weighted HAR(3,2) fitting models from the simulated data in
Figure 1.
Table 6.
Comparison of exponential weighted HAR(3,2) fitting models from the simulated data in
Figure 1.
| Model | Fitting | | |
|---|
| Parameter m | RMSE | MAE | AIC | BIC | RMSE | MAE | AIC | BIC |
|---|
| Conventional HAR | - | 0.9971 | 0.8253 | 1098.49 | 1153.57 | 0.9644 | 0.7596 | 1073.38 | 1128.47 |
| Exp. HAR | | 0.9424 | 0.7805 | 1043.88 | 1075.36 | 0.9226 | 0.7381 | 1027.80 | 1059.28 |
| Exp. HAR | | 0.9898 | 0.8147 | 1080.84 | 1112.32 | 0.9443 | 0.7535 | 1045.34 | 1076.82 |
| Exp. HAR | | 0.9949 | 0.8180 | 1084.83 | 1116.31 | 0.9709 | 0.7621 | 1066.24 | 1097.71 |
| Exp. HAR | | 1.0105 | 0.8334 | 1096.23 | 1127.70 | 0.9827 | 0.7745 | 1075.59 | 1107.07 |
Furthermore, to elaborate more on the comparison with the conventional HAR model, the efficiency of the proposed model vs. the conventional one, is computed by using two metrics of RMSE and MAE: The Exp. HAR Model Efficiency, relative to the benchmark HAR model, is defined by
where
RMSE and
MAE are
RMSE,
MAE of the conventional HAR model, respectively and
RMSE and
MAE are those of the exponentially weighted HAR model.
Table 7 displays the Exp. HAR model efficiency in the first case of
of
Table 3. We see that all values are positive with highest value 7.0817 in percentage, which means that the proposed model with the RE fitting improves the conventional HAR model with respect to residual errors.
Table 7.
Comparison with conventional HAR model by computing Exp. HAR model efficiency, defined by Effi, Effi of exponential weighted HAR model, where RMSE, MAE are the root mean square error (RMSE), and mean absolute error (MAE) of the conventional HAR model, respectively; and RMSE, MAE are those of Exp. HAR model.
Table 7.
Comparison with conventional HAR model by computing Exp. HAR model efficiency, defined by Effi, Effi of exponential weighted HAR model, where RMSE, MAE are the root mean square error (RMSE), and mean absolute error (MAE) of the conventional HAR model, respectively; and RMSE, MAE are those of Exp. HAR model.
| | | |
|---|
| Rates | Effi | Effi | Effi | Effi |
|---|
| () | | | | | | | | |
| (0.5, 0.1) | 4.1635 | 6.3361 | 5.2112 | 4.3094 | 4.8475 | 4.9433 | 7.0817 | 6.9621 |
| (0.5, 0.4) | 5.1794 | 6.8979 | 5.0989 | 2.8984 | 5.8510 | 5.4411 | 5.3964 | 5.4328 |
| (0.8, 0.1) | 5.9158 | 4.4523 | 4.5951 | 5.1982 | 5.3078 | 6.3053 | 4.7309 | 6.9481 |
| (0.8, 0.4) | 5.7379 | 3.6783 | 6.3833 | 3.7651 | 5.1028 | 4.4709 | 5.7066 | 6.0533 |
The HAR model has high applicability in the financial market. In particular, it is very powerful for the realized volatility forecasting [
1,
17,
18,
29]. However, besides volatility forecasting, as a theoretically linear AR model, it has many applications to various time series data as in [
12,
13,
14,
42]. The exponentially weighted multivariate HAR model, which is one of the special cases of HAR models, is suitable for joint data with strong cross-correlation. The decay rate of the model plays a key role in the common structure of the joint data with strong correlation. In economics and finance, there are many strongly correlated time series data that are important for policy decisions to improve the global economy and human society. For example, stock prices in the same category tend to have the same pattern. Stock price modellings are known to be based on efficient market hypotheses (EMH), according to which only relevant information on the stock is its current values. The proposed model may be proper to the stock price modelling because the current value and the current averages (with exponentially decaying coefficients) are used as regressor variables in the model. The following section will address empirical analysis of the joint data of strongly correlated stock prices to confirm the intuition of the proposed model for the stock prices.
4. Empirical Analysis
In this section, we provide empirical examples of U.S. stock prices that are applied to the exponentially weighted multivariate HAR models. Note that realized volatility does not fit for our model, but the stock price itself may be suitable for the proposed model with exponential decay coefficients. To this end, we choose some datasets of U.S. stock prices and conduct our proposed CUSUM tests. For a bivariate joint data (
), stock prices of Amazon.com Inc. (AMZN) (Seattle, WA, USA) and Netflix Inc. (NFLX) (Los Gatos, CA, USA), and for a triple joint data (
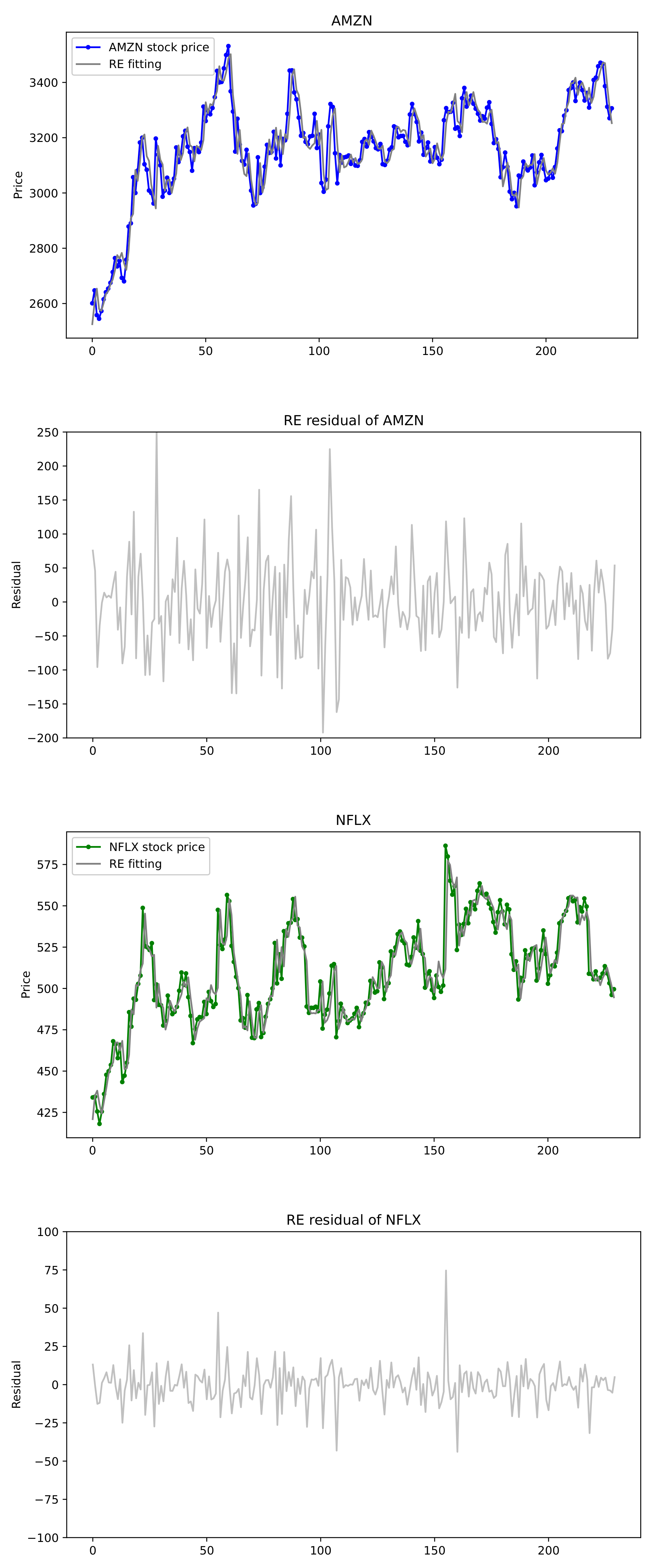
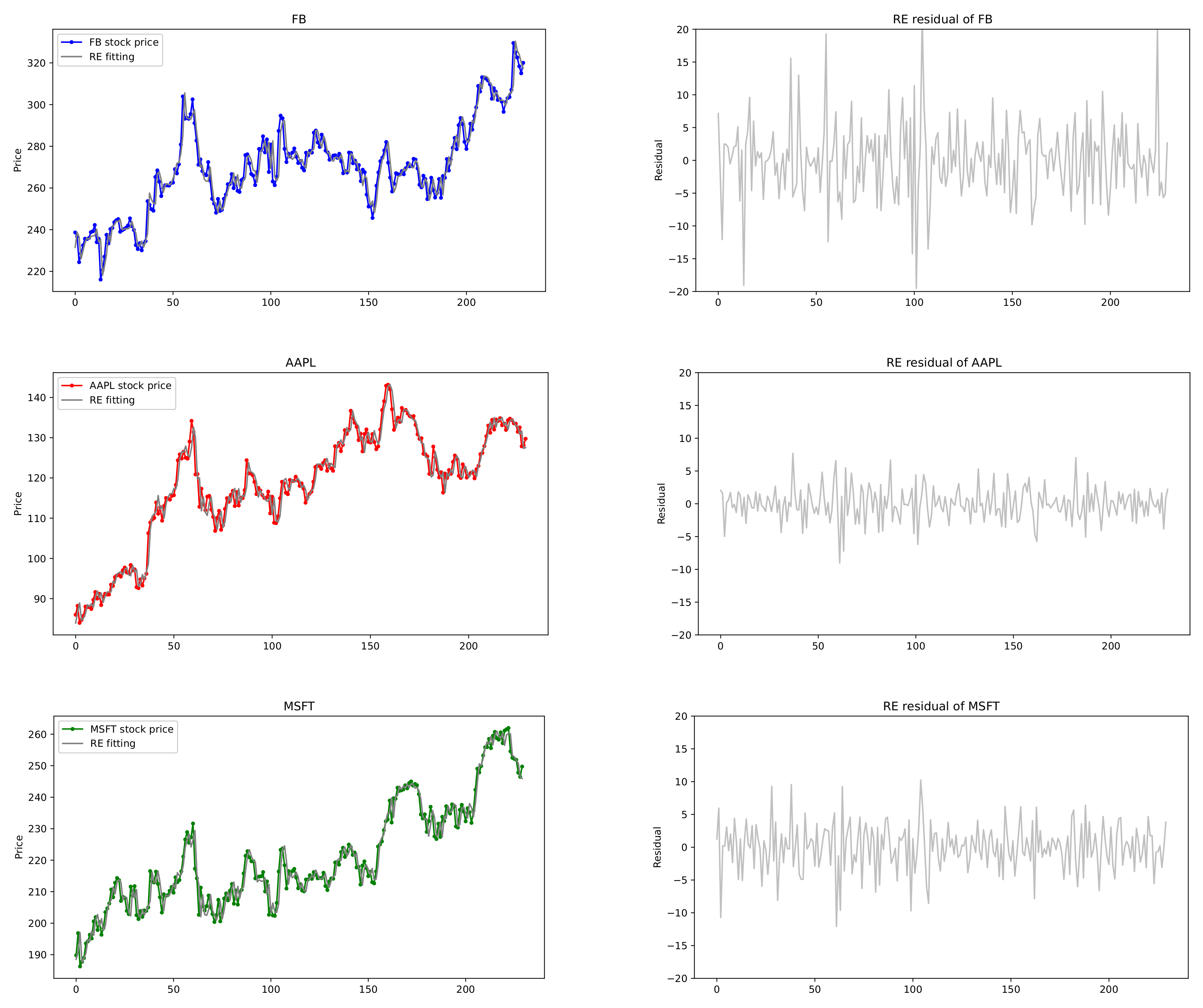
), those of Apple Inc. (AAPL) (Cupertino, CA, USA), Microsoft Corporation (MSFT) (Redmond, WA, USA) and Facebook Inc. (FB) (Menlo Park, CA, USA) are selected from 7 May 2020 to 6 May 2021. In the analysis, closing price is chosen because it reflects all the activities in a trading day. Plots of these stock prices are shown in
Figure 7 and
Figure 8, where we see that the time series data reveal somewhat similar patterns for the pair (AMZN, NFLX) and for the triple (FB, AAPL, MSFT).
First we adopt bivariate HAR(3,2) models for pairs of (AMZN, NFLX), (AAPL, MSFT), (FB, AAPL) and (FB, MSFT) for
, respectively, and second a multivariate HAR(3,3) model for three datasets (FB, AAPL, MSFT) for
. Order
and lag
are used. Results of tests and estimates as well as correlation coefficients are reported in
Table 8, where suprema of test statistics and decay rate estimates are computed by Theorem 1 and Equation (
9), respectively. More specifically, conducting the CUSUM test in Theorem 1 to detect the presence of the exponential decay rates, test statistics are evaluated as follows. In the case of (AMZN, NFLX) for detecting the existence of
and
, the CUSUM test statistics are computed as 0.3986 for AMZN and 0.3489 for NFLX. In the case of (AAPL, MSFT), the CUSUM test statistics are computed as 0.7508 for AAPL and 0.4979 for MSFT. These values imply that the null hypothesis is not rejected because the critical values of the standard Brownian bridge are 1.224 of level
and 1.358 of level
. On the other hand, as the test in Theorem 2 for a common rate is conducted, the test statistics are evaluated as values greater than 2, which rejects the null hypothesis with the common rate.
Now comparisons with the conventional HAR models are presented for the two pairs (AMZN, NFLX), (AAPL, MSFT), and for the triple (FB, AAPL, MSFT). We compare performances for these datasets applied to univariate HAR model, (conventional) multivariate HAR model and exponentially weighted multivariate HAR (Exp. HAR) model. For the conventional HAR models, two estimation methods of OLSE and LASSO used in [
43] are adopted. LASSO estimates are computed by LassoLarsCV in sklearn.linear_model with Python version 3.8.6. For the Exp. HAR model, the RE is computed. In
Table 9, for two joint datasets (
), the conventional HAR(3,2) model has 14 parameters, whereas the exponential weighted HAR(3,2) model has 8 parameters. Each univariate HAR model has 4 parameters, so the total number is 8.
Table 9 reports the comparison results of the HAR(3,2) models. The CUSUM test favors the existence of exponential decay rates, and thus the exponential bivariate HAR(3,2) is fitted with the rate estimates. The decay rates for AMZN and NFLX are estimated as
whereas those for AAPL and MSFT are
, which are presented in
Table 8. Four measures of RMSE, MAE, AIC, and BIC are compared in the three models via OLSE, LASSO, and RE. In
Table 9, the best values are displayed in bold. The exponential bivariate HAR(3,2) model has the best performance on RMSE and MAE, whereas the univariate HAR model with LASSO has the best performance on the AIC and BIC.
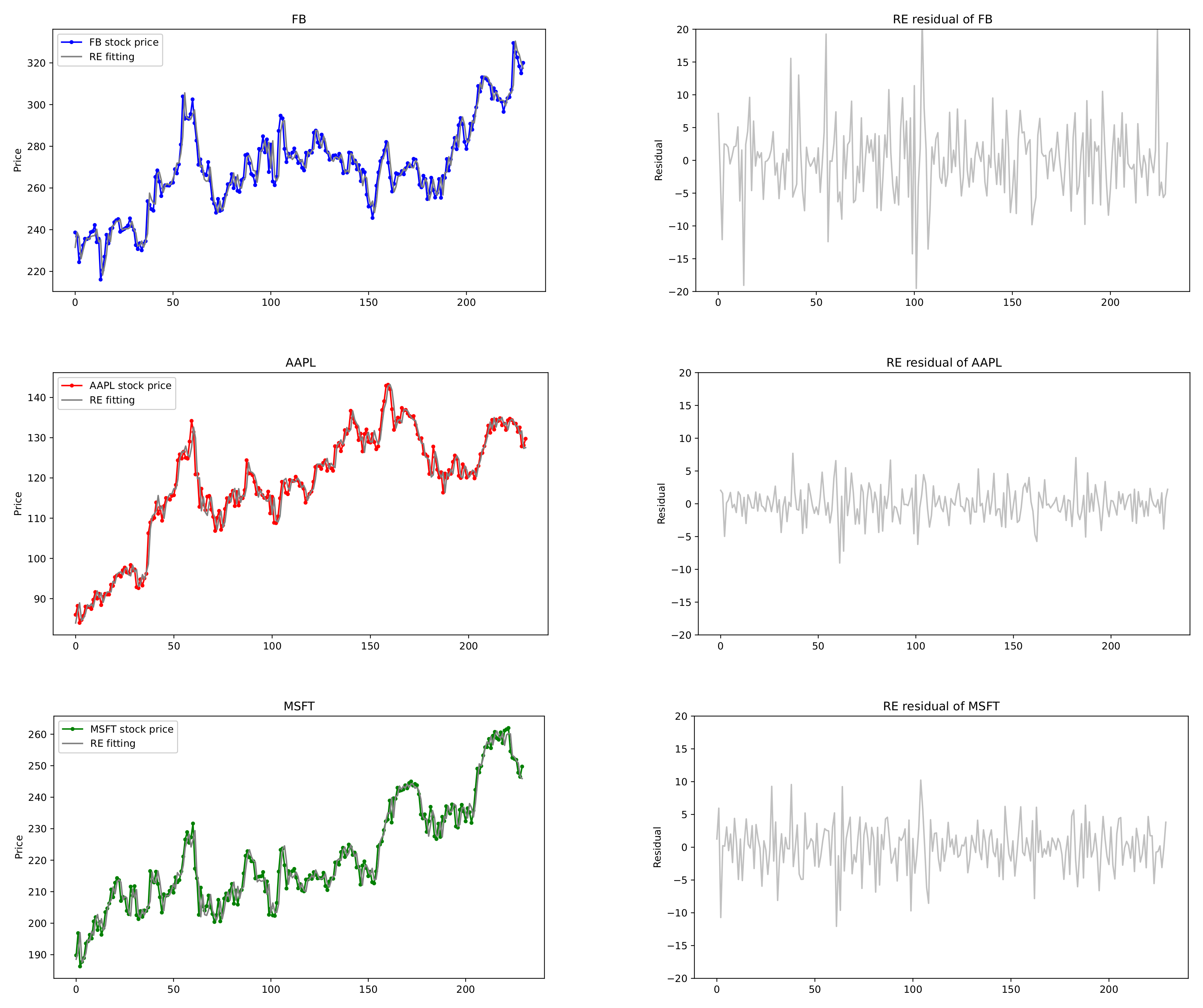
Figure 7 depicts the actual data of stock prices of (AMZN, NFLX) and the fitted Exp. HAR(3,2) model by the REs along with their residuals. It can be seen that the stock prices of (AMZN, NFLX) are well matched to the fitted model.
Table 8.
Results of tests and estimates for (MZN, NFLX) and (FB, AAPL, MSFT) in exponentially weighted HAR() models, .
Table 8.
Results of tests and estimates for (MZN, NFLX) and (FB, AAPL, MSFT) in exponentially weighted HAR() models, .
| | Correlation | q | Test Statistics | Rate Estimates |
|---|
| | Coefficient | | |
|---|
| (AMZN, NFLX) | 0.8268 | 2 | (0.3986, 0.3489) | () |
| (AAPL, MSFT) | 0.8396 | 2 | (0.7508, 0.4979) | () |
| (FB, AAPL) | 0.8185 | 2 | (0.4644, 0.7925) | () |
| (FB, MSFT) | 0.8203 | 2 | (0.4549, 0.4794) | (0.01255, 0.01322) |
| (FB, AAPL, MSFT) | - | 3 | (0.4889, 0.7424, 0.4762) | () |
Table 9.
Comparison of univariate HAR, bivariate HAR and exponential weighted bivariate HAR models for (AMZN, NFLX), (AAPL, MSFT) stock prices from 7 May 2020 to 6 May 2021; , ; , .
Table 9.
Comparison of univariate HAR, bivariate HAR and exponential weighted bivariate HAR models for (AMZN, NFLX), (AAPL, MSFT) stock prices from 7 May 2020 to 6 May 2021; , ; , .
| | Univariate HAR(3) | Bivariate HAR(3,2) | Exp. Bi. HAR(3,2) |
|---|
| Total # of Parameters | 8 | 14 | 8 |
|---|
| | Estimator | OLSE | LASSO | OLSE | LASSO | RE |
|---|
| AMZN | RMSE | 61.6182 | 62.9610 | 61.5780 | 62.9610 | 61.2005 |
| | MAE | 47.1019 | 47.6977 | 47.1447 | 47.6977 | 46.2293 |
| | AIC | 2556.35 | 2321.29 | 2576.05 | 2341.28 | 2561.21 |
| | BIC | 2570.10 | 2334.64 | 2624.18 | 2388.01 | 2588.71 |
| NFLX | RMSE | 13.3562 | 13.6602 | 13.3174 | 13.8798 | 12.3834 |
| | MAE | 9.0379 | 9.2866 | 9.0565 | 9.9867 | 8.4594 |
| | AIC | 1853.02 | 1685.89 | 1871.68 | 1712.52 | 1826.23 |
| | BIC | 1866.77 | 1699.25 | 1919.82 | 1759.25 | 1853.73 |
| AAPL | RMSE | 2.6255 | 2.6866 | 2.6061 | 2.6609 | 2.4899 |
| | MAE | 1.9478 | 1.9877 | 1.9346 | 1.9709 | 1.8520 |
| | AIC | 1104.74 | 1009.34 | 1121.31 | 1025.34 | 1088.24 |
| | BIC | 1118.48 | 1022.69 | 1269.45 | 1072.06 | 1115.75 |
| MSFT | RMSE | 3.8234 | 3.8979 | 3.8208 | 3.8975 | 3.5746 |
| | MAE | 2.9249 | 2.9625 | 2.9315 | 2.9633 | 2.7488 |
| | AIC | 1277.63 | 1164.14 | 1297.33 | 1184.10 | 1254.68 |
| | BIC | 1291.39 | 1177.49 | 1345.46 | 1230.83 | 1282.19 |
Table 10 reports the performances of the HAR(3,3) models for (FB, AAPL, MSFT). The conventional HAR(3,3) model has 30 parameters, whereas the exponential weighted HAR(3,3) model has 15 parameters. The decay rate estimates of (FB, AAPL, MSFT) are
, from which Exp. HAR(3,3) models are fitted in
Figure 8. As seen in
Table 10, our proposed model performs better than others with respect to the RMSE, MAE, and AIC whereas the univariate HAR model with LASSO has good performance on BIC, which are indicated by bold numbers in
Table 10. Consequently, the proposed model not only has fewer parameters than the conventional HAR models, but also yields the best performance on the loss errors such as RMSE and MAE. The exponentially weighted HAR model with decay rates is suitable for the stock prices of joint financial assets with strong cross-correlation, rather than the volatility, in the stock market.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}