Abstract
Stochastic separation theorems play important roles in high-dimensional data analysis and machine learning. It turns out that in high dimensional space, any point of a random set of points can be separated from other points by a hyperplane with high probability, even if the number of points is exponential in terms of dimensions. This and similar facts can be used for constructing correctors for artificial intelligent systems, for determining the intrinsic dimensionality of data and for explaining various natural intelligence phenomena. In this paper, we refine the estimations for the number of points and for the probability in stochastic separation theorems, thereby strengthening some results obtained earlier. We propose the boundaries for linear and Fisher separability, when the points are drawn randomly, independently and uniformly from a d-dimensional spherical layer and from the cube. These results allow us to better outline the applicability limits of the stochastic separation theorems in applications.
1. Introduction
It is generally accepted that the modern information world is the world of big data. However, some of the implications of the advent of the big data era remain poorly understood. In his “millennium lecture”, D. L. Donoho [1] described the post-classical world in which the number of features d is much greater than the sample size n: . It turns out that many phenomena of the post-classical world are already observed if , or, more precisely, when , where ID is the intrinsic dimensionality of the data [2]. Classical methods of data analysis and machine learning become of little use in such a situation, because usually they require huge amounts of data. Such an unlimited appetite of classical approaches for data is usually considered as a phenomenon of the “curse of dimensionality”. However, the properties or themselves are neither a curse nor a blessing, and can be beneficial.
One of the “post-classical” phenomena is stochastic separability [3,4,5]. If the dimensionality of data is high, then under broad assumptions any sample of the data set can be separated from the rest by a hyperplane (or even Fisher discriminant—as a special case) with a probability close to 1 even the number of samples is exponential in terms of dimensions. Thus, high-dimensional datasets exhibit fairly simple geometric properties.
Recently, stochastic separation theorems have been widely used in machine learning for constructing correctors and ensembles of correctors of artificial intelligence systems [6,7], for determining the intrinsic dimensionality of data sets [8,9], for explaining various natural intelligence phenomena, such as grandmother’s neuron [10,11].
In its usual form a stochastic separation theorem is formulated as follows. A random n-element set in is linearly separable with probability , if . The exact form of the exponential function depends on the probability distribution that determines how the random set is drawn, and on the constant (). In particular, uniform distributions with different support are considered in [5,12,13,14]. Wider classes of distributions (including non-i.i.d.) are considered in [7]. Roughly speaking, these classes consist of distributions without sharp peaks in sets with exponentially small volume. Estimates for product distributions in the cube and the standard normal distribution are obtained in [15]. General stochastic separation theorems with optimal bounds for important classes of distributions (log-concave distribution, their convex combinations and product distributions) are proposed in [2].
We note that there are many algorithms for constructing a functional separating a point from all other points in a data set (Fisher linear discriminant, linear programming algorithm, support vector machine, Rosenblatt perceptron, etc.). Among all these methods the computationally cheapest is Fisher discriminant analysis [6]. Other advantages of the Fisher discriminant analysis are its simplicity and the robustness.
The papers [5,6,7,12] deal with only Fisher separability, whereas [13,14] considered a (more general) linear separability. A comparison of the estimations for linear and Fisher separability allows us to clarify the applicability boundary of these methods, namely, to answer the question of what d and n are sufficient in order to use only Fisher separability and so that there is no need to search a more sophisticated linear discriminant.
In [13,14], there were obtained estimates for the cardinality of the set of points that guarantee its linear separability when the points are drawn randomly, independently and uniformly from a d-dimensional spherical layer and from the unit cube. These results give more accurate estimates than the bounds obtained in [5,12] for Fisher separability.
Our interest in the study of the linear separability in spherical layers is explained, among other reasons, by the possibility of applying our results to determining the intrinsic dimension of data. After applying PCA to the data points for the selection of the major components and subsequent whitening we can map them to a spherical layer of a given thickness. If the intrinsic dimensionality of the initial set of n points is ID, then we expect that the separability properties of the resulting set of points are similar to the properties of uniformly distributed n points in dimension d. In particular, we can use the theoretical estimates for the separation probability to estimate ID (cf. [8,9]).
Here we give even more precise estimations for the number of points in the spherical layer to guarantee their linear separability. We also consider the case of linear separability of random points inside a cube in more detail than it was done in [13]. In particular, we give estimates for the probability of separability of one point. We also report results of computational experiments comparing the theoretical estimations for the probability of the linear and Fisher separabilities with the corresponding experimental frequencies and discuss them.
2. Definitions
A point is linearly separable from a set if there exists a hyperplane separated X from M; i.e., there exists such that for all .
A point is Fisher separable from the set if for all [6,7].
A set of points is called linearly separable [5] or 1-convex [3] if any point is linearly separable from all other points in the set, or in other words, the set of vertices of their convex hull, , coincides with . The set is called Fisher separable if for all i, j, such that [6,7].
Fisher separability implies linear separability but not vice versa (even if the set is centered and normalized to unit variance). Thus, if is a random set of points from a certain probability distribution, then the probability that M is linearly separable is not less than the probability that M is Fisher separable.
Denote by the d-dimensional unit ball centered at the origin ( means Euclidean norm), is the d-dimensional ball of radius centered at the origin and is the d-dimensional unit cube.
Let be the set of points chosen randomly, independently, according to the uniform distribution on the ()-thick spherical layer , i.e., on the unit ball with spherical cavity of radius r. Denote by the probability that is linearly separable, and by the probability that is Fisher separable. Denote by the probability that a random point chosen according to the uniform distribution on is separable from , and by the probability that a random point is Fisher separable from .
Now let be the set of points chosen randomly, independently, according to the uniform distribution on the cube . Let and denote the probabilities that is linearly separable and Fisher separable, respectively. Let and denote the probabilities that a random point chosen according to the uniform distribution on is separable and Fisher separable from , respectively.
3. Previous Results
3.1. Random Points in a Spherical Layer
In [5] it was shown (among other results) that for all r, , n and d, where , , , if
then n points chosen randomly, independently, according to the uniform distribution on are Fisher separable with a probability greater than , i.e., .
The following statements concerning the Fisher separability of random points in the spherical layer are proved in [12].
- For all r, where , and for any
- For all r, , where , , and for sufficiently large d, ifthen .
- For all r, where , and for any
- For all r, , where , and for sufficiently large d, ifthen .
The authors of [5,12] formulate their results for linearly separable sets of points, but in fact in the proofs they used that the sets are only Fisher separable.
Note that all estimates (1)–(5) require with strong inequality. This means that they are inapplicable for (maybe the most interesting) case , i.e., for the unit ball with no cavities.
A reviewer of the original version of the article drew our attention that for better results are obtained in [6,15]. Specifically,
and provided that . See details in Section 4.4.
The both estimates (1) and (5) are exponentially dependent on d for fixed r, and the estimate (1) is weaker than (5).
The following results concerning the linear separability of random points in the spherical layer were obtained in [14]:
- For all r, where , and for any
- For all r, , where and for any , ifthen
- For all r, where , and for any
- For all r, , where and for any d, ifthen
3.2. Random Points Inside a Cube
In [5], a product distribution in the is considered. Let the coordinates of a random point be independent random variables with variances . In [5], it is shown that for all and n, where , if
then is Fisher separable with a probability greater than . As above, the authors of [5] formulate their result for the linearly separable case, but in fact they used only the Fisher separability.
If all random variables have the uniform distribution on the segment then Thus, the inequality (12) takes the form
We obtain that if n satisfies (13), then .
In [13], it was shown that if we want to guarantee only the linear separability, then the bound (13) can be increased. Namely, if
then . Here we give related estimates including ones for the linear separability of one point (see Theorems 5 and 6 and Corollary 3).
We note that better (and in fact asymptotically optimal) estimates for the Fisher separability in the unit cube are derived in [15]. The papers [13,15] were submitted to the same conference, so these results were derived in parallel and independently. Corollary 7 in [15] states that n points are Fisher separable with probability greater than provided only that for See details in Section 5.
4. Random Points in a Spherical Layer
4.1. The Separability of One Point
The theorem below gives the probability of the linear separability of a random point from a random n-element set in The proof develops an approach borrowed from [3,16].
The regularized incomplete beta function is defined as , where
are beta function and incomplete beta function, respectively (see [17]).
Theorem 1.
Let , . Then
- (1)
- for
- (2)
- for
Proof.
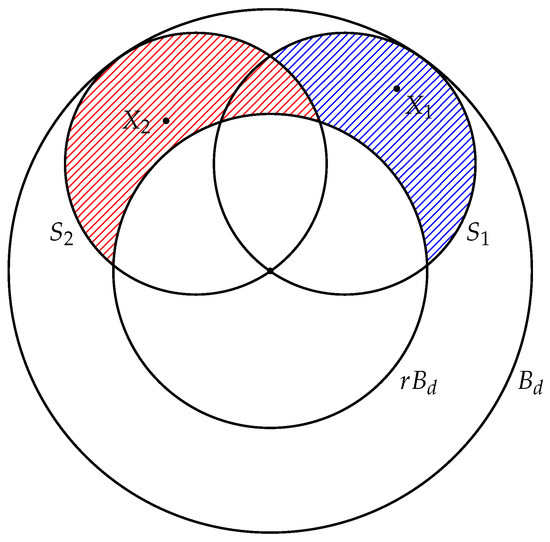
A random point Y is linearly separable from if and only if Denote this event by Thus, Let us find the upper bound for the probability of the event This event means that the point Y belongs to the convex hull of Since the points in have the uniform distribution, then the probability of is
First, estimate the numerator of this fraction. We denote by the ball with center at the origin, with the diameter 1, and the point lies on this diameter (see Figure 1). Then
and
where is the volume of a ball of radius 1. Hence
Figure 1.
Illustration to the proof of Theorem 1.
Now find It is obvious that is equal to the sum of the volumes of two spherical caps. We denote by the volume of a spherical cap of height H of a ball of radius It is known [18] that
if
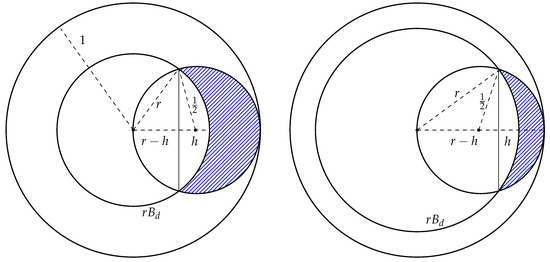
Consider two cases: and (see Figure 2)
Figure 2.
Illustration to the proof of Theorem 1: case 1 (left); case 2 (right).
Case 1 If , then the centers of the balls are inside of the spherical caps of height h of the ball (see the left picture on Figure 2). Therefore, the following equalities are true:
If , then , hence
If , then , hence
Thus,
Hence
Case 2 If , then the centers of the balls are outside of the spherical caps of height h of the ball (see the right picture on Figure 2). Therefore, the following equalities are true:
If , then ; hence,
where
where Thus,
Hence
The estimates (14) and (15) for are monotonically increasing in both d and r and decreasing in n, which corresponds to the behavior of the probability itself (see Figure 3 and Figure 4). On the contrary, the estimate (3) for the probability is nonmonotonic in r (see Figure 5).
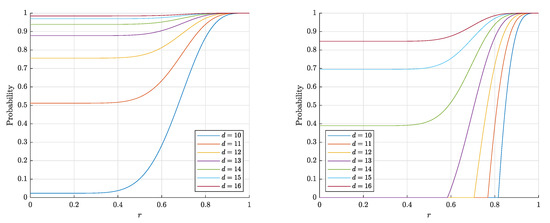
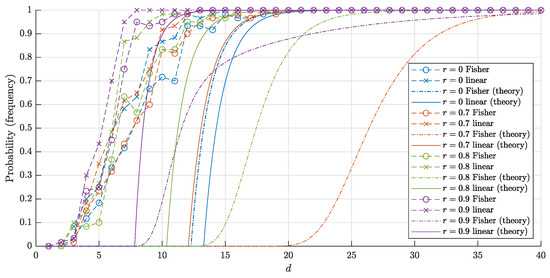
Figure 4.
The graphs of the estimates for the probabilities () that a random point is linearly (and respectively, Fisher) separable from a set of 10,000 random points in the layer . The solid lines correspond to the theoretical bounds (14) and (15) for the linear separability. The dash-dotted lines represent the theoretical bounds (2) and (6) for the Fisher separability. The crosses (circles) correspond to the empirical frequencies for linear (and respectively Fisher) separability obtained in 60 trials for each dimension d.
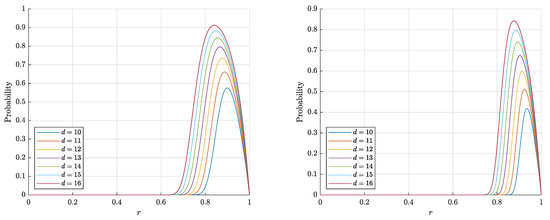
Figure 5.
The graphs of the right-hand side of the estimate (3) for the probability that a random point is Fisher separable from a set of (left) and 10,000 (right) random points in the layer .
Note that the estimates (14), (15) obtained in Theorem 1 are quite accurate (in the sense that they are close to empirical values), as is illustrated with Figure 4. The experiment also shows that the probabilities and (more precisely, the corresponding frequencies) are quite close to each other, but there is a certain gap between them.
The following corollary gives an estimate for the number of points n guaranteeing the linear separability of a random point from a random n-element set in with probability close to 1.
Corollary 1.
Let . If
- (1)
- or
- (2)
then
The theorem below establishes asymptotic estimates.
Theorem 2.
- (1)
- If then
- (2)
- If then
- (3)
- If then
Proof.
The paper [19] gives the following asymptotic expansion for the incomplete beta function
and
Since then
Since for b fixed and , then
for fixed and .
We have or and ; hence,
If , then ; hence,
If , then ; hence,
and
If , then ; hence,
If , then ; hence,
and
□
4.2. Separability of a Set of Points
The theorem below gives the probability of the linear separability of a random n-element set in .
Theorem 3.
Let , and . Then
- (1)
- for
- (2)
- for
Proof.
Denote by the event that is linearly separable and denote by the event that (). Thus, Clearly, and Let us find an upper bound for the probability of the event This event means that the point belongs to the convex hull of the remaining points, i.e., In the proof of the previous theorem, it was shown that if , then
and if , then
Therefore, using the inequality
we obtain what is required. □
The graphs of the estimates (16), (17) and corresponding frequencies in 60 trials for and n = 10,000 points are shown in Figure 6 and Figure 7, respectively. The experiment shows that our estimates are quite accurate and close to the corresponding frequencies.
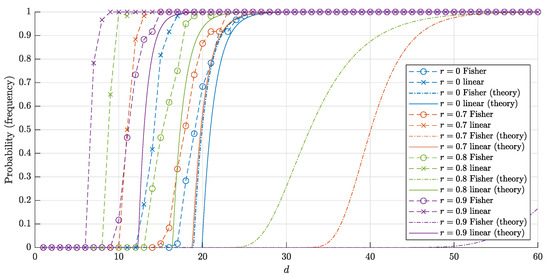
Figure 6.
The graphs of the estimates for the probabilities () that a random set of points in is linearly (and respectively Fisher) separable. The solid lines correspond to the theoretical bounds (16) and (17) for the linear separability. The dash-dotted lines represent the theoretical bound (4) and (7) for the Fisher separability. The crosses (circles) correspond to the empirical frequencies for linear (and respectively, Fisher) separability obtained in 60 trials for each dimension d.
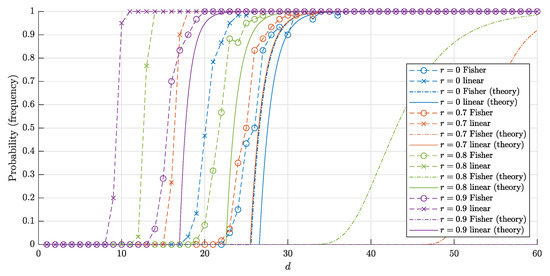
Figure 7.
The graphs of the estimates for the probabilities () that a random set of 10,000 points in is linearly (and respectively, Fisher) separable. The notation is the same as in Figure 6.
Another important conclusion from the experiment is as follows. Despite the fact that the estimates for both probabilities and and corresponding frequencies are close to 1 for sufficiently big d, the "threshold values" for such a big d differ greatly. In other words, the blessing of dimensionality when using linear discriminants comes noticeably earlier than if we only use Fisher discriminants. This is achieved at the cost of constructing the usual linear discriminant in comparison with the Fisher one.
The following corollary gives an estimate for the number of points n guaranteeing the linear separability of a random n-element set in with probability close to 1.
Corollary 2.
Let . If
- (1)
- or
- (2)
- then
The theorem below establishes asymptotic estimates for the number of points guaranteeing the linear separability with probability greater than
Theorem 4.
- (1)
- If then
- (2)
- If then
- (3)
- If then
4.3. Comparison of the Results
Let us show that the new estimates (16) and (17) for linear separability tend to be 1 faster than the estimate (4) in [12] for Fisher separability.
Statement 1.
Let and
For r and n fixed
- (1)
- if , then
- (2)
- if , then
- (3)
- if , then
Proof.
If then and (see the proof of Theorem 2); hence,
If then and (see the proof of Theorem 2); hence,
If then and (see the proof of Theorem 2), hence
□
Now let us compare the estimates for the number of points that guarantee the linear and Fisher separabilities of random points in the spherical layer obtained in Corollary 2 and in [12], respectively. The estimate in Corollary 2 for the number of points guaranteeing the linear separability tends to ∞ faster than the estimate (5), guaranteeing the Fisher separability for all .
Statement 2.
Let For r and ϑ fixed
- (1)
- if , then
- (2)
- if , then
- (3)
- if , then
Proof.
If then
If , then and ; hence,
If , then ; hence,
□
4.4. A Note about Random Points Inside the Ball ()
A reviewer of the original version of the article drew our attention to the fact that for the uniform distribution inside the ball (case ), better results are known. Specifically, let be the probability that i.i.d. points x, y inside the ball are not Fisher separable. Let be the indicator function of this event. Then
where denotes the probability that x is not Fisher separable from a given point y. In [6] (also discussed in [15]), there is a proof that . In the notation of our paper, this implies that
and provided that . This improves the estimate in Theorem 2 for the case twice. Note that the same estimate was derived for (see Theorem 2). The reviewer conjectured that estimate derived in this paper could be improved twice for the whole range . The experimental results give support for this hypothesis (see Figure 4, Figure 5, Figure 6 and Figure 7).
5. Random Points Inside a Cube
Consider a set of points choosing randomly, independently and according to the uniform distribution on the d-dimensional unit cube .
Theorem 5.
Let . Then
Proof.
A random point Y is linearly separable from if and only if Denote this event by Thus, Let us find the upper bound for the probability of the event This event means that the point Y belongs to the convex hull of Since the points in have the uniform distribution, the probability of is
In [20] it is proved that the upper bound for the maximal volume of the convex hull of k points placed in is where Thus, so
and
□
Corollary 3.
Let
Then
Theorem 6.
Let . Then
Proof.
Denote by the event that is linearly separable and denote by the event that (). Thus, Clearly and Let us find the upper bound for the probability of the event This event means that the point belongs to the convex hull of the remaining points, i.e., In the proof of the previous theorem, it was shown that
Hence
□
Corollary 4.
[13] Let ,
Then
We note that the estimate (21) for the number of points guaranteeing the linear separability tends to be ∞ faster than the estimate (13), guaranteeing the Fisher separability because
since
However better (and in fact asymptotically optimal) estimates for the Fisher separability in the unit cube are derived in [15]. Corollary 7 in [15] states that n points are Fisher separable with probability greater than provided only that for . This can be written as for . Thus,
Theorem 6 and Corollary 4 in our paper state the same results with , and for just linear separability instead of Fisher separability. However, [13,15] were submitted to the same conference, so these results were derived in parallel and independently.
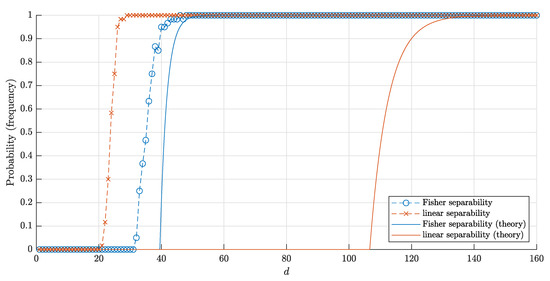
The bounds (18) and (20) for the probabilities and corresponding frequencies are presented in Figure 8 and Figure 9.
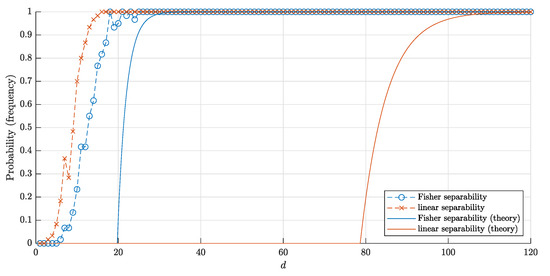
Figure 8.
The graphs of the estimate for the probabilities and that a random point is linearly (Fisher) separable from a set of n = 10,000 random points inside the cube . The solid red and blue lines correspond to the theoretical bounds (18) and (22) respectively. Red crosses (blue circles) correspond to the empirical frequencies for linear (and respectively, Fisher) separability obtained in 60 trials for each dimension d.
6. Subsequent Work
In a recent paper [2], explicit and asymptotically optimal estimates of Fisher separation probabilities for spherically invariant distribution (e.g., the standard normal and the uniform distributions) were obtained. Theorem 14 in [2] generalizes the results presented here. Since [2] was submitted to the arxiv later, we did not compare the results of that article with our results.
7. Conclusions
In this paper we refined the estimates for the number of points and for the probability in stochastic separation theorems. We gave new bounds for linear separability, when the points are drawn randomly, independently and uniformly from a d-dimensional spherical layer or from the unit cube. These results refine some results obtained in [5,12,13,14] and allow us to better understand the applicability limits of the stochastic separation theorems for high-dimensional data mining and machine learning problems.
The strongest progress was in the estimation for the number of random points in a -thick spherical layer that are linear separable with high probability. If
or
then n i.i.d. random points inside the spherical layer are linear separable with probability at least (the asymptotic inequalities are for ).
One of the main results of the experiment comparing linear and Fisher separabilities is as follows. The blessing of dimensionality when using linear discriminants can come noticeably earlier (for smaller values of d) than if we only use Fisher discriminants. This is achieved at the cost of constructing the usual linear discriminant in comparison with the Fisher one.
Author Contributions
Conceptualization, S.S. and N.Z.; methodology, S.S. and N.Z.; software, S.S. and N.Z.; validation, S.S. and N.Z.; formal analysis, S.S. and N.Z.; investigation, S.S. and N.Z.; resources, S.S. and N.Z.; data curation, S.S. and N.Z.; writing—original draft preparation, S.S. and N.Z.; writing—review and editing, S.S. and N.Z.; visualization, S.S. and N.Z.; supervision, S.S. and N.Z.; project administration, S.S. and N.Z.; funding acquisition, S.S. and N.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The work is supported by the Ministry of Science and Higher Education of the Russian Federation (agreement number 075-15-2020-808).
Acknowledgments
The authors are grateful to anonymous reviewers for valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Donoho, D.L. High-Dimensional Data Analysis: The Curses and Blessings of Dimensionality. Invited Lecture at Mathematical Challenges of the 21st Century. In Proceedings of the AMS National Meeting, Los Angeles, CA, USA, 6–12 August 2000; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.3392 (accessed on 9 November 2020).
- Grechuk, B.; Gorban, A.N.; Tyukin, I.Y. General stochastic separation theorems with optimal bounds. arXiv 2020, arXiv:2010.05241. [Google Scholar]
- Bárány, I.; Füredi, Z. On the shape of the convex hull of random points. Probab. Theory Relat. Fields 1988, 77, 231–240. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos. Trans. R. Soc. A 2009, 367, 4273–4293. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Tyukin, I.Y. Stochastic separation theorems. Neural Netw. 2017, 94, 255–259. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Golubkov, A.; Grechuk, B.; Mirkes, E.M.; Tyukin, I.Y. Correction of AI systems by linear discriminants: Probabilistic foundations. Inf. Sci. 2018, 466, 303–322. [Google Scholar] [CrossRef]
- Gorban, A.N.; Grechuk, B.; Tyukin, I.Y. Augmented artificial intelligence: A conceptual framework. arXiv 2018, arXiv:1802.02172v3. [Google Scholar]
- Albergante, L.; Bac, J.; Zinovyev, A. Estimating the effective dimension of large biological datasets using Fisher separability analysis. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Bac, J.; Zinovyev, A. Lizard brain: Tackling locally low-dimensional yet globally complex organization of multi-dimensional datasets. Front. Neurorobot. 2020, 13, 110. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. The unreasonable effectiveness of small neural ensembles in high-dimensional brain. Phys. Life Rev. 2019, 29, 55–88. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy 2020, 22, 82. [Google Scholar] [CrossRef]
- Gorban, A.N.; Burton, R.; Romanenko, I.; Tyukin, I.Y. One-trial correction of legacy AI systems and stochastic separation theorems. Inf. Sci. 2019, 484, 237–254. [Google Scholar] [CrossRef]
- Sidorov, S.V.; Zolotykh, N.Y. On the Linear Separability of Random Points in the d-dimensional Spherical Layer and in the d-dimensional Cube. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Sidorov, S.V.; Zolotykh, N.Y. Linear and Fisher Separability of Random Points in the d-dimensional Spherical Layer. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Grechuk, B. Practical stochastic separation theorems for product distributions. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Elekes, G. A geometric inequality and the complexity of computing volume. Discret. Comput. Geom. 1986, 1, 289–292. [Google Scholar] [CrossRef]
- Paris, R.B. Incomplete beta functions. In NIST Handbook of Mathematical Functions; Olver, F.W., Lozier, D.W., Boisvert, R.F., Clark, C.W., Eds.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Li, S. Concise Formulas for the Area and Volume of a Hyperspherical Cap. Asian J. Math. Stat. 2011, 4, 66–70. [Google Scholar] [CrossRef]
- López, J.L.; Sesma, J. Asymptotic expansion of the incomplete beta function for large values of the first parameter. Integral Transform. Spec. Funct. 1999, 8, 233–236. [Google Scholar] [CrossRef]
- Dyer, M.E.; Füredi, Z.; McDiarmid, C. Random points in the n-cube. DIMACS Ser. Discret. Math. Theor. Comput. Sci. 1990, 1, 33–38. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).