Abstract
A discrete system’s heterogeneity is measured by the Rényi heterogeneity family of indices (also known as Hill numbers or Hannah–Kay indices), whose units are the numbers equivalent. Unfortunately, numbers equivalent heterogeneity measures for non-categorical data require a priori (A) categorical partitioning and (B) pairwise distance measurement on the observable data space, thereby precluding application to problems with ill-defined categories or where semantically relevant features must be learned as abstractions from some data. We thus introduce representational Rényi heterogeneity (RRH), which transforms an observable domain onto a latent space upon which the Rényi heterogeneity is both tractable and semantically relevant. This method requires neither a priori binning nor definition of a distance function on the observable space. We show that RRH can generalize existing biodiversity and economic equality indices. Compared with existing indices on a beta-mixture distribution, we show that RRH responds more appropriately to changes in mixture component separation and weighting. Finally, we demonstrate the measurement of RRH in a set of natural images, with respect to abstract representations learned by a deep neural network. The RRH approach will further enable heterogeneity measurement in disciplines whose data do not easily conform to the assumptions of existing indices.
1. Introduction
Measuring heterogeneity is of broad scientific importance, such as in studies of biodiversity (ecology and microbiology) [1,2], resource concentration (economics) [3], and consistency of clinical trial results (biostatistics) [4], to name a few. In most of these cases, one measures the heterogeneity of a discrete system equipped with a probability mass function.
Discrete systems assume that all observations of a given state are identical (zero distance), and that all pairwise distances between states are permutation invariant. This assumption is violated when relative distances between states are important. For example, an ecosystem is not biodiverse if all species serve the same functional role [5]. Although species are categorical labels, their pairwise differences in terms of ecological functions differ and thus violate the discrete space assumptions. Mathematical ecologists have thus developed heterogeneity measures for non-categorical systems, which they generally call “functional diversity indices” [6,7,8,9,10,11]. These indices typically require a priori discretization and specification of a distance function on the observable space.
The requirement for defining the state space a priori is problematic when the states are incompletely observable: that is, when they may be noisy, unreliable, or invalid. For example, consider sampling a patient from a population of individuals with psychiatric disorders and assigning a categorical state label corresponding to his or her diagnosis according to standard definitions [12]. Given that psychiatric conditions are not defined by objective biomarkers, the individual’s diagnostic state will be uncertain. Indeed, many of these conditions are inconsistently diagnosed across raters [13], and there is no guarantee that they correspond to valid biological processes. Alternatively, it is possible that variation within some categorical diagnostic groups is simply related to diagnostic “noise,” or nuisance variation, but that variation within other diagnostic groups constitutes the presence of sub-strata. Appropriate measurement of heterogeneity in such disciplines requires freedom from the discretization requirement of existing non-categorical heterogeneity indices.
Pre-specified distance functions may fail to capture semantically relevant geometry in the raw feature space. For example, the Euclidean distance between Edmonton and Johannesburg is relatively useless since the straight-line path cannot be traversed. Rather, the appropriate distances between points must account for the data’s underlying manifold of support. Representation learning addresses this problem by learning a latent embedding upon which distances are of greater semantic relevance [14]. Indeed, we have observed superior clustering of natural images embedded on Riemannian manifolds [15] (but also see Shao et al. [16]), and preservation of semantic hierarchies when linguistic data are embedded on a hyperbolic space [17].
Therefore, we seek non-categorical heterogeneity indices without requisite a priori definition of categorical state labels or a distance function. The present study proposes a solution to these problems based on the measurement of heterogeneity on learned latent representations, rather than on raw observable data. Our method, representational Rényi heterogeneity (RRH), involves learning a mapping from the space of observable data to a latent space upon which an existing measure (the Rényi heterogeneity [18], also known as the Hill numbers [19] or Hannah–Kay indices [20]) is meaningful and tractable.
The paper is structured as follows. Section 2 introduces the original categorical formulation of Rényi heterogeneity and various approaches by which it has been generalized for application on non-categorical spaces [8,10,21]. Limitations of these indices are highlighted, thereby motivating Section 3, which introduces the theory of Representational Rényi Heterogeneity (RRH), which generalizes the process for computing many indices of biodiversity and economic equality. Section 4 provides an illustration of how RRH may be measured in various analytical contexts. We provide an exact comparison of RRH to existing non-categorical heterogeneity indices under a tractable mixture of beta distributions. To highlight the generalizability of our approach to complex latent variable models, we also provide an evaluation of RRH applied to the latent representations of a handwritten image dataset [22] learned by a variational autoencoder [23,24]. Finally, in Section 5 we provide a summary of our findings and discuss avenues for future work.
2. Existing Heterogeneity Indices
2.1. Rényi Heterogeneity in Categorical Systems
There are many approaches to derive Rényi heterogeneity [18,19,20]. Here, we loosely follow the presentation of Eliazar and Sokolov [25] by using the metaphor of repeated sampling from a discrete system X with event space and probability distribution . The probability that independent and identically distributed (i.i.d.) realizations of X, sampled with replacement, will be identical is
Now let be an idealized reference system with a uniform probability distribution over categorical states, , and let be a sample of q i.i.d. realizations of such that
We call an “idealized” categorical system because its probability distribution is uniform, and it is a “reference” system for X in that the probability of drawing homogeneous samples of q observations from both systems is identical. Substituting Equation (2) into Equation (1) and solving for yields the Rényi heterogeneity of order q,
whose units are the numbers equivalent of system X [1,26,27,28], insofar as is the number of states in an “equivalent” (idealized reference) system . Thus far, we have restricted the parameter q to take integer values greater than 1 solely to facilitate this intuitive derivation in a concise fashion. However, the elasticity parameter q in Equation (3) can be any real number (but ), although in the context of heterogeneity measurement only are used [1,25]. Despite Equation (3) being udefined at directly, L’Hôpital’s rule can be used to show that the limit exists, wherein it corresponds to the exponential of Shannon’s entropy [28,29], known as perplexity [30].
Equation (3) is the exponential of Rényi’s entropy [18], and is alternatively known as the Hill numbers in ecology [1,19], Hannah–Kay indices in economics [20], and generalized inverse participation ratio in physics [25]. Interestingly, it generalizes or can be transformed into several heterogeneity indices that are commonly employed across scientific disciplines (Table 1).

Table 1.
Relationships between Rényi heterogeneity and various diversity or inequality indices for a system X with event space and probability distribution . The function is an indicator function that evaluates to 1 if its argument is true or to 0 otherwise.
2.1.1. Properties of the Rényi Heterogeneity
Equation (3) satisfies several properties that render it a preferable measure of heterogeneity. These have been detailed elsewhere [1,20,25,28,33,38], but we focus on three properties that are of particular relevance for the remainder of this paper.
First, satisfies the principle of transfers [39,40] which states that any equality-increasing transfer of probability between states must increase the heterogeneity. The maximal value of is attained if and only if for all . This property follows from Schur-concavity of Equation (3) [20].
Second, satisfies the replication principle [1,38,41], which is equivalent to stating that Equation (3) scales linearly with the number of equally probable states in an idealized categorical system [25]. More formally, consider a set of systems with probability distributions over respective discrete event spaces . These systems are also assumed to satisfy the following properties:
- Event spaces are disjoint: for all where
- All systems have equal heterogeneity:
The replication principle states that if we combine into a pooled system X with probability distribution , then
must hold (see Appendix A for proof that Rényi heterogeneity satisfies the replication principle).
The replication principle suggests that Equation (3) satisfies a property known as decomposability, in that the heterogeneity of a pooled system can be decomposed into that arising from variation within and between component subsystems. However, we require that this property be satisfied when either (A) subsystems’ event spaces are overlapping, or (B) subsystems do not have equal heterogeneity. The decomposability property will be particularly important for Section 3, and so we detail it further in Section 2.1.2.
2.1.2. Decomposition of Categorical Rényi Heterogeneity
Consider a system X defined by pooling subsystems with potentially overlapping event spaces , respectively. The event space of the pooled system is defined as
Furthermore, we define the matrix whose ith row is the probability of system being observed in each state .
It may be the case that some subsystems comprise a larger proportion of X than others. For instance, if the probability distribution for subsystem was estimated based on a larger sample size than that of , one may want to weight the contribution of higher. Thus, we define a column vector of weights over the N subsystems such that and for all i. The probability distribution over states in the pooled system X may thus be computed as , from which the definition of pooled heterogeneity follows:
One can interpret as the effective number of states in the pooled categorical system X.
Jost [28] showed that the within-group heterogeneity, which is the effective number of unique states arising from individual component systems, can be defined as
For example, in the case where all subsystems have disjoint event spaces with heterogeneity equal to constant , then they each contribute unique states to the pooled system X.
Deriving the between-group heterogeneity , is thus straightforward. If the effective total number of states in the pooled system is , and the effective number of unique states contributed by distinct subsystems is , then
is the effective number of completely distinct subsystems in the pooled system X. A word of caution is warranted. If we require that within-group heterogeneity is a lower bound on pooled heterogeneity [42], then (Jost [28], see Proofs 2 and 3) showed that Equation (8) will hold (A) at any value of q when weights are equal (i.e., for all ), or (B) only at and if weights are unequal.
2.1.3. Limitations of Categorical Rényi Heterogeneity
The chief limitation of Rényi heterogeneity (Equation (3)) is its assumption that all states in a system X (with event space and probability distribution ) are categorical. More formally, the dissimilarity between a pair of observations from this system is defined by the discrete metric
where is Kronecker’s delta, which takes a value of 1 if and 0 otherwise. Since the discrete metric assumption is an idealization, we have continued to use the asterisk to qualify an arbitrary distance function as categorical in nature. The resulting expected pairwise distance matrix between states in X is
where is a column vector of ones, and is the identity matrix.
Clearly, many systems of interest in the real world are not categorical. For example, although we may label a sample of organisms according to their respective species, there may be differences between these taxonomic classes that are relevant to the functioning of the ecosystem as a whole [5]. It is also possible that no valid and reliable set of categorical labels is known a priori for a system whose event space is naturally non-categorical.
2.2. Non-Categorical Heterogeneity Indices
Consider a system X with probability distribution defined over event space and equipped with dissimilarity function . We assume that is more general than the discrete metric (Equation (9)), and further still need not be a true (metric) distance. For such systems, there are three heterogeneity indices whose units are numbers equivalent, and respect the replication principle [6,8,10,11,21]. Much like our derivation of the Rényi heterogeneity in Section 2.1, these indices quantify the heterogeneity of a non-categorical system as the number of states in an idealized reference system, but differ primarily in how the idealized reference is defined. We begin with a discussion of the Numbers-Equivalent Quadratic Entropy (Section 2.2.1), followed by the Functional Hill Numbers (Section 2.2.2) and the Leinster–Cobbold index [10] (Section 2.2.3).
2.2.1. Numbers Equivalent Quadratic Entropy
Rao [43] introduced the diversity index commonly known as Rao’s quadratic entropy (RQE),
where is an matrix where for states .
Ricotta and Szeidl [21] assume that means that states i and j are maximally dissimilar (i.e., categorically different), and that means , which occurs when is a categorical system. An arbitrary dissimilarity matrix can be rescaled to respect this assumption by applying the following transformation:
Under this transformation, Ricotta and Szeidl [21] search for an idealized categorical reference system with event space , probability distribution , and RQE equal to that of X. For a column vector of ones, , and the identity matrix , this is
Expanding the right-hand side, we have
Recalling that and substituting into Equation (14) yields
which establishes the units of as numbers equivalent.
For consistency, we require that if were categorical. This only holds at :
Based on this result, Ricotta and Szeidl [21] define the numbers equivalent quadratic entropy as
This can be interpreted as the inverse Simpson concentration of an idealized categorical reference system whose average pairwise distance between states is equal to .
2.2.2. Functional Hill Numbers
Chiu and Chao [8] derived the Functional Hill Numbers, denoted , based on a similar procedure to that of Ricotta and Szeidl [21]. However, whereas uses a purely categorical system as the idealized reference, requires only that
which means that the idealized reference system is one for which the between-state distance matrix is set to everywhere (or to 0 along the leading diagonal and on the off diagonals).
Chiu and Chao [8] generalized Rao’s quadratic entropy to include the elasticity parameter
and sought to find for the idealized reference system satisfying Equation (18) and the following:
Solving Equation (20) for yields the functional Hill numbers of order q:
which is the effective number of states in an idealized categorical reference system whose distance function is scaled by a factor of .
2.2.3. Leinster–Cobbold Index
The index derived by Leinster and Cobbold [10], denoted , is distinct from and in two ways. First, for a given system X, the is not derived based on finding an idealized reference system whose average between-state dissimilarity is equal to that of X. Second, it does not use a dissimilarity matrix; rather, it uses a measure of similarity or affinity.
The Leinster–Cobbold index may be derived by simple extension of Equation (3). Assuming X has state space with probability distribution , we note that
Here, is the identity matrix representing the pairwise similarities between states in X. The Leinster–Cobbold index generalizes to be any similarity matrix , yielding the following formula:
The similarity matrix can be obtained from a dissimilarity matrix by the transformation , where is a scaling factor. When , then is 1 everywhere. Conversely, when , then approaches . The Leinster–Cobbold index can thus be interpreted as an effective number if the states are in an idealized reference system (i.e., one with uniform probabilities over states) whose topology is also governed by the similarity matrix .
2.2.4. Limitations of Existing Non-Categorical Heterogeneity Indices
We illustrate several limitations of the , , and indices using a simple 3-state system X with event space over which we specify a probability distribution
where is a parameter that smoothly varies the level of inequality. When the distribution is perfectly even (Figure 1A). Since an undirected graph of the system is arranged in a triangle with height h and base b, we also specify the following parametric distance matrix,
which allows us to smoothly vary the level of dissimilarity between states in X. Importantly, Equation (25) allows us to generate distance matrices that are either metric (when ; Definition 1) or ultrametric (when ; Definition 2). This is illustrated in Figure 1B.
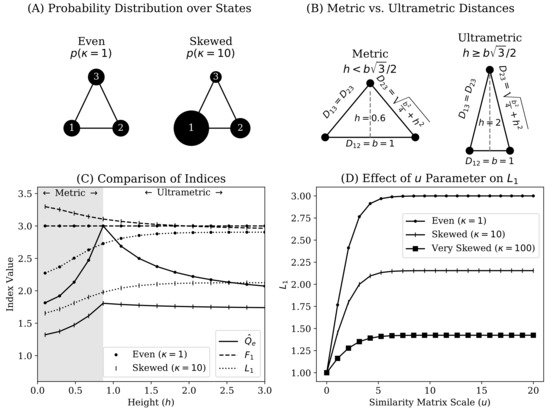
Figure 1.
Illustration of simple three-state system under which we compare existing non-categorical heterogeneity indices. Panel A depicts a three state system X as an undirected graph, with node sizes corresponding to state probabilities governed by Equation (24). As diverges further from , the probability distribution over states becomes more unequal. Panel B visually represents the parametric pairwise distance matrix of Equation (25) (h is height, b is base length, is distance between states i and j). In the examples shown in Panels B and C, we set . Specifically, we provide visual illustration of settings for which the distance function on X is a metric (Definition 1; when ) or ultrametric (Definition 2; when ). Panel C compares the numbers equivalent quadratic entropy (solid lines marked ; Section 2.2.1), functional Hill numbers (at , dashed lines marked ; Section 2.2.2), and the Leinster–Cobbold Index (at , dotted lines marked ; Section 2.2.3) for reporting the heterogeneity of X. The y-axis reports the value of respective indices. The x-axis plots the height parameter for the distance matrix (Equation (25) and Panel B). The range of h at which is only a metric is depicted by the gray shaded background. The range of h shown with a white background is that for which is ultrametric. For each index, we plot values for a probability distribution over states that is perfectly even (; dotted markers) or skewed (; vertical line markers). Panel D shows the sensitivity of the Leinster–Cobbold index (; y-axis) to the scaling parameter (x-axis) used to transform a distance matrix into a similarity matrix (). This is shown for three levels of skewness for the probability distribution over states (no skewness at , dotted markers; significant skewness at , vertical line markers; extreme skewness at , square markers).
Definition 1 (Metric distance).
A function on a set is a metric if and only if all of the following conditions are satisfied for all :
- 1
- Non-negativity:
- 2
- Identity of indiscernibles:
- 3
- Symmetry:
- 4
- Triangle inequality:
Definition 2 (Ultrametric distance).
A function on a set is ultrametric if and only if, for all , criteria 1-3 for a metric are satisfied (Definition 1), in addition to the ultrametric triangle inequality:
Figure 1C compares the , and indices when applied to X across variation in between-state distances (via Equation (25)) and skewness in the probability distribution over states (Equation (24)). With respect to the numbers equivalent quadratic entropy (; Section 2.2.1), we note that its behavior is categorically different with respect to whether the distance matrix is ultrametric. That is increases with the triangle height parameter h (Equation (25)) until it passes the ultrametric threshold, after which it decreases monotonically with h. The behavior of is sensible in the ultrametric range. When the distance matrix is scaled, as in Equation (12), pulling one of the three states in X further away from the remaining two should function similarly to progressively merging the latter states. Thus, the behavior of is highly sensitive to whether a given distance matrix is ultrametric (which will often not be the case in real-world applications).
With respect to , a notable benefit in comparison to is that behaves consistently regardless of whether distance is ultrametric. However, Figure 1 shows other drawbacks. First, we can see that becomes insensitive to when is perfectly even (shown analytically in Appendix A). Second, can paradoxically estimate a greater number of states than the theoretical maximum allows. That this occurs when the state probability distribution is more unequal violates the principle of transfers [20,33,39,40] (Section 2.1.1). This is made more problematic since Figure 1C shows it occurs when one state is being pushed closer to the others (i.e., with smaller values of h). To summarize, the functional Hill numbers are estimating more states than are really present despite the reduction in between-state distances and greater inequality in the probability mass function.
Figure 1C shows that the Leinster-Cobbold index compares favorably to because the former does not lose sensitivity to dissimilarity when is perfectly even. However, Figure 1D shows that the Leinster-Cobbold index is particularly sensitive to the form of similarity transformation. In the present case, the maximal value of the gradually approaches 3 as u grows (and only when does it reach 3), while progressively losing sensitivity to distance. As mentioned by Leinster and Cobbold [10], the choice of u or other similarity transformation is dependent on the importance assigned to functional differences between states. However, it is not clear how a given similarity transformation (e.g., u), and therefore the idealized reference system of , should be validated.
Above all of the idiosyncratic limitations of existing numbers equivalent heterogeneity indices, we must highlight two basic assumptions they all share. First, they continue to assume that some valid and reliable categorical partitioning on X is known a priori. Second, they assume that a distance function specified a priori describes semantically relevant geometry of the system in question. These two limitations are not independent, since an unreliable categorical partitioning of the state space will lead to erroneous estimates of the pairwise distances between states. Thus, we seek an approach for measuring heterogeneity that has neither these limitations, nor those shown above to be specific to the other numbers equivalent heterogeneity indices for non-categorical systems.
3. Representational Rényi Heterogeneity
In this section, we propose an alternative approach to the indices of Section 2.2 that we call representational Rényi heterogeneity (RRH). It involves transforming X into a representation Z, defined on an unobservable or latent event space , that satisfies two criteria:
- The representation Z captures the semantically relevant variation in X
- Rényi heterogeneity can be directly computed on Z
Satisfaction of the first criterion can only be ascertained in a domain-specific fashion. Since Z is essentially a model of X, investigators must justify that this model is appropriate for the scientific question at hand. For example, an investigator may evaluate the ability of X to be reconstructed from representation Z under cross-validation. The second criterion simply means that the transformation of must specify a probability distribution on upon which the Rényi heterogeneity can be directly computed.
Figure 2 illustrates the basic idea of RRH. However, the specifics of this framework differ based on the topology of the representation Z. Thus, the remainder of this section discusses the following approaches:
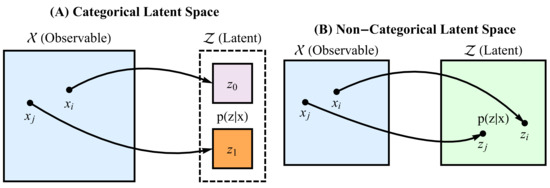
Figure 2.
Graphical illustration of the two main approaches for computing representational Rényi heterogeneity. In both cases, we map sampled points on an observable space onto a latent space , upon which we apply the Rényi heterogeneity measure. The mapping is illustrated by the curved arrows, and should yield a posterior distribution over the latent space. Panel A shows the case in which the latent space is categorical (for example, discrete components of a mixture distribution on a continuous space). Panel B illustrates the case in which the latent space has non-categorical topology. A special case of the latter mapping may include probabilistic principal components analysis. When the latent space is continuous, we must derive a parametric form for the Rényi heterogeneity.
- A.
- Application of standard Rényi heterogeneity (Section 2.1) when Z is a categorical representation
- B.
- Deriving parametric forms for Rényi heterogeneity when Z is a non-categorical representation
3.1. Rényi Heterogeneity on Categorical Representations
Let X be a system defined on an observable space that is non-categorical and -dimensional. Consider the scenario in which the semantically relevant variation in X is categorical: for instance, images of different object categories stored in raw form as real-valued vectors. An investigator may be interested in measuring the effective number of states in X with respect to this categorical variation. This requires transforming X into a semantically relevant categorical representation Z upon which Equation (3) can be applied.
Assume we have a large random sample of N points from system X. We can conceptualize each discrete observation in this sample as the single point in the event space of a perfectly homogeneous subsystem . When pooled, the subsystems constitute X. The contribution weights of each subsystem to X as a whole are denoted , where and .
We now specify a vector-valued function such that is a mapping from -dimensional coordinates on the observable space, , onto an -dimensional discrete probability distribution over . Thus, can be conceptualized as mapping subsystem onto its categorical representation . After defining , the effective number of states in the latent representation of can be computed as
When , then assigns to a single category with perfect certainty. Conversely, when , then either belongs to all categorical states with equal probability, or is maximally uncertain about the mapping of point .
Mapping all points onto the categorical latent space yields a collection of subsystems , which generate Z when pooled. Using Equation (6), we can compute the effective number of total states in Z as the pooled heterogeneity:
Unfortunately, counts some heterogeneity that is due to uncertainty in the model (i.e., that quantified by Equation (27)). We, therefore, compute the effective number of states in Z per point using the within-group heterogeneity formula (Equation (7)):
Finally, the effective number of states (points) in X—with respect to the categorical variation modeled by Z—can then be computed using the between-group heterogeneity formula (Equation (8)):
Example 1 demonstrates that current methods of measuring biodiversity and wealth concentration can be viewed as special cases of categorical RRH.
Example 1 (Classical measurement of biodiversity and economic equality as categorical RRH).
Definitions necessary for this example are shown in Table 2. The traditional analysis of species diversity and economic equality can be recovered from an RRH-based formulation when is assumed to be deterministic and . In this case within-group heterogeneity can be shown to reduce to 1:
Table 2.
Definitions in formulation of classical biodiversity and economic equality analysis as categorical representational Rényi heterogeneity. Superscripted indexing on denotes that this is a row vector.
Thus, we have
which yields the categorical Rényi heterogeneity (Hill numbers for biodiversity analysis and Hannah–Kay indices in the economic setting [19,20]), and by extension many diversity indices to which it is connected (Table 1). Thus, traditional analysis of species biodiversity and economic equality are special cases of representational Rényi heterogeneity where the representation is specified by a mapping onto degenerate distributions over categorical labels. The only differences lie in the definition of observable and latent spaces, and the representational models.
In the case of biodiversity analysis, the model in real-world practice may simply be a human expert assigning species labels to a sample of organisms from a field study. In the economic setting, one may speculate that would essentially reduce to contracts specifying ownership of assets, whose value is deemed by market forces.
3.2. Rényi Heterogeneity on Non-Categorical Representations
In Section 3.1, we dealt with instances in which semantically relevant variation in X is categorical, such as when object categories are embedded in images stored as real-valued vectors. Here, we consider scenarios in which the semantically relevant information in an observable system X is non-categorical: for instance, where a piece of text contains information about semantic concepts best represented as real-valued “word vectors” [44,45]. Measuring the effective number of distinct states in X with respect to this continuous variation requires transforming X into a semantically relevant continuous representation Z upon which procedures analogous to those of Section 3.1 may be undertaken.
Let Z be defined on an -dimensional event space over which there exists a family of parametric probability distributions of a form chosen by the experimenter. Let be a model that performs the mapping from a point on the observable space to a probability density on . For example, if is the family of multivariate Gaussians, then , where and are the Gaussian mean and covariance functions at , respectively. Given a sample , as in Section 3.1, we compute the continuous analogue of Equation (27) as follows
This formula yields the effective size of the domain of a uniform distribution on whose Rényi heterogeneity is equal to (proof is given in Appendix A). Thus, it is possible for to be less than 1, though it will remain non-negative.
Similar to the procedure in Section 3.1, we now define a continuous version of the within-observation heterogeneity
which estimates the effective size of the latent space occupied per observable point .
In order to compute the pooled heterogeneity , the experimenter must specify the form of the pooled distribution, here denoted . The conceptually most simple approach is non-parametric, using a model average,
whereby the pooled heterogeneity would be
The integral in Equation (36) may often be analytically intractable and potentially difficult to solve accurately in high dimensions with numerical methods. Furthermore, some areas of may be assigned low probability by for all . This is not a problem as the sample becomes infinitely large. However, with finite samples, it may be the case that some representational states in are unlikely simply because we have not sampled from the corresponding regions of . An alternative to Equation (35) is therefore to specify a parametric pooled distribution
where is a deterministic function that combines for into a valid probability density on . In this case, the pooled Rényi heterogeneity is simply
Using either Equation (36) or (38) as the pooled heterogeneity and Equation (34) as the within-group heterogeneity, the effective number of distinct states in X—with respect to the non-categorical representation Z—can then be computed using Equation (30).
Figure 3 demonstrates the difference between the parametric and non-parametric approaches to pooling for non-categorical RRH, and Example 2 demonstrates one approach to parametric pooling for a mixture of multivariate Gaussians.
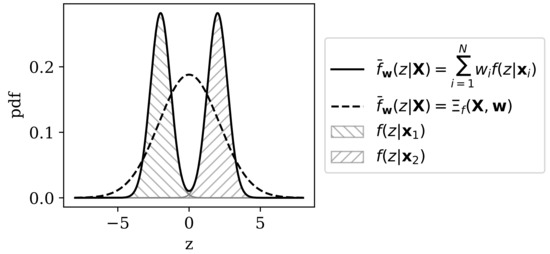
Figure 3.
Illustration of approaches to computing the pooled distribution on a simple representational space . In this example, two points on the observable space, , are mapped onto the latent space via model for , which indexes univariate Gaussians over (depicted as hatched patterns for and , respectively). A pooled distribution computed non-parametrically by model-averaging (Equation (35)) is depicted as the solid black line. The parametrically pooled distribution (see Example 2) is depicted as the dashed black line. The parametric approach implies the assumption that further samples from would yield latent space projections in some regions assigned low probability by and .
Example 2 (Parametric pooling of multivariate Gaussian distributions).
Let be a sample of -dimensional vectors from a system X with event space . Let Z be a latent representation of X with -dimensional event space . Let
be a model that returns a multivariate Gaussian density with mean and covariance given point . Finally, let be weights assigned to each sample in such that and .
If one assumes that the pooled distribution over given the set of components is itself a multivariate Gaussian,
with pooled mean,
and pooled covariance matrix
then the pooled heterogeneity is therefore simply the Rényi heterogeneity of a multivariate Gaussian,
evaluated at . The derivation is provided in Appendix A [46]. Equation (43) at is interpreted as the effective size of space occupied by the complete latent representation of X under model f.
The within-group heterogeneity can be obtained for the set of components by solving Equation (34) for the Gaussian densities, yielding:
where we denote for parsimony, and . Equation (44) estimates the effective size of the -dimensional representational space occupied per state .
The effective number of states in X with respect to the continuous representation Z is thus the between-group heterogeneity which can be computed as the ratio . The properties of this decomposition—specifically the conditions under which (Lande’s requirement [28,42])—are discussed further elsewhere [46].
4. Empirical Applications of Representational Rényi Heterogeneity
In this section, we demonstrate two applications of RRH under assumptions of categorical (Section 4.1) and continuous (Section 4.2) latent spaces. First, Section 4.1, uses a simple closed-form system consisting of a mixture of two beta distributions on the (0,1) interval to give exact comparisons of the behavior of RRH against that of existing non-categorical heterogeneity indices (Section 2.2). This experiment provides evidence that existing non-categorical heterogeneity indices can demonstrate counterintuitive behavior under various circumstances. Second, Section 4.2 demonstrates that RRH can yield heterogeneity measurements that are sensible and tractably computed, even for highly complex mappings . There, we use a deep neural network to compute the effective number of observations in a database of handwritten images with respect to compressed latent representations on a continuous space.
4.1. Comparison of Heterogeneity Indices Under a Mixture of Beta Distributions
Consider a system X with event space on the open interval , containing an embedded, unobservable, categorical structure represented by the latent system Z with event space . The systems’ collective behavior is governed by the joint distribution of a beta mixture model (BMM),
where is the probability density function for a beta distribution with shape parameters , and are parameters. The indicator function evaluates to 1 if its argument is true, and to 0 otherwise. The prior distribution is
and marginal probability of observable data is as follows (see Figure 4 for illustrations):
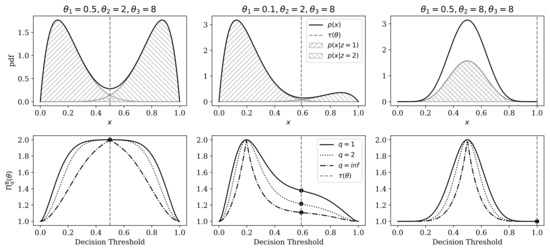
Figure 4.
Demonstration of data-generating distribution (top row; Equations (45)–(47)), and relationship between the representational model’s decision threshold (Equations (48) and (50)) and categorical representational Rényi heterogeneity (bottom row). The optimal decision boundary (Equation (50)) is shown as a gray vertical dashed line in all plots. Each column depicts a specific parameterization of the data-generating system (parameters are stated above the top row). Top Row: Probability density functions for data-generating distributions. Shaded regions correspond to the two mixture components. Solid black lines denote the marginal distribution (Equation (47)). The x-axis represents the observable domain, which is the (0,1) interval. Bottom Row: Effect of varying categorical representational Rényi heterogeneity (RRH) for across different category assignment thresholds for the beta-mixture models shown in the top row. Varying levels of decision boundary are plotted on the x-axis. The y-axis shows the resulting between-observation RRH. Black dots highlight the RRH computed at the optimal decision boundary.
To facilitate exact comparisons between heterogeneity indices, below, let us assume we have a model that maps an observation onto a degenerate distribution over :
The subscripting of denotes that the model is optimized such that the threshold is the solution to
which is
Under this model, the categorical RRH at point is
The expected value of with respect to the data generating distribution (Equation (47)) is
where is the generalized regularized incomplete beta function (BetaRegularized[] command in the Wolfram language and betainc(,regularized=True) in Python’s mpmath package). Equation (52) implies that . The pooled heterogeneity is thus expressed as a function of as follows:
As a function of , the within-group heterogeneity is
and therefore the between-group heterogeneity is .
Analytic expressions for the existing non-categorical heterogeneity indices (Equation (17)), (Equation (21)), and (Equation (23)) were computed as “best-case” scenarios, as follows. First, the probability distributions over states for all expressions was the true prior distribution (Equation (46)). Distance matrices—and by extension, the similarity matrix for —were computed using the closed-form expectation of the absolute distance between two beta-distributed random variables (see Appendix B and the Supplementary Materials).
Figure 5 compares the categorical RRH against , , and for BMM distributions of varying degrees of separation, and across different mixture component weights (). Without significant loss of generality, we show only those comparisons at (which excludes the numbers equivalent quadratic entropy), and .
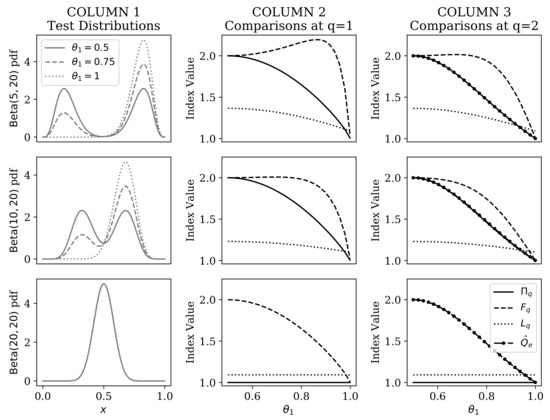
Figure 5.
Comparison of categorical representational Rényi heterogeneity (), the functional Hill numbers (), the numbers equivalent quadratic entropy (), and the Leinster–Cobbold index () within the beta mixture model. Each row of plots corresponds to a given separation between the beta mixture components. Column 1 illustrates the beta mixture distributions upon which indices were compared. The x-axis plots the domain of the distribution (open interval between 0 and 1). The y-axis shows the corresponding probability density. Different line styles in Column 1 provides visual examples of the effect of changing the parameter over the range [0.5,1]. Column 2 compares (solid line), (dashed line), and (dotted line), each at elasticity . The x-axis shows the value of the parameter at which the indices were compared. Index values are plotted along the y-axis. Column 3 compares the indices shown in Column 2, as well as (dot-dashed line).
The most salient differences between these indices occur when the BMM mixture components completely overlap (i.e., at ). The RRH correctly identifies that there is effectively only one component, regardless of mixture weights. Only the Leinster–Cobbold index showed invariance to the mixture weights when , but it could not correctly identify that data were effectively unimodal.
The other stark difference arose when the mixture components were furthest apart (here when and ). At this setting, the functional Hill numbers showed a paradoxical increase in the heterogeneity estimate as the prior distribution on components was skewed. The Leinster–Cobbold index was appropriately concave throughout the range of prior weights, but it never reached a value of 2 at its peak (as expected based on the predictions outlined in Section 2.2.3). Conversely, the RRH was always concave and reached a peak of 2 when both mixture components were equally probable.
4.2. Representational Rényi Heterogeneity is Scalable to Deep Learning Models
In this example, the observable system X is that of images of handwritten digits defined on an event space of dimension (the black and white images are flattened from pixel matrices into 784-dimensional vectors). Our sample from this space is the familiar MNIST training dataset [22] (Figure 6), which consists of images roughly evenly distributed across digits , and where approximately 10% of all images come from each class. We assume each image carries equal importance, given by a weight vector . We are interested in measuring the heterogeneity of X with respect to a continuous latent representation Z defined on event space . In the present example, this space is simply the continuous 2-dimensional compression of an image that best facilitates its reconstruction. We choose a dimensionality of for the latent space in order to facilitate a pedagogically useful visualization of the latent feature representation, below. Unlike Section 4.1, in the present case we have no explicit representation of the true marginal distribution over the data, .

Figure 6.
Sample images from the MNIST dataset [22].
Having defined the observable and latent spaces, measuring RRH now requires defining a model that maps a (flattened) image vector onto a probability distribution over the latent space. Our chosen model is the encoder module of a pre-trained convolutional variational autoencoder (cVAE) provided by the (https://colab.research.google.com/github/smartgeometry-ucl/dl4g/blob/master/variational_autoencoder.ipynb, Smart Geometry Processing Group at University College London) (Figure 7) [23,24]:
where are the encoder’s parameters, which specify a convolutional neural network (CNN) whose output layer returns a mean vector and a log-variance vector given . For simplicity, we denote the latter as the diagonal covariance matrix . Further details of the cVAE and its training can be found in Kingma and Welling [23,24], although the specific implementation in this paper was a pre-trained implementation by the (https://colab.research.google.com/github/smartgeometry-ucl/dl4g/blob/master/variational_autoencoder.ipynb, Smart Geometry Processing Group at University College London). Briefly, the cVAE learns to generate a compressed latent representation (via encoder , which is an approximate posterior distribution) that contains enough information about the input to facilitate its reconstruction by a “decoder” module. The objective function is a lower bound on the model evidence , which if maximized is equivalent to minimizing the Kullback–Leibler divergence between the approximate and true (but unknown) posteriors and , respectively.
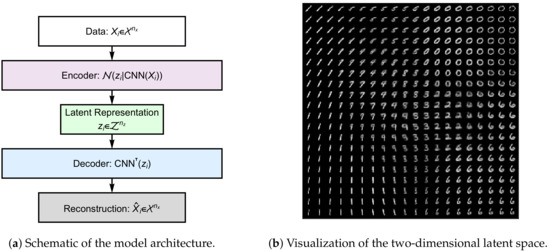
Figure 7.
Panel A: Illustration of the convolutional variational autoencoder (cVAE) [23]. The computational graph is depicted from top to bottom. An nx-dimensional input data Xi (white rectangle) is passed through an encoder (in our experiment this is a convolutional neural network, CNN) which parameterizes an nz-dimensional multivariate Gaussian over the coordinates zi for the image’s embedding on the latent space . The latent embedding can then be passed through a decoder (blue rectangle) which is a neural network employing transposed convolutions (here denoted CNN⊤) to yield a reconstruction of the original input data. The objective function for this network is a variational lower bound on the model evidence of the input data (see Kingma and Welling [23] for details). Panel B: Depiction of the latent space learned by the cVAE. This model was a pre-trained model from the (https://colab.research.google.com/github/smartgeometry-ucl/dl4g/blob/master/variational_autoencoder.ipynb, Smart Geometry Processing Group at University College London).
The continuous RRH under the model in Equation (55) for a single example can be computed by merely evaluating the Rényi heterogeneity of a multivariate Gaussian (Equation (43) in Example 2) for the covariance matrix given by . This is interpreted as the effective area of the 2-dimensional latent space consumed by representation of .
Since the handwritten digit images belong to groups of “Zeros, Ones, Twos, …, Nines,” this section will call the quantity the within-observation heterogeneity (rather than the “within-group” heterogeneity) in order to avoid its interpretation as measuring the heterogeneity of a group of digits. Rather, it is interpreted as the effective area of latent space consumed by representation of a single observation on average. It is computed by evaluation of Equation (44) at , given uniform weights on samples.
Finally, to compute the pooled heterogeneity , we use the parametric pooling approach detailed in Example 2, wherein the pooled distribution is a multivariate Gaussian with mean and covariance given by Equations (41) and (42), respectively. The pooled heterogeneity is then merely Equation (43) evaluated at , and represents the total amount of area in the latent space consumed by the representation of X under . The effective number of observations in X with respect to the continuous latent representation Z is, therefore, given by the between-observation heterogeneity:
Equation (56) gives the effective number of observations in X because it uses the entire sample (of course, assuming provides adequate coverage of the observable event space). However, one could compute the effective number of observations in a subset of , if necessary. Let be the subset of points in found in the observable subspace (such as the subspace of MNIST digits corresponding to a given digit class). Given corresponding weights , Equation (56) is then simply
Figure 8 shows the effective number of observations in the subsets of MNIST images belonging to each image class, under the continuous representation learned by the cVAE. One can appreciate that the MNIST class of “Ones” (in the training set) has the smallest effective number of observations. Subjective visual inspection of the MNIST samples in Figure 6 may suggest that the Ones are indeed relatively more homogeneous as a group than the other digits (this claim is given further objective support in Appendix C based on deep similarity metric learning [47,48]).
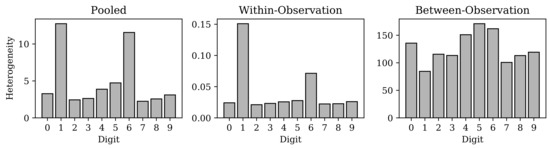
Figure 8.
Heterogeneity for the subset of MNIST training data belonging to each digit class respectively projected onto the latent space of the convolutional variational autoencoder (cVAE). The leftmost plot shows the pooled heterogeneity for each digit class (the effective total area of latent space occupied by encoding each digit class). The middle plot shows the within-observation heterogeneity (the effective total area of latent space per encoded observation of each digit class, respectively). The rightmost plot shows the between-observation heterogeneity (the effective number of observations per digit class). Recall that Rényi heterogeneity on a continuous distribution gives the effective size of the domain of an equally heterogeneous uniform distribution on the same space, which explains why the within-observation heterogeneity values here are less than 1.
Figure 9 demonstrates the correspondence of between-observation heterogeneity (i.e., the effective number of observations) and the visual diversity of different samples from the latent space of our cVAE model. For each image in the MNIST training dataset, we computed the effective location of its latent representation: for . For each of these image representations, we defined a “neighborhood” including the 49 other images whose latent coordinates were closest in Euclidean distance (which is sensible on the latent space given the Gaussian prior). For all such neighbourhoods defined, we then reconstructed the corresponding images on , whose between-observation heterogeneity was then computed using Equation (57). Figure 9b shows the estimated effective number of observations for the latent neighborhoods with the greatest and least heterogeneity. One can appreciate that neighborhoods with close to 1 include images with considerably less diversity than neighborhoods with closer to the upper limit of 49. These data suggest that the between-observation heterogeneity—which is the effective number of observations in X with respect to the latent features learned by a cVAE—can indeed correspond to visually appreciable sample diversity.

Figure 9.
Visual illustration of MNIST image samples corresponding to different levels of representational Rényi heterogeneity under the convolutional variational autoencoder (cVAE). Panel (a) illustrates the approach to this analysis. Here, the surface shows hypothetical contours of a probability distribution over the 2-dimensional latent feature space. The surface represents the observable space, upon which we have projected an “image” of the latent space for illustrative purposes. We first compute the expected latent locations m(xi) for each image
(A1) We then define the latent neighbourhood of image xi as the 49 images whose latent locations are closest to m(xi) in Euclidean distance. (A2) Each coordinate in the neighbourhood of m(xi) is then projected onto a corresponding patch on the observable space of images. (A3) These images are then projected as a group back onto the latent space, where Equation (57) can be applied, given equal weights over images, to compute the effective number of observations in the neighbourhood of xi. Panel (b) plots the most and least heterogeneous neighbourhoods so that we may compare the estimated effective number of observations with the visually appreciable sample diversity.
5. Discussion
This paper introduced representational Rényi heterogeneity, a measurement approach that satisfies the replication principle [1,38,41] and is decomposable [28] while requiring neither a priori (A) categorical partitioning nor (B) specification of a distance function on the input space. Rather, the experimenter is free to define a model that maps observable data onto a semantically relevant domain upon which Rényi heterogeneity may be tractably computed, and where a distance function need not be explicitly manipulated. These properties facilitate heterogeneity measurements for several new applications. Compared to state-of-the-art comparator indices under a beta mixture distribution, RRH more reliably quantified the number of unique mixture components (Section 4.1), and under a deep generative model of image data, RRH was able to measure the effective number of distinct images with respect to latent continuous representations (Section 4.2). In this section, we further synthesize our conclusions, discuss their implications, and highlight open questions for future research.
The main problem we set out to address was that all state of the art numbers equivalent heterogeneity measures (Section 2.2) require a priori specification of a distance function and categorical partitioning on the observable space. To this end, we showed that RRH does not require categorical partitioning of the input space (Section 3). Although our analysis under the two-component BMM assumed that the number of components was known, RRH was the only index able to accurately identify an effectively singular cluster (i.e., where mixture components overlapped; Figure 5). We also showed that the categorical RRH did not violate the principle of transfers [39,40] (i.e., it was strictly concave with respect to mixture component weights), unlike the functional Hill numbers (Figure 5). Future studies should extend this evaluation to mixtures of other distributional forms in order to better characterize the generalizability of our conclusions.
Section 3.1 and Section 3.2 both showed that RRH does not require specification of a distance function on the observable space. Instead, one must specify a model that maps the observable space onto a probability distribution over the latent representation. This is beneficial since input space distances are often irrelevant or misleading. For example, latent representations of image data learned by a convolutional neural network will be robust to translations of the inputs since convolution is translation invariant. However, pairwise distances on the observable space will be exquisitely sensitive to semantically irrelevant translations of input data. Furthermore, semantically relevant information must often be learned from raw data using hierarchical abstraction. Ultimately, when (A) pre-defined distance metrics are sensitive to noisy perturbations of the input space, or (B) the relevant semantic content of some input data is best captured by a latent abstraction, the RRH measure will be particularly useful.
The requirement of specifying a representational model implies the additional problem of model selection. In Section 3, we noted that the determination of whether a model is appropriate must be made in a domain-specific fashion. For instance, the method by which ecologists assign species labels prior to measurement of species diversity implies the use of a mapping from the observable space of organisms to a degenerate distribution over species labels (Example 1). In Section 4.2, we used the encoder module of a cVAE (a generative model based on a convolutional neural network architecture [23,24]) to represent images as 2-dimensional real-valued vectors in order to demonstrate our ability to capture variation in digits’ written forms (see Figure 7B and Figure 9). Someone concerned with measuring heterogeneity of image batches in terms of the digit-class distribution could choose a categorical latent representation corresponding to the digit classes (this would return the effective number of digit classes per sample). Regardless, the model used to map between observations and the latent space should be validated using either explanatory power (e.g., maximization of a lower bound on the model evidence), generalizability (e.g., out of sample predictive power), or another approach that is justifiable within the investigator’s scientific domain of interest.
In addition to the results of empirical applications of RRH in Section 4, we were also able to show that RRH generalizes the process by which species diversity and indices of economic equality are computed (Example 1). In doing so, we are able to clarify some of the assumptions inherent in those indices. Specifically, that assignment of species or ownership labels (in ecological and economic settings, respectively) corresponds to mapping from an observable space, such as the space of organisms’ identifiable features or the space of economic resources, onto a degenerate distribution over the categorical labels (Table 2). It is possible that altering the form of that mapping may yield new insights about ecological and economic diversity.
In conclusion, we have introduced an approach for measuring heterogeneity that requires neither (A) categorical partitioning nor (B) distance measure on the observable space. Our RRH method enables measurement of heterogeneity in disciplines where categorical entities are unreliably defined, or where relevant semantic content of some data is best captured by a hierarchical abstraction. Furthermore, our approach includes many existing heterogeneity indices as special cases, while facilitating clarification of many of their assumptions. Future work should evaluate the RRH in practice and under a broader array of models.
Supplementary Materials
The following are available online at https://www.mdpi.com/1099-4300/22/4/417/s1, Supplementary materials include code for Section 2, Section 3 and Section 4 and Appendix B (RRH_Supplement_3State_BMM_CVAE.ipynb), and Appendix C (RRH_Supplement_Siamese.ipynb).
Author Contributions
Conceptualization, A.N.; methodology, A.N.; validation, A.N.; formal analysis, A.N.; investigation, A.N.; resources, T.T.; data curation, A.N.; writing—original draft preparation, A.N.; writing—review and editing, A.N., M.A., T.B., T.T.; visualization, A.N.; supervision, M.A., T.B., T.T.; project administration, A.N.; funding acquisition, A.N., M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Genome Canada (A.N., M.A.), the Nova Scotia Health Research Foundation (A.N.), the Killam Trusts (A.N.), and the Ruth Wagner Memorial Fund (A.N.).
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Mathematical Appendix
Proposition A1.
Rényi heterogeneity (Equation (3)) obeys the replication principle.
Proof.
The Rényi heterogeneity for a single distribution , where is the size of the state space in system i, is
and for the aggregation of N subsystems is
The replication principle asserts that
Let and recall that for all . Then,
Since exists (it is the perplexity index), the result also holds at . □
Proposition A2.
For a system X with probability mass function represented by the vector on event space , with distance function represented by the matrix , the functional Hill numbers family of indices
is insensitive to for all when is uniform.
Proof.
The proof is direct given substitution of into Equation (A5).
□
Proposition A3 (Rényi Heterogeneity of a Continuous System).
The Rényi heterogeneity of a system X with event space and pdf is equal to the magnitude of the volume of an n-cube over which there is a uniform probability density with the same Rényi heterogeneity as that given by f.
Proof.
Let the basic integral of X be defined as . Furthermore, let be an idealized reference system with a uniform probability density on with lower bounds and upper bounds where is the side length of an n-cube. We assume that has basic integral such that
Solving Equation (A7) for gives the Rényi heterogeneity of order q. At ,
and in the limit of , Equation (A8) becomes the exponential of the Shannon (differential) entropy. Thus, is interpreted as the volume of an n-cube of side length , over which there is a uniform distribution giving the same heterogeneity as X. □
Proposition A4 (Rényi heterogeneity of a multivariate Gaussian).
The Rényi heterogeneity of an n-dimensional multivariate Gaussian with probability density function (pdf)
with mean and covariance matrix is
Proof.
Let be the eigendecomposition of the inverse covariance matrix into an orthonormal matrix of eigenvectors and diagonal matrix with eigenvalues down the leading diagonal. Furthermore, let and use the substitution to proceed as follows:
which holds only at . At , we have
and therefore,
One can then easily show that is undefined and that as ,
□
Appendix B. Expected Distance Between two Beta-Distributed Random Variables
To compute the numbers equivalent RQE , the functional Hill numbers , and the Leinster-Cobbold index under the beta mixture model, we must derive an analytical expression for the distance matrix. This involves the following integral:
where and . By exploiting the identity
and expanding, the integral is greatly simplified and gives the following closed-form solution:
where
and where , , and the ’s are regularized hypergeometric functions:

Figure A1.
Numerical verification of the analytical expression for the expected absolute distance between two Beta-distributed random variables. Solid lines are the theoretical predictions. Ribbons show the bounds between 25th–75th percentiles (the interquartile range, IQR) of the simulated values.
Appendix C. Evidence Supporting Relative Homogeneity of MNIST “Ones”
In our evaluation of non-categorical RRH using the MNIST data, we asserted that the class of handwritten Ones were relatively more homogeneous than other digits. Our initial statement was based simply on visual inspection of samples from the dataset, wherein the Ones ostensibly demonstrate fewer relevant feature variations than other classes. However, to test this hypothesis more objectively, we conducted an empirical evaluation using similarity metric learning.
We implemented a deep neural network architecture known as a “siamese network” [47] to learn a latent distance metric on the MNIST classes. Our siamese network architecture is depicted in Figure A2a. Training is conducted by sampling batches of 10,000 image pairs from the MNIST test set, where 5000 pairs are drawn from the same class (i.e., a pair of Fives or a pair of Threes), and 5000 pairs are drawn from different classes (i.e., the pairs [2,3] or [1,7]). The siamese network is then optimized using gradient-based methods over 100 epochs using the contrastive loss function [48] (Figure A2a). This analysis may be reproduced in the Supplementary Materials.
After training, we sampled same-class pairs (n = 25,000) and different-class pairs (n = 25,000) from the MNIST training set (which contains 60,000 images). Pairwise distances for each sample were computed using the trained siamese network. If the “ones” are indeed the most homogeneous class, they should demonstrate a generally smaller pairwise distance than other digit class pairs. We evaluated this hypothesis by comparing empirical cumulative distribution functions (CDF) on the class-pair distances (Figure A2b). Our results show that the empirical CDF for “1–1” image pairs dominate that of all other class pairs (where the distance between pairs of “ones” is lower).

Figure A2.
Depiction of the siamese network architecture and the empirical cumulative distribution function for pairwise distances between digit classes. (a) Depiction of a siamese network architecture. At iteration k, each of two samples, and , are passed through a convolutional neural network to yield embeddings zA and zB, respectively. The class label for samples A and B are denoted yA and yB, respectively. The L2-norm of these embeddings is computed as DAB. The network is optimized on the contrastive loss [48] . Here 𝕀[·] is an indicator function, (b) Empirical cumulative distribution functions (CDF) for pairwise distances between images of the listed classes under the siamese network model. The x-axis plots the L2-norm between embedding vectors produced by the siamese network. The y-axis shows the proportion of samples in the respective group (by line color) whose embedded L2 norms were less than the specified threshold on the x-axis. Class groups are denoted by different line colors. For instance, “0-0” refers to pairs where each image is a “zero.” We combine all disjoint class pairs, for example “0–8” or “3–4,” into a single empirical CDF denoted as “A≠B”.
References
- Jost, L. Entropy and diversity. Oikos 2006, 113, 363–375. [Google Scholar] [CrossRef]
- Prehn-Kristensen, A.; Zimmermann, A.; Tittmann, L.; Lieb, W.; Schreiber, S.; Baving, L.; Fischer, A. Reduced microbiome alpha diversity in young patients with ADHD. PLoS ONE 2018, 13, e0200728. [Google Scholar] [CrossRef] [PubMed]
- Cowell, F. Measuring Inequality, 2nd ed.; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Higgins, J.P.T.; Thompson, S.G.; Deeks, J.J.; Altman, D.G. Measuring inconsistency in meta-analyses. BMJ Br. Med. J. 2003, 327, 557–560. [Google Scholar] [CrossRef]
- Hooper, D.U.; Chapin, F.S.; Ewel, J.J.; Hector, A.; Inchausti, P.; Lavorel, S.; Lawton, J.H.; Lodge, D.M.; Loreau, M.; Naeem, S.; et al. Effects of biodiversity on ecosystem functioning: A consensus of current knowledge. Ecol. Monogr. 2005, 75, 3–35. [Google Scholar] [CrossRef]
- Botta-Dukát, Z. The generalized replication principle and the partitioning of functional diversity into independent alpha and beta components. Ecography 2018, 41, 40–50. [Google Scholar] [CrossRef]
- Mouchet, M.A.; Villéger, S.; Mason, N.W.; Mouillot, D. Functional diversity measures: An overview of their redundancy and their ability to discriminate community assembly rules. Funct. Ecol. 2010, 24, 867–876. [Google Scholar] [CrossRef]
- Chiu, C.H.; Chao, A. Distance-based functional diversity measures and their decomposition: A framework based on hill numbers. PLoS ONE 2014, 9, e113561. [Google Scholar] [CrossRef] [PubMed]
- Petchey, O.L.; Gaston, K.J. Functional diversity (FD), species richness and community composition. Ecol. Lett. 2002. [Google Scholar] [CrossRef]
- Leinster, T.; Cobbold, C.A. Measuring diversity: The importance of species similarity. Ecology 2012, 93, 477–489. [Google Scholar] [CrossRef]
- Chao, A.; Chiu, C.H.; Jost, L. Unifying Species Diversity, Phylogenetic Diversity, Functional Diversity, and Related Similarity and Differentiation Measures Through Hill Numbers. Annu. Rev. Ecol. Evol. Syst. 2014, 45, 297–324. [Google Scholar] [CrossRef]
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Publishing: Washington, DC, USA, 2013. [Google Scholar]
- Regier, D.A.; Narrow, W.E.; Clarke, D.E.; Kraemer, H.C.; Kuramoto, S.J.; Kuhl, E.A.; Kupfer, D.J. DSM-5 field trials in the United States and Canada, part II: Test-retest reliability of selected categorical diagnoses. Am. J. Psychiatr. 2013, 170, 59–70. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Arvanitidis, G.; Hansen, L.K.; Hauberg, S. Latent Space Oddity: On the Curvature of Deep Generative Models. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–15. [Google Scholar]
- Shao, H.; Kumar, A.; Thomas Fletcher, P. The Riemannian geometry of deep generative models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Nickel, M.; Kiela, D. Poincaré embeddings for learning hierarchical representations. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6339–6348. [Google Scholar]
- Rényi, A. On measures of information and entropy. Proc. Fourth Berkeley Symp. Math. Stat. Probab. 1961, 114, 547–561. [Google Scholar]
- Hill, M.O. Diversity and Evenness: A Unifying Notation and Its Consequences. Ecology 1973, 54, 427–432. [Google Scholar] [CrossRef]
- Hannah, L.; Kay, J.A. Concentration in Modern Industry: Theory, Measurement and The U.K. Experience; The MacMillan Press, Ltd.: London, UK, 1977. [Google Scholar]
- Ricotta, C.; Szeidl, L. Diversity partitioning of Rao’s quadratic entropy. Theor. Popul. Biol. 2009, 76, 299–302. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. ICLR 2014 2014, arXiv:1312.6114v10. [Google Scholar]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. Found. Trend. Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Eliazar, I.I.; Sokolov, I.M. Measuring statistical evenness: A panoramic overview. Phys. A Stat. Mech. Its Appl. 2012, 391, 1323–1353. [Google Scholar] [CrossRef]
- Patil, A.G.P.; Taillie, C. Diversity as a Concept and its Measurement. J. Am. Stat. Assoc. 1982, 77, 548–561. [Google Scholar] [CrossRef]
- Adelman, M.A. Comment on the “H” Concentration Measure as a Numbers-Equivalent. Rev. Econ. Stat. 1969, 51, 99–101. [Google Scholar] [CrossRef]
- Jost, L. Partitioning Diversity into Independent Alpha and Beta Components. Ecology 2007, 88, 2427–2439. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Eliazar, I. How random is a random vector? Ann. Phys. 2015, 363, 164–184. [Google Scholar] [CrossRef]
- Gotelli, N.J.; Chao, A. Measuring and Estimating Species Richness, Species Diversity, and Biotic Similarity from Sampling Data. In Encyclopedia of Biodiversity, 2nd ed.; Levin, S.A., Ed.; Academic Press: Waltham, MA, USA, 2013; pp. 195–211. [Google Scholar]
- Berger, W.H.; Parker, F.L. Diversity of planktonic foraminifera in deep-sea sediments. Science 1970, 168, 1345–1347. [Google Scholar] [CrossRef] [PubMed]
- Daly, A.; Baetens, J.; De Baets, B. Ecological Diversity: Measuring the Unmeasurable. Mathematics 2018, 6, 119. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Simpson, E.H. Measurement of Diversity. Nature 1949, 163, 688. [Google Scholar] [CrossRef]
- Gini, C. Variabilità e mutabilità. Contributo allo Studio delle Distribuzioni e delle Relazioni Statistiche; C. Cuppini: Bologna, Italy, 1912. [Google Scholar]
- Shorrocks, A.F. The Class of Additively Decomposable Inequality Measures. Econometrica 1980, 48, 613–625. [Google Scholar] [CrossRef]
- Jost, L. Mismeasuring biological diversity: Response to Hoffmann and Hoffmann (2008). Ecol. Econ. 2009, 68, 925–928. [Google Scholar] [CrossRef]
- Pigou, A.C. Wealth and Welfare; MacMillan and Co., Ltd: London, England, 1912. [Google Scholar]
- Dalton, H. The Measurement of the Inequality of Incomes. Econ. J. 1920, 30, 348. [Google Scholar] [CrossRef]
- Macarthur, R.H. Patterns of species diversity. Biol. Rev. 1965, 40, 510–533. [Google Scholar] [CrossRef]
- Lande, R. Statistics and partitioning of species diversity and similarity among multiple communities. Oikos 1996, 76, 5–13. [Google Scholar] [CrossRef]
- Rao, C.R. Diversity and dissimilarity coefficients: A unified approach. Theor. Popul. Biol. 1982, 21, 24–43. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and hrases and their compositionality. In Proceedings of the NIPS 2013, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1–9. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Nunes, A.; Alda, M.; Trappenberg, T. On the Multiplicative Decomposition of Heterogeneity in Continuous Assemblages. arXiv 2020, arXiv:2002.09734. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the Advances in Neural Information Processing Systems 6, Denver, CO, USA, 29 November–2 December 1993; pp. 737–744. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the CVPR 2006, New York, NY, USA, 17–22 June 2006; pp. 1735–1742. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).