



An Optimized Black-Box Adversarial Simulator Attack Based on Meta-Learning

 , and
, and 
Abstract
:1. Introduction
- The correct feature layer information of the simulator model obtained by meta-learning is ignored in the baseline, whereas it is actually valuable for acquiring proper adversarial perturbations;
- Ma’s attack framework [21] has an imbalance in the imitation effect before and after the simulator model is fully fine-tuned;
- Adversarial perturbation changing only considers global adjustment without specialization enhancement.
2. Related Works
2.1. Attacks Based on Query
2.2. Attacks Based on Transfer
2.3. Attacks Based on Meta Learning
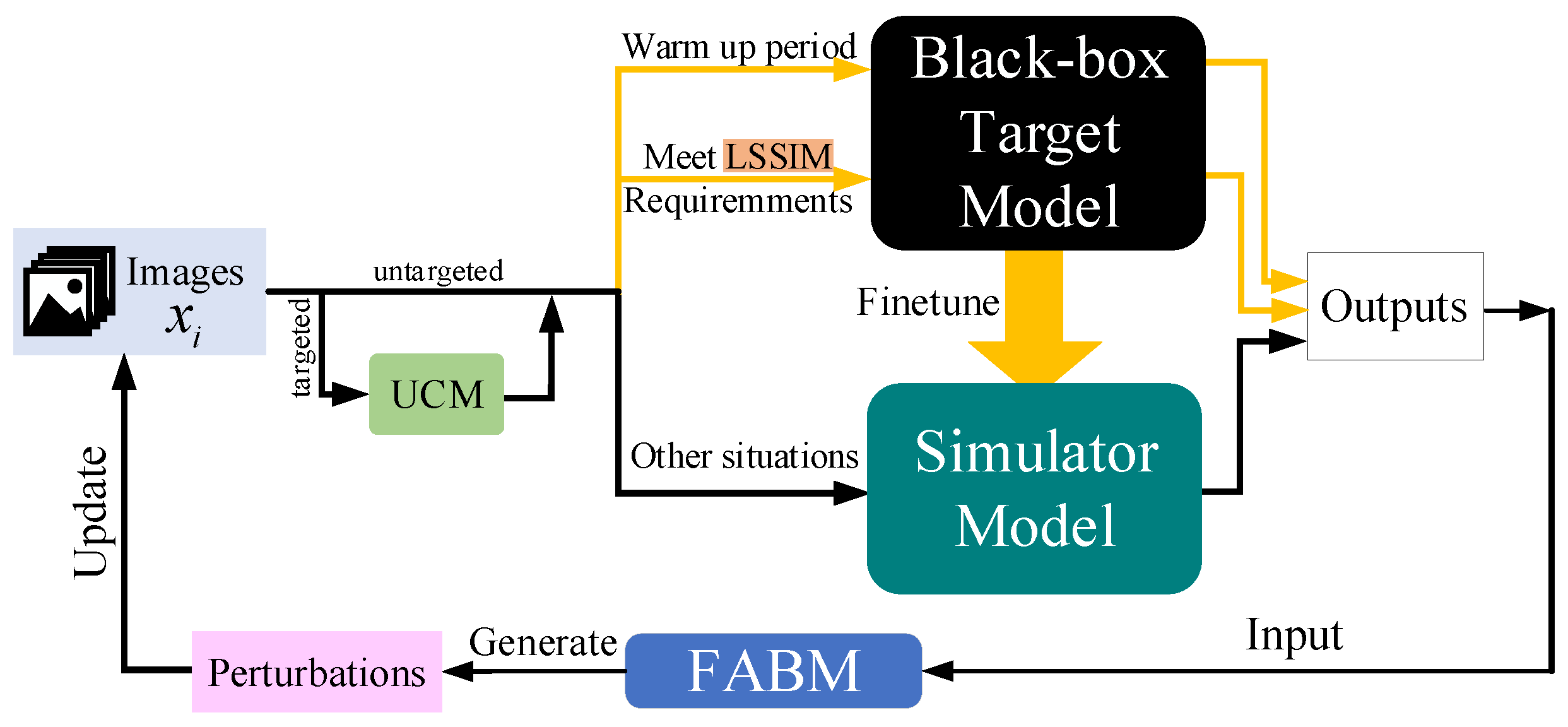
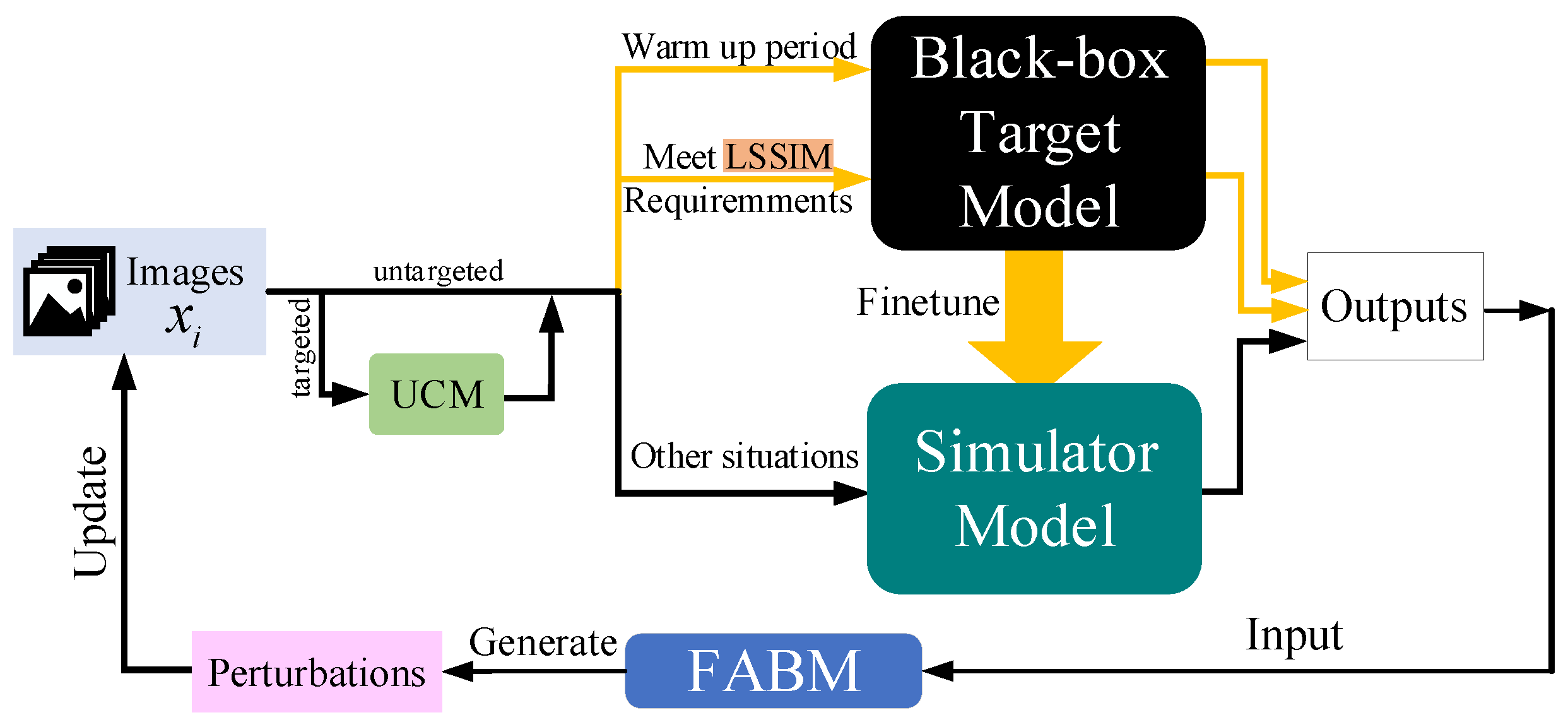
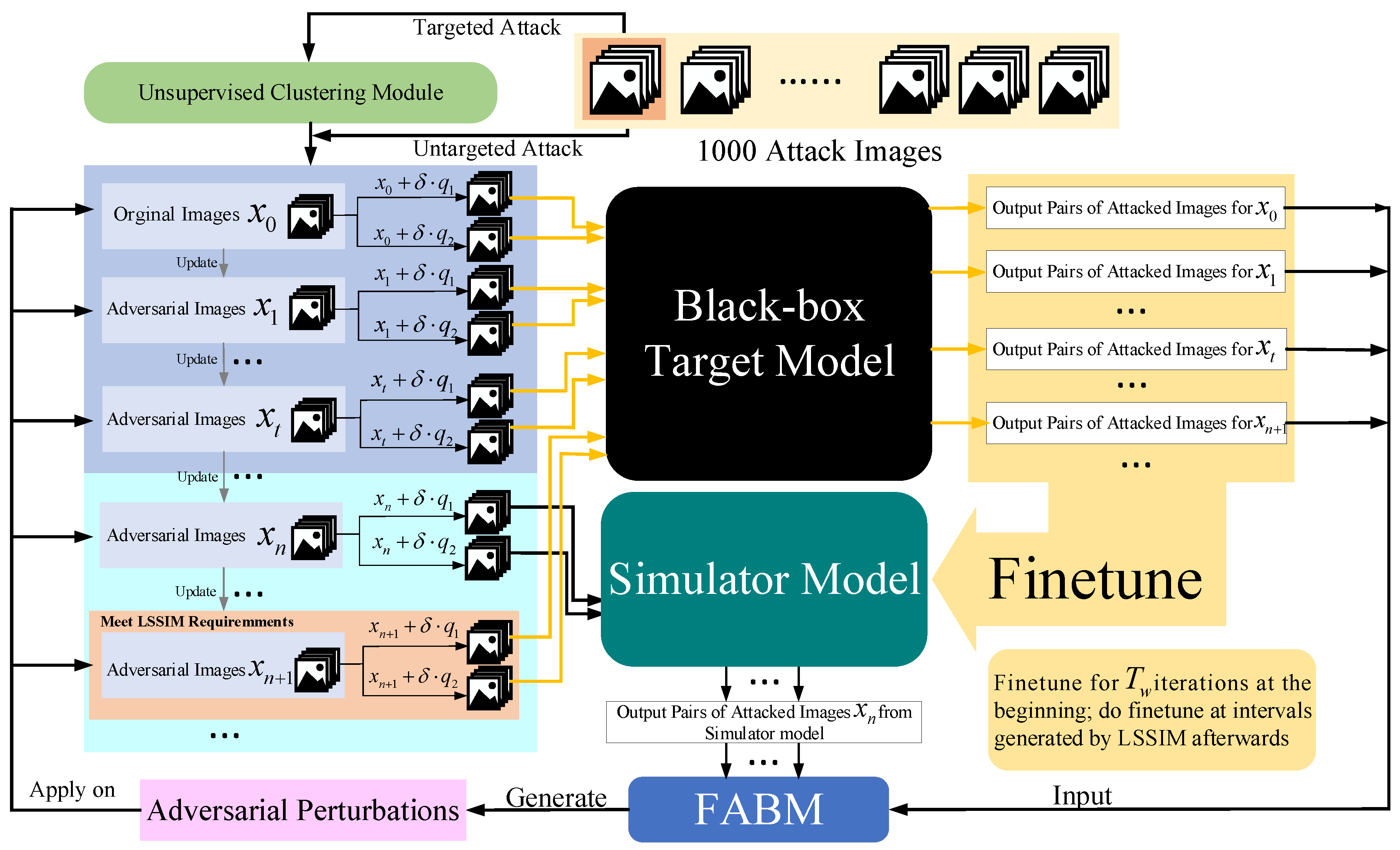
3. Methods
3.1. Feature Attentional Boosting Module
3.2. Linear Self-Adaptive Simulator-Predict Interval Mechanism
3.3. Unsupervised Clustering Module
4. Experiments
4.1. Experiment Settings
4.1.1. Dataset and Target Models
| Algorithm 1 Simulator Attack+ under the condition |
Input: The input image , where D means the image dimension, the label of the image x with groundtruth, the pre-trained simulator model , the forward function of the black-box target model interface f, and the finetuning loss function . Parameters: Warm-up iteration steps t, the adaptive predict-interval of LSSIM , Bandits Attack parameter , noise exploration parameter , Bandits prior learning rate , image updating rate , the momentum factor of FABM, group numbers of unsupervised clustering results, the center beginning perturbations , of input images, attack type , project function , and image update function . Output: Adversarial image that meets the requirements of norm-set attack, as .
|
4.1.2. Method Setting
4.1.3. Pre-Trained Networks
4.1.4. Compared Methods
4.2. Ablation Study
4.2.1. Ablation Study for Feature Attentional Boosting Module
4.2.2. Ablation Study for Linear Self-Adaptive Simulator-Predict Interval Mechanism
4.2.3. Ablation Study for Unsupervised Clustering Module
4.3. Comparisons with Existing Methods
4.3.1. Comparisons with Attacks on Normal Victim Models
4.3.2. Comparisons with Attacks on Normal Defensive Victim Models
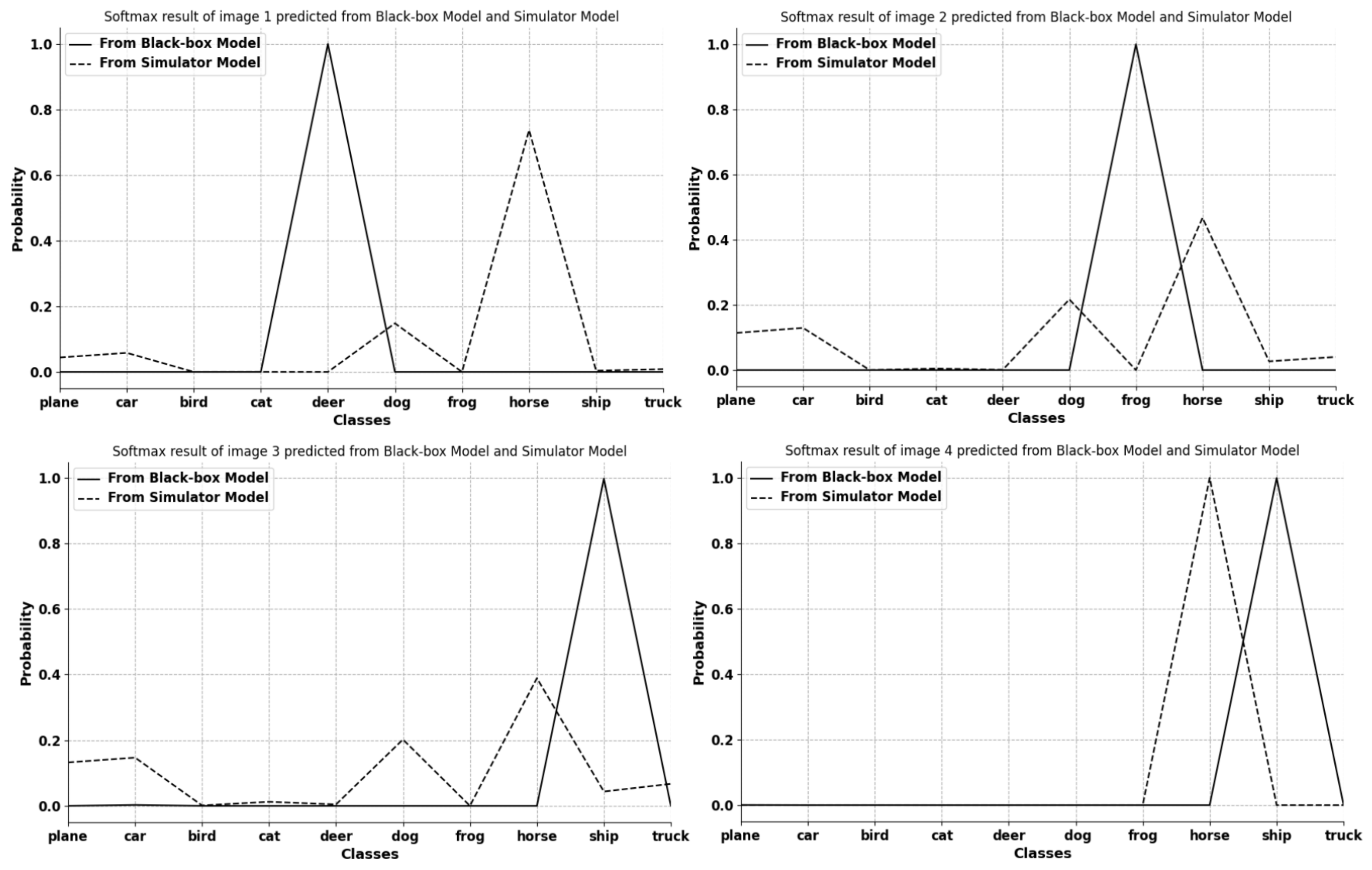
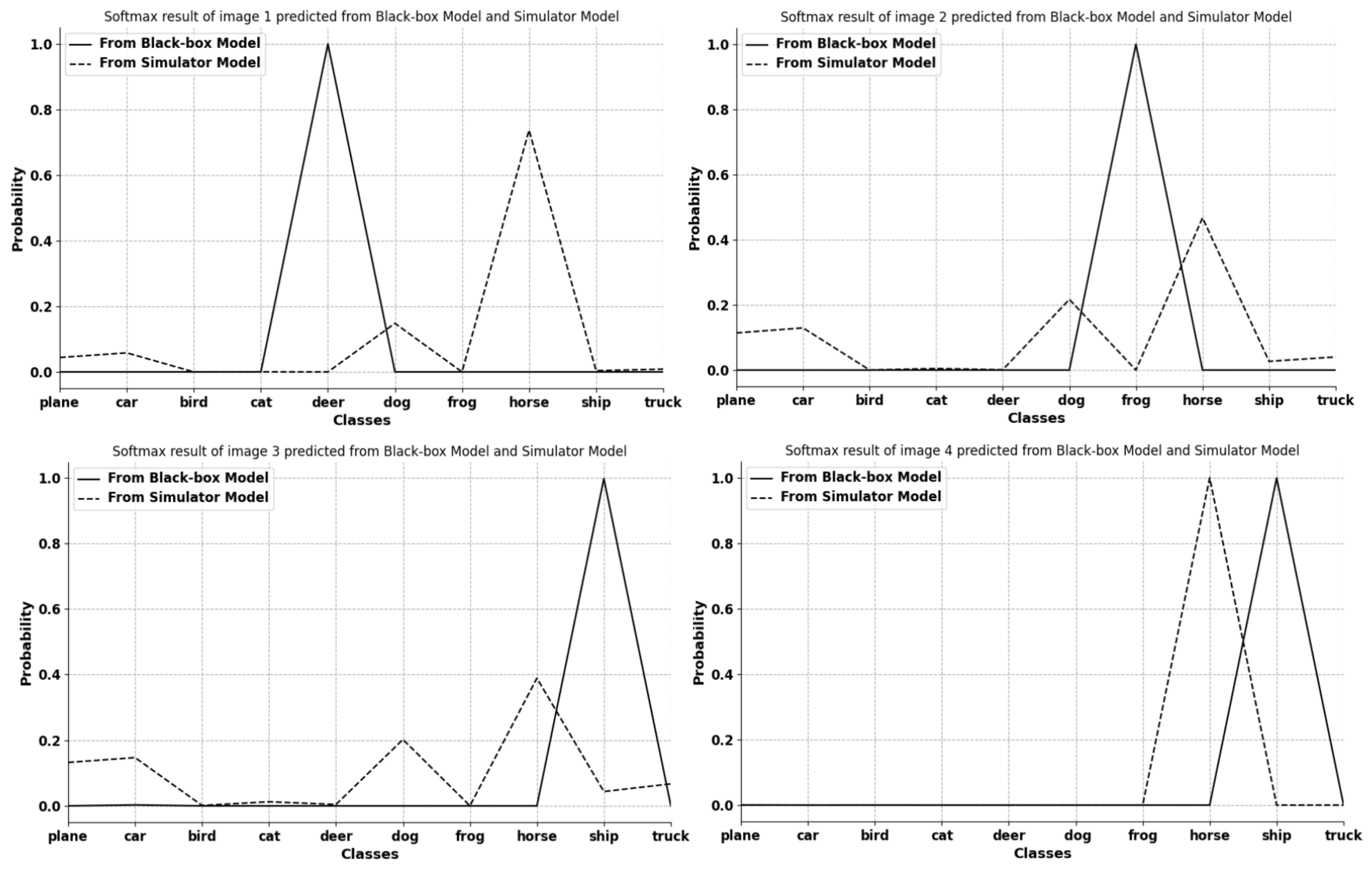
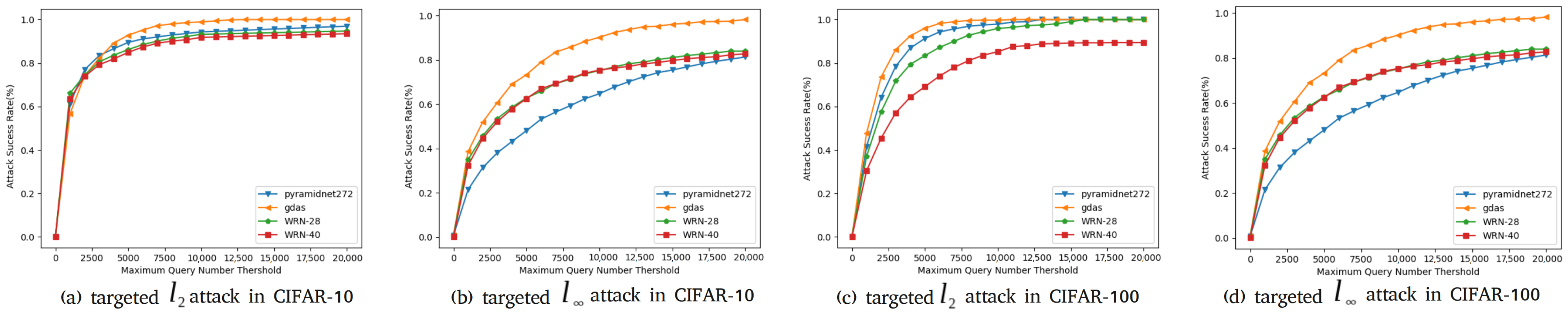
4.3.3. Experimental Figure and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B. Evasion attacks against machine learning at test time. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. Stat 2017, 1050, 9. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Tu, C.C.; Ting, P.; Chen, P.Y.; Liu, S.; Cheng, S.M. AutoZOOM: Autoencoder-Based Zeroth Order Optimization Method for Attacking Black-Box Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, Georgia, 8–12 October 2019; Volume 33, pp. 742–749. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box adversarial attacks with limited queries and information. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2137–2146. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Madry, A. Prior convictions: Black-box adversarial attacks with bandits and priors. arXiv 2018, arXiv:1807.07978. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Oh, S.J.; Schiele, B.; Fritz, M. Towards Reverse-Engineering Black-Box Neural Networks; Springer: Cham, Switzerland, 2019; pp. 121–144. [Google Scholar]
- Demontis, A.; Melis, M.; Pintor, M.; Jagielski, M.; Biggio, B.; Oprea, A.; Nita-Rotaru, C.; Roli, F. Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 321–338. [Google Scholar]
- Huang, Q.; Katsman, I.; He, H.; Gu, Z.; Belongie, S.; Lim, S.N. Enhancing adversarial example transferability with an intermediate level attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4733–4742. [Google Scholar]
- Chen, S.; He, Z.; Sun, C.; Yang, J.; Huang, X. Universal Adversarial Attack on Attention and the Resulting Dataset DAmageNet. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2188–2197. [Google Scholar] [CrossRef]
- Orekondy, T.; Schiele, B.; Fritz, M. Knockoff nets: Stealing functionality of black-box models. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4954–4963. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Tramr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction APIs. In Proceedings of the 25th USENIX security symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Lee, T.; Edwards, B.; Molloy, I.; Su, D. Defending against neural network model stealing attacks using deceptive perturbations. In Proceedings of the 2019 IEEE Security and Privacy Workshops, San Francisco, CA, USA, 19–23 May 2019; pp. 43–49. [Google Scholar]
- Orekondy, T.; Schiele, B.; Fritz, M. Prediction Poisoning: Towards Defenses Against DNN Model Stealing Attacks. arXiv 2019, arXiv:1906.10908. [Google Scholar]
- Xu, Y.; Ghamisi, P. Universal Adversarial Examples in Remote Sensing: Methodology and Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Ma, C.; Chen, L.; Yong, J.H. Simulating unknown target models for query-efficient black-box attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11835–11844. [Google Scholar]
- Zhou, B.; Cui, Q.; Wei, X.S.; Chen, Z.M. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9719–9728. [Google Scholar]
- Du, J.; Zhang, H.; Zhou, J.T.; Yang, Y.; Feng, J. Query-efficient Meta Attack to Deep Neural Networks. arXiv 2020, arXiv:1906.02398. [Google Scholar]
- Nesterov, Y.; Spokoiny, V. Random gradient-free minimization of convex functions. Found. Comput. Math. 2017, 17, 527–566. [Google Scholar] [CrossRef]
- Cheng, S.; Dong, Y.; Pang, T.; Su, H.; Zhu, J. Improving black-box adversarial attacks with a transfer-based prior. Adv. Neural Inf. Process. Syst. 2019, 32, 10934–10944. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Bhagoji, A.N.; He, W.; Li, B.; Song, D. Practical black-box attacks on deep neural networks using efficient query mechanisms. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 154–169. [Google Scholar]
- Cheng, M.; Le, T.; Chen, P.Y.; Zhang, H.; Yi, J.; Hsieh, C.J. Query-Efficient Hard-label Black-box Attack: An Optimization-based Approach. arXiv 2019, arXiv:1807.04457. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. arXiv 2018, arXiv:1712.04248. [Google Scholar]
- Wang, B.; Gong, N.Z. Stealing hyperparameters in machine learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 36–52. [Google Scholar]
- Ma, C.; Cheng, S.; Chen, L.; Zhu, J.; Yong, J. Switching Transferable Gradient Directions for Query-Efficient Black-Box Adversarial Attacks. arXiv 2020, arXiv:2009.07191. [Google Scholar]
- Pengcheng, L.; Yi, J.; Zhang, L. Query-efficient black-box attack by active learning. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1200–1205. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2484–2493. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square attack: A query-efficient black-box adversarial attack via random search. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 484–501. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar]
- Yang, J.; Jiang, Y.; Huang, X.; Ni, B.; Zhao, C. Learning black-box attackers with transferable priors and query feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 12288–12299. [Google Scholar]
- Inkawhich, N.; Liang, K.; Wang, B.; Inkawhich, M.; Carin, L.; Chen, Y. Perturbing across the feature hierarchy to improve standard and strict blackbox attack transferability. Adv. Neural Inf. Process. Syst. 2020, 33, 20791–20801. [Google Scholar]
- Dong, Y.; Su, H.; Wu, B.; Li, Z.; Liu, W.; Zhang, T.; Zhu, J. Efficient decision-based black-box adversarial attacks on face recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7714–7722. [Google Scholar]
- Wu, L.; Zhu, Z.; Tai, C. Understanding and enhancing the transferability of adversarial examples. arXiv 2018, arXiv:1802.09707. [Google Scholar]
- Milli, S.; Schmidt, L.; Dragan, A.D.; Hardt, M. Model reconstruction from model explanations. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 1–9. [Google Scholar]
- Ma, C.; Zhao, C.; Shi, H.; Chen, L.; Yong, J.; Zeng, D. Metaadvdet: Towards robust detection of evolving adversarial attacks. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 692–701. [Google Scholar]
- Guo, Y.; Yan, Z.; Zhang, C. Subspace attack: Exploiting promising subspaces for query-efficient black-box attacks. Adv. Neural Inf. Process. Syst. 2019, 32, 3825–3834. [Google Scholar]
- Han, D.; Kim, J.; Kim, J. Deep pyramidal residual networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5927–5935. [Google Scholar]
- Yamada, Y.; Iwamura, M.; Akiba, T.; Kise, K. Shakedrop regularization for deep residual learning. IEEE Access 2019, 7, 186126–186136. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Dong, X.; Yang, Y. Searching for a robust neural architecture in four gpu hours. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1761–1770. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. Comdefend: An efficient image compression model to defend adversarial examples. In Proceedings of the of Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6084–6092. [Google Scholar]
- Mustafa, A.; Khan, S.; Hayat, M.; Goecke, R.; Shen, J.; Shao, L. Adversarial defense by restricting the hidden space of deep neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3385–3394. [Google Scholar]
- Liu, Z.; Liu, Q.; Liu, T.; Xu, N.; Lin, X.; Wang, Y.; Wen, W. Feature distillation: Dnn-oriented jpeg compression against adversarial examples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 860–868. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Default | Detail |
|---|---|---|
| for inner updating | 0.1 | learning rate in the inner update |
| for outer updating | 0.001 | learning rate in the outer update |
| maximum queries | 10,000 | limit of queries of each sample |
| of norm attack | 4.6 | maximum distortion in norm attack |
| of norm attack | 8/255 | maximum distortion in norm attack |
| of norm attack | 0.1 | image learning rate for updating image |
| of norm attack | 1/255 | image learning rate for updating image |
| of norm attack | 0.1 | OCO learning rate for updating g(prior) |
| of norm attack | 1.0 | OCO learning rate for updating g(prior) |
| inner-update iterations | 12 | update iterations of learning meta-train set |
| simulator-predict interval | 5 | prediction iterations interval of simulator |
| warm-up iterations t | 10 | first t iterations of simulator attack |
| length of fine-tuning queue | 10 | maximum length of fine-tuning queue |
| M-Parms | Average Query | Median Query | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Cur | Avg | PN-272 | GDAS | WRN-28 | WRN-40 | PN-272 | GDAS | WRN-28 | WRN-40 |
| 0.91 | 0.09 | 108 | 91 | 148 | 163 | 30 | 26 | 60 | 50 |
| 0.92 | 0.08 | 106 | 101 | 147 | 157 | 30 | 26 | 54 | 52 |
| 0.93 | 0.07 | 104 | 92 | 133 | 139 | 30 | 24 | 56 | 48 |
| 0.94 | 0.06 | 109 | 94 | 158 | 149 | 30 | 26 | 56 | 54 |
| 0.95 | 0.05 | 110 | 94 | 148 | 155 | 30 | 26 | 56 | 54 |
| 0.96 | 0.04 | 103 | 103 | 158 | 155 | 32 | 28 | 56 | 56 |
| 0.97 | 0.03 | 110 | 101 | 145 | 160 | 30 | 28 | 60 | 52 |
| 0.98 | 0.02 | 106 | 99 | 153 | 168 | 30 | 26 | 56 | 58 |
| 0.99 | 0.01 | 109 | 108 | 159 | 162 | 32 | 28 | 60 | 58 |
| Baseline | 129 | 124 | 196 | 209 | 34 | 28 | 58 | 54 | |
| M-Parms | Average Query | Median Query | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Cur | Avg | CD | PCL | FD | Adv Train | CD | PCL | FD | Adv Train |
| 0.91 | 0.09 | 354 | 520 | 319 | 716 | 56 | 108 | 42 | 382 |
| 0.92 | 0.08 | 352 | 518 | 322 | 724 | 56 | 110 | 44 | 380 |
| 0.93 | 0.07 | 356 | 516 | 324 | 716 | 56 | 108 | 42 | 380 |
| 0.94 | 0.06 | 350 | 510 | 320 | 720 | 54 | 108 | 42 | 380 |
| 0.95 | 0.05 | 352 | 512 | 324 | 722 | 56 | 108 | 42 | 384 |
| 0.96 | 0.04 | 350 | 516 | 322 | 718 | 54 | 108 | 44 | 380 |
| 0.97 | 0.03 | 344 | 510 | 314 | 710 | 52 | 108 | 40 | 378 |
| 0.98 | 0.02 | 350 | 516 | 312 | 710 | 54 | 108 | 40 | 382 |
| 0.99 | 0.01 | 354 | 520 | 319 | 716 | 54 | 106 | 42 | 380 |
| Baseline | 388 | 577 | 350 | 812 | 60 | 112 | 44 | 392 | |
| LSSIM-Parms | Average Query | Median Query | |
|---|---|---|---|
| Interval Factor | Threshold | PN-272 | PN-272 |
| 80 | 6 | 866 | 654 |
| 85 | 7 | 820 | 658 |
| 90 | 7 | 837 | 648 |
| 95 | 8 | 814 | 672 |
| 100 | 8 | 816 | 666 |
| 110 | 8 | 846 | 670 |
| 120 | 8 | 837 | 678 |
| 120 | 9 | 808 | 644 |
| 150 | 8 | 860 | 708 |
| Baseline | 829 | 644 | |
| UCM | Average Query | Median Query | ||||||
|---|---|---|---|---|---|---|---|---|
| Victims | PN-272 | GDAS | WRN-28 | WRN-40 | PN-272 | GDAS | WRN-28 | WRN-40 |
| SA-UCM | 607 | 636 | 540 | 579 | 264 | 312 | 122 | 170 |
| Baseline | 815 | 715 | 836 | 793 | 368 | 400 | 206 | 245 |
| Dataset | Norm | Attack | Attack Success Rate | Average Query | Median Query | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PyramidNet-272 | GDAS | WRN-28 | WRN-40 | PyramidNet-272 | GDAS | WRN-28 | WRN-40 | PyramidNet-272 | GDAS | WRN-28 | WRN-40 | |||
| CIFAR-10 | NES [8] | 99.5% | 74.8% | 99.9% | 99.5% | 200 | 123 | 159 | 154 | 150 | 100 | 100 | 100 | |
| RGF [24] | 100% | 100% | 100% | 100% | 216 | 168 | 153 | 150 | 204 | 152 | 102 | 152 | ||
| P-RGF [25] | 100% | 100% | 100% | 100% | 64 | 40 | 76 | 73 | 62 | 20 | 64 | 64 | ||
| Meta Attack [23] | 99.2% | 99.4% | 98.6% | 99.6% | 2359 | 1611 | 1853 | 1707 | 2211 | 1303 | 1432 | 1430 | ||
| Bandits [9] | 100% | 100% | 100% | 100% | 151 | 66 | 107 | 98 | 110 | 54 | 80 | 78 | ||
| Simulator Attack [21] | 100% | 100% | 100% | 100% | 92 | 34 | 48 | 51 | 52 | 26 | 34 | 34 | ||
| Simulator Attack+ | 100% | 100% | 100% | 100% | 93 | 32 | 48 | 50 | 50 | 26 | 34 | 32 | ||
| NES [8] | 86.8% | 71.4% | 74.2% | 77.5% | 1559 | 628 | 1235 | 1209 | 600 | 300 | 400 | 400 | ||
| RGF [24] | 99% | 93.8% | 98.6% | 98.8% | 955 | 646 | 1178 | 928 | 668 | 460 | 663 | 612 | ||
| P-RGF [25] | 97.3% | 97.9% | 97.7% | 98% | 742 | 337 | 703 | 564 | 408 | 128 | 236 | 217 | ||
| Meta Attack [23] | 90.6% | 98.8% | 92.7% | 94.2% | 3456 | 2034 | 2198 | 1987 | 2991 | 1694 | 1564 | 1433 | ||
| Bandits [9] | 99.6% | 100% | 99.4% | 99.9% | 1015 | 391 | 611 | 542 | 560 | 166 | 224 | 228 | ||
| Simulator Attack [21] | 96.5% | 99.9% | 98.1% | 98.8% | 779 | 248 | 466 | 419 | 469 | 83 | 186 | 186 | ||
| Simulator Attack+ | 95.2% | 98.1% | 93.0% | 95.3% | 781 | 210 | 432 | 388 | 434 | 95 | 176 | 190 | ||
| CIFAR-100 | NES [8] | 92.4% | 90.2% | 98.4% | 99.6% | 118 | 94 | 102 | 105 | 100 | 50 | 100 | 100 | |
| RGF [24] | 100% | 100% | 100% | 100% | 114 | 110 | 106 | 106 | 102 | 101 | 102 | 102 | ||
| P-RGF [25] | 100% | 100% | 100% | 100% | 54 | 46 | 54 | 73 | 62 | 62 | 62 | 62 | ||
| Meta Attack [23] | 99.7% | 99.8% | 99.4% | 98.4% | 1022 | 930 | 1193 | 1252 | 783 | 781 | 912 | 913 | ||
| Bandits [9] | 100% | 100% | 100% | 100% | 58 | 54 | 64 | 65 | 42 | 42 | 52 | 53 | ||
| Simulator Attack [21] | 100% | 100% | 100% | 100% | 29 | 29 | 33 | 34 | 24 | 24 | 26 | 26 | ||
| Simulator Attack+ | 100% | 100% | 100% | 100% | 29 | 29 | 33 | 33 | 24 | 24 | 26 | 26 | ||
| NES [8] | 91.3% | 89.7% | 92.4% | 89.3% | 439 | 271 | 673 | 596 | 204 | 153 | 255 | 255 | ||
| RGF [24] | 99.7% | 98.8% | 98.9% | 98.9% | 385 | 420 | 544 | 619 | 256 | 255 | 357 | 357 | ||
| P-RGF [25] | 99.3% | 98.2% | 98% | 97.3% | 308 | 220 | 371 | 480 | 147 | 116 | 136 | 181 | ||
| Meta Attack [23] | 99.7% | 99.8% | 97.4% | 97.3% | 1102 | 1098 | 1294 | 1369 | 912 | 911 | 1042 | 1040 | ||
| Bandits [9] | 100% | 100% | 99.8% | 99.8% | 266 | 209 | 262 | 260 | 68 | 57 | 107 | 92 | ||
| Simulator Attack [21] | 100% | 100% | 99.9% | 99.9% | 129 | 124 | 196 | 209 | 34 | 28 | 58 | 54 | ||
| Simulator Attack+ | 100% | 100% | 99.8% | 99.9% | 133 | 126 | 188 | 200 | 32 | 32 | 62 | 60 | ||
| Dataset | Norm | Attack | Attack Success Rate | Average Query | Median Query | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PyramidNet-272 | GDAS | WRN-28 | WRN-40 | PyramidNet-272 | GDAS | WRN-28 | WRN-40 | PyramidNet-272 | GDAS | WRN-28 | WRN-40 | |||
| CIFAR-10 | NES [8] | 93.7% | 95.4% | 98.5% | 97.7% | 1474 | 1515 | 1043 | 1088 | 1251 | 999 | 881 | 881 | |
| Meta Attack [23] | 92.2% | 97.2% | 74.1% | 74.7% | 4215 | 3137 | 3996 | 3797 | 3842 | 2817 | 3586 | 3329 | ||
| Bandits [9] | 99.7% | 100% | 97.3% | 98.4% | 852 | 718 | 1082 | 997 | 458 | 538 | 338 | 399 | ||
| Simulator Attack(m = 3) [21] | 99.1% | 100% | 98.5% | 95.6% | 896 | 718 | 990 | 980 | 373 | 388 | 217 | 249 | ||
| Simulator Attack(m = 5) [21] | 97.6% | 99.9% | 96.4% | 94% | 815 | 715 | 836 | 793 | 368 | 400 | 206 | 245 | ||
| Simulator Attack+ | 91.9% | 97.7% | 89.3% | 89.6% | 570 | 653 | 519 | 592 | 328 | 404 | 166 | 194 | ||
| Simulator Attack++ | 98.0% | 100.0% | 97.0% | 94.0% | 765 | 674 | 782 | 750 | 350 | 414 | 180 | 200 | ||
| NES [8] | 63.8% | 80.8% | 89.7% | 88.8% | 4355 | 3942 | 3046 | 3051 | 3717 | 3441 | 2535 | 2592 | ||
| Meta Attack [23] | 75.6% | 95.5% | 59% | 59.8% | 4960 | 3461 | 3873 | 3899 | 4736 | 3073 | 3328 | 3586 | ||
| Bandits [9] | 84.5% | 98.3% | 76.9% | 79.8% | 2830 | 1755 | 2037 | 2128 | 2081 | 1162 | 1178 | 1188 | ||
| Simulator Attack (m = 3) [21] | 80.9% | 97.8% | 83.1% | 82.2% | 2655 | 1561 | 1855 | 1806 | 1943 | 918 | 1010 | 1018 | ||
| Simulator Attack (m = 5) [21] | 78.7% | 96.5% | 80.8% | 80.3% | 2474 | 1470 | 1676 | 1660 | 1910 | 917 | 957 | 956 | ||
| Simulator Attack+ | 73.8% | 86.0% | 71.4% | 70.8% | 1231 | 1014 | 1138 | 1201 | 897 | 589 | 729 | 684 | ||
| Simulator Attack++ | 79.0% | 97.0% | 81.0% | 81.0% | 2302 | 1307 | 1633 | 1567 | 1810 | 900 | 911 | 920 | ||
| CIFAR-100 | NES [8] | 87.6% | 77% | 89.3% | 87.6% | 1300 | 1405 | 1383 | 1424 | 1102 | 1172 | 1061 | 1049 | |
| Meta Attack [23] | 86.1% | 88.7% | 63.4% | 43.3% | 4000 | 3672 | 4879 | 4989 | 3457 | 3201 | 4482 | 4865 | ||
| Bandits [9] | 99.6% | 100% | 98.9% | 91.5% | 1442 | 847 | 1645 | 2436 | 1058 | 679 | 1150 | 1584 | ||
| Simulator Attack (m = 3) [21] | 99.3% | 100% | 98.6% | 92.6% | 921 | 724 | 1150 | 1552 | 666 | 519 | 779 | 1126 | ||
| Simulator Attack (m = 5) [21] | 97.8% | 99.6% | 95.7% | 83.9% | 829 | 679 | 1000 | 1211 | 644 | 508 | 706 | 906 | ||
| Simulator Attack+ | 96.2% | 99.3% | 92.1% | 80.0% | 803 | 698 | 908 | 1072 | 618 | 546 | 630 | 780 | ||
| Simulator Attack++ | 98.0% | 100.0% | 96.0% | 84.0% | 823 | 700 | 928 | 1130 | 630 | 550 | 645 | 852 | ||
| NES [8] | 72.1% | 66.8% | 68.4% | 69.9% | 4673 | 5174 | 4763 | 4770 | 4376 | 4832 | 4357 | 4508 | ||
| Meta Attack [23] | 80.4% | 81.2% | 57.6% | 40.1% | 4136 | 3951 | 4893 | 4967 | 3714 | 3585 | 4609 | 4737 | ||
| Bandits [9] | 81.2% | 92.5% | 72.4% | 56% | 3222 | 2798 | 3353 | 3465 | 2633 | 2132 | 2766 | 2774 | ||
| Simulator Attack (m = 3) [21] | 89.4% | 94.2% | 79% | 64.3% | 2732 | 2281 | 3078 | 3238 | 1854 | 1589 | 2185 | 2548 | ||
| Simulator Attack (m = 5) [21] | 83.7% | 91.4% | 74.2% | 60% | 2410 | 2134 | 2619 | 2823 | 1754 | 1572 | 2080 | 2270 | ||
| Simulator Attack+ | 70.8% | 78.3% | 61.0% | 54.6% | 1606 | 1443 | 1788 | 2011 | 1088 | 1194 | 1172 | 1322 | ||
| Simulator Attack++ | 84.0% | 92.0% | 75.0% | 60.0% | 2150 | 1913 | 2305 | 2603 | 1562 | 1435 | 1765 | 1954 | ||
| Dataset | Attack | Attack Success Rate | Average Query | Median Query | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CD [49] | PCL [50] | FD [51] | Adv Train [4] | CD [49] | PCL [50] | FD [51] | Adv Train [4] | CD [49] | PCL [50] | FD [51] | Adv Train [4] | ||
| CIFAR-10 | NES [8] | 60.4% | 65% | 54.5% | 16.8% | 1130 | 728 | 1474 | 858 | 400 | 150 | 450 | 200 |
| RGF [24] | 48.7% | 82.6% | 44.4% | 22.4% | 2035 | 1107 | 1717 | 973 | 1071 | 306 | 768 | 510 | |
| P-RGF [25] | 62.8% | 80.4% | 65.8% | 22.4% | 1977 | 1006 | 1979 | 1158 | 1038 | 230 | 703 | 602 | |
| Meta Attack [23] | 26.8% | 77.7% | 38.4% | 18.4% | 2468 | 1756 | 2662 | 1894 | 1302 | 1042 | 1824 | 1561 | |
| Bandits [9] | 44.7% | 84% | 55.2% | 34.8% | 786 | 776 | 832 | 1941 | 100 | 126 | 114 | 759 | |
| Simulator Attack [21] | 54.9% | 78.2% | 60.8% | 32.3% | 433 | 641 | 391 | 1529 | 46 | 116 | 50 | 589 | |
| Simulator Attack+ | 55.7% | 76.7% | 60.0% | 26.6% | 388 | 577 | 350 | 812 | 60 | 112 | 44 | 392 | |
| CIFAR-100 | NES [8] | 78.1% | 87.9% | 77.6% | 23.1% | 892 | 429 | 1071 | 865 | 300 | 150 | 250 | 250 |
| RGF [24] | 50.2% | 95.5% | 62% | 29.2% | 1753 | 645 | 1208 | 1009 | 765 | 204 | 408 | 510 | |
| P-RGF [25] | 54.2% | 96.1% | 73.4% | 28.8% | 1009 | 679 | 1169 | 1034 | 815 | 182 | 262 | 540 | |
| Meta Attack [23] | 20.8% | 93% | 59% | 27% | 2084 | 1122 | 2165 | 1863 | 781 | 651 | 1043 | 1562 | |
| Bandits [9] | 54.1% | 97% | 72.5% | 44.9% | 786 | 321 | 584 | 1609 | 56 | 34 | 32 | 484 | |
| Simulator Attack [21] | 72.9% | 93.1% | 80.7% | 35.6% | 330 | 233 | 250 | 1318 | 30 | 22 | 24 | 442 | |
| Simulator Attack+ | 73.0% | 74.3% | 80.0% | 29.7% | 346 | 230 | 202 | 1015 | 34 | 22 | 23 | 362 | |
| TinyImageNet | NES [8] | 69.5% | 73.1% | 33.3% | 23.7% | 1775 | 863 | 2908 | 945 | 850 | 200 | 1600 | 200 |
| RGF [24] | 31.3% | 91.8% | 9.1% | 34.7% | 2446 | 1022 | 1619 | 1325 | 1377 | 408 | 765 | 612 | |
| P-RGF [25] | 37.3% | 91.8% | 25.9% | 34.4% | 1946 | 1065 | 2231 | 1287 | 891 | 436 | 985 | 602 | |
| Meta Attack [23] | 4.5% | 75.8% | 3.7% | 20.1% | 1877 | 2585 | 4187 | 3413 | 912 | 1792 | 2602 | 2945 | |
| Bandits [9] | 39.6% | 95.8% | 12.5% | 49% | 893 | 909 | 1272 | 1855 | 85 | 206 | 193 | 810 | |
| Simulator Attack [21] | 43% | 84.2% | 21.3% | 42.5% | 377 | 586 | 746 | 1631 | 32 | 148 | 157 | 632 | |
| Simulator Attack+ | 41.0% | 80.3% | 19.0% | 39.7% | 348 | 530 | 704 | 1214 | 34 | 146 | 154 | 582 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Ding, J.; Wu, F.; Zhang, C.; Sun, Y.; Sun, J.; Liu, S.; Ji, Y. An Optimized Black-Box Adversarial Simulator Attack Based on Meta-Learning. Entropy 2022, 24, 1377. https://doi.org/10.3390/e24101377
Chen Z, Ding J, Wu F, Zhang C, Sun Y, Sun J, Liu S, Ji Y. An Optimized Black-Box Adversarial Simulator Attack Based on Meta-Learning. Entropy. 2022; 24(10):1377. https://doi.org/10.3390/e24101377
Chicago/Turabian StyleChen, Zhiyu, Jianyu Ding, Fei Wu, Chi Zhang, Yiming Sun, Jing Sun, Shangdong Liu, and Yimu Ji. 2022. "An Optimized Black-Box Adversarial Simulator Attack Based on Meta-Learning" Entropy 24, no. 10: 1377. https://doi.org/10.3390/e24101377
APA StyleChen, Z., Ding, J., Wu, F., Zhang, C., Sun, Y., Sun, J., Liu, S., & Ji, Y. (2022). An Optimized Black-Box Adversarial Simulator Attack Based on Meta-Learning. Entropy, 24(10), 1377. https://doi.org/10.3390/e24101377