Linear and Fisher Separability of Random Points in the d-Dimensional Spherical Layer and Inside the d-Dimensional Cube


Abstract
1. Introduction
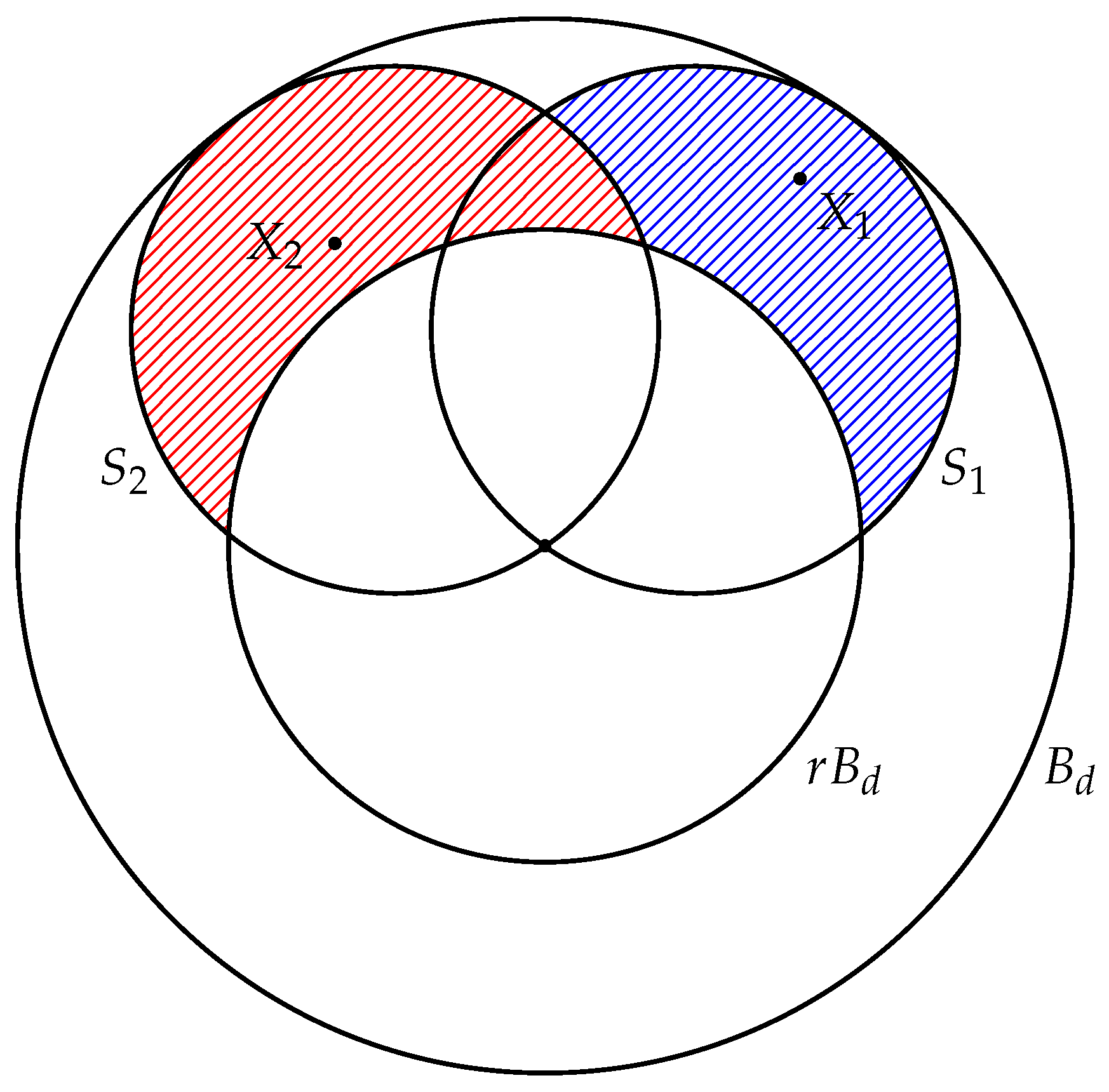
2. Definitions
3. Previous Results
3.1. Random Points in a Spherical Layer
- For all r, where , and for any
- For all r, , where , , and for sufficiently large d, ifthen .
- For all r, where , and for any
- For all r, , where , and for sufficiently large d, ifthen .
- For all r, where , and for any
- For all r, , where and for any , ifthen
- For all r, where , and for any
- For all r, , where and for any d, ifthen
3.2. Random Points Inside a Cube
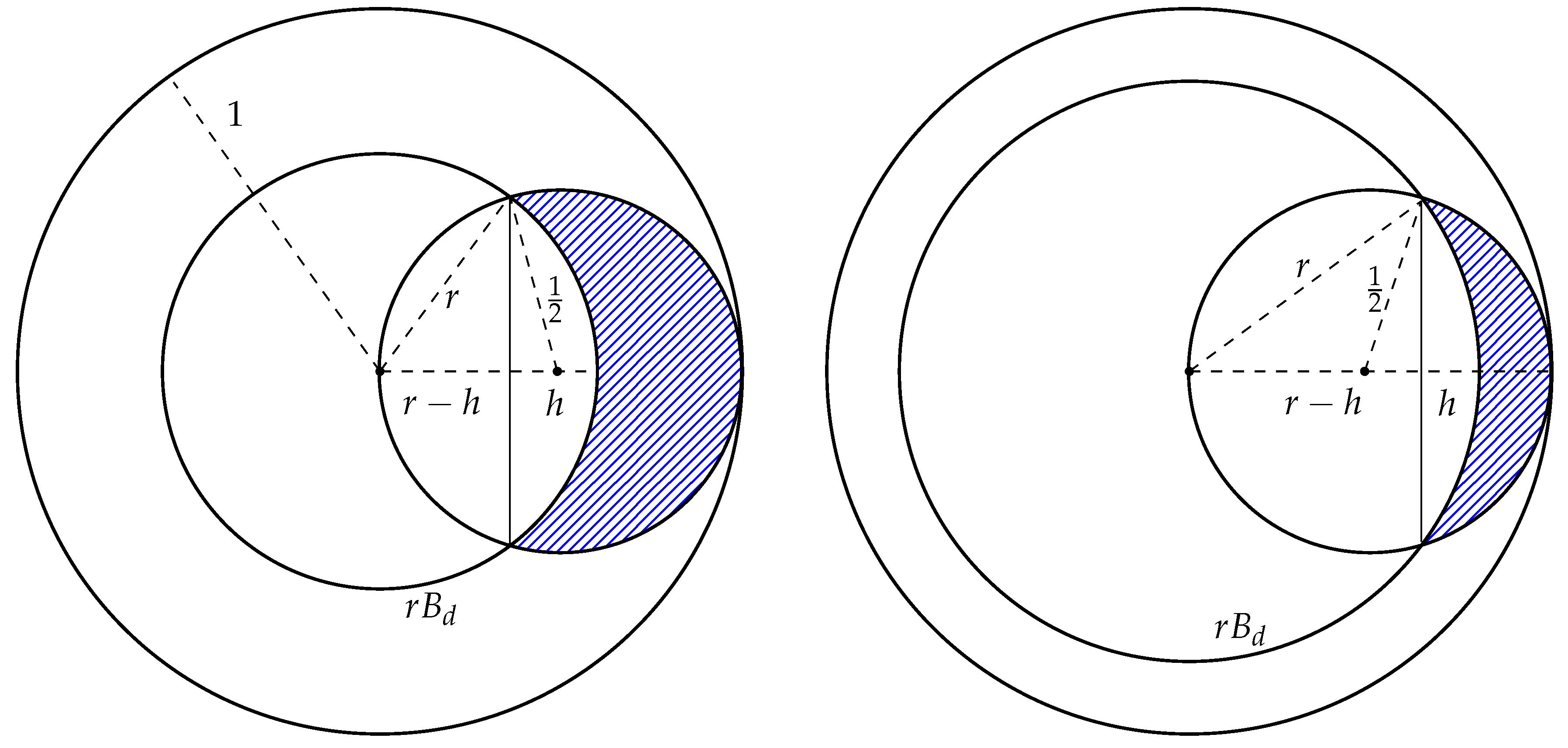
4. Random Points in a Spherical Layer
4.1. The Separability of One Point
- (1)
- for
- (2)
- for
- (1)
- or
- (2)
- (1)
- If then
- (2)
- If then
- (3)
- If then
4.2. Separability of a Set of Points
- (1)
- for
- (2)
- for
- (1)
- or
- (2)
- then
- (1)
- If then
- (2)
- If then
- (3)
- If then
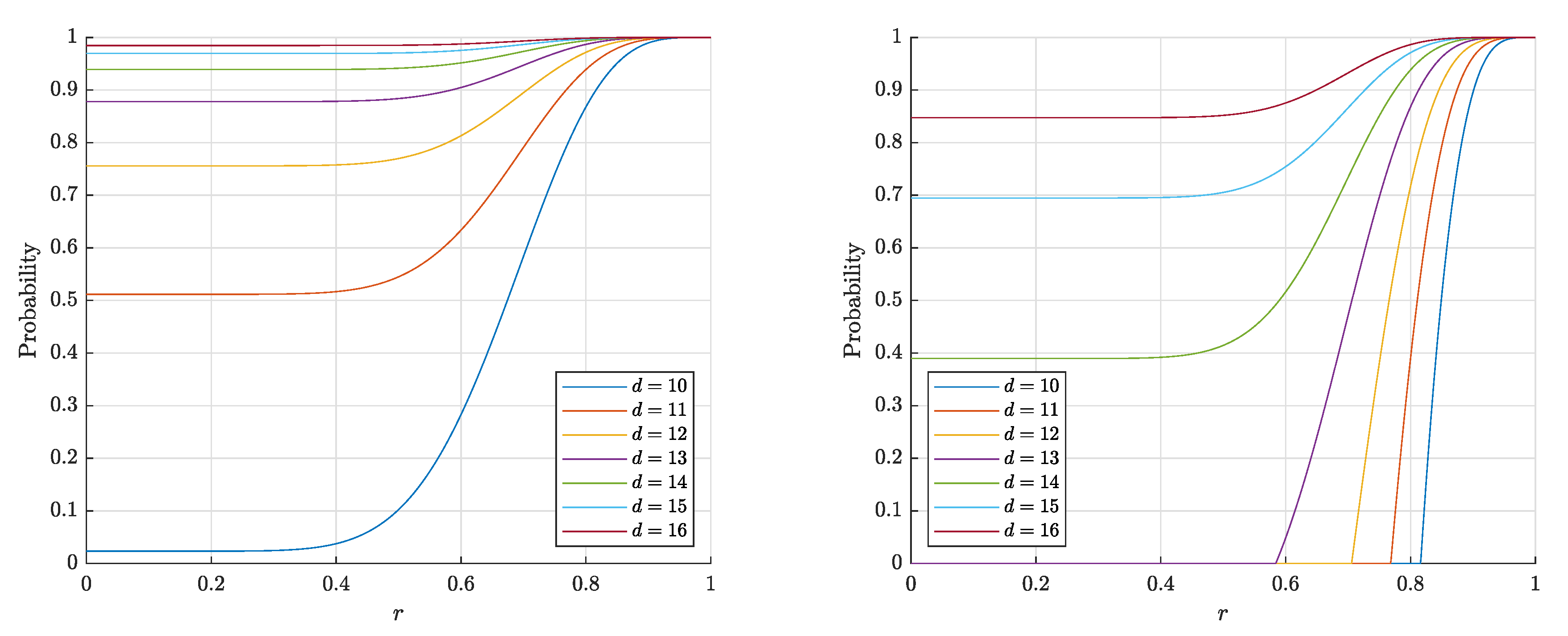
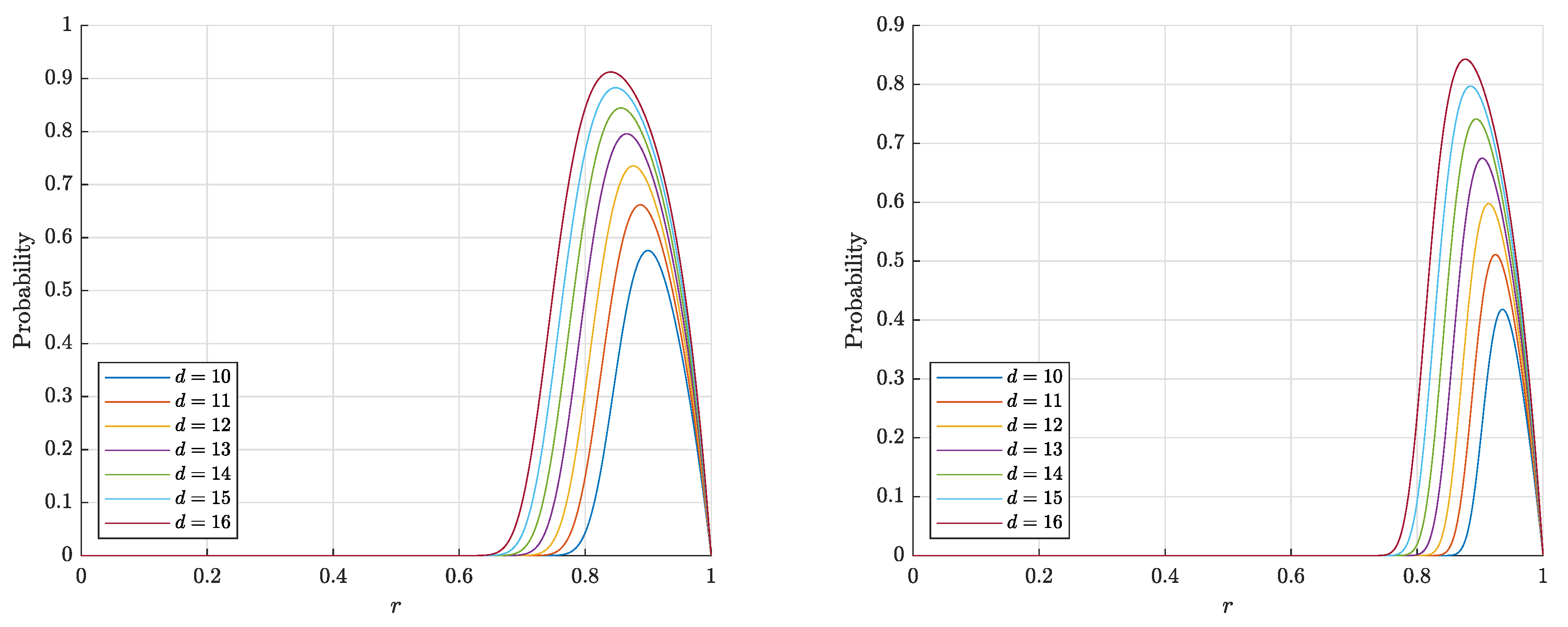
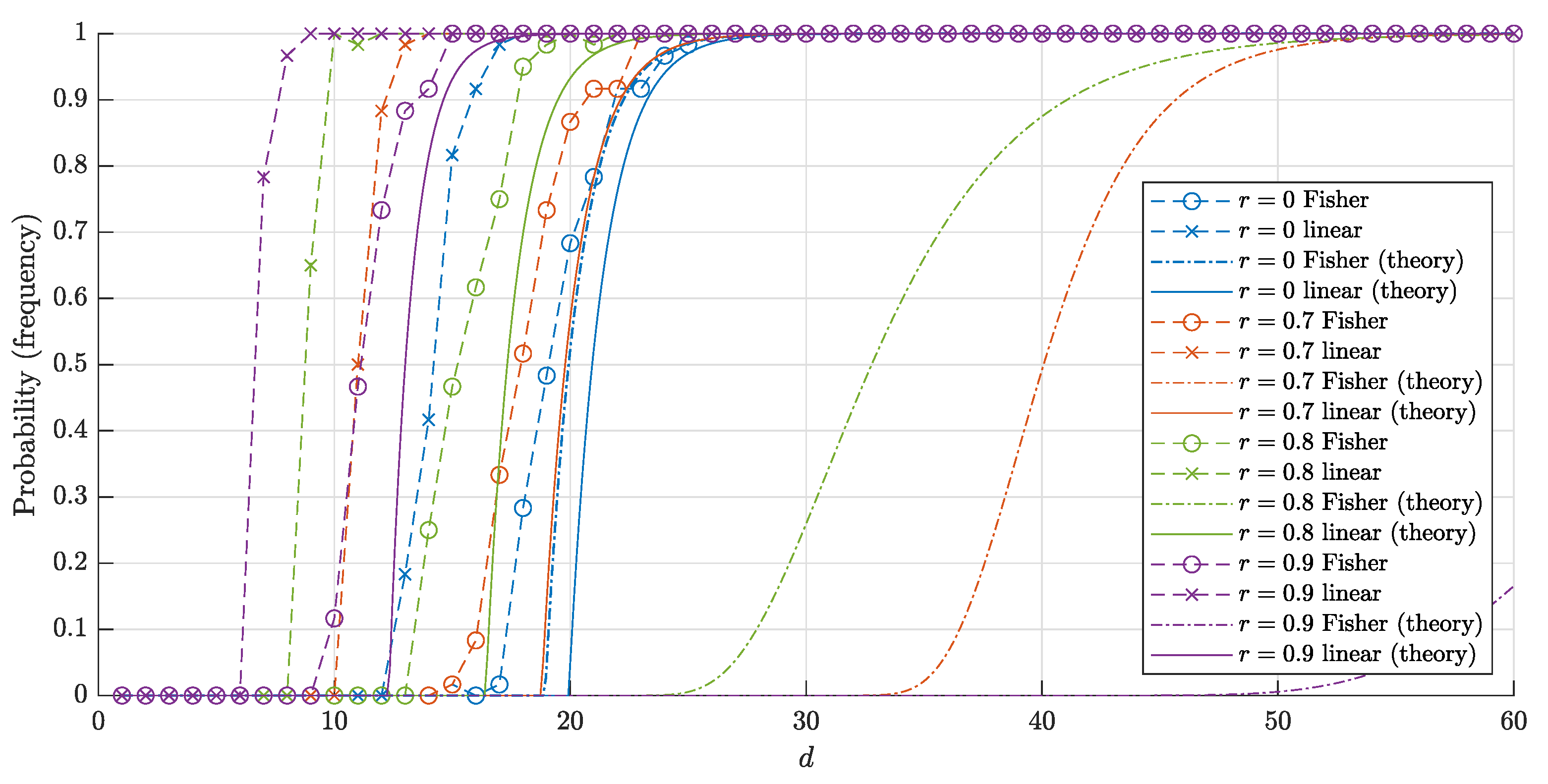
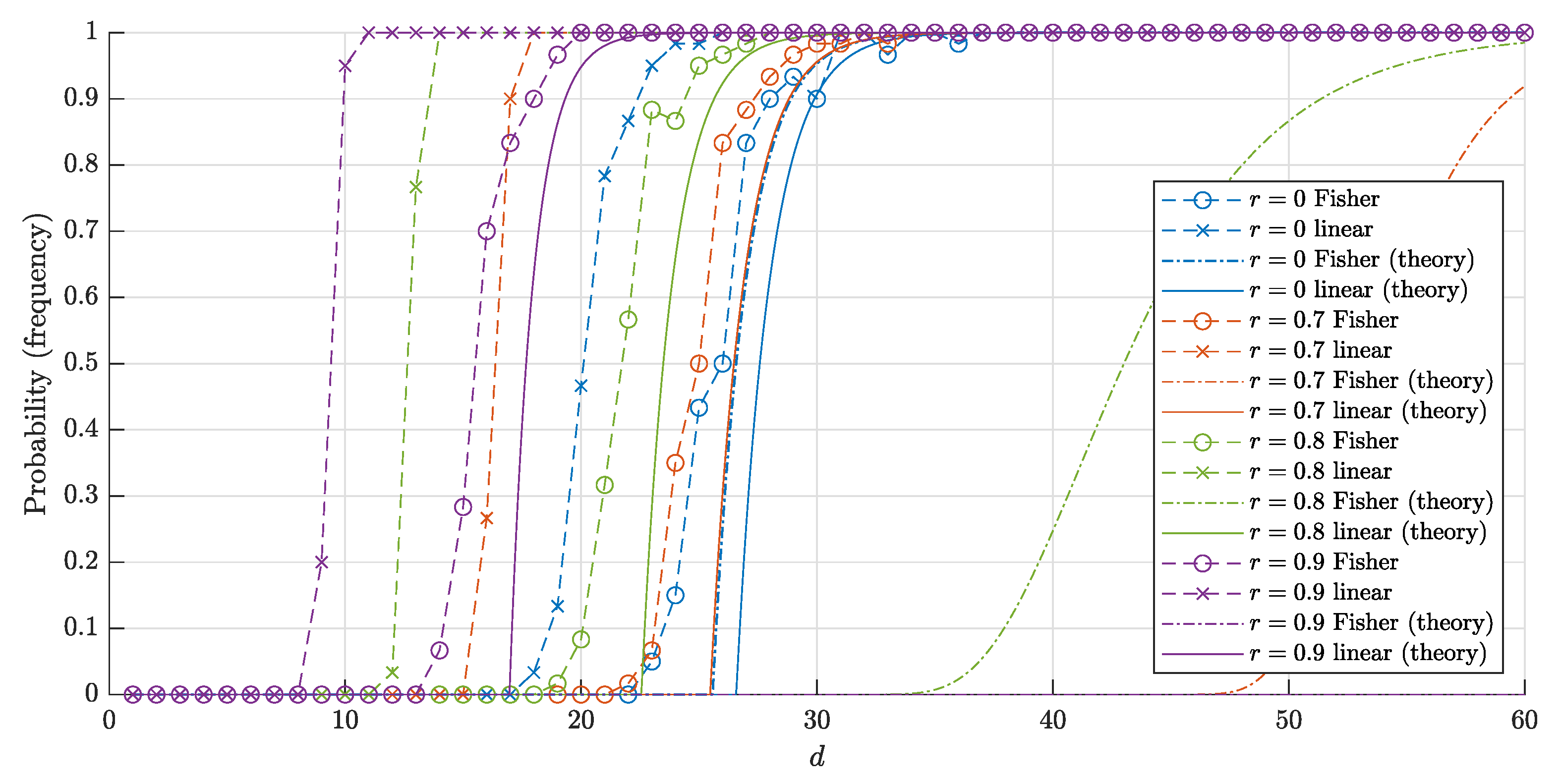
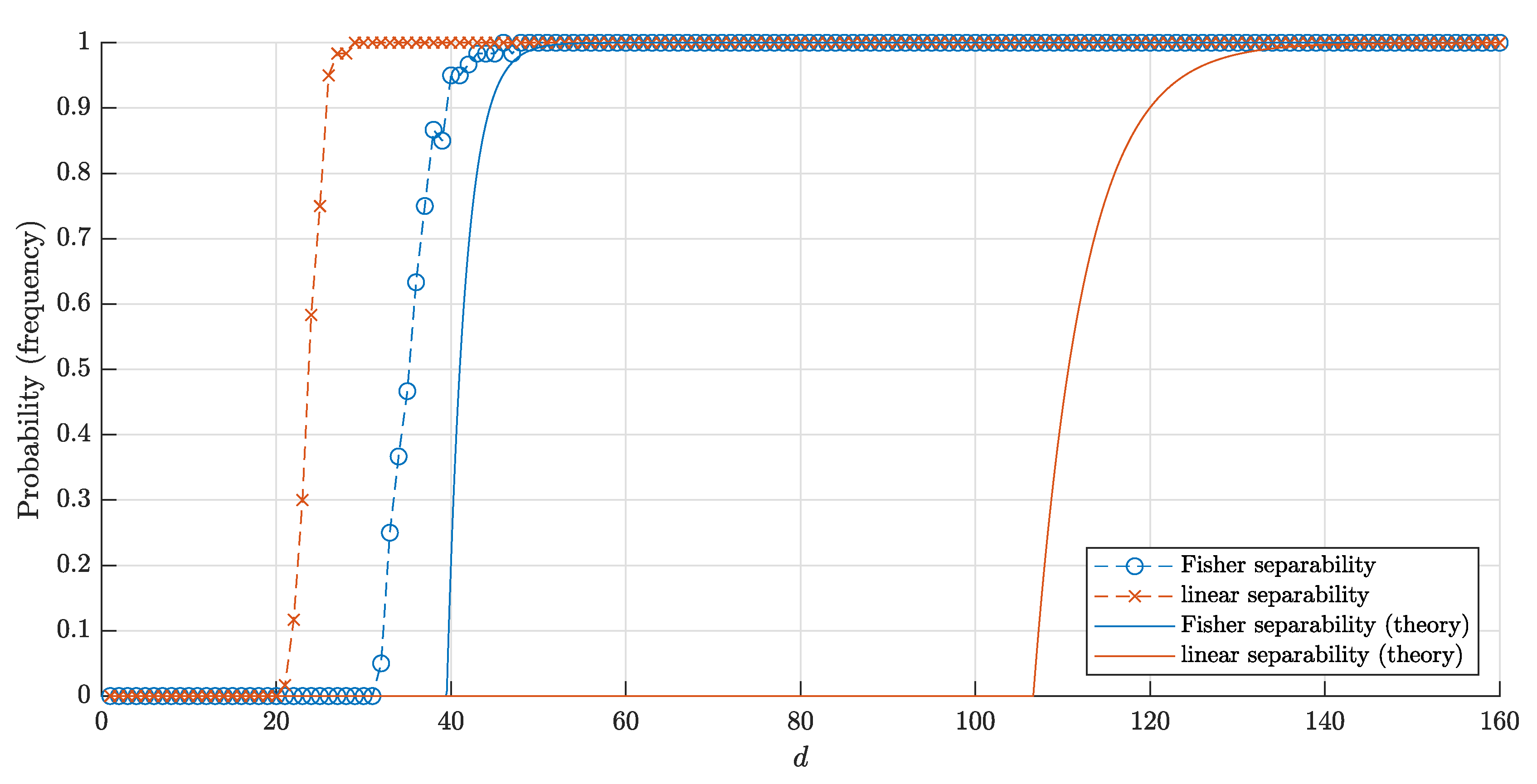
4.3. Comparison of the Results
- (1)
- if , then
- (2)
- if , then
- (3)
- if , then
- (1)
- if , then
- (2)
- if , then
- (3)
- if , then
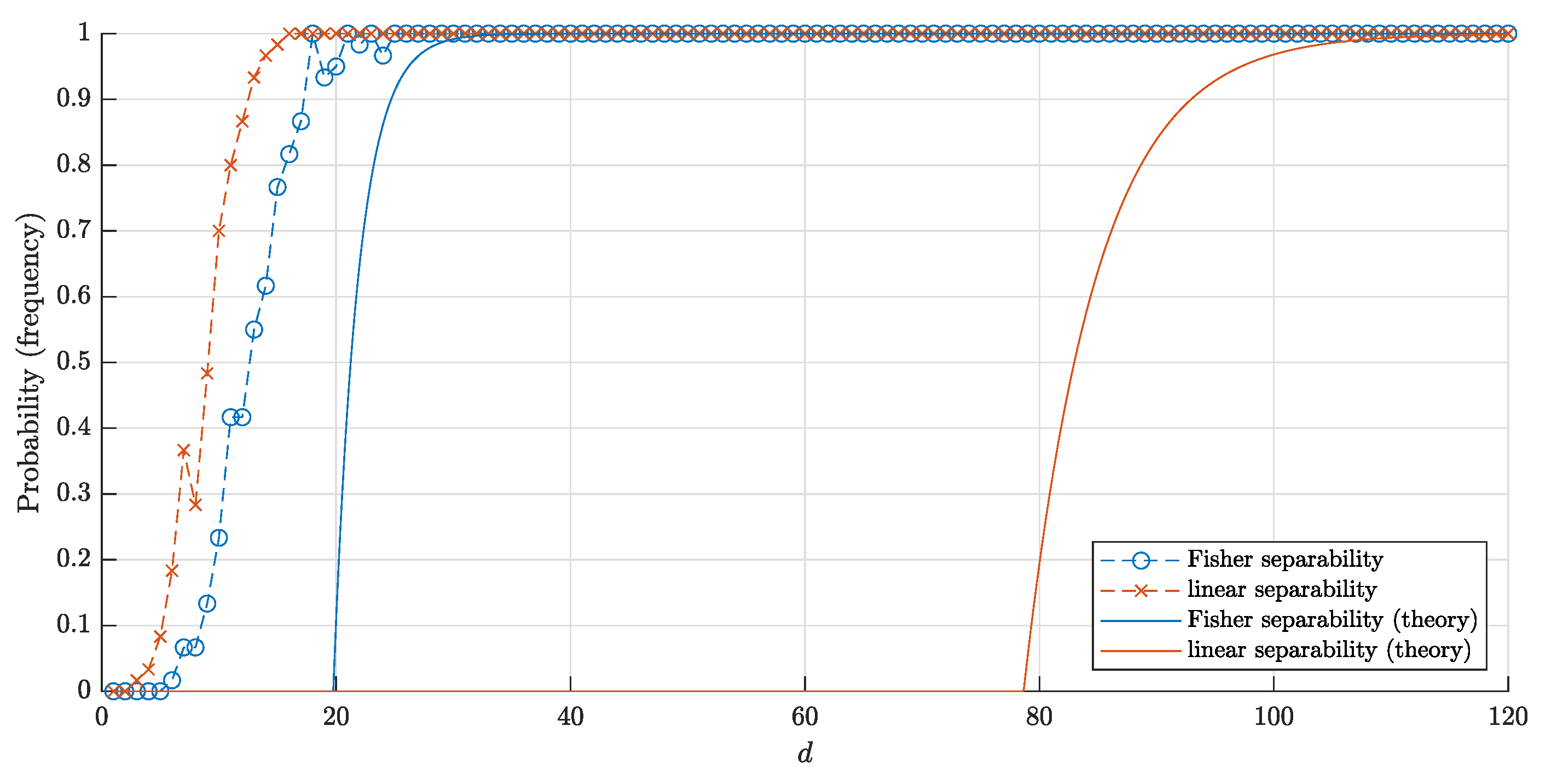
4.4. A Note about Random Points Inside the Ball ()
5. Random Points Inside a Cube
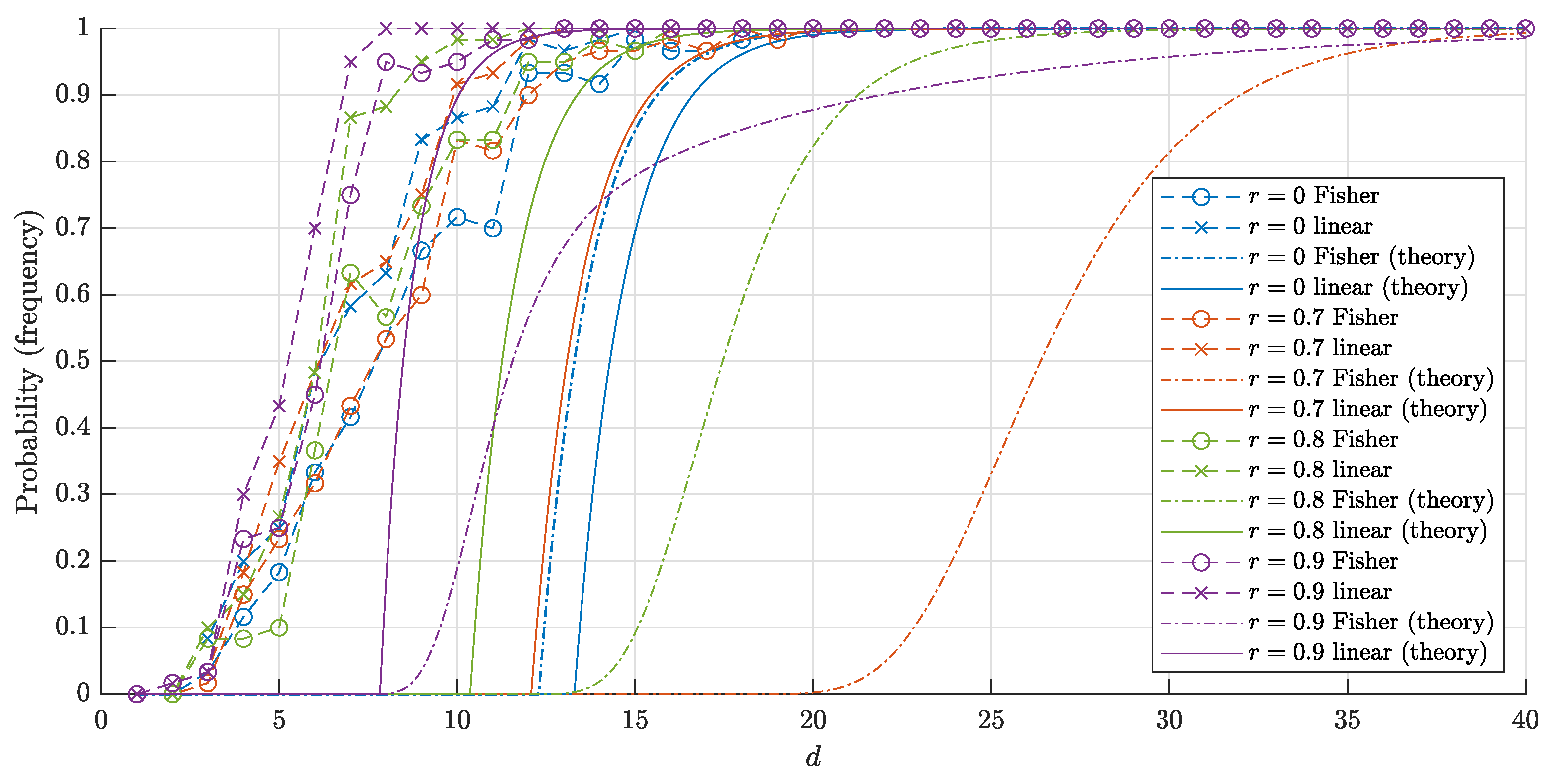
6. Subsequent Work
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Donoho, D.L. High-Dimensional Data Analysis: The Curses and Blessings of Dimensionality. Invited Lecture at Mathematical Challenges of the 21st Century. In Proceedings of the AMS National Meeting, Los Angeles, CA, USA, 6–12 August 2000; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.3392 (accessed on 9 November 2020).
- Grechuk, B.; Gorban, A.N.; Tyukin, I.Y. General stochastic separation theorems with optimal bounds. arXiv 2020, arXiv:2010.05241. [Google Scholar]
- Bárány, I.; Füredi, Z. On the shape of the convex hull of random points. Probab. Theory Relat. Fields 1988, 77, 231–240. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos. Trans. R. Soc. A 2009, 367, 4273–4293. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Tyukin, I.Y. Stochastic separation theorems. Neural Netw. 2017, 94, 255–259. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Golubkov, A.; Grechuk, B.; Mirkes, E.M.; Tyukin, I.Y. Correction of AI systems by linear discriminants: Probabilistic foundations. Inf. Sci. 2018, 466, 303–322. [Google Scholar] [CrossRef]
- Gorban, A.N.; Grechuk, B.; Tyukin, I.Y. Augmented artificial intelligence: A conceptual framework. arXiv 2018, arXiv:1802.02172v3. [Google Scholar]
- Albergante, L.; Bac, J.; Zinovyev, A. Estimating the effective dimension of large biological datasets using Fisher separability analysis. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Bac, J.; Zinovyev, A. Lizard brain: Tackling locally low-dimensional yet globally complex organization of multi-dimensional datasets. Front. Neurorobot. 2020, 13, 110. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. The unreasonable effectiveness of small neural ensembles in high-dimensional brain. Phys. Life Rev. 2019, 29, 55–88. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy 2020, 22, 82. [Google Scholar] [CrossRef]
- Gorban, A.N.; Burton, R.; Romanenko, I.; Tyukin, I.Y. One-trial correction of legacy AI systems and stochastic separation theorems. Inf. Sci. 2019, 484, 237–254. [Google Scholar] [CrossRef]
- Sidorov, S.V.; Zolotykh, N.Y. On the Linear Separability of Random Points in the d-dimensional Spherical Layer and in the d-dimensional Cube. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Sidorov, S.V.; Zolotykh, N.Y. Linear and Fisher Separability of Random Points in the d-dimensional Spherical Layer. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Grechuk, B. Practical stochastic separation theorems for product distributions. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Elekes, G. A geometric inequality and the complexity of computing volume. Discret. Comput. Geom. 1986, 1, 289–292. [Google Scholar] [CrossRef]
- Paris, R.B. Incomplete beta functions. In NIST Handbook of Mathematical Functions; Olver, F.W., Lozier, D.W., Boisvert, R.F., Clark, C.W., Eds.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Li, S. Concise Formulas for the Area and Volume of a Hyperspherical Cap. Asian J. Math. Stat. 2011, 4, 66–70. [Google Scholar] [CrossRef]
- López, J.L.; Sesma, J. Asymptotic expansion of the incomplete beta function for large values of the first parameter. Integral Transform. Spec. Funct. 1999, 8, 233–236. [Google Scholar] [CrossRef]
- Dyer, M.E.; Füredi, Z.; McDiarmid, C. Random points in the n-cube. DIMACS Ser. Discret. Math. Theor. Comput. Sci. 1990, 1, 33–38. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sidorov, S.; Zolotykh, N. Linear and Fisher Separability of Random Points in the d-Dimensional Spherical Layer and Inside the d-Dimensional Cube. Entropy 2020, 22, 1281. https://doi.org/10.3390/e22111281
Sidorov S, Zolotykh N. Linear and Fisher Separability of Random Points in the d-Dimensional Spherical Layer and Inside the d-Dimensional Cube. Entropy. 2020; 22(11):1281. https://doi.org/10.3390/e22111281
Chicago/Turabian StyleSidorov, Sergey, and Nikolai Zolotykh. 2020. "Linear and Fisher Separability of Random Points in the d-Dimensional Spherical Layer and Inside the d-Dimensional Cube" Entropy 22, no. 11: 1281. https://doi.org/10.3390/e22111281
APA StyleSidorov, S., & Zolotykh, N. (2020). Linear and Fisher Separability of Random Points in the d-Dimensional Spherical Layer and Inside the d-Dimensional Cube. Entropy, 22(11), 1281. https://doi.org/10.3390/e22111281