
Testing the Intercept of a Balanced Predictive Regression Model


Abstract
1. Introduction
2. Methodology and Main Results
- (C1)
- is a sequence of i.i.d. random vectors with mean zero, and for some arbitrarily small positive constant ;
- (C2)
- The predictive variable , with the initial value of being constant or random variable of order , belongs to one of the persistence classes following Cases (i)–(iii);
- (C3)
- All roots of with respect to x are outside the unit circle.
- For Case (i), under the local alternative hypothesis for some constant ,where ‘’ denotes the convergence in distribution, and a non-central chi-squared distributed variable with non-central parameter , where is the second component of with , and
- For Case (ii), under the local alternative hypothesis for some constant ,where sgn denotes the sign function, ξ a standard normally distributed variable, which is independent of , and with being a Gaussian process with covariance function ;
- ForCase (iii), under the local alternative hypothesis for some constant ,where .
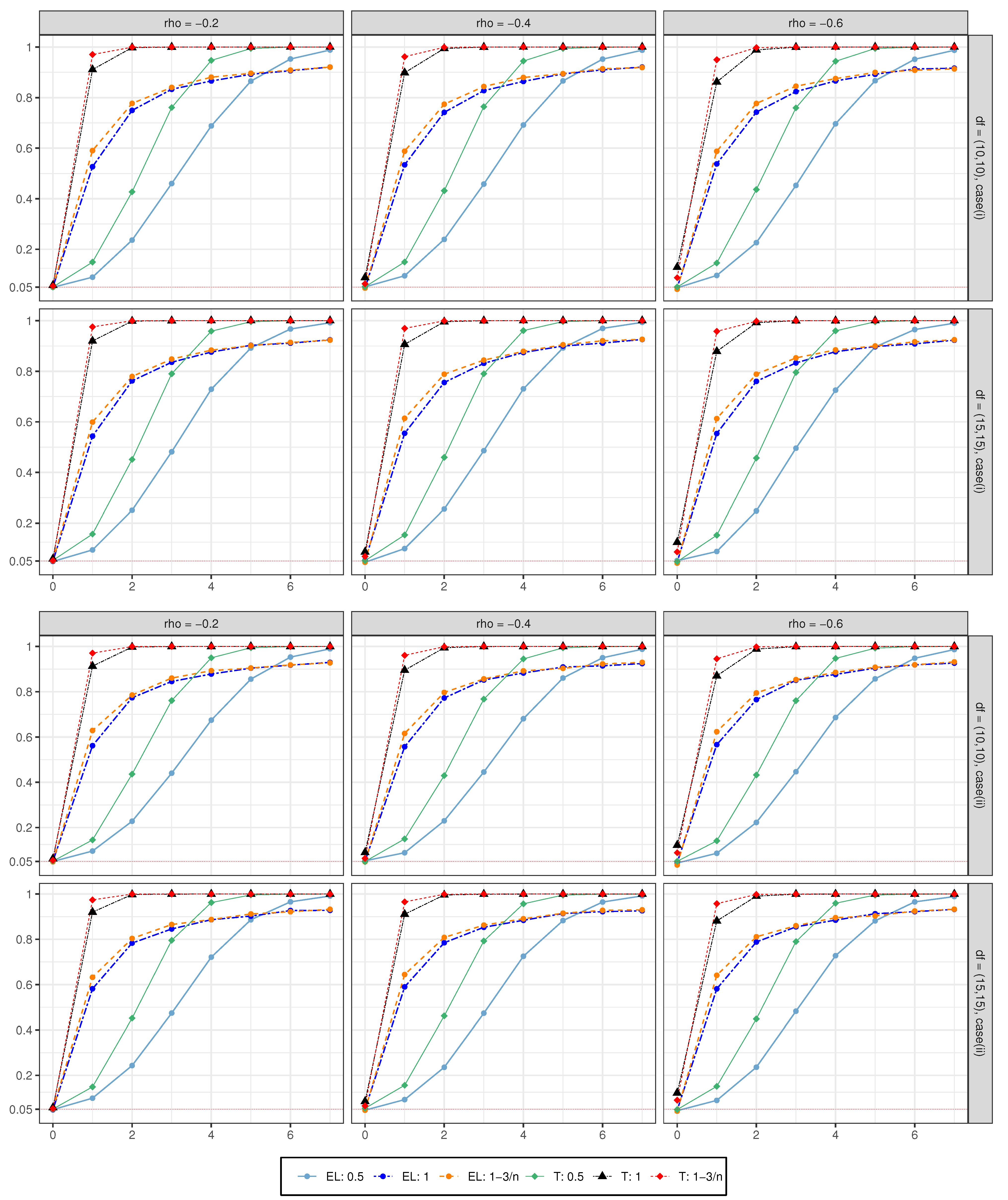
3. Simulation Results
4. A Real Data Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Detailed Proofs of the Main Results
- (a)
- ,
- (b)
- holds uniformly for ,
- (c)
- holds uniformly for ,
- (a)
- , and
- (b)
- ,
References
- Amihud, Y. Illiquidity and stock returns cross-section and time-series effects. J. Financ. Mark. 2002, 5, 31–56. [Google Scholar] [CrossRef]
- Baker, M.; Stein, J.C. Market liquidity as a sentiment indicator. J. Financ. Mark. 2004, 7, 271–299. [Google Scholar] [CrossRef]
- Campbell, J.Y.; Shiller, R.J. The dividend-price ratio and expectations of future dividends and discount factors. Rev. Financ. Stud. 1988, 1, 195–228. [Google Scholar] [CrossRef]
- Kaul, G. Predictable components in stock returns. Handb. Stat. 1996, 14, 269–296. [Google Scholar]
- Keim, D.B.; Stambaugh, R.F. Predicting returns in the stock and bond markets. J. Financ. Econ. 1986, 17, 357–390. [Google Scholar] [CrossRef]
- Lewellen, J. Predicting returns with financial ratios. J. Financ. Econ. 2004, 74, 209–235. [Google Scholar] [CrossRef]
- Fama, E.F.; French, K.R. Business conditions and expected returns on stocks and bonds. J. Financ. Econ. 1989, 25, 23–49. [Google Scholar] [CrossRef]
- Zhu, F.; Liu, M.; Ling, S.; Cai, Z. Testing for structural change of predictive regression model to threshold predictive regression model. J. Bus. Econ. Stat. 2022. [Google Scholar] [CrossRef]
- Cai, Z.; Jing, B.; Kong, X.; Liu, Z. Nonparametric regression with nearly integrated regressors under long-run dependence. Econom. J. 2017, 20, 118–138. [Google Scholar] [CrossRef]
- Liu, X.; Yang, B.; Cai, Z.; Peng, L. A unified test for predictability of asset returns regardless of properties of predicting variables. J. Econom. 2019, 208, 141–159. [Google Scholar] [CrossRef]
- Ren, Y.; Tu, Y.; Yi, Y. Balanced predictive regressions. J. Empir. Financ. 2019, 54, 118–142. [Google Scholar] [CrossRef]
- Campbell, J.Y.; Yogo, M. Efficient tests of stock return predictability. J. Financ. Econ. 2006, 81, 27–60. [Google Scholar] [CrossRef]
- Lanne, M. Testing the predictability of stock returns. Rev. Econ. Stat. 2002, 84, 407–415. [Google Scholar] [CrossRef]
- Torous, W.; Valkanov, R.; Yan, S. On predicting stock returns with nearly integrated explanatory variables. J. Bus. 2004, 77, 937–966. [Google Scholar] [CrossRef]
- Zhu, F.; Cai, Z.; Peng, L. Predictive regressions for macroeconomic data. Ann. Appl. Stat. 2014, 8, 577–594. [Google Scholar] [CrossRef]
- Owen, A.B. Empirical likelihood ratio confidence intervals for a single functional. Biometrika 1988, 75, 237–249. [Google Scholar] [CrossRef]
- Qin, J.; Lawless, J. Empirical likelihood and general estimating equations. Ann. Stat. 1994, 22, 300–325. [Google Scholar] [CrossRef]
- Chen, S.X.; Peng, L.; Qin, Y.L. Effects of data dimension on empirical likelihood. Biometrika 2009, 96, 711–722. [Google Scholar] [CrossRef]
- Chen, S.X.; Van Keilegom, I. A review on empirical likelihood methods for regression. Test 2009, 18, 415–447. [Google Scholar] [CrossRef]
- Kitamura, Y. Empirical likelihood methods with weakly dependent processes. Ann. Stat. 1997, 25, 2084–2102. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Lu, F. Empirical likelihood-based unified confidence region for a predictive regression model. Commun. Stat.-Simul. Comput. 2022, 51, 2122–2139. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Rao, Y.; Lu, F. A Unified test for the Intercept of a Predictive Regression Model. Oxf. Bull. Econ. Stat. 2021, 83, 571–588. [Google Scholar] [CrossRef]
- Li, C.; Li, D.; Peng, L. Uniform test for predictive regression with AR errors. J. Bus. Econ. Stat. 2017, 35, 29–39. [Google Scholar] [CrossRef]
- Kostakis, A.; Magdalinos, T.; Stamatogiannis, M.P. Robust econometric inference for stock return predictability. Rev. Financ. Stud. 2015, 28, 1506–1553. [Google Scholar] [CrossRef]
- Klaussner, C.; Vogel, C. Temporal predictive regression models for linguistic style analysis. J. Lang. Model. 2018, 6, 175–222. [Google Scholar] [CrossRef]
- Pesaran, M.H.; Timmermann, A. Predictability of stock returns: Robustness and economic significance. J. Financ. 1995, 50, 1201–1228. [Google Scholar] [CrossRef]
- Ashby, S.A.; Taylor, M.A.; Chen, A.A. Statistical models for predicting rainfall in the Caribbean. Theor. Appl. Climatol. 2005, 82, 65–80. [Google Scholar] [CrossRef]
- Cai, Z.W.; Wang, Y.F. Testing predictive regression models with non-stationary regressors. J. Econom. 2014, 178, 4–14. [Google Scholar] [CrossRef]
- Elliott, G.; Stock, J.H. Inference in time series regression when the order of integration of a regressor is unknown. Econom. Theory 1994, 10, 672–700. [Google Scholar] [CrossRef]
- Phillips, P.C.B. Towards a unified asymptotic theory for autoregression. Biometrika 1987, 74, 535–547. [Google Scholar] [CrossRef]
- Hall, P.; Heyde, C.C. Martingale Limit Theory and Its Application; Academic Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Ma, Y.; Zhou, M.; Peng, L.; Zhang, R. Test for zero median of errors in an arma–garch model. Econom. Theory 2022, 38, 536–561. [Google Scholar] [CrossRef]
- Owen, A.B. Empirical Likelihood; Chapman and Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar]



{kind=link}
{kind=link}
| EL | t-Test | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 400 | 800 | 1000 | 1200 | 200 | 400 | 800 | 1000 | 1200 | ||||
| 0.5 | 0 | −0.2 | 0.0477 | 0.0461 | 0.0514 | 0.0497 | 0.0521 | 0.0485 | 0.0525 | 0.0536 | 0.0509 | 0.0494 | |
| −0.4 | 0.0430 | 0.0453 | 0.0486 | 0.0514 | 0.0453 | 0.0505 | 0.0493 | 0.0510 | 0.0516 | 0.0518 | |||
| −0.6 | 0.0417 | 0.0442 | 0.0495 | 0.0476 | 0.0425 | 0.0496 | 0.0521 | 0.0516 | 0.0506 | 0.0505 | |||
| 0.01 | −0.2 | 0.0476 | 0.0488 | 0.0501 | 0.0515 | 0.0503 | 0.0471 | 0.0474 | 0.0495 | 0.0525 | 0.0481 | ||
| −0.4 | 0.0448 | 0.0458 | 0.0477 | 0.0462 | 0.0466 | 0.0523 | 0.0536 | 0.0526 | 0.0514 | 0.0498 | |||
| −0.6 | 0.0426 | 0.0434 | 0.0442 | 0.0491 | 0.0481 | 0.0560 | 0.0499 | 0.0517 | 0.0506 | 0.0519 | |||
| 1 | 0 | −0.2 | 0.0526 | 0.0511 | 0.0483 | 0.0503 | 0.0475 | 0.0586 | 0.0615 | 0.0559 | 0.0575 | 0.0574 | |
| −0.4 | 0.0501 | 0.0508 | 0.0502 | 0.0469 | 0.0457 | 0.0827 | 0.0836 | 0.0814 | 0.0881 | 0.0917 | |||
| −0.6 | 0.0478 | 0.0440 | 0.0445 | 0.0481 | 0.0484 | 0.1321 | 0.1246 | 0.1333 | 0.1289 | 0.1329 | |||
| 0.01 | −0.2 | 0.0558 | 0.0508 | 0.0506 | 0.0472 | 0.0519 | 0.0552 | 0.0587 | 0.0574 | 0.0607 | 0.0594 | ||
| −0.4 | 0.0483 | 0.0506 | 0.0473 | 0.0486 | 0.0498 | 0.0827 | 0.0805 | 0.0843 | 0.0867 | 0.0825 | |||
| −0.6 | 0.0488 | 0.0493 | 0.0493 | 0.0432 | 0.0443 | 0.1277 | 0.1208 | 0.1184 | 0.1292 | 0.1229 | |||
| 1− | 0 | −0.2 | 0.0484 | 0.0468 | 0.0465 | 0.0502 | 0.0512 | 0.0533 | 0.0513 | 0.0544 | 0.0550 | 0.0543 | |
| −0.4 | 0.0475 | 0.0507 | 0.0453 | 0.0467 | 0.0440 | 0.0683 | 0.0707 | 0.0679 | 0.0634 | 0.0703 | |||
| −0.6 | 0.0463 | 0.0389 | 0.0366 | 0.0422 | 0.0403 | 0.0911 | 0.0893 | 0.0845 | 0.0876 | 0.0846 | |||
| 0.01 | −0.2 | 0.0507 | 0.0481 | 0.0489 | 0.0496 | 0.0487 | 0.0513 | 0.0578 | 0.0526 | 0.0522 | 0.0505 | ||
| −0.4 | 0.0467 | 0.0501 | 0.0458 | 0.0454 | 0.0470 | 0.0695 | 0.0682 | 0.0677 | 0.0690 | 0.0658 | |||
| −0.6 | 0.0386 | 0.0409 | 0.0403 | 0.0397 | 0.0415 | 0.0869 | 0.0898 | 0.0898 | 0.0835 | 0.0868 | |||
| 0.5 | 0 | −0.2 | 0.0421 | 0.0497 | 0.0495 | 0.0486 | 0.0486 | 0.0471 | 0.0495 | 0.0495 | 0.0529 | 0.0495 | |
| −0.4 | 0.0427 | 0.0455 | 0.0463 | 0.0455 | 0.0499 | 0.0463 | 0.0528 | 0.0490 | 0.0516 | 0.0505 | |||
| −0.6 | 0.0361 | 0.0439 | 0.0429 | 0.0519 | 0.0486 | 0.0549 | 0.0480 | 0.0531 | 0.0477 | 0.0527 | |||
| 0.01 | −0.2 | 0.0446 | 0.0498 | 0.0453 | 0.0497 | 0.0496 | 0.0499 | 0.0541 | 0.0523 | 0.0514 | 0.0517 | ||
| −0.4 | 0.0435 | 0.0462 | 0.0460 | 0.0455 | 0.0471 | 0.0512 | 0.0457 | 0.0499 | 0.0528 | 0.0504 | |||
| −0.6 | 0.0417 | 0.0444 | 0.0460 | 0.0451 | 0.0488 | 0.0477 | 0.0518 | 0.0513 | 0.0508 | 0.0528 | |||
| 1 | 0 | −0.2 | 0.0494 | 0.0511 | 0.0519 | 0.0497 | 0.0448 | 0.0566 | 0.0617 | 0.0567 | 0.0584 | 0.0572 | |
| −0.4 | 0.0542 | 0.0496 | 0.0505 | 0.0527 | 0.0497 | 0.0839 | 0.0881 | 0.0914 | 0.0862 | 0.0798 | |||
| −0.6 | 0.0506 | 0.0492 | 0.0454 | 0.0464 | 0.0432 | 0.1226 | 0.1266 | 0.1282 | 0.1244 | 0.1248 | |||
| 0.01 | −0.2 | 0.0518 | 0.0469 | 0.0514 | 0.0533 | 0.0498 | 0.0632 | 0.0568 | 0.0607 | 0.0587 | 0.0588 | ||
| −0.4 | 0.0533 | 0.0481 | 0.0486 | 0.0486 | 0.0472 | 0.0802 | 0.0818 | 0.0829 | 0.0823 | 0.0821 | |||
| −0.6 | 0.0483 | 0.0463 | 0.0468 | 0.0482 | 0.0435 | 0.1284 | 0.1275 | 0.1224 | 0.1317 | 0.1304 | |||
| 1− | 0 | −0.2 | 0.0511 | 0.0468 | 0.0502 | 0.0511 | 0.0508 | 0.0502 | 0.0546 | 0.0534 | 0.0525 | 0.0514 | |
| −0.4 | 0.0476 | 0.0476 | 0.0476 | 0.0457 | 0.0419 | 0.0657 | 0.0635 | 0.0670 | 0.0685 | 0.0677 | |||
| −0.6 | 0.0436 | 0.0412 | 0.0435 | 0.0422 | 0.0408 | 0.0908 | 0.0831 | 0.0890 | 0.0866 | 0.0886 | |||
| 0.01 | −0.2 | 0.0539 | 0.0500 | 0.0481 | 0.0472 | 0.0492 | 0.0559 | 0.0545 | 0.0561 | 0.0506 | 0.0565 | ||
| −0.4 | 0.0467 | 0.0474 | 0.0427 | 0.0476 | 0.0428 | 0.0678 | 0.0681 | 0.0659 | 0.0641 | 0.0702 | |||
| −0.6 | 0.0428 | 0.0445 | 0.0438 | 0.0410 | 0.0417 | 0.0855 | 0.0844 | 0.0864 | 0.0857 | 0.0840 | |||
| EL | t-Test | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 400 | 800 | 1000 | 1200 | 200 | 400 | 800 | 1000 | 1200 | ||||
| 0.5 | 0 | −0.2 | 0.0484 | 0.0470 | 0.0510 | 0.0503 | 0.0547 | 0.0505 | 0.0509 | 0.0507 | 0.0515 | 0.0509 | |
| −0.4 | 0.0402 | 0.0420 | 0.0500 | 0.0531 | 0.0500 | 0.0490 | 0.0523 | 0.0479 | 0.0499 | 0.0502 | |||
| −0.6 | 0.0406 | 0.0382 | 0.0465 | 0.0432 | 0.0470 | 0.0532 | 0.0520 | 0.0532 | 0.0507 | 0.0500 | |||
| 0.01 | −0.2 | 0.0434 | 0.0435 | 0.0481 | 0.0480 | 0.0497 | 0.0527 | 0.0475 | 0.0493 | 0.0476 | 0.0508 | ||
| −0.4 | 0.0422 | 0.0462 | 0.0485 | 0.0472 | 0.0439 | 0.0506 | 0.0463 | 0.0519 | 0.0486 | 0.0492 | |||
| −0.6 | 0.0418 | 0.0419 | 0.0452 | 0.0454 | 0.0464 | 0.0524 | 0.0481 | 0.0483 | 0.0507 | 0.0500 | |||
| 1 | 0 | −0.2 | 0.0514 | 0.0484 | 0.0534 | 0.0511 | 0.0499 | 0.0565 | 0.0601 | 0.0606 | 0.0618 | 0.0566 | |
| −0.4 | 0.0533 | 0.0473 | 0.0520 | 0.0515 | 0.0511 | 0.0834 | 0.0872 | 0.0858 | 0.0896 | 0.0864 | |||
| −0.6 | 0.0497 | 0.0497 | 0.0470 | 0.0452 | 0.0503 | 0.1263 | 0.1228 | 0.1279 | 0.1218 | 0.1265 | |||
| 0.01 | −0.2 | 0.0536 | 0.0506 | 0.0493 | 0.0513 | 0.0461 | 0.0581 | 0.0597 | 0.0556 | 0.0558 | 0.0577 | ||
| −0.4 | 0.0523 | 0.0476 | 0.0515 | 0.0479 | 0.0501 | 0.0802 | 0.0817 | 0.0814 | 0.0788 | 0.0770 | |||
| −0.6 | 0.0481 | 0.0448 | 0.0465 | 0.0467 | 0.0464 | 0.1193 | 0.1234 | 0.1198 | 0.1187 | 0.1133 | |||
| 1− | 0 | −0.2 | 0.0533 | 0.0492 | 0.0489 | 0.0488 | 0.0492 | 0.0502 | 0.0540 | 0.0536 | 0.0552 | 0.0554 | |
| −0.4 | 0.0522 | 0.0439 | 0.0469 | 0.0487 | 0.0472 | 0.0675 | 0.0704 | 0.0691 | 0.0641 | 0.0659 | |||
| −0.6 | 0.0445 | 0.0442 | 0.0445 | 0.0348 | 0.0406 | 0.0881 | 0.0869 | 0.0847 | 0.0886 | 0.0885 | |||
| 0.01 | −0.2 | 0.0513 | 0.0493 | 0.0504 | 0.0489 | 0.0472 | 0.0574 | 0.0512 | 0.0550 | 0.0505 | 0.0580 | ||
| −0.4 | 0.0477 | 0.0467 | 0.0488 | 0.0461 | 0.0454 | 0.0654 | 0.0635 | 0.0615 | 0.0650 | 0.0658 | |||
| −0.6 | 0.0464 | 0.0429 | 0.0404 | 0.0401 | 0.0422 | 0.0870 | 0.0868 | 0.0853 | 0.0845 | 0.0873 | |||
| 0.5 | 0 | −0.2 | 0.0457 | 0.0471 | 0.0498 | 0.0487 | 0.0453 | 0.0491 | 0.0503 | 0.0536 | 0.0513 | 0.0523 | |
| −0.4 | 0.0419 | 0.0436 | 0.0435 | 0.0462 | 0.0463 | 0.0499 | 0.0519 | 0.0482 | 0.0545 | 0.0490 | |||
| −0.6 | 0.0393 | 0.0430 | 0.0444 | 0.0439 | 0.0464 | 0.0542 | 0.0527 | 0.0516 | 0.0488 | 0.0559 | |||
| 0.01 | −0.2 | 0.0438 | 0.0479 | 0.0457 | 0.0525 | 0.0484 | 0.0515 | 0.0468 | 0.0536 | 0.0523 | 0.0485 | ||
| −0.4 | 0.0394 | 0.0431 | 0.0479 | 0.0459 | 0.0483 | 0.0486 | 0.0486 | 0.0524 | 0.0536 | 0.0516 | |||
| −0.6 | 0.0361 | 0.0426 | 0.0443 | 0.0481 | 0.0462 | 0.0499 | 0.0514 | 0.0487 | 0.0520 | 0.0478 | |||
| 1 | 0 | −0.2 | 0.0507 | 0.0546 | 0.0518 | 0.0482 | 0.0492 | 0.0563 | 0.0600 | 0.0554 | 0.0572 | 0.0583 | |
| −0.4 | 0.0560 | 0.0490 | 0.0501 | 0.0503 | 0.0501 | 0.0803 | 0.0841 | 0.0840 | 0.0847 | 0.0842 | |||
| −0.6 | 0.0521 | 0.0508 | 0.0445 | 0.0461 | 0.0455 | 0.1322 | 0.1318 | 0.1294 | 0.1225 | 0.1258 | |||
| 0.01 | −0.2 | 0.0529 | 0.0489 | 0.0506 | 0.0490 | 0.0514 | 0.0570 | 0.0584 | 0.0565 | 0.0522 | 0.0587 | ||
| −0.4 | 0.0510 | 0.0469 | 0.0494 | 0.0487 | 0.0494 | 0.0780 | 0.0812 | 0.0793 | 0.0808 | 0.0815 | |||
| −0.6 | 0.0454 | 0.0491 | 0.0501 | 0.0486 | 0.0454 | 0.1237 | 0.1223 | 0.1135 | 0.1195 | 0.1121 | |||
| 1− | 0 | −0.2 | 0.0513 | 0.0478 | 0.0490 | 0.0505 | 0.0522 | 0.0541 | 0.0515 | 0.0537 | 0.0534 | 0.0523 | |
| −0.4 | 0.0485 | 0.0484 | 0.0458 | 0.0461 | 0.0471 | 0.0675 | 0.0674 | 0.0629 | 0.0651 | 0.0664 | |||
| −0.6 | 0.0447 | 0.0425 | 0.0410 | 0.0421 | 0.0413 | 0.0860 | 0.0851 | 0.0896 | 0.0903 | 0.0860 | |||
| 0.01 | −0.2 | 0.0527 | 0.0540 | 0.0485 | 0.0495 | 0.0486 | 0.0571 | 0.0566 | 0.0554 | 0.0563 | 0.0539 | ||
| −0.4 | 0.0545 | 0.0501 | 0.0445 | 0.0482 | 0.0450 | 0.0623 | 0.0690 | 0.0653 | 0.0684 | 0.0639 | |||
| −0.6 | 0.0491 | 0.0465 | 0.0407 | 0.0429 | 0.0478 | 0.0874 | 0.0820 | 0.0833 | 0.0871 | 0.0849 | |||
| Predictor | Adf.Test | Cor(, ) | GARCH-V | EL | t-Test | ||
|---|---|---|---|---|---|---|---|
| Dividend–price ratio | 0.0319 | 0.9928 | ** | −0.9618 | *** | 0.4200 | ** |
| Dividend yield | 0.0357 | 0.9929 | ** | −0.0791 | *** | 0.4626 | *** |
| Earnings–price ratio | 0.0308 | 0.9870 | ** | −0.7966 | *** | 0.2730 | *** |
| Dividend payout ratio | 0.0072 | 0.9913 | *** | −0.0407 | *** | ** | |
| Book-to-market value ratio | −0.0050 | 0.9858 | *** | −0.8031 | *** | 0.1322 | 0.2146 |
| T-bill rate | 0.0097 | 0.9934 | 0.5266 | -0.0762 | *** | 0.2945 | *** |
| Default yield spread | 0.0013 | 0.9752 | *** | −0.2433 | *** | 0.2027 | 0.6769 |
| Long-term yield | 0.0105 | 0.9965 | 0.9568 | −0.1098 | *** | 0.2722 | ** |
| Term spread | 0.0033 | 0.9608 | *** | −0.0070 | *** | 0.2126 | 0.2350 |
| Net equity expansion | 0.0090 | 0.9805 | *** | −0.0619 | *** | 0.7741 | *** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Liu, X.; Fan, Y.; Peng, L. Testing the Intercept of a Balanced Predictive Regression Model. Entropy 2022, 24, 1594. https://doi.org/10.3390/e24111594
Wang Q, Liu X, Fan Y, Peng L. Testing the Intercept of a Balanced Predictive Regression Model. Entropy. 2022; 24(11):1594. https://doi.org/10.3390/e24111594
Chicago/Turabian StyleWang, Qijun, Xiaohui Liu, Yawen Fan, and Ling Peng. 2022. "Testing the Intercept of a Balanced Predictive Regression Model" Entropy 24, no. 11: 1594. https://doi.org/10.3390/e24111594
APA StyleWang, Q., Liu, X., Fan, Y., & Peng, L. (2022). Testing the Intercept of a Balanced Predictive Regression Model. Entropy, 24(11), 1594. https://doi.org/10.3390/e24111594