Abstract
A change point is a location or time at which observations or data obey two different models: before and after. In real problems, we may know some prior information about the location of the change point, say at the right or left tail of the sequence. How does one incorporate the prior information into the current cumulative sum (CUSUM) statistics? We propose a new class of weighted CUSUM statistics with three different types of quadratic weights accounting for different prior positions of the change points. One interpretation of the weights is the mean duration in a random walk. Under the normal model with known variance, the exact distributions of these statistics are explicitly expressed in terms of eigenvalues. Theoretical results about the explicit difference of the distributions are valuable. The expansions of asymptotic distributions are compared with the expansion of the limit distributions of the Cramér-von Mises statistic and the Anderson and Darling statistic. We provide some extensions from independent normal responses to more interesting models, such as graphical models, the mixture of normals, Poisson, and weakly dependent models. Simulations suggest that the proposed test statistics have better power than the graph-based statistics. We illustrate their application to a detection problem with video data.
1. Introduction
A change point is a location or time at which observations or data obey two different models: before and after. Detecting change points is a nontrivial problem and has been studied by many authors; see a book treatment in [1] and recent advances in CUSUM-based change point tests [2,3,4]. In real problems, we may know some prior information about the location of the change point, say at the right or left tail of the sequence. How does one incorporate prior information into current CUSUM-based statistics? We consider a new class of weighted CUSUM statistics for a simple model and provide some extensions to more complicated models.
Given a series of univariate random variables , we consider the problem of testing whether there is a change in the mean of their distribution. The test statistic we use is:
where , , , and
where , and n account for three different prior positions of the change point, respectively. We call a weighted CUSUM (WC) statistic.
Inspired by the change point literature, we consider these types of quadratic weights. The term is introduced to ensure that the weight is positive for any . Usually, we choose to capture the change in the mean. When , the weight corresponds to the likelihood ratio test; see Csörgö and Horváth [1] and a related review in Jandhyala et al. [5]. If prior information indicates that the change point more likely occurs in the right or left tail of the sequence, we can set the weight (left drifted to the symmetry center point 0) or (right drifted to the symmetry center point n) to improve the power of the test.
One interpretation of the weights is the mean duration in a random walk on states, , whose transition probability is given by for , and . Let T denote the random time at which the process first reaches 0 or N. Then, for , if ; if ; and if . Figure 1 depicts four vectors for . The centers of symmetry of these quadratic weights are at different positions.
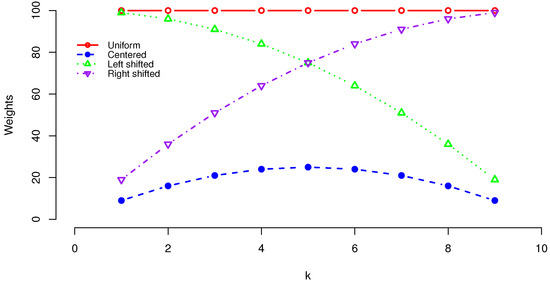
Figure 1.
Plot of weights: (uniform), (centered), (left shifted), and (right shifted).
The weights in (1) can be thought of as an inverse prior probability on the change point, giving a Bayesian flavor, as in Gardner [6], who used the uniform prior , or Perron [7], who devised a unit-root test for time series. From a frequentist perspective, the weighted sum statistic offers an alternative to the maximum statistic most commonly used Csörgö and Horváth [1], which we show (in small simulations omitted here) has higher power, especially when the change point is at the center of the sequence for any , in the right tail of the sequence for , and in the left tail of the sequence for .
For these types of quadratic weights, a couple of questions naturally arise: will different weights lead to different distributions of WC in Equation (1)? If so, how significant will the differences in the distribution be? If two different weights lead to the same distribution, are there any intrinsic reasons? Although one can estimate the distribution of WC by simulation, theoretical results about the explicit differences of the distributions are valuable. Moreover, simulations and computations of eigenvalues for large n are computationally expensive. To answer the aforementioned questions, we shall study the distribution of the WC theoretically; we derive Karhunen–Loève expansions of the exact and asymptotic distributions of the WC statistics. The calculation of a Karhunen–Loève expansion is a nontrivial task, even under the normal model. Gardner [6] discussed the uniform weight under the normal assumption, but the quadratic weights we consider here increase the difficulty substantially. We present below a unified theory that enables us to establish the distribution of WC using dual Hahn polynomials. The asymptotic distributions for the quadratic weights and are identical, and the expansions of asymptotic distributions between and another quadratic weight differ by an odd number of terms. We make a comparison with the expansion of the limit distributions of the Cramér-von Mises statistic and the Anderson and Darling statistics; see also MacNeill [8].
The WC has some variants in other models. For example, in the graphical model, can be 1 if we replace with a count of edges. Here, the main challenge is to approximate the covariance of edge-count statistics under the null permutations. In the normal mixed model, a variant of WC can be derived by considering a marginal likelihood function. In the Poisson mixed model, however, the calculation of the marginal likelihood function is hindered by an integral without a closed form. To approximate this integral, one may use Laplace, or saddle point approximation [9,10,11,12,13]. Here, we apply the saddle point approximation to the integral and provide a variant of WC related to the log link. For the classical change point Poisson model without latent variables, see [1] (p. 27); for the Poisson process with a change point, we refer readers to Akman and Raftery [14], Loader [15]. Moreover, to adopt the assumption of weak dependence in practice, we avoid the estimation of the variance and provide a randomized version of WC.
The structure of the paper is outlined as follows. In Section 2, we derive the explicit expansions of the distribution of the WC statistics and explore their connections with the Karhunen–Loève expansion. We derive extended versions of WC by considering the observations as nodes in the graphical model and allowing the observations from a normal or Poisson mixed model to be weakly dependent. In Section 3, we discuss the power of the proposed WC test. In Section 4, we use simulation to compare the performance of this test with that of a graph-based test statistic. In Section 5, we present an application for video data. In Section 6, we discuss the extension to multiple change points and suggest future work on other quadratic weights.
2. Exact and Asymptotic Distributions of the WC Statistics
2.1. Explicit Distribution for a Normal Model
We assume here that are independent following a normal distribution with a common known variance . The case of unknown is addressed in Remark 3, and an extension relaxing the independence assumption is given in Section 2.6.
Following the derivation in Gardner [6], we write (1) as a quadratic form
where , and with . Here, such that the first k entries of are and the last entries .
By using the recurrence identity and the dual Hahn polynomial, we obtain a new exact result in terms of the eigenvalues of Q in (3).
Theorem 1.
Assume that are independent normally distributed random variables with a common mean and known variance . The exact distribution of is
where are independent and identically distributed normal random variables with mean zero and variance 1, , and
The proof of Theorem 1 is given in Appendix A. We make the following remarks.
Remark 1.
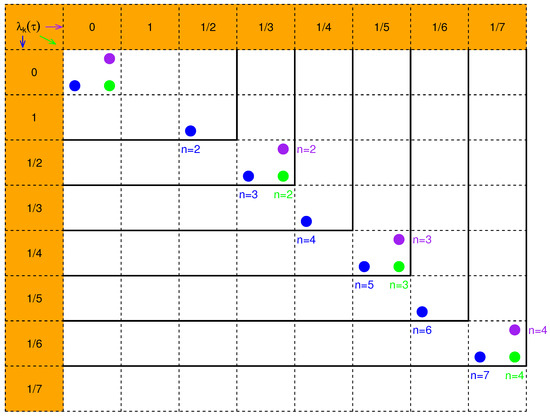
It is interesting that for all ; namely, the eigenvalues for with even indices coincide with the eigenvalues for with indices less than . As the sample size increases from n to , the nonzero eigenvalues are retained and the added nonzero eigenvalue must be for or for or . This interesting phenomenon has not been seen in the uniform weights of Gardner [6]. As far as we know, this recursive property of the eigenvalues for the non-uniform weights is new. Figure 2 depicts the pattern of eigenvalues (cross products of rows and columns) illustrated by dots for three weights (blue), (green), and (purple) with the increase of n.
Figure 2.
The pattern of eigenvalues (cross products of rows and columns) illustrated by dots for three weights for (blue), for (green) and for (purple) with the increase of n.
Remark 2.
The distribution in (4) can be calculated numerically using Imhof’s method [16] or simulated by a Monte Carlo method, but accurate analytical approximations are potentially faster and more stable. A saddle point approximation to the distribution of quadratic forms in normal variates was studied in Kuonen [17], building on Daniels [9,18] and Lugannani and Rice [19].
Remark 3.
When the variance is unknown, we can replace with a consistent estimator
by using Slutsky’s lemma. This also holds in Corollary 1. For dependent data, one issue is to give a valid estimate of the variance; see Section 2.6.
2.2. Karhunen–Loève Expansion
The squared integral of a Brownian bridge arises in the study of tests for goodness-of-fit. Given a sample of independent and identically distributed random variables with an empirical distribution function , the statistic
provides a test of the null hypothesis that the observations come from the distribution . The Cramér-von Mises statistic has , and the Anderson-Darling statistic has . Here, we shall discuss two new weights: and .
MacNeill [8] showed that
using a Fourier expansion of , where is an orthonormal basis in and is a standard Brownian motion and is a Brownian bridge.
Anderson and Darling [20] showed that
In Appendix B, we use Jacobi polynomials to derive the Karhunen–Loève expansion for the integrals of the weighted square of the Brownian bridge with two new weights and . The results are stated in the following theorem.
Theorem 2.
The two weights and lead to the same Karhunen–Loève expansions:
and
The proof of the above two equalities will be provided in Appendix B. One can see the equivalence of these two equalities by using a change of variable.
Given different probabilities (p), Table 1 presents the critical values for which for different n, where and calculations of critical values for finite n are based on Imhof’s method [16] implemented in R package CompQuadForm [21]. A few critical values are tabulated in Anderson and Darling [22] for with . One can see the critical values converge very quickly as n increases to ∞.

In fact, we can connect the limit distribution of WC statistic and its functional limit distribution by the Karhunen–Loève expansion of the integral of the weighted square of Brownian bridge in terms of the Jacobi polynomials. Theorem 1 immediately implies the following asymptotic distribution as .
Corollary 1.
Under the assumptions of Theorem 1, when ,
One can check by Markov’s inequality. Hence, converges to in probability as . By the functional limit theorem,
2.3. Graphical Model
Assume the are independent and have common mean and variance . Consider testing
where or , the parameters , , , , , and are unknown.
A graphical model can be established by treating each q-dimensional vector as a node and assigning the Euclidean distance between any two vectors. Here, we consider a path with an ordering of nodes and edges for . Associated with the path, the count of edges that connect nodes between arbitrary two disjoint sets and is defined to be:
where is an indicator function that takes 1 if true otherwise 0. The counts edges between two groups and .
Denote the expectation and variance of under permutations of nodes as and . By [23],
A WC statistic may be constructed as
A large value of observed based on the shortest Hamiltonian path (SHP), , indicates a rejection of the null hypothesis, i.e., there is a change point; see the heuristic algorithm of SHP in Biswas et al. [24] and the analysis of power and change point in Shi, Wu and Rao [25], Shi, Wu and Rao [26] for and . Here, we will establish the asymptotic distribution of for . First, we give the following Lemma.
Lemma 1.
For with ,
By the functional limit theorem,
and
which solves an open problem in [25,26]. Different values of lead to different rates of convergence and different ”normings”.
2.4. Normal Mixed Model
Assume where , , are independent and identically normally distributed with mean zero and variance , and are independent latent variables following a normal distribution with mean zero and variance .
Consider testing
where , the parameters , and are unknown, and we tentatively assume the time , called the change point, and the variances and to be known.
The marginal log-likelihood function of under is
where does not depend on and
Therefore,
where .
In a similar way, the marginal log-likelihood function of and under can be obtained. Then, the marginal log-likelihood ratio is
which is equal to
As the change point could be unknown in practice, we may sum over and consider the average value, which leads to
where .
By Theorem 1 and Remark (3) in terms of weighted version for any , as ,
2.5. Poisson Mixed Model
Assume follows a Poisson distribution with conditional mean . Consider testing
where , the parameters , and are unknown. Under normal distribution for , the likelihood ratio contains an integral. With the focus on the simple Poisson mixed model without a change point, Hall et al. [27,28] applied the Gaussian variational approximation (GVA) to approximate the integral so as to avoid solving the integral. We provide a saddle point approximation here.
The marginal log-likelihood function of under is
where does not depend on r and .
The calculation of is hindered by the lack of a closed form of the integral . Here, we apply the saddle point approximation to the integral as shown in Lemma 2.
Lemma 2.
For the integral ,
where the symbol ≈ means asymptotic equivalence and the saddle point c solves with , i.e., .
In a similar way, under can be approximated, giving the approximate log-likelihood ratio
Considering that the change point is unknown, we may sum (17) over as shown in (1) and consider the average value,
Note that the term is derived from the approximate likelihood ratio statistic, different from the classical Poisson change point statistic in Csörgö and Horváth [1] (p. 27).
By Theorem 1 and Remark 3 in terms of weighted version for any , as ,
2.6. Weak Dependence
Now, we consider a space-time model for the distribution of , where i indexes time and j indexes space. First, we assume some weak dependence conditions on space by supposing the central limit theorem holds:
where .
Next, we assume some weak dependence conditions on time by supposing that the following invariance principle or functional central limit theorem holds for any [29,30]:
where and .
The weak dependence conditions in (19) and (20) are satisfied if the series is m-dependence, mixing, or linear process. Shao and Zhang [31] proposed a normalized change point statistic
where and is a random weight.
They showed that
where and .
Similarly, with the same as above, we propose a randomized version of WC:
By the functional central limit theorem, when ,
3. Power and Change Point Estimation
Considering the WC statistic in (14), we now consider the power of change point test based on
under the alternative hypothesis in Section 2.4. We assume some weak dependence conditions in Section 2.6. We note that (23) has the same asymptotic null distribution as (4) in Theorem 1. The asymptotic distribution is shown in Theorem 2. To establish the consistency of the test, we make a further assumption that the change point index is bounded away from the endpoints.
Theorem 3.
The proof of Theorem 3 is in Appendix E. As expected, the power of the test based on (23) increases with n, q, and the size of the change in the mean.
The estimated change point is
We refer the reader to Bai [32,33] for some early works on the asymptotic distribution of and [34] for a treatment on the convergence rate of .
4. Simulations
The main purpose of this simulation is to assess the effect of different values for , n, q, and change magnitude on the power of our test in (23), and that of the graph-based tests [25,26,35], as both can handle high-dimensional data, and the distance of the graph can be changed to test different changes of parameters for a fair comparison. For example, if we are not sure whether the mean or variance changes, the Euclidean distance can be used to measure the distance between any two nodes in the graph:
see Chen and Zhang [35], and Shi, Wu and Rao [25]. Another pseudo-distance can be used
if only the change in the mean needs to be detected; see Shi, Wu and Rao [26]. We denote the maximal test of Chen and Zhang based on Euclidean distance by MST and based on the pseudo-distance by MST*. The associated algorithm is in the R package gSeg [36]. Similarly, we denote Shi, Wu, and Rao’s test (Shi, Wu and Rao [25,26]) based on Euclidean distance by SHP and based on the pseudo-distance by SHP, and the associated R package can be accessed from [37].
First, we simulate independent standard normal random variables and independent normal random variables with mean and variance 1. The critical values for are given in Table 1 with . We use these critical values and generate 200 simulations with sample sizes , dimensions , change point locations , and change magnitude .
In Table 2, we show the percentage of rejections of the null hypothesis at level for each of the change point tests. We can see that the power of the graph-based method MST or SHP is higher than that of MST and SHP, which use the pseudo-distance for detecting changes in the mean. Interestingly, the power of the graph-based method for change point detection is still not as high as that of (23). This aspect of the comparison, which we have not seen in other literature so far, is considered a new and meaningful comparison, and at least we can claim that there is room for improvement in the change point detection of the graph-based method.
Table 2.
Estimated power (%) for the , , and in (23), MST, MST, SHP, and SHP, based on 200 simulations; n are the sample sizes, q are the dimensions, are the change point locations, and is the size of the change in the mean of the normal random variables.
Now we look at the effect of the weights on the power. This weight yields the highest power when the change point is in the middle; however, the weight yields the highest power when the change point is near the beginning of the sequence, and conversely, the weight yields the highest power when the change point is near the end of the sequence. Moreover, the power increases with increasing n, q, and , which agrees with Theorem 3.
Now, we introduce a mixture distribution and slightly change the way the random variables are generated. We simulate from a mixture of two normal distributions with mixture weights (0.5, 0.5) or (0.8, 0.2), means (0, 0.2) or (0, 1), and variance always being (1, 1), which corresponds to or . We keep the other settings from the previous comparison. As we expected, the difference between Table 2 and Table 3 is very small.
Table 3.
Estimated power (%) for the , , , MST, MST in (23), SHP, and SHP, based on 200 simulations; n are the sample sizes, q are the dimensions, are the change point locations, and is the size of the change in the mean of mixed normal distributions.
5. Data Analysis
Here, we analyze the video data provided by Dr. Mathieu Lihorea, which are available from [26]. In Lihoreau, Chittka and Raine [38], the authors used artificial pollen to attract bees and an automatic monitoring camera to capture the bee’s flight path. However, this automatic monitoring feature does not fully start recording when the bee enters and stops recording when the bee leaves, in fact in this video, the recording starts before the bee enters and does not stop when the bee leaves. Since we only care about the part of the video with bees, detecting the arrival and departure of bees helps us to automatically cut the original video. Although the video contains the interference of ants, the bees are much larger compared to the ants, so it can be assumed that the presence and departure of the bees cause a change in the mean value of the pixel values of the image.
This video has a length of 49 seconds, a frame width of 352, a frame height of 288, and a frame rate of 29.97 frames per second. Shi, Wu and Rao [26] extracted the video into images according to the rate of one frame per second. From these 49 images, we can obtain that the image positions corresponding to the bee entering and leaving are 4 and 40, respectively. Moreover, we can extract this video into more images according to the rate of 2 or 5 frames per second. So, the number of images obtained, n, increases to 98 or 245, and at the same time, the positions of the images corresponding to the entry and exit of the bees also change with n. If we call the image locations where these bees appear and leave as change points, , we assume that is constant with respect to n and close to 0 or 1, respectively. In Figure 3 the first row is four images located at 4 (change point), 5, 40 (change point), and 41 from extracted 49 images; the second row is four images located at 7 (change point), 8, 79 (change point), and 80 from extracted 98 images; and the third row is four images located at 19 (change point), 20, 198 (change point), and 199 from extracted 245 images. Since the images contain R, G, and B components, we use a weighted average of the R, G, and B components and same-scale transformations on the weighted average as suggested by Shi, Wu and Rao [26].

Figure 3.
Typical images in three different image sets extracted from the same video data with different frame rates. The first row contains four images located at 4 (change point), 5, 40 (change point), and 41 from the first set of extracted 49 images (1 frame per second); the second row contains four images located at 7 (change point), 8, 79 (change point), and 80 from the second set of extracted 98 images (2 frames per second); and the third row contains four images located at 19 (change point), 20, 198 (change point), and 199 from the third set of extracted 245 images (5 frames per second).
Our quadratic weight test statistics are able to detect these two change points. We compared them to the graph-based change point estimates by applying the method of SHP and MST once to the whole sequence. As shown in Table 4, all tests are significant at a level 0.05 except the quadratic weight for the size of 49 returns a p-value 0.067; and ) give the estimates of the second and first change points, respectively; gives the same estimates of change points as , and both cannot give the estimates of the second change point, such as SHP and MST. Thus, we recommend these two weights and for detecting the departure and arrival of the bee.
Table 4.
Estimated change points for the , , , MST, and SHP, based on extracted 49, 98, and 245 images; n are the sample sizes and are the change point locations.
6. Discussion
This paper mainly focuses on single change point detection. However, it is possible to extend our method and apply the WC statistic to the detection of multiple change points. An approach recommended in the literature is to select data intervals where there is evidence for a single change point. Some researchers suggested penalty procedures based on either the adaptive lasso [39] or smoothly clipped absolute deviation [40,41,42]; others applied CUSUM statistics [4,43,44,45]. As long as the aforementioned intervals have been chosen, one could use tests based on WC. If the tests are rejected for some of the intervals, then the change point can be estimated by (24).
It would also be of interest, although challenging, to consider other quadratic weights, such as and , as these statistics may be more powerful to detect some change points that are close to the third-quarter and quarter positions of the sequence. The eigenvalues of these quadratic terms may not have recursive formulas.
Author Contributions
X.S., X.-S.W. and N.R. designed research; X.S., X.-S.W. and N.R. performed research; X.S. analyzed data; X.S., X.-S.W. and N.R. wrote the paper. All authors have read and agreed to the published version of the manuscript.
Funding
Shi’s work was supported by NSERC Discovery Grant RGPIN 2022-03264, the Interior Universities Research Coalition and the BC Ministry of Health, and the University of British Columbia Okanagan (UBC-O) Vice Principal Research in collaboration with UBC-O Irving K. Barber Faculty of Science.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank two anonymous reviewers for helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Theorem 1.
The exact distribution of is determined by the eigenvalues of Q. Define the matrix with such that all entries of are zeros except the k entry and the entry . It is readily seen that and thus . Note that
where P is a diagonal matrix with and T is a tridiagonal matrix with and .
We shall find the relationship between Q and . We diagonalize with and diagonal matrix with . Set . We have and . Finally, we introduce such that , and . Define . It then follows that and
This implies that the nonzero eigenvalues of Q are reciprocals of those of .
Let be the eigenvector corresponding to an eigenvalue of . We have the recurrence identity
where , , and . The above recurrence relation appears in Gardner [6] (1.7) as an eigenvalue equation for a forward difference operator. As mentioned in Gardner [6], it is difficult to find an explicit formula for the eigenvalues unless the prior distribution is uniform; i.e., is independent of k. To overcome this difficulty, we make use of the above recurrence relation and then apply the classical theory of orthogonal polynomials and special functions. To be more specific, we shall link the eigenvector in (A1) to the dual Hahn polynomial by making some transformations.
Let . The above recurrence relation becomes
We further denote and . It is readily seen that
and (by shifting the index k)
where and . By induction, is a monic kth order polynomial of .
Now, we consider three quadratic weights in (2).
Case I. If for , then is related to the dual Hahn polynomial
where is the Pochhammer symbol which is commonly used in the field of orthogonal polynomials and special functions, is the dual Hahn polynomial of degree k and . In particular,
This implies that the eigenvalues of are for . Consequently, the eigenvalues of Q are 0 and for .
Case II. If for , then is related to the dual Hahn polynomial as follows
where is the dual Hahn polynomial of degree k and . In particular,
By Watson’s sum, when or with . This implies that the eigenvalues of are for . Consequently, the eigenvalues of Q are 0 and with .
Case III. If for , then the eigenvalues of Q are also 0 and with because the sequence is just the reverse of that in Case II.
Since it is a quadratic form in normal random variables, the results follow. □
Appendix B
Proof of Theorem 2.
Case I. For the weight , we define . By the Karhunen–Loève expansion,
where random variables are stochastically independent normal and are an orthonormal basis. Then, the integral of the square of becomes and we need the variance of . We consider the covariance of , called the Mercer Kernel:
By Mercer’s theorem, there exists a set such that
where are eigenvalues and are eigenfunctions satisfying the Fredholm integral equation .
Thus, we have the eigenvalue problem
Denote . After the multiplication of on both sides, the above eigenvalue problem becomes
Let . It follows that
Note that
We then have
Obviously, ; otherwise for all . Now, we compare the coefficients of with on both sides of the above identity. It follows that
and
We shall prove that are eigenvalues of . To see this, we obtain from the above recurrence relation
Making use of the Pochhammer symbol , we obtain
Consequently,
Since
we then have
which agrees with . By normalizing , we can express the eigenfunction as
where
is the Jacobi polynomial.
So, we have
where are independent normal random variables, each having mean zero and variance 1. That proves (5).
Case II. For the weight , we intend to solve the eigenvalue problem
Denote . After the multiplication of on both sides, the above eigenvalue problem becomes
Let . It follows that
Note that
We then have
Obviously, ; otherwise for all . Now, we compare the coefficients of with on both sides of the above identity. It follows that , and
and
On account of , the above recurrence relation implies that for all . Now, we set with . The above recurrence relation (with ) becomes
For convenience, we let . It is readily seen that
Making use of the Pochhammer symbol , we obtain
Consequently,
The left-hand side is . When with , by Pfaff-Saalschütz identity, we calculate the right-hand side as
Hence, , are the eigenvalues. By normalizing , we can express the eigenfunction as
So, we have
where are independent normal random variables, each having mean zero and variance 1. This gives (6). □
Appendix C
Proof of Lemma 1.
It is well known that We first show the covariance: for . Note that .
Since , we have and by the independence of increments. These lead to
Therefore, we have
where
So, .
In the next step, we will show that for , , and .
We first decompose Note that and . Then,
To calculate the covariance, we need the following moments for any disjoint subsets , , and of . Their sizes are denoted as , and with .
The following calculations of second moments need to consider three cases , and for , with and Therefore, we have
In a similar way, we have
Appendix D
Proof of Lemma 2.
Consider the integral
where is large and . The saddle point for the phase function is . We set and define
such that z is analytic near and as . It is easily seen that
Moreover,
Now, we can rewrite the integral as
A simple calculation gives
and
Consequently,
By Watson’s lemma, we obtain
□
Appendix E
Proof of Theorem 3.
We denote , . Under the alternative hypothesis,
We first find a lower bound , i.e., Then, we decompose the lower bound into three terms:
where .
By the weak dependence, and Furthermore, .
holds because and . □
References
- Csörgö, M.; Horváth, L. Limit Theorems in Change-Point Analysis; Wiley: Chichester, UK, 1997. [Google Scholar]
- Jiang, F.; Zhao, Z.; Shao, X. Modeling the COVID-19 infection trajectory: A piecewise linear quantile trend model. J. R. Statist. Soc. B 2021, accepted. [Google Scholar]
- Liu, B.; Zhou, C.; Zhang, X.; Liu, Y. A unified data-adaptive framework for high dimensional change point detection. J. R. Statist. Soc. B 2020, 82, 933–963. [Google Scholar] [CrossRef]
- Yu, M.; Chen, X. Finite sample change point inference and identification for high-dimensional mean vectors. J. R. Statist. Soc. B 2021, 83, 247–270. [Google Scholar] [CrossRef]
- Jandhyala, V.; Fotopoulos, S.; MacNeill, I.; Liu, P. Inference for single and multiple change-points in time series. J. Time Ser. Anal. 2013, 34, 423–446. [Google Scholar] [CrossRef]
- Gardner, J.A. On detecting changes in the mean of normal variates. Ann. Math. Statist. 1969, 40, 116–126. [Google Scholar] [CrossRef]
- Perron, P. Dealing with structural breaks. In Palgrave Handbook of Econometrics: Volume 1, Econometric Theory; Mills, T.C., Patterson, K., Eds.; Publisher: Palgrave Macmillan, London, UK, 2006; pp. 278–352. [Google Scholar]
- MacNeill, I. Properties of sequences of partial sums of polynomial regression residuals with applications to tests for change of regression at unknown times. Ann. Statist. 1978, 6, 422–433. [Google Scholar] [CrossRef]
- Daniels, H.E. Saddlepoint approximations in statistics. Ann. Math. Statist. 1954, 25, 631–650. [Google Scholar] [CrossRef]
- Reid, N. Saddlepoint methods and statistical inference (with discussion). Statist. Sci. 1988, 3, 213–238. [Google Scholar]
- Reid, N. Approximations and asymptotics, In Statistics Theory Model; Essays in Honor of D.R. Cox; Chapman and Hall: London, UK, 1991; pp. 287–334. [Google Scholar]
- Shi, X.; Wang, X.-S.; Reid, N. Saddlepoint approximation of nonlinear moments. Statist. Sinica 2014, 24, 1597–1611. [Google Scholar] [CrossRef][Green Version]
- Shi, X.; Reid, N.; Wu, Y. Approximation to the moments of ratios of cumulative sums. Can. J. Statist. 2014, 42, 325–336. [Google Scholar] [CrossRef]
- Akman, V.E.; Raftery, A.E. Asymptotic inference for a change-point Poisson process. Ann. Statist. 1986, 14, 1583–1590. [Google Scholar] [CrossRef]
- Loader, C.R. A log-linear model for a Poisson process change point. Ann. Statist. 1992, 20, 1391–1411. [Google Scholar] [CrossRef]
- Imhof, J.P. Computing the distribution of quadratic forms in normal variables. Biometrika 1961, 48, 419–426. [Google Scholar] [CrossRef]
- Kuonen, D. Saddlepoint approximations for distributions of quadratic forms in normal variables. Biometrika 1999, 86, 929–935. [Google Scholar] [CrossRef]
- Daniels, H.E. Tail probability approximations. Int. Statist. Rev. 1987, 55, 37–48. [Google Scholar] [CrossRef]
- Lugannani, R.; Rice, S.O. Saddlepoint approximations for the distribution of the sum of independent random variables. Adv. Appl. Probab. 1980, 12, 475–490. [Google Scholar] [CrossRef]
- Anderson, T.; Darling, D. Asymptotic theory of certain “goodness of fit”criteria based on stochastic processes. Ann. Math. Statist. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- de Micheaux, P.L. R Package CompQuadForm. 2017. Available online: https://cran.r-project.org/web/packages/CompQuadForm/index.html (accessed on 25 December 2020).
- Anderson, T.; Darling, D. A test of ‘‘goodness of fit”. J. Amer. Statist. Assoc. 1954, 49, 765–769. [Google Scholar] [CrossRef]
- Wald, A.; Wolfowitz, J. On a test whether two samples are from the same distribution. Ann. Math. Statist. 1940, 11, 147–162. [Google Scholar] [CrossRef]
- Biswas, M.; Mukhopadhyay, M.; Ghosh, A.K. A distribution-free two-sample run test applicable to high-dimensional data. Biometrika 2014, 101, 913–926. [Google Scholar] [CrossRef]
- Shi, X.; Wu, Y.; Rao, C.R. Consistent and powerful graph-based change-point test for high-dimensional data. Proc. Natl. Acad. Sci. USA 2017, 114, 3969–3974. [Google Scholar] [CrossRef]
- Shi, X.; Wu, Y.; Rao, C.R. Consistent and powerful non-Euclidean graph-based change-point test with applications to segmenting random interfered video data. Proc. Natl. Acad. Sci. USA 2018, 115, 5914–5919. [Google Scholar] [CrossRef]
- Hall, P.; Ormerod, J.T.; Wand, M.P. Theory of Gaussian variational approximation for a Poisson mixed model. Statist. Sinica 2011, 21, 369–389. [Google Scholar]
- Hall, P.; Pham, T.; Wand, M.P.; Wang, S.S.J. Asymptotic normality and valid inference for Gaussian variational approximation. Ann. Statist. 2011, 39, 2502–2532. [Google Scholar] [CrossRef]
- Peligrad, M. An invariance principle for ϕ-mixing sequences. Ann. Probab. 1985, 13, 1304–1313. [Google Scholar] [CrossRef]
- Phillips, P.C.B.; Solo, V. Asymptotics for linear processes. Ann. Statist. 1992, 20, 971–1001. [Google Scholar] [CrossRef]
- Shao, X.; Zhang, X. Testing for change points in time series. J. Am. Statist. Assoc. 2010, 105, 1228–1240. [Google Scholar] [CrossRef]
- Bai, J. Least square estimation of a shift in linear processes. J. Time Ser. Anal. 1994, 15, 453–472. [Google Scholar] [CrossRef]
- Bai, J. Estimation of a change point in multiple regressions. Rev. Econ. Stat. 1997, 79, 551–563. [Google Scholar] [CrossRef]
- Kokoszka, P.; Leipus, R.D. Change-point in the mean of dependent observations. Statist. Probab. Lett. 1998, 40, 385–393. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, N. Graph-based change-point detection. Ann. Statist. 2015, 43, 139–176. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, N. gSeg: Graph-Based Change-Point Detection (G-Segmentation). R Package Version 0.1. 2014. Available online: https://cran.r-project.org/web/packages/gSeg/index.html (accessed on 27 December 2020).
- Chen, M.; Shi, X.; Li, H. GraphCpClust: Graph-Based Change-Point Detection and Clustering. R Package Version 0.1. 2021. Available online: https://github.com/Meiqian-Chen/GraphCpClust (accessed on 27 April 2021).
- Lihoreau, M.; Chittka, L.; Raine, N.E. Monitoring flower visitation networks and interactions between pairs of bumble bees in a large outdoor flight cage. PLoS ONE 2016, 11, e0150844. [Google Scholar] [CrossRef]
- Zou, H. The adaptive Lasso and its oracle properties. J. Am. Statist. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Statist. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Jin, B.; Shi, X.; Wu, Y. A novel and fast methodology for simultaneous multiple structural break estimation and variable selection for non-stationary time series models. Statist. Comput 2013, 23, 221–231. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Statist. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Cho, H.; Fryzlewicz, P. Multiple-change-point detection for high dimensional time series via sparsified binary segmentation. J. R. Statist. Soc. B 2015, 77, 475–507. [Google Scholar] [CrossRef]
- Fryzlewicz, P. Wild binary segmentation for multiple change-point detection. Ann. Statist. 2014, 42, 2243–2281. [Google Scholar] [CrossRef]
- Wang, T.; Samworth, R.J. High dimensional change point estimation via sparse projection. J. R. Statist. Soc. B 2017, 80, 57–83. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).