
Grand Canonical Ensembles of Sparse Networks and Bayesian Inference


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
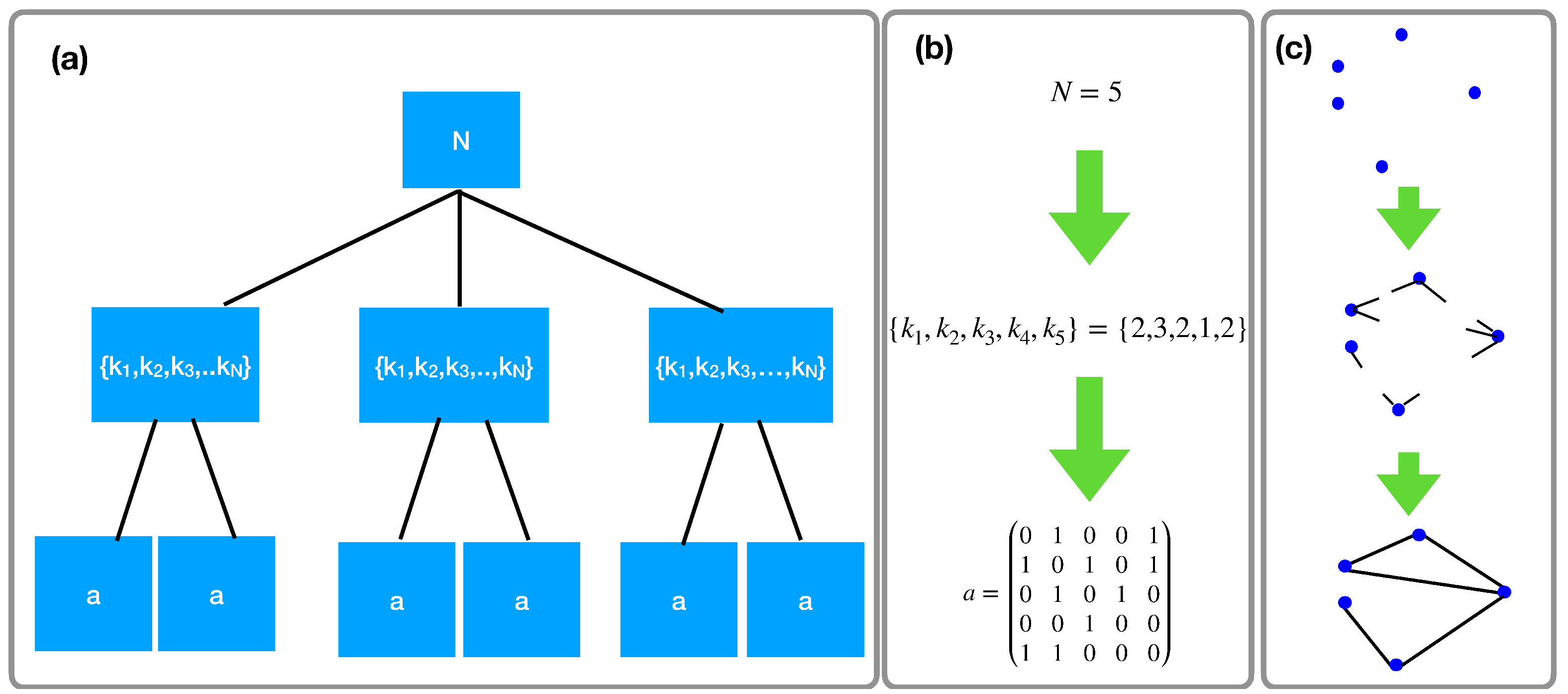
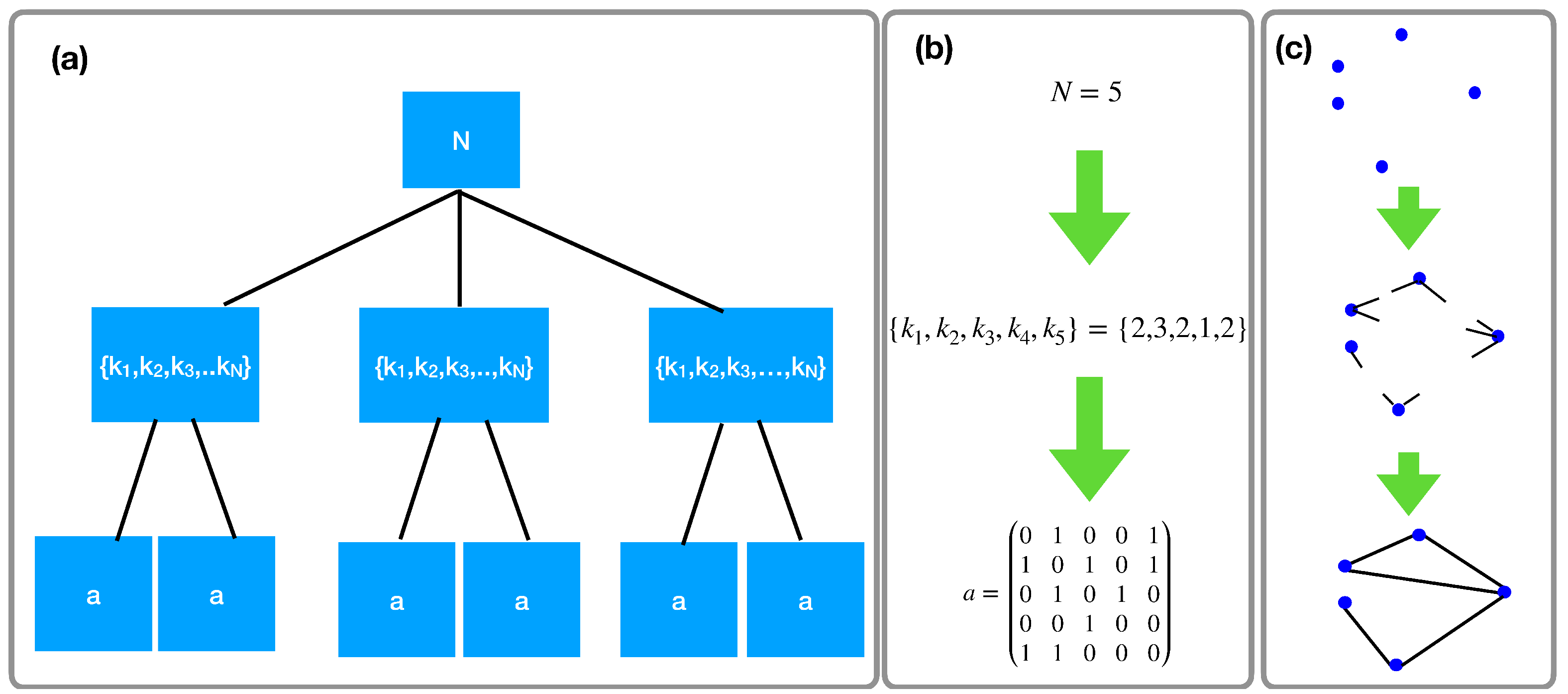
2. The Grand Canonical Network Ensemble with Given Degree Distribution
- (1)
- Drawing the total number of nodes N of the network. Let us discuss suitable choices for the distribution of the number of nodes N with N greater or equal than some minimum number of nodes . We indicate the distribution asWhile a statistical mechanics approach would suggest to take a distribution with a well defined mean value (such as the exponential distribution)where C is a normalization constant and , in the context of network science it might actually be relevant to consider also broad distributions such as power-law distributionswhere D is a normalization constant and .
- (2)
- Drawing the degree sequence of the network. In order to obtain a sparse exchangeable network ensemble with given degree distribution having finite average degree , minimum allowed degree and maximum allowed degree K we consider the following expression for the probability of a given degree sequence given the total number of nodeswhere indicates the Heaviside function if and otherwise and where we used the notation . In the following we will indicate with L the total number of links of the network given by . Note that is independent of the labels of the nodes, i.e., all the degree sequences that can be obtained by a permutation of the node labels of a given degree sequence have the same probability .
- (3)
- Drawing the adjacency matrix of the network. The probability of a network G with adjacency matrix given the total number of nodes N of the network and the degree sequence is chosen in the least biased way by drawing the network from a uniform distribution, i.e., the conditional probability is equivalent to the probability of a network in the microcanonical ensemble. Therefore, by indicating with the total number of networks with N nodes and degree sequence and with the entropy of the ensemble we can express as
3. The Grand Canonical Network Ensemble with Given Distribution of the Latent Variables
4. The Entropy of Grand Canonical Ensembles
4.1. Entropy of the Grand Canonical Ensemble with Given Degree Distribution
4.2. Entropy of the Grand Canonical Ensemble with Given Latent Variable Distribution
5. Marginal Probability of a Link
5.1. The Case of the Grand Canonical Ensemble with Given Degree Distribution
5.2. The Case of the Grand Canonical Ensemble with Given Latent Variable Distribution
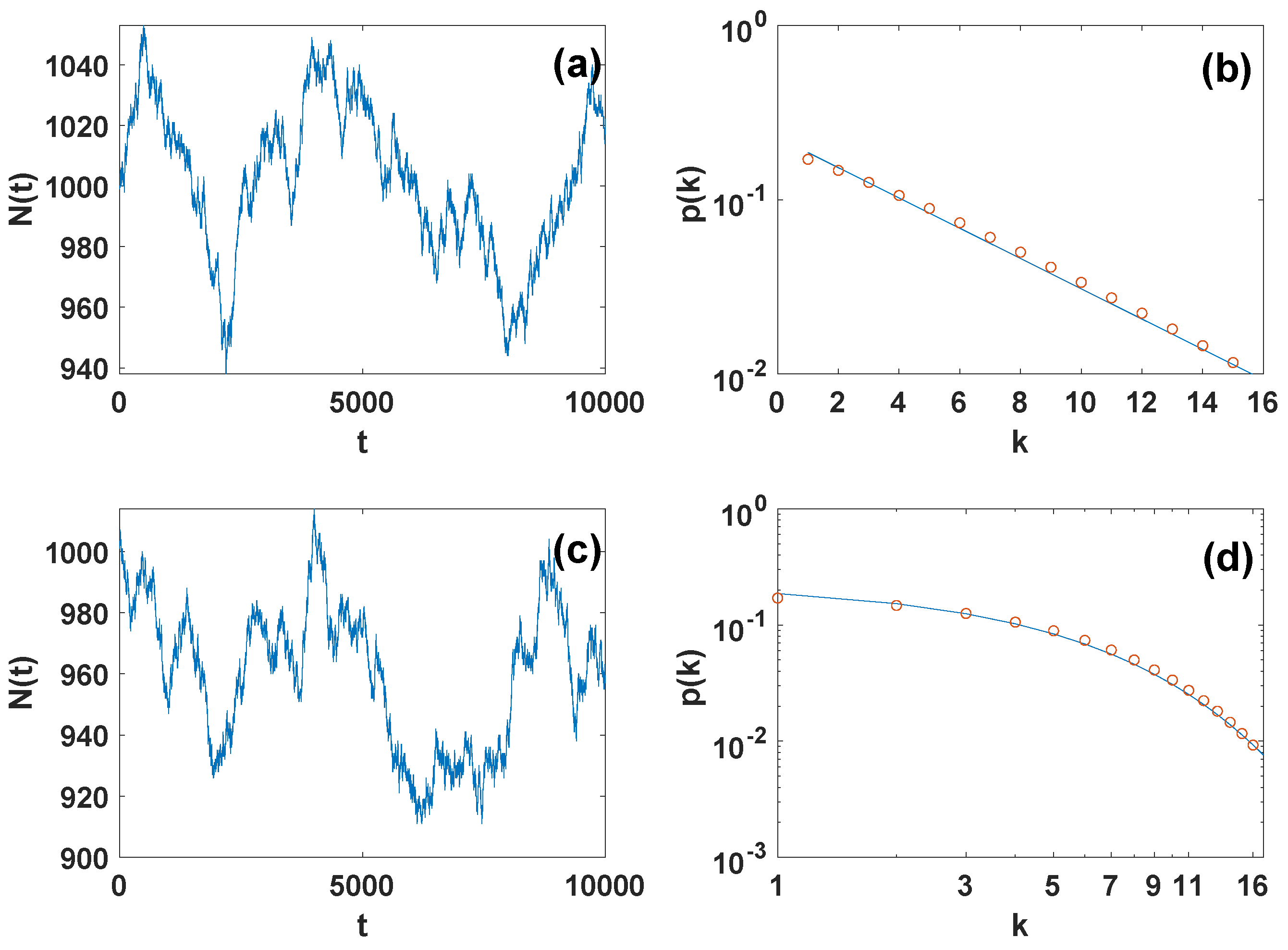
6. Generating Single Instances of Grand-Canonical Network Ensembles
6.1. Metropolis-Hastings Algorithm for the Grand-Canonical Ensemble with Given Degree Distribution
- (1)
- Start with a network of N nodes having exactly links and in which the minimum degree is greater of equal to and the maximum degree is smaller or equal to K.
- (2)
- Perform the Metropolis-Hastings algorithm for exchangeable sparse networks with N nodes (defined below);
- (3)
- Propose to change the number of nodes to (addition of one node) or (removal of one node) with equal probability and accept the move with probability as long as . If the move is accepted change the number of nodes adding or removing a node, set the number of links to and ensure that each node has minimal degree at least and maximum degree less than K. In particular if a node is added ensure it has at least links by rewiring randomly the existing links of the networks and adding a number of links so that the total number of links is the integer that better approximates . Instead, if a node needs to be removed, choose a random node of the network remove it and rewire/remove links in order to enforce that the total number of links is the integer that better approximates .
- (1)
- Start with a network of N nodes having exactly links and in which the minimum degree is greater of equal to and the maximum degree is smaller or equal to K.
- (2)
- Iterate the following steps until equilibration:
- (i)
- Let be the adjacency matrix of the network;
- (i)
- Choose randomly a random link between node i and j and choose a pair of random nodes not connected by a link.
- (ii)
- Let be the adjacency matrix of the network in which the link is removed and the link is inserted instead. Draw a random number r from a uniform distribution in , i.e., . If where and if the move does not violate the conditions on the minimum and maximum degree of the network, replace by .
6.2. Monte Carlo Generation of Grand Canonical Network Ensemble with Given Latent Variable Distribution
- 1
- Draw the network size N from the distribution;
- 2
- Draw the latent variable of each node i independently from the latent variable distribution .
- 3
- Draw each link of the network with probability .
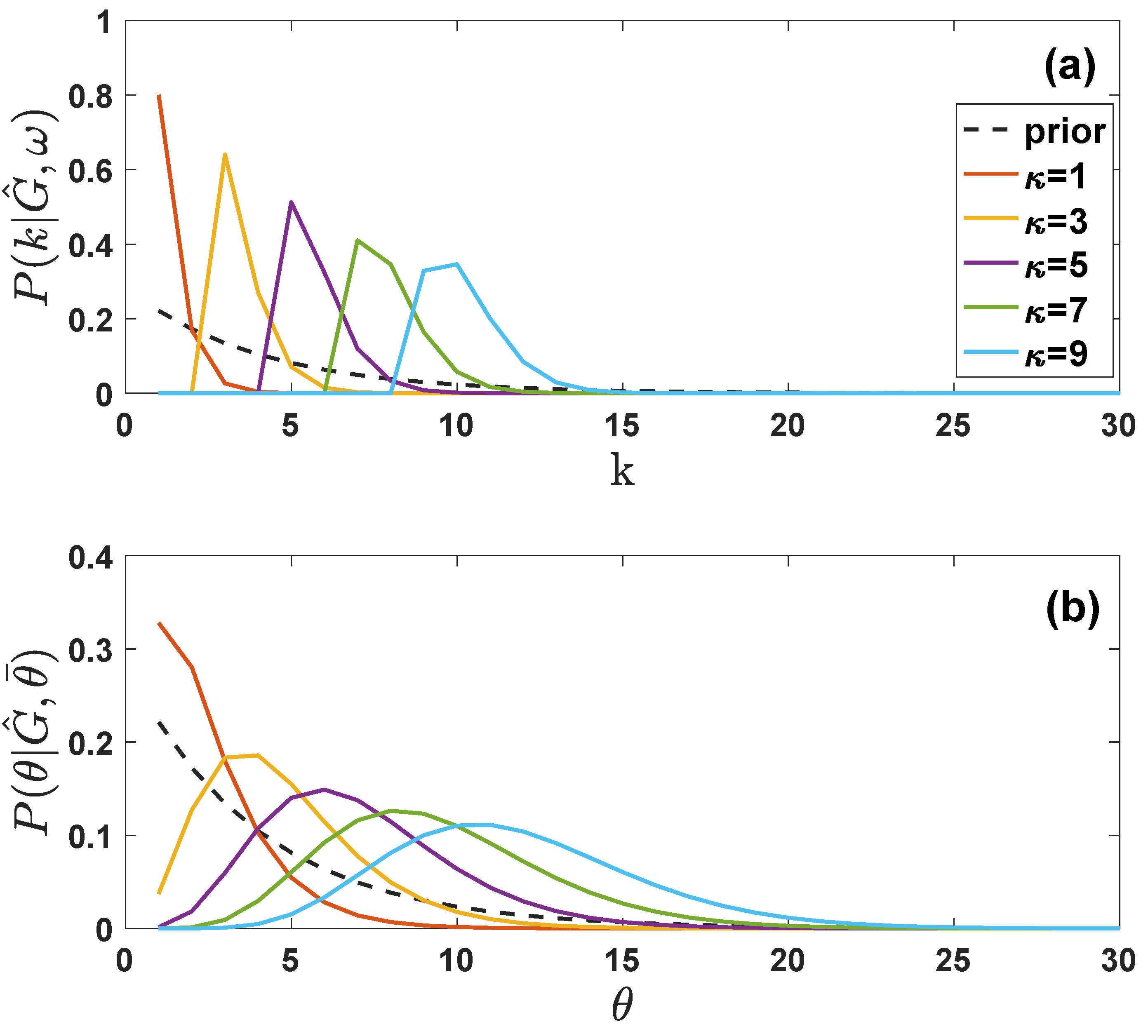
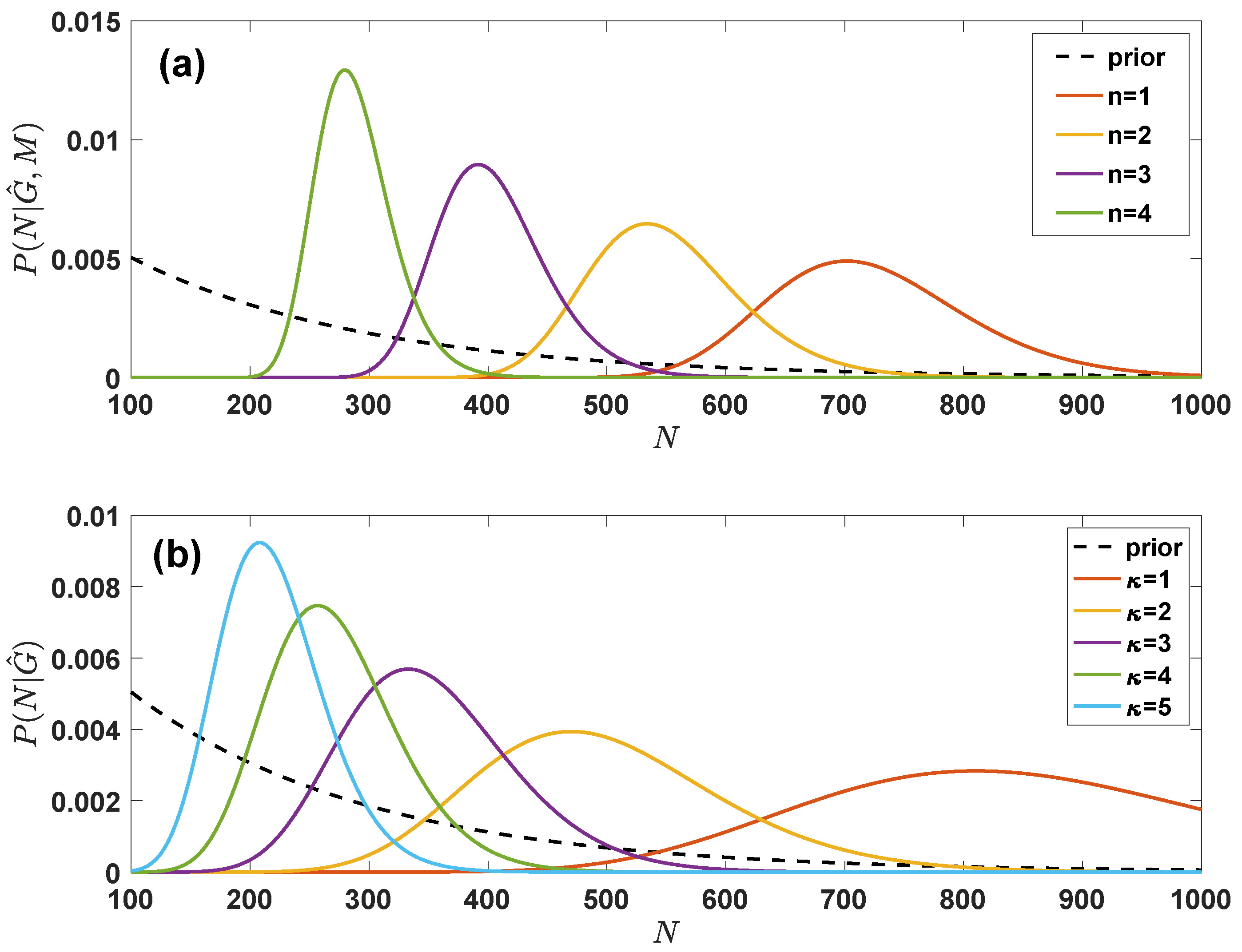
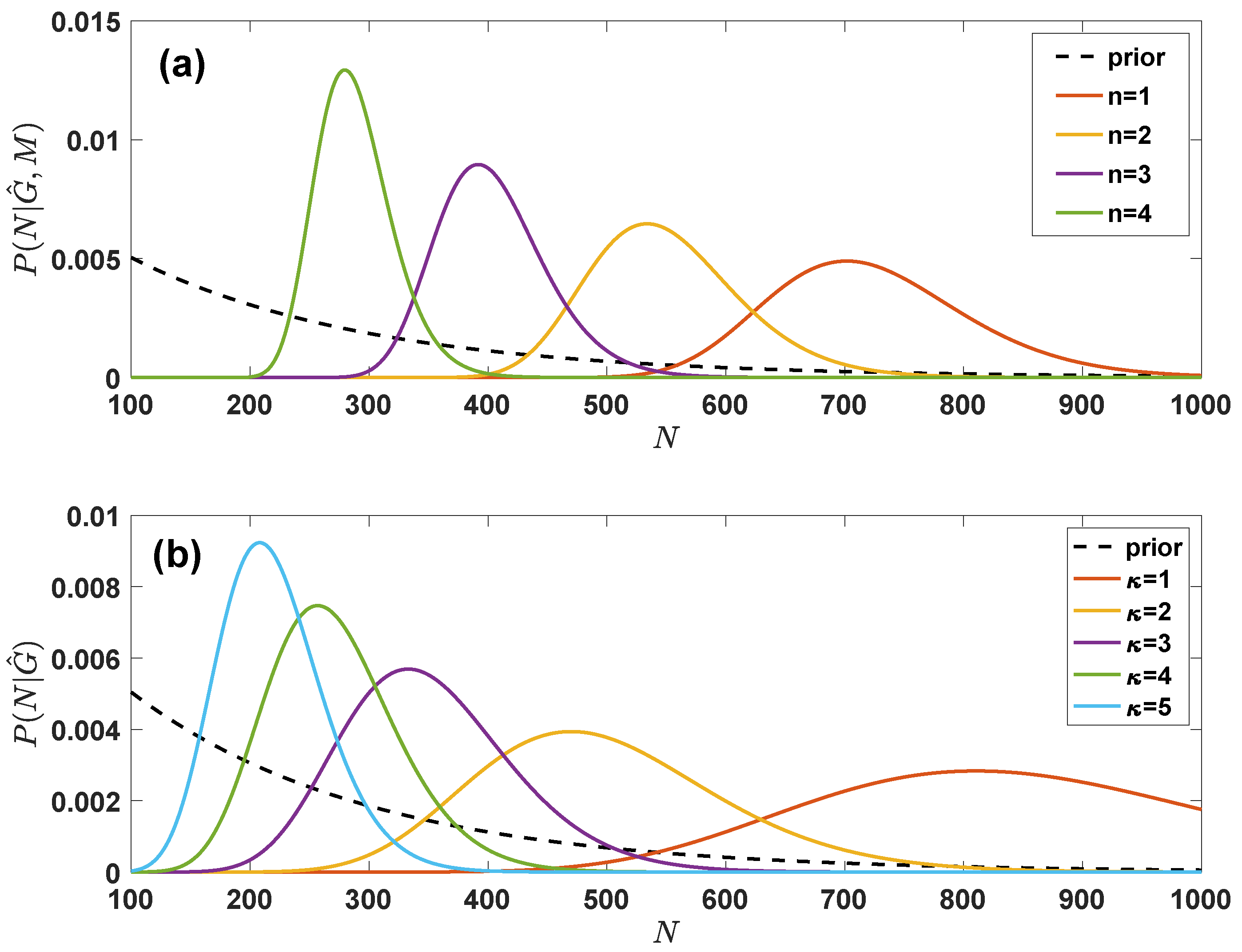
7. Bayesian Estimation of the Network Parameters Given Partial Knowledge of the Network
7.1. Inferring the True Parameters with the Grand Canonical Ensemble with Given Degree Distribution
7.2. Inferring the True Parameters with the Grand Canonical Ensemble with Given Latent Variable Distribution
8. Conclusions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation of (k,q|κ)
References
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Newman Mark, E. Networks: An Introduction; Oxford University Press: Cambridge, UK, 2010. [Google Scholar]
- Anand, K.; Bianconi, G. Entropy measures for networks: Toward an information theory of complex topologies. Phys. Rev. E 2009, 80, 045102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, J.; Newman, M.E. Statistical mechanics of networks. Phys. Rev. E 2004, 70, 066117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bianconi, G. Information theory of spatial network ensembles. In Handbook on Entropy, Complexity and Spatial Dynamics; Edward Elgar Publishing: Cheltenham, UK, 2021. [Google Scholar]
- Cimini, G.; Squartini, T.; Saracco, F.; Garlaschelli, D.; Gabrielli, A.; Caldarelli, G. The statistical physics of real-world networks. Nat. Rev. Phys. 2019, 1, 58–71. [Google Scholar] [CrossRef] [Green Version]
- Krioukov, D.; Papadopoulos, F.; Kitsak, M.; Vahdat, A.; Boguná, M. Hyperbolic geometry of complex networks. Phys. Rev. E 2010, 82, 036106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Orsini, C.; Dankulov, M.M.; Colomer-de Simón, P.; Jamakovic, A.; Mahadevan, P.; Vahdat, A.; Bassler, K.E.; Toroczkai, Z.; Boguná, M.; Caldarelli, G.; et al. Quantifying randomness in real networks. Nat. Commun. 2015, 6, 8627. [Google Scholar] [CrossRef]
- Peixoto, T.P. Entropy of stochastic blockmodel ensembles. Phys. Rev. E 2012, 85, 056122. [Google Scholar] [CrossRef] [Green Version]
- Radicchi, F.; Krioukov, D.; Hartle, H.; Bianconi, G. Classical information theory of networks. J. Phys. Complex. 2020, 1, 025001. [Google Scholar] [CrossRef]
- Pessoa, P.; Costa, F.X.; Caticha, A. Entropic dynamics on Gibbs statistical manifolds. Entropy 2021, 23, 494. [Google Scholar] [CrossRef]
- Kim, H.; Del Genio, C.I.; Bassler, K.E.; Toroczkai, Z. Constructing and sampling directed graphs with given degree sequences. New J. Phys. 2012, 14, 023012. [Google Scholar] [CrossRef] [Green Version]
- Del Genio, C.I.; Kim, H.; Toroczkai, Z.; Bassler, K.E. Efficient and exact sampling of simple graphs with given arbitrary degree sequence. PLoS ONE 2010, 5, e10012. [Google Scholar] [CrossRef] [Green Version]
- Coolen, A.C.; Annibale, A.; Roberts, E. Generating Random Networks and Graphs; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Bassler, K.E.; Del Genio, C.I.; Erdős, P.L.; Miklós, I.; Toroczkai, Z. Exact sampling of graphs with prescribed degree correlations. New J. Phys. 2015, 17, 083052. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dorogovtsev, S.N.; Dorogovtsev, S.N.; Mendes, J.F. Evolution of Networks: From Biological Nets to the Internet and WWW; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Kharel, S.R.; Mezei, T.R.; Chung, S.; Erdős, P.L.; Toroczkai, Z. Degree-preserving network growth. Nat. Phys. 2021, 18, 100–106. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Huang, K. Introduction to Statistical Physics; Chapman and Hall: London, UK; CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Anand, K.; Bianconi, G. Gibbs entropy of network ensembles by cavity methods. Phys. Rev. E 2010, 82, 011116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bianconi, G.; Coolen, A.C.; Vicente, C.J.P. Entropies of complex networks with hierarchically constrained topologies. Phys. Rev. E 2008, 78, 016114. [Google Scholar] [CrossRef] [Green Version]
- Caldarelli, G.; Capocci, A.; De Los Rios, P.; Munoz, M.A. Scale-free networks from varying vertex intrinsic fitness. Phys. Rev. Lett. 2002, 89, 258702. [Google Scholar] [CrossRef] [Green Version]
- Bianconi, G.; Pin, P.; Marsili, M. Assessing the relevance of node features for network structure. Proc. Natl. Acad. Sci. USA 2009, 106, 11433–11438. [Google Scholar] [CrossRef] [Green Version]
- Airoldi, E.M.; Blei, D.; Fienberg, S.; Xing, E. Mixed membership stochastic blockmodels. Adv. Neural Inf. Process. Syst. 2008, 21, 1981–2014. [Google Scholar]
- Ghavasieh, A.; Nicolini, C.; De Domenico, M. Statistical physics of complex information dynamics. Phys. Rev. E 2020, 102, 052304. [Google Scholar] [CrossRef]
- Bevilacqua, B.; Zhou, Y.; Ribeiro, B. Size-invariant graph representations for graph classification extrapolations. In Proceedings of the International Conference on Machine Learning, PMLR, London, UK, 8–11 November 2021; pp. 837–851. [Google Scholar]
- Cotta, L.; Morris, C.; Ribeiro, B. Reconstruction for powerful graph representations. Adv. Neural Inf. Process. Syst. 2021, 34. [Google Scholar] [CrossRef]
- De Finetti, B. Funzione Caratteristica Di un Fenomeno Aleatorio; Accademia Nazionale Lincei: Rome, Italy, 1931; Volume 4. [Google Scholar]
- Lovász, L. Large Networks and Graph Limits; American Mathematical Society: Providence, RI, USA, 2012; Volume 60. [Google Scholar]
- Chung, F.; Lu, L. The average distances in random graphs with given expected degrees. Proc. Natl. Acad. Sci. USA 2002, 99, 15879–15882. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bianconi, G. Statistical physics of exchangeable sparse simple networks, multiplex networks, and simplicial complexes. Phys. Rev. E 2022, 105, 034310. [Google Scholar] [CrossRef] [PubMed]
- Caron, F.; Fox, E.B. Sparse graphs using exchangeable random measures. J. R. Stat. Soc. Ser. Stat. Methodol. 2017, 79, 1295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borgs, C.; Chayes, J.T.; Cohn, H.; Holden, N. Sparse exchangeable graphs and their limits via graphon processes. arXiv 2016, arXiv:1601.07134. [Google Scholar]
- Veitch, V.; Roy, D.M. The class of random graphs arising from exchangeable random measures. arXiv 2015, arXiv:1512.03099. [Google Scholar]
- Veitch, V.; Roy, D.M. Sampling and estimation for (sparse) exchangeable graphs. Ann. Stat. 2019, 47, 3274–3299. [Google Scholar] [CrossRef] [Green Version]
- Borgs, C.; Chayes, J.T.; Smith, A. Private graphon estimation for sparse graphs. arXiv 2015, arXiv:1506.06162. [Google Scholar]
- Borgs, C.; Chayes, J.; Smith, A.; Zadik, I. Revealing network structure, confidentially: Improved rates for node-private graphon estimation. In Proceedings of the 2018 IEEE 59th Annual Symposium on Foundations of Computer Science (FOCS), Paris, France, 7–9 October 2018; pp. 533–543. [Google Scholar]
- Bianconi, G. Multilayer Networks: Structure and Function; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Bianconi, G. Higher-Order Networks: An Introduction to Simplicial Complexes; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Aldous, D.J. Representations for partially exchangeable arrays of random variables. J. Multivar. Anal. 1981, 11, 581–598. [Google Scholar] [CrossRef] [Green Version]
- Hoover, D.N. Relations on Probability Spaces and Arrays of Random Variables; Institute for Advanced Study: Princeton, NJ, USA, 1979; Volume 2, p. 275. [Google Scholar]
- Paton, J.; Hartle, H.; Stepanyants, J.; van der Hoorn, P.; Krioukov, D. Entropy of labeled versus unlabeled networks. arXiv 2022, arXiv:2204.08508. [Google Scholar]
- Peixoto, T.P. Hierarchical block structures and high-resolution model selection in large networks. Phys. Review X 2014, 4, 011047. [Google Scholar] [CrossRef] [Green Version]
- Gabrielli, A.; Mastrandrea, R.; Caldarelli, G.; Cimini, G. Grand canonical ensemble of weighted networks. Phys. Rev. E 2019, 99, 030301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Straka, M.J.; Caldarelli, G.; Saracco, F. Grand canonical validation of the bipartite international trade network. Phys. Rev. E 2017, 96, 022306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bender, E.A.; Canfield, E.R. The asymptotic number of labeled graphs with given degree sequences. J. Comb. Theory Ser. A 1978, 24, 296–307. [Google Scholar] [CrossRef] [Green Version]
- Bianconi, G. Entropy of network ensembles. Phys. Rev. E 2009, 79, 036114. [Google Scholar] [CrossRef] [Green Version]
- Courtney, O.T.; Bianconi, G. Generalized network structures: The configuration model and the canonical ensemble of simplicial complexes. Phys. Rev. E 2016, 93, 062311. [Google Scholar] [CrossRef] [Green Version]
- Monasson, R.; Zecchina, R. Statistical mechanics of the random K-satisfiability model. Phys. Rev. E 1997, 56, 1357. [Google Scholar] [CrossRef] [Green Version]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bianconi, G. Grand Canonical Ensembles of Sparse Networks and Bayesian Inference. Entropy 2022, 24, 633. https://doi.org/10.3390/e24050633
Bianconi G. Grand Canonical Ensembles of Sparse Networks and Bayesian Inference. Entropy. 2022; 24(5):633. https://doi.org/10.3390/e24050633
Chicago/Turabian StyleBianconi, Ginestra. 2022. "Grand Canonical Ensembles of Sparse Networks and Bayesian Inference" Entropy 24, no. 5: 633. https://doi.org/10.3390/e24050633
APA StyleBianconi, G. (2022). Grand Canonical Ensembles of Sparse Networks and Bayesian Inference. Entropy, 24(5), 633. https://doi.org/10.3390/e24050633