Abstract
Time-varying autoregressive (TVAR) models are widely used for modeling of non-stationary signals. Unfortunately, online joint adaptation of both states and parameters in these models remains a challenge. In this paper, we represent the TVAR model by a factor graph and solve the inference problem by automated message passing-based inference for states and parameters. We derive structured variational update rules for a composite “AR node” with probabilistic observations that can be used as a plug-in module in hierarchical models, for example, to model the time-varying behavior of the hyper-parameters of a time-varying AR model. Our method includes tracking of variational free energy (FE) as a Bayesian measure of TVAR model performance. The proposed methods are verified on a synthetic data set and validated on real-world data from temperature modeling and speech enhancement tasks.
1. Introduction
Autoregressive (AR) models are capable of describing a wide range of time series patterns [1,2]. The extension to Time-Varying AR (TVAR) models, where the AR coefficients are allowed to vary over time, supports tracking of non-stationary signals. TVAR models have been successfully applied to a wide range of applications, including speech signal processing [3,4,5], signature verification [6], cardiovascular response modeling [7], acoustic signature recognition of vehicles [8], radar signal processing [9], and EEG analysis [10,11].
The realization of TVAR models in practice often poses some computational issues. For many applications, such as speech processing in a hearing aid, both a low computational load and high modeling accuracy are essential.
The problem of parameter tracking in TVAR models has been extensively explored in a non-Bayesian setting. For example, ref. [12] employs over-determined modified Yule-Walker equations and [13] applies the covariance method to track the parameters in a TVAR model. In [14], expressions for the mean vector and covariance matrix of TVAR model coefficients are derived and [15] uses wavelets for TVAR model identification. Essentially, all these approaches provide maximum likelihood estimates of coefficients for TVAR models without measurement noise. In [16], autoregressive parameters were estimated from noisy observations by using a recursive least-squares adaptive filter.
We take a Bayesian approach since we are also interested in tracking Bayesian evidence (or an approximation thereof) as a model performance measure. Bayesian evidence can be used to track the optimal AR model order or more generally, to compare the performance of a TVAR model to an alternative model. To date, Bayesian parameter tracking in AR models has mostly been achieved by Monte Carlo sampling methods [17,18,19,20,21]. Sampling-based inference is highly accurate, but it is very often computationally too expensive for real-time processing on wearable devices such as hearing aids, smartwatches, etc.
In this paper, we develop a low-complexity variational message passing-based (VMP) realization for tracking of states, parameters and free energy (an upper bound on Bayesian evidence) in TVAR models. All update formulas are closed-form and the complete inference process can easily be realized.
VMP is a low-complexity distributed message passing-based realization of variational Bayesian inference on a factor graph representation of the model [22,23]. Previous work on message passing-based inference for AR models include [24], but their work describes maximum likelihood estimation and therefore does not track proper posteriors and free energy. In [25], variational inference is employed to estimate the parameters of a multivariate AR model, but their work does not take advantage of the factor graph representation.
The factor graph representation that we employ in this paper provides some distinct advantages from other works on inference in TVAR models. First, a factor graph formulation is by definition completely modular and supports re-using the derived TVAR inference equations as a plug-in module in other factor graph-based models. In particular, since we allow for measurement noise in the TVAR model specification, the proposed TVAR factor can easily be used as a latent module at any level in hierarchical dynamical models. Moreover, due to the modularity, VMP update rules can easily be mixed with different update schemes such as belief propagation and expectation [26,27] in other modules, leading to hybrid message passing schemes for efficient inference in complex models. We have implemented the TVAR model in the open source and freely available factor graph toolbox ForneyLab [28].
The rest of this paper is organized as follows. In Section 2, we specify the TVAR model as a probabilistic state space model and define the inference tasks that relate to tracking of states, parameters, and Bayesian evidence. After a short discussion on the merits of using Bayesian evidence as a model performance criterion (Section 3.1), we formulate Bayesian inference in the TVAR model as a set of sequential prediction-correction processes (Section 3.2). We will realize these processes as VMP update rules and proceed with a short review of Forney-style factor graphs and message passing in Section 4. Then, in Section 5, the VMP equations are worked out for the TVAR model and summarized in Table 1. Section 6 discusses a verification experiment on a synthetic data set and applications of the proposed TVAR model to temperature prediction and speech enhancement problems. Full derivations of the closed-form VMP update rules are presented in Appendix A.

Table 1.
Variational message update rules for the autoregressive (AR) node (dashed box) of Equation (30).
2. Model Specification and Problem Definition
In this section, we first specify TVAR as a state-space model. This is followed by an inference problem formulation.
2.1. Model Specification
A TVAR model is specified as
where , and represent the the observation, state and parameters at time t, respectively. M denotes the order of the AR model. As a notational convention, we use to denote a Gaussian distribution with mean and co-variance matrix . We can re-write (1) in state-space form as
where , , is an M-dimensional unit vector, , and
Technically, a TVAR model usually assumes indicating that there is no measurement noise. Note that the presence of measurement noise in (2c) “hides” the states in the generative model (2) from the observation sequence , yielding a latent TVAR. We add measurement noise explicitly, so the model is able to accept information from likelihood functions that are not constrained to be delta functions with hard observations. As a result, the AR model that we define here can be used at any level in deep hierarchical structures such as [29] as a plug-in module.
In a time-invariant AR model, are part of the parameters of the system. In a time-varying AR model, we consider and together the set of time-varying states. The parameters of the TVAR model are .
At the heart of the TVAR model is the transition model (2b), where is a companion matrix with AR coefficients. The multiplication performs two operations: a dot product and a vector shift of by one time step. The latter operation can be interpreted as bookkeeping, as it shifts each entry of one position down and discards .
2.2. Problem Definition
For a given time series , we are firstly interested in recursively updating posteriors for the states and . In this context, prediction, filtering and smoothing are recovered for , and , respectively.
Furthermore, we are interested in computing posteriors for the parameters , , , and .
Finally, we are interested in scoring the performance of a proposed TVAR model m with specified priors for the parameters. In this paper, we take a full Bayesian approach and select Bayesian evidence as the performance criterion. Section 3.1 discusses the merits of Bayesian evidence as a model performance criterion.
3. Inference in TVAR Models
In this section, we first discuss some of the merits of using Bayesian evidence as a model performance criterion. This is followed by an exposition of how to compute Bayesian evidence and the desired posteriors in the TVAR model.
3.1. Bayesian Evidence as a Model Performance Criterion
Consider a model m with parameters and observations y. Bayesian evidence is considered an excellent model performance criterion. Note the following decomposition [30]:
The first term (data fit or sometimes called accuracy) measures how well the model predicts the data , after having learned from the data. We want this term to be large (although only focusing on this term could lead to over-fitting). The second term (complexity) quantifies the amount of information that the model absorbed through learning by moving parameter beliefs from to . To see this, note that the mutual information between two variables and , which is defined as
can be interpreted as expected complexity. The complexity term regularizes the Bayesian learning process automatically. Preference for models with high Bayesian evidence implies a preference for models that get a good data fit without the need to learn much from the data set. These types of models are said to generalize well, since they can be applied to different data sets without specific adaptations for each data set. Therefore, Bayesian learning automatically leads to models that tend to generalize well.
Note that Bayesian evidence for a model m, given a full times series , can be computed by multiplication of the sample-based evidences:
3.2. Inference as a Prediction-Correction Process
To illustrate the type of calculations that are needed for computing Bayesian model evidence and the posteriors for states and parameters, we now proceed to write out the needed calculations for the TVAR model in a filtering context.
Assume that at the beginning of time step t, we are given the state posteriors , . We will denote the inferred probabilities by , in contrast to factors from the generative model that are written as . We start the procedure by setting the state priors for the generative model at step t to the posteriors of the previous time step
Given a new observation , we are now interested inferring the evidence , and in inferring posteriors and .
This involves a prediction (forward) pass through the system that leads to the evidence update, followed by a correction (backward) pass that updates the states. We work this out in detail below. For clarity of exposition, in this section we call states and parameters. Starting with the forward pass (from latent variables toward observation), we first compute a parameter prior predictive:
Then the prior predictive for the state transition becomes:
Note that the state transition prior predictive, due to its dependency on time-varying , is a function of the observed data sequence. The state transition prior predictive can be used together with the state prior to inferring the state prior predictive:
The evidence for model m that is provided by observation is then given by
When has not yet been observed, is a prediction for . After plugging in the observed value for , the evidence is a scalar that scores how well the model performed in predicting . As discussed in (5), the results for in (11) can be used to score the model performance for a given time series . Note that to update the evidence, we need to integrate over all latent variables , , and (by (8)–(11)). In principle, this scheme needs to be extended with integration over the parameters , and .
Once we have inferred the evidence, we proceed by a backward corrective pass through the model to update the posterior over the latent variables given the new observation . The state posterior can be updated by Bayes rule:
Next, we need to compute a likelihood function for the parameters. Fortunately, we can re-use some intermediate results from the forward pass. The likelihood for the parameters is given by
The parameter posterior then follows from Bayes rule:
Equations (11), (12) and (14) contain the solutions to our inference task. Note that the evidence is needed to normalize the latent variable posteriors in (12) and (14). Moreover, while we integrate over the states by (11) to compute the evidence, (14) reveals that the evidence can alternatively be computed by integrating over the parameters through
This latter method of evidence computation may be useful if re-using (11) in (14) leads to numerical rounding issues.
Unfortunately, many of Equations (8) through (14) are not analytically tractable for the TVAR model. This happens due to (1) integration over large state spaces, (2) non-conjugate prior-posterior pairing, and (3) the absence of a closed-form solution for the evidence factor.
To overcome this challenge, we will perform inference by a hybrid message passing scheme in a factor graph. In the next section, we give a short review of Forney-Style Factor Graphs (FFG) and Message-Passing (MP) based inference techniques.
4. Factor Graphs and Message Passing-Based Inference
In this section, we make a brief introduction of Forney-Style Factor graph (FFG) and sum-product (SP) algorithm. After that we review the minimization of variational free energy and Variational Message Passing (VMP) algorithm.
4.1. Forney-Style Factor Graphs
A Forney-style Factor graph is a representation of a factorized function where the factors and variables are represented by nodes and edges, respectively. An edge is connected to a node if and only if the (edge) variable is an argument of the node function. In our work, we use FFGs to represent factorized probability distributions. FFGs provide both an attractive visualization of the model and a highly efficient and modular inference method based on message passing. An important component of the FFG representation is the equality node. If a variable x is shared between more than two nodes, then we introduce two auxiliary variables and and use an equality node
to constrain the marginal beliefs over x, , to be equal. With this mechanism, any factorized function can be represented as an FFG.
An FFG visualization of the TVAR model is depicted in Figure 3, but for illustrative purposes, we first consider an example factorized distribution
This distribution can be visualized by an FFG shown in Figure 1. An FFG is in principle an undirected graph but we often draw arrows on the edges in the “generative” direction, which is the direction that describes how the observed data is generated. Assume that we are interested in computing the marginal for , given by
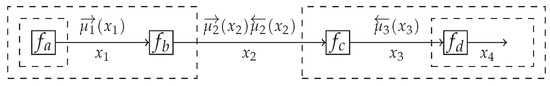
Figure 1.
An FFG corresponding to model (17), including messages as per (19). For graphical clarity, we defined , , and .
We can reduce the complexity of computing this integral by rearranging the factors over the integration signs as
These re-arranged integrals can be interpreted as messages that are passed over the edges, see Figure 1. It is a notational convention to call a message that aligns with the direction of the edge arrow a forward message and similarly, a message that opposes the direction of the edge is called a backward message.
This message passed-based algorithm of computing the marginal is called belief propagation (BP) or the sum-product algorithm. As can be verified in (19), for a node with factor , the outgoing BP message to variable y can be expressed as
where is an incoming message over edge . If the factor graph is a tree, meaning that the graph contains no cycles, then BP leads to exact Bayesian inference. A more detailed explanation of belief propagation message passing in FFGs can be found in [26].
4.2. Free Energy and Variational Message Passing
Technically, BP is a message passing algorithm that belongs to a family of message passing algorithms that minimize a constrained variational free energy functional [31]. Unfortunately, the sum-product rule (20) only has a closed-form solution for Gaussian incoming messages and linear variable relations in . Another important member of the free energy minimizing algorithms is the Variational Message Passing (VMP) algorithm [22]. VMP enjoys a wider range of analytically computable message update rules.
We shortly review variational Bayesian inference and VMP next. Consider a model with observations and unobserved (latent) variables . We are interested in inferring the posterior distribution . In variational inference we introduce an approximate posterior and define a variational free energy functional as
The second term in (21) (log-evidence) is not a function of the argument of F. The first term is a KL-divergence, which is by definition non-negative and only equals zero for . As a result, variational inference by minimization of provides
which is an approximation to the Bayesian posterior . Moreover, the minimized free energy is an upper bound for minus log-evidence and in practice is used a model performance criterion. Similarly to (4), the free energy can be decomposed as
which underwrites its usage as a performance criterion for model m, given observations .
In an FFG context, the model is represented by a set of connected nodes. Consider a generic node of the FFG, given by where in the case of VMP, the incoming messages are approximations to the marginals , see Figure 2.
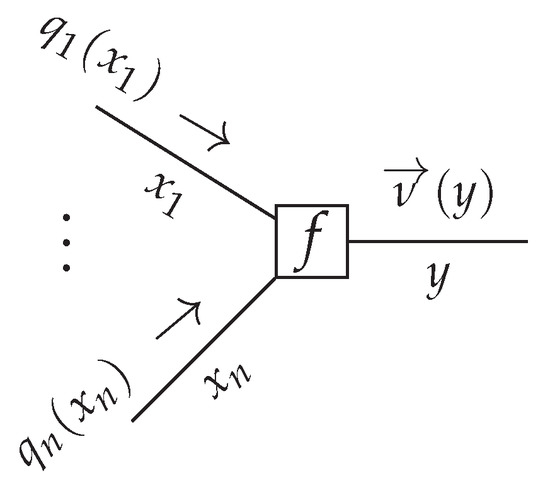
Figure 2.
A generic node with incoming variational messages and outgoing variational message , see Equation (24). Note that the marginals propagate in the graph as messages.
It can be shown that the outgoing VMP message of f towards edge y is given by [32]
In this paper, we adopt the notational convention to denote belief propagation messages (computed by (20)) by and VMP messages (computed by (24)) by . The approximate marginal can be obtained by multiplying incoming and outgoing messages on the edge for y
This process (compute forward and backward messages for an edge and update the marginal) is executed sequentially and repeatedly for all edges in the graph until convergence. In contrast to BP-based inference, the VMP and marginal update rules (24) and (25) lead to closed-form expressions for a large set of conjugate node pairs from the exponential family of distributions. For instance, updating the variance parameter of a Gaussian node with a connected inverse-gamma distribution node results in closed-form VMP updates.
In short, both BP- and VMP-based message passing can be interpreted as minimizing variational free energy, albeit under a different set of local constraints [31]. Typical constraints include factorization and form constraints on the posterior such as and , respectively. Since the constraints are local, BP and VMP can be combined in a factor graph to create hybrid message passing-based variational inference algorithms. For a more detailed explanation of VMP in FFGs, we refer to [32]. Note that hybrid message passing does in general not guarantee to minimize variational free energy [33]. However, in our experiments in Section 6 we will show that iterating our stationary solutions by message passing does lead to free energy minimization.
5. Variational Message Passing for TVAR Models
In this section, we focus on deriving message passing-based inference in the TVAR model. We develop a TVAR composite factor for the FFG framework and specify the intractable BP messages around the TVAR node. Then we present a message passing-based inference solution.
5.1. Message Passing-Based Inference in the TVAR Model
The TVAR model at time step t can be represented by an FFG as shown in Figure 3. We are interested in providing a message passing solution to the inference tasks as specified by Equations (8)–(14). At the left-hand side of Figure 3, the incoming messages are the priors and . At the bottom of the graph, there is a new observation . The goal is to pass messages in the graph to compute posteriors (message ⑯) and (message ⑪). In order to support smoothing algorithms, we also want to be able to pass incoming prior messages from the right-hand side to outgoing messages ⓭ and ⓲ at the left-hand side. Forward and backward messages are drawn as open and closed circles respectively.
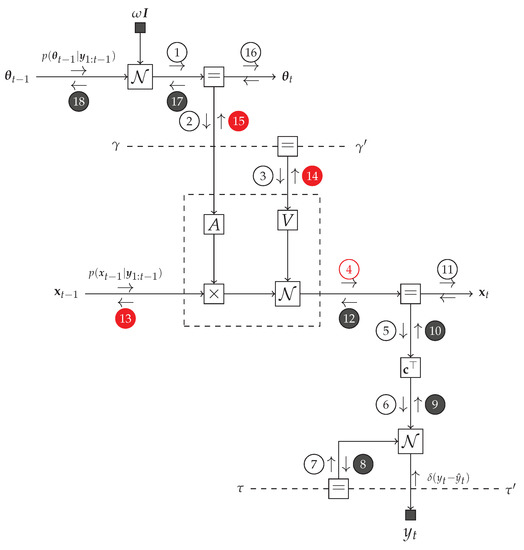
Figure 3.
One time segment of an FFG corresponding to the TVAR model. We use small black nodes to denote observations and fixed given parameter values. The observation node for sends a message into the graph to indicate that has been observed. Dashed undirected edges denote time-invariant variables. Circled numbers indicate a selected computation schedule. Backward messages are marked by black circles. The intractable messages are labeled with red. The dashed box represents a composite AR node as specified by (30).
Technically, the generative model (2) at time step t for the TVAR model can shortly be written as , where are the latent variables. On this view, we can write the free energy functional for the TVAR model at time step t as
and minimize by message passing. In a smoothing context, we would include a prior from the future , yielding a free energy functional
5.2. Intractable Messages and the Composite AR Node
The modularity of message passing in FFGs allows us to focus on only the intractable message and marginal updates. For instance, while there is no problem with the analytical computation of the backward message ⓬, the corresponding forward message ➃,
cannot be analytically solved [34]. Similarly, some other messages ⓭, ⓮ and ⓯ do not have a closed-form solution in the constrained free energy minimization framework. For purpose of identification, in Figure 3 intractable messages are marked in red color.
In an FFG framework, we can isolate the problematic part of the TVAR model (Figure 3) by introducing a “composite” AR node. Composite nodes conceal their internal operations from the rest of the graph. As a result, inference can proceed as long as each composite node follows proper message passing communication rules at its interfaces to the rest of the graph. The composite AR node
is indicated in Figure 3 by a dashed box. Note that the internal shuffling of the parameters and , respectively by means of and , is hidden from the network outside the composite AR node.
5.3. VMP Update Rules for the Composite AR Node
We isolate the composite AR node by the specification
where, relative to (29), we used substitutions .
Under the structural factorization constraint (See Appendix A.1 for more on structural VMP).
and consistency constraints
the marginals , , and can be obtained from the minimisation of the composite-AR free energy functional
Recalling (25), we can write the minimizer of FE functional (33) with respect to as
where is associated with the incoming message to AR node and is a variational outgoing message. Hence, the outgoing message from the AR node toward can be written as
In Appendix A we work out a closed-form solution for this and all other update rules plus an evaluation of free energy for the composite AR node. The results are reported in Table 1. With these rules in hand, the composite AR node can be plugged into any factor graph and take part in a message passing-based free energy minimization process.
6. Experiments
In this section, we first verify the proposed methodology by a simulation of the proposed TVAR model on synthetic data, followed by validation experiments on two real world problems. We implemented all derived message passing rules in the open source Julia package ForneyLab.jl [28]. The code for the experiments and for the AR node can be found in public Github repositories. (https://github.com/biaslab/TVAR_FFG, accessed on 27 May 2021, https://github.com/biaslab/LAR, accessed on 27 May 2021) We used the following computer configuration to run the experiments. Operation system: macOS Big Sur, Processor: 2,7 GHz Quad-Core Intel Core , RAM: 16 GB.
6.1. Verification on a Synthetic Data Set
To verify the proposed TVAR inference methods, we synthesized data from two generative models and , as follows:
with priors
where M is the number of AR coefficients. Although these models differ only with respect to the properties of the AR coefficients , this variation has an important influence on the data generative process. The first model specifies a stationary AR process, since in (36a) indicates that is not time-varying in . The second model represents a proper TVAR process as the prior evolution of the AR coefficients follows a random walk. One-time segment FFGs corresponding to the Equation (36) are depicted in Figure 4.
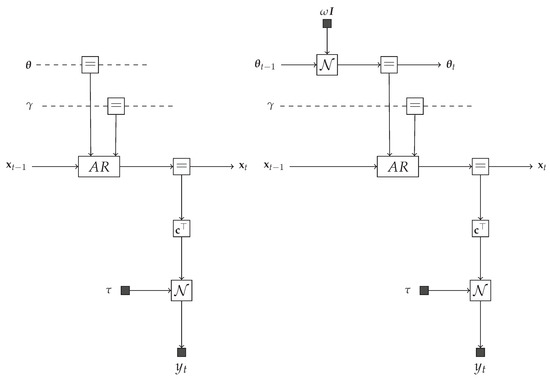
Figure 4.
Forney-style Factor Graphs corresponding to Equation (36). (Left) model . (Right) model .
For each model, we generated a data set of 100 different time series, each of length 100 (so we have data points). For each time series, as indicated by (37a), the AR order M of the generative process was randomly drawn from the set . We used rather non-informative/broad priors for states and parameters for both models, see (37). This was done to ensure that the effect of the prior distributions is negligible relative to the information in the data set.
These time series were used in the following experiments. We selected two recognition models and with the same specifications as were used for generating the data set. The recognition models were trained on time series that were generated by models with the same AR order.
We proceeded by computing the quantities , , and (where comprises all latent states and parameters) for both models, following the proposed rules from Table 1.
As a verification check, we first want to ensure that inference recovers the hidden states for each . Secondly, we want to verify the convergence of FE. As we have not used any approximations along the derivations of variational messages, we expect a smoothly decreasing curve for FE until convergence. The results of the verification stage are highlighted for a typical case in Figure 5. The figure confirms that states are accurately tracked and that a sliding average of the AR coefficients is also nicely tracked. Figure 5 also indicates that the FE uniformly decreases towards lower values as we spend more computational power.
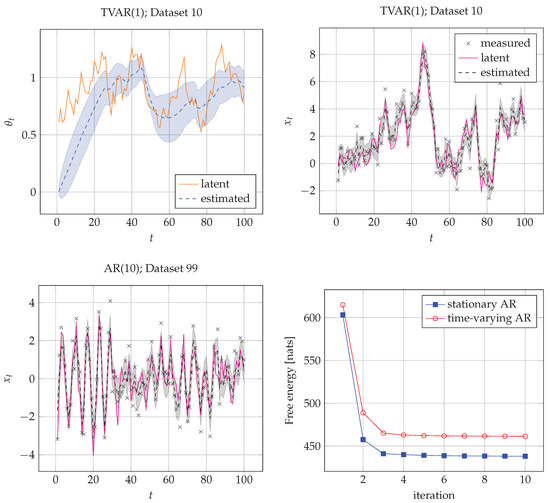
Figure 5.
Verification results. The solid line corresponds to the value of the latent (hidden) states in the generative processes. The dashed line corresponds to the expected mean value of the posterior estimates of hidden states in the recognition models. The shadowed regions corresponds to one standard deviation of the posteriors in the recognition models below and above the estimated mean. The top two plots show inference results for the coefficients (top-left) and states (top-right) of TVAR(1) (model , AR order ) for time series ♯10. (bottom-left) State trajectory model , AR order on time series ♯99. (Bottom-right) Evolution of FE for (AR) and (TVAR), averaged over their corresponding time series. The iteration number at the abscissa steps through a single marginal update for all edges in the graph.
We note that the FE score by itself does not explain whether the model is good or not, but it serves as a good measure for model comparison. In the following subsection, we demonstrate how FE scores can be used for model selection.
6.2. Temperature Modeling
AR models are well-known for predicting different weather conditions such as wind, temperature, precipitation, etc. Here, we will revisit the problem of modeling daily temperature. We used a data set of daily minimum temperatures (in °C) in Melbourne, Australia, 1981–1990 (3287 days) (https://www.kaggle.com/paulbrabban/daily-minimum-temperatures-in-melbourne, accessed on 27 May 2021). We then corrupted the data set by adding random noise sampled from to the actual temperatures. A fragment of the time-series is depicted in Figure 6.
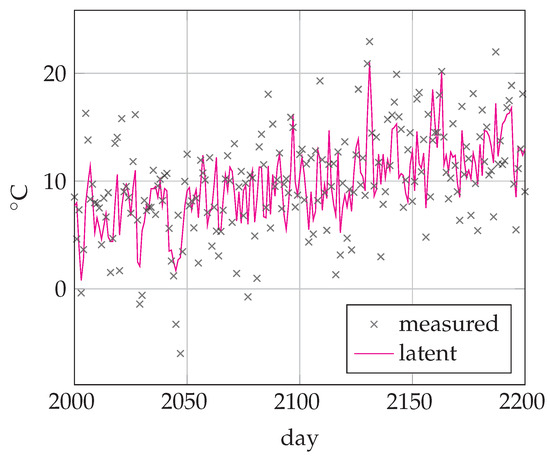
Figure 6.
Temperature time-series from days 2000 to 2200. Crosses denote the thermometer readings plus added noise. The solid line corresponds to the latent (hidden) daily temperature.
To estimate the actual temperature based on past noisy observations by computing , we use a TVAR model with measurement noise to simulate uncertainty about corrupted observations. The model is specified by the following equation set
with priors
Since the temperature data is not centered around 0 °C, we added a bias term to the state . The corresponding FFG is depicted in Figure 7.
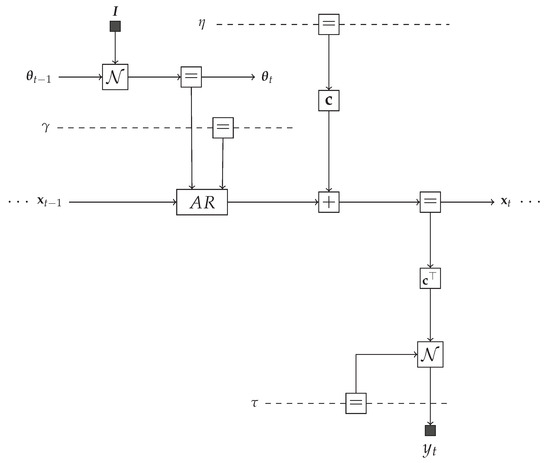
Figure 7.
One time segment of a Forney-style factor graph (FFG) for the TVAR model in the temperature modeling task (38).
Note that we put a Gamma prior on the measurement noise precision , meaning that we are uncertain about the size of the error of the thermometer reading. The inference task for the model is computing , in other words, we track the states based only on past data. Of course, after training, we could use the model for temperature prediction by tracking for . We compare the performance of four TVAR models with AR orders . To choose the best model, we computed the average FE score for each TVAR(M) model.
Figure 8 shows that on average TVAR(3) outperforms its competitors. The complexity vs accuracy decomposition (23) of FE explains why a lower order model may outperform higher order models. TVAR(4) maybe as accurate or more accurate than TVAR(3) but the increase in accuracy is more than offset by the increase in complexity. For the lower order models, it is the other way around: they are less complex and involve fewer computations than TVAR(3), but the loss in model complexity leads to too much loss in data modeling accuracy. Overall, TVAR(3) is the best model for this data set. Practically, we always favor the model that features the lowest FE score. In the next subsection we will use this technique (scoring FE) for online model selection.
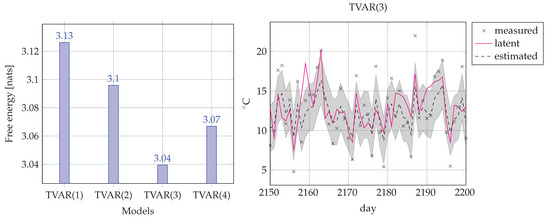
Figure 8.
(Left) Comparison of four TVAR(M) models for the temperature filtering problem. Bars correspond to the averaged (over 3287 days) FE score for each model. (Right) Inference example of the best performing model (TVAR(3)). Crosses denote the thermometer reading plus added noise. The solid line corresponds to the latent (hidden) daily temperature. The dashed line corresponds to the mean of the posterior estimates of hidden temperature and the shadowed region corresponds to one standard deviation below and above the estimated temperature.
6.3. Single-Channel Speech Enhancement
Single-channel speech enhancement (SCSE) is a well-known challenging task that aims to enhance noisy speech signals that were recorded by a single microphone. In single microphone recordings, we cannot use any spatial information that is commonly used in beamforming applications. Much work has been done to solve the SCSE task, ranging from Wiener filter-inspired signal processing techniques [35,36] to deep learning neural networks [37]. In this paper, we use data from the speech corpus (NOIZEUS) (https://ecs.utdallas.edu/loizou/speech/noizeus/, accessed on 27 May 2021) [38] and corrupted clean speech signals with white Gaussian noise, leading to a signal-to-noise ratio (SNR)
where and are clean and corrupted speech signals. is a speech signal at time t and T is the length of the signal.
Historically, AR models have shown to perform well for modeling speech signals in the time (waveform) domain [39,40]. Despite the fact that speech is a highly nonstationary signal, we may assume it to be stationary within short time intervals (frames) of about 10 [ms] each [41]. Since voiced, unvoiced and silence frames have very different characteristics, we used 5 different models (a random walk model (RW), AR(1), AR(2), TVAR(1) and TVAR(2)) for each frame of 10 [ms] with 2.5 [ms] overlap. Given a sampling frequency of 8 [kHZ], each frame results into 80 samples with 20 samples overlap. The AR and TVAR models were specified by Equation (36). For each frame, we evaluated the model performance by minimized FE and selected the model with minimal FE score. We used identical prior parameters for all models where possible. To recover the speech signal we computed the mean values of of the selected model for each frame. The SNR gain of this SCSE system was
Figure 9 show the spectrograms of the clean, noisy and filtered signal respectively.
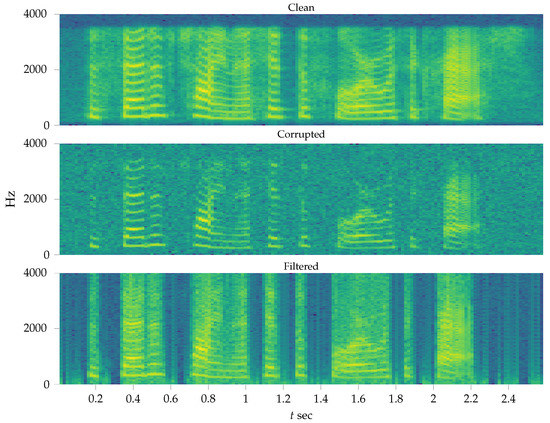
Figure 9.
Spectrogram of recovered speech signal in the experiment of Section 6.3.
Next, we analyze the inference results in a bit more detail. Table 2 shows the percentage of winning models for each frame based on the free energy score.
Table 2.
Percentage of preferred models (based on FE scores) for all frames on the speech enhancement task.
As we can see, for more than 30% of all frames, the random walk model performs best. This happens mostly because for a silent frame the AR model gets penalized by its complexity term. We recognize that in about 90% of the frames the best models are AR(1) and RW. On the other hand, for the frames where the speech signal transitions from silent or unvoiced to voiced, these fixed models start to fail and the time-varying AR models perform better. This effect can be seen in Figure 10.
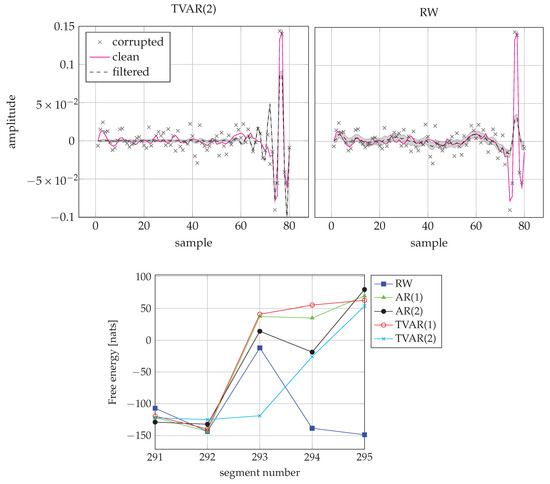
Figure 10.
(Top) (Top-left) Inference by TVAR(2) for the segment 293. (Top-right) Inference by RW for the segment 293. Note how the TVAR model is able to follow the transitions at the end of the frame, while the RW cannot adapt within one frame. (Bottom) FE scores from segment 291 to 295. TVAR(2) wins frame 293 as it has the lowest FE score.
Figure 11 shows the performance of the AR(2) and RW models on a frame with a voiced speech signal. For this case, the AR(2) model performs better.
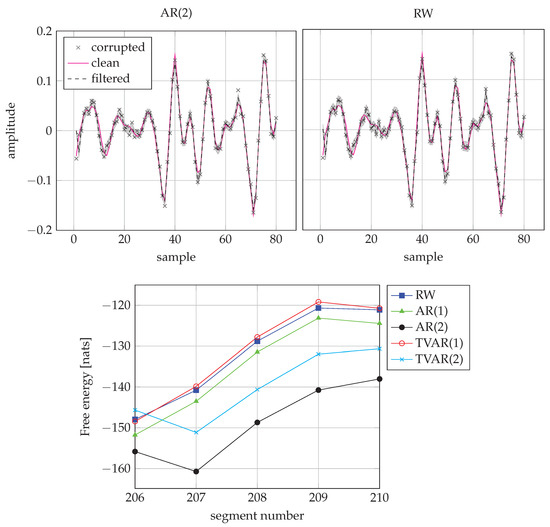
Figure 11.
Comparison of AR(2) and RW models for a voiced signal frame. (Top-left) Inference by AR(2) for the segment 208. (Top-right) Inference by RW for the segment 208. (Bottom) FE scores from segment 206 to 210. The AR(2) model wins frame 208.
Finally, Figure 12 shows how the TVAR(2) model compares to the RW model on one of the unvoiced/silence frames. While the estimates of TVAR(2) appear to be more accurate, it pays a bigger “price” for the model complexity term in the FE score and the RW model wins the frame.
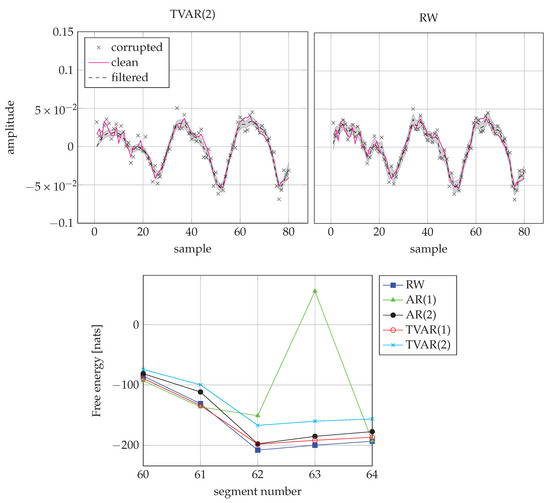
Figure 12.
Comparison of TVAR(2) and RW models for an unvoiced/silence frame. (Top-left) Inference by TVAR(2) for the frame 62. (Top-right) Inference by RW for the frame 62. (Bottom) FE scores from segment 60 to 64. The RW model scores best on frame 62 due to its low complexity.
7. Discussion
We have introduced a TVAR model that includes efficient joint variational Bayesian tracking of states, parameters and free energy. The system can be used as a plug-in module in factor graph-based representations of other models. At several points in this paper, we have made some design decisions that we shortly review here.
While FE computation for the AR node provides a convenient performance criterion for model selection, we noticed in the speech enhancement simulation that separate FE tracking for each candidate model leads to a large computational overhead. There are ways to improve the model selection process that we used in the speech enhancement simulation. One way is to consider a mixture model of candidate models and track the posterior over the mixture coefficients [42]. Alternatively, a very cheap method for online Bayesian model selection may be the recently developed Bayesian Model Reduction (BMR) method [43]. The BMR method is based on a generalization of the Savage-Dickey Density Ratio and supports tracking of free energy of multiple nested models with almost no computational overhead. Both methods seem to integrate well with a factor graph representation and we plan to study this issue in future work.
In this paper, the posterior factorization (31) supports the modeling of temporal dependencies between input and output of the AR node in the posterior. Technically, (31) corresponds to a structural VMP assumption, in contrast to the more constrained mean-field VMP algorithm that would be based on , where is the set of all latent variables [44]. We could have also worked out alternative update rules for the assumption of a joint factorization of precision and AR coefficients . In that case, the prior (incoming message to AR node) would be in the form of a Normal-Gamma distribution. While any of these these assumptions are technically valid, each choice accepts a different trade-off in the accuracy vs. complexity space. We review structural VMP in Appendix A.1.
In the temperature modelling task, we added some additional random variables (bias, measurement noise precision). To avoid identifiability issues, in (38a) we fixed the covariance matrix of the time-varying AR coefficient to the identity matrix. In principle, this constraint can be relaxed. For example, an Inverse-Wishart prior distribution can be added to the covariance matrix.
In our speech enhancement experiments in Section 6.3, we assume that the measurement noise variance is known. In a real-world scenario, this information is usually not accessible. However, online tracking of measurement noise or other (hyper-)parameters is usually not a difficult extension when the process is simulated in a factor graph toolbox such as ForneyLab [28]. If so desired, we could add a prior on the measurement noise variance and track the posterior. The online free energy criterion (23) can be used to determine if the additional computational load (complexity) of Bayesian tracking of the variance parameter has been compensated by the increase in modeling accuracy.
The realization of the TVAR model in ForneyLab comes with some limitations. For large smoothing problems (say, >1000 data points), the computational load of message passing in ForneyLab becomes too heavy for a standard laptop (as was used in the paper). Consequently, in the current implementation it is difficult to employ the AR node for processing large time series on a standard laptop. To circumvent this issue, when using ForneyLab, one can combine filtering and smoothing solutions into a batch learning procedure. In future work we plan to remedy this issue by some ForneyLab refactoring work. Additionally, the implemented AR node does not provide a closed-form update rule for the marginal distribution when the probability distribution types of the incoming messages (priors) are different from the ones used in our work. Fortunately, ForneyLab supports resorting to (slower) sampling-based update rules when closed-form update rules are not available.
8. Conclusions
We presented a variational message passing approach to tracking states and parameters in latent TVAR models. The required update rules have been summarized and implemented in the factor graph package ForneyLab.jl, thus making transparent usage of TVAR factors available in freely definable stochastic dynamical systems. Aside from VMP update rules, we derived a closed-form expression for the variational free energy (FE) of an AR factor. Free Energy can be used as a proxy for Bayesian model evidence and as such allows for model performance comparisons between the TVAR models and alternative structures. Owing to the locality and modularity of the FFG framework, we demonstrated how AR nodes can be applied as plug-in modules in various dynamic models. We verified the correctness of the rules on a synthetic data set and applied the proposed TVAR model to a few relatively simple but different real-world problems. In future work, we plan to extend the current factor graph-based framework to efficient and transparent tracking of AR model order and to online model comparison and selection with alternative models.
Author Contributions
Conceptualization, A.P., W.M.K. and B.d.V.; methodology, A.P., W.M.K.; software, A.P.; validation, A.P.; formal analysis, A.P., W.M.K.; investigation, A.P., W.M.K. and B.d.V.; resources, A.P., W.M.K. and B.d.V.; data curation, A.P., W.M.K. and B.d.V.; writing—original draft preparation, A.P., W.M.K.; writing—review and editing, W.M.K. and B.d.V.; visualization, A.P., W.M.K. and B.d.V.; supervision, W.M.K. and B.d.V.; project administration, B.d.V.; funding acquisition, B.d.V. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly financed by research program ZERO with project number P15-06, which is (partly) financed by the Netherlands Organisation for Scientific Research (NWO).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank the BIASlab team members, in particular Thijs van de Laar, Ismail Senoz and Semih Akbayrak for insightful discussions on various topics related to this work.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivations
Figure A1 represents a composite AR node.

Figure A1.
Autoregressive (AR) node.
Appendix A.1. Structural Variational Message Passing
The message update rule (24) implies a mean-field factorization, meaning that all variables represented by edges around the factor node f are independent. In this paper, we impose a structural dependence between states. To illustrate how structured VMP works, let us consider the example depicted in Figure A2.

Figure A2.
A node representing an arbitrary joint distribution. Arrows above the messages indicate the direction (incoming or outgoing).
Suppose that we constrain the joint posterior (A1) as
The message passing algorithm for updating the marginal posteriors and can now be executed as follows:
- (1)
- compute outgoing messages , :
- (2)
- update joint posterior :
- (3)
- compute the outgoing message :
- (4)
- update posterior :
Appendix A.2. Auxiliary Node Function
Before obtaining the update messages for TVAR we need to evaluate the auxiliary node function . We also need to address the issue of invertability of the covariance matrix V. To tackle this problem, we assume , which allows us to introduce matrix .
We work out the expectation term inside the trace separately. To do this, we notice, that the product can be separated in the shifting operator and the inner vector product in the following way:
where
Hence
We can write the auxiliary node function as
Appendix A.3. Update of Message to y
In this way, the message
Appendix A.4. Update of Message to x
Owing Equation (A7),
Let us consider the log of :
Which yields,
Therefore,
where
Appendix A.5. Update of Message to θ
The outgoing variational message to is defined as
Instead of working out , we will work with corresponding log message
To proceed further, we recall one useful property
where is an arbitrary diagonal matrix. Now, let us work out the following term
Therefore,
We move terms which do not depend on to the , hence
Hence,
where
Appendix A.6. Update of Message to γ
First of all, let us work out the term
We split the expression under the expectation into four terms:
- I:
- II:
- III:
- and
- IV:
Term I:
Recalling Equation (A6), term II:
Term III:
Term IV:
As the resulting message should depend solely on we need to get rid of all terms which incorporate matrix . We notice that
where is an arbitrary matrix of the same dimensionality as the matrix ( denote the first element of the matrix). In this way
After exponentiating it yields the gamma distribution:
or
where
Appendix A.7. Derivation of q(x,y)
The joint recognition distribution is given by
where
Let us rearrange the terms in the Gaussian
where
The precision matrix , to put it mildly, is quite far from a nice shape as it contains “unpleasant” matrix with on the diagonal. Let us workout the covariance matrix . To do this, we recall two important matrix identities:
and
Let us denote the block elements of as follows:
In this way,
Let us work out the auxiliary terms
Hence,
Next, let us consider , and :
Although the resulting expressions do not have a nice form, we got rid of “unpleasant” matrix .
Appendix A.8. Free Energy Derivations
In this section we describe how to compute the variational free energy of AR node . Note that essentially AR node implements the univariate Gaussian (Multivariate formulation is needed for bookkeeping previous states). The free energy functional is defined as
At first, let us work out the entropy term .
where denotes digamma function.
Now, let us consider the average energy
We split the expression under the expectation into two terms:
- I:
- II:
Term I:
Term II:
hence
where
References
- Akaike, H. Fitting autoregressive models for prediction. Ann. Inst. Stat. Math. 1969, 21, 243–247. [Google Scholar] [CrossRef]
- Charbonnier, R.; Barlaud, M.; Alengrin, G.; Menez, J. Results on AR-modelling of nonstationary signals. Signal Process. 1987, 12, 143–151. [Google Scholar] [CrossRef]
- Tahir, S.M.; Shaameri, A.Z.; Salleh, S.H.S. Time-varying autoregressive modeling approach for speech segmentation. In Proceedings of the Sixth International Symposium on Signal Processing and its Applications (Cat.No.01EX467), Kuala Lumpur, Malaysia, 13–16 August 2001; Volume 2, pp. 715–718. [Google Scholar] [CrossRef]
- Rudoy, D.; Quatieri, T.F.; Wolfe, P.J. Time-Varying Autoregressions in Speech: Detection Theory and Applications. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 977–989. [Google Scholar] [CrossRef]
- Chu, Y.J.; Chan, S.C.; Zhang, Z.G.; Tsui, K.M. A new regularized TVAR-based algorithm for recursive detection of nonstationarity and its application to speech signals. In Proceedings of the 2012 IEEE Statistical Signal Processing Workshop (SSP), Ann Arbor, MI, USA, 5–8 August 2012; pp. 361–364. [Google Scholar] [CrossRef]
- Paulik, M.J.; Mohankrishnan, N.; Nikiforuk, M. A time varying vector autoregressive model for signature verification. In Proceedings of the 1994 37th Midwest Symposium on Circuits and Systems, Lafayette, LA, USA, 3–5 August 1994; Volume 2, pp. 1395–1398. [Google Scholar] [CrossRef]
- Kostoglou, K.; Robertson, A.D.; MacIntosh, B.J.; Mitsis, G.D. A Novel Framework for Estimating Time-Varying Multivariate Autoregressive Models and Application to Cardiovascular Responses to Acute Exercise. IEEE Trans. Biomed. Eng. 2019, 66, 3257–3266. [Google Scholar] [CrossRef]
- Eom, K.B. Analysis of Acoustic Signatures from Moving Vehicles Using Time-Varying Autoregressive Models. Multidimens. Syst. Signal Process. 1999, 10, 357–378. [Google Scholar] [CrossRef]
- Abramovich, Y.I.; Spencer, N.K.; Turley, M.D.E. Time-Varying Autoregressive (TVAR) Models for Multiple Radar Observations. IEEE Trans. Signal Process. 2007, 55, 1298–1311. [Google Scholar] [CrossRef]
- Zhang, Z.G.; Hung, Y.S.; Chan, S.C. Local Polynomial Modeling of Time-Varying Autoregressive Models With Application to Time–Frequency Analysis of Event-Related EEG. IEEE Trans. Biomed. Eng. 2011, 58, 557–566. [Google Scholar] [CrossRef]
- Wang, H.; Bai, L.; Xu, J.; Fei, W. EEG recognition through Time-varying Vector Autoregressive Model. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 292–296. [Google Scholar] [CrossRef]
- Sharman, K.; Friedlander, B. Time-varying autoregressive modeling of a class of nonstationary signals. In Proceedings of the ICASSP’84—IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, CA, USA, 19–21 March 1984; Volume 9, pp. 227–230. [Google Scholar] [CrossRef]
- Reddy, G.R.S.; Rao, R. Non stationary signal prediction using TVAR model. In Proceedings of the 2014 International Conference on Communication and Signal Processing, Bangkok, Thailand, 10–12 October 2014; pp. 1692–1697. [Google Scholar] [CrossRef]
- Souza, D.B.d.; Kuhn, E.V.; Seara, R. A Time-Varying Autoregressive Model for Characterizing Nonstationary Processes. IEEE Signal Process. Lett. 2019, 26, 134–138. [Google Scholar] [CrossRef]
- Zheng, Y.; Lin, Z. Time-varying autoregressive system identification using wavelets. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing (Cat. No.00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 1, pp. 572–575. [Google Scholar] [CrossRef]
- Moon, T.K.; Gunther, J.H. Estimation of Autoregressive Parameters from Noisy Observations Using Iterated Covariance Updates. Entropy 2020, 22, 572. [Google Scholar] [CrossRef]
- Rajan, J.J.; Rayner, P.J.W.; Godsill, S.J. Bayesian approach to parameter estimation and interpolation of time-varying autoregressive processes using the Gibbs sampler. IEE Proc. Vis. Image Signal Process. 1997, 144, 249–256. [Google Scholar] [CrossRef]
- Prado, R.; Huerta, G.; West, M. Bayesian tIme-Varying Autoregressions: Theory, Methods and Applications; University of Sao Paolo: Sao Paulo, Brazil, 2000; p. 2000. [Google Scholar]
- Nakajima, J.; Kasuya, M.; Watanabe, T. Bayesian analysis of time-varying parameter vector autoregressive model for the Japanese economy and monetary policy. J. Jpn. Int. Econ. 2011, 25, 225–245. [Google Scholar] [CrossRef]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Zhong, X.; Song, S.; Pei, C. ime-varying Parameters Estimation based on Kalman Particle Filter with Forgetting Factors. In Proceedings of the EUROCON 2005—The International Conference on “Computer as a Tool”, Belgrade, Serbia, 21–24 November 2005; Volume 2, pp. 1558–1561. [Google Scholar] [CrossRef]
- Winn, J.; Bishop, C.M.; Jaakkola, T. Variational Message Passing. J. Mach. Learn. Res. 2005, 6, 661–694. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Korl, S. A Factor Graph Approach to Signal Modelling, System Identification and Filtering. Ph.D. Thesis, Swiss Federal Institute of Technology, Zurich, Switzerland, 2005. [Google Scholar]
- Penny, W.D.; Roberts, S.J. Bayesian multivariate autoregressive models with structured priors. IEE Proc. Vis. Image Signal Process. 2002, 149, 33–41. [Google Scholar] [CrossRef]
- Loeliger, H.A.; Dauwels, J.; Hu, J.; Korl, S.; Ping, L.; Kschischang, F.R. The Factor Graph Approach to Model-Based Signal Processing. Proc. IEEE 2007, 95, 1295–1322. [Google Scholar] [CrossRef]
- Dauwels, J.; Korl, S.; Loeliger, H.A. Expectation maximization as message passing. Int. Symp. Inf. Theory 2005, 583–586. [Google Scholar] [CrossRef]
- Cox, M.; van de Laar, T.; de Vries, B. A factor graph approach to automated design of Bayesian signal processing algorithms. Int. J. Approx. Reason. 2019, 104, 185–204. [Google Scholar] [CrossRef]
- De Vries, B.; Friston, K.J. A Factor Graph Description of Deep Temporal Active Inference. Front. Comput. Neurosci. 2017, 11. [Google Scholar] [CrossRef] [PubMed]
- Beck, J. Bayesian system identification based on probability logic. Struct. Control. Health Monit. 2010. [Google Scholar] [CrossRef]
- Zhang, D.; Song, X.; Wang, W.; Fettweis, G.; Gao, X. Unifying Message Passing Algorithms Under the Framework of Constrained Bethe Free Energy Minimization. arXiv 2019, arXiv:1703.10932v3. [Google Scholar]
- Dauwels, J. On Variational Message Passing on Factor Graphs. In Proceedings of the IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 2546–2550. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, W.; Fettweis, G.; Gao, X. Unifying Message Passing Algorithms Under the Framework of Constrained Bethe Free Energy Minimization. arXiv 2017, arXiv:1703.10932. [Google Scholar]
- Cui, G.; Yu, X.; Iommelli, S.; Kong, L. Exact Distribution for the Product of Two Correlated Gaussian Random Variables. IEEE Signal Process. Lett. 2016, 23, 1662–1666. [Google Scholar] [CrossRef]
- Wu, W.-R.; Chen, P.-C. Subband Kalman filtering for speech enhancement. IEEE Trans. Circuits Syst. Analog. Digit. Process. 1998, 45, 1072–1083. [Google Scholar] [CrossRef]
- So, S.; Paliwal, K.K. Modulation-domain Kalman filtering for single-channel speech enhancement. Speech Commun. 2011, 53, 818–829. [Google Scholar] [CrossRef]
- Nossier, S.A.; Wall, J.; Moniri, M.; Glackin, C.; Cannings, N. An Experimental Analysis of Deep Learning Architectures for Supervised Speech Enhancement. Electronics 2021, 10, 17. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun. 2007, 49, 588–601. [Google Scholar] [CrossRef]
- Paliwal, K.; Basu, A. A speech enhancement method based on Kalman filtering. In Proceedings of the ICASSP’87—IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 6–9 April 1987; Volume 12, pp. 177–180. [Google Scholar] [CrossRef]
- You, C.H.; Rahardja, S.; Koh, S.N. Autoregressive Parameter Estimation for Kalman Filtering Speech Enhancement. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV-913–IV-916. [Google Scholar] [CrossRef]
- Grenier, Y. Time-dependent ARMA modeling of nonstationary signals. IEEE Trans. Acoust. Speech Signal Process. 1983, 31, 899–911. [Google Scholar] [CrossRef]
- Kamary, K.; Mengersen, K.; Robert, C.P.; Rousseau, J. Testing hypotheses via a mixture estimation model. arXiv 2014, arXiv:1412.2044. [Google Scholar]
- Friston, K.; Parr, T.; Zeidman, P. Bayesian model reduction. arXiv 2019, arXiv:1805.07092. [Google Scholar]
- Podusenko, A.; Kouw, W.M.; de Vries, B. Online variational message passing in hierarchical autoregressive models. In Proceedings of the 2020 IEEE International Symposium on Information Theory, Los Angeles, CA, USA, 21–26 June 2020; pp. 1337–1342. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).