Abstract
Software products in the market are changing due to changes in business processes, technology, or new requirements from the customers. Maintainability of legacy systems has always been an inspiring task for the software companies. In order to determine whether the software requires maintainability by reverse engineering or by forward engineering approach, a system assessment was done from diverse perspectives: quality, business value, type of errors, etc. In this research, the changes required in the existing software components of the legacy system were identified using a supervised learning approach. New interfaces for the software components were redesigned according to the new requirements and/or type of errors. Software maintainability was measured by applying a machine learning technique, i.e., Naïve Bayes classifier. The dataset was designed based on the observations such as component state, successful or error type in the component, line of code of error that exists in the component, component business value, and changes required for the component or not. The results generated by the Waikato Environment for Knowledge Analysis (WEKA) software confirm the effectiveness of the introduced methodology with an accuracy of 97.18%.
1. Introduction
Software engineering consists of process, product, and resources entities. Processes are related to software activities, e.g., specification, design, or testing [1]. Products are correlated to documents which result from the activity of the process, e.g., specification, design document, deliverables, artifacts, etc. [2]. Resources are related to entities that are considered by the process activity, e.g., personnel, CASE tools, or hardware [3]. The entities consist of external and internal attributes. External attributes describe the entity behavior while internal attributes are those that portray the entity itself. In literature [4], machine learning applications are incorporated with software engineering tasks for: (i) predicting external or internal attributes of resources, product, or process, (ii) recycling of processes or product, (iii) improving the processes by retrieving the specification, etc.
In this research, we measure software maintainability with a Naïve Bayes classifier. This research also classifies the software components that do not require modification, based on whether it contains errors or not. Low quality requirements [5] and software components can provoke errors or defects in the software, which increases the software development cost. The requirements engineering process and design of software components are considered an important factor in software development.
Requirements engineering is defined as a “systematic process of developing requirements through an iterative co-operative process of analyzing the problem, documenting the resulting observations in a variety of representation formats, and checking the accuracy of the understanding gained” [6]. Component are defined by Scott and Morgado [7] “as an independent piece of software. This standalone, discrete piece of software has a clear boundary that is accessible via an API and contains all of the application dependencies. This enables teams to build the user interface quickly, leveraging the library of components”, e.g., freeze-user, close, and download are represented by  ,
,  , and
, and  , user interfaces, respectively.
, user interfaces, respectively.
, , and , user interfaces, respectively. Software maintainability can be measured either in reverse or forward engineering. In this research, authors measure a quality attribute (e.g., maintainability). According to IEEE standard glossary of software engineering terminology, software maintainability is defined as “the ease with which a software system or component can be modified” [8]. The maintainability process starts after the delivery of software, which is the key stage of the system development life cycle. Software requires maintainability to remove faults, improve performance, or to adopt the software according to modified environment [9]. Due to COVID-19 (coronavirus disease 2019), business organizations brought revolutionary changes in their working environment and education institutes changed to e-learning. The objective of this research is to measure the software maintainability (e.g., by Naïve Bayes classifier) and to extract the errors from the software components.
Supervised learning is that in which we have input data and an expected output result. Supervised learning is grouped into classification and regression problems [10]. If any type of change is required or the software component does not provide the required functionality according to user new requirements, then type of error or defect is reported else it is a correct component. Types of errors or defects are described in detail in Section 1.1. The supervised learning approach is applied to extract errors in the software components. Details on how to extract errors by supervised learning are discussed in Section 3.
Each software component is validated against its specification. Software components are represented by a component-based user interface. In this research, we validated the software requirements using requirements a validation framework [11]. Machine learning techniques such as Naïve Bayes classifier are applied for measuring software maintainability and also determine the business value of software. The business value of the software determines whether the software requires maintainability by reverse engineering or by forward engineering. If the business value of software is high, then software is maintained by reverse engineering, else by forward engineering [12].
The designed dataset consisted of following attributes: component-state, successful/error-type, error-LOC, business-value and changes. The component-state attribute determines whether the software components require small-changes, average-changes, or superior-changes, or is accurate-component. The successful/error-type attribute specifies the type of error in the software component or it is the correct component. The error-LOC attribute represents the number of lines of the code (LOC) that had error in it. The business-value attribute specifies whether the software component has business value or not (e.g., true or false). The changes attribute determines whether the software component requires changes or not (e.g., yes or no). Values were assigned to the attributes of the dataset with the collaboration of software engineers of the software company. The introduce approach helps to improve the performance of software, remove faults, and extract the errors from exact software component, and by this approach software is easily modified. This approach also keeps a record regarding the software maintainability in the dataset.
1.1. Types of Errors/Defects
The quality problems that are identified in the software before it is handed over to end-users are called errors whereas if they are identified after the software has been handed over to end-users are called defects. In this research, authors monitored the following types of errors in the software [12].
1.1.1. Incomplete Erroneous Specifications (IES)
Incomplete or erroneous specification (IES) result from deviations from manual process, lacking or partial implementation of software specification. IES occurs if goals and objectives of software are not completely assembled in the functional and non-functional requirements [13].
1.1.2. Misinterpretation of Customer Communication (MCC)
Misinterpretation of customer communication (MCC) errors occur due to incorrect extraction of requirements from user stories during requirements gathering phase or due to negligence of not adopting the requirement gathering techniques in the software development [12]. For example, consider the software component that was developed due to MCC from the requirement . In this software component, online fee payment was only by credit card. During the validation process, a MCC error was found in the software component. Therefore, was corrected to and . The following payment options were made to be available in the software component: credit card, PayPal, Apple Pay, Alipay, Western Union, Union Pay International. Rejected requirement “: The user will be able to pay online fee by credit card”. Corrected requirement “ The system shall display online payment options, The user shall be able to select one online payment option from the system”.
1.1.3. Intentional Deviation from Specification (IDS)
Intentional deviation from specifications (IDS) result from negligence of the software engineers. In this, basic approved requirements are missed during the implementation of software components without any appropriate reason. Often, software developed from component-based development requires removal of extra functionalities or alteration in the software components in order to satisfy the approved requirements [14]. Consider the requirement number m of the software. “ The administrator of the company will be able to calculate the employees over time charges according to company rules and regulations”. According to the rules and regulations of the company if any employee is on half day leave or short leave in any working day and if the leave employee works in the evening time in the same day for over time charges, then the number of overtime hours of that employee will be included in the number of leave time hours. After this, the hours that are more than the morning working hours will be paid. For full day leave, the employee of the company will not be eligible to work in the evening time for same day. In the developed software, there was an error of IDS in which the software was calculating the overtime charges by ignoring the rules and regulations of the leave.
1.1.4. Violation of Programming Standards (VPS)
When any modification is done in the programming standards by the software engineers or it is deviation from the programming standards then this injects violation of programming standards (VPS) errors in the software [15].
1.1.5. Error in Data Representation (EDR)
Data formats must be specified in the software specification or software architecture, any negligence of this results in error in data representation (EDR) [16]. In order to avoid EDR, it is recommended to use data modeling tools such as [17] Visio, StarUML, Erwin, Entity Framework Add-on, DataArchitect, ConceptDraw, CASEWise, CA Gen, Altova Database Spy, etc.
1.1.6. Error in Design Logic (EDL)
Software design can be illustrated by Unified Modeling Language (UML) [18], Data flow Diagram (DFD) [19], or Entity Relationship Diagram (ERD) [20]. If there is any error in the software component due to error in design, then this type of error is called error in design logic (EDL). Causes of error include elimination of vital system states and elimination of procedures that were responsible for reporting prohibited operations.
1.1.7. Inconsistent Component Interface (ICI)
Inconsistent component interface (ICI) errors are result from violation in the recommended visuals designs, layouts, and standards [21]. Consider Figure 1 that represents the component interfaces.

Figure 1.
Component interfaces: (a) recommended component interface, (b) inconsistent component interface.
1.1.8. Incomplete or Erroneous Testing (IET)
The software that is developed according to approved requirements and by using modeling tools still contains errors or defects because during the testing phase, verification of code was not properly performed. These errors or defects result when some modules of the software are not tested, testing is not done thoroughly, failure to correct reported faults due to limitation of time, or incorrect identification of error location [22].
1.1.9. Inaccurate or Incomplete Documentation (IID)
The incomplete user manuals in the documentation often operates the software with erroneous results. If the documentation does not support implementation design, in future any modification in the software leads to software failure [23].
1.2. Disruptive Change
Heraclitas was a Greek philosopher famous for his opinion that constant change is the basic reality of this universe. This reality has been observed in every part of the history, as quickly evolving societies have regularly faced eras of discovery, disruptive change, and innovation. Gradual change occurs step by step and allows societies to adjust in it accordingly, whereas disruptive change is a dominant force that blasts on the scene by presenting unseen practices and new solutions [24].
In disruptive change, errors or defects occurs in the software due to unexpected movement of components from one module to another module. These changes can be in software specification or design of software and/or modules of software. Figure 2 represents the errors or defects that occur due to disruptive change.
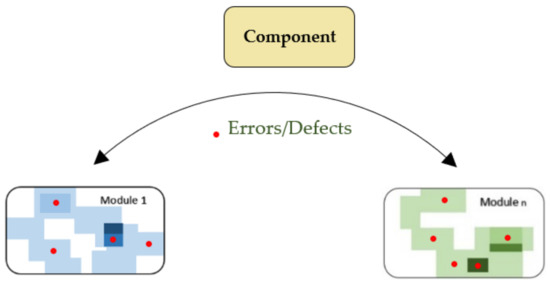
Figure 2.
Errors or defects due to disruptive change.
2. Related Work
In this section, we discuss how researchers have used machine learning techniques in their research to solve problems related to software engineering. In [25], scenario based requirements Engineering (RE) was supported by concept learning (CL) for extracting requirements and goals from system specification. In [26], researchers used genetic programming for generating software quality models. Software metrics were collected before software implementation, then these were entered as input. During testing or deployment, genetic programming predicted the quantity of faults for each module. Figure 3 illustrates the extracting of software engineering (SE) activities at different phases of system development life cycle (SDLC) by machine learning (ML) techniques [4].
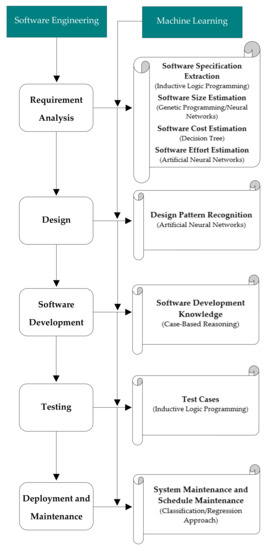
Figure 3.
Extracting software engineering activities by machine learning techniques.
In [27], Cohen used inductive logic programming (ILP) for extracting functional and non-functional requirements from the software. In this paper [28], researchers estimated line of code from the function point of software by applying neural network (NN) and genetic programming (GP) algorithms of machine learning. In [29], genetic programming (GP) and a neural network (NN) were used to calculate software size in line of code (LOC) by validating the component-based methods. Briand et al. in [30] described a technique named optimized set reduction which is based on decision tree (DT) learning. This technique is used to estimate software cost by examining data of software engineering. In the study [31] conducted by Ertugrul et al., several algorithms of machine learning were examined with feature transformation, feature selection, and also with the techniques of parameter optimization. They introduced a new model which provides improved effort estimation by considering the artificial neural networks (ANN) specifically “multilayer perceptron topology”.
Alhusain et al. in [32] proposed approach for design pattern recognition which is based on machine learning technique called artificial neural network (ANN). For each design pattern or role, a separate ANN was trained with feature vector as diverse input. In [33], tools were introduced for the management of knowledge regarding software development through case-based reasoning. In [34], researchers discussed how to generate test cases for the testing of software based on inductive logic programming (ILP). Machine learning techniques [35] such as classification approach and/or regression approach can be used for the prediction of system maintenance in order to monitor the system from future failures and schedule in advance the system maintenance.
In literature, different machine learning techniques have been used to extract different software engineering activities. In addition, to the best of the authors’ knowledge no related work or guideline has been found in which software maintainability has been measured by the authors’ introduced approach. In order to measure software maintainability in accurate form, the authors analyzed the software manually, e.g., identification of component state, errors in LOC per component, business value of component, and change required in a component or not. Error types were identified by supervised learning. Based on these five attributes, software maintainability was measured. Software size depends upon number of software components.
3. Material and Methods
In this research, a case study was conducted in order to determine the business value of the software. The business value of the software determines which approach is feasible for software modification forward engineering or reverse engineering. Figure 4 represents the software maintainability process. The red circle represents the errors. The white portion in module/software represents a component with single function whereas colored portion represents components with multiple functionalities. The increase in shade of any color indicates the increase in functionalities of the component. In this research, software specification of the new software was checked against its recently developed components/modified components of legacy system in order to identify the type of errors that exists in it.
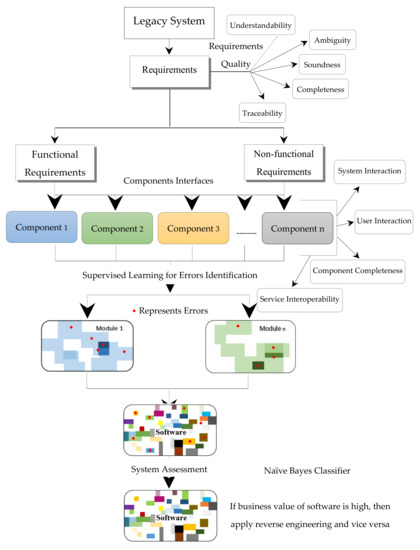
Figure 4.
Software maintainability process
Let B and C represents the module  and component
and component  of the executable code of software (e)
of the executable code of software (e)  .
.
and component of the executable code of software (e) .
e: B → C

The maintenance of the legacy system was accomplished by component-based development. Therefore, each functionality of the software was monitored with the new demanded functional and nonfunctional requirements during the validation process. Each component, module, and the complete software was examined with respect to IES, MCC, IDS, VPS, EDR, EDL, ICI, IET, and IID. Let F represents the specification of the e.
e: C → F
In this research, software defects were detected by supervised learning. In this input, data were entered and the output results were matched with the expected output demanded by the user of software. If there was any contradiction between the system output and the expected output, then type error was identified. As defined by Murphy [10],
T stands for training set, whereas input is represented by and output by . Based on the test cases designed , valued were entered, the type of errors that were identified are represented in Table 1.

Table 1.
Validation of legacy system by supervised learning approach.
Table 1 represents the validation of the legacy system by supervised learning approach, in which software components are represented by component-based user interfaces. New software components ( to ) are represented in module 9 () in Table 1. Modules, software components, requirements, system response, successful, error type are denoted by upper case letters M (1 ≤ i ≤ n), SC (1 ≤ j ≤ n), R (1 ≤ l ≤ n), SyRp (1 ≤ m ≤ n), Sf, Et respectively whereas lower case letters such as i, j, l, m denote the range of indexes. stands for jth software component of ith module. In Table 1, requirements are written in standard format as “The system shall…”. In this research, only errors were monitored, if the software component is error-free then it is called correct component represented by CC (successful). If there is any error, then type of error is mentioned; type of errors are as described in Section 1.1. The asterisk * in red indicates that it is mandatory for the user to enter the data. When client identified what the system must not consist of, then these requirements are called inverse requirements. Inverse requirements can be functional and/or non-functional [36].
In , there was an error of IDS because in this, an alternative email address was accepted in the text box, whereas the text box was to confirm the email address that was entered in . Suppose user email address is abcde@hotmail.com. System response and expected system response are represented by and respectively. j, m, and k denote the indexes of software component (1 ≤ j ≤ n), system response (1 ≤ m ≤ n) and expected system response, (1 ≤ k ≤ n).
: if email address: abcde@hotmail.com → : email address verified
: email address verified
: if email address: jklmno@hotmail.com → : email address verified (Error type: IDS)
: email address does not match the confirm email address
Output: Error type: IDS
Expected output: CC
In , there was an error of IET because the system was accepting the application of applicants above 35 years. Inverse requirement: the system does not accept the application if the age of applicant is more than 35 years before the deadline of application. The text box will become red in color indicating that applicant is not eligible. Cell number consists of eleven digits.
: if date of birth: 1990/01/01 → : system stores the date of birth in the record
: system stores the date of birth in the record
: if date of birth: 1984/01/01 → : system stores the date of birth in the record (Error type: IET)
: applicant is not eligible to apply
Output: Error type: IET
Expected output: CC
In , there was an error of MCC because the system was also generating a PIN for landline telephones. Inverse requirement: the system will not send a PIN code to a landline telephone. Figure 5 represents the software components, error (MCC) and the correct software component.

Figure 5.
Software components.
: if cell number: +86-123-2399-9999 → : cell number is updated in the system
: cell number is updated in the system
: if cell number: 123-7777-2222 → : please enter the country code
: please enter the country code
: if cell number: +86-123-4444 → : cell number is updated in the system (Error type: MCC)
: please enter cell number in correct format
Output: Error type: MCC
Expected output: CC
In , there was an error of EDR, because the date was wrongly formatted in the implementation, i.e., YYYY/DD/MM whereas the correct format was YYYY/MM/DD. Inverse requirement: expiry date of passport must be more than 6 months before the deadline of application. If the expiry date of passport is less than 6 months, then the system shall display error message (displays the text box for expiry date in red color) and asks the user to reenter the renew passport details.
: if passport number: AB123456 → : system stores the passport number in the record
: system stores the passport number in the record
: if issue date: 2017/12/31 → : system stores the passport issue date in the record : system stores the passport issue date in the record
: if issue date: 2017/31/12 → : system stores the passport issue date in the record (Error type: EDR)
: please enter issue date according to the format YYYY/MM/DD
: if expiry date: 2022/12/30 → : system stores the passport expiry date in the record
: system stores the passport expiry date in the record
: if expiry date: 2020/30/12 → : system stores the passport expiry date in the record (Error type: EDR)
: please enter expiry date according to the format YYYY/MM/DD
: if expiry date: 2021/03/15 → please enter the renew passport details
: please enter renew passport details
Output: Error type: EDR
Expected output: CC
In , there was an error of IET because the system was also accepting the date with validity of three months. Inverse requirement: if the validity of address is less than 6 months, the system shall display error message to reenter the address with more than 6 months of valid date.
: if address is valid until: 2025/01/15 → : address date is updated in the system
: address date is updated in the system
: if address is valid until: 2021/01/15 → : address date is updated in the system (Error type: IET)
: please reenter the address with more than 6 months’ validity date
Output: Error type: IET
Expected output: CC
In , there was an error of EDL because the system was not sending the email to the relevant professors to whom the applicant research interests matches with, when the application was submitted.
: the applicant selects the research interests from the drop-down list → : the system sent the email to all the professors (Error type: EDL)
: the system sent the email to the relevant professors to whom the applicant research interests match with
Output: Error type: EDL
Expected output: CC
In , there was an error of IES because the update option was providing the delete functionality.
: if user clicks on update option to update the entered information such as ISSN, authors name, article title, journal title, volume number, issue number, pages, year → : the required information has been deleted (Error type: IES)
: please click enter the information
Output: Error type: IES
Expected output: CC
In , there was an error of VPS because when conference was selected in publication category software components (from to ) of journal were displayed instead of conference software components.
: user selects the publication category e.g., conference → : the system displays software components from to e.g., ISSN, author names, article title, journal title, volume number, issue number, pages, year (Error type: VPS)
: the system displays software components from to e.g., ISSN, authors name, article title, conference name, location (city, country), date, pages
Output: Error type: VPS
Expected output: CC
In , there was an error of EDR because the entered details of the conference article were displayed in journal reference format.
: user clicks on the update option → : the system displays the entered details according to journal reference format (Error type: EDR)
: the system displays the entered details according to conference reference format
Output: Error type: EDR
Expected output: CC
: : if student ID: MSSE201701 → : student ID verified
: student ID verified
: if student ID: SE201803 → : this is not valid student ID
: this is not valid student ID
Output: CC
Expected output: CC
: : if student full name: Rachel Melo → : student name verified
: student name verified
: if student full name: Glaucia Vital → : this is not registered name in the system
: this is not registered name in the system
Output: CC
Expected output: CC
: : if passport number: ABC123456 → : passport number saved in the system : passport number saved in the system
Output: CC
Expected output: CC
: : if user selects PhD as his/her student category → : system updates PhD as his/her student category in the system
: system updates PhD as his/her student category in the system
: if user selects Master as his/her student category → : system updates Master as his/her student category in the system
: the system updates Master as his/her student category in the system
: if user selects Bachelor as his/her student category → : system updates Bachelor as his/her student category in the system
: the system updates Bachelor as his/her student category in the system
Output: CC
Expected output: CC
: : student selects his/her address from the available options → : system updates the address of the student in the system
: system updates the address of the student in the system
Output: CC
Expected output: CC
: : student enters the name and contact number in emergency details → : system saves the name and contact number in the emergency details
: system saves the name and contact number in the emergency details
Output: CC
Expected output: CC
: : if first entry date: 2019/09/31 → : first entry date is updated in the system
: first entry date is updated in the system
: if first entry date: 2019/31/09 → : please enter date in correct format (YYYY/MM/DD)
: please enter date in correct format (YYYY/MM/DD)
: airport city: Chongqing → : airport city name updated in the system
: airport city name updated in the system
Output: CC
Expected output: CC
: : user selects one option regarding COVID-19 test (negative, positive, not tested) → : system saves the results of COVID-19 test
: system saves the results of COVID-19 test
Output: CC
Expected output: CC
: : user enters the visa number → : visa number is updated in the system
: visa number updated in the system
: if visa expiry date: 2021/12/31 → : visa expiry date is updated in the system
: visa expiry date is updated in the system
: if visa expiry date 2021/31/12 → : please enter date in correct format (YYYY/MM/DD)
: please enter date in correct format (YYYY/MM/DD)
Output: CC
Expected output: CC
: : student enters his/her student ID: MSSE201701 → : student ID is verified
: student ID is verified
: student enters the end date of degree: 2021/12/31→ : end date of degree is verified
: end date of degree is verified
Output: CC
Expected output: CC
: : if user enters ISSN: 1234–5678 → : system displays that the journal is recognized by SCI, web of science, and CCF
: system displays that the journal is recognized by SCI, web of science and CCF
: if user enters title SEDB → : system displays that the conference is recognized by EI, and CCF
: system displays that the conference is recognized by EI and CCF
Output: CC
Expected output: CC
: : if user enters the number of published articles in the indexing e.g., SCI, ESCI, CCF, EI → : system displays candidate is eligible
: system displays candidate is eligible
: if user does not enter any number of published articles in the indexing e.g., SCI, ESCI, CCF, EI → : system displays candidate is not eligible
: system displays candidate is not eligible
Output: CC
Expected output: CC
: : if final defense date: 2021/12/31 → : final defense date is updated in the system
: final defense date is updated in the system
: if final defense date: 2021/31/12 → please enter date in correct format (YYYY/MM/DD)
: please enter date in correct format (YYYY/MM/DD)
Output: CC
Expected output: CC
: : user enters student ID and supervisor name → : system displays defense information (student ID, thesis title, date, time, location)
: system displays defense information (student ID, thesis title, date, time, location)
Output: CC
Expected output: CC
: : user enters student ID and school name → : system generates transcript
: system generates transcript
Output: CC
Expected output: CC
: : user enters student ID and degree completion date → : system generates university clearance form
: system generates university clearance form
Output: CC
Expected output: CC
: : user enters train or flight number and leaving date → : system saves the information
: system saves the information
Output: CC
Expected output: CC
4. Results
The dataset consisted of 71 instances and 5 attributes: component-state, successful/error-type, error-LOC, business-value, changes. WEKA stands for “Waikato Environment for Knowledge Analysis”, it is a machine learning software introduced by the University of Waikato, New Zealand. WEKA consists of algorithms and visualization tools which are used for predictive modeling and data analysis [37]. Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10 represent the attributes of the dataset used in the WEKA software.
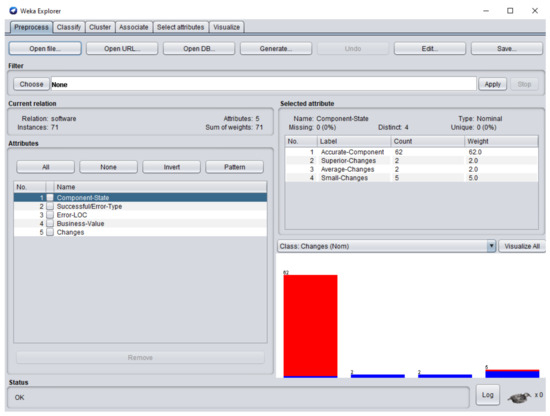
Figure 6.
Component-state attribute of the dataset in Waikato Environment for Knowledge Analysis (WEKA).
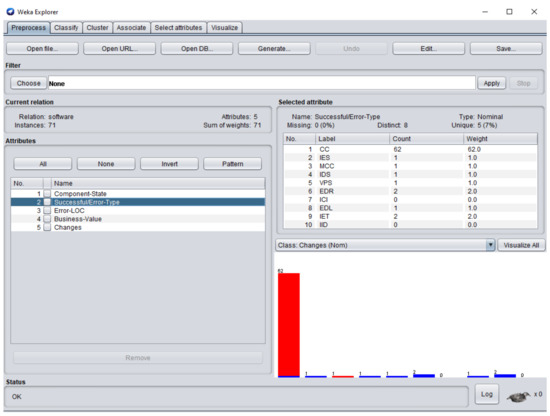
Figure 7.
Successful/error-type attribute of the dataset in WEKA.
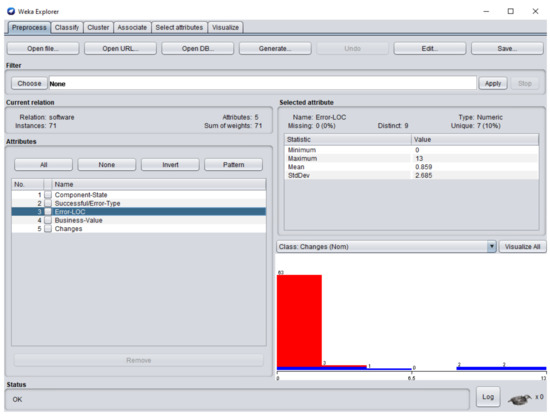
Figure 8.
Error-LOC (line of code) attribute of the dataset in WEKA.
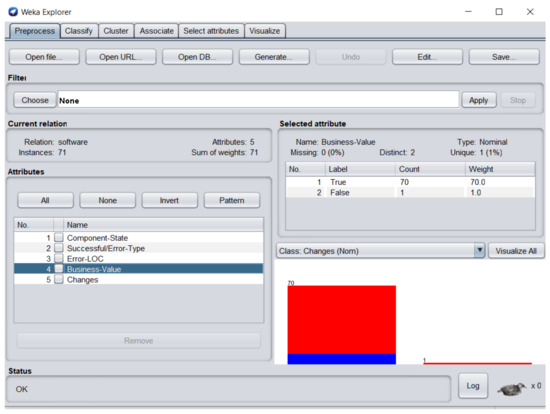
Figure 9.
Business-value attribute of the dataset in WEKA.
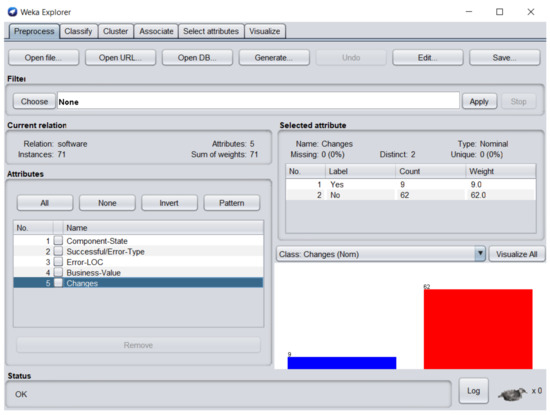
Figure 10.
Changes attribute of the dataset in WEKA.
Figure 6 represents component-state attribute; 62 software components were accurate-component (CC), software component and required superior changes, software component and required average changes, whereas small changes were performed in the software components , , , . Figure 7 represents successful/error-type attribute. In software components , , , , , , , , , and , the error types IDS, IET, MCC, EDR, IET, EDL, IES, VPS, and EDR were extracted respectively. Figure 8 represents the error-LOC attribute. Software components , , , , , , , , , and consisted of 9, 12, 3, 13, 3, 4, 10, 5, and 2 error-LOC respectively.
Figure 9 represents business-value attribute, in which one software component business value was zero. Figure 10 represents changes attribute; 9 software components required changes and 62 software components were perfect.
Figure 11 represents the Naïve Bayes classifier results, in which 97.18% are correctly classified instances whereas 2.82% are incorrectly classified instances. Reverse engineering is applied when percentage of accuracy is high whereas forward engineering is applied when percentage of accuracy is below 50% and changes required in the software are difficult to handle due to change in business processes or due to advancements in technology. Based on the case study, correctly predicted errors: IES = 1, MCC = 1, IDS = 1, VPS = 1, EDR = 2, ICI = 0, EDL = 1, IET = 2, IID = 0. By substituting the values of errors in Equation (2).
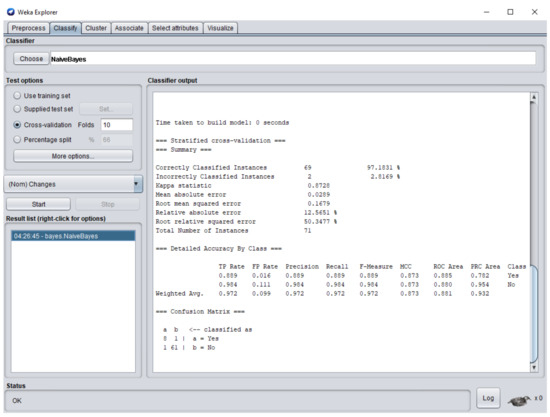
Figure 11.
Naïve Bayes classifier results for the software.
According to Equation (2), total correctly predicted errors are 9, so 9 software components require maintainability, whereas new components (NC) required to be developed according to new functional and nonfunctional requirements are NC = 17. According to the dataset used in the Naïve Bayes classifier, the total number of software components was 71. Software total components (STC) is the sum of previous total components and new components to be developed. The answer is calculated in index value (0–1) whereas 0.29 indicates the maintainability required in the software. By substituting the values of CPE, NC, and STC in Equation (3) given below, software maintainability was determined.
In this research, the legacy system was changed according to new requirements of the user. For each new functional and non-functional requirement, new software components were designed, whereas for minor modifications in previous functional and non-functional requirements, the previous software components of legacy system were upgraded. The modification in the system was done by component-based development, in which each software component was validated with a supervised learning approach to detect errors in it. The total number of software components in the complete system is 71. The results generated by the supervised learning approach detected 9 errors in the software components and 62 software components were error-free. Therefore, the correctness rate of the system was 87.32%, whereas the results of Naïve Bayes classifier show that only 2 instances were incorrectly classified, and 69 instances were correctly classified with precision = 0.97.
5. Discussion
The results presented in the study have internal and external validity threats to the system. Internal validity: attributes data used in the research significantly depend on age of the legacy system and the number of changes requested in the new software requirements. The change rate in the system increases with time because the systems evolve due to evolutionary changes in the working environment, and faults rate also increases due to new requirements. In order to avoid these threats, we used a requirements validation framework that helps to design the software components according to software requirements. External validity: the threat to validity is the implementation languages, e.g., Visual Basic .Net, C++, Java etc. During the design of the system, completeness and consistency are considered important factors. To avoid this threat, the introduced methodology focused on the correctness of the software components, which reduces the error rate in the software.
6. Conclusions
As the number of errors and/or defects increases in the software, the business value of the software also decreases. Reverse engineering can only be applied if there are fewer errors or defects in the software. The business value of the software increases if there is smaller number of errors or defects. Forward engineering is applied in the software having high business value. Illustrating the software components in the form of component-based user interfaces helped in the identification of potential problems in the software. The conducted case study showed that predicted values by WEKA software were approximately equal to the values calculated by the software components. It has been observed that the software components that were developed by considering the inverse requirements were error-free and were easily changeable according to the customer requirements. The design of the software components helped in better understanding of software requirements. The dataset stores complete records about maintainability of the software, as well as about each software component. This approach reduces the fault rate, which has been a challenging task for software engineers.
Author Contributions
Conceptualization, N.I. and J.S.; formal analysis, J.C.; funding acquisition, X.X.; investigation, J.C.; methodology, N.I.; resources, N.I.; supervision, J.S.; validation, J.C. and X.X.; writing—original draft, N.I.; writing—review and editing, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Chongqing Graduate Tutor Team Construction Project (No. ydstd1821).
Data Availability Statement
The data used to support the findings of this study are included within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Moore, J.W. The Road Map to Software Engineering: A Standards-Based Guide, 2nd ed.; Wiley-IEEE Computer Society Press: Hoboken, NJ, USA, 2006; pp. 183–216. [Google Scholar]
- Fairly, R.E. Managing and Leading Software Projects, 2nd ed.; Wiley-IEEE Computer Society Press: Hoboken, NJ, USA, D2009; pp. 207–258. [Google Scholar]
- Kan, S.H. Metrics and Models in Software Quality Engineering, 2nd ed.; Addison-Wesley Professional: Boston, MA, USA, 2002; pp. 70–130. [Google Scholar]
- Zhang, D.; Tsai, J.J.P. Introduction to machine learning and software engineering. Ser. Softw. Eng. Knowl. Eng. 2005, 11, 1–36. [Google Scholar] [CrossRef]
- Parra, E.; Dimou, C.; Llorens, J.; Moreno, V.; Fraga, A. A methodology for the classification of quality of requirements using machine learning techniques. Inf. Softw. Technol. 2015, 67, 180–195. [Google Scholar] [CrossRef]
- Loucopoulos, P.; Karakostas, V. System Requirements Engineering; McGraw-Hill Education: New York, NY, USA, 1995; pp. 30–75. [Google Scholar]
- Scott, D.; Morgado, M. 6 Reasons for Employing Component-Based UI Development. Available online: https://sruthik926.github.io/mvc_vs_component_based_architecture/ (accessed on 29 September 2020).
- Institute of Electrical and Electronics Engineering. IEEE Standard Glossary of Software Engineering Terminology; IEEE Std 610.121990; IEEE: Piscataway, NJ, USA, 1990. [Google Scholar]
- Mamone, S. The IEEE standard for software maintenance. ACM SIGSOFT Softw. Eng. Notes 1994, 19, 75–76. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018; pp. 1–10. [Google Scholar]
- Iqbal, N.; Sang, J.; Gao, M.; Hu, H.; Xiang, H. Forward engineering completeness for software by using requirements validation framework. In Proceedings of the 31st International Conference on Software Engineering and Knowledge Engineering, Lisbon, Portugal, 10–12 July 2019; KSI Research Inc.: Pittsburg, PA, USA, 2019; pp. 523–528. [Google Scholar]
- Pressman, R.S. Software Engineering: A Practitioner’s Approach, 8th ed.; McGraw-Hill Education: New York, NY, USA, 2014; pp. 1–830. [Google Scholar]
- Boulanger, J.-L. Software specification verification stage. In Certifiable Software Applications 3; ISTE Press Ltd.: London, UK, 2018; pp. 155–171. [Google Scholar]
- Alshazly, A.A.; Elfatatry, A.M.; Abougabal, M.S. Detecting defects in software requirements specification. Alex. Eng. J. 2014, 53, 513–527. [Google Scholar] [CrossRef]
- ISO/IEC Information Technology. Guidelines for the Preparation of Programming Language Standards, 4th ed.; ISO: Geneva, Switzerland, 2003. [Google Scholar]
- Miller, A.; Wu, L. Daily Coding Problem; Independently Published: NY, USA, 2019; pp. 80–120. [Google Scholar]
- Sommerville, I. Software Engineering, 10th ed.; Pearson Education Limited: London, UK, 2015; pp. 110–310. [Google Scholar]
- Hakim, H.; Sellami, A.; Abdallah, H.B. Identifying and localizing the inter-consistency errors among UML use cases and ac-tivity diagrams: An approach based on functional and structural size measurements. In Proceedings of the 15th International Conference on Software Engineering Research, Management and Applications, London, UK, 7–9 June 2017; pp. 289–296. [Google Scholar]
- Zhang, H.; Liu, W.; Xiong, H.; Dong, X. Analyzing data flow diagrams by combination of formal methods and visualization techniques. J. Vis. Lang. Comput. 2018, 48, 41–51. [Google Scholar] [CrossRef]
- Genero, M.; Poels, G.; Piattini, M. Defining and validating metrics for assessing the understandability of entity–relationship diagrams. Data Knowl. Eng. 2008, 64, 534–557. [Google Scholar] [CrossRef]
- Lanzaro, A.; Natella, R.; Winter, S.; Cotroneo, D.; Suri, N. An empirical study of injected versus actual interface errors. In Proceedings of the ISSTA 2014 International Symposium on Low Power Electronics and Design, San Jose, CA, USA, 21–25 July 2014; ACM: New York, NY, USA, 2014; pp. 397–408. [Google Scholar]
- Pomeranz, I. Incomplete tests for undetectable faults to improve test set quality. ACM Trans. Des. Autom. Electron. Syst. 2019, 24, 23. [Google Scholar] [CrossRef]
- Barker, T.T. Writing Software Documentation: A Task-Oriented Approach, 2nd ed.; Pearson Education Limited: London, UK, 2002; pp. 75–188. [Google Scholar]
- Cleland-Huang, J. Disruptive change in requirements engineering research. In Proceedings of the 2018 IEEE 26th International Requirements Engineering Conference (RE), Banff, AB, Canada, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–2. [Google Scholar]
- Lamsweerde, V.; Willemet, L. Inferring declarative requirements specification from operational scenarios. IEEE Trans. Softw. Eng. 1998, 24, 1089–1114. [Google Scholar] [CrossRef]
- Evett, M.; Khoshgoftar, T.; Chien, P.; Allen, E. GP based software quality prediction. In Proceedings of the Third Annual Genetic Programming Conference, Madison, WI, USA, 22–25 July 1998; pp. 60–65. [Google Scholar]
- Cohen, W.W. Inductive specification recovery: Understanding software by learning from example behaviors. Autom. Softw. Eng. 1995, 2, 107–129. [Google Scholar] [CrossRef]
- Regolin, E.; De Souza, G.; Pozo, A.; Vergilio, S. Exploring machine learning techniques for software size estimation. In Proceedings of the 23rd International Conference of the Chilean Computer Science Society, SCCC 2003 Proceedings, Chillan, Chile, 6–7 November 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 130–136. [Google Scholar]
- Dolado, J. A validation of the component-based method for software size estimation. IEEE Trans. Softw. Eng. 2000, 26, 1006–1021. [Google Scholar] [CrossRef]
- Briand, L.; Basili, V.; Thomas, W. A pattern recognition approach for software engineering data analysis. IEEE Trans. Softw. Eng. 1992, 18, 931–942. [Google Scholar] [CrossRef]
- Ertugrul, E.; Baytar, Z.; Catal, C.; Muratli, C. Performance tuning for machine learning-based software development effort prediction models. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1308–1324. [Google Scholar] [CrossRef]
- Alhusain, S.; Coupland, S.; John, R.; Kavanagh, M. Towards machine learning based design pattern recognition. In Proceedings of the 2013 13th UK Workshop on Computational Intelligence (UKCI), Guilford, UK, 9–11 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 244–251. [Google Scholar]
- Henninger, S. Case-based knowledge management tools for software development. Autom. Softw. Eng. 1997, 4, 319–340. [Google Scholar] [CrossRef]
- Gunetti, D. ILP Applications to Software Engineering in Advances in Machine Learning Applications in Software Engineering; Zhang, D., Tsai, J.J.P., Eds.; Idea Group Publishing: Hershey, PA, USA, 2007. [Google Scholar]
- Alwis, R.; Perera, S. Machine Learning Techniques for Predictive Maintenance. Available online: https://www.infoq.com/articles/machine-learning-techniques-predictive-maintenance/ (accessed on 30 September 2020).
- Ansari, M.Z.A. Softrology: Learn Software Technologies. Available online: https://softrology.blogspot.com/search?q=inverse (accessed on 30 September 2020).
- Machine Learning at Waikato University. Available online: https://www.cs.waikato.ac.nz/ml/index.html (accessed on 30 September 2020).
























































































Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).